
Abstract
This article explores the existing research literature on data journalism. Over the past years, this emerging journalistic practice has attracted significant attention from researchers in different fields and produced an increasing number of publications across a variety of channels. To better understand its current state, we surveyed the published academic literature between 1996 and 2015 and selected a corpus of 40 scholarly works that studied data journalism and related practices empirically. Analyzing this corpus with both quantitative and qualitative techniques allowed us to clarify the development of the literature, influential publications, and possible gaps in the research caused by the recurring use of particular theoretical frameworks and research designs. This article closes with proposals for future research in the field of data-intensive newswork.
Keywords
Introduction
In late August 2010, around 50 international journalists and researchers convened in Amsterdam for a new roundtable conference. The participants, who included leading personnel from organizations such as the New York Times, the Guardian, the Financial Times, the Open Knowledge Foundation, and Hacks/Hackers, presented their works and discussed the state of a craft which had a few months earlier been labeled ‘data journalism’ (Rogers, 2008, as cited in Knight, 2015: 55-56). The publication that documented this meeting – ‘Data-driven journalism: What is there to learn?’ (European Journalism Centre, 2010) – helped to shape the early discourse around a practice that has since been adopted by individuals and organizations all over the world. As academics across a variety of disciplines have taken notice, the research literature has grown tremendously – far beyond journalism studies itself. In this article, we revive the motto ‘What is there to learn?’ for a meta-analysis of the research publications on the topic.
Anderson (2013) suggested ‘six approaches to a sociology of computational journalism’ (p. 1010), outlining a framework to investigate a phenomenon that, until then, had been explored primarily by computer scientists and practitioners active in the field. His proposal seemed driven by a discontent with the ‘internalist tendencies at [the] early stage of academic research’ (p. 1007) that often defaulted toward hopeful or fearful statements of how the practice would affect the future of journalism. To counter this trend, Anderson recommended studies that used political, cultural, organizational, technological, or field perspectives for their research – in effect following and extending Schudson’s (2005) typology of the sociology of news. While the extent of his influence is unclear, the field changed rapidly: only 2 years later, together with Fink, Anderson spoke of ‘an explosion in data journalism-oriented scholarship’ (Fink and Anderson, 2015: 476). Lewis (2015) also attested to a ‘rapidly growing body’ (p. 322) of scientific studies investigating the field (as mentioned in Loosen et al., 2015: 2).
What was all this research about? Empirically, ‘the first wave of data journalism research’ (Uskali and Appelgren, 2015) produced a number of studies, detailing the national scenes and data desks of Western newsrooms. Many covered the practice in one (or more) media organization(s) over several weeks and were descriptive, examining the organizational culture, newsroom structures, the epistemologies of data journalists, and the characteristics of data-intensive pieces. Typical of the ‘first wave’ research, the findings were rather detailed and led to a fragmented publication landscape. Both then and now, the interdisciplinary nature of the field also seems to reinforce this fragmentation, for while it stands to benefit from broad academic engagement, the fact that researchers publish in outlets important to their discipline means that many efforts happened (and continue to happen) in parallel, resulting in similar findings.
Research questions
To address the granularity and fragmentation of data journalism research, this article adheres to the guidelines of structured literature reviews. It positions itself in the tradition of other meta-studies devoted to special areas of journalism (e.g. Neuberger et al., 2007, who surveyed the potential of blogs for journalism; or Steensen and Ahva, 2015, who collected the theoretical underpinnings of journalism research). In a related meta-analysis, Diakopoulos (2012) analyzed and explored ‘the potential for technical innovation in journalism’ (p. 2). By systematically analyzing the computer science literature that covered journalism, he found areas previously neglected by the computer science community that he suggested could further its development. This article is complementary to Diakopoulos’ publication. While he explored the potential for computational technologies in journalism, we have drawn on research from the social sciences and neighboring disciplines that investigated data-intensive journalism. In combination, these two articles provide a functional roadmap for further developing and researching the field.
In line with the method of structured literature reviews, the first aim of this article is to describe the development and current state of scholarship on data journalism. This will help scholars assess both the development of the field and to identify works that have had the greatest influence on its current state. Consequently, our research questions are as follows:
RQ1. How is the research literature on data journalism developing, among other aspects, in terms of publication activity, publication outlets, and citations?
RQ2. What are the theories of data journalism research?
RQ3. What are the methods of data journalism research?
RQ4. Which research gaps have data journalism researchers identified and what are their suggestions for future research?
Each of these questions is answered in the ‘Results’ section of this article and lays the groundwork for the second aim of this article: Providing propositions for future research on data journalism. A reflection on the development, theories, methods, and research gaps in the ‘Conclusion’ section clarifies several possible areas of study, while noting that the means to explore them are in essence two: recombining established research interests, theories, and methods into novel approaches or integrating new interests, theories, or methods into existing frameworks. This article supports future research of either kind.
Data journalism and data-intensive newswork
Before proceeding, we would like to clarify what we mean by data journalism and data-intensive newswork – two umbrella terms used synonymously in this article. Both relate to computer-assisted reporting (CAR), a journalistic movement, which for decades has been concerned with the use of computational technologies in newsrooms (e.g. described in Howard, 2014; Stavelin, 2013). However, the focus with our term is to emphasize the increased availability of data and the technical sophistication of analysis as well as modes of representation, which have developed significantly since the beginning of CAR. As is often the case with emerging phenomena, there is no commonly agreed-upon definition of data journalism. Some definitions focus on the change in the process of newswork (Appelgren and Nygren, 2014b; Bounegru, 2012; Davenport et al., 2000; Diakopoulos, 2011; Felle, 2016; Flew et al., 2010; Karlsen and Stavelin, 2014; Parasie and Dagiral, 2013; Tandoc and Oh, 2015; Uskali and Kuutti, 2015; Weber and Rall, 2012; Weinacht and Spiller, 2014; Young and Hermida, 2015). These definitions stress the role of data as an additional source in the news-gathering process that requires special skills to handle. Other definitions emphasize that data journalism produces news items based on data analysis that include some form of interactive visualization, for example, maps or diagrams (Baack, 2013; Hullman et al., 2015). However, a large corpus of works highlights that data journalism is both a process and a product (Aitamurto et al., 2011; Appelgren and Nygren, 2014a; Ausserhofer, 2015; Coddington, 2015; Cohen et al., 2011a; Gynnild, 2014; Hamilton and Turner, 2009; Hannaford, 2015; Howard, 2014; Knight, 2015; Loosen et al., 2015; Radchenko and Sakoyan, 2014; Stavelin, 2013; Tabary et al., 2016). While each definition has a different emphasis, there are common elements which essentially outline a journalistic process (developing ‘data stories’ by analyzing large sets of data with (mostly) quantitative, computational methods), as well as a special form of presentation (interactive visualizations). 1 To capture this diversity, this article emphasizes the process and the product equally.
