
Abstract
Previous research has indicated that investigative interviews with adult victims and witnesses are often of low quality. Earlier findings also indicate that interviewing skills exhibit improvement when the interviewers are given feedback on their performance. Technological innovations make it possible to implement such an approach in a scalable manner. Simulated interviews with child avatars have shown that repeated feedback improves the proportion of recommended questions in those interviews. We created adult witness avatars (AWA) to simulate investigative interviews with adult victims and witnesses. We examined whether avatar interviews coupled with feedback (vs no feedback) would result in improvements in interview quality. Of the 60 participants, half received process feedback after each of four simulated interviews. The avatars revealed predefined memories and made errors as a function of algorithms formulated based on previous empirical research on the response behavior of adult witnesses in experimental studies. Results showed that receiving feedback after the simulated interviews increased the proportion of recommended questions (free recall and open questions) in avatar interviews compared with not receiving feedback (90.3% vs 72.6%, respectively). There was also a significant correlation between the question types and accuracy of details, even when analyzed separately for feedback and control groups. We demonstrated that with feedback after each AWA interview, the proportion of recommended questions was significantly higher in the AWA group than in the control group. The implications for practice are discussed.
Keywords
Witness and victim statements (hereafter witness statements for the sake of brevity) are frequently the sole evidence available to authorities (Powell et al., 2005). The criminal justice system considers eyewitness testimony largely factual despite psychological research showing that witness reports may be misleading even while appearing credible (Brewer et al., 2005). Irrespective of the witnesses’ age and background, their statements may be influenced by inappropriate interviewing style, possibly resulting in miscarriages of justice.
When witnesses have to give evidence, they are asked to reconstruct and recount personally experienced episodes that have occurred in a particular temporal and spatial context (Tulving, 1993). The reconstructive nature of the memory leaves recollections susceptible to external influences, such as questions asked, as shown by Loftus and Palmer (1974). In their study (Experiment 1), participants were shown several films of traffic accidents. Afterwards, the participants were asked to estimate the speed of the cars in the films. However, the researchers manipulated the wording of the question (using words like “smashed” or “contacted” among three other words) and found that this affected the participants’ speed estimates. Specifically, when the word “smashed” was used, participants estimated higher speeds than when the word “contacted” was used. Thus, the wording and framing of questions are crucial in eliciting accurate information, because they can significantly influence the reconstruction of memories.
Research so far has identified certain elements of police interviews, including questions asked, that promote factual and detailed eyewitness statements (Bull and Blandon-Gitlin, 2019). To increase the quality and quantity of information elicited from eyewitnesses, it is recommended to use free recall questions (“Tell me what happened!” or cued recall “Tell me more about the car!”), open-ended questions (“Where were you?”) and “facilitators” (e.g., “Go on!”) with both children (Orbach et al., 2000; Roberts et al., 2004) and adults (Geiselman et al., 1985; Valentine and Maras, 2011; Webster et al., 2021). Conversely, the use of option-posing (“Did he push you once or twice?”), repeated (repeating a question with the exact same wording), suggestive (“You were there, weren’t you?”) or misleading questions (“The car was green, wasn’t it?”; Lamb et al., 2018) is not recommended in investigative interviews (Powell et al., 2005). Although it may seem straightforward which types of questions are recommended for use in police interviews, the categorization of the question types can be complex because of the various ways of distinguishing between them (Oxburgh et al., 2010). Question types can be dichotomized (Nunan et al., 2020) as either productive or unproductive (Griffiths and Milne, 2006), and appropriate or inappropriate (Phillips et al., 2012). For example, closed questions can be both appropriate and inappropriate, depending on the context. They are appropriate when used at the end of a topic where open and probing questions have been exhausted. However, they can be inappropriate if used prematurely in the interaction, resulting in a closing down of the range of responses (Nunan et al., 2020).
In addition to general recommendations, it is crucial to understand how different question types affect the responses of adults. Studies have shown that the answers of adults are affected by question types (Lipton, 1977; Oxburgh et al., 2010; Sutherland and Hayne, 2001). It has been determined that, in general, adults are most accurate during free recall (Allwood et al., 2008; Cassel et al., 1996; Lipton, 1977), and compared with non-recommended questions that reduce accuracy (Kebbell and Johnson, 2000), open questions lead to more accurate accounts (Ibabe and Sporer, 2004; Lipton, 1977). More research with adults has been done on the effect of non-recommended and leading questions. Regarding non-recommended questions, it has been shown that option-posing (Ibabe and Sporer, 2004), repeated (Sharps et al., 2012), negative and double-negative (Wade and Spearing, 2022), and complex question forms (Chrobak et al., 2015; Jack and Zajac, 2014; Valentine and Maras, 2011) impair accuracy of answers. Adults even tend to speculate and provide answers to specific questions that are unanswerable (Waterman et al., 2001) or that they have no information on (Poole and White, 1991). Although the effect of misleading and suggestive questions on the accuracy of answers is stronger in children (Cassel et al., 1996; Roebers and Schneider, 2000), and older adults (Saunders and Jess, 2010; but see West and Stone, 2014), adults are also susceptible to misleading information in questions (Molyneaux and Larsen, 1992; Roebers and Schneider, 2000; Shapiro et al., 2005). Both closed and open presumptive questions have been shown to generate misinformation effects (Bowles and Sharman, 2014), but open leading questions (e.g. “Tell me about the shotgun” when a shotgun has not been mentioned by the witness) may be even more dangerous (Brubacher et al., 2020; Sharman et al., 2015). Thus, police officers need to be mindful of the questions asked in interviews with adults as well.
Launay and Py (2015) point out that relatively little work so far has focused on the methods and goals for investigative interviewing of adult witnesses. Fisher et al. (1987) conducted the first systematic study of such interviews, analyzing 11 interviews conducted by police officers with adults and children. They found that the interviews had little structure and that the interviewers used many closed as well as negative or leading questions. Launay and Py (2015) in their overview of eight studies of investigative interviews with adult witnesses noted that free recall was rarely used (see Ginet and Py, 2001; Wright and Alison, 2004) and that the collection of facts typically began with focused Wh- (e.g. Who, What, Where) questions. They concluded that interviewers continue to use more questions that are deleterious to witness’ memory recall than non-deleterious ones, even after being trained in interviewing techniques. This suggests that investigative interviewing practices may be difficult to modify with investigators maintaining strategies and tactics learned in the field using a series of specific, mostly closed, questions. Thus, it seems that transferring theoretical knowledge of best-practice guidelines into real-life interviews is surprisingly difficult (Sternberg et al., 2001).
Theory-based training remains the most common training format for investigators (Pompedda, 2018). Although the traditional classroom-based training model improves participants’ knowledge of interviewing skills, it is not successful in translating this theoretical knowledge into practical skills (Lamb, 2016). To overcome this problem, serious games in virtual environments combined with feedback have been proposed as a solution to improve the quality of child sexual abuse interviews (Benson and Powell, 2015; Powell et al., 2016).
