
Abstract
The uniqueness of the European Parliament, as well as the magnitude of impact its decisions wield over member states, are elements that capture researchers’ attention. However, several of this institution’s particularities have made broad analysis of the textual content it produces difficult. This research note presents Vitrine Démocratique, a new, publicly accessible, and centralized database structuring interventions made in the European Parliament starting in 2014, both in their original languages and translated to English. The process by which this high-velocity database was created is presented, as well as a descriptive overview of the contents of this data source, which is continuously updated on a daily basis.
Introduction
As with other European Union (EU) institutions, the European Parliament (EP) has been the subject of numerous studies. The uniqueness of this legislature as well as the magnitude of impact its decisions have on the member states that constitute the EU are elements that capture the attention of researchers from different disciplines. Research on this institution should be facilitated by the fact the EP makes all of its proceedings available as open data on its official website. However, analyzing such a large corpus of texts requires the use of an entire software infrastructure. Moreover, several particularities that make the EP such a fascinating research topic have the additional effect of rendering a broad analysis of its textual content more difficult. This paper presents a novel database that will help researchers overcome many of these challenges.
Text-as-data approaches are increasingly used to study legislative politics (Proksch et al., 2019; Hopkins and King, 2010; Lowe, 2008). Nonetheless, several challenges are linked to these approaches, especially when the objective is to convey analyses capable of transcending language. EP speeches were previously made accessible in multiple languages on its website, but this service was terminated in 2012 for cost reasons (European Parliament, 2012). Because speakers are free to communicate in their home country’s language and translation is no longer provided, the 24 official languages of the EU are used in addition to three others that have been identified since 2014, totaling 27 different languages spoken in the EP, making comparative studies difficult to conduct and validate. The EP has therefore become a particularly complex case study for carrying out textual analyses.
In terms of automated data scraping, another challenge arises in the case of the EP: the web structure in which the data was embedded was HTML until the end of 2019 and has been hosted in XML since. Consequently, developing an automated data extraction process requires the construction of two separate scrapers, which should ultimately provide the same outputs.
Thus, most of the research on the EU and proceedings have had to opt for analyses that select only a few languages or countries of focus (Proksch et al., 2019), emphasize specific types of debates (Eising et al., 2015; Proksch et al., 2019), analyze a circumscribed period (Ulnicane et al., 2021; Krijgsman, 2018), adopt more qualitative, or descriptive approaches, use proxy data (such as votes to analyze legislative proceeding dynamics), or manually collect data limiting the possibility for large-n research (Ulnicane et al., 2021; Rasmussen et al., 2019; Beyers et al., 2018; Häge, 2007; Princen, 2007; Tsebelis and Garrett, 2000; Harcourt, 1998; Kim et al., 1978). Other research has circumvented these difficulties by analyzing, for example, the salience of certain EP topics through their coverage in media or in media releases, while others have used votes or legislative proposals. The content of these sources is often available in English, making it more widely accessible to researchers everywhere (De Bruycker and Beyers, 2015; Beyers et al., 2018; Schuck et al., 2011). While all of these studies are highly relevant, they are limited by the challenge of accessing data for a more comprehensive analysis of European politics.
What if we could systematically analyze the complete content of all debates held in the EP, unlocking the full potential of this intricate resource and building upon the foundations laid by previous studies? An automated approach empowers researchers to capture the entire content of plenary sessions in the EP. This represents a significant advancement in the study of European politics, complementing and extending the insights gained from earlier research efforts. Automated scraping ensures the inclusion of every legislative debate, speech, and discussion into the dataset, eliminating the risk of sampling bias. By encompassing the entirety of EP proceedings, an automated approach also provides an accurate and holistic representation of the parliamentary process, which can be particularly valuable for examining the evolution of the EP over time and its response to various political challenges. Moreover, automation grants researchers real-time or minimal-delay access to data, facilitating timely analyses of contemporary political events and developments as they unfold within the EP. This feature addresses the need for up-to-date information crucial for understanding the dynamic nature of European politics. An automated data collection approach therefore streamlines large-scale comparative studies, enabling the examination of political dynamics, discourse patterns, and legislative activities across different sessions, time periods, and language groups. In so doing, it builds upon the existing body of research by offering a more comprehensive, accessible, and dynamic dataset that enhances our ability to explore and uncover new insights into the EP’s functioning and its impact on the EU.
We are not the first to note these issues. Eising et al. (2015: 516) observed that “studies of framing in the EU political system are still a rarity and they suffer from a lack of systematic empirical analysis.” Since then, numerous tools and databases have been created and made accessible to the scientific community. However, one of the challenges facing these tools is sustainability, particularly in the face of changes in web structures. The LinkedEP database developed by Van Aggelen et al. (2017) filled exactly this gap by presenting a database of debates translated into several languages and rendering the database manipulable through a web interface. Although the interface was non-intuitive (made accessible either under .ttl format to be processed in Python language or by SPARQL queries), this tool allowed access to EP speeches in an analyzable form. Unfortunately, the project was stopped in 2017. If LinkedEP were to be launched again, the tool would be confronted with the modifications that have been brought to the web structure of the EP’s website (changing from an HTML to XML language) and could only be launched by completely reviewing its scraping process. Another EP corpus database project similar to ours, Europarl, was created in 2005 and, unfortunately, aborted in 2011. It compiled parliamentary proceedings since 1996 in both their original version as well as translations (Koehn, 2005). Additionally, two recent tools structuring EP data are accessible through online repositories. ParlEE Plenary Speeches V2 contains the full-text speeches from six legislative chambers including the EP, covering 2009 to 2019. The dataset provides the plenary speeches split to the sentence level annotated with date, speaker, party, EU versus domestic politics classification, and policy area (Sylvester et al., 2023). ParlLawSpeech is a data structure that covers the EP’s data spanning from 1999 to 2019. This project semi-automatically collects text data from publicly available archives including the EP. This collection includes machine-readable full-text data related to legislative bills, speeches, and adopted legislation, all linked through a common identifier (Kiss and Sebők, 2022). Regrettably, these two tools were not updated following the EP’s transition from an HTML website to an XML one. Data after 2019 is therefore not accessible. Finally, a separate tool, created to render large-n analyses of the EP easier, was an open database created by Hoyland et al. (2009), which stored background information about members of the EP (MEPs) and could be used conjointly with the aforementioned databases. This tool centralized data on the exact period representatives served in the EP and the positions they held during their service (Hoyland et al., 2009). This database is, however, no longer kept up-to-date, nor is it openly accessible online. It is also important to note that all of these tools share the common feature of presenting texts and speeches in their original languages, thus reducing comparability.
