
Abstract
The evolution of statistical modelling has historically been constrained by the practical limitations of computation; early statistical modelling favoured models which could feasibly be estimated. As increased mathematical complexity often implies more intricate computation, statistical models have grown both mathematically and computationally more complex. However, paradoxically, sometimes conceptually simpler models present more computational challenges than complex ones, and these have historically been neglected. In the case of binary responses, logistic regression models are the gold standard; covariates are modelled additively on the log-odds scale. In the case of time-to-event responses, the Cox proportional hazards regression model has additivity on the log-hazard rate scale. Both of these methods are computationally convenient, and yet the scales on which covariates are modelled are far from intuitive. We demonstrate the use of alternative models which are computationally more complex, yet feasible, but in which modelling is on a more interpretable scale. In the case of binary responses, a more intuitive alternative is log-binomial regression, in which modelling is on the log-relative risk scale. In the case of time-to-event responses, distributional regression enables modelling on the time scale. While logistic regression and proportional hazards regression qualitatively both deliver the same conclusions as the alternative models, log-binomial and distributional regression provide more interpretable coefficients, which are readily estimated.
Keywords
Background
Statistical models are necessarily abstractions of the real world (‘All models are wrong’; Box, 1979). In the physical sciences, the abstraction may be rather close to reality, when the phenomenon under study is well understood; in other areas such as social sciences, the abstraction may be more speculative. In all cases, we observe data and formulate a statistical model to describe the data-generating mechanism, which is a mathematical abstraction of the real process.
When the purpose of the modelling is for prediction, the model’s predictive ability is all that matters. Interpretability is not important, and in fact the model may be a ‘black box’ (as in machine learning). However, when the purpose of the modelling is exploratory or confirmatory, whatever the extent of the abstraction, it is generally accepted that the model should be as simple as possible while retaining interpretability and usefulness.
Before going further, we need to define what we understand by ‘simple’, and to do this we distinguish between simplicity and mathematical convenience. By simplicity we mean closeness to the truth of the data or the evidence. For example, consider that we observe occurrences of a binary event. The most natural summary is the relative frequency, interpreted as a probability. Our contention is that this is as close as we can get to the evidence; and because it is close to the data, it is easily interpreted. We therefore regard the relative frequency or probability as a simple abstraction of the data. Another commonly used summary of such data is the odds, defined as the relative frequency of occurrences to non-occurrences. This is not an intuitive concept, yet because of its mathematical convenience (discussed below), it is ubiquitous in the analysis of binary and categorical data. Despite the mathematical and computational convenience of statistical models for the odds, the odds is a complex abstraction of the data.
Binary outcomes
We consider the simplest situation of modelling a binary outcome as a function of a binary predictor (or risk factor or exposure or treatment allocation). The predictor at level 0 generally means the risk factor or exposure is absent or the treatment allocation is to control; 1 means presence or active treatment. Standard notation and terminology are given in Table 1.
Binary data: Two-way table for a binary predictor and a binary outcome.

Binary data: Two-way table for a binary predictor and a binary outcome.
The event rates R0 and R1, for the predictor at levels 0 and 1, respectively, are alternatively referred to as risks of the event. To quantify the discrepancy between the event rates, two natural extensions are to define relative risk and risk difference:
relative risk: risk difference:
both of which are intuitive quantities, in that, for example, a doubling of risk or a risk difference of 10% are concepts close to the data and unlikely to be misinterpreted. Clearly RR = 1, or equivalently RD = 0, indicate no difference in the risk for the predictor present or absent; there are simple statistical tests for this hypothesis.
