
Abstract
I describe an approach to analysing the affective flows produced in sociomaterial assemblages of visual images and humans in research processes. The approach combines Deleuzian understandings of repetition and difference, and of lines of articulation and flight, with interpretative techniques drawn from visual social semiotics. I use examples from my research into images shared by professionals on Twitter to illustrate how this approach can reveal not only the forces, intensities and hidden logics that lead to particular responses, but also the ways in which these responses impact on research decisions and interpretations.
Introduction
The diffusion of digital and mobile screens throughout professional and personal spheres has brought with it a substantial increase in our use of and immersion in visual images. In particular, visual images now form a significant mode of communication, with users of social media such as Instagram, Facebook and Twitter sharing images about all aspects of their lives and contexts. When shared publicly on platforms such as Twitter, these images provide a freely-available, continuously renewing and rich resource for researchers attempting to trace flows of knowledge and affect (e.g. Rose and Willis, 2019; Stuart et al., 2019; Thelwall et al., 2016a; Vis et al., 2013). But they also pose a challenge: how can we understand the forces, intensities and hidden logics involved when we and others ‘read’ them?
In this paper, I draw on research I conducted into the image-sharing practices of two groups of professionals on Twitter (Wilson, 2016a, b, 2020) to describe an approach to analysing the sociomaterial agency of images as parts of ‘image-viewer’ research assemblages. I suggest that combining a DeleuzoGuattarian material semiotics (Deleuze, 1994; Deleuze and Guattari, 1988) with a visual social semiotics informed by iconology (Jewitt and Oyama, 2001; Kress and van Leeuwen, 1996) can provide a way of talking about flows of affect in image-viewer assemblages – and thus a way of talking not just about what an image says, but what an image does to/with a viewer. This work thus builds on work on assemblage analysis (Feely, 2020) and Deleuzian approaches to visual sociology (e.g. Hultman and Lenz Taguchi, 2010; Lorimer, 2013; Taylor, 2013).
In this paper, I focus on the assemblages I formed with images in the process of researching them. I recount my own developing response to them and some of the moments of assumption and selection these led to. I bring to the fore the affective responses certain images had the power to elicit in me; in doing so, I surface what might otherwise have remained hidden or taken-for-granted forces and intensities that influenced my own decisions and interpretations as the researcher selecting and examining images. This account thus contributes to broader discussions of reflexivity in research by using this analytical lens to explicate selections, assumptions and cuts made by a researcher working with the sociomateriality of images.
The research project
The methodology and sensitivities described in this paper developed during a study of images shared among two groups of professionals (one of midwives, the other of teachers) during regular Twitter ‘chats’ (Wilson, 2016a, b, 2020). I observed these chats over a 4-month period in 2014, recording details of over 500 images and the visible interactions (commenting, retweeting and favouriting) they elicited. I then selected some of these for use in subsequent image-elicitation interviews and focus groups with chat participants, pre-service student professionals and their educators. The aims of the research included developing an understanding of what can be, and what is, learned from such images, both by professionals involved in the chats and potentially by student professionals in higher education contexts. This focus on learning from images quickly led to the question of how images work on or with their viewers to generate particular responses.
Twitter is increasingly being used as a platform through which to hold real-time conversations or chats among interest groups or communities. Twitter chats are loosely synchronous exchanges coalescing around the use of an identifying keyword or hashtag. Anyone who tweets or views tweets with the relevant hashtag is a participant and chats are, by default, public exchanges. Growth in popularity of Twitter chats is particularly marked among professionals (Megele, 2014), who use them as spaces in which to exchange ideas, practice and opinion. These exchanges, as with many forms of social media-based communication, frequently involve the sharing of visual images. This may be particularly common on Twitter because of the platform’s message length limit. The fact that users are allowed only 280 characters of text (140 at the time of this research) limits what can be said in a micro-blog; accompanying that text with an image significantly increases what the tweeter can ‘say’ and what his/her followers can ‘read’.
Images shared on social media in general (e.g. Bell, 2019; Pearce et al., 2018; Thelwall and Vis, 2017) and Twitter in particular (Procter et al., 2013; Prøitz, 2018; Stuart et al., 2019; Thelwall et al., 2016b; Vis et al., 2013) have recently started to attract research attention. As such images are used more widely as resources for social research, it is important to develop methods for discussing and analysing their power. As one of the participants in this research project said, ‘pictures really do speak a thousand words’; as another observed, images seem to be processed more immediately and somehow more intuitively than text: ‘they’re in your brain very quickly, and they stay in your brain a long time’. In this paper, I describe an approach that attempts to explore why certain pictures seem to have such communicative and affective agency, focusing on my own responses during the unfolding research process.
Theoretical basis
The theoretical basis on which the analysis rests derives from the work of Deleuze (1994) and Deleuze and Guattari (1988). In this section, I outline some of the key DeleuzoGuattarian concepts that underpin my approach: assemblage; immanence, difference/repetition and learning; and lines of flight and articulation.
