
Abstract
Application of Convolutional neural network in spectrum of Medical image analysis are providing benchmark outputs which converges the interest of many researchers to explore it in depth. Latest preprocessing technique Real ESRGAN (Enhanced super resolution generative adversarial network) and GFPGAN (Generative facial prior GAN) are proving their efficacy in providing high resolution dataset.
Keywords
Introduction
Integrated framework of deep learning model with advanced preprocessing technique like Real ESRGAN 1 and GFPGAN 2 gives significant elevation in terms of efficiency of these models. Efficiency shoots up to 5–10% via pipe lining of these preprocessing technique with base models. On a way to further optimize the deep learning models, usage of optimizer is explored. Optimizer plays an indispensable role in the functioning of CNN. They help in adjusting weights so as to minimize the incurred losses. Many optimizers have been employed in CNN like Gradient descent,3–8 Stochastic Gradient descent,9–14 Ada grad,15–18 Ada delta19–21 and Adam22–25 etc. for classification and segmentation of Medical image. Gradient descent iteratively reduces a loss function by moving in the direction opposite to that of steepest ascent. As its uses entire training set for calculation which requires large amount of memory and hence slow down process. Stochastic gradient descent is a variant of gradient descent and update model parameter one by one which leads to high variance and make it computationally expensive. Stochastic gradient descent with momentum is an improved version which takes in account the previous update to fine tune the final update direction and hence leads to more stability but extra hyper parameter is added. So far learning rate has been constant but with the introduction of Ada grad (Adaptive Gradient descent) concept of adaptive learning rate emerges that is it uses different learning rate for each and every neuron and for each and every hidden layer based on different iteration but it too leads to dead neuron problem. RMS-prop26–30 (Root mean square propagation) is a special version of Ada grad in which learning rate is exponential average of gradient instead of cumulative sum of squared gradient but it suffers from slow learning rate. Ada delta is an extension of Ada grad. Here it, does not set default learning rate and uses the ratio of running average of previous time steps to current gradient. It removes decaying rate problem but it is computationally expensive. Adam (Adaptive moment estimator) optimizer is one of the popular gradient descent optimization algorithm. It computes adaptive learning rate for each parameter and stores both the decaying average of past gradients and also the decaying average of past squared gradient. It has little memory requirement and is computationally efficient.
Aforementioned optimization techniques operate on activation or weight vectors and hence their adoption to pre-trained models pose a great challenge. So a new method, Gradient centralization31–34 is used which acts on gradient of weight vectors and centralizes the gradient vector to have zero mean. Thus introduction of Gradient centralization accelerate the training process and enhances the generalization performance.
Our research work explores the functioning of GC (Gradient centralization) on our integrated framework of deep learning models. Next Section illustrates the related work, Proposed work describes the achieved result via integrated framework and proposed work which includes further optimization with novel Gradient Centralization optimizer. Experimental result and discussion tabulates the experimental result and comparison of loss curves and Future work and conclusion winds the research paper with Future work and conclusion.
Related work
Significant efforts are made in the direction of improving the efficiency of deep learning models. Application of voting based method to deep learning models helps in strengthening the correct classification of lung disease. 35 Preprocessing techniques plays an important role in boosting efficacy of deep learning models. 36 Other factor like Optimizer too plays an pertinent role in efficiency improvement of Deep learning algorithms as they decide the rate of convergence of algorithm towards an optimal value. Many Researchers are evolving the usage of new optimizers to explore their functioning in deep learning models. Zhang 37 proposes method, normalized direction-preserving Adam (ND-Adam), which enables more precise control of the direction and step size for updating weight vectors and experimentally proves to improve in generalization performance of adam optimizer. Khaire and Dhanalakshmi 38 brings out another improvement in momentum of adam optimizer by evaluating the gradient after applying the current velocity and called its as iAdam. It works efficiently for the high-dimensional dataset and converges rapidly. iAdam is simple to execute, computationally effective, well suited for high-dimensional datasets, converge