We would generally want to extend the analysis of Table 1 to include multiple predictors, that is, multiple regression with a binary outcome. This will enable quantification of risk, after adjustment for covariates. Clearly the appropriate response distribution is the Bernoulli, in which the probability parameter π is modelled with covariates:
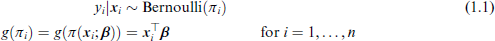
where Relative risk regression model: and Risk difference regression model: Similar mathematical reasoning as above shows that
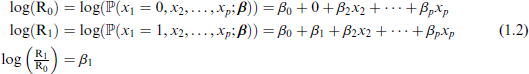
So by varying the link function g(.), we easily define regressions on the scale of relative risk and risk difference. Yet these regressions are infrequently used in the analysis of binary data. Estimation of the relative risk and risk difference regression models poses problems due to the fact that the log and identity link functions do not guarantee constraint of the fitted values 
When the inverse of the link function,
Another statistic shown in Table 1 is the odds, defined as O0 and O1 for the predictor at levels 0 and 1, respectively. To quantify the discrepancy between these, the odds ratio is used:
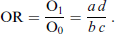
Much better known for the analysis of binary outcomes is logistic regression, which is based on the logistic link function, giving effects on the odds:
Logistic regression model:

We define the adjusted odds for 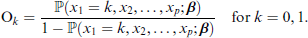
Then use of the link function (1.4) in model (1.1), and similar mathematical reasoning as (1.2) yields
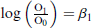
and
As is well known, the logistic link function is the canonical link for the Bernoulli distribution, so importantly delivers estimates
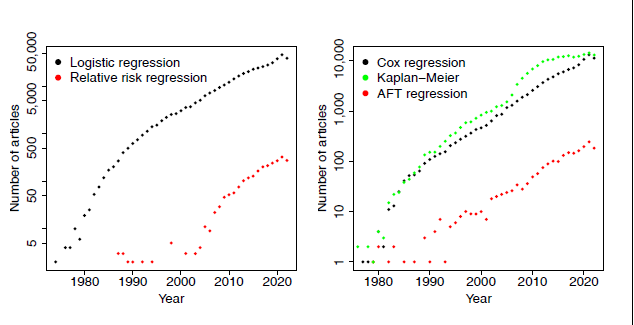
The left panel of Figure 1 shows the results of a search on PubMed Central of the terms ‘logistic regression’ and (‘relative risk regression’ or ‘log-binomial regression’ or ‘log binomial regression’), confirming the ubiquitous use of logistic regression, despite its interpretational difficulties discussed above, and the far more sparse use of relative risk regression.
Number of journal articles on PubMed Central containing the search terms. Left panel: ‘logistic regression’ and (‘relative risk regression’ or ‘log-binomial regression’ or ‘log binomial regression’). Risk difference regression has been omitted as very few instances were found. Right panel: (‘proportional hazards regression’ or ‘cox regression’), ‘Kaplan-Meier’ and (‘accelerated failure time’ or ‘parametric survival’). The y-axes are on the log scale.
Time-to-event or survival outcomes have the typical feature of right-censoring, due to subjects either leaving the study or the study ending before observation of the event of interest. The simplest summary of the data, analogous to the computation of risks for binary data, is the estimated survival function, typically plotted as the Kaplan-Meier (KM) survival curve. This involves a relatively straightforward computation of the sample probability of survival over time, dependent on the number of subjects at risk at any time point.
Proceeding to the next level of analysis, we incorporate multiple predictors into a model for survival time. A natural approach is a regression model for time to event t; were it not for the censoring issue, a GLM-like multiple regression model could look like
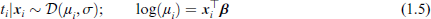
where
The development of regression models and the ability to perform complex iterative computations were limited until the early 1970s, when the seminal paper by Nelder & Wedderburn (1972) introduced generalized linear models. These would have gone part of the way to solving (1.5); however, this is not the trajectory that the analysis of survival data took. The closest model to (1.5) in the survival field is the accelerated failure time model (AFT):

where
While this parametric approach to the modelling of survival time seems to be a natural one, historically things took quite a different turn. The ubiquitous approach to the modelling of survival data is the well-known proportional hazards (PH or Cox) model (Cox, 1972):

where the hazard function h(t) is the instantaneous probability of an event at time t, conditional on survival to time
The PH model (1.7) is very familiar to most statisticians; it is the go-to method for the analysis of survival data. And yet we contend that regression model (1.5) is a far more natural way of thinking about and modelling such data: survival time is observed, and effects on the mean or median survival time are simple and intuitive concepts. The hazard function, on the other hand, is not observed. It is a modelling abstraction and effects on it are, in the authors' experience, not well understood by applied researchers.
