
Abstract
Sequential regression approaches can be used to analyze processes in which covariates are revealed in stages. Such processes occur widely, with examples including medical intervention, sports contests and political campaigns. The naïve sequential approach involves fitting regression models using the covariates revealed by the end of the current stage, but this is only practical if the number of covariates is not too large. An alternative approach is to incorporate the score (linear predictor) from the model developed at the previous stage as a covariate at the current stage. This score takes into account the history of the process prior to the stage under consideration. However, the score is a function of fitted parameter estimates and, therefore, contains measurement error. In this article, we propose a novel technique to account for error in the score. The approach is demonstrated with application to the sprint event in track cycling and is shown to reduce bias in the estimated effect of the score and avoid unrealistically extreme predictions.
Introduction
Consider a stochastic control process or prediction problem in which a random outcome depends on a set of non-random covariates such that (a) disjoint subsets of the covariates are revealed in stages and (b) at each stage, a model (explanatory or predictive) for the outcome is required. Such processes, which have a natural order given by the discretization of time into stages, occur in many fields: for example, medics may wish to model patient survival prior to intervention, immediately post intervention, and prior to discharge taking account of patient, disease and intervention characteristics revealed at each stage; in a sporting context, coaches and players would like to understand the effect of tactical decisions on overall outcome as the contest progresses; and politicians may wish to assess the effectiveness of tactics used during various stages of a political campaign. At each stage, a vector of covariates is revealed, and a modeller/statistician might take one of the following approaches:
At each stage At the first stage, fit a model that contains the covariates revealed at the first stage, and then at each stage
The naïve approach (1) may be practical if both the total number of covariates and the number of stages are not too large. Otherwise, we should anticipate difficulties regarding covariate selection: for example, if a covariate enters the model at stage i, should it enter the model at all stages, or should its selection at stage i not influence selection at other stages? A solution to this problem is to proceed sequentially as in approach (2), so that a covariate that enters the model at stage i continues to have an effect at all subsequent stages, albeit becoming more dilute as the sequential model fitting proceeds. Approaches (1) and (2) are considered further in Section 2.
A drawback of the sequential approach (2) is that the estimates of the covariate effects can be biased since the score is itself a random variable. This article develops a measurement error model to alleviate this problem and, to our knowledge, is the first to do so. In particular, we describe a measurement error model for sequential generalized linear models (GLMs); we do this in Section 3, with a particular focus on sequential logistic regression. We will call our approach sequential measurement error regression. The approach is demonstrated in Section 4 by application to the sprint event in track cycling; here, the object is to explain race outcome at each of a number of intermediate stages in the race. The novel technique we develop avoids biases in the estimates of the effect of the score at each stage and, hence, is essential for making appropriate inferences about the size of covariate effects. In the example we describe, such biases were up to 19%, when measured relatively to the size of the effect. We also demonstrate that the difference in the predicted probabilities of overall outcome, between the standard sequential approach (2) and the sequential measurement error approach, propagates through the stages leading to unrealistically high or low values of the predicted probability when not accounting for measurement error.
Review of the statistical analysis of sequential processes
A key feature of such sequential processes is that the number of influential covariates increases with each stage, since the model at stage i should consider all covariates revealed so far in the process. If there are too many influential covariates compared to the number of cases, the variability in the parameter estimates becomes large (Peduzzi et al., 1996; Vittinghoff and McCulloch, 2007). Vittinghoff and McCulloch (2007) suggest that there should be at least five events per covariate (an event being the outcome, either success or failure, whichever occurs least often). Therefore, the naïve approach (1) will not be applicable for many processes. Each stage could be considered in isolation, by fitting a model with only the covariates revealed in the current stage. However, this can lead to the effect of covariates being misinterpreted. In particular, covariates at one stage may act as surrogates for other covariates revealed in earlier stages. For example, Hill et al. (2000), when studying coronary artery bypass treatment, developed a model containing covariates relating to a bypass operation as well as a covariate to capture pre-operative factors. They found that one of the operative covariates did not significantly affect outcome, in contrast to an earlier study that did not account for pre-operative factors.
To overcome this problem, Elisheva et al. (2000), Hill et al. (2000), Van Wermeskerken et al. (2000) and Welsby et al. (2002) used the estimated score (or the implied outcome probability) from the model developed at the previous stage as a covariate in place of all covariates revealed in the prior stages, that is, approach (2) of Section 1. This estimated linear predictor or estimated score (or its equivalent) is effectively a collective covariate describing the influential covariates prior to the current stage. However, the sequential logistic regression approach of Elisheva et al. (2000) makes the assumption that the score is a non-random covariate when it is, in fact, a random variable, since it is a function of the fitted parameter estimates from the preceding model and, therefore, contains intrinsic measurement errors. Measurement error has three effects, collectively known as the ‘triple whammy’ (Carroll et al., 2006). First, it causes bias in the parameter estimates. Second, it leads to a loss of power for detecting relationships between the outcome and the covariates. Finally, it masks features of the data that would otherwise be evident in plots of outcome against covariates. While measurement error methods have been successfully adopted in many fields, for example, blood pressure monitoring (time-varying measurement) and nutrient intake (significant measurement inaccuracies), they have not been used to adjust for error when the score from a model developed in an earlier stage of a process is used as a covariate in a later stage. We develop a methodology to do just this by combining the sequential regression approach with a likelihood-based measurement error method.
Sequential regression models
Formally, let us suppose that we would like to predict the outcome of a process comprising m stages and that in the past we have observed n cases. Let us denote the covariates revealed by stage i as
Naïve sequential regression
The naïve sequential model can be fitted in the standard way. At each stage
Sequential regression
At the first stage, we fit the regression model
Variable selection can proceed in a standard way at each stage, using, for example, forward stepwise, because one is now only selecting covariates from those revealed at stage i,
Sequential measurement error regression
The sequential model described above assumes that the estimated score
Derivation of the sequential measurement error regression
The likelihood approach maximizes the joint probability density

This equation contains three components, and therefore three sub-models are required to specify the full likelihood. These are:
The outcome sub-model The measurement error sub-model The sub-model for the true unknown score
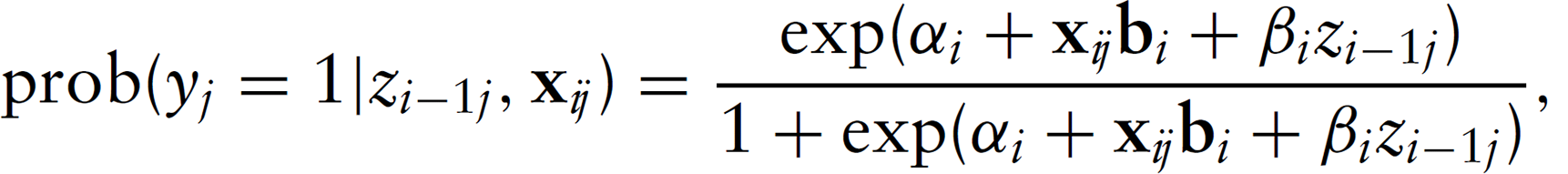
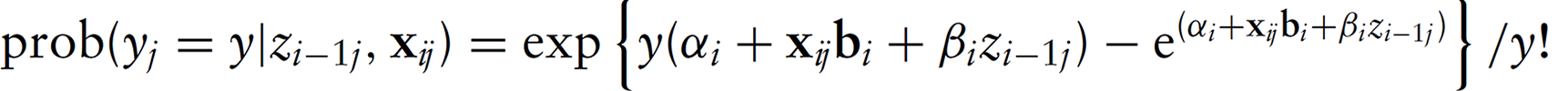
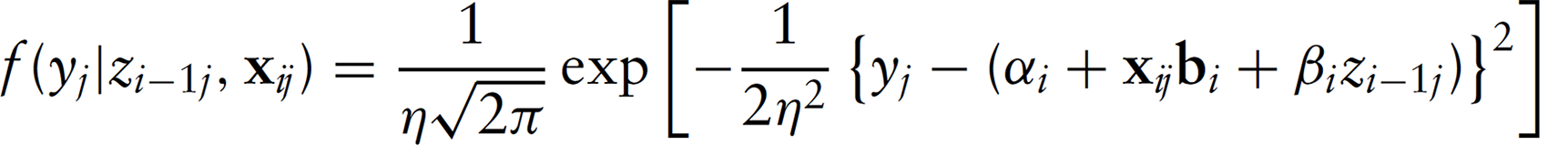
For sequential logistic measurement error regression, the likelihood function is then
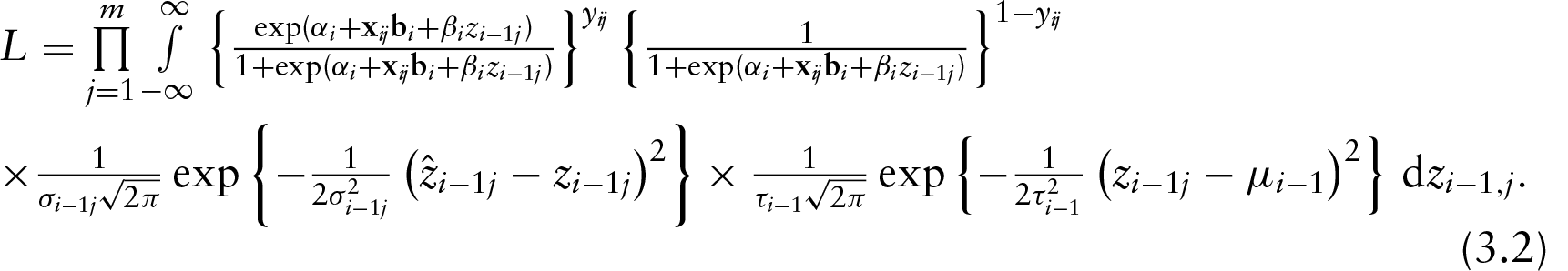
The process of maximizing this likelihood function with respect to parameter vector
The steps required to fit the sequential measurement error model are as follows:
The measurement error variance is estimated using bootstrap samples. The estimated score is calculated from the model at the previous stage. The likelihood is evaluated numerically using Gauss—Hermite quadrature. The log-likelihood is maximized using the Newton—Raphson method.
