
Abstract
In this article, we advocate for qualitative research using LLM chatbots. While qualitative research may seem incompatible with generative artificial intelligence, we argue that these tools are fundamentally qualitative as they are built from text and are sensitive to social meaning. However, research using LLM chatbots should adhere to standards for reflexivity, in which researchers critically reflect on and accept accountability for the complexity and ambiguity inherent in the research process. Instead of emphasizing statistical validity and generalizability, responsible research with LLM chatbots requires technological reflexivity: examining model bias; researcher-algorithm interaction; critical evaluation; transparency; methodological reflexivity; and ethical considerations. We describe LLM chatbots, highlighting key considerations with using them. We demonstrate technological reflexivity in research with LLM chatbots and consider the impact of LLM chatbots on qualitative research outcomes. LLM chatbots can accelerate the research process, assist with thematic analysis, reveal researchers’ background assumptions, and make coding decisions more transparent. However, LLMs also introduce additional complexity into the research process, requiring researchers to manage important issues related to LLM model selection, personal and sensitive data protection, and the limits of informed consent. We conclude that, when used reflexively, LLM chatbots can make a positive contribution to the analysis of qualitative data. However, LLM chatnots cannot replace human researchers because research results must still be interpreted qualitatively.
Introduction
The rise of generative artificial intelligence in the form of chatbots driven by large language models (LLMs)—the AI behind widely known platforms like ChatGPT, Gemini, and Microsoft Copilot—is one in a long line of technological developments likely to influence the way qualitative research is conducted (for more information on other digital tools shaping qualitative data collection and analysis, see Paulus et al., 2025 and Reyes et al., 2024). Qualitative social scientists have adjusted their methods in response to the advent of computers (Brent, 1984), the introduction of word processing programs (Freidheim, 1984), the development of software for qualitative analysis (Shelly and Sibert, 1986), and the emergence of voice recognition software for transcribing interviews (Park and Zeanah, 2005). More recent innovations for digital data collection, like Skype (Deakin and Wakefield, 2014) and Zoom (Archibald et al., 2019), are used in qualitative interviews, and software like NVivo and ATLAS.ti support automatic coding (Kalpokas and Radivojevic, 2022; Kirgil and Voyer, 2022). Like these past developments, we can expect that qualitative researchers will work with LLM chatbots.
There is a growing literature on the use of LLMs in qualitative research (e.g. Bano et al., 2024; Barany et al., 2024; Chen et al., 2018; Friedman et al., 2025; Hau, 2025). However, this literature is often written by computational social scientists who presume a data science background, and sometimes even argue that only those with expertise in data science should use LLMs for qualitative research (e.g. Azaria et al., 2024; Bano et al., 2024). Meanwhile, many qualitative researchers remain skeptical. For example, Friedman et al. (2025) argue that LLMs do not achieve the credibility, consistency, and intersubjective accountability required for rigorous and ethical qualitative analyses. We disagree.
This paper addresses the clear need for literature geared to qualitative researchers deciding if and how to use LLM chatbots 1 in their research. Given that much of the computational social science literature already concludes that LLMs and related tools are reliable and effective for qualitative text analysis (e.g. Do et al., 2024; Gilardi et al., 2023; Törnberg, 2023), we ask the next logical question: What does it mean to use LLMs as a qualitative research tool, and how can researchers do so responsibly?
The qualitative characteristics of LLMs
Qualitative analysis positions human meaning-making and the interpretation of meaning at the center of research. For this reason, qualitative research generally involves the interpretive analysis of qualitative data through the systematic labeling or tagging of specific elements, such as themes, sentiments, entities, or events (Deterding and Waters, 2021). Coding enables researchers to identify patterns, observe changes over time, and draw meaningful insights (Grimmer et al., 2022; Reyes et al., 2024). Through interpretive analysis, researchers move from specific details and descriptions to broader conclusions and explanatory accounts (Reed, 2011).
The human and interpretative characteristics of qualitative research may seem incompatible with generative artificial intelligence like LLM chatbots, but we argue that these tools are fundamentally qualitative (see also Nelson, 2021). Bias and ambiguity are key characteristics of both qualitative research and LLM chatbots—arising from the complexity of the texts that LLM models are trained on and from the fact that generative AI is designed to improvise when it produces text of its own (Cambo and Gergle, 2022; Langenohl, 2021). This makes LLM-based tools less aligned with quantitative research. Quantitative research operates in a more positivistic paradigm characterized by a preference for parsimonious research designs, randomization, and statistical techniques that minimize the impact of confounding variables along with a corresponding focus on verification, consistency of results, and external validity (Cambo and Gergle, 2022). However, these ideas about quality in quantitative research were also shaped by technological developments—most importantly, the rise of statistical computing (Blalock, 1989).
Meanwhile, qualitative research quality is grounded in the emphasis on reflexivity in which researchers embrace, reason through, and accept accountability for the complexity and ambiguity that arise and are managed during the research process (Bourdieu, 1990; Giddens, 1984). Qualitative researchers, therefore, already work in a research context compatible with LLM use—a context characterized by the acceptance of subjectivity and positionality of both the researcher and the research participants (Reyes, 2020; Yin, 2011). Indeed, qualitative social scientists and researchers in the digital humanities were among the first to recognize the research value of language-based AI-driven technologies (Do et al., 2024; Mohr, 1998; Underwood, 2019).
