
Abstract
This article presents a novel methodology to examine the tracking infrastructures that extend datafication across a sample of 14 menopause-related applications. The Software Development Kit (SDK) Data Audit is a mixed methodology that explores how personal data are accessed in apps using ChatGPT4o to account for how digital surveillance transpires via SDKs. Our research highlights that not all apps are equal amid ubiquitous datafication, with a disproportionate number of SDK services provided by Google, Meta, and Amazon. Our three key findings include: (1) an empirical approach for auditing SDKs; (2) a means to account for modular SDK infrastructure; and (3) the central role that App Events—micro-data points that map every action we make inside of apps—play in the data-for-service economy that SDKs enable. This work is intended to open up space for more critical research on the tracking infrastructures of datafication within our apps in any domain.
Keywords
Since the pandemic, FemTech—a portmanteau for “female technology”—has rapidly expanded (Erickson et al., 2022; Mehrnezhad et al., 2022), catalyzed by the promise that these apps and devices might finally close the gendered data gap (Perez, 2019). The FemTech industry, currently valued at US$60 billion (Statista, 2024), provides women with new ways to manage health conditions ranging from maternal health, sexual health, and menopause. This fast-growing and largely unregulated marketplace raises concerns about who truly benefits, especially as more women turn to these apps and share intimate health data—sensitive information about women’s bodies, health, sex, gender, sexual orientation, close relationships, online searches, reading habits, or even private communications (Citron, 2022a, 2022b). In the United Kingdom, for example, nearly half (49.5%) of the population experience menopause but only 59% of general practitioners have received adequate training to recognize and manage related symptoms (Arnot, 2023). This lack of medical support has driven many women to seek help from these apps, the limited regulatory protection for this kind of intimate health data notwithstanding (Schäfke-Zell, 2022). Our article presents a novel method for auditing the infrastructures of datafication that underlie how a sample of FemTech menopause apps are tracking end-user behavior.
The primary means by which health data are shared between apps and advertisers is through “Software Development Kits” (SDKs). This understudied infrastructure offers manifold services and represents the building blocks of app creation. SDKs are “modular” connectors that come preloaded with an array of tools and code, representing an integral part of the software supply chain in our apps. Because their primary function is to connect apps to third-party services, they contain several APIs (application programming interfaces) that amplify their capacity to profile and track end-users (Pybus and Coté, 2024; Gontovnikas, 2020). Platform companies like Google, Meta, and Amazon provide a disproportionate number of these services, which affords them greater access to end-user data as developers become increasingly dependent on their use. While apps are supposed to adhere to existing privacy regulations, their infrastructure is complex and constituted by myriad actors who provide proprietary software within a data-for-service economic model. Consequently, the back-end of applications is opaque, creating blind spots for regulators and policymakers.
The following discussion examines how apps and third parties work together to capitalize on women’s health data. We propose a novel methodology to audit the tracking infrastructures that break down the datafied body into intimate, discrete, and actionable data points. We argue that the modularity of the SDK plug-and-play service delivery has been overlooked, with little attention devoted to understanding how this infrastructure can intensify digital surveillance. Our mixed methodology, which we term the SDK Data Audit, is attentive to the formation of these modular practices, providing a way to examine and account for how applications process and share user data. We have created three SDK Discovery Tools that delineate Google, Meta, and Amazon’s services, and engaged a large language model (LLM), ChatGPT4o, to audit Android manifest files (which are documents that account for every data point that can be shared between the end-user device, the developer, and the third parties embedded in apps). Our study of menopause apps offers three key findings which advance the study of the mobile infrastructures of datafication, highlighting asymmetries that span well beyond the domain of FemTech applications. We provide: (1) a more granular and expansive approach for auditing mobile app surveillance; (2) a means to assess the modular service infrastructure of SDKs; and (3) evidence of how “App Events,” the micro-data points which map every single action we take inside of apps, should be understood as a fundamental conduit for datafication. We see this work in dialogue with policymakers who want to develop more meaningful ways to augment agency and choice for women who deserve menopause apps that do not track, profile, and effectively compromise their intimate health data. In so doing, we aim to contribute to a safer and more empowering regulatory environment.
Personal and intimate health exposed: FemTech tracking infrastructures
Within scholarship on FemTech, there is growing consensus that there are not enough safeguards for protecting health data, which puts the security, privacy, and safety of women who use these services at risk (Jacobs and Evers, 2023; Mehrnezhad et al., 2022; Scatterday, 2021). Data governance and privacy issues are further exacerbated when considering that intimate data sell for 50 times more than the price of credit data, making it highly lucrative to monetize (Gilman, 2021; Mehrnezhad et al., 2024). These scholars underscore the significant privacy concerns related to FemTech applications and technologies, specifically in how they handle intimate data. Mehrnezhad et al. (2022) argue that the potential risks associated with FemTech technologies outweigh their benefits, especially given the extensive amount of health-related data that can be used to reveal intimate insights about the female body and mind. Erickson et al. (2022) identify several privacy harms stemming mainly from the illegal and unregulated use of health data sold to US workplaces, insurance companies, or data brokers. In addition, privacy risks also emerge when personal and intimate data are inferred from data that have been anonymized or de-identified.
Consequently, feminist legal scholarship has raised alarms about the lack of data protection in the context of unrestrained corporate intimate surveillance enabled by these apps and devices (Citron, 2021; Gilman, 2021; McMillan, 2022). Further regulatory challenges arise because these data are not classified as health data within its traditional definitions, creating what Schäfke-Zell (2022) describes as a legal “gray area” in applying for health data protection. App stores then compound these legislative challenges by allowing the majority of FemTech apps to be categorized as “health and fitness” instead of “medical,” further instantiating the claim that these apps are gathering non-medical health data and leaving users more vulnerable to their monetization strategies (Rosas, 2019; Scatterday, 2021; Shipp and Blasco, 2020).
For app users who share data about their intimate bodies, there are scant resources beyond privacy policies to help women discern meaningful differences in how ostensibly “similar” apps might be accessing and sharing their data. Yet, FemTech app users rated third-party access to their data among their top two privacy concerns (Cao et al., 2024). Since SDKs have a “modular” structure—in that they constitute “structurally independent” units that are highly interconnected (Baldwin and Clark, 2000)—developers can use as many or as few of their services to monetize their apps, affording them different degrees of surveillance (Pybus and Coté, 2024). However, few resources or methods are available to study their modular infrastructure. We aim to fill this gap with a methodology to audit these tracking infrastructures that facilitate datafication in our applications.
