
Abstract
This article critically examines the social implications of data infrastructures designed to moderate contested content categories such as disinformation. It does so in the context of new online safety regulation (e.g. the EU Digital Services Act) that pushes digital platforms to improve how they tackle both illegal and ‘legal but harmful’ content. In particular, we investigate and conceptualise X’s Community Notes, a tool that uses ‘human-AI cooperation’ to add context to tweets, as a data infrastructure for ‘soft moderation’. We find that Community Notes is limited when dealing with under-acknowledged online harms, such as those derived from the intersection between disinformation and humour. While research points to the potential of content moderation solutions that combine automation with humans-in-the-loop, we show how this approach can fail when disinformation is poorly defined in policy and practice.
Keywords
Introduction
Governments and supranational entities (e.g. the European Commission) around the world are passing new regulations to push digital platforms to do better in how they tackle online harms (Bartolo and Matamoros-Fernández, 2023). The European Union’s Digital Services Act (DSA), for example, marks a significant step in Europe’s ongoing efforts at tackling disinformation. 1 The DSA (Digital Services Act, 2022) places new obligations on large online platforms such as Facebook and X (formerly Twitter) to assess and mitigate so-called ‘systemic risks’ stemming from the design, functioning and use of their services (Article 34 and 35). While the regulation makes frequent mention of disinformation, 2 it does not directly define disinformation, nor does it constitute it as a ‘systemic risk’ per se. Rather, the DSA (2022) asks large online platforms to pay particular attention to how disinformation on their services might ‘contribute to’ systemic risks (Recital 84), particularly in relation to civic discourse, public security and public health (DSA, 2022: Article 34). By largely referencing disinformation in relation to platforms’ due diligence obligations around systemic risks, the regulation implicitly places disinformation under the ‘legal but harmful’ content category. 3 That is, disinformation is harmful, but not necessarily illegal, and so is best addressed by design changes and ‘soft moderation’ techniques, such as downranking, fact-checking and interstitial warnings (Gorwa et al., 2020).
This article seeks to highlight the challenges that arise when the concept of disinformation is considered a ‘policy domain’ (Ó Fathaigh et al., 2021: 7) without careful consideration of how it manifests online and its associated harms. Specifically, we are interested in interrogating platforms’ development of data infrastructures for content moderation to solve particular problems – for example, disinformation – and to reflect on whether these solutions are well-fitted to mitigate harm, a requirement set by regulation such as the DSA. Drawing on infrastructure studies, a subfield of science and technology studies, we use the term ‘infrastructure’ as a ‘relational concept’ that ‘emerges for people in practice, connected to activities and structures’ (Bowker et al., 2010: 99; see also Larkin, 2013). Data infrastructures enact and advance particular logics, ‘shaping what questions can be asked, how they are asked, how they are answered, how the answers are deployed, and who can ask them’ (Kitchin and Lauriault, 2019: 90).
In particular, we investigate and conceptualise X’s Community Notes (‘CN’ hereafter, for the sake of brevity) – a crowdsourced fact-checking initiative that allows users to add context to tweets, – as a data infrastructure for ‘soft moderation’ designed to solve the problem of disinformation. 4 Conceptualising CN as a data infrastructure allows us to study the tool not merely as a technical object, but rather as a socio-technical system that enables different forms of knowledge and practice. Our work responds to calls for more research-led socio-technical audits 5 of platform systems (Terzis et al., 2024), by offering an approach that is ‘purposively’ focused on a known challenge (Griffin and Stallman, 2024), in our case, the difficulty of moderating content at the intersection of disinformation and humour (Ajder and Glick, 2023).
We ask: How does CN’s design, associated practices and algorithmic outcomes 6 reflect particular understandings of disinformation and how to solve it? What are the social implications of this orientation towards solving the disinformation problem? To answer these questions, the article is structured as follows: First, we problematise disinformation and its intersection with humour. We then review literature on fact-checking: a popular platform solution for addressing disinformation, and dedicate a section to our conceptualisation of CN as a data infrastructure for ‘soft moderation’. Next, we introduce our methods, present our findings and conclude with a critical reflection on the forms of value-creation that CN enacts, alongside the broader data logics and processes of problematisation that incentivise tools like CN to get built in the first place. In other words, we situate the tool in its broader socio-political context and propose suggestions for improvement.
Problematising disinformation and its intersection with humour
Definitional debates have long plagued attempts to research and regulate disinformation, particularly ambiguities around its relationship to intent, falsity and harm (Ó Fathaigh et al., 2021). A popular framework that has informed new online safety regulation (Nenadić, 2019) has been Wardle’s (2018) ‘information disorder’ framework, which distinguishes misinformation from disinformation based on ‘intent’. However, a growing body of work rejects this differentiation (Appelman et al., 2022; Wardle, 2023), highlighting the diverse range of actors, interests and motivations involved in the sharing of false information online (Starbird, 2019) that make intent extremely difficult to verify or prove (Jack, 2017). While scholars, practitioners and regulators all agree that notions of ‘inaccuracy’ or ‘falsity’ 7 are essential to definitions (Zeng and Brennen, 2023), they offer a vast array of different frameworks to identify, measure and categorise falsehoods (Kapantai et al., 2021). This has led some to warn that the overall emphasis on ‘falsity’ within disinformation studies risks spawning an industry of automated solutions (Farkas and Schou, 2018; Marres, 2018) that erroneously assume false content is easily identifiable and equal in the risk of harm that it poses (Krause et al., 2022). Indeed, the lack of attention granted to harm in prominent policy definitions has been criticised by practitioners across disciplines (Dunn et al., 2021) and regions (Gibbons and Carson, 2022). It has also been contested ‘by both feminist and social justice actors who argue that, irrespective of intent, it is the resulting harms that must be foregrounded’ when assessing the risks of disinformation (Gallagher, 2023: 55).
A good example to illustrate the practical implications of these definitional ambiguities is content at the intersection of disinformation and humour. Despite humour’s exclusion from some disinformation research (Kapantai et al., 2021) and online safety regulatory frameworks (European Commission EC, 2022: 1), scholars have raised the alarm about how humour (e.g. satire, parody, irony) is commonly entwined with and used to excuse disinformation (Ajder and Glick, 2023; Wardle, 2018), becoming especially dangerous when it deploys ridicule, stereotyping and discriminatory overtones to target historically marginalised groups (Gallagher, 2023; McSwiney and Sengul, 2023). The ambiguity inherent in humour can be instrumentalised to disinform, prompting unwitting users to spread disinformation because it is presented as a joke (Donovan et al., 2022). In this context, nefarious actors can always claim their actions were ‘just a joke’ in the face of criticism, mobilising plausible deniability and framing anyone who objects as intolerant of free speech (Ajder and Glick, 2023; Jack, 2017). For example, in 2019, the US conservative commentator Allie Stuckey posted on her Facebook page a manipulated video of American left-wing politician and activist Alexandria Ocasio-Cortez that made her appear not fit for office. After it went viral and people complained about it, the platform refused to take it down because Stuckey claimed ‘it was meant as satire’ and Facebook maintained it was not in the business of policing humour (Halpern, 2019). But media scholars have been trying for years to de-individualise these incidents and conceptualise them as ‘gendered’ and ‘racialised disinformation’, terms used to describe disinformation campaigns that target gender and racial minorities (Donovan et al., 2019; Khan, 2021). Such campaigns involve not only the spread of false information, but also the sharing of negative stereotypes and narratives that reinforce systemic biases in society (Freelon et al., 2022; Reddi et al., 2021).