The characteristics of LLMs and LLM chatbots are so well-aligned with qualitative research practice that data scientists have argued for the need for qualitative reflexivity in working with LLMs and other generative AI (Cambo and Gergle, 2022; Langenohl, 2021). In other words, qualitative researchers do not need to adopt quantitative understandings of research quality when working with LLM chatbots. Instead, responsible research with LLM chatbots requires technological reflexivity (Paulus et al., 2025), which includes examining how LLMs influence the research findings by reasoning through the impacts of model bias, researcher-algorithm interaction, critical evaluation, transparency, methodological reflexivity, and ethical considerations, as described below.
In the following pages, we describe and demonstrate technological reflexivity in qualitative research using LLM chatbots. The paper consists of two parts. The first part discusses the growing use of LLM chatbots and other technological developments in qualitative analysis. 2 We explain what LLM chatbots are, highlighting important considerations that should determine if and how they are used. The interactive nature of LLM chatbots lowers the bar for accessing such technologies, making their use feasible for researchers without specialized training in data science—although qualitative researchers should understand the basics of LLMs as described below. This position is consistent with existing standards for quantitative research in the social sciences: not all researchers using statistical methods can derive new statistical approaches or reproduce the formulas on which those methods are based. Instead, it is sufficient for them to understand the methods, their parameters, and their strengths and limitations (see Davis, 1994: 182, 192). We see no reason to hold qualitative researchers to a different standard.
In the second part, we demonstrate techniques for using LLM chatbots, with examples from our research using ChatGPT. 3 We conclude that qualitative research with LLM chatbots can support a streamlined and possibly accelerated research process, contribute to increased transparency regarding the researchers’ background ideas and greater clarity in the construction of concepts and categories, and lead to the identification of additional categories and themes not discovered by the researcher. Furthermore, given rising expectations for how much data qualitative researchers are expected to work with, for example, expectations for more interviews and more hours of observation (Deterding and Waters, 2021), LLM chatbots can help qualitative researchers meet these increasing demands.
LLM chatbots in qualitative research
Qualitative research and LLM chatbots have a shared foundation in language. Qualitative social science is largely language-based and text-mediated (Elder-Vass, 2012), and the interpretive analysis of text data like fieldnotes, transcripts, and textual representations of images is fundamental to qualitative research. As explained by Smith, text is a crucial link between the experiences of individuals and the broader social context: Text enters the laboratory, so to speak, carrying the threads and shreds of the relations it is organized by and organizes. The text before the analyst, then, is not used as a specimen or sample, but as means of access, a direct line to the relations it organizes. (Smith, 1990: 3)
However, when it comes to computational tools like LLM chatbots in qualitative research, human researchers are still central (Mohr, 1998). It is not enough to leverage high-powered computational tools to analyze texts, because the results of such analyses must still be interpreted in a humanistic and qualitative way by people relying on their expertise and judgment. Nelson’s (2020) computational grounded theory is a prime example of an approach that applies qualitative logic to computational analysis, where the focus is on using computational methods to assist in interpretation (see also Nelson, 2021, 2022). Along these lines, LLMs and other NLP tools have also been used in interpretive studies of gender- and race-based stereotypes (Bolukbasi et al., 2016; Boutyline et al., 2023; Garg et al., 2018), political elites (Bonikowski and Gidron, 2016; Kirgil and Voyer, 2022), class distinction-making (Kozlowski et al., 2019; Voyer et al., 2022), and social movements (Almquist and Bagozzi, 2019; Nelson, 2021), among other topics.
A short primer on LLMs
LLMs are artificial intelligence systems built using machine learning techniques and text training data, and their function is to process text inputs and generate coherent language output (Azaria et al., 2024). LLMs operate using a neural network, a model consisting of layers of interconnected units that work together (Dayhoff, 1990). LLMs typically have millions or even billions of parameters to recognize statistical patterns in text data. The model develops these parameters through unsupervised learning, where the model attempts to predict the next word in a sentence based on the previous words. LLMs are built using enormous collections of digitized text. This text is used to train the model to “learn” language patterns, including how words are used in relation to other words. Over time, the model adjusts to improve its predictions (Wang et al., 2022). Once trained, LLMs can generate new text by selecting the next word in a sequence, based on the input provided. Trained LLMs can be fine-tuned for specific tasks by using smaller, specialized collections of texts (Chae and Davidson, 2025).
Due to the text-based nature of LLM chatbots, they perform well on language-based tasks. For example, they are good at finding specific words, determining the sentiment of words, and observing patterns in languages (Hau, 2025). However, LLM chatbots are not a source of facts as they provide answers to user questions without consideration of accuracy (Emsley, 2023; Goddard, 2023; Lozić and Štular, 2023). Furthermore, LLMs can only be described as “understanding” and having “knowledge” to the extent they are trained to recognize patterns connected to the expression of meaning, tone, and intention within and through text. However, this understanding is statistical and pattern-based comprehension, not human comprehension, which is grounded in the broader contexts of language use, including social contexts, body language, emotion, and identity (Kbaiah and Nashwan, 2024; Kooli, 2023; Zhang et al., 2019). As a result of their limitations, LLM chatbots can struggle to accurately process specialized and highly contextualized language (Hou et al., 2024). This is an important consideration for researchers working with highly specialized texts or theories.
Challenges of LLM chatbots
Qualitative researchers are well-equipped to manage the challenges of working with LLMs and LLM chatbots. We outline some of these challenges here.
