
Abstract
The double-edged nature of generative artificial intelligence (AI) underscores the importance of understanding complex and paradoxical public views about this emerging technology. Heeding to this call, this study examined how the general public perceives and reacts to Chat GPT and the implications of these perceptions, drawing on the third-person and first-person effect. A national survey in the United States (N = 1004) revealed that individuals tend to believe they would personally benefit from the positive influence of Chat GPT, while others will benefit relatively less. Also, results showed that people believe that self is more capable of using Chat GPT critically, ethically, and efficiently than others. Interestingly, the self-other gap in perceived efficacy was influenced by subjective knowledge but not by objective knowledge about Chat GPT. The self-other gap in perceived efficacy negatively predicted support for government regulation of Chat GPT, while the self-other gap in both perceived influence and efficacy positively predicted support for literacy interventions.
Keywords
As with the introduction of any new media technologies, the release of ChatGPT has sparked both enthusiasm and concerns. Experts who see opportunities in generative artificial intelligence (AI) technology foresaw that by utilizing ChatGPT to efficiently handle a range of mundane tasks; individuals can save time and focus on more high-value work (Noy and Zhang, 2023). However, many others highlight significant risks of misusing this novel technology, such as lowering the costs of disinformation campaigns and its potential exploitation for financial gain, political purposes, or creating chaos and confusion (Hsu and Thompson, 2023).
The rapid advancement of generative AI has prompted regulators worldwide to urgently understand, manage, and ensure the safety of this technology. In the United States, for example, active discussions are underway about updating existing federal or state laws and creating new sector-specific legislation to address challenges posed by generative AI (Kang, 2024). There have also been growing calls for literacy programs related to generative AI (e.g., Ciampa et al., 2023). However, little is known about how the public thinks about regulating and approaching generative AI. Considering the double-edged nature of generative AI—having both positive and negative aspects or outcomes (Ali et al., 2024; Rane et al., 2023), the public may have paradoxical views about the technology. For example, individuals may presume that ChatGPT has a positive influence on themselves while exerting a negative impact on others. These contradictory perceptions can result in varying levels of support for regulatory approaches. Understanding such intricate public sentiments will guide policymakers and industry leaders in developing balanced regulations that address public concerns while fostering technological innovation.
Against this backdrop, this study examines how the public views ChatGPT and relevant regulatory approaches, along with the underlying mechanisms shaping these attitudes. The third-person effect (Davison, 1983), which elucidates the perceived discrepancy in media influence on self versus others and its impact on behavior, offers a valuable theoretical framework for this exploration. In this pursuit, we address several aspects that have been overlooked in the existing third-person effect literature. First, by centering on the double-edged nature of generative AI technology, we not only examine third-person perception concerning ChatGPT’s negative impacts (i.e., greater negative influence on others than self) but also first-person perception regarding its positive impacts (i.e., greater positive influence on self than others). Second, recognizing that the appropriate use of ChatGPT significantly depends on users’ competence and awareness (Rivas and Zhao, 2023), we investigate how individuals assess their own and others’ abilities to use ChatGPT ethically and effectively, moving beyond the traditional “media influence” measurement. Third, we aim to clarify the relationship between third-person or first-person perceptions and support for regulatory approaches concerning generative AI, addressing the fragmented findings in previous research (e.g., Jang and Kim, 2018; Lo and Wei, 2002). We explore these three points through a national survey of US residents conducted in the early days of ChatGPT dissemination.
Third-person effect and ChatGPT
The third-person effect refers to a well-documented phenomenon where individuals believe that media content has a greater impact on others than on themselves and thus take actions to deter such perceived influence (Davison, 1983). The third-person effect can be divided into perceptual and behavioral components. The perceptual hypothesis suggests that people tend to underestimate the influence of media on themselves while overestimating its impact on others (i.e., third-person perception). The behavioral hypothesis predicts that the discrepancy between perceived media influence on self versus others drives individuals to take actions in accordance with this perceptual gap (Perloff, 1999).
With the emergence of AI technology, researchers have begun exploring the third-person effect within AI contexts. For instance, a recent study discovered that people believe AI-generated deepfakes have a greater impact on others than on themselves (Ahmed, 2023). Likewise, in situations where both human and AI are involved in a transgression (e.g., a pedestrian being hit by a self-driving car), people tend to perceive themselves as less responsible than others when evaluating their own transgressions compared to those of others (Dong and Bocian, 2024). However, these studies focused only on the negative influence of AI technology, neglecting the first-person effect (i.e., self is influenced by the media more than others) resulting from the positive aspect of the technology.
This gap warrants further investigation because people’s engagement with AI technology, such as ChatGPT, often encompasses both positive and negative activities. For example, HR professionals might train ChatGPT with their organization’s HR documents, enabling it to answer common employee questions and allowing human resources to focus on more complex or human-centered tasks. On the other hand, scammers could leverage ChatGPT to generate malware code. These distinct engagements with ChatGPT highlight the double-edged nature of ChatGPT, potentially evoking both the third-person and first-person effect.
At the core of the double-edged nature of ChatGPT is social desirability, defined as the extent to which the media benefits or helps society (Henriksen and Flora, 1999; Jensen and Hurley, 2005). This concept is often operationally defined as exerting desirable or positive influence on society (e.g., Jang and Kim, 2018; Rainie et al., 2021). According to ego-enhancement theories, individuals are typically reluctant to acknowledge being influenced by the media, especially when such admission negatively affects their self-image (Perloff, 2002). That is, the third-person effect is pronounced when individuals perceive it is not “cool” to admit being influenced by particular media, while the effect diminishes or even reverses (i.e., first-person effect) when the media is considered cool to be influenced by (Gunther and Mundy, 1993).
