
Abstract
Objective
This study aimed to assess the performance of Artificial Intelligence (AI) compared to human experts in healthcare policymaking.
Methods
This was a mixed-methods cross-sectional study conducted in Iran during the years 2024-2025, comparing, and analyzing the responses of multiple AI Large Language Models (LLMs) including Bing AI Copilot and Gemini and a sample of 15 human experts—using confusion matrix analysis. This analysis provided comprehensive data on the respondents’ ability to answer context-specific questions regarding healthcare policy making, evaluated through multiple parameters including sensitivity, specificity, negative predictive value (NPV), positive predictive value (PPV), and overall accuracy.
Results
Copilot demonstrated a sensitivity of 0.867, specificity of 0, PPV of 0.722, NPV of 0, and accuracy of 0.65. In comparison, Gemini exhibited a sensitivity of 0.733, specificity of 0.4, PPV of 0.786, NPV of 0.333, and also an accuracy of 0.65. Additionally, the human experts’ responses indicated a sensitivity of 0.5808, specificity of 0.2571, PPV of 0.7189, NPV of 0.1579, and an accuracy of 0.5050.
Conclusion
The AI LLMs outperformed human experts in responding to the study questionnaire. The findings demonstrated the considerable potential of the LLMs in enhancing healthcare policy-making, particularly by serving as complementary tools and collaborators alongside humans.
Keywords
Introduction
Healthcare and medical policy refers to the process through which decisions, programs, and actions are formulated to achieve specific healthcare objectives within a community. This process involves various stakeholders, including government officials, health service managers, and professional organizations, who make evidence-based decisions that influence health services and policies at both national and local levels.1–3
During the policy-making process within health systems, a significant challenge arises in substantiating health policies with existing evidence and making decisions based on that evidence. In this regard, policymakers may find it difficult to obtain actionable data that supports their policies and programs, leading to decision-making based on incomplete or insufficient information. Furthermore, this challenge is exacerbated by the need for robust evaluation frameworks to assess the impact of policies post-implementation.4,5 In such context, artificial intelligence (AI) has emerged as a transformative technology that aids in the collection and analysis of data, which is crucial for accurate and evidence-based decision-making and policymaking. AI can assist policymakers in evaluating the effectiveness of existing health policies and in developing new strategies grounded in evidence. Additionally, by simulating various health interventions and analyzing their potential effects, AI facilitates rational and innovative policymaking that can significantly alter health outcomes.6,7
AI is defined as the use of computers and technology to simulate intelligent behavior and critical thinking comparable to that of a human. This term was first introduced by John McCarthy in 1956, who described it as “the science and engineering of creating intelligent machines.8,9” AI encompasses various subfields, including machine learning and deep learning, which enable machines to learn from data, recognize patterns, and make independent decisions. This capability allows AI models to perform tasks that typically require human intelligence, such as problem-solving and learning from experience.10,11
AI models have demonstrated the ability to enhance diagnostic accuracy, often outperforming human practitioners in specific tasks. For instance, AI algorithms have shown remarkable proficiency in analyzing medical images, such as X-rays and MRIs, identifying conditions like tumors with greater accuracy than some radiologists.11,12 AI has demonstrated substantial capabilities in answering healthcare questions, ultimately enhancing patient education and serving as a decision-support tool.13,14 Furthermore, AI facilitates the development of personalized treatment strategies by analyzing large volumes of patient data and identifying patterns that suggest appropriate therapies. 15 This approach enhances precision in medicine, enabling healthcare providers to tailor interventions based on individual patient profiles, including genetic information and lifestyle factors.11,16 Additionally, AI streamlines administrative processes within healthcare settings, thereby reducing the burden on healthcare professionals. By automating tasks such as scheduling, billing, and data entry, AI allows physicians to devote more time to patient care rather than administrative duties.7,12 This automation not only increases operational efficiency but also contributes to cost reduction in healthcare and enhances productivity among healthcare professionals.16,17 Beside all, interestingly, AI has presented the ability to simplify and provide clear summaries of highly complex healthcare contexts for readers.18,19 The ability to provide categorized data from a large corpus dataset within a single prompt constitutes another significant capability of artificial intelligence. 20