Assemblage
An assemblage (Deleuze and Guattari, 1988; Massumi, 1992) is a heterogeneous collection of humans and things through which desire, energy, knowledge and so on can flow. In Deleuze’s thinking, what connects elements into an assemblage is affect – that is, capacity to affect or be affected – and thus an assemblage can be understood as a dynamic and sometimes ephemeral ‘confluence of elements in affective relationship to each other which changes their states, and their ability to act’ (Fox, 2015: 306). The idea of assemblages initially seemed a useful way to conceptualise the Twitter chats, which are themselves complex constellations of Twitter users, digital images and text. As the study progressed, I realised that the same idea could be used to think about both the interactions I created during the interviews I conducted – and, equally importantly, my own interactions with the images I came across. In all contexts, the notion of assemblage encouraged me to look for circulating intensities of knowledge and affect, and indications that these machines sometimes generated new ways of functioning or becoming.
Immanence, difference/repetition and learning
In seeking to understand the sociomaterial agency of digital images caught up in research assemblages, I am essentially trying to trace what happens in contextualised interactions as a single person looks at a specific image. Deleuze’s philosophy, which is one of immanence, provides a helpful way to think about such interactions. According to Deleuze, reality includes a plane of virtual possibilities: all the things that might happen and that are open to us to connect to. The solidifying of one of these virtual possibilities into an actual happening is described by Deleuze alternatively as an actualisation or a contraction, highlighting the reduction of many possibilities into one; and an actualisation can only happen if there is a difference in pure intensities to provide a motive force. For Deleuze (1994), difference is thus positive, rather than negative: it operates within, a connection rather than a division or separation.
Deleuze’s reconceptualisation of difference requires a parallel reconceptualisation of repetition (Deleuze, 1994). Just as difference is not defined in terms of something missing that would otherwise have made two objects identical, repetition can no longer be taken to be sameness or identity: ‘Variation is not added to repetition in order to hide it, but is rather its condition or constitutive element, the interiority of repetition par excellence’ (Deleuze, 1994: pxvi). Repetitions within a series are, by definition, different; thus, repetition is an act of differentiation.
Deleuze links his conceptions of difference and repetition to learning through his descriptions of three different types of synthesis (Deleuze, 1994; Williams, 2013). First, he describes the passive synthesis exemplified by habit. This is the synthesis of a series of repeated actions or experiences, which might be related to learning in a continuous present. The second type of synthesis is that of pure memory, which creates relationships between temporally separated events: ‘it implies between successive presents non-localisable connections, actions at a distance, systems of replay, resonance and echoes, objective chances, signs, signals, and roles which transcend spatial locations and temporal successions’ (Deleuze, 1994: 83). This kind of synthesis creates a new repetition of the series being remembered, as the memory itself is a member of that series. Both of these passive forms of synthesis, while seeming to rely on sameness, in fact rely more on the background of differentiation and variation that allows similarity. The third type of synthesis that Deleuze describes is that of the caesura or cut. In this type of synthesis, it is pure difference that is most important. It is a synthesis that produces a break, that erases the past and creates the possibility for a radically different future: it is ‘a genuine cut’ (Deleuze, 1994: 172) which ‘brings together the before and after in a becoming’ (Deleuze, 1989: 155). Thus, learning as becoming is inextricably linked with repetition and differentiation.
As I explored the Twitter chats, I noticed just how much repetition and differentiation there was in the series of shared images. Different images repeated certain messages and produced certain responses in me; and these seemed to be repetitions that were more like ‘[r]eflections, echoes, doubles and souls’ which ‘do not belong to the domain of . . . equivalence’ (Deleuze, 1994: 1). This suggested that I, and anyone else who connected with such streams of images, must be learning from them.
Lines of flight and articulation
The idea of an assemblage provides a way of thinking and talking about the coming together of humans and images in both online and offline contexts, and difference, repetition and synthesis are useful concepts in attempting to understand learning from the images shared in the Twitter chats. However, on their own, they do not provide ways to think about the dynamics within the assemblages – that is, the forces and intensities that produce or inhibit certain flows of knowledge and affect.
The notions of lines of articulation and flight (Deleuze and Guattari, 1988), and the related concepts of striation and smoothness, provide a means for thinking about such flows. Lines of articulation may be thought of as channels that constrain and direct; they produce striated regions of space. Lines of flight, in contrast, are bursts of differentiation that point to escape, arcing out across smoother, less-striated space in perhaps uncontrolled or undirected ways (Deleuze and Guattari, 1988; Dewsbury, 2011; Martin and Kamberelis, 2013). Thus, lines of articulation may be produced by social norms, our own past histories, and any forces that lead us to respond to a given image in a constrained way, while lines of flight may be created by the uncertainties and contingencies that allow us the freedom to doubt, to remain ambivalent or to respond in new and unexpected ways – to experience the third type of synthesis described above.
