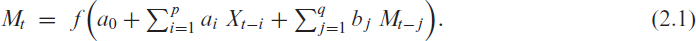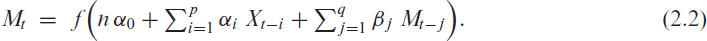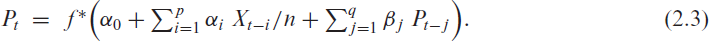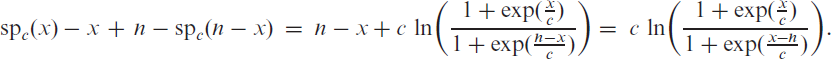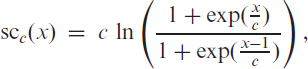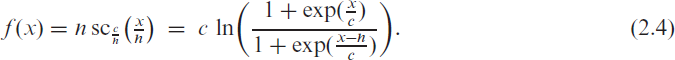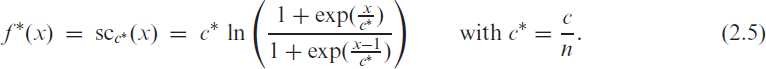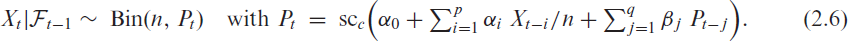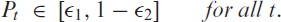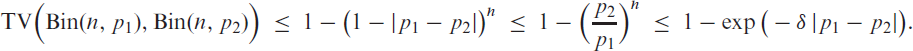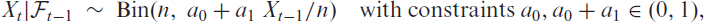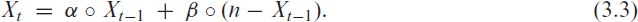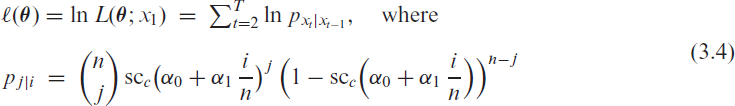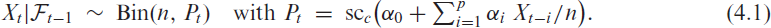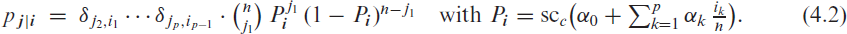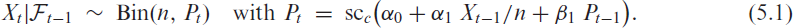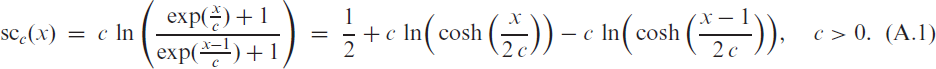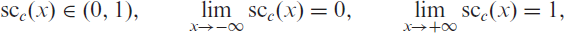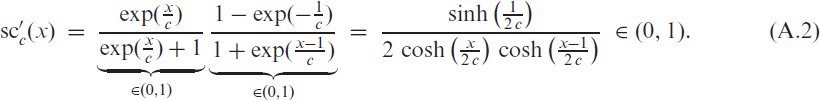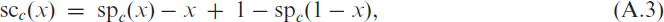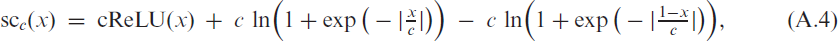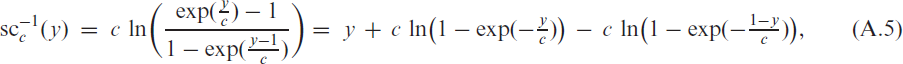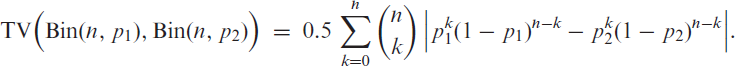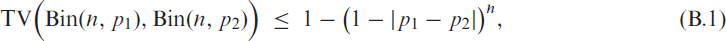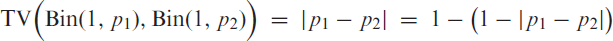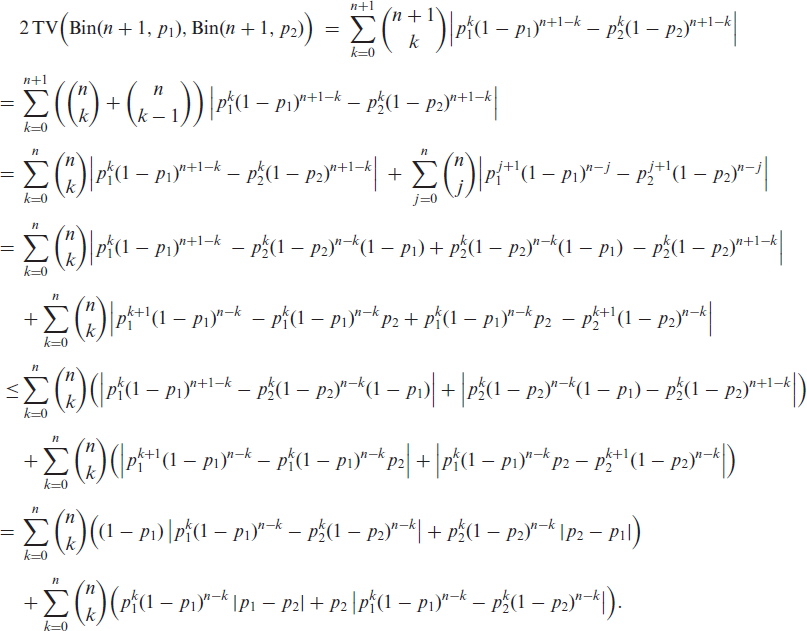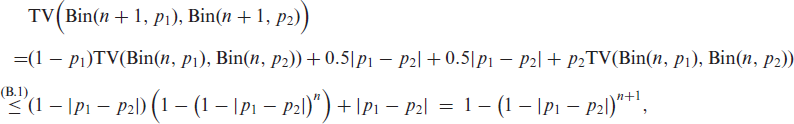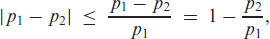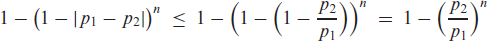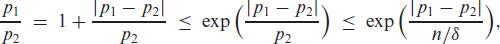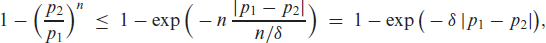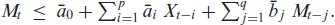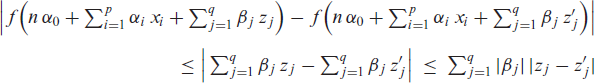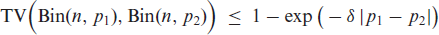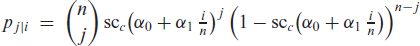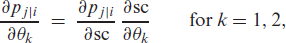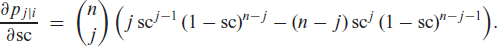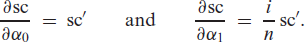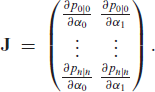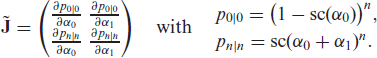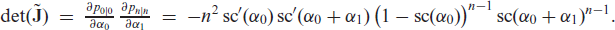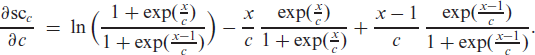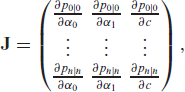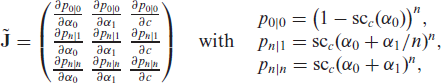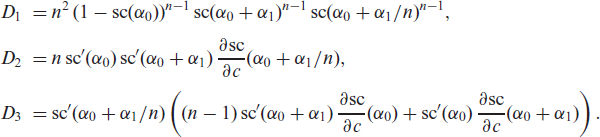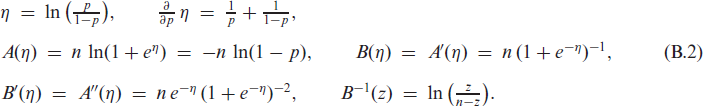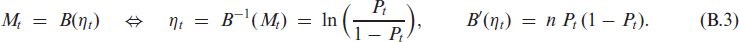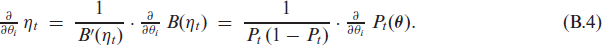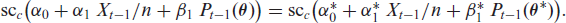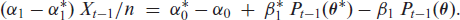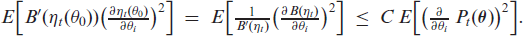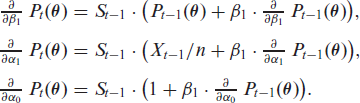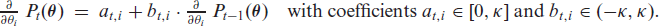The soft-clipping binomial INGARCH (scBINGARCH) models are proposed as time series models for bounded counts, which have a nearly linear structure and also allow for negative autocor-relations. Conditions that guarantee the existence and certain mixing properties of the scBINGARCH process are derived, and further stochastic properties are discussed. The consistency and asymptotic nor-mality of maximum likelihood estimators are established, and finite-sample properties are studied with simulations. The practical relevance of the scBINGARCH model’s ability to allow for negative parameter and ACF values is demonstrated by some real-data examples.
