
Abstract
We investigate how news values differ between online and print news articles. We hypothesize that print and online articles differ in terms of news values because of differences in the routines used to produce them. Based on a quantitative automated content analysis of N = 762,095 Dutch news items, we show that online news items are more likely to be follow-up items than print items, and that there are further differences regarding news values like references to persons, the power elite, negativity, and positivity. In order to conduct this large-scale analysis, we developed innovative methods to automatically code a wide range of news values. In particular, this article demonstrates how techniques such as sentiment analysis, named entity recognition, supervised machine learning, and automated queries of external databases can be combined and used to study journalistic content. Possible explanations for the difference found between online and offline news are discussed.
Introduction
Over the last years, citizens have become more and more reliant on online news at the expense of print news. 1 While the news coverage on these two channels may seem interchangeable to the average news consumer, it is, in fact, not at all clear to what extent online and print news content are different.
Based on the hierarchy of influences model (Shoemaker and Reese, 2014), we argue that the routines of online news production can be expected to differ from the routines of offline news production. Journalism is going through a process of commercialization, which McManus (2009) defines as ‘any action intended to boost profit that interferes with a journalists or news organizations best effort to maximize public understanding of those issues and events that shape the community they claim to serve’ (p. 219). One example for this is journalists who try to reach as large an audience as possible to attract advertisers and investors. By analyzing website metrics, journalists have detailed insights into the preferences of the readers of their online content (Anderson, 2011; Tandoc and Thomas, 2014; Welbers et al., 2015), which makes it comparatively easy to strive to maximize their audience. To gather similar information about their print audience, journalists have to rely on occasional surveys or focus groups, which provide a much less fine-grained picture. Especially popular outlets (as opposed to quality outlets) can be expected to make use of this and to select stories that promise commercial success (Barnhurst and Nerone, 2009). Others have argued that in an online environment, journalists have a much higher workload than in a print environment. Journalists have to produce more stories per day and usually have to work in a smaller team. As a consequence, they have less time for important journalistic tasks like fact-checking (Witschge and Nygren, 2009), which also can be seen as a change of journalistic routines. In a print environment, journalists find it more important to fulfill an interpretative and investigative role than in an online environment, while in an online environment, they attach most importance to the dissemination of news (Cassidy, 2005). Online journalists want to publish news stories as soon as possible, while in the case of print newspapers with only one daily deadline, such extreme time pressure is less of an issue.
But do these differences in routines really lead to a difference in the journalistic gatekeeping process, ‘the process of selecting, writing, editing, positioning, scheduling, repeating and otherwise massaging information to become news?’ (Shoemaker et al., 2009). To shed light on this question, we conducted a quantitative content analysis of Dutch online and print news articles. It aims to answer the following overarching question: To what extent does the content differ between online and print news? In addition, as we included both popular and quality outlets in our sample, we will also address differences between them.
Theoretical background and related research
In the latest version of their hierarchy of influences model, Shoemaker and Reese (2014) distinguish five levels of what shapes media content: social systems, social institutions, media organizations, routine practices, and individuals (p. 9). When we compare online news and print news, 2 it seems obvious that the two outer levels, social systems and social institutions, are identical for both.
On the organizational level, undoubtedly, the introduction of online news has led to changes. When the first news sites emerged in the 1990s, their production was organizationally distinct from the production of a newspaper, featuring different newsrooms and different routines. Over the last couple of years, however, the division has become less clear (Avilés et al., 2009; Tameling, 2016; Vobic, 2011). In an effort to cut costs, media companies aim for convergence between the online and the print crew. Journalists of different platforms cooperate, stories are published on both channels, and some journalists work for both platforms. However, as Avilés et al. (2009) point out, many media companies struggle with finding the right level of convergence. For instance, Tameling (2016) describes how Dutch quality newspaper de Volkskrant moved back-and-forth between integration, de-integration, and again integration of online and offline newsrooms.
A direct consequence of the convergence is that, as many journalists work for both online and print, differences on the individual level are a problematic starting point for an analysis. Historically, although, role conceptions (an important point on the individual level, see Shoemaker and Reese, 2014: 232) of online and print journalists have shown to differ (e.g. Beam et al., 2009; Paulussen, 2006). More specifically, online journalists more often than print journalists saw themselves as disseminators and less often as interpreters (Carpenter et al., 2016; Cassidy, 2005; Deuze and Dimoudi, 2002; Hartley, 2013). We argue that even though print and online articles are nowadays often written by the same journalists, the results of such studies still can inform us about the differences in the routines that are applied when writing content produced for publishing on the online outlet, the offline outlet, or both.
Summing up, we argue that differences between online and offline news production are most likely to be explained by studying the level that Shoemaker and Reese (2014) refer to as routine practices.
Different routines in online and offline news production
Regardless of the state of newsroom convergence, there is at least one organizational goal that journalists can act upon to a very different degree, depending on whether they publish online or offline. Entman (2005) mentions both ‘reporting on important events, people, and issues’ and ‘generating […] revenue’ (p. 58) as central aim of media organizations (see also Shoemaker and Reese, 2014: 139). The hierarchy of influences model suggests that these organizational level goals will constrain and shape the next level, the level of routines.
Accordingly, while they may be reluctant to admit it, economic considerations can be a factor in the daily work of journalists (Tandoc, 2014). For example, when journalists publish a story online, they often monitor the number of readers and aim to maximize it. The trend to increasingly take these organizational demands into account in journalistic work routines can be described as commercialization (see also McManus, 2009).
In online news websites, journalists have a wide set of website metrics which enable them to see exactly which stories are read a lot and which are not (Karlsson and Clerwall, 2013; Tandoc and Thomas, 2014; Tandoc and Vos, 2015). Accordingly, several studies suggest quite a strong influence from audience clicks on the gatekeeping process (Anderson, 2011; Jacobi et al., 2015; Lee et al., 2012; Welbers et al., 2015). In the case of print media, such numbers are not available, and therefore it is inherently impossible to adapt news selection decisions immediately to the readers’ preferences. In online, it is very easy for news consumers to visit another website, whereas in case of print newspapers, readers are less flexible because they often have a subscription, canceling of which is a much higher hurdle than just directing your browser to a different site. Furthermore, online news consumers often visit news sites through links they find on other platforms like GoogleNews, Facebook, and Twitter, which increases competition. Thus, for online journalists, it is important to monitor and live up to the preferences of news consumers.