To understand why a less-obvious model has come to dominate the field, we need to look at the history of survival analysis. In a wide-ranging interview with Nancy Reid (1994), Sir David Cox explained that he had been approached by
Quite a few people ... said they were getting a certain kind of data, censored survival data, with a lot of explanatory variables. Nobody knew quite how to handle this sort of data in a reasonably general way, and there seemed to be dissatisfaction with assuming an underlying exponential distribution or Weibull distribution modified by some factor.
Cox developed the PH model in response, with the breakthrough being the separation of the likelihood into a part that involved
So by 1972 there were two competing regression models for survival data: the AFT (1.6) and PH (1.7) models. The PH model completely eclipsed the AFT model in popularity, and continues to do so: Cox’s original paper (Cox, 1972) is ranked 24th in Nature’s list of most cited papers of all time in all fields (Van Noorden et al., 2014). Citations are in fact an underestimate of the popularity of the method: It has become so mainstream that generally papers in applications journals use the 'Cox model' without reference or with reference to a textbook. A better indicator of usage of the models is the number of journal articles using the terms 'Cox model' or 'proportional hazards model'. This is shown in the right panel of Figure 1, together with 'accelerated failure time models' and 'Kaplan-Meier' (obtained from PubMed searches). The pattern of PH vs AFT models is strikingly similar to logistic vs relative risk regression, albeit on a smaller scale. Note that Meier is even more widely used (according to this measure) than the PH model.
Sir David Cox was equivocal about the proliferation of his method. When asked about how he felt about the 'cottage industry that’s grown up around it' (Reid, 1994), Cox replied:
Don't know, really. In the light of some of the further results one knows since, I think I would normally want to tackle problems parametrically, so I would take the underlying hazard to be a Weibull or something. I'm not keen on nonparametric formulations usually ... if you want to do things like predict the outcome for a particular patient, it’s much more convenient to do that parametrically ... another issue is the physical or substantive basis for the proportional hazards model. I think that’s one of its weaknesses, that accelerated life models are in many ways more appealing because of their quite direct physical interpretation.
The AFT model (1.6) was developed in parallel to the GLM, and while it goes part of the way to addressing the specialized modelling needed for time-to-event outcomes, more general formulations are now possible. Following (1.5), we specify a distributional regression (or Generalized Additive Models for Location, Scale and Shape, GAMLSS) model (Stasinopoulos et al., 2024):

where
Parametric models typically model the location of the survival time distribution, as well as possibly one or more shape parameters. In the case of heavy right censoring, they cannot reasonably be expected to estimate the central tendency accurately, when the central portion and upper tail of the distribution are unobserved. In this case, it makes sense to model the observed data, that is, the left tail. Quantile regression, another member of the distributional regression family, is useful in this context, in which we model the lower quantiles of the survival time distribution using censored quantile regression (Koenker, 2008), implemented in the R package quantreg (Koenker, 2023).
HNcSCC data
We analyse an observational study of n = 366 patients with head and neck cutaneous squamous cell carcinoma (HNcSCC) with regional metastases, treated between 1988 and 2020 (Hurrell et al., 2022). These patients typically have poor outcomes, and the purpose of this analysis is to identify predictive risk factors for mortality. The risk factors and outcomes we analyse are summarized in Table 2.
HNcSCC data: Outcomes and risk factors.
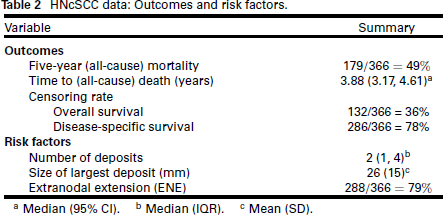
HNcSCC data: Outcomes and risk factors.
a Median (95% CI). b Median (IQR). c Mean (SD).