The “black box problem”
Skepticism toward AI often concerns what is referred to as the “black box” problem (Castelvecchi, 2016). The complexity of LLMs and the fact that many LLM chatbots are proprietary means there is often little information available about the data, details, or decisions that shape the model. While this is cause for concern in any research endeavor, qualitative researchers already conduct research in the face of the “black box” of human thought and subjectivity. The opacity of algorithms is not unlike human coders whose perspectives, biases, and contexts influence the research process. We see technological reflexivity when working with LLM chatbots as an extension of the reflexivity typical of fully human qualitative research. For example, Reflexive Thematic Analysis explicitly accepts the researcher's positionality and interpretive agency, treating reflexive engagement with the subjectivity of the researcher as a crucial element of research practice (Braun and Clarke, 2019).
Privacy and ethics
Many LLM chatbots are products of for-profit companies that may retain user data (Jiao et al., 2024). Good research ethics demand that researchers comply with legal restrictions regarding personal data and requirements for informed consent that include making research participants aware that their data will be analyzed using LLM-based tools. For researchers working with LLM chatbots, it is of utmost importance to ensure that data is not retained by the LLM or that data given to LLMs is anonymized and pre-selected in a way that guarantees no harm to research participants should the data be accessed by a non-authorized party. This can also be an issue with regulations regarding personal data and privacy (Kooli and Al Muftah, 2022), which depend on the country where research is being conducted. For example, the European Union has taken specific steps to address this issue by instating the General Data Protection Regulation (GDPR), which outlines how personal data can be used. There have been documented cases of individual data being used in LLMs without consent (c.f. De Vynck, 2023).
LLM bias
Bias is introduced into LLMs through the biases in the selected training data and the selection of the training data itself. Large-scale digitization projects aimed at the world's biggest archives and libraries have produced abundant digital texts. Simultaneously, the 21st century has ushered in a golden age of natively produced digital text; from social media to closed captioning of debates to community announcements and newsletters, but there is a lack of representativeness in whose words, perspectives, and experiences are included in digitized texts (Navigli et al., 2023). As a result, LLMs can perpetuate stereotypes around gender, race, religion, and other social categories (Schramowski et al., 2022), with discriminatory results (Benjamin, 2019). Significant research examines LLMs’ biases (e.g. Liang et al., 2021; Navigli et al., 2023; Schramowski et al., 2022). Other efforts focus on debiasing LLMs, which is important not only for democratizing LLMs (Chen et al., 2018) but also to ensure better performance.
From the perspective of qualitative research using LLM chatbots, the biases of LLMs can be managed through reflexivity, which already takes into account researcher bias and positionality. LLM standpoint detection is an active area of research inquiry (e.g. Lan et al., 2024; Liang et al., 2021). Using Moral Foundations Theory as a baseline, researchers found that LLMs most closely resemble Western, educated, industrialized, rich, and democratic nations (Atari et al., 2023). This is good to bear in mind when accounting for the impact of LLMs on research. When selecting an LLM for use in qualitative research, the researcher should learn what they can about bias in the model and take it into account through technological reflexivity, as described below.
Model parameters
LLMs have internal parameters controlling how the model processes inputs and generates responses. One important parameter is temperature, which controls the randomness or creativity of the model's responses (Gilardi et al., 2023). A higher temperature introduces more randomness, allowing for diverse and creative responses, while a lower temperature makes the output more deterministic, providing more consistent results. For most LLM chatbots, model parameters are not manipulable by the user. However, qualitative researchers should learn what they can about the pre-set and adjustable model parameters of LLM chatbots they are considering. If they can adjust model parameters, qualitative researchers might choose to do so, just as they may provide more or less flexible instructions to human co-researchers (Goodell et al., 2016). For exploratory tasks, such as generating ideas or uncovering new themes in the data, a higher temperature can produce more diverse responses. For tasks that require consistency, such as applying codes, a lower temperature can make the model's responses more stable.
Selecting LLM chatbots
Like any methodological choice, the selection of an LLM chatbot should be explained and justified based on the question, theory, and aims of the research. We argue for a practical approach to model selection that supports methodological rigor without overburdening qualitative researchers with technical validation tasks. Computational social scientists routinely publish work comparing models that vary in size, training data, and architecture to understand their capabilities and limitations (e.g. Buttrick, 2024; Chae and Davidson, 2025; Do et al., 2024; Gilardi et al., 2023; Götz et al., 2024; Jacomy and Borra, 2024; Navigli et al., 2023; Törnberg, 2024; Zhou et al., 2023). Despite the variety of technical validation methods in use, human evaluation by experts remains the most trusted method for evaluating the nuance and contextual accuracy of LLM outputs (Abeysinghe and Circi, 2024). This reliance on expert human evaluators is consistent with our claims that LLMs are essentially qualitative tools that work well with the human, interpretive, and reflexive nature of qualitative research.
Qualitative researchers should consult the literature to understand how models differ, but they should rely on their own evaluation of the models’ performance in preliminary analyses. As described by Van der Lee et al. (2021), key criteria for evaluating whether a model functions as a useful and trustworthy analytic tool are: (1) adequacy or accuracy of the model's outputs in interpreting the data; (2) coherence in which the model's outputs are consistent across different responses; (3) relevance to the research question or analytic task; and (4) whether biases in the training data cause the model to miss, flatten, or misrepresent forms of meaning relevant to the research—particularly those associated with marginalized groups, non-dominant perspectives, or culturally specific language patterns. For example, some models, like OpenAI's GPT LLMs, are programmed to detect offensive language as part of a “community guidelines” setting, which leads the model to err on the more cautious side with rhetorical questions, sarcasm, poor language such as profanity, slurs, and stereotypes even in instances of neutral or positive connotations (Kumar et al., 2024). This model characteristic has an impact. If a researcher were examining toxicity on the Internet, the OpenAI model would not be suitable. However, if the research aim is to filter out offensive language (Argyle et al., 2023), OpenAI's LLMs would be appropriate to use.
