
Abstract
Maintenance of computer-interpretable guidelines is complicated by evolving medical knowledge and by the requirement to customize content to local practice settings. We developed a framework to support knowledge engineers in customization and maintenance of computer-interpretable guidelines specified in the PROforma formalism. In our layered approach, the computer-interpretable guidelines containing the original clinical guideline serves as the primary layer and local customizations form secondary layers that adhere to its schema while augmenting it. Java code unifies the layers into a single enactable computer-interpretable guidelines. We performed a pilot experiment to verify the effectiveness of a layered framework. In this first attempt, we evaluated the hypothesis that the layered computer-interpretable guidelines framework supports knowledge engineers in maintenance of customized computer-interpretable guidelines. Participants who used the layered framework completed an update process of the primary knowledge in less time and made fewer errors as compared to those using the single-layer framework.
Introduction
Clinical practice guidelines (CPGs) include evidence-based recommendations intended to optimize patient care.1,2 Representing them formally as computer-interpretable guidelines (CIGs) 3 allows their enactment, delivering to the user patient-specific recommendations at the point of care. This increases the potential to impact clinicians’ decision-making. 4
Sharing CIGs could reduce development costs while providing consistency in guideline interpretation and potentially reducing variability in clinical practice.5,6 Some professional societies, such as the American Association of Clinical Endocrinologists, have developed, shared and published CIG versions of their narrative guidelines. 7
However, implementation of CIGs could be improved if they are adapted to the local settings of the implementing organization. 8 As discussed in Boxwala et al., 8 local settings may differ in many respects, including (1) delivery platform (e.g. Smartphone), (2) type of user and his or her mode of interaction with the system (e.g. patient users interacting asynchronously with the CIG to receive advice based on their self-monitored data), (3) practice environment (e.g. hospital, home), (4) resource availability, (5) local policies that may result in preference of specific treatment options, (6) differences in the physical environment (e.g. climate) or (7) differences in patient population, including comorbidities and patient preferences. In order to create local versions, the CIG should be customized 9 to the new context by including additional knowledge.
But CPG evolve due to the expanding clinical knowledge. Such changes should be translated into the locally adapted CIG. Approaches for CIG versioning-support focus on implementing data structures for efficient management of CIG versions,10,11 natural language processing to aid knowledge engineers in identifying updated text in a revised clinical guideline and formalizing it as CIG elements, 12 or visualization of changes made to a CIG in a newer version. 13
The aim of our approach is to support guideline modelers in the task of CIG specification and specification revision in the presence of local adaptations. We present the layered CIG framework and the results of a pilot experiment to verify the effectiveness of the layered framework. The layered model separates the specification of guideline local adaptations into secondary layers that are coordinated with the primary CIG representing the original clinical guideline.
While the layered model could be used with different CIG formalisms, 3 we implemented it within the PROforma 14 CIG formalism using PROforma authoring and enactment tools. PROforma has rigorous foundations in cognitive science and software engineering 15 and was designed for use in safety critical situations. 16 It is one of the most highly cited CIG languages and it has been used to develop applications that have been deployed by commercial companies at scale in several countries.
The layered CIG model
Because local-adaptation knowledge is not necessarily evidence-based and not necessarily within the focus of all potential organizations, we partition the CIG knowledge into a primary layer and a secondary one. These can represent different considerations of decision making, for example, clinical goals (primary) versus quality-of-life goals (secondary); goals related to the main disease (primary) and its comorbidities (secondary); goals provided by guideline authors (primary) and those dictated by an implementing organization (secondary) and so on. This separation can help modelers during CIG customization by choosing the primary layer corresponding to the evidence-based CPG and combining it with the one or more relevant secondary layers that are considered for a specific implementation.
The layers are coordinated, yet changes to evolving layers could be made to each layer separately and in parallel, depending on which knowledge has evolved. To minimize the variation between the structure of the primary CIG and its future versions, we assume that it is structured in a flexible and abstract way, considering clinical goals and using design patterns 17 that introduce modularity to minimize changes in structure due to expanding medical knowledge. 13 The primary CIG typically starts with a choice of suitable clinical goals, followed by decisions for selecting among candidate actions. Order is imposed only for establishing that patient data needed to evaluate decision arguments are available.
A class diagram describing the conceptual model of the two-layered decision-model is provided in Figure 1. The primary layer of the model is inspired by the PROforma 14 CIG formalism. The primary layer specifies the task network, including its scheduling constraints, the decision candidates, their clinical arguments (which include decision criteria that refer to primary data items and the numerical support for each argument) and primary data items.
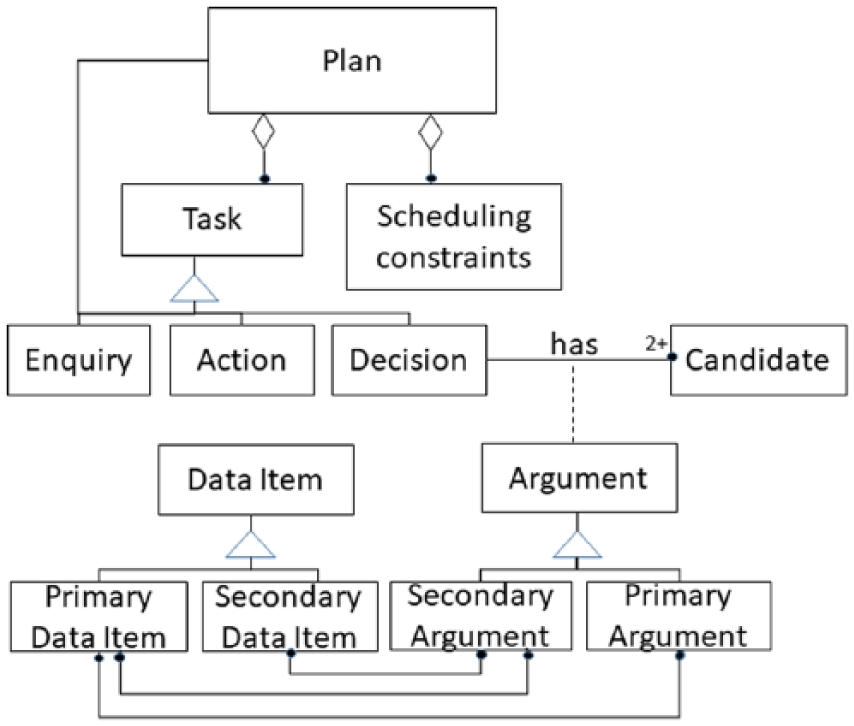
A conceptual model of the layered CIG model.
Figure 2 shows the primary layer CIG for an Asthma guideline. 18 Its first decision concerns the treatment goal whose candidates are an aggressive or basic goal. Three subsequent decisions are made, once a goal has been decided upon: medication type, dose and frequency. A special plan concerns cases where the number of monthly attacks is greater than 20.