In the following, I show how these ideas can be applied to create an understanding of the process that unfolds as we – researchers, chat participants or others – plug in to images shared on social media to form image-viewer assemblages. I describe different phases of ‘seeing-with’ Deleuze, through repetition and difference. In order to move beyond the initial phases (which I describe as becoming sensitive and becoming affected), I propose that researchers need to explain the strong affective responses elicited by certain images. To achieve this, I suggest this Deleuzian background can be augmented with an approach drawn from visual social semiotics.
Becoming sensitive
To illustrate Deleuze’s first type of repetition, that of passive habit (Deleuze, 1994), Williams (2013: 12) gives the example of an animal patrolling the perimeter of its territory. The circuit is repeated over and over but is never the same; the animal learns its territory by the differences and variations it experiences. Like that animal, I prowled around the Twitter conversations, patrolling my research territory. As I built up records of images and image-Twitter user interactions, I was gradually developing my sensitivity to difference and repetition within the tweeted images themselves. The gross features that initially dominated my consciousness (pictures of babies and post-it notes), once learned, became objects of automatic recognition, allowing a new awareness of difference (details of lighting, geometry, visual texture and colour). I began to see subtle differences such as variations around particular repeated visual motifs, as well as what seemed to be more substantial differences between the images associated with the two different chat series.
In terms of content, images posted in the midwives’ chats were dominated by images of mothers and babies, uplifting images and quotations, images advocating particular midwifery practices and images of midwives. Images posted in the teachers’ chats were dominated by teacher-produced artefacts such as corridor displays and usable resources, work produced by students (sometimes with the teacher’s ticks and comments visible), students engaged in activities in classrooms and outdoors and empty classroom scenes. In marked contrast with the frequent images of practitioners posted during the midwives’ chats, only two of the (hundreds of) teacher chat images included teachers.
There were also differences between the two groups in terms of the visual styles of the images. Images posted during the midwives’ chats tended to show natural, soft colours such as pastels and earth tones. Their geometries were characterised by curves and arcs, with a deliberate softening of text through the use of materials such as handmade paper or embroidered cloth. Blank spaces were allowed within their images. In contrast, the images posted during the teachers’ chats were dominated by printed text or children’s handwriting, displayed in the rectangles and squares of exercise book pages and post-it notes. The colours tended to be acid or bright – post-it notes and sugar paper – or the buff of display backgrounds and notebook pages. Most images showed flat surfaces, such as paper-based displays mounted on corridor walls, posters on doors or sheets of paper on tables. Very few images included blank space.
I began to speculate as to whether and how these different recurring motifs, and different uses of colour, font and layout might impact the responses of chat participants (and thus the potential for professional learning within the chats). The content of the images might constrain as well as open up possibilities: repeated presence might reinforce particular understandings, perhaps creating lines of articulation; absence might be thought of as a reduction of the virtual space of potential meaning; and difference might potentially trigger lines of flight.
Becoming affected
As I immersed myself in the shared images, I began to notice differences in their power. Some images were favourited and retweeted far more often than others, and a few seemed to elicit extended conversational threads (although most did not). Certain concepts seemed to trend at various times. For example, compassion and ‘skin-to-skin’ 1 (Moore et al., 2007) were popular in the midwives’ chats during my observations; Bloom’s taxonomy 2 (Anderson et al., 2001) and Dweck’s growth mindset 3 (Dweck, 2012) featured in many images tweeted in the teachers’ chats. However, there was variation in the scale of visible responses to these images (commenting, retweeting, favouriting) that did not seem to be entirely on the basis of content. For example, one image of a compassion-related homily sparked an extended series of responses, while another remained unanswered and un-retweeted; one Bloom’s taxonomy image elicited 766 interactions, while another elicited only two.
I also noticed differences in my own responses to images as I formed assemblages with them. While I viewed all images posted in the chats, I found myself beginning to glance only briefly at some images while concentrating more on, and repeatedly going back to, others. I found myself strongly affected and indeed was becoming quite judgemental, initially with respect to the images posted during the teachers’ chats. I was irritated by the endless use of post-it notes and the rectilinearity of the teachers’ images, and slightly disturbed to see so many resources featuring simplistic interpretations of growth mindset ideas. As time went on, I realised I was becoming equally judgemental about images posted in the midwives’ chats. I began to wonder whether there would ever be an image of a man (there was one, once, in the 4-month period I observed the chats). The fact I labelled the affirmative messages as ‘homilies’ belied a certain impatience with them. Some images struck me as more powerful than others: sometimes more beautiful, sometimes more shocking, sometimes more eloquent. My responses seemed to illustrate what Massumi refers to as ‘the primacy of the affective in image reception’ (1995: 84, original emphasis).
