
Abstract
To reduce the modeling burden for control of spark-ignition engines, reinforcement learning (RL) has been applied to solve the dilute combustion limit problem. Q-learning was used to identify an optimal control policy to adjust the fuel injection quantity in each combustion cycle. A physics-based model was used to determine the relevant states of the system used for training the control policy in a data-efficient manner. The cost function was chosen such that high cycle-to-cycle variability (CCV) at the dilute limit was minimized while maintaining stoichiometric combustion as much as possible. Experimental results demonstrated a reduction of CCV after the training period with slightly lean combustion, contributing to a net increase in fuel conversion efficiency of 1.33%. To ensure stoichiometric combustion for three-way catalyst compatibility, a second feedback loop based on an exhaust oxygen sensor was incorporated into the fuel quantity controller using a slow proportional-integral (PI) controller. The closed-loop experiments showed that both feedback loops can cooperate effectively, maintaining stoichiometric combustion while reducing combustion CCV and increasing fuel conversion efficiency by 1.09%. Finally, a modified cost function was proposed to ensure stoichiometric combustion with a single controller. In addition, the learning period was shortened by half to evaluate the RL algorithm performance on limited training time. Experimental results showed that the modified cost function could achieve the desired CCV targets, however, the learning time was reduced by half and the fuel conversion efficiency increased only by 0.30%.
Introduction
Advances in computing technology, as well as cost reduction of sensors and data storage, have allowed the transportation sector to move away from simple rule-based static controllers to adaptive machine-learning-based strategies. Big data analytic tools have allowed the optimization of traffic patterns using real-time traffic feedback. 1 Computer vision and wireless communication have enabled a plethora of modern adaptive control strategies to optimize and guarantee a safe operation of connected and automated vehicles.2,3 Hardware acceleration, sensing technology, and adaptive methods have enabled energy optimization at a variety of operating conditions for different powertrain architectures, ranging from hybrid powertrains 4 to advanced combustion engines.5–7 This study focuses on the latter, applying data-driven adaptive optimal control strategies to improve the efficiency of internal combustion engines.
Spark-ignition (SI) combustion engines dominate the current light-duty vehicle market, corresponding to 94% market share. In recent years, battery electric vehicles and plug-in hybrid electric vehicles have steadily gained market penetration. However, the U.S. Energy Information Administration forecasts that gasoline vehicles will remain the dominant vehicle type, comprising over 70% of the market through 2050. 8 Medium- and heavy-duty vehicles will remain dependent on internal combustion engines for the foreseeable future due to their heavier duty cycles, with dilute SI engines offering the potential for efficiency and emissions improvement, particularly in the medium-duty sector.
Dilute combustion accomplished with exhaust gas recirculation (EGR) is a technologically proven and cost-effective way to reduce fuel consumption in a variety of engine platforms.9,10 However, EGR affects combustion kinetics, reducing the combustion rate and making stable combustion more difficult to achieve. At the combustion stability limit, also called the dilute limit, the ignition becomes highly sensitive to the in-cylinder charge composition and sporadic misfires and partial burns occur, exacerbating cycle-to-cycle variability (CCV). These issues may become more pronounced for future medium-duty SI gaseous and low-carbon fuels with reduced flame speeds. Moreover, similar stability limits have been found in diesel combustion during cold starts,11,12 diesel combustion in aerial powertrains, 13 spark-assisted compression ignition, 14 and gasoline compression ignition. 15 Thus, a robust and adaptable control strategy for minimizing combustion CCV can have wide applications within the transportation sector to improve vehicle efficiencies.
Current production engines avoid regions of unstable combustion through extensive manual calibration efforts, utilizing tables to define acceptable operating conditions, leaving efficiency opportunities on the table. Active controls to stabilize combustion at the limits would enable further efficiency gains, but robust methods for achieving this have thus far proven elusive. Previous studies have determined that CCV at the dilute limit presents deterministic patterns, 16 with cycle-to-cycle communication based on the composition of residual gases carried over from the previous cycle.17,18 The feasibility of using the dynamics of dilute CCV for combustion stability control was demonstrated using a proportional feedback control to adjust the fuel injection quantity, 19 providing a proof of concept that changing the quantity of fuel injected on a cycle-resolved basis can impact combustion stability. Model-based predictive control has also been attempted, 20 but was limited by the difficulty of achieving a control-oriented model that is both predictive and computationally inexpensive. 21 Machine learning approaches, including artificial neural networks (ANNs), offer the potential to address these difficulties. Early attempts at using ANNs for combustion stability control were demonstrated for lean combustion 22 and for EGR dilution,23–25 using an ANN-based observer for state estimation and an ANN-based controller to determine next-cycle fueling. This approach was later improved by a reinforcement learning (RL)-based controller that used an ANN-based adaptive-critic structure.26,27 All these applications, however, were trained offline using the model of Daw et al. 28 While they showed improvements in CCV, they also exhibited fuel enrichment, and it was not possible to determine how much of the improvement was due to next-cycle control actions. Even though the model has been improved 29 and recent model-based controllers have been designed,30,31 offline training suffers from inaccuracies and uncertainties of the model. Additionally, the resulting control policy is restricted to the domain from where the data used to calibrate the model were collected, rendering a suboptimal solution.
The implementation of model-free control with online learning for internal combustion engines remains a challenging problem, 32 with the bigger advantage of providing globally optimal solutions for the problem of combustion CCV control. Modern engine control units (ECUs) are now capable of online calculation of advance control strategies for cycle-to-cycle33,34 and even in-cycle 35 combustion control. Online learning has proven useful to avoid the dilute limit 36 and to exploit the stochastic properties of CCV for optimized combustion. 37 Even though online learning has been part of the control design, the control command itself was calculated thanks to a simplified model of the SI engine. Recently, a model-free RL controller has been designed by Henry de Frahan et al. to adaptively adjust the fuel injection timing in diesel engines. 38 However, the controller was trained offline on a computer model rather than using an experimental engine in real-time.
This study introduces a novel reinforcement learning strategy for optimal fuel quantity control, leveraging online model-free learning of combustion dynamics during real-time engine operation. Reinforcement learning was chosen as the preferred data-driven adaptive optimal control method based on its strong theoretical foundation and convergence guarantees. 39 The approach involved operating the engine under increased dilution levels beyond the dilute limit and utilizing a control-oriented model for data-efficient reinforcement learning. The proposed algorithm, tested under three scenarios, demonstrated significant improvements in fuel conversion efficiency and combustion stability, effectively extending the dilute limit. The results highlight the effectiveness of model-free learning in comparison to traditional model-based approaches, paving the way for future research to explore the method’s applicability across diverse engine operating conditions.
The remaining sections are organized as follows. The experimental setup is first introduced. The combustion conditions at the dilute limit and the definition of the objectives of the controller are later discussed. The control-oriented model used for selecting the system states and the cost function is then presented. The RL algorithm used for model-free learning of the optimal control policy follows. The experimental results for three different control designs and the comparison between open-loop and closed-loop performance are later presented. Finally, the paper presents conclusions.
Experimental setup
A single-cylinder version of a 2.3L Ford Ecoboost engine was used for experimental demonstration. The SI direct-injection experimental engine was equipped with an external, cooled, low-pressure EGR system. The airflow was kept constant using an Alicat mass flow controller. The cam timing was chosen to avoid positive or negative valve overlap. The engine speed was kept constant using an engine dynamometer. The spark advance was controlled by a slow proportional-integral (PI) controller targeting an optimal combustion phasing. A wide-band exhaust oxygen sensor was used to monitor the air-fuel equivalence ratio
Engine geometry and settings.