Two components foster learning: high realism and immediate feedback. Virtual environments are computer simulations that represent activities at a high degree of realism (see Witmer and Singer, 1998). In investigative psychology, simulations in virtual environments have involved three-dimensional (3D) avatars on a computer screen (Pompedda et al., 2022) as well as virtual reality (VR) in which participants interact with 3D avatars in a 3D virtual environment using a VR headset (Baugerud et al., 2021; Taylor and Dando, 2018). In the interviewing of witnesses, Taylor and Dando (2018) have found advantages of gathering witness information in virtual environments where episodic performance improved with a significant reduction in errors. In addition, research into the use of structured interview protocols with children has found training to be effective when feedback is provided on a continuous basis and is detailed and immediate (Sternberg et al., 2002). It seems that learning the skills to elicit a narrative account effectively requires time and practical exercises that include personalized feedback (Sternberg et al., 2002).
Regarding immediate and detailed feedback, Pompedda and colleagues (2022) conducted a mega-analysis of the effects of feedback on the quality of simulated child sexual abuse interviews with avatars. Their analysis, involving 2208 interviews, showed that feedback increased recommended questions and decreased non-recommended questions, improving the quality of details elicited from the avatar, and resulted in more correct conclusions regarding the suspected “abuse”. Thus, it provided overall strong support for immediate feedback during avatar training. In the studies included in this mega-analysis, interview quality was considerably improved in just one hour when the interviewers were given feedback on their performance after each completed interview with child avatars (Haginoya et al., 2020; Krause et al., 2017; Pompedda, 2018; Pompedda et al., 2015, 2017, 2021).
Importantly, Pompedda et al. (2021) found evidence for transfer with those interviewers who were provided feedback during the avatar training–—these interviewers asked more recommended questions in interviews with actual children who had experienced a mock event. Similarly, Kask and colleagues (2022) found evidence for transfer to actual police interviews with child victims. Because investigative interviewing is cognitively demanding, serious games are ideal to increase training effect transfer in the light of theoretical frameworks for understanding how these effects can be facilitated (Blume et al., 2010). Instead of reading a guideline or hearing an explanation from an expert, participants learn about the negative effects of using suggestive questions and the positive effects of using open questions through their questioning and the feedback given to the questions they ask. Taken together, serious games in virtual environments that lead to high realism together with feedback may be more successful than traditional training models in training practical skills.
Current study
Because previous research with child avatars has shown that repeated feedback in simulated investigative interviews improves the proportion of recommended questions used, and that the quality of investigative interviews with adults is lacking, we decided to develop a computer-based solution to train investigators (police officers, prosecutors, judges, and lawyers) in interviewing adult witnesses (see Tohvelmann and Kask, 2022 for a review). In addition, recent guidelines, the Mendez Principles (Principles on effective interviewing for investigations and information gathering, 2021) and United Nation's manual on investigative interviewing for criminal investigation (United Nations, 2024) both indicate that asking questions that enhance more accurate answers are extremely important in implementing investigative interviewing best practices all over the world (similarly to PEACE model in England and Wales, and similar models elsewhere. (Halley et al., 2023).
In this study, we examined whether training with adult witness avatars (AWAs) coupled with feedback would result in improvements in interview quality compared with receiving no feedback. To achieve our aim, we posed two hypotheses and a study question. First, we hypothesized that receiving feedback regarding questions asked results in a larger proportion of recommended questions asked compared with not receiving feedback. More specifically, (a) receiving feedback results in a larger number of recommended questions asked compared with not receiving feedback; and (b) receiving feedback results in a smaller number of non-recommended questions asked compared with not receiving feedback (Hypothesis 1). Second, we hypothesized that over four consecutive interviews, those subjects receiving feedback after each subsequent interview will have a larger increase in the proportion of recommended questions compared with those not receiving feedback (Hypothesis 2). We also posed a study question in which we expected recommended questions to be associated with more correct and fewer incorrect details elicited from the avatars and non-recommended questions to have the reverse pattern. We also conducted analyses using age, gender and education as covariates to ensure that any significant effects were not due to possible random differences in participants’ background or previous experiences in the two groups given the relatively small sample size. Although not a substantive finding, this pattern would show that the algorithms driving the avatar responses are working as they should, because this is the pattern found in actual witness interviews (Tohvelmann and Kask, 2022).
Method
The desired sample size, included variables, hypotheses and planned analyses for the study were pre-registered on AsPredicted.com (https://aspredicted.org/blind.php?x=JQN_DX3) prior to any data being collected. The data set containing all primary study variables can be obtained from the authors.
Participants
A total of 60 participants (age M = 33.53, SD = 10.47, range 19–61, 18 male) took part in the study. The interviews were conducted in Estonian; 59 participants were native Estonian speakers and 1 was a native Russian speaker, who spoke Estonian freely. The highest level of education for 2 participants (3.3%) was basic education, for 15 (25%) was secondary education and for 21 (20%) was vocational education, 21 (35%) had a bachelor's degree and 10 (16.7%) had a master's degree. The participants were recruited by posting advertisements on university internal and external communication channels including social media. The participants had no background in either psychology or law, and had conducted no prior investigative interviews. The participants did not receive any reward for their participation. The feedback and control groups did not differ significantly in terms of participant gender, χ2(1) = .00, p = 1.000, age, t(58) = .811, p = .20 or education level, χ2(4) = 2.45, p = .69.
Power analysis [repeated-measures analysis of covariance (ANCOVA) within–between interaction] on the entire sample (N = 60) was conducted using the software package GPower (Faul et al., 2009) with the recommended effect sizes being small (w = 0.10), medium (w = 0.25), and large (w = 0.40; Cohen, 1988). The alpha level used for this analysis was p < .05. The analyses indicated that a statistical power of.41 is needed to detect a small effect,.99 to a medium effect, and 1.00 to a large effect. In sum, there was adequate power at the medium and large effect sizes, but less than adequate statistical power to detect a small effect size.
Study design
We used a between-subjects design with two groups: (a) the feedback group (n = 30), in which participants received process feedback after interviewing each avatar; and (b) the control group (n = 30), in which participants did not receive any process feedback. Each participant performed four interviews with avatars. The four avatars were the same for each participant, but we randomized the order of avatars between the participants.
Materials
For this study, four (two male and two female; three victims and one bystander) AWAs were created based on real-life crime scenarios in which either a victim or a bystander witnessed a criminal event where the offenders were either familiar or not familiar to the witness or victim. In all events, the victim or witnesses were sober. The scenarios were of different types of crimes (Table 1) retrieved from the county court verdicts (Court Verdict Database, 2023 https://www.riigiteataja.ee/kohtulahendid/koik_menetlused.html). The scenarios were anonymized. For each scenario we created a list of details based on the information described in the court verdicts. These constituted the AWAs memories.
