
Abstract
Simulations, in which healthcare professionals are observed in dialogue with role-played patients, are widely used for assessing professional skills. Medical education research suggests simulations should be as authentic as possible, but there remains a lack of linguistic research into how far such settings authentically reproduce talk. This article presents an analysis of a corpus of general practice simulations in the United Kingdom, comparing this to a dataset of real-life general practitioner (GP) consultations. Combining corpus linguistic and conversation analytic methodologies, key interactional features of the simulations are identified, particularly those associated with successful/unsuccessful performance in terms of the examiner’s grading. The corpus analysis identifies various forms of the phrase ‘tell me more about’ to occur significantly more frequently in the simulations compared to real GP consultations, typically in the opening sequences and most frequently in successful cases. It falls to a conversation analysis of the data, examining this phrase within the interactional context of these opening sequences, to better understand the actions it performs. Successful candidates in the simulations are found to perform a consistent sequential pattern, often incorporating this phrase. Although simulated, these interactions have real professional consequences for those being assessed. Linguistic findings about what constitutes successful interaction or differences to real-life practice therefore have important implications for professional education and assessment.
Keywords
Introduction
Simulated consultations, particularly where a role-player is used to imitate a real patient, are a popular tool for training and assessing health professionals, providing the opportunity to evaluate competences, including communicative competence, in an ostensibly controlled and standardized way. It is on this type of role-played medical simulation that this study focuses, examining whether these interactions mimic the competences required for real clinical encounters and the interactional features associated with high or poor performance in terms of the overall grading from the examiner. This linguistic understanding is important if we are to use simulations to effectively assess communicative abilities.
Although questions of authenticity in simulations have been addressed in medical education research, this has usually focused on the best means of delivering an authentic experience, through recreating real-life medical cases (Van Hasselt et al., 2008) or weighing up how to train the best simulated patients (Lane et al., 2008). Post hoc questionnaires have also been used to establish whether participants felt a simulation to be ‘real’ (Bosse et al., 2010). It is widely felt that, if done well, ‘students, residents and practising physicians cannot distinguish between real and well-trained simulated patients’ (Kurtz et al., 1998: 62) and the scenario will be more immersive and reliable (Rollnick et al., 2002).
Interaction, though, is a complicated matter. post hoc questionnaires are a notoriously problematic means of understanding talk and recreating ‘real’ medical cases does not necessarily translate into an ‘authentic’ interaction. This attempt at simulated authenticity has been questioned, with Niemants (2013) describing interpreter-mediated simulations as unable to ‘reproduce the orientations of real interactions … [W]hat is authentic to those users when they “live” a specific situation cannot be authentic to trainers/trainees when they play it’ (p. 317). But how might these different orientations play out in the interactions themselves?
A more reliable means of gauging interactional authenticity is to look at the talk itself. The approach of this article, applying corpus linguistics (CL) and conversation analysis (CA) to a unique dataset of general practice simulations, will be informative, offering a means of accessing the dialogue of simulated interactions, identifying features of ‘successful’ talk in this assessed setting and comparing these to interactional competences demonstrated by general practitioners (GPs) in real clinical consultations. In the following sections, I outline the existing linguistic research on simulation, highlighting key findings and useful concepts. I go on to make a broad, CL analysis of 50 simulated medical interactions from a GP assessment, comparing these to data from 37 real GP consultations to identify any significant differences. This corpus overview is used to direct an analysis of the turn-by-turn sequential interaction using a CA approach, looking at which conversational actions are typically associated with success in the simulated encounter and those that can lead to interactional difficulties.
Background: Participant roles and contingencies in simulation
Authenticity has been a key issue for medical simulation then, but the altered contingencies for participants present difficulties in creating this authentic experience. The contingencies and shifted participation structures in simulation are worth unpicking further, particularly since power and participant status have been central theoretical topics for discourse studies of clinical interaction.
A number of studies have suggested a completely inverted power relationship between participants in simulations compared to real clinical practice, particularly a more powerful position for the role-player, who, unlike a real patient, will usually know the diagnosis and assessment criteria for a case. The notion of an inverted power relationship proceeds from the traditional assumption that, in real-life, the medical professional is the more powerful interactional participant (cf. Parsons, 1951). Hanna and Fins (2006) state this boldly, arguing that in a simulation the authoritative agency of the doctor in the interaction is wholly reversed, ‘because knowledge and judgement rest with the simulation patient’ (p. 266). They describe hypothetical examples that might suggest increased power, such as the simulated patient’s likely refusal of a brusque request by the clinician, compared with a real-life patient who may consent. De la Croix and Skelton (2009) take up this question of interactional power in an evidence-based, CL study of undergraduate Objective Structured Clinical Examination (OSCE) simulations. They find role-players talk and interrupt more than the candidate doctors, similarly citing this as evidence of the conversational dominance role-players exert. They acknowledge difficulties in the interpretation of interruptions, particularly since overlaps can be supportive in nature in medical encounters (Robinson, 2003), but the orthodoxy that in real-life clinical practice the doctor holds the interactional power is not fully interrogated interrogated.
However, research on interaction has demonstrated the complexities of asymmetry in practice and that particular interactional behaviours do not consistently equate to dominance (Linell et al., 1988). The reflexive relationship between talk and context means the interactional footing between participants is continually renegotiated in moment-by-moment talk, as is well demonstrated in CA studies of healthcare interactions. Stivers (2007), for example, analyses sequences in which patients challenge a doctor’s decision not to prescribe antibiotics so that the interaction becomes a negotiation of authority. Moreover, there are phases within the routinized structure of the consultation where the asymmetrical relationship can be shifted and certain patient actions, such as asking questions, are not so dispreferred (ten Have, 1991: 146). Power in clinical interactions, then, is not an entirely straightforward, predetermined participation structure to be simply reversed in simulations. Nevertheless, much CA research does find recurrent patterns of asymmetric talk in doctor–patient encounters, likely ‘embedded within a wider functionality of the institution of medicine in society’ (Pilnick and Dingwall, 2011: 1381). Asymmetry can certainly be negotiated at a local interactional level, but the most common pattern is for local sequences of talk to instantiate an authoritative footing for the clinician. Given that asymmetry in real doctor–patient encounters is a complex phenomenon, it is difficult to claim a straightforward inversion of this in simulation. It is more analytically sound to talk of interactional ‘contingencies’ for participants, which may be evident in the conversational moves they make.