These steps are discussed further below:
Step 1: In the first step, the measurement error variance for the observed score at the previous stage is calculated for each observation. A number of methods have been suggested for this calculation: (a) via a validation dataset (e.g., Guo and Little, 2011), where the true score is actually observed; (b) using replicate measurements of
Step 2: At each stage, the estimated scores

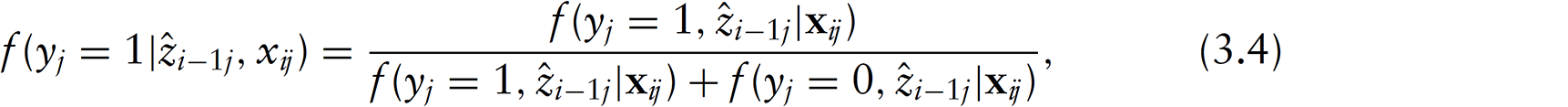
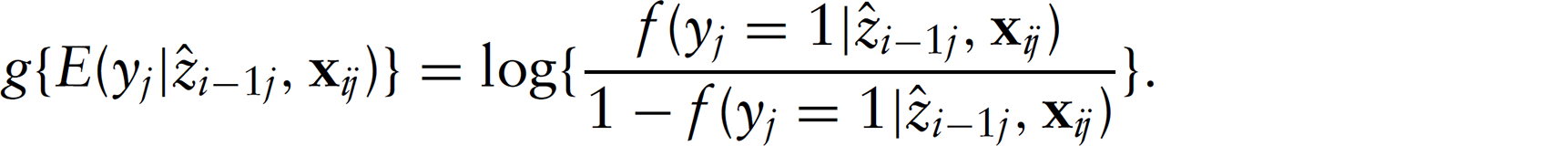
The terms in the right-hand side of Equation (3.4) are evaluated in the same way as the likelihood function (3.1; described next) and setting parameters equal to their maximum likelihood estimates.
Step 3: The likelihood is evaluated numerically using, for example, Gauss—Hermite quadrature (Hildebrand, 1974), which is an ideal technique for approximating integrals involving exponentials as follows:
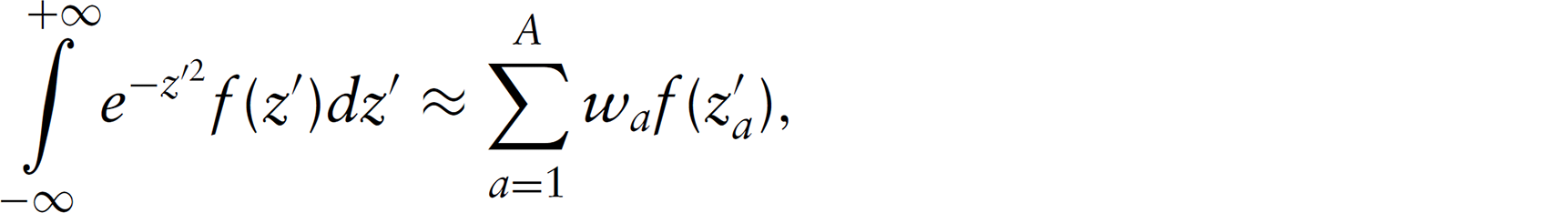

In order to apply Gauss—Hermite quadrature, the likelihood of Equation (3.2) needs to be transformed to the correct form by defining

The likelihood (Equation 3.2) can then be written as
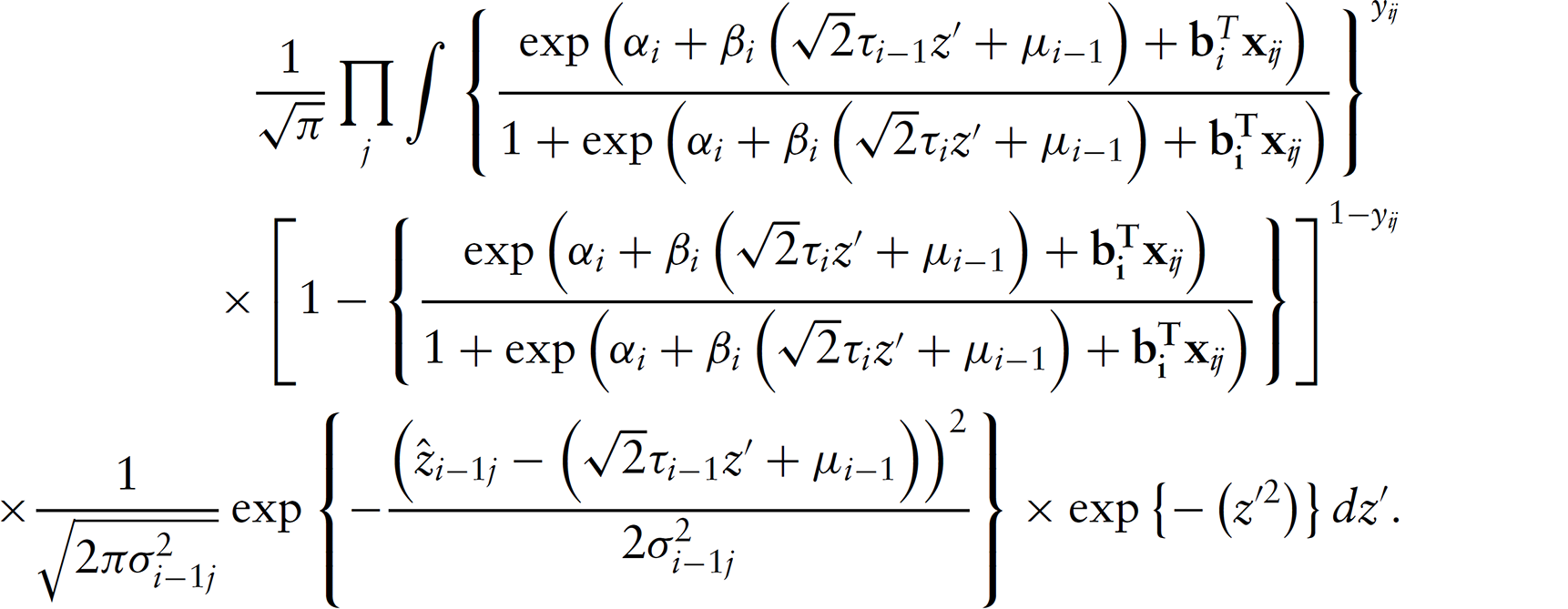
This is now in the form of Gauss—Hemite quadrature and can be approximated numerically as
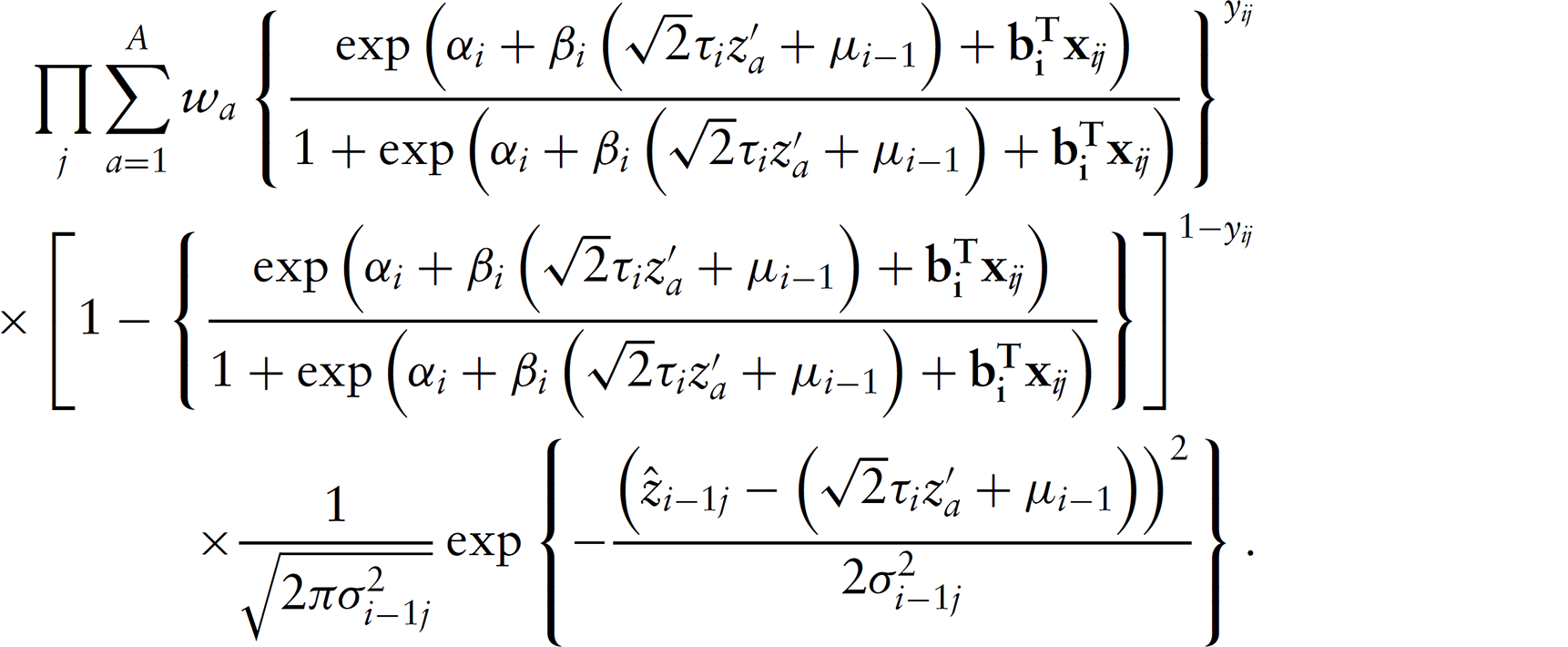
Step 4: For computational purposes, it is easier to work with the log-likelihood. The accuracy of the quadrature depends on the number of points selected. We recommend evaluating the log-likelihood for increasing number of points starting with 10 in steps of 10 until a required accuracy is attained. The log-likelihood is then maximized to determine the unknown parameters, using, for example, Newton—Raphson method (Collett (2002)), which has been found to work well for measurement error models Rabe-Hesketh et al. (2003). We recommend using the fitted values from the sequential regression as initial values for
At each stage, one would expect to carry out a variable reduction procedure, proceeding in the same way as for the sequential regression model, Section 3.2.
We now illustrate our ideas using an example from sport: the match sprint in track cycling. This is a highly tactical race that takes place between two riders in a velodrome. In major competitions, the riders race over three laps of a 250 m track. They start together and the first across the finish line wins. In major competitions, the event is organized in knock-out rounds, each round being a best-of-three race. An initial qualifying round, in which riders race individually against the clock over a ‘flying’ 200 m, determines the qualifiers and pairings for the knock-out rounds. The time an individual sets in the flying 200 m is called the ‘flying time’ and the implied speed the ‘flying speed’: This is an important covariate that we will use later. More details of the event can be found with UCI (2016). As the outcome of a single race is win or loss, we use logistic regression. Now, we want to (a) compare the ‘novel sequential logistic measurement error regression’ (Model 3) with ‘naïve sequential logistic regression’ (Model 1) and ‘sequential logistic regression’ (Model 2) and (b) briefly describe some tactical implications for riders and coaches that our preferred model suggests.
The factors that determine the outcome of a race are described in the next sub-section. We then present our results and compare and contrast the three models.
