
Abstract
To achieve accurate sound field reconstruction in reverberant environments, a method based on the principle of equivalent sources and a mixed-wave model is proposed with rigid spherical microphone arrays. The method assumes that the near-field sound sources are sparsely distributed and decomposes the sound field into the direct sound components modelled by monopole sources and the reflected sound components represented by plane waves, thereby constructing a mixed-wave model. The alternating direction method of multipliers is then used to alternately estimate the weights of monopole sources and plane waves, enabling the sound field decoupling. Finally, the target sound field in the region of interest is reconstructed using the obtained weights. Both numerical simulations and finite element method-based virtual validation experiment demonstrate that the proposed method generally expands the effective reconstruction region to twice that of Ambisonics, while improving reconstruction accuracy by 32% and 12.5% within a region spanning two to three times the array radius, compared with the plane wave decomposition method.
Keywords
1. Introduction
Sound field reconstruction1,2 estimates the acoustic information at arbitrary positions by post-processing the signals captured by microphone arrays, and this technique has been widely applied in areas such as personal sound zones,3,4 virtual reality,5,6 and noise control.7,8 The effective reconstruction region and application scenarios are closely related to the geometry of microphone arrays. Common array configurations include linear arrays,9–11 planar arrays,12–14 and spherical arrays.15–17 Compared to linear and planar arrays, spherical arrays, especially rigid spherical arrays, are more compact, flexible, and capable of capturing more spatial acoustic information.
Ambisonics,18–20 an early proposed sound field reconstruction method with spherical microphone arrays, represents sound fields using spherical harmonics and reconstructs the sound field at unmeasured locations by exploiting the estimated expansion coefficients. However, due to the limited number of microphones and discrete spatial sampling, Ambisonics performs poorly in reconstructing the sound field far from the array. To overcome this limitation, Samarasinghe et al. 21 employed a distributed higher-order microphone array to expand the effective reconstruction region. The equivalent source method (ESM), another sound field reconstruction method, assumes that the target sound field is generated by a set of monopole sources or plane waves surrounding the region of interest, and estimates source strengths or plane wave weights via sparse optimization to achieve sound field reconstruction. Fernandez-Grande 22 used the equivalent sources emitting spherical waves to model the sound field recorded by rigid spherical microphone arrays and adopted the regularization technique to estimate source strengths, achieving accurate three-dimensional sound field reconstruction. Verburg et al. 23 represented sound fields using a limited number of plane waves and reconstructed the room’s spatial frequency responses over the extended regions via compressive sensing. Compared to Ambisonics, ESM is not constrained by the spherical harmonic order truncation and thus provides a larger effective reconstruction region. However, the above ESM is based on the free-field assumption, which limits its applicability to reverberant environments, where sound reflections violate this assumption and degrade reconstruction accuracy.
To achieve accurate sound field reconstruction in reverberant environments, Koyama et al.24,25 established a mixed wave model with monopole sources and plane waves. Damiano et al. 26 modeled early reflections using the image source method, represented the late-reverberant components with a set of plane waves, and simulated the directivity using multipole sources. These mixed wave models are constructed based on linear and planar microphone arrays for one-dimensional and two-dimensional sound field reconstruction. In this paper, we extend the mixed wave modeling framework to three-dimensional space. The signals captured by rigid spherical microphone arrays are decoupled into direct and reflected components using monopole sources and plane waves. Then, sparse constraints are imposed, and an alternating direction method of multipliers (ADMM) is used to estimate the weights of monopole sources and plane waves, enabling accurate three-dimensional sound field reconstruction in reverberant environments.
The remainder of this paper is organized as follows. Sections 2 and 3 introduce the mixed wave model with rigid spherical microphone arrays and ADMM solver. Sections 4 and 5 present numerical simulations and finite element method-based virtual validation experiment, respectively. Section 6 draws the conclusions and outlines the perspectives for future research.