We can thus state that online news websites act in a much more competitive environment than traditional newspapers. In particular, journalists working in an online environment have to produce more stories and have to work much faster than their print colleagues (Bivens, 2008; Witschge and Nygren, 2009). Also, they have to work on several tasks at the same time (Boczkowski, 2009; Mitchelstein and Boczkowski, 2009; Quandt, 2008) and have less time for fact-checking because of the high speed in which stories must be published (Cassidy, 2006). Occasionally, even ethical standards are violated in order to be fast enough (Agarwal and Barthel, 2013; Cassidy, 2006). In short, their workload is much higher.
Shoemaker and Reese (2014) highlight that routines ‘stem from three domains: audiences, organizations, and suppliers of content’ (p. 168). This implies that routines differ between outlets with different audiences. Media research regularly distinguishes between quality outlets and popular outlets, and as Trilling and Schoenbach (2015) show for the Dutch case, their audiences overlap only to a limited extend. This will be reflected in different work routines of the journalists. Indeed, Boukes and Vliegenthart (2016) show that news values in quality and popular outlets differ, and Esser (1999) even suggests that there are distinct ‘tabloid news values’ (p. 293). Similarly, Barnhurst and Nerone (2009) argue that ‘the mass circulation press included more event-oriented news, especially crime news, and also more reporting on social and cultural concerns, or so-called human interest stories’ (p. 20).
Therefore, when studying the differences between online and offline news, it makes sense to also take into account whether the outlets in question can be categorized as popular or quality, to eliminate a possible confounding factor.
News values as dependent variables on the routine level
As Shoemaker and Reese (2014) point out, content characteristics can be studied both as dependent and as independent variables. In particular, they suggest that news values found in news articles can be analyzed as an outcome of journalistic work routines. Consequently, the differences outlined above can be expected to be reflected in the presence or absence of news values. News values can be seen as properties of an event, although – depending on their epistemological background – scholars differ in whether they see these properties as inherent to the event or as constructions made by journalists to justify their choices (e.g. Eilders, 2006). But regardless of whether we regard them as ascribed or inherent, we can state that news values are properties of an event that explain to which extent it is considered newsworthy.
We focus on a subset of news values (based on Harcup and O’Neill, 2001) on which online and print news are likely to differ and which were feasible to measure.
Power elite
Focus on power elite is probably one of the most clear-cut news values: if a story deals with important, relevant, well-known entities, it is newsworthy. This also makes sense, because in a democracy one of the most important tasks of the media is to control the elites.
RQ1. To what extent is there a difference in references to the power elite between news outlets?
Reference to persons
While Harcup and O’Neill (2001) initially considered this factor, they dropped it from their definite list of news values. Nevertheless, it has been investigated by many researchers since. Örnebring and Jönsson (2004) found that popular newspapers are more likely to focus on people than quality newspapers. Boukes and Vliegenthart (2016) even identify reference to persons as the one news value that differs most strongly between popular and quality newspapers. Furthermore, the difference in focus on political leaders between quality and popular newspapers is larger online (Jacobi et al., 2015). Thus, it may be expected that popular newspapers are more likely to apply a personalized reporting style, and that this difference is larger online.
H1a. Articles from popular outlets contain more references to persons than articles from quality outlets.
H1b. The difference between quality outlets and popular outlets in references to persons is larger in online news than in print news.
Celebrity news and entertainment news
Celebrity news and entertainment news may be the most despised categories of news by those who see news standards declining. It deals with topics like sex, show business, and human interest (Harcup and O’Neill, 2001). Examples from the tabloid press (see also Barnhurst and Nerone, 2009) show that it attracts large audiences. Since, especially online, journalists focus on an article’s reach, the prevalence of such stories may be higher. Maier (2010) found that celebrity/entertainment news was one of the only three news categories (out of a total of 19) in which online newspapers published more stories than print newspapers, and also Van Der Wurff et al. (2008) found that news websites publish more entertainment stories than print newspapers. Furthermore, such stories often do not require a lot of research, which makes them easy to produce (Bird and Dardenne, 2009; Lehman-Wilzig and Seletzky, 2010).
H2. The likelihood that an article contains celebrity news is higher in online news than in print news.
H3. The likelihood that an article contains entertainment news is higher in online news than in print news.
Bad news/good news
Journalists have a tendency to cover mainly bad news (e.g. Leung and Lee, 2014). Galtung and Ruge (1965) offer several explanations for this: negative news is usually unexpected, unambiguous, it has a higher frequency and it fits into most peoples’ picture of the world. It generally tends to attract a larger audience than positive news. Thus, especially routines that are shaped by commercial needs can be expected to lead to the publishing of bad news. In addition, Shoemaker and Cohen (2006) argue that negative news is newsworthy because it is ‘deviant’ and thus important to monitor.
On the other hand, the rise of infotainment and soft news may also contribute to the production of positive news. As Leung and Lee (2014) found, journalists tend to believe that touching positive stories are popular; and Shoemaker and Cohen (2006) concede that even though ‘deviant’ bad news is newsworthy, positive news is also asked for by the audience. It is possible that online news contains not only more negative emotions but also more positive emotions compared to print news. In order to write entertaining articles, journalists may make use of an emotional tone of voice rather than a neutral writing style or select stories that lend themselves for such writing. Emotionality, in this context, can be seen as the presence of positivity and/or negativity as opposed to the absence of both.
RQ2a. To what extent is there a difference in the relative amount of negative news between print and online news?
RQ2b. To what extent is there a difference in the relative amount of positive news between print and online news?
RQ2c. To what extent is there a difference in the degree of emotionality between print and online news?
Follow-up news
When writing articles for an online outlet, journalists have to produce more articles than when writing for a print outlet (Witschge and Nygren, 2009). They also want to publish stories as quickly as possible (Agarwal and Barthel, 2013). As an event unfolds, news sites place updates on the issue. In contrast to a newspaper that is published once a day, a website therefore can have several stories on the same item within the same time period. Such stories on the same news topic that already has been in the news, can be called ‘follow-up’ news.