Added to this was my response to the conversation participants’ responses. For example, the immense popularity of that particular Bloom’s taxonomy image irritated me: in my various formal and informal academic development roles, I had seen how such taxonomies could become formulae that trivialised the complexity of learning and teaching, and I resented its wildfire-like spread. In contrast, some images that were not strongly responded to in the Twitter chats struck me as extremely powerful. I found myself alternating between anger, indignation and pleasure.
A sociomaterial visual semiotics
Reactions such as those I experienced made descriptions based on content, colour, geometry and light alone seem inadequate. Such descriptions did not seem to provide accounts of what I was actually seeing in each viewing or what the images were ‘doing’ to/with me when I plugged into them to form assemblages. Rose describes a kind of ‘visual connoisseurship’ (2007: 48) that allows one to appreciate the impact of images. She suggests breaking down compositionality into a range of components: content, colour, spatial organisation, light and ‘expressive content’ (Rose, 2007: 49). This last component includes descriptions of both the apparent behaviour or feelings of human/animal subjects depicted in the image and the mood produced in the viewer by the image. Reflecting on the preliminary analysis described above, I had naturally arrived at this kind of analytical breakdown, identifying the various compositional elements and becoming sensitive to expressive content or emotional response. However, I lacked a means to account for this last effect. To achieve this, I found it helpful to develop the visual social semiotic approaches described by Jewitt and Oyama (2001) and Kress and van Leeuwen (1996), which themselves incorporate elements of the traditions of iconography and iconology.
Iconography is the study of images with the aim of recognising and characterising visual motifs. It examines ‘visual lexis’ – the people, places, things and situations depicted in images – but also ‘pays attention to the context in which the image is produced and circulated, and to how and why cultural meanings and their visual expression come about historically’ (van Leeuwen, 2001: 92). Iconology extends iconography by adding a critical social element to the analysis, attempting to draw out cultural dependence of both intended and recognised meanings. It posits three layers of meaning: representational meaning, iconographical symbolism and iconological symbolism.
Representational meaning is established through a range of mechanisms, including personal experience (the viewer has seen this before) and reference to other pictures with similar content (Hermerén, 1969); that is, it is established through the passive syntheses of repetition in habit and memory described by Deleuze (1994).
Iconographical symbolism refers to ideas and concepts ‘attached’ to the particular person, thing or place being represented. For example, the midwives’ chats use cartoon bluebirds in images tweeted to promote participation. The iconographical symbolism here may be that midwives are associated with and maybe even responsible for the bringing of happiness; this interpretation again relies on the passive synthesis of repetitions along pre-formed lines of articulation.
The level of iconological symbolism is that at which the analyst attempts to interpret the image and its iconographical symbolism in a wider context and at a deeper level. According to Panofksy, to analyse iconological symbolism is to ‘ascertain those underlying principles which reveal the basic attitude of a nation, a period, a class, a religious or philosophical persuasion’ (Panofsky and Drechsel, 1970). This is consistent with the development of criticality towards the sociomaterial forces and intensities that create lines of articulation and flight in image-viewer assemblages. In order to identify such intensities, the analyst must read images as autobiographical, psycho-analytical, theological, philosophical and so forth – that is, it is the level at which the analyst brings an explicit lens to the interpretation, which may not be that intended by the image producer.
Visual social semiotics (Jewitt and Oyama, 2001; Kress and van Leeuwen, 1996; Oyama, 1999) takes these ideas further to view images as resources having meaning potential. As Jewitt and Oyama (2001) note, viewers ‘use whatever resources of interpretation and intertextual connection they can lay their hands on to create their own new interpretations and interconnections’ (p135). This contextual dependence allows for a fluidity or ambiguousness that accommodates the notion that each actualisation of ‘image-viewer-response’ is essentially unique, and leaves room for lines of flight that take thought away from passive syntheses and established norms, and on to the cusp of the third type of synthesis, which is also a cut.
Visual social semiotics describes the interpretative potential of images in terms of three metafunctions (Hodge and Kress, 1988; Kress and van Leeuwen, 1996). The representational or ideational metafunction refers to an image’s ability to represent objects outside itself. In relation to this, visual social semiotics introduces the idea of visual syntax. Visual syntax refers to the patterns which relate components of visual lexis to each other. Kress and van Leeuwen (1996) differentiate between two types of pattern – narrative and conceptual – and relate them to elements of images such as the presence of vectors (indicating the former) or the use of classification, attributive or analytical structures (indicating the latter). The interpersonal or interactive metafunction refers to an image’s ability to project relations between producer, viewer and represented object. This function is carried out by features such as contact with the viewer, social distance, point of view and modality (‘true-to-lifeness’). The compositional or textual metafunction refers to an image’s ability to form a text, or coherent complex of signs. Kress and van Leeuwen describe three semiotic resources related to this function: information value determined through placement within the composition (foreground, margins, top/bottom, left/right); framing as a means of connecting and disconnecting elements of the image; and salience – that is, making some elements more eye-catching than others, for example, through size, colour, contrast and so forth.
