
Abstract
This paper presents an analysis of how three interlocutors sequentially organize and accomplish mutual understanding in naturally occurring audiovisual recordings of therapy sessions. The analysis is in keeping with microanalysis of face-to-face dialog (MFD) and follows operational definitions of three-step micro-processes that interlocutors use when they calibrate new information; that is, how they agree that they have understood each other’s words and actions well enough for current practical purposes. Pointing to some of the complexities that characterize triadic interactions, the analysis contributes with new documentations of ‘suspended’, ‘nested’, ‘branched’, ‘multi-paced’, and ‘mixed interpretations’ calibrations. The analysis also demonstrates how interlocutors may calibrate the ‘tone’ of an utterance before the topical content is mutually understood. The results and their implications may be relevant to practitioners of institutional talks at large, where the quality and outcome of, for instance, assessments and interventions largely rely on accomplishing mutual understanding.
Keywords
The quality and outcome of child and family therapies largely depend on therapists and clients accomplishing mutual understanding. In child and family therapies, it is common for three or more interlocutors to be involved. However, research on how interlocutors accomplish mutual understanding (as outlined by Bavelas et al., 2017) has focused on dialogs between only two people. This gap in research highlights the need for studies that explore how three or more people organize this process.
Doing mutual understanding
Therapists and clients do mutual understanding in incremental interactive processes. It is essentially a social event (Clark, 1996; Garfinkel, 1967; Lindgren et al., 2007; Linell, 2009; Roberts and Bavelas, 1996; Schegloff, 1992; Svennevig, 2009). Put differently, mutual understanding is not only a thing that interlocutors may have or share, it is also an interactive activity they do together (Bavelas et al., 2017). In this study, ‘doing mutual understanding’ refers to the interactive microprocess that interlocutors accomplish together as they make inferences, respond to each other, and calibrate on their meaning (Bavelas et al., 2017). A calibration sequence consists of the following three steps:
The speaker initiates the sequence by presenting new information (the A-initiation).
The addressee responds in a way that implies or demonstrates understanding (the B- response).
The speaker follows up in a way that implies or demonstrates that the addressee’s response was sufficient for current purposes (the C-follow up).
(p. 96, italics original)
That is, according to Bavelas et al. (2017), interlocutors use three-step calibration sequences to change the status of individual presentations to mutually understood contributions (cf. Lindgren et al., 2007; Tsui, 1989). In contrast to Clark’s two-phase grounding process (e.g. Clark, 1996; Clark and Brennan, 1991), calibrating sequences are micro-units consisting of three observable steps (cf. Bavelas et al., 2017; Linell, 1998), which can include both visible and audible minimal responses, such as a quick shrug or a brief ‘mhm’. This is similar to Deppermann’s (2015) and Enfield and Sidnell’s (2021) reasoning and analyses of achieving intersubjectivity; for understanding to be mutual, interlocutors must make their understanding of each other’s utterances publicly available and ensure that these understandings are ‘compatible enough for practical purposes’ (Deppermann, 2015: 78; cf. Clark and Brennan, 1991; Clark and Schaefer, 1987; Garfinkel, 1967; Linell, 2009; Linell and Lindström, 2016; Schuetz, 1953; Svennevig, 2009). In Arundale’s terminology, interpretings are ‘operative’ in that interlocutors may use them to design their subsequent utterances (Arundale, 2022). That is, calibrations do not necessarily bring about cognitive intersubjectivity, but rather a practical one. Hence, doing mutual understanding does not require that interlocutors have, or share, a final or identical interpreting of an utterance (cf. Arundale, 2020). Instead, calibrating is an interactive activity in which interlocutors presuppose more and more information, allowing their dialog to progress.
The following example, abstracted from one of the audiovisual recordings of triadic child and family therapies (De Jong and Berg, 2013) that I return to in the results section, illustrates the nature and scale of doing mutual understanding: Alex (ch, child), his mom (pt, parent), and their therapist (th) are talking about issues that are going on at home. Alex is unhappy with his amount of household chores, and the therapist asks him what he is going to do about it:
Th: So (turns her hands up and down) what are you going to do?
