
Abstract
Local newspapers are increasingly subject to predatory corporate acquisition—corporate takeovers in which media conglomerates purchase publications in financially precarious states, drastically cut staff, and in certain cases consolidate newsroom operations. We investigate how this practice alters the information environment of 31 corporate-owned local newspapers across over 130,000 articles. Formalizing local information across three dimensions, we find (a) that corporate acquisition is associated with a reduction in the volume of local content produced, (b) that the coverage of local places following acquisition is significantly more concentrated than prior to acquisition, and (c) that articles produced to be shared across regional hubs of corporate-owned publications are significantly less local—and discursively more national—than articles produced for a single local market. Our findings identify reductions in newsroom resources and regional hubs of publications as detrimental to the information environment of local communities.
Introduction
In 2010, The Denver Post (DP) was acquired by hedge fund Alden Global Capital. Eight years later, staffers at the publication released an opinion piece pleading for the newspaper’s sale. In it, they cite an inability to perform their journalistic duties under Alden’s ownership—the number of employees at the publication had decreased from 180 in 2013, when it was awarded a Pulitzer prize for its coverage of the Aurora shooting, to fewer than 70 (The Denver Post Editorial Board, 2018).
Triggered by drops in advertising revenue and readership, the number of staffers in local newsrooms has steadily dwindled in recent years (Martin and McCrain, 2019; Peterson, 2021; Siles and Boczkowski, 2012). These declines in employment have been described as eroding the quality and quantity of local news output (Hayes and Lawless, 2018; Martin and McCrain, 2019; Napoli et al., 2017; Peterson, 2021). In the case of local political news, quantitative work studying industry-wide employment reductions has corroborated these claims, finding a significant relationship between staffing cuts and a decline in the political coverage provided by newspapers (Peterson, 2021).
This industry-wide decrease in employment has in part been accelerated by a particular strand of predatory corporate acquisition. Described as “vulture capitalism,” this financial behavior, typically perpetrated by hedge fund-owned media conglomerates, involves purchasing publications in financially precarious states, drastically cutting staff, and subsequently raising subscription rates (Abernathy, 2018, 2020). Such corporate takeovers have been identified as detrimental to publications in at least two respects. The first is the reduction in resources that acquisition brings about (Abernathy, 2018, 2020; The Denver Post Editorial Board, 2018). The second is the creation of regional hubs of geographically proximate publications in order to consolidate newsroom functions (Abernathy, 2018; Martin and McCrain, 2019).
Given the role local news publications have in driving citizen political engagement (Hayes and Lawless, 2018; Schulhofer-Wohl and Garrido, 2013; Shaker, 2014), in disseminating information during crisis events (Emery et al., 2021), and in sustaining and developing local identity (Buchanan, 2009b; Funk, 2013), understanding the impacts of acquisition on local news output is crucial in identifying and drawing attention to unhealthy media environments. For local television stations, acquisition has been found to induce increases in the coverage of national politics at the expense of local politics (Martin and McCrain, 2019). In the case of newspapers, however, the effects of corporate acquisition on the local media output of individual publications have, despite significant media attention (e.g. Farhi and Izadi, 2021; Izadi and Ellison, 2021; Noe-Payne, 2020; Sullivan, 2018; Wick, 2017), yet to be quantitatively analyzed.
In this work, we investigate the relationship between predatory corporate acquisition and the representation of local news coverage. Using named entity recognition and tools from information theory, we explore how the acquisition of publications and the consolidated environment engendered by such acquisitions affect the local information environment of affected communities. Building a corpus of 31 corporate-owned publications consisting of more than 130,000 articles, we compare local content in the period before and after acquisition, and explore how articles produced to be shared across a regional hub of newspapers differ from those which are not.
Across all publications studied, we find evidence indicating that predatory corporate acquisition leads to a reduction in the quantity and quality of local journalistic content. Our three main findings can be summarized as follows:
Acquisition leads to a significant, but not disproportional, decrease in the volume of local content produced by local newspapers;
Coverage of local places in the periods following acquisition is significantly more concentrated than coverage in the periods prior to acquisition;
Articles produced to be shared across regional hubs of newspapers are significantly less local—and discursively more national—than articles unique to a given newspaper.
We structure this article as follows. We begin by summarizing our corpus of corporate-owned publications. We then investigate delocalization in these publications using three computational models of local content: the amount of mentions of local locations and people, the concentration in the coverage of local news, and the discursive nationalization of affected publications. We conclude by discussing the implications of our results and relate them to previous studies of corporate acquisition in media.
Overall, our findings establish reductions in newsroom resources and the creation of regional hubs of local newspapers as practices which negatively affect the local information disseminated by publications. We release our analysis code and data set to motivate future computational work exploring the effects of corporate ownership on newspapers. 1
Data overview
We assemble a corpus of 31 publications, which we partition into two groups: corporate acquisition publications (CAP) and corporate consolidation publications (CCP).
CAP are local newspapers which have been identified by outside sources as having undergone a transformational corporate acquisition. We use these publications to investigate differences in local content pre- and post-corporate acquisition. This part of our corpus is made up of three metro-based publications: LA Weekly (LAW), an alternative weekly acquired by a smaller-scale Limited Liability Corporation; The New York Daily News (NYD), a daily city-based tabloid acquired by a large publicly traded corporation; and the DP, a traditional metropolitan daily newspaper purchased by a large hedge fund. We study these newspapers in particular because each of their acquisitions have been and continue to be well documented by journalists (see, for example, Abbruzzese and Atkinson, 2018; Coppins, 2021; Feuer, 2015; Sullivan, 2018; Wick, 2017). In addition, because these publications differ significantly in (a) journalistic mission and (b) structure of corporate ownership, any findings found to hold across all three would lend support to a more general theory of the effects of corporate acquisition on local metropolitan newspapers. We therefore hypothesize that regardless of the journalistic mission and corporate structure, corporate acquisition will negatively affect the quantity and quality of the local content produced by acquired publications relative to the period prior to acquisition. To test this claim, we collect articles by randomly sampling from those listed on each publication’s website during a fixed period of time in the periods before and after acquisition, which we describe below.
CCPs are a group of geographically proximate local newspapers under the ownership of a single newspaper chain. We use these publications to investigate how a particular practice common in regional hubs of corporate-owned publications—article sharing—affects local media coverage. We assemble a group of 28 local Californian publications under the ownership of newspaper chain Digital First Media (DFM). We investigate differences between articles distributed across multiple publications (shared articles) and articles published in a single local paper (non-shared articles). Shared articles thus represent content produced to be distributed across multiple markets within a regional hub of publications. We visualize this practice in Figure 1. Note that since the majority of CCP are located in regions outside major metropolitan areas, this set of articles acts as a way to explore how corporate ownership affects smaller, non-metro-based newspapers.
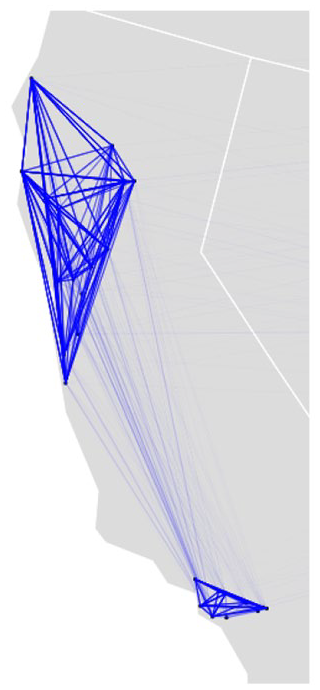
Graph of article sharing across DFM California publications.
In all cases, we scrape articles listed on the publication’s sitemap using BeautifulSoup. A summary of our corpus is given in Tables 1 and 2, and we describe each publication in detail below.
Summary of the corporate acquisition publication (CAP) corpus.