Combining this social visual semiotics with a Deleuzian materialism expands the discussion of what happens in an image-viewer assemblage beyond meaning-making to include affective flow. That is, it suggests that a viewer does not ‘just’ engage in a complex process of reading an image, but that their state and ability to act may be changed by the encounter. Recognising the change in state or ability to act is then a crucial part of understanding what images do to/with viewers.
Becoming analytical: applying the approach in practice
In this section, I illustrate how combining the Deleuzian sensitivity to repetition, difference and actualisation with the analytical vocabulary of visual social semiotics, can help to better understand the affective flows in a given image-viewer assemblage, and the resulting changes in state or ability to act.
I use four example images, two from each of the two series of chats. Each image evoked a strong response in me, leading me to select them from the hundreds of images I had encountered as foci for my analysis and prompts to use in subsequent research interviews and focus groups (Wilson, 2016a. b, 2020). They form what I had subconsciously recognised as two compositionally similar pairs.
The first pair is shown in Figure 1. Figure 1(a) was posted in the midwives’ chat. It shows the head and shoulders of a uniformed midwife, standing in the foreground of a strip-lit hospital corridor. It attracted only a low number of visible responses compared to other images tweeted in these chats, and particularly compared to other images of smiling midwives. This seemed odd to me, as I found it a particularly striking image. The young midwife has such a warm smile.
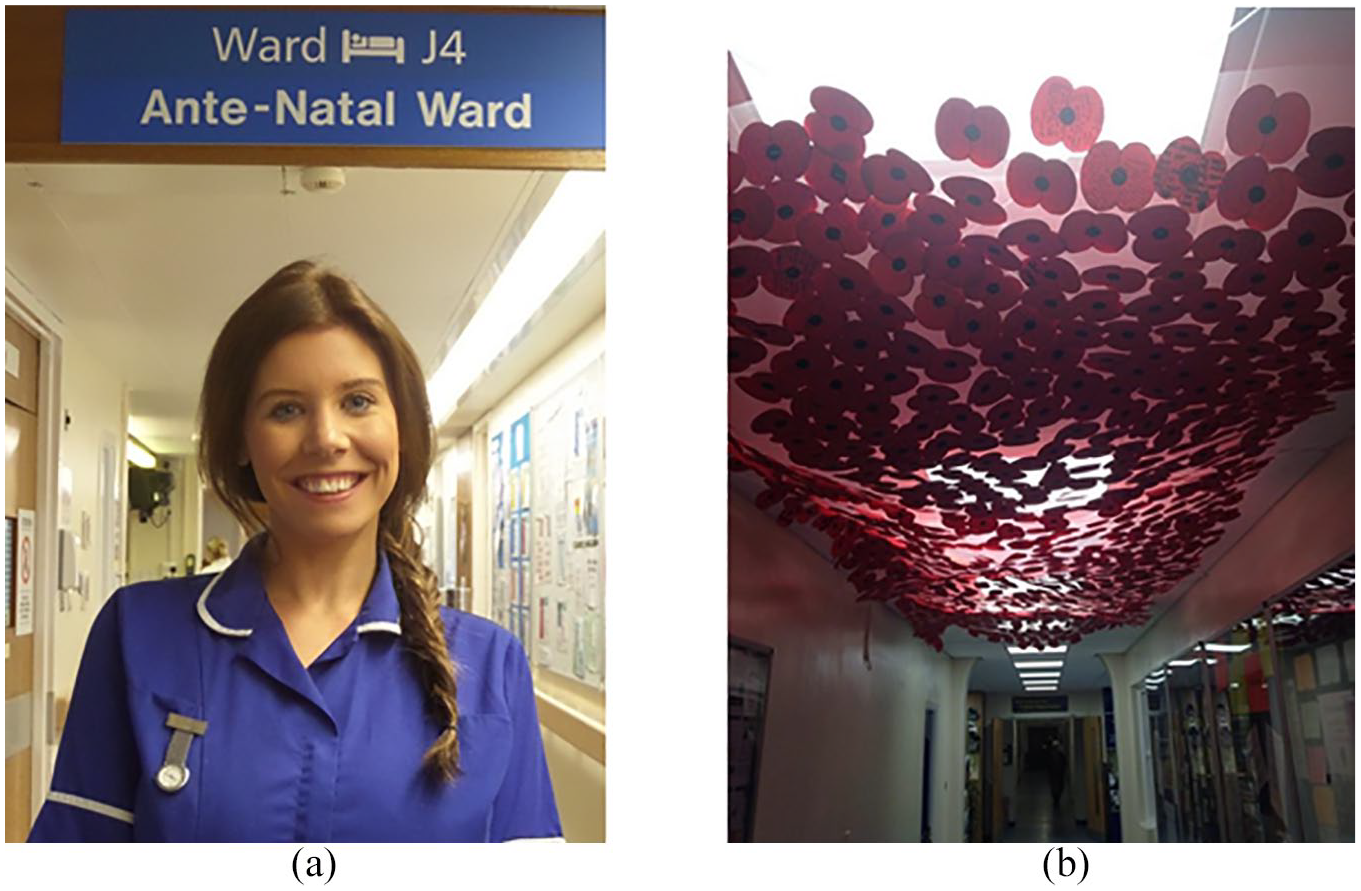
(a) Smiling midwife. (b) Poppies.
