
Abstract
This study investigated how “teacher” avatar customization and exposure to “learner” virtual humans who display mind-affected participants’ behavior and emotions in a re-creation of Milgram’s obedience experiment. Female participants customized avatars that merged their physical self with hero, antihero, or villain archetypes and then interacted with a mindful or non-mindful virtual human; 82.8% of participants went above the maximum electric shock intensity. Women who customized hero avatars delivered lower voltage shocks to a virtual human compared with those who customized antihero and villain avatars. Virtual humans’ display of mind did not affect shock intensity, guilt, or negative emotion though participants reported increased shame after shocking a mindful versus a non-mindful virtual human. Customizing antihero avatars increased shame and negative affect, especially after interacting with mindful virtual humans. We discuss the implications of these findings for the Proteus effect and Computers Are Social Actors perspective in extreme virtual encounters.
The ubiquity of human–machine interactions with computer-controlled agents, robots, and chatbots offers a testing bed for basic social phenomena that is nearly impossible to carry out because of ethical concerns. For instance, Slater et al. (2006) modify and adapt Stanley Milgram’s obedience to authority paradigm (Doliński et al., 2017; Haslam et al., 2014; Milgram, 1963, 1974) to examine whether individuals respond to an extreme situation with a virtual human as if it is real. When placed in the role of a “teacher” tasked with administering electric shocks to a “learner” virtual human who provides incorrect answers in a purported memory test, participants display increased physiological stress and more self-awareness of somatic indicators, especially if virtual humans are visible instead of hidden from view (Slater et al., 2006). In addition, participants exposed to visible learner virtual humans express more negative affect after delivering electric shocks (Slater et al., 2006). Exposure to the pain-related displays of a learner virtual human may evoke self-oriented personal distress on participants (i.e. greater activation of the right amygdala) instead of empathic concern for the wellbeing of a virtual human (Cheetham et al., 2009). In addition, teachers who are primed to identify with science give more help, show less stress, and shock virtual human learners less frequently compared with teachers who are not primed because science identification priming increases participants’ concern for other study subjects (Gonzalez-Franco et al., 2019).
In this context, the present study investigates how customizing and operating a digital body or avatar can influence the degree to which individuals cause pain to a virtual human along with the specific self-oriented distress emotions resulting from such experience. In physical settings, teacher–learner factors such as decreased physical proximity, less intimacy, and lack of a direct personal relationship increase the delivery of electric shocks (Haslam et al., 2014). Replications in virtual settings have confirmed the effects of visibility of a virtual human (Slater et al., 2006) and uncovered the aforementioned effects of science identification priming (Gonzalez-Franco et al., 2019), but studies have not yet investigated how teacher avatar customization and use influence behavior and negative affect in virtual replications of Milgram’s paradigm. Negative affect represents subjective distress and aversive moods, such as contempt, fear, nervousness, and disgust (Watson et al., 1988). This study also focuses on guilt and shame, which are distinct forms of negative affect. Guilt is triggered by breaches of personal standards, whereas shame follows public exposure and disapproval of a behavior (Tangney et al., 1996). While guilt involves a sense of regret that can motivate confessions and apologies, shame involves painful self-scrutiny mixed with a desire to escape, hide, or disappear (Tangney et al., 1996). Avatar customization effects are important to consider as a hallmark of virtual reality and video games is allowing users to create and operate avatars for them to be able to interact with digital objects, virtual humans, and other users (Bailenson, 2018). For instance, role-playing video games allow individuals to customize their avatar and make moral choices as “Paragon” or “Renegade” player archetypes (Boyan et al., 2015). We hypothesize that individuals who customize and use a hero teacher avatar will inflict less pain to a virtual human learner compared with those who customize a villain or antihero teacher avatars.
We also examine whether individuals who customize and use a hero teacher avatar experience more negative affect, guilt, and shame when visiting pain to a learner virtual human compared with those who create villain or antihero avatars. Comparing how customizing teacher avatars with different social connotations (e.g. hero, villain, antihero archetypes) affect individuals’ emotions and willingness to cause pain to a virtual human allows this study to expand current models which describe avatar embodiment effects to virtual replications of Milgram’s study. The sections below outline the Proteus effect (Peña et al., 2009; Yee and Bailenson, 2007) to articulate how using and customizing avatars can steer individuals’ behavior in line with their social overtones.