Prototypical examples include the Guardian’s ‘Afghan’ and ‘Iraq War Logs’ (mentioned in Baack, 2013, and Knight, 2015); ‘ChicagoCrimes’, a website which allowed users to check crimes in a particular neighborhood (mentioned in Parasie and Dagiral, 2013); and the ‘Toxic Waters project’ from the New York Times which examined pollution in American waters (mentioned in Gynnild, 2014). Such news items and the work leading to them have been described by a variety of terms (see Table 1), many of which are connected with different communities, histories, epistemologies, and visions of the public (Bounegru, 2012; Coddington, 2015). However, what is important to this article is what unites these practices: the concentrated use of structured information in the making of news. Thus, the terms data journalism and data-intensive newswork describe (the production of) news that is predominantly based on the concentrated collection and analysis of structured information. Like numerous other authors, we see this phenomenon as journalism’s response to an increasingly data-dependent society.
Synonymic search terms used for the literature retrieval.

Other related terms, more general concepts, and abbreviations such as ‘accountability journalism’, ‘CAR’, ‘crowdsourced journalism’, ‘data visualization’, ‘DDJ’, ‘drone journalism’, ‘investigative journalism’, ‘online journalism’, and ‘open journalism’ were tested as well but not included in the final list because the search results were too cluttered.
Method
Methodological framework: Structured literature reviews
This article is a structured literature review, which represents a very rigid form of a meta-analysis (Massaro et al., 2016). The goal of a structured literature review is ‘to develop insights, critical reflections, future research paths and research questions’, and it should ‘contribute to developing research paths and questions by providing a foundation on which to build on prior discoveries’ (p. 768). In addition, structured literature reviews provide the basis and justification for new research, and the ‘the background to develop research synthesis’ (p. 794) for more mature areas of research. Systematic reviews adopt ‘a replicable, scientific and transparent process […] that aims to minimize bias […]’ (Tranfield et al., 2003: 209). While based on a ‘positivist, quantitative, form-oriented content analysis method for reviewing literature’, they also strongly use hermeneutic and interpretative methods, especially when developing insight and critique (Massaro et al., 2016: 768). The purpose of critique in this context ‘is to counteract the dominance of taken-for granted goals, ideas, ideologies and discourses […]’ (Alvesson and Deetz, 2000: 18).
Figure 1 illustrates the steps we took: First, we defined the questions the review should answer. Second, we selected relevant literature, following a rigid and reproducible path. Third, we analyzed and coded the material. In order to pay tribute to the shift toward more inclusive research findings in meta-analyses (Tsakalerou and Katsavounis, 2015), we integrated both qualitative and quantitative research.
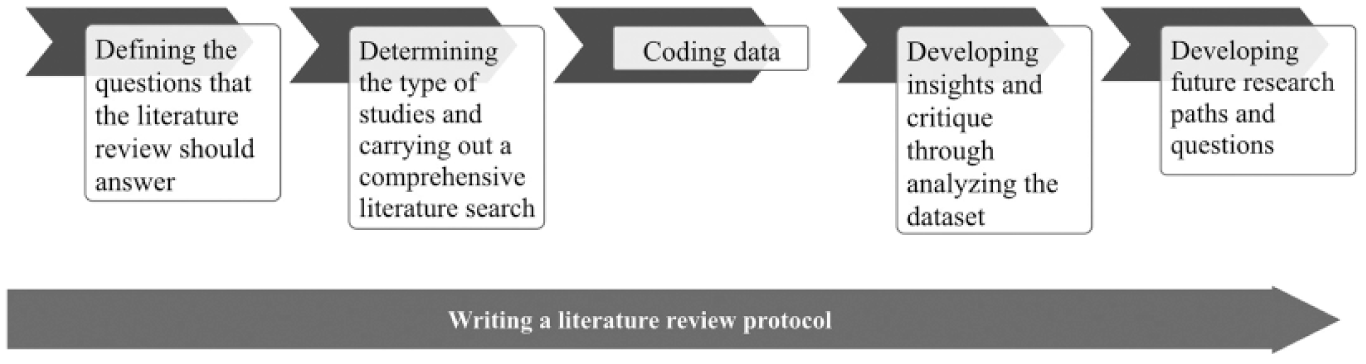
Undertaking a systematic literature review.
Literature retrieval and selection
We started the process of literature retrieval by discussing formal inclusion and exclusion criteria for the literature corpus. These decisions were based on our evaluation of other structured literature reviews (e.g. Fecher et al., 2015; Guthrie and Murthy, 2009; Jungherr, 2016; Lecheler and Kruikemeier, 2016; Massaro et al., 2015; Neuberger et al., 2007). Although there are many excellent theoretical and conceptual publications on the subject, we decided to only include articles in the analysis that were empirically grounded, irrespective of whether the investigation focused on quantitative, qualitative, or mixed-methods research. This decision mirrored other meta-analyses and was made because we considered empirical proximity to be key for our research interest. Our focus was on publications from the social sciences, but we also included articles from other disciplines. In terms of publication type, we considered journal articles, book chapters, conference papers, industry reports, and PhD theses. Due to the high number of publications, we excluded bachelor’s and master’s theses, press reports, and blog posts, as well as popular textbooks such as the Data Journalism Handbook (Gray et al., 2012), Precision Journalism (Meyer, 2002), or Scraping for Journalists (Bradshaw, 2014) due to their target readership and self-reporting writing style. Due to limited language proficiency, we could not include publications written in languages other than in English or German. Finally, we decided to include all articles published online between 1996 and 2015, as the scattered research on CAR published before 1996 seemed to have investigated a very different practice. In total, two articles published in print in 2016 were accessible online during this evaluation period and were thus included in the review.
The next step was to create a list of relevant keywords that served as search terms for the literature retrieval from scientific databases. For this, we conducted a preliminary search on Google Scholar using the terms ‘data-driven journalism’ and ‘data journalism’ and then extracted related terms from the abstracts and keyword sections of the articles. This led us to the list of synonyms for data journalism as shown in Table 1.
Based on the synonymic search terms from Table 1, we undertook a literature search in 15 scientific databases, obtaining 772 records in total (Table 2). The search terms were combined with the Boolean ‘OR’ operator.