Figure 1(b) was posted in the teachers’ chats. It shows stylised paper poppies suspended in a net or some transparent material below fluorescent lights along the ceiling of a corridor. Close attention reveals that the poppies are covered with inscriptions, but the distance and resolution means that they are illegible. It elicited a higher than average (for images shared in the teachers’ chats) number of responses, although still 20 times fewer than the Bloom’s taxonomy image mentioned above. Again, I found this to be a very powerful image, one that evoked in me feelings approaching pathos and hope, but one that also intimated something ominous. It also struck me as unusual among the teachers’ images in what I felt was a compositional, aesthetic beauty.
The second pair of images is shown in Figure 2. While the images shown in Figure 1 might be ‘candid’ photographic shots, both of these are overtly edited and produced. Figure 2(a) was tweeted in the midwives’ chats. It depicts a figurine of a woman cradling a baby in her right arm, with her knees drawn up in front of her. The figurine is placed to the right of a stack of old, worn-looking books. The image has been edited so that text floats about the books. It elicited a fairly typical number of interactions for an image posted during a midwives’ chat.

(a) Affirmation. (b) Knowledge vomit.
Figure 2(b) was tweeted in the teachers’ chats. It is an apparently unedited photograph of a teacher-produced teaching artefact: instructions to students at the start of an in-class exercise. Like the image on the left, it consists of a combination of text and graphical imagery. The text consists of a heading, stretching across the width of the image, below which lies instructions to students regarding a short learning activity, which occupy the left-hand side of the image. On the right, a cartoon image depicts an adult male (teacher? doctor? parent?) standing in the path of (or possibly behind) a stream of vomit exiting the mouth of a young person of indeterminate sex. The vomit includes words and phrases. It elicited a very high number of responses, in the top 5% of images in terms of the number of visible interactions in the teachers’ chats. It left me cross and upset, offended on behalf of both Of Mice and Men and the students who read it.
In the following, I apply the analytical approach described in the previous section in an attempt to understand why and the assemblages I formed with these images changed my state so differently, and to analyse how research decisions and understandings emerged from these affective flows.
Representational work
I first explore the representational work unfolding in the assemblages I formed with each image.
Visual lexis and iconographical/iconological symbolism
The identification of the subject of Figure 1(a) as a midwife relies on my recognition of the midwife’s uniform; I connect this image up with a series of encounters and representations through which I have already learned that midwives wear clothes like this. In other cultures, midwives might wear very different uniforms or no uniform at all, meaning this ascription is not obvious or unproblematic for all potential viewers. Similarly, I saw the flat, red paper shapes in Figure 1(b) as poppies because I connected them to a series of Remembrance Day poppies sold in the UK, not because they are, or even look like, real poppies. Not all countries/cultures use this stylised form of the poppy; there is a requirement for some pre-existing cultural knowledge even to recognise the elements of this image for what they are, or what they are expected to be interpreted as. The two images in Figure 2 require less pre-existing cultural knowledge; the old books to the left of the figurine lend weight to and reassert the notion of the wisdom of the past made explicit in the text, although knowing the content of those books might add nuance to the basic representational meaning. Similarly, the visual lexis of the knowledge vomit image does not leave much room for ambiguity or novel interpretations at the representational level.
Beyond this basic visual lexis, we can look for further indications of iconographical and/or iconological symbolism. The midwife in Figure 1(a) is almost glowing; for me, her appearance has echoes of the angelic or Virginal in the tradition of 18th-century Dutch religious art or perhaps the work of American artist Abbott Handerson Thayer. 4 The representational work that this image does to me thus plugs into these series of repetitions to form a (passive) synthesis with these other, either profoundly religious or sugary works. Similarly, while the figurine in Figure 2(b) may be a literal reference to the work of the midwife, it simultaneously has echoes of church depictions of Madonna and child, and the smooth, ivory-coloured stone suggests serenity or purity, again plugging in to series of repetitions in my experience and memory including those already evoked by Figure 1(a) but extending to include the sense of old knowledge and political/earthly power that I associate with medieval churches.