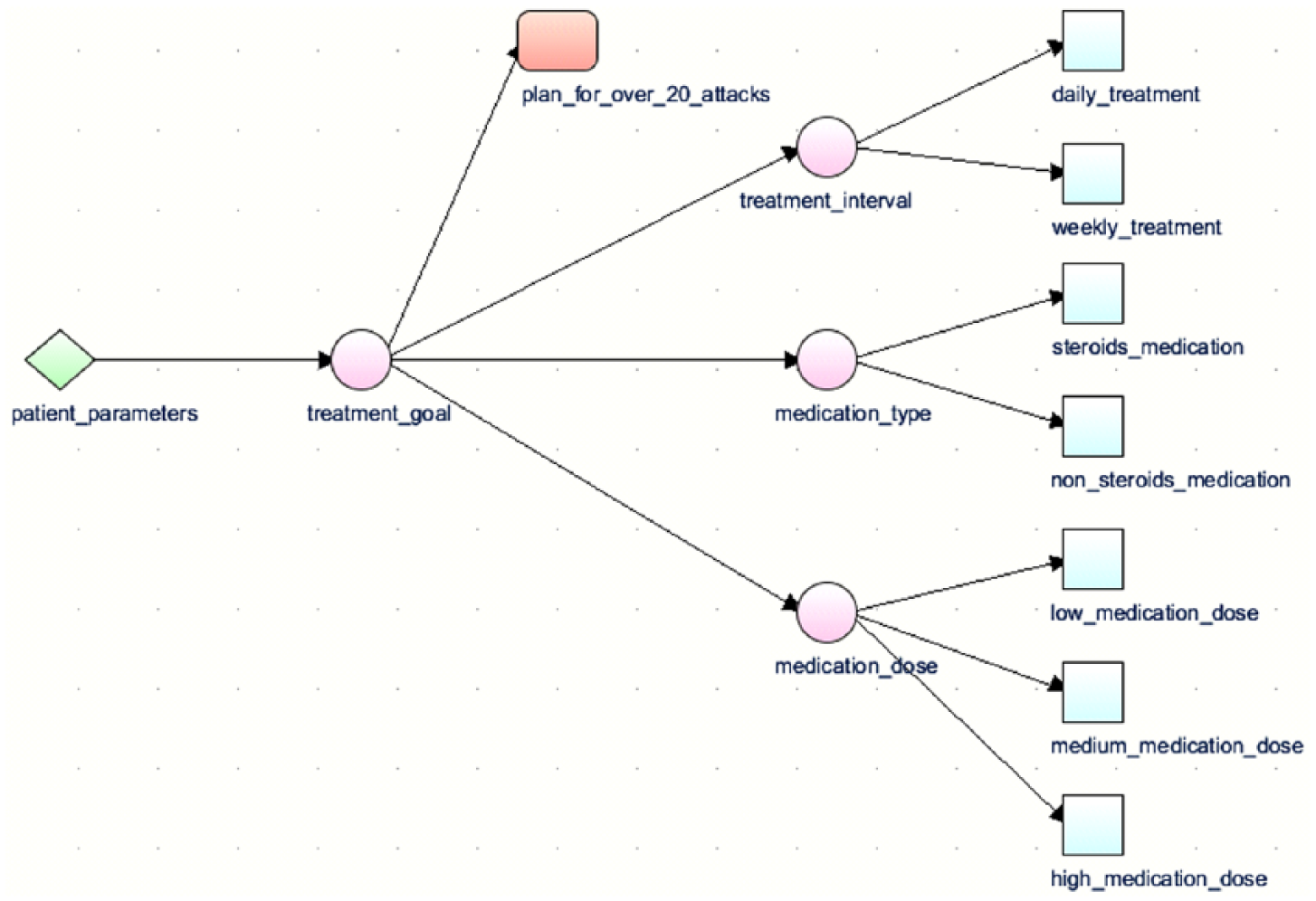
PROforma asthma CIG.
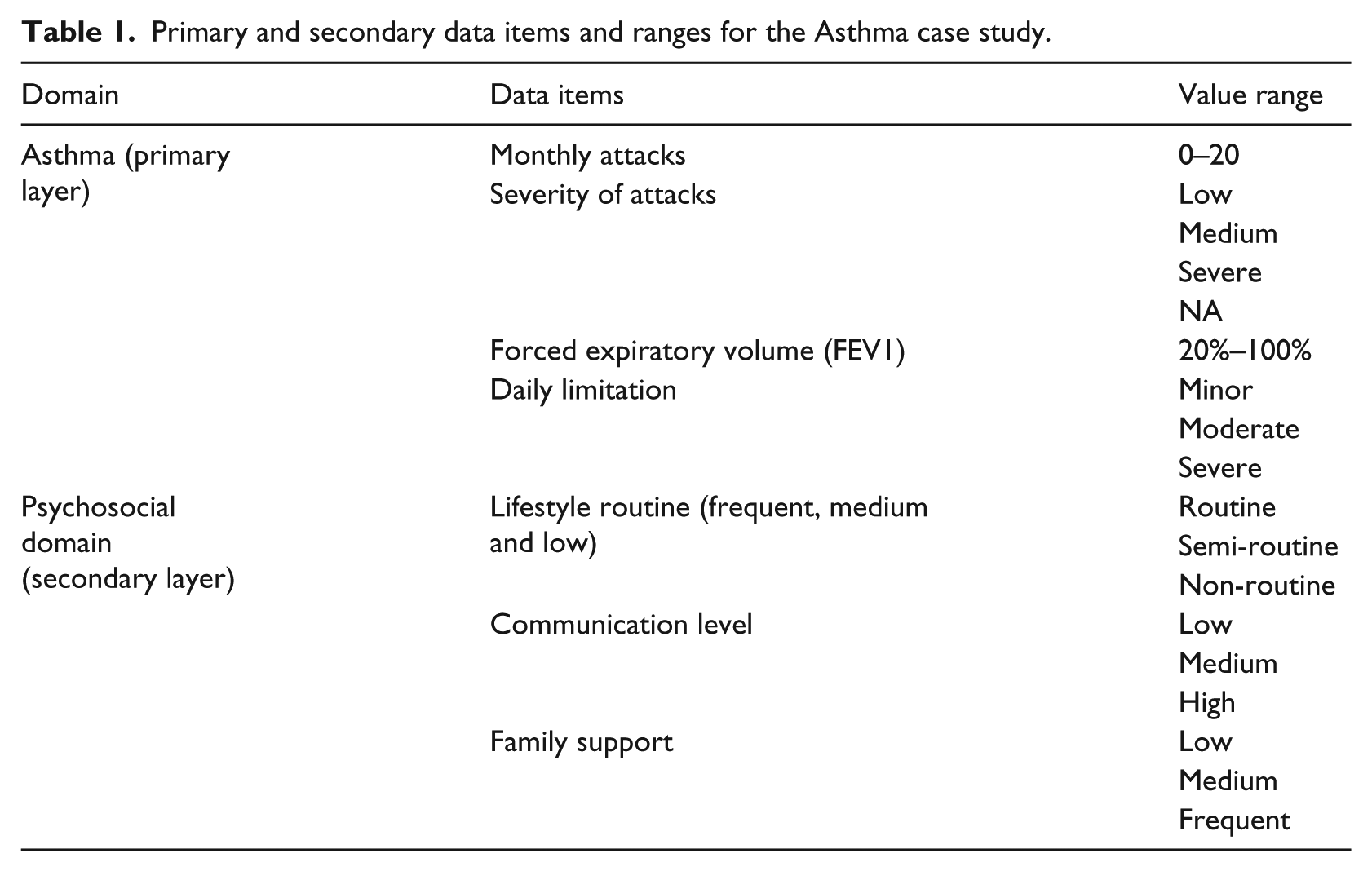
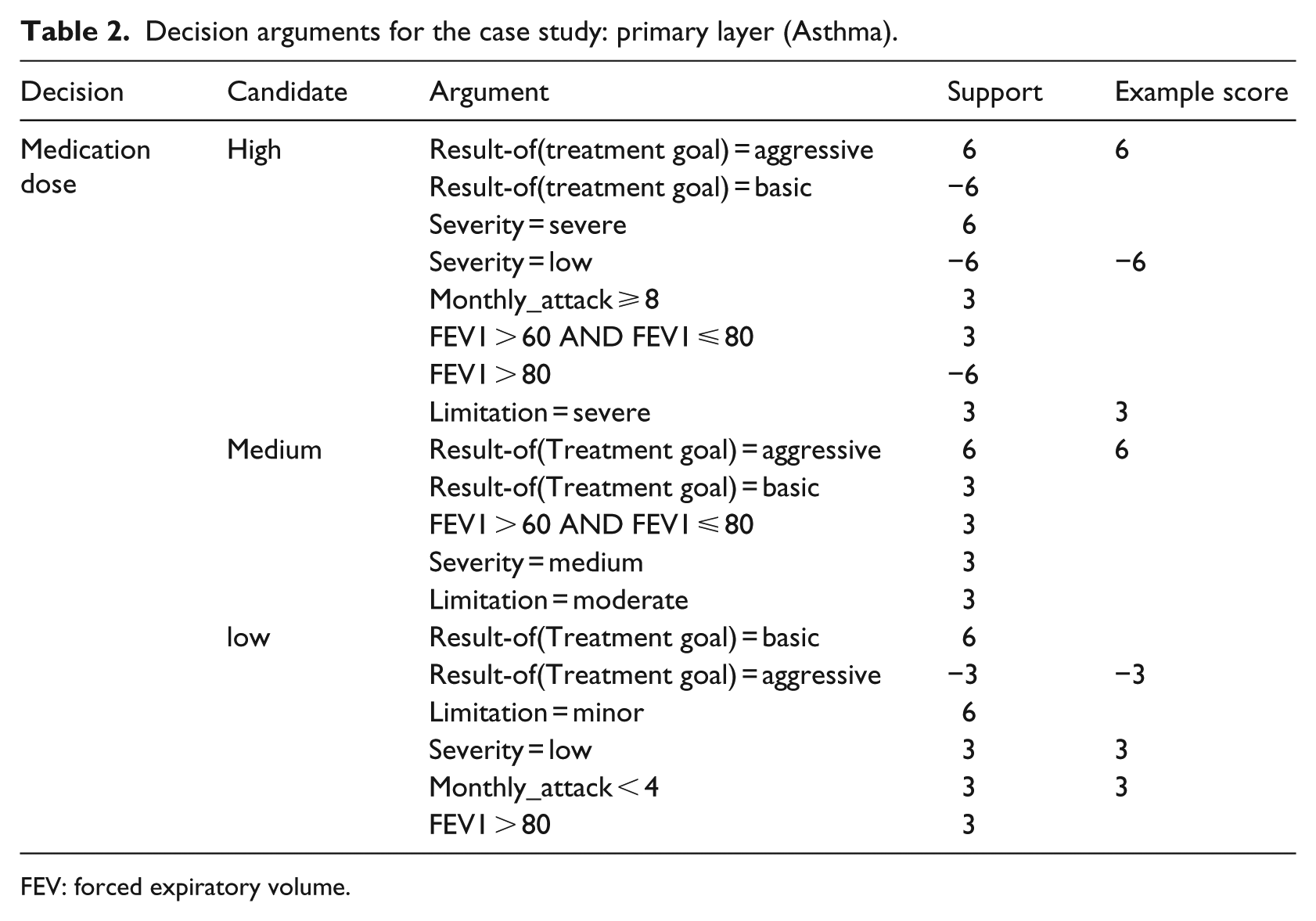
The top part of Table 1 presents the primary data items. They include the number of the asthma attacks per month, the severity of attacks, the forced expiratory volume (FEV1) and the degree of daily limitation. Table 2 presents the primary arguments for the candidates of the decision on medication dose. For example, the medium medication dose is supported (+6) by previous selection of the aggressive treatment goal (i.e. “result-of(treatment goal) = aggressive”).
Primary and secondary data items and ranges for the Asthma case study.
Decision arguments for the case study: primary layer (Asthma).
FEV: forced expiratory volume.
Secondary layers refer to the primary layer’s decisions and add arguments based on secondary data items; unlike primary data items, secondary data items are not contained in the primary CIG but are added due to local adaptation (e.g. they may address psychosocial attributes of the patient or refer to his comorbidities). Only secondary arguments may refer to secondary data items. Secondary