smoothly and operate efectively even for higher levels of learning Usage of appropriate optimizer for particular input dataset greatly affects the efficiency of architecture used for classifying that dataset. Halgamuge et al. 39 carried out comparison of six optimizer Ada grad], Ada delta, Rms prop, Adam, Nadam, and SGD (Stochastic gradient descent) and identify the best optimizer as Ada grad which estimate potential fire occurrences in given locations and gives precise predictions with less error and processes real-time data. Adagrad has highest prediction rate 43.93 min and Nd adam and has highest accuracy and lowest loss rate that is 98.86% and 0.03%. Kandel et al. 40 improves the efficiency of its CNN based classifier by comparing six different first-order stochastic gradient-based optimizers and adaptative based optimizers emerges out as best for classifying histopathology images for low learning rate and produces an AUC of 94% and Ada grad proves to be low performer even on low learning rate. Yaqub et al. 41 perform a comparative analysis of 10 different gradient descent-based optimizers, Adaptive Gradient (Ada grad), Adaptive Delta (Ada Delta), Stochastic Gradient Descent (SGD), Adaptive Momentum (Adam), Cyclic Learning Rate (CLR), Adaptive Max Pooling (Ada max), Root Mean Square Propagation (RMS Prop), Nesterov Adaptive Momentum (Nadam), and Nesterov accelerated gradient (NAG) for CNN for brain tumor classification and segmentation and Adam optimizer helps in attaining the greatest efficiency of 99.2%. Chowdhury et al. 42 explores the CNN with one, two, three, four and five hidden layers with combination of three optimizers namely,Rms prop, Adam and SGD and finds CNN with four hidden layer using SGD optimizer having greatest testing accuracy of 91%. Bera and Shrivastava 43 performs Hyper spectral image (HSI) classification with seven different optimizers SGD, Ada grad, Ada delta, Rms prop, Adam, Ada Max, and Nadam using Deep CNN model and establishes the superiority of Adam optimizer achieving average accuracy of 98% on every HSI datasets. Perin and Picek 44 illustrates that hyper parameter optimizer plays indispensable role in in deep learning-based side-channel analysis. He experimentally shows that Adam and Rmsprop works well for shorter training phases as they easily overfitand strongly supports Ada grad for longer training phases. Poojary and Pai 45 used CNN based model Resnet 50 and Inception v3 for kaggle cat versus dog classification and carried out comparative analysis for three optimizer namely Adam, SGD, RMS prop and RMS prop performed extremely well with training accuracy of 99%. Vani and Rao 46 implemented the usage of seven optimizers namely Stochastic Gradient Descent (SGD), RmsProp, Adam, Ada max, Ada grad, Ada delta, and Nadam are implemented in CNN on Indian Pines Dataset Ada max excels with 99.58% accuracy. Yaqub et al. 41 carries out Brain tumor classification and segmentation using BraTS2015 data set for 10 optimizer namely namely Adaptive Gradient (Ada grad), Adaptive Delta (Ada Delta), Stochastic Gradient Descent (SGD), Adaptive Momentum (Adam), Cyclic Learning Rate (CLR), Adaptive Max Pooling (Ada max), Root Mean Square Propagation (RMS Prop), Nesterov Adaptive Momentum (Nadam), and Nesterov accelerated gradient (NAG) and proves Adam to be efficient with accuracy of 99.2%. Dubey et al. 47 works out on step size taken for each parameter and proposed an Diffgrad optimization technique which takes larger step size for faster gradient changing parameter and lower step size for lower gradient changing parameter. This method outperforms optimizer technique like SGDM, Ada Grad, Ada Delta, RMS Prop, AMS Grad, and Adam. Taqi et al. 48 proposes Alzheimer disease (AD) classification based by using four different optimizers Ada grad, ProximalAda grad, Adam, and RMS Prop and Rms prop works with 100% accuracy. Thavasimani and Srinath 49 experimented with various optimizers such as ADAM, SGD, RMS prop, Ada delta, Ada max, Ada grad, Nadam to detect bot accounts with the help of deep learning model from CRESCI-2017 twitter dataset issued by Indiana University and establishes the highest accuracy of 98.90% with RMS prop. Elangovan and Nath 50 bring out the role of optimizer in improving the performance of deep neural network for image classification problem and analyzes three standard first-order optimizers like stochastic gradient descent with momentum (SGDM), adaptive moment estimation (Adam), and root mean square propagation (RMS Prop) for detecting glaucoma employing architectures like Alex net,VGG-19 and Resnet 101. Adam optimizer shows better result in this.
Proposed work
Result of integrated model.
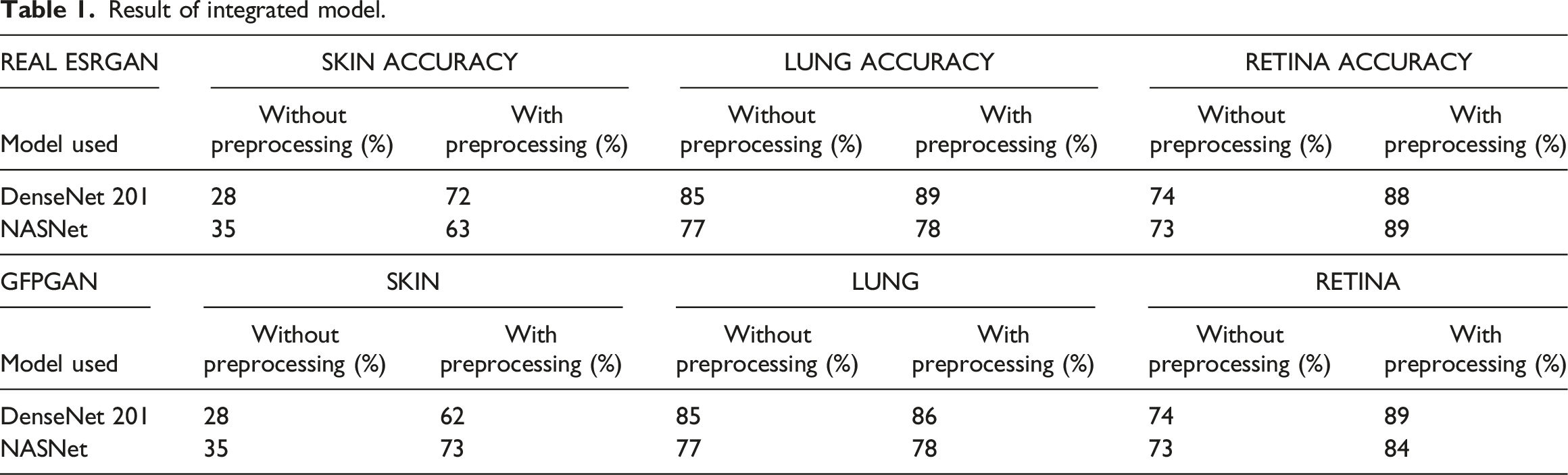
For skin dataset massive improvement is achieved for validation accuracy. Retina dataset also responds well for integrated framework. Minimal enhancement is observed for lung dataset. But overall positive trends are observed using images preprocessed with Real ESRGAN and GFPGAN as input to our base models.