AI facilitates innovative analyses and solutions that improve decision-making capabilities, particularly during the evaluation of health policies. The application of AI supports the development of evidence-based policies by providing robust data and mitigating political constraints in policymaking. 6 Research findings in this field highlight the transformative potential of AI across various aspects of healthcare decision-making and policy formulation, advocating for ongoing research and implementation efforts to enhance healthcare delivery systems. 21 In such context, the literature indicates that AI is predominantly being adopted as a tool to augment, rather than replace, expert decision-making within healthcare and related disciplines. 22 In this context, AI-driven clinical decision support systems (CDSS) are increasingly employed to offer recommendations; however, ultimate decision-making authority remains with clinicians, thereby ensuring accountability and oversight. Consequently, evaluating the performance of AI—particularly large language models (LLMs)—can yield valuable insights. Such analysis may facilitate the broader adoption of LLMs as collaborative partners alongside human professionals in healthcare services, especially within policy-making domains.23,24
There are multiple studies within the literature examining the capabilities of AI LLMs in diverse contexts. In a study published in 2024 in Germany, the accuracy and consistency of ChatGPT in responding to medical examination questions were examined. The study findings highlighted the advancements in the reliability of artificial intelligence for medical education and decision-making while emphasizing the continued necessity for human oversight in healthcare delivery. 25 In another study, the performance of ChatGPT was analyzed across 2377 United States Medical Licensing Examination (USMLE) practice questions. Following the analysis, ChatGPT achieved an overall accuracy of 55.8%, with an inverse correlation observed between question difficulty and performance. The findings ultimately underscored the need for further research to explore the potential and limitations of ChatGPT in medical education and assessment. 26 Furthermore, in another study published in 2023 in Italy, the potential use of ChatGPT within healthcare settings was evaluated, focusing on its applications and limitations across clinical and research scenarios. The capabilities of ChatGPT were examined concerning clinical performance support, scientific writing generation, addressing medical malpractice issues, and reasoning about public health topics. Findings indicated that while ChatGPT could effectively summarize information and generate structured medical notes, it struggled with complex causal relationships and lacked the necessary medical expertise to analyze cause-and-effect relationships adequately. Additionally, ethical concerns regarding its misuse—such as data fabrication or dissemination of incorrect information—were highlighted. The study concluded that while AI models like ChatGPT could enhance scientific literacy and assist in research efforts, it was crucial to fully understand their limitations and establish regulatory policies to mitigate risks associated with their use in healthcare. 27
The existing literature reveals a significant gap and a scarcity of studies evaluating the capabilities of AI and its performance relative to human experts across various contexts within healthcare services, especially in the area of health policy. To the best of the authors’ knowledge, this study represents one of the first, if not the very first, investigations assessing the performance of AI LLMs in the context of healthcare policymaking. Given the aforementioned points, assessing the capabilities, including accuracy, and precision of various AI LLMs—particularly those that are freely accessible to the public—in comparison with human experts is of significant importance. This evaluation can help identify the strengths and weaknesses of AI LLMs relative to human experts in evidence-based decision-making and policymaking processes. Ultimately, it can facilitate the effective integration of LLMs into health policy frameworks across all regions, especially in under-resourced areas where free access to AI models can provide substantial benefits to the global population.
The aim of this study was to evaluate the performance of AI LLMs in comparison to human experts in healthcare policy-making. The findings of the research would benefit various stakeholders including healthcare managers, policymakers, researchers in this field, and companies developing LLMs. The research provides the necessary data to enhance the utilization of AI in healthcare services, particularly in the domain of policy-making, while facilitating the improvement of weak areas of LLMs by reporting them in detail.
Methods
Study design
This research was a mixed-methods cross-sectional study conducted in 2024-2025 in Iran, adhering to the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) guidelines for cross-sectional studies. The research was conducted in two phases comprising multiple steps, including:
Phase one: • Identifying scenarios, policies implemented, and their outcomes within the Iranian healthcare system through a scoping review and incorporating them into the research questionnaire.
Phase two: • Obtaining the responses of the AI LLMs to the research questionnaire. • Obtaining the responses of human experts in health policy to the research questionnaire. • Analyzing and comparing the performance of AI LLMs and human experts in responding to the research questionnaire.
Study settings
The study was conducted in Iran, in diverse settings, such as the central organization of the ministry of health and medical education of Iran, healthcare research centers for policymaking, and multiple healthcare universities.
Data collection
Phase 1: Data collection from the literature and developing the research questionnaire
Search strategy.