arguments may also refer to primary data items. Secondary arguments may impact the support for decision candidates, which impacts their potential ranking (for a patient’s case).
Based on the conceptual model, we define the Primary Layer and Secondary Layer as follows.
Primary Layer—a Plan that has some Decision-Candidate Arguments, all of which are Primary_Arguments;
Secondary Layer—A set of Secondary_Arguments and their Secondary_Data_Items that are associated with the Decision Candidates of a given Primary_Layer.
Formally, let
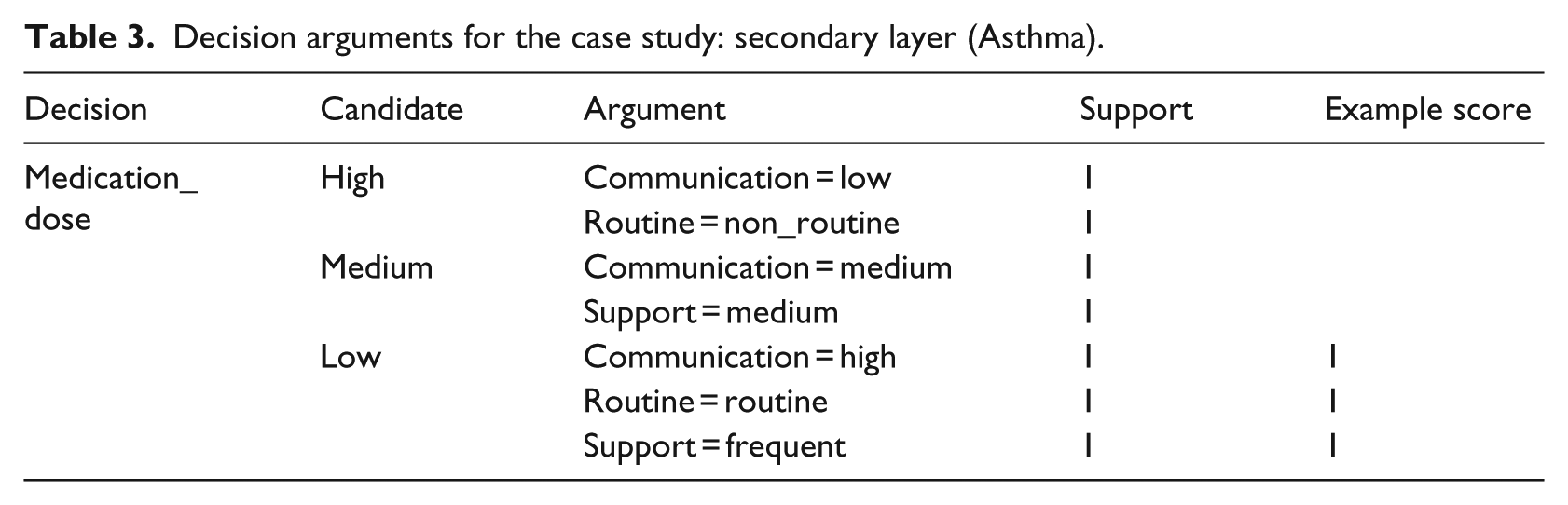
The secondary locally adapted layer of the asthma CIG includes a set of arguments for the decision of the primary CIG, which refer to secondary data items taken from the psychosocial domain. These data items were not mentioned in the asthma CIG, but are being used by the physicians in the organization that has locally adapted the asthma guideline. The second part of Table 1 presents the secondary data items: the patient’s degree of routine, his communication level and level of family support. Table 3 presents the secondary arguments for the candidates of the decision on medication dose.
