
Abstract
This study qualitatively investigates user responses to privacy invasion by social media algorithms and identifies the fundamental needs that drive the feelings of privacy violation. In-depth interviews with 17 users in the United States revealed that the dimensions of physical, social, informational, and psychological privacy, originally defined in interpersonal communication, can be extended to human–algorithm interaction and are still deemed to be significant by users. Popular episodes of privacy invasions showed three main themes that privacy violation perceptions are grounded upon: lack of choice, non-interpretability of algorithms, and lack of understanding and respect. The three basic human needs for growth and motivation proposed by the self-determination theory (SDT) – autonomy, competence, and relatedness – are extended to understand why these invasions matter to users.
Introduction
Privacy has gained unprecedented significance as AI (artificial intelligence) algorithms develop. Social media algorithms rapidly become more intelligent in grasping what users want to see by collecting engagement data, such as thumb scrolls and gazing time (Von der Weth et al., 2020). These anonymous data are then used to curate personalized content on social media, where we spend an average of 2.5 hours per day (Kemp, 2024). Social media companies also utilize user data on demographics, relationship status, and the number/characteristics of their friends to engineer personalized advertising, which has been a successful model of business for mainstream social media platforms. However, as users acknowledge the pervasiveness of personalized media feeds, concerns regarding the vast amount of personal data available to social media companies have also increased (Frick et al., 2021).
Yet, the impact of privacy concerns on privacy management decisions is often mitigated if such targeted content is perceived to be useful. Cumulative literature on privacy-related theories suggests that social media users manage their disclosure behaviors based on different criteria ranging from rules of thumb to more complex ones. For example, privacy calculus theory identifies that disclosure occurs when the effect of expected benefits on information sharing on social media platforms surpasses the perceived risks of the sharing practices (Meier et al., 2021; Ostendorf et al., 2022). Meanwhile, as communication privacy management theory suggests, users might also set multiple privacy rules to control their privacy boundaries and avoid privacy boundary turbulences (e.g. Petronio and Child, 2020). Given the popularity and wide adoption of social media, users seem to accept the inevitability of information sharing and disclosure on social media platforms, although they also yearn for greater interpretability and transparency of social media algorithms (König, 2022).
The current study is set in this context of dynamically evolving human–algorithm interaction on social media and aims to explore how users understand and apply privacy. Privacy is broadly defined as the degree of control we have over information about ourselves and how much access others have to this information (Nissenbaum, 2009). When privacy is reduced, individuals feel that the necessary physical or psychological boundaries between them and the outside world are violated (Burgoon, 1982). Privacy is an essential condition for human autonomy both in thought and action; without privacy (or with constant surveillance imposed by other social actors), we cannot have opportunities to form independent belief systems and act based on our own principles (Nissenbaum, 2009). Thus, the discussion of privacy issues can serve as a significant reminder of the structural problem embedded in human–algorithm interaction that our choices for media content are outsourced to algorithms, and our behaviors are subjected to seemingly voluntary surveillance.
The current study explores how contemporary users perceive and interpret this fundamental challenge to their agency posed by content curation algorithms on social media. We employ the self-determination theory (SDT) (Ryan and Deci, 2000) to highlight the ways human–algorithm interaction on social media compromises the three fundamental human needs: autonomy, competence, and relatedness. We intend to update our knowledge of how privacy is understood in human–algorithm interaction and use the SDT to make sense of users’ attempts and desires to regain control over privacy. By doing this, the current study extends the framework of SDT to analyze how privacy concerns on social media might be connected to the fundamental desires of human agency and connection.
Literature review
Definitions and dimensions of privacy
Privacy can be defined both in descriptive and normative ways. Descriptive definitions of privacy focus on its neutral meanings regarding the degree of access that others have to personal information or the degree of control one has over one’s experience; normative definitions highlight its moral and political values (Nissenbaum, 2009). In theories of communication, privacy has long been discussed as a key concept to understanding individuals’ needs for adjusting social and psychological distance from others. Many definitions of privacy include the ability to exert control over information, physical spaces, and boundaries related to oneself and the social groups that one belongs to (Burgoon, 1982). Other definitions address the psychological dimension of privacy by defining it as the desired state of hiding one’s thoughts and feelings from others or maintaining freedom of choice in their beliefs and thoughts (Gavison, 1980). While the definition of privacy may vary across different disciplines and researchers, its core values are associated with human autonomy (Nissenbaum, 2009).
In her pioneering work, Burgoon (1982) proposes a more structured way of understanding privacy by proposing four categories: physical, social, psychological, and informational privacy. All four categories of privacy emphasize an individual’s agency over physical, psychological, social, and informational boundaries. First, physical privacy refers to the degree to which one’s body and home territory are inaccessible to others without one’s permission; this includes maintaining proper physical distance or nonverbal distance (e.g. eye contact) in interactional settings. Physical privacy is deemed a prerequisite for “not being seen, heard, or sensed” by other people (Burgoon, 1982: 214). Second, social privacy is defined as “the ability to withdraw from social intercourse” (Burgoon, 1982: 216). Exposure to unwanted social interactions causes stress; thus, individuals have natural desires to maintain a balance between engagement and disengagement. Social privacy includes the control of not only whom individuals want to interact with but also the control of how often and long the communication should be, as well as the control of the content of interactions. Social privacy is a necessary condition to achieve intimacy in relationships, which itself “becomes a private retreat” (Burgoon, 1982: 221) when individuals need to escape from the daily demands of public roles. Without social privacy, individuals cannot protect their intimate relationships from others.
Third, psychological privacy refers to “one’s ability to control affective and cognitive inputs and outputs” (Burgoon, 1982: 224). Inputs refer to thoughts, attitudes, beliefs, and values; outputs include how individuals want to reveal these thoughts and feelings. Psychological privacy provides one’s control of maintaining a sense of identity and self-esteem, which has a broader implication for human autonomy and liberty (Gavison, 1980). By controlling the inputs, individuals can determine what’s unique to their value systems free from external influences; by controlling the outputs (e.g. hiding their thoughts and feelings if necessary), individuals can be free from censorship and informational “panopticon” (Nissenbaum, 2009). Fourth, informational privacy refers to the ability to control the distribution of personal information to others, including its amount, content, and recipients; this concept has been widely discussed in the recent privacy literature (e.g. Sarikakis and Winter, 2017; Trepte, 2021). The common concern regarding personal information being sold to third parties without one’s knowledge on social media represents the situation where users have little control over their informational privacy.
Before we apply the four dimensions of privacy to human–algorithm interaction, the following section defines what algorithm is and what we mean by human–algorithm interaction.
Human–algorithm interaction on social media
The term algorithm is defined as “a computational formula that autonomously makes decisions based on statistical models or decision rules without explicit human intervention” (Lee, 2018: 3). In a broader sense, algorithms can be defined as a socio-technical system that governs how humans interact with technology (Shin and Park, 2019). Algorithms can increase proficiency and accuracy of data processing and improve user experience in content curation, content production, and networking (Kim and Moon, 2021). In our study, we use the term algorithm in a more narrowly defined way, referring to the content curation algorithm. Content-curation algorithms are the computational formulas that “arrange content by prioritizing, classifying, and filtering information” on social media platforms to fit users’ profiles and tastes and provide personalized information and entertainment (Fouquaert and Merchant, 2022: 1769). For example, Instagram’s content-curation algorithm arranges the posts on users’ pages according to their personal interests, content recency, social connections, and users’ activities (Fouquaert and Merchant, 2022).
As social media algorithms keep evolving by feeding on an enormous amount of user data, the capability of algorithms also creates unease among the stakeholders of social media. Algorithms that deploy machine learning and gradually become more agentic are often regarded as threats to human agency and privacy (Sundar, 2020). In this regard, Siles et al. (2019) propose the concept of mutual domestication, which emphasizes not only that users incorporate algorithms into their everyday lives but also that algorithms actively shape users’ self-awareness and sense of control over their practices. Even when users try to exert their agency through different strategies, their actions remain constrained by what the platform allows. In this sense, content curation algorithms are not only objects of domestication but also function to exercise control over users. In this context, studying human–algorithm interaction becomes essential to understand how people become aware of and make sense of the complex functions of algorithms. Computer scientists are striving to provide explainable AI (XAI) to “un-black box” the decision-making mechanism of algorithms (Ågerfalk, 2020: 6) to achieve a more transparent, accountable, and fair system (Shin and Park, 2019). Lay users also develop various patterns of human–algorithm interaction and use their own theories (called algorithmic imaginary or folk theories of algorithms) to figure out how the algorithms function and even strive to counteract the algorithms’ influence (Bucher, 2017; Ytre-Arne and Moe, 2021; Zhang et al., 2024). Siles et al. (2019) explicated folk theories of algorithmic recommendation and found that users tend to either personify the algorithm or perceive it as a machine that requires their training. In other words, users often tend to believe they understand the underlying logic of the algorithm’s content curation process. The dynamic interplay behind human–algorithm interaction also implies that users can indirectly, often unintentionally, co-shape, embrace, or resist algorithms.