After conducting the search in the database, the titles and abstracts of the obtained references were independently reviewed by two researchers. Following a screening process based on titles and abstracts, the full texts of the remaining references were examined. Ultimately, after identifying the final relevant studies that reported on the implementation of one or more health policies and their outcomes, 20 studies from which policy scenarios could be extracted were selected by two authors of the research, with this process being validated by a third author. The selection of 20 studies was based on the requirement for a minimum of 10 questions mentioned within the literature; Thus, to enhance the credibility of this study, 20 questions derived from these 20 studies were utilized. 29
Inclusion criteria for studies in this research: • Availability of the full text of articles in English • Publication date between 2000 and 2024 • Feasibility of extracting and designing scenarios from the content of the article
Exclusion criteria for studies from this research: • Articles published as letters to editors and studies presented at conferences
Finally, two authors fluent in English and specialized in health policy extracted, translated into Persian, and designed scenarios, questions, and policy options from the texts of the included studies in Phase 1of the study. Then, the developed scenarios and policy options underwent a review by a third researcher with the same characteristics.
The questionnaire was designed solely to evaluate respondents’ ability to answer each question accurately. Given the diverse range of topics covered and the fact that the questions and the answers were derived from peer-reviewed, published manuscripts in journals, no methodological validation process was deemed necessary for the questionnaire items. Nevertheless, the development of the questionnaire was closely monitored and supervised by multiple authors who were experts in the field of health policy-making. Moreover, the questionnaire was pilot-tested by three experts specializing in healthcare policy. This oversight ensured the validity of the questionnaire and minimized the risk of bias. The primary objective of this approach in designing the study questionnaire was to assess the extent to which the responses provided by human experts and AI models are supported by evidence published in the relevant literature (which was considered as the gold standard). This evaluation aimed to determine the accuracy and quality of the answers given by both human experts and AI models for each question within the specified context.
Phase 2
Data collection from AI LLMs
In this phase of the research, the sample under investigation aimed to enhance diversity, inclusivity, and coverage of results in the field of AI by incorporating two well-known and freely accessible AI LLMs available on the World Wide Web, each with distinct characteristics and developers. The selected AI models included Bing AI Copilot from Microsoft and Gemini from Google DeepMind. These models were chosen for this phase of the research due to their availability to the public at no cost.16,30
Microsoft Copilot, originally introduced as Bing Chat in February 2023, is an AI-driven chatbot aimed at enhancing user interaction within the Microsoft ecosystem. It was rebranded to “Copilot” during the Microsoft Ignite event in November 2023, signifying its expanded integration across various Microsoft services. Utilizing OpenAI’s GPT-4 model, Copilot is optimized for search and conversational tasks, delivering detailed, human-like responses with source citations.31,32 On the other hand, Gemini, formerly known as Google Bard, is a sophisticated AI chatbot developed by Google that utilizes advanced conversational AI and generative AI technologies. It is designed to enhance user interaction through improved performance, usability, and integration with services such as Google Workspace and third-party applications. 33
During this phase, a sample consisting of 20 scenario-based multiple-choice questions (Study Questionnaire) derived from the literature review conducted in the previous phase was presented to the AI models. The research questions were entered sequentially into the chat interface of the AI models.
To complete the process of answering the presented questions using the aforementioned AI models, a written prompt had to be provided to reduce bias and enhance the quality and accuracy of the results obtained. This prompt was formulated by two researchers and subsequently reviewed and approved by a third researcher. The prompt was designed as the following: Answer the following question based on the content provided in the given scenario.
Due to limitations in word count within certain AI models’ chat interfaces, it was not feasible to present all questions simultaneously. Therefore, each question was submitted individually after refreshing the platform page. At the end of this process, the responses were recorded in thedata extraction form that included details such as the name of the responding AI model, and the response given to each question. This information wasdocumented in a Microsoft Word 2020 file by one researcher and subsequently reviewed by another researcher to ensure data accuracy.
Inclusion criteria for AI LLMs: • Being completely free and accessible on the World Wide Web. • The capability to present questions to the AI model. • A minimum ability to analyze and respond to questions related to health policy scenarios by default. • Support for the Persian language.
Exclusion criteria for AI LLMs: • Inaccessibility to the general public • The inability to support the Persian language.
Data collection from health policy experts
During this phase of the research, a sample consisting of 15 health policy experts was utilized, taking into account the number of experts engaged in the previous similar literature. 34
In this section of the study, similar to the procedures followed in the previous section concerning AI models, the study questionnaire was presented to the selected experts. Prior to distributing the questionnaire, one of the researchers initially familiarized the experts with the purpose of the study accompanied by providing a consent form for participation. At the conclusion of this step, as in the previous step, the responses given by the health policy experts were recorded in the data extraction form that included data such as gender, age, field of study, academic degree, and final responses to the questions. This data was documented in a Microsoft Word 2020 file by one researcher and subsequently reviewed by another researcher to ensure data accuracy. Inform consent was taken from all of the study participants.