We begin with analysis of the binary outcome 'death within five years of diagnosis' (1 = dead; 0 = alive), and to keep things simple, we evaluate whether the binary factor extranodal extension (ENE, extension of tumour beyond the capsule of the lymph node into the surrounding tissue) is a significant risk factor. Table 3 gives the summary.
HNcSCC data: Five-year mortality and ENE.
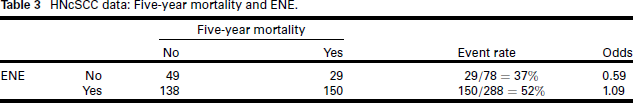
HNcSCC data: Five-year mortality and ENE.
The relative risk for ENE is 1.40; the risk difference is 0.15 ; and the odds ratio is 1.84. Association between ENE and five-year mortality can be tested in a few ways: chi-square test: p = 0.027; z-test for log(RR) : p = 0.033; z-test for log (odds ratio): p = 0.020. Qualitatively, whichever statistic we compute and test, the conclusion regarding the significance of the association of ENE with five-year mortality is the same. However, if the magnitude of the effect matters, the odds ratio implies an 84% increase in "risk" (however that is understood), whereas relative risk shows a 40% increase and risk difference a 0.15 increase, much less alarming statistics.
The next level of complexity is to incorporate the other risk factors (number of deposits and size of largest deposit) into a multiple regression model for five-year mortality. We compare logistic regression with relative risk and risk difference regression.
Variable selection was performed on the logistic regression model. As the number of covariates is only p = 3, the best-subsets method (Hastie et al., 2009) (effectively, enumeration) was used, with the BIC as the model selection criterion. All first-order interaction terms were considered for inclusion, making the number of models to be compared 18. Prior to performing the selection, it was determined that the appropriate form in the model for a number of deposits was logarithmic. (These workings are shown, for the simulated dataset, in the Supplementary Material.) The chosen covariates were size and log(number of deposits). For comparability, the same model was then used for the relative risk and risk difference regression models. Table 4 gives these results. We see a similar effect as above for ENE: while the predictors are significant in all models, the estimated odds ratios are far larger than the corresponding estimated relative risks.
HNcSCC data: Logistic, relative risk and risk difference regression, with covariates size of the largest deposit (mm), and log(number of deposits).

Overall survival
The KM curve for the HNcSCC overall survival is shown in the top left panel of Figure 2; fairly even mortality over the 16 -year study is evident.
HNcSCC data: KM curves, by all (top left), size (top right), ENE (bottom left), and number of deposits (bottom right). P-values shown are for the log-rank test.
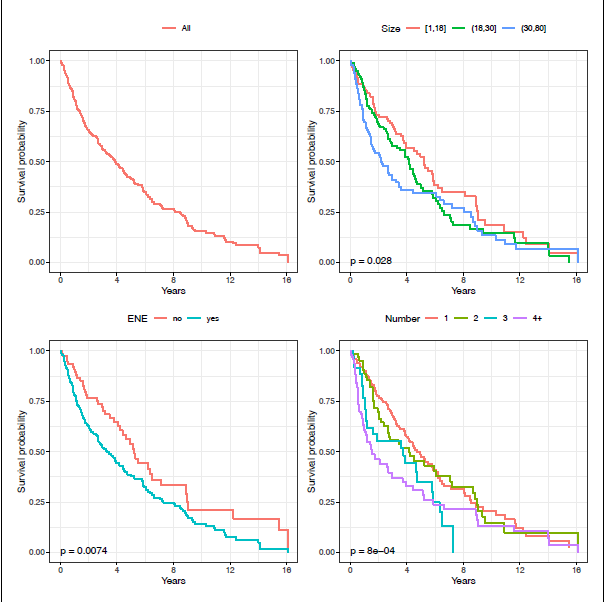
HNcSCC data: KM curves, by all (top left), size (top right), ENE (bottom left), and number of deposits (bottom right). P-values shown are for the log-rank test.