Adult witness avatar case scenarios.

AWA images were created morphing different images of real adults. Using website “SitePal”, first audio clips for the avatar answers were recorded in Estonian by three persons (two male, one female), and then merged with the images to create animated video clips containing all the predefined answers of the AWAs.
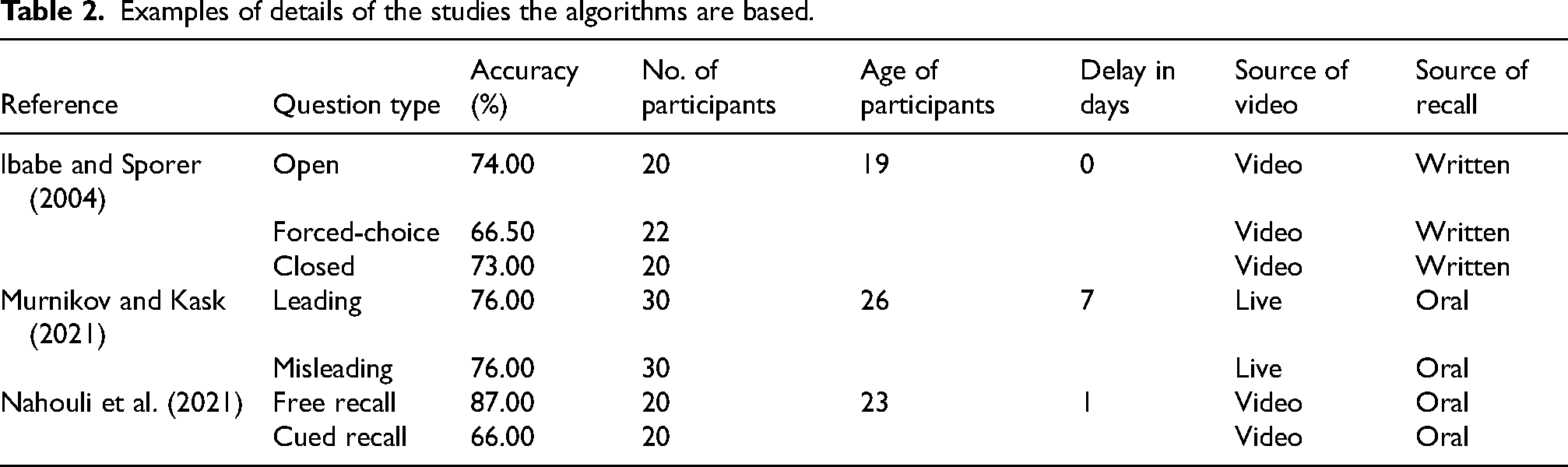
We created response algorithms based on a systematic review of experimental studies about how actual adult witnesses behave during interviews. The algorithms were finalized based on 53 studies identified in the systematic review as containing relevant empirical findings, see examples in Table 2 (Allwood et al., 2006, 2008; Bärthel et al., 2017; Bjorklund et al., 2000; Bonham and González-Vallejo, 2009; Boon and Noon, 1994; Boon et al., 2020; Brackmann et al., 2017; Brubacher et al., 2020; Buratti et al., 2014; Carol et al., 2021; Cassel and Bjorklund, 1995; Cassel et al., 1996; Collins et al., 2002; Dahl et al., 2015; Dando et al., 2011; De La Fuenter Vilar et al., 2020; Eastwood et al., 2019; Eisen et al., 2002; Evans and Fisher, 2011; Gawrylowicz et al., 2014, 2019; Ginet et al., 2014; Hagsand et al., 2013; Hope et al., 2014; Ibabe and Sporer, 2004; Jack et al., 2014; Karlen et al., 2017; Kebbell and Johnson, 2000; Knutsson et al., 2011; Krix et al., 2014, 2016; Ma et al., 2021; Matsuo and Miura, 2016; Murnikov and Kask, 2021; Nahouli et al., 2021; Rechdan et al., 2017; Roebers, 2002; Roebers and Fernandez, 2002; Roebers and Howie, 2003; Roebers and McConkey, 2003; Roebers and Schneider, 2000, 2001, 2005; Roebers et al., 2001, 2007; Saraiva et al., 2020; Sarwar et al., 2011; Schreiber Compo et al., 2017; Scoboria et al., 2008, 2013; Wang et al., 2014; Wysman et al., 2014). Use of the algorithms allowed a realistic simulation of how a real adult would respond to a certain question type (i.e., free or cued recall, open, closed, forced-choice, suggestive or misleading questions). Potential responses consisted of answers containing correct details (mentioned by the victims and witnesses based on the information from actual court verdicts) and incorrect details (one or two different options) were created. For example, based on the calculations regarding accurate responses to certain question types from the literature review, if an interviewer asks a free recall question, then in 89% of the cases the algorithm would launch a correct answer (e.g., “I did not see them at first because they were not passing by the cashiers”) and in 11% of the cases the algorithm would launch one of the two incorrect answers (e.g., “I had seen them earlier in the store” or “I didn’t see him as he was near the cashiers”).
Examples of details of the studies the algorithms are based.
Procedure
Participants were tested individually in Tallinn University Experimental Psychology Laboratory. All participants signed an informed consent form before taking part in the study. The participants were informed that “the aim of the study is to examine the AWA software which is created to increase the quality of investigative interviews. The results of the study will provide us information about if and how effective this software could be in increasing interviewers’ interviewing skills of adult witnesses in criminal justice system”. The participants were informed that they could withdraw from the study anytime during the experiment.
Participants were seated in front of a 13.3-inch Lenovo ThinkPad X13 laptop computer where the videos of the AWAs were displayed. First, participants had to read a description of the best practices of investigative interviewing of adults and answer two control questions about what they read. If they answered incorrectly, the same questions were asked again until both questions were answered correctly (Appendix A).
Each participant interviewed four different avatars. Before interviewing each avatar, participants read a short description of the criminal case of the AWA to be interviewed (e.g., “a security guard reported that two men left a store without paying for a teddy bear, then one of them punched the security guard in the face”). The participants then had 10 minutes to interview the AWA to find out what happened. If they were satisfied that they had found out what had happened, they could finish the interview earlier. The participants’ questions were audio recorded. To ask a question, participants had to press a red button that initiated recording of the question. After asking a question, they had to press a black square that finished recording the question (Figure 1). The operator then manually coded the question type (free or cued recall, open, closed, forced-choice, suggestive or misleading questions) and the detail type [general information (yes, no, don’t know, etc.), avatar personal information (name, etc.), location, time, action (who did what), objects (e.g., knife), offender characteristics, victim/witness characteristics and a way how the crime was committed (e.g., he hit with a knife)] the question addressed. The software then launched a video clip with the avatar's response, which included either correct or incorrect details, depending on the question asked. If there were two possible incorrect answers available, the operator manually chose which answer to play depending on the storyline (but not accuracy) of previous AWA answers. At the end of the interview, the participants had to report what they believed had happened to the AWA.