This study also examines how the social cues transmitted by virtual humans may influence individuals’ emotions and readiness to inflict pain. Consistent with the computers are social actors (CASA) approach, which assumes that individuals mindlessly apply stereotypes and heuristics to machines, robots, and avatars that display social traits and behaviors (Gambino et al., 2020; Nass and Moon, 2000; Reeves and Nass, 1996), exposure to a visible learner virtual human in pain elicits more negative affect on participants compared with hidden learner virtual humans (Slater et al., 2006). In order to expand CASA, we examine how learner virtual humans who display “mind” (i.e. the ability to think and feel) can influence behavior, negative affect, guilt, and shame. This is based on the prediction that virtual humans who display intelligence and affect may steer individuals to assign a moral status to such entity, which then may increase guilt, shame, and negative affect among those who harm such virtual human (Hartmann, 2017). By combining Proteus effect and CASA assumptions, this study can chart the effects of the social cues exuded by both teacher avatars and learner virtual human counterparts. This study may also deepen our knowledge about negative emotions as reported by participants in such context, thus complement existing research on physiological markers (Cheetham et al., 2009; Gonzalez-Franco et al., 2019; Slater et al., 2006). Although Slater et al. (2006) assessed self-awareness of physiological indicators (e.g. heat, perspiration), this study instead captures negative emotions as reported by participants. The following section articulates avatar customization and CASA mechanisms and outlines preregistered hypotheses.
Avatar effects on human behavior
The mere act of operating an avatar can influence individuals’ cognition, affect, and behavior. In particular, the Proteus effect predicts that the social expectations implied by avatar appearance can steer individuals’ responses. Three theoretical mechanisms are invoked as fundamental causes for the Proteus effect.
According to Yee and Bailenson (2007), self-perception underlies the Proteus effect as individuals who operate avatars are theorized to observe their own behavior and deduce that such action is caused by an avatar’s external appearance. For instance, individuals assigned to more physically attractive avatars self-disclose more information and stand closer to a virtual confederate compared with those assigned to less attractive avatars (Yee and Bailenson, 2007). According to Peña et al. (2009), automaticity drives the Proteus effect as avatar appearance primes learned concepts, stereotypes, and behaviors on users. For example, participants assigned to avatars dressed in black cloaks express more aggressive attitudes in comparison with those assigned to avatars in white cloaks (Peña et al., 2009). In addition, Ratan and Dawson (2016) propose self-relevance as a psychological mechanism behind the Proteus effect. From their perspective, using an avatar can trigger associations between a user’s perception of the self and the avatar’s characteristics. As an individual uses an avatar, the schema of concepts that are linked to the self may become more connected to the schema related to the avatar. The more a schema of self-related concepts is activated during avatar use, the more likely that users will display behaviors consistent with their avatar’s characteristics (Ratan et al., 2020). As such, avatar self-relevance refers to the extent to which a user perceives their avatar as relevant to the self (Ratan and Dawson, 2016). This assumption is based on the distinction that people generally experience the self in terms of body schema (i.e. proto self), through emotions experienced in response to interactions between body schema and the environment (i.e. core self), and based on personal identity previous emotions and future plans (i.e. autobiographical self). Based on these distinctions, Ratan and Dawson (2016) predict that avatar customization will increase self-relevance compared with using a generic avatar among participants who play a sword-fighting video game. Using a sample exclusively comprised of women, this hypothesis was not confirmed. However, women who use same-gender avatars show increased self-relevance compared with those who use a gender-mismatched avatar. In addition, women who maintain a psychological connection to their customized avatars after its use show increased physiological responses to observing their avatar get beaten up compared with those who feel more disconnected from their customized avatars after use (Ratan and Dawson, 2016).
There is evidence for Proteus effects on prosocial and antisocial behavior that is relevant to this study. Participants assigned to play a game using a premade heroic avatar (i.e. Superman) pour more chocolate than chili sauce for their partner in a “first taste” post-game task compared with those who played with premade villainous (i.e. Voldemort) or neutral geometric avatars (Yoon and Vargas, 2014). Moreover, participants who play with a villain avatar pour more chili sauce than those who play with a hero or a neutral avatar (Yoon and Vargas, 2014).
However, researchers diverge on whether avatar customization is part of the purview of the Proteus effect or whether it is better explained by other mechanisms. Ratan et al. (2020) regard customization as a moderating factor that increases the potency of the Proteus effect. Others propose that avatar customization triggers mindset priming effects to seek desirable outcomes and avoid negative consequences (Kim and Sundar, 2012; Sah et al., 2017). A mindset is a frame of mind that, when activated, steers individuals toward specific actions (Crum et al., 2013). For example, individuals who customize an avatar for it to represent their “actual self” (i.e. attributes they already possess) along with individuals who customize avatars to represent their “ideal self” (i.e. attributes they want to possess) spend more game resources to stay healthy compared with individuals who merely use attractive avatars (Kim and Sundar, 2012). More health-conscious participants select healthier foods inside and outside of a game after customizing an avatar to reflect their “ought self” or attributes they wished to possess (Sah et al., 2017).