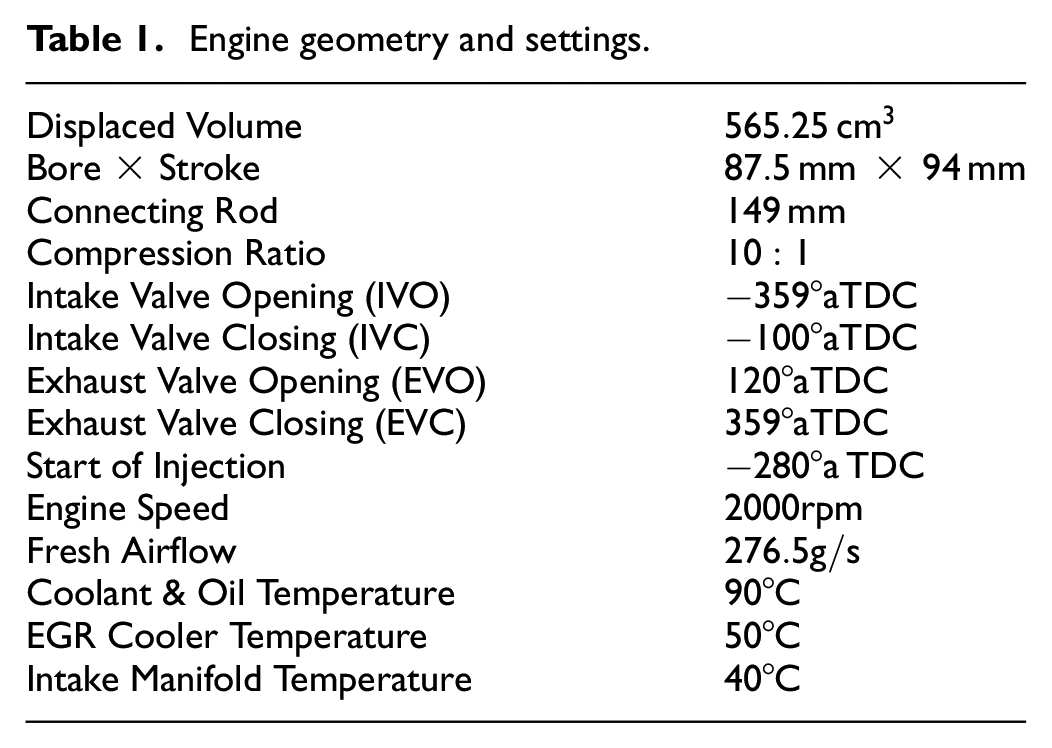
An open LabVIEW-based ECU implemented on a National Instruments Powertrain Controls (formerly Drivven, Inc.) platform was used for low-level and high-level control of the engine actuators. In-cylinder pressure data processing needed for control design was done using an in-house LabVIEW-based Oak Ridge Combustion Analysis System (ORCAS) embedded in the ECU. In order to guarantee cycle-to-cycle control at an engine speed of 2000 rpm, equivalent to 60 ms per combustion cycle, the proposed learning algorithm was integrated into the ECU without communication overhead. 40 Finally, the control parameters of the ECU were modified through a host computer with a LabVIEW interface. Figure 1 shows the setup and instrumentation of the experimental engine test cell.
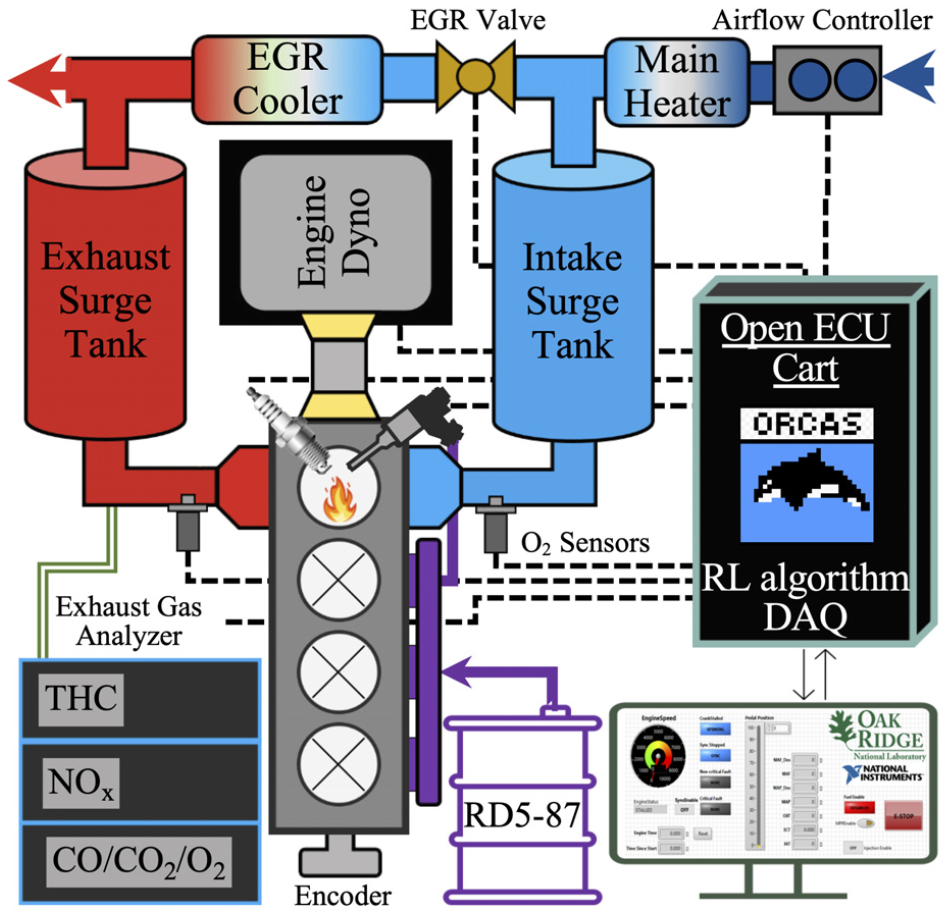
Experimental setup with rapid prototyping ECU.
Dilute limit in spark-ignition engines
While EGR increases the overall fuel efficiency, it does so up to the stability limit. At high levels of EGR, ignition becomes highly sensitive to changes in cylinder composition. This results in a decrease of efficiency past the dilute limit due to either poor flame initiation (misfires)41,42 or propagation (partial burns) 43 which increase the combustion CCV even if the spark advance is optimized. 44 Moreover, the fundamental characteristics of combustion CCV can change depending on engine speed, load, and phasing.45–47 Since SI engines operate over a wide range of speeds and loads, complete characterization of the dilute limit over the entire operating regime requires a large amount of time and effort. To reduce the testing burden, the Advanced Combustion and Emission Control (ACEC) tech team of the United States Council for Automotive Research (USCAR) has chosen a relevant engine speed and load condition for different technology applications. 48 In particular, for a downsized boosted engine that seeks to operate at heavier loads, an engine speed of 2000 rpm and 20% load is suggested. For this engine, that load equates to 4 bar brake mean effective pressure (BMEP), or about 5 bar indicated mean effective pressure (IMEP).
Figure 2 shows different combustion metrics at 2000 rpm, 5 bar IMEP, 0% EGR fraction, and stoichiometric combustion, approximately recreating the operating condition suggested by the ACEC tech team. EGR fraction was then increased until efficiency losses due to high CCV were detected. Each marker corresponds to an average value over 2000 engine cycles. At each cycle k, the combustion features have been estimated from the in-cylinder pressure sensor as follows:
• Indicated mean effective pressure:
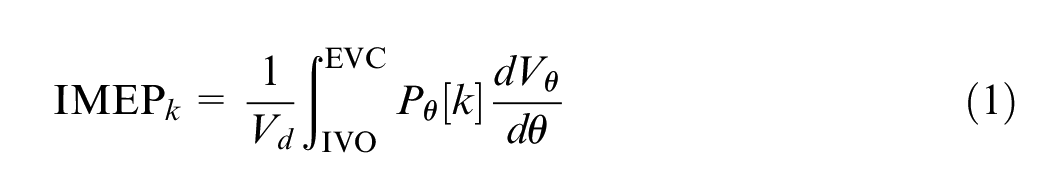
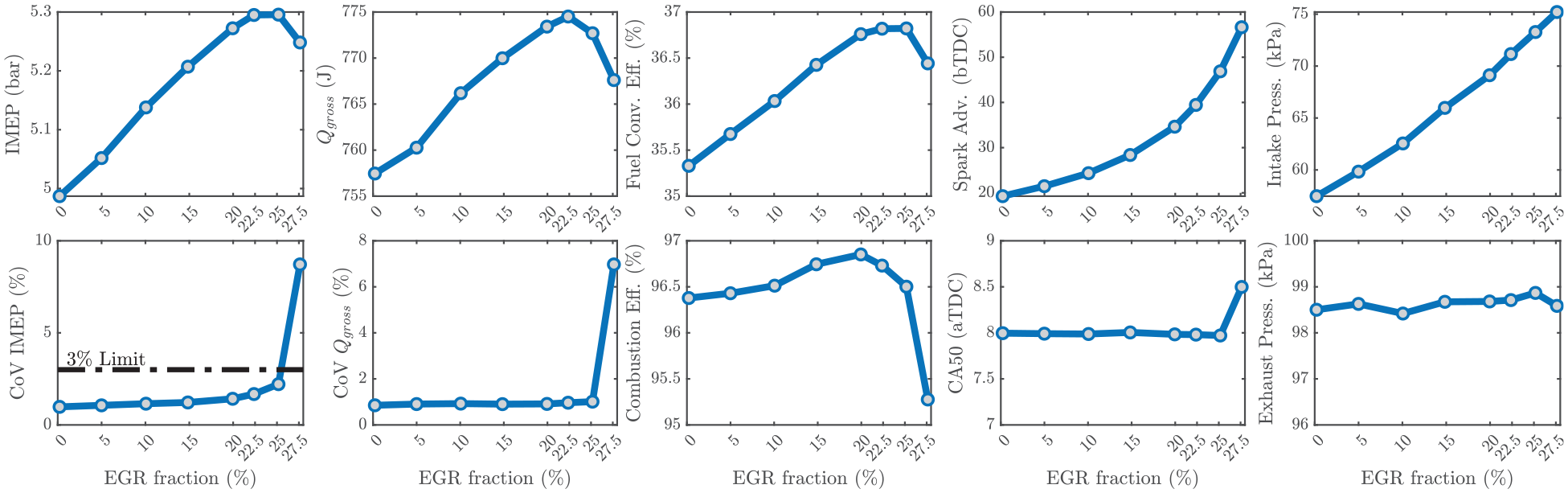
Averages over 2000 cycles of different combustion metrics as EGR increases toward the dilute limit.