While the role of social desirability is a well-established aspect of third-person effect research (see Sun et al., 2008 for a meta-analysis), past studies have typically examined media content or platforms where social desirability was rather clear-cut. For example, pornography, misogynistic rap music, and cigarette advertisements are undesirable (Henriksen and Flora, 1999; Lo and Wei, 2002); public-service announcements, prosocial news articles, and fact-checking content are desirable (Chung and Kim, 2021; Chung, 2024; Meirick, 2005). Even when considering platforms that offer opportunities for both positive and negative activities (e.g., social media and online games), the different types of use were often distinguished and labeled (e.g., “posting selfies” is undesirable, “liking others’ posts” is desirable; Pham et al., 2019). This dichotomized view inhibits an accurate assessment of what happens when the same platform offers both benefits and risks. As an exception, an online survey among Facebook users (Kim and Hancock, 2015) offers a useful insight into how people may apply double standards in presuming the influence of double-edged new media. The study revealed that if individuals view Facebook use as undesirable, they tend to presume that others are more influenced by Facebook than self (i.e., third-person effect). Conversely, if individuals view Facebook as desirable, they believe that themselves are more influenced by Facebook than others (i.e., first-person effect). In a similar vein, for generative AI technology such as ChatGPT, there may be a natural variation among people in how they view the technology, ranging from highly desirable to highly undesirable. In these instances, considering their attitudes toward the technology, whether they see it as desirable or undesirable, is essential to accurately assess the direction of self-other discrepancy.
In this light, we examine how people presume the influence of ChatGPT on self and others, by considering the full extent of people’s perceptions of the desirability of the technology. We posit that for those who see the generative AI technology as socially desirable, self-other perceptual discrepancy (i.e., the difference between perceived influence on self and perceived influence on others) will increase compared to those who see the technology as less desirable, due to greater first-person perception (i.e., greater positive effect on self than others). For those who see the technology as socially undesirable, self-other perceptual discrepancy will also increase, compared to those who see the technology as less undesirable, due to greater third-person perception (i.e., greater negative effect on others than self). Taken together, this suggests that perceived desirability of ChatGPT might exhibit a curvilinear association with the self-other gap in presumed influence of ChatGPT, as the self is always considered to be more positively (less negatively) influenced than others, especially as the (un)desirability level increases. Put differently, the first- and third-person perceptions can be seen as essentially the same effect, only regarding different things (desirable versus undesirable things) and focused on different aspects of the effect (more positive/negative influence on self/other). These possibilities are rooted in the arguments and empirical findings for the third-person and first-person effect (see Sun et al., 2008), but they have rarely been tested due to the aforementioned issues. This study aims to fill this gap.
Beyond media influence: self- and other-efficacy for ChatGPT use
Prior third-person effect research has primarily focused on the traditional scenarios where individuals experience media content or platforms as outside self (Perloff and Shen, 2023). That is, most third-person effect studies have asked people to estimate the level of “influence” they and others would experience from media (e.g., Ahmed, 2023; Kim and Hancock, 2015). This approach assumes that message recipients are passive consumers of media content.
However, when examining the third-person and first-person effect in ChatGPT contexts, it is important to consider users’ dynamic and personalized interactions with ChatGPT, as the content generation on ChatGPT largely depends on the user’s input (Nield, 2024). ChatGPT is an advanced language model trained based on large amounts of textual data and reinforcement learning from human feedback, allowing it to understand the human intent in a question and generate contextually appropriate responses in conversations (Ouyang et al., 2022). Therefore, the more a user possesses a solid understanding of the subject, formulates well-constructed queries, and becomes aware of the ethical implications associated with ChatGPT, the more efficiently and ethically the user can utilize this versatile tool (Li et al., 2023; Rivas and Zhao, 2023).
In this light, to fully understand self-other perceptual discrepancies concerning ChatGPT, it is essential to examine how individuals evaluate their own ability to use the tool critically, ethically, and effectively in comparison to others, rather than simply asking people to assess how ChatGPT would influence themselves and others. To this end, this study draws upon the concepts of self- and other-efficacy. Self-efficacy refers to self-perceived capability to attain certain skills or take actions to manage relevant issues (Bandura, 1994). Prior studies found that individuals demonstrate significant variations in the self-evaluation of their new media use capabilities (Lee and Tamborini, 2005), making self-efficacy worth exploring in the context of third-person effect research. Other-efficacy is defined as individuals’ belief in others’ capabilities to perform a given behavior (Lent and Lopez, 2002). While other-efficacy has received less scholarly attention than self-efficacy, this study highlights it as a crucial comparison point for self-efficacy.
Some prior studies have found that the self-other perceptual gap extends to self- and other-efficacy. For instance, a multi-country study revealed that people assume they are better at identifying misinformation on social media than others (Chung and Wihbey, 2024a). Another recent study found that people believe their use of AI-mediated communication would be responsible and normatively acceptable, but they do not expect others to adhere to the same principles (Purcell et al., 2024). Building on these findings, we predict that individuals are inclined to feel confident in their responsible and appropriate use of ChatGPT while assuming that others are less competent in doing so.
Subjective versus objective knowledge
Extant literature on the third-person effect points to the level of knowledge as an important predictor of the self-other gap (Driscoll and Salwen, 1997; Lasorsa, 1989). Knowledge is likely to accelerate the process of ego-enhancement, leading people to believe that they have some control over the media content and instilling a sense of optimism that they are less likely than others to suffer negative outcomes (Helweg-Larsen and Shepperd, 2001; Lev-On, 2017). That is, when individuals possess background knowledge or a comprehensive understanding of a specific issue, they tend to believe that they can shield themselves from the adverse influence of media content.
The role of knowledge may be particularly pronounced in the context of ChatGPT, as the use of emerging technology requires specific skills or knowledge, unlike the passive consumption of traditional media such as reading newspapers or watching television (Lee and Tamborini, 2005; Lev-On, 2017). Scholars suggested that people believe others to be less likely to benefit from ChatGPT due to the lack of tech literacy and skill sets (Li et al., 2023; Rivas and Zhao, 2023). Then, it is possible that individuals who perceive themselves as possessing a certain level of knowledge about ChatGPT may exhibit a greater inclination to believe that they are less negatively influenced or more positively influenced by ChatGPT and can use this novel technology more critically, ethically, and effectively than others.
Of note is that previous studies largely relied on self-reporting to measure the knowledge level (i.e., subjective knowledge; Driscoll and Salwen, 1997; Lasorsa, 1989). Thus, while the role of subjective knowledge, a metacognitive evaluation about one’s own knowledge (Metcalfe and Shimamura, 1994), in predicting third-person perception has been well documented, the role of objective knowledge (i.e., factual knowledge stored in memory) remains underspecified. Although some studies identified the level of education (Salwen, 1998; Tiedge et al., 1991) or actual political knowledge (Price and Tewksbury, 1996) as predictors of the third-person effect, other studies (e.g., Lasorsa, 1989) found that objective knowledge was not associated with the third-person effect. Hence, Lasorsa (1989) observed that “perceived political knowledge rather than real political knowledge fuels the third-person effect (p. 377).”