While such follow-up news can involve investigative reporting, we may speculate that more often, they are comparatively cheap to produce, as they usually do not involve digging up a completely new story. Online journalists report that they feel like they are not executing proper (i.e. investigative) journalism, because the workload is too high (Witschge and Nygren, 2009). This trend is in line with statements from newsmakers themselves who say that in online they strive for the ideal of ongoing 24-hour coverage, where being just minutes behind the competitors is already seen as failure (Bivens, 2008) – again giving an incentive to rather quickly publish small piecemeal stories than waiting for the one, great story to write.
H4. The amount of follow-up news is higher in online news than in print news.
Methods
Sample
In the period between 2 January 2014 and 31 December 2015, we collected all available news items from a selection of major Dutch news outlets, both online and print. For the print data, we used the LexisNexis database. For the online data, every hour during the whole research period, we executed a Python script to check whether the main Really Simple Syndication (RSS) feeds of the news sites contained new items. All information from the feeds and the full webpage containing the article were downloaded, parsed, and stored in a database.
The original dataset consisted of a total of
Number of articles per source.
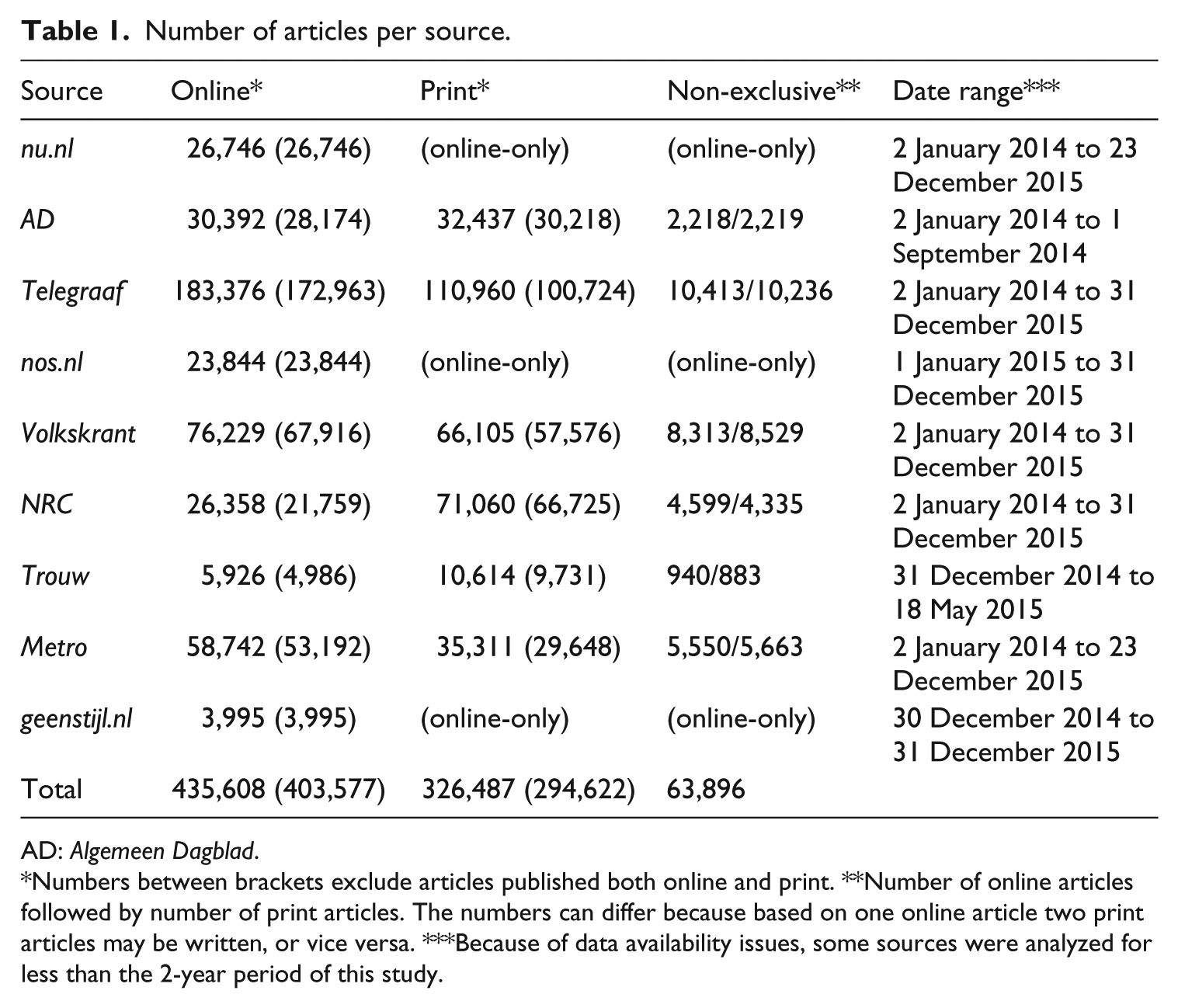
AD: Algemeen Dagblad.
Numbers between brackets exclude articles published both online and print. **Number of online articles followed by number of print articles. The numbers can differ because based on one online article two print articles may be written, or vice versa. ***Because of data availability issues, some sources were analyzed for less than the 2-year period of this study.
Nu.nl is the largest Dutch news site. Although it has no offline counterpart, it is owned by publishing house Sanoma. De Volkskrant, NRC Handelsblad, and Trouw are the three largest quality papers. Algemeen Dagblad (AD) and De Telegraaf are the two newspapers with the highest overall circulation figures. Geenstijl is a weblog-style site owned by the same publisher as De Telegraaf. Nederlandse Omroep Stichting (NOS) is a Dutch public-service broadcaster, and Metro is the leading free daily newspaper. We explicitly did not include small regional papers or niche media, to avoid confounding the comparison by too large differences in the resources available.