This paper presents a new, publicly accessible, and structured database called Vitrine Démocratique. This centralized database has been automatically and continuously fed since its creation and contains all interventions made in EP plenary sessions from 2014 to the day of the data request in their original language and translated into English. This is because translation increases the confidence in the measurement device since the same analytical approach is used for all languages. Thus, Vitrine Démocratique adds value by moving all texts into a single pivot language. This feature will facilitate comparative research by: (a) offering the possibility of crowd-coding various concepts of interests, which can be more easily accomplished and compared when dealing with one standardized language rather than 27 different languages; (b) providing the opportunity to train, improve and validate supervised and unsupervised text-as-data methods; (c) it can also be used for topic modeling, scaling (e.g., using Wordfish or Wordshoal) and content analysis on the whole corpus simultaneously; and (d) allow the analysis of qualitative text as inductive approaches of discourse analysis or extracting policy positions throughout the EP. The automated method employed by Vitrine Démocratique presents numerous benefits compared to earlier approaches. It guarantees the inclusive coverage of all plenary sessions, overcoming language barriers to allow for multilingual analysis. Immediate access to real-time data equips researchers with the latest information, which is essential for examining current political trends. Additionally, this tool streamlines large-scale comparative studies, improves efficiency, and aids in conducting longitudinal analyses. This database should therefore help the scientific community fill the need for a free, up-to-date, and structured database of EP proceedings
The Vitrine Démocratique platform is also complementary to existing tools commonly used in the analysis of decision-making processes in Europe. The PreLex tool, created by Werner and Kovats (2010) and the CELEX tool (see König et al., 2006), are previous databases now integrated into the EUR-Lex database made available by the Publications Office of the EU. Different from Vitrine Démocratique, EUR-Lex provides access to EU legal documents, such as treaties, legal acts, international agreements, preparatory documents related to EU legislation, and national implementation measures for community directives. It also monitors inter-institutional procedures, by following Commission proposals and communications transmitted to the Council or the EP (König et al., 2006). The database has been notably used to analyze the salience of a policy field in the government parties’ manifesto compared to the proportion devoted to the same issue in the Council Presidency speech (Warntjen, 2007). EUR-Lex is therefore focused on documents produced by European institutions and has its own particular purpose. Vitrine Démocratique acts as a companion to these tools by structuring different data, namely the discourses in the EP. The way EUR-Lex and Vitrine Démocratique data can be cross-referenced is discussed after the presentation of our new database.
This research note presents: (a) the method used to collect and structure the data through the Vitrine Démocratique tool; (b) the data themselves; and (c) a descriptive analysis of the data collected up to March 2023. The parliamentary data detailed above are stored on the Université Laval’s VALERIA servers integrated solution. Following an access request, the data can be easily imported into .csv or .xls format for analysis. 1 By bridging the gap between historical and contemporary analyses, Vitrine Démocratique strengthens the continuity of research efforts while opening doors to novel research questions and methodologies. In this way, it enriches the scholarly landscape by contributing to a deeper understanding of European politics.
Automated extraction of parliamentary data
The Vitrine Démocratique tool allows for the extraction and automated analysis of data, making it possible to follow the evolution of parliamentarians’ discourses on a daily basis. To automatically collect online content from speeches by elected officials, an essential component of Vitrine Démocratique is its web scraper. 2 However, the Vitrine Démocratique project is much larger than the database presented in this article. The project was created in 2020 and originally targeted data from various provincial and federal Canadian parliaments. Vitrine Démocratique has recently been extended to the EP, and could eventually be extended to other parliaments around the world, while maintaining the same data structure in order to optimize comparability from one parliament to another. The creation of these various scrapers requires the identification of the content to be extracted, and its organization into a structured database in order to facilitate the use of said content in subsequent analyses. This section describes these steps in greater detail.
To be effective and reproducible, a data extractor must be designed to systematically locate information within the structure of web pages (Munzert et al., 2014). In the case of the EP platform, the Information Technology structure has been built using XML tags since 2020, but was originally built in HTML. Specific recurrent information is present in both languages, such as the date, the body of the text, the language spoken, and the identification of speakers. This allowed the research team to pinpoint relevant data in both versions of the site, and, in turn, create a script capable of automatically extracting data into a single structure optimized for research. Thus, the final output is a single structured database.
Precise data extracted
The plenary session scraper collects the data listed on the EP’s website from a single hypertext link leading to the plenary sittings. In this first edition of the database, data are collected from 1 January 2014 to the date on which the data frame is downloaded. In its current form, the database therefore includes the eighth legislature, which began on 1 July 2014, and all subsequent ones. 3 Once on the webpage for an individual session, the data extractor locates the tags containing the title and the full text of the session in a single block. Each session then is separated by intervention. An intervention is defined as an uninterrupted speech by a member, a moderator, or another speaker. Interventions may consist of just a few words or several paragraphs.
For each intervention, the data is automatically identified and then hosted in the database. One should note that all of the variables in the database are, by default, in character format (see Online appendix for the list of all variables and their format).