• Gross heat release (neglecting crevices):
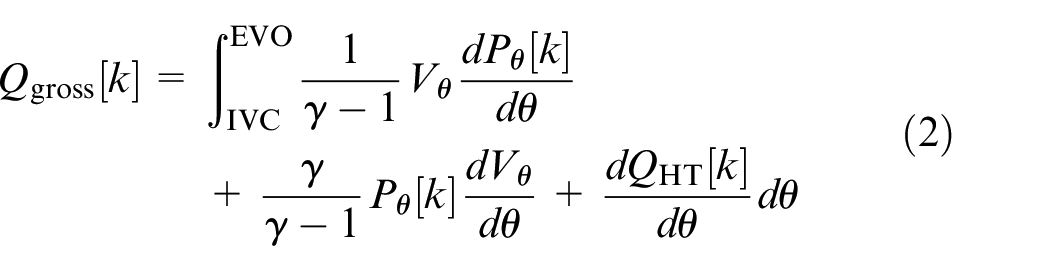
• Combustion efficiency:

• Fuel conversion efficiency:

• Combustion phasing (50% mass burned):

Here,
As the EGR fraction increases, the combustion kinetics change and the combustion duration elongates, retarding the combustion phasing. A proportional-integral (PI) controller was used to increase the spark advance to compensate for the longer combustion duration and maintain an optimal combustion phasing of CA50 = 8°aTDC.49,50 Since the intake airflow was kept constant at 276.5 g/s, the increase in EGR fraction produced the increase in intake manifold pressure observed in Figure 2. The exhaust manifold pressure, however, remained fairly constant at different EGR levels, indicating that the observed increase in IMEP and fuel conversion efficiency are due to improved combustion rather than improved gas exchange. On the other hand, the combustion efficiency showed a minor increase with EGR up to the dilute limit. Combustion CCV was characterized by the coefficient of variation (CoV) of IMEP and gross heat release. The increase in IMEP and gross heat release are followed by an increase in CoV due to the increased sensitivity to in-cylinder composition. The industry CoV of IMEP limit is 3%, based on the levels of noise, vibration, and harshness experienced by the driver. For this operating condition, the dilute limit was reached at approximately 25% EGR fraction at optimal spark advance. Furthermore, the experimental data in Figure 2 showed that peak IMEP and peak fuel conversion efficiency also occur at the dilute limit of 25% EGR fraction.
When the dilution levels were increased past the limit, to 27.5% EGR fraction, a drastic increase in CCV driven by sporadic partial burns and misfires rapidly increased the CoV of IMEP and the CoV of
Model-based cost function
For the cost function in the RL algorithm, a control-oriented model was considered. The physics-based approach for lean combustion modeling presented by Daw et al. 28 was used. The coupling between combustion cycles is through the carryover of residual gas from the previous cycle to the next and can be described by the following discrete-time system:
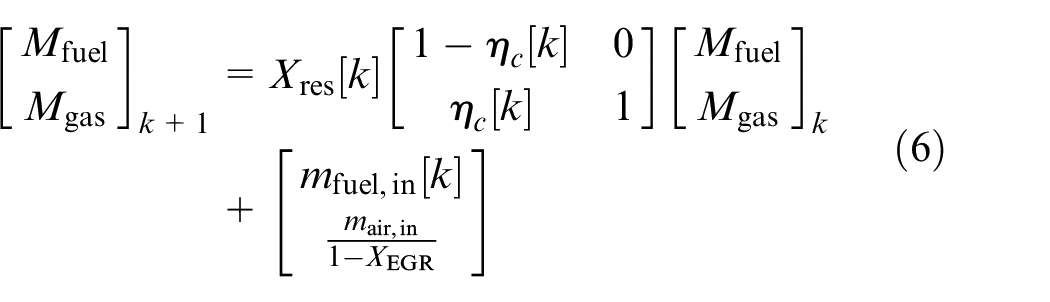

where
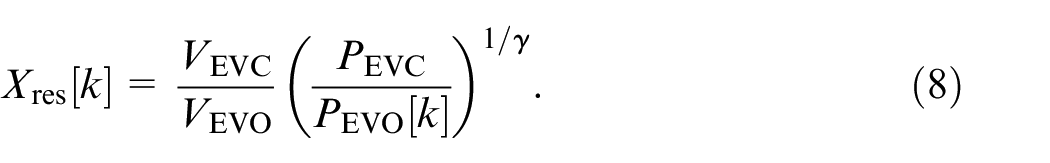
The subscripts indicate that only the values EVO and EVC are needed. However, in order to perform online calculations of the in-cylinder mass, it was assumed that

To avoid engineering units and maintain the variables at similar scales, consider the following normalization:



Finally, one can show that the normalized system obeys the following set of equations:
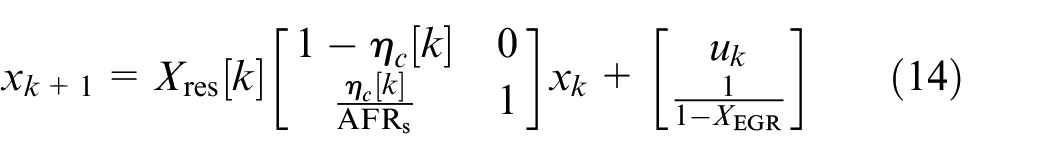

where
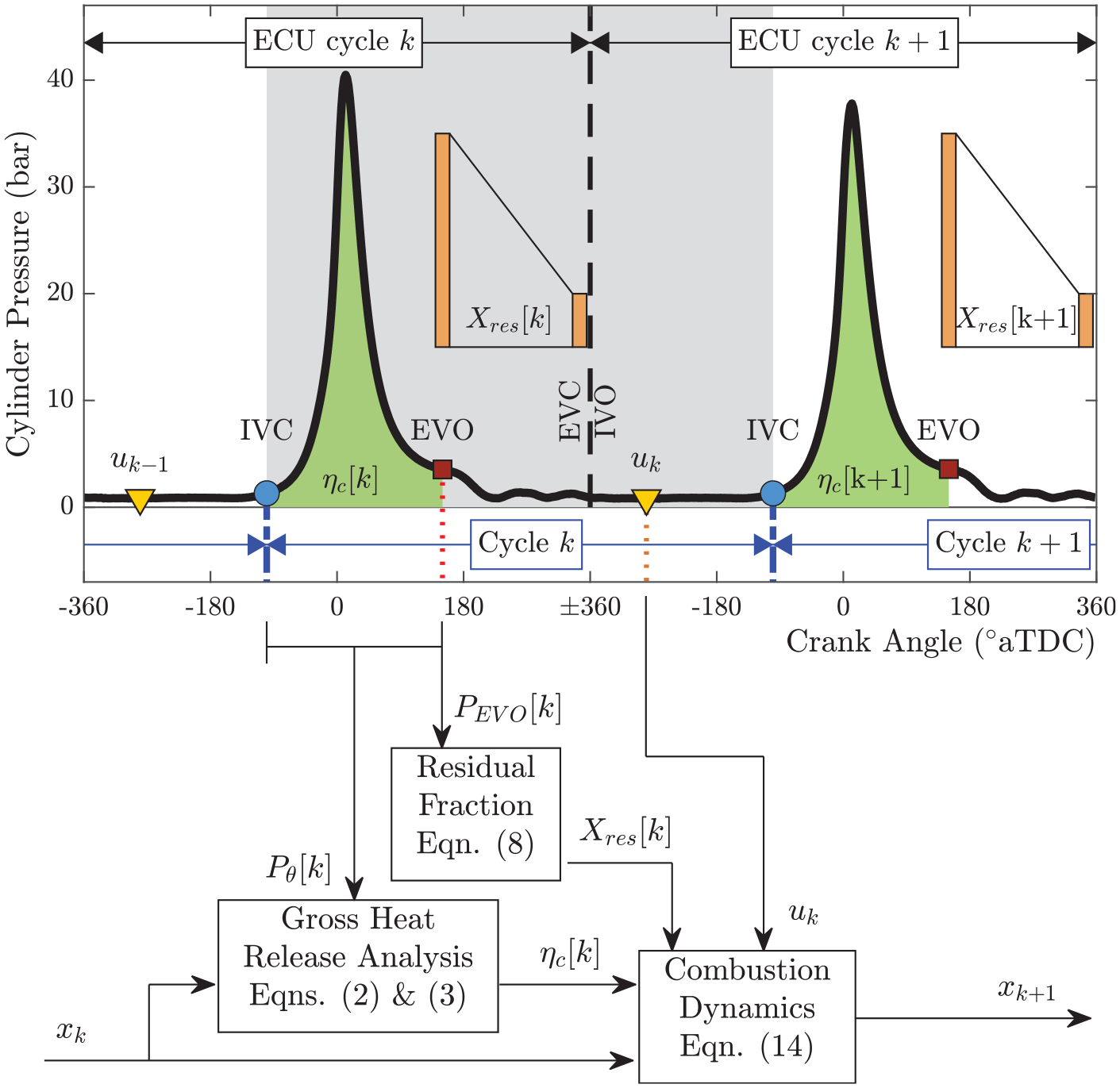
Calculations needed for cycle-to-cycle analysis.