Independent variables
Article length
The articles in the sample varied greatly in length. After some impossible values were removed, the overall average article length was
Platform
We created a dummy variable that was coded as 1 for all print articles and 0 for all online articles. In addition, we created a second dummy variable that was 1 if the article was non-exclusive, that is, if a highly similar article was published on the other platform on the same day or the day before. If the cosine similarity between two articles was
Popular and quality news
We created a dummy variable that was coded 0 for quality outlets and 1 for popular outlets. Telegraaf, AD, Geenstijl, and Metro were considered popular outlets. Sparks (2000) and Deuze (2005) see the lack of clear distinction between information and entertainment as characteristic for the latter; however, as Deuze (2005) notes, the Dutch news media landscape lacks extreme forms of tabloid papers. Therefore, we also relied on an additional indicator, namely the self-description of the outlets and their target audiences. Telegraaf, AD, and Metro all define themselves as papers for ‘the ordinary citizen’, and GeenStijl clearly lacks the information/entertainment distinction.
Dependent variables
In order to investigate the prevalence of different news values on these various platforms, we used Python to conduct an automated content analysis (see Boumans and Trilling, 2016; Grimmer and Stewart, 2013; Günther and Quandt, 2016). In doing so, we extend earlier work by Trilling et al. (2017), who used such techniques to automatically code a smaller set of news values than we do in this article.
Power elite
News on power elite was defined in terms of political, economic, and geographical power. In order to find characteristic words of political power, from a set of articles that were known to be political news, we compiled a list of words that unambiguously referred to political power. The coding was iterative and was continued until no new words came up. The same process was repeated to add characteristic words of economic power to the list.
In order to find countries that can be considered to be part of the power elite, for those countries belonging to the global G20, and for those with the highest gross domestic product (GDP) per citizen and for those with the highest overall GDP, the country name, capital, seat of government, and the biggest city were added to the list.
Every occasion of one of the words from the list in the body of an article meant an increase in power elite score by 1 point, an occurrence in the title meant an increase by 2 points
References to persons
References to persons were determined using named entity recognition (NER) (e.g. Nadeau and Sekine, 2007). NER identifies entities (like locations or persons) in a text. We used the Python Natural Language Toolkit (Bird et al., 2009) to train a Naïve Bayes classifier and chunker. As training data, the Dutch version of the conll2002 data were used (Tjong Kim Sang and De Meulder, 2003). The trained model achieved an F1-score of 69.3 percent (precision: 66.9%, recall: 71.9%). Using this NER-model, we counted references to persons (
Celebrity news
In order to find characteristic words of celebrity news, from a set of articles that were known to contain celebrity news, we compiled a list of roles or ‘jobs’ (like actor, anchorman, …) that unambiguously referred to celebrities. Again, the coding was iterative and was carried out until no further references could be found. In order to make sure that only well-known celebrities were included, the word ‘famous’ was added for most keywords. With the resulting list of potential jobs, a SPARQL Protocol and RDF Query Language (SPARQL) query was set up in order to find DBpedia articles (the machine-readable form of Wikipedia). The objective of this query was to find Dutch Wikipedia articles about persons, where one of the ‘celebrity jobs’ was mentioned in the abstract. For some of the more specific keywords (like TV-anchormen), a prerequisite to be included was that they were Dutch in order to avoid an unnecessary high number of false positives, while in the case of, say, actors (which in Dutch has a less broad meaning than in English), this requirement was not set. Still, the query resulted in a list of almost 10,000 celebrities. The dataset was then searched for the appearance of three or more of those celebrities, resulting in a celebrity score for every article by simply counting the number of occurrences
Entertainment news
Our database also stored the subdirectories of the website where a given article was published. Not all news sources categorize their articles reliably, but nu.nl does: Each article has a label attached that identifies its category, for example, ‘economic news’, ‘sports’, ‘entertainment’, and so on. These labels were used for a supervised machine learning approach. After comparing the performance of different classifiers, we chose to train a Naïve Bayes classifier (
Positive/negative news
In order to measure the amount of positive and negative news, a sentiment analysis was carried out for each article using the Sentistrength software for Dutch (Thelwall et al., 2010). Each article was assigned a score for the amount of positivity
Follow-up news
An article was considered a follow-up article if its topic was covered in another article from the same source that was published up to 2 days in advance. In order to find such articles, the cosine similarity between a published article and all articles on the following 2 days were calculated. If the cosine similarity was higher than 0.5, an article was considered a follow-up article of the previously published article. This threshold was determined by trying several thresholds on a random dataset of 100 different articles, and it turned out that a threshold of 0.5 yielded the best results. In total,
Results
To give a first overview of the results, we present the descriptive statistics of all variables of interest, split by category, in Tables 2 and 3. While these are interesting to get a general understanding of the data, we employ regression models to answer our research questions and to test our hypotheses.
Overall means and standard deviations of continuous variables.