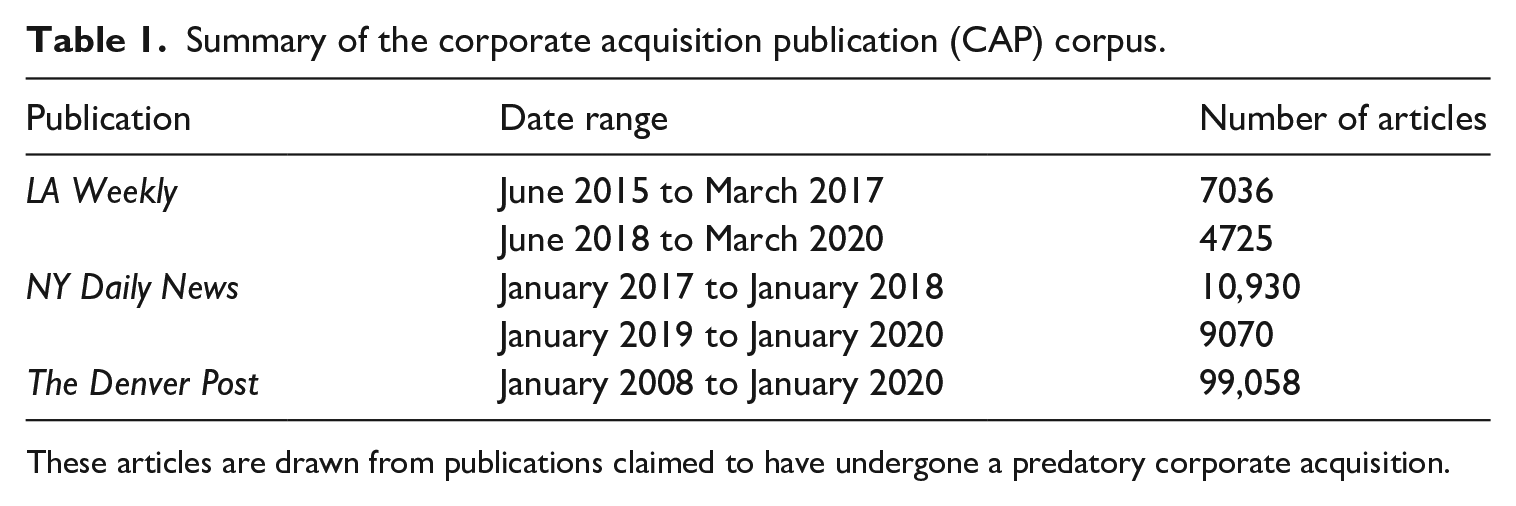
These articles are drawn from publications claimed to have undergone a predatory corporate acquisition.
Summary of the corporate consolidation publication (CCP) corpus.

These articles are drawn from 28 California publications under the ownership of media conglomerate Digital First Media.
Publications
LAW
LAW is an alternative newspaper covering arts and culture in the city of Los Angeles. Within hours of being acquired by Limited Liability Corporation Semanal Media on 30 November 2017, 9 of LAW’s 13 editorial staffers were fired, including all five editors and all but one staff writer (Wick, 2017). We plot this reduction in Figure 2, and compare it to aggregate trends at the national level. 2 To build a collection of LAW articles, we randomly sample n = 11,761 articles from the publication’s sitemap. This sample covers two 21-month periods: 30 to 9 months before (n = 7036) and 9 to 30 months after (n = 4725) the publication’s acquisition.
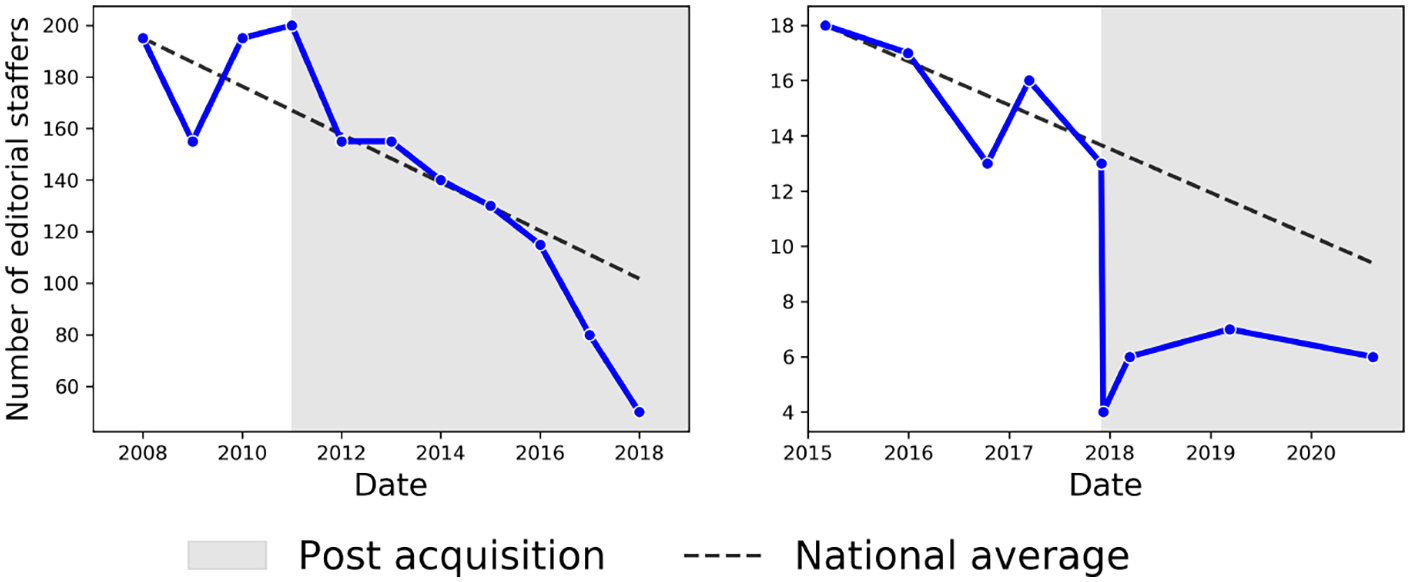
Number of editorial staffers for LA Weekly and The Denver Post.a
The NYD
A daily newspaper covering New York City, the NYD has been described as a voice of the city’s working class, with an editorial style focused on “doorstep reporting” (Feuer, 2015). The NYD was acquired by media conglomerate Tribune publishing, a publicly traded corporation, on 4 September 2017. In July 2018, Tribune fired half of the publication’s editorial staff, leaving only 50 reporters to cover New York City’s 8 million residents (Abernathy, 2020).
We randomly sample a total of n = 20,000 articles, covering the periods 18 to 6 months prior to (n = 10,930) and 6 to 18 months following (n = 9070) July 2018. We note that the distribution of articles scraped from the NYD sitemap contains a suspicious influx of articles from November to December 2018. Since this period does not follow the distributional trend, we exclude these articles from our analysis.
The DP
A daily newspaper acquired by hedge fund media conglomerate Alden Global Capital in 2010, the number of journalists at the DP has steadily declined from more than 250 before acquisition to less than 70 in 2020 (The Denver Post Editorial Board, 2018). We visualize this decline in Figure 2. As of May 2021, the DP is one of the few remaining publications covering the city of Denver—a city which at one time was covered by more than 600 journalists (Sullivan, 2018).
Since the decline in the number of DP employees did not occur on a given date, but rather occurred steadily over time, we randomly sample n = 99,058 articles published between 1 January 2008, roughly 2 years before the acquisition, and 31 December 2019. Note that this distinguishes this publication from the previous two in its lack of a clear separation between periods. Accordingly, we conduct analyses over time as opposed to pre- and post-acquisition.
DFM California
To study how regional content sharing affects local coverage, we assemble a collection of articles drawn from 28 Californian publications, all under the ownership of newspaper chain DFM. 3 DFM is one of the largest newspaper groups in the United States, and is of particular interest in the study of consolidation since it is known for purchasing small daily newspapers in a single area and subsequently consolidating their operations (Reynolds, 2019; The Future Today Institute, 2020).
We compare articles which are shared across newspapers (shared articles) to those which are unique to a single newspaper (non-shared articles). We sample, from each publication, min(250,|Sp|) shared articles and min(100,|Np|) non-shared articles, where Sp and Np, respectively, denote the set of shared and the set of non-shared articles for a publication p. We select these sample sizes in order to obtain a uniform sample as possible across publications. This leaves us with n = 5953 shared articles and n = 2581 non-shared articles.