Count time series have attracted a lot of interest in research and practice during the last decades, see Weiß (2018) for a survey. These quantitative time series have a range consisting of either the full set of non-negative integers, (unbounded counts), or a finite subset thereof, with some (bounded counts). Many count time series models are inspired by the traditional autoregressive moving-average (ARMA) models for real-valued time series, that is, they are defined such that the upcoming observation depends linearly (in some sense) on past observations and possibly further information. This might be achieved by defining ARMA-like recursions using so-called ‘thinning operations’, or by utilizing a regression approach to ensure a linear conditional mean. The latter models are often referred to as the integer-valued generalized autoregressive conditional heteroskedasticity (INGARCH) models, although they are, in fact, closely related to the ARMA models, also see the discussion on p. 74 in Weiß (2018). The cutting feature of such linear count time series models is an ARMA-like autocorrelation structure, that is, their autocorrelation function (ACF) satisfies a set of Yule–Walker equations. As a consequence, moment properties are easily expressed by closed-form formulae. But unlike the original ARMA models, it is problematic (if not even impossible) to allow for negative ACF values, which, in turn, is caused by parameter constraints that are necessary to ensure the non-negative outcomes (counts) for the data-generating process. More precisely, for unbounded counts, an exactly linear model with negative AR parameters is not possible as past observations might be arbitrarily large such that we would end up with a negative conditional mean, which is not allowed for a count random variable (r. v.). For bounded counts with their additional reflecting barrier at , by contrast, negative ACF values can be achieved but only under rather restrictive conditions. Examples are the binomial AR (BinAR) model (McKenzie, 1985) and the binomial INARCH (BINARCH) model (Weiß & Pollett, 2014; Ristić et al., 2016), which are discussed in more detail later in Section 3. If one does not insist on conditional linearity, then one can certainly get rid of such restrictions on parameter and ACF values. An example is given by the binomial logit-ARCH model (Chen et al., 2020), which uses a logit link to ensure the boundedness of the range; also see Chen et al. (2022) for a more general discussion. But then, parameter values are more difficult to interpret, and closed formulae for the ACF and further moments are not available. Further recent articles on bounded INGARCH models are Liu et al. (2022a, 2022b).
To resolve the ‘linearity versus negative ACF’ dilemma for the case of unbounded counts, Weiß et al. (2022) recently proposed the so-called ‘softplus INGARCH model’ to enable both a nearly linear structure and negative ACF (approximately satisfying the Yule–Walker equations), which is achieved by using the softplus link for model definition (see Section 2 for further details). However, the softplus approach cannot be applied to bounded counts as the softplus function is not bounded from above. Therefore, in this article, we develop a novel model family for time series of bounded counts, referred to as the soft-clipping INGARCH models, which are nearly linear and allow for negative ACF values at the same time. In Section 2, we motivate our approach and derive its relation to the soft-clipping function as well as to a type of mollified uniform distribution (also see Appendix A). The soft-clipping function has been discussed previously in the context of neural network activation functions (Klimek & Perelstein, 2020). In particular, we derive conditions that guarantee the existence and certain mixing properties of the soft-clipping binomial INGARCH process (scBINGARCH). Then, we focus on important special cases. In Section 3, the scBINARCH model, which constitutes a rather well-behaved finite Markov chain allowing for likelihood inference, is compared to its exactly linear competitors, the aforementioned BinAR and BINARCH models, which assume an exactly linear relationship between and . Afterwards in Section 4, we show how to extend our findings to the higher-order Markovian scBINARCH models, which allow to model a wide range of autocorrelation structures. In Section 5, in turn, we consider the scBINGARCH model, which includes a feedback term and, thus, allows to capture some kind of ‘long memory’. The practical relevance of the scBINGARCH’s ability to allow for negative parameter and ACF values is demonstrated in Section 6 with some real-data examples. Finally, Section 7 concludes and outlines issues for future research.
The Soft-clipping approach for bounded counts
Motivation
To motivate our proposed solution for time series consisting of bounded counts, let us start with a look at INGARCH-type models for processes of unbounded counts. Their basic idea is to define the conditional mean at time , with being the -field generated by , by the recursive scheme
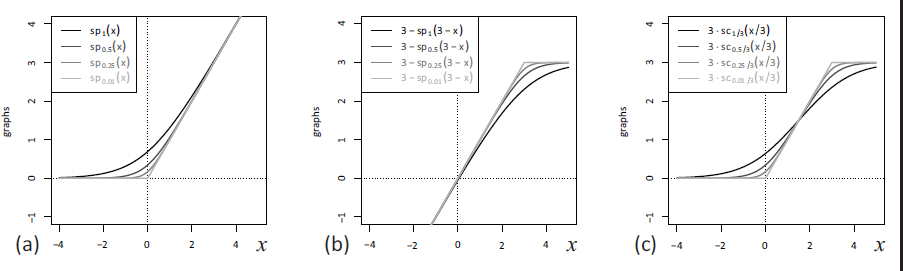
Then, the upcoming count value is generated according to some count distribution having the mean , for example, the Poisson distribution . Choosing the response function as the identity leads to the ordinary and exactly linear INGARCH model of Ferland et al. (2006), but then, the constraints and are required to ensure that . An intuitive way to overcome these parameter constraints is to choose in a way that it ensures the correct range of for any parameter values. One might choose (log-linear model), but this leads to a distinctly non-linear structure. Another idea would be to choose as the rectified linear unit function, , but then might happen, which leads to a degenerate count distribution. Therefore, Weiß et al. (2022) proposed to define as the softplus function with adjustment parameter (see Mei & Eisner, 2017), which approaches for , also see Figure 1(a).