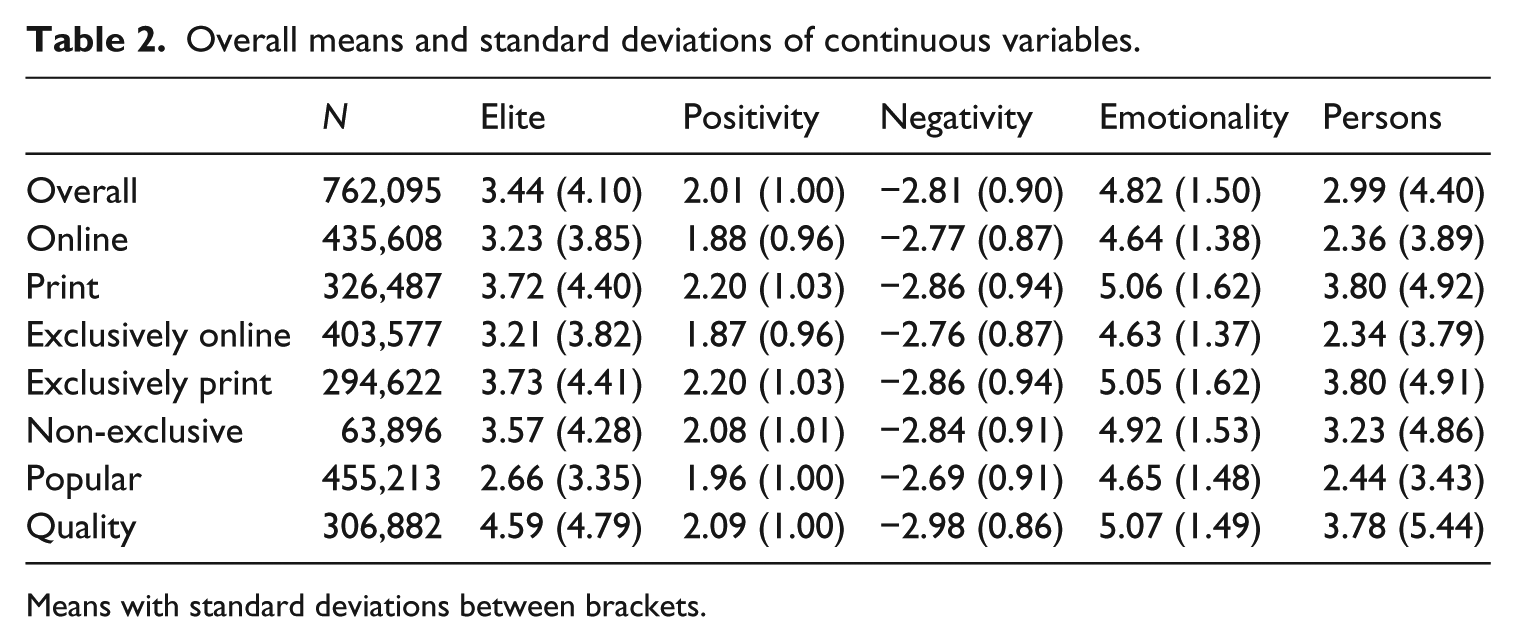
Means with standard deviations between brackets.
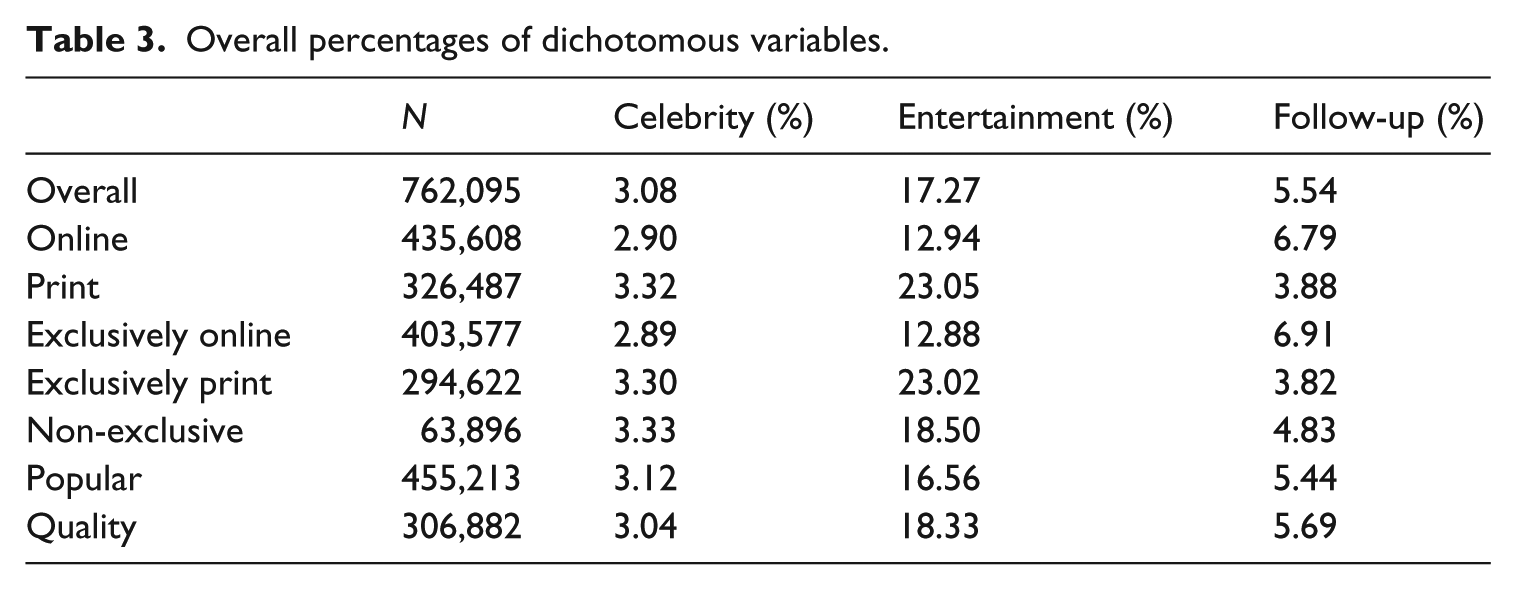
Overall percentages of dichotomous variables.
Research Question 1 asked in how far different outlets differ in their references to elites. The descriptive statistics (Table 2) suggested that on average, the number of elite references is higher in print news
Ordinary least squares (OLS) regressions for RQ1 and H1.