A key contingency for participants in assessed simulations is of course the assessment itself. As Stokoe (2011) writes on police interview role-plays, ‘[f]or those having their interactional skills evaluated, what is at stake is their performance and ‘score’ as trainees’ (p. 1653). In the medical simulation, even though most of the dialogue will take place between a candidate and a role-player, the entire exchange is performed for the benefit of an examiner, a ‘ratified overhearer’ to borrow Goffman’s (1981: 226) term, who is making a professional assessment (Atkins et al., 2016). Heritage and Clayman (2010) look at question and answer patterns in various institutional settings with ratified overhearers, such as courtrooms and television interviews, identifying consistent differences in turn-taking compared to casual conversation (pp. 27–31). In particular, they demonstrate the lack of receipt tokens from the questioning participant when an answer is gained from a witness or interviewee, which allows ‘the elicited talk to be understood as produced, not for them, but for the audience who is listening in’ (p. 225). There is therefore reasonable evidence to suggest turn-design and patterns alter when oriented to overhearers in institutionally observed settings. In simulations, Stokoe (2011) convincingly evidences how formulaic rapport-building behaviours from police training materials, such as asking the suspect if it is alright to use their first name, are strikingly apparent in the openings to simulated police interviews compared to real police talk. Conversational actions, such as explaining the suspect’s rights, are performed in more elaborate ways, potentially demonstrating a learned competence for the benefit of the overhearing assessor (Stokoe, 2013). Such interactional behaviours, for the benefit of an examiner, may also be relevant to the medical simulations analysed here.
What is not clear from prior research though is whether such behaviours make for a successful simulated interaction (for the professional being assessed) and whether the interactional, turn-by-turn negotiation of footing requires different communicative skills to real-life practice. If, as Seale et al. (2007) suggest, simulation requires a considerable amount of additional interactional work from participants to maintain the illusion, we must better understand what form these linguistic demands take and where successful features might depart from the skills required for real clinical practice, particularly in the context of high-stakes professional assessment (p. 181). The CL and detailed CA approach to analysing consultations taken by this article, looking at both successful and unsuccessful simulations, will be an insightful approach that adds to our understanding of this genre.
Data and methods
The data for this study include 50 transcribed video recordings (98,000 words) of candidates sitting a UK exam for general practice, collected as part of a large sociolinguistic study (Roberts et al., 2014). Ethical approval for the study was granted by King’s College London and each individual GP candidate and patient role-player individually consented. The exam consists of stations with standardized patient role-players, in which candidates are assessed on their interpersonal skills, as well as clinical management and data-gathering. Equal numbers of passing and failing candidates were transcribed, using a time-stamping software tool CLAN (MacWhinney, 2000), which broadly follows Jeffersonian conventions for notating speech (Jefferson, 2004). As a comparative dataset, I use a corpus of consultations from real-life GP surgeries in London (Roberts et al., 2003), with 37 consultations providing just over 110,000 words of interactional data. The study was originally approved by the St Thomas’ Hospital Local Research Ethics Committee and each GP and patient consented individually for their consultation to be recorded.
Following Walsh (2013), O’Keefe and Walsh (2012) and Walsh et al. (2011) in their studies of classroom interactions, I take these two specialist corpora to conduct a CL overview for the first layer of analysis, ‘as a means of scoping out and quantifying recurring linguistic features’ and enabling the identification of recurring patterns specific to the specialist context (Walsh, 2013: 45). CA then forms the ‘second layer’ of analysis, which ‘draws upon these contextual patterns in the quantitative analysis and investigates them more closely’ (Walsh, 2013: 45). CA is an approach that examines the structure of an interaction in terms of its sequential organization, the turn-taking between speakers, the actions each turn at talk achieves and how they are designed, ultimately identifying patterns across interactional data (Schegloff, 2007). The initial identification of lexical patterning through CL is one means of directing the researcher, from a data-driven position, to discourse segments that merit close analysis. However, where CL is only able to make general observations about a dataset, CA is then able to provide a granular understanding of the interactional sequences in which these features occur. This layered CL and CA analysis is used effectively by O’Keefe and Walsh (2012) in analysing a small, specialist 50,000-word dataset of classroo interactions, using information about frequency and word-clusters to shape an analysis of stretches of discourse at the level of the turn and interactional sequence, suggesting such corpora ‘lend themselves very well to a combined approach’ (pp. 162–163).
For Walsh et al. (2011), the initial CL analysis includes frequency information about recurrent single words and word-clusters (words that occur frequently together, sometimes termed ‘multi-word units’), as well as ‘concordancing’, which displays these lexical items in their immediate linguistic context, enabling an initial analysis of the likely actions they perform. These are techniques I run on the simulated and real GP consultations datasets here, using WordSmith Tools software (Scott, 2017). This CL overview not only allows me to quantitatively identify recurrent linguistic features, but flags up key differences between the simulated and real consultations, identifying the particular ‘linguistic fingerprint’ of simulated consultations.
From this initial CL analysis of the word-clusters and patterns that occur, CA is then used to identify how they are employed in an interactional context. I analyse how sequences unfold, turn-by-turn, linking up an understanding of general information about the success or failure of candidates with endogenous evidence about the success of particular sequences in achieving interactional projects, such as requesting the patient’s history, or instances where interactional difficulties and repair ensue. However, although the analysis focuses on the interactional sequences themselves, some external contextual and ethnographic information is helpful in understanding performances in the exam, particularly to shed light on the overall success of a candidate and the social context in which decisions are made about their communicative competence (Scollon and Scollon, 2007: 618). I use information on candidates’ marks and transcribed feedback from examiners to glean an understanding of the way talk is assessed. This is a means of incorporating the perspective of the examiner, who produces an assessment on which the ultimate success of the interaction depends but whose evaluation cannot be immediately be accessed through the talk itself.
Analysis
The following sections present the CL and CA findings. In the first section. ‘CL comparison between the simulated and the real’, a quantitative CL overview of the datasets is given and some of the key lexical differences identified, providing a rationale for the direction of the subsequent CA analysis of the opening sequences. Section ‘CA analysis of opening sequences in simulations’ goes on to give a detailed conversation analytic account of the opening sequential patterns in the simulations, in which the highly frequent ‘tell me *more about’ cluster is found. The following section ‘Comparison to opening interactional sequences in real-life practice’ compares these to opening sequences found in real-life clinical practice and the final section ‘Pattern-breaking differences in the opening sequence of a failing simulated interaction’ discusses how disrupting the standardized opening sequence in the simulation can impact on the interaction, with implications with implications for the relative ‘success’ of these candidate doctors in their overall assessment.