Amount of local news content
We begin by testing whether there exists a statistically significant relationship between corporate ownership and the volume of local journalistic output produced by a publication. In Buchanan (2009b), local content is defined as the description of events “occurring within the circulation area (the area in which the newspaper was delivered to subscribers) of the newspaper at the time of its publication.” Subsequent empirical studies of local news have shown that local content is in most cases contingent on the presence of named entities from the geographic area the publication purports to cover (Buchanan, 2009a, 2009b; Lindgren, 2009). Local content is thus not understood here as pertaining to a region’s population density (i.e. local as a proxy for small town or rural), but rather as a concept defined by the isomorphism of a news platform and its geographical location. Building off this prior work, we define local content as information pertaining to entities—either places or people—that are located within the geographical area the publication purports to cover. In the following section, we describe how we operationalize these two dimensions of local content.
Local content as place bound information
Our first model defines local content in terms of the frequency of mentions of places within the geographic area the publication purports to cover. Specifically, we measure the number of local articles produced by publications, where an article is classified as local based on two thresholds: one for the number of local places in the article and another for the point at which a given place is considered local. Because the concept “local” is not a straightforwardly bounded unit, we explore different parameters of locality as a function of distance from a geographic center. In what follows, we describe these thresholds in detail and investigate changes in the amount of local content by averaging over many possible instances of them.
Methods
We extract named entities from articles using Stanza (Qi et al., 2020), and pair the mentions of locations (e.g. Sandia Peak) and geopolitical entities (e.g. Denver) with the geographical locations they denote using the Google Maps geocoding application programming interface (API). We refer to named entities geocoded to a particular location as toponyms.
To test whether the mentions of locations and geopolitical entities provide a robust proxy for the classification of local articles, we conduct a brief validation study. We randomly sample 100 articles from our corporate acquisition corpus, and hand-tag each article as “local” or “non-local” based on the definition of local content provided above. Specifically, we tag an article as local if it describes events which occur within the city the publication purports to cover. Using these tagged articles, we run a model which classifies an article as local if at least one of the detected toponyms in the article is geocoded to a location within the city the publication covers. The model’s accuracy on this hand-tagged set of articles should indicate the reliability of using locations and geopolitical entities to classify articles.
In Table 3, we report four metrics which quantify the performance of this classification model: precision (the percentage of articles classified as local which were tagged as local), recall (the percentage of articles tagged as local which were classified as local), F1 (the harmonic mean of the precision and recall), and accuracy (the percentage of articles which were correctly classified). Overall, Table 3 indicates that while imperfect, the mentions of locations and geopolitical entities make for a useful proxy for classifying articles as local.
Local article classification model validation scores in percentages on a subset of hand-tagged articles.
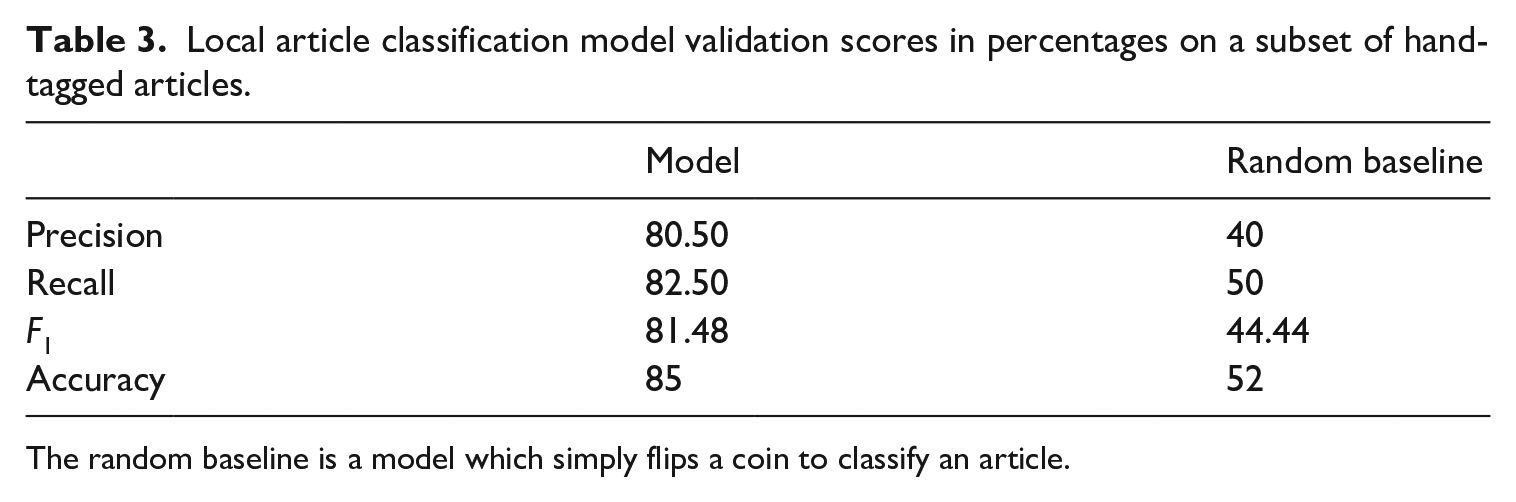
The random baseline is a model which simply flips a coin to classify an article.
In the above validation study, both the model’s classification and our hand-tagging were done according to the following classification procedure: an article is considered local if it describes events which occurred within the city of the publication. This straightforward procedure provided us with clear conditions with which to compare human judgments to model outputs. However, as a model for the amount of local news content, classifying articles according to this simple condition leads to two shortcomings.
The first is that it does not account for areas which, while outside of the geographical boundaries of the city, nevertheless rely on the publication’s coverage. Therefore, instead of considering a toponym local if it occurs within the city of the publication, we define a toponymic distance threshold (dt). The threshold dt denotes the maximal distance from the publication’s city center at which we consider a given toponym local. We compute this distance using the geodesic ellipsoidal distance between the toponym’s coordinates and the coordinates denoting the center of the publication’s city. We consider values of dt which range from 20 to 50 km, in increments of 5.
The second shortcoming of the conditional statement given above is that it does not distinguish between articles which exclusively discuss local events and those which discuss local events alongside non-local events. We solve this by defining a local toponym threshold (pt). Given the set of toponyms extracted from an article, pt is the minimum proportion of local toponyms required for the article to be classified as local. We modulate pt in order to account for all thresholds between 0.05 (5% of all toponyms are classified as local) and 1.0 (all toponyms are classified as local), in increments of 0.05.
Given these thresholds, we can summarize our definition of a local article as follows: An article is considered local if pt proportion of the toponyms mentioned in the article are within dt distance from the center of the city the article’s publication purports to cover.
For instance, setting dt = 50 and pt = .75, this definition states that an article is local if at least three quarters of its toponyms are within 50 km from the center of the publication’s city. We compute, for a given set of articles, the number of local articles by averaging over all possible definitions of locality, that is, all (pt, dt) ϵ {0.05, 0.1, . . ., 1} × {20, 25, . . . 50}, where × denotes the cartesian product operation.
We compute the amount of local news as both (a) the proportion of local articles and (b) the total number of local articles for a given period. 4 To obtain measures of statistical significance, we compute these values on a weekly basis, thereby obtaining a distribution over (a) and (b).
Results
Figure 3 visualizes the relative amount of local content per week for LAW and the NYD. We do not find evidence for a reduction in the relative share of local articles following acquisition. Averaging across all threshold values (dt and pt), we find small yet statistically significant increases in the mean proportion of local articles, from 42.32% to 44.49% in the case of LAW, and from 24.30% to 26.22% local for the NYD.
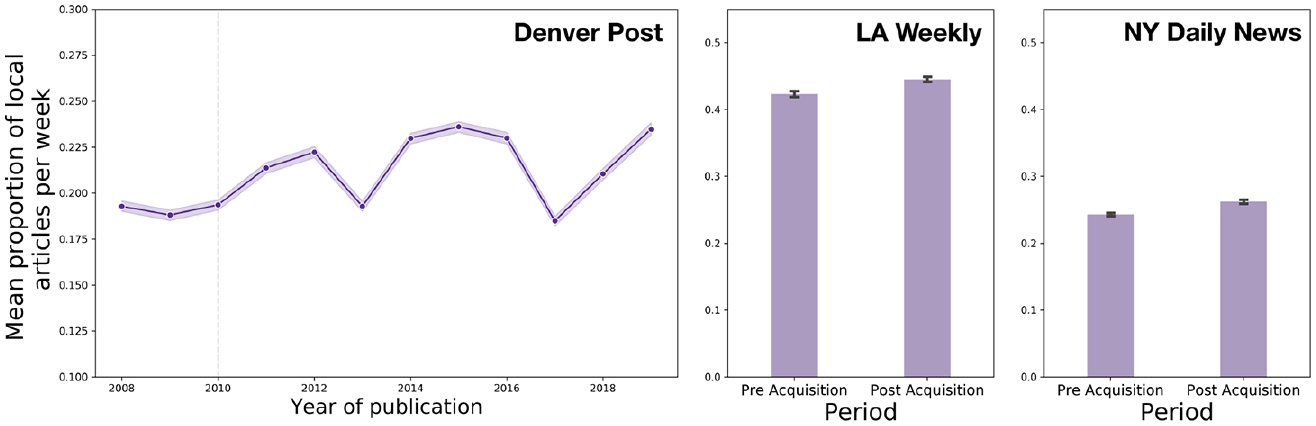
Relative amount of local content per week averaged across all locality threshold values dt and pt.