Equation (14) can be written as
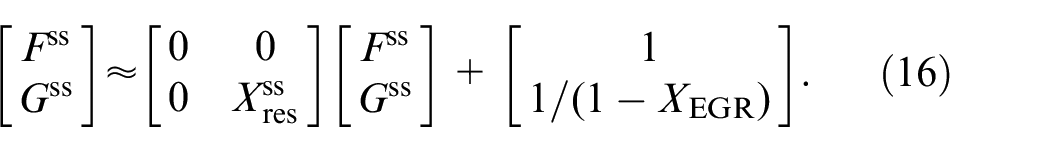
Then,
The steady-state analysis only applies to nominal combustion cycles. During misfires, the combustion efficiency drops to zero (no combustion) increasing the combustion CCV. Therefore,
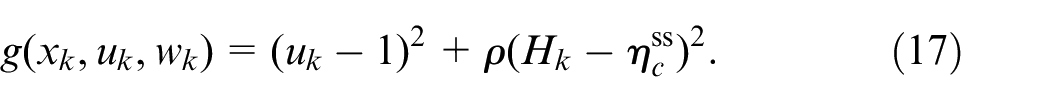
The first term penalizes the deviations from stoichiometric combustion while the second term penalizes the deviations from nominal combustion without misfires or partial burns. The parameter
Reinforcement learning algorithm
Consider the control problem of finding an optimal stationary policy
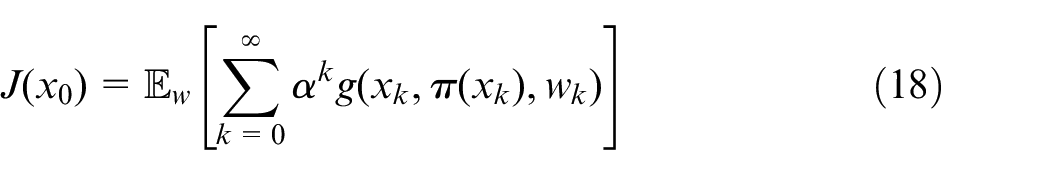
where
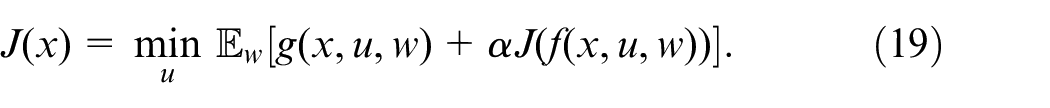
This is a challenging functional equation that could not be solved analytically for the problem at hand. RL was used to approximate the solution of the infinite horizon discounted cost problem. Q-learning was the method of choice for the following reasons: (1) simplicity in implementation, given that we wrote the algorithm within the native LabVIEW programing environment, (2) convergence, given that the update rule ensures that the Q-values eventually converge to the optimal value, and (3) off-Policy Learning, given that it can learn from data generated by a different policy. The third aspect is particularly important since one proposed method merges RL and
Let
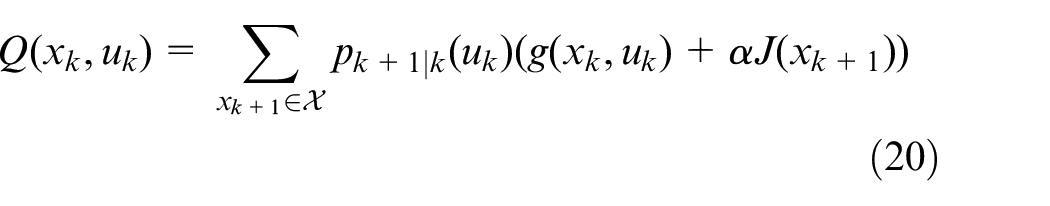
Since the optimal cost satisfies
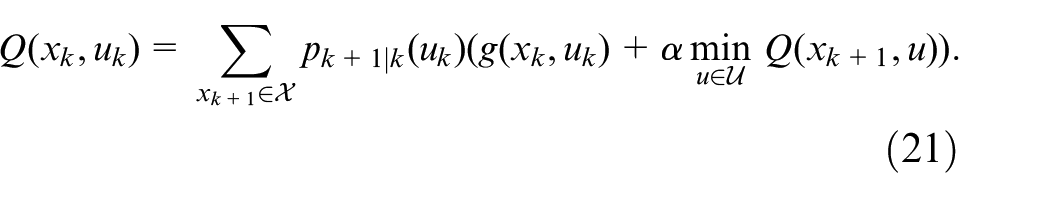
Let
The Q-learning algorithm introduced by Watkins
56
was used to adaptively learn the Q-table without knowledge of the transition probability (model-free learning). The Q-factor update law used a constant learning rate
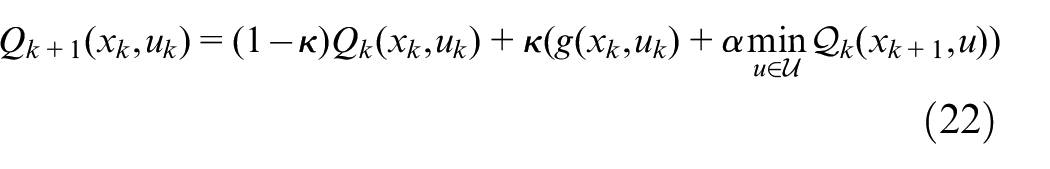

A
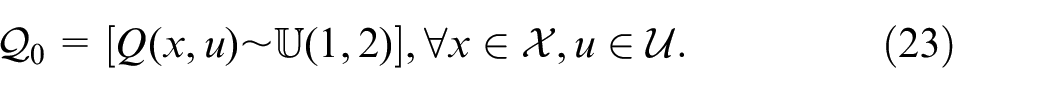
Such an interval was chosen to guarantee a large enough initial condition. For each episode, let
Experimental results
The Q-learning hyperparameters N,
Two training scenarios were considered, pictured in Figure 4. In the first, the cylinder-pressure-based controller was given full authority over the control action, resulting in
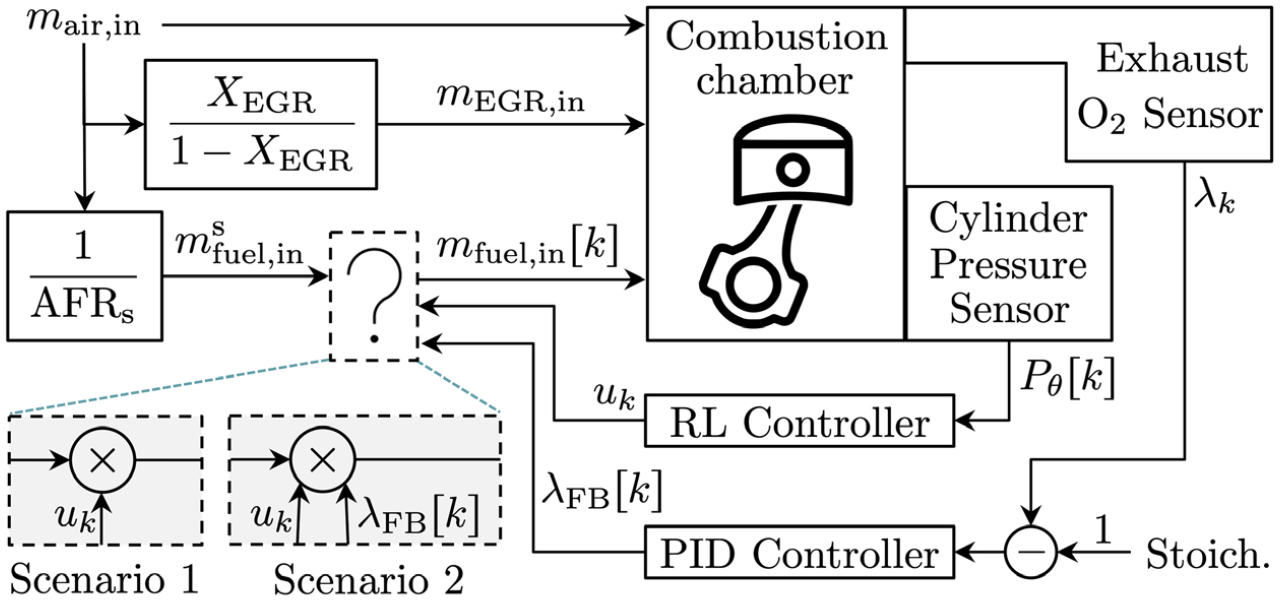
Feedback controllers considered during experiments.