CL comparison between the simulated and the real
Frequency information for 2-3 and 3-5 word-clusters, in both the simulated and real GP consultations, was identified using WordSmith Tools (three to five word-clusters given in Appendices 1 and 2), and the two settings compared for significant differences. It is notable that a few phrases show similarity across both the real and simulated settings, such as word-clusters ‘Do you …’ (e.g. ‘Do you think’ and ‘Do you know’), addressed to the patient, and various formulations of the GP’s initial elicitation request, ‘how can I help’/‘what can I help you with …’, which occurred in the top 20 word-clusters for both datasets. There are therefore some lexical parallels to suggest a degree of resemblance between the real and simulated domains.
However, a key difference in the most frequent clusters does become apparent; 7 of the top 10 most frequent 3-5 word-clusters in simulated consultations (table in Appendix 1) represented some variant of ‘can you tell me a bit more about’/‘tell me a little bit more about’/‘tell me more about …’, referred to collectively in this article as ‘tell me *more about’ formulations (where the * represents a wildcard for the addition of ‘a bit’ or ‘a little bit’). This is a word-cluster that is statistically salient when compared to the real GP encounters, where it occurs very infrequently, an important difference and one worth unpicking further for its function and location in the interaction. The use of this highly frequent phrase in the assessed simulations seems likely to be complex in terms of its relation to successful performance by the candidate, particularly since examiners identified ‘formulaic phrases’ as a negative feature. Formulaic word-clusters are not an inherently negative characteristic – much of our everyday talk consists of formulaic phrases (Erman and Warren, 2000). However, when video clips were played to examiners, a complaint was often the formulaic way candidates sounded: sometimes the candidates can say that and it can sound a bit formulaic It seems just very formulaic and a lot of it seems learned … (Examiner feedback, from Roberts et al., 2014)
Despite negative assessments, formulaic phrasing was in fact slightly more frequent for successful candidates (Roberts et al., 2014: 57–58). In exploring this apparent paradox, it is therefore helpful to examine the context in which these phrases occur in more detail.
Using further CL techniques to explore this phrase, a ‘key word in context’ concordance output was made (table in Appendix 3), indicating that nearly all instances of this phrase occur within questions, functioning as general requests by the candidate doctor for further information from the patient, such as ‘Can you tell me a bit more about it’. A further plot of these clusters, identifying their location in the interaction as a whole, shows the majority occur at the start of the simulated interactions. This immediate contextual information gives us some indication of their typical function and location then, but it falls to a conversation analytic approach to unpick how they work sequentially in interaction. That this word-cluster, so specific to the simulated setting, was found by the CL analysis to occur consistently at the start of the simulations directs us to examine opening sequences further, as the following sections explore using CA.
CA analysis of opening sequences in simulations
The opening 30 seconds in each of the 50 simulated cases was analysed for sequential structure and the location of the ‘tell me *more about’ word-cluster if it occurred. In demonstrating the findings, I give a detailed analysis in this section of openings from the same simulated ‘Ms Ainscombe’ case, performed by two different candidate doctors in Extracts 1 and 2. All names have been changed in these transcripts to uphold the anonymity of the participants, and the name of the exam case itself has been obscured for confidentiality. The ‘Ms Ainscombe’ case involves a woman enquiring about inheritance risks for cystic fibrosis. This is a complex case in which the candidate doctor (CAN) must communicate inheritance patterns in an understandable manner, as well as demonstrate person-centred care for the role-played patient (RPL) (see full transcription conventions in Appendix 4):
1 ((BUZZER)) 2 CAN: Joyce Ainscombe 3 RPL: yes= 4 CAN: = hello there↘ 5 RPL: hi→ 6 CAN: please have a seat my name is doctor Huang↗ 7 (1.6) 8 ((EXM entering the room)) 9 CAN: er: (.) how may I help you↘ 10 RPL: ∙hhhh my sister’s baby has cystic fibrosis→ 11 ∙hhhh I was wondering whether my children would get this disease→ 12 CAN: ((CAN 3 nods)) 13 mhm sorry to hear about your ⌈ sister’s↘ ⌉ 14 RPL: ⌊((RPL 1 small nod)) ⌋ 15 CAN: erm (.) can I ask (.) > 16 can can you tell me a bit more about that
1 ((BUZZER)) 2 (0.4) 3 CAN: Joyce Ainscombe 4 RPL: hi 5 CAN: hi good morning please take a seat 6 RPL: hi 7 (1.9) 8 CAN: my name is doctor Amari I’m one of the doctors here 9 what can I do for you today 10 RPL: er my sister’s baby has cystic fibrosis 11 (0.7) 12 RPL: I was wondering whether 13 my children will get this disease 14 CAN: oh dear (0.3) all right okay 15 ∙hhh 16 (1.1) 17 CAN: ((CAN looks at notes)) 18 erm 19 (0.9) > 20 CAN: t-t-tell me more about (0.3) you sister’s↗ baby↘
Aside from the BUZZER, these extracts begin with a similar conversational move to real GP consultations, with an initial greeting and introduction followed by an opening enquiry from the doctor to elicit the patient’s presenting concern, such as ‘what can I do for you today?’ (Robinson, 2006: 25). The two candidates perform this in near identical positions (Extract 1, line 9; Extract 2, line 9). So far, these sequences are akin to real GP interactions.