Recent literature in this area also suggests that human–algorithm interaction may have some psychological elements of social interactions. Human–machine interaction literature has long argued that users constantly adapt their social strategies and cognitive processing to deal with gradually anthropomorphic machines who talk to us and sense what we are doing (Gambino and Liu, 2022; Sundar, 2020). Even though social media algorithms do not have any anthropomorphic cues like chatbots or virtual agents, users are aware of the algorithm’s influence and orient to the algorithm as the message source that selects and delivers media content for them (Bucher, 2017; Schellewald, 2022). As a result, algorithms can be “frustrating,” “confusing,” and even perceived as “cruel” when they fail to meet the users’ expectations (Bucher, 2017).
The current study focuses on this new area of human–algorithm interaction where users constantly strive to somehow understand and communicate with content-curation algorithms on social media by imagining, interpreting, and influencing the algorithms. In sum, we define human–algorithm interaction as users’ cognitive and behavioral efforts to understand, communicate with, and influence the imagined as well as the actual functions of content-curation algorithms which their experiences are grounded upon.
Extending four dimensions of privacy to human–algorithm interaction
Literature on human–algorithm interactions suggests that the agentic capacity of contemporary AI-powered algorithms—driven by recent innovations in algorithms and AI technology—compromises human agency in various ways. For example, algorithmic media platforms collect excessive user data through practices of “dataveillance” and may manipulate user perspectives via personalized communication (Zhang et al., 2024). Despite such immense data collection and influential practices, AI-powered algorithms are advancing rapidly and becoming increasingly complex for lay users to understand. This study explores the privacy-eroding practices of algorithmic social media to understand how they affect fundamental human desires for agency.
As the first step, this study explicates how privacy can be understood and practiced by users in the context of human–algorithm interaction. We posit that how individual users perceive privacy-related matters on social media can differ in various ways, depending on their interactions with content-curation algorithms. Thus, the concept of privacy in this intricate relationship between humans and algorithms needs to be re-examined and updated. In this section, we offer preliminary definitions of privacy in human–algorithm interaction below by extending the four dimensions of privacy proposed by Burgoon (1982), which will serve as our theoretical guidance for understanding how users define and experience privacy in human–algorithm interaction through their subjective experiences.
Physical privacy in interpersonal communication refers to the ability to control one’s body, interaction setting, and home territory so as not to be seen, heard, or sensed by other people (Burgoon, 1982). Extending this concept to human–algorithm interaction, we highlight the fact that social media users are concerned that social media algorithms can “see” and “listen to” them through their phone cameras and microphones. Even though social media platforms have clarified that they do not use microphones unless users record something on the platform, many users still believe that they are listened to. The current study defines physical privacy in the context of human–algorithm interaction as the users’ ability to maintain a protected space that prevents social media algorithms from detecting what they are doing.
Social privacy in Burgoon (1982) is defined as the ability to engage or disengage with social intercourses as needed. This includes individuals’ control over the frequency and content of social interactions as well. Applying this to human–algorithm interaction, the imminent challenge seems to be the fact that there is no way for users to be completely disengaged from the content-curation algorithms on social media; algorithms are already embedded in the platform, and users are keenly aware that algorithms select media content for them in real time (Bucher, 2017; Schellewald, 2022). Algorithms also push frequent notifications for users to come back to the platform as often as possible. In other words, the current way algorithms communicate with users is like an annoying salesman or acquaintance who keeps calling you or visiting you with seemingly interesting baits. According to Burgoon (1982), this easily creates an overload problem; when there are too many social encounters, individuals do not have a chance to heal and be prepared for more meaningful, intimate relationships.
In short, social privacy in human–algorithm interaction on social media can be defined as the users’ ability to control how often and with what content they want to be engaged through social media algorithms.
Psychological privacy in interpersonal communication refers to one’s ability to control affective and cognitive inputs and outputs in the society they belong to (Burgoon, 1982). In human–algorithm interaction, users’ feelings, thoughts, and opinions are automatically collected to construct the categories of “algorithmic identity” such as the presumed gender, race, and class of each user (Cheney-Lippold, 2011: 164). The categories exist as vectors that continuously fluctuate (e.g. 75% male and 25% female based on browsing history), all of which can be used to define who the user is and to suggest personalized content. Recent studies also suggest that these algorithms function as a “crystal,” reflecting certain aspects of users’ identities and playing a crucial role in how individuals understand their identities (Lee et al., 2022). Furthermore, personalized content consistently fed through social media algorithms significantly influences individual users’ self-construction, leading to the formation of “the algorithmized self” (Bhandari and Bimo, 2022).
Even though users are acutely aware that personalized feeds are based on their previous clicks, prior research pointed out that they do not like to be profiled and categorized by social media. Users get offended when social media makes stereotypical assumptions even if the recommended content is relevant (Bucher, 2017), let alone when they realize that targeted ads misidentify their preference (Herder and Zhang, 2019). The ongoing concerns on the social media echo chambers (Terren and Borge-Bravo, 2021) also showcase our desires to be independent of the algorithms’ influence on our belief system, even if the algorithms merely reflect what we like to see. When algorithms automatically choose what we want, we are also deprived of the introspective decision-making process that precedes the choices (Savolainen and Ruckenstein, 2022). Taken together, psychological privacy in human–algorithm interaction can be defined as the users’ ability to construct and maintain their unique belief system and sense of identity without influence from social media algorithms.
Informational privacy refers to the ability to control the distribution of personal information to others (Burgoon, 1982). In fact, how social media algorithms take advantage of or distribute personal information is rarely known to lay users (Kang and Lou, 2022). Earlier studies on social media algorithms showed that some users were not even aware of such practices (Eslami et al., 2015). Since personal information can be gathered and shared without the user’s knowledge of social media, informational privacy often goes beyond one’s control.
As human–algorithm interaction is going through the transforming digitization process of collection, distribution, storage, and usage of personal data, the definition and boundary of informational privacy have changed. First, the source of personal data has been immensely expanded. Various sensors embedded in smart devices can collect users’ visual, audio, location, and health-related data, making all of these digitized human activities form a significant part of personal information (Yang et al., 2024). Second, the boundary of informational privacy has been expanded from users’ factual information to inferred information (Sekba and Baumer, 2020: 101:11) that can be actualized by AI and machine learning. Driven by the algorithm’s ability to construct user profiles (Mai, 2019), conventional private information (e.g. name and address) is not enough to capture user characteristics. Predictive analytics combine multidimensional data–like behavioral (e.g. browsing and searching) and transactional data (e.g. online shopping) (Zhang et al., 2022) and can even infer sexual orientation and mental health status based on mined data (Skeba and Baumer, 2020). Thus, informational privacy in human–algorithm interaction encompasses not only what we decide to disclose or what we can control but also how much we are aware of and give consent to the algorithm that uses personal information to predict who we are. In short, informational privacy in human–algorithm interaction can be defined as the ability to control, be aware of, and give consent to how personal information is used and distributed by content-curation algorithms.
Understanding privacy in human–algorithm Interaction from the self-determination perspective
Building on our discussion regarding how users define and experience privacy within the context of human–algorithm interaction on social media, this study further examines the fundamental needs that are affected when users perceive their privacy as being violated by algorithmic practices. To this end, it employs SDT as a theoretical framework to illuminate the psychological needs that may be undermined by the privacy-invading mechanisms of algorithmic social media.