Technological reflexivity in working with LLM chatbots
Reflexivity is a core element of qualitative research and refers to the ways in which researchers critically examine their influence on the research process, including biases, assumptions, positionality, and ethical considerations (Bourdieu, 1990; Reyes et al., 2024). Paulus et al. (2025) developed the concept of technological reflexivity to represent the ways qualitative researchers account for the impact of digital data collection practices, but we extend this concept to qualitative analysis with LLM chatbots as well. For our purposes, technological reflexivity includes considering the influence of LLM chatbots on study design, methods of analysis, and research results—more specifically, examining LLM model bias, researcher-algorithm interaction, performing a critical evaluation of findings, and engaging in transparency in analytical choices, epistemic reflection, and ethical critique. A visual overview of technological reflexivity is illustrated in Figure 1.

A checklist of the six different elements to consider when engaging with LLMs. These six elements make up good research practice in technological reflexivity.
To illustrate technological reflexivity, we provide two working examples from our research using the LLM ChatGPT (GPT-3). We selected this LLM as it was the most readily accessible large-scale model at the time, with a growing body of evidence attesting to its utility in qualitative research. Because our analytic tasks involved broad, non-specialist language, we determined that we did not require a domain-specific or fine-tuned model. As we worked with GPT-3, we confirmed through the early and pilot analyses that its responses were consistently accurate to the data, coherent, and relevant, satisfying the adequacy, coherence, relevance, and bias-sensitivity criteria outlined above.
In terms of our two examples, one took a deductive approach while the other took an inductive approach. The first example, henceforth referred to as Study A, is the deductive task of identifying different lifestyle items in politicians’ Twitter self-descriptions (Twitter bios). This task takes advantage of LLM chatbots’ ability to recognize words when guided with a direct prompt. We refer to this type of deductive and researcher-guided task as a specific use case that is directed on account of the delimited task and detailed instructions provided to the model. The second example, henceforth referred to as Study B, uses an LLM chatbot to uncover overarching themes in texts. We refer to this type of data-driven, inductive task as undirected due to the open questions provided to the LLM chatbot.
Model bias
As previously discussed, LLMs inherit biases from training data. Technological reflexivity in research using LLM chatbots means critically considering how these biases might shape the generated responses or analyses. This requires familiarity with research related to the specific LLM's positionality. Furthermore, bias in language can lead LLMs to miss the nuances of local language use and vocabulary (Kooli, 2023). Researchers should test the model's ability to understand local nuances and inflections important in their research setting or population.
The first step we took to examine the impact of model bias when it came to our data was to select and analyze a subset of data by hand. For Study A, we randomly selected 100 Twitter bios and manually coded them to make a codebook. 4 In qualitative research, a codebook is a living document that guides the process of data analysis by defining categories and codes assigned to the qualitative data, providing examples of where those codes can be applied, and including a record of decision-making (Reyes et al., 2024). Codebooks are particularly important when multiple researchers are collaborating (Roberts et al., 2019), and the LLM chatbot can be considered a participating researcher. We also use the selected Twitter bios as holdout data, also known as validation data or test data, to evaluate chatbot performance and check for bias (Dwork et al., 2015). By taking a sample of the data and hand-coding it independently, we can compare our results to the LLM chatbot's results and qualitatively assess the discrepancy to determine whether the model is doing what we intend it to do, just as one would do when looking to determine intercoder reliability in a project with multiple qualitative researchers. When it comes to technological reflexivity in the selection of LLM chatbots, different chatbots can be tested using the same holdout data, and the researcher can choose the model that performs best (Dwork et al., 2015).
Study B focused on uncovering themes in excerpts from etiquette books that dealt with smoking. The excerpts about smoking from each book were combined into a document consisting of the selected texts from that book, identified by year of publication (e.g. 1922_smoking.txt). Since the research was inductive, no key concepts or theories guided the analysis, and we did not use holdout data or develop a codebook in advance. Instead, before sharing the texts with the LLM, we read each document, memoing and jotting down ideas and observations as is customary in grounded theory and other inductive research (Glaser, 1992).
Researcher-algorithm interaction
When researchers use LLM chatbots, their interactions with the chatbot shape the direction of the research. Technological reflexivity requires that researchers consider how their use of the LLM chatbot impacts their research questions and analysis. Technological reflexivity means being mindful of how prompts and queries directed to the LLM chatbot are framed and how that framing expresses the researcher's perhaps implicit ideas and beliefs, eliciting particular responses from the LLM chatbot. Researcher-algorithm interaction also includes considering how the LLM chatbot impacted the thinking of the researcher. This is similar to considerations of team reflexivity among co-researchers in a project (Case et al., 2024) and considerations of researchers’ influence on interviews or focus groups through their questions and presence (Berger, 2015).
The codebook is a crucial tool for managing and documenting researcher-algorithm interaction. Furthermore, the chat interface is a record of the human-algorithm interaction, allowing for consideration and reflection on the researcher's role in guiding the model. Chats should be saved and analyzed by the researcher as a timeline of human-algorithm interaction.