An overemphasis on falsity in prominent policy definitions of disinformation also overlooks the fact that humour often uses fiction to offer important commentary on real-world issues (Godioli et al., 2022). For example, part of the point of satire is to use humour to distort reality and offer a broader critique of a person, practice or institution (Condren et al., 2008). Thus, the focus on falsity and intent in disinformation frameworks produces a blind spot; an inability to distinguish between content that intentionally mobilises the ambiguities within humour to harm, and content that intentionally uses humour to skew reality and convey a generative political point. In the context of online hate, key advocacy groups are urging digital platforms to engage with these ‘particularly complex issues’ such as ‘truth and validity; and humour and irony’ (Vidgen et al., 2021). At the same time, Matamoros-Fernández et al. (2023: 27) observe that ‘it is significant’ that policymakers ‘have recently shown a willingness to evolve their understanding of online harm to include ‘social harms’ when it relates to activity that threatens to disrupt political power, and specifically platform-enabled disinformation that threatens to undermine state-based democratic systems’, while other forms of disinformation targeting historically marginalised individuals and groups tend to be granted less attention. Since humour is deeply intertwined with online harms targeting historically marginalised groups, they have called for this form of expression to be treated as an ‘online safety issue’ (Matamoros-Fernández et al., 2023: 1). This proposition seeks to encourage media regulators to push platforms to find adequate and targeted mechanisms, such as fact-checking, to assess when humour contributes to these particularly pernicious harms.
Fact-checking as the go-to solution to address disinformation
Fact-checking – the practice of identifying potentially false claims and finding ways of verifying them – first began as a practice within newsrooms then later transformed into a unique form of journalism that specialised in checking claims made by politicians and other public figures (Graves, 2016). More recently, there has been a shift towards ‘debunking’ viral online claims (Reidlinger et al., 2024) and fact-checking has gained popularity as the go-to ‘soft moderation’ solution for tackling online disinformation (Graves et al., 2023). Platforms such as Facebook, 8 Instagram and TikTok collaborate with independent third-party fact-checking organisations to review and verify ‘false’ or ‘misleading’ claims, with some labelling this trend as the ‘platformization of truth’ (Cotter et al., 2022: 1). Once the information identified by these experts is confirmed to be false or misleading, platforms take proactive steps to moderate the content in line with their Community Guidelines. 9 Other platforms, such as X, have invested in crowdsourced fact-checking systems like CN, to achieve similar aims.
A growing critique of fact-checking has been its hyper-focus on ‘verifiable facts’ (Bengtsson and Schousboe, 2024: 6) and individual content (Wardle, 2023), alongside its reliance on Western-centric definitions of disinformation that do not situate the sharing of false information within diverse histories and cultures of media use (Madrid-Morales et al., 2021) or recognise how deliberate false claims often harness broader meta-narratives about identity and inequality such as race and gender, disproportionately impacting historically marginalised groups (Kuo and Marwick, 2021). In her critical examination of practical fact-checking tools and services, Marres (2018) critiques the rise of tools reliant on technical procedures that make binary assessments based on content attributes, alongside their allocation of responsibility onto individuals for the epistemic quality of debate. Marres (2018) argues that this trend represents a ‘return to demarcationism’: a politics that aims to re-establish a hierarchy between knowledge and anti-knowledge, that risks reinforcing social dichotomies and stereotypical oppositions between those considered ‘capable of knowledge’ and others. Vinhas and Bastos (2022) also warn that there is a risk of fact-checkers pushing alleged ‘consensual narratives’ around certain facts, especially when these narratives can be attached to hegemonic projects that do not benefit the interests of marginalised and disadvantaged groups (p. 450). What is more, as Montaña‐Niño et al (2024) demonstrate, a broad spectrum of fact-checking entities have arisen in recent times, with some fringe actors mimicking and exploiting the operations and practices of accredited fact-checkers for political gain.
Despite these challenges and critiques, platforms are strengthening their fact-checking capabilities, increasingly relying on automation (Guo et al., 2022) and volunteer labour (Matias, 2019) in the form of ‘crowdsourced fact-checking’, largely because it is fast, cheap and easily scalable (Arcila and Griffin, 2023). While automated content moderation tools have been criticised for their limited ability to compute context, nuance and problematic meta-narratives (Griffin, 2023), much faith has been placed in their capabilities when combined with volunteer moderators, their potential otherwise referred to as ‘the wisdom of the crowd’ (Allen et al., 2021). Indeed, Spina et al. (2023) have described a new paradigm of ‘Human-AI cooperation’ emerging; a trend towards the productive interplay between algorithms and people to tackle disinformation (p. 40). These scholars argue that ‘a close collaboration between experts, systems, and non-experts such as crowd workers is crucial to scaling up while maintaining the quality, agency, and accountability of the [fact-checking] process’ (Spina et al., 2023: 42). Yet, it is important to note that Spina et al. (2023) foreground the need for experts in the process, particularly because experts are important for assessing things like the check-worthiness of statements. That is, assessments that consider the ‘potential harm that a certain statement being false could create’ (Demartini et al., 2020: 68).
What this transdisciplinary body of work suggests is that, while fact-checking, and crowdsourced fact-checking systems have a role to play in tackling disinformation (Arcila and Griffin, 2023), they are no panacea or silver bullet solution (Bovermann, 2024). This is because fact-checking is fundamentally insufficient at mitigating certain online harms and puts forward a narrow vision of the requirements for a healthy public sphere (Yarrow, 2021: 622). Consequently, some authors such as Yarrow (2021) suggest ‘value checking’ as a complement to fact-checking. Yarrow explains that ‘value checking’ goes beyond the factual validity of claims and seeks to (1) improve public understanding of the normative content underpinning claims, (2) help people identify assumptions embedded in different bodies of expertise, and (3) provide supplementary information to unpack these assumptions. Such an approach would allow fact-checking interventions to go beyond the fact/value distinction and invite more deliberation around the potential for content to harm. In the next section, we operationalise this fact-checking literature by critically examining a particular content moderation intervention, X’s Community Notes, and how it is oriented to solve the disinformation problem.
Community Notes as a data infrastructure for ‘soft moderation’
In this article, we conceptualise CN as a data infrastructure for ‘soft moderation’. We borrow from infrastructure studies the idea that ‘we need to look to the whole array of organisational forms, practices, and institutions that accompany, make possible, and inflect the development of new technology, their related practices, and their distributions’ (Bowker et al., 2010: 103; see also Larkin, 2013). Through its technical design, its related practices and its embeddedness in X’s culture, norms and activities, CN contributes to creating particular kinds of value and standards around disinformation and its associated harms. Importantly, in this conceptualisation, we are attentive to ‘bringing the people back’ into the study of data infrastructures (Denton et al., 2020: 1; see also Bowker et al., 2010). This allows us to flesh out, for example, how the volunteer work of CN contributors is both determined by the tool’s design and influences the functioning of CN as a ‘soft moderation’ system.
Concepts emerging from big data and platform studies such as ‘datafication’ (Cukier and Mayer-Schönberger, 2014) and ‘programmability’ (van Dijck and Poell, 2013) are productive to understand CN as a data infrastructure for ‘soft moderation’. Datafication refers to platforms’ ‘ability to render into data many aspects of the world that have never been quantified before’ (Cukier and Mayer-Schönberger, 2014: 29) and it is considered a key element of what van Dijck and Poell (2013) call ‘the logic of social media’ (p. 2). CN relies on intensive processes of datafication: it captures and abstracts online content (e.g. tweets and notes) into qualitative categories (e.g. users can classify tweets as ‘potentially misleading’ and ‘not misleading’) and measures (e.g. notes are given scores for their ‘helpfulness’) continuously, in a fast and standardised manner. ‘Programmability’, in turn, can be described as a platforms’ ability to ‘trigger and steer users’ creative or communicative contributions, while users, through their interaction with these coded environments, may in turn influence the flow of communication and information activated by such a platform’ (van Dijck and Poell, 2013: 5). Algorithms play a big role in platforms’ programmability, yet they are ‘often invisible’ and hard to study (van Dijck and Poell, 2013: 6; see also Rieder et al., 2018). In the case of CN, its bridging algorithm is a core component of how the data infrastructure makes decisions on which notes will be made visible to X users, as we explain in more detail further down.