2. The mixed wave model with rigid spherical microphone arrays
As shown in Figure 1, a near-field source is located in a bounded space The mixed wave model.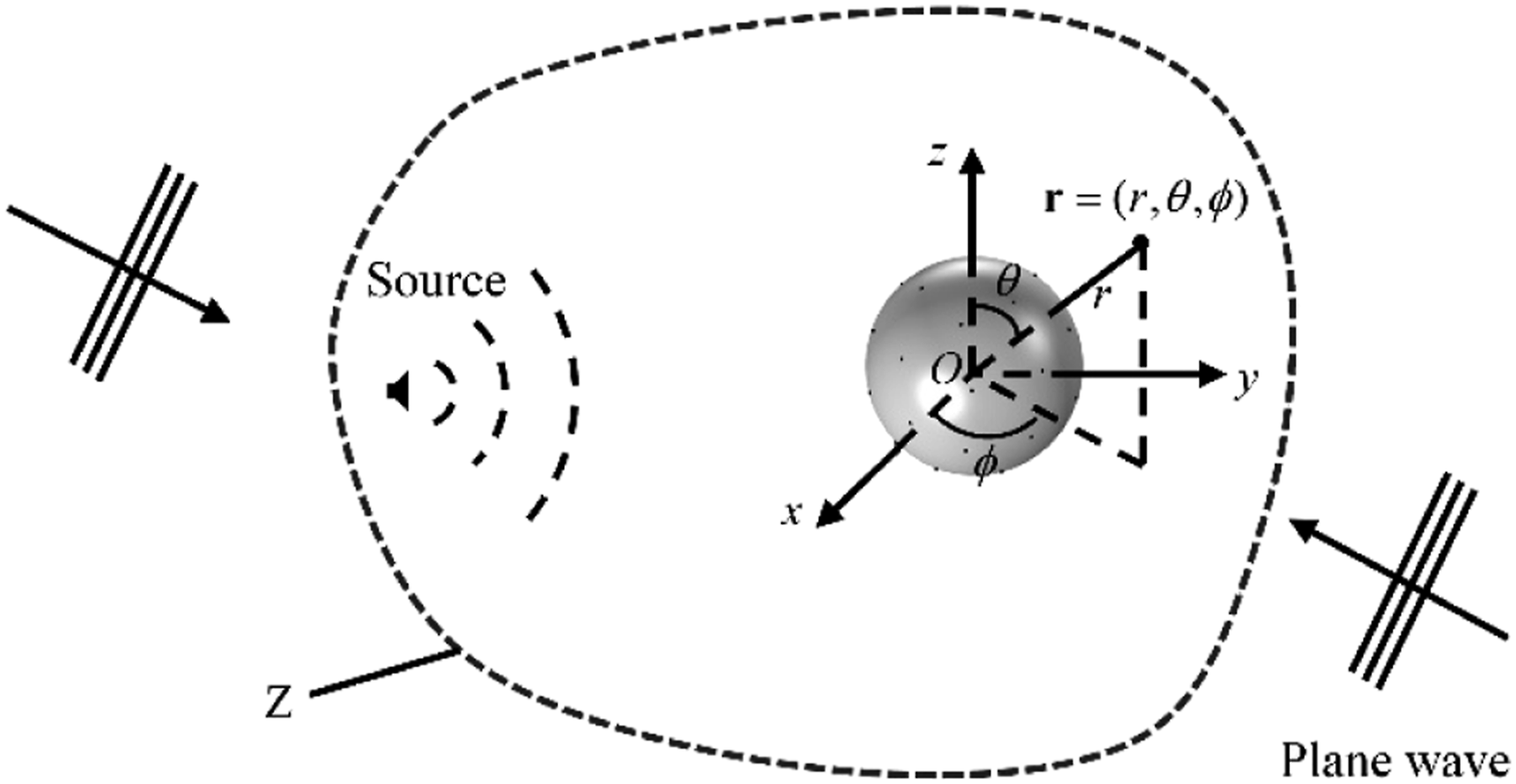


In Eq. (2),

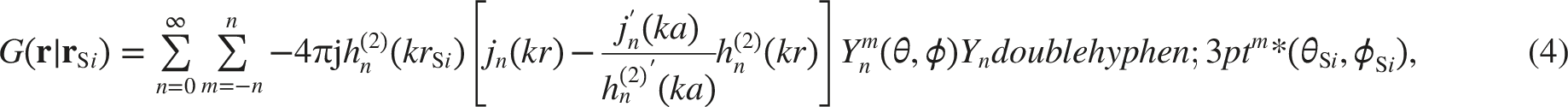

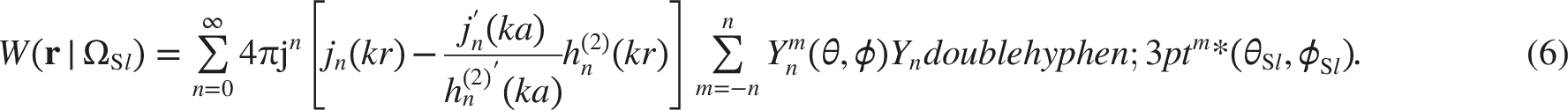
Based on Eq. (2), Eq. (3), and Eq. (5), we construct a mixed wave model to express the pressures measured by rigid spherical microphone arrays,

3. ADMM solver
The source distribution is usually spatially sparse, so


ADMM
30
is adopted to solve Eq. (9) due to its computational efficiency and flexibility, where each variable is updated alternately while keeping the other variables fixed. The steps are as follows. We introduce two additional variables,