Although the precise theoretical mechanism behind the Proteus effect is yet unclear (Nowak and Fox, 2020; Peña, 2020; Ratan et al., 2020), we capitalize on its general predictions to investigate how customizing and controlling avatars which merge an individual’s physical self with known narrative archetypes, such as heroes, villains, and antiheroes affect people who interact with learner virtual humans. This experience may affect individuals’ responses in the context of Milgram’s paradigm because people hold expectations about the personality and behavior of such narrative archetypes (Raney, 2006a, 2006b). For instance, villains are portrayed as wearing dark colors and having darker hair (Grizzard et al., 2018). Heroes are typically shown as physically attractive and display more pleasant and happy facial expressions than villains, who are instead portrayed as stern and angry (Grizzard et al., 2018). Exposure to visual cues associated with heroes and villains triggers character-consistent attributions of morality, warmth, heroism, and duplicitousness on observers (Grizzard et al., 2018). In addition, people judge media characters to be “good” or “bad” based on their behavior. If people judge a character to be “good,” then they may show empathy and identification and expect positive outcomes for such character but the opposite is predicted if people judge a character to be “bad” (Zillmann, 2006). In addition, antiheroes display morally ambiguous behaviors to achieve noble goals, play the role of loners seeking revenge, defy authority, and possess both positive qualities and flaws (Shafer and Raney, 2012). Exposure to antiheroes in media also triggers predictable responses. Individuals who experience salient moral shortcomings show more positive affect and enjoyment after reading narratives featuring antiheroes instead of villains (Krakowiak and Tsay-Vogel, 2015). However, individuals with more salient moral virtues show more positive affect and enjoyment following exposure to narratives featuring heroes instead of antiheroes (Krakowiak and Tsay-Vogel, 2015). Thus,
H1: Participants who customize self-as-hero avatars (a) will deliver lower voltage electric shocks to virtual humans, (b) experience more guilt and shame, and (c) increased negative affect compared with those who customize (i) self-as-villain and (ii) self-as-antihero avatars.
CASA
CASA describes how individuals respond to machines and social technologies. It assumes that the presence of contextual cues results in individuals applying mindless scripts, labels, and expectations to robots, chatbots, and virtual humans. A script is a structure that describes a predetermined, stereotyped sequence of events in a particular context (Schank and Abelson, 1977). Scripts are learned from general and specific knowledge derived from first- and secondhand experiences and information (Langer, 1992). In particular, CASA assumes that individuals respond mindlessly to computers to the degree to which they apply scripts for human–human interaction to human–virtual human interaction while ignoring the inorganic nature of a virtual human (Nass and Moon, 2000; Reeves and Nass, 1996). CASA argues that the human brain may not fully distinguish between real and artificial entities. Thus, when artificial representations are similar to real events or persons, individuals may automatically treat them in a social manner. This can result in attributing personality to robots, applying stereotypes and social conventions to virtual humans, and making judgments as if technological entities were almost human (Reeves and Nass, 1996). Although the effects of virtual humans’ mind displays have not yet been examined in previous virtual replications of Milgram’s procedure, CASA predictions have been tested by comparing between factual or emotional disclosure in chatbot conversations (Ho et al., 2018), researching the persuasive effects of helpful or unhelpful robots who reciprocate to participants (Lee and Liang, 2016), and investigating the effects of robots who use politeness strategies when requesting favors (Srinivasan and Takayama, 2016).
In support of CASA, participants exposed to computers with male or female voices attribute increased expertise at personal relationships to a female-voiced machine along with more knowledge about computers to a male-voiced machine (Nass et al., 1997). Participants also rate a female-looking robot as more capable of stereotypically female tasks (e.g. household maintenance, child and elderly care) compared with a male-looking robot torso (Bernotat et al., 2021). In addition, participants rate a male-looking robot as more capable of stereotypically male tasks (e.g. transporting goods, repairing equipment) compared with a female-looking robot torso (Bernotat et al., 2021). Compared with participants who receive generic feedback from a computer, those who receive flattery show increased positive affect and performance, along with more positive evaluations of the interaction with a computer (Fogg and Nass, 1997).
There are two essential criteria for a technology to prompt CASA effects (Gambino et al., 2020). Individuals must be presented with virtual humans who display sufficient cues to prompt users to categorize them as worthy of social responses. In addition, virtual humans should elicit attributions as if they were autonomous sources of communication endowed with mind (Gambino et al., 2020). Individuals perceive mind or mental capacity in humans, animals, and virtual humans along two dimensions: “Agency” or the capacity to do, plan, and exert self-control, along with “experience” or the capacity to feel and to sense pleasure or pain (Gray et al., 2007; Gray and Wegner, 2012). Thus, we anticipate that learner virtual humans who display the capacity to think and suffer should be more likely to receive moral treatment from teachers (Hartmann, 2017). Consider that mind perception is correlated with intentional harm avoidance toward humans, animals, and robots (Gray et al., 2007). People who observe humans, animals, and robots that express mind shown as victims of violence also experience sympathetic distress (Gray et al., 2007). Moreover, harming mindful virtual humans can increase guilt, along with other negative states (Grizzard et al., 2017; Hartmann and Vorderer, 2010). Thus,
H2: Participants randomly assigned to mindful virtual humans will (a) deliver lower voltage electric shocks, (b) experience more guilt and shame, and (c) increased negative affect compared with those assigned to non-mindful virtual humans.