Our next step to further optimize the integrated deep learning models with the use of novel optimizer Gradient centralization technique.
Gradient centralization
Gradient centralization (GC) can enhance DNN(Deep neural network) ultimate generalisation performance while also accelerating the training process. As indicated in Figure 1 GC works by by centralizing the gradient vectors to have a mean of zero and thus directly manipulates gradients. Gradient Centralization further enhances the loss function and its gradient Lipschitzness, making the training process more effective and stable. Batch Normalization and Weight standardization technique also reduces the Lipschitzness of loss function but they operate on activation and weight vectors and were not able to adapt to pre trained models but Gradient Centralization takes in account the gradients vectors to achieve improvement. Z-score standardization can also be used to normalize the gradient but normalising gradient does not increase training’s stability. Instead, calculating the gradient vectors’ means and then centralizing the gradients so that their means are zero effectively helps in achieving the desired result. This is the underlying principle of Gradient centralization method. It can be easily embedded into gradient based current optimization algorithm like Adam, SGDM with one line of code and helps in increasing training process, improves generalization capability and better tune it to pre trained models. Illustration of GC operation on matrix/tensor of weights in fully connected layer (left) and convolutional (right). GC computes the column/slice mean of gradient matrix/tensor and centralizes each column/slice to have zero mean.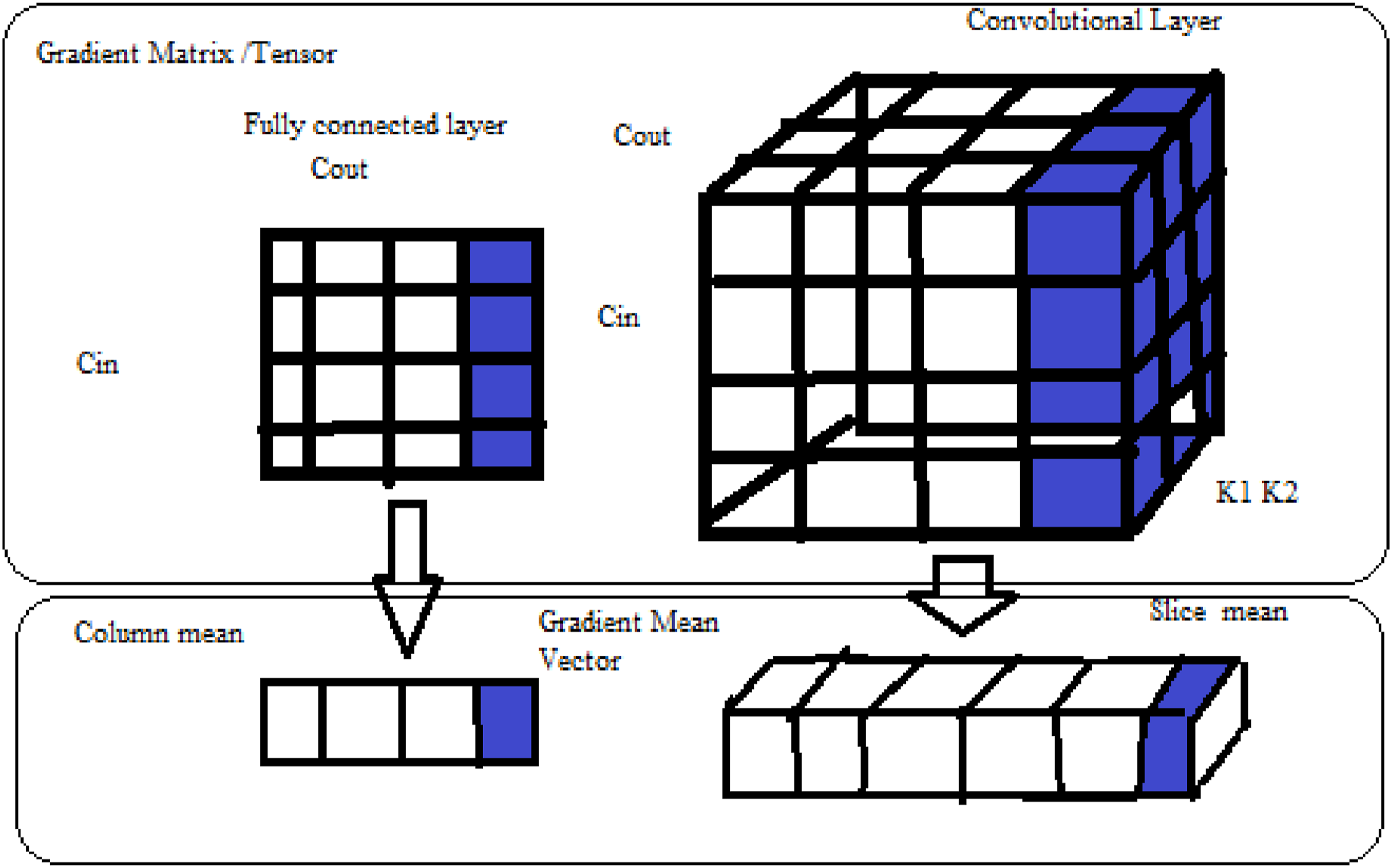
Formula of GC
Let Gradient of a weight vector obtained through back propagation for a Fully connected layer or Convolutional layer be 
Mean value of each column of gradient matrix is subtracted from its each column value. In this way each gradient of loss function w.r.t to weight vector is transform so that its mean becomes zero. computation of GC is quite simple and efficient. Matrix formulation of equation (1) is also given by:

Experimental result and discussion
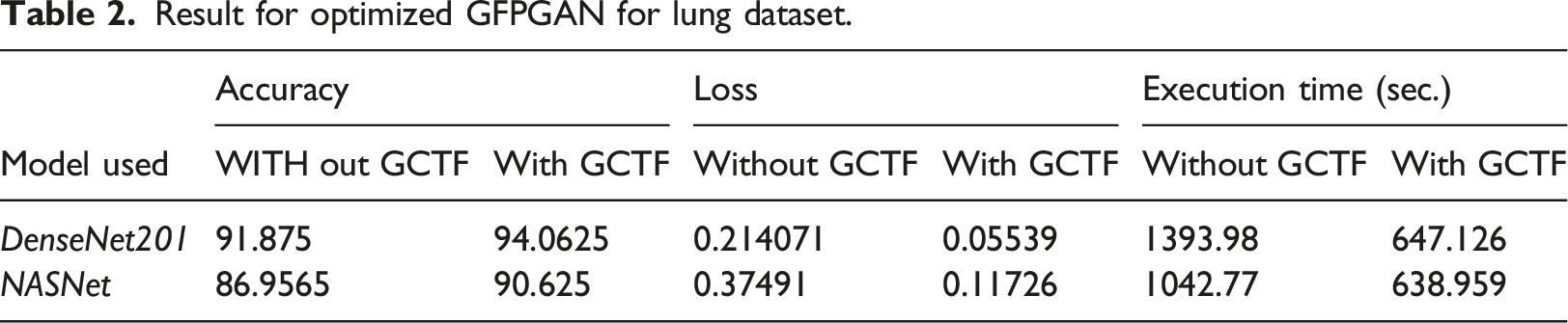
Result for optimized GFPGAN for lung dataset.
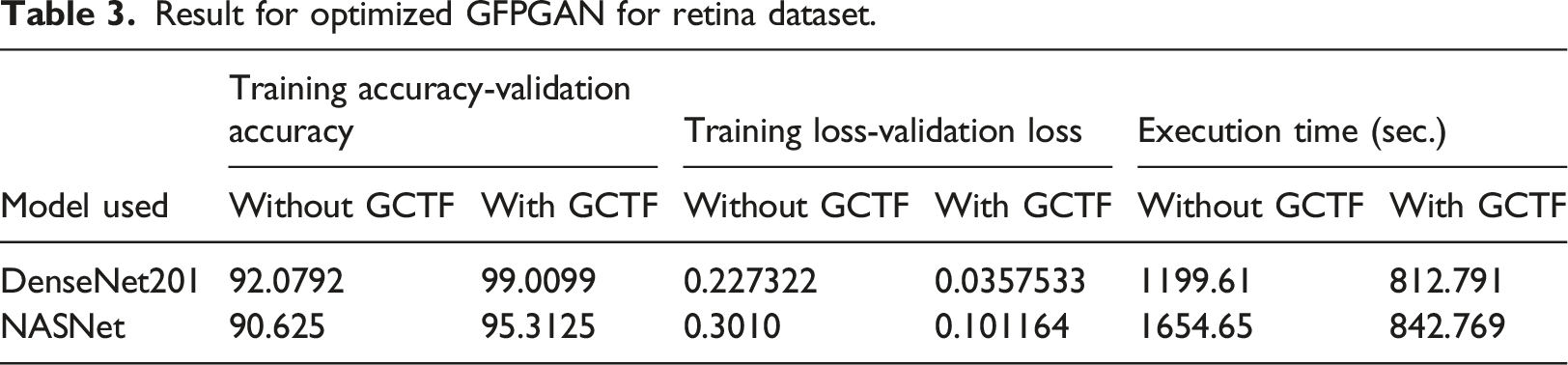
Result for optimized GFPGAN for retina dataset.
Result for optimized GFPGAN forskin dataset.
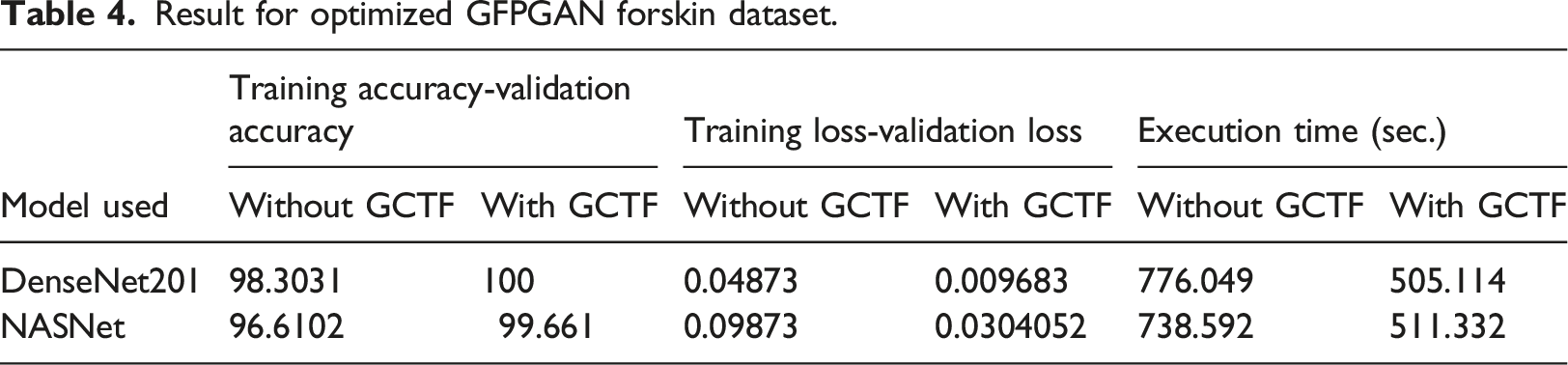
Enhancement in Accuracy has been observed for all three datasets but retina dataset responds remarkably better as compared to other datasets. Training loss has also been reduced which appends to our positive result. Improvement in execution time is the major break through achieved via this new optimizer algorithm. Significant reduction has been observed as clear from table. Our result supports the underlying principle of GC which states of accelerating the training process.