Ch: (looks down) Eh, just try to keep, keep (looks at the therapist) talking about it, keep bringing it up.
Th: (nods and smiles) Yeah (keeps nodding), wow.
When the therapist says, ‘So what are you going to do’ (utterance 1), she cannot assess whether her client, Alex, has understood her until he displays his understanding in a response (utterance 2). However, Alex cannot know whether he has understood his therapist until the third utterance, when the therapist displays her evaluation of Alex’s response. Once the therapist answers ‘(nods and smiles) Yeah (keeps nodding), wow’, Alex can infer that he has understood the therapist’s first utterance well enough for current practical purposes. According to Bavelas et al. (2017), these three steps are the minimal unit for interlocutors to infer that they have accomplished mutual understanding, in this case on the therapist’s question. Doing mutual understanding does not require that the utterances are dedicated to displaying understanding (cf. Deppermann, 2015). If Alex and his therapist had to explicitly state how they understand previous utterances, their conversation would become ‘endless’ (Heritage and Atkinson, 1984), ‘uneconomical’ (Deppermann, 2015), and ‘less on track’ (Enfield and Sidnell, 2021).
One could argue that the example is made up of two overlapping two-part sequences (Jovanovic et al., 2006). However, the ‘wow’ in the third utterance does not make sense except in relation to the first utterance; that is, utterances 2 and 3 are not a canonical adjacency pair.
Contextualizing three-step sequences in previous research
Using audio-recorded telephone calls between two interlocutors and analyzing meticulous transcripts of these, pioneering approaches established that the smallest units of conversational organizations are adjacency pairs (Schegloff and Sacks, 1973). These pairs consist of two parts, where the second utterance is functionally dependent on the first. Examples of adjacency pairs include, ‘greeting–greeting’, ‘question–answer’, and ‘offer–accept/decline’ (Schegloff, 2007; Schegloff and Sacks, 1973). According to Bavelas et al. (2017), the possibility of a third step has been mainly treated as an exception that expands the two-turn standard (e.g. Peräkylä, 2011; Seedhouse, 1996). That is, three-step sequences have mainly been treated as specific to the analyzed settings, not as evidence of a generic structure (Bavelas et al., 2017; Heritage, 2022). Despite strong evidence, it is not until recently that the centrality of the three steps has been embraced (Heritage, 2022).
In contrast, other scholars have built on or are in line with Mead (1934) and Goffman (1976, 1981). They argue that ‘the bulk of conversation is not constructed from adjacency pairs’ (Levinson, 1981: 482–483) and propose that mutual understanding is accomplished in three-step units (e.g. Arundale, 2010; Bavelas et al., 2012, 2017; De Jong et al., 2013; Heritage, 1984, 2022; Linell and Markovä, 1993; Severinson Eklundh and Linell, 1983; Svennevig, 2009; Tsui, 1989). Severinson Eklundh and Linell (1983) illustrated that it takes a minimum of three steps for interlocutors in a dialog to display shared agreement on what has been said. Indeed, in their words, a systematic holding back of third steps generates a sense of dissatisfaction. As in the opening example, without the third step, the therapist and Axel would not have been able to accomplish mutual understanding (cf. Deppermann, 2015; Heritage, 2022; Severinson Eklundh and Linell, 1983); instead, understanding would have remained implicit or inferred. In the therapist-client example provided, only the therapist would have been able to assess whether Alex had understood the initiation after two steps. Alex would not have known whether his response was sufficient for the current purpose until the therapist had followed up on it.