For consistency with the binomial regression models, we do not perform variable selection for the PH model; instead, we use the same predictors as were selected for the logistic regression model. Table 5 gives these results: size and log(number of deposits) are highly significant. However, the test of the PH assumption is strongly rejected for both covariates; this is confirmed graphically by the crossing of the survival curves for these two covariates in the KM plots (Figure 2, top right and bottom right panels). Although both appear to be important risk factors, we would be ill-advised to estimate their effects using a PH model.
HNcSCC data: Proportional hazards model of overall survival.

Moving to parametric models, we consider AFT and GAMLSS models. For the AFT model (1.6), survival time distributions considered were those available in the
Response distribution choice was conditioned on the covariates size and log(number of deposits) in (1.6). The exponential distribution for survival time is chosen on the basis of the BIC (Table 6), which implies the Gumbel(0, 1) distribution for the error term of the AFT model.
Choice of AFT model, using the BIC criterion, and conditioned on the covariates size and log(number of deposits). Survival time distributions available in the survival::survreg() function were fitted.

For the GAMLSS model (1.8), model selection is more complex, and we perform this without reference to the model selection of previous models. The first task is to select the response distribution: right-censored versions of all available distributions with support on the positive real line in the gamlss package were considered. Response distribution choice was conditioned on the covariates size, log(number of deposits) and ENE in the model equations for all distribution parameters
Choice of the GAMLSS model, using the BIC criterion.
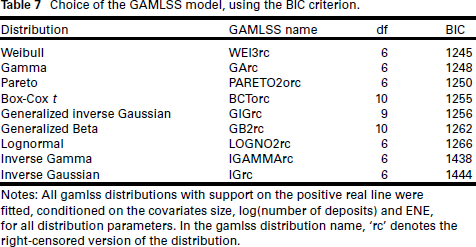
We now proceed to variable selection. As the number of covariates is small, a variant of best-subset selection (Hastie et al., 2009) is used. Size, log(number of deposits), ENE and their first-order interactions are considered for both μ and σ. As for the variable selection performed for logistic regression, the number of models to be compared for a single distribution parameter is 18. With two distribution parameters μ and σ, the number of models to be compared is then 182. = 324. While this is feasible for this application, as p increases, this number will quickly blow out. We adopt the pragmatic method suggested by Stasinopoulos et al. (2024, Chapter 9): using best-subsets selection, first the model for μ is selected, conditional on a null model for σ; conditional on the chosen model for μ, the model for σ is selected; then the process is repeated. Size and log(number of deposits) are chosen for μ; and log(number of deposits) for σ. Formulations of both AFT and GAMLSS models are shown in (2.1).
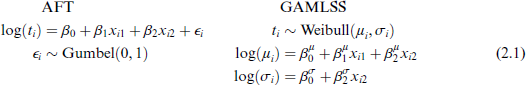
where x1 is the size of the largest deposit and x2 is log(number of deposits).
Parameter estimates are given in Table 8. Noteworthy is the similarity between the PH, AFT and GAMLSS models: The covariates for the location parameter all point in the direction of increasing number and size of deposits being significantly detrimental to survival. In addition, in the GAMLSS model, log(number of deposits) also affects the shape parameter σ.
HNcSCC data: Parametric models of overall survival: AFT exponential model and GAMLSS Weibull model.
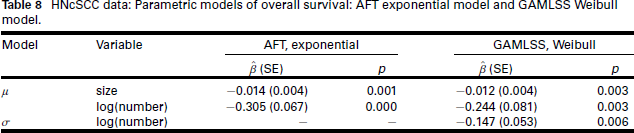
We contrast the information given on the effect of the size of the largest deposit on survival time by the three models. A 1 mm increase in size is associated with a 1.2% increase in the hazard rate (PH model), a 1.4% decrease in median survival time (AFT model) and a 1.2% decrease in mean survival time (GAMLSS model). While the messages from the three models are qualitatively the same, effects on mean or median survival are surely more accessible to applied researchers than effects on the hazard rate.