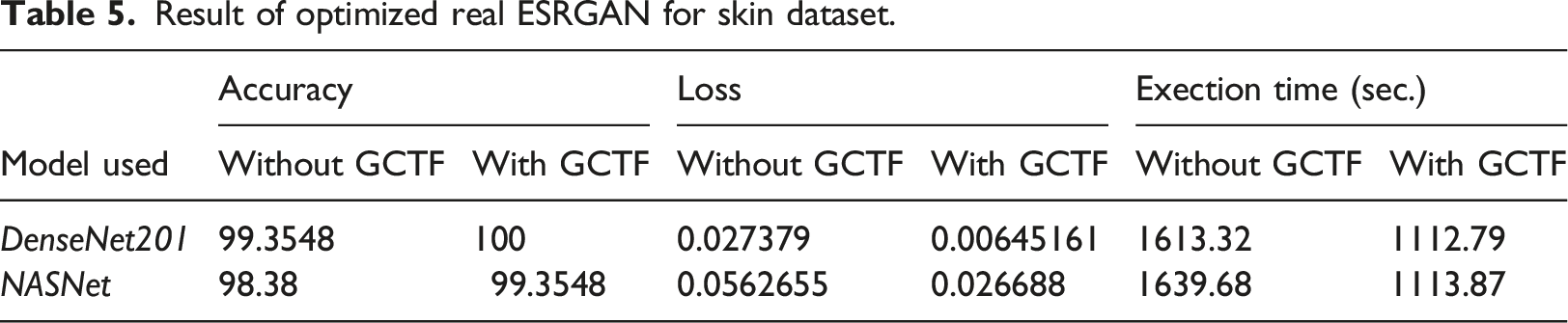
Result of optimized real ESRGAN for skin dataset.
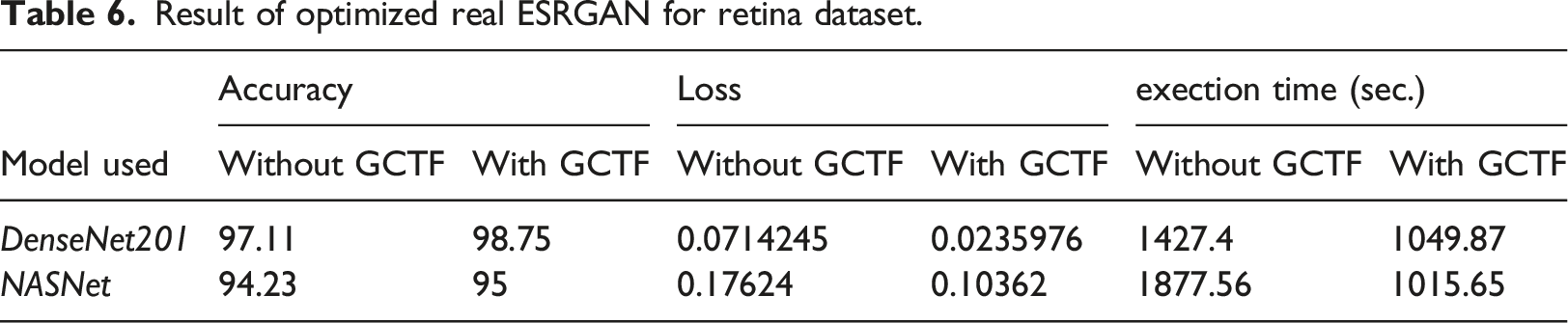
Result of optimized real ESRGAN for retina dataset.
Result of optimized real ESRGAN for lung dataset.