Combining the tenets of avatar customization and CASA research leads to an additive statistical interaction effect hypothesis. If customizing an avatar as a hero primes a more prosocial mindset while virtual humans’ displays of mind promote the application of human-likeness scripts, then we should observe increased harm reduction, negative affect, guilt, and shame compared with interacting with mindful virtual humans after customizing an avatar as a villain or antihero. Examining this effect may shed light on whether the social cues of teacher avatars and learner virtual humans has combinatory effects on participants’ behavior and affect in virtual replications of Milgram’s procedure. Thus,
H3: Participants who customize self-as-hero avatars will (a) deliver lower voltage electric shocks to mindful artificial partners, (b) experience more guilt and shame, along with (c) more negative affect compared with those who customize (i) self-as-villain and (ii) self-as-antihero avatars.
Method
Participants
A total of N = 146 female participants were recruited from a subject pool at a large university in the US West Coast. A male sample was not gathered as data collection was interrupted by the COVID-19 pandemic. Female participants were randomly assigned to the conditions of a 3(avatar customization: superhero, antihero, supervillain) × 2(artificial intelligence [AI] display: mind, no-mind) factorial experiment. The majority of the participants were in their early twenties (M = 20.19, SD = 2.29). In the sample, 54.1% (129) participants were Asian American/Asian, 21.4% (43) were Hispanic/Latino, 18.2% (32) were Caucasian/White, 1.3% (3) were African American/Black, and 4.2% (9) identified as Other race. A power analysis using G*Power (Faul et al., 2007) with 1 − β = .80 which assumed an effects size of d = . 26 (Ratan et al., 2020) with p = .05 for F tests with main effects and interactions with six groups indicated that 146 participants were needed to obtain significant results. Therefore, this study had sufficient statistical power. The procedures and materials were approved by the local Institutional Review Board, IRB ID 1451041-1. The study was preregistered and its anonymized data is publicly available at https://osf.io/kpt7v/?view_only=cdaf2af555774f18aece657b34672799.
Procedure
Upon arriving at the lab and using a random numbers table, participants were randomly assigned to an experimental condition: hero avatar/mindful partner (n = 24), hero avatar/non-mindful partner (n = 25), antihero avatar/mindful partner (n = 24), antihero avatar/non-mindful partner (n = 24), villain avatar/mindful partner (n = 24), and villain avatar/non-mindful partner (n = 25). Using the creation kit included in “Fallout 4,” the third author modeled Milgram’s experiment as a game quest based on publications and video recordings describing the original experiment (Doliński et al., 2017; Haslam et al., 2014; Milgram, 1963; Slater et al., 2006). There were 40 teacher–learner trials, thus allowing for a maximum of 40 electric shocks though learners consistently provided only 30 incorrect responses.
After providing informed consent and once inside the custom game quest, the participants’ avatar appeared in a room which included two large portraits and character descriptions of equal length for heroes (Wonder Woman, Superman), antiheroes (Catwoman, Han Solo), or villains (Cruella de Ville, Emperor Palpatine). These characters were selected as primes as they were popular and also appeared in previous research (Eden et al., 2017; Konijn and Hoorn, 2005; Krakowiak and Tsay-Vogel, 2015; Nelson and Norton, 2005; Raney, 2006a; Shafer and Raney, 2012; Yoon and Vargas, 2014). Participants then inspected each character description and portrait. Following this, the experimenter asked participants to “please create an avatar that looks like you as if you were the type of character described in the profiles within the computer terminal. In your case, please create a character that looks like you as if you were a hero / antihero / villain.” To do this and with the help of a human experimenter, participants found a premade avatar they deemed similar in physical appearance and then modified its features (e.g. nose, eyes, eyebrows, forehead, cheeks, mouth, chin, jaw, and neck) for 10 minutes to make it more like themselves as if they were a hero, antihero, or villain. Next and depending on condition assignment, a finalized avatar was shown in third-person view dressed in a bright red-and-blue suit for heroes, a dusty leather outfit for antiheroes, or a dark uniform for villains.
The participants then walked their customized avatar into a lab room within the game (Figure 1). A male non-player character dressed as an experimenter in a white coat introduced the teacher–learner procedure and a male virtual human that, depending on random assignment, was described as either a mindful or non-mindful learner. The experimenter character was fully voiced, and it explained to participants that they were in the role of a teacher tasked with delivering electric shocks to a learner virtual human if it provided incorrect answers. In the mindful condition, the experimenter character described the virtual human as able to think and feel and that each action from the participant would generate a line of code that translated into a memory. In the non-mindful condition, the experimenter character described the virtual human as unable to think and feel and thus it would not remember the participant’s actions. Consistent with these descriptions, the mindful virtual human complained as the intensity of the shocks increased, whereas the non-mindful virtual human remained silent. There were no other differences in regard to virtual humans’ emotional display (e.g. grimace, intonation). The virtual human sat in a separate room and, thus, it was not visible to participants after being introduced. The experimenter character demanded the participants to fully complete the trials but discouraged them from delivering electric shocks if learners provided correct answers (Milgram, 1963). Participants could also choose to remain idle and, if so, the experimenter character demanded the participant to obey at every 10 seconds. At 50 seconds of refusing to continue, the experimenter character delivered a fifth and final prompt and then ended the trials.