Scientific databases used with the search terms from Table 1.
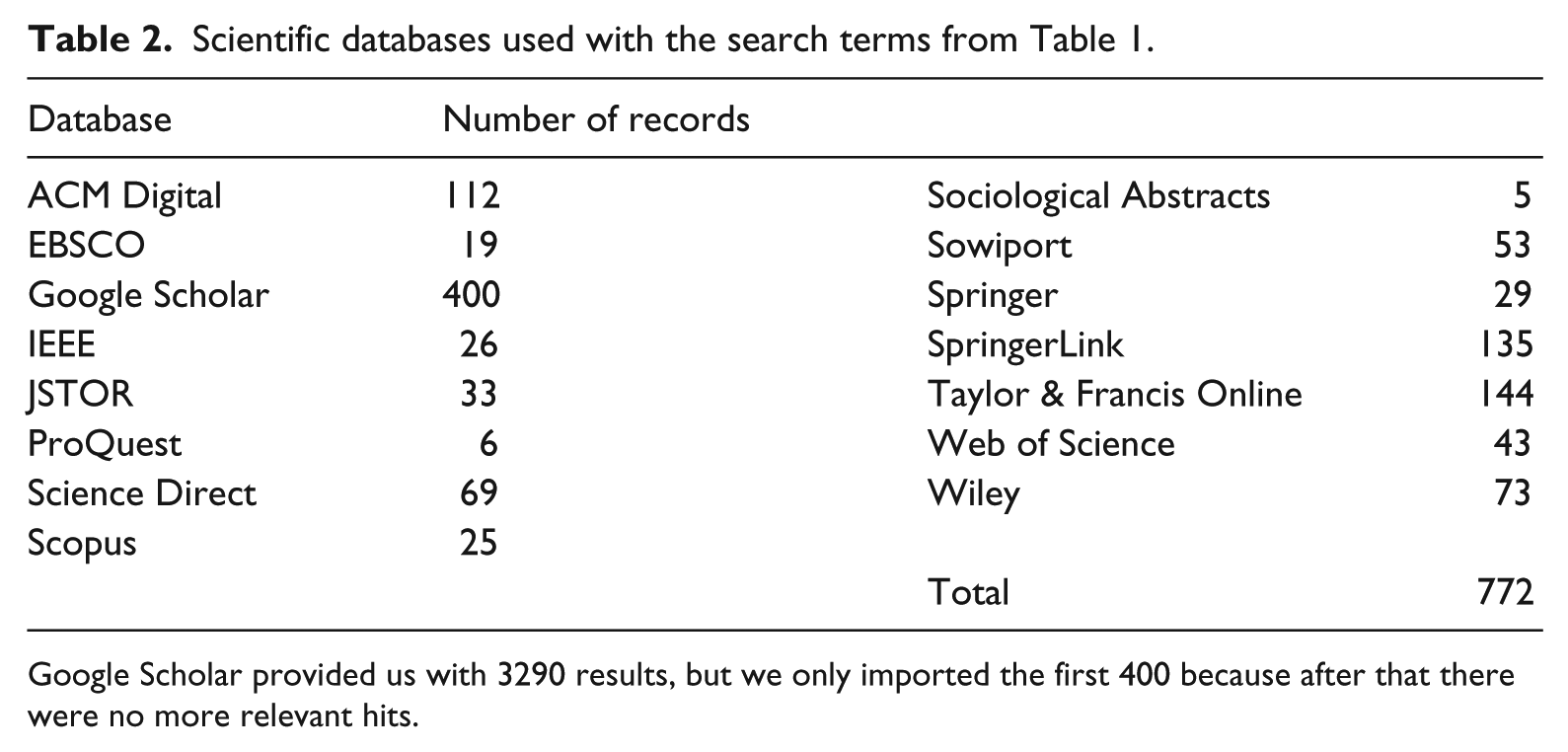
Google Scholar provided us with 3290 results, but we only imported the first 400 because after that there were no more relevant hits.
The records were imported into Zotero; assessed independently by two researchers considering title, abstract, and keywords; and selected according to the above-mentioned formal criteria and research focus (see first paragraph of this section for detailed criteria). Publications that both researchers marked as ‘not relevant’ were dismissed, while those both marked as ‘relevant’ were included in the preliminary corpus. The researchers discussed divergent assessments until an agreement was reached. This screening resulted in a preliminary corpus that we then cleaned of duplicates.
In total, two further measures were taken to select the literature for the corpus. First, we asked three domain experts, all researchers in the field of data journalism, to add relevant work based on their expertise. Second, we checked the references of our selection, computer supported and manually: We scraped the references of all selected articles from the preliminary corpus into a database, employing a bibliographic data recognition algorithm (Lopez, 2009) to assess all references that had been cited by at least two articles. Finally, the references of the selected works published in 2015 and 2016 were checked by hand. This process resulted in a corpus of 40 publications. Figure 2 illustrates the retrieval and selection process in a flowchart.