Factors in the match sprint: Description and data collection
Using video footage, supplied by British Cycling, of 367 races from major competitions between 2006 and 2008 (see Table 1), the times and the position (perpendicular distance from the inside of the track) at which riders crossed each of the five visible marks (the solid longitudinal lines shown in Figure 1) for each of the races were found. Times were determined to an accuracy of 1/50th second. Positions were ordinally categorized and were also collected at each mark and each virtual mark as shown in Figure 1 (11 marks in total). The track is not flat but slopes upwards, linearly from the inside. The slope is greatest at the apex of the curves. Using the known three-dimensional geometry of the track and the information collected from video footage, riders’ average speeds over a stage were estimated; this is discussed further in Moffatt et al. (2014). The flying speeds of riders from the qualifying round were obtained from the Tissot Timing website (Tissot Timing, 2016). The average flying speeds were 63 km/hr and 69 km/hr for female and male riders, respectively (see Table 1).
Number of races, average flying speed in km/hr and the percentage of faster riders (by flying speed) who won the race for the dataset used to build the models by gender

Number of races, average flying speed in km/hr and the percentage of faster riders (by flying speed) who won the race for the dataset used to build the models by gender
Plan view of a track, showing the track division for determining speed and position and describing covariates and tactics: The latitudinal lines divide the track into six positions. The Finish, 200 m and 100 m, lines divide the track into stages, with stage 1 occurring in lap 1 and stages 2–4 occurring in lap 2. The diagram also shows the marks on the track at which data were collected, which correspond to either actual markings on the track (– –), or to virtual marks (—) where additional information regarding riders’ positions was collected. Each mark is given a label comprising two numbers: The first number refers to the stage and the second refers to the mark within the stage.
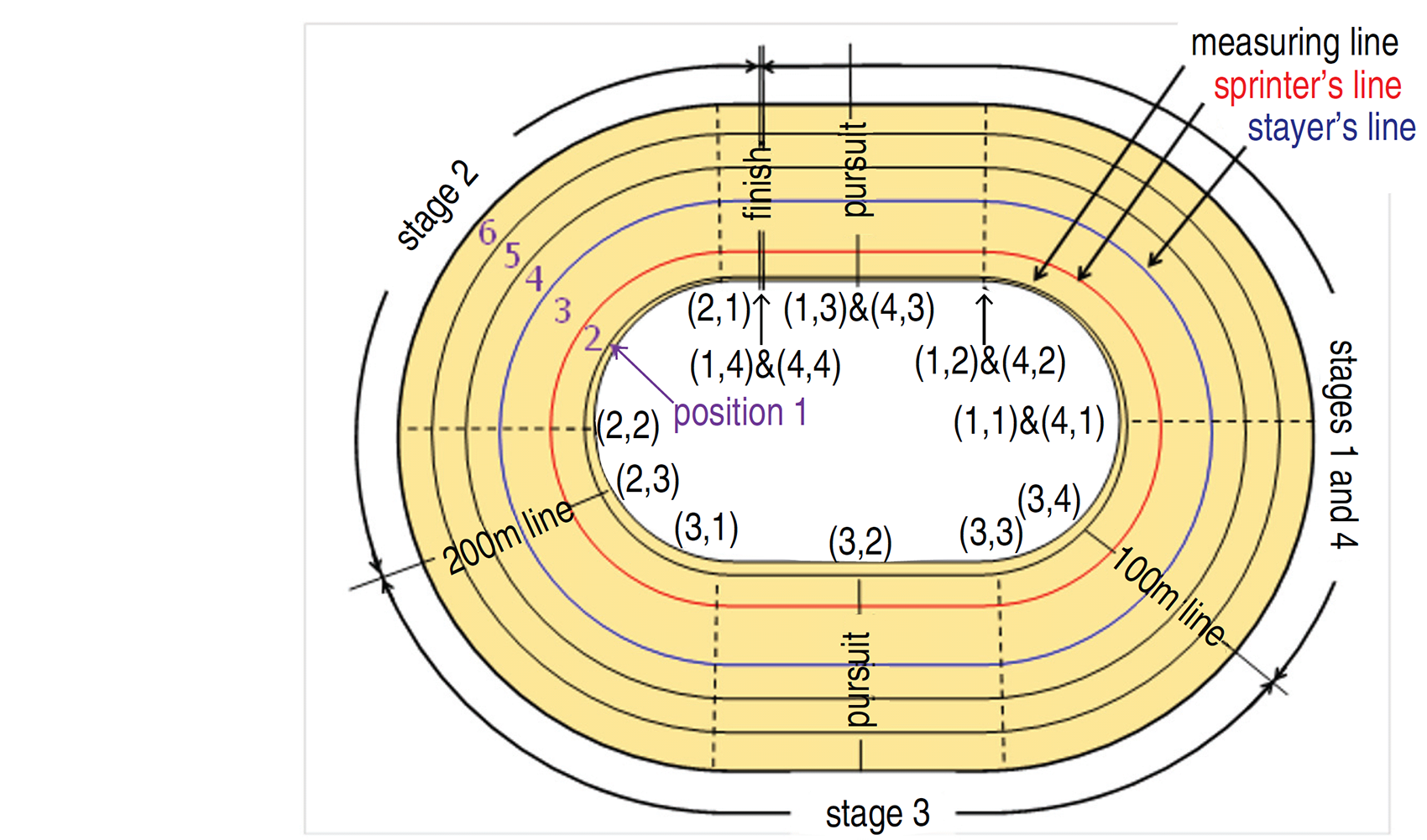
The faster rider (rider with the faster flying speed) does not always win; in the dataset used to build the model, the faster rider won 71
In each model (1–3), we assign the reference rider as the faster rider by ‘flying speed’, and the outcome is recorded from the point of view of this rider. For modelling, we divide the race into the following stages as shown in Figure 1. Stage 1 is the last 100 m of the first lap (600 m to 500 m to go). Moffatt et al. (2014) found race tactics not to be important prior to 600 m to go; therefore, this part of the race was not considered. At the end of stage 1, there are two laps (500 m) to go. Stage 2 is the next 50 m, stage 3 is the next 100 m and stage 4 is the final 100 m of the second lap (see Figure 1). Thus, four regressions are fitted at 500 m, 450 m, 350 m and 250 m to go. Tactically, the second lap is the crux of the race, and riders are committed to their actions as they enter the final lap: sprinting flat-out to hold the lead while staying inside the sprinter's line or slipstreaming and overtaking around the final bend.