While three-step sequences are largely treated as exceptions in everyday discourse (Bavelas et al., 2017; e.g. Cullen, 2002; Mehan, 1979; Peräkylä, 2019; Schegloff, 2007; Sinclair and Coulthard, 1975), several scholars have argued for more context-independent occurrences (e.g. Bavelas et al., 2012, 2017; Deppermann, 2015; Goffman, 1981; Heritage, 2022; Severinson Eklundh and Linell, 1983; Tsui, 1989). In addition to analyses of getting acquainted conversations (Bavelas et al., 2017), detailed analysis of doctors’ appointments (Tsui, 1989), communication during rescue operations (Lindgren et al., 2007), psychotherapies (Bavelas et al., 2012; De Jong et al., 2020), medical emergency calls (Gerwing and Indseth, 2016), customer calls (Kevoe-Feldman and Robinson, 2012), classroom settings (Mehan, 1979; Sinclair and Coulthard, 1975), as well as more theoretically driven papers (e.g. Goffman, 1976, 1981; Mead, 1934; Severinson Eklundh and Linell, 1983) indicate that three-step micro-sequences are fundamental units in conversational interactions (Bavelas et al., 2017; Goffman, 1976, 1981; Mead, 1934; Severinson Eklundh and Linell, 1983; Tsui, 1989). However, how three interlocutors accomplish this has, until now, not been documented. In fact, a recent survey of available corpore for multi-party dialogs and their topics (Mahajan and Shaikh, 2021) revealed that none of them explored intersubjectivity at this level of granularity.
The present study
This study is part of a larger research project on children’s involvement in child and family therapy sessions (e.g. (Edman et al., 2022; Edman et al., 2023)). It combines two main themes: First, it focuses on the interactive micro-process interlocutor use when they do mutual understanding, drawing on a recent conceptual framework, methodology, and terminology (Bavelas et al., 2017). Second, it extends this framework from dyadic to triadic dialogs.
By exploring how therapists and clients organize and accomplish mutual understanding in both staged and naturally occurring audiovisual recordings of triadic child and family therapy sessions, I aim to delineate complexities associated with multiparty therapies. Such knowledge has the potential to improve the quality of child and family therapies and dialogs in allied fields and to advance research on dialogs at large.
The results are based on a detailed analysis informed by Microanalysis of Face-to-face Dialogue (Bavelas et al., 2016). In keeping with this method, I have attended to the pragmatics in the audiovisual recordings: only behaviors that are recognizable through observation (including audition) are analyzed. Observable behaviors involve both speech, co-speech gestures (Bavelas et al., 2014), and embodied non-verbal behaviors (cf. Goodwin, 2000), including quick shrugs, an exclamatory oh, raised brows, and so forth. I interpreted the interactive function of speech, co-speech gestures, and embodied behaviors (Bavelas et al., 2017).
I utilized the ELAN software for qualitative data analysis of the recordings. ELAN kept the annotated utterances and sequences synchronized with the recordings and allowed me to watch the recording frame by frame (e.g. Lausberg and Sloetjes, 2009), which was helpful as the analysis demands a very focused attention to brief micro units (Bavelas et al., 2017).
Materials and methods
Dataset
The data consist of four audiovisual recordings of triadic child and family therapy sessions (Table 1). The first recording is published as supplementary material in Interviewing for Solutions (De Jong and Berg, 2013). Recordings 2–4 are extant, that is, products of every-day therapeutic practices that took place from September 2019 to January 2022. They are part of a larger dataset and belong to an overarching research project on children’s involvement (e.g. Edman et al., 2022; Edman et al., 2023). At the time of recording, none of the interlocutors were aware of this particular analysis on doing mutual understanding.
Dataset.

Three main reasons determined the dataset: (1) Because the first recording is not protected by confidentiality, parts of the study can be replicated. Such transparency can provide a solid base for further research. (2) Recordings 2–4 are naturally occurring audiovisual recordings of practice. They enhance the results’ applicability to real-world settings. (3) The interlocutors are visible in the frame at the same time, which enables detailed analyses of their interactions.
Analysis
To identify calibrating sequences, the procedure consists of three stages (see below), which are based on the microanalysis developed by Gerwing and Healing (2017). In addition to decision trees and guidelines, the manual includes operational definitions of utterances (Table 2, with examples from the first recording), minimal responses, A-initiations, B-responses, and C-follow ups (Table 3, with examples from the first recording). The different operational definitions have inter-analyst agreements ranging from 89% to 98% (Gerwing and Healing, 2017). The manual is available upon request from any of its authors. Because the first recording is not protected by confidentiality, I have not anonymized the examples in the tables.
Utterance.

A-initiation.