Another key element of the researcher-algorithm interaction is prompt engineering (Giray, 2023). The prompt is the question or command delivered to the model, which plays a determining role in the quality and relevance of a chatbot's responses (Atreja et al., 2025). A prompt should include (1) instructions: a clear task or goal, (2) context: supporting details and relevant background knowledge to help the model interpret the text accurately, (3) input data: the text for the model to process, and (4) output indicator: the preferred style or structure of the output, for example, outline format (Giray, 2023). Prompt refinement is an iterative process that mirrors the creation of interview protocols and subject-researcher interaction. Research that was published after the conclusion of our studies finds that LLM compliance and accuracy are prompt-dependent: (1) providing the LLM chatbot with definitions for the categories or concepts it will apply increases accuracy; (2) asking the LLM chatbot to assign numerical scores instead of giving categorical labels reduces compliance and accuracy; and (3) asking the LLM chatbot to provide explanations for its work can raise compliance and shift the model output (Atreja et al., 2025). This research is further evidence that LLM chatbots are best used for qualitative tasks of categorization and interpretation, and should be prompted to explain themselves, something we did not do in our research.
In our examples, the formulation of a prompt varied depending on the task. In the case of Study A, there is a clear classification task, so after settling on the most specific and sufficient prompt, the prompt can remain the same each time. In Study B, the prompt was adjusted in interaction with the model, based on how the researcher chose to follow up on the response to the preceding prompt. Creating prompts is an iterative process. We started by providing the least information possible to gauge how much direction the LLM chatbot needed to produce useful results. For Study A, initially, we gave the LLM chatbot we worked with one Twitter bio and asked it to identify lifestyle words (see Figure 2).

Initial deductive prompt asking the chatbot to identify lifestyle elements from a single Twitter bio, used to gauge baseline performance and settle surface ambiguities in what counts as “lifestyle.”.
After this first prompt attempt, we notice one thing. The chatbot is unsure about what counts as lifestyles, something we had implicitly in mind when manually coding the selection of Twitter bios by hand, but did not specify in the prompt. Furthermore, there are some things in our codebook that have not been picked up by the chatbot. For example, the reference to graduating from MIT is a signal of education, which in the codebook is a lifestyle element and category of interest in the research. Additionally, it picks up the word “native” but not the entire phrase “San Fernando Valley native.”
As a result of these observations, we adjust the prompt to provide a more expansive definition of lifestyles. We also request the results in a clear table format (see Figure 3). The expanded lifestyle definition is sufficient to capture items outlined in the codebook. It has also led the chatbot to provide extra information, the relation to lifestyle, which we did not explicitly request. For example, there are new categories related to “advocacy or activism” and “aspirations or goals.” This was not in the original codebook, but it is an element of lifestyle that we did not capture, so we updated the codebook (see final codebook in Appendix) and retested the prompt again in a new chat. When the prompt in the new chat does not give the same categories, we rewrite the prompt to include new categorizations. Then we increase the number of bios we give the model to test if the categories are being detected correctly.
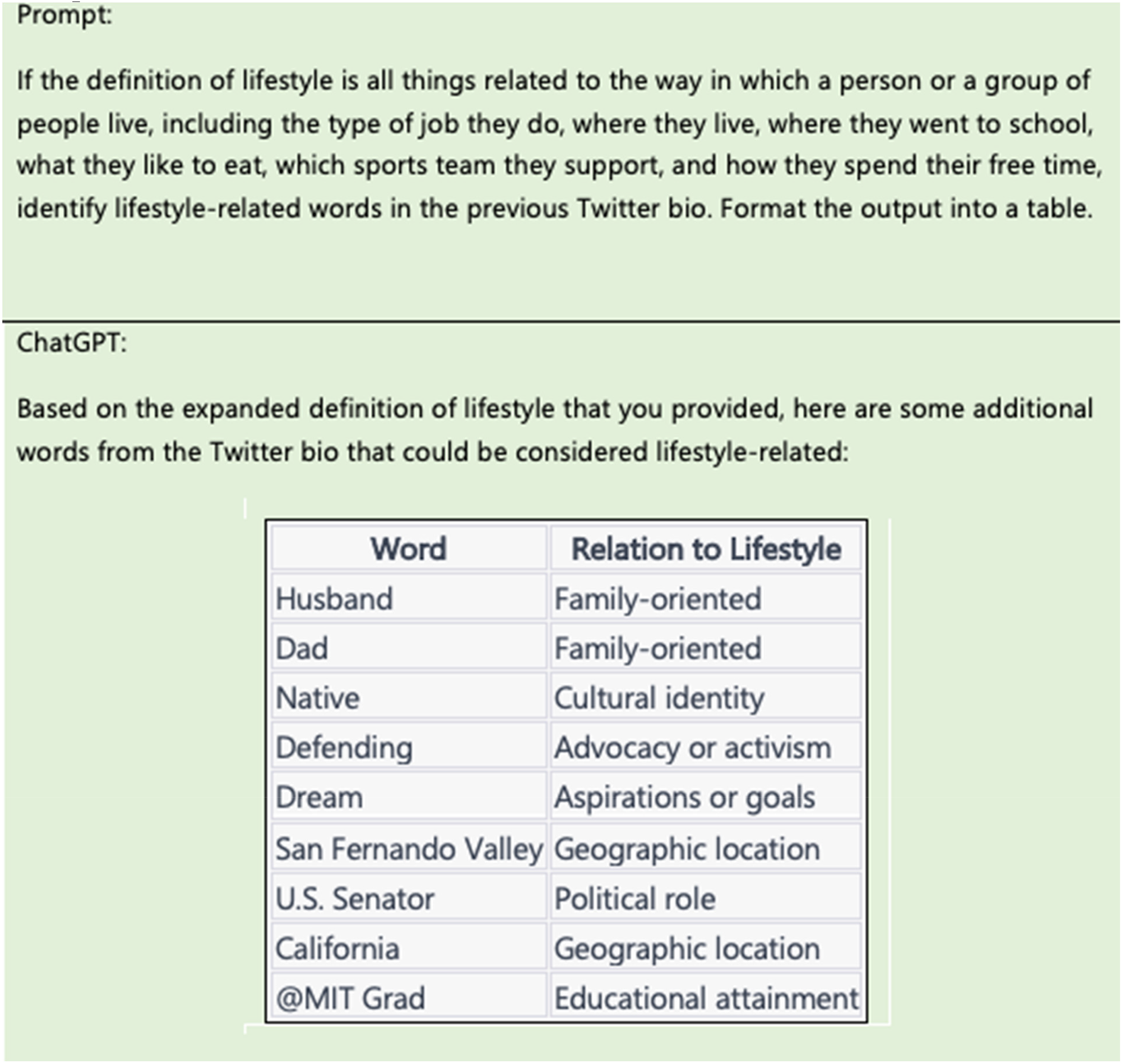
Revised prompt with an expanded definition of “lifestyle” and a request for tabular output; this version captured additional categories (e.g., advocacy/activism, aspirations/goals) that informed codebook updates.