By paying attention to the social implications of moderation systems that use automation to make decisions upon content, we also align our work with scholarship on ‘algorithmic governance’: a term used to describe ‘a form of social ordering that relies on coordination between actors, is based on rules and incorporates particularly complex computer-based epistemic procedures’ (Katzenbach and Ulbricht, 2019: 2). A common thread within this literature, at least regarding the field of platform studies and content moderation, is the need to interrogate the underlying design orientation of systems that rely (fully or partially) on algorithms to govern content, as well as the broader economic, cultural and political contexts that shape the design of and practices within these systems (Gillespie, 2018; Gorwa et al., 2020).
The invisibility aspect of some of the components of socio-technical systems, from algorithms to human labour, is a shared concern by platform and infrastructure scholars who have called for methods that make these hidden elements more visible (Edwards et al., 2007; Rieder et al., 2018). By grounding our analysis of CN in the combined framework of platform and infrastructure studies (Plantin et al., 2018), we are committed to interrogating CN’s technical, social and institutional components, and to render visible some elements that sit in the background, such as the work of volunteer contributors and the tool’s bridging algorithm.
The availability of CN data for public scrutiny – datasets of notes are free to access and its bridging algorithm is open source – has prompted researchers to audit the tool as purely a technical object. For example, scholars have assessed the effectiveness of CN at surfacing public notes that add context to potentially misleading tweets (Allen et al., 2022; Borwankar et al., 2022). This is important work but, as Arcila and Griffin (2023: 75) note, these types of technical audits are limited when assessing ‘the relevance of design and business factors’ in the spread of online harms. Responding to the call to audit platform systems’ ‘holistically’ (Arcila and Griffin, 2023: 85) and ‘purposively’ (Griffin and Stallman, 2024: 6), in the next section we explain how we audited CN with a very particular and well-known challenge for online safety in mind: the difficulty of moderating content at the intersection of disinformation and humour (Ajder and Glick, 2023; Matamoros-Fernández et al., 2023). At the same time, we are mindful of the limitations involved in studying infrastructures ‘given the ever-proliferating networks that can be mobilised’ to understand them (Larkin, 2013: 330). Any study of an infrastructure needs to define which aspects of the socio-technical system will be discussed and which parts ‘will be ignored’ (Larkin, 2013: 330). We lay out our approach in what follows.
Auditing public Community Notes in relation to satirical tweets
CN was launched first in the United States in January 2021 and then globally in December 2022. At the time of analysis, in July 2023, the tool had anonymous contributors in 44 countries around the world (Hutchinson, 2023). To become a CN contributor, any X user with an account can sign-up to the programme, provided they have a verified phone number, joined X at least 6 months ago and have not received a recent notice of X Rules violation. 10 At the start, new contributors can only rate existing notes as ‘helpful’, ‘somewhat helpful’ or ‘not helpful’ (see Figure 1). When contributors achieve enough ‘rating impact’, 11 they can start classifying tweets based on predetermined categories and write notes. Notes need to be accompanied by a source and explain the context of why the tweet may be misleading or not.
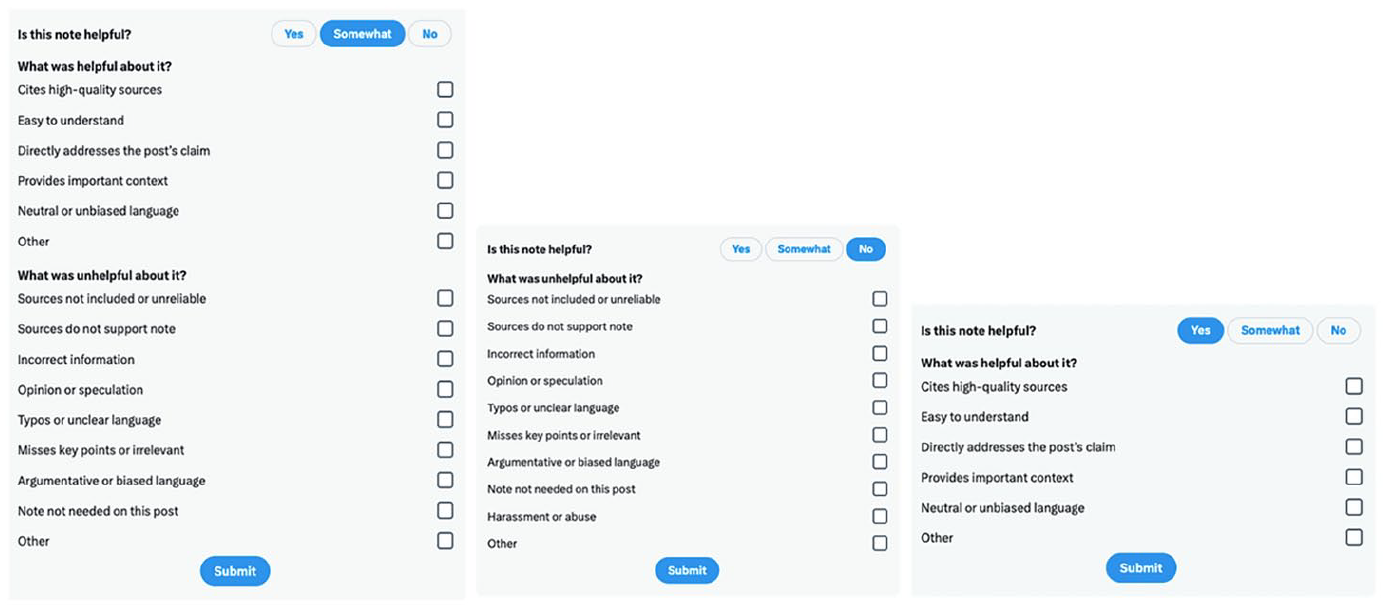
Interface design choices displayed when Community Notes contributors want to rate notes as ‘helpful’, ‘somewhat helpful’ or ‘not helpful’. (Screengrab by authors in November 2023.)
Tweets can receive multiple notes and it is the CN bridging algorithm that decides which note will be shown publicly on the X interface based on a number of variables: from the number of helpful votes the note receives to the diversity of these votes. In fact, this latter aspect is what differentiates CN’s bridging algorithm from other ranking algorithms; bridging algorithms aim to ‘bridge divides’ among participants (Ovadya and Thorburn, 2023). While a simpler algorithm would just calculate the sum or average of user ratings and use that as the final result, bridging algorithms aim to prioritise content that receives positive ratings from people across a diverse range of perspectives (Ovadya and Thorburn, 2023). In the case of the CN bridging algorithm, if people who usually disagree on how they rate notes end up agreeing on a particular note as ‘helpful’, that note is scored especially highly. The bridging algorithm does not just use the raw helpfulness score to calculate if the note should go public, but extends it to give contributors a ‘friendliness score’ (how likely they are to give high ratings) and a ‘polarity score’ (their position among the dominant axis of political polarisation) (Buterin, 2023). The helpfulness that a particular note is assigned is the note’s final score: if a note’s helpfulness is at least +0.4, it gets shown under a tweet on X’s public interface (Community Notes, Under the Hood, n.d.). The core idea here is that selecting for ‘helpfulness’ identifies notes that get cross-viewpoint approval, and selects against notes that get cheering from people holding a particular viewpoint, at the expense of outrage from people holding the opposite view.