Decision arguments for the case study: secondary layer (Asthma).
Modeling CPGs and their local adaptation using the layered model
The support given to arguments affects the ranking of decision candidates, hence they should be carefully selected. In Guyatt et al., 19 the authors have used a weighting scheme that provides larger weight to arguments against decision candidates. In their case, evidence grades were not available in the CPG. In our approach, the support for primary arguments is initially selected from values that are spaced out to reflect grades of evidence, based on the levels of recommendation used in the primary guideline. For example, in CPGs that use two grades of evidence, 20 the values used are: +wp, +2wp, -wp, -2wp, providing support for positive or negative recommendations with a weight of wp or 2wp. If more grades are used, then the higher grades have higher weights.
Furthermore, in our layered approach, primary arguments, which address data items that are part of the primary guideline, by design should outweigh secondary arguments, which are based on data items not mentioned in the clinical guideline (see details in the next section). Thus, the scale of support for secondary arguments should be more granular than that used for the primary arguments. Therefore, the support for secondary arguments also use the same number of grades, but use different weights, which are smaller than those used in the primary layer. For example, as shown in Tables 2 and 3, the support values for primary arguments are ±3 or ±6, whereas the support for secondary arguments is ±1. The support values are determined by local clinical experts, allowing to modulate the net support for each candidate decision option.
Using verification to correct the support of decision-candidate’s arguments
In Wilk et al., 21 we demonstrated how constraint logic programming can be used to verify the layered model for two important properties:
Secondarity property: Secondary arguments should only modulate existing primary recommendations, while not suggesting recommendations that are not clinically indicated. Modulation includes re-ranking of decision options, changes in dose or frequency of treatment or monitoring and changes in treatment or monitoring schedule. In this work, we address re-ranking of decision options.
Completeness property: for any valid combination of primary and secondary decision-parameters (data items and results of previous decisions), at least one recommendation is indicated. This property guarantees that the customized CIG would not encounter a situation where no valid candidate exists.
In Wilk et al., 21 we provide a constraint-logic-programming (CLP) verification framework that validates these two properties for layered PROforma CIGs. If any violation of the secondarity property is detected, it can be resolved by changing the scale of the support such that the secondary arguments will not outweigh the primary ones. Violations of the completeness property can be handled by adding constraints regarding valid combinations of data items. CLP is used to adjust the weights of the arguments, which were defined by local experts, such that appropriate support weights are selected for arguments that will not violate the secondarity property.
Enactment of CIGs represented using the layered approach
Once a CIG has been modeled using the layered approach, its two layers can be unified into a single-layer CIG using a Java program that we have developed. This allows verification (section “Using verification to correct the support of decision-candidate’s arguments”) and enactment of the CIG using standard tools. Because the secondary layer has the same decisions as the primary layer, but contains additional arguments and data items, it is straight forward to add these data items and arguments automatically into the primary CIG, resulting in a unified single-layer CIG. Note that the two layers are unified by the java tool “at execution time” only to show a unified CIG to users. However, they are kept separate by the system, to allow future updates.
Single-layer PROforma CIGs can be enacted using enactment engines such as Tallis (http://archive.cossac.org/tallis/index.html) used in our study. In the following, we demonstrate how secondary arguments can switch the preferred choice from medium to low medication dose. Considering only the primary data items and arguments taken from the asthma clinical guideline, picture a patient for which the preferred treatment goal is “aggressive,” whose FEV1 = 50 percent, whose severity of the asthma attacks is low, whose daily limitation is severe and who has number of monthly attacks = 3. For this patient, the total support of the medium medication dose would be the highest (+6) compared to support of (+3) for each of the other two dose candidates (low and high). However, depending on the values of secondary arguments, the preferred candidate may change to the low dose. For example, if the patient’s communication level is high, his daily routine is routine and his family support is frequent, low medication dose would also have total support of (+6). The support of the two other candidates would not change. Hence, both the medium and the low medication doses would be recommended at the same level of support (+6). The rationale for the change of recommendation for patients with these psychosocial characteristics is that such patients could be trusted to comply to treatment recommendations and to report to the physician if there is any deterioration in their state; this allows the physician the possibility to start with a low dose, which hopefully may be enough to achieve the aggressive goal. Because the patient’s profile indicates a responsible patient, then if the low dose will not suffice, the dose will be changed to medium. However, for patients who are not as responsible, it is safer to apply the medium dose initially.
Evaluation methods
During the maintenance of CIGs, errors may occur. We conjectured that using the layered model can ease maintenance of locally adapted CIGs, when a new CPG version is released. We considered changes that involve just the primary layer, representing new clinical knowledge rather than changes in local settings. Due to feasibility considerations, we performed a pilot evaluation study with 30 advanced information systems students, who are being trained as information system analysts/knowledge engineers. The hypotheses for the study were:
Participants perform more correctly (fewer errors) when using the layered CIG model, in tasks in which these two models differ (deleting and updating logical arguments).
In tasks in which there is no difference between the layered and single-layered CIG models (addition of arguments, addition or deletion of data items), there is no difference in correctness (the number of specification errors in the customized CIG is the same).
Using the layered CIG model reduces update time.
Two-sided Wilcoxon rank-sum test (at a significance level of 0.05) was used to compare the groups on two measures taken pre-intervention, in order to verify no baseline differences between groups: in terms of their understanding of the underlying PROforma model (the single-layered model), upon which the layered model was developed) and the time it took them to understand a PROforma model. The students’ understanding was assessed by evaluating their ability to correctly map a set of narrative guideline recommendations to PROforma arguments found in a single-layered PROforma specification.