SDT explains three basic human needs (autonomy, competence, and relatedness) work conjointly to enhance individuals’ intrinsic motivations, whereas thwarting any of these three basic needs can undermine their motivations (Ryan and Deci, 2000). In the theory, the concept of autonomy and self-determination is used interchangeably; both refer to the state where individuals have freedom of choice in their behaviors and perceive an internal locus of causality as a result (Ryan and Deci, 2000). In the privacy literature, autonomy is more specifically defined as the ability to make decisions and govern actions based on one’s own beliefs (Nissenbaum, 2009). Nissenbaum (2009) argues that privacy is a necessary condition for human autonomy. Without privacy, our actions cannot be truly volitional since we fear that we are being monitored and judged, or in a worse case, internalize the gaze of the observer and follow their principles, not ours.
Whereas the fundamental role of privacy in constituting human autonomy is clear, how privacy is related to the other two needs – competence and relatedness – has been less explored. However, the very significance of autonomy found in SDT literature suggests that if privacy is a necessary condition for human autonomy, it may serve a comparable role for the other two needs as well. The cognitive evaluation theory (CET) (Deci and Ryan, 1985), as a sub-theory of SDT, suggests that autonomy is so fundamental in human agency that competence and relatedness needs cannot be successfully met unless individuals can self-determine their behaviors (Ryan and Deci, 2000). When learning is externally motivated (i.e. low autonomy), for instance, individuals tend to feel more pressured and experience less competence (Levesque et al., 2004); individuals also feel more alienated and disconnected from other learners when the contexts are controlling than autonomous (Ryan and Powelson, 1991).
Thus, given that privacy is a necessary environment where autonomy can be achieved (Nissenbaum, 2009), it would be natural for social media users to feel some threats to their self-determination when algorithms invade their privacy, and therefore to their competence and relatedness needs as well. Specifically, we extend the roles of autonomy, competence, and relatedness to understanding privacy issues in human–algorithm interaction as explained below.
The need for autonomy refers to the fundamental desire to feel in control of their life; individuals want to act with volition and perceive accountability and causality in their behaviors and goals (Deci et al., 1999). When a task is driven by external forces instead of self-initiating behaviors, they tend to experience lower intrinsic motivation (Deci et al., 1999). The continuum of autonomy (Ryan and Deci, 2000) spans from the state of external regulation where individuals are controlled by external rewards or punishments to the state of integrated regulation where they do things truly for enjoyment. Between these two ends of the continuum, individuals can also partially internalize a goal by thinking that they should do something for their values while still feeling pressured (introjection), or fully embrace a regulation as valued and meaningful while not necessarily enjoying it (identification).
The need for autonomy in human–algorithm interaction can be easily compromised as users rely on social media as essential communication tools, and their freedom of choice over whether they are engaged in the exchange of personal information or not can be very limited (Kang and Lou, 2022). Informational privacy has become a necessary commodity (Sarikakis and Winter, 2017) in exchange for personalization, and users do not have enough control over when and how personal information is used by algorithms. In this regard, prior literature suggests that asking users for explicit consent to use their personal information and sending clear privacy notifications can alleviate privacy invasion perceptions (Patrick and Kenny, 2003). Giving users (at least) control over which information they would like to disclose can create some sense of autonomy (Zarouali et al., 2018). On the other hand, autonomy needs can also be met when algorithms allow individuals to accomplish a desired task, behavior, or goal and to experience coherence between their actions and their authentic sense of self in the process (Dietrich et al., 2024).
In addition, the fact that algorithms make choices for users regarding what to watch and read on an everyday basis poses a more fundamental, almost structural issue to psychological privacy as well. As algorithms select things for us, individuals are deprived of the basic ground of psychological privacy; that is, the mundane opportunities to think and choose what they want to read or watch (Savolainen and Ruckenstein, 2022). As the algorithms rely on users’ past click behaviors to suggest content, they create feedback loops that reinforce existing patterns without requiring deliberate user input (Savolainen and Ruckenstein, 2022), thereby bypassing the introspective evaluation that is necessary for psychological privacy. In short, both the lack of informational and psychological privacy in HAI can compromise individuals’ autonomy.
The need for competence refers to individuals’ desire to experience and demonstrate their abilities. Prior research points out that the balance between challenge and skill levels plays a significant role in predicting perceived competence (Ryan and Deci, 2000); too challenging or too unchallenging tasks can be demotivating since individuals do not have an opportunity to demonstrate or improve their abilities. Whereas skills decide functional competence, knowledge and understanding of tasks determine cognitive competence (Le Deist and Winterton, 2005).
The fact that algorithms remain as a black box limits informational privacy since users would not be aware of how their personal information is used for commercial purposes. More importantly, this unknown mechanism of algorithms also constrains physical privacy. Users feel anxious about constantly being monitored and listened to by social media (even though algorithms cannot record their conversation) because they cannot see through how algorithms work (Chou, 2019; Frick et al., 2021). Studies have found that users keep trying to understand how algorithms operate by doing little experiments and imagining their mechanisms (Bucher, 2017); the presence of such algorithmic imaginary ironically shows how much users strive to regain control over the knowledge of how algorithms work, which is bound to be unsuccessful given that lay users would never be able to decode how algorithms work. Supporting this, prior literature pointed out that the cognitive inability to understand the mechanism of algorithms causes anxiety and induces the sense that they have lost control over their personal information (Jhaver et al., 2018). In short, algorithms as a black box provide a condition where users’ informational and physical privacy can be easily compromised, which reduces their efficacy in understanding and controlling the process of human–algorithm interaction.
The need for relatedness refers to individuals’ desire for secure relational bases. Humans have natural desires to feel belonging to and be supported by significant others, coworkers, and communities. Individuals motivated by emotional bonds and attachment are more willing to invest energy toward the tasks that promote such feelings of relatedness (Ryan and Deci, 2000). Given that the current study’s focus is on the human–algorithm interaction, we focus on users’ desire to connect with the algorithms, not with other social media users. As in other human–algorithm interactions (e.g. interaction with generative AI), users of social media orient to the algorithm as the message source (Bucher, 2017; Schellewald, 2022; Sundar, 2020). Recent studies have found that personalized advertising provides the satisfaction of being “seen” and “understood” by social media algorithms (Ruckenstein and Granroth, 2020). Savolainen and Ruckenstein (2022) proposed the concept of “algorithmic intimacy” (p. 12)—as we are aware that personalized social media content is generated by algorithms, we develop “closeness and familiarity” (p. 12) with the algorithms. Thus, human–algorithm interaction on social media can be also understood as a process of developing a relationship; social media users expose their personal information to the algorithmic system, expecting that the system gradually shows a better understanding of their preferences and identities.
In this process, the platform requires users to partially give up their physical, informational, and social privacy – in order to be better and more readily understood by social media and receive precise recommendations, users allow a certain degree of surveillance by social media (e.g. tracking locations, Cookies, list of friends, click behaviors, and sharing them with third parties, etc.) and give permission to the algorithm to contact them with notifications or push personalized content. As the human–algorithm relationship evolves, the algorithms develop greater predictive ability for users’ preferences, which also compromises psychological privacy. Users can feel “seen” and appreciated but also feel exploited (Swart, 2021), as the algorithms push not only the content they want but also the unwanted and exploitative content as well, constantly “rewarding and feeding you” (Swart, 2021, p. 6). In short, users are asked to yield all four types of privacy that Burgoon (1982) theorized to construct a better human–algorithm relationship, but giving up or exchanging privacy may not always result in feelings of relatedness and trust in human–algorithm interaction.
Therefore, the current study investigates when and why users perceive social media algorithms reduce their privacy, and how users’ natural desires to achieve autonomy, competence, and relatedness are compromised as the consequence of privacy invasions in human–algorithm interaction. We use in-depth interviews with social media users to explore how the different dimensions of privacy are perceived and felt in their subjective experiences of human–algorithm interaction. Therefore, we ask the following research questions:
RQ1: How do contemporary social media users experience and define privacy in human–algorithm interaction?
RQ2: In what situations do social media users perceive that privacy is reduced by social media algorithms?
RQ3: How are users’ fundamental needs for autonomy, competence, and relatedness compromised when they perceive their privacy is reduced by social media algorithms?
Method
Participants and procedure
We conducted in-depth interviews with active social media users between September and November in 2022 in the United States. Two graduate students with experience in in-depth interviews were hired and trained to recruit participants and conduct the interviews. Seventeen social media users were recruited via email and in person using convenience sampling. In order to maximize diverse perspectives, we intentionally varied the sex, race, and age of the interview participants in the sample. Upon completing the interview, each participant was given monetary compensation equivalent to USD $20. The sample included 10 female and 7 male participants with an average age of 33 years old (ranging from 21 to 62). The data reached a point of saturation upon the completion of the 17th interview. Table 1 summarizes self-reported demographics and social media usage data of interviewees.