Inclusion criteria for experts: • Expertise and experience in health policy, such as participation in the formulation and implementation of health policies. • A PhD degree in Health Policy, Health Services Management, or Health Economics. • A minimum of 3 years of work experience.
Exclusion criteria for experts: • Lack of consent to participate in the research.
Data analysis
During the process of data analysis, in alignment with the approach established in the research literature, the definitive responses to each question derived from the texts of the studies incorporated into this research were used as the gold standard (the correct and definitive answer for each question) for comparison. Subsequently, the accuracy of the responses provided by the AI models and human experts was evaluated by one of the researchers specializing in Health Policy, who categorized the responses into “correct” and “incorrect” answers.34,35 After completing this process, another researcher, also specializing in Health Policy, reviewed the categorization to ensure the accuracy of the procedure.
To analyze and compare the performance of the AI models and the human experts in responding to the research questions, a confusion matrix analysis was employed along with four metrics: sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) (Table 2). In this context, choosing one of the policy options was regarded as a positive selection, indicating the belief in the existence of a policy option within the question. Conversely, selecting the ‘none of these‘ option was considered a negative selection, signifying the denial of the existence of any policy option. The overall accuracy score was also utilized to provide an ultimate performance score for each of the study participants (AI models and human experts). The calculation of these metrics was performed by one researcher and subsequently reviewed by another researcher for validation. The methodology for calculating each of these metrics was as follows35,36: • True Positive (TP): The number of correct positive responses among questions that contained a correct policy option (selecting the correct policy option when it was available). • False Positive (FP): The number of incorrect positive responses among questions that didn’t contain a correct policy option or contained a correct policy option (failure to select the ‘none of these‘ or the correct policy option). • True Negative (TN): The number of correct negative responses among questions that didn’t contain a correct policy option (selecting the ‘none of these‘ option, when no correct policy option existed). • False Negative (FN): The number of incorrect negative responses among questions that contained a correct policy option (selecting the ‘none of these‘ option when a correct policy option existed). Default confusion matrix for the study.

In calculations, sensitivity was derived by dividing the number of true positives by the sum of true positives and false negatives:
Specificity was calculated by dividing the number of true negatives by the sum of true negatives and false positives:
The positive predictive value was determined by dividing the number of true positives by the sum of true positives and false positives:
The negative predictive value was calculated by dividing the number of true negatives by the sum of false negatives and true negatives:
Finally, overall accuracy was obtained by summing true positives and true negatives, then dividing by the total number of cases, which included true positives, true negatives, false positives, and false negatives:
During the process of designing the study questionnaire, to facilitate the necessary analysis using a confusion matrix, it was essential to include genuinely incorrect responses (false negatives) in the study. Therefore, one of the response options for all questions in the study questionnaire was ‘none of these.’ As a result, the correct answer for one-fourth of the questions (five questions) was ‘none of these.’ This detail was deliberately concealed from both the artificial intelligence models and human experts throughout the research process to avoid any potential bias.
Results
The results of the study are presented as follows:
Phase one
As presented within Appendix 1 (Scoping Review Data), the review resulted in the identification of 34 references. Following the completion of the screening process, 20 studies were selected for inclusion in the research. Subsequently, the research questionnaire consisting of 20 questions was developed. As mentioned earlier, the study questionnaire was in Persian. It consisted of multiple scenarios, each presenting a specific public health issue in Iran and asking respondents to evaluate the effectiveness of different proposed interventions. The issues referred by the scenarios ranged from data gaps in health monitoring to alcohol treatment accessibility, stakeholder engagement in hepatitis C policy, hospital autonomy challenges, disaster management, and more. The study questionnaire and the corresponding references for each question are presented in Appendix 2 (Research Questionnaire-Persian) and Appendix 3 (Research Questionnaire-English).
Phase two
AI models
As mentioned earlier, the questionnaire comprised 20 questions, with responses categorized as either positive or negative. In this regard, both Copilot and Gemini, achieved a total score of 13 out of 20 for correct responses. However, the distribution of TPs, FNs, and FPs differed between the two models (Figure 1). Comparison of Copilot and Gemini in their responses to the study questionnaire.