RL controller without
feedback
The first model-free online learning experiment was conducted using the cost function in equation (17) without
Training of the RL controller without
Figure 6 shows the closed-loop response of the controller after the learning phase. Several partial burns were identified, but no misfire occurred during closed-loop. The control
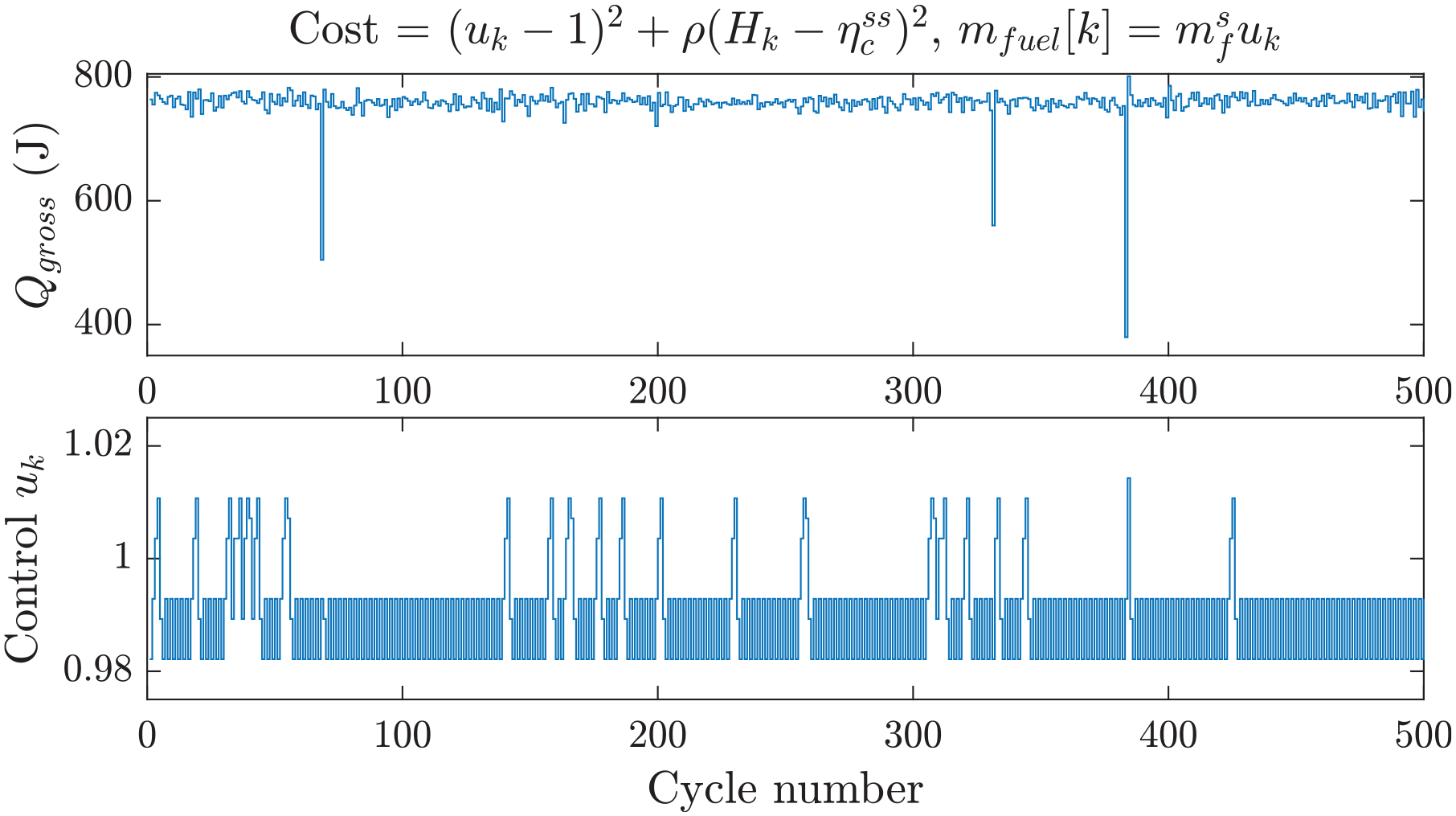
Closed-loop response of RL without
The average lean condition that the controller generated for combustion, although effective for increasing efficiency, is not compatible with a current three-way catalyst (TWC) that requires stoichiometric combustion to work effectively. To maintain TWC compatibility, consider using the exhaust oxygen sensor feedback controller
Performance of controller trained without
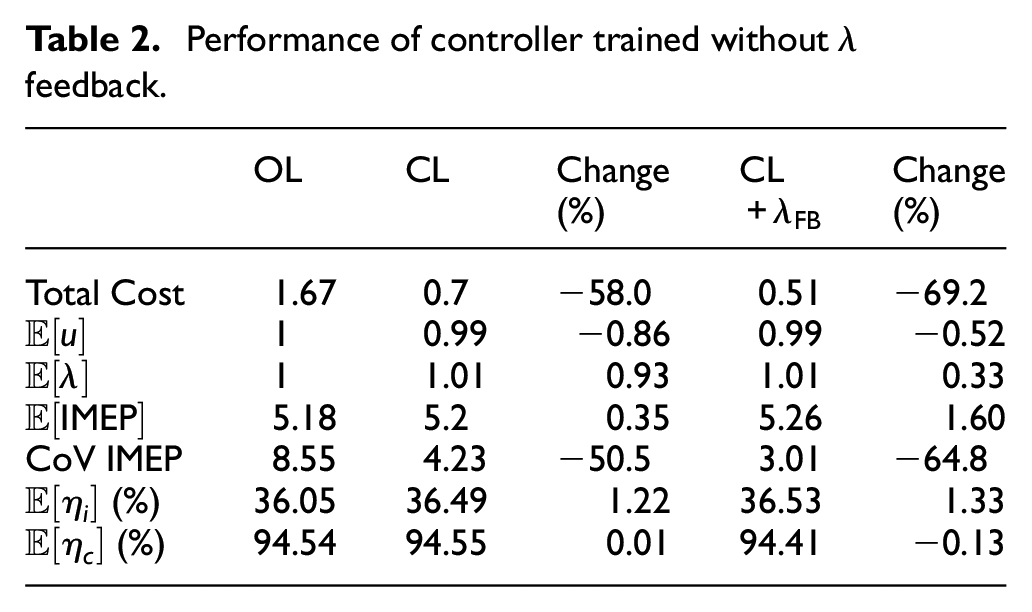
The previous study by the authors solved the one-step-ahead control problem with the same cost function proposed here.
37
In such a study, online learning was done to model the stochastic properties of CCV but the solution was calculated using the model described by equation (14). An increase of 0.5% in fuel conversion efficiency was reported under rich conditions. The current result of a 1.33% increase in fuel conversion