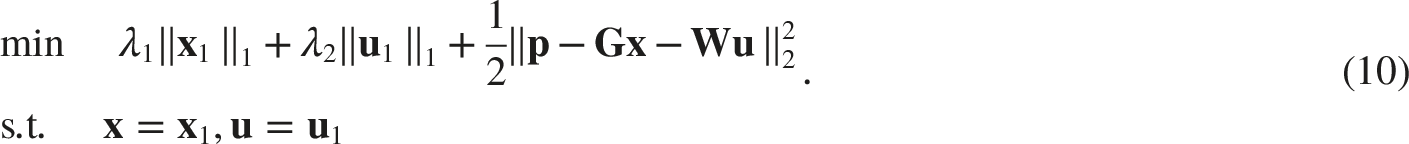
Eq. (10) can be further transformed into a non-constrained optimization problem,
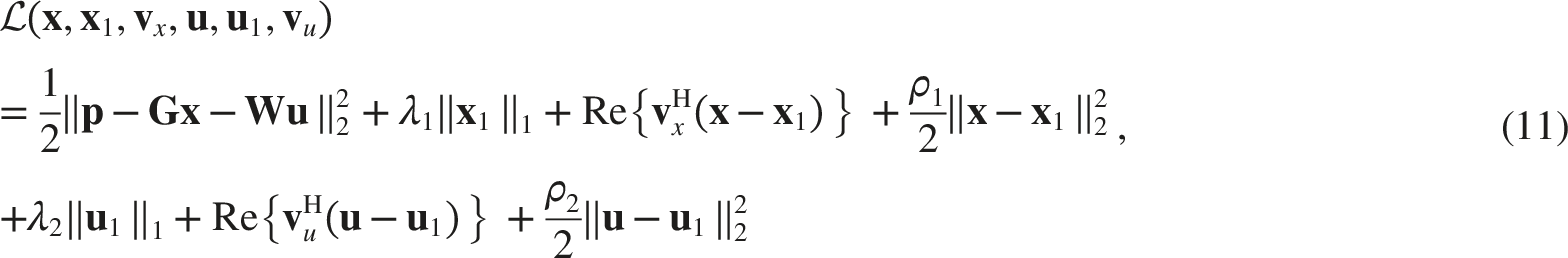
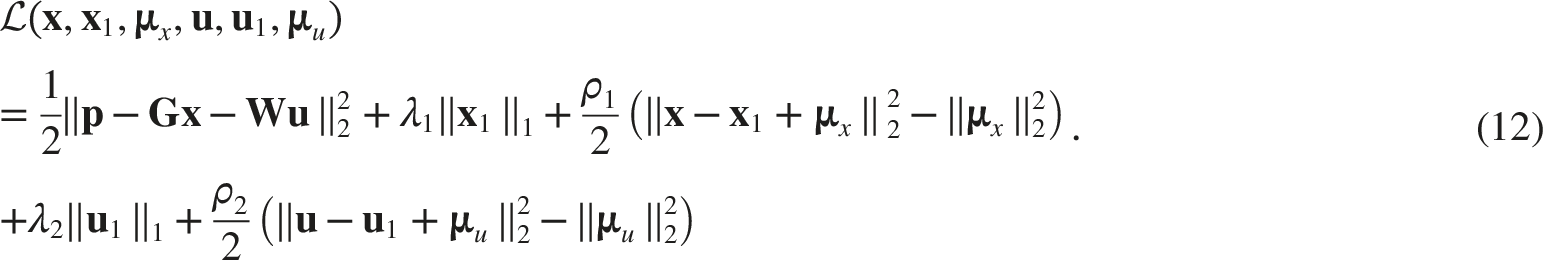
Eq. (12) can be solved iteratively. In the
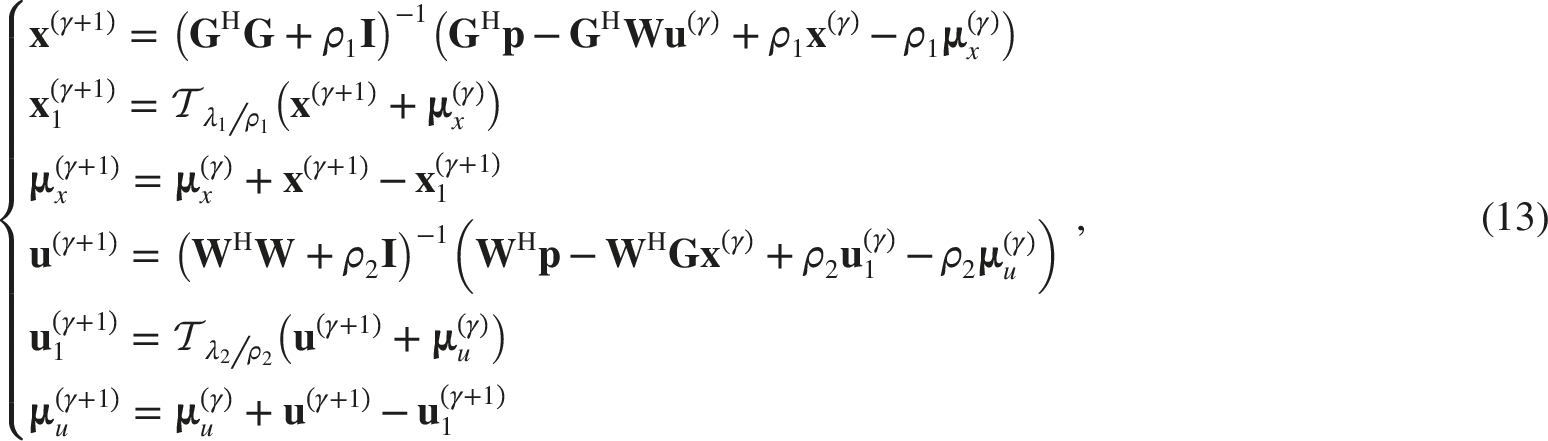
The estimated strengths
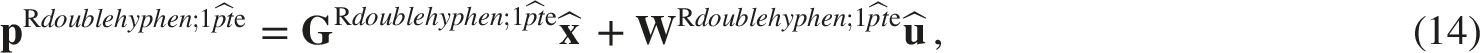
4. Numerical simulations
In this section, the performance of the proposed method is evaluated and compared with the Ambisonics method
18
and the plane wave decomposition method
31
through numerical simulations. Brüel & Kjær Type 8608 rigid spherical microphone array with 36 microphones is used. The radius is 0.0975 m. Figure 2 shows the microphone array and the mixed wave model. The center of the array is placed at the origin