Plots of different (a) softplus functions , (b) reversed softplus functions with and (c) rescaled soft clipping functions with
Because of the bounded range, one may also use the following equivalent characterization based on the normalized conditional mean, , together with :
Then, the counts are emitted by, for example, the conditional binomial distribution ; further options for the conditional distribution of are briefly discussed in Section 7. Using the identity as the response function (Weiß & Pollett, 2014; Ristić et al., 2016) requires strict parameter constraints, whereas the choice of the inverse logit function (Chen et al., 2020) leads to a distinctly non-linear model. It is also clear that neither nor could control an additional upper bound , whereas the function , which approaches for (also see Figure 1(b)), would be unbounded from below. Defining as the clipped ReLU function (Cai et al., 2017) causes the problem of a possibly degenerate count distribution with all probability mass in either or , also recall the above discussion of . Furthermore, is not continuously differentiable in and . Thus, the idea is to combine and in such a way that we end up with a smoothed type of . Here, it is crucial to note the decomposition , which is easily verified. Inspired by this, we choose the response function in (2.2) as
namely as plotted in Figure 1(c). Properties of the soft clipping function (A.1) are discussed in Appendix A, where we also show the relation to a type of mollified uniform distribution (in analogy to the relation between the logit link and the logistic distribution). To sum up, we refer to following (2.2) as a soft-clipping INGARCH model if the response function is equal to
Equivalently, the soft-clipping INGARCH model can be defined based on the normalized conditional mean in (2.3), by using
For a numerically more stable implementation of (2.4) and (2.5), we use (A.4).
Adapting the properties of in Appendix A, we know that in (2.4) takes values in , it approaches for , also see Figure 1(c), and it is differentiable in up to any order. The maximal deviation of (2.4) to is in and (of opposite sign), and it is of absolute size . Analogous results hold for the normalized version of , that is, for in (2.5), which approaches for , with maximal deviation to in and .
The soft-clipping binomial INGARCH model
Let with range be defined by (2.3) and (2.5). If the counts are emitted by the binomial distribution , then we abbreviate the model as ‘soft-clipping BINGARCH’ (scBINGARCH), with ‘B’ like binomial. So, the scBINGARCHmodel is defined by
While the model would be well-defined also without further restrictions, we assume that for and to prevent a degenerate behaviour. In (2.6), for the sake of readability, we simply write instead of for the adjustment parameter. While play the role of dependence parameters, can be understood as the (normalized-)mean parameter, see the discussion in the last paragraph of Section 2.2. Thus, to ensure the interpretability of , a further constraint such as appears to be reasonable. Note that because of the point symmetry in (Appendix A), so the ‘mirrored version’ of model (2.6), that is, where and , satisfies with the same dependence parameters as in (2.6) and a modified intercept term.
Lemma 1.With the aforementioned parameter constraints, and with, it follows that there existsuch that
We have , and for a cReLU-INGARCH model, it would also be possible that reaches the bounds and of this range. However, Lemma 2.2 states that for a scBINGARCH model with positive , the conditional normalized mean is truly bounded away from to . The proof of Lemma 2.2 is simple: considering the extreme parameter scenarios and the extreme cases for , and using that is strictly monotone increasing in , it follows that and . Note that these bounds are only established to obtain theoretical results, but they do not imply any relevant restrictions for practice. For example, for and , we have the lower bound , and for still , which is a negligible deviation from zero.
As another preliminary step towards proving the existence of the scBINGARCH process defined by (2.6), we present the following auxiliary result about the total variation (TV) distance between two binomial distributions.
Lemma 2.Letandfor some. Then,
The proof of Lemma 2 is provided in Appendix B.1. Note that just denotes a truly positive lower bound for . For (2.6), the existence of such a lower bound is ensured by Lemma 1.
Now we proceed in analogy to Weiß et al. (2022) and derive a theorem stating the existence and uniqueness of a stationary distribution of (2.6), as well as its absolute regularity (see Bradley, 2005 for a survey on strong-mixing concepts), provided that some regularity conditions are satisfied. For this purpose, we show that conditions (A1)–(A3) in Doukhan & Neumann (2019) hold such that their Corollary 2.1 as well as Theorems 2.1 and 2.2 are applicable. Our results are summarized in Theorem 1 as follows.
Theorem 1.If the scBINGARCHprocess (2.6) satisfiesand, then the following assertions hold:
The Markov process defined by possesses a unique stationary distribution;
A stationary version of is absolutely regular with -mixing coefficients bounded by for some constant , some , and time lag ;
A stationary version of is ergodic.
The proof of Theorem 1 is provided in Appendix B.2. As in Weiß et al. (2022), let us point out that would be a sufficient (but not necessary) condition for Theorem 1 to hold.
Before discussing important special cases of the scBINGARCH family in more detail, let us present some further general results. By definition (2.6), the conditional mean and variance are given by and , respectively. Here, it is interesting to compare with the ordinary BINGARCH model, which uses a linear link. Let denote the normalized mean of such a truly linear model, that is, . Then, it holds that , that is, the conditional variance of the scBINGARCH model is larger than if using a linear link. This can be seen by considering that is maximized at 0.5, and that the soft-clipping function is mapping each value towards 0.5: because of the curvature of , we have .
There is no explicit formula for the unconditional mean , but our computations show that it is generally close to the value obtained by plugging in the parameters into the formula for the unconditional mean of the exactly linear BINGARCH model, that is, (RistiÀ et al. 2016, Theorem 8). This approximation can also be justified as follows. By Taylor’s formula, we have . Note that for small , while and . Thus, a second-order Taylor approximation yields , as in a truly linear model. Analogously, the Yule–Walker equations in Theorem 9 and Example 2 of RistiÀ et al. (2016) are used to approximate the autocorrelation properties of the scBINGARCH process, irrespective of any parameter constraints.
The soft-clipping BINARCH(1) model
As the first important special case of the scBINGARCH family (2.6), we discuss the scBINARCH model (that is, and ), the model recursion of which can be summarized as
Since is guaranteed if (also recall Lemma 1), the transition probabilities of this finite Markov chain are always truly positive, that is, it is primitive and thus ergodic with a unique stationary solution. In addition, it is also -mixing with geometrically decreasing weights (Weiß, 2018), which strengthens Theorem 1. Obviously, leads to independent and identically distributed (i. i. d.) binomial counts, so we have a true Markov model only if . But otherwise, no parameter restrictions are required. Note that the above conclusions would also hold if taking the beta-binomial (zero-inflated binomial) distribution for emitting the counts, that is, with an additional dispersion (zero) parameter, because this distribution has a truly positive probability mass function on whole as well.