Taken together, users may think that they are less negatively or more positively influenced by ChatGPT (i.e., self-other gap in influence) and can utilize ChatGPT more ethically and effectively than others (i.e., self-other gap in efficacy) when they have a high level of subjective knowledge about the technology. However, it is challenging to predict the direction of the influence of objective knowledge given the inconsistent findings in extant literature.
Behavioral outcomes of the self-other gap
Research has shown that both third-person perception and first-person perception lead to behavioral reactions (Perloff, 1999). The behavioral response takes the form of either restrictive or corrective actions. Restrictive actions include support for censorship or regulations of undesirable media content (e.g., McLeod et al., 1997), and corrective actions involve literacy interventions, education, or campaigns (e.g., Chen and Atkin, 2021). Yet, it is worth noting that prior studies have reported inconsistent findings regarding the link between the self-other gap and restrictive approaches. While many studies found that the self-other perceptual gap is a stronger predictor of censorship attitudes (see Xu and Gonzenbach, 2008 for meta-analysis), other studies failed to find a positive association between third-person perception and censorship attitudes (Jang and Kim, 2018; Lo and Wei, 2002). In the context of misinformation, for example, the belief that others are more vulnerable to misinformation than themselves (i.e., third-person perception) did not predict support for government regulation of social media platforms (Chung and Wihbey, 2024a). This finding could be attributed to people’s reluctance to compromise their constitutional right to free speech to safeguard others who might be susceptible to misinformation (Jang and Kim, 2018).
Applying this reasoning to the ChatGPT context, people may not support government regulation of the technology solely because others are susceptible to the negative influence of ChatGPT or lacking capabilities to use it sensibly. That is, those who believe themselves to be less negatively (or more positively) influenced by ChatGPT than others or feel confident in using this new technology more sensibly than others may consider stringent guidelines or restrictions on generative AI as unnecessary or irrelevant to themselves. Such perception may lead to them not to prefer a solution that enforces uniform restrictive measures on everyone, including themselves.
An alternative approach to restrictive actions is corrective measures such as literacy initiatives (Heins and Cho, 2003). A key aspect of literacy intervention is to allow media users to control their media experiences (Rosenthal et al., 2018). Previous research found that the self-other gap in presumed influence of misinformation positively predicts support for literacy interventions (Cheng and Chen, 2020; Jang and Kim, 2018). Literacy interventions can be appealing because they do not require everyone to sacrifice their autonomy (Chung and Wihbey, 2024a). If so, those who overestimate others’ vulnerability to the negative influence of ChatGPT and underestimate others’ ability to use and control over this novel technology may support literacy interventions to protect those presumably vulnerable others, while maintaining their own freedom to use ChatGPT as they wish.
Hypotheses and research questions
Based on the literature review and the reasoning above, we propose the following hypotheses and research question.
H1: Perceived social desirability of ChatGPT is curvilinearly associated with the self-other gap in presumed influence of ChatGPT.
H2: People perceive that they can use ChatGPT more critically, ethically, and effectively than others (i.e., self-other gap in efficacy).
H3: Subjective knowledge of ChatGPT will positively predict the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to appropriately use ChatGPT.
RQ1: How are objective knowledge of ChatGPT and the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to appropriately use ChatGPT associated?
H4: The self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to use ChatGPT will negatively predict support for government regulation.
H5: The self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to use ChatGPT will positively predict support for literacy intervention.
Method
Data
We collected data from an online panel provided by Dynata. 1 To address the non-representative nature of an online panel, we carefully selected samples that matched the demographic characteristics of US adults, including age, gender, education, income, and race/ethnicity. 2 The online survey was conducted between February 20 and 27, 2023, and invitations were sent to 2103 panel members. Ultimately, 1004 respondents completed the survey, resulting in a response rate of 47.7% (as per AAPOR Cooperation Rate 1). The sample closely resembled the national population in terms of gender, education, and income but was slightly younger and had a higher proportion of White individuals. Table 1 compares the demographic breakdowns of our sample with the census data.
Sample comparison with population.
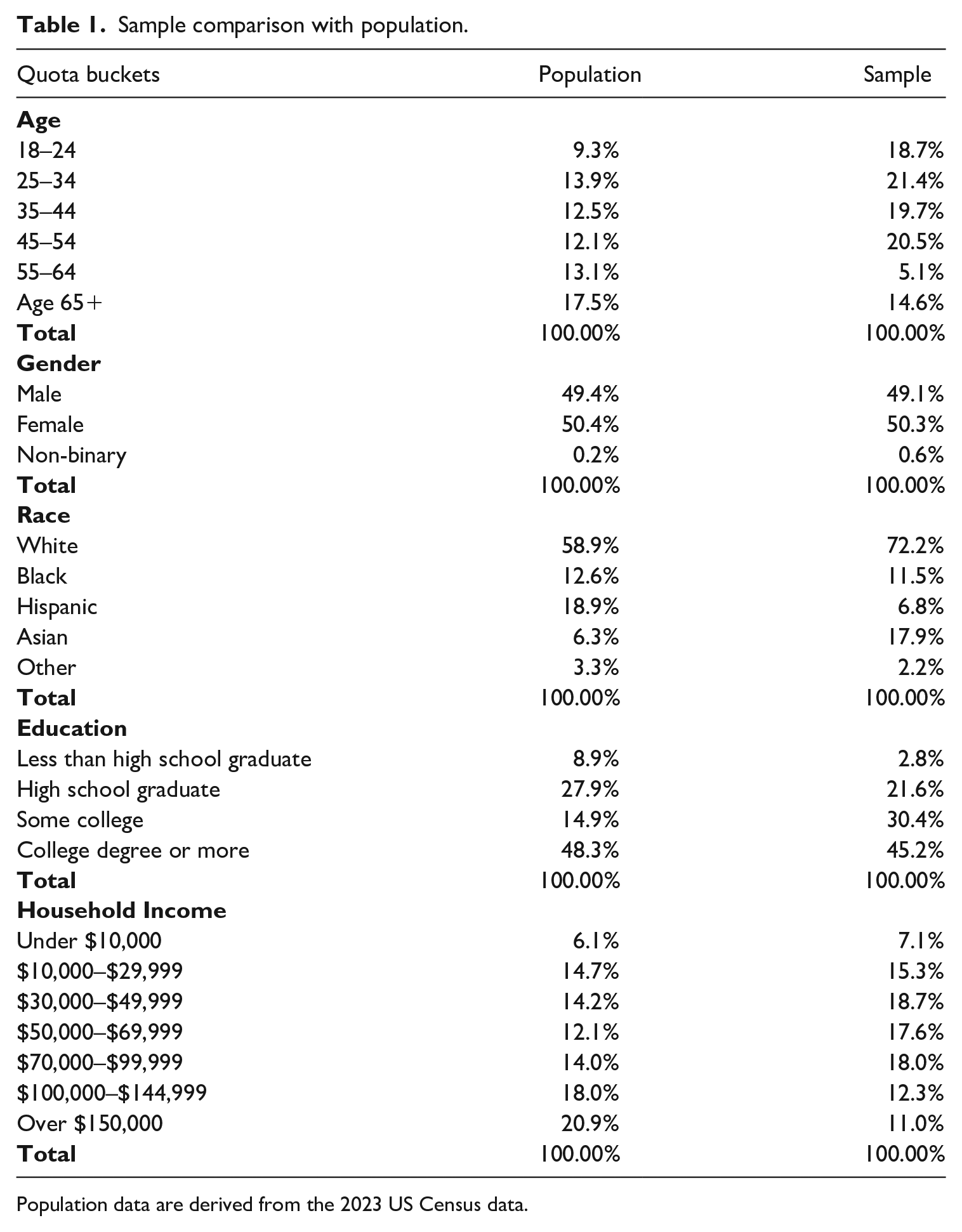
Population data are derived from the 2023 US Census data.