Demographics and social media usage data of interviewees.
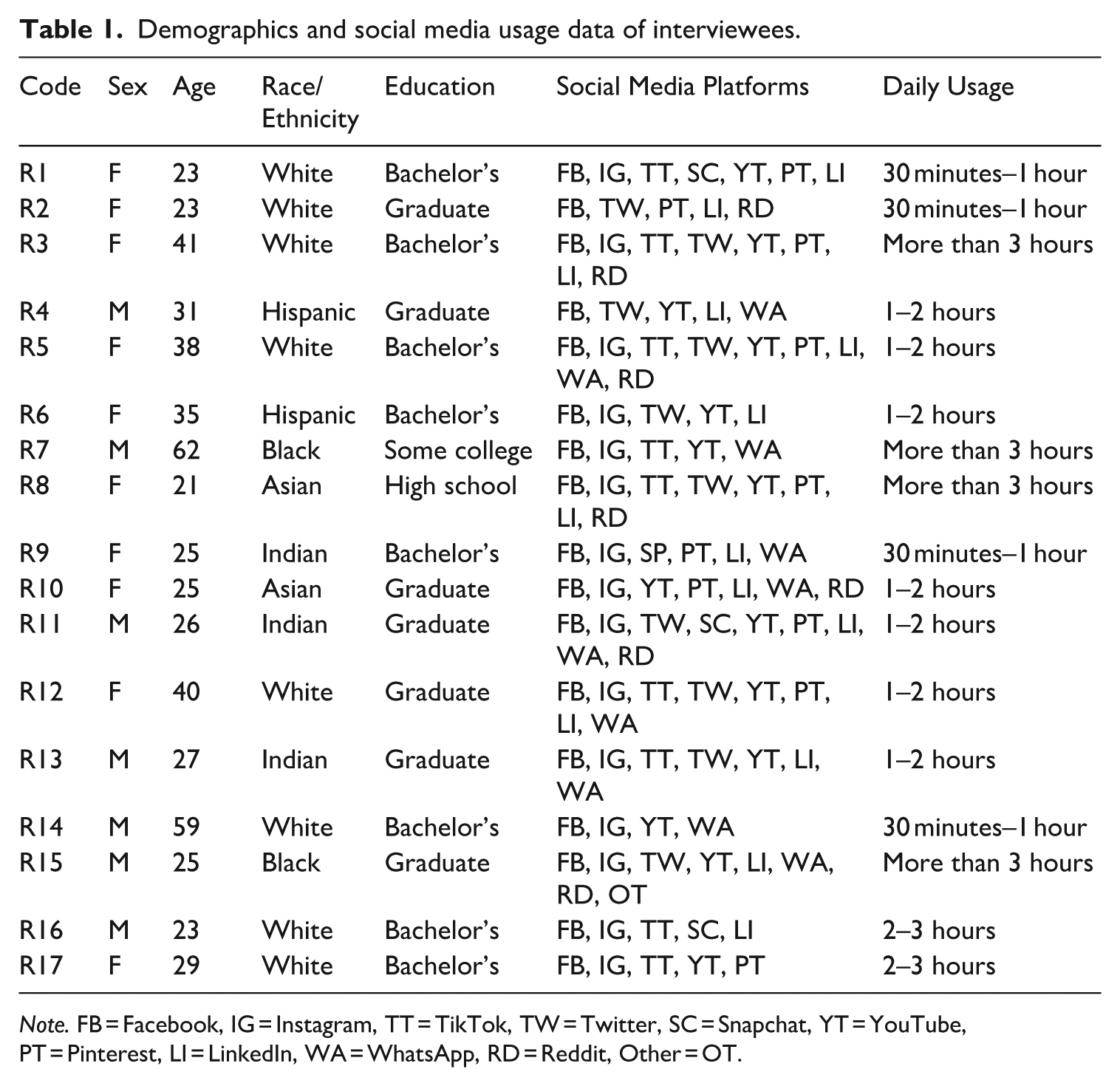
Note. FB = Facebook, IG = Instagram, TT = TikTok, TW = Twitter, SC = Snapchat, YT = YouTube, PT = Pinterest, LI = LinkedIn, WA = WhatsApp, RD = Reddit, Other = OT.
Interviews were conducted through Zoom in English. At the beginning of each interview, interviewees were asked to sign the consent form and fill out a short questionnaire to collect demographic information and social media use frequency. They were explicitly told that both the survey and interview data would be anonymized. Next, interviewees were asked to briefly summarize their daily use of social media to initiate the conversation on the topic of privacy. Then we asked them to elaborate on their definitions of privacy (with questions like: “When you hear the word privacy, what comes to your mind?”) and some of the recent, prominent privacy reduction experiences on social media (e.g. “Have you recently had any experience on social media where you felt that your privacy was violated?”), following a semi-structured protocol. Interviewers were instructed to focus on the privacy issues of personalization, as opposed to the issues of phishing, identity theft, or scams. Interviewers were trained to provide some preliminary definitions and examples of personalization-based privacy invasions in terms of surveillance, intrusion, and data use without agreement when it was deemed necessary.
After they brought up their recent experiences of privacy reduction, we asked, “Are you aware that AI algorithms analyze your browsing and interaction behaviors on social media?” to encourage them to think of human–algorithm interaction, especially focusing on the content-curation algorithms on social media. Most participants were aware that there is an algorithm involved in the issues of privacy; if they didn’t, the interviewers were instructed to provide a brief explanation of what content-curation algorithms do on social media and other platforms using examples like Netflix recommendation system and personalized videos on TikTok. Next, we asked whether they had any privacy concerns related to the AI algorithms of social media; as a follow-up question, we specifically asked whether they think algorithm-based personalization on social media violates their privacy. Their feelings and thoughts associated with personalization and the role of algorithms in these experiences were the foci of the interviews. Follow-up probing questions were asked if the answers warranted further exploration. All interviews were audio-recorded for verbatim transcription. Audio files from the interviews were anonymized and transcribed by a transcription service company. Interview sessions lasted around 30–50 minutes.
Data analysis
The transcript-based analysis followed a three-step process based on grounded theory, using the constant comparative method (Glaser and Strauss, 1967). In the first stage of open coding, two coders, different from the interviewers, were hired and trained. They read all transcripts line-by-line while breaking the data down to meaningful units (e.g. Instagram recommending same ads continuously) and assigned initial keywords that summarize each unit following the protocol (e.g. DOP = definition of privacy; PAG = perceptions of algorithms; PV = privacy violation experience). In the second stage of axial coding, the independent works from two coders were combined by identifying common keywords, and the data were grouped and categorized into higher-level themes by the PIs to form theoretical connections between the concepts. Privacy definitions were interpreted and grouped into a few themes that represent different types of privacy (physical, social, informational, and psychological) following Burgoon’s (1982) theory and our extended definitions proposed in the literature review. Privacy violation episodes were summarized into several main scenarios. Finally, in the selective coding stage, the second-level themes in privacy invasion scenarios were connected to the concepts of autonomy, competence, and relatedness and formed a theoretical model that answered our research questions.
Initially, we planned to conduct interviews with 15 participants, based on prior studies with similar aims and our available resources (e.g. Hennink et al., 2017; Saunders et al., 2018). Using an iterative approach, we coded and analyzed interviews as data collection progressed. By the 15th interview, we observed that code saturation had been reached, with no more meaningful new codes emerging. To confirm and further enrich our understanding of the identified themes, we conducted two additional interviews. After analyzing all 17 interviews, we found that these provided some additional nuance but did not generate new thematic directions. Thus, we concluded that both code and content (meaning) saturation (Hennink et al., 2017; Rahimi, 2024) had been achieved with 17 interviews.