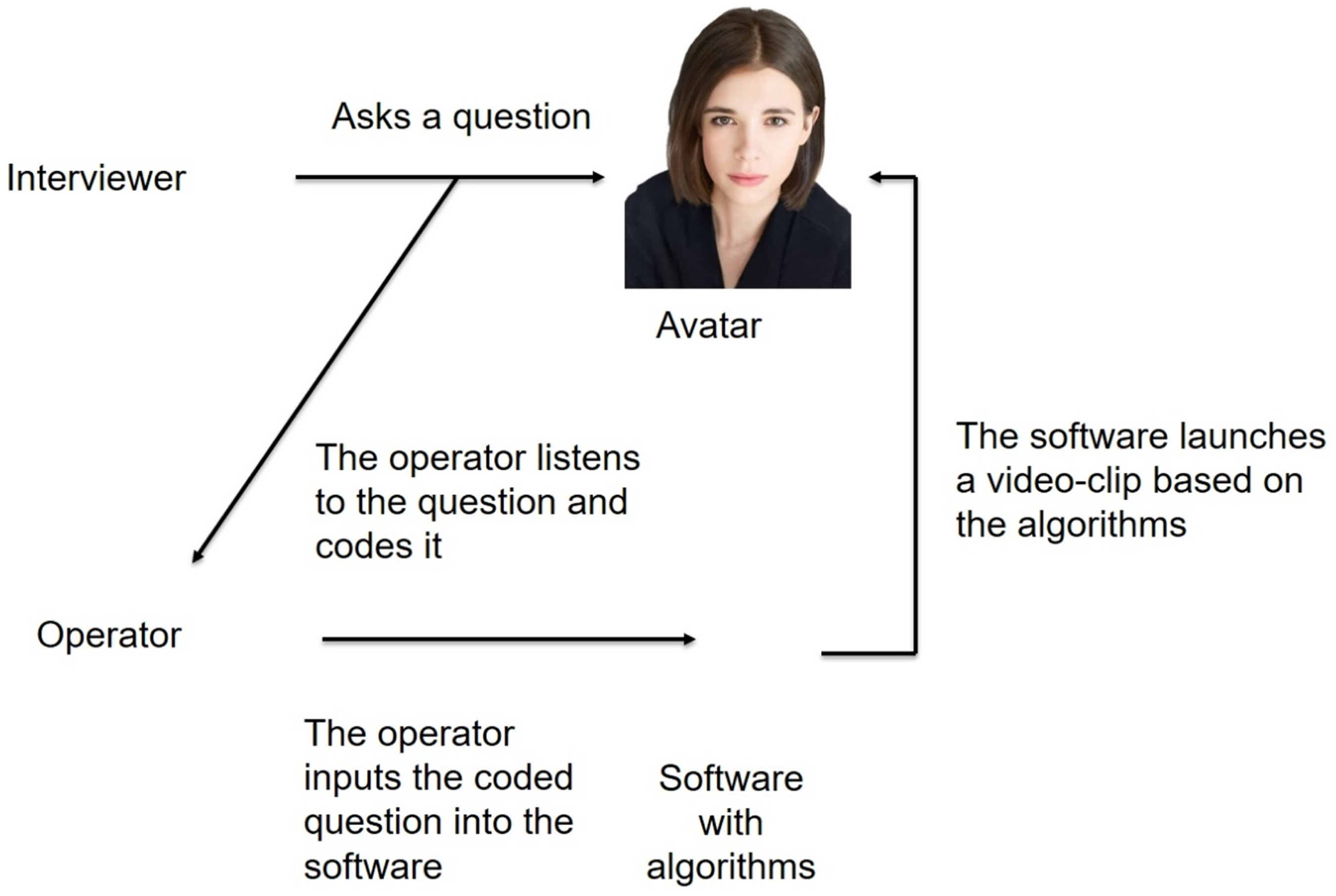
Adult witness avatar working mechanism.
After interviewing each avatar, the control group (n = 30) proceeded to learn the story of the next avatar and started the next interview. Participants in the feedback group (n = 30) received feedback on four questions (two recommended and two non-recommended questions) they had used during that interview. Feedback was provided in a way that covered as many question types as possible. Specifically, if the interviewer used several different new question types during the interview, these were prioritized during the feedback session. Regardless, feedback was always provided for at least two recommended and two non-recommended questions. However, if the interviewer did not ask any questions of a particular type at all (either recommended or non-recommended), feedback was given on only two questions. As a result, the number of questions receiving feedback could vary among participants. Example feedback to recommended questions would be “You asked the avatar, ‘Where were you?’ which is an open question; carry on with these types of questions”. For non-recommended questions, feedback might be “You asked ‘Was there one or two persons?’ which is an option-posing question; try to phrase this question in a more open manner next time”.
The experiment lasted for about 90 minutes. At the end of the experiment, all participants were briefed about the aim of the study.
Coding of interviews and participants’ reports
During the interviews with the AWAs, the operator (first author) coded all the questions asked by the participants. The following schema (Table 3), which is based on the literature review, was used. The coded question types were saved by the program together with the correct and incorrect details that the AWAs elicited in response to the questions.
Question categories with definitions and examples.