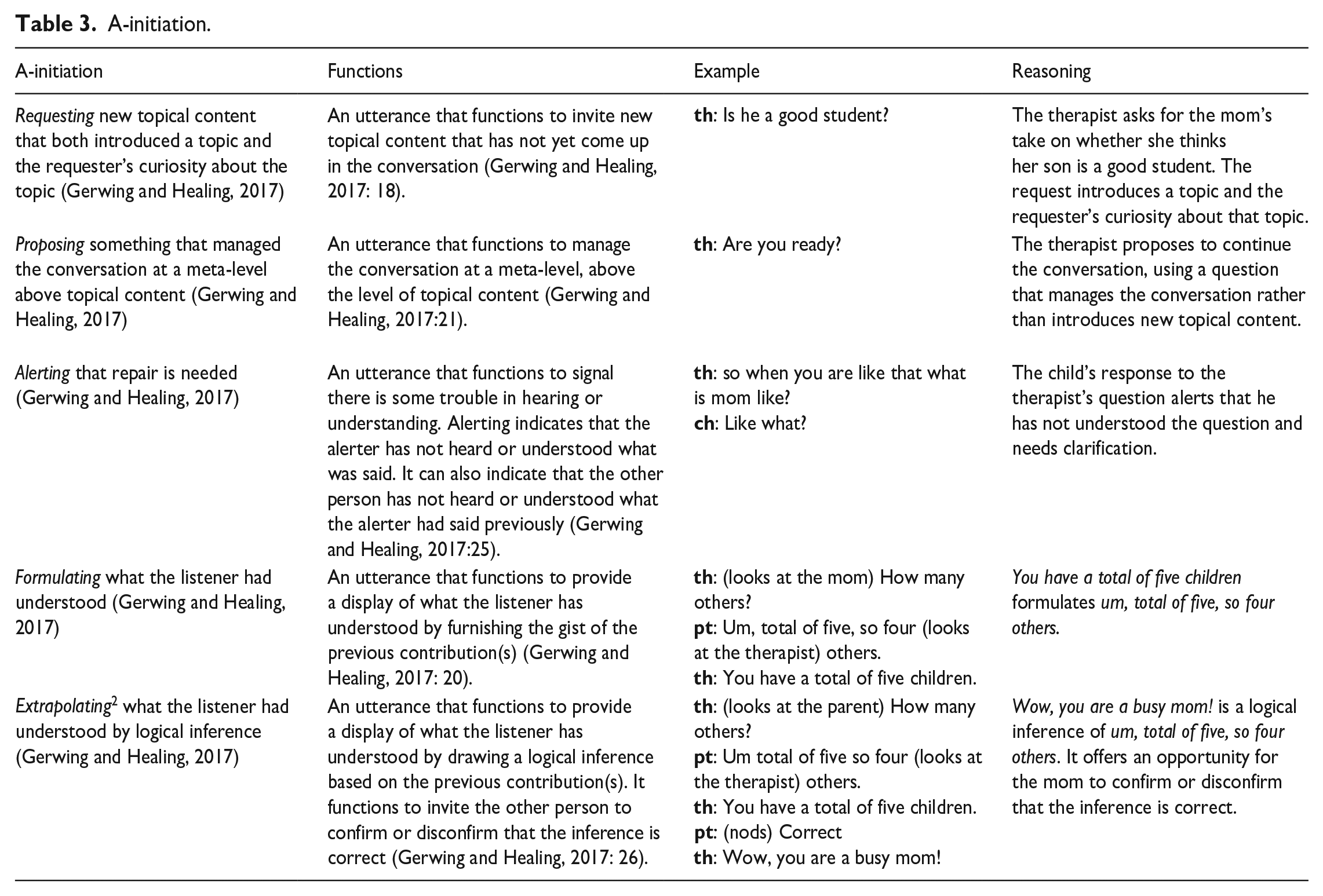
Stage 1. I identified, categorized, and selected utterances by which the child, parent, or therapist presented new information (A-initiation, Table 3). These utterances were the initial steps in potential three step sequences.
Stage 2. For each potential A-initiation, I evaluated whether the next utterance fulfilled the criteria for a B-response (Table 4).
B-response and C-follow up.

Stage 3. For each identified B-response, I evaluated whether the original speaker’s next utterance fulfilled the criteria for a C-follow up (Table 4).