The widely cited walkthrough method developed by Light et al. (2018) provides invaluable guidance for inferring surveillance practices in our apps; however, it encounters an opacity challenge in accounting for how SDKs (primarily provided by platforms) are enacted in the back-end. While it is no surprise that all apps access our data, some apps collect and share far more than others—how and through which processes this asymmetry manifests is not immediately apparent. Addressing this problem, we present the SDK Data Audit to move beyond merely identifying trackers toward more comprehensively quantifying and qualifying the monetization services embedded in our apps. We do so by providing tools and an empirical approach that will enable more focused inquiries into how third parties can access intimate data and offer a means to assess which apps have a higher potential to cause privacy harms through intimate surveillance.
Datafication of SDK tracking infrastructures in apps
SDKs have increasingly become an object of study within app studies, which focus on the complex and multi-situated infrastructures of apps (Dieter et al., 2019). This scholarship highlights the relationality between SDKs and apps (Pybus and Coté, 2024; Gerlitz et al., 2019; Van der Vlist and Helmond, 2021), their relationship to datafication (Flensburg and Lai, 2022; Pybus and Coté, 2021; Lomborg et al., 2024), and their role in extending platform power and monopolization (Cohen, 2024; Nieborg et al., 2024; Blanke and Pybus, 2020). This literature has also been informed by discussions about the relationship between infrastructures and platforms, wherein Plantin et al. (2018) have argued that platforms are becoming infrastructuralized. Similarly, SDKs are an integral component of this infrastructuralization, such that it is now almost impossible for developers to make apps without platforms, allowing new dependencies to emerge.
From a political economy perspective, SDKs are also intensifying surveillance- (Zuboff, 2019), data- (West, 2019), and/or platform- (Srnicek, 2017) capitalism by facilitating data extraction and monetization in exchange for their services. Scholarship focusing on the datafied infrastructures of applications also interrogates how these agents facilitate complex end-user data extraction (Flensburg and Lai, 2022; Flensburg and Lomborg, 2023; Pybus and Coté, 2021) by privileging its non-rivalrous qualities. This foundational logic, which underscores the app economy, facilitates the continuous (un)coupling, (re)use, and seamless (re-)integration of end-user data to produce value in this new data-for-service economy (Blanke and Pybus, 2020). Thus, SDKs can represent a conduit for platformization (Poell et al., 2019; Van Dijck et al., 2018), making mobile applications more “platform-ready” (Helmond, 2015; Poell et al., 2019). They achieve this by extending the multi-sided business model (Rieder and Sire, 2014; Van Dijck et al., 2018), which positions developers as new complementors (Van Dijck et al., 2019) for platforms by offering an extensive range of monetization and development services (Pybus and Coté, 2024). Yet despite this rich literature, few methodologies exist for auditing SDK services in apps.
Auditing mobile infrastructures
Auditing techniques have been proposed to enhance transparency in data-driven systems (Mittelstadt et al., 2016; Sandvig et al., 2014). One approach we draw on is “code auditing,” which aims to discern which technical and legal harms might be embedded. However, as Sandvig et al. (2014) caution, this approach alone would be insufficient without a broader perspective attentive to the normative discussions of having “accountability by auditing.” That is, if auditing is to be effective—which for apps would ideally facilitate the detection of privacy harms and/or risks—we must have a clearer idea about how we want these technologically advanced systems to behave (Sandvig et al., 2014). The SDK Data Audit addresses this question by developing a methodological intervention attentive to the modularity and behavior of SDKs embedded in apps. In so doing, we compare our analysis of what resides in the back-end, with the existing governance tools in the front-end (i.e. privacy policies and Data Safety Agreements) to ask if they align or whether there are discrepancies that can be observed.
Auditing SDKs comes with several challenges. Apple, for example, is a closed ecosystem that prevents meaningful external oversight or inspection. Subsequently, almost all research, including ours, has focused predominantly on the open-source Android ecosystem, wherein the code for any app in the Google Play Store is made accessible in objects known as Android Package (APK) files. Databases like Exodus Privacy (n.d.), which display the third parties and privacy permissions inside most Android applications, are helpful but as we shall demonstrate, only partially reliable. Other considerations must also be made when choosing how to audit mobile applications. For instance, some scholars interested in these questions have developed mixed methodologies that examine the networked relationship between apps and platforms (Weltevrede and Jansen, 2019), developed tools to make API codes and privacy permissions more visible (Chao et al., 2024), mapped partnerships that emerge from SDKs (Helmond and Van der Vlist, 2021), or categorized the services third parties provide (Pybus and Coté, 2024). Building on this work, we have focused on two key objects: manifest files and SDKs.
Android manifest files, located in APK files, represent a record of every data requisition that will be enacted by an application (Pybus and Coté, 2021). Like a ship’s manifest that names every person on board, an Android manifest should list every way an app and its third parties access data from an end-user’s phone. These are interesting files to qualitatively explore, namely because they contain: (1) all the AdTech SDKs; (2) privacy permissions, which are labeled in accordance with the level of risk deemed as either “normal” or “dangerous” by Google. 1 “Normal” permissions are described as low risk, so the end-user is never alerted to their presence. “Dangerous” permissions should be listed because they give access to more sensitive data such as location, microphone, or contacts; and (3) metadata tags, which can automatically turn on or off software identifiers like Ad IDs or analytic tracking.
Next, to examine SDKs, Pybus and Coté (2024) offer a taxonomy which we have adopted in our methodology to account for the AdTech services in the menopause apps. This provides three distinct kinds of service clusters (development, app extension, and AdTech services), and we have decided to focus only on those services that enable monetization. These AdTech services break down further into: attribution services (tracking that occurs predominantly outside of apps to see if ad campaigns are working), engagement services (tracking within apps used for behavioral profiling and audience segmentation), and advertising services (delivery of ads by services such as ad networks and exchanges that SDKs provide).
The SDK Data Audit
The manifest file is one of the most valuable documents for auditing Android apps, but it is primarily structured for machine readability rather than human comprehension. We questioned if ChatGPT4o could be used to make these manifests more legible. ChatGPT4o is a LLM that enables the processing of significantly larger datasets. The “GPT” stands for generative pre-trained transformers (Campello de Souza et al., 2023), developed to perform various tasks in real-time, based on prompts or questions. What differentiates OpenAI’s model is its scaled-up capacity to closely mimic human conversation (Roumeliotis and Tselikas, 2023). However, how it communicates raises serious concerns, especially around the accuracy of its information, potential misinformation (such as hallucinations), and the replication of biases, discrimination, and stereotypes in its responses (Lambert and Stevens, 2024). Despite these challenges—and its significant environmental impact (Haque and Li, 2024)—ChatGPT4o’s semantic capabilities offer a possible opportunity for code explanations and auditing, opening a potential new space for critical engagement with inaccessible technical objects.