Model 1 was fitted using the standard functions available in the R programming language (R Development Core Team, 2016). The fitting of Models 2 and 3 was implemented in MATLAB
As discussed in Section 3.3.1, for this application we assume that
In order to directly compare Models 1 to 3, the same sets of covariates were used. These covariates were selected when applying the sequential model (Model 2) rather than the measurement error model (Model 3). This approach is likely to be more stringent because the sequential regression model is more optimistic about the size of effects, and this approach also had the advantage of reducing the computational burden (Moffatt, 2012).
Results
Tables 2 and 3 show how the interpretative complexity of the naïve sequential regression (Model 1) increases through the stages. The parameter estimates are generally more significant and the standard errors are generally larger for the naïve sequential model (Model 1). There are many more covariates in the naïve sequential models; therefore, there are not as many events (event being the outcome which occurred less often, i.e., win or lose in this case) per covariate term. Even at 450 m to go, there are only nine events per covariate term, reducing to five events per covariate term at 250 m to go. This suggests that the naïve sequential models in general are likely to be unstable/poorly estimated at later stages, particularly when there are many covariates in the models. Peduzzi et al. (1996) found in a simulated study that the variability in the parameter estimates becomes large and, hence, inaccurate when there are less than 10 events per covariate.
Parameter estimates, standard errors and p-values for the three models at stages 1, 2 and 3: 1, naïve sequential logistic regression; 2, sequential logistic regression; 3, sequential logistic measurement error regression.
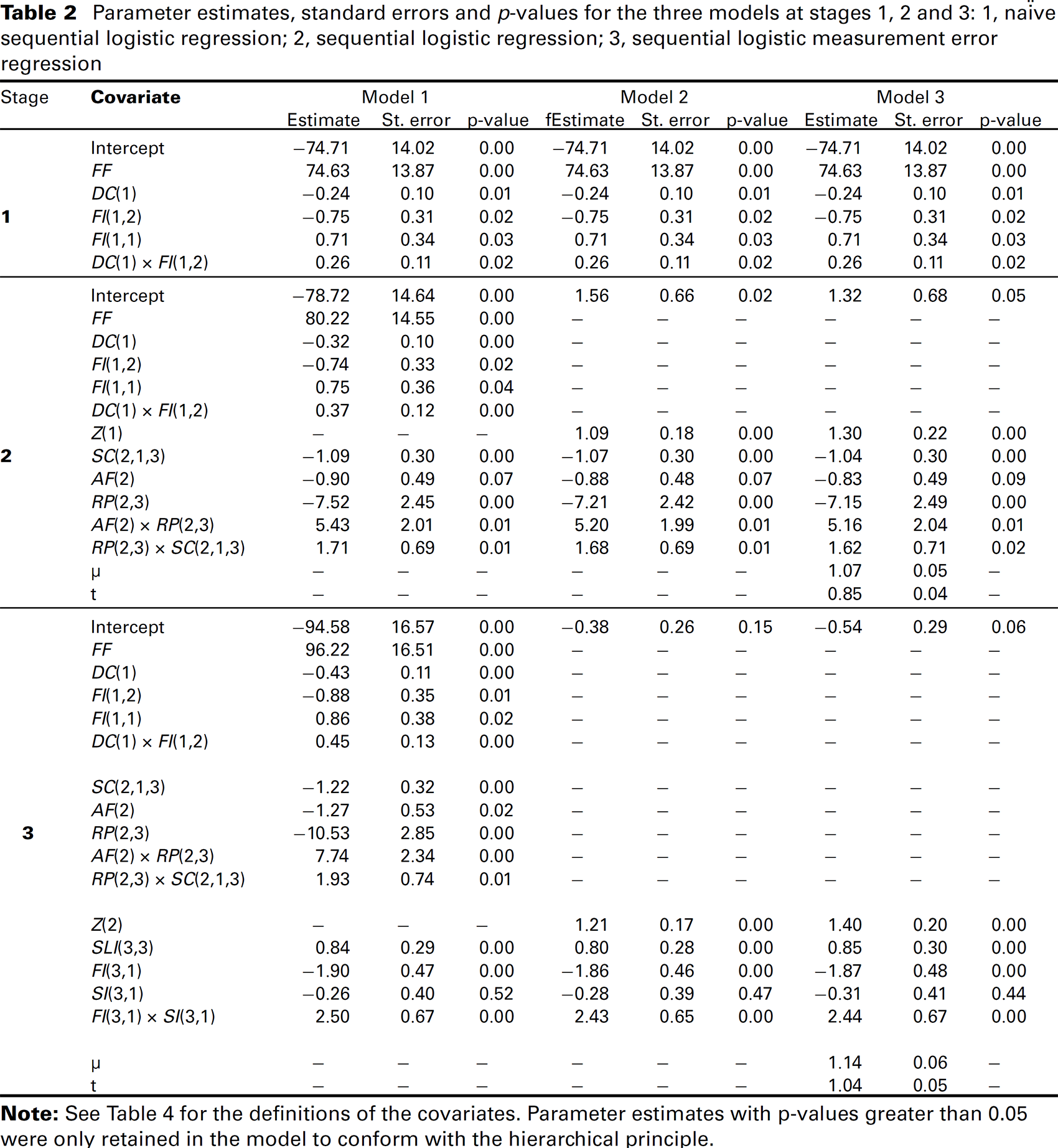
Parameter estimates, standard errors and p-values for the three models at stages 1, 2 and 3: 1, naïve sequential logistic regression; 2, sequential logistic regression; 3, sequential logistic measurement error regression.
Parameter estimates, standard errors and p-values for three models at stage 4: 1, naïve sequential logistic regression; 2, sequential logistic regression; 3, sequential logistic measurement error regression.