A notable feature of standardized simulated consultations is the scripted opening for the role-player, meaning each case begins with the same lines. We see the role-players here follow the scripted lines, giving a two-part account and enquiry in each: ‘my sister’s baby has cystic fibrosis/I was wondering whether my children will get this disease’. In Extract 1, the candidate acknowledges this with a head nod and a token empathy phrase, albeit incomplete: ‘sorry to hear about your sister’s↘’ (line 13). Similarly, in Extract 2, we have a receipt token from the candidate indicating the distressing nature of the news (line 14). After this initial empathy token then, both candidates provide a ‘tell me *more about’ request for more information, using the word-cluster identified in the corpus analysis (Extract 1, line 16; Extract 2 line 20). This action is in fact performed with striking consistency in the simulations, with some variation of ‘tell me *more about’ appearing in similar sequential positions, following the initial greeting and problem elicitation, in 28 of the 50 cases. The particular sequence illustrated here, where the candidate issues an empathetic acknowledgement of the role-player’s distressing account before the ‘tell me *more about’ request, was particularly consistent in cases where an emotionally difficult situation was being presented. For example, in Extract 3, we see the same sequence in a similarly complex simulated case, in which a role-played patient asks about the sudden death of his friend:
1 ((BUZZER)) 2 (0.7) 3 CAN: hello 4 (0.2) 5 RPL: hello 6 (0.5) 7 CAN: a seat please 8 (1.6) 9 my name is doctor Mandalia 10 (0.5) 11 how can I help you today 12 RPL: um (0.8) well um (0.4) I’m a bit worried (.) um (0.2) 13 my friend tommy (.) died two weeks ago 14 when we were playing football↗ (.) 15 CAN: ⌈right⌉ 16 RPL: ⌊and⌋ I’m just wondering if it will happen to me too 17 (0.7) 18 CAN: right I can understand why (.) you would be worried↘ > 19 do you want to tell me more about what happened 20 on on on the on the day↘ 21 (0.3) 22 RPL: er we we were we were having a match ⌈at⌉ school→
Again, at line 11, we have the open-ended, initial elicitation, ‘how can I help you’, followed by scripted lines from the role-player (lines 12–16), the candidate’s acknowledgement of distressing news (line 18) and her subsequent ‘tell me *more about’ request to garner a longer account (line 19). From the analysis across 50 cases, we can be confident that this is a reasonably consistent pattern, which perhaps multiple candidates and role-players have become acculturated to in simulations to the extent that its performance is conventionalized.
It is worth noting though that, as a strategy, the recurring ‘tell me *more about’ request does not reap a great deal more information from the role-player. For example, we can see Doctor Huang’s simulated case from the first extract continued in Extract 4. After a pause, he receives a few lines of faltering dialogue from the role-player (‘hhh um because um she’d been getting um …’ lines 19–24), which she closes down quickly at line 25 with ‘er yes (0.2) quite a shock really’:
> 16 CAN: can can you tell me a bit more about that 17 (0.3) 18 RPL: ∙hhhh erm (0.5) well (0.5) 19 she found out three weeks ago↗ 20 CAN: hm 21 RPL: ∙hhh um because um xxxxxx she’d been getting um 22 (0.8) 23 RPL: ⁇including⁇ infections a bi- she’s a bit poorly she wasn’t 24 faring very well→ 25 ∙hhhh er yes (0.2) quite a shock really 26 (1.2) > 27 CAN: yeah (.) ∙hh er::m (.) do you mind if I ask you a few more 28 questions↘ ⁇about er⁇ this 29 (0.3) 30 RPL: no 31 (0.4) 32 CAN: erm (0.5) so y-your sister has a child has that been confirmed 33 (0.4) that that (.) ⌈the⌉ child has cystic fi⌈brosis⌉ 34 RPL: ⌊yeah⌋ ⌊yeah⌋ 35 (0.3) 36 CAN: ∙hhh erm (0.2) is there anyone else in your family who has had 37 this problem↗ 38 RPL: no
Without a longer reply at line 26, the candidate must continue to push the consultation forward and ask permission for further, more structured questions (lines 27–28), to which the role-player subsequently provides ‘yeah/no’ answers. The focus is now kept tightly on information around cystic fibrosis and family members. On the face of it, ‘tell me *more about’ requests may not be that successful in gaining long replies from the role-player, particularly when compared with the narratives we see in real-life practice, Explored in the next section. However, they are a consistent feature in the interactions by candidates who are successful overall and the potential reasons for this are considered further throughout this article.
Comparison to opening interactional sequences in real-life practice
The conventionalized opening structure shows important differences to the dataset from real-life general practice. Although there could be considerable variation in the opening few turns of the real GP consultations, depending on wide variety of contextual features, a notable feature was the much longer duration of the patient’s presenting concern. For example, in Extract 5,
1 DOC: ((laughs)) okay (.) I’m doctor Burton hi= > 2 how can I help today= 3 PAT: alright well it started last (.) last Sunday= 4 DOC: mhm 5 PAT: =I was just lying down= 6 DOC: mhm 7 PAT: =got up and suddenly was very short of breath 8 DOC: right 9 PAT: and I think more than anything (.) panicked 10 because it never happened to me before 11 (0.2) 12 DOC: sure 13 PAT: and I nearly f- I didn’t faint (.) I nearly fainted 14 DOC: yeah 15 PAT: and then for a for a- it’s gone 16 for about a week 17 starting this week it hasn’t been too bad= 18 DOC: mhm 19 PAT: =but I think more than anything is where I’ve been thinking about the incident 20 what happened 21 DOC: yes 22 (0.3) 21 PAT: every time I think about it 22 DOC: yea 23 PAT: I get sort of (.) part of goes like that= 24 DOC: mhm 25 PAT: =I can feel that pulse in my neck going there as well
There is no need for the doctor to follow up the patient’s opening remark with a request that he say ‘a bit more about’ the problem; the patient himself volunteers this long description immediately after the first open-ended elicitation ‘how can I help today’ (line 2), describing his symptoms and driving forward the agenda for the visit (lines 3–25). The GP gives minimal response tokens, such as ‘mhm’, ‘sure’, ‘yeah’, throughout, described as ‘continuers’ in linguistics (Greatbatch, 1988: 411) and ‘facilitative responses’ in communication skills literature (Silverman et al., 2013: 50), widely considered useful in encouraging a patient to continue with their account.
A key difference that also becomes apparent from this opening sequence is the design of doctor’s introduction at line 1; ‘okay I’m doctor Burton hi’. By contrast, the simulations in Extracts 1–3, all began with an introduction designed as ‘my name is doctor x …’. This might seem a subtle difference, but interestingly it aligns with a finding about simulations in a different professional setting – that of police interviews. Stokoe (2013) finds precisely the same distinction in the design of introductions, with police officers in simulations introducing themselves with ‘my name is …’, compared with ‘I am pee cee …’ in real police interviews. Stokoe (2013) suggests this may be a means of performing recommended rapport-building practices in simulation, stating an introduction for the record and then going on to ask, on-record, whether it is okay to use the suspect’s first name. This parallel IN the design of introductions is certainly an interesting one and suggests there may be particularities that are common to simulated interactions across multiple professional contexts.