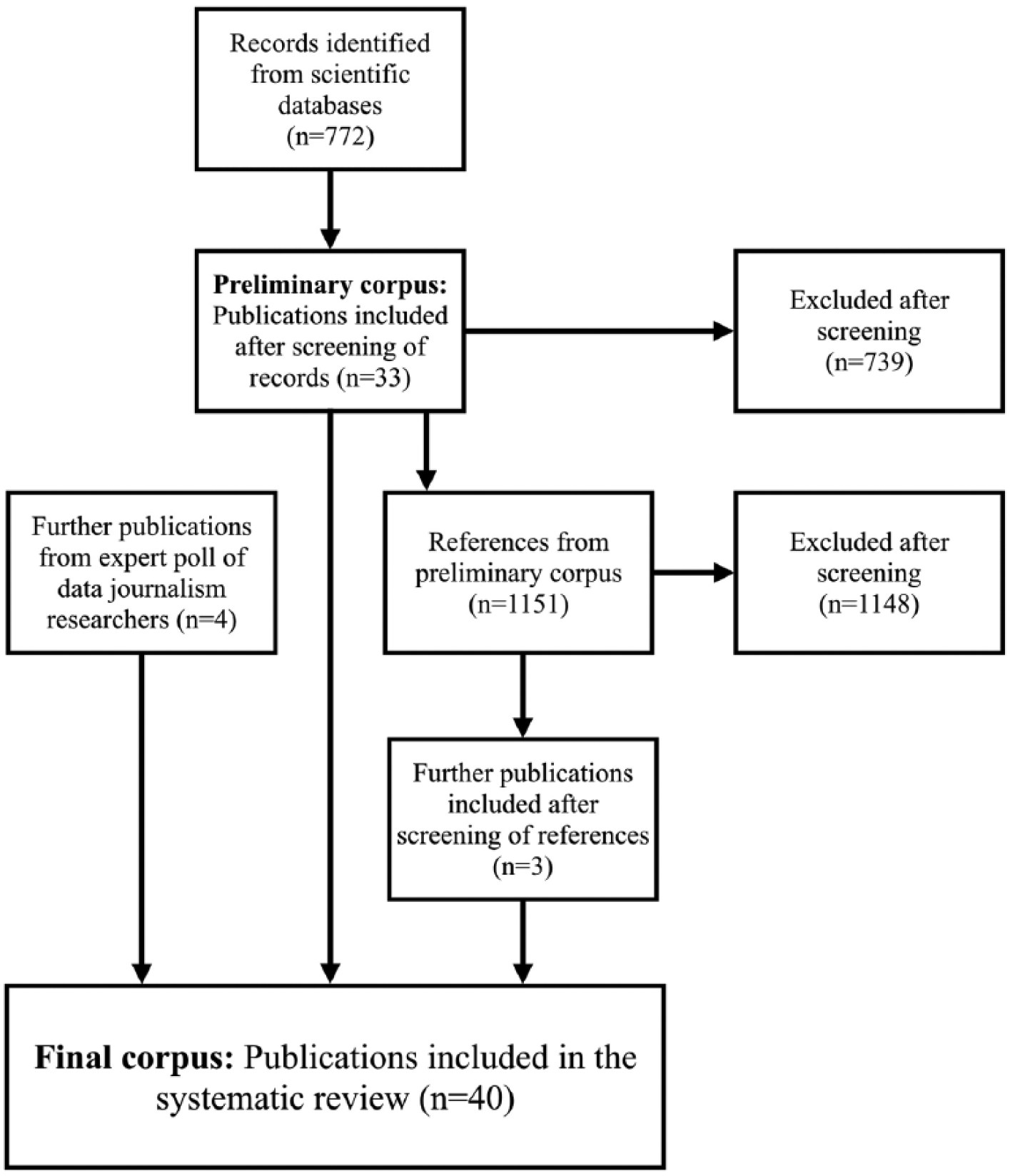
Workflow of literature retrieval and selection.
Quantitative and qualitative content analyses
The final corpus of 40 research publications allowed us to perform different types of quantitative and qualitative analyses. We began by extracting and comparing different structural aspects of each piece. Among other dimensions, we collected the publishing date of each article and coded their publication outlets. Furthermore, we extracted the authors’ names and affiliations, and the numbers of citations on Google Scholar using a Python module (Kreibich, 2016). Next, we took a closer look at the references, which we obtained using the same algorithm that we had employed for the preliminary corpus. We then cleaned the reference data, removed duplicates, and finally parsed it into a network-analysis-friendly format to identify central publications.
Parallel to the computational exploration of the corpus, we conducted a software-assisted qualitative content analysis (Kaefer et al., 2015; Mayring, 2000; Schreier, 2012), starting with the development of a codebook. While the codebook’s main categories were defined by our research interest and research questions, we derived the subcategories out of the material manually. Such an inductive coding process helped to establish ‘novel interpretative connections based on the data material, rather than […] a conceptual pre-understanding’ (Fecher et al., 2015: 6) of the topic. In a pre-test, three researchers coded two articles, continuously discussing and modifying the category system. We then compared the coding and discussed differences until an agreement on the codebook was reached. We used the qualitative data analysis software NVivo for the coding.
Finally, we supplemented the manual coding with an automated content analysis, which used a Python implementation of the term frequency-inverse document frequency (TF-IDF) algorithm to extract the central terms of each article. TF-IDF is a statistical measure that evaluates the importance of a word within an individual document, as well as the corpus as a whole.
Among other aspects, this mixed-method approach brought insights into the development of the research literature, the theoretical frameworks and the research designs used in the publications, and the areas potentially neglected within the field – matters addressed in the following section.
Results
The results presented here refer to the research questions formulated in the ‘Introduction’ section. In the first subsection, we go into detail about the current state of data journalism research and provide a citation and collaboration analysis. The following two subsections explore the employed theoretical frameworks and research methods. The final subsection covers the research gaps identified by other scholars. For further perspectives on the corpus, please also visit our interactive literature explorer at http://literature.validproject.at.
Corpus characteristics and bibliometry
Our first research question was: How is the research literature on data journalism developing? Figure 3 indicates that there has been an increase of research publications on data journalism and related fields since 2010. Although what is known as CAR has been practiced since the 1960s (Cox, 2000), the scientific investigation of it has started only recently. Before 2010, only a small number of isolated research publications dealt with the topic of data and journalism. Authored by US journalism researchers, these first publications mainly investigated how journalists used different computational technologies in the newsroom (Davenport et al., 1996, 2000; Garrison, 1999). The recent increase of research activity on the subject has to be seen in association with the introduction or renaming of different practices of data-intensive newswork as ‘data journalism’ or ‘data-driven journalism’ in the late 2000s. This reframing seemed to have sparked the interest of journalism practitioners and journalism researchers alike.
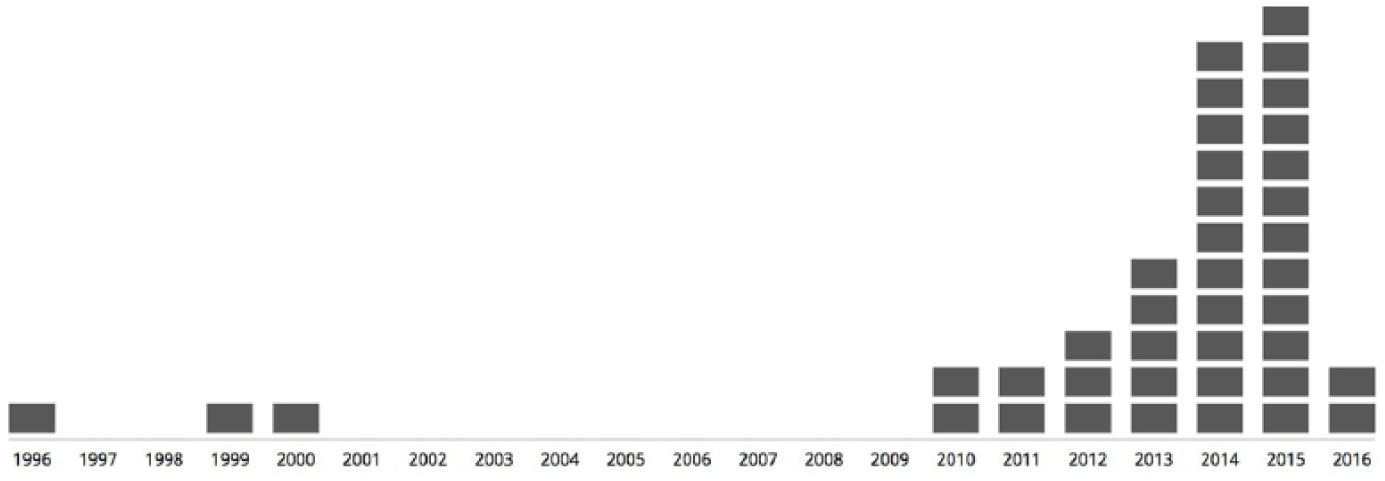
Development of the literature over time.