The SDK Data Audit methodology, illustrated in Figure 1, uses four steps to compare and triangulate our findings. This involves: (1) opening an app’s APK file (containing the manifest and SDKs), (2) analyzing manifest files with ChatGPT4o, (3) consulting Exodus Privacy, 2 and, finally, (4) examining the app’s Data Safety and privacy policy agreements. We selected 14 menopause-related applications from the Google Play Store across the United Kingdom, European Union, United Sates, and Canada to evaluate our mixed methodology. Our main criteria stipulated that apps appear under the category “menopause” and have a minimum of 10,000 downloads. We then downloaded their APK file from either APKpure or APK Mirror (open-source databases) and used an open-source decompiler tool called ClassyShark 3 to open and read these files in order to access their manifests and the third-party SDKs. 4 Next, we imported the manifest files from ClassyShark into ChatGPT4o and asked the LLM a series of questions informed partly by a growing body of prompt engineering literature (Giray, 2023; Henrickson and Meroño-Peñuela, 2023; Marvin et al., 2024).
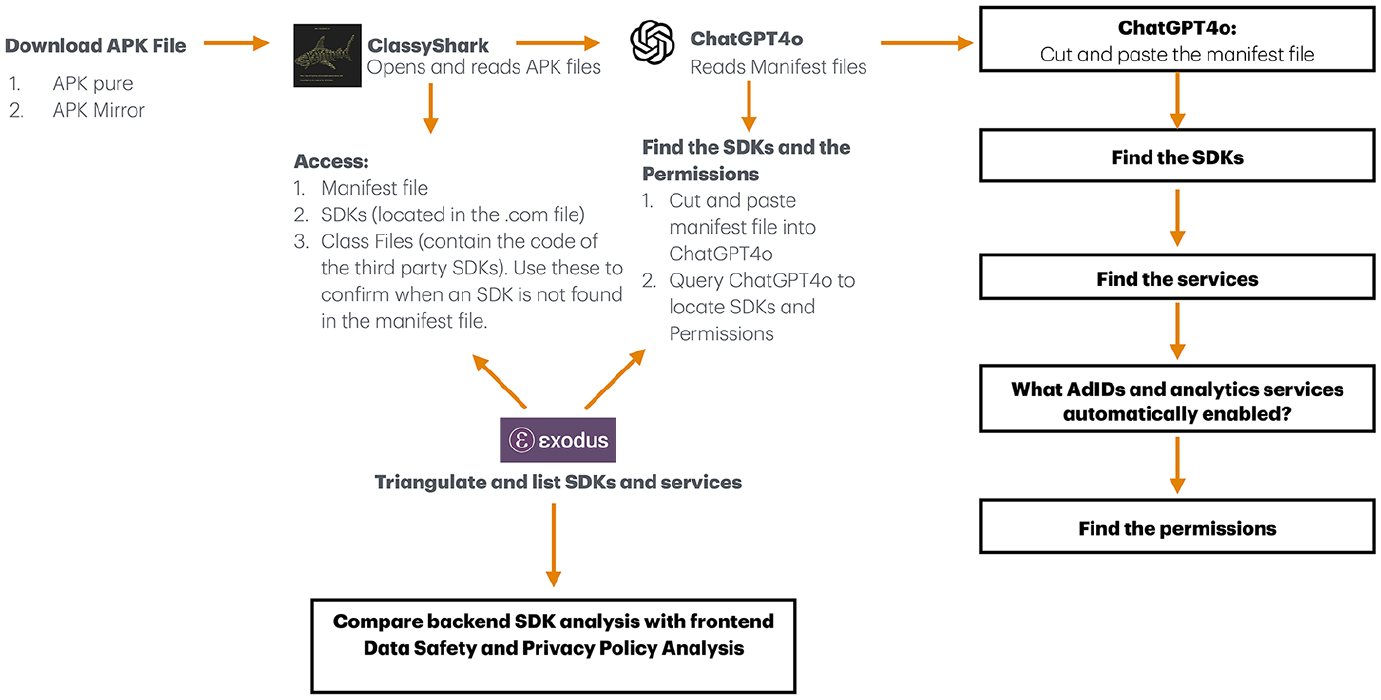
The SDK Data Audit method overview.
To minimize inaccuracies and enhance our results’ repeatability, we used a strategy known as “specifying output structure” (Azure OpenAI, 2024), which directs ChatGPT to “cite” and refer to the source material, which in our case meant the manifest file. We then used this document to discover: (1) the SDKs, (2) the SDK services that were integrated, (3) whether Ad Identifiers and analytic services were automatically enabled, and, finally, (4) the permissions that were inside the app, which we have put aside for further research. To facilitate comparisons, we focused only on third parties used for monetization to align with the “trackers” listed by Exodus Privacy. We then categorized the SDK services our apps were using in accordance with the AdTech services in Pybus and Coté’s (2024) taxonomy. In this step, our emphasis was not on quantifying the number of third parties, but rather on qualifying how these services were being used to access end-user data by identifying their purposes—namely: attribution, engagement, or advertising.
Finally, we compared our findings with our apps’ privacy policies and Data Safety Agreements, the two key documents available to end-users. Here, we evaluated differences in how data access was reported and observed in our SDK Data Audit. For this step, our aim was not just to reveal whether end-users were being tracked—this much is obvious—but rather to understand how this tracking infrastructure is mobilized by third parties and, equally, to ascertain differences in how apps datafy, profile, and track their users. As a corollary, when our findings revealed a disproportionate number of SDK services were providing App Event analytics, we supplemented our method with the walkthrough method (Light et al., 2018) to assess what intimate health app events could be tracked in our sample. While it is beyond the scope of this article to create a new metric that demarcates a “threshold” which might determine how little or how much an app accesses our personal data, our research addresses the need for new resources so that end-users, like the women using these apps, can make more meaningful and informed choices based on how their data are leveraged within this service-for-data economy.
SDK Discovery Tools for a modular data-for-service economy
As we applied our methodology and cross-matched results with Exodus Privacy, we immediately noticed what we might call a “translation” issue. Exodus Privacy (n.d.) refers to third-party software found in apps as “trackers,” which they define as “pieces of software meant to collect data about you or what you do.” However, given that both an SDK and its services are software, how do we distinguish between the whole and its parts? This is an especially important consideration because the parts in question access and action data differently, which can intensify value extraction depending on the developer’s in-app monetization strategy. We are using the more technical term for trackers—SDKs—to distinguish between the whole SDK and the sum of its service parts (Pybus and Coté, 2024). This allows us to emphasize why SDKs’ modular infrastructure matters. In short, the more services embedded by the developer, the more significant the app’s data collection capabilities will be. Thus, by distinguishing between an SDK (like Firebase, AdMob, or Google AdManager) and their services (such as Google Analytics, Crashlytics, or Dynamic Links), our methodology critically examines the different types of end-user data which result from embedding their unique services.