of the coordinate system, and a sound source is located on the y–z plane at Spherical microphone array and the equivalent source model.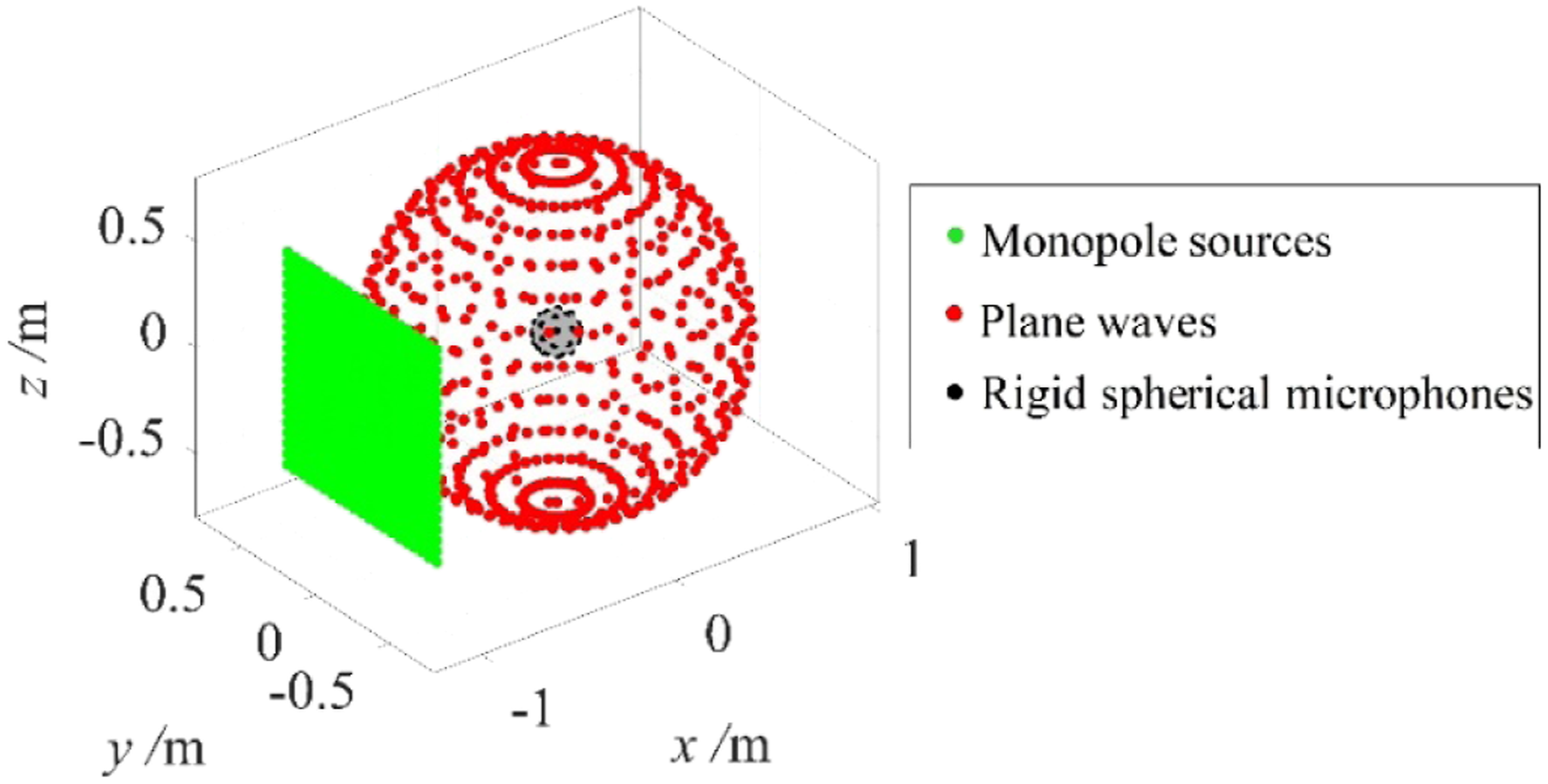

4.1. Sound field reconstruction in a semi-enclosed rectangular space
To simulate a semi-enclosed rectangular space, an infinitely long rectangular duct is modeled. Free boundary conditions are applied along the x-axis, indicating the space is infinitely extended in both the positive and negative x-directions. Along the y- and z-axes, rigid boundary conditions are set at y=0.75 m, y=-0.75 m, z=1.2 m and z=-1.2 m, with an absorption coefficient of 0.3. According to the Eyring formula, 34 T60=190 ms. A source is placed at (-1 m, 0, 0), with a strength of 94 dB (referenced to 20 μPa).