Further to this parallel, Stokoe and Sikveland (2017) observe that questions designed to prompt ‘free narratives’ from suspects in simulated police interviews, such as ‘I’d like y’t’tell me about (0.8) your day …’, although they were aligned to communication guidance for police interviews, tended, a little like these simulated GP consultations, not to generate the desired accounts from the role-played suspects (pp. 80–81). It is similarly a well-known directive in the medical communications skills literature that doctors elicit the agenda of patients, their ‘ideas, concerns and expectations’ (‘ICE’). The ‘tell me *more about’ question in the GP simulations may, in the absence of a long response from the role-played patient, be an attempt to achieve this ICE directive, demonstrating adherence to patient-centred models and a similarly ‘learned competence’. Nevertheless, since the ‘tell me *more about’ strategy did not elicit a long description from the role-player, the majority of simulated consultations subsequently moved quickly into closed questioning, making it a complex phenomenon to understand in terms of successful performance. This question of the relative ‘success’ of assessed simulated interactions is explored further in the section ‘Pattern-breaking differences in the opening sequence of a failing simulated interaction’.
The longer opening patient narratives in real GP consultations become even more evident in consultations in which a patient discusses complex or distressing problems. Extract 6 is from a real consultation in which a woman visits the GP with a complex mental health issue. This excerpt represents the first 1 minute 20 seconds of the consultation, during which the only verbal turn we see from the GP is her ‘morning’ as the opening at line 1. The GP invites the opening from the patient, at line 11, by turning away from her computer to look at her, at which point the patient picks up the cue and begins talking. The patient gives a long narrative about the difficulties she is experiencing, with the occasional nod from the GP to signal that she should continue (lines 14, 16, 36 and 44). At line 55, when the patient has started crying, the GP quietly passes a box of tissues without saying anything, and the patient continues talking without being prompted. The GP does not in fact utter a turn until nearly 2 minutes into the consultation and, overall, the patient holds the majority of the floor time for the first 5 minutes and 32 seconds of this 11-minute consultation, before the GP starts asking some structured questions. This very long opening narrative enables the patient to give a long account of the problems in her marriage. It demonstrates how much can be gleaned in a consultation by allowing the patient to talk for an extended period, particularly in a complex situation such as this one. However, it is an interactional approach that would be difficult to employ in the simulated consultations analysed above, due to the difficulties in prompting for responses from the role-player:
1 DOC: morning 2 ((looking at computer, hits key on computer keyboard)) 3 PAT: good morning 4 (1.1) 5 DOC: ((moves mug across table)) 6 (0.7) 7 DOC: ((reaches for computer keyboard)) 8 (0.8) 9 DOC: ((hits key on computer keyboard)) 10 (1.5) 11 DOC ((sits back from computer, looks at patient)) 12 PAT: feeling very (0.7) ti::red 13 and (1.2) I feel dizzy (.) ⌈ most of the time ⌉ 14 DOC: ⌊((1 small head nod)) ⌋ 15 if I look up then I seem to feel (0.2) ⌈ lose ⁇the⁇ balance ⌉ 16 DOC: ⌊((3 small head nods))⌋ 17 PAT ∙hhhh u:::m pressure of work- (0.8) 18 ((shakes head)) 19 of um (0.4) work 20 (0.9) 21 PAT: I had had to come in Saturday and Sunday to try and (0.5) 22 you know 23 (0.8) 24 PAT: tidy up my in tray 25 ∙hhhh an (0.3) I’m also having pressure at work 26 you know manager (0.7) pushing pushing pushing all the time 27 (1.0) 28 DOC: ((3 small nods)) 29 PAT: she just rang me twice on the mobile 30 ∙hhhh 31 (0.3) 32 DOC: ((shakes head)) 33 PAT: I had a duty last night 34 (0.5) 35 PAT: an- I did’n- finish till (0.7) seven er (.)twenty (.) ⌈five ⌉ 36 DOC: ⌊((1 small head nod))⌋ 37 (1.2) 38 PAT: an not knowing that I had (0.5) appointment with her this morning so 39 (1.0) 40 PAT: she rang me up→ 41 I just 42 (1.8) 43 PAT: been bullied for the last (1.4) ⌈four months in the office ⌉ (.) you know 44 DOC: ⌊((2 small head nods))⌋ 45 (0.8) 46 PAT: and um 47 (3.8) 48 PAT: ∙hhhh 49 ((looks down)) 50 (2.5) 51 PAT: I’m going 52 ∙hhhh sorry 53 ((begins crying)) 54 (2.5) 55 DOC: ((passes box of tissues from desk to patient))
There is good reason to suppose these longer opening narratives from the patient occur in GP encounters generally, beyond the dataset analysed here. Patients who know the format of the consultation have been found to produce an almost pre-prepared narrative (McKinley and Middleton, 1999). Heritage and Robinson (2006) found that GP consultations which opened with a general enquiry designed to elicit a presenting concern, such as ‘What can I do for you today?’, gained an average response time of 27 seconds from the patient. In the data from simulations analysed here, this response to the initial enquiry lasts only an average 11.1 seconds across all the cases and, in the Ms Ainscombe cases above, lasts just an average 9.8 seconds before the follow-up request.
These much shorter presenting concerns by role-played patients are perhaps inevitable in a setting where the contingencies are so different to real patients, who have a genuine back-story and complaint. This is, though, an important deviation from real clinical interaction and seems to require that the candidate doctor make an interactional move much earlier. The ‘tell me *more about’ requests at the opening stages may therefore be a function of this semi-scripted setting, with the candidate dealing with a shorter, scripted problem presentation, from which they must work hard to gain further information.