Labeling third-party SDK components as “trackers” obfuscates the extensive ways in which each service has the potential to amplify extraction. This is particularly relevant when examining “Super SDKs” (Pybus and Coté, 2024) that belong to major platforms like Google, Meta, and Amazon. Theirs are the most common and offer the most significant number of services, creating new dependencies for developers. Thus, by embracing the complexity of the SDK taxonomy, our more granular approach exposes the underlying relationships between developers, SDKs services, and access to end-user data, that go well beyond simplistic notions of “tracking.” Instead, we provide a more comprehensive understanding of how datafication occurs inside apps.
The SDK Data Audit demonstrated that many Super SDK services were only partially represented in Exodus Privacy. For example, in all three of Google’s AdTech SDKs in our sample, we found 17 monetization services, while Exodus Privacy named only five trackers. Since the SDKs belonging to platform companies were among the most prominent, we decided to create what we have called “Super SDK Discovery Tools” that: (1) compare the differences between our SDK audit method and the Exodus Privacy database; (2) develop a clearer way to distinguish between SDKs and their services; and (3) facilitate a more consistent approach to code these services in the manifest file. The Super SDK Discovery Tools in Tables 1 (Google), 2 (Meta), and 3 (Amazon) should be read as “living” tools, which will inevitably change and evolve alongside platform service offerings. These are guides we created to streamline our decisions about which modular services to account for in the platform companies we encountered throughout the SDK Data Audit. They also briefly summarize what each of these services do by applying the SDK taxonomy created by Pybus and Coté (2024).
Google firebase, AdMob, and Ad Manager SDK Discovery Tool.
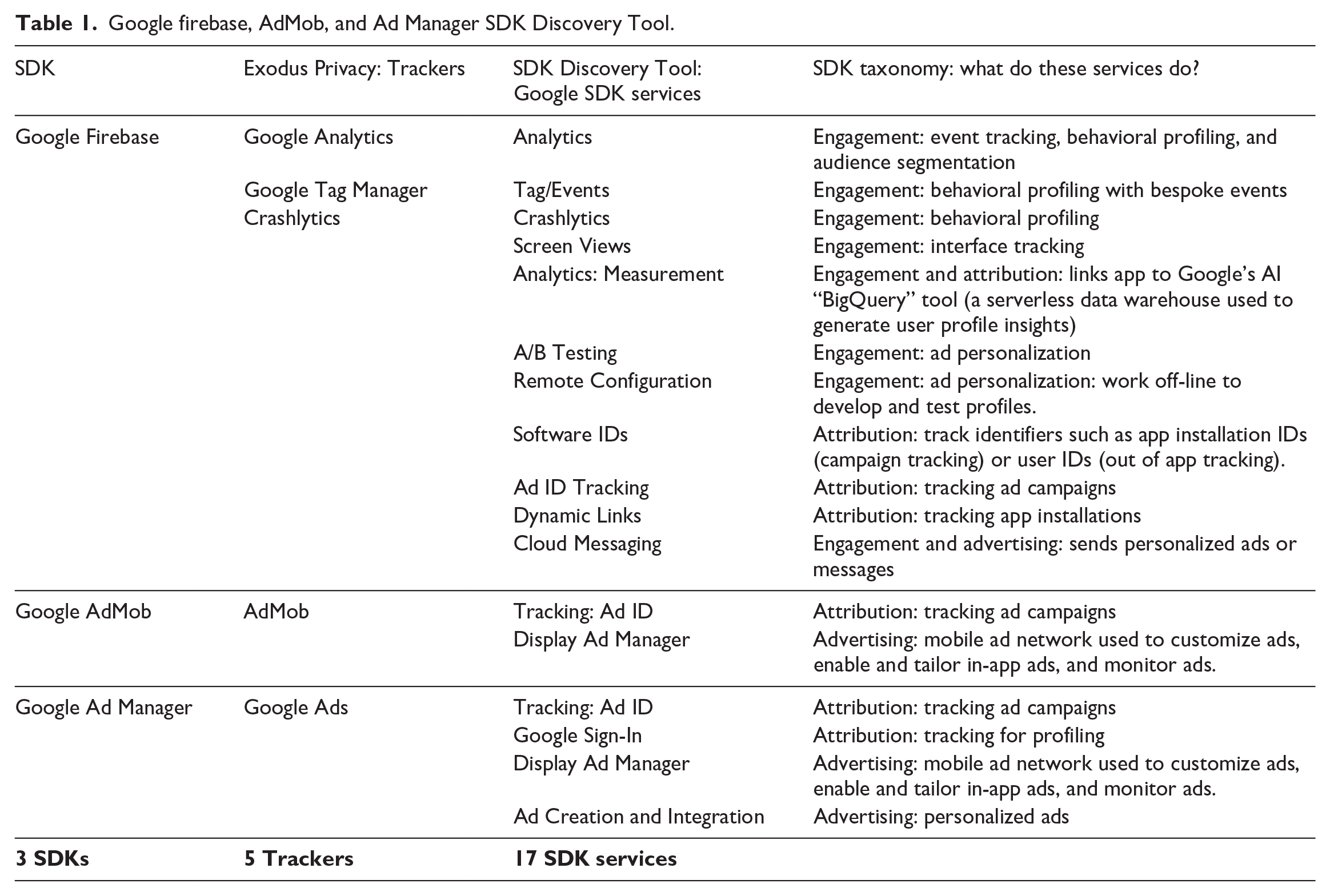
Meta Facebook SDK Discovery Tool.
Amazon SDK Discovery Tool.

The services that we have included in our Discovery Tools have all been verified and cross-referenced with the developer tools provided by Google (Firebase, n.d.; Google, n.d.-a), Meta (Meta, n.d.-a), and Amazon (Amazon Developers, n.d.). In some instances, services appeared ambiguous or unclear and we could not immediately discern if they were used for monetization; these have been excluded. Other services, which seemed more like “features,” have also been excluded. For example, apps like “Balance” and “Health and Her” were both using Google Analytics and had this code in their manifest files:
<meta-dataname=
We decided against using “Ad Personalization” as its own service because it appears more like a feature of Google Firebase Analytics. However, since this feature is turned on (“value = true”), Health and Her is named in our results as an app with its Advertising Identifiers automatically enabled. To sum up, the SDK auditing tools represent our decisions on what counts as an Ad Tech service. Others may disagree, highlighting an important research challenge: What counts as an SDK? What counts as a service? And, how do we create better ways to agree on these distinctions? Thus, these Discovery Tools should be considered a starting point for more critically engaged SDK scholarship which would focus on making platform services that access end-user data more legible and accessible.