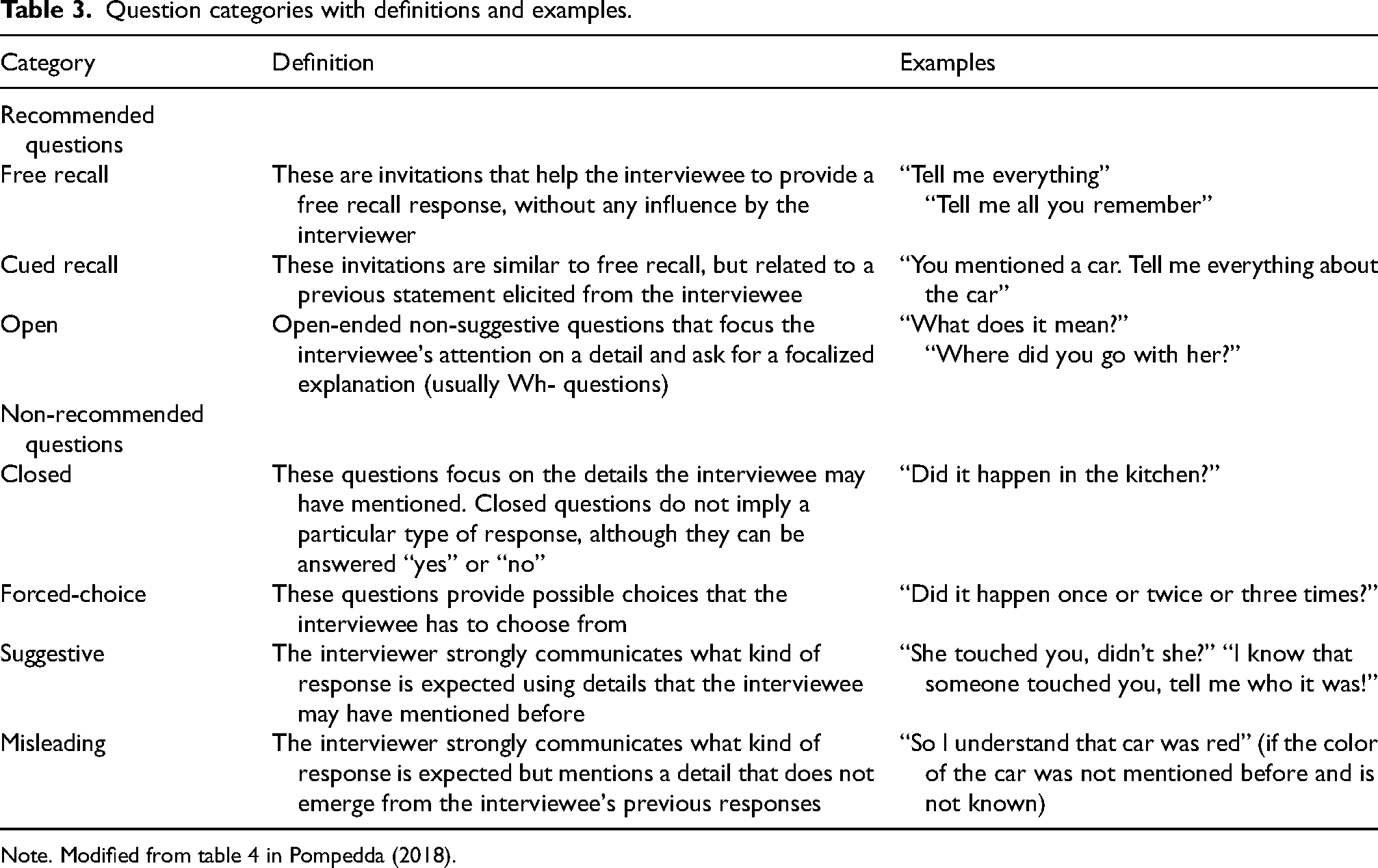
Note. Modified from table 4 in Pompedda (2018).
After the interviews, an independent research assistant re-coded the question type classifications (recommended or not recommended) for a random sample of 40 interviews. Transcripts of the interviews were used for this purpose. The interrater reliability of the codings was Cohen's κ = .91 (95% CI.86 to.96), p < .001.
Participants’ reports of what had happened to the AWAs were also coded as accurate (the details reported by the participant matched with the details reported by the avatars) or inaccurate (participant reported something not mentioned in the accurate avatar answer files). The interrater reliability for the accuracy codings of these reports was calculated using 10 randomly selected participants’ reports. These were coded by two coders and reliability was analyzed using Kendall tau analysis, the interrater reliability was τ = .988, p < .01.
We counted the number of correct and incorrect responses produced by the avatars for each participant, and also calculated the proportion of correct avatar responses out of all of the potential correct avatar responses that were available in the system.
Statistical analyses
The dependent measures for testing hypotheses 1 and 2 were the proportion of recommended questions. In addition, the dependent measures for Hypothesis 1 were the number of recommended questions and the number of non-recommended questions. Free recall, cued recall, and open questions were grouped as recommended questions; closed, forced-choice, suggestive, and misleading questions were grouped as non-recommended questions. The proportions of recommended questions were calculated by dividing the number of recommended questions by the sum of recommended and non-recommended questions in each interview.
To evaluate how receiving feedback affects the questions asked, we conducted three separate 2 (Group: Feedback × Control; Between-Subjects) × 4 (Time: Interviews 1–4; Within-Subjects) repeated-measures ANCOVAs with either the proportion of recommended questions, the number of recommended questions, and the number of non-recommended questions as dependent variables. When Mauchly's test of sphericity was significant, we used a Greenhouse–Geisser correction. The analyses were conducted using SPSS version 27 with the p level adjusted to < .05. To test Hypothesis 1, we were interested in the Group (Feedback vs Control) main effect. To test Hypothesis 2, we were interested in the interaction effect of Group (Feedback vs Control) and Time (Interviews 1–4) on the proportion of recommended questions. When the interaction effect was statistically significant, we conducted pairwise comparisons with a Bonferroni correction. All these analyses were controlled for gender, age, and the level of education to explore the robustness of the finding. Although not in our preregistration report, we conducted three 2 (Group: Feedback vs. Control; Between-Subjects) × 4 (Time: Interviews 1–4; Within-Subjects) mixed analyses of variance with the aforementioned dependent variables without controlling for covariates. We report these analyses first to create a baseline to examine whether the demographic variables (age, gender, education) influence the results.
To analyze the study question (associations between question types and accuracy of the details) we used generalized estimating equations with a binomial logit model given that this allowed us to control for dependencies between the behavior of the same participant over all four interviews and also for the behavior of the same participant within one interview. We performed these analyses separately with the feedback and control groups.
Ethics
The Board of Research Ethics at Tallinn University (Estonia) approved the study before the data collections commenced. The study was conducted following the guidelines of the Declaration of Helsinki.
Results
Descriptive analyses
The average length of the avatar interviews from the first to the last question asked was 564 s (SD = 48, range 310–600 s). There were no differences in interview length between the feedback and control groups, t(238) = .70, p = .242 (feedback M = 566, SD = 48 vs control M = 562, SD = 47).
Effect of feedback on question type without controlling for covariates
The descriptive statistics for the number of recommended and non-recommended questions and the proportion of recommended questions in both the feedback and control group and for each interview are presented in Table 4.
Differences in interview quality between feedback and control group.