However, when considering the absolute number of local articles per week in Figure 4, we find that in the periods following corporate acquisition, the average number of local articles per week decreases from 32.22 to 22.72 for LAW and from 50.85 to 37.60 for the NYD. Concretely, this means that readers have access to around 30% and 26% less local content per week following corporate acquisition for LAW and the NYD, respectively.
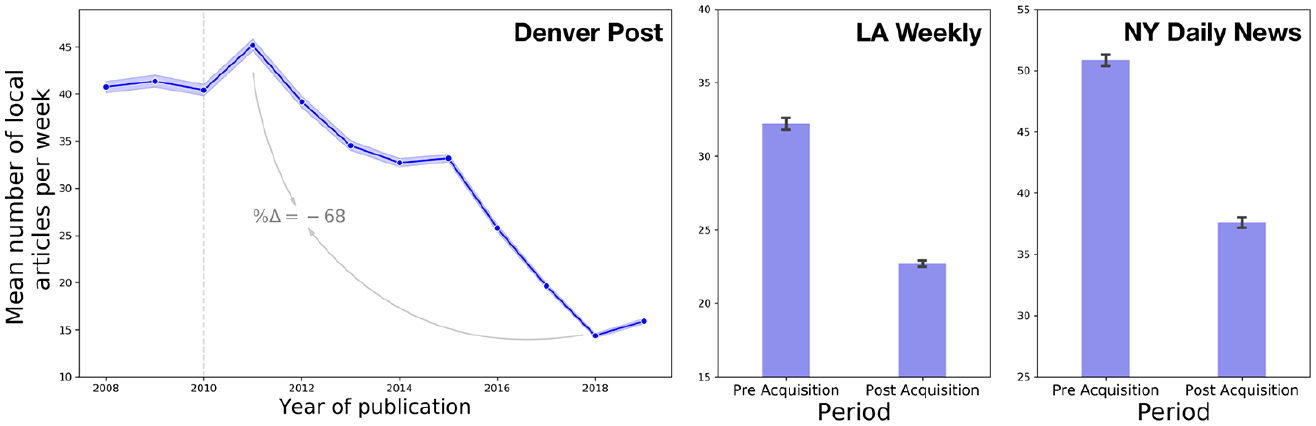
Absolute amount of local content per week averaged across all locality threshold values dt and pt.
The left-most plot of Figure 3 visualizes the proportion of local articles per week averaged across all values of dt and pt for the DP. Similar to LAW and the NYD, we do not find evidence for a decrease in the proportion of the publication’s output considered local. In fact, with the exception of 2012, 2017, and 2018, we find that the relative share of local articles has increased by around 5% compared to the period before acquisition.
In the case of absolute output, however, Figure 4 shows a systematic reduction in the number of local articles published per week. This reduction begins in 2011, a year after the publication’s purchase. Relative to the lowest point in 2018, this amounts to a decrease of around 68% in the amount of local content produced per week.
Across the corporate network of 28 Californian publications, we find that articles which are shared among publications are significantly less local than articles unique to each publication. On average, 46% of non-shared articles are classified as local with respect to their publication whereas only 13% of the shared articles can be considered local. We visualize this discrepancy in Figure 5.
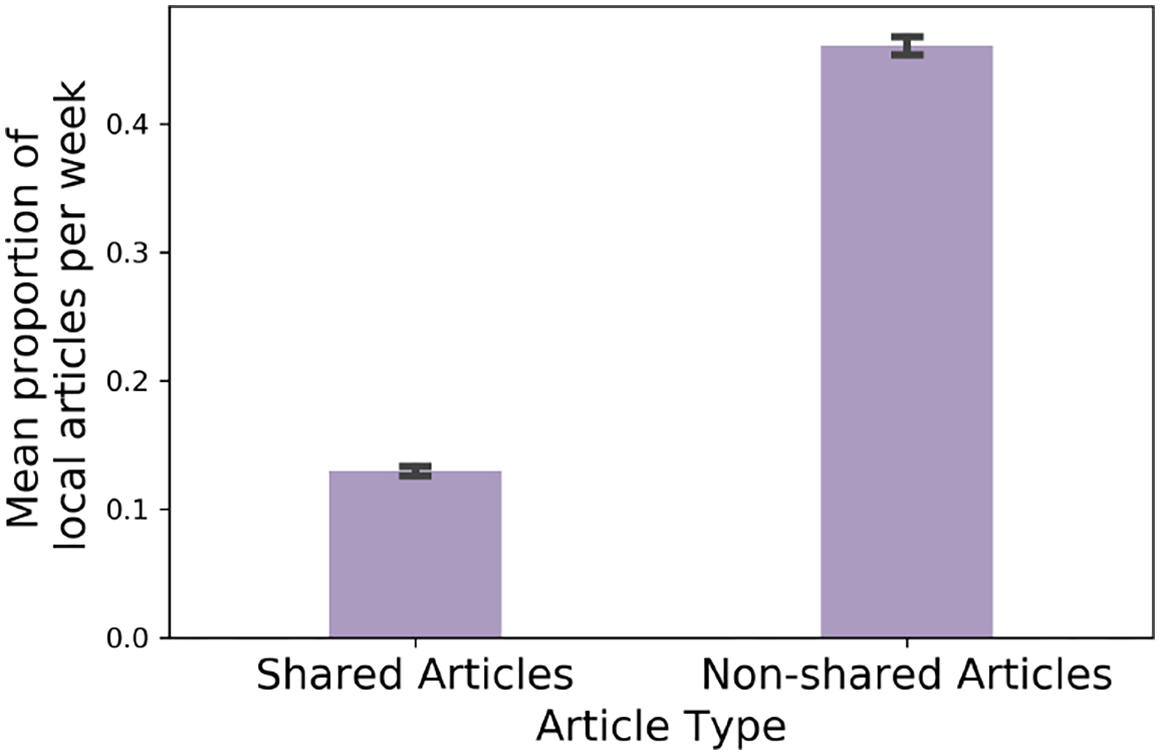
DFM California: mean proportion of local articles per week by article type.
Local content as people-centered information
In the previous section, we defined the amount of local content in terms of the frequency of local places mentioned in articles. Here, we define local content in terms of the frequency of “local people” mentioned in articles, conditioning on public officials as representatives of local, civically important figures. Specifically, we investigate for a single publication (the DP) how the amount of attention allocated to people at different levels of government (i.e. city, state, and national) 5 evolves throughout the publication’s consistent layoffs.
Methods
We extract the mentions of persons in articles using Stanza NER. To detect the mentions of politicians, we build a list of names of people who have served on the executive and legislative branches of government at the city, state, and national levels. Given the labor required to assemble such a list, we focus analyses in this section solely on the DP.
We compute the number of mentions of people at each level of government on a monthly basis. To match a person mentioned in an article to a politician in our list, we require that the politician’s name occurs in full at least once in the article (i.e. first and last names), and that the article be published during the period in which the politician was in office. We conduct these analyses on n = 99,058 articles.
We investigate trends across time using a linear regression model. Importantly, the computed monthly counts include clusters of outlier values, as can be seen in Figure 6. These periods in most cases coincide with municipal and national elections, indicating a departure from normality during periods of heightened political attention. To capture the underlying trend while accounting for these periods, we use a Bayesian regression model augmented to include inlier and outlier classifications for each data point. In short, the model classifies each point as an inlier or outlier, and fits a regression line only to those points classified as inliers. By simulating many such fits, this model allows us to estimate a (posterior) distribution over regression lines, in which each data point’s effect on the slope and noise parameters of the regression line is inversely proportional to its outlier probability. From this, we can obtain a nuanced characterization of the underlying trend without having to exclude these periods of increased political attention. For a more detailed explanation of the model, see the appendix.