Transferring a framework and methodology developed in one context (getting acquainted conversations among undergraduates) to a new context is not without challenges. In child and family therapies, for example, when therapists request new topical content, it may be part of a treatment model and does not necessarily introduce the therapist’s personal curiosity in the topic. Further, in triadic dialogs one person’s utterance does not always build on a just prior utterance. During or after a B-response, for instance, a third interlocutor may insert an utterance before the person who uttered the A-initiation provides a C-follow up. The meaning of ‘after’ (cf. Table 4) is interpreted in line with the works of Severinson Eklundh and Linell (1983), who argued that it takes a minimum of three steps for interlocutors in a dialog to display shared agreement on what has been said. The overarching definitions acted as a guide when a detail in an operational definition did not explicitly correspond to utterances in the recordings. To ensure consistency with the microanalysis of face-to-face dialog, an independent analyst and I applied the manual to 10% stratified random samples from the first dataset. As the recording is not protected by confidentiality, it was thus possible to share with an external analyst. We determined an inter-analyst agreement by dividing our number of agreements with our total amount of agreements and disagreements: A-initiations 84%, B-responses 100%, and C-follow ups 90%. I also presented a selection of three-step sequences at data sessions, and I reviewed my findings several times. After this final stage of identifying three-step sequences, I looked at how the child, parent, and therapist in each recording organized and accomplished mutual understanding.
Ethical considerations
The research project was approved by the Swedish Ethical Review Authority in August 2019. In addition, local boards of ethics approved of the research collection at the mental health clinics and the social service department. In the study, the 15-year-old provided hir own consent. According to Swedish ethical guidelines, children under the age of 15 are protected from being burdened with consent issues. Therefore, the legal guardians of the 13-year-old and 14-year-old approved of their participation, which the children did not oppose. The confidentiality of the social services departments and mental health clinics was transferred to the research project. The children and parents were informed about the study after the sessions had taken place to avoid affecting the children’s engagement in their treatments. The procedure also ensured that children whom the social workers considered likely to be burdened by the study were not subjected to it (cf. Westlake, 2016; Winter et al., 2017). To safeguard the anonymity of the participants, I have pseudonymized the excerpts from the protected recordings (recordings 2–4). I use ze/hir pronouns to safeguard these participants’ anonymity.
Results
Most of the identified calibrations had the same structure as in the initial example. That is, the participants uttered B-responses and C-follow ups immediately after the A-initiations. However, while the children, parents, and therapists calibrated 95.3% of the identified 669 A-initiations using a minimum of three-steps, I observed complexities linked to the three-person setting in 14.4% of the calibrations. I identified six patterns of interaction that point to complexities in three-person dialogs in child and family therapies. I termed the patterns as follows: (1) suspended calibrations, (2) nested calibrations, (3) branched calibrations, (4) multi-paced calibrations, (5) calibrations of different interpretations, and (6) calibrations of the tone. The sixth pattern is, however, not necessarily specific to triadic or multiparty therapies, nor to triadic or multiparty dialogues at large.
Please note that the calibrating sequences are inevitably more visible in the recordings, which I analyzed directly, than in the following transcribed excerpts (cf. Bucholtz, 2007; Hammersley, 2010; Ochs, 1979). In addition, while there are various examples of calibrating sequences and other conversational activities in the excerpts, they are beyond the scope of the analysis. I concentrate on patterns that highlight complexities in how three interlocutors accomplish mutual understanding, and I elaborate on these patterns and their possible implications on both practice and research in the concluding discussion.
Suspended and nested calibrations
Suspended and nested calibrations occur when a competing A-initiation puts ongoing calibrating sequences on hold. They delay initiations that could otherwise have been calibrated in straightforward three-step processes.
This first excerpt (from the publicly available recording) starts with the therapist (th) asking Alex (ch, child) what his mom (pt, parent) is like when he is like ‘that’ (first A-initiation at line 814–815 and 817), to which Alex alerts that he is not following (second A-initiation at line 818). Excerpt
At lines 819 and 821, the therapist provides a B-response to Alex’s A-initiation (line 818), to which Alex follows up much later, at line 827. In between the therapist’s B-response and Alex’s C-follow up lies a nested calibration initiated by the mom: A-initiation at line 822 (‘maniac’ formulates the therapist’s ‘jovial good humor’ and refers to a discussion they had earlier in the session), a B-response at line 823, and a C-follow up at line 825. This nested calibration sequence means that the first and second A-initiations are suspended for eight and seven utterances, respectively.