Approach and methods
For our auditing of Community Notes as a data infrastructure for ‘soft moderation’, we are inspired by Rieder and Skop’s (2021) ‘fabrics for machine moderation’ approach as a way to think critically about content moderation infrastructures that rely on automation. In their study on Perspective API, an automated system developed by Google to identify and moderate toxic content, Rieder and Skop (2021) use the metaphor of ‘fabrics’ to emphasise how the different ‘threads’ of a system are woven together with purpose, into an ‘assemblage’ of work processes, technologies, partnerships and normative choices that actively produce machine moderation. In paying attention to CN’s different ‘fabrics’, and acknowledging that any study of complex data infrastructures will leave some elements out of the analysis (Larkin, 2013), we directed our attention to three constitutional elements of CN for close examination: the tool’s design and documentation (see Figure 1), the work of CN contributors (see Figure 2) and the outcomes of CN’s bridging algorithm; that is, the notes that go public on X’s interface (see Figure 3). As noted in the previous sections, we did this by having a very specific known policy challenge in mind: the difficulty of moderating content at the intersection of disinformation and humour (Ajder and Glick, 2023).
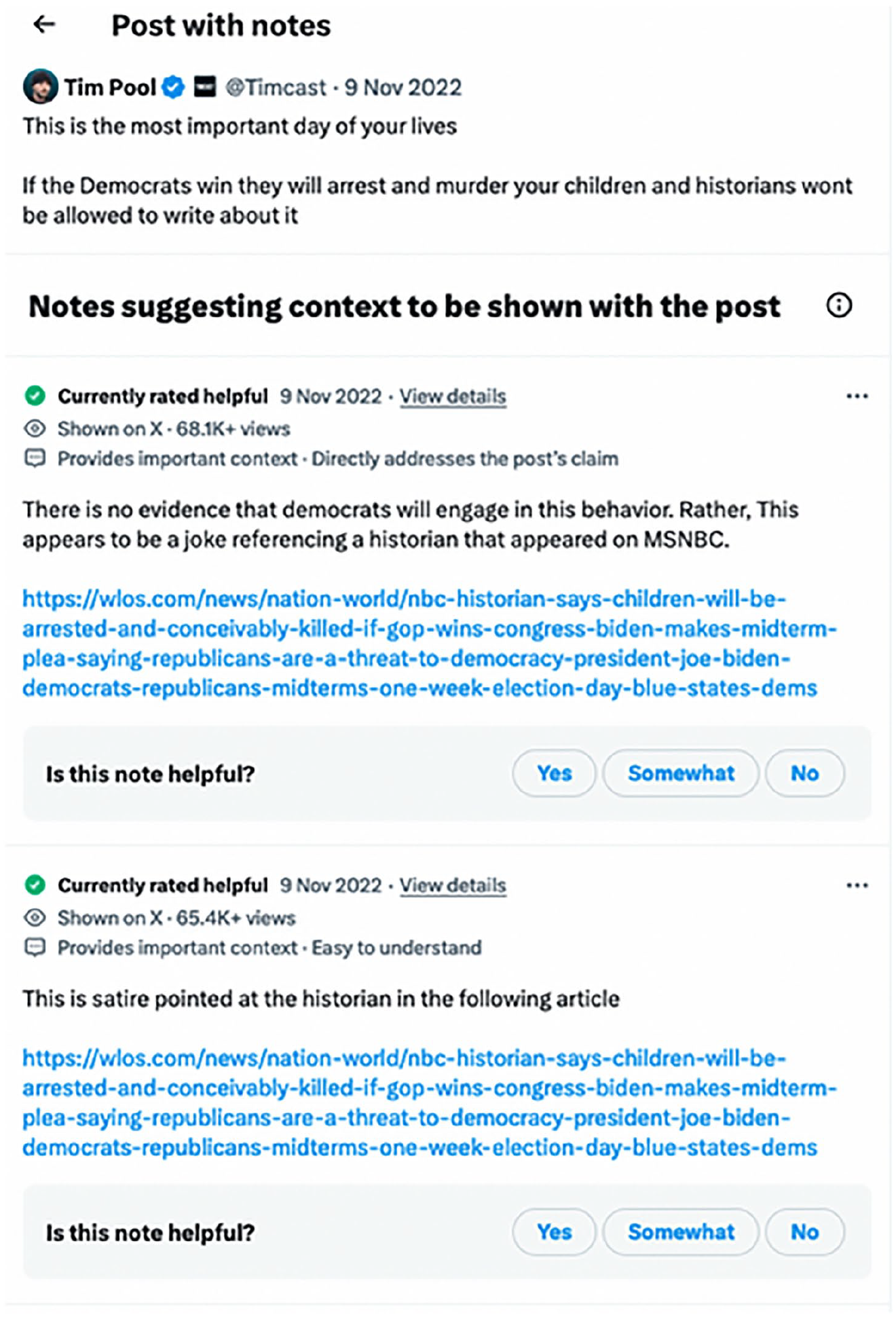
Community Notes that were added to a tweet by right-wing YouTuber Tim Pool on 9 November 2022. Figure 3 shows the note that received the most ‘helpful’ score and hence went public on X’s interface. (Tweet screengrab by authors in July 2024.)
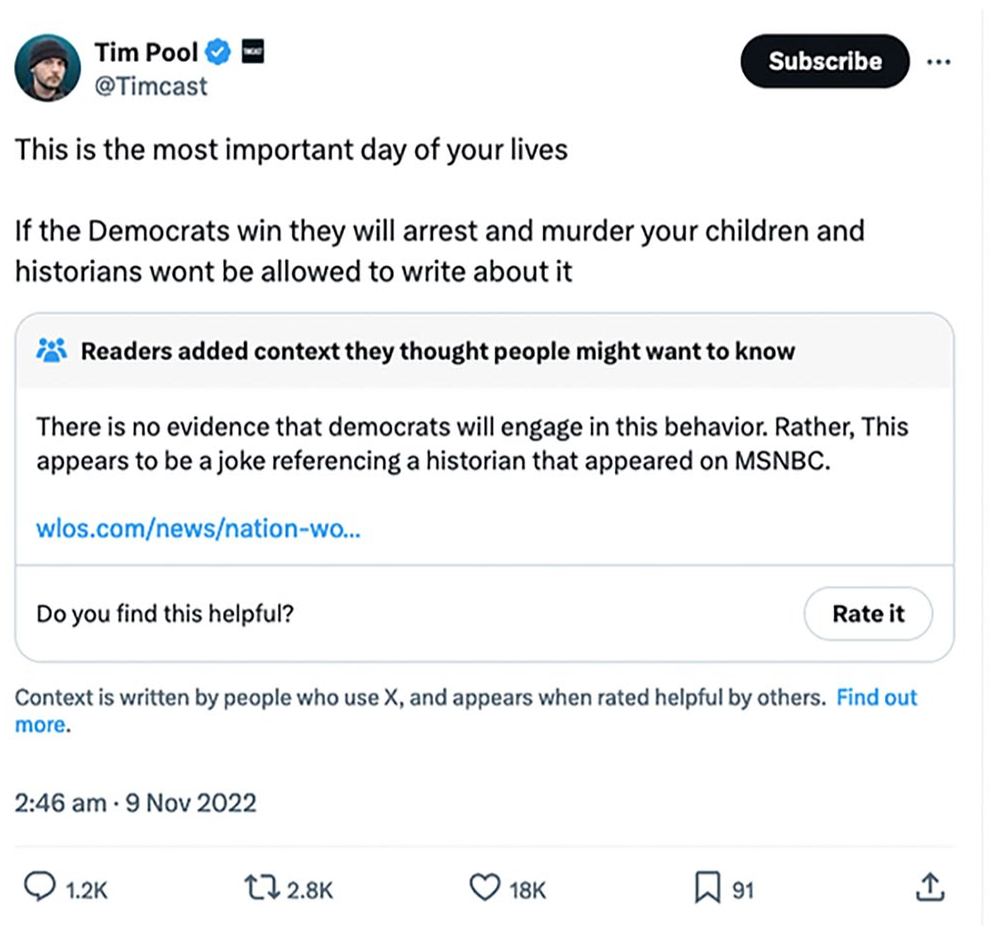
Public community note that appears under right-wing YouTuber Tim Pool’s tweet posted on 9 November 2022. The note reads: ‘There is no evidence that democrats will engage in this behaviour. Rather, this appears to be a joke referencing a historian that appeared on MSNBC [link]’ (emphasis added) (tweet screengrab by authors in July 2024).