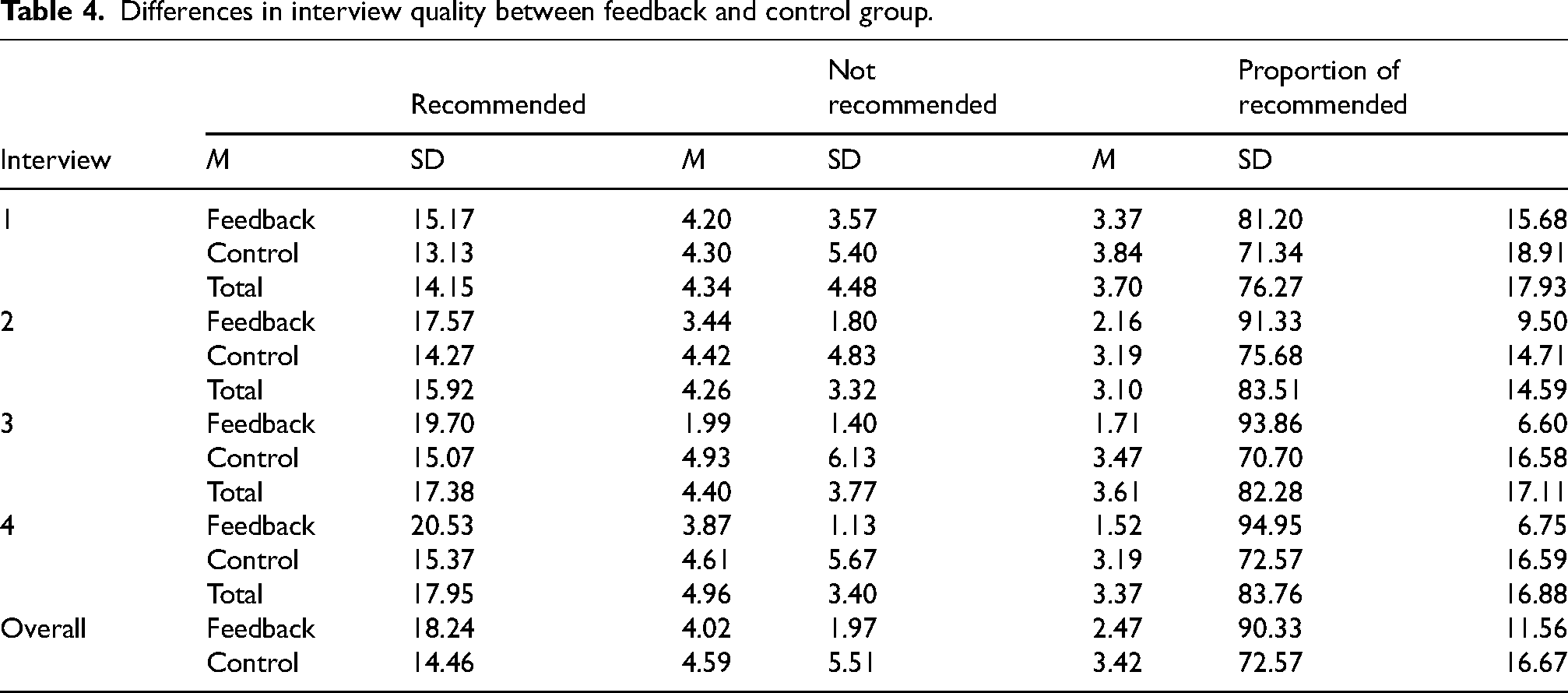
First, we analyzed the results concerning the number of recommended questions. Mauchly's test of sphericity was not significant, so sphericity was assumed. The analysis showed that there was a significant main effect of Group, F(1, 58) = 27.39, p = .001, ηp2 = .32, 1 – β = .99 and Time, F(3,174) = 15.01, p = .001, ηp2 = .206, 1 – β = 1.00. As can be seen from Table 4, participants in the feedback group used more recommended questions (90.3%) than participants in the control group (72.6%). Although the overall interaction between Group and Time was not significant, F(3,174) = 2.57, p = .056, ηp2 = .042, 1 – β = .626, pairwise comparisons indicated differences within Interviews 2, 3 and 4 (p = .002).
Next, we analyzed the results concerning the number of non-recommended questions. Because Mauchly's test of sphericity was significant, we used a Greenhouse–Geisser correction. The analysis showed that there was a significant main effect of Group, F(1, 58) = 33.64, p = .001, ηp2 = .37, 1 – β = .99 and Time, F(2.314, 134.076) = 4.27, p = .012, ηp2 = .069, 1 – β = .78. Overall, participants in the control group used non-recommended questions more than twice as often as participants in the feedback group. There was also a significant interaction between Group and Time, F(2.312, 134.076) = 7.03, p = .001, ηp2 = .108, 1 – β = .948. For Time and Group interaction, pairwise comparisons indicated differences within Interviews 2, 3 and 4 (p = .001).
Finally, we analyzed the results concerning the proportion of recommended questions. Because Mauchly's test of sphericity was significant, we used a Greenhouse–Geisser correction. The analysis showed that there was a significant main effect of Group, F(1, 58) = 38.85, p = .001, ηp2 = .40, 1 – β = 1.00 and Time, F(2.138, 124.017) = 7.75, p = .001, ηp2 = .124, 1 – β = .96. As with the number of recommended questions, the proportion of recommended questions used was higher for participants in the feedback group than participants in the control group. There was also a significant interaction between Group and Time, F(2.138, 124.017) = 6.12, p = .002, ηp2 = .095, 1 – β = .897. For Time and Group interaction, pairwise comparisons indicated differences between the Feedback and Control group within Interviews 2, 3 and 4 (p = .001).
Effect of feedback on question style while controlling for covariates
As described in our preregistration, we conducted the analyses with gender, age, and level of education as covariates. Figure 2 shows the differences in our dependent variables between feedback and control groups in all four interviews.
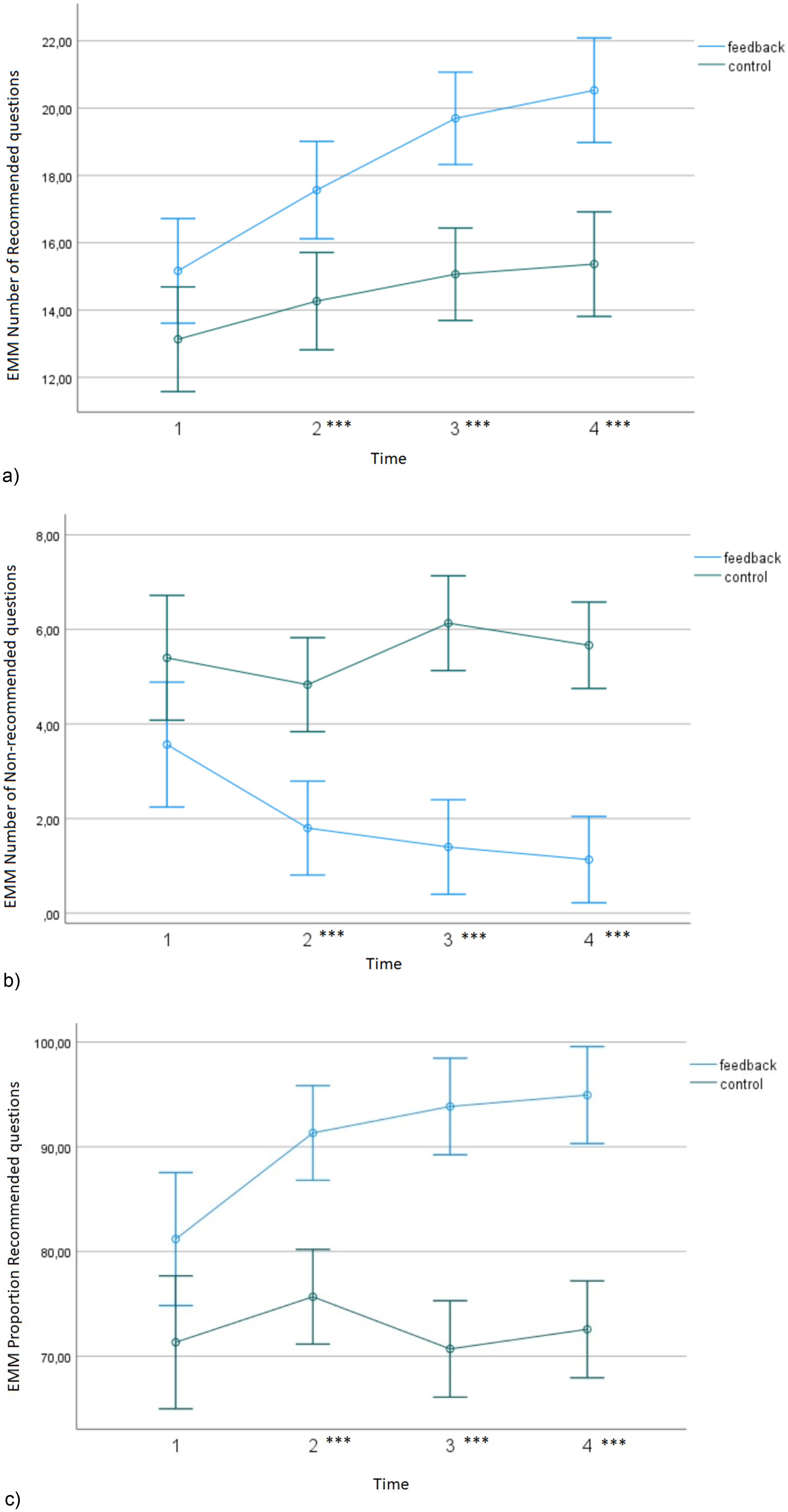
Estimated marginal means (EMM) of the difference in four adult witness avatar interviews between feedback and control groups in the number of recommended questions (A), the number of non-recommended questions (B) and the proportion of recommended questions (C). Error bars show 95% confidence intervals.