The excerpt and introductory paragraph illustrate some of the complexities that characterize calibrations in triadic child and family therapies. When the mom inserts a joke (initiated at line 822), she puts the two ongoing calibrations on hold while the inserted joke is calibrated. That is, what could have been calibrated in two straightforward sequences was suspended over several utterances (cf. Severinson Eklundh and Linell, 1983).
Branched and multi-paced calibrations
Branched calibrations occur when A-initiations branch out in two calibration sequences involving different addressees. When calibrations branch out, the interlocutors will inevitably accomplish mutual understandings of the same A-initiation at different stages of the dialog. That is, their temporal processes will differ.
In the next excerpt, the therapist’s A-initiation (at lines 440–441) generates two different calibration sequences, indicated by two identifiable B-responses – one from the child (at line 442) and one from the parent (at line 443). The excerpt starts with the therapist formulating why the child is disappointed over hir parent’s plan to stay at home. Excerpt
In this excerpt, we see that the calibration branches out, and the child and the therapist, as well as the parent and the therapist, accomplish mutual understanding at different stages. For the therapist’s A-initiation at lines 440–441 to be fully calibrated, the separate B-responses demand their own C-follow ups from the therapist, each directed at the relevant addressee (at lines 444 and 446–448). The therapist and the child accomplish mutual understanding at line 444, when the therapist looks at the child while saying ‘and stuff’. However, the parent and the therapist’s mutual understanding remains implicit until lines 446–448, where the therapist, by directing hir gesture and speech toward the parent, follows up in a way that demonstrates that the parent’s response was also sufficient for current purposes (C-follow up, Bavelas et al., 2017).
Accomplishing mutual understanding with different clients who both respond requires that therapists engage in divergent calibrations simultaneously. The next excerpt provides an additional example of this pattern. When the excerpt begins, the child is looking down, and the therapist and the parent have exchanged eye contact. The therapist extrapolates what ze has understood so far (that both the parent and the child are happy with a conversation they had earlier that morning) and invites the parent and the child to confirm or disconfirm hir inference. ‘That’ at line 782 refers to that conversation. Excerpt
As can be seen, the parent and the therapist accomplish mutual understanding of the therapist’s A-initiation before the child and the therapist: the therapist makes an A-initiation at line 782–784, to which the parent responds to at line 785 (B-response) and the therapist follows up on at line 786 (C-follow up). The child, who is looking down, cannot see that the therapist is rounding up hir utterance by looking at the parent, hirself and then at the parent again (at lines 772–773, cf. utterance operationalization, Table 2). As a result, the child does not provide hir B-response until later (at line 787). The therapist follows up on the child’s B-response at lines 789–890 (C-follow up). The therapist’s C-follow up also follows up on the parent’s second B-response (at line 788). Put differently, the therapist and the parent accomplish mutual understanding at a faster pace than the therapist and the child. They manage to complete two calibrations at the same time as the therapist and the child complete one.
Calibrations of different interpretations
Calibrations of different interpretations occur when addresses provide different B-responses that imply different understandings of the same A-initiation, which the initial speaker accepts in hir C-follow up/s. Calibrating different interpretations is possible in three-person interaction and exemplifies one of many complexities in multiparty therapies.
The excerpt below shows where the three interlocutors engage in overlapping calibrations of different interpretations of the same A-initiation. The excerpt begins with the child proposing that ‘you’ may also bring up issues (A-initiation at lines 157–158), which gets calibrated twice: once between the child and the therapist (B response at line 161 and C-follow up at line 162) and once between the child and the parent (B-response at line 159) and C-follow up at line 160. Excerpt
As can be seen, the child/therapist and the child/parent calibrate different understandings of the A-initiation: While the child/therapist calibrate that the child invites the therapist to bring up what the therapist finds important, the child/parent calibrate that the invite (‘you’) is directed to the parent. Because the therapist is looking down at the notepad while the child is talking, ze is unable to see that the child is turned to hir parent when ze utters ‘you’ (at line 157). As the therapist continues to look down, ze is also unable to register the parent’s B-response (at line 159), as well as the child’s C-follow up to that response (at line 160). Instead, the therapist provides a B-response (at line 161) to a longer A-initiation (at lines 157–158, 160), which the child follows up on (supposedly unintentionally as the child is still focusing on hir parent) at line 162. Because the two calibrations are paced differently, the excerpt also illustrates multi-paced calibrations.