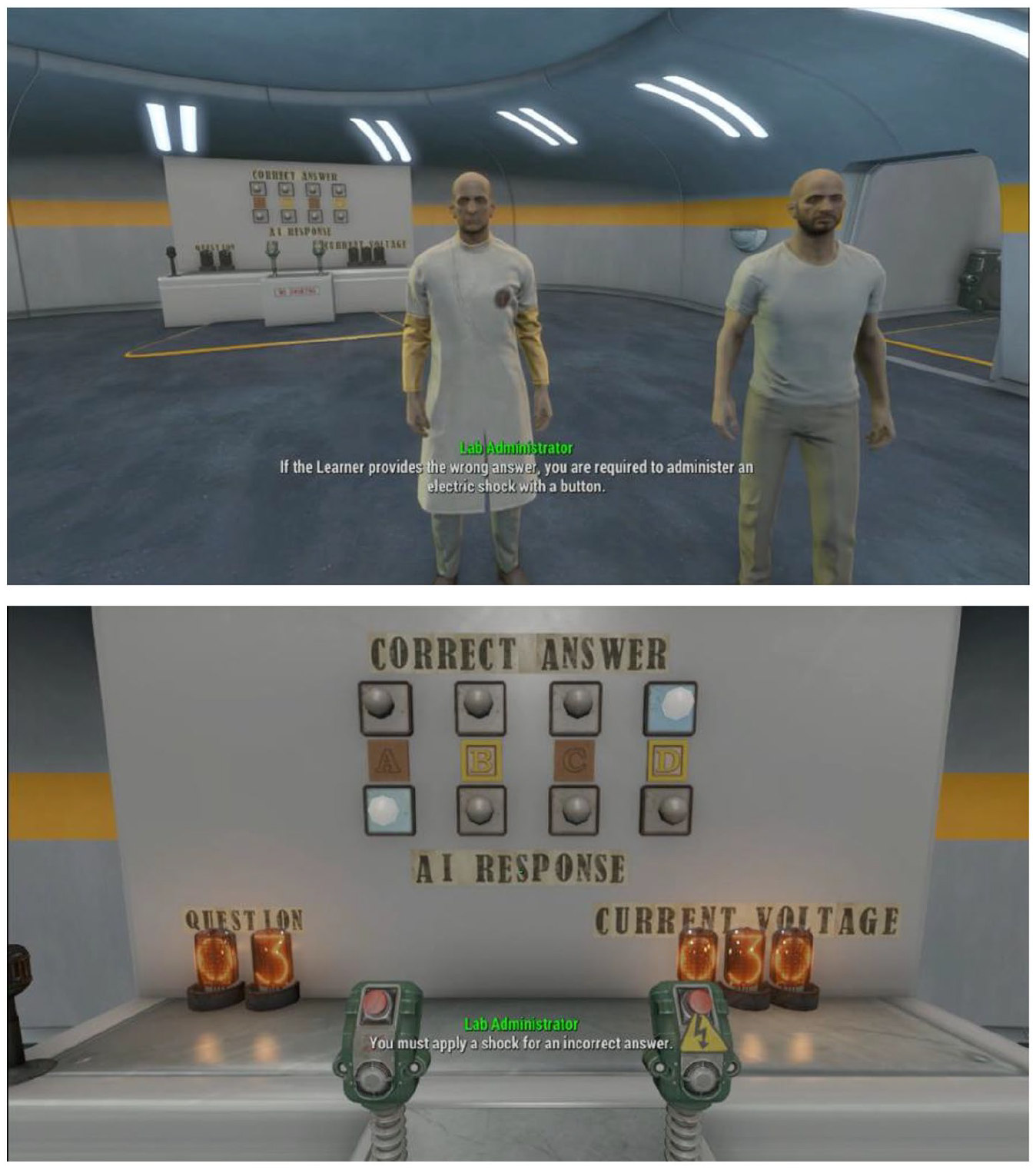
Introduction to teacher–learner task and adapted shock machine.
Dependent variables
All self-reported dependent variables (i.e. guilt, shame, negative affect), manipulation checks (i.e. similarity identification, AI mind attributions), and an awareness check were collected after the teacher–learner trials. Table 1 includes descriptive statistics for this study.
Descriptive statistics per experimental condition.
AI: artificial intelligence.