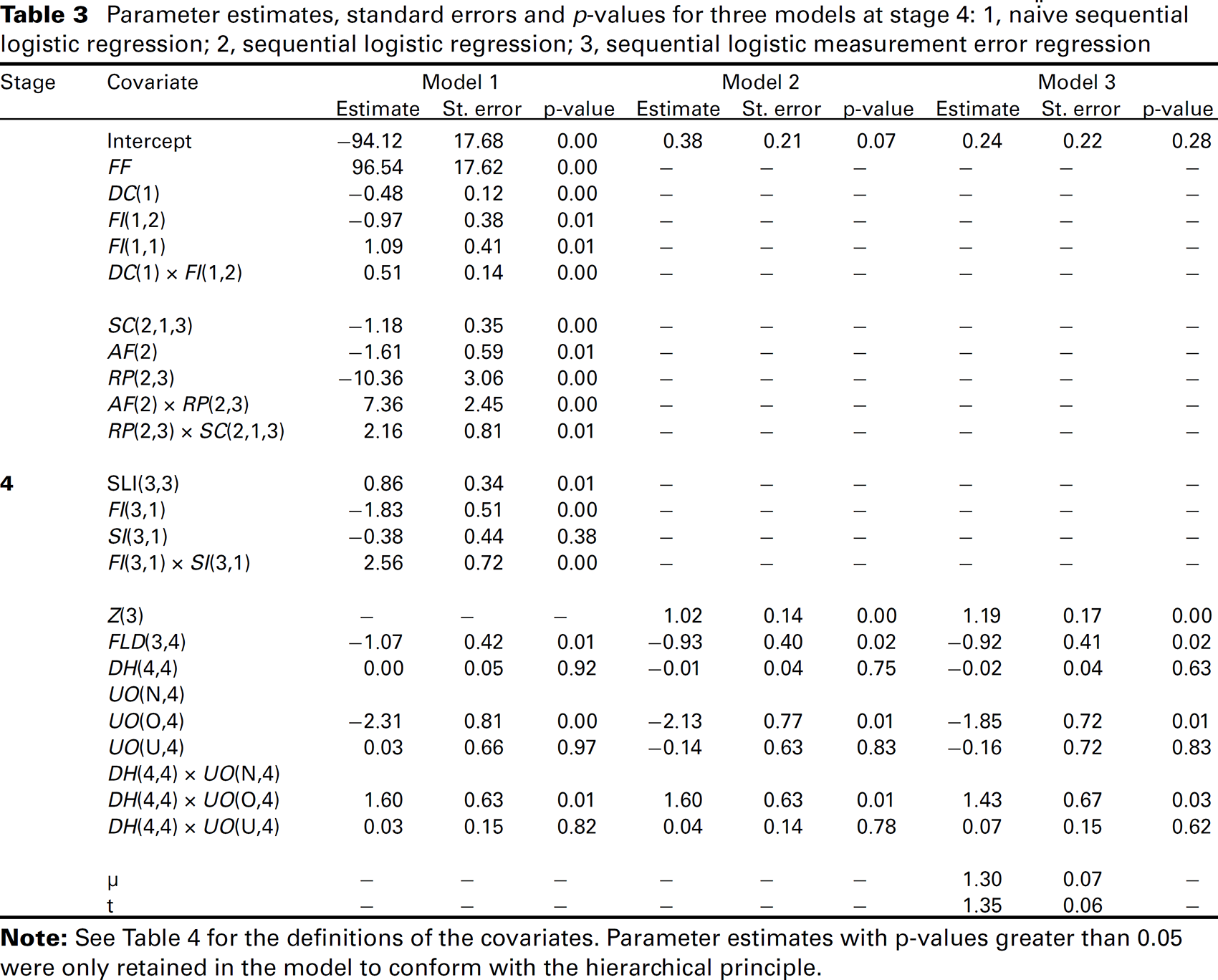
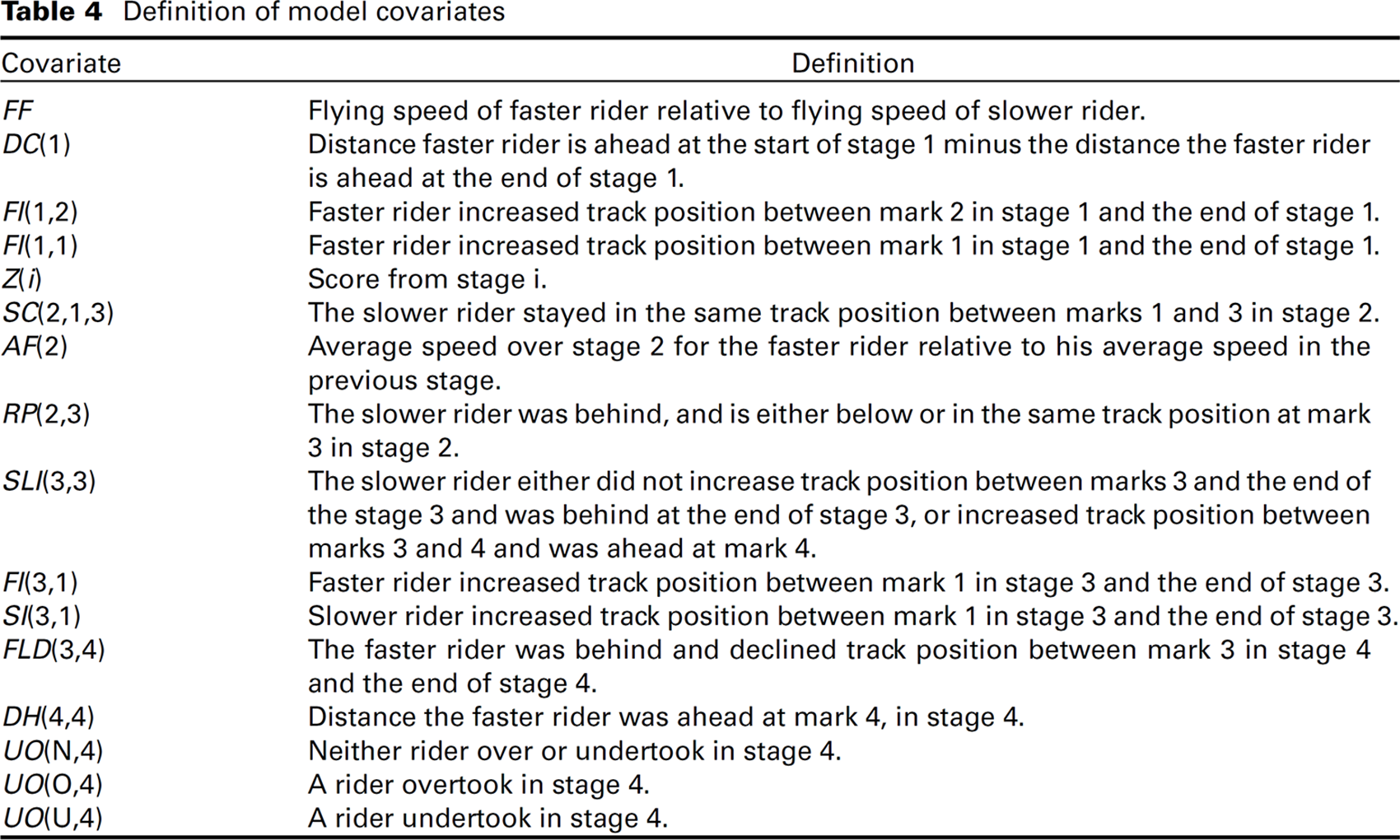
Definition of model covariates
The sequential regression (Model 2) reduces this complexity; however, as discussed in Section 3, the sequential model assumes that the estimated score is measured without error, which is not true. When accounting for error in the score (Model 3) with a well-established measurement error method for our dataset, the estimated effect of the score at each stage is between 16% and 19% higher than when not accounting for error in the score (Model 2). This indicates that not accounting for the error in the score can lead to the estimate of the effect of the true unknown score being biased towards zero. The parameter estimates for most of the revealed covariates are similar for the sequential and sequential measurement error models. Therefore, the effect of the actions riders apply on win probability at each stage is similar for the sequential and sequential measurement error models. The key actions and race states that appear to influence race outcome at each stage are described in the next sub-section. However, the sequential model which underestimates the effect of the true unknown score, therefore, conversely overestimates the effects of revealed covariates. In this way, the sequential model places more importance on race actions and less on the ratio of flying speeds (the covariate that dominates the score) than the sequential measurement error model.
The parameter estimates which are most dissimilar for the sequential and sequential measurement error models are UO(O,4) and DH(4,4)
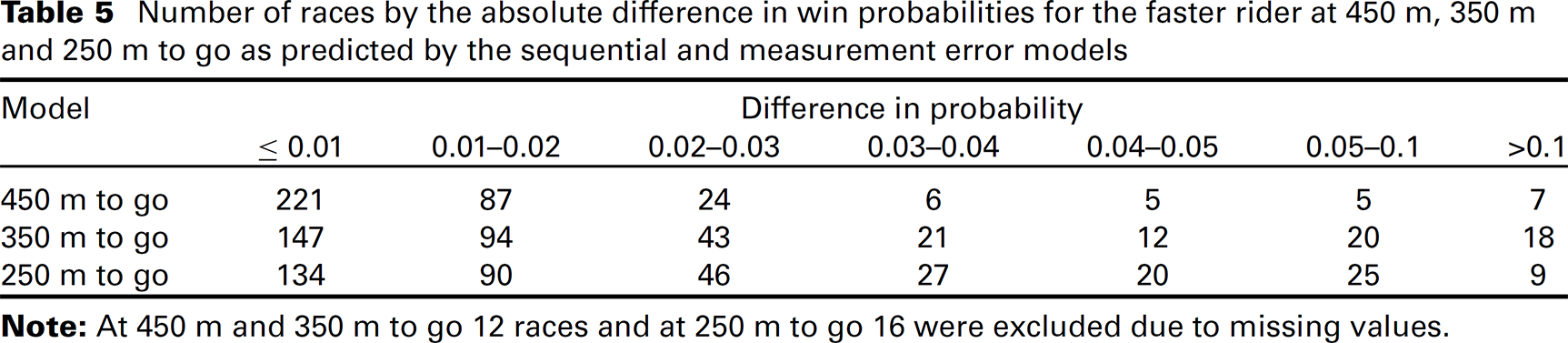
Accounting for the error in the score also led to differences in the predicted win probabilities, which generally increase with the stage. At 450 m to go, for the majority of races, these differences are within the range
Number of races by the absolute difference in win probabilities for the faster rider at 450 m, 350 m and 250 m to go as predicted by the sequential and measurement error models.