Results
RQ1: privacy definitions in human–algorithm interaction on Social Media
When they were asked to describe what came to mind upon hearing the term “privacy,” the concept of physical privacy was often mentioned first. Interviewees defined privacy as occupying a secure, quiet physical space in the real world without being watched or surveilled (R2, R8), supporting the presence of physical privacy (Burgoon, 1982) in their schemas. The desire for protected space was easily extended to their resistance to social media algorithms detecting where they are and what they do. Many interviewees specifically mentioned the location-sharing feature in social media apps as something that invades their privacy (R3, R13, R14): I don’t think about that [location-tracking by the algorithm] as much because it feels like it’s happening in the background. Then I’ll get an email from Google Maps, and it says where you’ve been in the last month. I’m like, “Wow.” It shows me all the places I’ve been and just from carrying my phone around. (R6)
They also expressed concerns regarding algorithms “seeing” them and “listening” to their conversation in physical space; for instance, R13 mentioned, “I’ve seen there are friends who always keep some cloth or some covering on the cameras just to keep their microphones covered while they’re not using their phones . . . these [social media] apps do access microphone and listen.”
Many of them also revealed a perception of social privacy, the ability to control the frequency and content of their interactions with social media. Interviewees expressed concerns about being contacted or targeted by unwanted advertisements at unwanted times: “I search for something and put in my information and then next week I have got like a million emails from this company” (R3). They also complained about being targeted by algorithmic content at unwanted times: “Every time I try to see something or watch something with my friends, it keeps showing what I previously watched on YouTube. It’s pretty embarrassing” (R8).
Informational privacy was mentioned most frequently; “controlling what people know about you” (R5) and “being anonymous” (R14) were commonly used as definitions of privacy among interviewees. However, what information they consider private varied a lot. The list includes not only personal identifiers like social security numbers or birthdays but also resumes/photos/files saved on personal devices, or “everything (about) what I do, whom I talk to, and where I am” (R13). Many of them agreed that the control over access to medical, health, and financial information was most crucial, supporting prior literature (Rohm and Milne, 2004). Relationship/family information was also deemed to be crucial to be kept private (e.g. R12, R15).
Interestingly, the concepts of consent appeared to be crucial to defining informational privacy. If users “allow” companies or others to know certain information about them (R16), the information is no longer considered private. For instance, search history was sometimes considered not private since users thought they already “agreed to share my search history with Google” (R10). Conversely, “anything that I am not (consciously) sharing with the world” (R13) was deemed private. In other words, the breadth of informed consent to how algorithms use and repurpose personal data also impacts user perceptions of informational privacy. As R8 noted, “We are using their platforms but we didn’t consent or agree for them to use our private information on advertisement and everything.”
None of the interviewees directly mentioned the aspects of psychological privacy as what they think privacy is, but they expressed concerns about losing control over both the input (thoughts, attitudes, beliefs, and values) and output (expressions and behaviors) aspects of psychological privacy. Some were worried about the potential effects of echo chambers on their perceptions and beliefs (R4, R8); political bias and fake news (R5, R8) were also mentioned as the source of concerns. They were also worried about how their decisions are influenced by algorithmic content: “Usually, I’m not somebody who orders something off social media apps, but I think I fall prey, like I saw too many advertisements of sweet products that I ended up buying” (R13).
Participants were also aware that the output aspect of psychological privacy—especially what they click—cannot be hidden from algorithms. The way algorithms automatically “learn” from their behavior was concerning to many interviewees (R1, R12). For instance, R12 said, “It (who decides what I see on social media) is an algorithm. This is why they do so well. They know exactly what you are interested in reading based on what you’ve clicked on before.”
Figure 1 visualizes the main themes of privacy definitions found in the interview across the four different types of privacy.
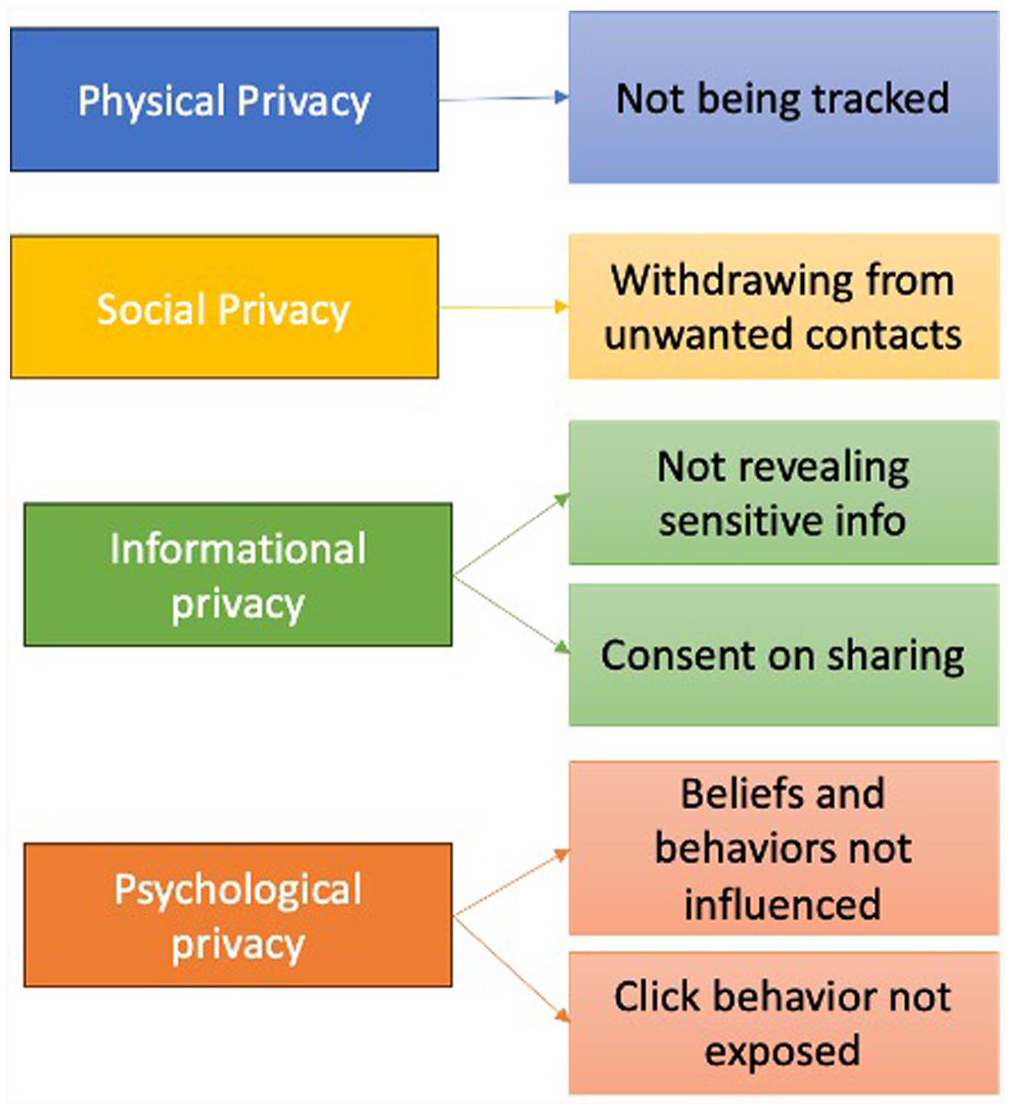
Privacy definitions emerged from the interviews.
Privacy invasion episodes and compromise of autonomy, competence, and relatedness (RQ2 and RQ3)
Interviewees were asked to share their prior experiences when they felt social media algorithms seriously invaded their privacy. We categorized interviewees’ responses into the themes of autonomy, competence, and relatedness.
Compromised autonomy
Many interviewees felt that their privacy was violated when they perceived the algorithm used their information without their consent or against their will (R2, R4, R8, R11, R16). Specifically, interviewees responded that when the algorithms sent pop-up ads based on their social media activities without consent (R4, R8) or shared their information with third parties against their will (R11), they felt their privacy was violated or even “stolen” (R2). An interviewee thought pop-up ads are an invasion of privacy because “I didn’t really consent to share my interest, but they just monitor my click and what I view, what I see, what I read, everything” (R8).