Academic journals focused on journalism research published the largest number of works (26) in the corpus. Among them the periodicals Digital Journalism (6), Journalism Studies (3), Journalism (2), and Journalism Practice (2) were the most popular places to publish. Digital Journalism owes its lead position to the publication of a special issue (Lewis, 2015). Journal articles not only outnumber other channels of academic dissemination, they were also cited considerably more often than conference articles (6), book chapters (4), and other publication types (4; see Figure 4). The most-cited article in the corpus (Segel and Heer, 2010) was published in a computer science journal.
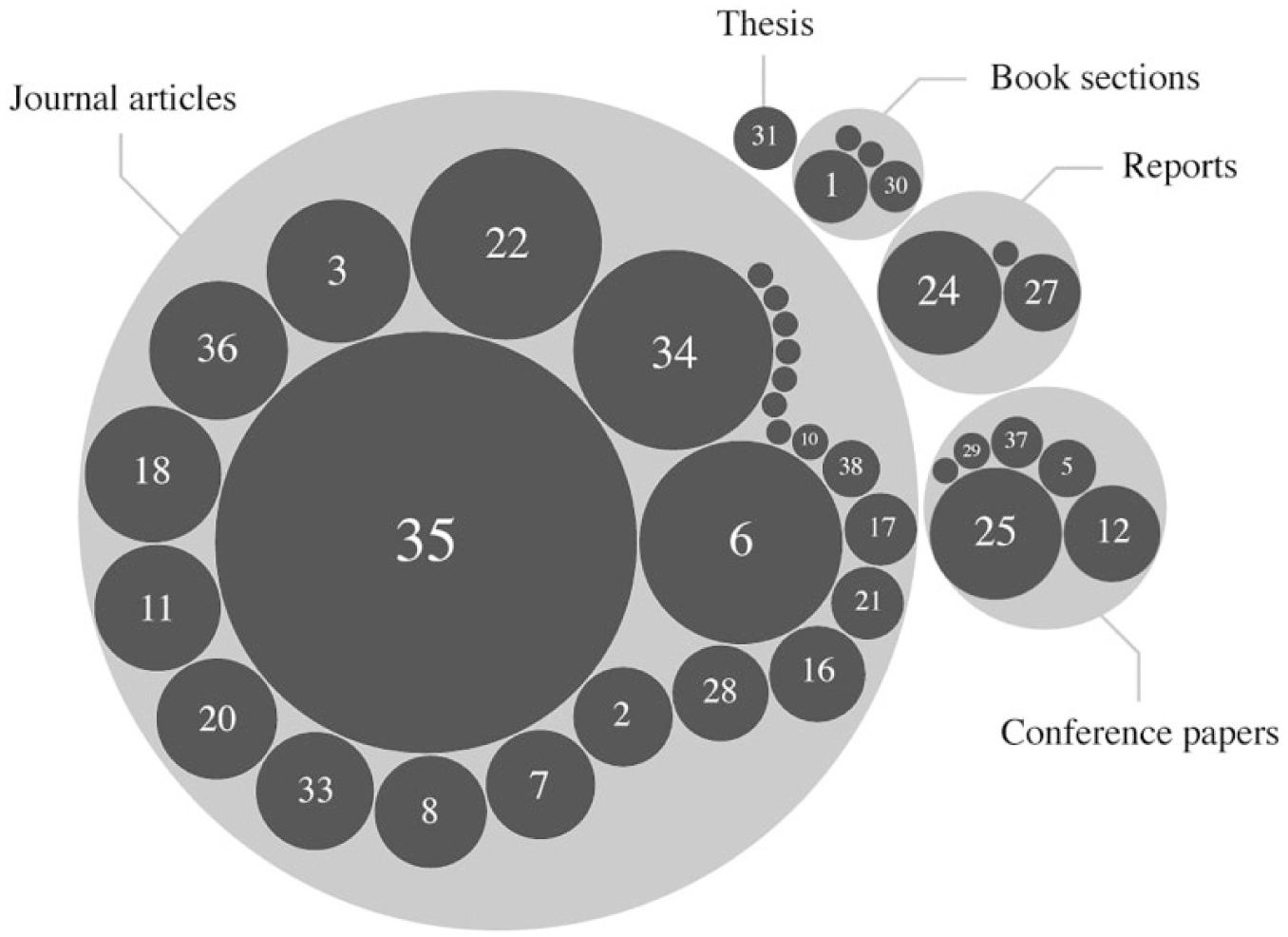
Publications by type and number of citations.
What are the most influential publications in the field of data journalism research thus far? A count of the references of all publications hinted at an answer, though a high number of citations does not necessarily equal high influence, as many cited publications are not geared toward an academic audience. Phil Meyer’s (2002) book Precision Journalism, which has helped to build the ‘computer-assisted reporting legacy’ (Parasie and Dagiral, 2013) since the 1970s, was the most-cited work in the corpus together with Parasie and Dagiral’s investigation of the community and epistemologies of data journalists in Chicago. Their article can be considered as a prototypical piece of contemporary data journalism research since its theoretical framework, research methods, and scope of investigation have resurfaced in many later publications. Both publications, Meyer’s and Parasie and Dagiral’s, have been cited by 15 of the 40 articles in our corpus. Other often-cited and influential works on data journalism can be seen as part of research that has ‘focused on the technological promises of computing on journalism’ (Gynnild, 2014: 714) or publications that explore the potential of the practice (Cohen et al., 2011a, 2011b; Flew et al., 2012; Hamilton and Turner, 2009). Table 3 lists the 10 most-cited publications in our corpus.