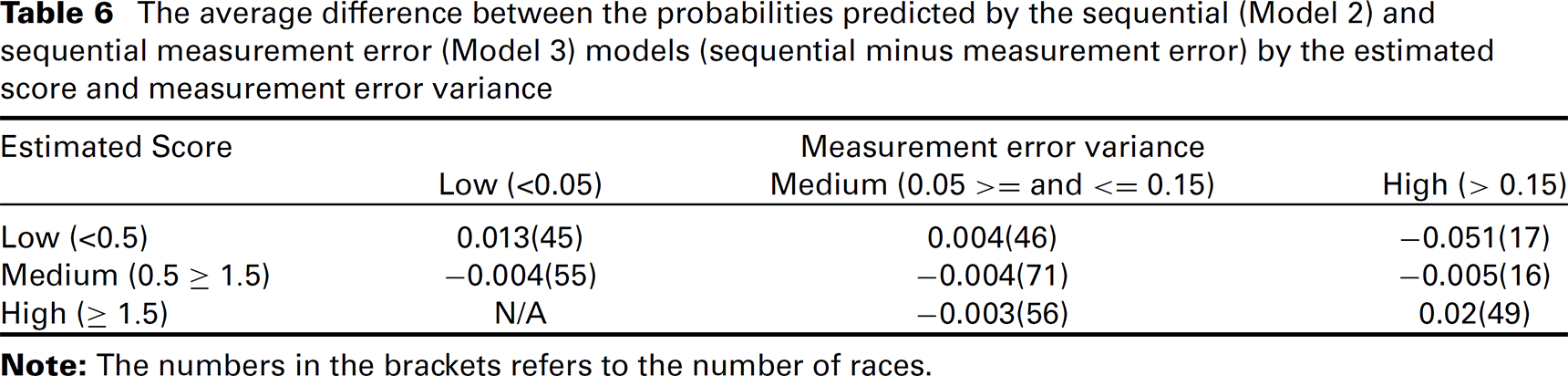
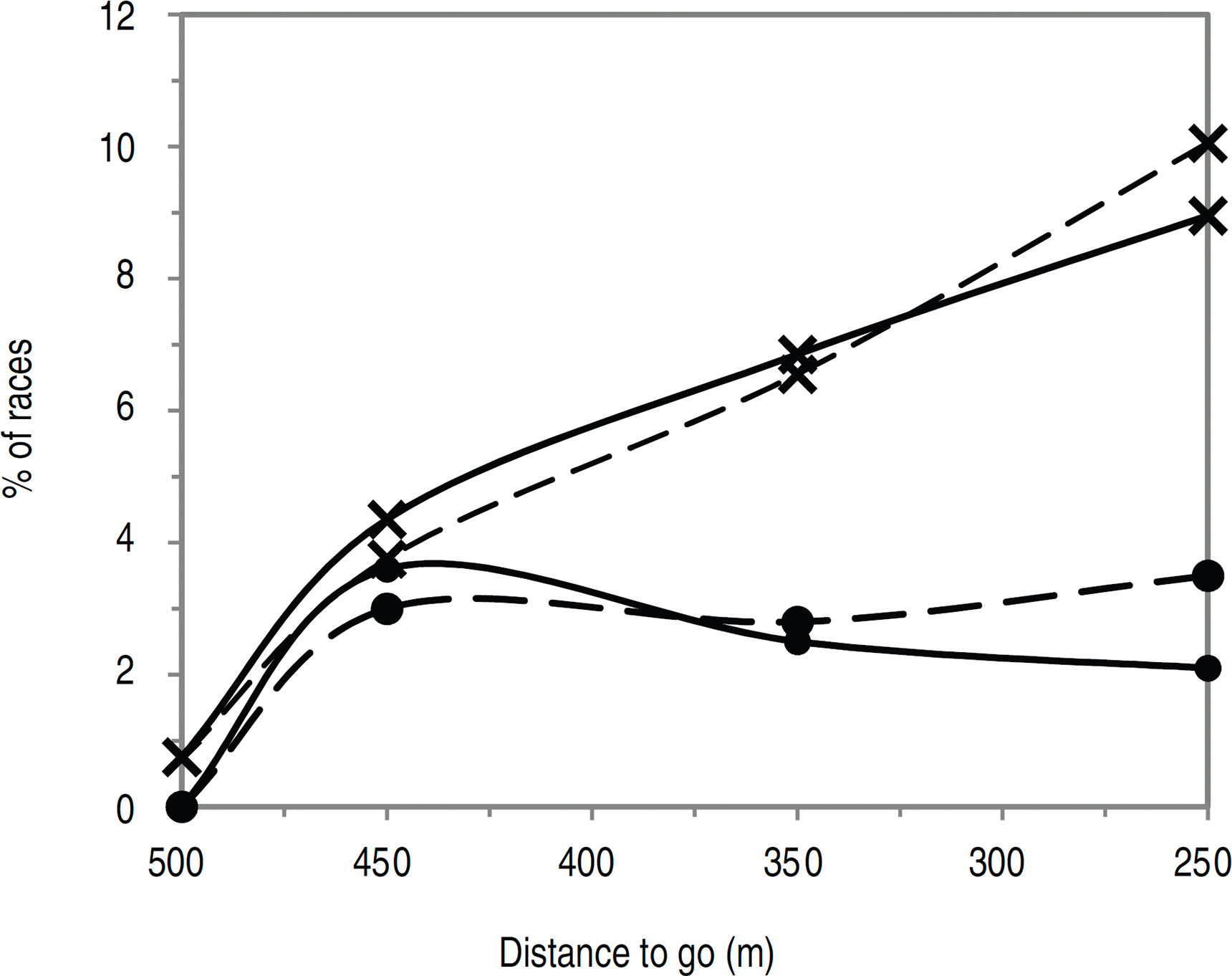
The differences in the probabilities predicted by the sequential and sequential measurement error models were investigated further. It was found that the model which predicted the higher probability of winning depends on the size of the measurement error variance as shown in Tables 6 and 7. When the measurement error variance is high and the estimated score is extreme (i.e., away from the median value), the sequential measurement error model predicts a less extreme win probability, as there is more uncertainty in the estimated score. An exception to this is when the estimated score for Model 3 is much more extreme than that for Model 2. Then, the sequential measurement error model predicts the more extreme probability (see Table 7 where the estimated score for Model 3 is more extreme and, at least, 0.02 lower). Overall, however, the measurement error model produces less extreme probabilities. A race which has an extremely high or low score at this stage of the race suggests that the outcome of the race has been decided. This seems very unlikely to be the case before 250 m to go and suggests that the extreme probabilities (less than 0.05 or greater than 0.95) predicted by the sequential model are questionable. For example, at 450 m to go, the riders are typically riding relatively slowly (around half of their maximum speed) and only around half of leading riders at this stage go on to win. Figure 2 shows an example of the effect a high measurement variance has on the difference in the predicted probabilities for a set of influential actions at 450 m to go for one particular race.
The average difference between the probabilities predicted by the sequential (Model 2) and sequential measurement error (Model 3) models (sequential minus measurement error) by the estimated score and measurement error variance
Win probability for the faster rider at 450 m to go (end of stage 2) as a function of AF(2), when SC(2,1,3) = 1 and RP(2,3) = 0 (see Table 4 for covariate definitions) for three cases with a low score Z(1), (–x–) =
0.12, (– –) =
0.38 and (–
–)=
1.16, and with a low (0.05), medium (0.14) and high measurement error variance (0.67), respectively. Win probabilities are shown for the sequential model (
) and the (—) sequential measurement error model.