The results regarding the accuracy, NPV, PPV, specificity, and sensitivity analysis delineated that Copilot had a sensitivity of 0.867, a specificity of 0, a PPV of 0.722, an NPV of 0, and an accuracy of 0.65. In comparison, Gemini exhibited a sensitivity of 0.733, a specificity of 0.4, a PPV of 0.786, an NPV of 0.333, and also an accuracy of 0.65 (Figure 2). Accuracy, NPV, PPV, Specificity, and Sensitivity values for Copilot and Gemini.
Human experts
The final sample of human experts utilized in this step of the study consisted of a higher number of male experts (approximately 62%) compared to female experts (approximately 38%). The ages of the experts ranged from 32 to 60 years, with the majority being in their 40s and early to mid-50s. The predominant area of expertise was health policy, and most of the experts were professors at medical universities, working simultaneously in research centers or at the Iranian Ministry of Health in the realm of healthcare policymaking (Appendix 3. Study Experts).
Figure 3 presents the comparison of the human experts in their responses to the study questionnaire. The range of total scores for the human experts reflected a notable diversity, with values varying from 7 to 13. Comparison of the human experts in their responses to the study questionnaire.
As presented in Figure 4, the analysis of experts’ responses to the questionnaire yielded the following results: sensitivity was 0.5808, specificity was 0.2571, positive predictive value was 0.7189, negative predictive value was 0.1579, and accuracy was 0.5050. Overall accuracy, NPV, PPV, Specificity, and Sensitivity values for the human experts.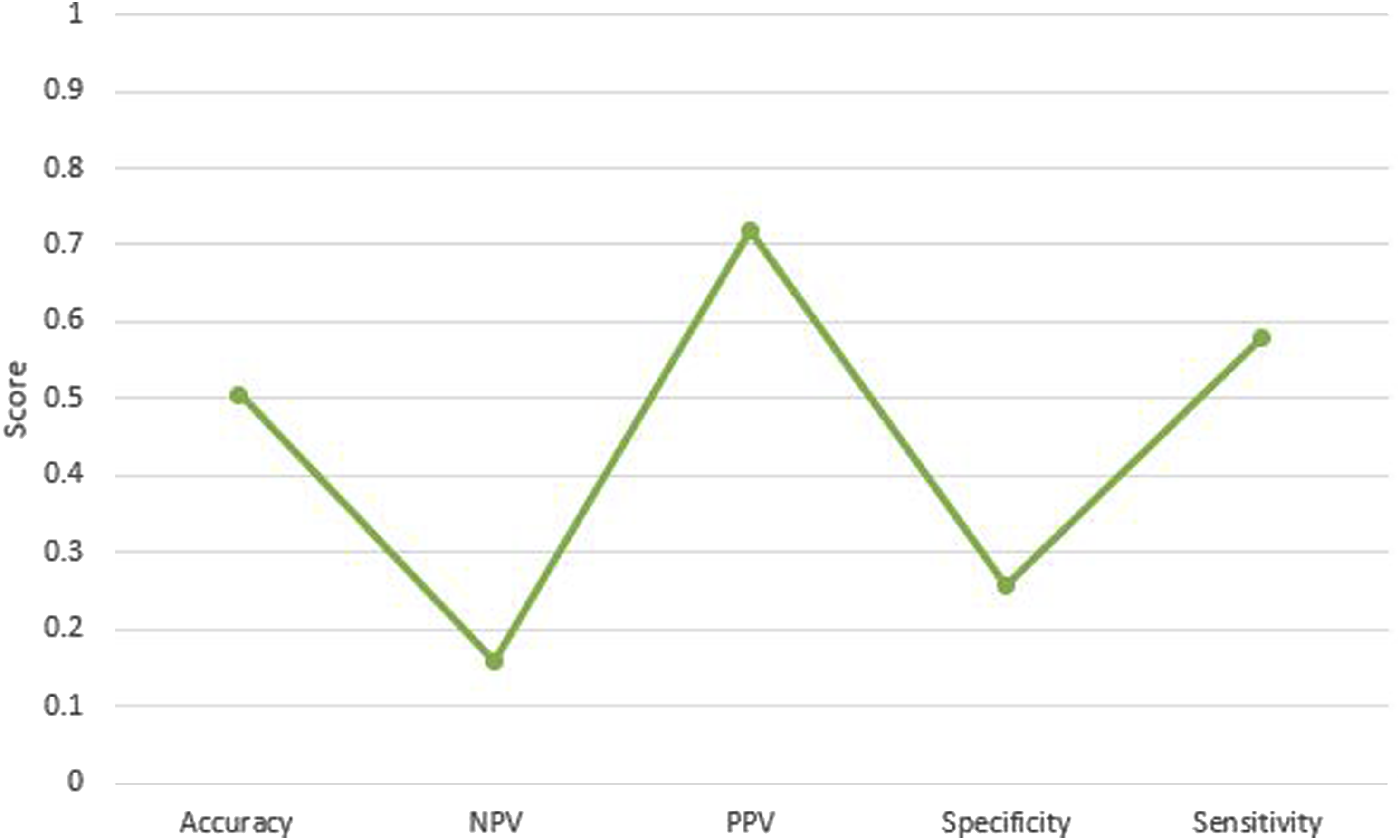
The comparison of the overall performance of AI models and human experts is presented in Figure 5. Performance of AI LLMs compared to human experts.