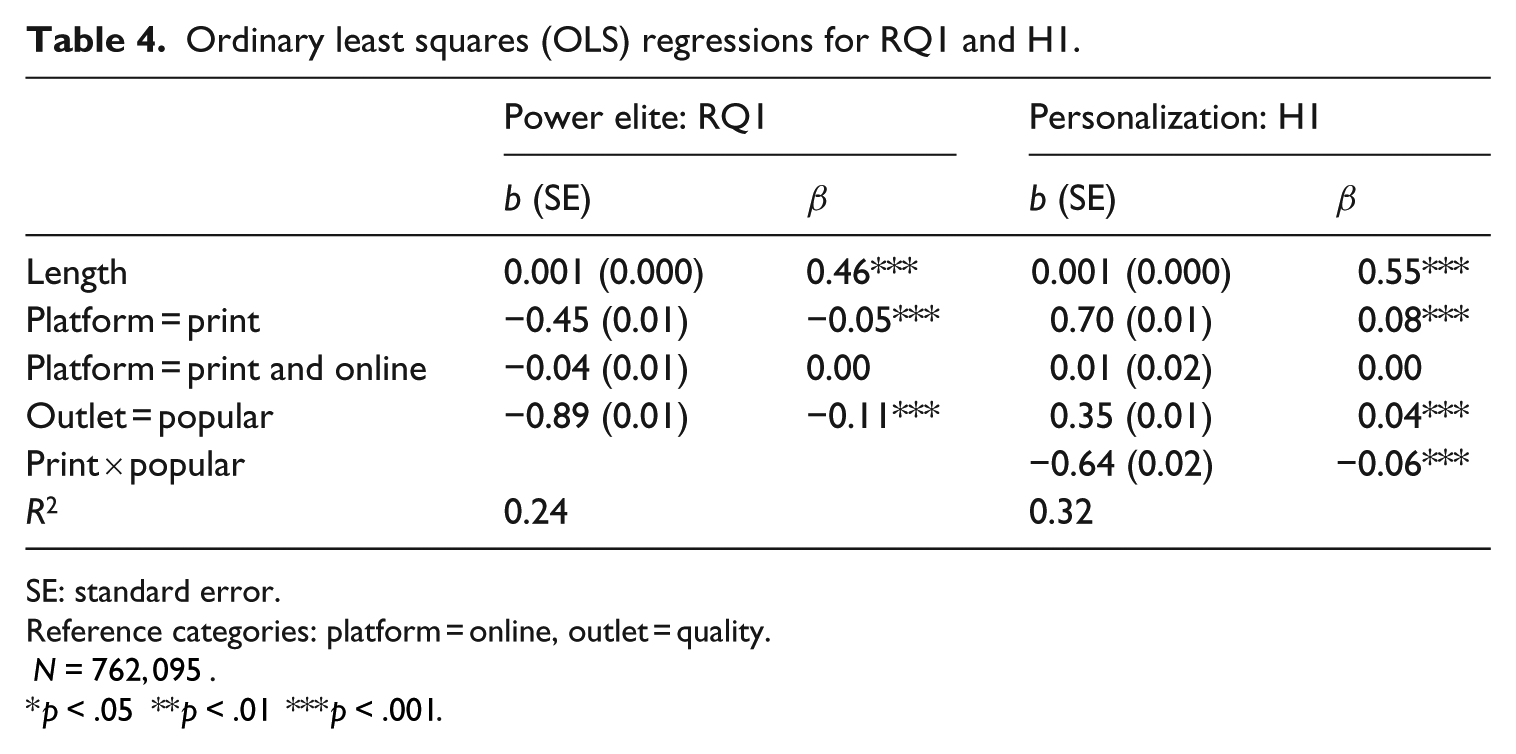
SE: standard error.
Reference categories: platform = online, outlet = quality.
Hypothesis 1a predicted that the degree of personalization is higher in popular outlets compared to quality outlets. The descriptive statistics in Table 2 indicate that popular outlets score lower on personalization than quality outlets. However, the print articles were considerably longer than online articles
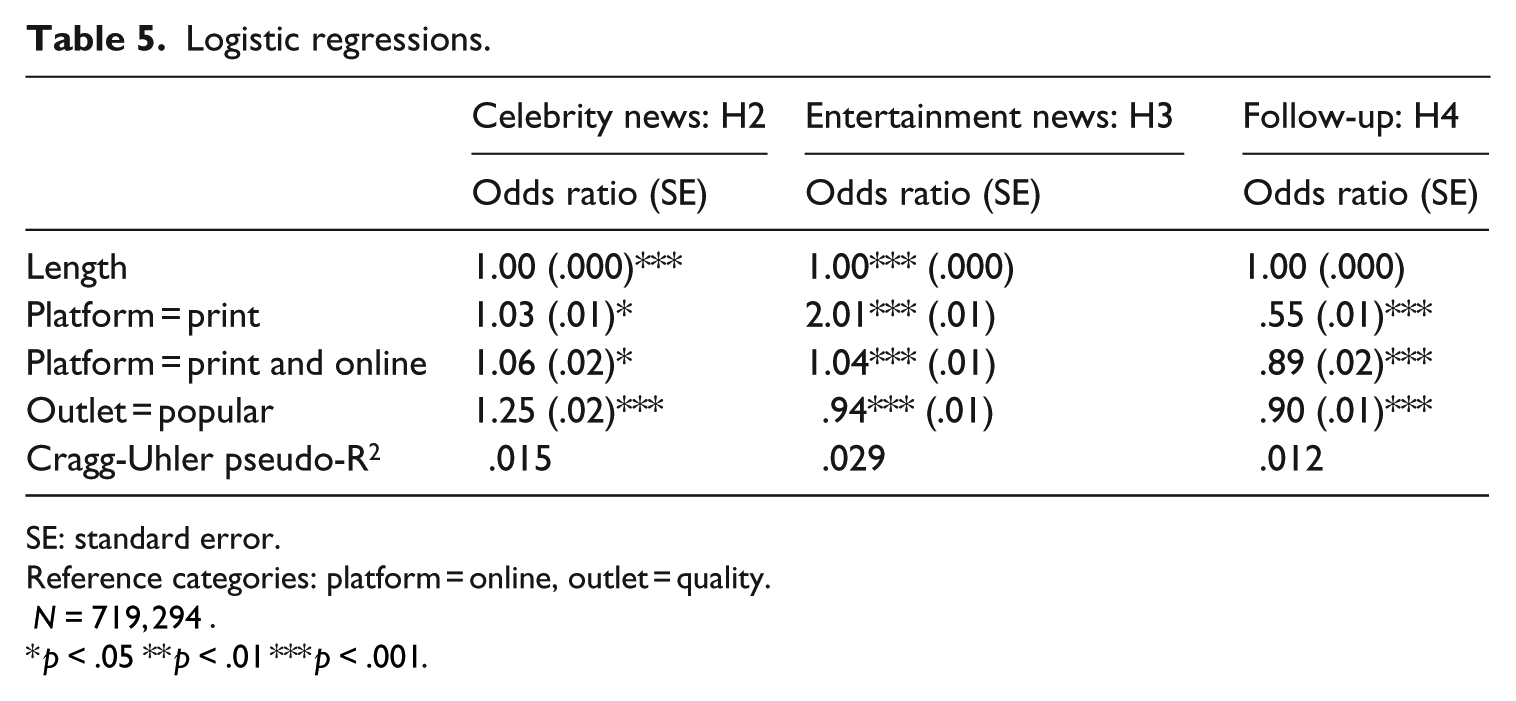
Hypothesis 2 predicted that online articles are more likely to be about celebrity news than print articles. Our logistic regression model in Table 5 shows that – while the model exhibits a poor model fit – there even is a small effect in the opposite direction. H2 was not supported. Further analysis showed that popular outlets are more likely to contain celebrity news than quality outlets. No significant difference was found between non-exclusive articles and the other articles. To ease interpretation, we calculated the likelihood for an article to contain celebrity references. 3 Based on the regression model, we estimated these likelihoods as follows: 2.95 percent for online articles, 3.03 percent for print articles, 2.62 percent for quality outlets, and 3.26 percent for popular outlets.