Participants’ background
The experiment took place during the year 2015 as part of the course “Knowledge Representation and Decision-Support Systems,” an advanced elective course in the Information Systems undergraduate program at the University of Haifa. The procedures followed were in accordance with the ethical standards of the University of Haifa’s committee on human experimentation. The 30 participants were undergraduate students in their last year of studies (N = 25) or graduate students (N = 5).
The Knowledge Representation and Decision-Support course covers knowledge-representation methods including rule bases, ontologies, first-order logic and Bayesian Networks.
To make the two groups comparable, the students were matched with respect to relevant potentially confounding variables that captured their background and skills, including (1) their year of study (either graduate school or third or fourth year for undergraduates); (2) their current grade-point average (75–92); (3) their performance level on homework (high, medium or low); (4) their class attendance record; (5) their first language (Hebrew, Arabic or Russian) and (6) their prior knowledge of the diabetes domain, which was used in the experiment.
Participants’ training
As part of the course, the participants were given a 1 h introduction to CIGs, followed by a set of tutorials that had a similar design to that of the experiment, which took place 3 weeks after the tutorials. The experimental design is shown in Figure 3.
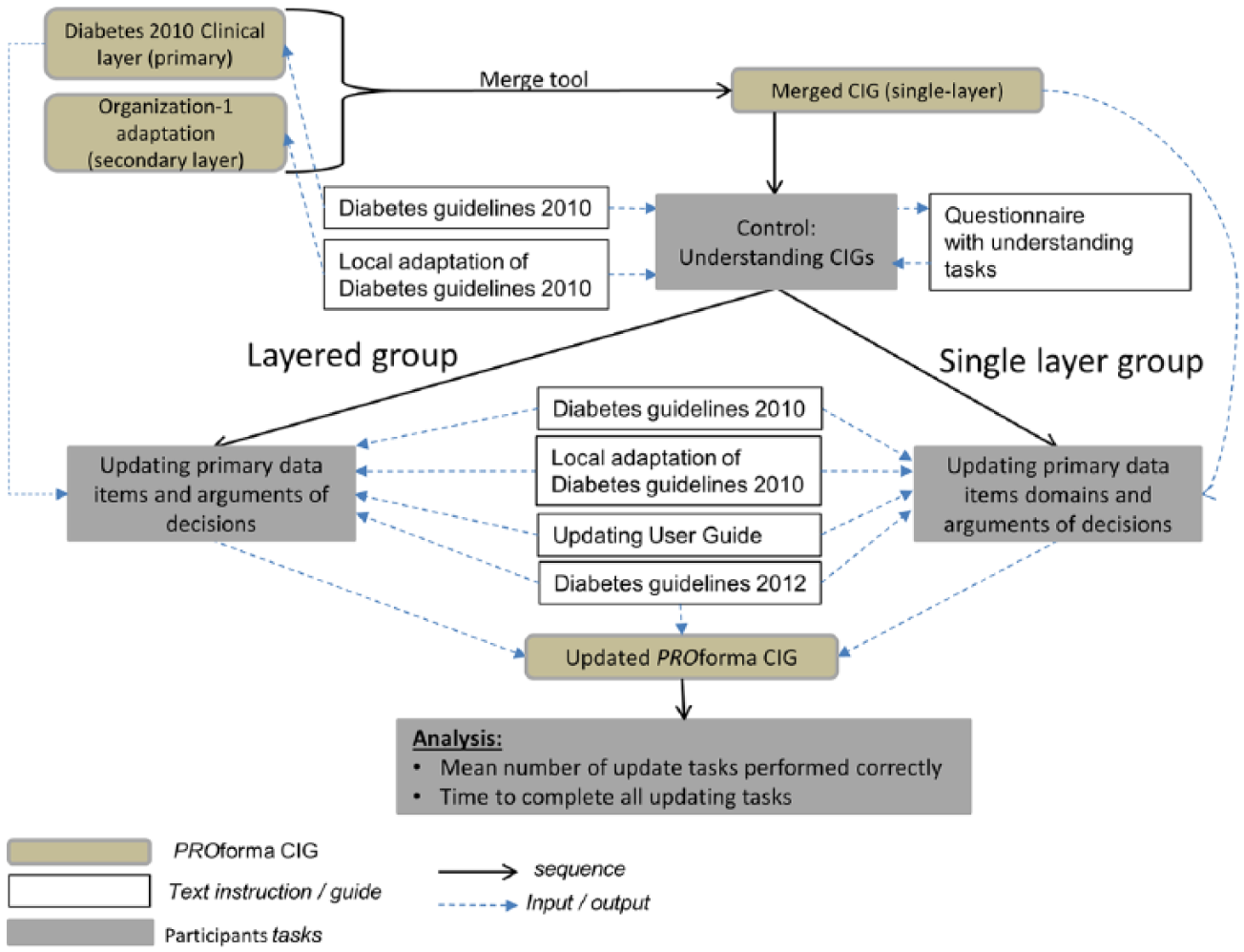
Experimental design.
The first part of the tutorial included a 3 h lab using the Tallis tool. The goal of this tutorial was to achieve an understanding of PROforma and its single-layered decision model. The tutorial was similar to the control part of the experiment. The participants received the narrative 2010 Diabetes CPG, 22 its narrative 2010 local adaptation and a questionnaire with a set of tasks that tested their understanding of the PROforma language. Three tasks presented excerpts from the CPG (two tasks) or its local adaptation (one task) and asked the participants to map CPG recommendations into PROforma decision-candidate arguments. Participants specified the arguments as rows in a table, such as Tables 2 or 3. To do that, the participants examined the recommendations from the CPG and located them as decision-candidate arguments in the PROforma CIG, using the Tallis tool. They were asked to copy the arguments’ IDs and their level of support. Then, the participants were asked to calculate the net support for each decision candidate for a patient who has a given set of data item values.
After 3 weeks, a 1 h tutorial on CIG updating was given to the entire class at the computer lab, using the Tallis tool. While in the experiment, the knowledge that changed was primary knowledge, this tutorial demonstrated a change in the local knowledge. The students performed the same set of update tasks in the cases of the tutorial and the experiment. In this tutorial, both groups received in addition to the 2010 Diabetes CPG and its 2010 local adaptation by organization 1, the 2012 local adaptation version of the CPG. To make the changes in the 2012 version more apparent, deleted parts were crossed out, parts that remained the same were grayed out and parts that were new were bold. The students also received an updating instruction guide, which specified the actions that should be carried out in order to update an earlier PROforma CIG version (See supplemental Appendix 1).
After the tutorial was completed, the participants were divided into two groups, based on their pairing, and half of them moved to an adjacent computer lab. Both groups had an additional half-hour tutorial in which they had practiced CIG update tasks. In the first 10 min of this tutorial, one group was exposed to the layered model and practiced updating one of the layers (the local adaptation layer). Both groups practiced using the 2012 update of the 2010 locally adapted CIG knowledge; for this part of the tutorial, the local adaptation by a different organization (organization 2) was considered.
Experimental design
As in the tutorials, the first part of the experiment was a control step that assessed the participants’ ability to understand the PROforma formalism. All participants used the single-layer model.