The data on MEP’s personal attributes is found in a separate table, called persons, which updates the MEP-level variables of the EP database continuously. The persons table is automatically updated any time the scraping algorithm encounters a name not already present in the table. In such cases, another algorithm searches the unknown name in the MEP search page of the EP website and parses the XML sent back from this search into the persons table in order to inform the personal attribute variables mentioned above (such as the MEPs’ party affiliation and political group). This means that the dataset only includes MEPs who have given at least one speech during their time in the EP. Additionally, if a new entry presents a new category for a variable, for example, if a party group changes names between terms, it is highlighted to our team. That way, this new information can be cleaned by the researchers. Continuing with the example of a new party group name, the research team can associate it with the last party name in order to be analyzed conjointly.
Data translation
During EP debates, politicians may speak in their preferred language. 27 languages are used in the EP. Although debates were initially translated by professional translators, this service was terminated in 2011. To carry out a complete analysis, it is therefore necessary to deploy methods that make it possible to transcend different languages.
Proksch et al. (2019) demonstrate that sentiment dictionaries can simply be translated into various languages when analyzing text data for sentiment analysis. However, we argue that Vitrine Démocratique adds value by moving all texts into a single pivot language as this facilitates comparative research. Thus, the construction of this database required the use of an automated translation process, and the original texts were translated into a single language for analysis.
In this case, all speeches have been translated into English. Each intervention is translated as soon as it is extracted from the XML and HTML structures using Microsoft’s Azure cognitive services. To do so, an
Once the original language is automatically detected and this characteristic is stored in the database, the translated text is then inserted in the intervention_text_en field of the database and the original text remains in the intervention_text field. However, an intervention could contain several languages. This is the case for 54 interventions, including the one identified by intervention_id 2020-07-09-920200709EN92, which contains both English and Greek. Interventions with multiple languages were automatically identified and subsequently manually processed in Azure for translation before being added to the intervention_text_en column. Finally, the entire translated content of a debate is reconstituted from the concatenation of all the interventions and transferred to the database.
Data description
Covering the period from 1 January 2014 to the date on which the database was downloaded, the 23 variables stocked in the database allow researchers to analyze the EP from multiple angles. Table 1 presents descriptive data collected up to March 2023.
Data summary.

Note: Summary from the data collected up to 30 March 2023.
Prior to using the data, it is important to note some of the database’s peculiarities and how changes to EP procedures affect the data gathered. Specifically, we observe a shift from numerous but shorter interventions to fewer and longer interventions over time. This makes plenary sessions less comparable than they were years previously, in terms of the number of interventions.
Figure 1 presents the evolution of the number of interventions in plenary sessions by day. The figure shows that, until 2017, the number of interventions was much more disparate than in the following years. However, as of 2017, the number of interventions presents a much lower standard deviation (102.8 since 2017, compared to 934.5 between 2014 and 2017). For the period prior to 2017, the mean number of interventions per session is 1599.9 with the highest number of interventions during the plenary session held on 4 April 2016, which included 4907 distinct interventions. For all plenary sessions after 2017, the average number of interventions is 274.4. At the same time, however, other changes are observed between these two periods. Especially, the average number of words per intervention increased from 133.9 between 2014 and 2017 to 223.6 after 2017. In addition, the average number of subjects of business discussed by day in the EP decreased from 20.9 before 2017 to 15.8 after 2017. These diverse data insights show significant changes in plenary session procedures.
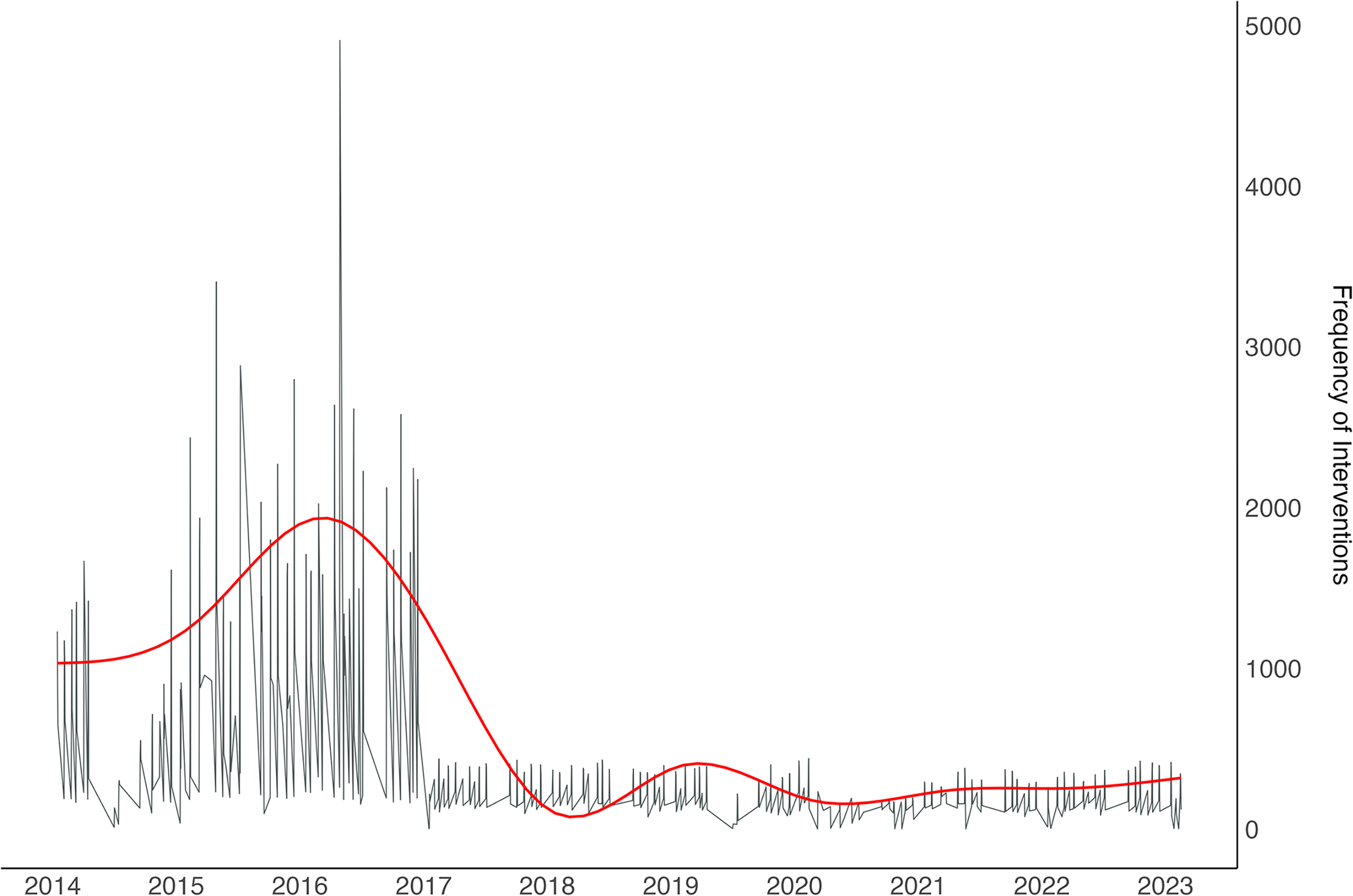
Number of distinct interventions by day.