Model properties
We shall now compare the properties of this nearly linear model with two well-established exactly linear finite Markov chains: the ordinary BINARCH model (Weiß & Pollett, 2014) defined by using the identity link instead of the soft-clipping one,
and the BinAR model by McKenzie (1985). The latter uses the binomial thinning operation ‘’ (Steutel & van Harn, 1979) for model definition, given by for . Let and , denote and . Then, the BinAR model is defined by
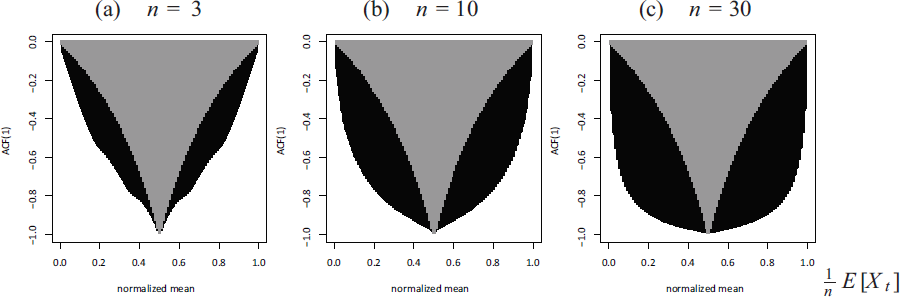
Setting and , the BinAR and BINARCH model have the same mean and ACF, namely and at lag , and also their parameter constraints agree (thus, they have a common grey region in Figure 2). But they differ in their variance: while the BinAR model has the binomial variance , the BINARCH model exhibits extra-binomial variation, namely , see Weiß & Pollett (2014). Equivalently, the binomial index of dispersion (BID), defined as , equals 1 for the BinAR model, and for the BINARCH model. Note that might be negative at odd lags, because might be negative. However, the maximal extend of negativity depends on the actual normalized mean, , see the grey regions in Figure 2. The black regions in Figure 2 are the corresponding moment properties of the scBINARCH model, which have been computed numerically exactly by utilizing the scBINARCH model’s Markov property: solving the invariance equation corresponding to scBINARCH’s transition matrix, we get the stationary marginal distribution and, thus, arbitrary lag- distributions, from which we compute the discrete moments by simple summation. The black region consists of dots computed for a grid of parameter values for .
Plots of attainable pairs of against for different upper bounds , where black region corresponds to scBINARCH model with , and grey region to BinAR model (or equivalently, BINARCH model)
Before looking at the scBINARCH model’s potential for negative values, a more general discussion is necessary. In contrast to, for example, the Gaussian AR model, where can attain any value within independent of the actual mean, the possibility for negative values is usually limited for discrete-valued processes (also see Lin et al., 2014, Section 2). For , all three models agree with a (re-parametrized) general binary Markov chain, that is, the grey region in Figure 2 cannot be exceeded in that case (for negative ACF values of more general binary time series, also see Jentsch & Reichmann (2019)). For , the BinAR and BINARCH model are still not able to exceed this grey region, whereas the scBINARCH model reaches more and more pairs with increasing , see the black regions in Figure 2. So this model is much more flexible with respect to negative ACF values.
The next question to be analyzed is the ‘extent of linearity’ that is achieved by the scBINARCH model. For this purpose, for diverse model parameterizations, we computed the values of the normalized mean, the BID, and the partial ACF (PACF) at lags 1–3. These are compared with the corresponding ‘linear values’, that is, the values obtained by plugging in the parameters into the above formulae of the BINARCH model (irrespective of any parameter constraints). Note that the latter model has PACF values equal to 0 for lags . The obtained results are summarized in the tables of Supplement S.1, where we have to compare the ‘sc’ values to the ‘lin’ values. It can be seen that the linearity improves if the normalized mean approaches 0.5, which is reasonable in view of the areas plotted in Figure 2. It is also plausible that the linearity improves with increasing . But the most important factor is certainly given by the parameter , recall Figure 1(c), where the values printed for were computed by using the response function instead of . This boundary case is not relevant for applications in practice because of the problems explained in Section 2, but it serves as the ‘best case’ regarding the attainable linearity. Comparing with , it can be seen that there are sometimes notable deviations from linearity for , whereas and especially often lead to nearly identical values as . So for practice, appears to be a reasonable choice to obtain a nearly linear model. Nevertheless, there are a few scenarios where we observe deviations from linearity even for , namely low (especially ) and low in the case of strongly negative dependence parameters. This can be explained from our discussion in Figure 2, where we realized that Markov chains cannot reach ACF values being arbitrarily close to in such scenarios. But except for these extreme cases, the scBINARCH model with low (such as ) does very well in imitating linearity.
Likelihood-based statistical inference
Results regarding likelihood-based inference, especially about the asymptotics of the conditional maximum likelihood (CML) estimator of the scBINARCH’s model parameter vector , follow immediately once Condition 5.1 of Billingsley (1961) has been shown. Let us focus on parameter estimation from a given time series of length here. The scBINARCH’s conditional log-likelihood function is given by
denotes the transition probabilities of this finite Markov chain (which are truly positive for ). The CML estimate of is obtained by numerically maximizing , where approximate moment estimates (obtained by applying the approximate moment relations of Section 3.1 to the respective sample moments) might be used as initial values. If , the existence of a consistent CML estimator, almost surely, is ensured, which is also asymptotically normally distributed according to
where denotes the expected Fisher information. (3.5) follows from Theorems 2.1 and 2.2 of Billingsley (1961), and is non-singular according to Billingsley (1961, p. 24. The proof of this assertion is provided in Appendix B.3.
Simulations results (with 10 000 replications per scenario and with ) for checking the finite-sample performance of are summarized in Supplement S.2. It can be seen that the CML estimation performs rather well even for such small sample sizes as . We have a low bias, quickly decreasing standard errors (s. e.), and the approximate s. e. obtained from the Hessian of agree quite well with the simulated s. e. in the mean.
Remark 1. Note that our main intention is to use the scBINGARCH models as approximations of truly linear models. Thus, we specify the adjustment parameter in advance, chosen sufficiently small such that approximate linearity holds (such as as recommended in Section 3.1). If one wants to use a scBINGARCH model as a truly non-linear model, with , then it would be relevant to include into estimation. This issue is briefly discussed at the end of Appendix 2.3. Our simulation experiments showed that a reasonable finite-sample performance is only achieved if is sufficiently distant from 0. This is plausible as we recognized in Section 3.1 that models with are hard to distinguish in their stochastic properties.