Comparing the model's output to the hand-coding, we refined the prompt by tweaking new prompts while keeping the same set of Twitter bios for every iteration of the prompt in order to properly assess the prompt irrespective of input. After a few more iterations of this process, we settled on the following final prompt, which produced results we determined to be consistent and accurate (Figure 4).

Finalized classification prompt, settled upon after iterative testing against the same set of bios to achieve stable, accurate results.
The goal of Study B was to perform a thematic analysis. Following a preliminary analysis by the researchers, the LLM chatbot was used as a virtual researcher whose thematic coding could challenge and supplement the researchers’ reading and interpretation, but could also be rejected or dismissed by the researchers based on their expertise and reasoned engagement with the text data. Similar to Study A, we developed the inductive prompts through an iterative process in Study B. We concluded with a specific question that guided the model in summarizing consistent aspects of smoking across documents (seeFigure 5). We also used analytical queries to prompt the LLM chatbot to produce a higher-level analysis more closely related to theorizing across the documents (see Figure 6). These analytical queries were posed directly within the same chat, directly after the model had completed with its analysis of each document.

Inductive prompt guiding the chatbot to summarize consistent aspects of smoking across etiquette-book excerpts, supporting the researchers' thematic analysis.

Follow-up analytical queries posed in the same chat as the inductive prompts to elicit higher-level theorization across document summaries.
By working with the prompts and observing the LLM chatbot's responses, the researchers conducted secondary analyses that supplemented their prior conclusions about relevant themes when it came to smoking norms and their change over time. When it came to human-algorithm interaction in the inductive analysis, the chatbot contributed to the analysis by creating abstract restatements that assisted the thematic analysis, both in terms of “seeing” what each document contains and also in identifying patterns across documents.
Critical evaluation
Just as reflexivity in traditional qualitative analysis includes the practice of questioning one's interpretations, triangulating the LLM chatbot's outputs with other data and independent human analysis is important (Grimmer et al., 2022). Researchers should use their specialized expertise and background knowledge to assess whether the generated text aligns with or contradicts existing data and theory, and explore alternative reasons for and interpretations of the LLM chatbot's responses, including considering how the LLM chatbot might respond differently based on alternative training data or prompts.
In Study A, the chatbot's output needed to be regularly cross-checked against human analysis, similar to the way a researcher would deal with concerns of inter-coder reliability in traditional qualitative analysis. In the case of Study B, we triangulated model output with our independent reading and analysis of the data, drawing on our background knowledge. Given the inductive nature of the work, the researchers were free to retain and use or dismiss the model output when extending their analysis of prevalent themes and their change over time.
In Study B, we examined the LLM chatbot's responses and noted that the overarching thematic categories supplied by the model were logical and identified some, but not all, themes that we had picked up in our exploratory analyses. The model also picked up other themes we had not identified. For example, we had not noted the significance of legal restrictions or technology in our human analysis. However, we did not just accept the LLM chatbot's assertion that these were prevalent themes. As is common in qualitative research and an element of technological reflexivity, we questioned the output, testing it against our understanding and triangulating it with other sources of information. We returned to the texts to see if we could uncover evidence in the texts supporting the LLM chatbot's claims. We determined there was sufficient support for some of the themes, for example, the discussion of the rise of formal rules and laws around smoking is prevalent in some of the text data. However, we judged other themes to be more marginal and out of sync with their prominent place in the LLM chatbot's analysis. For example, technological developments like vaping are discussed in only 1 of the 21 documents and are not a prevalent theme even in that text. So, even though technological changes were relevant in one of the books and so the chatbot's view that technological changes could be seen as a source of variation for the reason that they were not discussed consistently is logical, we determined from our knowledge and interests that there was insufficient justification to consider technology as a major theme or source of change in smoking norms.
Critical evaluation should also extend to prompting. We discovered three elements that can impact the output the LLM chatbot generates in response to a prompt: (1) the formulation of a prompt as described above, (2) the timing of the prompt, and (3) the sequence of the prompt within a chat. Additionally, proprietary LLM models are updated without consideration for the researcher's timeline. As such, the model may change without the researcher's knowledge. There is little a researcher can do to control for this, so the best practice is to keep testing a prompt in the interests of consistent and stable results across multiple time points. Sequencing within the chat can also make a difference. Responses to prompts build off previous prompts within a chat to optimize answers. For this reason, there is no “undo” feature. To test the stability of the prompt, it is best to enter the prompt in a new chat to examine the robustness of the prompt and qualitatively assess the discrepancy in the model's response. Thus, one must take a cautious approach to the model outputs, with ongoing critical examination and testing of the model's performance.