Pattern-breaking differences in the opening sequence of a failing simulated interaction
We noted that the ‘tell me *more about’ strategy in the simulations, though it received a reply, did not elicit a long response from the role-player and the majority of the simulated consultations subsequently moved quickly into structured questioning. In trying to understand the conventionalized opening sequencing further, it is worth looking at examples where it is deviated from. Extract 7 comes from the opening of another simulated consultation (Doctor Malik) performing the same Ms Ainscombe case, but does not demonstrate quite the same sequential features identified in the initail section,
4 CAN: Mrs Ainscombe 5 RPL: yes ⁇sure⁇ 6 CAN: ⌈I’m⌉ doctor Malik nice to meet you 7 ((door slam)) 8 please have a seat 9 EXM: COUGH 10 CAN: how can I help you Mrs Ainscombe 11 RPL: well (.) um (1.2) 12 my: sister↗ (0.2) my sister’s baby→ (0.5) 13 um (0.3) has cystic fibrosis↘ 14 (1.4) 15 RPL: ((ACT nods 4 times)) 16 CAN: ((raises chin, nods together with ACT on her 4th nod)) 17 RPL: and um→ 18 (1.0) 19 RPL: I would like to know if:: (0.5) 20 my children (.) will have this disease↘ 21 (0.7) > 22 CAN: sure↘ (0.2) sure↘ (0.6) > 23 so: (.) I mean um→ > 24 did you find that out recently↘ 25 RPL: yeah she was diagnosed about three weeks ago 26 (1.4) 27 CAN: ok 28 and um (.) 29 obviously (.) it is worrying you (.) 30 at the moment 31 (1.8) 32 CAN: ok (.) er now (.) 33 Mrs Ainscombe (.) 34 I know that you work as a secretary [lines_removed] > 38 =would you mind telling me a bit more about yourself 39 RPL: what would you like to know 40 CAN: so I mean do you work at um 41 (1.0) 42 RPL: do I↗ 43 CAN: do you work 44 RPL: as a secretary yes≈ 45 CAN: =um I’m sorry um 46 yes of course and how are 47 er are you still working as a secretary then≈
We get an analogous opening enquiry, ‘how can I help you …’ (line 10), but when the role-player has come to the end of her scripted response (lines 11–20), after a 0.7-second pause, the candidate gives a brief ‘(0.7) sure↘ (0.2) sure↘’ (line 22) receipt which, after another pause, is followed by the more specified question ‘did you find that out recently’ (line 24). An empathy token, acknowledging the distressing news, is not offered, as it was from Doctors Huang and Amari in Extracts 1 and 2, potentially a problematic omission in a context where interpersonal skills such as showing understanding for the patient are being assessed. More strikingly perhaps, compared to the earlier sequences from simulations, it does not take the form of a ‘tell me *more about’ request. ‘Sure sure’ can occur as a type of continuer in real GP consultations, encouraging the patient to talk further, but in this context, followed by a question about timescales from the candidate, it does not seem to work well. We can see this gains an especially short answer from the role-player (line 25), much shorter even than those elicited by the ‘tell me *more about’ request, followed by a long 1.4-second pause. At this point, the candidate must say something again, resulting in a series of difficult turns (lines 27–38). The pauses and difficulties seem to indicate that he is struggling to formulate another interactional move. A short silence follows his initial comment that ‘obviously (.) it is worrying you at the moment’ (lines 29–31), which, though it was potentially designed to prompt an account from the role-player, fails to get a response. The candidate struggles to formulate a further interactional move (‘ok (.) er now …’), shifting the consultation into general questions about the patient’s lifeworld (lines 32–38). Here, we do see a ‘tell me *more about’ request (line 38), but much later than the sequences we saw with the successful candidates above and relating to an entirely new topic on the role-player’s background, taking the focus away from cystic fibrosis. Rather than successfully eliciting a description about her (fictional) background, the role-player instead asks the candidate to clarify the request (line 39), perhaps foreshadowing further interactional difficulties. The candidate struggles to clarify this (lines 40–41), which the role-player picks up on by repeating his incomplete turn back as a question, ‘do I↗’ (line 42), highlighting the misunderstanding further. Attempting a repaired formulation, the candidate quickly asks, ‘Do you work’, repeating information he himself has already stated from the case notes (back at line 34), that she works as a secretary. It is a repetition the role-player highlights and leads to an on-record apology from the candidate (lines 45–46). Unlike the earlier candidate doctors we saw (Doctor Huang from Extract 1 and Doctor Amari from Extract 2), this episode means the candidate does not get into the structured yes/no questioning early on, potentially missing crucial information during this timed case.
This awkward interactional exchange puts the candidate in the relatively difficult position of having to conduct an increasing amount of work to keep the interaction going. Unlike increased talk by the role-player identified by De la Croix and Skelton (2009), the increased talk by the candidate here does not indicate dominance but establishes a more powerful position for the role-player. It equates to a finding by Linell et al. (1988) that, ‘in some situations and social relations, activity and talkativeness on the part of a given actor may be a sign of relative powerlessness’ (p. 437). In the sequence analysed here, the role-player can withhold longer responses and request clarification, culminating in disfluency and ultimately a deferential on-record apology from the candidate (line 45). Role-players, then, have the ability to take more powerful positions in the participation framework of these simulated interactions than do real patients, from whom we do not often see this type of interactionally assertive behaviour (Britten et al., 2000), but they do not necessarily do it through increased talk. It is important to note that the interaction does not always unfold this way, since in the first two Ms Ainscombe cases, we find the role-player responding to the more typical sequential moves of the candidates in a compliant manner, albeit with shorter responses than real-life patients. It is possible that the trouble for the failing candidate here stems from his initiating a topic, the role-player’s lifeworld (lines 32–34), that is not seen as relevant to her opening request. These questions may risk coming across as inappropriate and perhaps even amplify the formulaic nature of the later ‘tell me *more about’ phrase (line 38), which was not so apparent for the other two candidates, when they used this in its conventional sequence. Knowing conventionalized phrases such as ‘tell me *more about’ is not enough for successful performance on its own then; understanding the conventionalized sequential structures of the talk and where to place these phrases seems to be of greater importance to the interaction. This difference in the use of the ‘tell me *more’ request in this particular simulation would not have been apparent from the CL analysis alone, particularly since it still occurs roughly around the opening stages, so would look to be a reasonably similar location on a concordance plot. It falls to CA to highlight the different sequential position and the shift to a new topic, within an already problematic interactional exchange, that renders this an unsuccessful strategy.