Higher-order soft-clipping BINARCH models
According to (2.6), the scBINARCH model discussed in previously in Section 3 is extended to a th-order Markov model with by the recursive scheme
Model (4.1) constitutes a counterpart to the truly linear BINARCH model of RistiÀ et al. (2016) but with much weaker parameter constraints. In particular, the moment properties in Theorems 1–2 of RistiÀ et al. (2016) hold true in approximation, even if negative parameter values are employed. As in Section 3, results exceeding those of Theorem 1 are derived by utilizing the Markov properties of the scBINARCH model. The idea is to consider the process of vectors , which again constitutes a finite Markov chain. Given , the corresponding 1-step-ahead transition probabilities are non-zero iff , ..., , namely
Furthermore, the -step-ahead transition probabilities are truly positive throughout. Thus, we can conclude on the existence of a unique stationary solution (ergodic and -mixing) as well as on likelihood inference like in Section 3, also see the analogous arguments in RistiÀ et al. (2016).
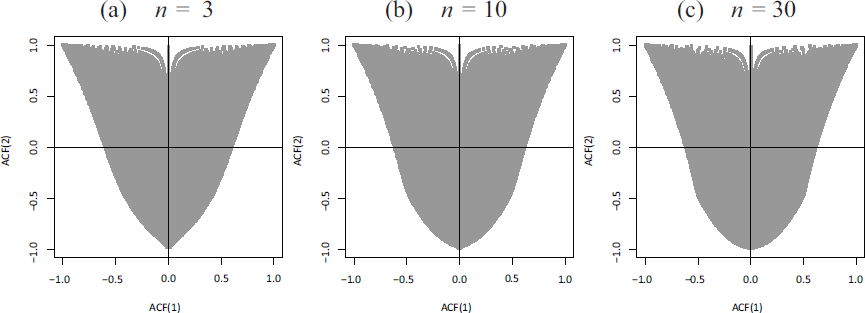
To get an idea about the abilities of the scBINARCH model for explaining different autocorrelation structures, we created some ACF–ACF plots for the scBINARCH model in Figure 3, in analogy to Figures 6(b) and 7 of Jentsch & Reichmann (2019). More precisely, for the values , , , and , we computed the values of and plotted them against each other. Note that the ordinary BINARCH model of RistiÀ et al. (2016) only allows for non-negative values of the AR parameters, that is, it only allows to achieve pairs in the top-right quadrants of Figure 3. So it becomes clear that the novel scBINARCH model is much more flexible w. r. t. the achievable autocorrelation structures, with increasing range of ACF pairs for increasing in analogy to Figure 2.
Plots of attainable pairs of against for the scBINARCH model, for different upper bounds and with
Including a feedback term: scBINGARCH(1,1) model
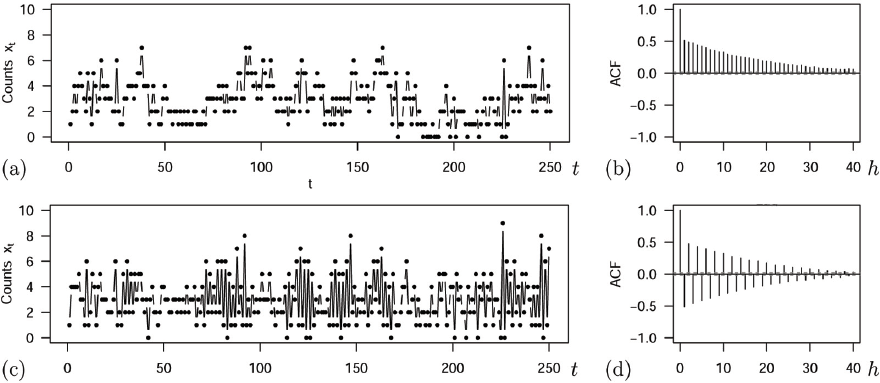
Within families of INGARCH-type models, the model order is a rather common choice in practice, as it constitutes a parsimonious way of providing some kind of ‘long memory’ (in the sense of a very slowly decreasing ACF like in Figure 4), see Fokianos (2011). This is achieved by including the feedback term (or , respectively) into the model recursion (2.6) for ,
Plots of a sample path and ACF of a scBINGARCH process with , , , and (a–b) , ; (c–d) ,
The model order considered in (2.14) is also a special case of the beta-binomial GARCH model in Chen et al. (2022), as the scBINGARCH process satisfies their contraction condition (2.4), see our derivations for (A2) in Appendix B.2. (4.1) results in a dependence of on all past observations , but with (approximately) exponentially decreasing weight for increasing , see the discussions in Section 3 of Fokianos (2011) or Example 4.1.4 of Weiß (2018). For the illustrative examples shown in Figure 4, a sample path of length was simulated (the time series plot refers to the first observations) and used to compute the sample ACF. Since is close to in both cases, the ACF converges only slowly towards .
The existence of a unique stationary solution (ergodic and -mixing) is ensured by Theorem 1. But it could also be concluded from Propositions 1 and 2 in Davis & Liu (2016), as the conditional binomial distribution belongs to the one-parameter exponential family (and since the soft-clipping function satisfies a contraction condition, recall the proof of Theorem 1 in Appendix B.2). Theorems 1 and 2 in Davis & Liu (2016), in turn, are now used to conclude in the following result about CML estimation.
Theorem 1.If the scBINGARCHprocess (5.1) satisfies the conditions of Theorem 1, then the CML estimatoralmost surely, and it is asymptotically normally distributed,
The proof of Theorem 1 is provided in Appendix B.4. Note that Theorems 1 and 2 in Cui & Zheng (2017) provide an extension of Davis & Liu (2016) to general model orders . For the model order considered in Theorem 1, in turn, also the results in Chen et al. (2022) could have been used for a proof.
The finite-sample performance of was again investigated by simulations (with 10 000 replications per scenario and with ), see Supplement S.2. This time, however, in analogy to the findings of Weiß al. (2022), we recognize that clearly larger sample sizes are required for achieving a good estimation performance, say . Then, the performance is better if is much smaller than 1. For the simulation scenarios with , we have a notable bias even for , especially for . This is plausible as controls the length of the process memory. It is also interesting to note that the bias for often increases with increasing , while we usually have a stable bias for . Simulated and approximate s. e., by contrast, agree quite well in the mean.
Data examples
Geyser eruption data
As our first data example, we consider the geyser eruption data analyzed by Jentsch & Reichmann (2019). This binary time series (so ) of length refers to successive eruptions of the Old Faithful Geyser (Data provided in R’s MASS package, https://cran.r-project.org/package=MASS), where the value 1 (0) was recorded if the eruption duration was at least (less than) three minutes. The geyser eruption data exhibit strong negative autocorrelations with significant sample PACF values for lags , see Figure 5. Therefore, Jentsch & Reichmann (2019) fitted the second-order autoregressive gbAR model from their generalized binary ARMA (gbARMA) family to these data and showed the adequacy of this model fit. Jentsch & Reichmann (2019) developed their gbARMA family as an extension of the so-called NDARMA model by Jacobs & Lewis (1983): By adding a switching facility to the NDARMA’s multinomial selection mechanism, they circumvented the NDARMA’s disadvantage of only capturing positive ACF values. In what follows, we demonstrate that our novel scBINARCH model may serve as a ‘more user-friendly’ alternative to the gbAR model, while the scBINGARCH model leads to a different ACF than the gbARMA model for (‘long memory’ vs traditional ARMA ACF).