Discussion
This section of the study presents an overall analysis and comparison of the findings regarding the performance of the AI models utilized in the study, both in relation to each other and to the human experts involved. In the next step, their performance are discussed in light of the findings from the previous literature.
AI LLMs: Copilot versus Gemini
The results of the study revealed that Copilot demonstrated a high sensitivity, indicating a strong ability to correctly identify relevant responses; however, it exhibited a very low specificity, suggesting a complete failure to recognize irrelevant responses. In contrast, Gemini displayed a lower sensitivity than Copilot but achieved a better specificity, indicating some capability in identifying non-relevant inquiries. Also, the accuracy of the two AI models was deemed as equal.
The results of our study regarding the high sensitivity of Copilot were in line with the previous literature, which also demonstrated the high ability of Copilot to answer questions within the healthcare context correctly, outperforming other AI models.37–41 In this regard, it has been reported that the disparity between the capabilities of Copilot (utilizing ChatGPT 4) and those of Gemini in delivering accurate responses to inquiries within the healthcare context is statistically significant. This indicates that Copilot is generally more likely to provide correct answers than Gemini. 39 Furthermore, although Copilot possesses the ChatGPT-4 model, it has been determined to have the highest accuracy in the interpretation of healthcare data compared to both ChatGPT and Gemini. 42 In other words, Copilot has achieved even better performance than the stand-alone ChatGPT.42,43 On the other hand, it has been reported that Gemini significantly improves its ability to provide accurate answers in comparison to Copilot after undergoing training by the users. 40 This suggests that Gemini has the potential to outperform Copilot if it is trained with relevant data and contextual information pertaining to the users’ questions.
The results of our study regarding the higher specificity of Gemini in comparison to Copilot are in line with the findings of the previous literature.44,45 In this regard, the previous literature indicates that Gemini outperforms Copilot (integrated with ChatGPT) in specificity scores, delineating that Gemini generally provides more accurate classifications particularly concerning true negatives, presenting a statistically significant difference between the two models regarding specificity (p-value <0.001). 44 This suggests that Gemini is potentially more reliable in avoiding false positives, particularly when recommending costly and controversial policies and interventions within the healthcare context, such as treatment options.
Based on the literature, it seems that Copilot generally has weaker performance in terms of specificity, while the results regarding its comparison with the rest of AI LLMs are diverse and mixed.36,46 Such phenomena can be traced back to the fact that Copilot operates primarily as an information retrieval tool, akin to a search engine, focusing on data compilation rather than in-depth analysis, which may result in less specific responses. Although it demonstrates higher accuracy in interpreting biochemical data compared to models like ChatGPT-3.5 and Gemini, variability in response quality can occur depending on query complexity and context. Furthermore, the specificity of its outputs is influenced by the quality of its training data and its limited contextual understanding compared to human experts. 42
An analysis of the data regarding the performance of the two LLMs on the study questionnaire indicates that both models failed to answer three specific questions (questions 11, 12, and 19). These items were all negative, requiring the selection of the ‘none of these’ option. The subject matter of these questions primarily pertained to environmental health, healthy behaviors, and health information technology management. The varied contexts of these questions suggest that the observed failure to answer them is likely attributable to the limited ability of the LLMs to demonstrate specificity and accurately identify TN responses. This issue has been previously discussed earlier. On the other hand, Gemini demonstrated the ability to correctly answer two negative questions (questions 4 and 13), whereas Copilot did not succeed in these instances again. The subject matter of these questions pertained to structural adjustments in hospitals and medication adherence. In this regard, one of the factors contributing to the inability of the LLMs to correctly answer certain questions was the seemingly long length of the study questionnaire items. In this context, existing literature indicates that LLMs frequently encounter difficulties when processing longer texts and more complex questions.47–49
AI LLMs versus human experts
The analysis of the experts’ responses to the study questionnaire revealed a moderate sensitivity, indicating a moderate ability to correctly identify positive cases. The specificity was found to be relatively low (particularly lower than Gemini), suggesting a relatively low capacity to accurately identify negative cases. This suggests that the experts in the study generally performed worse than the AI models, except for specificity, which was low for both the human experts and the AI models.