Findings from the SDK Data Audit: how menopause apps leverage the data-for-service economy
The SDK Data Audit reveals three key findings that demonstrate the value of our methodology and highlight the need for further research into the infrastructures of datafication that reside within mobile applications. These can be summarized as follows: (1) the methodology provides a more granular and explainable approach to analyze SDK services, surpassing the capabilities of resources like Exodus Privacy; (2) a means to examine SDKs’ modular infrastructure, which intensifies datafication within mobile applications; and (3) insight into the overlooked importance of “App Events,” the cornerstone for the data-for-service economy, constituting foundational infrastructure for the analytic services that SDKs provide.
SDK Data Audit versus Exodus Privacy: Our SDK analysis (Figure 2) demonstrates discrepancies between the APK files we examined in ClassyShark, the manifest files we examined with the Discovery Tools and ChatGPT4o, and finally with Exodus Privacy. These differences primarily arose from how we accounted for SDK services, especially within Super SDKs. Auditing the manifest files with ChatGPT proved successful 5 and closely aligned with what we observed in the original APK files. This outcome was intentionally orchestrated. The prompts for ChatGPT4o were meticulously fine-turned until the LLM reflected what we saw in the original APK file. Thus, if something were missing, we would prompt ChatGPT4o to double-check its work, or we developed specific prompts to alleviate any inconsistencies we were observing. For example, while Google Firebase Analytics consistently appeared in our results, other services like Firebase’s “Events” and “A/B testing” required specific prompt adjustments for ChatGPT4o to register them. By the end of our experimentation, the LLM gave us fairly consistent and repeatable results with the prompts we developed. Choices were also made about which SDK services to include in the Discovery Tools. For instance, ChatGPT4o identified 15 Google Firebase services inside Omena’s manifest file, but we included only the 9 we could verify via Firebase’s developer website. These decisions highlight more general challenges for auditing SDKs and using LLMs—a burgeoning area for further study.
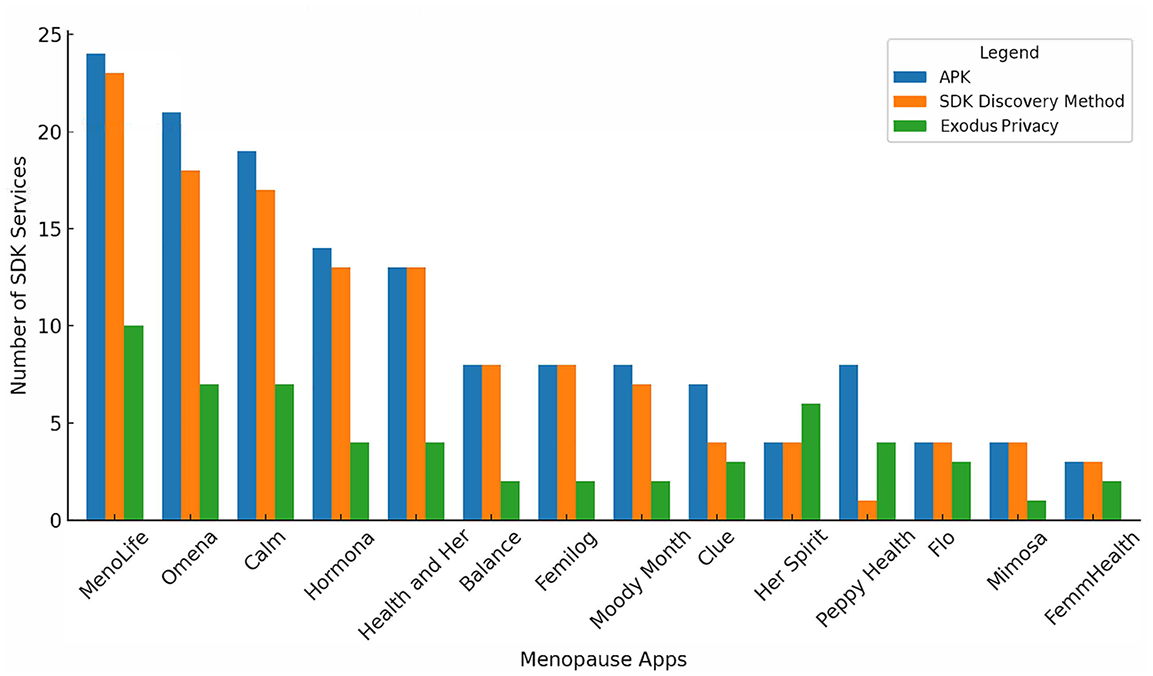
SDK services inside menopause apps.
Our final observation here was that not all the SDKs were listed in the manifest files, despite this being the expected requirement (Google, n.d.-b). For example, Mixpanel, an event analytic service for tracking and profiling users, was found in Her Spirit, Hormona, MenoLife, Omena, and Peppy Health. However, only Her Spirit correctly declared this in their manifest file. Similarly, Sentry, an analytic reporting service, was only identified in the manifest of two of the four apps using this service in our sample. These may be legacy SDKs, but there could have also been an oversight by developers who forgot to account for them. Regardless, third-party SDKs cannot be captured if they do not exist in the manifest file that ChatGPT4o is examining. We set these findings aside for further research.
2. Discovering the modularity of SDK services inside our apps: The SDK Data Audit reveals variations in the number of SDK services developers integrate when building apps, offering unique insight into the technical implementation of monetization strategies. Figure 3 shows significant divergences between the menopause apps we audited. For example, MenoLife and Omena draw upon almost every single Super SDK service from Google and Meta, using 22 of their 23 AdTech services. Conversely, Flo, Her Spirit, and FemmHealth have embedded only one to three services each. From this vantage point, we argue that privacy risks and harms can be exacerbated with the number of embedded services that can intensify the capture and use of personal data. And yet, the different degrees of integration remain hidden from the end-user. Instead, the only information we are provided when deciding which app is safe to download is vague declarations that it “may” have third parties or has Google Firebase installed.