These trends coincide with two significant changes in the EP procedures: the adoption, in December 2016, of the Interinstitutional Agreement between the EP, the Council of the EU and the European Commission on Better Law-Making and the new Rules of Procedure of the EP adopted in January 2017. The Interinstitutional Agreement aims, in particular, to improve and shorten internal and inter-organizational procedures. An example is Rule 129, which states that a member has one minute to formulate a question, and can ask an additional question no longer than 30 seconds having direct bearing on the main question (Martínez Iglesias, 2020). These rules can also be freely interpreted by the President of the EP. Changes in the Rules of Procedure in 2017 also removed numerous steps in legislative procedures, such as the Blue Card Procedure, and restrained the possibility for speeches and questions from MEPs while prioritizing partisan balance (see Sorace, 2021 for the history of these procedural changes). These modifications and the addition of various procedural regulations in late 2016 had the objective of increasing efficiency and avoiding MEPs abusing their speaking rights (Sorace, 2021). In January 2017, the number of written questions was also capped at 20 per MEP over three months, which could also account for the consistently lower number of interventions (Brack and Costa, 2018). While the database includes only oral interventions, it is important to note that written questions can also be answered orally. Therefore, considering the limited number of written questions since 2017, it is worth mentioning that the reduced cap on written questions may have contributed to a decrease in the number of interventions addressing them.
These amendments to the rules and procedures should therefore be kept in mind while analyzing the EP data over time, as they have a direct influence on the breadth of data being analyzed. In light of this information, we strongly recommend weighting the data when frequency measures are used. By doing so, the differences potentially generated by disparities in the way in which interventions are managed during the plenaries will be controlled.