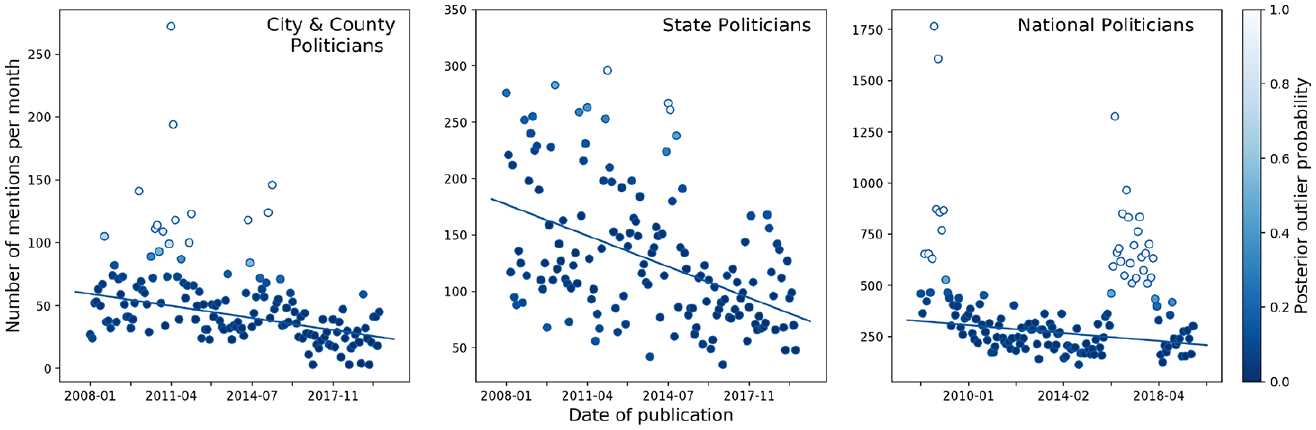
The Denver Post: number of mentions of people at different levels of government.
Using the probabilistic programming language Gen, 6 we run 10,000 Markov Chain Monte Carlo (MCMC) simulations for each data set and use the mean of the posterior distribution over model parameters as the regression line which best explains the data. As in the previous section, we compute both the relative and absolute number of mentions per month. To obtain the relative count for a given month, we normalize the number of mentions by the number of articles published during that month.
Results
We summarize the mean posterior regression lines for the relative number of mentions in Table 4. Included as well are the 95% credible intervals, which state the range of values defining 95% of the parameter’s posterior samples. The slopes of the models indicate a slight increase in the relative amount of attention given to politicians at all three levels of government.
Summary of the regression lines for the relative number of mentions of people at different levels of government in The Denver Post.

Reported are the mean posterior slope and intercepts along with 95% credible intervals (CI).
However, none of these relative increases amount to an increase in absolute attention, nor are they significant enough to prevent a decrease in absolute attention. Indeed, visualized in Figure 6 are the number of mentions across three levels of government, along with the mean posterior regression lines. These regression models suggest that the number of mentions of politicians at the local, state, and national levels decreases throughout the period studied. Note that each monthly count is shaded based on the proportion of posterior samples in which it was classified as an outlier. This means that the outlier counts, typically aligning with election periods, have less of an influence on the values of the slope and intercept of the regression line.
Comparing the change in the predicted number of mentions from January 2008 to December 2020, these reductions amount to around 33% less attention in the national case, compared to 55% less in the state and local case. National political attention is therefore comparatively less affected by acquisition than state and local attention when it comes to the mentions of politicians.
Geographic concentration of local content
In the previous section, we established a significant relationship between corporate ownership and the amount of local content produced by publications. In this section, we investigate whether the corporate acquisition of publications is associated with a decreased diversity of local places covered.
Methods
Given a set of toponyms, we aim to understand how a finite number of mentions (counts) are allocated to the toponyms in the set. To do so, we use the information-theoretic entropy (Shannon, 1948). Formally, the entropy of the random variable T denoting the distribution over a set of toponyms is computed as follows

where p(t) is the relative frequency of the toponym t.
This entropy measures the uncertainty inherent in the distribution of toponymic mentions. Expression 1 is maximized when a uniform amount of attention is given to each toponym (minimal concentration) and is minimized when all attention is given to a single toponym (maximal concentration). This value therefore inversely quantifies concentration: a decrease in entropy indicates an increase in concentration.
To tease apart concentration at different geographical levels, we partition the set toponyms into five disjoint subsets. Beginning with the set of toponyms consisting only of places within the city of the publication, we progressively expand the geographical threshold (i.e. county, state, country, and international) to include all topoynms which lie within the geographical boundaries denoted by that threshold yet do not lie within the boundaries of more precise thresholds. Thus, for example, the “rest of state” subset contains all toponyms from the state of the publication which are not in the publication’s county. 7
We compute the toponymic concentration for each level on a weekly basis and compare the distributions of weekly toponymic entropy values using Cohen’s d effect size. Under the assumption of normality, the absolute value of the effect size roughly measures the number of standard deviations of change in the distributions. The sign of the effect size denotes the direction of change (here, a negative d indicates a decrease in entropy). As a rule of thumb, |d| ≈ 0.2 is considered a “small” effect, |d| ≈ 0.5 as “medium,” and |d| ≈ 1 as “large.”
Results
Table 5 summarizes the distributions of weekly toponymic entropy values for LAW and the NYD before and after acquisition. We find statistically significant decreases in entropy for toponyms at the city, county, and state levels across both publications. We also find significant decreases for toponyms at the national and international levels in the case of LAW, but not for the NYD. Comparing effect sizes, the greatest change for LAW occurs in the set of toponyms denoting places in the rest of LA County. In the case of the NYD, the largest change occurs in the coverage of places from the rest of the state of New York.
LA Weekly (LAW) and The New York Daily News (NYD): mean values and Cohen’s d effect sizes of change of the distributions of mean weekly toponymic entropy.
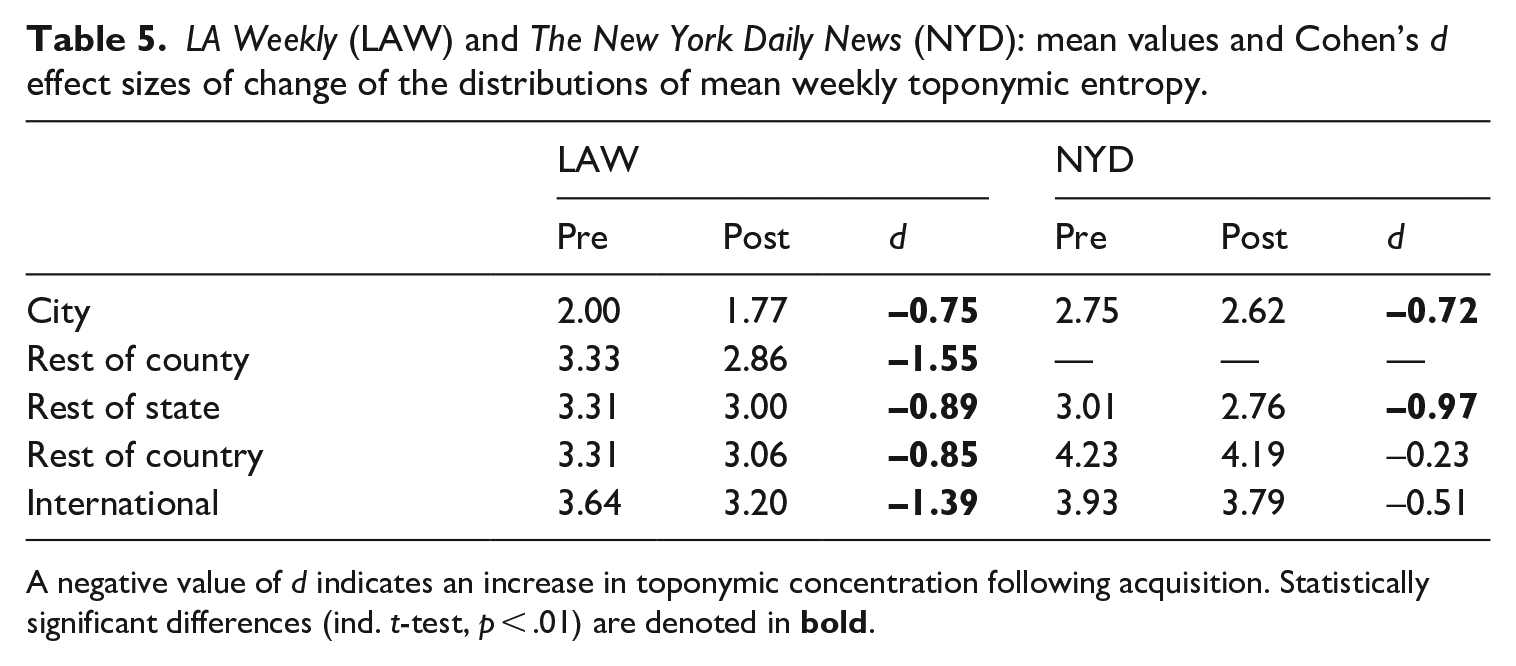
A negative value of d indicates an increase in toponymic concentration following acquisition. Statistically significant differences (ind. t-test, p < .01) are denoted in
Analogous to the two other publications, we find a significant decrease in weekly toponymic entropy at the city and rest of state levels in the DP, as visualized in Figure 7. A statistically significant decrease in toponymic entropy also exists at the national and international levels. We summarize ordinary least squares (OLS) regression models for each set of toponyms in Table 6. Comparing regression line slopes, the most significant rates of increase in concentration occur in the coverage of places in the rest of the state of Colorado and places outside of the country.