Logistic regressions.
SE: standard error.
Reference categories: platform = online, outlet = quality.
Ordinary least squares (OLS) regressions for RQ2.
SE: standard error.
Reference categories: platform = online, outlet = quality.
Hypothesis 3 predicted that online articles are more likely to be about entertainment news than print articles. In contrast with the hypothesis, Table 5 shows that, all other variables being equal, the odds for a print article to be about entertainment news are twice as high as for an online article. We find such a strong effect only for articles that are exclusively published in print. Interestingly, quality outlets are slightly more likely to publish entertainment articles than quality papers. Again, we calculated the likelihood for an article to be about entertainment news: online 12.94 percent, print 23.03 percent, quality outlets 17.27 percent, and popular outlets 16.34 percent.
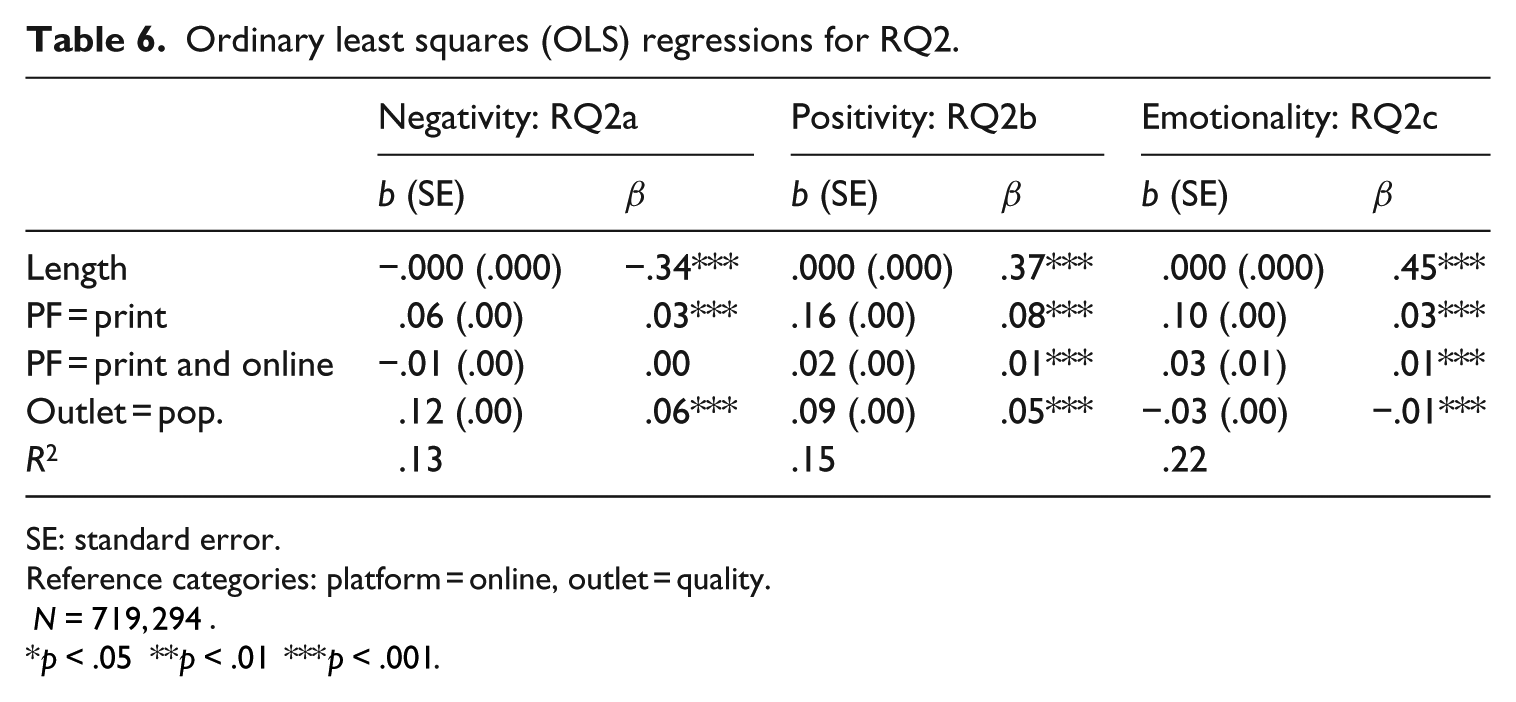
Research Question 2 asked about the differences in tone. The descriptive statistics in Table 2 indicate that print news score higher on both positivity and on negativity. However, as mentioned before, in the longer print articles the chance that emotional words are found can be expected to be higher than in the shorter online articles. Accordingly, when controlling for length in a regression analysis (Table 6), the standardized β-coefficients show that length has the by far the strongest influence on the tone. Our first impression regarding the differences between online and offline outlets seems to hold only in the case of positivity: print news seem to be more positive, but slightly less negative (recall that negativity was coded on a scale from
We subsequently computed the overall emotionality by adding up the absolute values on positivity and negativity. Our regression model in Table 6 suggests that on average, print articles score higher on emotionality than online articles.