Calibrations of the tone
Below, the interlocuters calibrate the ‘tone’, or the ‘quality’, of an A-initiation before the ‘topical content’ of the utterance is established as mutually understood. It starts with the therapist asking the mom what it is like when her son is in a good mood and then smiles widely (A-initiation starting at line 787). At this stage, both Alex and his mom are looking at the therapist. Excerpt
The mom and Alex provide separate B-response at line 791 and at line 792, to which the therapist follows up on at lines 793–794. By looking and smiling at both Alex and his mom, the therapist indicates that both of their responses are acceptable. However, it is only at line 795 that the mom provides a B-response regarding the topical content of the therapist A-initiation, to which the therapist follows up on at lines 797–798 (C-follow up).
Concluding discussion
The analysis identifies how therapists, children, and parents organize and accomplish mutual understanding in triadic child and family therapies. It contributes with new documentations of how three interlocutors do mutual understanding in ‘suspended’ (excerpt 1), ‘nested’ (excerpt 1), ‘branched’ (excerpt 2–3), ‘multi-paced’ (excerpt 2–4), and ‘mixed interpretations’ (excerpt 4) calibrations. The analysis also demonstrates how interlocutors may calibrate the ‘tone’ of an A-initiation (e.g. that what is put forward is said with humor) before the topical content of the same A-initiation is mutually understood (excerpt 5).
Implications on practice
Calibrations coexist with elements that are specific to their setting. Their implications therefore depend on context-specific parameters. For instance, when interlocutors in a family therapy session calibrate different interpretations of the same A-initiation (excerpt 4) – sometimes at different times and paces (excerpts 2–4) – it may contribute to generating or enhancing an imbalance among them. If a therapist and a parent, for instance, calibrate at a faster pace than the therapist and the child, the child may fall behind (or even further behind), which may lead to the therapist-parent-child relationship evolving unevenly (cf. ‘working alliance’, McLeod et al., 2014). As a result, the child may be less willing to share hir concerns with the therapist and thus less inclined to exercise hir right to express hir view in matters that affect hir (United Nations, 1989). Such imbalances may also pertain to other triadic and multiparty dialogs.
Similar implications may arise when two or more clients provide separate B-responses to different fragments of the same A-initiation. If one client is looking in another direction, that person may respond to a longer utterance than the client who is looking at the therapist and uses minimal responses (cf. excerpt 4). Further, when a therapist asks several questions in a single utterance, the clients’ B-responses may imply or demonstrate understanding of different sections of that utterance. Another possible implication may arise when a therapist and a client calibrate the tone of an utterance differently than the therapist and another client, or perhaps not at all. When the tone of an utterance is calibrated differently among the interlocutors, the utterance may come to serve different functions, which may steer a therapy session in conflicting directions. Furthermore, there is likely a great frequency of nested and suspended calibrations in triadic child and family therapies, which therapists supposedly need to both anticipate and address to stay on track.
This knowledge about complexities related to how three interlocutors sequentially organize and accomplish mutual understanding in child and family therapies has the potential to prevent misunderstandings and to modify imbalances, including uneven working alliances. For instance, if the therapist in excerpt 3 had taken control of the calibration pace, the therapist and the child could have calibrated their understanding quicker than the therapist and the parent. By calibrating both the tone and the topical content with every interlocutor, the therapist could also prevent possible misunderstandings.
The results could be useful to professionals working with different types of institutional talks and be invaluable to, for example, therapists who work with families or health care providers who talk with patients and next of kin. There may also be implications for institutional talks involving assessments or evaluations, including service-users who depend on accurate social work assessments or asylum seekers at citizenship and immigration services.