Measures
Perceived influence of ChatGPT on self
To assess the perceived influence of ChatGPT on self, participants indicated to what extent they agree with the following statements: “How much would the use of ChatGPT influence the personal life of yourself?” and “How much would the use of ChatGPT influence your work?” (modified from Chung et al., 2015; 1 = Very negatively influence, 5 = Very positively influence, M = 3.29, SD = 1.01, rs = .74). In contrast to many previous studies that employed generic questions (e.g., “how much do you think yourself/others are influenced by the content?”), our approach aimed to assess both the positive and negative impact, taking into account the double-edged nature of ChatGPT.
Perceived influence of ChatGPT on others
Perceived influence of ChatGPT on others was measured using the following items: “How much would the use of ChatGPT influence the personal life of others?” and “How much would the use of ChatGPT influence others’ work?” (modified from Chung et al., 2015; 1 = Very negatively influence, 5 = Very positively influence, M = 3.21, SD = .99, rs = .71).
Self-other gap in influence
Self-other gap in perceived influence was computed by subtracting perceived influence on others from perceived influence on self (M = .07, SD = .61). A greater mean score indicates that an individual presumes that self is relatively more positively influenced by ChatGPT than others.
Self-efficacy
Self-efficacy was measured with three items modified from Chung and Wihbey (2024a); “I can use ChatGPT critically,” “I can use ChatGPT ethically,” “I can use ChatGPT effectively” (1 = Strongly disagree, 5 = Strongly agree; M = 3.47, SD = .88, Cronbach’s alpha = .86).
Other-efficacy
Other-efficacy was measured with three items modified from Chung and Wihbey (2024a); “Others can use ChatGPT critically,” “Others can use ChatGPT ethically,” “Others can use ChatGPT effectively” (1 = Strongly disagree, 5 = Strongly agree; M = 3.37, SD = .88, Cronbach’s alpha = .86).
Self-other gap in efficacy
Self-other gap in perceived ability to use ChatGPT appropriately was computed by subtracting the scores on other-efficacy from self-efficacy (M = .10, SD = .65). A greater mean score indicates that an individual thinks self can use ChatGPT more appropriately than others.
Support for regulation
Support for ChatGPT regulation was measured with three items modified from previous studies (Chung and Wihbey, 2024a; Jang and Kim, 2018), “ChatGPT should be banned,” “I support legislation to prohibit ChatGPT,” and “ChatGPT should be regulated by the government” (1 = Strongly disagree, 5 = Strongly agree; M = 2.98, SD = .95, Cronbach’s alpha = .74).
Support for literacy intervention
Support for literacy intervention was measured with three items modified from Jang and Kim (2018), “People should be taught how to use ChatGPT critically,” “People should be taught how to use ChatGPT ethically,” and “People should be taught how to use ChatGPT effectively” (1 = Strongly disagree, 5 = Strongly agree; M = 3.93, SD = .83, Cronbach’s alpha = .87).
Social desirability of ChatGPT
Based on Pew Research Center’s survey (Rainie et al., 2021), perceived social desirability of ChatGPT was measured using two pairs of bipolar adjectives. Respondents were asked to indicate the degree of impact ChatGPT has upon society: undesirable (1) to desirable (5), negative (1) to positive (5) (M = 3.08, SD = 1.22, rs = .74).
Subjective knowledge
Based on Lee et al. (2022), subjective knowledge of ChatGPT was measured with a single item, “How much do you think you know about Chat GPT?” (1 = Not at all, 5 = A great deal; M = 1.96, SD = 1.22).
Objective knowledge
Drawing upon previous scholarship on various subjects such as politics (Matthes et al., 2023), science (Nisbet et al., 2015), and health (Jiang et al., 2022), we created eight True/False/Don’t know questions to assess respondents’ factual knowledge of ChatGPT (e.g., “ChatGPT can provide a personalized response,” “ChatGPT can generate biased responses,” “ChatGPT is the first chatbot,” and “ChatGPT is designed by Google”). Correct responses were coded as 1, while incorrect responses and “Don’t know” responses were coded as 0. Correct scores were summed to create an index of objective knowledge (possible range from 0 to 8, M = 2.65, SD = 1.50). 3
Demographics
Demographic variables including age, gender, education, ethnicity, monthly household income, and political ideology (1 = Strongly liberal, 7 = Strongly conservative) were controlled.
Results
Statistical approach
To examine our hypotheses and research question, we ran a path analysis. Prior to delving into the individual hypotheses and research questions, we evaluated the overall fit of our theoretical model (see Figure 1) to the data by examining several fit indicators. These included the chi-square test statistic comparing our model against the saturated model (χ2), comparative fit index (CFI), Tucker–Lewis index (TLI), and root-mean-square error of approximation (RMSEA). Our theoretical model demonstrated a good fit to the data: χ2 = 7.42, df = 3, p = .060, CFI = .99, TLI = .91, RMSEA = .04 (90% confidence interval: .00–.07).