Transparency
Technological reflexivity requires that researchers are transparent in describing their approach to working with LLM chatbots, including sharing the specific prompts they used, variations in model responses, and their adaptation to the model. Transparency also involves explicitly recognizing the “black box” nature of LLMs and communicating its implications for the research findings. Researchers should be clear about what they know and do not know about the model's architecture, training data, and fine-tuning processes.
The codebook is important here because it makes the often hidden decisions in qualitative analysis visible, thereby enhancing the transparency of the research (Reyes et al., 2024). Audit trails can also provide a practical route to transparency in qualitative research using LLMs (see, for example, Yang and Ma, 2025). By systematically logging prompt versions, codebook revisions, memos, and adjudication notes, audit trails make the decisions behind the research visible so others can assess the trustworthiness of the analysis (Lincoln and Guba, 1985). Whatever form is used to provide transparency regarding methods, the checklist in Figure 1 is a guide to help establish that all aspects of work with the LLM chatbot are considered and explained.
Epistemic reflection
Beyond the research at hand, technological reflexivity requires researchers to reflect on how using LLM chatbots affects their approach to qualitative research in general. Has the introduction of an LLM chatbot changed the nature of data analysis, theory building, or the interpretative process? Do LLMs transforms the research process, creates new forms of knowledge, or introduces new problems?
We did feel that LLM chatbots made it possible for us to work with more data, particularly when it came to the deductive example in Study A of identifying lifestyle elements in Twitter bios. However, if the aim is to generalize across diverse linguistic contexts toward efficiency, what implications does this have for the epistemology of qualitative research? Will this shift the foundational logic of understanding, and what are the potential consequences? While chatbots can accelerate certain tasks, such as coding or categorizing large datasets, this does not mean they should be considered de rigueur qualitative research practice. There may be times when they are not appropriate for research, for example, in cases where the contextual specifics represented in the data are likely not well represented in the LLM's training data.
The use of LLM chatbots also raises questions about the role of the human researcher at the center of a qualitative study and the nature of collaboration with non-human researchers. In the inductive example of Study B, we approached the LLM chatbot as an independent thinker whose insights should be taken into account. Even if LLM chatbots are not a replacement for human judgment and understanding, their interpretive contributions were not dismissed out of hand. For example, in Study B, the chatbot provided topics that the researchers initially missed, revealing themes that researchers needed to take seriously. Upon closer examination, some of the topics provided by the chatbot were accepted, while others were deemed irrelevant. Only the researcher is in a position to conduct an analysis that takes full account of the broader academic literature, weighs elements of the text data based on their significance, incorporates key theories and context, and considers the practical and ethical concerns that are fundamental to qualitative research.
Ethical reflection
The integration of LLMs must be considered in terms of research ethics. Many of the issues related to transparency and bias that have been described above also have ethical implications (Kooli, 2023; Kooli and Al Muftah, 2022). For example, documenting research practices and understanding the risks of reproducing stereotypes. However, technological reflexivity also requires that researchers manage additional ethical challenges: risks to privacy, managing informed consent and ethical approval, and broader social and environmental impacts of LLMs.
Considering data integrity
When using LLMs, researchers need to be mindful of privacy risks. First, when the model is in use by the researcher, it will process all the data provided, including any sensitive or personal information. If the LLM is hosted online as a proprietary service, the data may be retained in logs that are used to monitor and improve model performance. When the LLM is updated or retrained, the data may be used again. Finally, when a model is retired, the data that was collected by it may be repurposed. In other words, sharing sensitive and personal data with an LLM can lead to unintended privacy risks long after the research project is over (Barberá, 2025).
To address these issues, some proprietary LLM chatbots allow users to work in a zero data retention mode, which mitigates privacy risks. 5 Researchers using LLM chatbots can further manage issues of privacy and data integrity by turning to open-source LLMs. Open-source models can be downloaded and run locally, allowing researchers to process sensitive data without sharing it with for-profit and third-party services. However, these options may not have a built-in chat interface, making greater technical demands on researchers. When a built-in chat interface is not available, there may be programming/coding required to interact with the model, but these vary. We recommend that researchers find model-specific programming scripts written by individuals in the data science community, such as those on Stack Overflow, to facilitate communication with the model. Qualitative researchers should consider open-source LLMs to the greatest extent possible, inquire about existing tools to build a locally run chatbot, and encourage the development of in-house LLM chatbots in their university and research communities. There is rapid expansion in the use of LLMs, with a trend away from subscriptions to proprietary models and toward in-house model development and customization, particularly in sectors with higher privacy concerns or specialized needs (Barberá, 2025).
Informed consent and ethical review
The use of LLMs in qualitative research raises important questions about informed consent. Participants should be aware that the information they share will be processed using LLMs. Researchers should disclose not only that an LLM is being used, but also what kinds of data processing this involves, whether third parties may have access to the data, and what steps are being taken to protect privacy. For this reason, informed consent forms should be updated to explicitly address the use of LLMs in any stage of the research process (Samuel and Wassenaar, 2025; Schroeder et al., 2025). Consent forms should outline whether the data will be anonymized before it is processed with AI. Researchers should explain, in accessible terms, what this means—such as whether the AI processes data locally or through an external service, whether any data is retained by the model, and associated risks of unintended data retention, potential exposure through AI system logs, or the long-term reuse of data in future versions of the model (Barberá, 2025). This level of transparency is especially important when working with communities who may be more vulnerable to surveillance, discrimination, or exploitation (Benjamin, 2019).