Corroborating existing research results on doing mutual understanding
The interlocutors calibrated 95.3% of the identified 669 A-initiations using a minimum of three-steps. This suggests that the interactive micro-process two interlocutors use when they do mutual understanding (as defined by Bavelas et al., 2017) is likely applicable to triadic dialogs. This would be in line with what both Mead (1934) and Goffman (1976, 1981) have suggested and what succeeding researchers have proposed – three-step sequences are a fundamental unit of conversational organization (e.g. Bavelas et al., 2012, 2017; Deppermann, 2015; Gerwing and Indseth, 2016; Heritage, 2022; Linell and Markovä, 1993; Severinson Eklundh and Linell, 1983; Svennevig, 2009; Tsui, 1989). As mentioned in the introduction, the ubiquity of such three-step sequences has been identified in classroom settings (Mehan, 1979; Sinclair and Coulthard, 1975), doctors’ appointments (Tsui, 1989), rescue operations (Lindgren et al., 2007), customer calls (Kevoe-Feldman and Robinson, 2012) psychotherapies (Bavelas et al., 2012; De Jong et al., 2020), emergency calls with a language barrier (Gerwing and Indseth, 2016), and getting acquainted conversations (Bavelas et al., 2017). The present article adds child and family therapy and audiovisual recordings of three person interactions to the list of activity types in which three-step sequences are common. That they are common in such a diverse array of contexts suggests that when it comes to organizing and accomplishing mutual understanding of new information, adjacency pairs are probably insufficient. In Heritage’s words, ‘Although a great deal has been written about the significance of adjacency pairs, it may not do to exaggerate their empirical frequency. Conversations are far from being constructed exclusively from them’ (Heritage, 2022: 318). Demonstrating understanding of the just-prior utterance is especially difficult to apply to multiparty interactions where progression appears less straightforward. Instead of anticipating what will come next based on the just-prior utterance, each interlocutor must subprehend (Enfield and Sidnell, 2021) the unexpected.
Methodological issues and future research directions
Besides replicating previous studies with similar findings (e.g. Bavelas et al., 2012, 2017; De Jong et al., 2020; Tsui, 1989), this study’s results are supported by an analysis that used a manual with operational definitions, numerous presentations and discussions of three-step micro sequences at data sessions, and a high inter analyst agreement on stratified random samples of three-step micro sequences, as well as on separate A-initiations, B-responses and C-follow ups. However, applying a framework and methodology developed on getting-acquainted conversations between two persons to triadic child and family therapy sessions has not been a straightforward process. This could explain why I, for instance, achieved a lower inter-analyst agreement on A-initiations than the original study’s authors (84% vs 94%).
The number of calibrated sequences may be underestimated, and they were possibly both greater and the pace even more rapid than what I account for here. As several of the interlocutors in the recordings were mostly visible in profile, some utterances may have been unavailable for analysis. An addressee’s crooked smile or one-eyed wink (utterances that may have been unavailable for analysis) could, for instance, have split an initial speaker’s utterance in two (Table 2), thus possibly resulting in additional calibrations and faster rates than what were observable. To address this limitation and further detach research on face-to-face dialog from written – or ‘spoken’ – word bias (cf. Linell, 1982, 2005), future research could analyze recordings in which the interlocutor’s faces (and preferably bodies) are fully visible.
How children, parents, and therapists organize and accomplish mutual understanding in triadic child and family therapies may inform future research on interactions with more than two interlocutors. Additional microanalyses on organizing and accomplishing mutual understanding in triadic and multiparty interactions could, for instance, advance knowledge on how to modify imbalances and prevent and repair misunderstandings.
Footnotes
Acknowledgements
I thank Jennifer Gerwing and Sara Healing for generously sharing their manual on identifying three-step sequences, including operational definitions of utterances, A-initiations, B-responses, and C-follow ups. I thank Harry Korman for independently applying the manual to stratified random samples from which I determined an inter analyst agreement. I also thank Carin Cuadra, Anna W Gustafsson, and Per Linell for reading and providing feedback on different versions of the analyses and manuscript. And thank you to the anonymous reviewers.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by The Department of Social Work, Malmö University.