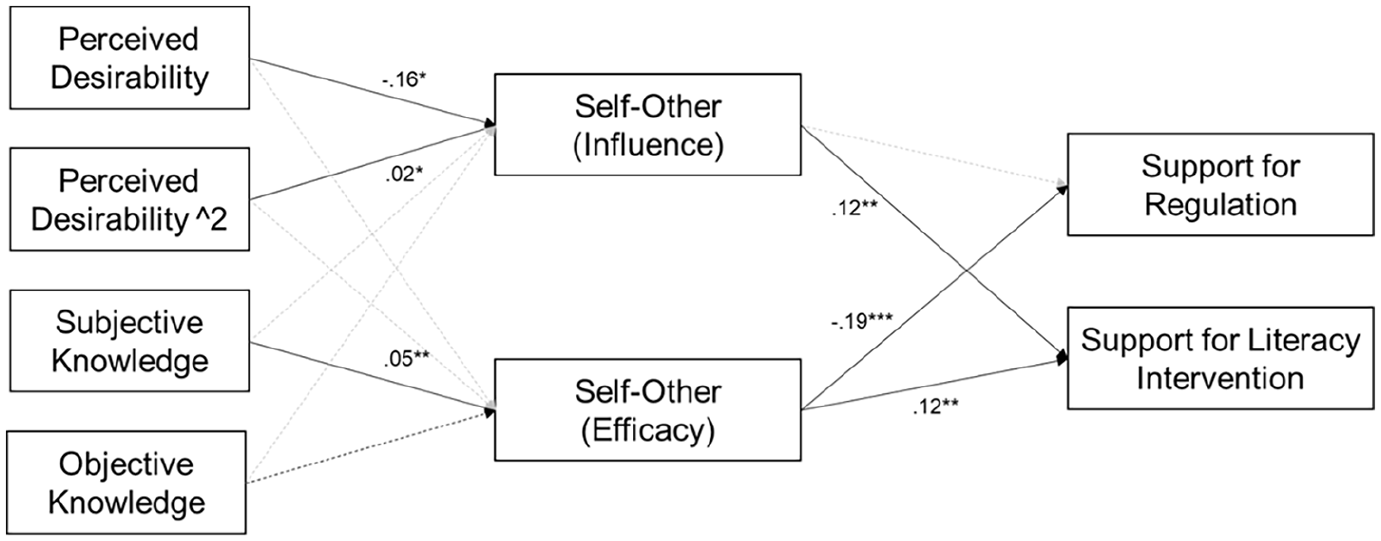
The result of path analysis.
Hypotheses test
The zero-order correlations among the variables are presented in Table 2. To test whether perceived social desirability of ChatGPT is curvilinearly associated with the self-other gap in presumed influence of ChatGPT (H1), a quadratic form was evaluated for perceived social desirability. The results showed that perceived social desirability was a quadratic predictor of perceived self-other gap in influence. In particular, the coefficient for the squared term for social desirability was positive (b = .02, p = .048), indicating a U-shaped relationship peaking at the bottom. The linear term, which indicates the rate of change when social desirability is 0, was negative (b = −.16, p = .038), suggesting an initial downward slope at social desirability 0. To better understand this quadratic trend, we plotted the marginals of perceived self-other gap in influence by perceived social desirability (see Figure 2). As can be observed, all predicted values were positive; regardless of perceived social desirability level, people thought self is more positively influenced compared to others. Those who perceived ChatGPT to be more desirable or undesirable—as compared to the midpoint—showed a greater gap in perceived influence on self and others.
Zero-order correlations among the variables in the model.
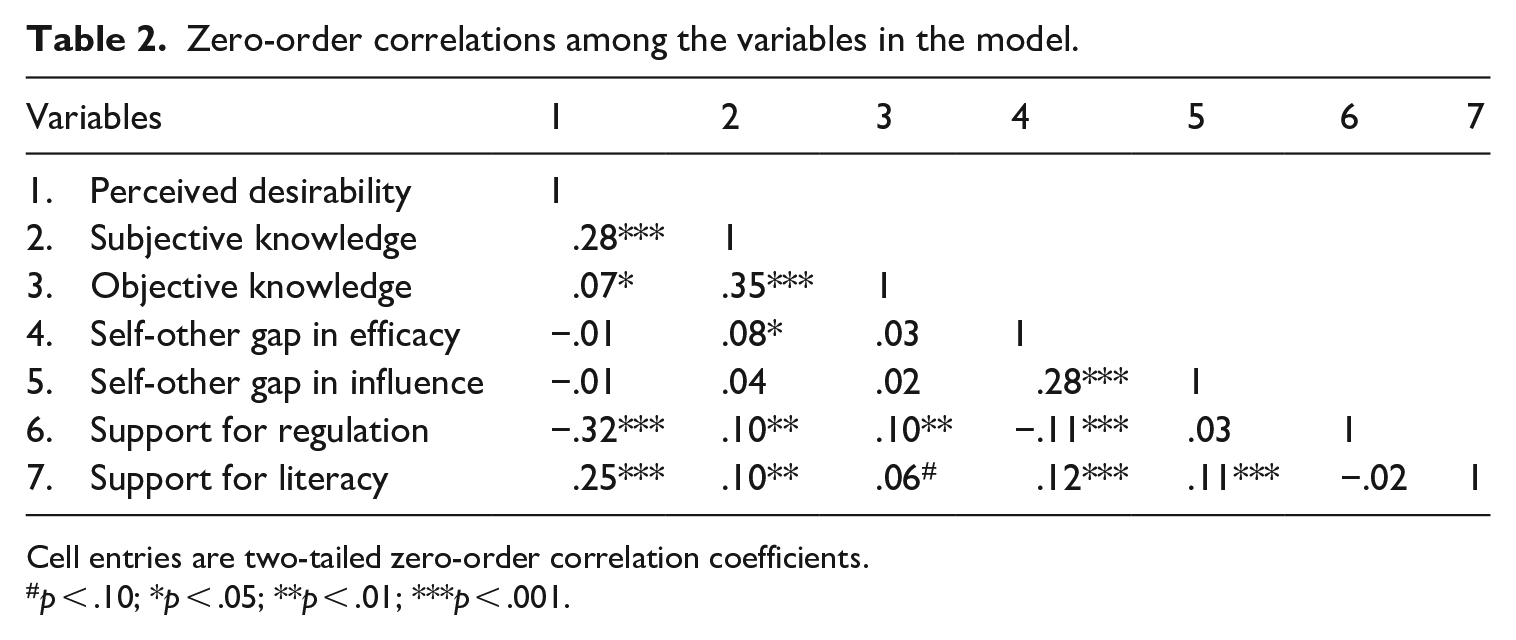
Cell entries are two-tailed zero-order correlation coefficients.
p < .10; *p < .05; **p < .01; ***p < .001.