To interrogate CN as data infrastructure for ‘soft moderation’, we borrow from platform studies scholars methods for identifying, mapping and disassembling socio-technical assemblages to analyse their components. We adapt (Light et al., 2018: 881) walkthrough method to study ‘an app’s environment of expected use’ for describing CN’s design, vision, operating models and modes of governance. We signed up 12 to be CN contributors in 2023 and systematically documented the various stages of registration and expected use of the tool. The walkthrough method allowed us to collect data on CN’s interface, interstitials, drop-down menus, instructions, notifications and general documentation. We gathered this data purposively to answer our research questions.
We also draw on methods for ‘auditing algorithms’ (Sandvig et al., 2014) and studying ‘algorithmic cultures’ (Rieder et al., 2018) to describe the different agencies involved in CN’s generation of algorithmic outcomes (notes shown publicly under tweets): from developers’ design choices (e.g. an orientation to ‘bridge divides’) to CN contributors work (e.g. their voting and writing of notes). Rather than examining CN’s bridging algorithm as an open source formula on Github and trying to reverse engineer it, we chose to investigate what the algorithm does (the public notes it generates) in order to move closer to understanding how it works and its social implications. This approach is similar to Bucher’s (2018) notion of ‘technography’, which offers ‘a way of describing and observing the workings of technology, in order to examine the interplay between a diverse set of actors (both human and nonhuman)’ (p. 61). 13 Bucher (2018: 61) notes, ‘While the ethnographer seeks to understand culture primarily through the meanings attached to the world by people, the technographic inquiry starts by asking what algorithms are suggestive of’. Through a close reading of satirical tweets that received public notes, and a close examination of the notes publicly shown under those tweets, we were able to start unpacking a presumably ‘common idea’ of what constitutes ‘helpful’ notes in relation to humorous tweets that have the potential to disinform.
In practice, examining CN’s algorithmic outcomes entailed a detailed process of data collection, filtering and analysis. First, we downloaded CN data from X’s website 14 on 25 April 2023, when the tool had already been launched globally. X offers CN data in four broad categories: notes data, ratings data, notes status history data and user enrolment status data. 15 To prepare the data, we used the ‘notes data’ file containing 77,230 notes and retrieved every note that had a satirical classification (‘misleading satire’ OR ‘not misleading, clearly satire’) which yielded a total number of 5964 notes (7.72%). Since one tweet can have more than one note classifying it as ‘misleading satire’ OR ‘not misleading, clearly satire’, we calculated the number of unique tweets with at least one satirical classification (n = 4556). From these 4556 tweets that received at least one satirical classification, 905 (19.86%) of them were deleted/redacted, 16 which left us with a total of 3651 (80.14%) tweets that received at least one satirical classification. We then manually checked which of these 3651 tweets received a public community note by opening each tweet on the X interface. Of these 3651 tweets, 588 (16.11%) received a public community note. 17
Finally, from these 588 tweets that received at least one satirical classification and received a public community note, we selected for close qualitative analysis tweets that had a public note that mentioned an English-language term 18 related to humour (terms included were satire, satirical, joke, joking, parody, humour, humor, comedy, comedian, meme, funny, hoax, impersonat*, exaggerat*). This left us with 29 satirical tweets 19 (<1%) and their notes to qualitatively analyse, in order to observe the interplay between different sets of actors (human and non-human) in producing algorithmic outcomes; in our case, algorithmically selected notes rated as ‘helpful’ by people from a diversity of perspectives, that also mentioned humour in the text of the note. For us, it was important that the public notes shown in the interface mentioned a term related to humour (see Figure 3) since this was an indication that the CN contributors took the time to stress that the tweet was humorous. While CN contributors can only classify tweets as ‘misleading satire’ OR ‘not misleading, clearly satire’, in their notes we found that they were more concrete in their descriptions of the humorous content they were assessing, noting that these were ‘Internet jokes’, ‘parody’ or ‘memes’ (see Table 1 in the Supplementary Appendix and also Figure 3). This nuance was important to us, and it served our aim to audit the tool purposively to evaluate how CN’s design, associated practices and algorithmic outcomes reflect particular understandings of the disinformation problem and how to solve it (RQ1).
From our sample of 29 satirical tweets that we selected for close qualitative analysis, we extracted rich contextual information about them (e.g. its author, targets of the joke, humour cues, themes), alongside both their submitted and public notes (see Table 1 in the Supplementary Appendix, and also Table 2 for an example of how we analysed the tweets). In our data analysis of these tweets and their notes, we were interested in understanding whether CN contributors, through their interactions with the tool, were reproducing long-standing critiques of fact-checking for being hyper focused on ‘verifiable facts’ (Bengtsson and Schousboe, 2024: 6) and limited for mitigating societal harms associated with disinformation (Kuo and Marwick, 2021). For example, we paid attention to whether CN contributors were correcting satirical tweets based on their ‘fakeness’ or ‘falsity’, whether they mentioned harm in their written notes, and whether they selected that satirical tweets could pose ‘considerable harm’ or ‘little harm’ via the tool’s drop-down menus. For our own assessment of whether the 29 satirical tweets in our sample had the potential to harm, we draw on humour scholars (Godioli et al., 2022) who argue that it is important to consider contextual aspects such as the joke’s communication setting, its target, its play frame (Dynel et al., 2016), the genre that the joke can be ascribed to, as well as the speaker/author’s positionality (when applicable) to judge humour’s potential to harm. In this regard, we evaluated the tweets’ potential to harm not only in relation to its risk to mislead – which is implied in the tool’s design – but also in relation to the broader harms derived from humour such as its link to discrimination and prejudice (e.g. Gallagher, 2023; Matamoros-Fernández et al., 2023; Pérez, 2022). To this end, we were particularly attentive to humour targeted at historically marginalised groups that would not necessarily reach a legal harm threshold (e.g. incitement to violence), but that nonetheless is worthy of platforms’ and regulators’ attention in their online safety efforts (Matamoros-Fernández et al., 2023) for its contribution, for example, to gendered and racialised disinformation (Donovan et al., 2019; Gallagher, 2023; Khan, 2021).
CN comes with its own biases, including contributors’ motivations to participate (Allen et al., 2022; Wirtschafter and Majumder, 2023), their demographics and gender, and the system’s potential to suggest largely US content for contributors to add notes to. Although our dataset contained notes in English from contributors around the world, the sample that we analysed were about US politics and topics. This could be explained by the fact that the United States is X’s larger market (Statista, 2023), but also because we collected data just a few months after CN was launched globally and hence non-US contributors might not have reached enough ‘rating impact’ to write notes.