Hypothesis 4 predicted a higher amount of follow-up news in the case of online articles. The results of a logistic regression (Table 5) show striking differences: for print articles, the odds ratio to be a follow-up article is 45 percent lower than for online articles. For non-exclusive articles, the odds ratio to be a follow-up article is 11 percent lower compared to other articles. These findings offer support for hypothesis 4, although we have to keep in mind that the model fit is rather poor. This is also illustrated by the likelihood scores we calculated: the likelihood for an article to be a follow-up article is 6.78 percent in the case of online news, 3.87 percent in the case of print news, 5.13 percent in the case of popular outlets, and 5.67 percent in the case of quality outlets.
Discussion and conclusion
The contribution of this article is twofold: methodological and substantial. Methodologically, we showed how automated content analysis can be employed to analyze news values on a large-scale; substantially, we identified differences between online and offline news as well as between popular and quality news outlets. We will first discuss the strengths, weaknesses, and implications of our methods, before we turn to a discussion of the results themselves.
While there are more and more studies that employ automated content analysis to analyze journalistic products, to the best of our knowledge, only one study (Trilling et al., 2017) has done so with the explicit goal of automatically coding news values, although others have essentially automatically coded the same or similar variables with slightly different goals, for example, to assess the quality of journalism (Jacobi, 2016). In this article, we extended this line of research by showing that automated content analysis can be used to identify a number of news factors that had not been coded in an automated way before.
In particular, to our knowledge, we are the first to employ resources like DBpedia and techniques like NER to identify news values. We believe that such linking of different data sources can be a fruitful way to automatically identify actors and other entities in a text. Nevertheless, more research is needed to further improve and validate our methods.
Reliability is not an issue in a automated content analysis, as re-running the analysis will yield the same results, but validity can be problematic (Boumans and Trilling, 2016; Grimmer and Stewart, 2013). Over the given time frame, all articles were included. External validity should be guaranteed with regard to the current state of the media landscape. Yet, extrapolations to the past and the future are dangerous because the media environment is in a continuous state of transition. Concerning internal validity, where possible, precision and recall were calculated. While in case of entertainment articles, the results were excellent, the precision and recall for the NER-tagger were acceptable but left room for improvement. With regard to the validity of our coding of positive and negative emotions, Sentistrength (the algorithm we used) has so far mainly been used for analysis of rather short texts. While the software seems capable of analysis of longer texts as well, it would be useful to evaluate the method in comparison to, for example, a supervised machine learning approach (Gonzalez-Bailon and Paltoglou, 2015). Concerning follow-up news and non-exclusive articles, it may be useful for future research to check if the results match manual coding, but no reasons were found to question the results of the applied method, that is, the use of the cosine similarity, which is a very widespread measure of overlap between texts.
The way in which we categorized entertainment news probably can be improved. Most notably, after conducting some additional analyses, we realized that our theoretical ideas about what constitutes entertainment and the empirical classification diverged. In line with the vanishing distinction between low and high culture, we observed that also our classifier picked up both, for instance, rumors about artists, and serious reviews about movies, CDs, or books. This explains the unexpected result of print and quality news having a high amount of what we called entertainment news – what we measured should rather be called ‘culture and entertainment’.
On the substantial side, our analyses show that there are significant differences between online and print news. We argued that they can be explained by focusing on the journalistic routines, which can be understood using the hierarchy of influences model (Shoemaker and Reese, 2014). A content analysis cannot provide evidence what has caused the difference we found. Nevertheless, for instance, it seems very plausible to assume that it is the high workload in online journalism that affects the form and the content of online news (Boczkowski, 2009; Mitchelstein and Boczkowski, 2009; Witschge and Nygren, 2009). In our data, we saw that some newsrooms even publish more articles online than offline. In order to be able to publish so many articles online, journalists seem to publish shorter articles. This may have to do with the characteristics of the Internet itself, but it seems reasonable to assume that the workload contributes to this.
The working speed of in the production of online news may also explain, for instance, differences in the personalization score. Print articles, on average, score higher, but this does not necessarily mean that print articles focus more on private lives. It can also mean that in print articles, journalists quote more human sources (e.g. spokespersons), while online, they rely more on written information like press releases. This is a faster way of working because no extra research needs to be done. But of course, it is mainly the power elites who have access to such means. If this is the case, it could explain why elite news coverage is so dense in online news, while personalization is rather low. For their print articles, journalists might tend to make more effort in approaching several (human) sources when doing research, while online, they might prefer to mention only the name of a power elite, for example, an organization, instead of doing further research (Witschge and Nygren, 2009). The fact that popular news contains more references to persons is consistent with research showing that popular papers personalize more (e.g. Örnebring and Jönsson, 2004). We showed that especially in online, this is true: while both in popular and quality outlets, journalists may use less human sources online, in popular online outlets, journalists still write quite some personal stories, while their quality colleagues do not do this.
This findings on source usage match the finding that online, journalists are much more likely to publish follow-up articles. In fact, here, we find one of the biggest differences between print and online articles: online articles are almost twice as likely to be a follow-up article than print articles. Follow-up articles are easier to produce than other articles, because instead of finding a completely new idea, journalists can work on one story for which they only have to look for updates. Often, this is an easy way to produce many articles, even under time pressure. In line with findings of, among others, Cassidy (2006), Bivens (2008), and Carpenter et al. (2016), in an online environment, journalists seem to want to publish news as soon as possible and therefore rather publish a second article with new findings than wait until they had time for further research.
Contrary to our expectations, online news were neither characterized by a high amount of celebrity news nor entertainment news. Given that we used an innovative method for the measurement of these variables, further research should validate this finding to exclude the possibility that this is a measurement artifact.
Overall, we showed that there are visible differences between online and print news in terms of news values. These differences are related to the different routines used in the two news environments. While this article provides a rather general overview and can be seen as a first step in the quantitative analysis of news values in online and offline news, further (also qualitative or comparative) research is necessary. For future research, it may be fruitful to also investigate the actual amount of readers in order to shed further light on the use of website metrics. Given the importance of journalism for democracy, we call for further investigation of differences between online and print journalism, in order to be able to get a more complete picture of the changing nature of journalism in today’s changing media environment.
Footnotes
Acknowledgements
This work was carried out on the Dutch national e-infrastructure with the support of SURF Cooperative. The authors would like to thank Anne Kroon and Joanna Strycharz for their invaluable contribution to the data collection.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.