Apart from the consent procedure, some users also expressed more fundamental discomfort regarding the fact that algorithms choose what they see: “. . . it is curated towards things that I am interested in; to some extent, I am like, that’s what I do want to see, but it also creeps me out” (R17). Another interviewee pointed out the issue of losing a sense of autonomy more directly: I don’t think I need to be suggested about everything that I talk about or do. If I want to search for something, I am going to search for it myself. I don’t want something to be always telling me to look at this, look at that. (R9)
From the perspective of SDT, the lack of control in the sharing of personal data and choice of content represents the lack of freedom and loss of causality. In order to feel autonomous, individuals ought to perceive that they initiate something and are causing something to happen, with freedom of choice in the process. When algorithms govern the overall process of data sharing and content curation, users are left with strong resentment: I have the right to be able to share something, and then someone (on social media) has stolen that right from me, and shared something of mine or at least gotten information about me that I didn’t share with them . . . I didn’t give them the ability to know about me. (R2)
On the contrary, when users perceived that they explicitly consented to social media using their information, feelings of privacy violation were alleviated. They even mentioned that social media algorithms’ use of private information is a simple “trade-off” (R15) if users consent to the terms and conditions. One mentioned, “As long as I’m in control of what I’m sharing (with the algorithm), I’m totally happy with sharing” (R13). In the framework of SDT, this may be the case where users are in the introjection state of autonomy continuum by partially internalizing the goal (Ryan et al., 1985) while still extrinsically motivated; they believe that they can share their data with the algorithms and outsource some daily choices to get the full benefit of personalized content.
Noticing that they have very limited control over the content curation process, users also expressed concern over the evident power disparity between lay users and the algorithms. R9 says, “I just feel they already know a lot about you, so it’s not going to be difficult for them to find things about you through other ways, even if you choose the (privacy) setting now.” R13 mentions, They (social media algorithms) are able to take in my information anonymously and still target me precisely . . . I’m scared because if they are able to take in (the data) anonymously and still understand me, then they have the power to manipulate me even without knowing me.
Some users seemed to entirely give up their expectation toward autonomy in choosing what content to see and with whom the data should be shared: “I’m like,” I really don’t care. I want targeted ads to tell me what to buy. It’s okay” (R6); “They’re taking my data. I don’t care. I would say I just gave up” (R15).
In short, our findings revealed not only the procedural aspect of privacy (lack of consent) is problematic in human–algorithm interaction, but also the technological structure of human–algorithm interaction, where users entirely outsource their choice of media content, further compromises autonomy. As a result, users either give up their autonomy with resentment or indifference or remain in the introjection state where they accept that it is goal-consistent to do outsourcing as long as they give some consent in the process.
Compromised competence
Responses also revealed that algorithm interpretability is linked to interviewees’ perceptions of privacy invasion, supporting prior findings (Rai, 2020; Shin et al., 2022). Interviewees perceived their privacy was violated when they were not able to understand the underlying process of how social media algorithms worked. Particularly, when personalized advertisements and content based on their previous social media and real-life activities appeared on the feed too quickly, it further decreased the perceived interpretability of the algorithms and exacerbated physical and informational privacy concerns (R11, R14, R15). For instance, an interviewee recounted an experience where a product he verbally mentioned while YouTube was playing appeared on YouTube just minutes later (R11) and expressed physical privacy concerns regarding whether the platform might have listened to him. The quick update of algorithms also brought up informational privacy concerns regarding how the personal data were handled by the platform. For instance, R15 said, “ [After I browsed a website selling jeans] then I saw an ad from that same jeans website, and I’m thinking, no, that’s not possible. This was five seconds ago. How is it automatically updated?” The speed at which algorithms reflect user activities on social media seems to fuel a negative perception as well. Interviewees responded that it is “shocking and surprising” (R11) and “creepy” (R15) when advertisements about a certain object popped up within minutes after they discussed it or browsed it. Similarly, when the result is too precise, it triggered psychological privacy concerns: “Sometimes, when I just think about things, and I get an ad for it, and so I’m like, how in the world did that even happen?” (R17). In other words, the preciseness and immediacy of algorithmic content stirred some ironical privacy concerns since the algorithms did not allow any space for users to hide their thoughts and preferences.
Especially, interviewees felt their informational privacy violated when their activities on certain social media were shared with other social media platforms (R4, R10, R13): “WhatsApp is using my information to show me on Facebook, for example, advertising about the things that I mentioned indirectly in the chat in WhatsApp” (R4). “Cross-platform information sharing made the algorithmic suggestions less transparent and less interpretable, as interviewees “could not understand how different platforms were communicating with each other” (R15).
R10 mentioned that when an advertisement about a product previously searched on Google appeared on Instagram, it was even “intimidating” as she could not understand “how these two [platforms] are linked and how Instagram knows my Google search history.”
The SDT suggests competence relies on both skills and knowledge (Le Deist and Winterton, 2005), and proper contextual events like feedback, reward, or communication, can enhance feelings of competence (Ryan and Deci, 2000). In human–algorithm interaction on social media, none of these contextual factors is available, and the way algorithms work remains proprietary. The lack of knowledge of or communication with the algorithms is linked to informational, physical, and even psychological privacy issues; users do not know how their information, inner thoughts, and preferences are shared, listened to, or exposed. In this process, they are left with conjectures and confusion, or sometimes even fear, regarding how the recommended content could be so precise, all of which compromises their competence needs. Such non-interpretability of the social media algorithms becomes even more prominent when users see cross-platform advertisements or the ads that almost immediately followed previous click behavior. It seems that the short time lag between their click behavior and follow-up personalized content matters; the shorter the time lag is, the more they felt the experience was invasive. Often, they tried to figure out the algorithms or influence their operation by “clicking less” (R17) or intentionally “doing more search for what I want to see more often, like motivational TED talk” (R13). These endeavors suggest that our interviewees attempt to “un-black box” algorithms (Ågerfalk, 2020: 6) in order to compensate for the need for competence, but ultimately, they often reported feeling intimidated due to their lack of knowledge on how the content they view is determined by algorithms. Naturally, many interviewees expressed their desire for a more transparent system. R4 mentioned, “I think that YouTube should have a way to tell me, hey, this is why I am showing you these kinds of things, at least.”
Compromised relatedness
The SDT suggests that the need for meaningful relationships and a sense of connectedness are basic human needs. Intriguingly, we find the desire for the need for relatedness in human–algorithm interaction as well. Especially, the need for relatedness serves a significant role in privacy perceptions – it seemed that when their need for relatedness was not met by algorithms, participants felt more privacy concerns, and privacy concerns also reduced trust in human–algorithm interaction. Whereas too precise and quick recommendations can be creepy and intimidating because they threaten informational, psychological, and physical privacy and erode users’ sense of competence, irrelevant results, ironically, also seem to evoke privacy issues. Irrelevant result reminds users that the algorithm constantly follows them, analyzes their behaviors, only to provide something not useful. For instance, when asked to provide an example when she felt AI algorithms analyzing her browsing behaviors on social media, R12 brought up this incident: “I’m getting my PhD in nutrition and so I spend a lot of time looking up nutrition-related things. For a while, my computer thought I had diabetes . . . so it [algorithm] acted like I needed diabetes education . . . I’m like, “No, I just researched diabetes. I don’t have diabetes” (R12). R1 described a similar incident where she started getting ads from a brand she just researched for a class project: “I wasn’t shopping. The purpose of my search should matter [to the algorithms].” When R1 was asked whether she considered this a privacy invasion, she answered, “Yes, because I wasn’t shopping, I was researching. If I was shopping for something, it would make sense—when I am in a physical store looking at pants, it would make sense if a person came up and was like,”
Hey, have you considered these shorts? I noticed you looking at those. “[However,] when you’re researching [it doesn’t make sense], purpose of your search matters.”
In other words, when users were being classified by algorithms in the wrong way, such incidents triggered physical and social privacy concerns, specifically because their true intentions were not being understood by the algorithm. Given that they traded off their privacy for the platform to provide relevant results, as this kind of error happened, they also felt “cheated” (R13) by commercial algorithms. R12 summarized this kind of experience as: “You’re no longer getting any value, and you’re just giving out free information.” R4 expressed frustration regarding how this desire of being “listened to” by the algorithm has not been met successfully but the algorithm still attempts to push the content: “Sometimes I feel like if you show me one [irrelevant] ad once or twice, and I don’t react to it, I think they should stop showing me that advertisement” (R4).
Even if results are relevant to their interests, repetitive algorithmic content could be perceived as a privacy reduction experience as well. R10 described the following as an example of privacy violation: “Yesterday, I saw this post about an incident occurring in Korea that became viral, and then after that, I kept seeing the same post of it, but by different influencers, but it was literally the same post.” R1 pointed out, “I was going to say that I don’t mind it (personalized ad) there, but you end up seeing the same type of stuff, same types of graphic design, same types of jewelry, stuff like that, yes, I wish they didn’t curate it.” When they received repeating recommendations, it was as if someone was stalking them, invading their social privacy: “I feel algorithmized . . . it makes me feel like I’m being stalked” (R9). R7 described a similar feeling: “Then the bad thing is that there’s no way to turn that [repeating recommendations] off. It will just keep coming, keep coming, keep coming.” At the end, repetitions motivated interviewees to engage less with the algorithm-driven output: “Once I click a clothing company, it keeps showing me more and more. I try not to click it even if I’m interested because I don’t really want to see those advertisements” (R8).