The most-cited references.

Where was the research on data journalism produced? Geo-coding the first affiliation of each author as they were mentioned in a publication, we found that most researchers came from institutions in Europe (38) and North America (29). Of the 71 authors in our corpus, 22 were affiliated with institutions in the United States. Clearly a collaborative field, more than two-thirds (27) of all data journalism publications were written by more than one author. For comparison, in 2000, roughly half of social science articles were written collaboratively (Wuchty et al., 2007). In total, seven of the articles have been international collaborations. Figure 5 places the authors’ affiliations on a map and shows that almost no non-Western research on data journalism has been published in English. 2
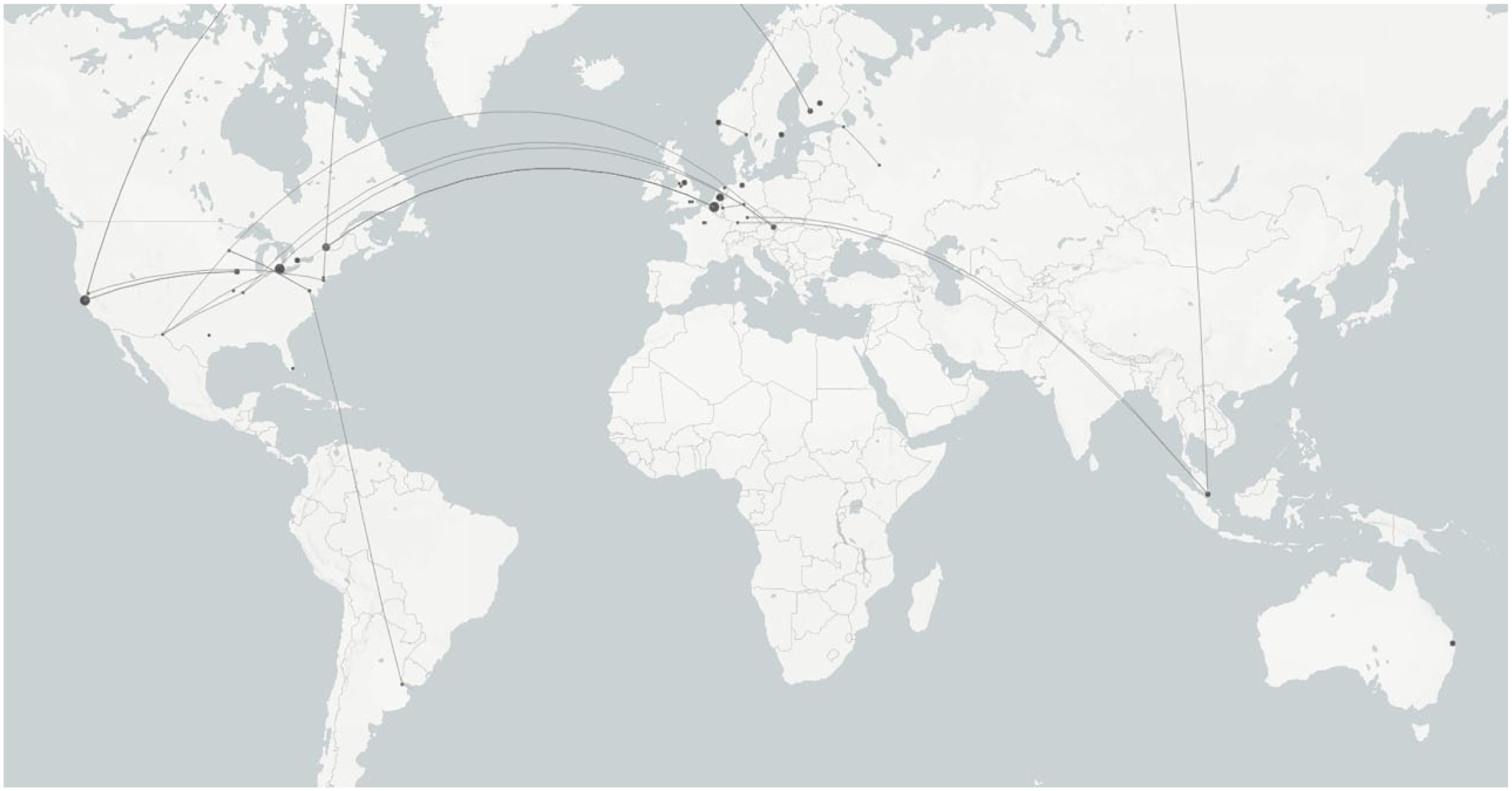
Affiliations and collaborations.
Theoretical frameworks
Journalism studies in general tends to be a ‘multidisciplinary field in the borderland between humanities, social science and technology’ (Appelgren and Nygren, 2014a). Hence, several articles in the corpus mentioned certain theoretical frameworks which are to be understood in a broader sense than when applied in their original fields. These articles also revealed how research on data journalism situated itself within the research stream, and as always, theoretical concepts had an influence on the selection of possible objects of research, on what to investigate specifically, and finally which research methodologies were selected and made explicit.
Theoretical frameworks were often combined, suggesting that certain clusters of frameworks were frequently used in data journalism studies. Science and technology studies were repeatedly mentioned (Ausserhofer, 2015; Lewis and Usher, 2013, 2014; Stavelin, 2013), and actor network theory was often applied in the analysis (Ausserhofer, 2015; De Maeyer et al., 2015; Parasie, 2015; Parasie and Dagiral, 2013; Stavelin, 2013). More specific theoretical concepts were also used, for example, ‘understanding […] computational journalism as a rhetorical craft, using the Aristotelian concept of techné’ (Karlsen and Stavelin, 2014), role theory (Weinacht and Spiller, 2014), and trading zones (Lewis and Usher, 2014). The fact that only few publications mentioned theoretical frameworks might indicate that data journalism research is more oriented toward practice than theory currently, which is very common for journalism studies (Scholl, 2011).
Research designs
The analysis of research designs is summarized in Table 4. It revealed a certain scarcity of quantitative research designs and digital methods, in contrast to qualitative exploratory ones. At this early stage of research, this is not unusual since the characteristics of a new practice have to be explored and defined before quantitative methods can be applied.
Research methods of publications on data journalism.

DIN: data-intensive newswork. QI: Qualitative interviews. CA: Content analysis.
Content analysis includes analysis of news, databases, blogs, job ads, visualizations, briefings, manuals, and more. Short-term observation encompasses visits to the newsroom and participation in meetings. A newsroom ethnography is defined as an observational study of a newsroom over the course of several days.