The proposed method, the Ambisonics method, and the plane wave decomposition method are used to reconstruct the sound field within the region The theoretical values of the real parts of the sound pressures at 1000 Hz in a semi-enclosed rectangular space. Reconstruction results and error in the semi-enclosed rectangular space.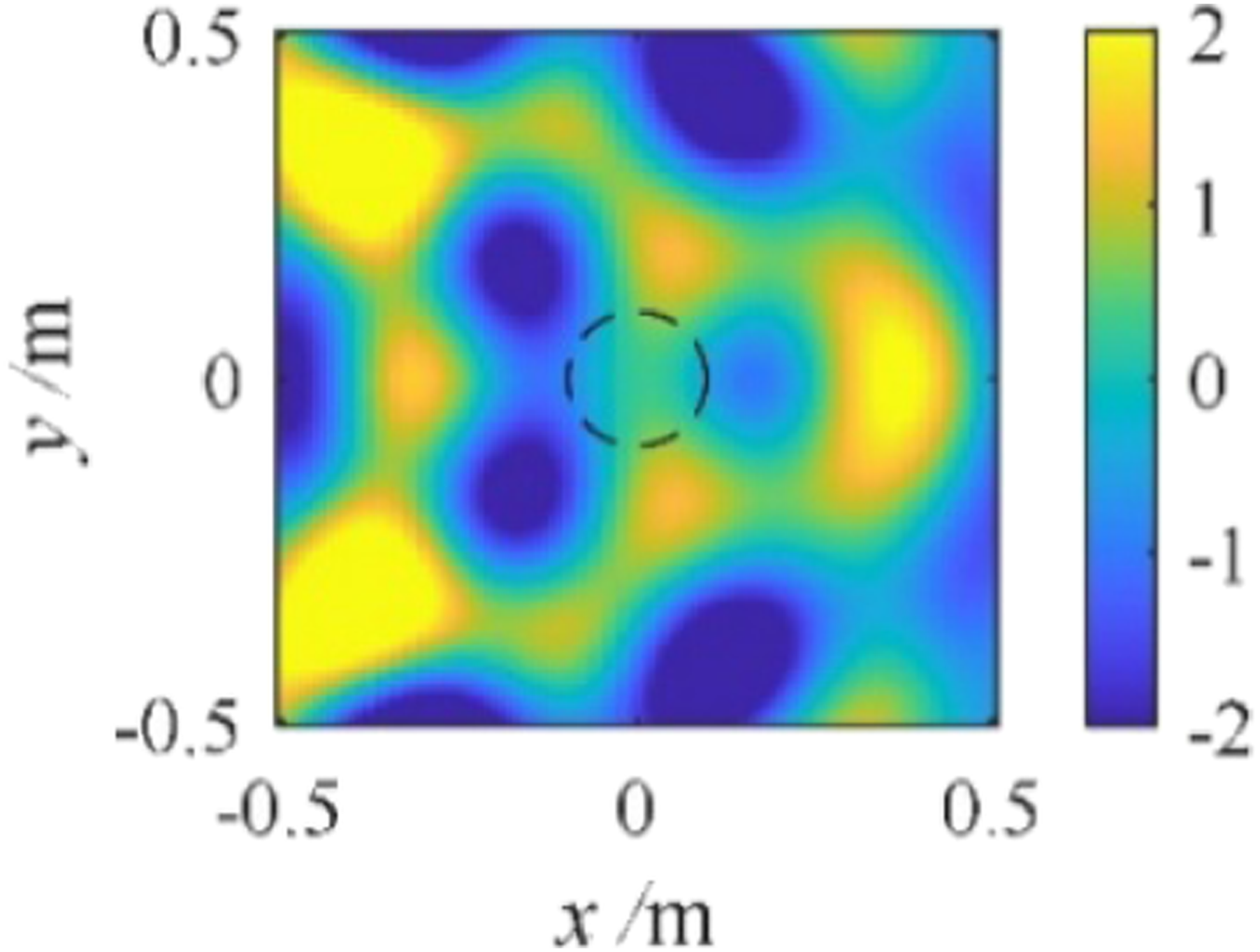

As for computational cost, the proposed method requires longer running time for sound field reconstruction than Ambisonics and the plane wave decomposition method. Specifically, for the above case, the running time of the proposed method, Ambisonics and the plane wave decomposition method is 4.29 s, 1.09 s, and 2.07 s on the 3.6GHz AMD Ryzen7 7745HX CPU, respectively.