This analysis begins to indicate why the dataset of simulated consultations showed candidate GPs talk in the simulations more than in real-life practice, speaking for around 68% of the total floor time, compared to 61% in real GP consultations (contrasting with de la Croix and Skelton’s (2009) finding that role-players spoke more than candidate doctors in undergraduate simulations). It is difficult to establish, from the corpus finding alone, why there is more talk by the candidate but, from CA, it is apparent that since the opening from the role-player is not produced as a narrative as it is with real patients, and requires longer acknowledgments and questions from the candidate, there must inevitably be a greater amount of talk from the candidate as they work to keep the interaction on track within the 10-minute time-constraint. Although the ‘tell me *more about’ request does not gain the type of long accounts we see from patients in real-life consultations, the fact that it gains any reply may be helpful in keeping the simulated interaction going. When this structure was not followed, as in Extract 7, the replies became even shorter. The conventionalized ‘tell me *more about’ does perhaps give the candidate a little bit more time to formulate the next interactional move and subsequent structured questions.
There are, however, marginal differences in the role-player’s delivery of the opening lines in Extract 7, which may compound these interactional disfluencies and how they are perceived. In Extracts 1 and 2, the role-player’s scripted openings were delivered as one whole turn, and she displayed that her turn-at-talk was not complete after ‘my sister’s baby has cystic fibrosis’ by adopting a continuing intonation followed by an audible in-breath, indicating she intended to talk further. Once the second part of the scripted opening had been given, on her wish to know about hereditary risks, she closed her mouth, indicating that her turn-at-talk was complete. Given these cues, Doctors Huang and Amari were both able to hold off from responding until the end of the full scripted opening. It was at this point that these two candidates spoke in the respective sequences, moving into the conventionalized sequence of acknowledging the distressing news and the ‘tell me *more about’ request. For Doctor Malik in Extract 7, however, although the role-player delivered the same account, it was produced as two more separate, lengthy formulations. Between lines 11 and 13, the role-player produced the first part of the account, but the end component of this unit was, in contrast Extracts 1 and 2, produced with falling, turn-final intonation, following which she closes her mouth and produces four head nods. The way this juncture is produced might suggest she is already inviting a response from the candidate, although she only receives one short head nod from him (line 16). Failing to produce a more substantial contribution may come across as unsympathetic to the observing examiner and the following extended silence and subsequent disfluencies perhaps emphasize this. It is an indication of turn-completion within the role-player’s delivery that did not happen in Extracts 1 and 2, where there were consequently no awkward silences. The very slight differences in role-player delivery, even at this most scripted, stable point of the simulation, may impact on the sequence and the potential impression of a candidate. It may be near impossible to standardize all role-players to the degree that they mechanically reproduce the same performance at this micro-level but, for the assessment, it is important to acknowledge the possible effects of small variation in what is an ostensibly standardized interaction.
Doctor Malik in Extract 7 fails the case overall, performing poorly in interpersonal skills and, for this case, receiving feedback that he fails to ‘show sensitivity to the patient’s feelings’. Making a claim that local interactional sequences have a bearing on the overall success or failure of a case is tricky. Simply identifying a particular interactional sequence as problematic does not necessarily account for why a candidate fails overall. Nevertheless, the difficulties this candidate experiences during the opening sequence lead to further difficulties and misunderstandings in the subsequent data-gathering, and this would seem likely to impact on his poor marks overall. In assessing interpersonal skills, this may be an acceptable outcome. However, if we are using simulated settings to make high-stakes judgements about professional skills, it is worth reflecting on whether these interactional features replicate the professional requirements of real-life GP consultations.
Discussion and conclusion
The study demonstrates how CL and CA methods can be usefully applied in analysing simulated interactions, identifying key linguistic features and participation structures that may not easily be recognized in real-time assessment. Although Seale et al. (2007) have noted that simulated consultations are more interactionally demanding, we can begin to see, in the detail of the talk, what these demands might be.
The simulated consultations are is a hybrid discourse, where some features of real-life GP interactions are present, such as the standard ‘what can I do for you today’ opening, but others are notably different. CL analysis shows there is a greater amount of talk from candidates than role-players in these simulations and that certain formulaic phrases occur much more frequently than in real GP encounters, particularly variations of the word-cluster ‘tell me *more about’. These findings therefore suggest a slightly different linguistic fingerprint for simulated interaction. However, it was difficult to establish, from the corpus overview alone, the interactional reasons for this. Using these corpus findings to direct a CA study of opening sequences in the simulations, it was found that empathy phrases and formulaic requests were employed in strikingly consistent sequential turns-at-talk, at least for candidate doctors who performed well in the assessment. They offered much longer acknowledgement receipts than are found in the openings of real-life GP settings, where often the patient’s narrative is acknowledged with short continuer responses such as ‘mhm’. In the simulations, longer receipts expressed understanding for the role-player in some way, before following up with a request for more information, often ‘tell me *more about’. Without a longer, narrative response from the role-played patient, candidates in the simulations then moved into structured data-gathering questions relatively more quickly than has been identified in real primary care.
The altered sequential structures for the openings of simulated consultations are potentially a response to the scripted scenarios candidates are presented with, in which they do not receive a long, narrative-style opening turn from the role-player, but rather a shorter turn from which they must work to glean more information. Together these findings begin to indicate why candidates were found to talk more in the simulations than real-life clinical practice, but this increased amount of talk did not instantiate an interactionally dominant position. This became particularly apparent in the performance of less successful candidates, where the additional interactional work required, particularly the need to formulate acknowledgements and questions early on in the consultation, could cause disfluencies which positioned them in a less advantageous position in the participation structure.
Although the formulaic ‘tell me *more about’ phrase appeared in both successful and unsuccessful candidates’ interactions, successful candidates seemed to use the prefabricated phrases at more conventionalized points in the opening sequence. It seems reasonable to suggest where these phrases are placed in the overall sequence and interactional environment might affect how they come across to an examiner. Difficulties in the opening stages of simulations seemed to occur when opportunities for empathy phrases were missed, when formulaic questions were delivered on the wrong topic or at the wrong interactional juncture, and when mistakes and misunderstandings meant that formulaic utterances were issued into an already difficult interactional environment. In real-life GP consultations, though interactional difficulties occur, there is often more space for repair and they tend to be different in nature, related to issues of mutual comprehension flagged up by the GP rather than the patient (Roberts et al., 2005). The interactional contingencies for real patients also make them less likely to raise problems (Britten et al., 2000; Roberts et al., 2014: 49). This suggests, again, a greater potential for role-played patients to shift the participation framework in simulated settings and for the candidate to be put on the back foot.