Qualitative interviews were by far the most common method (25 publications) used within the examined literature corpus. Many of them were in-depth interviews that followed semi-structured guidelines and were conducted with practitioners and/or experts ranging from 5 to 35 individuals or in 1 case over 100 (Howard, 2014). In total, seven of the interviews questioned 5 to 9 individuals, six interviewed between 10 and 19, and six interviewed over 20 individuals. Interviews either took place in person or via phone. Commonly, those interviews were the main method used for the publication, though many publications employed mixed-method approaches. In total, eight used interviews in addition to other methods. In some cases, initial interviews were supported by content or document analysis and vice versa. For instance, De Maeyer et al. (2015) conducted 20 semi-structured interviews with individuals involved in data journalism in Belgium, while also analyzing documents and artifacts.
Content analysis was also employed quite often. Overall, we were able to identify 21 publications within our corpus that use some sort of analysis of text or images, though very few actually examined data journalistic news items. Examples of these included an article by Lugo-Ocando and Brandão (2015) that analyzed news items produced by journalists in the United Kingdom, and one publication, which analyzed articles within the Guardian Datablog with respect to news values, sources, and topics (Tandoc and Oh, 2015). Loosen et al. (2015) focused on pieces nominated for the Data Journalism Awards in the years 2013 and 2014. Segel and Heer (2010) chose to explore 58 visualization examples from online media.
Other research publications employing content analysis looked at the discourse around data journalism and not data journalistic news items themselves. For instance, Hullman et al. (2015) analyzed comments from the Economist’s Graphic Detail blog, while Gynnild (2014) studied both original data journalistic items – pieces on the Guardian Datablog – and online news accounts, listservs, and journalism blogs to grasp the discourse around data journalism.
The method of survey was used less frequently, though Appelgren and Nygren (2012a, 2014b) made use of an online survey and combined the findings with semi-structured interviews for their research.
Some authors used observation as a method to study newsrooms, though in the case of Royal (2012), who observed members of the New York Times’ Interactive News Technology department for several days, it seemed appropriate to classify her method as ethnography. Smit et al. (2014) attended editorial meetings and brainstorming sessions at a leading broadcasting organization in the Netherlands, while Dick (2014) spent 8 hours observing the BBC News Online Specials team.
The studied cases tended to be in the United States and the United Kingdom, though some were also in Western countries such as Germany and Sweden. There exists almost no English language research on practices outside of Europe and North America. Some author collectives tended to focus on activities in less explored countries, for instance, Sweden (Appelgren and Nygren, 2014a, 2014b) and Norway (Karlsen and Stavelin, 2014; Stavelin, 2013). The restriction to certain geographical areas coincides largely with the researchers’ location. The fact that even large Western countries such as France are not represented in our sample might be partly due to the lack of a longstanding tradition of CAR there (Parasie and Dagiral, 2013).
Which media organizations did researchers associate with data journalism and investigate? The list in Figure 6 was compiled through manual coding in combination with automatic term extraction of the texts. The visualization shows the frequency and total mentions of a specific media organization, as well as how many publications were connected to it. The Guardian, the New York Times, and ProPublica occurred most often and in most documents, but Figure 6 also helps to identify smaller news organizations that were only rarely mentioned but might be suitable for future research.
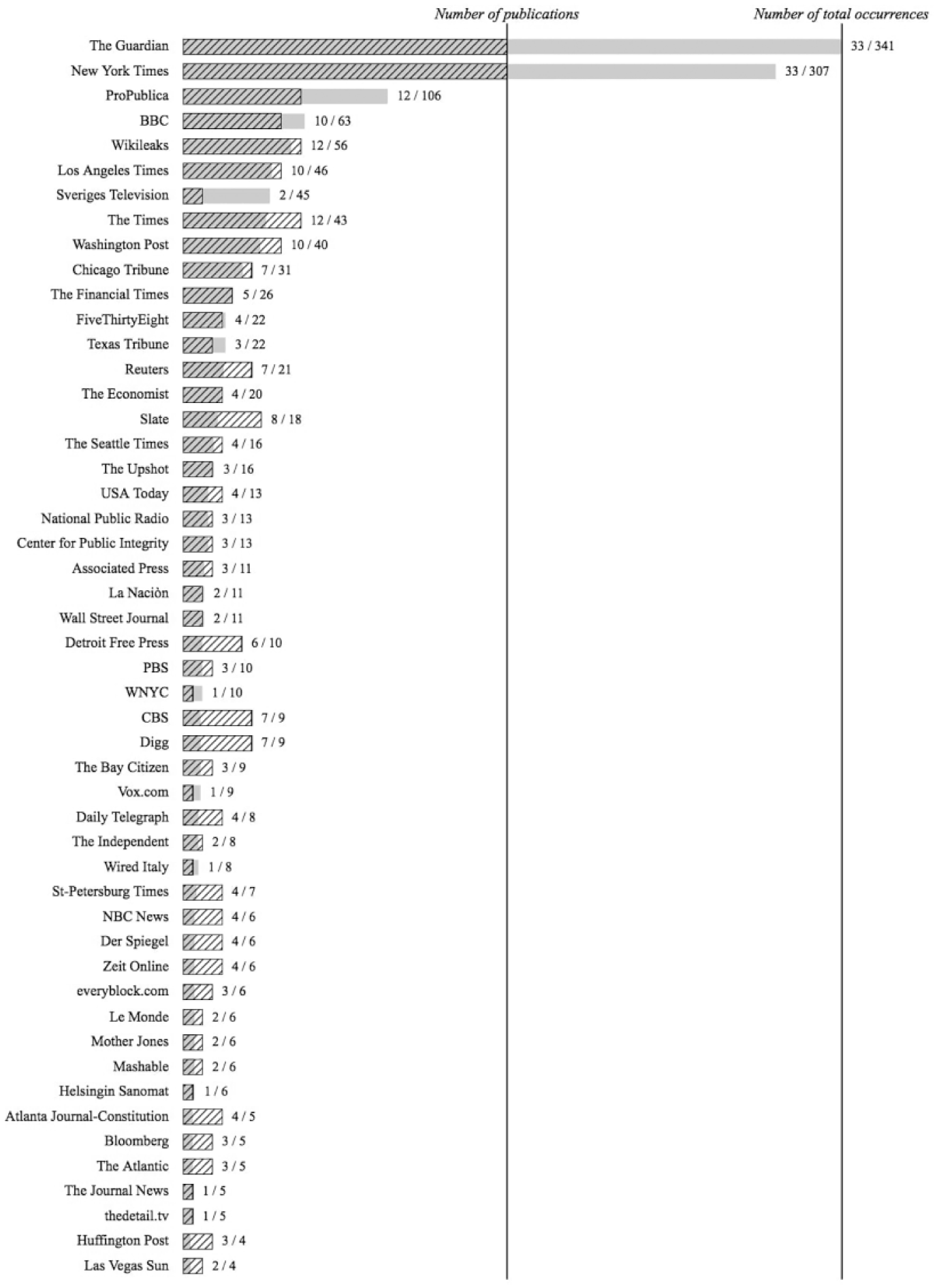
Occurrence of media organizations.