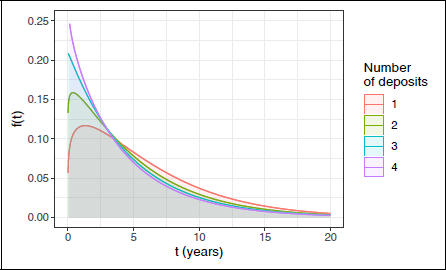
The effect of the number of deposits in the AFT model is reasonably straightforward. Because the predictor is log(number of deposits), the effect of a 100p% increase in number of deposits on median survival time is
Distributional regression Weibull model for overall survival. Probability density functions of survival time by number of deposits, with size of the largest deposit fixed at its mean 26.4 mm.
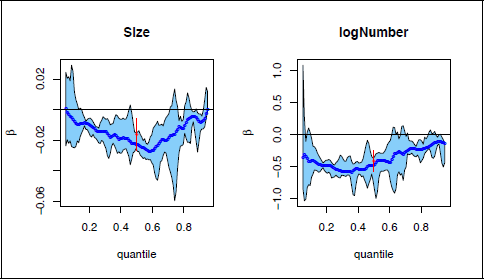
The censoring rate for disease-specific survival is high at 78% (cf. 36% for overall survival). While PH regression is feasible in this case, it is not very informative since estimates of the log hazard ratio will have low precision. Parametric regression models for the mean or median survival time will also not be useful as only the lower tail of the survival time distribution is observed. A distributional regression model that will provide reliable information in this scenario is censored quantile regression, estimated at the lower quantiles of the survival time distribution. We illustrate the use of censored quantile regression for disease-specific survival and overall survival. Figure 4 depicts the regression estimates and 95% confidence band for size of largest deposit and log(number of deposits), at quantiles in the range of 0-1, for the overall survival outcome. The left panel shows that size has the most effect on the distribution of overall survival in the centre (around the 0.6 quantile), and the least effect in the tails; the right panel shows the strong effect of log(number of deposits) in the lower tail and centre of the distribution, but not in the upper tail. The parametric estimates for the median (shown in red) were obtained from a model similar to the GAMLSS model in (2.1), but using the lognormal rather than the Weibull so that effects are on the median rather than the mean, for comparability with quantile regression. These estimates are fairly similar to the quantile regression estimates.
Censored quantile regression estimates for HNcSCC overall survival times. The blue lines and the light blue region give the censored quantile regression estimates and their
confidence band; the red estimates and confidence intervals at the 0.5 quantile are for the median in corresponding parametric models.
Censored quantile regression estimates for HNcSCC overall survival times. The blue lines and the light blue region give the censored quantile regression estimates and their
confidence band; the red estimates and confidence intervals at the 0.5 quantile are for the median in corresponding parametric models.
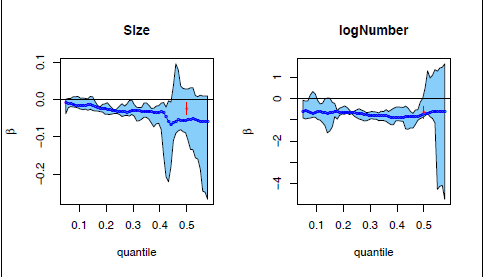
For disease-specific survival, the quantile regression results are shown in Figure 5. As could have been expected, estimates above the 0.4 quantile are completely unreliable, and in fact could not be computed above the 0.6 quantile. However, below the 0.4 quantile the estimates appear to be stable and demonstrate a similar effect as in overall survival, viz., a harmful effect on survival of increasing size and number of deposits. The parametric estimates of the median severely underestimate the variability.