efficiency at near-stoichiometric conditions highlights the benefits of the model-free RL strategy. A graphical comparison of the improvements made by the RL controller is depicted in Figure 7, which shows the return maps of
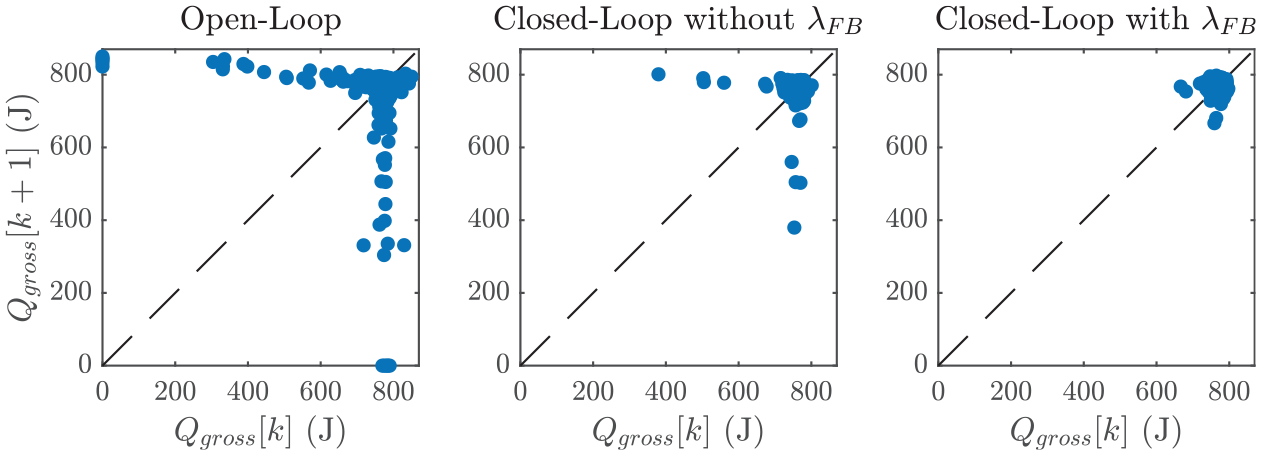
Return maps of gross heat release at OL (left), CL without
RL controller with
feedback
Given the benefits of using the
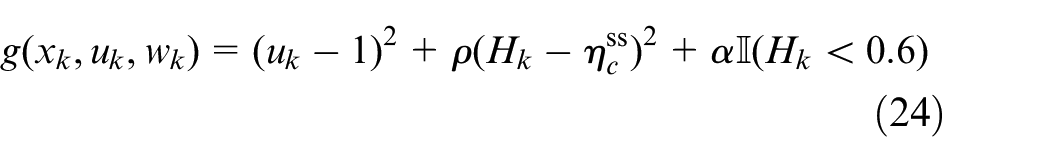
where
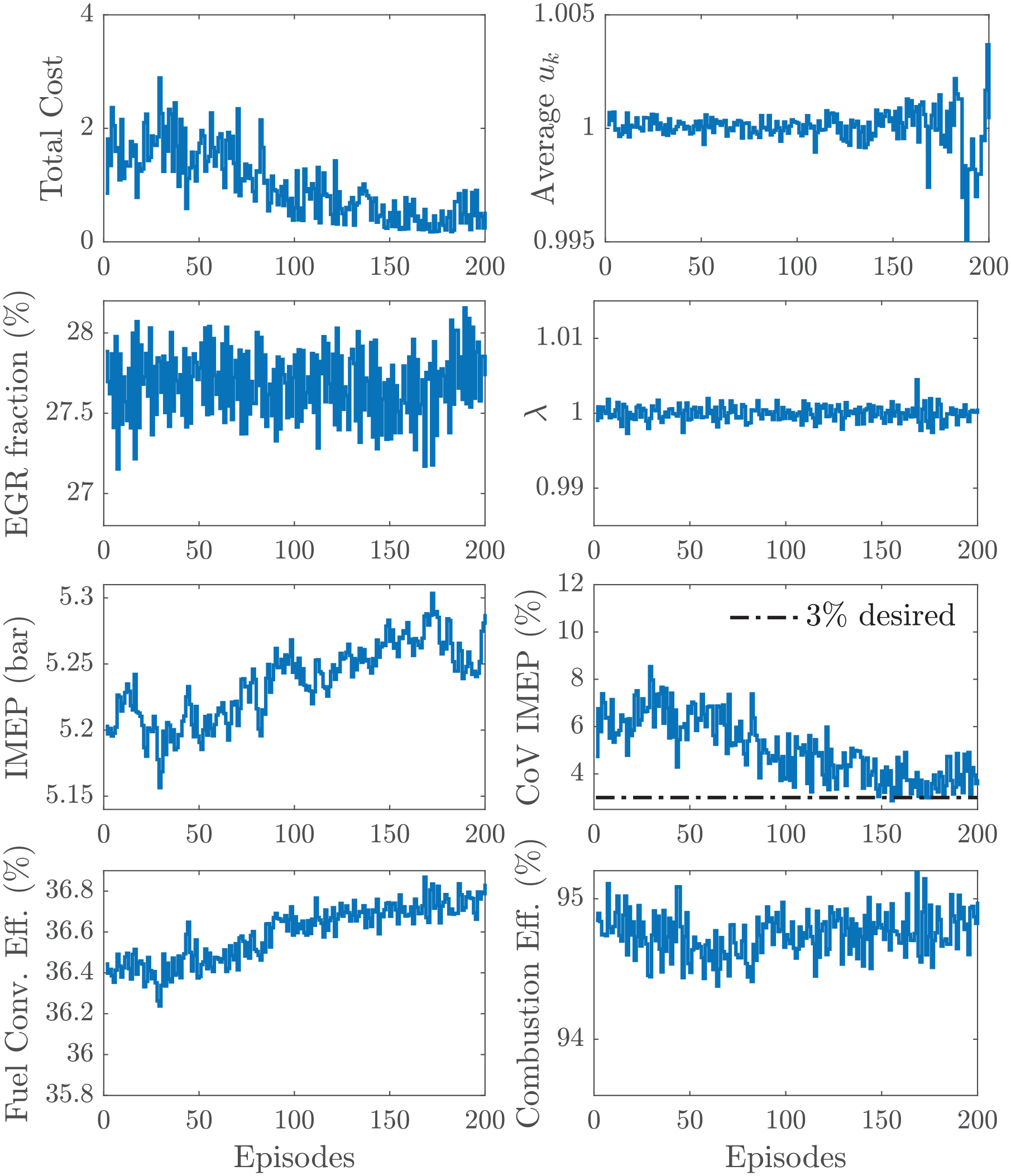
Training of the RL controller with
Figure 9 shows the closed-loop response of the RL controller within the proposed coordinated control strategy after the learning phase. Once more, no misfires were observed during the experiment. This highlights the importance of the additional penalty term in the cost function. Therefore, the CoV of IMEP was reduced fairly close to the desired 3% limit. For this control strategy, the injection quantity command does not follow a simple pattern. For some cycles, the controller switches between stoichiometric and lean conditions. After some time, the average command switches to the rich region
Closed-loop response of RL and
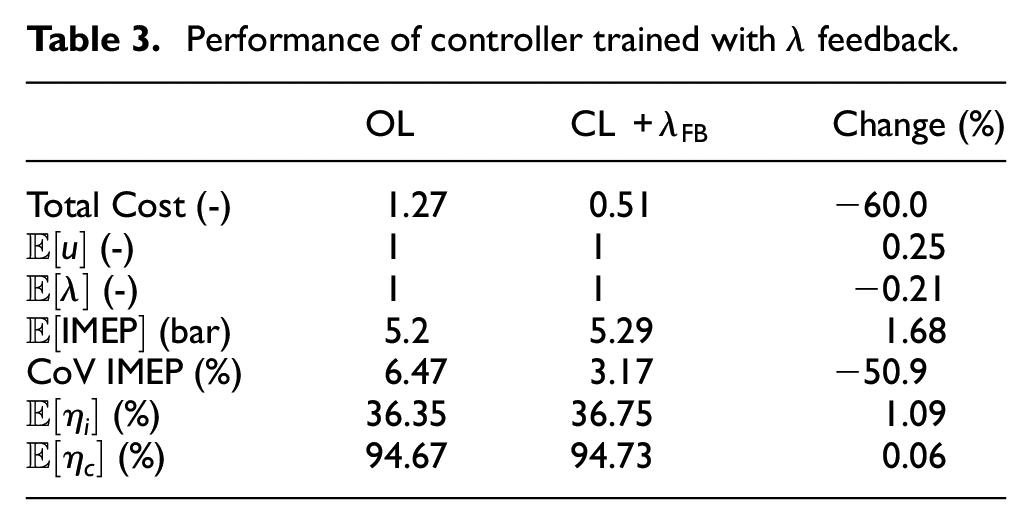
Table 3 shows the comparison between the open- and closed-loop systems after being trained with