The second part of the experiment was carried out in the two computer labs that were used for the CIG update training. All participants were asked to update the 2010 CIG, based on the 2012 version of the diabetes CPG. 23 One group received the single-layered PROforma CIG for the local adaptation (of organization 1) of the 2010 diabetes guideline, and the paired group received the layered CIGs: generic 2010 CIG and the local adaptation of this CIG. The latter did not play a role in the experiment, as participants of the layered group had to update just the generic 2010. In addition, all participants received the generic 2010 diabetes CPG and its newer generic version of 2012. As in the tutorial, to make the changes in the 2012 version more apparent, deleted parts were crossed out, parts that remained the same were grayed out and parts that were new or modified were presented in bold. Supplemental Appendix 2 presents the experiment’s CPGs and questionnaires.
The amount of time allocated to perform the control and the intervention part of the experiment was 90 min each, while all participants completed the tasks in less time.
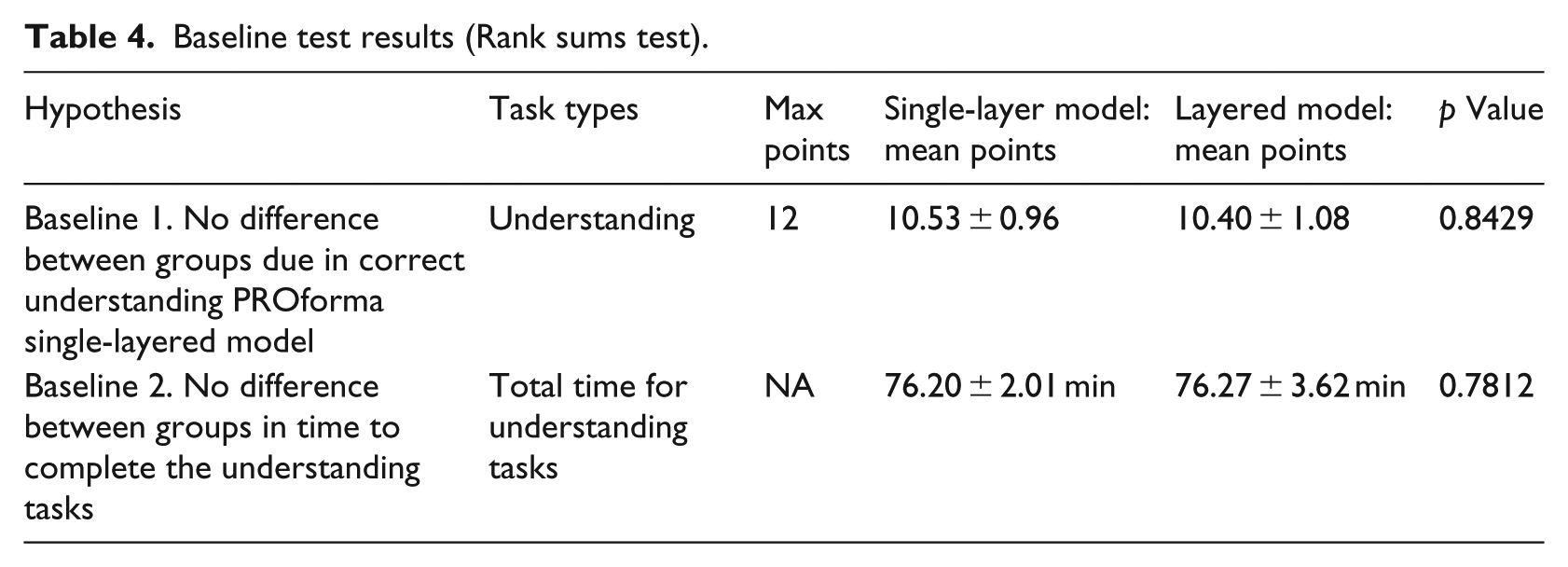
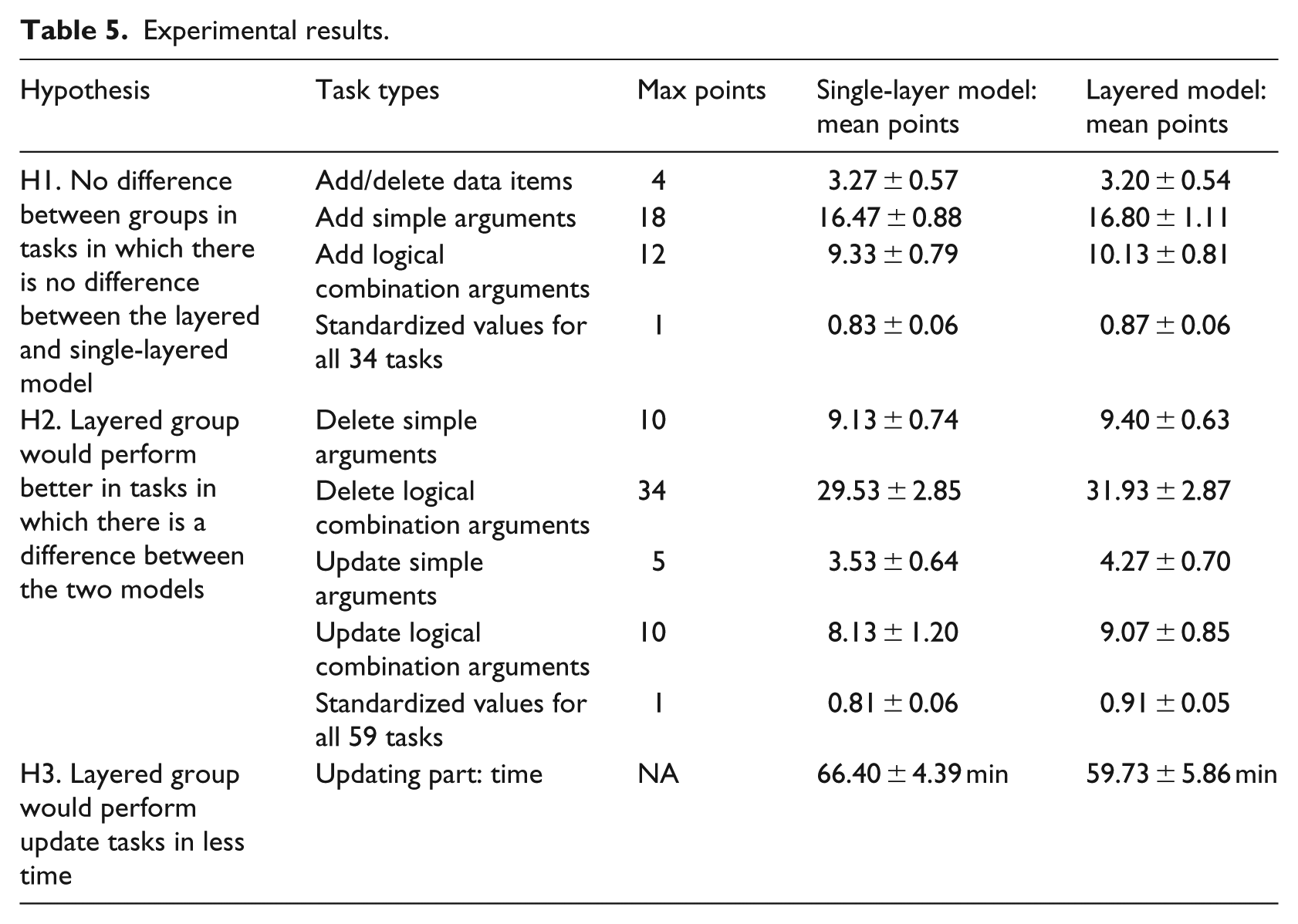
Based on the three hypotheses presented at the beginning of this section, specific tasks with repeats were defined for the baseline hypotheses (Table 4) and the experiment hypotheses (Table 5). Figure 4 shows an example of how three tasks were done deleting arguments that refer to a specific data item, a task that was different in the two models, and deleting a data item—a task that was done in the same way in the two models. Because fewer data items are included in the layered model, this reduces the probability of errors when deleting arguments from the layered model.