The conventionalized opening sequence in simulated cases may also reflect the ratified overhearing presence of the examiner, leading candidates to make interactional moves that explicitly speak to perceived assessment requirements. Aspects such as person-centred care and empathy, as instituted by communication skills directives like Cambridge-Calgary (Silverman et al., 2013), are almost over exaggerated for the benefit of an overhearing audience. Playing the game of role-play in these openings required that candidates knew when to deploy formulaic phrases. However, whether using these formulaic phrases at the correct moment is actually an indication of real consulting abilities is questionable. Stokoe (2013) raises this issue in the context of police interview role-plays: If simulations contain actions that are not present in actual encounters, or if actions are formulated differently in them, then, a person may receive a high score for, say, the presence of rapport-building features in training when such features may not appear in their actual workplace interactions. (p. 183)
The differences we have seen in the opening sequences suggest simulated consultations potentially test slightly different competences to real-life clinical practice, with severe consequences for those candidates who do not manage the conventional interactional patterns of this genre well. Simulation can be a useful tool in the affordances it provides to systematically design cases around a curriculum of medical topics. However, the difficulties of recreating the same discourse features of real-life interaction mean that we must be careful in using this setting as a reliable measure of real professional competence.
Footnotes
Appendix
Transcription conventions.
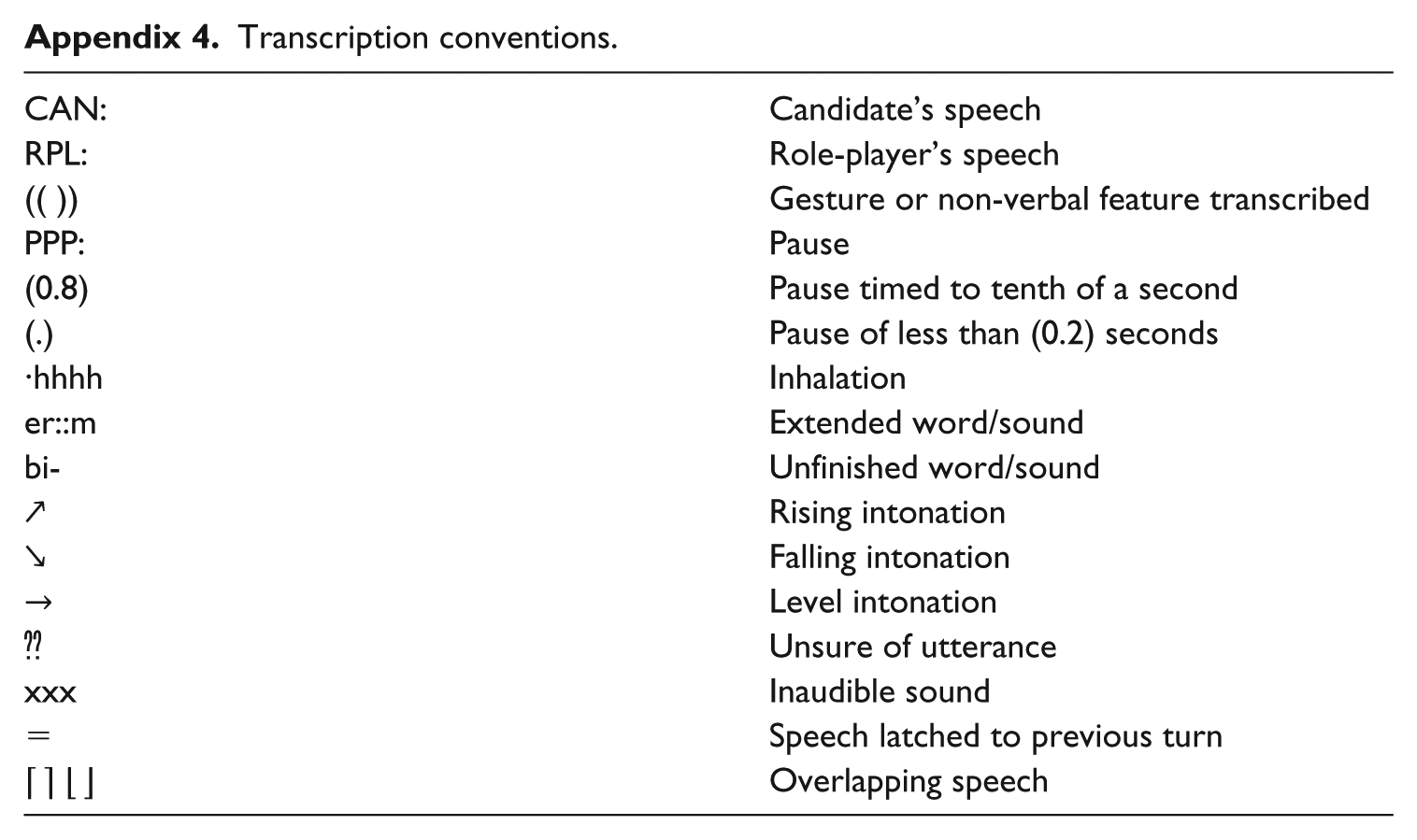
| CAN: | Candidate’s speech |
| RPL: | Role-player’s speech |
| (( )) | Gesture or non-verbal feature transcribed |
| PPP: | Pause |
| (0.8) | Pause timed to tenth of a second |
| (.) | Pause of less than (0.2) seconds |
| ∙hhhh | Inhalation |
| er::m | Extended word/sound |
| bi- | Unfinished word/sound |
| ↗ | Rising intonation |
| ↘ | Falling intonation |
| → | Level intonation |
| ⁇ | Unsure of utterance |
| xxx | Inaudible sound |
| = | Speech latched to previous turn |
| ⌈ ⌉ ⌊ ⌋ | Overlapping speech |
Acknowledgements
I am grateful to Professor Alison Pilnick for commenting on early drafts of this article and to Professor Elizabelth Stokoe for invaluable feedback on refining the study. I am enormously grateful to Professor Celia Roberts for providing me with access to datasets of real-life GP interactions for the purposes of this comparative study, as well as for her continued support of this research, long after the Knowledge Transfer Partnership with which it all started.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Ethical approval
Ethical approval for this work was gained from King’s College London, application REP(EM)/10/11-36 and latterly the University of Nottingham.
Funding
This work was supported by the Economic and Social Research Council (Grant Number ES/K00865X/1) 2013–2016 and by a Knowledge Transfer Partnerships award (Grant Number KTP008346), 2011–2013.