Performance of controller trained with
RL controller with modified cost function
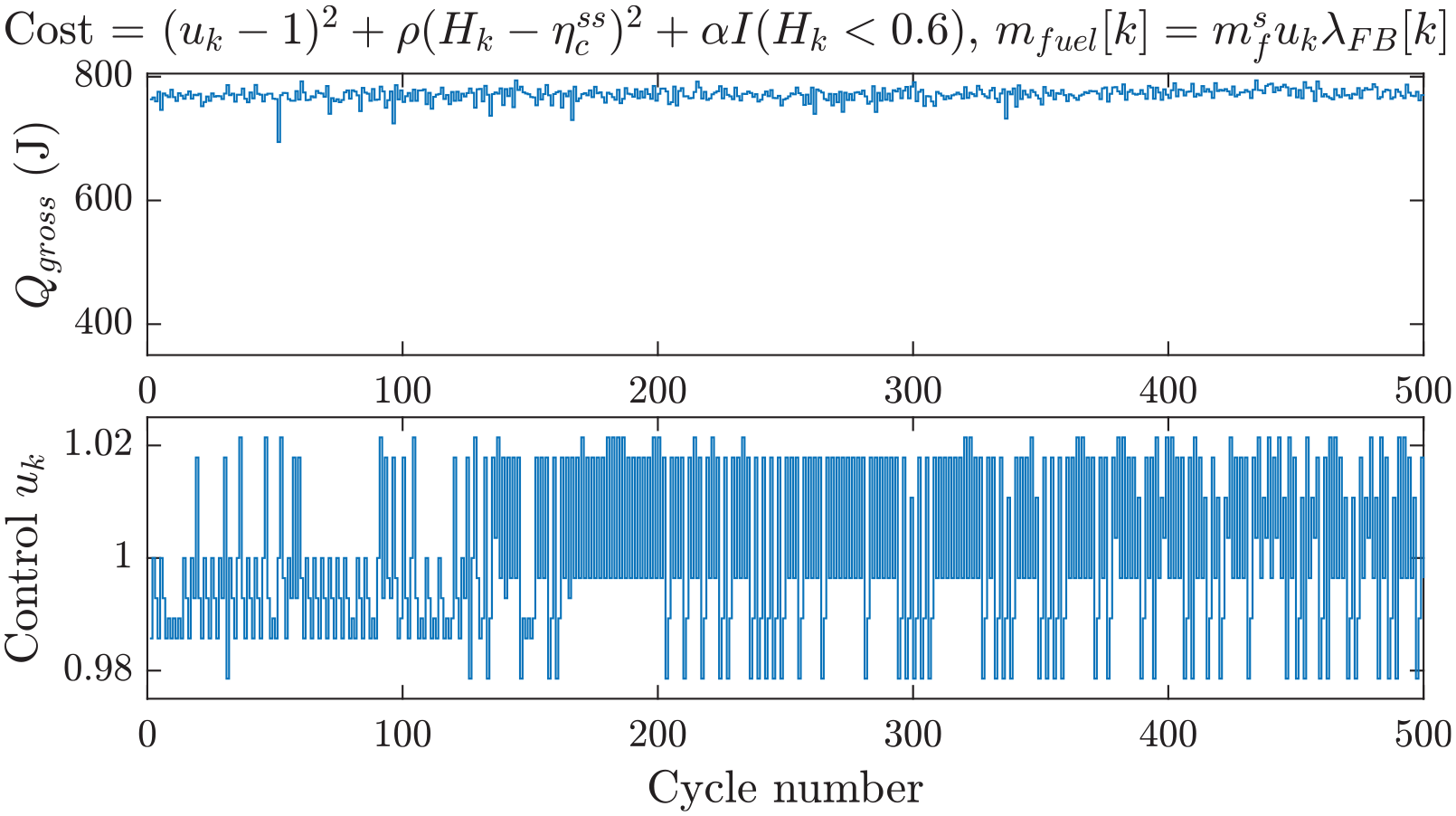
Recall that the cost functions defined by equations (17) and (24) are based on the physical understanding of the cycle-to-cycle dynamics. Although they were designed to achieve the goals of stoichiometric combustion, higher fuel efficiency, and reduction of combustion CCV, they rely on the explicit variables
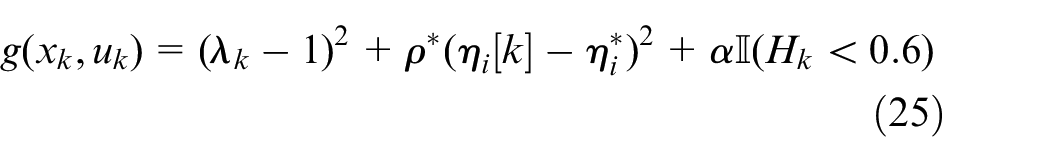
The first term uses the exhaust oxygen sensor to penalize deviations from stoichiometric conditions and serves as the replacement of the PI controller previously used. The second term attempts to directly increase the fuel conversion efficiency to a maximum value of
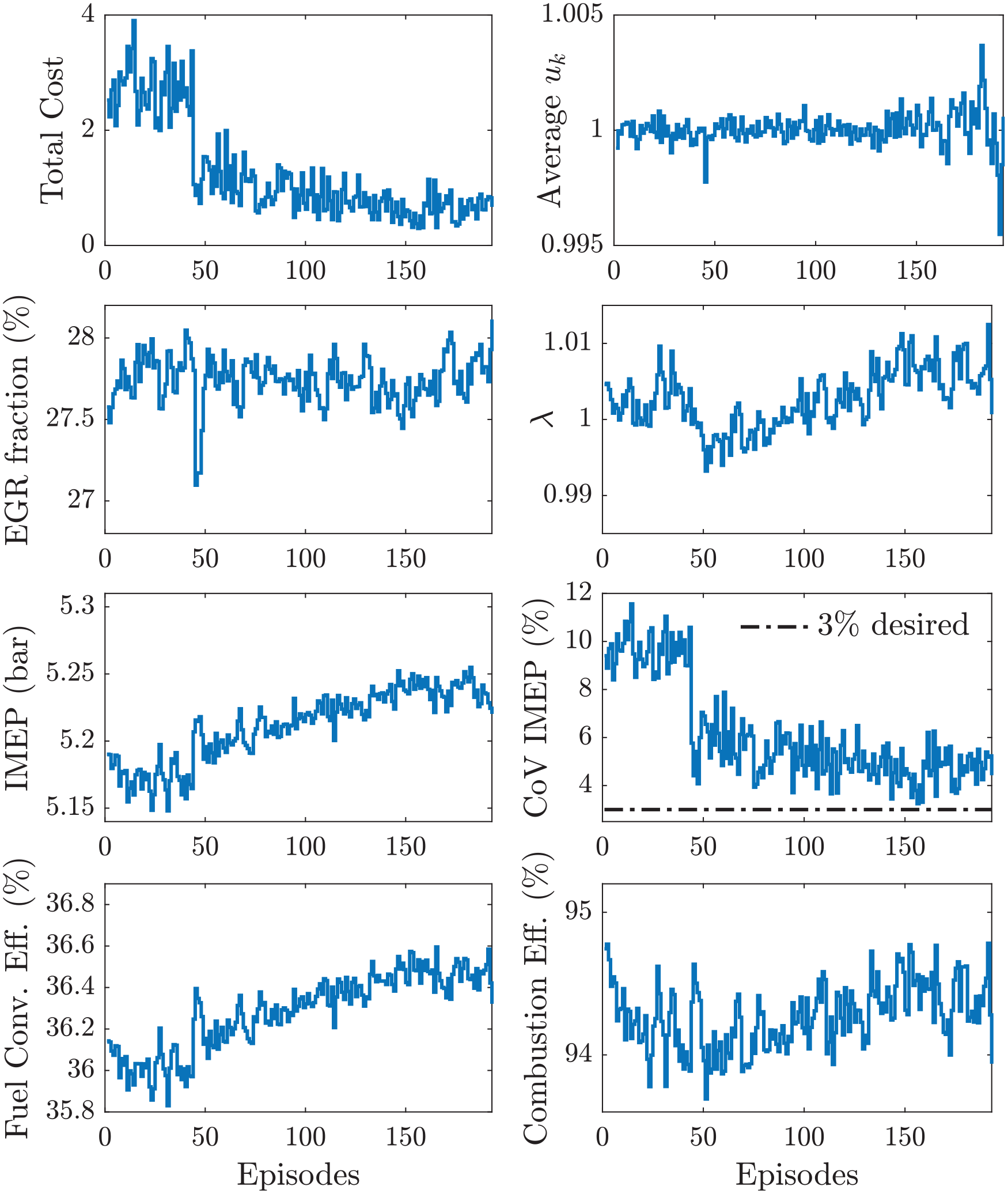
Figure 10 shows the experimental results over the training period using the modified cost function. The results display a reduction of the total cost due to (1) average stoichiometric conditions, (2) a moderate increase in fuel conversion efficiency, and (3) elimination of misfires and partial burns. Note that, toward the end of the learning phase, the controller consistently maintained rich conditions
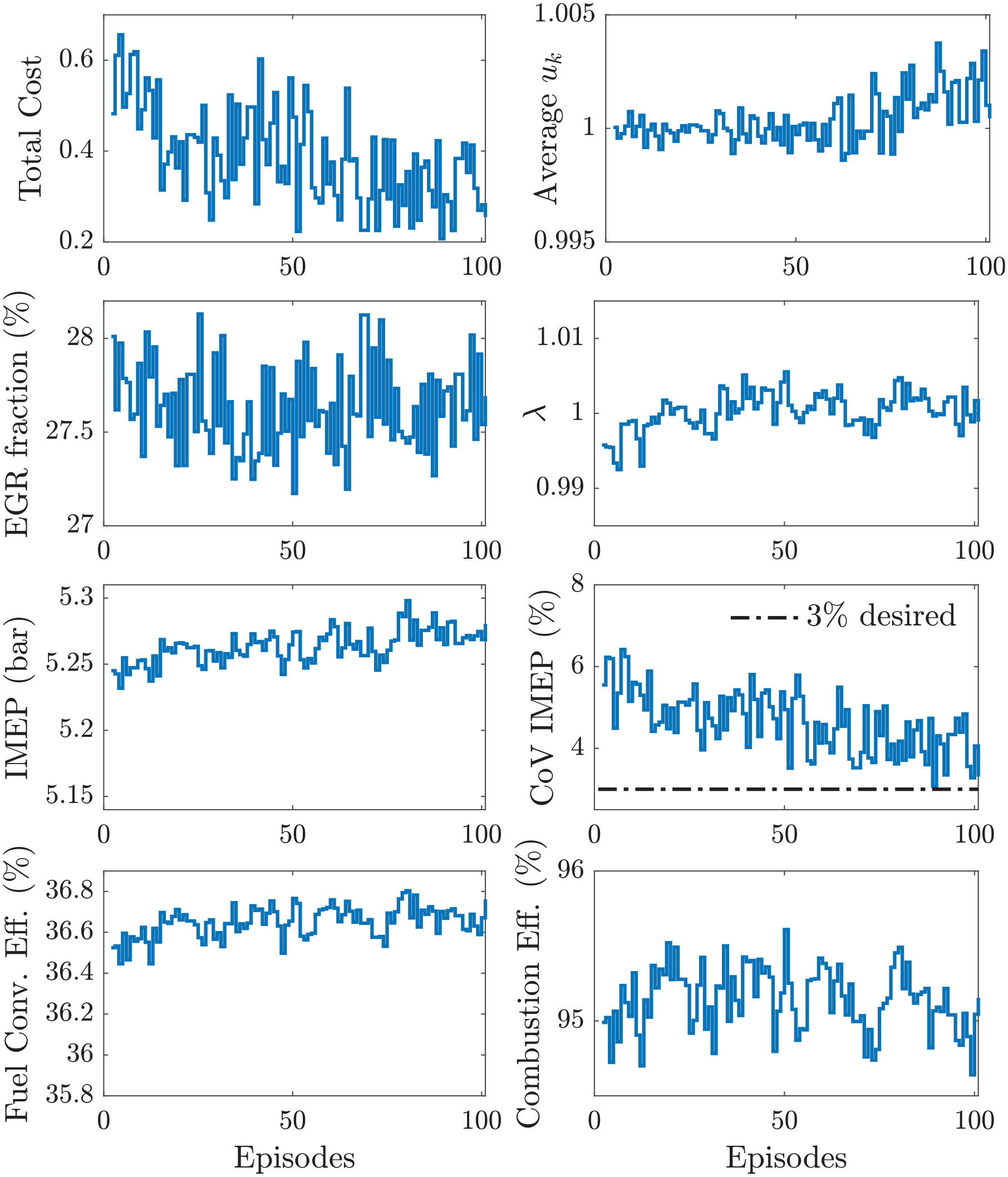
Training of RL controller with modified cost.