In what is next, we present our two main findings from our critical interrogation of CN’s design and documentation, the work of CN contributors and our close examination of the system’s algorithmic outcomes in relation to satirical tweets. They can be summarised as follows: The CN system (1) reflects an operational logic that inscribes true-false, real-fake binaries into its design and outcomes and (2) is limited as a harm mitigation solution. These findings have implications for broader discussions on ‘human-AI cooperation’ to address disinformation (Spina et al., 2023) and for researchers and other stakeholders concerned with how some harms associated with disinformation are under-acknowledged in policy and technology circles (Gallagher, 2023; Matamoros-Fernández et al., 2023).
An operational logic that inscribes true-false, real-fake binaries
CN is informed by an operational logic that inscribes true-false, real-fake binaries into its design, and these binaries can be observed in the system’s interface, the volunteer work of its contributors and its algorithmic outcomes. For example, the tool requires contributors identify tweets based on their potential to mislead first and foremost. Yet, it offers little guidance on what ‘misleading content’ is, and how one might subsequently identify and assess the check-worthiness of it (Demartini et al., 2020). X provides some guidance via its ‘values’ prompts, 20 ‘onboarding system’ 21 (the process of rating notes) and ‘note-writing tips’ 22 : a guidance page that offers a simple list of attributes for ‘what makes a good Community Note’. However, all three initiatives merely prompt contributors to reflect on the way they (or others) should rate and write notes, highlighting attributes associated with a note’s form or style. Thus, in CN’s documentation, there is an emphasis on how to write a good note, and a neglect of what makes for misleading content and its risk of harm on the platform (e.g. how a contributor might first identify and assess tweets as worthy of a note). To write notes, CN contributors must first classify tweets as ‘misinformed or potentially misleading’ or ‘not misleading’. They can then allocate other attributes to tweets by selecting non-mandatory options such as whether the tweet contains for example a ‘factual error’, ‘a digitally altered photo or video’, or is ‘a joke or satire that might be misinterpreted as fact’ (see Figure 4). When conducting this research, CN contributors could also classify tweets as being ‘believable by many’ or ‘believable by few’ and as posing ‘considerable harm’ or ‘little harm’. However, these latter classifications (believability and harm) were first optional and then later removed from the system’s design in 2024. Importantly, the tool did not provide a definition of ‘harm’, despite it being an ‘essentially contested concept’ that requires careful conceptualisation in order for content moderation solutions to be able to effectively identify, document and address risks of harm occurrence online (Bartolo and Matamoros-Fernández, 2023).
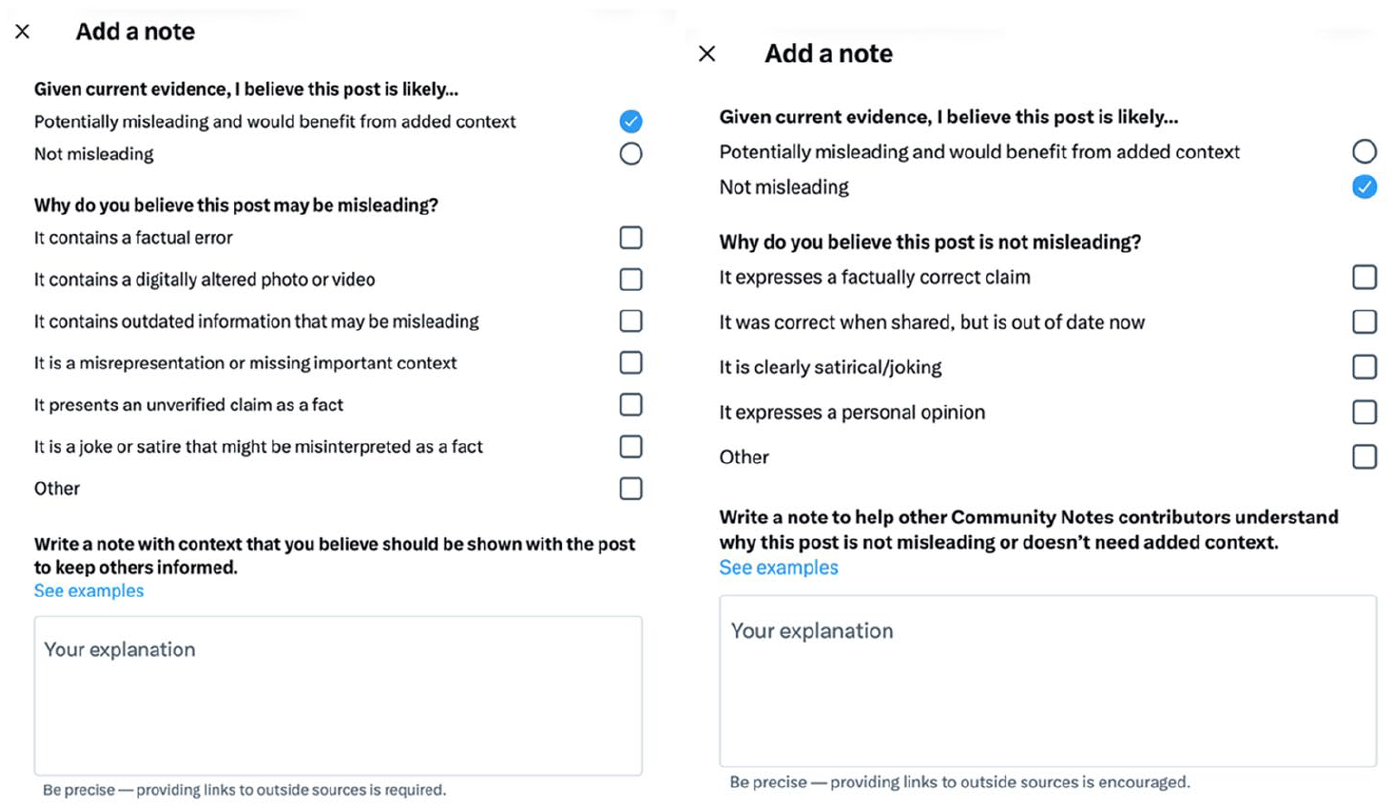
Contributors to Community Notes must select whether a Tweet is ‘Potentially misleading’ or ‘Not misleading’. They then receive the option to select different reasons for their decision, for example that the Tweet ‘is a joke or satire that might be misinterpreted as a fact’.
CN’s binary logic becomes more visible when examining the work of its volunteer contributors. We find contributors often use notes to merely demarcate between what they think is true and false, or real and fake, based on their own judgements. Existing research has shown how volunteer moderators often rely on ‘an implied set of heuristics’ to help them make decisions around content (Seering et al., 2022: 623). In our case, implied heuristics to correct fakeness and falsity were salient in how CN contributors selected and assessed humorous tweets. For example, under a tweet that humorously jumped on the bandwagon of the #TrumpIsDead hoax, 23 we find the following public note: ‘This Tweet is misleading. Donald Trump remains alive; this Tweet is made in light of the currently-Trending hashtag “#TrumpIsDead” itself linked to a false Tweet thread by comedian Tim Heidecker [emphasis added]’. Another public note appearing under a tweet that shared a parody of TikTok CEO Shou Chew testifying at a US congressional hearing over concerns about user data collected by the video-sharing platform, read: ‘This is not a real question from the recent testimony of TikTok CEO Shou Chew to congress; the audio has been added after the fact. Testimony transcript [emphasis added]’. These notes exemplify Marres’ (2018) critique of fact-checking, or what she calls the ‘politics of demarcation’: debates that overemphasise the validity and value of content based on binary attributes such as whether it is true or false; real or fake. While CN contributors reverted to notions of falsity, authenticity and reality to correct these tweets, the tweets themselves used satire and parody to ‘punch up’, 24 mocking powerful figures such as US president Donald Trump, Elon Musk and the US Congress members questioning TikTok’s CEO. These examples show how humour’s intrinsic incongruent attributes and its play with notions of truth (Godioli et al., 2022) are at odds with CN’s binary logic. In a way, the concept of ‘misleading satire’ – as captured in the CN interface – is a tautology. Satire is misleading by nature; it plays with notions of truth to relay a deeper critical commentary (Condren et al., 2008). Thus, we argue that what becomes more important in assessing content at the intersection of disinformation and humour is not truth or intent to mislead, but the benefits or harms of that deeper critical commentary.