Voltage intensity
Participants could deliver shocks in 30 out of the 40 teacher–learner trials in 15 V increments, starting at 15 V and expected to go up to 450 V. Participants could refuse to comply with delivering shocks. The observed minimum number of trials was 4 and the maximum was 40 (M = 37.16, SD = 7.96). The observed minimum electric shock intensity was 45 V and the maximum was 495 V (M = 433.52, SD = 93.49) as though the expected maximum was 450 V; participants could deliver electric volts to virtual humans who provided correct answers, though this behavior was explicitly discouraged. A human experimenter in the room recorded each participant’s last voltage selection as shown in the final game quest screen.
Negative affect
This factor was assessed with the negative affect PANAS subscale (Watson et al., 1988). The subscale had 10 items in a 1–5 Likert-type scale format. Negative affect items included self-descriptors such as “distressed” and “upset.” This scale was also reliable (Cronbach’s α = .90).
Guilt and shame
These factors were measured with the guilt and shame subscales from the differential emotions scale (DES-IV) (Izard et al., 1974). Each subscale had five items in a 1–5 Likert-type scale format. Guilt items included “I feel remorse, regret.” Shame items included “I feel like I am a bad person.” The guilt subscale was reliable (Cronbach’s α = .93). The shame subscale was also reliable (Cronbach’s α = .88).
Manipulation checks
We conducted a 3 × 2 multivariate analysis of variance (ANOVA) to establish how the manipulations influenced avatar similarity identification and mind attributions toward virtual humans. Similarity identification was expected operate as a confound as some participants may “like it good” or “like it bad” (Konijn and Hoorn, 2005) and, thus, they would have shown more similarity identification if their avatar melded their physical self with a hero or villain archetype. Similarity identification was measured with a suitable subscale (Van Looy et al., 2012) which had six items in a 1–5 Likert-type scale format. Sample items included “My character resembles me.” The similarity identification subscale was reliable (Cronbach’s α = .89). Mind attributions were measured with the AI mind attributions scale (Waytz et al., 2010), which featured seven items framed as 1–5 semantic differentials. Sample items included “My AI partner: does not have free will-definitely has free will” and “My AI partner: does not have emotions-definitely has emotions.” The AI mind attributions scale was reliable (Cronbach’s α = .89).
There were no significant differences in similarity identification and mind attributions across avatar customization conditions, F(2, 141) = 1.65, p = .20 and F(2, 141) = 1.39, p = .25. Participants expressed increased similarity identification with their avatar when the virtual human was introduced as non-mindful instead of mindful, F(2, 141) = 5.04, p < .03, Cohen’s d = .37. This implies that participants were more likely to attribute similarity identification to their avatar when it delivered shocks to a non-mindful instead of mindful virtual human. As expected, participants attributed more mind to virtual humans when they were introduced as mindful instead of non-mindful, F(2, 141) = 14.42, p < .001, Cohen’s d = .57.
Awareness check
Participants completed funneled debriefing questions that gauged their knowledge about the aims of the study (Bargh and Chartrand, 2000). Twenty-four participants linked our study to Milgram’s research. Out of 24 aware participants, 1 stopped after delivering four shocks, another after eight shocks, and 3 excused themselves halfway through the trials. The hypotheses below were initially tested with highly aware individuals being excluded from the analysis. The results did not change the statistical significance of intensity of electric shock differences reported below. Excluding highly aware participants resulted in slight increases in guilt coupled with small decreases in shame as interaction effects between the manipulations. Thus, highly aware participants were retained in the analyses as their exclusion did not change the results.
Results
Regarding compliance with delivering electric shocks to a virtual human, 82.8% of the participants delivered up to 465 V in the teacher–learner trials. A total of 4.8% of participants reached 480 V, 2.1% of participants reached either 135 or 225 V, 1.4% reached 210 or 240 V, and .7% of participants reached up to 45, 90, 100, 105, or 255 V. In sum, the majority of participants provided electric shocks to the virtual human at lethal intensities.
To establish how the manipulations influenced the dependent variables, the data were analyzed with a 3 × 2 multivariate ANOVA. According to H1(a)(i,ii), participants who customized self-as-hero avatars would deliver more intense electric shocks to virtual humans compared with those who customized self-as-villain and self-as-antihero avatars. There were significant differences between the avatar customization conditions, F(2, 139) = 5.70, p < .004, ωp² = .06. Planned contrasts revealed that participants who customized hero avatars delivered less intense electric shocks to a virtual human compared with those who customized villain avatars, t(145) = 61.48, p = .001, Cohen’s d = .37 and also compared with those who customized antihero avatars, t(145) = 39.92, p = .034, Cohen’s d = .65. Thus, H1(a)(i,ii) were confirmed.
H1(b,c) predicted that participants randomly assigned to customize self-as-hero avatars would feel guiltier, more ashamed, and show more negative affect compared with those who customized villain and antihero avatars. H1(b,c) was disconfirmed as there were no significant differences between the avatar customization conditions in regard to guilt F(2, 141) = 1.52, p = .22; shame F(2, 141) = 2.15, p = .12; and negative affect F(2, 141) = 1.55, p = .22.