4.2. Sound field reconstruction in a closed rectangular space
The proposed method is further applied to reconstruct the sound field within a closed space, and compared with the Ambisonics method and the plane wave decomposition method. To simulate a closed space, rigid planar boundaries are applied at x=1.5 m, x=-1.5 m, y=0.75 m, y=-0.75 m, z=1.2 m and z=-1.2 m with an absorption coefficient of 0.3. The sound source position and strength remain the same as those used in Section 4.1. Figure 5 shows the closed space and the theoretical values of the real parts of the sound pressures at 1000 Hz, which are computed through the 10th-order image source method. The closed space and the theoretical values of the real parts of the sound pressures at 1000 Hz.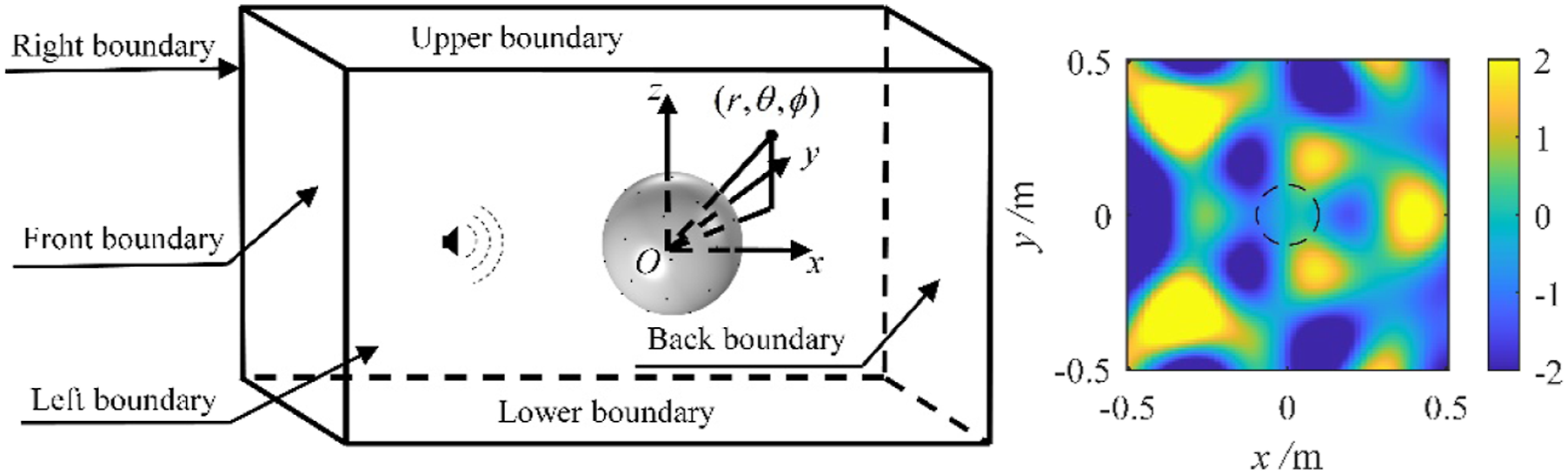
Figure 6 presents the sound field reconstruction results and reconstruction error at 1000 Hz in the closed rectangular space. By comparing the results and the error of the three methods, similar conclusions can be drawn. Among the three methods, the reconstructed field of the proposed method is the most consistent with the theoretical field. Correspondingly, the area with reconstruction error less than 10% (i.e., the bright region) is the largest for the proposed method, followed by the plane wave decomposition method. The Ambisonics method maintains reconstruction error below 10% only within the region close to array. These results demonstrate that the proposed method outperforms the plane wave decomposition method and the Ambisonics method. Reconstruction results and error in the closed rectangular space.