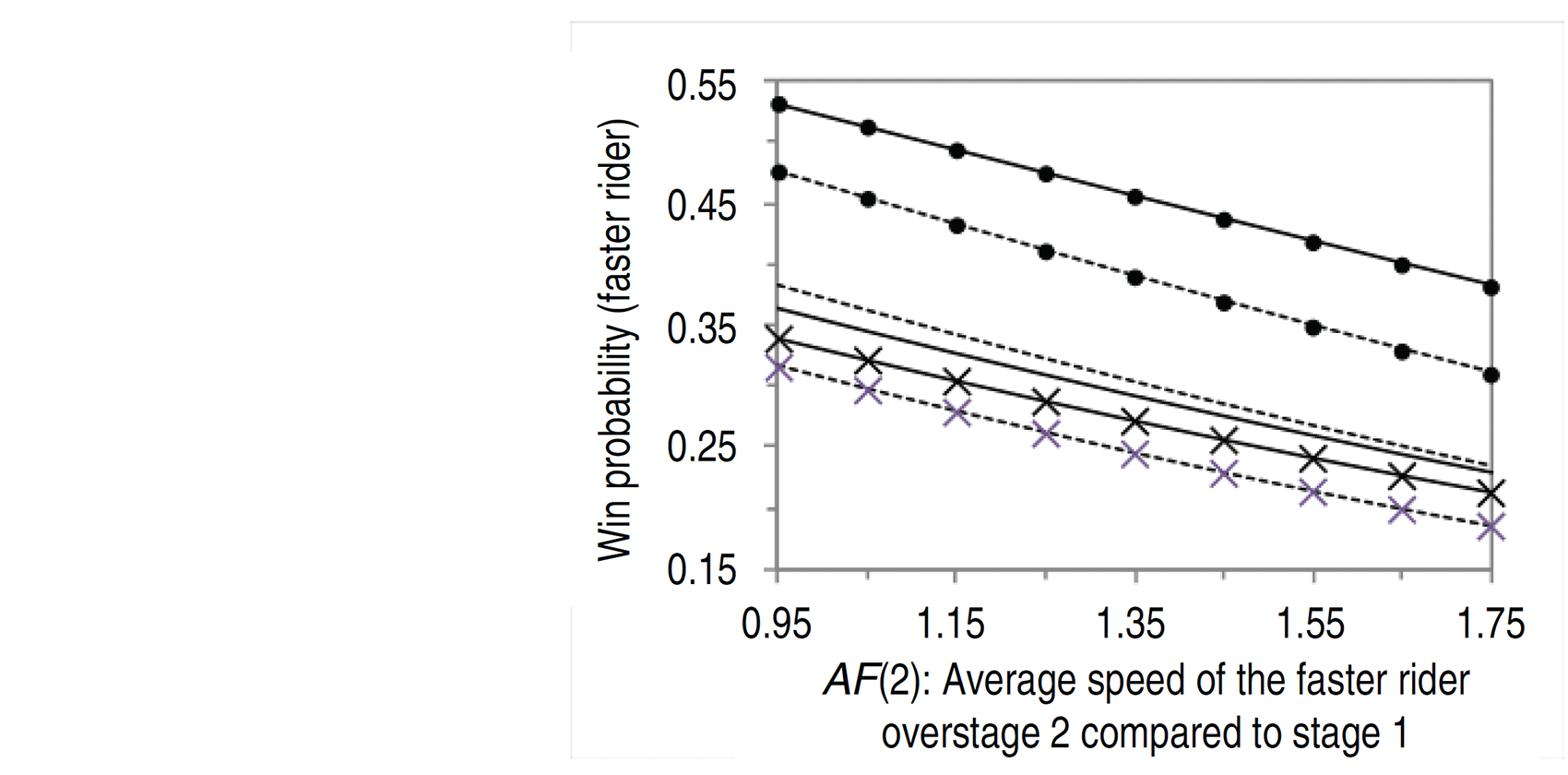
When the measurement error variance is low and the estimated score is extreme, the sequential measurement error model predicts a more extreme probability of winning for the faster rider, as there is more certainty in the estimated score. Tables 6 and 7 show the average difference predicted by the two models and Figure 2 shows an example of the effect a low measurement variance has on the predicted win probabilities for one race. The exception is when the estimated score for Model 3 is less extreme in comparison to the estimated score for Model 2. Then, the opposite becomes true in that the measurement error model predicts the less extreme probability. When the estimated score or measurement error variance is close to the median value (over all races), the win probabilities are similar at 450 m to go. At both 350 m and 250 m to go, when the estimated score for Model 3 is close to the median value, the difference in the win probabilities mostly depends on the difference between the estimated scores for Models 2 and 3.
The fit of both Models 2 and 3 were compared by calculating the Somers’ D value, which is a measure of association between the observed and predicted responses. No extra data was available to test how well the models fit on a different dataset. Instead,
The average difference between the probabilities predicted by the sequential (Model 2) and sequential measurement error (Model 3) models (sequential minus measurement error) by the estimated score from the sequential measurement error model (Model 3), measurement error variance and whether the estimated score for the sequential measurement error model (Model 3) is higher than, similar to or lower than the estimated score for the sequential model (Model 2).
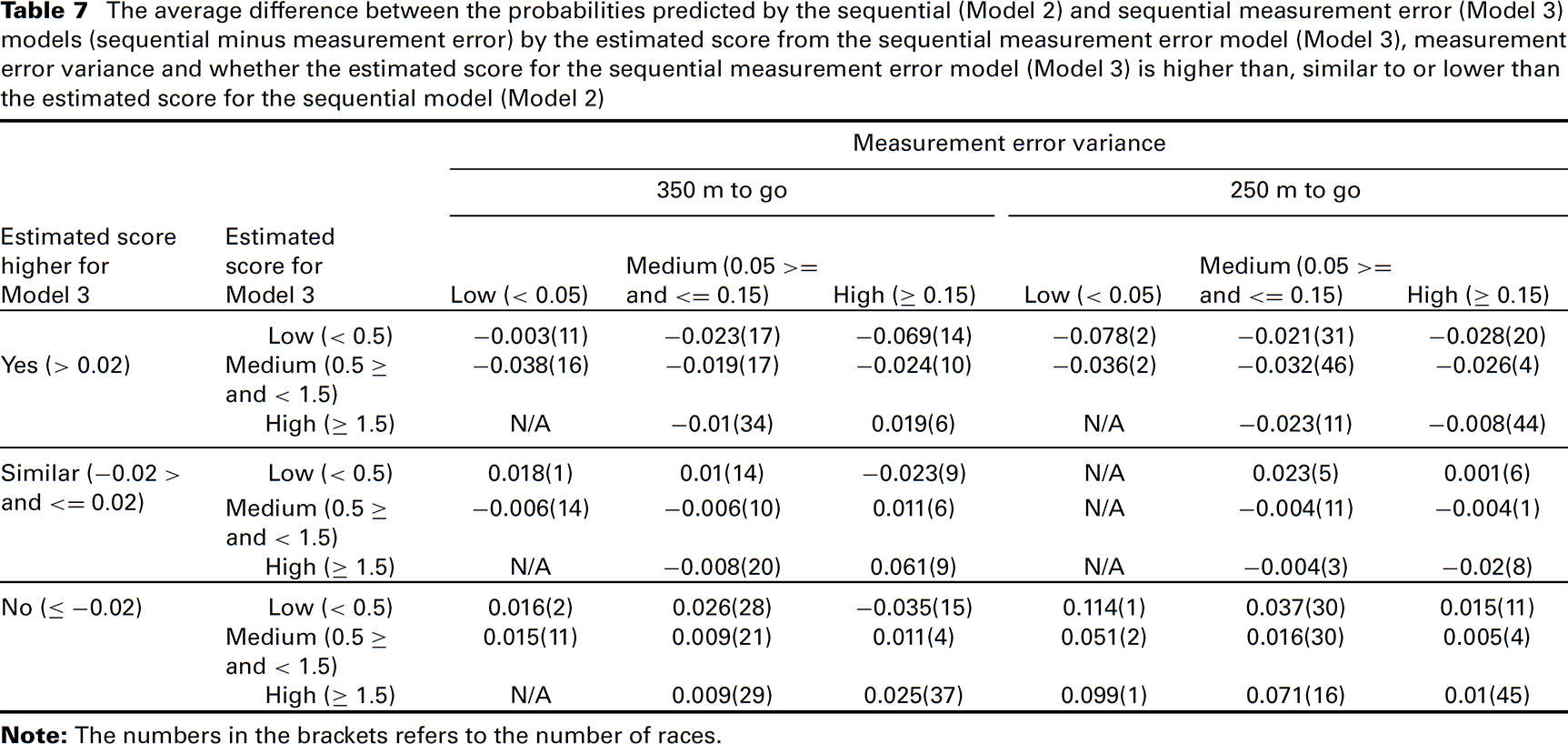
the Somers’ D value was calculated on the same dataset used to the build model, but this value was adjusted using Efron's 0.682 estimator (Efron, 1983), which is used to adjust for the over-optimism in a Somers’ D value which is calculated based on the dataset used to fit the model. The Somers’ D value was similar for both the sequential and sequential measurement error models at all stages, with some evidence of the sequential model performing better at 350 m to go (see Figure 3). However, because large differences in the probabilities predicted between Models 2 and 3 were found for only a few races, the differences between the Somers’ D values will also be small.
The association between observed and predicted responses at each stage for the sequential model (–
–) and the measurement error model (–x–) as measured by Somers’ D (adjusted using Efron's 0.682 estimator).