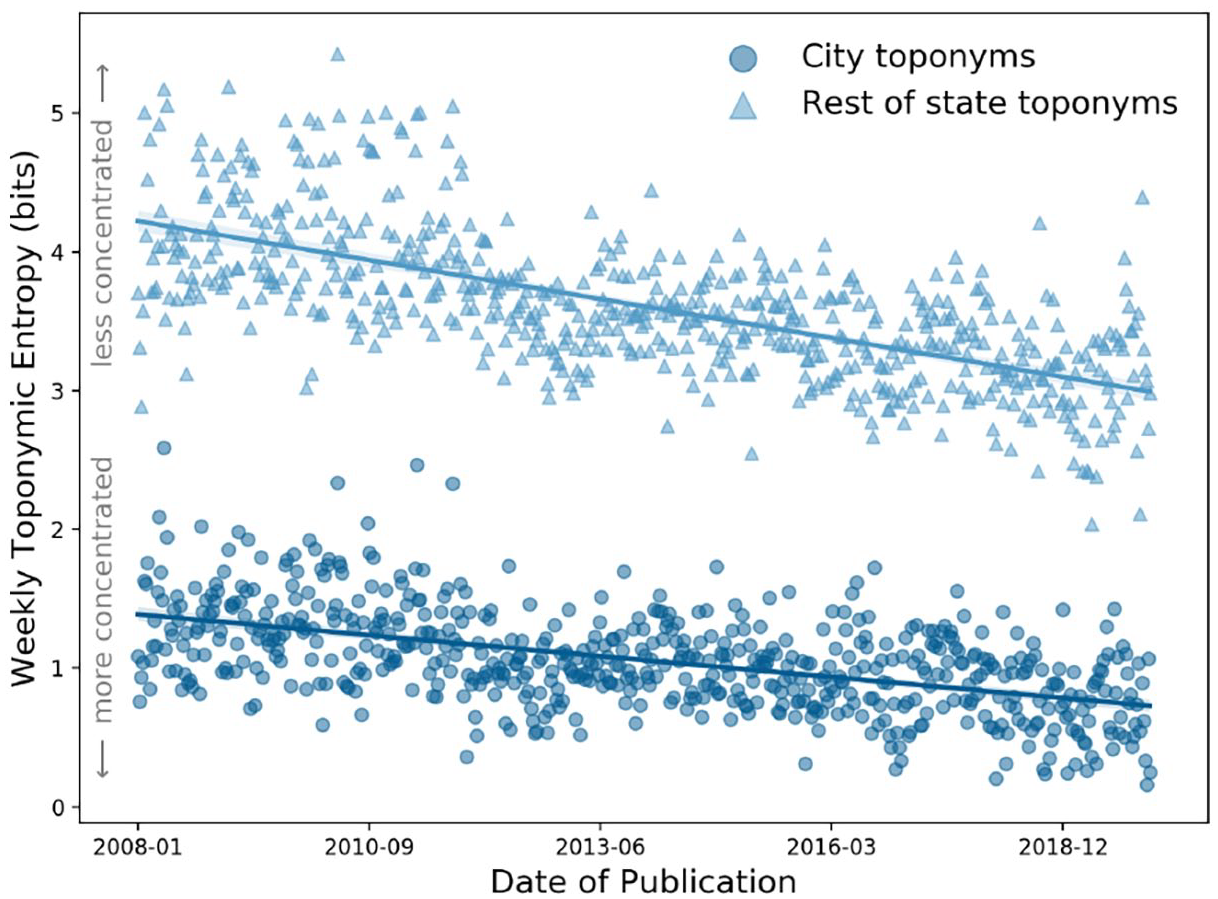
The Denver Post: weekly toponymic entropy for city and rest of state toponyms with OLS regression lines.
Summary of The Denver Post toponymic entropy linear regression models.
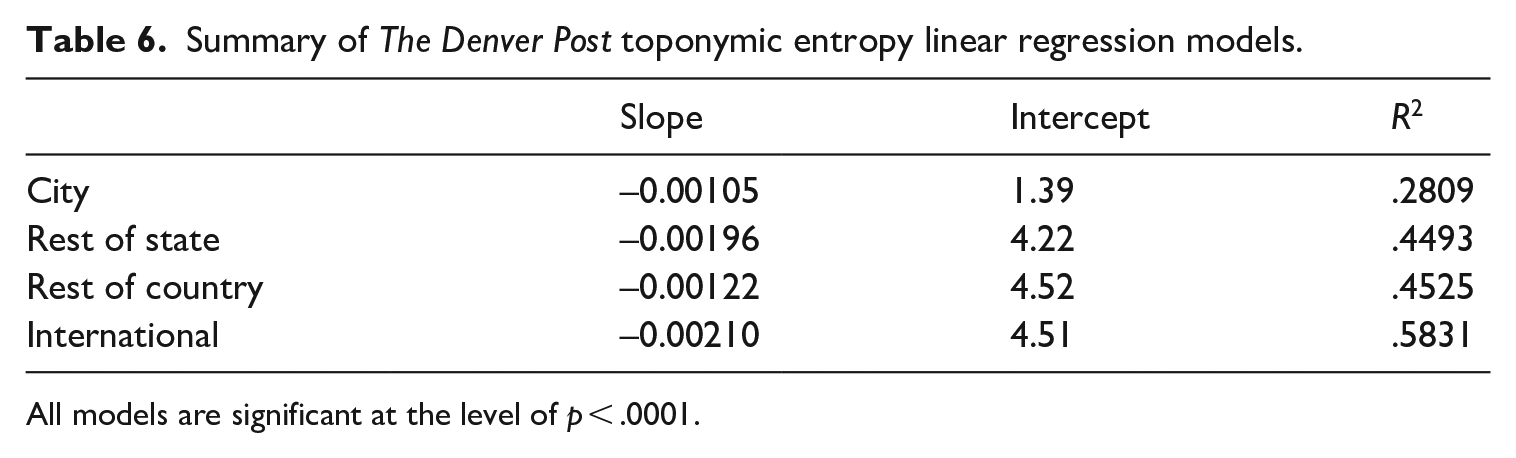
All models are significant at the level of p < .0001.
Finally, Table 7 summarizes the distributions of weekly toponymic entropy values for DFM California. Non-shared articles exhibit significantly less concentration in their coverage of places in the publication’s city, county, and in the rest of the state of California. In contrast, shared articles exhibit less concentration in their coverage of places in the rest of the United States and those outside of the United States.
DFM California: mean values and Cohen’s d effect sizes of change of the distributions of mean weekly toponymic entropy.