Monte Carlo trials are conducted to analyze the reconstruction performance under different frequencies and absorption coefficients. The frequency ranges from 500 Hz to 2000 Hz in a step of 500 Hz. The absorption coefficient
Figure 7 shows average reconstruction error of the three methods within regions marked by radius 0∼a, a∼2a and 2a∼3a. In the region 0∼a, the average reconstruction error of Ambisonics, the plane wave decomposition method, and the proposed method is below 10% across all cases. In other words, the area corresponding to error below 10% in the error map accounts for 100%. This indicates that all three methods can achieve accurate reconstruction within the region of 0∼a. However, the maximum error of the three methods is 9.4%, 1.5% and 1%, respectively, indicating that the proposed method has the higher reconstruction accuracy than the other two methods. In the region a∼2a, the average reconstruction error of Ambisonics exceeds 10% under all conditions. By comparison, the plane wave decomposition method and the proposed method achieve reconstruction error below 10% over 43% and 75% of the error map, respectively. In the region 2a∼3a, the three methods show larger reconstruction error, and the proportion of the area where the error is below 10% decreases to approximately 6.3% for the plane wave decomposition method and 18.8% for the proposed method. In addition, the average reconstruction error of the proposed method is obviously lower than the plane wave decomposition for all cases. In summary, the proposed method achieves higher reconstruction accuracy over a larger spatial region compared with both Ambisonics and the plane wave decomposition method. Specifically, the proposed method generally expands the effective reconstruction region to twice that of Ambisonics, and even up to three times under low-frequency and weakly reverberant conditions. Meanwhile, it improves the reconstruction accuracy (measured by the proportion of the area with error below 10%) by 32% and 12.5% within a region spanning two to three times the array radius, compared with the plane wave decomposition method. The average reconstruction error within regions marked by radius 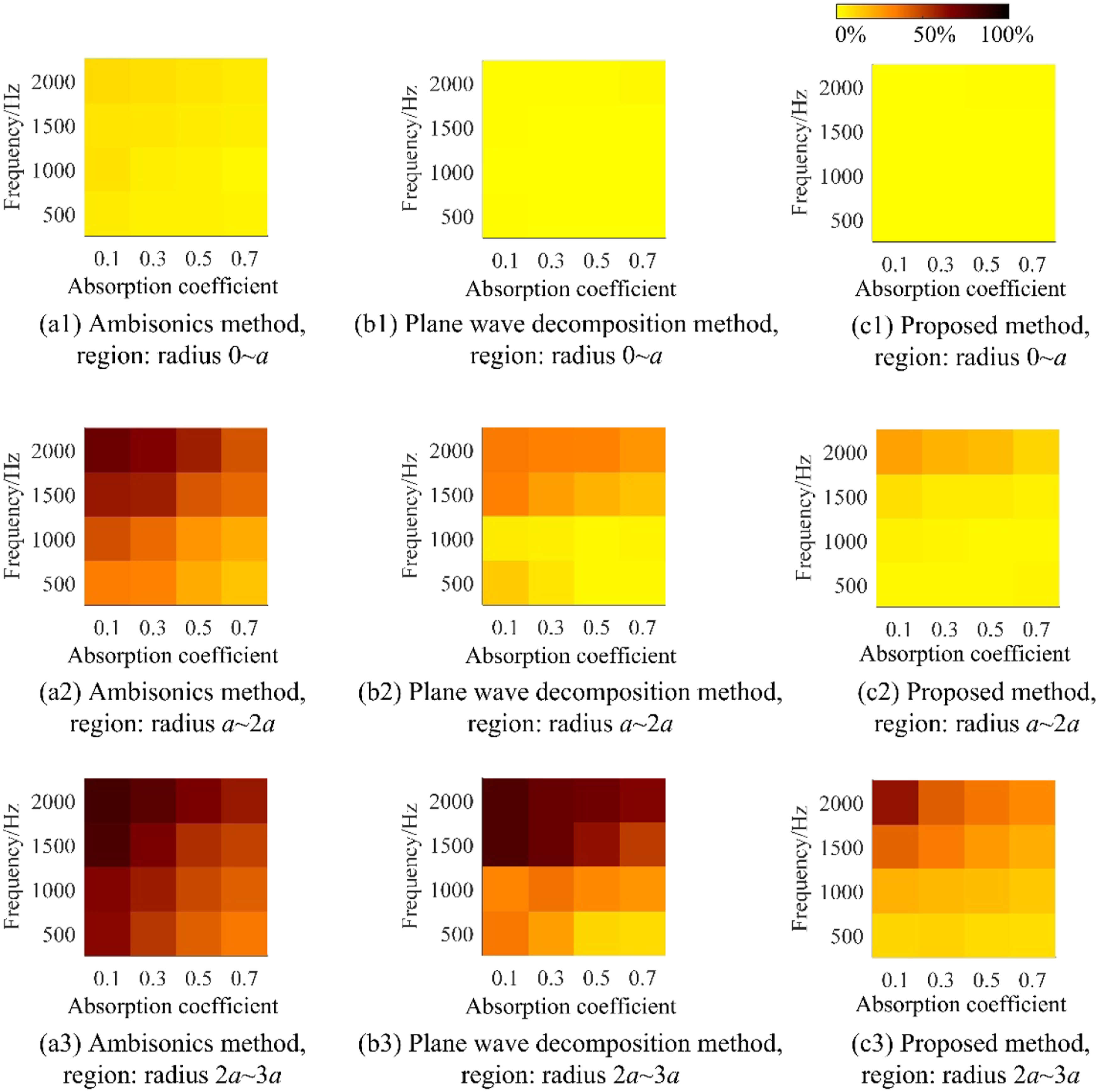
The proposed method outperforms both Ambisonics and the plane wave decomposition method primarily because these conventional methods rely on spherical harmonics expansion, whose effective reconstruction region is inherently constrained by the microphone array.35,36 Specifically, due to the finite number of microphones and discrete spatial sampling, the spherical harmonics expansion must be truncated, which limits the spatial region over which Ambisonics and plane wave decomposition can achieve accurate reconstruction. In contrast, the proposed method formulates the mixed wave model directly in the spatial domain rather than in the spherical harmonics domain. As a result, it avoids the truncation-related limitations imposed by the microphone array, enabling more accurate sound field reconstruction over an extended spatial region.
5. Finite element method-based virtual validation experiment
In this section, the performance of the proposed method is evaluated based on finite element analyses.