Now that these caveats have been highlighted, the descriptive distribution of some variables contained in the database is presented to inspire researchers to carry out their own in-depth analyses of the content of interventions spoken in parliament and collected in Vitrine Démocratique.
Figure 2 displays the average number of interventions made in the EP per speaker for each country. As the figure makes evident, members from some countries speak much more frequently than others. An example of this is the members of the Croatian delegation who speak the most in proportion to their number with an average number of 427.68 interventions by members. This is nearly double the country with the second number of speakers who intervene most, Slovenia, with an average number of 266.82 interventions by its members. Denmark is the country whose members intervene in EP the least often with an average of 40.56 interventions by members, followed by Luxembourg with an average of 51.69 interventions by members.
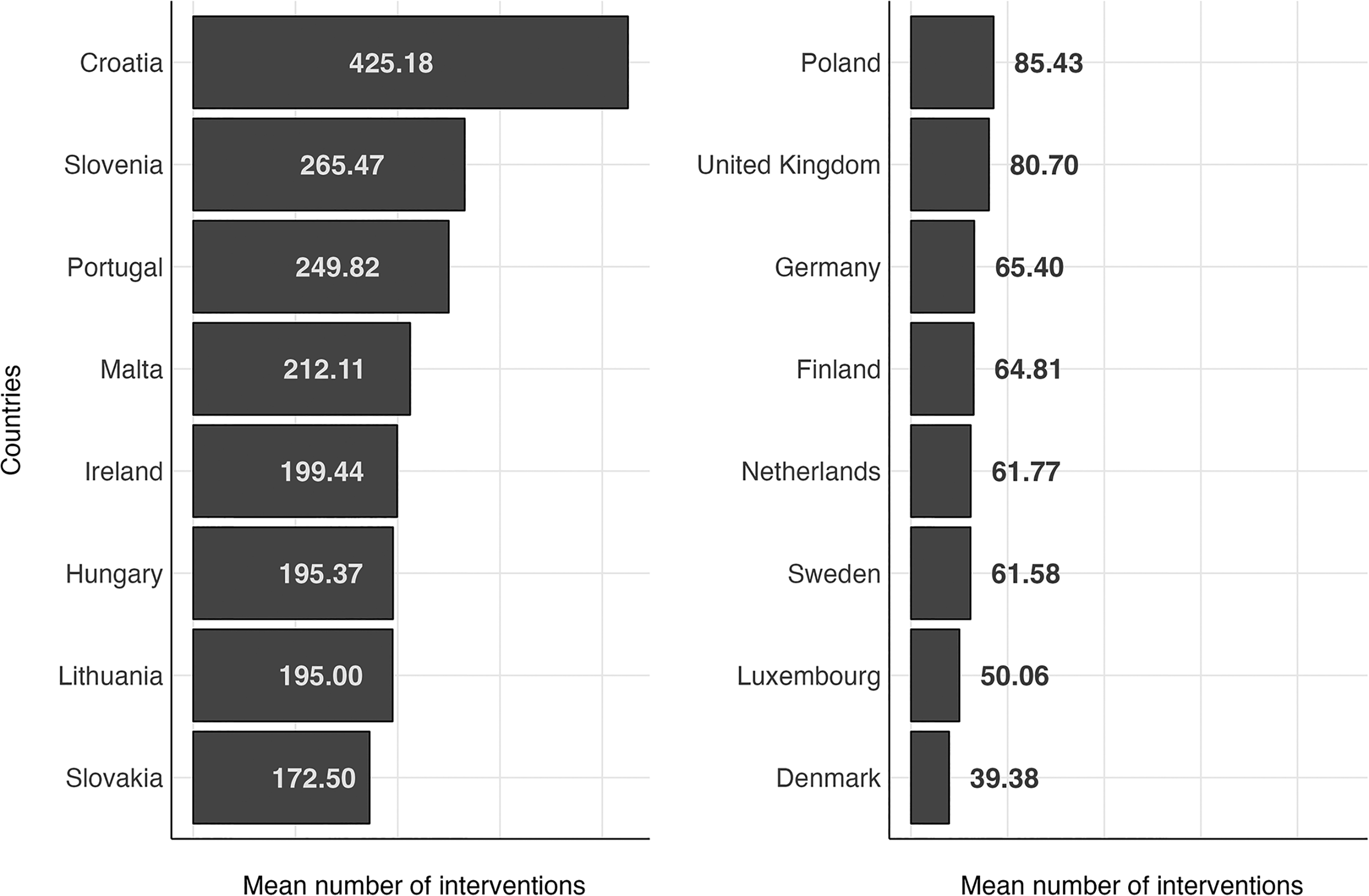
Member states whose members of MEPs speak the most and the least.
When observing the distribution of speakers intervening most frequently in the EP aggregated by the EU’s political groups (Figures 3 and 4), we find that the European People’s Party Group (Christian Democrats) ranks highest with 28.8% of all interventions during the period. Among the other political groups that speak the most, the Progressive Alliance of Socialists and Democrats comes in second with 28.1% of interventions, followed by the Left Group with 10.3% of all interventions. When political parties at the national, rather than European level, are considered (Figure 4) representation is much lower. All in all, 413 national parties have intervened during plenary sessions since 2014. Independents (MEPs without a national party affiliation) are those who spoke most often during parliamentary sessions with 5.3% of the interventions. Following the Independents, the Partito Democratico (Italy) intervenes second most with 3.6% of all the interventions during the period, and Rassemblement National (France) comes in third with 3.2%.
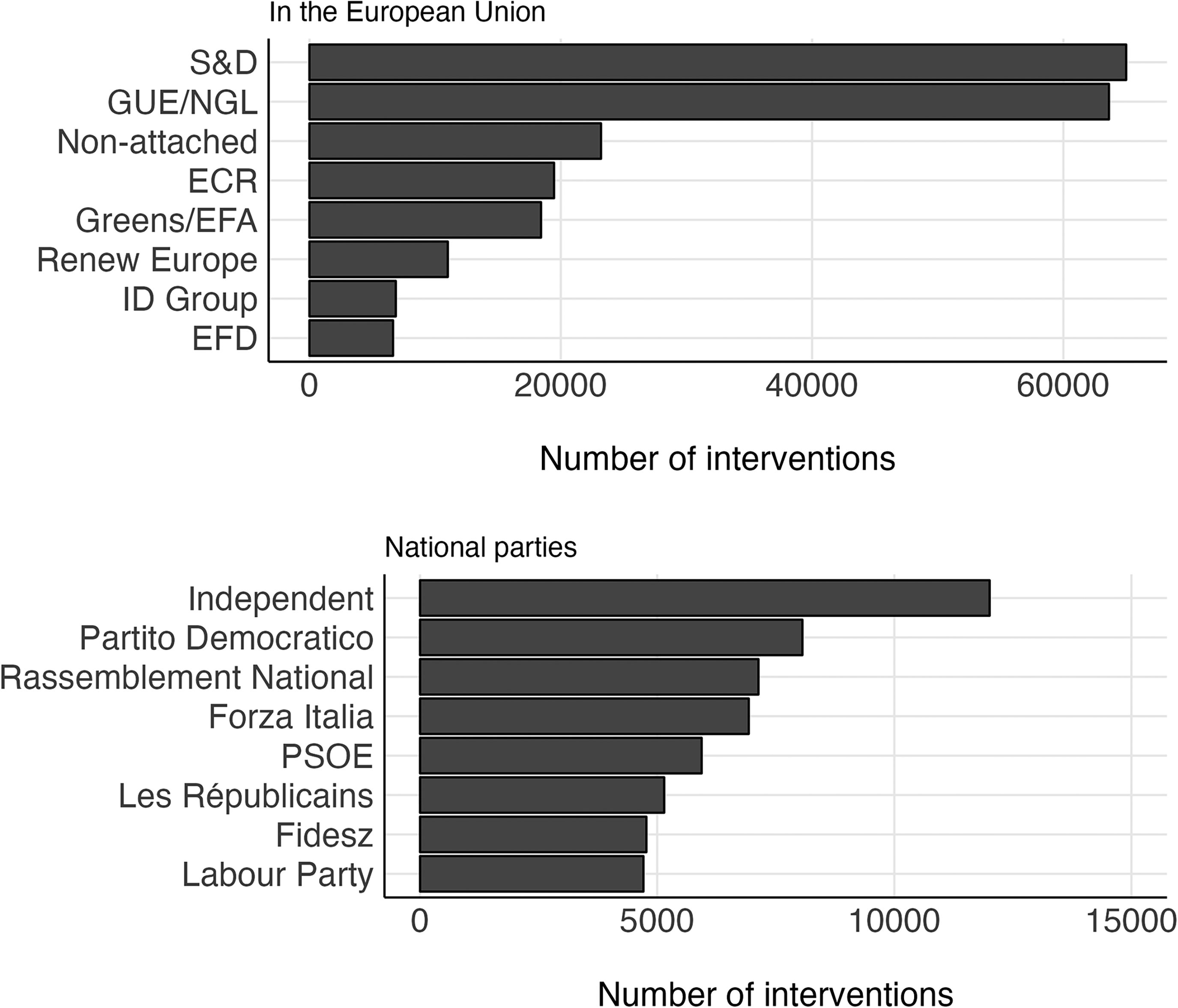
Political groups that speak the most.