The poppies in Figure 1(a) also provide a clear example of iconographical/iconological symbolism. Once a viewer has recognised the poppies as replicas of Remembrance Day poppies, they may be freighted with associations, although this does not guarantee that the same meaning and emotion, or the same change in state, will be generated in each image-viewer-response actualisation. For example, a viewer who connects intertextual resources such as the poems of Rupert Brooke into the assemblage might experience a rush of patriotism and pride. In contrast, a viewer who connects to the work of Kipling following the death of his son might experience bitterness or cynicism. For me, the image triggered a complex web of personal meaning-making resources including my grandfather (who served in the Merchant Navy in the First World War) and the experience of doing English A level (where I first encountered the poetry of that War), which combined to give this image an affective agency that resulted from the syntheses of these very different series of repetitions.
Visual syntax
Following Kress and van Leeuwen, the syntax of the images in Figure 1 is largely narrative, with a similar vector present in both, travelling along the lines between corridor walls and ceiling. These vectors seem to propel the foregrounded participants (midwife and poppies, respectively) out of the background, along rays of light, adding to the spiritual or angelic tone already noted. The images in Figure 2 have both conceptual and narrative components to their (similar) syntax. In both, text is situated to the left of visual imagery; different fonts are used to indicate headlines and elaborations. The non-textual imagery on the right contains oppositely directed vectors; the upturned face of the mother in the first image contrasts with the downward flow of the stream of vomit in the second. Similarly, the encircling action of the mother’s arms, cradling both her child and her drawn-up knees, contrasts with the halting, keep-away signal of the vomiting student’s outstretched arms and outwardly-turned palms. Figure 2(b) has an additional vector running through the baby’s body, into the calves of the woman and the arm that encircles them, and finally running into the spines of the piled books. This makes a direct connection between the baby, the mother and the wisdom/knowledge contained in the books.
These images thus also make clear the importance of visual syntax in establishing not only what images say, but also what they do. Indeed it was the similar syntax that had led me to see the images as pairs, and thus synthesise them into new and unexpected series of repetitions where smiling midwife connects with poppies and affirmation connects with knowledge vomit.
Interpersonal work
Of the four images shown in Figures 1 and 2, the interpersonal work of the image of the midwife in Figure 1(a) is the most immediately obvious, with her direct, smiling gaze. This attitude, interpreted through the lens of visual social semiotics, simultaneously offers support and empathy while demanding attention and trust, actively seeking to trigger affective flows in image-viewer assemblages.
The point of view of the viewer of Figure 1(b) is also important. The angle of the shot, placing the poppies above the viewer as if the viewer must raise his eyes and crane back his head, emphasises their power, suggesting that the viewer is expected to be somewhat in awe of the poppies and what they represent.
The upturned face of the mother in the statue in Figure 2(a), as well as establishing a vector within the image, avoids the gaze of the viewer, suggesting a detachment that might indicate a rather aloof serenity, or perhaps submission. Even the impact of the cartoon features of the vomiting student may be better understood if the interpersonal work between image and viewer is identified. The wide eyes and slightly averted gaze may indicate that the viewer should respond with apprehension or pity as well, perhaps, as share in the student’s horror. Similarly, the outward-facing palms may serve as a warning against closer approach, not just to the depicted male figure, but also to the viewer.
Compositional work
In Figure 1(a), a powerful focus on the midwife’s face is achieved not only through its central position, but also by its framing between the blue-and-white overhead sign and the blue-and-white uniform. It may seem that the centrality of the smiling face is obvious without resorting to complex analysis, but it is details such as this additional emphasis through framing that may provide an explanation as to why the assemblage I formed with this particular image triggered stronger affective flows than many of the other images of smiling midwives tweeted during the Twitter conversations.
In Figure 1(b), the lighting and aerial suspension of the poppies combine to create an otherworldly effect. According to the interpretation of position in Western imagery (van Leeuwen, 2001), the high positioning of the poppies within the compositional structure connects them to the ideal, rather than the worldly. Together, these suggest a spiritual, poetic meaning, reinforcing the representational and interpersonal work described above.
In Figure 2(a), although lighting effects highlight the figure of the mother and child, it is the books that are foregrounded. In contrast to the poppies in Figure 1(b), the positioning of the books at the base of the image and in the foreground suggests a focus on the worldly, connecting the otherwise spiritual elements of the composition, emphasised in the analysis of the representational and interpersonal work, with practical skill and knowledge.
In Figure 2(b), the foregrounding of the vomit and the use of the same green in the title text send the message that vomit should, indeed, be the key message understood by a viewer. Similarly, colour is used to make the phrases ‘empty your guts,’ ‘spew’ and ‘big chunky piles’ inescapably obvious. While one may feel that such an analysis is not needed to identify the key messages in this image, it does provide an explanation as to why this image provoked a strong response (of anger in me and approval in the Twitter conversation participants) rather than a mild one (of, say, simple dismissiveness): the compositional work combines with the interpersonal work to make the grossness of the image, which a viewer may find patronising or amusing, inescapable.