First, we analyzed the results concerning the number of recommended questions. Mauchly's test of sphericity was not significant, so sphericity was assumed. The analysis showed that there was significant main effect of Group, F(1, 55) = 27.22, p = .001, ηp2 = .33, 1 – β = .99 but not for Time, F(3,165) = 2.06, p = .107, ηp2 = .036, 1 – β = .52. As can be seen from Figure 2A, participants in the feedback group used more recommended questions than participants in the control group. There was a significant interaction between Group and Time, F(3,165) = 2.86, p = .038, ηp2 = .049, 1 – β = .677. Pairwise comparisons indicated differences within Interviews 2, 3 and 4 (p = .001).
Next, we analyzed the results concerning the number of non-recommended questions. Mauchly's test of sphericity was not significant, so sphericity was assumed. The analysis showed that there was a significant main effect of Group, F(1, 55) = 33.87, p = .001, ηp2 = .38, 1 – β = 1.00 but not for Time F(2.248, 123.621) = .91, p = .414, ηp2 = .016, 1 – β = .22. Figure 2B shows that the number of non-recommended questions was higher for the control group than the feedback group. There was significant interaction between Group and Time, F(2.248, 123.621) = 7.21, p = .001, ηp2 = .116, 1 – β = .95. Pairwise comparisons indicated differences within Interviews 2, 3 and 4 (p = .001).
Finally, we analyzed the results concerning the proportion of recommended questions. Because Mauchly's test of sphericity was significant, we used a Greenhouse–Geisser correction. ANCOVA indicated a significant main effect of Group, F(1, 55) = 37.23, p = .001, ηp2 = .40, 1 – β = 1.00. The proportion of recommended questions used was significantly higher in the feedback group than the control group (Figure 2C). There was no significant main effect of Time, F(2.088, 114.832) = 1.11, p = .34, ηp2 = .02, 1 – β = .25. However, there was a significant interaction between Group and Time, F(2.088, 114.832) = 6.33, p = .002, ηp2 = .103, 1 – β = .900. Pairwise comparisons indicated differences within Interviews 2, 3 and 4 (p = .001). Figure 2C illustrates that the proportion of recommended questions increased in the feedback group with each subsequent interview, while in the control group they did not.
Associations between question types and the accuracy of details
In addition to the analysis stated in our preregistration, we used Pearson correlation analyses to look at different correlations between the number of different question types used. We found significant correlations between the number of recommended and non-recommended questions, r(238) = −.542, p < .001, the number of recommended questions and proportion of recommended questions, r(238) = .688, p < .001, and the number of non-recommended questions and proportion of recommended questions, r(238) = −.963, p < .001.
As stated in our preregistration, we looked at the association between question type (recommended or non-recommended) and the accuracy of details the question produced (correct vs incorrect). Using non-recommended questions was negatively related to the accuracy of the responses given by the avatars (B = −0.403, SE = 0.084, Wald χ2 (1) = 23.143, p < .001). This was also the case when the analysis was run separately in the feedback (B = −0.585, SE = 0.164, Wald χ2 (1) = 12.671, p < .001) and control (B = −0.320, SE = 0.100, Wald χ2(1) = 10.137, p < .001) groups.
Additional analyses
Using generalized estimating equations, we found that feedback and control group participants did not differ in the amount of correct details they reported in their descriptions of what had happened to the avatars χ2(1) = .32, p = .57 (feedback M = 40.43, SD = 19.25 vs control M = 38.22, SD = 17.21). Finally, the proportion of correct avatar responses produced by the avatars out of all possible correct avatar responses available in the system was calculated. Generalized estimating equations indicated that feedback and control groups did not differ, χ2(1) = 2.78, p = .096 (feedback M = 15.61, SD = 4.51 vs control M = 17.95, SD = 5.65).
Discussion
In this study, we examined whether the quality of interviews with adults can be increased by training with AWAs coupled with feedback compared with training with no feedback. Overall, we found that combining feedback with simulated avatar training is effective in improving the quality of interviews in terms of the questions used. We continue to discuss each hypothesis in turn.
Our first hypothesis, stating that compared with receiving no feedback, receiving feedback about the questions asked results in a larger proportion of recommended questions being asked, as well as a larger number of recommended questions and a smaller number of non-recommended questions was supported. In all of our analyses, with or without gender, age and education included as covariates, we demonstrated that receiving feedback after AWA interviews resulted in a larger number of recommended questions, a smaller number of non-recommended questions, and a higher proportion of recommended questions, similar to what has been found with Empowering Interviewer Training (EIT) software in the case of simulating child witness interview training (Pompedda et al., 2022). Thus, we confirmed that an experiential serious game that includes personalized feedback (Sternberg et al., 2002) will improve the use of recommended question types in interviews with adult avatars as well. Our results indicate that if the requirements of the task of interviewing adult witnesses are introduced to the participants and immediate feedback is provided, then the performance of novice interviewers will potentially benefit from it.