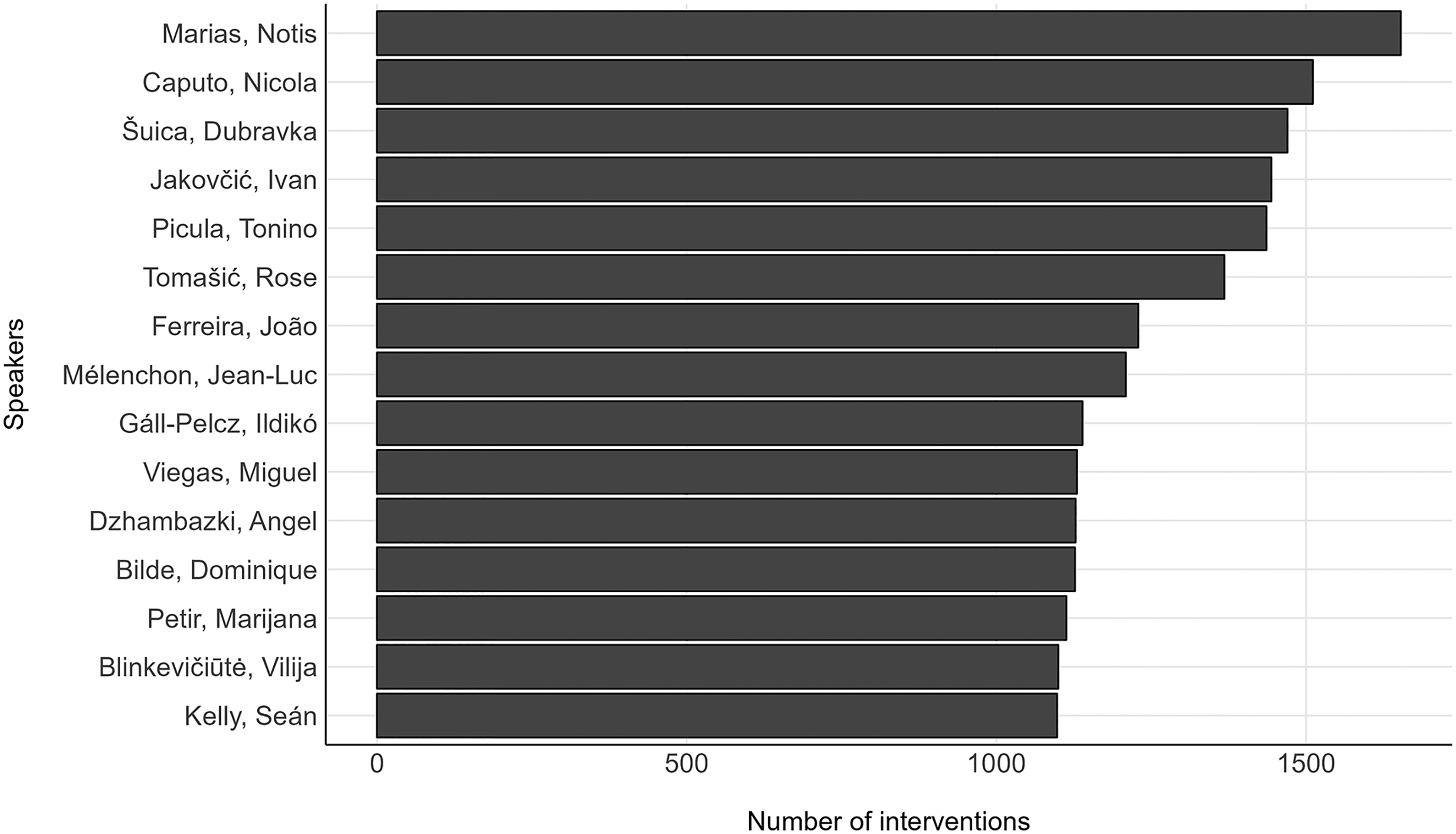
Which MEPs speak the most?
Upon disaggregating the data by speaker, we observe that the Greek politician Notis Marias has spoken the most in the EP. This member was present in the parliament from 2014 to 2019; meaning he had his seat for much of the time covered by our scraping. In addition, Marias was a member of several committees over the years and vice-chair of his party, the European Conservatives and Reformists Group, for two years. Nicola Caputo, the Italian politician, has been an active speaker since his debut in the EP in 2014. Dubravka Suica from Croatia, who holds the third position, was a MEP from 2013 to 2019 and serves as the Vice-President of the European Commission at the time of the publication of this paper. In her official capacity, she delivered numerous speeches in the EP during the entire period under review, totaling 1470 interventions. Although these data are primarily descriptive, they contribute to the validation of structured interventions in the database.