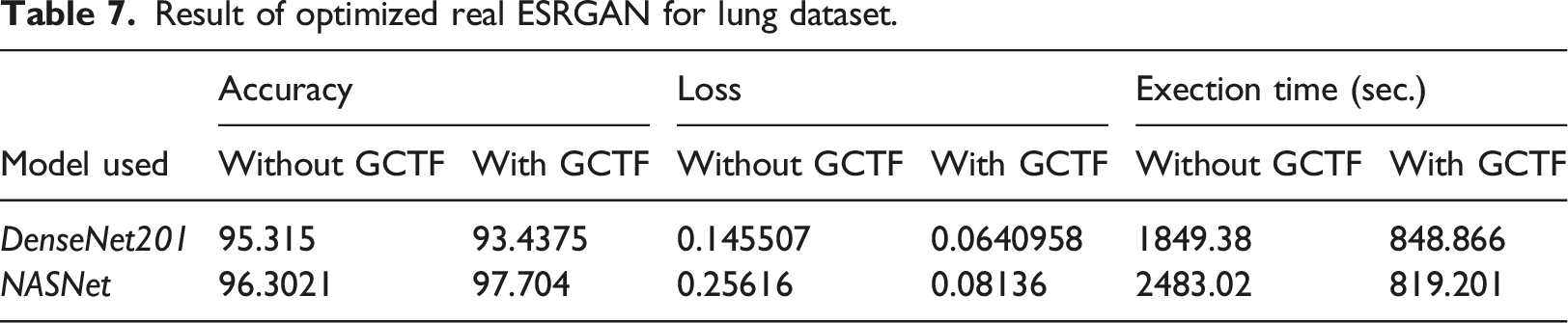
Upward trends are observed for integrated DenseNet 201 in terms of accuracy for skin and retina dataset but slight down trend is noticed for lung dataset which shows an deviation from our expectation. NASNet exhibit an similar trend for all three datasets. Training loss comes out with positive result and significant drop is observed for three datasets. Execution time too shows substantial drop which further strengthen the concept of imbibing this new optimized technique in our integrated model.
Evaluation of loss curve on imbibing Gradient Centralization technique for Dense net model pipe lined with Real ESRGAN and GfpGan for all three datasets: Retina, Lung and Skin brings out an interesting predictions as indicated by Figures 2–4 respectively as shown below: (a)Loss curve for real ESRGAN pipe lined DenseNet model for retina dataset (b) loss curve for GFPGAN pipe lined DenseNet model for retina dataset. (a)Loss curve for real ESRGAN pipe lined DenseNet model for lung dataset (b) loss curve for GFPGAN pipe lined DenseNet model for lung dataset. (a) Loss curve for real ESRGAN pipe lined DenseNet model for skin dataset (b) loss curve for GFPGAN pipe lined DenseNet model for skin dataset.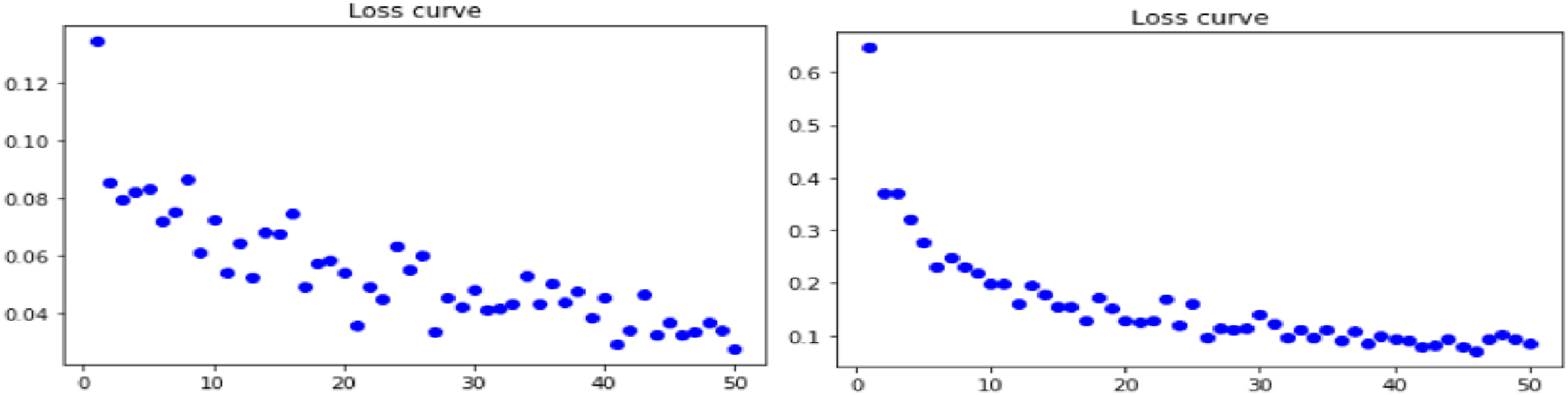
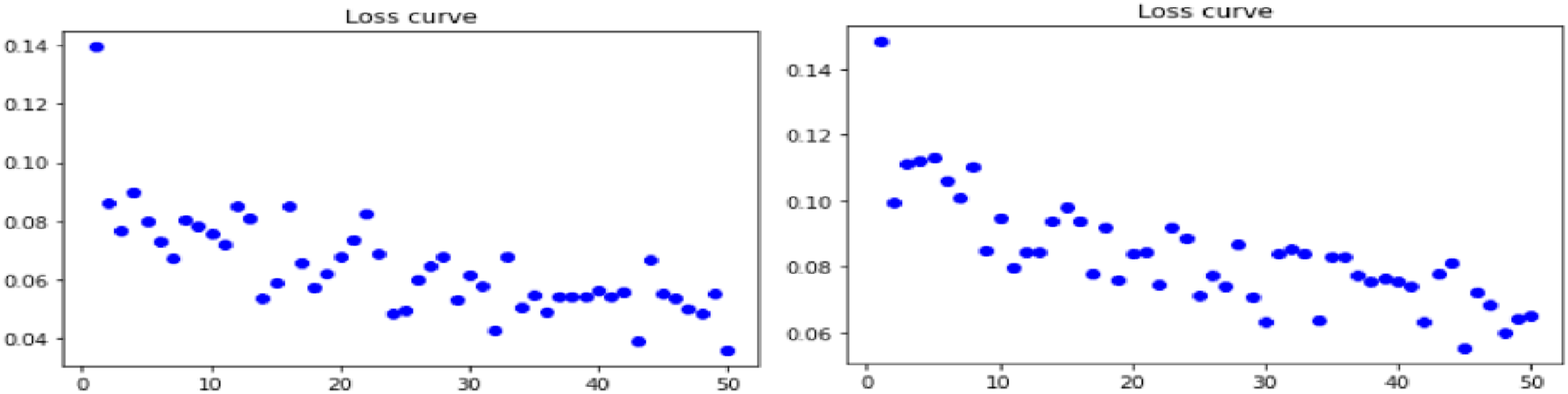
Experiments shows that DenseNet model when pipe lined with Real ESRGAN preprocessing technique for skin dataset gives optimum results for losses incurred during training which is 0.006451 and is minimum as compared with other combinations of dataset and technique.