Time series plot and sample PACF of geyser eruption data
Computing CML estimates for the AR parameters and the error term’s mean of the gbAR model, we get , , and , where actually equals the upper bound used for the box constraints of . The corresponding value of Akaike’s information criterion (AIC) computes as . Note that Jentsch & Reichmann (2019) used the AIC for model order selection, with the result nicely confirming the outcome of the sample PACF in Figure 5. The conditional distribution of our scBINARCH model (4.1) from Section 4 and, thus, numerical likelihood computations appear to be slightly more easy to implement than for the gbAR model. Furthermore, the parameterization with the intercept parameter instead of the error term’s mean turns out to be advantageous, as we do not get in conflict with the box constraints. Fitting the model orders and using , we get the estimates with , with , and with , respectively. Thus, we confirm the choice of the model order . The identical AIC values (up to the given numerical precision) for the gbAR and scBINARCH models follow from nearly identical stochastic properties of both model fits.
Within the scBINGARCH family, also the scBINGARCH model (4.1) from Section 5 is a plausible candidate model, as the sample ACF values for lags are slowly decaying in absolute extent. CML estimation leads to with . While the tiny advantage in terms of AIC should not be overestimated for practical purposes, it is interesting to note that the fitted scBINGARCH model has ACF values being more close to those of the sample ACF than the ACF values of the fitted scBINARCH model. Thus, in summary, the scBINARCH model can be used as an alternative to the gbAR model, as it leads to nearly identical stochastic properties except a reparameterization, while the full scBINGARCH model has the ability to describe a slowly decaying ACF.
Air quality data
As our second application, let us consider the air quality data (Data provided as online supplementary material for Liu et al., 2022a.) discussed by Liu et al. (2022a, 2022b). For 30 Chinese cities, they analyzed a time series of daily air quality levels (December 2013–July 2019, so length ). Here, air quality is measured on an ordinal scale with levels to . But for modeling purposes, Liu et al. (2022a) used a ‘rank-count approach’ as in Weiß (2020), that is, the ordinal r. v. at time in city is substituted by with being a bounded-counts r. v. with . Then, they applied a linear INGARCH model to these data, where the conditional distribution is a truncated Poisson distribution with additional zero and one inflation. This ‘ZOB Poisson’ distribution was used by Liu et al. (2022a) as the categories and turned out to be dominant in the data (‘normalcy-dominant’ categorical data). Certainly, the conditional binomial distribution of our scBINGARCH model is not able to explain zero and one inflation, so we do not propose it as an alternative model for the full set of time series. But for some of the time series, our scBINGARCH model performs well even without the zero-one-inflation feature. Thus, our subsequent discussion shall focus on two such exemplary series. For future research, it is recommended to develop a zero-one-inflated scBINGARCH (scZOBINGARCH) model for dealing with the whole set of air quality time series.
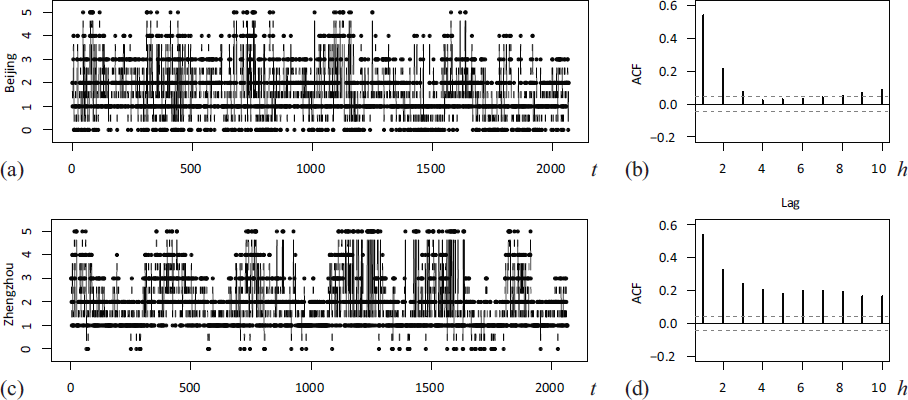
We consider the count time series corresponding to Beijing () and Zhengzhou () as examples. Plots of these time series as well as their sample ACFs are provided in Figure 6. For the Zhengzhou series in (b), we have a slowly decaying ACF as to be expected for INGARCH-type data. For the Beijing series in (a), by contrast, the ACF decays rather quickly such that the model choice INGARCH is not clear in advance. But following Liu et al. (2022a), we fit an scBINGARCH model (with ) to both time series.
Time series plot and sample ACF of air quality data for (a–b) Beijing and (c–d) Zhengzhou
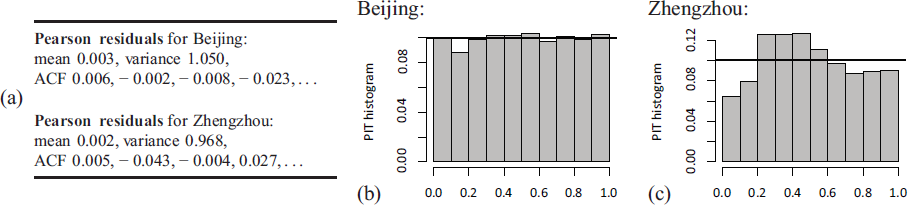
For the Beijing series , we get the CML estimates , that is, a negative estimate for the feedback parameter . Such a negative value is not possible for ZOB-INGARCH model of Liu et al. (2022a), as all parameters are restricted to non-negative values. Accordingly, the estimate ‘0.0000’ is reported in Table 3 of Liu et al. (2022a). Thus, it is interesting to compare the ACFs of the fitted models to the sample ACF in Figure 6(b), where the fitted models’ ACF was computed as the sample ACF of a simulated sample path of length . We get the ACF values for our scBINGARCH fit and for the ZOB-INGARCH fit reported by Liu et al. (2022a)], while the sample ACF takes the values for lags 1–4. So we recognize a better agreement for our scBINGARCH model, that is, the possibility for negative parameter values is clearly advantageous. Also the ACF values of the scBINGARCH’s standardized Pearson residuals in Figure 7(a) are not significant on a 5%-level, confirming that the serial dependence structure is captured adequately. Furthermore, the model’s conditional distribution for appears adequate, as the residuals’ mean is close to 0, the variance is only slightly larger than 1, and the PIT histogram in Figure 7(b) is close to uniformity; see Weiß (2018, Section 2.4) for details on these diagnostic tools. While the conditional properties of the data are very well described by the fitted scBINGARCH model, it is not fully able to mimic the marginal distribution: we have a close agreement between the means, 0.317 versus 0.321 (model vs data) but the BIDs 1.297 versus 1.410 are a bit more distant. More flexibility w. r. t. zero and one inflation could help to better explain the marginal dispersion.