We also found support for our second hypothesis, which stated that over four consecutive interviews, the participants receiving feedback after each subsequent interview will have a larger increase in the proportion of recommended questions than those not receiving feedback. In both our analyses (with and without controlling for gender, age and education), we found an interaction effect of the presence of feedback and the number of the interview. Because the first time the participants in the feedback group received feedback was after the first interview, there were no differences in the proportion of recommended questions between the groups in the first interview. However, we found that for participants who received feedback about their performance, but not for participants who did not receive feedback, the proportion of recommended questions increased with each subsequent interview. Thus, we replicated previous results that a training session with just four avatars can improve the participants’ interview performance with avatars (Haginoya et al., 2020; Krause et al., 2017; Pompedda, 2018; Pompedda et al., 2015, 2017, 2021). If the effects of this training transfer to practitioners as they do with child avatars (Kask et al., 2022), the relatively short training time can be of huge benefit to police investigators. It has been shown that police investigators use a large number of non-recommended questions (Launay and Py, 2015) in investigative interviews with adults, which leads to decreased quality of responses in adults (Ibabe and Sporer, 2004; Jack and Zajac, 2014; Molyneaux and Larsen, 1992; Roebers and Schneider, 2000; Shapiro et al., 2005; Sharps et al., 2012; Wade and Spearing, 2022). Because the police officers may be under constant time pressure collecting evidence, training with AWAs could potentially result in an increase in performance in a short amount of time.
Finally, we established that different question types (recommended and non-recommended) were associated with each other, and that using non-recommended questions was negatively related to the accuracy of the responses given by the avatars, both overall and when the analysis was run separately in the feedback and control groups. These results show that the algorithms were working as expected (see Tohvelmann and Kask, 2022).
However, there were no significant differences between the feedback and control groups in the amount of correct detail that participants reported in their descriptions of what had happened to the avatars, as well as in the proportion of correct responses produced by the avatars out of all possible correct responses. These findings are probably because the difference in the likelihood of correct or incorrect responses being elicited (based on the algorithms, i.e. 89% correct answers in case of a free recall question was asked) as a function of recommended vs non-recommended questions is not particularly large. It is therefore particularly important to conduct a transfer study where the participants also interview a real mock witness.
Strengths and limitations
One of the main strengths of this study is that the case scenarios are based on court verdicts, which make the cases realistic. Furthermore, the algorithms we used in the AWA software were based on a literature review of how accurately participants in previous research have responded to different question types. In this way, we can say that the AWAs behaved as real humans would have behaved under similar circumstances. However, different papers operationalize question types in various ways. Therefore, we used examples of questions in these papers to determine whether our categorization of question types in creating the algorithm was similar to that presented in the papers. Despite controlling for participants’ backgrounds in law and psychology, a potential limitation of the study is that participants may still have had some prior interviewing experience. Thus, the fact that we used a convenience sample and the specific field of education is unknown to us could have influenced our results. This is especially true when considering the ceiling effects in the feedback group when asking recommended questions. Nonetheless, we have to bear in mind that the interviewers were novices in the field. They did their best to adhere to the guidelines of best-practice investigative interviews. Therefore, their approach to interviewing may differ from that of police officers, especially when it comes to asking questions intended to gather evidence (where, when and what happened with whom; Code of Criminal Procedure, 2023).
AWA training was conducted by a single experimenter. This could raise a question of whether categorization of the question types was conducted in an unified manner. To diminish this risk, we performed a post-experiment interrater reliability analysis, which demonstrated good reliability.
The feedback group almost reached a ceiling in the proportion of recommended questions asked. One way to interpret this (and to compare with previous results with EIT avatar software) could be that in EIT (compared with AWA), the case scenarios that participants received before interviewing the avatar contained more facts about what may have happened. This could have led the participants to investigate whether the facts were correct or not. However, in AWA training we provided the participants with only a short crime report notice with the instruction to find out what happened. Because it did not contain many facts, this may have resulted in a more generic description of the crime compared with what may be important for police officers to ask from a victim/witness (Code of Criminal Procedure, 2023). Rivard et al. (2015) also noted that if the interviewers were “blind” about the case before interviewing, then they were more likely to have begun their interviews with a non-suggestive question than the informed interviewers. In addition, in EIT training, the time frame of 10 minutes per interview was chosen, because younger children (four- and six-year-olds) could get tired after a long interview; however, because the interviews with adults can last longer (an average interview with child witnesses lasted 30 minutes in Kask et al., 2022 but 89 minutes with adult suspects in Oxburgh et al., 2014), 10 minutes could have been too short for asking more specific questions in AWA interviews.
When providing feedback on question types to the participants, this was given on two recommended and two non-recommended questions. However, if a participant did not ask any questions from one broader category (either recommended or non-recommended), or asked only one type of question from one broader category, then feedback was given on fewer than four questions. In future studies, it is important to record this type of information in more detail because there could have been some variability between the participants regarding this matter.
Conclusion
To our knowledge, this is the first study that has used web-based software to train the skill of interviewing adult witnesses. We demonstrated that with feedback after each AWA interview, the proportion of recommended questions asked was significantly higher than the proportion of recommended questions asked by the control group by the end of the fourth interview. This study shows great potential for applying the methods of serious gaming into the training of not only investigative interviewing of children, but also of adult witnesses.
Training programs are often logistically complicated and expensive, in addition to requiring a lot of time from those participating (Pompedda, 2018). The AWA solution could contribute to training interviewers in a structured witness interviewing method such as the cognitive interview (Fisher et al., 1987). It could help interviewers practice the skill of asking (and if not recommended, then rephrasing) questions from a witness at their work location at a time most convenient to them, and receive immediate feedback on their questioning skills.
Further research is needed to examine whether this effect also transfers to increasing the proportion of recommended questions in real-life interviews with adult witnesses. The next step in validating the effectiveness of AWA would be to test whether a transfer effect is present (i.e., whether the AWA software would also be effective among police officers conducting real adult witness interviews). We anticipate that there would be an increase in the proportion of recommended questions in not only AWA interviews, but also interviews conducted with real adult witnesses.
Supplemental Material
sj-docx-1-psm-10.1177_14613557241310014 - Supplemental material for Providing feedback in simulated investigative interviews with adult witness avatars increases the use of free recall and open questions
Supplemental material, sj-docx-1-psm-10.1177_14613557241310014 for Providing feedback in simulated investigative interviews with adult witness avatars increases the use of free recall and open questions by Mari-Liis Tohvelmann, Kristjan Kask, Annegrete Palu, Shumpei Haginoya and Pekka Santtila in International Journal of Police Science & Management
Footnotes
Acknowledgments
The authors wish to thank Tatsuro Ibe for programming the AWA and Emily Patterson for English proofreading.
Data availability
The data set containing all primary study variables can be obtained from the authors.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Tallinn University grant number TF/2221.
Supplemental material
Supplemental material for this article is available online.
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.