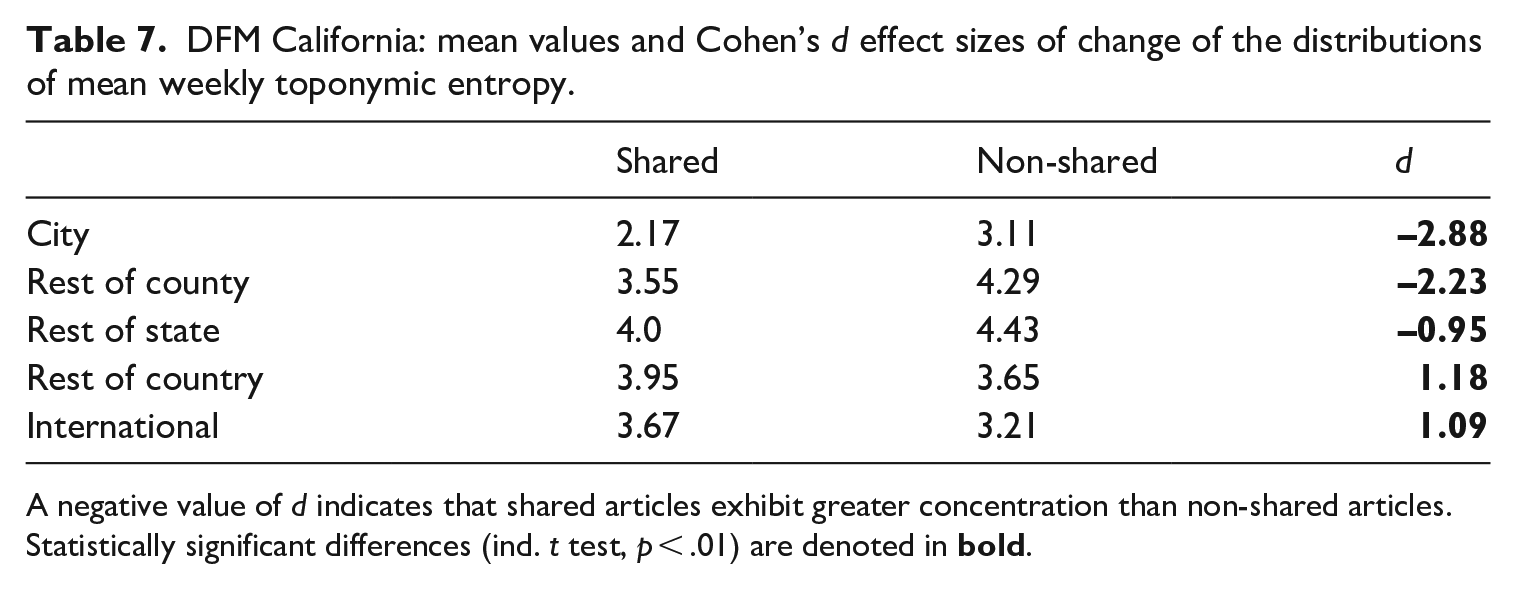
A negative value of d indicates that shared articles exhibit greater concentration than non-shared articles. Statistically significant differences (ind. t test, p < .01) are denoted in
Discursive nationalization
Our previous tests conditioned on specific features of locality, such as people and places, and observed their frequency distributions over time. Here, we wish to model a broader understanding of content, for which we use the term discourse. According to Reiner Keller’s (2011) “Sociology of knowledge approach to discourse,” discourse is understood as a set of “regulated, structured practices of sign usage,” which are strongly influenced by institutional and organizational pressures. In this, discourse is similar to the construct of “register” from the field of linguistics introduced by Halliday and Hasan (2011 [1989]), which captures contextually defined language use. Researchers have used computational models to capture discursive phenomena such as parliamentary discourse (Naderi and Hirst, 2015), fictional discourse (Piper, 2018), and scientific English (Degaetano-Ortlieb et al., 2018) among others.
In this section, we model the concept of “national news discourse” using common methods from computational text analysis and then observe the similarity of our articles to this model using information-theoretic measures (Chang and DeDeo, 2020; Degaetano-Ortlieb and Teich, 2018). Increased similarity to the national news discourse would provide another potential indicator of the delocalization of the news outlets we are studying, a process which we term “discursive nationalization” to distinguish this effect from the specifically entity-driven models above. Our models are designed to capture a more general practice of language use characteristic of national news in order to observe whether specific publications become increasingly similar to this discourse over time.
Methods
In order to represent the discourse of national news, we first build a corpus consisting of articles from two canonical US national news sources: CNN and Fox News. We sample an equal number of articles from each news source by either scraping the publication’s website or using a historical database of news articles (Factiva). Articles in this sample were published during the same period as articles in the corporate-owned publication sample. This set of articles acts as a proxy for the discursive patterns of national news sources.
Our aim is to quantify the similarity between the discursive patterns of national publications and the discursive patterns of acquired publications. More precisely, given a set of articles C belonging to a corporate-owned publication (e.g. LAW articles post-acquisition) and a set of national news articles N, we aim to investigate the degree of similarity between the relative frequency of word occurrences in C and N.
To do so, we represent a set of articles A using a Bag-of-Words (BOW) language model. A BOW model defines a categorical probability distribution over a set of words W. We estimate this probability distribution empirically; given a set of articles A, the probability of a word p(w) is computed as the relative frequency of w in A. Formally, this can be written as follows:

where count(w,a) is a function which returns the number of times the word w occurs in article a. Note that we add a single count to each word (Laplace smoothing) to avoid entries with zero probability.
Given an empirical probability distribution P representing the discursive patterns of the corporate-owned set of articles C and an empirical distribution Q representing the discursive patterns of the national set of articles N, we measure the similarity between P and Q using the Kullback–Leibler (KL) divergence

where W denotes the set consisting of the 5000 most frequent words in the union of C and N. Note that this means that P and Q are defined over the same set of words W, hence why smoothing is required in Expression 2.
The KL between P and Q measures the amount of information lost when encoding P with Q. Thus, the smaller the value of Expression 3, the more similar C is to N. In our analyses, C will denote the set of articles for a given publication at a given period (i.e. pre- or post-acquisition in the case of LAW and the NYD, the year in the case of the DP, 8 and shared or non-shared in the case of DFM), and N will denote the set of national articles published during the date range defined by C. We down-sample where needed such that |C| = |N|, and we run 1000 computations for each comparison.
Results
Figure 8 visualizes the mean KL divergence between national articles and the NYD (C) and LAW (D) articles before and after acquisition. In both cases, we find an increase in KL divergence following corporate acquisition. This increase in KL is interpreted as a decrease in similarity to national news sources, suggesting that discourse in the periods following acquisition is less similar to national discourse than it was in the periods prior to acquisition. This effect is particularly pronounced in the case of LAW.
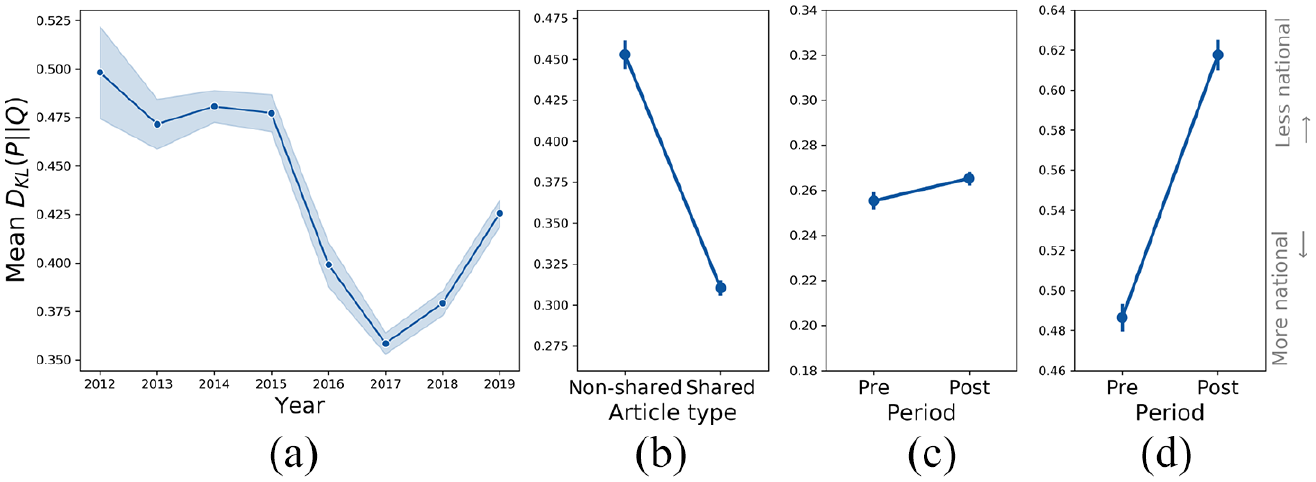
(a) The Denver Post: mean yearly KL divergence between national and DP articles, (b) DFM California: mean KL divergence between national and consolidated publication articles by article type, (c) NY Daily News, and (d) LA Weekly: mean KL divergence between national and publication articles before and after corporate acquisition.