Model diagnostics for scBINGARCH fits: sample statistics of Pearson residuals in (a), and PIT histogram for (b) Beijing and (c) Zhengzhou
For the Zhengzhou series , by contrast, all CML estimates are positive, namely . We do not only have a close agreement between the model’s and data’s ACF, namely versus , also the non-significant values of the Pearson residuals’ ACF in Figure 7(a) confirm the adequacy of the modelled dependence structure. Regarding the marginal distribution, we now have an even closer agreement between the means (0.391 vs 0.396) and BIDs (1.287 vs 1.260) than for the Beijing series. The reason might be given by the fact that only few zeros are observed in Figure 6(c), that is, we do not have inflation in both zero and one. This time, however, there are some reservations with respect to the conditional distributions of : while mean and variance of the Pearson residuals in Figure 7(a) are close to their target values 0 and 1, respectively, the PIT histogram exhibits an asymmetric behaviour. So mean and variance of the conditional distribution are adequately described by the scBINGARCH fit but not its shape. To sum up, the scBINGARCH model is able to flexibly adapt to diverse types of dependence structure, because it is not subject to unduly stringent parameter restrictions. It is not the perfect choice for the air quality data, as it is not able to explain the zero and one inflation. The air quality data also seem to exhibit some yearly pattern, so the inclusion of covariates into the scBINGARCH model might be helpful in this regard. Thus, such extensions appear to be an interesting direction for future research.
Conclusions
The scBINGARCH family for time series of bounded counts was proposed as an extension of the linear BINGARCH model, as it gets by with less severe parameter restrictions. In particular, it behaves like the linear BINGARCH model for positive parameter values, but it also allows for negative parameter and thus ACF values. This was achieved by using the nearly linear soft-clipping function as the response function. It was shown that the moment properties of the scBINGARCH model are generally well approximated by simply using the moment formulae from the exactly linear model; this approximation is less accurate only for extreme parameter scenarios. We established the existence and mixing properties for the scBINGARCH model, as well as the consistency and asymptotic normality of the CML estimator. The finite sample performance of the CML estimator was studied by simulations, and the practical relevance of the scBINGARCH model was demonstrated with real-data examples.
However, the data examples also made clear that further research is needed for the model. In particular, the conditional binomial distribution seems to be too restrictive for some applications. Future research could therefore turn to the development of, for example, a beta-binomial scINGARCH model (that is, with an additional parameter for controlling the extend of extra-binomial variation), also see Chen et al. (2022), or to a zero-inflated (or even zero-one-inflated) scINGARCH model (that is, with additional parameter(s) for controlling the zero (and one) probability), with the latter being motivated by the air quality data discussed in Section 6.2. Also, recall Section 3 regarding the Markov case. The air quality example also gives rise to think of a spatio-temporal extension, as there might be some spatial dependence between the air quality of the 30 cities.
Appendices
Soft clipping and mollified uniform distribution
The (unit) clipped ReLU function is defined by clipping the identity function to the interval , that is, by Cai et al. (2017). A smoothed version of it, the soft clipping function, was proposed by Klimek & Perelstein (2020) as
Let us derive important properties of the soft clipping function. It satisfies
and it is point symmetric in . approaches the clipped ReLU function for . It is infinitely differentiable, with the first derivative being given by
Thus, is strictly monotone increasing from 0 to 1, but its increase is weaker than that of on . Therefore, the maximal deviation between and is in , given by . Note that approaches the unit rectangular function for , where the indicator function equals 1 (2.0) if (). Finally, the soft clipping function is related to the softplus function by
in analogy to the decomposition . Inserting the equality Wiemann et al. (2021) into (A.3), we can rewrite the soft clipping function as
which, together with the log1p function, allows for a numerically stable implementation of .
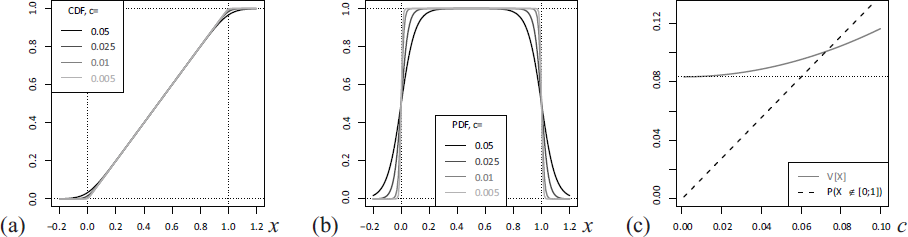
Soft/mollified uniform distribution with scale parameter . Plots of (a) CDF and (b) PDF for different against . (c) Plots of variance and ‘out of unit interval’-probability against
Besides serving as a response function in regression modeling, the soft clipping function is also related to the uniform distribution. Note that just equals the cumulative distribution function (CDF) of the (unit) uniform distribution, , see Chapter 26 in Johnson et al. (1995). Since from (A.1) is itself a CDF, see Figure A1 (a) for some plots, the corresponding distribution might be thought of as a ‘soft uniform distribution’, which has the full set of real numbers, , as its range but which approaches for . Its probability density function (PDF) is then given by (A.2), see Figure A1 (b) for illustration. Its quantile function equals
where the latter version can again be implemented using the log1p function. It is easily seen that this distribution is equal to the convolution of with the logistic distribution having mean 0 and scale parameter , see Chapter 23 in Johnson et al. (1995). Therefore, the ‘soft uniform distribution’ might also be referred to as a ‘mollified uniform distribution’ in the sense of Friedrichs (1944), using a logistic mollifier. The decomposition with independent summands and can be utilized for moment calculations. For example, the mean and variance of the soft/mollified uniform distribution are given by and , respectively. Figure A1(c) plots the variance against (which converges to for ) as well as the probability of falling outside the unit interval, that is, .
Derivations
Proof of Lemma 2
For the discrete binomial distribution, the TV distance is computed as (Gibbs & Su, 2002, p. 424)
The proof of the first inequality in Lemma 2,
is done by induction. Recall that such that . For the initial case , we get
such that (B.1) holds. So let us turn to the inductive step. Given that the proposed inequality (B.1) holds for some , we have for that
So,
which completes the proof of (B.1). Then, using that
The argumentation for (A1) and (A2) is nearly identical to the one in Supplement S.4 of Weiß et al. (2022). With according to (2.4), and with and , it holds that
Therefore, the drift condition (A1’) and, thus, the geometric drift condition (A1) in Doukhan & Neumann (2019) are satisfied.
To prove the semi-contractive condition (A2), we utilize the mean value theorem and conclude that for some with . Since according to (A2), also such that is Lipschitz-continuous with constant 1. In particular,
for all , so (A2) follows.
A major difference to Weiß et al. (2022) is the argumentation for the similarity condition (A3). Here, Lemmata 21 and 2 allow to conclude that there exists a such that
holds for the conditional distribution of the scBINGARCH process (2.6). So the proof of Theorem 2.2 is complete.
Proof of (3.5)
To prove that Condition 5.1 of Billingsley (1961) holds, first note that the set of pairs , where the transition probability
is truly positive, is independent of the parameter vector , because always holds, and the binomial distribution always has the full support . Furthermore, the have continuous (third-order) partial derivatives w. r. t. , because they are a composition of continuously differentiable functions.