On the other hand, privacy concerns about the algorithms’ use of personal information seem to be mitigated when they feel the algorithms provide inspiration or understand who they are (R1, R2). “I use Pinterest to get inspiration for things that I need to buy . . . whenever I’m trying to get inspiration from something, then I appreciate it (Pinterest) feeding things that are personal to me” (R2). “I appreciate the way they (TikTok) are using the algorithm because they’re sending me funny stuff . . . they know what my sense of humor is” (R1). Respondents even mentioned that well-targeted, personally interesting ads give them a “relaxed feeling” (R6). In this case, interviewees also appreciated what algorithms do for them as if algorithms had intentions; R2 said, “it (algorithm) is trying to personalize the platform as best as it can for me to have more use for it in my life.” Similarly, R8 appreciated, “I feel really comfortable about it [recommended video] because they [algorithms] actually recommend me what they think I would like to watch.”
In short, irrelevant results and repeating recommendations evoked physical and social privacy concerns by reminding them of how algorithms constantly stalk individuals but how the resulting communication was inappropriate and blind to their true intentions and purposes. These privacy concerns were closely related to their sense of not being understood or respected by the algorithms – in fact, those who sensed that the algorithms inspired them or understood actually reported feeling comfortable and relaxed instead of privacy concerns. These responses suggest the need for relatedness serves an important role in privacy invasion perceptions; when the need is met, privacy concerns can be reduced, whereas when the need is unmet, it triggers greater privacy concerns. In turn, privacy concerns also erode feelings of relatedness in human–algorithm interaction, which ultimately discourages users from being engaged further.
Figure 2 summarizes the role of autonomy, competence, and relatedness in shaping the privacy invasion perceptions.
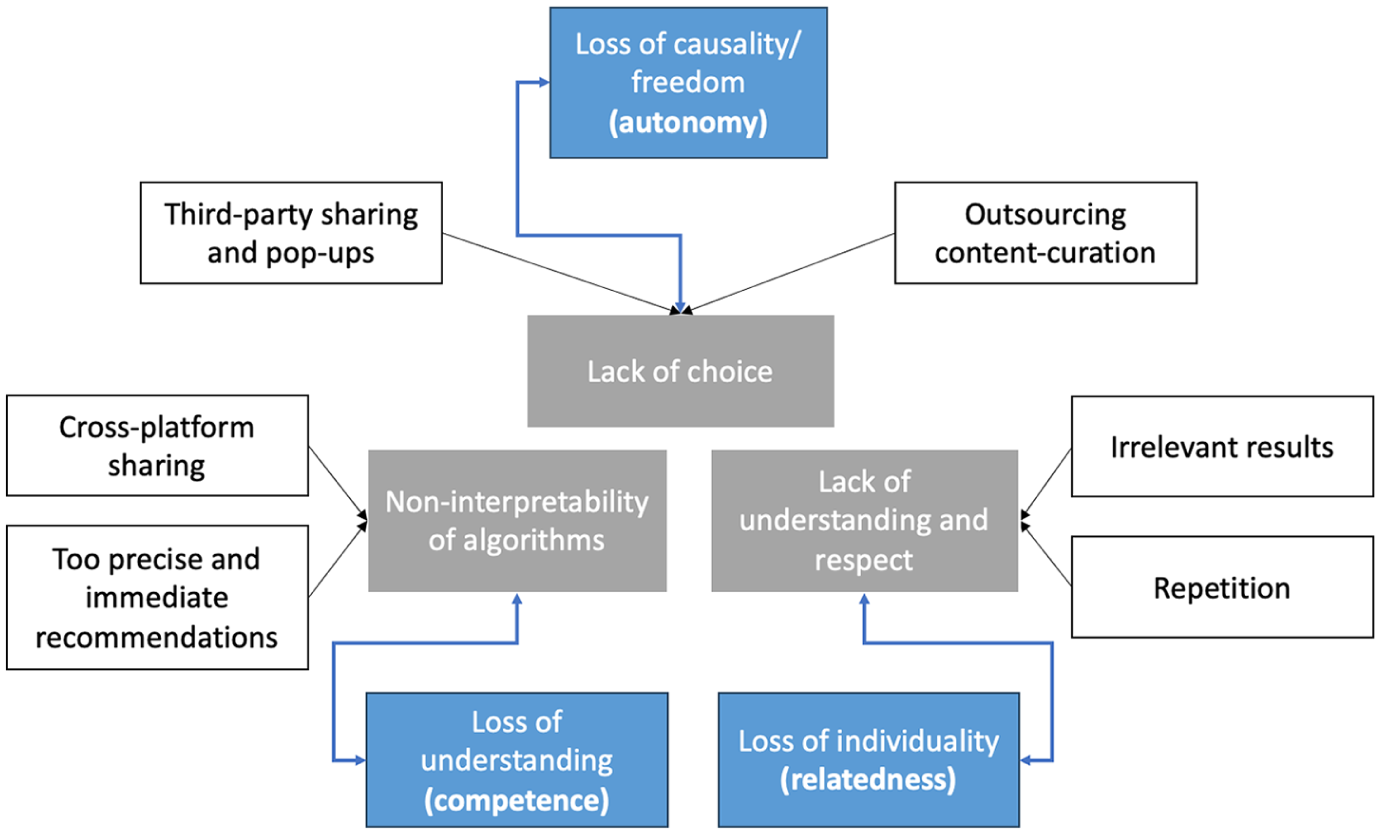
How lack of autonomy, competence, and relatedness is linked to privacy invasion themes.
Discussion
Theoretical implications
The current study extended four types of privacy previously defined in the context of interpersonal communication to the context of human–algorithm interaction. All four dimensions of privacy (Burgoon, 1982) – physical, social, informational, and psychological – were observed in the interviewees’ perceptions of privacy in the context of human–algorithm interaction. Physical privacy was most intuitively understood by the participants as we observed their desire to maintain a safe space where they can prevent the algorithms from detecting where they are and what they do. Given the mobility of our personal devices, the concept of physical privacy seems to be extended to wherever they bring their phones; interviewees were particularly worried about the location-sharing feature of the social media apps, in addition to the possibility that their phone camera and microphone can watch/listen to what they do/say. Informational privacy was most highlighted in the areas of health, finance, and relationships, but it also remained somewhat flexible since participants thought their consent to share personal information should determine what is private or not.
Findings regarding social privacy highlighted the importance of user control over the frequency and content of their interaction with the algorithms. When algorithms are perceived to contact the interviewees with unwanted content at unwanted times, it resembles the overload issue discussed by Burgoon (1982)—too many social interactions prevent individuals from creating more meaningful, intimate relationships since they do not have time to recover and maintain their private boundaries. Psychological privacy was brought up as they were encouraged to think about the actual risks of losing privacy. It seems that the abilities to construct and maintain their unique belief system and sense of identity are considered more meta-level when users define privacy. Yet once the issue was brought up, interviewees were genuinely concerned about losing control over psychological privacy surrounded by echo chambers and fake news. They felt that “applications like Instagram, they shape your perception and your ideas” (R4). Burgoon’s framework does not argue that the four dimensions of privacy are mutually exclusive; in fact, a dimension of privacy can be a natural consequence or correlate of other dimensions of privacy. For instance, only if users have physical privacy—a protected space to stop algorithms from detecting where they are and what they say—they would also have social privacy, informational privacy, and psychological privacy. We encourage future research to investigate this topic further.