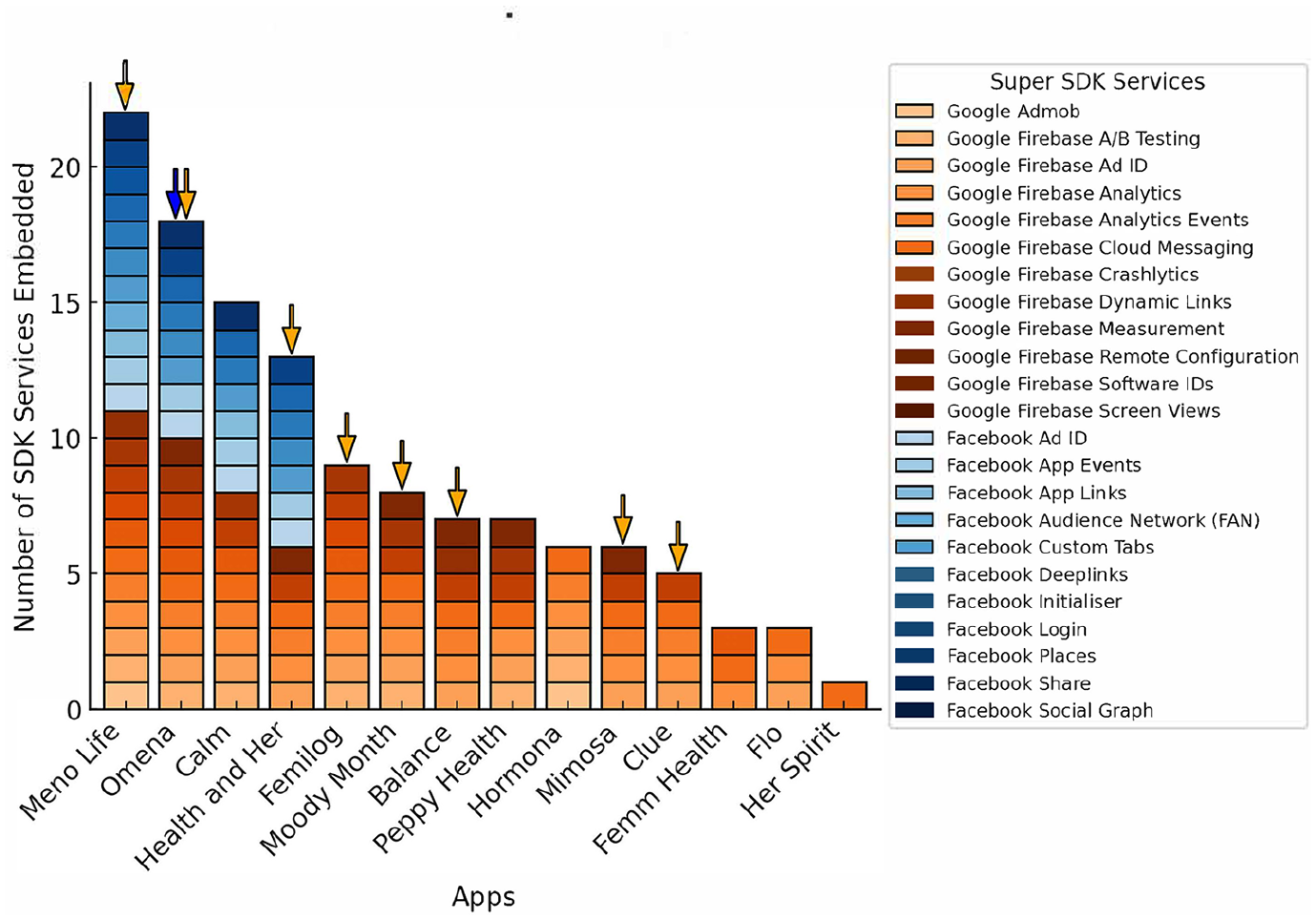
Super SDK services in menopause apps.
A closer look at the kinds of monetization services these apps have embedded reveals that seven apps use Firebase’s A/B testing and Remote Configuration services (Google, n.d.-c). This combination enables streamlined “marketing experiments” by allowing developers to test app features, campaigns, and targeted messages to profile and engage end-users. The remote configuration features enable these experiments to run even when the app is not actively in use. In addition, 10 apps employ Firebase’s Measurement service, which connects them to Google’s advanced AI-powered cloud tool, BigQuery. This serverless data warehouse equips developers with the ability to track user behavior in real-time, providing insights about their interactions with App Events (discussed in depth below). Subsequently, the scope and scale of these modular platform services streamline how apps datafy end-user behavior and this audit offers more nuanced insights into how this surveillance is conducted. Reducing this complex infrastructure to mere “trackers” obscures this more granular perspective, which can more fulsomely demonstrate the difference between how an app like MenoLife versus Her Spirit is more intensively leveraging Firebase’s services.
Finally, our method reveals that Ad IDs (Advertising Identifiers used to track and serve ads to end-users) are yet another modular service developers can activate or disable. These allow apps to track end-users across different devices to measure which ad campaigns they have encountered, and which have been successful; we can call these attribution services. While they do not directly access sensitive user data, they still track location and other private information. Apple’s App Tracking Transparency offers users more control over this dataveillance affordance with the clear opportunity to turn these IDs off, whereas to date, Android does not. Our results, in Figure 3, reveal that eight apps (with orange arrows on top) have automatically enabled tracking Ad IDs with Google, and one app (with the blue arrow), Omena, has automatically enabled Ad IDs with Meta without clearly indicating that they are in use.
These findings raise concerns about representing when tracking is enabled without explicit consent. While end-users should ideally have a choice, the approach varies among apps. For instance, of the six remaining apps in Figure 3, two (Her Spirit and Femilog) have chosen not to include Ad IDs. In contrast, the other four apps (Calm, Flo, Hormona, and Peppy Health) include them but have not enabled them by default, thereby allowing end-users to opt out of tracking when the app is downloaded. This difference highlights the varying degrees of user agency across the apps. Arguably, having these tracking features more clearly explained and represented is even more critical in FemTech apps, primarily because the intimate data they generate are often used for targeted advertising in a wholly opaque manner. These findings also point to the need for more meaningful modes of consent given the manifold ways in which the modularity of SDK services can access end-user data.
3. App Events: Supercharging the data-for-service economy: Finally, the SDK Data Audit reveals the prominent role of App Events’ in the datafication of how FemTech end-users log their interactions within these apps. Here, our findings show that each app in our sample uses some kind of analytics service. Google Analytics is the most popular, with 13 out of 14 apps using it, represented in Figure 4. App Events are provided by companies that offer a range of analytic tools to analyze every “action performed by users within an app [that] a developer or marketer chooses to measure” (Adjust, n.d.). These can include anything from what users click on, when they log in, and what they look at or purchase. They provide deep insights into behavior and preferences and promise to facilitate different data-driven decision-making that can drive in-app optimization for monetization and engagement strategies (Field Drive, n.d.). App Events, therefore, represent an increasingly lucrative site of investment. Services like Firebase Analytics (which includes Google Analytics) provide 500 different pre-made events built into their dashboard for developers to leverage. These might include actions like: “search,” “select content,” “select an item,” “click,” or “notification open.”