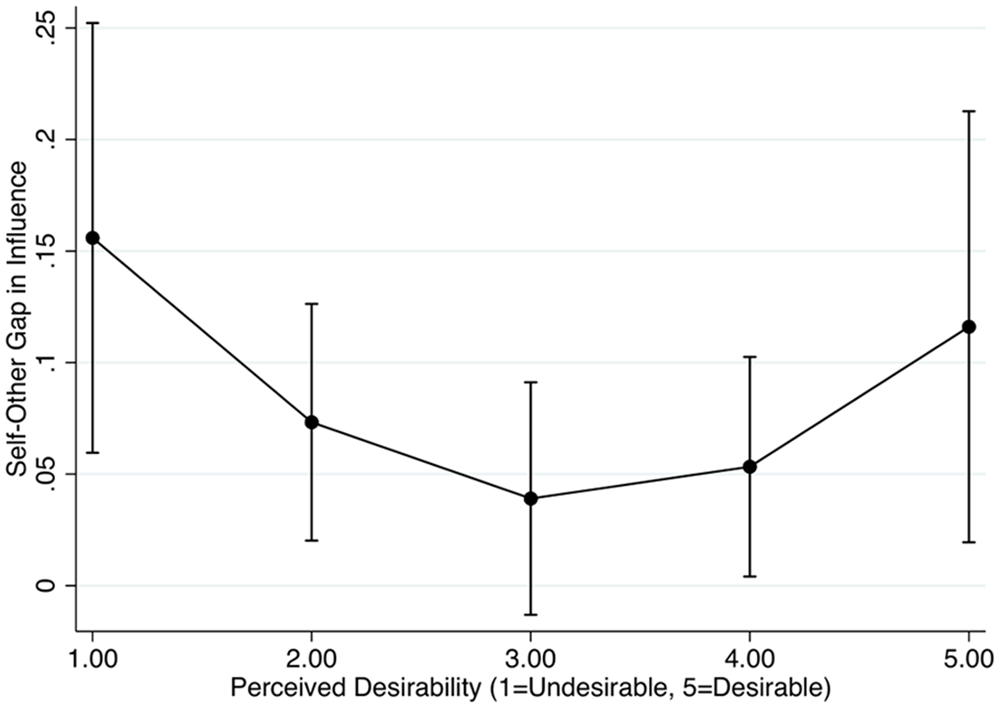
Predicted self-other influence gap (with 95%CI) plotted by perceived desirability of ChatGPT.
To examine whether people believe that they can use ChatGPT in a more critical, ethical, and effective manner than others (H2), a paired sample t-test was conducted. Participants exhibited a significantly higher self-efficacy (M = 3.47, SD = .88) and other-efficacy (M = 3.37, SD = .88), diff = .10, t(1003) = 4.74, p < .001. Hence, H2 was supported.
H3 predicted that an increase in subjective knowledge of ChatGPT would lead to an increase in the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to appropriately use ChatGPT. The results found no significant association between subjective knowledge of ChatGPT and the self-other gap in presumed influence. However, we found a positive association between subjective knowledge of ChatGPT and the self-other gap in efficacy (b = .05, p < .01). Hence, H3a was not supported but H3b was supported.
Then, RQ1 explored how objective knowledge of ChatGPT and the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to appropriately use ChatGPT are associated. The results suggest that objective knowledge of ChatGPT is not significantly associated with either the self-other gap in influence or the self-other gap in efficacy.
Next, H4 tested whether the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to use ChatGPT would negatively predict support for government regulation. The results indicate that there is no association between the self-other gap in influence and support for government regulation, failing to support H4a. However, there was a negative association between the self-other gap in efficacy and support for government regulation (b = −.19, p < .001), rendering support for H4b.
Finally, H5 predicted that the self-other gap in (a) presumed influence of ChatGPT and (b) perceived efficacy to use ChatGPT would positively predict support for literacy intervention. We found a positive association between the self-other gap in influence and support for literacy intervention (b = .16, p < .01), supporting H5a. The results also indicate that the self-other gap in efficacy positively predicts support for literacy intervention (b = .12, p < .01), thereby supporting H5b.
Discussion
Theoretical and practical implications
While the industry’s discourse on generative AI has prominently featured the battle between boomers (those seeing opportunities) and doomers (those seeing threats) (Roose, 2023), there has been a notable lack of research on the public’s views on this emerging technology. Given that the public’s views and uptake of generative AI are among the key factors shaping how the technology is developed, utilized, and regulated (Nielsen, 2024), it is crucial to understand intricate public sentiments to guide balanced development and regulations of the technology. Heeding this call, this study examined public perceptions and reactions to ChatGPT and related regulatory measures, through the lens of the third-person and first-person effect.
Our main finding highlights the public’s tendency to apply double standards when evaluating ChatGPT, depending on whether they are assessing it for themselves or for others. Specifically, the results demonstrated that perceived social desirability has a quadratic relationship with the self-other gap in perceived influence; people who perceived ChatGPT to be socially desirable (i.e., boomers) or undesirable (i.e., doomers) showed a greater gap in perceived influence on self and others, as compared to those that had neutral or ambivalent views toward the technology.
Of note, while the perceptual gap uniformly increased among boomers and doomers, the driver of the increase was different. That is, among those who perceive ChatGPT as socially desirable, the self-other gap increased because of a stronger first-person perception, reflecting a stronger perceived positive impact on themselves as compared to others (see Table 3). Conversely, among those who view ChatGPT as socially undesirable, the self-other gap increased due to a heightened third-person perception, reflecting a stronger perceived negative effect on others than themselves. While these two relationships have been examined separately in either the first-person or third-person perception context, they have never been put to a formal test simultaneously through quadratic relationships (see Sun et al., 2008). By exploring public perceptions of a new technology that invokes a wide spectrum of desirability perceptions – from the highly positive to the highly negative – we integrated the two sides of the desirability effect and connect the dots among existing work (e.g., Chung, 2024; Gunther and Mundy, 1993; Henriksen and Flora, 1999).