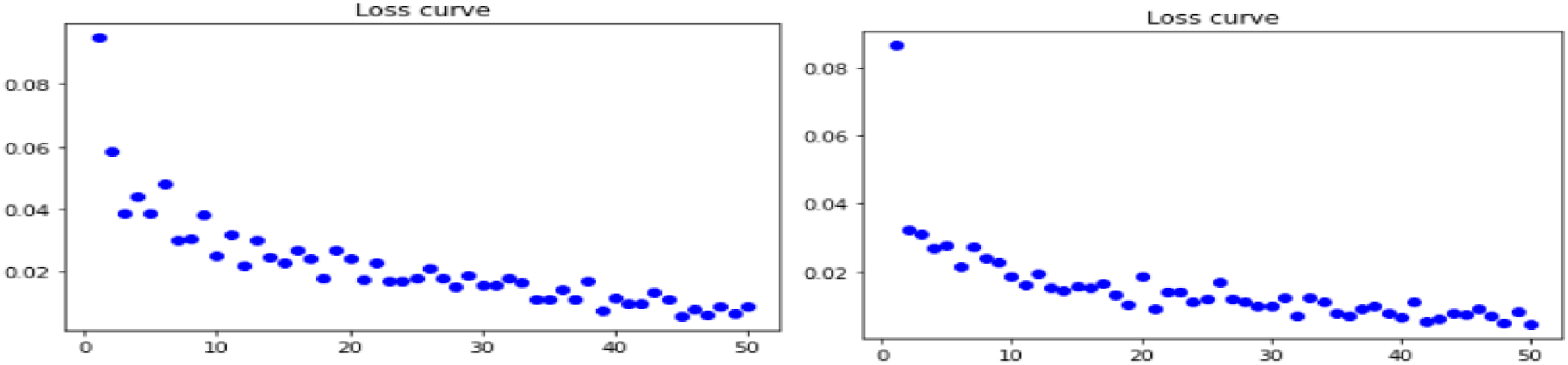
Loss curves for combination of Gradient Centralization with NASNet model pipelined with Real ESRGAN and GFPGAN technique are shown in Figures 5–7 below for all three datasets. (a) Loss curve for real ESRGAN pipe lined NASNet model for skin dataset (b) loss curve for GFPGAN pipe lined NASNet t model for skin dataset. (a) Loss curve for real ESRGAN pipe lined NASNet model for lung dataset (b) loss curve for GFPGAN pipe lined NASNet t model for lung dataset. (a) Loss curve for real ESRGAN pipe lined NASNet model for retina dataset (b) loss curve for GFPGAN pipe lined NASNet t model for retina dataset.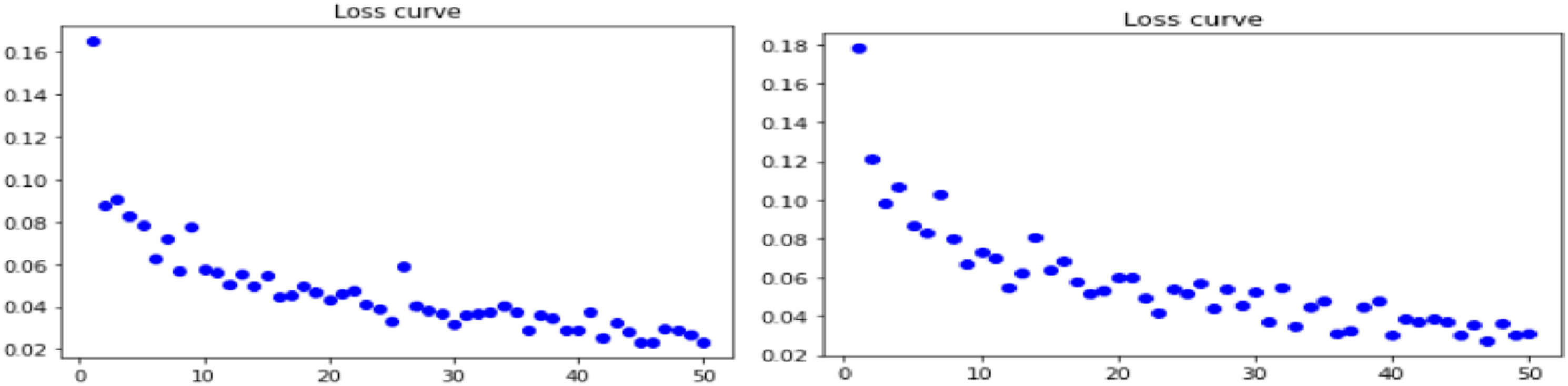
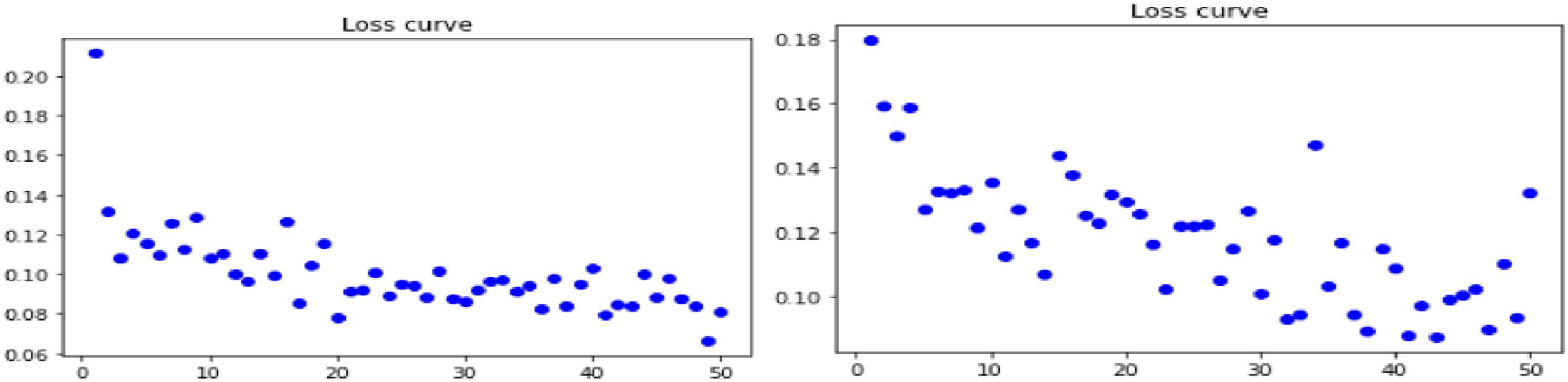
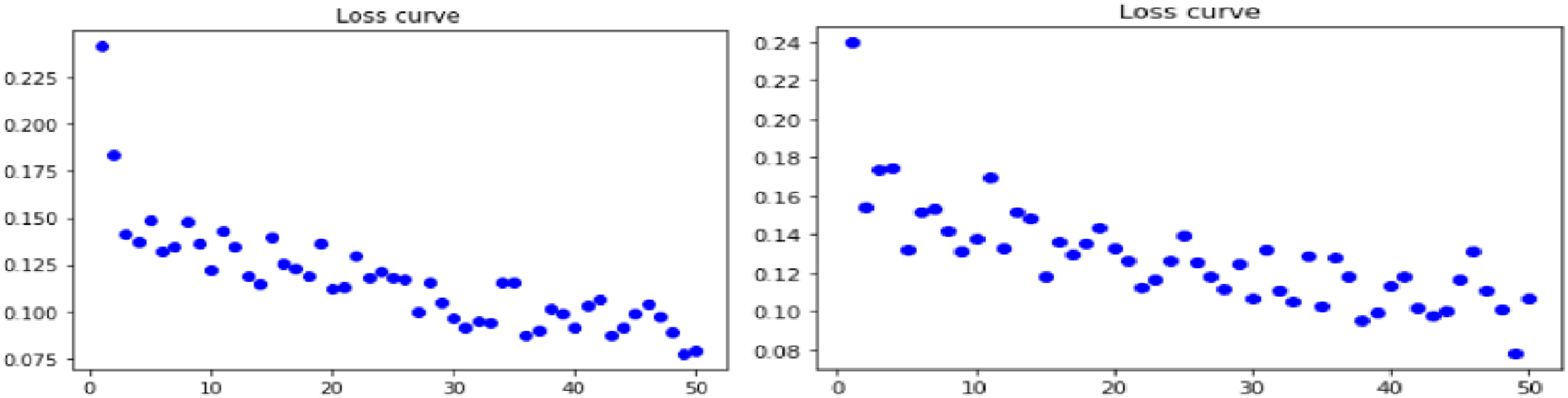
Smooth loss curves are observed for skin dataset when NASNet pipe lined with Real ESRGAN is employed with GC is used. Though downward trend is shown by all datasets with both the preprocessing techniques but integrated Real ESRGAN with GC shows better result than GFPGAN.
Future work and conclusions
Our research work explores the Gradient Centralization optimization on integrated deep architecture using NASNet and DenseNet as base models. We get motivating results for parameters like Training loss and execution time. Reduction in execution time is a pertinent outcome achieved in our research work. Though Training accuracy was slight down for DenseNet in lung database but others parameters shows, this inculcation of new optimization technique, a significant step towards optimizing the performance of deep learning architecture for Medical Image analysis. In future, various other permutations can be explored like using other deep learning model like Resnet, Mobile net etc.We have embedded Gradient Centralization with Rms prop optimizer to carry out our experiment. Other optimizer like Adam, SGDM can also be used to embed Gradient Centralization. We have used Real ESRGAN and GFPGAN preprocessing integrated model and taken Skin, Lung and retina datasets. Analysis can also be carried out by advanced preprocessing technique like Swin transformers which basically require more GPU. Wide Spectrum of Medical dataset for experimentation can also be increased to evaluate effect of this new integrated approach.
Footnotes
Acknowledgements
We want to thank Graphic era hill university for their efficient support regarding this study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.