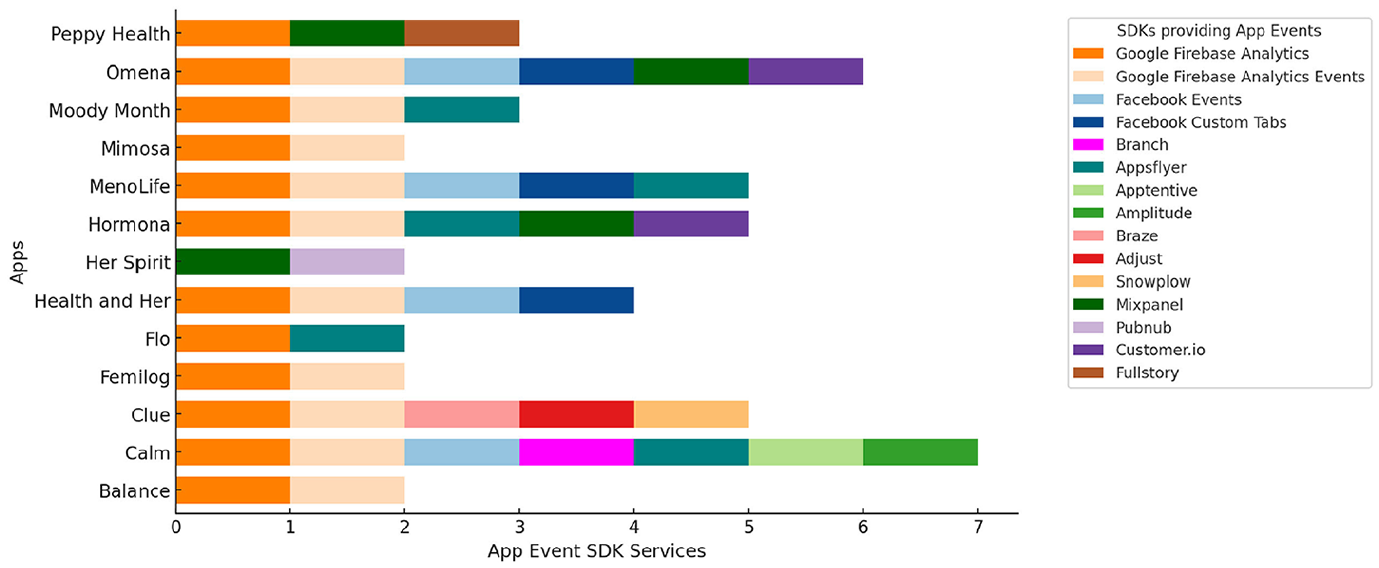
Summary of app events analytics services.
App Events can also be customized to meet developers’ more specific needs. These can be used in combination with pre-made services to maximize insights. While there are limits to how many App Events can be simultaneously deployed, Facebook SDK still allows developers to use up to 1000—pre-made and/or customized App Events—at a time (Meta, n.d.-b). These can be swapped in and out and paired with other analytics companies like AppsFlyer or AI tools like Google’s BigQuery to leverage in-app behavior (Meta, n.d.-b; AppsFlyer, n.d.). From our analysis, we see different companies that provide App Events analytics for: (1) granular behavioral tracking (e.g. Adjust, Mixpanel, Snowplow, FullStory, Apptentive, Customer.io, Pubnub, or Amplitude); (2) granular attribution tracking (Braze); (3) both behavior and attribution tracking (Google, Meta, AppsFlyer); (4) more customizable events (Google, Meta, Mixpanel, AppsFlyer, Apptentive, Customer.io); (5) segmentation or profiling based on the convergence of demographic and behavioral data (Google, Facebook, Mixpanel, or Braze); and (6) custom reporting tools such as dashboards for tailored insights about how these services profile end-users (provided by all). These are then leveraged and transformed into strategies to drive more engagement, attribution, and personalized marketing within most apps.
Discussion
Returning to our menopause sample, one of our original concerns centered around how these apps share intimate health data. Shipp and Blasco’s (2020) study revealed that “third parties . . . receive period-related data in the form of App Events (p. 502).” Given that App Events are used to personalize app experiences and drive “precision targeting” for advertisers (Field Drive, n.d.), we can conclude that one of their most critical functions is tracking and designing end-user engagement strategies. Within menopause apps, we infer that engagement would likely mean how long women might spend on these apps, the articles they click on, and/or the kinds of intimate health data they reveal about themselves. Figure 5 summarizes 14 kinds of intimate health data we observed when deploying the walkthrough method (Light et al., 2018) to qualitatively assess what data women might upload about themselves when they use these apps. Our results show that some apps ask users to provide data about their sleep patterns, symptoms, moods, or diet information, including their weight. Other apps, which are also for period tracking, ask women about when they had their last period, details about their sex drive, or to disclose intimate details about their bodies. Apps like Balance also provide articles about menopause and its myriad effects on the mind and body. These points of contact are all potential App Events that can be used for behavioral profiling.