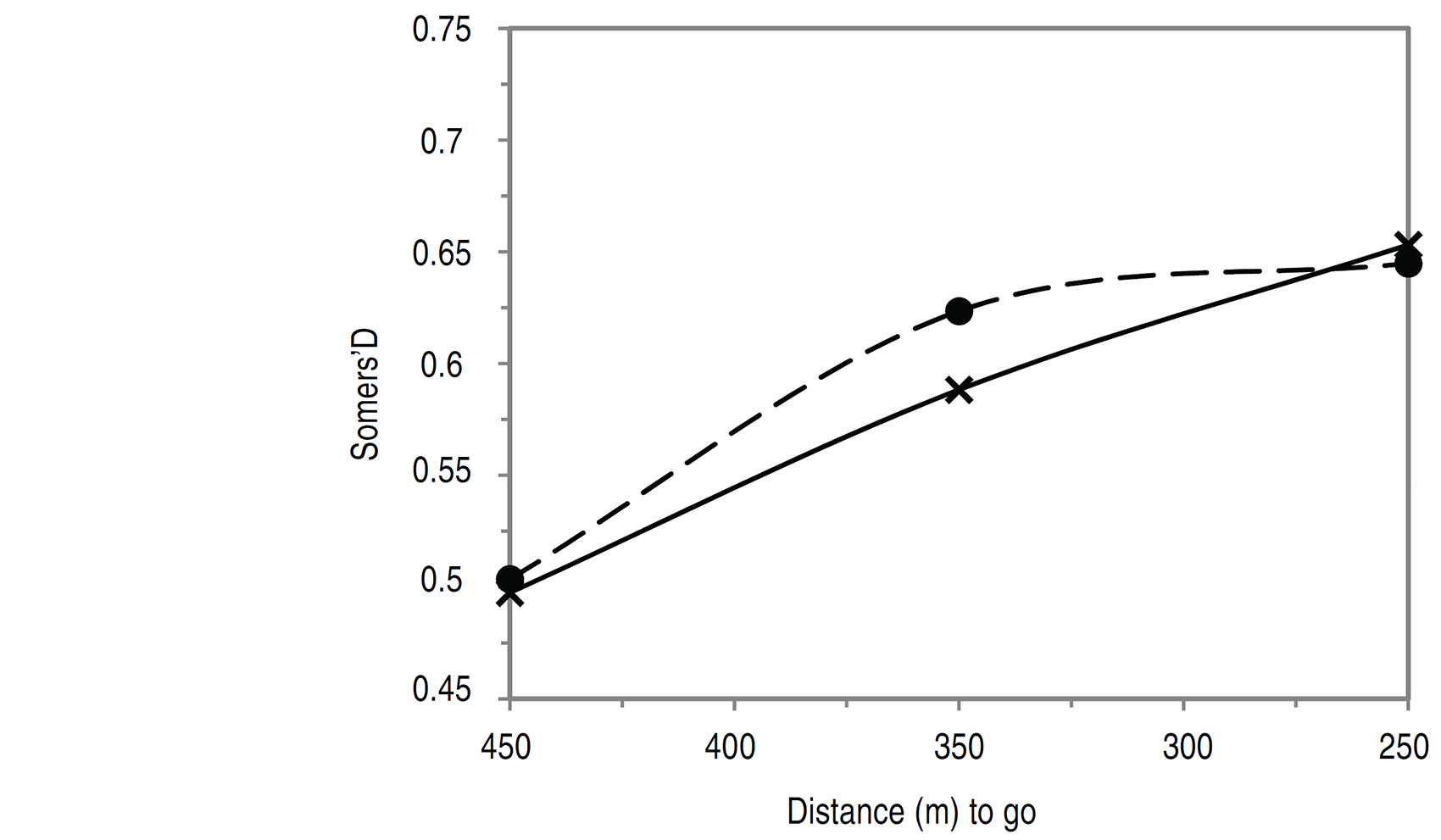
The key actions and race states that appear to influence race outcome, at each stage, are discussed here. The relative flying speed (FF) is the most important covariate. However, all models indicate that the faster rider will not always win and that tactics (quantified through the revealed covariates) have important effects. The importance of race tactics is demonstrated and compared for both the sequential and measurement error models in Figure 4 which shows the percentage of race outcomes correctly predicted over and above that predicted by assuming the faster rider wins (71%). This gives the proportion of races for which race states and actions applied before the end of each stage are influential. This is similar for both models, only 1% at 500 m to go rising to 9% at 250 m to go for the sequential model and slightly lower (8%) at 250 m to go for the measurement error model. Figure 4 also shows the proportion of races which can be accounted for by the actions and states applied during each stage (the percentage of race outcomes correctly predicted over and above that predicted by assuming that the faster rider wins at the current stage minus that at the previous stage), which remains approximately constant between 450 m and 250 m to go at around 3% for both models. Overall, the similar performance is not surprising considering that for the majority of races, the predicted win probabilities are similar for the two approaches.
Percentage of races accounted for by race states and actions: (–x–) applied up to and including the end of the current race stage, (–
–) during the current stage for the sequential (–––) and sequential measurement error models (– –).
Percentage of races accounted for by race states and actions: (–x–) applied up to and including the end of the current race stage, (–
–) during the current stage for the sequential (–––) and sequential measurement error models (– –).
As discussed in the previous section, the parameter estimates for both models are similar and so are the key actions and race states that appear to influence race outcome. From the parameters estimates which are displayed in Tables 2 and 3, the key actions and race states that appear to influence race outcome are identified for each stage.
In stage 1, a key finding is that the faster rider should increase track position between mark 1 and mark 2 and then either stay in the same track position or move to a lower one by the end of stage 1. He/she should also reduce the distance ahead over the stage if leading to better judge any sudden overtaking attempts or save energy for later in the race. A faster rider who is following should reduce the distance behind if following.
In stage 2, the slower rider can take advantage, if the opponent is not accelerating, by being behind and either in the same track position or lower than the faster rider by the end of the stage. The slower rider should also change track position between marks 1 and 2 in stage 2. Changing track position may allow the rider to save energy where the track gradient is high.
In stage 3, the faster rider has a very low chance of winning if he/she increases track position between mark 2 and the end of stage 3 when the opponent does not increase track position. This implies the faster rider has wasted energy by increasing track position and, hence, loses an advantage at later stages in the race.
In stage 4, both riders should overtake if behind; the faster rider should also be far ahead (2 m). It is better to overtake than undertake or already be leading the race at the beginning of this stage. A faster rider who is behind and does not over take or under take considerably reduces his/her chances of winning by decreasing track position during this stage (see Table 2; FLD(4) = 1), as the rider may have been unsuccessful in overtaking during this stage, and so overtaking during the remainder of the race will be more difficult to achieve.
A new approach is presented for analyzing the relationship between the outcome of a process with several stages and covariates that are revealed at each stage when the number of influential covariates is large. The approach extends the sequential model of Elisheva et al. (2000) by accounting for the measurement error in the estimated score. The approach is applied to the sprint event in track cycling with the aim of explaining race outcome and the following is found:
The score allows stable models to be created while capturing information from previous stages. Fewer terms in a sequential approach (in comparison to the naïve approach) also mean that the models are easier to interpret. However, the score is measured with an error. A new approach is developed to incorporate for this error and we show for our application that not accounting for measurement error in the score leads to the estimated effect of the score being biased. For other terms, the bias is small, except for terms where the corresponding states or actions occurred infrequently in the dataset. The sequential model places more importance on race actions and less on the ratio of flying speeds (the covariate that dominates the score) than the sequential measurement error model. In application to the sprint cycle race, the difference in predicted win probabilities between the sequential and measurement error models is also found, and it generally increases with each stage. The sequential model would predict on an average the more extreme probability, which when used in the subsequent stage via conversion to a score leads to an even more extreme probability. For some races, the probabilities predicted by the sequential model are unrealistically high or low, which are compounded at later stages. The sequential model predicts high chances of outcomes at 450 and 350 m to go for some races, but for this event it is highly unlikely that the outcome of the race has been decided at this stage. This illustrates that the measurement errors propagate through the stages in a sequential approach. The measurement error technique adjusts the win probabilities (compared to the sequential approach) depending on the magnitude of the measurement error. The measurement error model predicts more extreme win probabilities when the measurement error variance is low and less extreme win probabilities when the measurement error variance is high. At stages 3 and 4, this effect also depends on the difference between the sequential and estimated scores, with the measurement error model predicting more extreme probabilities if the estimated score is more extreme and vice versa.
It is assumed that the true score is not correlated with the other observed covariates revealed in the current stage. This assumption is tested and shown to be valid for the application we described in Section 4. However, this may not be the case for a different application. Future work could involve adjusting the model to allow for such correlations. The approach could also be readily extended to incorporate variable selection techniques when little prior information is available about which covariates are influential on outcome.
Overall, we would suggest that it is essential to use measurement error techniques in a sequential approach to avoid bias in the estimation of the parameter for the score and, hence, to avoid misleading conclusions being drawn when determining the effects of covariates on outcome, especially when considering the relative importance of previous and current actions and states. These conclusions are applicable to the statistical analysis of sequential processes more generally outside of the sports example presented in this article, including, for example, medical intervention where extreme predicted probabilities could lead to the wrong decision being made about the most appropriate treatment. The real benefit of this approach will vary with application and may be assessed by preforming simulations.
Footnotes
Acknowledgments
This work has been supported by the Engineering and Physical Sciences Research Council of the UK under grant number EP/F005792/1. Data underlying the findings are fully available without restriction from [DOI: 10.17866/rd.salford.3839703]. We are grateful for the cooperation of the English Institute for Sport for use of the data and the help of Paul Barrett, Mike Hughes, and Duncan Locke and Jan Van Eijden of British Cycling.