The results of our study comparing the performance of AI models with that of humans were supported by existing literature, which suggests higher performance of AI models’ in comparison to humans’performance within the healthcare context.43,46,50–52 In this regard, while the literature acknowledges the benefit of AI models primarily in the information segments of healthcare delivery networks, there are some claims suggesting that the quality and accuracy of information generated by AI models depend on the prompts provided by users.53–57 However, such positive findings regarding the superior performance of AI compared to humans should be considered alongside the various ethical challenges associated with AI use, particularly in the healthcare context. In this regard, several ethical concerns have been identified, including accountability, elimination of bias, the irreplaceability of human judgment, accuracy, transparency, accessibility, fairness, utility of outcomes, privacy, and the transparency of data and information inputs. These issues are recognized as inherent challenges in the application of AI within healthcare.58–61
Regarding the results about specificity, although Gemini presented the highest level of specificity within this study, it appears that AI models generally lag behind human experts in identifying true negative cases. This can be regarded as a major weakness of AI models, as noted in the literature.17,54,62,63 In such context, studies indicate that AI models may encounter difficulties in addressing specific patient contexts, resulting in incomplete or irrelevant responses. These systems frequently overlook critical factors such as patient demographics and clinical nuances, which can substantially affect diagnostic accuracy and treatment recommendations.63,64 Consequently, there is a growing consensus advocating for the integration of AI into healthcare as a complementary tool, rather than a substitute for human expertise. This is particularly important in complex healthcare contexts that necessitate empathy and thorough judgment.63,65
It is presented that AI demonstrates optimal effectiveness when integrated within expert-guided, human-AI collaborative teams. 66 Human intuition, domain-specific experience, and contextual sensitivity are consistently recognized as critical complements to the computational capabilities of AI. While AI excels in processing and analyzing large-scale, complex datasets, it inherently lacks the nuanced judgment, contextual understanding, and experiential intuition possessed by human experts.10,67 Empirical research further substantiates that human intuition and domain expertise are vital in determining when to rely on or override AI-generated recommendations.68,69 In conclusion, artificial intelligence is most effectively employed as a supportive instrument that augments expert policymaking and decision-making through collaborative integration, rather than replacing human expertise. 70
There are several additional reasons that support the promotion of human-AI collaboration instead of replacing humans with AI. In this context, human experts possess critical capabilities in ethical reasoning, contextual awareness, and philosophical judgment that artificial intelligence cannot replicate. Extensive research highlights these unique human faculties as essential for ethical decision-making, encompassing moral judgment, empathy, and complex contextual understanding. Conversely, AI’s capabilities are constrained by its reliance on statistical patterns and pre-established rules. While AI can aid and enhance the decision-making process, it cannot substitute the sophisticated ethical considerations conducted by humans. The literature consistently emphasizes the necessity of sustaining human accountability in ethical decisions, positioning AI as a complementary instrument that supports and elevates human judgment, particularly in complex scenarios. This synergy between human intuition and AI’s computational power fosters improved outcomes across various domains, illustrating the superior efficacy of collaboration over replacement.71–73
Limitations and implications
This research had several limitations. Firstly, the study questionnaire was in Persian due to the limited sample of human experts residing in the study region and the unfamiliarity of some experts with English. Therefore, results could be different if conducted with English-fluent experts and if the questionnaire had been provided to the AI models in English. Future researchers could address this limitation by conducting similar studies globally with questionnaires in English and samples of human experts for whom English is the native language. Moreover, Although the development of the study questionnaire was overseen and validated by multiple experts within the relevant context, no methodological psychometric analyses were conducted due to time constraints and the absence of a previously validated questionnaire within this context. This omission can be considered a limitation of the study. Moreover, the authors did not evaluate inter-rater reliability when establishing the “gold standard” answers for the study questionnaire, which constitutes a notable limitation of the study. Another limitation was the restricted number of AI models used in the study, due to limited access in the authors’ region (Iran). This can be addresssed by future research involving a broader range of AI models. Moreover, a relatively small number of human experts included in the sample, attributable to constraints in time, resources, and limited access to a larger pool of healthcare policy experts at the time of the study. Future research should consider addressing this limitation by incorporating larger sample sizes. Finally, There was a potential for disparity between the study human and AI respondents, as the prompts provided to the LLMs were in English to ensure broader applicability of the study findings beyond Persian-speaking audiences. This approach was deemed appropriate given that the LLMs’ responses consisted solely of selecting options (A, B, C, D) without additional descriptive elaboration. Nevertheless, this should be acknowledged as a potential limitation of the study.