37
A sound field model, as shown in Figure 8(a), is built in the COMSOL. The gray cuboid represents the computational area, with dimensions of Sound field model and the theoretical value of the real part of the sound pressure field at 1000 Hz provided by COMSOL.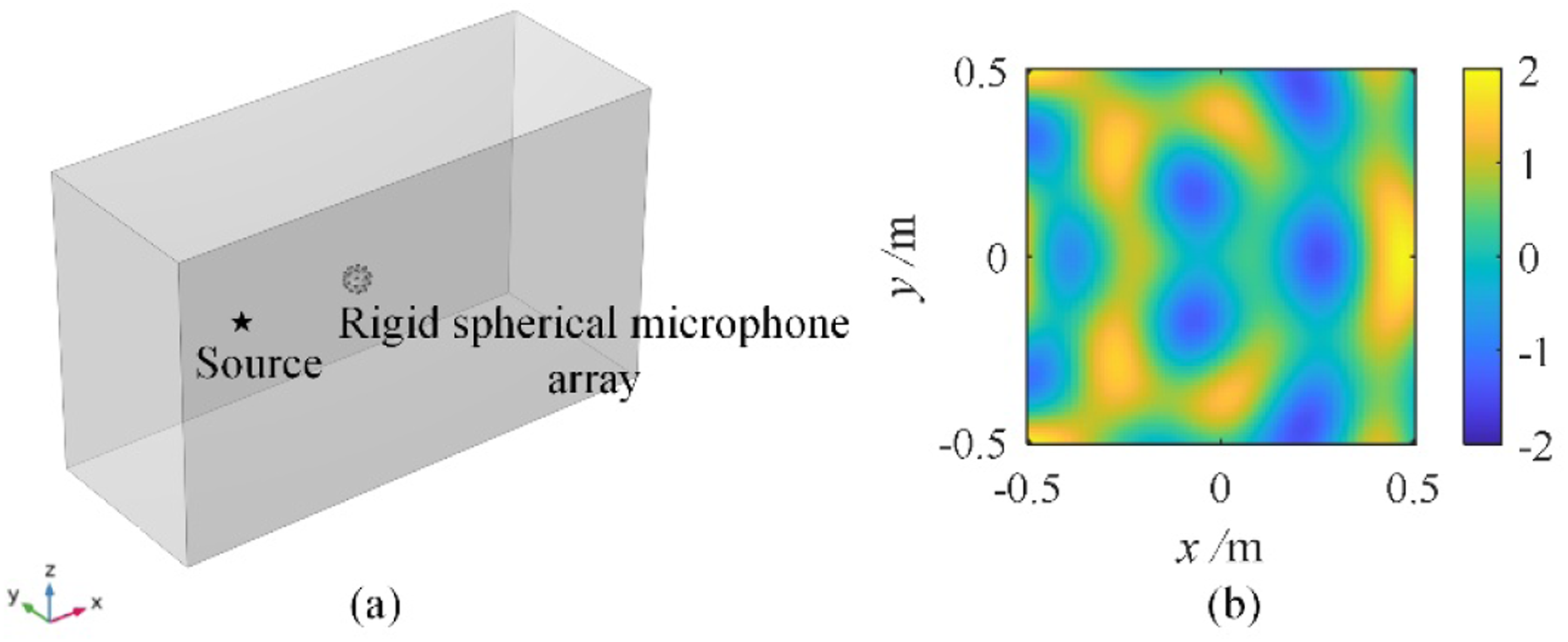
Figure 9 presents the reconstruction results and reconstruction error of the Ambisonics method, the plane wave decomposition method, and the proposed method. It is clear that the proposed method continues to demonstrate the best reconstruction performance. It provides a larger region where reconstruction error is below 10%, effectively enabling accurate sound field reconstruction in reverberant environments. These findings are consistent with the conclusions in Section 4.2. Reconstruction results and error in the closed rectangular space based on finite element analyses.
6. Conclusions and perspectives
This paper proposes a method with rigid spherical microphone arrays for sound field reconstruction in reverberant environments. This method establishes a mixed wave model that represents incident and reflected sound fields using monopole sources and plane waves, and achieves sound field reconstruction via sparse constraint and ADMM. The proposed method generally doubles the effective reconstruction region of Ambisonics and improves reconstruction accuracy by up to 32% and 12.5% within a range of two to three times the array radius, compared with the plane wave decomposition method. Its superiority stems from operating in the spatial domain and avoiding limitations associated with spherical harmonics expansion.
As the frequency increases and reflections become stronger, the proposed method experiences some performance degradation. Future work will focus on addressing this limitation to enhance the method’s applicability. In addition, the real-world validation experiments are currently not possible due to the lack of suitable experimental conditions. We therefore plan to improve our experimental setup to provide validation under practical acoustic conditions in the future.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the National Natural Science Foundation of China, grant number 12304519, the New Chongqing Youth Innovation Talent Project, grant number CSTB2024NSCQ-QCXMX0068, and the Science and Technology Research Program of Chongqing Municipal Education Commission, grant number KJZD-K202303202.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.