Let us have a closer look at the first-order derivatives. For the sake of readability, we omit the subscript ‘’ in the sequel. Then, we compute
where the partial derivative of with respect to the soft-clipping function is given by
The partial derivatives of the soft-clipping function with respect to , in turn, are
We define the following ( Jacobian matrix:
If this matrix has full rank throughout the parameter space, then Condition 5.1 holds. We consider the following (22) quadratic sub-matrix:
The determinant of is given by
Because , we have . Therefore, and have full rank, which completes the proof of (2.11).
Additional Estimation of (Remark 1)
Generally, the previous argumentation could be extended to also cover the adjustment parameter . Since a bivariate Markov chain is fully specified by two model parameters, the upper bound needs to satisfy if also needs to be estimated. In addition to the previous derivatives, one now also needs the partial derivative of w. r. t. , that is,
While with a maximum in , has a point of symmetry in : . Next, one defines the ( Jacobian matrix
which needs to be shown to have full rank throughout the parameter space. Again, one may look at appropriate (33) quadratic sub-matrices for proving the full rank. For example, the sub-matrix
has the determinant with
Since the first factor is always positive, it remains to show that is non-zero for the considered paremeter scenario.
Proof of Theorem 1
We have to verify the conditions (A0)–(A7) in Davis & Liu (2016). For this purpose, we adapt the notations of Davis & Liu (2016). The distribution belongs to the one-parameter exponential family with
Applied to model (2.14) with , we have the relations
Furthermore, the partial derivatives are determined by differentiation of the inverse function :
is satisfied because of the parameter restrictions for the scBINGARCH process.
Because of Lemma 2.2, there exist such that for all . Thus, the range of has a truly positive lower bound.
holds because is continuous and, thus, is a continuous function of . Actually, is continuously differentiable up to any order, so (A6) also holds.
does not apply here.
Because of , also is a bounded r. v.. So to show (A4), the mean of a bounded r. v. needs to be computed, which necessarily takes a finite value.
We adapt the argumentation in Appendix C.6 of Davis & Liu (2016). Assume that there is a such that almost surely, that is,
Since is injective, implies , so
In particular, and for some functions , that is, . So with an analogous argumentation as in Appendix C.6 of Davis & Liu (2016), we conclude .
is bounded by (B.3). Together with Lemma 2.2, it holds that . Using (B.4), we compute
Here, with with , we have
So each partial derivative satisfies a linear first-order difference equation of the form
Thus, has a bounded range, and (A7) holds.
Supplementary materials
Supplementary materials for this article are available online.
Supplemental Material for Soft-clipping INGARCH models for time series of bounded counts by Christian H. Weiß, Malte Jahn, in Statistical Modelling
Footnotes
Acknowledgements
The authors thank the editor, the associate editor and the two referees for their useful comments on an earlier draft of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors received no financial support for the research, authorship and/or publication of this article.
References
1.
BillingsleyP (1961) Statistical Inference for Markov Processes. Chicago: University of Chicago Press.
2.
BradleyRC (2005) Basic properties of strong mixing conditions: a survey and some open questions. Probability Surveys2, 107–144.
3.
CaiZ, HeX, SunJ and VasconcelosN (2017) Deep learning with low precision by halfwave Gaussian quantization. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, pp. 5406–5414.
4.
ChenH, LiQ and ZhuF (2020) Two classes of dynamic binomial integer-valued ARCH models. Brazilian Journal of Probability and Statistics, 34, 685–711.
5.
ChenH, LiQ and ZhuF (2022) A new class of integer-valued GARCH models for time series of bounded counts with extra-binomial variation. AStA Advances in Statistical Analysis, 106, 243–270.
6.
CuiY and ZhengQ (2017) Conditional maximum likelihood estimation for a class of observation-driven time series models for count data. Statistics & Probability Letters, 123, 193–201.
7.
DavisRA and LiuH (2016) Theory and inference for a class of nonlinear models with application to time series of counts. Statistica Sinica, 26, 1673–1707.
8.
DoukhanP and NeumannM (2019) Absolute regularity of semi-contractive GARCH-type processes. Journal of Applied Probability, 56, 91–115.
9.
FerlandR, LatourA and OraichiD (2006) Integer-valued GARCH processes. Journal of Time Series Analysis, 27, 923–942.
10.
FokianosK (2011) Some recent progress in count time series. Statistics, 45, 49–58.
11.
FriedrichsKO (1944) The identity of weak and strong extensions of differential operators. Transactions of the American Mathematical Society, 55, 132–151.
12.
GibbsAL and SuFE (2002) On choosing and bounding probability metrics. International Statistical Review, 70, 419–435.
13.
JacobsPA and LewisPAW (1983) Stationary discrete autoregressive-moving average time series generated by mixtures. Journal of Time Series Analysis, 4, 19–36.
14.
JentschC and ReichmannL (2019) Generalized binary time series models. Econometrics, 7, 47.
15.
JohnsonNL, KotzS and BalakrishnanN (1995) Continuous Univariate Distributions, Volume 2, 2nd edition. Hoboken, NJ: John Wiley & Sons.
16.
KlimekMD and PerelsteinM (2020) Neural network-based approach to phase space integration. SciPost Physics, 9, 053.
17.
LinGD, DouX, KurikiS, and HuangJ-S (2014) Recent developments on the construction of bivariate distributions with fixed marginals. Journal of Statistical Distributions and Applications, 1, 14.
18.
LiuM, ZhuF and ZhuK (2022a) Modeling normalcy-dominant ordinal time series: An application to air quality level. Journal of Time Series Analysis, 43, 460–478.
19.
LiuM, LiQ and ZhuF (2022b) Modeling air quality level with a flexible categorical autoregression. Stochastic Environmental Research and Risk Assessment, 1–11. https://doi.org/10.1007/s00477-021-02164-0
20.
McKenzieE (1985) Some simple models for discrete variate time series. Water Resources Bulletin, 21, 645–650.
21.
MeiH and EisnerJ (2017) The neural Hawkes process: a neurally self-modulating multivariate point process. In: Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), edited by von Luxburg., pages 6757–6767. Red Hook, NY: Curran Associates Inc.
22.
Ristic´MM, WeißCH and Janjic´AD (2016) A binomial integer-valued ARCH model. International Journal of Biostatistics, 12, 20150051.
23.
SteutelFW and van HarnK (1979) Discrete analogues of self-decomposability and stability. Annals of Probability, 7, 893–899.
24.
WeißCH (2018) An Introduction to Discrete-valued Time Series. Chichester: John Wiley & Sons.
25.
WeißCH (2020) Distance-based analysis of ordinal data and ordinal time series. Journal of the American Statistical Association, 115, 1189–1200.
26.
WeißCH and PollettPK (2014) Binomial autoregressive processes with density dependent thinning. Journal of Time Series Analysis, 35, 115–132.
WiemannPFV, KneibT and HambuckersJ (2021) Using the softplus function to construct alternative link functions in generalized linear models and beyond. arXiv: arXiv:2111.14207v1.
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.