Descriptive statistics (M, SD) of self and other influence by desirability level ranges.
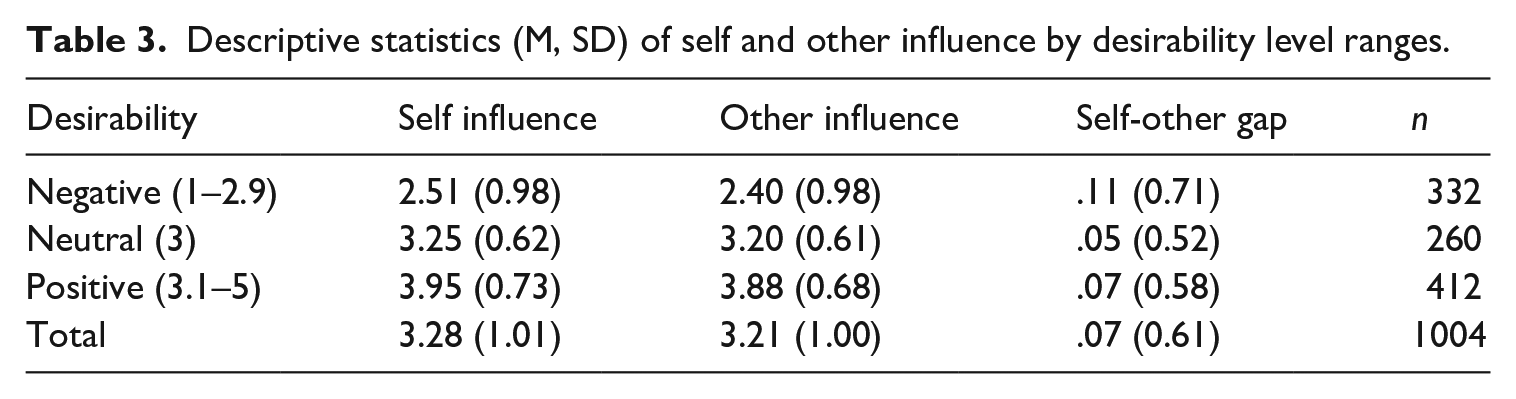
It is important to carefully interpret the low self-other discrepancy observed when the perceived desirability score was at the midpoint (i.e., perceiving ChatGPT as neither undesirable nor desirable). While this could reflect respondents’ nuanced assessment of the technology’s impact on self and others due to the perceived neutral desirability of ChatGPT, it might simply reflect respondents’ indifference or lack of strong opinions toward all the questions. For instance, respondents with no specific opinion about ChatGPT’s desirability (i.e., midpoint on social desirability) might also select the middle point as a safe choice for perceived influence on self and other, leading to “zero” difference between self and other. This interpretational ambiguity suggests that further investigation in future research is needed to clarify respondents’ true attitudes and motivations.
Our results also revealed an amplification of double standards in individuals’ assessment of their own and others’ ability to use ChatGPT sensibly. When appraising their own efficacy, individuals adopt a boomer position, expressing confidence in their ability to use ChatGPT critically, ethically, and effectively. In contrast, a doomer position is taken when evaluating others’ capacities, implying concerns about others’ potential lack of sensibility in using ChatGPT. This dual pattern suggests that people tend to believe they would benefit from the opportunities presented by ChatGPT (i.e., first-person perception), simultaneously assuming that others are susceptible to the threats posed by ChatGPT (i.e., third-person perception). This finding contributes to the broadening of horizons in third-person effect research, addressing the call for a more contextualized exploration of the third-person effect in the new media era by examining both third-person and first-person perceptions (Perloff and Shen, 2023). In addition, extending beyond the assessment of generic “media influence” perceptions, this discovery highlights a specific action-oriented element, providing deeper insights into the interactive and personalized experiences individuals have with ChatGPT.
While we posited ego-enhancement or self-interest as the key mechanism underlying the self-other gap in perceived efficacy, some alternative explanations are worth noting. One possibility is that individuals who see themselves as tech-savvy or as critical thinkers may believe they can use ChatGPT more responsibly than others. For instance, a recent study found that people who perceive themselves as tech-savvy are more likely to experiment with new AI features, potentially because they believe they can use the tool effectively (Biswas and Murray, 2024). Also, social cognitive theory posits a pathway from need for cognition – a key predictor of critical thinking (Kim et al., 2019) – to individuals’ self-efficacy. Critical thinkers tend to be curious about exploring problems, enjoy complex and effortful thinking, and are more likely to successfully solve problems (Watts et al., 2017), which can lead to higher levels of self-efficacy in using ChatGPT. While it is beyond the scope of this study to test these possibilities with our data, future research examining the role of participants’ perceived tech-savviness or critical thinking skills could provide a deeper understanding of the mechanisms underlying the self-other gap in efficacy.
Another intriguing finding pertains to the link between the self-other perceptual gap and behavioral outcomes. While traditional third-person effect research implied that the self-other perceptual gap prompts individuals to endorse restrictive measures like censorship or regulation (Perloff, 1999; Xu and Gonzenbach, 2008), our data diverged from this pattern. When individuals believed they could use ChatGPT sensibly while perceiving others as less capable, they tended to resist government regulation on ChatGPT. Similar to the findings in some recent studies (Chung and Wihbey, 2024a; Jang and Kim, 2018), this result suggests that self-efficacy may be the primary driving force behind public attitudes toward regulations. In other words, when deciding their support for regulations, individuals are more concerned with their own sufficient efficacy than with others’ lack of efficacy. If people believe they can use ChatGPT responsibly, they may view regulations imposing uniform restrictions on everyone as unnecessary or even offensive, even if such regulations could potentially protect those who are less capable. Consistent with this conjecture, a post hoc analysis showed that self-efficacy exhibits a more pronounced negative association with the support for government regulation (r = −.23, p < .01) compared to other-efficacy (r = −.15, p < .01). At the same time, however, it is important to consider that reduced support for government regulation of generative AI technology might simply reflect participants’ general attitudes toward government intervention. That is, those who are opposed to any type of government regulation might also oppose regulations on ChatGPT, regardless of their perceived self- and other-efficacy in using the technology. Therefore, future research that assesses respondents’ broader views on government intervention, alongside their opinions on ChatGPT regulations, could help clarify the extent to which the self-other gap in perceived efficacy influences behavioral outcomes.