Vitrine Démocratique also automatically collects and stores the speakers’ gender. Because information on gender is not directly accessible on the EP website, an automated gender detection approach was deployed to populate the persons table using the gender package in
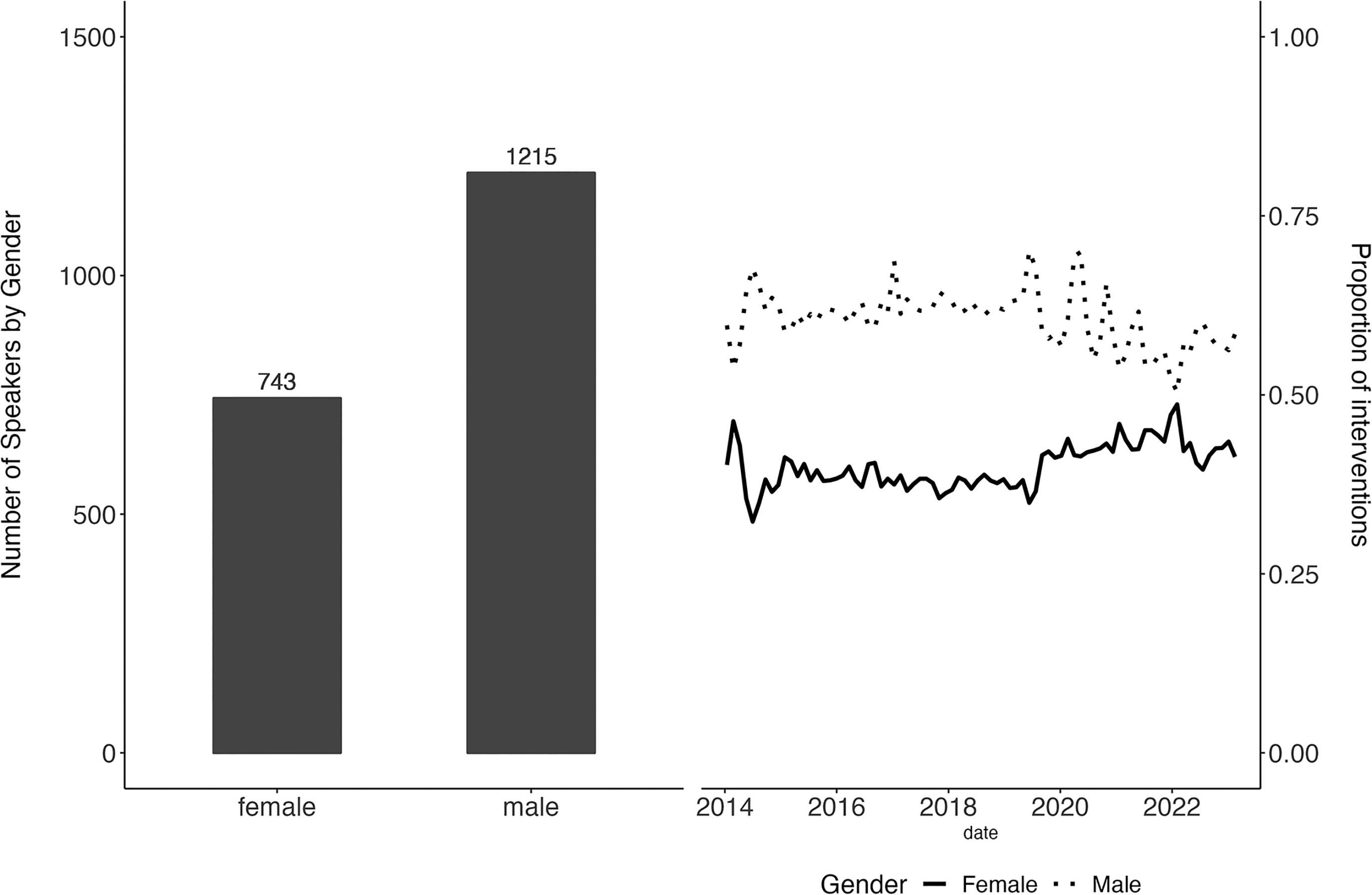
Interventions in the EP by gender.
Data validation
The construction of a new database requires numerous validations of the data extraction, storage, and calling processes in order to ensure its quality and therefore the validity of future research. Numerous validation steps were carried out to ensure the highest quality standards for the database.
To begin, the first 10 plenary sessions per year extracted for each of the two scrapers were validated in their entirety before launching the extraction more widely. Manual validation was then carried out on the number of interventions per session by comparing them directly with the transcriptions of the plenary sessions accessible on the EP website. This validation involved ensuring the accurate extraction of data, including the number of interventions per session and the correct association of interventions with the corresponding speakers. Once these validations were completed, the extraction was launched year after year.
Additionally, given the observed decrease in the number of interventions since 2017 (as illustrated in Figure 1), the research team conducted focused validation on the number of interventions per session. This entailed sampling and manually validating the data for the 50 plenary sessions with both the most and least interventions by comparing the extracted interventions with those available on the EP website. By selecting sessions with the most and least interventions, the aim was to ensure that the validation process encompasses the entire range of variability in the data. Analyzing these data helps uncover patterns and challenges in the scraper’s performance, offering insights for refining the tool and gaining a deeper understanding of its limitations, especially in handling sessions with unique characteristics like multilingual interventions or non-standard formats. A random sample of 100 plenary sessions was also selected, and data was validated using the same method.
As a final step, each variable within the dataset underwent validation to ensure accuracy and consistency. For instance, we summarized and validated the various entries for political parties and political groups to ensure unique and accurate party identification. Furthermore, we verified that the identified parties were genuinely EU parties. Alongside this, a manual validation was performed on a random sample of 300 speakers to validate their automatically identified gender. The rate of positive identification by the gender package was 93.6%. This process of summarizing and validating entries by variable was systematically applied to all data within the persons table.
Conclusive observations
The EP has been the subject of numerous research studies, each grappling with data collection challenges and limitations. Prior studies have often faced constraints in sample size and data availability, restricting the breadth and depth of analysis. The Vitrine Démocratique database addresses these limitations, aiming to contribute to the study of the EP by providing a comprehensive and accessible resource for researchers from various disciplines. Designed to facilitate both quantitative and qualitative approaches, Vitrine Démocratique organizes and structures original speeches from the EP in a unified language, opening the door to innovative research methodologies. Researchers can easily download the dataset in various formats or access it directly via web servers, making systematic analysis of the EP more accessible and inclusive.