Research gaps
Given the emerging nature of the field, we wanted to know what scholars identified as research gaps. Recommendations for further study included cross-national investigations of data journalism, as well as the ethnographic study of those practices. Parasie and Dagiral (2013), for example, suggested comparing practices between countries while accounting for the differences in the cultures of journalists and hackers. They suggested that those differences influenced the way data journalism is practiced within various countries. They also proposed that ethnographic studies of newsrooms could clarify how programmer–journalists were integrated into different organizations. Along those lines, Appelgren and Nygren (2014b) suggested further comparative international research that took national regulations and constraints into account.
Most of the publications we analyzed focused on a rather short period. Therefore, Knight (2015) pointed out the need for long-term studies, which Davenport et al. (2000) had already recommended more than a decade before. Interested in the influence of technology on content, Garrison (1999) recommended determining whether the discrepancy of resources between small and large newspapers led them to tell different stories (scope, depth, and size of databases). Lewis and Usher (2013) also suggested research into the influence of technology on the news-production process, while Stavelin (2013) more specifically called for the study of how software design and its use affected the production of news. Segel and Heer (2010), however, proposed studies focused on reader experience to clarify how audiences engaged with visual elements and, therefore, how their design could be improved. Despite this variety of suggestions, most authors and author collectives within our corpus did not discuss research gaps or suggest paths for further research.
Conclusion
In this article, we analyzed the structure and topics of research literature on data journalism that has been published in the last 20 years. Following the rigid method of a structured literature review, we selected a corpus of 40 publications and examined them using computational methods and qualitative software-assisted content analysis.
Both data journalism and its accompanying research have been developing rapidly in the past two decades. Since 2014 in particular, we have seen a major increase of scholarship on the topic. This growth has led to quality improvements and contributed to the establishment of a solid foundation for the field. An indicator for the quality improvement is that newer publications increasingly reference publications that have been produced by researchers following consistent methods and published in peer-reviewed journals. Another indicator for improvement is the high percentage of collaborations within the research community. This coincides with the ‘collaboration imperative’ of modern research which is also found to have beneficial impacts regarding the creation and diffusion of knowledge (Bozeman and Boardman, 2014). The frequent collaboration across countries can be read as a tendency toward internationalization.
At the same time, we also see issues with parts of the current literature. For instance, only a minority of empirical data journalism research refers to theoretical or methodological concepts. Many publications just report what has been investigated. Thus, we welcome research that either draws from different strands of theory or continues to develop theoretical concepts. This effort could build upon those of a number of scholars doing theoretical work related to the role of data and journalism in our society (e.g. Anderson, 2015; Bunz, 2011; Cohen, 2015; Fairfield and Shtein, 2014; Lewis and Westlund, 2015; Schudson, 2010). For instance, capturing concepts of data journalism through a history-of-ideas lens could be very enriching. While we acknowledge that descriptive research is very important – especially with new phenomena – it also seems like some data journalism researchers have adopted the objectivist epistemology of many journalists working with quantitative data (Godler and Reich, 2013). This means, for example, that some authors reported their results without taking their method of data collection into account: responses of interviewees are presented as facts without acknowledging that some degree of idealization is inevitable. In most interview-based publications, the respondents were personally identifiable; given the fact that many of the practitioners engage in extra-institutional communities (Usher, 2016), which monitor and shape the field’s (meta) discourse, it can be assumed that the interviewees tried to present themselves in the best possible way.
Another issue is the lack in variety of research methods. While many research projects employ two different qualitative methods or triangulation, there is almost no research based on quantitative methods. While exploratory studies are typical for newly developing research fields, it seems appropriate to begin testing some existing theories using larger samples. Furthermore, we believe that ‘digital methods’ (Rogers, 2013; see also Maireder et al., 2015), or methods that try to grasp the field through online trace data or by observing the interactions on the major platforms for data journalism discourse, such as GitHub, Slack, Twitter, Facebook, or Meetup, would offer new avenues for data journalism research.
In addition to the research gaps described above, data journalism research currently has little to say about questions of gender. As women seem to be a minority in data journalism, some articles proposed gender issues regarding the (male-dominated) field of technology as general topic. However, questions concerning the more specific interests, experiences, or challenges of women in data journalism were rudimentarily addressed. We would be happy to see research focusing on this and similar matters.
Finally, very little is known about data journalism outside of the news desks of famous organizations. We would thus welcome research directed toward local and mobile data journalism, toward small news outlets working on data-intensive projects, and toward the many freelancers who provide services for news organizations. Here, an economic perspective would be an especially valuable contribution to the field.
In journalism research, there is a strong connection between the research interest, the chosen theory, the methods of data collection and analysis, and the reporting of results (Scholl, 2011). Some works combine these aspects in a systematic way, while others generate new perspectives from integrating new or remixing proven perspectives, theories, and methods into novel frameworks (Markham, 2013). Whichever way is chosen for future investigations on data journalism – a traditional or a bricolage approach – this article provides the groundwork for both. By critically surveying essential elements of publications and providing additional research propositions, it allows future researchers to choose their research interests, theoretical concepts, and methods with respect to the continuity and innovation of the field of data journalism research.
Footnotes
Acknowledgements
The authors would like to thank Wolfgang Aigner, Dominikus Baur, Štefan Emrich, Wiebke Loosen, Silvia Miksch, Christina Niederer, Ulrike Pölzl-Hobusch, Julius Reimer, Alexander Rind, Joseph Robinson, Elena Rudkowsky, Michael Sedlmair, Thomas Wolkinger, and the two anonymous reviewers for their helpful feedback.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Austrian Ministry for Transport, Innovation and Technology (BMVIT) through the Austrian Research Promotion Agency (FFG; grant number 845598), the Volkswagen Foundation (grant number 90858), the Internet Foundation Austria (grant number 1836), and the Open Access Publishing Fund of the University of Vienna.