In Figure 8(a), we visualize the mean yearly KL divergence between DP and national articles. In contrast with LAW and the NYD, we find a reduction in KL divergence throughout time, albeit with a slight increase toward the end of the period studied. This trend generally represents an increase in discursive similarity to national news sources in the period following corporate acquisition.
Across the regional hubs of DFM publications, we find that the KL between non-shared and national articles is significantly greater than the KL between shared and national articles. Figure 8(b) visualizes this comparison. This discrepancy indicates that at the discursive level, articles which are shared among geographically proximate publications are significantly more national than articles which are unique to publications.
Discussion
In the previous sections, we formalized local content using three computational models, and we explored how predatory corporate acquisition and the consolidating structures brought about by acquisition alter the information environment of affected publications. Below we summarize and interpret these findings for each of the two sets of articles in our corpus.
CAP
In section “Amount of local news content,” we saw that in the periods following corporate acquisition, there exists an absolute but not relative decrease in the amount of local content produced by publications. Consistent with the effects of industry-wide staffing cuts on political news (Peterson, 2021), these findings lead to two conclusions of note.
First, the lack of relative decrease in local content indicates that acquisition affects newspapers differently than other media. In Martin and McCrain (2019), the acquisition of local television stations was found to trigger a decrease in the coverage of local politics. In contrast, we do not find evidence for a disproportionate shift in editorial attention away from local content. This discrepancy suggests medium-dependence in the effects of acquisition; in this case, newspapers are less vulnerable than television stations to editorial shifts following acquisition.
Second, while local content is not disproportionately affected, corporate acquisition nevertheless gives rise to a local information gap. The decreases found at the local level indicate that following acquisition, publications are no longer able to allocate the same amount of coverage to the communities they serve. These findings therefore indicate that corporate acquisition leads to a significant reduction in the amount of local news disseminated by affected publications.
In addition to the effects on the amount of coverage, section “Geographic concentration of local content” presented evidence suggesting that corporate acquisition also has a detrimental effect on the quality of coverage—significantly increasing its locational concentration. Across all acquired publications, the periods following acquisition exhibit less diversity in the coverage of places within the publication’s city and the areas just outside of it (the rest of the publication’s county or state). In fact, for the NYD and LAW, we find that the most significant increases in concentration occur in the geographical areas just outside the publication’s proximate area. In the DP, increase in concentration of the coverage of this area is second only to increase at the international level. This finding indicates that, at least in the case of concentration of coverage, it is not the areas closest to the publication which are most affected by corporate acquisition. Rather, it is the communities just outside of the publication’s city, many of which are likely not covered by a daily newspaper of their own (Abernathy, 2018, 2020).
Finally, at the discursive level, we did not find conclusive evidence indicating that corporate acquisition necessarily triggers discursive nationalization. In the case of LAW and the NYD, we do not find evidence suggesting that corporate acquisition engenders increased national discursive similarity; on the contrary, we find that, particularly in the case of LAW, post-acquisition discourse is less similar to national news than pre-acquisition discourse. However, in the case of the DP, we find evidence suggesting the periods following corporate acquisition are indeed associated with increased similarity to national discourse.
It is difficult to offer a satisfying explanation for why we do not observe clear directionality in results. In computational modeling, there exists a trade-off between the complexity and interpretability of a given model. Models which attempt to capture high-dimensional phenomena may be applied to study more complex questions, yet their output typically increases in opacity as this complexity grows. In this case, the model used to investigate discursive nationalization leans toward the side of complexity. We therefore cannot speculate possible explanations for why we fail to find a clear effect, and leave exploring discursive nationalization at a more granular level to future work.
CCP
In addition to publications having undergone transformational corporate acquisitions, we also studied how the structures of corporate ownership affect local media coverage. Investigating the practice of content sharing within regional hubs of publications, we found overwhelming evidence suggesting that articles made to be distributed across multiple publications within a corporate network are significantly less local than articles unique to a publication.
In particular, subsection “Local content as place bound information” in showed that articles which are published by multiple newspapers contain proportionally less content about local places than articles which are published by a single newspaper. Section “Geographic concentration of local content” expanded on this, finding that these articles also tend to provide more diverse coverage of national and international places at the expense of coverage of places located within the limits of the cities and counties the publications purport to cover. Finally, this increased focus on national information was shown to be reflected at the discursive level as well. Our analysis of discursive nationalization presented evidence indicating that articles which are shared across newspapers are discursively more similar to national news publications than are articles which are unique to a given newspaper.
These findings shed light on the sensitivity of local content to multi-market production. Local information output is significantly affected by the practice of article sharing even despite the fact that most of the sharing between DFM publications is relatively localized within two regional hubs (see Figure 1, which depicts two clusters of article sharing). Our findings therefore suggest that regional hubs of local publications are not valid substitutes for independent local newspapers, especially as media conglomerates acquire an increasing number of publications and grow in geographical reach—a likely scenario given industry struggles.
Limitations and future work
Here, we acknowledge two important limitations to the above study and propose directions for future work. First, while many of the corporate network publications we studied cover geographical areas outside of major metropolises, our three CAP were each located in metropolitan areas. Since a large number of non-metro publications have also been affected by predatory acquisition, future work should seek to conduct in-depth analysis on the effects of acquisition for publications outside of densely populated regions. Second, our indices measuring local information represent just one of many possible operationalizations of features of local news. Future work should seek to develop complementary indices of local content. In addition, we encourage future analyses such as whether it is possible to distinguish between staff-written and newswire material, the length and subject matter of local stories pre- and post-acquisition, as well as the size of the communities the articles are about.
Conclusion
A growing body of literature has emerged raising concerns about the erosion of local news environments under corporate ownership (Abernathy, 2018, 2020; Hayes and Lawless, 2018; Martin and McCrain, 2019; Napoli et al., 2017; Peterson, 2021; Siles and Boczkowski, 2012). In this work, we built a corpus of 31 corporate-owned local newspapers and investigated the ways in which corporate acquisition alters the local media output of affected publications across a sample of more than 130,000 news articles. Our computational analysis established a significant relationship between predatory corporate acquisition and a reduction in the quantity and quality of local journalistic output. According to our findings, corporate acquisition is associated with the following: a significant decrease in locally focused content; a significant increase in the concentration of locally focused content (fewer areas are served), with some of the highest level of impact being observed in the near-city regions of interest; and a potential increase in the nationalization of news discourse, though this finding was not consistent across all publications.
We illustrate these associations across two different models of ownership: (a) corporate acquisition models where newspapers are bought by corporate owners resulting in significant declines in newsroom staff and (b) corporate consolidation models where corporate ownership leads to high levels of article sharing across regional publications. Our findings underscore that it is not only declines in staff which reduce locality following acquisition but also that the structure of content distribution brought about by corporate acquisition can have a detrimental effect on the local information environment of affected communities.
We expect this trend to worsen as conglomerates continue to grow. For example, at time of writing, Alden Global Capital—the owner of DFM and the DP—is set to purchase a majority stake in Tribune publishing—the owner of the NYD and one of the largest newspaper publishers in the United States (Izadi and Ellison, 2021). Given the increasing sparsity of information sources at the local level (Abernathy, 2018, 2020; Martin and McCrain, 2019; Peterson, 2021), we hope this article contributes to and motivates the expansion of the growing body of work drawing attention to the practices causing the decline of institutions vital not only to our sense of community but also to our trust in democracy.
Footnotes
Appendix
Acknowledgements
The authors would like to thank Michaela Drouillard for her insightful contributions to early versions of this work, the members of .txtLAB@McGill for their feedback and support, and the anonymous reviewers for their comments and suggestions.
Authors’ note
All authors have agreed to the submission and that the article is not currently being considered for publication by any other print or electronic journal.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The research for this paper was generously funded by the Social Sciences and Humanities Research Council of Canada.