The research also had some implications. Firstly, the study revealed poor performance of Copilot in specificity, despite its highest sensitivity rate among the sample. This finding highlighted a significant weakness for the manufacturer of Copilot within the healthcare context, as well as for researchers and policymakers aiming to utilize it. The findings indicate that this failure may be attributed to the relatively lengthy nature of the study questionnaire items, a conclusion that is supported by existing literature. This finding holds significant implications for stakeholders, including manufacturers and researchers, within the relevant context. Accordingly, manufacturers are encouraged to enhance the capability of their LLMs to accurately respond to longer questions. Simultaneously, researchers are advised to conduct systematic analyses of LLM performance across questions of varying lengths. Conversely, Gemini demonstrated a notable strength with its highest specificity rate among the sample, albeit low, suggesting that integrating AI models with diverse strengths could enhance the overall quality and accuracy of the AI models. Finally, despite models outperforming human experts in some areas, due to certain limitations, we recommend using AI models as complementary tools rather than substitutes for human expertise, particularly in critical healthcare contexts affecting human lives. In such context, although the scope of this study was confined to the Iranian healthcare system, its findings offer valuable insights for a broad audience, particularly those operating in contexts similar to Iran, such as low- and middle-income countries. These findings hold significant relevance for stakeholders in such settings, especially healthcare policymakers, by enabling evidence-based planning for the integration of AI large language models into healthcare policymaking processes.
Conclusions
The study results indicated that AI models presented the highest accuracy in comparison to the human experts. Copilot exhibited the highest sensitivity, while Gemini displayed the highest specificity. Overall, the AI models outperformed human experts in responding to the study questionnaire. However, some ethical and technical issues still exist that need to be addressed, suggesting that AI should complement rather than replace human expertise in critical healthcare contexts.
Supplemental Material
Supplemental Material - Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study
Supplemental Material for Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study by Mohsen Khosravi, Reyhane Izadi, Mina Aghamaleki, Hossein Bouzarjomehri, Milad Ahmadi Marzaleh, Ramin Ravangard in Health Informatics Journal
Supplemental Material
Supplemental Material - Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study
Supplemental Material for Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study by Mohsen Khosravi, Reyhane Izadi, Mina Aghamaleki, Hossein Bouzarjomehri, Milad Ahmadi Marzaleh, Ramin Ravangard in Health Informatics Journal
Supplemental Material
Supplemental Material - Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study
Supplemental Material for Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study by Mohsen Khosravi, Reyhane Izadi, Mina Aghamaleki, Hossein Bouzarjomehri, Milad Ahmadi Marzaleh, Ramin Ravangard in Health Informatics Journal
Supplemental Material
Supplemental Material - Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study
Supplemental Material for Performance of artificial intelligence large language models (Copilot and Gemini) compared to human experts in healthcare policy making: A mixed-methods cross-sectional study by Mohsen Khosravi, Reyhane Izadi, Mina Aghamaleki, Hossein Bouzarjomehri, Milad Ahmadi Marzaleh, Ramin Ravangard in Health Informatics Journal
Footnotes
Acknowledgements
The present article was extracted from a project financially supported by Shiraz University of Medical Sciences grants No. 31447. The authors should thank all participants for their kind cooperation with the researchers in collecting and analyzing the data.
Ethical considerations
The research was approved by the corresponding ethical committee in Iran with the ethical code: IR. SUMS.NUMIMG.REC.1403.080. Throughout all phases of this research, all ethical principles related to studies involving human subjects as outlined in the Helsinki Declaration were strictly adhered to. Personal information about human experts, such as names and addresses, were remained confidential.
Consent to participate
Informed consent was also be obtained from all experts participating in the study. During the course of the research, participating experts had the option to withdraw from the study at their discretion. Finally, data extracted from this research was to be retained by researchers for up to 3 years following the study publication.
Author contributions
MK conducted the review, performed the data analysis, and wrote the manuscript. RI and MA collaborated on data gathering and designed the study questionnaire. HB assisted in data gathering and contributed to writing the manuscript. MAM also contributed to writing the manuscript. RR was involved in all steps of the research.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article
Data Availability Statement
The research data can be accessed by contacting the corresponding author of the paper.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.