Censored quantile regression estimates for the lower tail of HNcSCC disease-specific times. The blue lines and the light blue region give the censored quantile regression estimates and their
confidence band; the red estimates and confidence intervals at the 0.5 quantile are for the median in corresponding parametric models.
Statistical methods which are entrenched as the standard for analysis may not necessarily be based on conceptually simple abstractions of the data-generating mechanism and may have gained acceptance due to their mathematical convenience or computational feasibility within the limits of computing power at the time they were developed. Logistic regression and proportional hazards regression both fall into this category. Odds ratios and hazard ratios deliver qualitatively the same information as more intuitive quantities such as relative risks and effects on the mean or median survival time, but quantitatively they are not well interpreted. We have demonstrated that under current computing capability, these simpler concepts are readily estimated.
For tumour outcomes, the timing of mortality is considered to be more important than the binary notion of 'dead/alive within X years', as this gives clinicians an understanding of tumour behaviour. In that sense, the survival analysis is of far more clinical interest than the analysis of five-year mortality; nevertheless, we have presented the latter for statistical interest. For HNcSCC, clinical interest is in the five years following diagnosis; however, we have analysed the survival data to their limit of 16 years post-diagnosis.
Survival data are structurally different from non-temporal outcomes, because of the temporal nature of the outcome and possibly the covariate(s). Regression modelling may be accomplished on different scales:
hazard function h(t) : PH (Cox) regression and its many variants time t: AFT regression, distributional regression (GAMLSS, quantile regression) survival function S(t): generalized survival models (Liu et al., 2018).
There is a very rich body of survival modelling based on the hazard function. While the hazard function is not observable and perhaps less well understood than the survival function, it is informative of the course of a disease (when estimated). PH regression has the ability to incorporate the important feature of time-varying covariates and time-varying coefficients. It is difficult to overstate the pervasive nature of the hazard function and proportional hazards concept in survival analysis; and almost impossible to find a discussion of time-to-event data without mention of the hazard function. The AFT model, on the other hand, is the sadly neglected 'poor relation' of survival analysis. And yet it was ahead of its time, foreshadowing the development of the rich framework of distributional regression models, which have superseded it.
We urge applied researchers to be mindful of the interpretability of their analyses, and as far as possible to model the observed outcome on a simple and intuitive scale. Models which historically may not have been computationally feasible are readily accessible in the rich framework provided by distributional regression and generalized linear models with non-canonical links.
Data and software
The HNcSCC dataset was extracted from the Sydney Head and Neck Cancer Institute (SHNCI) Database, which is currently housed at the Chris O'Brien Lifehouse, Sydney. The data are not available openly. R version 4.2.3 (R Core Team, 2023) was used; the packages logbin (Donoghoe & Marschner, 2018) and addreg (Donoghoe & Marschner, 2014) were used for the estimation of log-binomial and risk difference regression, respectively, for distributional regression, the packages gamlss (Stasinopoulos & Rigby, 2007) and quantreg (Koenker, 2008) were used.
Supplementary materials
All computations in this article are reproduced on a dataset simulated to have similar characteristics to the HNcSCC dataset. The supplementary materials include the analysis code and output and the simulated dataset. They are available from the journals page at https://journals.sagepub.com/home/smj .
Supplemental Material for Simple or complex statistical models: Non-traditional regression models with intuitive interpretations by Gillian Z. Heller, in Statistical Modelling
Footnotes
Acknowledgements
This work was presented as an invited talk at the 37th International Workshop on Statistical Modelling (IWSM) held in Dortmund, Germany, in 2023. The author thanks the IWSM organisers for their support; Professor Tsu-Hui (Hubert) Low of the Chris O'Brien Lifehouse, Sydney, and Sydney Medical School, Faculty of Medicine and Health, University of Sydney, for the provision of the HNcSCC data and clinical guidance; and Wilson Luna Guzman, database manager at SHNCI.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author received no financial support for the research, authorship and/or publication of this article.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.