Changed states and abilities to act: research decisions and understandings emerging from image-viewer assemblages
The above account describes changes in my mood, as repeated encounters with these example images produced pleasure, pathos, irritation, disgust. But these shifting assemblages also changed my ability to act, my decisions about how to proceed in my research and my understandings of what the research was revealing.
Of the images above, I decided not to use Figure 1(b) as an elicitation device in subsequent interviews, perhaps because I was subconsciously aware of the highly personal nature of the assemblage I formed with it. Thus, the quite profound affective response this image produced in me actually led to me making a cut between it and my research participants, putting up a (protective) barrier that saved me from being drawn into assemblages including other people, that might be characterised by quite different flows. In contrast, I used Figure 2(b), which had sparked in me a need to share and have reaffirmed my irritation. The prolonged series of assemblages I had formed with this image reinforced my despair that such a tool was being used in classrooms, but provided me with a clearer understanding of why the image seemed so powerful. I was thus disappointed when an interviewee suggested it was a good idea, well worth sharing online – and pleased (and somehow proud) when the student teachers I discussed it with tore it apart. The aversion that this image had triggered in me had deflected my research to include a deliberate desire to provoke critical responses.
Despite fairly low response rates in the chats, I also used both Figure 1(a) and 2(a) as elicitation devices. It is true that they were in some way representative of other images with similar content (‘homilies’ and ‘angels’), but more rational choices (and ones following my initial research design) would have been to let the chats select the elicitation images for me by using the most favourited, retweeted or responded to images only. Yet despite all the other, often more popular, images of smiling midwives, I chose Figure 1(a). My encounters with this image had changed my ability to act, simultaneously liberating me from the ‘logical’ requirement to use images other people had found powerful and constraining me to use an image that had exerted especial power on me.
This particular choice, emerging out of the affective flows in assemblages I had formed with the images on my own, without the presence of others, had quite unanticipated consequences in encounters including practising and student midwives. My analysis of the repeated images of midwives posted in the Twitter chats suggested these were together creating an icon, a symbolic, angelic midwife blessed with calming compassion; but this depended on my own reading of the series of images in an assemblage that connected strongly to religious imagery. In fact, the research assemblages involving other people included cultural resources I had not been able to plug into: for almost all participants, she was a familiar face, having starred in a reality TV show about midwives. Thus far from triggering flows of quasi-religious empathy, seeing her as an iconic representation of compassionate midwifery, the responses actualised in these assemblages tended to trigger more prosaic concerns about this particular midwife’s appearance – her hair, her fob-watch, the fact she seemed neither exhausted nor stressed. The affective responses of my participants were strong, but utterly unlike my own, changing their states to either deeply critical or empathising enough to create excuses for what was seen as unprofessional behaviour (Wilson, 2016a, 2020). This generated a synthesis of the third kind for me, breaking away from the lines of articulation I had created and followed in my earlier assemblages with images of smiling midwives and creating new understanding for me – but perhaps not for my research participants, whose discussion seemed to reinforce the lines of articulation and judgementality they were already constrained by.
Conclusions
Through this account, I have suggested that when we undertake research with images posted on social media, we form assemblages with those digital objects, and that each time we interact with a given image, we actualise one possible image-viewer-response within that assemblage.
As we do this repeatedly, we may go through different phases in relation to how we connect to, synthesise and learn from images, corresponding to the three different types of synthesis described by Deleuze (Deleuze, 1994). During the first of these, I became sensitive to difference and repetition, leading me to identify themes or trends. Following this, I started to make interpretations or judgements about the content and style of images – that is, I started to become affected by them. However, to move beyond these passive syntheses, where flows of affect and understanding were largely along well-established lines of articulation, to a more productive criticality that allows for lines of flight that lead to new understandings, I found I needed to combine immersion in these streams of images with an overt analytical lens such as that provided by visual social semiotics. Doing so helped me to identify the forces and intensities shaping my affective responses – the agencies both within and outside of the images – and to reveal the lines of articulation I had been following.
The analysis was also effective in surfacing and refining my understandings of visual tone and the cultural resources that connect up to image-viewer assemblages. When we are dealing with materials shared publicly online, we may find our affective responses are heightened by multiple exposure to similar images, memes or opinions, and without engaging with the authors or posters of this material, we may have to rely heavily on our own responses in our sense-making.
As well as suggesting a process which may help other researchers working with social media-based images to move beyond sensitivity and affect to become productively analytical, this work also suggests that researchers need to be very careful in both selecting ‘found’ images such as these to use as elicitation devices in interviews and focus groups, and in assuming that they can themselves interpret images chosen by others and arrive at the same, or even similar, meanings.
Footnotes
Disclosure
The author reports no conflict of interest. The authors alone are responsible for the content and writing of the paper.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the UK Higher Education Academy through a Mike Baker Doctoral Fellowship.