Baseline test results (Rank sums test).
Experimental results.
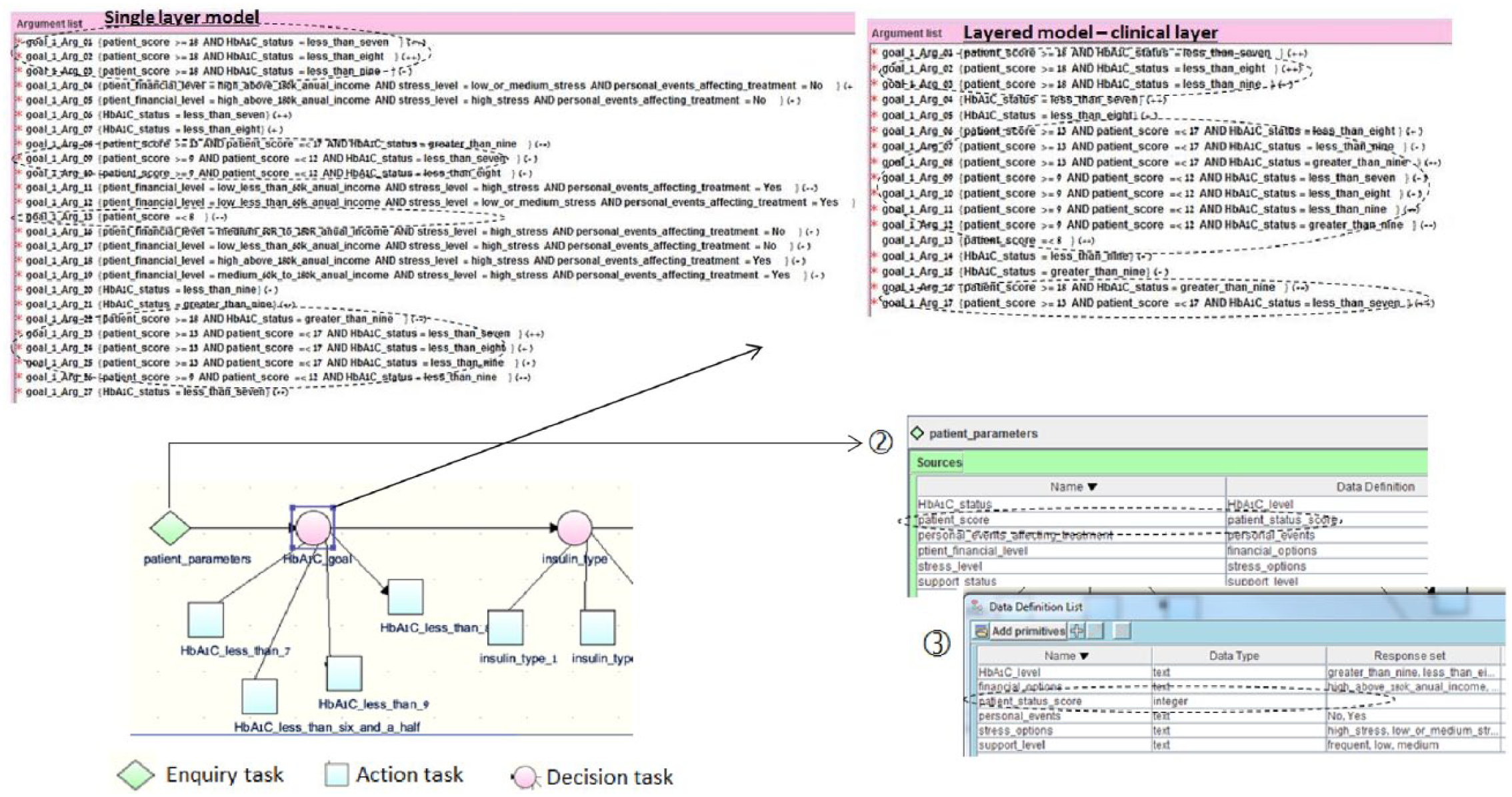
Deleting “patient score” data item in the single-layer and layered CIGs (when updating primary knowledge and a secondary local adaptation exists). This involves three tasks. (1) Deleting simple and logical combination arguments that refer to this data item, shown within ovals, and deleting the data item by (2) removing data item from the enquiry task and (3) deleting the data item from the data definition list. The only difference between the single and layered models is in (1).
Data analysis
When grading the tasks, each iteration of a task received one point. No points were awarded for partial completion of iterations. We standardized the results by calculating for each participant the ratio of points awarded divided by maximum points possible, for each type of task. We then calculated the average ratio for each student for all tasks within a hypothesis.
Due to logistic constraints, we did not pair students in the two groups by age and gender, and these two variables could have affected the results in addition to the effect of the model type (single-layered or layered; the single-layered group had 40% male students and the mean age was 26.0 ± 3.0. The layered group had 60% male students and a mean age of 26.5 ± 4.4). Therefore, to test the hypotheses, we added these variables to the linear regression model as control variables.
Results
Table 4 presents a summary of the baseline pre-intervention tests. For the baseline line group comparison, as expected, no significant differences between groups were obtained for either model understanding nor understanding part time (p = 0.8429 and 0.7812, respectively). Furthermore, all students performed correctly at least 75 percent of the understanding tasks (at least 7 of 12 tasks), showing that they knew the material.