The automated approach of Vitrine Démocratique offers several distinct advantages over previous methods. It ensures the comprehensive coverage of all plenary sessions, transcending language barriers to enable multilingual analysis. Real-time data access provides researchers with up-to-the-minute information, crucial for studying contemporary political dynamics. Furthermore, the tool facilitates large-scale comparative studies, enhances efficiency, and supports longitudinal analyses. By overcoming the limitations associated with narrower data collection methods and manual coding, Vitrine Démocratique elevates the quality, scope, and timeliness of data available for researching European politics. This not only expands the possibilities for comprehensive and nuanced analyses but also contributes to a deeper understanding of political processes within the EU, building upon and extending the insights gained from prior research efforts. As a result, Vitrine Démocratique not only complements existing studies but also paves the way for innovative research questions, methodologies, and a more holistic exploration of the EP’s role and impact within the EU.
The Vitrine Démocratique database will be updated continuously as new plenary sessions take place (now that the scrapers are built, the hard part of the task is done). It will therefore be possible to access the most recent existing data with each new analysis. With the cross-referenced data relating to the speakers, this database makes it possible to produce analyses by country, party, gender, and speaker in addition to all the possible textual and thematic analyses.
On its own, the new Vitrine Démocratique database enables analysis of speeches in the EP, spanning across parties, languages, time, and much more. By structuring MEPs' discourse, the database also aims to be complementary to the EUR-Lex tool, which contains data on documents produced by the European institutions. With its rich collection of plenary session debates in the EP, Vitrine Démocratique therefore serves as a valuable resource that can be connected to the EUR-Lex database. Researchers can establish connections between these databases using various variables depending on their specific research needs. For instance, EUR-Lex provides comprehensive documentation on regulations, directives, decisions, and positions taken in the EP, all categorized by the date of the plenary session. This aligns well with the event_date variable in the Vitrine Démocratique database, allowing researchers to cross-reference data from both sources to analyze the documents adopted and the discourse surrounding them. Additionally, EUR-Lex enables users to explore the Official Journal of the EP by European parliamentary part-session, which can be effectively correlated with the event_title variable in the Vitrine Démocratique database, enabling researchers to explore correlations between legislative documents and the corresponding parliamentary debates. This integration facilitates a deeper examination of the decision-making process and offers an unprecedented opportunity to triangulate data for a more comprehensive analysis of European politics over time. In essence, Vitrine Démocratique enhances the breadth, depth, and richness of data available to scholars, opening new avenues for research and providing a more holistic understanding of the European political landscape.
One of the challenges in automated data extraction projects is the long-term sustainability of these initiatives. As evidenced by past discontinuations of similar and highly relevant platforms, initiatives like Vitrine Démocratique require the involvement of research teams, data quality maintenance teams, as well as ongoing expenses related to data hosting and translation. Nevertheless, Vitrine Démocratique aims to be a sustainable long-term project to ensure continuous access to EP data for the academic community. To achieve this, the project has been institutionalized within the university responsible for its development with the financial and personnel commitments from multiple research chairs, as well as a commitment from the university to maintain the software infrastructure.
One of the limitations of the database is that the data on parliamentarians is updated on the EP site according to the functions they currently occupy or the last function they have occupied. With the Vitrine Démocratique, the information on the speakers is extracted at the time of the speech and is therefore up-to-date. On the other hand, for past data, the last function of the speaker is used. It would be very relevant to combine the data from the Forum Section, another automated database of the EP, which can be combined based on the speaker’s name, in order to obtain the function of the EU member at the time of their speeches. Also, to enable a temporal analysis of parties, each party name is adjusted in the database when it changes. For example, all interventions by the Front National are labeled as Rassemblement National because the party changed its name in 2018. To mitigate this limitation, studies focusing on parties should require a cross-reference table if it is necessary to specifically identify the party’s name at a certain time.
The descriptive analyses of the database presented in this paper only scratch the surface of the endless array of possibilities for analysis. The opportunities for in-depth analysis of EP discourses in their original language or a unified language have now been made more easily accessible. Whether to analyze the tone of speeches, the subjects most covered by country, the evolution of the treatment of a subject over time, the place taken by women in political discourse in the EU, or even the rise of populism in speeches, textual speech data is now structured to be easily accessible and parsed.
Supplemental Material
sj-pdf-1-eup-10.1177_14651165241239637 - Supplemental material for An open window into politics: A structured database of plenary sessions of the European Parliament
Supplemental material, sj-pdf-1-eup-10.1177_14651165241239637 for An open window into politics: A structured database of plenary sessions of the European Parliament by Camille Tremblay-Antoine, Steve Jacob, Yannick Dufresne, Patrick Poncet and Shannon Dinan in European Union Politics
Supplemental Material
sj-zip-3-eup-10.1177_14651165241239637 - Supplemental material for An open window into politics: A structured database of plenary sessions of the European Parliament
Supplemental material, sj-zip-3-eup-10.1177_14651165241239637 for An open window into politics: A structured database of plenary sessions of the European Parliament by Camille Tremblay-Antoine, Steve Jacob, Yannick Dufresne, Patrick Poncet and Shannon Dinan in European Union Politics
Footnotes
Author Contributions
C.T-A., D.Y., and P.P. contributed to acquisition, structuration, translation, and validation of the data. C.T-A. contributed to the analysis, drafted the article, critically revised the article, gave final approval, and agreed to be accountable for all aspects of the work ensuring integrity and accuracy. J.S. and D.S. critically revised the article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding for this research was provided by the Fonds de recherche du Québec – Sociétéet culture [FRQ-SC/Grant no. 268938] and the International Observatory on the Societal Impact of AI and Digital Technology (OBVIA).
Data availability statement
The replication material, including a dataset, are published online with the Supplemental Material.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.