While the self-other perceptual gaps in influence and efficacy did not lead to the support for government regulation, they predicted the support for literacy interventions. Interestingly, the main driving force in this connection was also self-related perceptions; both the perceived influence of ChatGPT on self (r = .35, p < .01) and self-efficacy (r = .45, p < .01) exhibited a more robust positive association with the support for literacy intervention compare to perceived influence of ChatGPT on others (r = .29, p < .01) and other-efficacy (r = .36, p < .01). This result indicates that individuals perceive literacy interventions not as a restriction demanding their sacrifice of autonomy but rather a beneficial approach that helps themselves more and others. Taken together, this specific role of self-related perceptions – often deemed insignificant or unclear in traditional third-person effect research (e.g., Chung and Moon, 2016; Gunther and Storey, 2003)—underscores the importance of challenging fundamental assumptions, aligning with the suggestions put forth by Schmierbach et al. (2023).
Our finding also elucidates the contrasting roles of subjective and objective knowledge in predicting the self-other perceptual gap. When individuals believed that they possess a certain level of knowledge about ChatGPT (i.e., subjective knowledge), they expressed heightened confidence in their ability to use this novel technology more critically, ethically, and effectively than others. However, individuals’ factual knowledge about ChatGPT (i.e., objective knowledge) did not lead to such a perception. There could be several interpretations for this finding. To begin, considering that third-person or first-person perception is a subjective concept, the predictive power of objective knowledge may inherently be limited. In line with this reasoning, Lee et al. (2022) proposed that subjective political knowledge, rather than objective political knowledge, acts as the driving force in developing self-efficacy and subsequently promoting political participation. They emphasized that the feeling of efficacy may not necessarily align with one’s objective knowledge about politics. Alternatively, this finding may align with the Dunning-Kruger effect, which suggests that less knowledgeable individuals tend to overestimate their cognitive abilities, while more competent individuals tend to underestimate their abilities compared to others (Dunning, 2011). That is, the more objective knowledge individuals have about ChatGPT, they may see that they do not necessarily outperform others in using ChatGPT appropriately. When such a realization occurs, it may remove the self-other gap in perceived efficacy. Also, at the time of data collection, which was in the very early stage of ChatGPT, public knowledge about ChatGPT was limited. This could have led to a minimal difference between individuals with high and low levels of objective knowledge, leading to a null association between objective knowledge and the self-other gap. While our current data does not offer a conclusive explanation for the lack of association between objective knowledge and the self-other gap in perceived efficacy, future research conducted during a later stage of generative AI technology can explore diverse potential mechanisms to gain a deeper understanding of the phenomenon.
The current study carries meaningful practical implications for governments, AI experts, and tech companies. The recent ouster and return of Sam Altman, the CEO of Open AI, have prompted numerous questions about the future of generative AI and its governance. The “Five Days of Chaos” at OpenAI underscored the inability of tech companies to independently achieve the level of safety and trust society demands for generative AI technology (Sorkin et al., 2023). Witnessing the intrinsically unstable and weak self-governance within the industry, governments worldwide, including the United States, are weighing how to regulate this rapidly growing technology to mitigate potential harm. In these deliberations, acknowledging the divergent beliefs and concerns individuals hold about generative AI technology becomes crucial for designing effective educational initiatives, guidelines, and policies. For example, considering our finding that the self-other perceptual gap regarding ChatGPT influence and use differently predict the general public’s attitudes toward government regulations and literacy interventions, prioritizing literacy interventions over relying solely on regulatory options may be a more pragmatic and feasible strategy. Our data indicated that participants lacked a clear understanding of ChatGPT’s personalized nature, and the potential biases or false information present in its content. Relatedly, a recent study found that enhancing people’s understanding of how AI filter and present information (i.e., algorithmic knowledge) increases their likelihood of taking action against misinformation (Chung and Wihbey, 2024b). In this context, educational interventions aimed at improving algorithmic literacy could serve as an effective starting point. At the same time, literacy intervention that imparts a well-rounded comprehension of generative AI technology could prompt the general public to objectively acknowledge the potential impacts of ChatGPT on both self and others. This, in turn, may inspire a reconsideration of more effective ways to govern this continually advancing technology.
Limitations and suggestions for future research
It is important to acknowledge some limitations of this study, which can guide future research in more fruitful directions. First, our data collection took place in February 2023, at a time when the concept of generative AI and ChatGPT was still new to the majority of people. For instance, slightly less than half of our respondents (47%) indicated that they had heard about ChatGPT. 4 In this light, public perceptions of ChatGPT are malleable and likely to evolve as the technology matures; what is currently acceptable to the public may not remain so later, and vice versa. Particularly, given the strong support for literacy interventions among the survey respondents, it is reasonable to assume that an increase in literacy levels would also lead to an improvement in the public’s understanding of ChatGPT. As a result, this could potentially reduce the self-other discrepancy and enable individuals to view the risks and benefits associated with ChatGPT from a more balanced perspective. Further research is warranted to examine these possibilities. In addition, when measuring self- and other-efficacy in using ChatGPT, our survey questions did not specify which aspects of critical, ethical, or effective use participants felt confident about. Since responsible use of ChatGPT can vary in meaning for different individuals (e.g., avoiding biases, detecting misinformation, or recognizing other potential pitfalls), incorporating an open-ended question to explore participants’ interpretations of these concepts and analyzing their responses thematically could provide a more comprehensive understanding of public perceptions regarding ChatGPT use. Another limitation pertains to the measurement of objective knowledge. In this study, we operationalized objective knowledge that drew on previous scholarly work in areas such as politics, health, and science. This involved creating a set of true or false questions pertaining to the subject matter, where correct answers were assigned a value of 1 and incorrect or “don’t know” responses were assigned a value of 0. However, this approach is prone to subjectivity, as researchers must rely on their own judgments to determine which items are essential for constructing the knowledge variable. This subjectivity issue is particularly pertinent in the context of ChatGPT knowledge, as the novelty of ChatGPT means that there are no pre-validated items that researchers can readily utilize. While such limitations are inherent in pioneering research endeavors, future research can benefit from developing more comprehensive items to fully capture individuals’ objective knowledge about ChatGPT.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.