Researchers may be in the position of vetting their work with institutional review boards (IRBs) and ethics committees without clear policies or frameworks for evaluating the use of LLMs in research. In such situations, it is important for researchers to exceed the stated requirements of the IRB by communicating their plans for LLM use and the privacy risks, technical uncertainties, and data handling practices they are implementing (Kapania et al., 2025). Furthermore, IRBs should seek to update their screening process to take LLMs into account by requiring that researchers disclose LLM use, including (1) whether researchers working with personal data are using an LLM that allows for local processing or zero data retention; (2) whether participants will be informed that their data will be processed by an AI system; and (3) whether sensitive data is being anonymized before processing. In evaluating ethics proposals, IRBs should express a preference for open-source, locally hosted LLMs or alternative analysis methods that better align with ethical obligations to protect research subjects’ privacy.
Social and environmental impacts
LLM chatbots have social and environmental impacts. Material flows of electricity, water, air, heat, metals, minerals, and rare earth elements undergird these technologies (Monserrate, 2022). Data centers, with their dependency on cool air and infrastructure, take up important resources like space (Solon, 2021), water (Mytton, 2021), and electricity (Jones, 2018). Machine learning is one of the most energy-intensive computing activities (Hao, 2019). Additionally, data centers are common culprits for social problems, including job displacement (Ren et al., 2024) and a greedy need for resources, particularly water, in light of freshwater scarcity that affects already disadvantaged populations (Li et al., 2023). They also contribute to noise pollution, which is bad for the communities that live within and around these data centers, many of which are already disadvantaged (Monserrate, 2022). Researchers must acknowledge these environmental and social costs and push, whenever possible, for greener, more sustainable technology. In the meantime, these considerations can be managed in the same ways that qualitative researchers approach social harm (Scheytt and Pflüger, 2024), which includes navigating the risk of exposing social organizations and institutions to criticism (Fine and Shulman, 2009), reproducing stereotypes (Britton, 2020), and legitimizing harmful groups and practices (Askanius, 2019), and environmental impacts (Podjed, 2021).
Conclusion
Qualitative researchers frequently work with text data or with qualitative observations that are represented in text form, and, when it comes to the analysis of texts, LLM chatbots can perform tasks much like a research assistant or co-researcher might. LLM chatbots can assist with the coding, classification, and thematic interpretation of texts, and they can be used to compare substantive and thematic differences across texts. In fact, the language-based, dynamic, context-dependent nature of LLMs aligns them more closely with qualitative research methodologies than those based on social statistics and other more positivistic approaches (Cambo and Gergle, 2022), presenting a provocative possibility: that the research of the future may become increasingly interpretive and qualitative.
Technological reflexivity is necessary for this qualitative and interpretive future. Qualitative research is inherently human-centric, focused on understanding social phenomena through the lenses of subjectivity, positionality, and interpretation. Qualitative research methods require that researchers critically examine their influence on the research process, including biases, assumptions, positionality, and ethical considerations. Technological reflexivity builds upon that foundation to incorporate research with LLM chatbots: critically examining LLM model bias and researcher-algorithm interaction, describing and critically evaluating the impact of the LLM chatbot on research findings, transparency in analytical choices when it comes to working with LLM chatbots, reflecting on the epistemic and ethical aspects of the use of LLM chatbots in qualitative research practice.
As we have demonstrated in this article, incorporating LLM chatbots into qualitative research does not diminish the central role of the human researcher. Instead, adopting these tools can enhance transparency, making the researcher's background assumptions and decision-making processes more visible. They can also uncover new, unexpected, and relevant themes that might otherwise go unnoticed. With technological reflexivity, qualitative researchers can use LLMs in ways that respect the methodological integrity and interpretive benefits of qualitative research, ensuring that the rich, context-specific insights central to qualitative work are extended by LLM chatbots and other emerging digital tools.
Supplemental Material
sj-docx-1-qrj-10.1177_14687941251390794 - Supplemental material for Qualitative research with LLM chatbots: Technological reflexivity for interpretative technology
Supplemental material, sj-docx-1-qrj-10.1177_14687941251390794 for Qualitative research with LLM chatbots: Technological reflexivity for interpretative technology by Elida Izani Ibrahim and Andrea Voyer in Qualitative Research
Footnotes
Acknowledgements
The authors are grateful to the Stockholm University Computational Sociology Working Group (SUCS), Stockholm School of Economics’ DYSTENA: Text & Network Analyses Conference held in September 2023, University of British Columbia's Centre for Computational Social Science workshop in Large Language Models for Qualitative Analyses in September 2024, and the 2024 Computational Social Science & Language Technology Workshop at Linköping University where portions of this manuscript were presented. They would also like to thank Anna Lund and Vanessa Barker for their feedback on previous versions of this manuscript.
Ethical approval
The study from the Twitter bios example used as an illustration in this manuscript received ethical approval by Etikprövningsmyndigheten (Swedish Ethical Review Authority) (Dnr 2022-03325-01) on 16 August 2022.
Author contributions
The authors confirm their contribution to the paper as follows: all authors contributed to the study conception and design. Data collection for Twitter bios: Elida Izani Ibrahim; data collection for etiquette corpus: Andrea Voyer. All authors contributed to the analysis and interpretation of results, drafted manuscript preparation, reviewed the results, and approved the final version of the manuscript.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author upon reasonable request.
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.