CN’s binary logic is also evident when examining the tool’s algorithmic outcomes. That is, the notes that appeared publicly under tweets because they received ‘cross ideological agreement’. Notes that got ‘cross ideological agreement’ were those that added context to tweets that intentionally played with notions of fakeness, as an expression of their humour. Indeed, 62.1% (n = 18) of tweets in our sample involved a fake, parody account or contained digitally ‘altered’, ‘doctored’ or ‘edited’ content to varying degrees of quality. Tweets ranged from edited screenshots to sketch videos made by comedians. 25 Most contained either subtle or noticeable humour cues, indicating that the author intended them to be humorous. We hypothesise that these tweets’ edited nature appealed to CN contributors to correct for ‘fakeness’ and facilitated agreement of ‘helpfulness’ across the ideological spectrum. Other notes that got ‘cross ideological agreement’ were those that recontextualised humorous content. 20.7% (n = 6) of tweets in our sample were posted by users that appeared to have been misled or fooled by content originally intended as humorous or satirical. In this regard, these notes were helpful for adding context to tweets that were first intended as jokes, as they capitalise on the forensic work of the crowd to return humour cues (or an explanation of them) to the content. This is important, as existing research suggests it is common for people to misinterpret satire on the Internet (Poulsen et al., 2023). However, the tool’s orientation to correct for ‘fakeness’ also prompts CN contributors to fact-check inconsequential jokes and memes, diminishing the usefulness of this data infrastructure for ‘soft moderation’ to mitigate harm.
This pattern is exemplified by Tweet 15 (see Table 1 in Supplementary Appendix), which contains an edited screenshot of another tweet that had the like button coloured in yellow and reads: ‘no way elon musk already changed the like button’s color’. ‘Twitter Changed The Colour of the Like Button’ is a frequently repeated Internet joke 26 that aims to get users to test whether the like button has changed, in the process generating engagement for the Twitter account posting the meme. Despite this being a harmless meme, Tweet 15 received four notes, with one note receiving enough ratings as helpful for it to go public. With research suggesting that less than 12.5% of all written notes go public on X (Wirtschafter and Majumder, 2023), this begs the question, what were the factors that allowed this innocuous internet joke to be one of the few tweets to receive a public note? Indeed, virality is often closely associated with humour (Highfield, 2015; Phillips and Milner, 2017), and a common feature of humour is to play with notions of ‘fakeness’. Thus, it makes sense for humorous tweets that play with notions of ‘fakeness’, like Tweet 15, to garner ratings and attention in a content moderation system designed to correct for falsity first and foremost. It also makes sense for apolitical tweets with clear humour cues to receive public notes, as their ‘fakeness’ is less ideologically divisive or debatable. While studies on CN suggest that it is difficult to reach consensus around polarising topics (Pröllochs, 2022; Wojcik et al., 2022), some have speculated that it might be easier to get ‘cross ideological agreement’ around ‘low stakes, sometimes funny or satirical tweets’ with potential to mislead (Mahadevan as quoted in Czopek, 2023). Our findings lend evidence to this suggestion. Our analysis also aligns with research that has found CN performs worse than expert fact-checkers when dealing with more complex content that is, for example, sarcastic, vague or interleaved (Saeed et al., 2022). Such complexities are common in humorous tweets that have the potential to harm. This paves the way towards our second finding.
Lack of critical reflection on the potential for content to harm
As noted earlier, CN as a system does not provide any guidance on how content can harm, particularly when it might be off-limits or when an intervention (like a note) might be required. This oversight is a common criticism of fact-checking as a practice more broadly, since its reliance on the ‘fact’/‘value’ distinction is ‘a narrow account of the requirements of a healthy public sphere’ (Vinhas and Bastos, 2022; Yarrow, 2021: 622). Of all the contributors (n = 64) that submitted notes to the 29 satirical tweets in our dataset, only 14.5% (n = 9) filled out the ‘harm’ or ‘believability’ fields before writing their note, as these fields are not mandatory. This suggests that most contributors do not actively or critically reflect on the potential believability or harm of a humorous tweet, before writing and submitting their note. Even when contributors did fill out the optional harm field (14.5% of contributors on 20.7% of tweets), they did not expand on the tweet’s potential risk of harm in the writing of their notes. This finding was reinforced upon closer inspection of all written notes attached to the 29 tweets included in our analysis, regardless of whether they went public or not. In submitted notes, contributors frequently focused on explaining content as satire or parody, to either help the X community interpret the content as a joke, or defend the joke and argue that ‘no note is needed’. 27 When explaining or defending content, contributors often point to evidence of fakeness or falsity in the content or account, to justify their note. 28
For example, Tweet 23 contains a doctored video of Alvin Leonard Bragg Jr., an African American prosecutor who serves as the New York County District Attorney (see Table 1 and 2 in Supplementary Appendix). At the time the video was posted to X, Bragg had brought charges against the former US president Donald Trump over alleged hush money paid to former actress Stormy Daniels during the 2016 elections. The fake video falsely depicts Bragg dropping these charges and explaining why he has decided to do so. The video ridicules Bragg, depicting him making unusual, derogatory admissions. The use of exaggeration and incongruity is a common feature of humour (Godioli et al., 2022) and it is visible in Bragg’s video. This tweet received notes from three contributors, none of whom filled out the ‘harm’ field in the tool. Two contributors classified the tweet as ‘misinformed or potentially misleading’ and ‘manipulated media’. They focused on highlighting how the video is ‘fake’, stating that ‘it is not his voice’ and that ‘this video has been edited for Satire’. This latter note received enough ratings as ‘helpful’ for it to go public. The third contributor classified the tweet as ‘not misleading’ and then selected ‘clearly satire’ from the drop down. They wrote, ‘The text of the tweet clearly labels this as a “pre creation” of a speech from “next week”. No note needed’. This contributor appears to be pointing to what they believe are clear humour cues (an absurd claim that is not possible), to defend the joke as satire and argue that a note is not necessary. This collection of notes shows how contributors focus on highlighting how clearly a piece of content might be ‘fake’ or ‘false’ first and foremost, with the aim of either explaining or defending jokes on X. None of the notes added context about how the tweet had the potential to contribute to racialised disinformation. The video pokes fun at Bragg’s weight and appearance, playing into racist tropes. At the time the tweet was made, Trump had urged his followers to protest Bragg’s charges against him (Orden, 2023). This spawned an onslaught of claims that branded Bragg as ‘racist’ and allied him with George Soros, tapping into deep-rooted antisemitic and racist conspiracy theories and ideas (Teter, 2023). The author of the tweet, alt-right political activist Jack Posobiec, is a fervent Trump supporter. His tweet could also be considered part of a broader trend of Trump tactics to intimidate Black prosecutors, reported at the time (Bero, 2023).