Next, our findings also contribute to the understanding of the fundamental desires that underlie the feelings of privacy invasion among social media users. What were considered significant forms of privacy invasion could be categorized into three main themes, and we extended the framework of SDT to grasp why these themes were deemed important. First, the practice of pop-up ads and third-party sharing was a reminder of the lack of choice in the data-sharing process for users and the invasion of informational privacy—they felt that the social media platforms were overusing their personal information without explicit consent. In contrast, when users perceived that they provided a certain form of consent to get personalized ads, it was not considered a privacy invasion. Users’ explicit consent to the use of their information by social media was a vital factor influencing perceptions of privacy invasions, consistent with prior literature (Patrick and Kenny, 2003). As prior literature suggested (e.g. Zarouali et al., 2018), providing enough user control over what information they want to disclose or creating more accessible, easy-to-understand terms of condition seem to be a necessary step to maintain a sense of autonomy in human–algorithm interaction. In addition, the fact that pop-up ads were particularly memorable as invasive events implies that this format of advertising carries a high risk to create negative associations regarding privacy. Perhaps pop-up ads serve as a visually prominent reminder of the invasion of social privacy that algorithms can push content when users did not ask for it, which exacerbates the feeling of losing autonomy.
However, a more significant insight emerged from those who complained about the structural issue of content-curation algorithms where users’ psychological privacy was compromised—they simply do not have the capacity to make daily choices over what they read and watch. As users realize that they completely outsource the content-curation process to the algorithms, they feel the loss of psychological privacy, which signifies the loss of causality and freedom. Prior literature has analyzed this issue as “a structural opposition to accountability” (Savolainen and Ruckenstein, 2022: 7). The human decision-making process naturally presumes psychological privacy, or a mental space for reflective process of what the self likes or dislikes; thus, when algorithms make all choices for us, we are not only deprived of the choice of what to watch but also the process of how we deliberate what we really like.
With the inherent power disparity between individual users and the social media platform structure, it was not surprising to find that some users reported completely giving up their autonomy over this issue by saying this is a mere “trade-off.” As the continuum of autonomy by the SDT suggests, those who are in the introjection state partially internalize the goal as their own but still feel stressed and guilty that they are driven by external motivations. The introjection state eventually leads to the feeling of alienation, which was manifested in some of the interviewees’ dismissal of their rights to protect privacy by saying, “I don’t care any longer” (e.g. R6 and R15).
Second, informational, physical, and psychological privacy issues became prominent when users were surprised by a sudden cross-platform sharing practice or when a precise recommendation was made in a very short amount of time. The fact that algorithmic operation remains proprietary seems to exacerbate privacy concerns; as users realize that these concerns cannot be solved, it contributes to feelings of confusion, fear, and ultimately incompetence. Interviewees reported trying to decode or “hack” (R16) the algorithms, but as previous literature points out, many of these techniques remained imaginary at best (Bucher, 2017; Ellison et al., 2020). The SDT points out that individuals should possess enough skills and knowledge to complete a task in order to feel competent. Their sense of competence should be also supported by positive situational factors like positive performance feedback. Thus, users’ endeavors to influence the algorithms ultimately cannot enhance their sense of competence since there won’t be any feedback that can promote their sense of efficacy nor any direct outcome that confirms their positive performance to understand and control the recommended content. Given the lack of competence, it wasn’t surprising that most interviewees were not particularly motivated to protect privacy—they mostly just received whatever available on social media and rarely mentioned any proactive endeavors that could help them understand how the algorithms work and fundamentally change the way personalized content is given to them. As prior research suggested (Shin and Park, 2019), transparency of algorithms becomes more important in human–algorithm interaction not only to build trust and long-term engagement but also to promote their sense of competence, which is integral to privacy protection behaviors.
The lack of competency in understanding how algorithms work can easily extend to the issue of surveillance, where privacy issues are fundamentally grounded. Interviewees reported changing their behaviors by clicking less (e.g. R17) or searching positive content (e.g. R13) to meet the algorithms’ operation while also feeling intimidated and creeped out by the non-transparent, but precise recommendations. As the classic literature of panopticon implies, when individuals are not sure whether they are being watched or not, they must act as if they are; when we can’t see the presence of the watchers, we internalize their gaze and act according to their principles (Nissenbaum, 2009). Thus, the non-interpretability of algorithms is not just a matter of competence either – understanding how algorithms work provides a necessary material condition for users to be free from the constant anxiety of being watched and analyzed.
Third, users acutely noticed privacy invasions when the recommended content was irrelevant or repetitive. SDT explains that individuals not only yearn to connect with others but also receive affection and care in return in order to build a meaningful relationship (Ryan and Deci, 2000). As users disclose more personal information, it seems that they also expect the algorithms to truly understand and respect their needs. The failure of algorithms to meet their personalized needs seems to trigger privacy concerns and hurt algorithmic intimacies (Savolainen and Ruckenstein, 2022) that users try to build—interviewees think the intention of their search or what they really want should matter to the algorithms—otherwise, it is considered to be invading their (psychological) privacy; they also expect algorithms to respect their behaviors if they make it clear that they don’t like something.
Whereas prior literature explains users’ behavior to make their posts more “algorithmically recognizable” (Bucher, 2017: 37) as part of optimization strategies, we would argue that such behaviors are grounded upon a more fundamental human need to be recognized and understood by someone, even if it is just an algorithm that they interact with. From this perspective, it also makes sense that repetitive results were considered particularly invasive and induced social privacy concern—a sense of being stalked—since those recommendations would be clear indications of not being understood and respected by the algorithms. Ultimately, when algorithms fail to understand users’ relatedness needs, it is connected to the loss of privacy and individuality. Users feel that they are profiled by algorithms (Bucher, 2017) or treated as commercial values (van Es and Poell, 2020), which compromises both their boundaries for being independent and their fundamental need for relatedness.
Practical implications
Our study findings could offer far-reaching implications not only for individual users and algorithmic social media, but also for broader societal, political, and economic systems. The results highlight social media users’ significant concerns around privacy, particularly the lack of consent and transparency in how social media algorithms operate. This underscores the need for policymakers to implement stricter regulations on data privacy, consent mechanisms, and the transparency of algorithmic processes. Such measures are particularly important in the context of social media, where defining privacy boundaries is complex yet essential for safeguarding personal digital space, social connections, and the sharing of information. Moreover, the negative perception of privacy-invading practices on algorithmic social media suggests that the social media industries may need to reshape their advertising and personalization strategies. As consumers demand less intrusive personalization, and as regulatory bodies potentially impose stricter restrictions on the use of personal data for targeted advertising, these industries may face economic pressure to shift toward less invasive forms of personalization and advertising, allowing for greater user agency.
Moreover, our findings on users’ concerns about psychological privacy and echo chambers point to broader cultural shifts toward the normalization of surveillance, with potential implications for social inequality. For instance, less digitally literate groups may be disproportionately impacted by the opaque algorithmic practices that our interviewees commonly brought up. Policymakers may need to expand privacy laws to include algorithmic accountability frameworks, such as mandatory audits conducted by third parties, and international coordination for cross-platform data governance. In addition, both our study and emerging scholarship increasingly highlight users’ feelings of alienation and helplessness. As such, policymakers could integrate users’ mental health considerations into algorithmic regulation.
Our findings also provide practical insights for algorithm developers and social media platforms. Given users’ frustration about the uncontrollable length of social media consumption, they may appreciate platforms incorporating “design friction” such as screen time reminders (Zimmermann and Sobolev, 2023); these nudges could enhance users’ awareness and control of time management on social media. Such strategic interruption of user experience could also manifest as reminders of prior consent. Relatedly, thoughtful delays of personalized ads may buffer negative sentiments about the immediacy of cross-platform sharing. Prudently timed ads may achieve “moderate personalization” that evades privacy concerns as suggested in our data, with greater potential for balancing ad effectiveness and user satisfaction.
Conclusion
Our in-depth interviews with 17 social media users provided richer stories of how privacy-invasive practices of social media algorithms compromise the needs for autonomy, competence, and relatedness. The lack of choice in content curation and data-sharing practices, the non-interpretability of algorithmic suggestions, and the lack of understanding and respect that users experience from human–algorithm interaction turned out to be significant factors that diminish their fundamental needs for autonomy, competence, and relatedness. Overall, our findings advocate greater transparency of algorithms and more respect for users’ choices and individuality. Sustainable algorithms should enhance users’ autonomy and cognitive competence in understanding the link between their input and algorithmic decisions and foster the sense of relatedness that users’ needs and goals are being truly understood by the algorithms. SDT suggests that when the three fundamental needs are not met, their intrinsic motivation and growth diminish. Human–algorithm interaction without enough autonomy, competence, and relatedness would not be able to engage users in the long term.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Meta Platforms, Inc. (People’s Expectations and Experiences with Digital Privacy Research Grant).