H2(a) predicted that the mind displays of a virtual human would influence the intensity of electric shocks delivered by participants. H2(a) was rejected as mind display manipulations did not influence the intensity of electric shocks given to a virtual human, F(1, 139) = .07, p = .80. There were no significant interactions between avatar customization and virtual human mind display manipulations on electric shock intensity, F(1, 139) = .03, p = .97.
H2(b,c) anticipated that participants randomly assigned to interact with mindful virtual humans would feel guiltier, more ashamed, and report increased negative affect compared with those assigned to non-mindful virtual humans. Participants reported more shame after delivering electric shocks to a mindful compared with a non-mindful virtual human, F(1, 141) = 5.10, p = .03, ωp² = .03. However, there were no differences in guilt and negative affect scores, F(1, 141) = 2.12, p = .15 and F(1, 141) = 2.37, p = .13.
These main effects were qualified by significant interaction effects on shame and negative affect, F(2, 141) = 3.46, p = .03, ω p ² = .03 and F(2, 141) = 3.72, p = .03, ωp² = .04, respectively. There were no interaction effects on guilt, F(2, 141) = 2.56, p = .08. Post hoc Bonferroni tests revealed that participants who customized antihero avatars and interacted with a mindful virtual human reported increased shame than those who interacted with a non-mindful partner using antihero or villain avatars. This result was not hypothesized. In addition, among participants who interacted with mindful virtual humans, those who customized antihero avatars experienced more negative affect compared with those who created hero avatars. H3 was all but disconfirmed, except for H3(b)(ii), which was supported. No other effects were found.
Discussion
This study investigated how customizing teacher avatars as narrative archetypes along with exposure to mind displays of learner virtual humans affected individuals’ behavior and affective responses in a video game recreation of Milgram’s paradigm. In regard to H1, individuals who customized avatars that merged their physical self with a hero archetype delivered less intense electric shocks to a virtual human compared with those who customized antihero and villain avatars. This finding was consistent with the general predictions of the Proteus effect, which assumes that individuals conform with the expected behavior, cognition, and affect implied by their avatar (Peña et al., 2009; Yee and Bailenson, 2007). This finding was also consistent with mindset priming, which predicts that avatar customization can influence individuals’ frame of mind and thus induce specific behaviors (Kim and Sundar, 2012; Sah et al., 2017). Considering that avatar customization effects had been primarily documented in personal health contexts (Kim and Sundar, 2012; Sah et al., 2017), this study expanded the purview of this effect by providing initial evidence for how avatar customization can influence extreme behavior toward virtual humans. Future research should illuminate exactly how participants incorporated their respective narrative archetypes into their avatar. For example, participants who merged their physical self with a villain archetype may have selected darker hair, unattractive features (Grizzard et al., 2018), and untrustworthy facial features, such as low inner eyebrows, shallow cheekbones, thin chins, and a deeper nose sellion (Todorov et al., 2008). Conversely, participants who customized hero avatars may have selected more attractive features, lighter hair (Grizzard et al., 2018), and more trustworthy facial features for their avatar (Todorov et al., 2008). Future studies should also examine whether participants who made more interactive customization choices may show enhanced effects. This prediction is consistent with Sundar et al. (2015), who proposed that increased use of customization features can augment users’ perceived sense of agency, realism, and engagement, which can subsequently boost psychological effects.
It is worth noting that the attenuation effect of hero avatar customization occurred in the context of 82.8% of the participants delivering up to 465 V in the teacher–learner trials. This was possible because 120 participants delivered electric shocks to virtual humans who provided correct responses, thus surpassing the 450 V expected maximum. Although 24 participants showed awareness of the link between this study and Milgram’s research, their exclusion from the analysis did not change the results. In addition, our participants delivered more intense shocks compared with previous research. For comparison, participants tended to stop at 150 V, because at this junction they became aware of the conflict between continuing with the study and their partner’s plea to end the experiment (Burger, 2009; Packer, 2008). Consistent with this, 90% of participants reached up to 150 V in a recent replication in a physical setting (Doliński et al., 2017). Increased shocking has been observed though less frequently; 65% of teachers delivered 450 V in a physical iteration of the paradigm (Milgram, 1974). Across Milgram’s original studies, a meta-analysis shows that 43.6% of participants reached 450 V (Haslam et al., 2014).
Why did participants in this study impart more intense shocks compared with previous research? It is possible that our video-game scenario enabled participants to test boundaries and, thus, display behaviors that otherwise they would have avoided in physical social environments with real people. To decrease such high electric shocking intensity, future studies may attempt replications using virtual reality goggles to increase immersion or may visually display the aversive reactions of mindful virtual humans to each shock (Slater et al., 2006).