This was not an isolated occurrence. We deemed 41.38% (n = 12) of public notes could have been improved to mitigate harm, with some tweets potentially perpetuating harmful anti-Black, sinophobic, misogynistic and antisemitic narratives. 29 People experiencing homelessness and people living with obesity were also targeted in some jokes. 30 Importantly, Bragg’s example reflects the limitations of fact-checking initiatives like CN and opens the door to consider ‘value-checking’ (Yarrow, 2021) as a useful addition to these types of tools. That is, the public community shown under Bragg’s video could have mentioned the author of the tweet’s normative positioning and subjective background, or the fact that he is a Trump supporter who uses his account to spread far-right conspiracy theories. It thereby obscures important context that would otherwise help ‘make sense’ of the tweet author’s own epistemic assumptions and their use of satire in this setting.
Conclusion – a system skewed to correct narrow understandings of the disinformation problem
Drawing on infrastructure and platform studies, which consider technologies as socio-technical objects that need to be studied in relation to their broader context and associated practices, in this article we have conceptualised CN as a data infrastructure for ‘soft moderation’ that combines automation and humans-in-the-loop to solve disinformation. Through our qualitative inquiry, we find that CN enacts and advances an operational logic that inscribes true-false, real-fake binaries into its design, and overlooks the potential for content to harm. These findings align with long-standing critiques of fact-checking for its reliance on a Western epistemology-based framing of disinformation (Berger, 2022; Zeng and Brennen, 2023) that centres falsity (Marres, 2018) and intent (Gallagher, 2023), and ignores under-acknowledged online harms derived from the interplay between disinformation and humour (Ajder and Glick, 2023; Matamoros-Fernández et al., 2023). At the time of writing, 31 X changed the design of CN to entirely remove the options to assess tweets’ risk of posing ‘considerable harm’ or ‘little harm’. This feature evolution doubles down on our argument that CN is a data infrastructure for ‘soft moderation’ that pays little attention to the complexities of online harms (Bartolo and Matamoros-Fernández, 2023). Our findings align with Cotter et al.’s (2022) argument that digital platforms’ increasing investment into fact-checking infrastructures represent the ‘platformization of truth’ (p. 1). In our case, a platform-based understanding of the problem of disinformation that centres falsity and pays little attention to harm, shaping the nature and work of fact-checking practices according to platform logics. Thus, our findings are a reminder of the importance of critically examining processes of problematisation that orient the development of technologies and their evolution. CN’s design reproduces X’s libertarian ideology (Maddox and Malson, 2020), devolving responsibility to individual users to hash out what they believe is false and true (Cotter et al., 2022). In fact, transferring responsibility to users to manage online experiences is a broader trend in online safety that has been critiqued for ignoring ‘how particular features of the platform environment can and do directly support the accumulation of harms’ (Bartolo and Matamoros-Fernández, 2023: 9). CN also reproduces the DSA’s orientation to ‘solve’ a narrow understanding of the disinformation problem, not attune to the complexities of disinformation, humour and harm. And so, like the DSA, CN requires a better policy definition of disinformation to guide good practice in identifying and mitigating disinformation’s risk of harm, alongside its entanglement with other prevalent online practices, such as humorous, irreverent and ambivalent Internet cultures (Highfield, 2015; Phillips and Milner, 2017).
Our work also invites reflection on best practices for designing data infrastructures that rely on algorithms and people to mitigate the harms derived from disinformation. Even if CN were to readdress its design to include more data points and information on how content at the intersection of disinformation and humour has potential to harm, it is unlikely that CN’s bridging algorithm would surface consensus on this issue. Indeed, X’s own research warns that within CN, it is more difficult for notes to gain consensus on polarising issues (Wojcik et al., 2022), particularly when notes are attached to tweets by influential accounts with a high number of followers (Pröllochs, 2022). It would potentially be harder to reach ‘cross ideological agreement’ on humorous content, as ‘consensual narratives’ (Vinhas and Bastos, 2022) attached to humour’s potential to harm often do not benefit the interests of marginalised and disadvantaged groups (Matamoros-Fernández et al., 2023). While we find that the CN bridging algorithm works relatively well at reaching consensus when notes reflect the mundane and somewhat straightforward parts of content moderation (e.g. Is this media altered? Is this a parody account? Is this a popular internet joke out of context?), it is likely to struggle when the issue is more political and harder to judge, even for humans. Including experts in the process, as Spina et al. (2023) argue, could be a possible solution to improve CN – for example by integrating CN within X’s larger content moderation pipelines, which X does not currently do (Bovermann, 2024). Experts, like journalists, fact-checkers and professional content moderators, are deeply attuned to local languages, cultures and socio-political nuances (Riedlinger et al., 2024), and so are important for assessing both the check-worthiness of narratives and their potential harm (Demartini et al., 2020).
Finally, our article is a direct response to research that has called for creative and research-led socio-technical audits of platform systems (Terzis et al., 2024) that ‘purposively’ respond to known challenges in online safety (Griffin and Stallman, 2024). It is precisely through our auditing of the tool holistically and with a known challenge in mind – how to best address the harms derived from content at the intersection of disinformation and humour (Ajder and Glick, 2023) – that our approach differs from other research that has analysed CN as merely a technical tool (e.g. Wojcik et al., 2022). Our socio-technical audit goes beyond identifying technical (in)accuracies and instead incentivises platforms to make structural design changes based on academic research and best practice that centre harm in conceptualisations of the disinformation problem and how to solve it. This is particularly important considering X largely relies on CN to counter disinformation (Twitter, 2023) and when other large platforms, such as Facebook, Instagram and YouTube, are planning data infrastructures for ‘soft moderation’ similar to CN (Kaplan, 2025; The YouTube Team, 2024).
Although our methods and findings address research gaps, it is also important to acknowledge the limitations of our study. First, we analysed notes and tweets in English that were largely about US politics and topics. Further research could draw on our approach to investigating how CNs as a data infrastructure for ‘soft moderation’ reflects particular understandings of the disinformation problem and how to solve it in other socio-cultural contexts. Second, we did not talk to CN contributors to discuss how they make sense of content they classify as satirical. Incorporating interviews is an important additional step to move this type of research forward. Finally, we gathered data in April 2023, just a few months after CN was launched globally in December 2022. Repeating a study like ours in 2024 or later would likely include notes from contributors outside the United States who would have reached a ‘rating impact’ to write notes. Our hope is that the insights we have gathered and our approach to auditing data infrastructures for ‘soft moderation’ serve as a reminder of the importance of qualitative inquiry to make sense of what complex socio-technical systems such as CN do, alongside the social implications of this doing.
Supplemental Material
sj-docx-2-nms-10.1177_14614448251314399 – Supplemental material for The importance of centering harm in data infrastructures for ‘soft moderation’: X’s Community Notes as a case study
Supplemental material, sj-docx-2-nms-10.1177_14614448251314399 for The importance of centering harm in data infrastructures for ‘soft moderation’: X’s Community Notes as a case study by Ariadna Matamoros-Fernández and Nadia Jude in New Media & Society
Supplemental Material
sj-pdf-1-nms-10.1177_14614448251314399 – Supplemental material for The importance of centering harm in data infrastructures for ‘soft moderation’: X’s Community Notes as a case study
Supplemental material, sj-pdf-1-nms-10.1177_14614448251314399 for The importance of centering harm in data infrastructures for ‘soft moderation’: X’s Community Notes as a case study by Ariadna Matamoros-Fernández and Nadia Jude in New Media & Society
Footnotes
Acknowledgements
We would like to thank Laura Vodden for her help with automatically checking whether tweets in our dataset had been removed or a user had been suspended. We would also like to extend our gratitude to the three anonymous scholars who review this paper and to the special issue editors for providing invaluable feedback that helped us improve this work. All errors are our own.
Author’s Note
Ariadna Matamoros-Fernández is now affiliated to University College Dublin, Ireland.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by an Australian Research Council DECRA grant (DE230101558).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.