Figure 11 shows the response of the controller after the learning phase. Similar to the previous cases, no misfire was observed during 2000 cycles, contributing to the reduction of CoV of IMEP. The control command showed some distinct patterns during sustained periods of time, oscillating between four particular values. There were, however, moments where the controller was less predictable, probably leveraging the cycle-to-cycle dynamics to avoid partial burns and misfires.
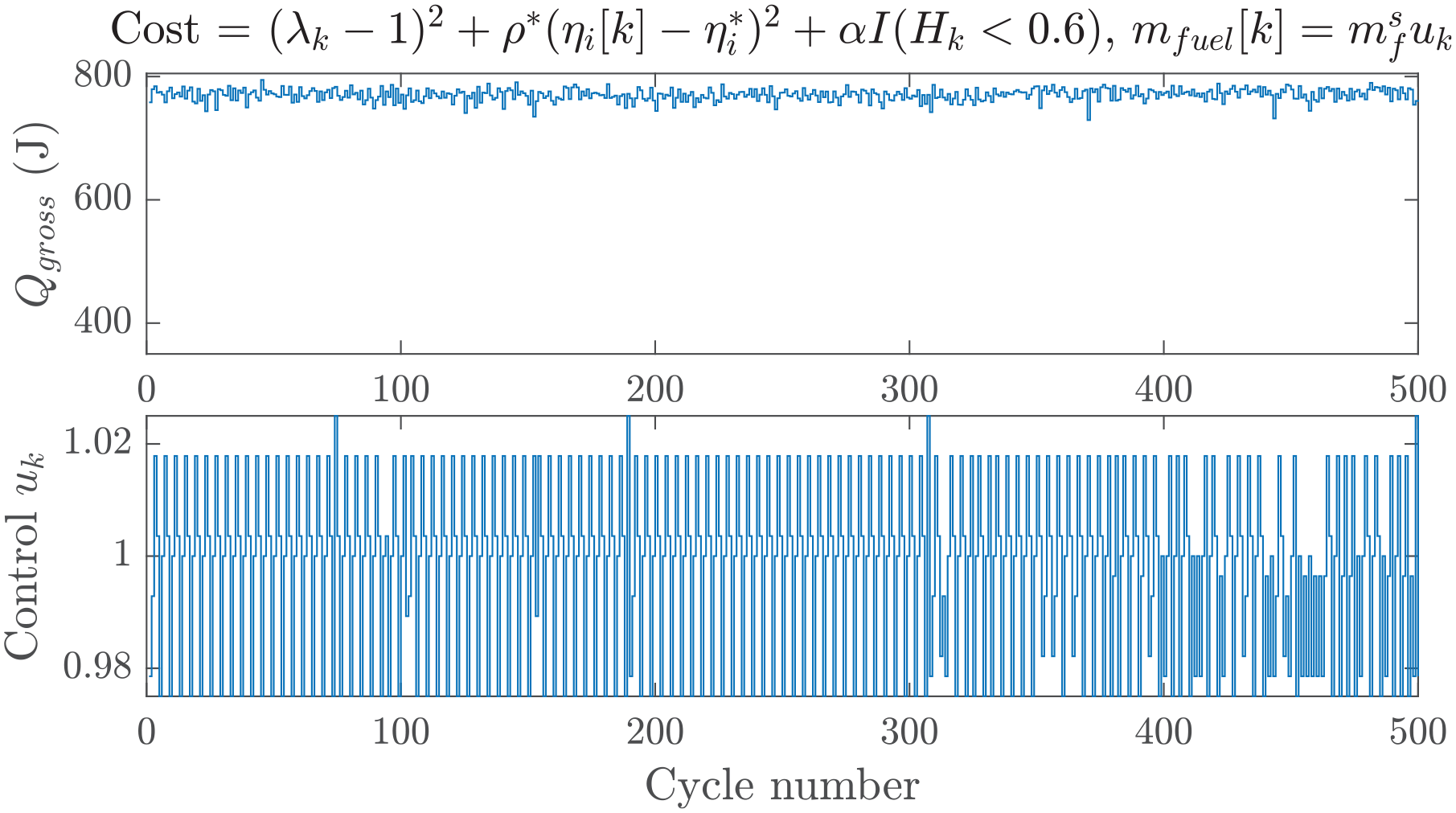
Closed-loop response of RL with modified cost.
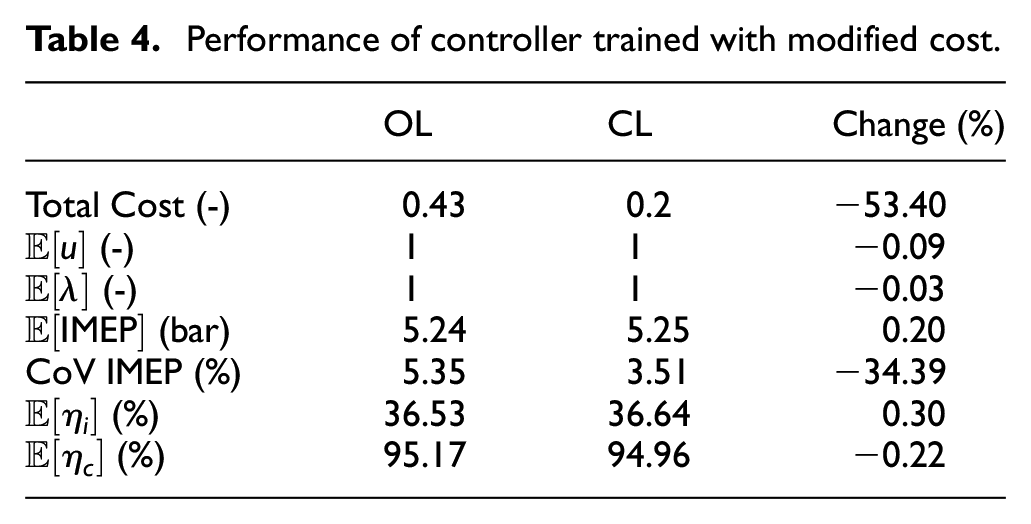
Table 4 presents the comparison between open- and closed-loop results of the average combustion indicators. The design of the new cost function guarantees average stoichiometric combustion by maintaining the control command centered at one. A net increase in fuel conversion efficiency of 0.3% was observed. The modest increase in efficiency was probably the consequence of the shortened learning phase. Nonetheless, the cost function was reduced by 53.4% with a reduction of 34.4% in the CoV of IMEP near the desired CCV target.
Performance of controller trained with modified cost.
Conclusion and outlook
A reinforcement learning strategy was proposed to design an optimal fuel quantity control based on online model-free learning of the combustion dynamics by running the engine in real-time. Full authority over the fuel injection control strategy was achieved using a LabVIEW-based open ECU on an experimental SI engine. The engine was operated at a constant speed and intake airflow according to the ACEC tech team guidelines. The dilution levels were increased to 27.5% EGR fraction, corresponding to a condition past the dilute limit. At each cycle, several combustion parameters were calculated using a simple cycle-to-cycle combustion dynamics model. The control-oriented model allowed for the identification of the system states needed for a data-efficient RL algorithm. The cycle cost was designed to extend the dilute combustion limit by (1) reducing combustion CCV, (2) improving fuel conversion efficiency, and (3) operating at stoichiometric conditions. An infinite horizon discounting cost problem was formulated and the solution was approximated by discretizing the state and control spaces to use Q-learning. A
Full authority, training for 6h30min
Coordination +
Full authority + modified cost, training for 3h20min
In the first scenario, the controller was trained with full authority over the control space. During closed-loop, the improvement of fuel conversion efficiency was the highest observed, at 1.33% over the open-loop condition. However, this was due to a slightly leaner mixture, rendering it incompatible with standard TWCs. In the second scenario, the controller was trained in coordination with a
Footnotes
Appendix
Authors’ note
This manuscript has been authored in part by UT-Battelle, LLC, under contract DEAC05-00OR22725 with the US Department of Energy (DOE). The US government retains and the publisher, by accepting the article for publication, acknowledges that the US government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this manuscript, or allow others to do so, for US government purposes. DOE will provide public access to these results of federally sponsored research in accordance with the DOE Public Access Plan (![]() ).
).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the Laboratory Directed Research and Development Program of Oak Ridge National Laboratory and used resources at the National Transportation Research Center, a DOE User Facility.