In regard to the CASA effects represented in H2, learner mind displays did not affect the intensity of shocks delivered to a virtual human and had no influence on negative affect or guilt. However, participants reported increased shame after shocking a mindful instead of a non-mindful virtual human. It is possible that this emotion was uniquely affected by mind manipulations because shame is felt when breaching personal standards, whereas guilt is self-punitive and implies recognizing a premeditated intent to harm, which is less applicable to Milgram’s obedience to authority paradigm. This implies that learner mind displays may be uniquely suited to make participants feel as if they were violating their morals, thus increasing shame more so than guilt in virtual replications of Milgram’s procedure. Future studies may attempt to fortify virtual humans’ mind displays by asking participants to hold extended interactions with virtual humans that convey seemingly autonomous decisions and affect.
In regard to additive interaction effects, participants who customized antihero avatars and interacted with mindful virtual humans reported more shame after delivering shocks than those who customized antihero and villain avatars and interacted with a non-mindful partner. In addition, among participants who interacted with mindful virtual humans, those who customized antihero avatars experienced more negative affect compared with those who customized hero avatars. These effects may have stemmed from the expectations primed by the antihero exemplars used in this study, which were individualists with redeeming moral qualities and also defiant of authority (Shafer and Raney, 2012). Participants who customized antihero avatars were actually doing as told when they delivered shocks to a mindful virtual human, and thus it is possible that the dissonance stemming from obeying the experimenter character while embodying a rebellious antihero may have triggered more shame. Although antiheroes may activate some of the qualities of both heroes and villains (Shafer and Raney, 2012), future studies should clarify precisely which mental concepts were activated by customizing and operating antihero avatars. This could be measured with think-aloud procedures in which participants voice salient thoughts as they modify and control their avatar (Vasalou and Joinson, 2009). The influence of customizing antihero avatar archetypes deserves more attention from researchers as its effects were unique and reliable effects on shame and negative affect, especially when interacting with mindful virtual humans.
While studies have focused on the effects of committing violent acts on feelings of guilt and shame as if these two constructs would be equally affected by game role manipulations (Hartmann and Vorderer, 2010), the present findings place a square focus on the effect of individuals’ moral decisions on feelings of shame. In order to further separate differential effects on guilt and shame, future research may incorporate predictions related to anonymity effects in computer-mediated communication. For instance, the warranting hypothesis predicts that individuals will experience increased accountability when their online persona matches their real identity as this allows observers to compare the veracity of identity claims (Walther and Parks, 2002). Considering that guilt is a private emotion triggered by breaching a personal standard, whereas shame is linked to public exposure of disapproved behavior (Tangney et al., 1996), future studies should investigate how reducing anonymity (e.g. use of photorealistic self-avatars) may affect feelings of shame more strongly than guilt in Milgram-style experiments and commercial video games. Consider that compared with those who customized avatars to look like someone else, participants who customized avatars to look more similar to their physical self also experienced increased perceived identifiability or link between their online and real persona, which was then associated with decreased social distance toward outgroup members (Peña et al., 2021). Future research should investigate how using avatars bearing the participant’s face may increase perceived identifiability and thus decrease shock intensity and augment negative affect, guilt, and shame by augmenting accountability.
Limitations
A main limitation is that only women were recruited in this study because of the COVID-19 outbreak. Future research should test for similar effects with a male population. Although sex differences in obedience rates were not found in reviews of Milgram’s studies once controlling for additional factors (Haslam et al., 2014), it is possible that effects on men could be stronger in virtual replications of Milgram’s procedure due to increased previous exposure to violent media. For instance, men show decreased empathy, increased justification of physical violence, and greater need for aggression and sensation in video games compared with women (Hartmann et al., 2015). In addition, there are sex differences in feelings of guilt and shame, especially in regard to gender role expectations (Baldwin et al., 2006; Gilchrist et al., 2020), thus further implying potential sex differences to be uncovered.
Another limitation was that the means for most dependent variables except for number of electric shocks were low, implying that participants did not experience elevated levels of similarity identification, guilt and shame, negative affect, and mind attributions. This may not be a fatal flaw as the manipulations affected the outcome variables beyond potential floor effects. Future studies improve on the present study’s procedure by collecting such measures while participants are still engaging with virtual humans in teacher–learner trials rather than after the interaction. In addition to potential similarity identification effects, future studies may investigate how customizing hero, villain, and antihero avatars may influence wishful identification or participants’ desire to be like their avatar (Van Looy et al., 2012). Future research may also attempt to separate the potential identification effects of user–avatar physical similarity from the influence of perceived shared values between users and their virtual persona (Downs et al., 2019).
Conclusion
Teacher avatar customization and learner virtual human mind displays had the capacity to influence individuals’ behavior and emotion in extreme virtual scenarios. The findings illustrated how a video game adaptation of Milgram’s paradigm can be used to ethically study extreme behavior toward artificial characters, and in doing so it sheds light on longstanding questions about how individuals will conduct themselves in simulated environments when taking on archetypal roles to make consequential moral choices.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.