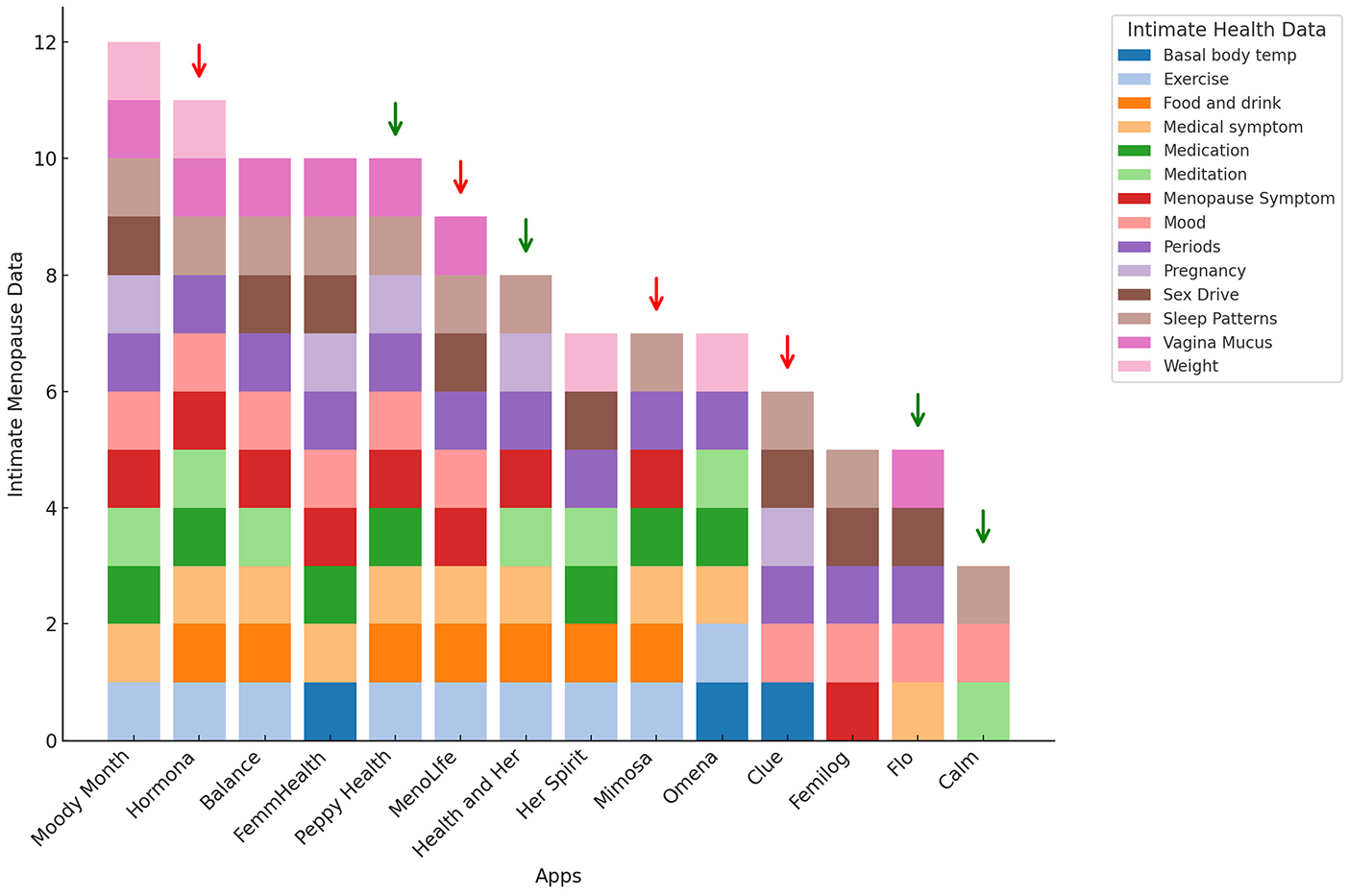
Types of intimate health data captured by app events.
One of the limitations of the SDK Data Audit is that static analysis of the back-end cannot tell us which App Event data are actively being shared with third parties. Instead, it brings to our attention what services apps use and shows whether they have set their permissions to access this data automatically. The Google Play Store does provide a “Data Safety Agreement” which, working in tandem with privacy policies, is meant to give users a snapshot of collected data and who it is shared with, so the people can make an informed decision before they install an app (Google, n.d.-a). However, these documents are often inaccurate or sometimes simply missing (Kollnig, 2021; Story et al., 2019). Revisiting Figure 5, the four apps with green arrows (Peppy Health, Health and Her, Flo, and Calm) have indicated they are sharing “app activities” or App Events with third parties. Conversely, the apps with the red arrows (Hormona, MenoLife, Mimosa, and Clue) only disclose that these data are being shared in their privacy policies, but not in their Data Safety Agreements. Ultimately, this is confusing and misleading. Moreover, there is no description of what these App Events or app activity might be, what is being shared, or how this might be used for behavioral profiling and advertising. MenoLife, for example, promises only to share their user’s email address in their Data Safety Agreement. However, the SDK Data Audit reveals how they have embedded almost every behavioral profiling service from both Google and Meta, and their privacy agreement states that “usage data” (App Event data) are being shared with both platforms, in addition to an advertising platform called Rakuten (which we did not observe in their SDK).
Our methodology remains attentive to both the front-end and back-end, allowing us to capture how datafication unfolds within mobile applications. We identify a crucial disconnect between how SDKs are declared and represented as trackers. We draw attention to their modular infrastructure and the extensive range of third-party services apps can embed. The SDK Data Audit uncovers a broad spectrum of app tracking behaviors, with some apps engaging in more comprehensive tracking and profiling of end-users than others. These critical differences should be more accurately represented to give real meaning to the rather vague notion of end-user consent. We also demonstrate that datafication within apps is an iterative, socio-technical process shaped both by user interactions with the interface and by the modular SDK infrastructures provided by platforms and third parties. In this instance, by gaining a clearer understanding of what might constitute an “intimate health data App Event,” the SDK Data Audit throws into stark relief the number of apps using these services and their role in supporting the data-for-service economy. This economic model, which maximizes monetization strategies and behavioral tracking, is facilitated by developers who (un)knowingly provide different degrees of access to myriad actors. Indeed, App Events are likely why 17% of UK women report receiving “distressing” targeted ads directly based on their in-app activities in FemTech applications (ICO, 2023).
Conclusion
In conclusion, our SDK Data Audit contributes a novel approach for auditing datafication infrastructures. This method combines both a front- and back-end approach to provide a more granular way to examine what kinds of personal data are being accessed by SDKs, lending greater insight into how digital surveillance operates within our apps. Our methodology highlights that not all apps are equal amid ubiquitous datafication. This can be observed by paying attention to their modular infrastructure to audit how extensively third parties can monetize personal data. Our findings show that analytic tracking, facilitated mainly by App Events, is a significant apparatus for data capture. Looking back at Figure 5, this suggests that women are being asked to disclose personal information about their health that does not appear to be adequately protected. Eight of the apps in our study indicated that they were sharing “app interactions” or App Event data with third parties. Finding better ways to prevent this kind of data sharing and represent these differences is paramount, especially if we are to provide more meaningful agency rather than resignation when it comes to deciding which app to download.
Based on this case study, we recommend expanding options for end-users to opt out of automatic Ad identifiers and analytics tracking in Android, which were enabled in over 57% of the menopause apps we examined. Given the sensitive nature of intimate health data potentially made accessible through FemTech apps, we suggest an additional opt-out mechanism to prevent developers from converting this data into App Events via SDK services. While some apps did disclose sharing this data with third parties, users—especially women using these apps—deserve more than vague declarations on how their data “may” be accessed and shared. Whether anonymized or not, if health data are monetized within an app, users should have control over how this occurs and by whom it is used, particularly considering potential privacy risks, discrimination, and unexamined harms that may arise. Finally, although we have focused on menopause applications, the SDK Data Audit is ultimately designed to audit the tracking infrastructure of apps across any domain. Therefore, we hope this work will contribute to ongoing struggles for more agency over our personal data and open up space for more critical research on the tracking infrastructures of datafication in our apps.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Social Science and Humanities Research Council, Canada and National Research Centre on Privacy, Harm Reduction and Adversarial Influence Online, Bristol UK.