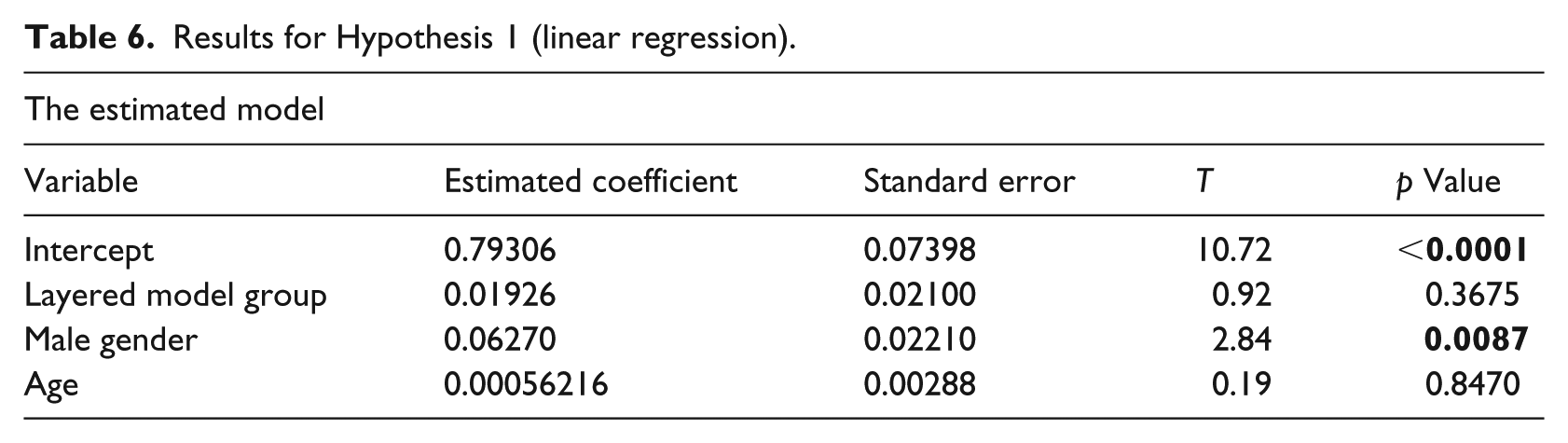
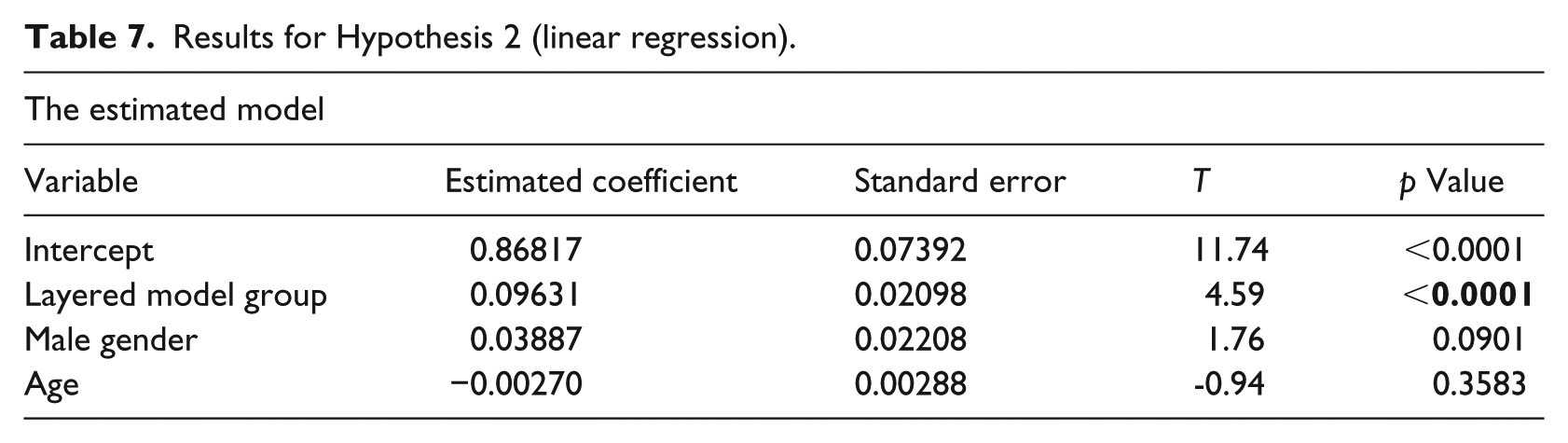
Table 5 presents a summary of the mean points and time achieved in the CIG updating tasks. Tables 6–8 present the results of the linear regression for the three hypotheses regarding model update.
Results for Hypothesis 1 (linear regression).
Results for Hypothesis 2 (linear regression).
Results for Hypothesis 3 (linear regression).
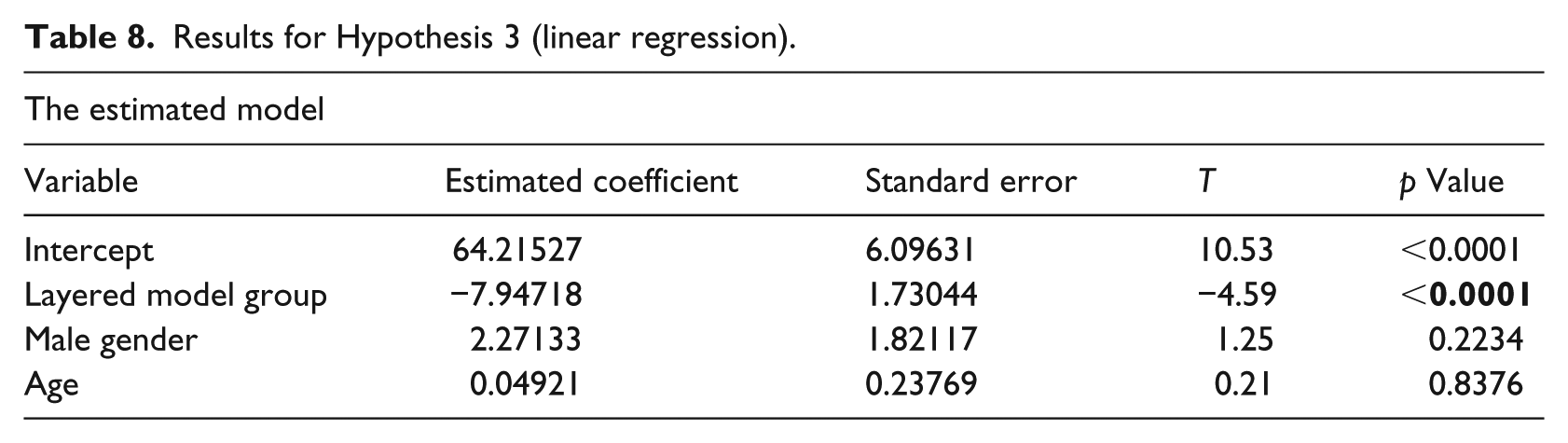
Table 6 shows that the total model is significant (F(3,26) = 3.93, p = 0.0195, R2 = 0.2323). The performance of update tasks in which there was no difference between the single-layered and layered model did not differ between the two groups. There was a significant difference between male and female students; apparently, male students, who were more abundant in the layered model group, performed better on these tasks. Hypothesis 1 was confirmed because there was no difference between the two groups in the achievements in update tasks in which there was no difference between the single-layer and layered methods.
Table 7 shows that the total model is significant F(3,26) = 9.40, p = 0.0002, R2 = 0.4649. Hypothesis 2 was confirmed because student who used the layered model performed more correctly in update tasks in which there was a difference between the single-layer and layered methods. As shown in Table 8, these students also performed the update tasks in less time, thus Hypothesis 3 was confirmed. The total model for this hypothesis was significant (F(3,26) = 7.11, p = 0.0012, R2 = 0.4508). Age and gender did not have a significant effect on the results of hypotheses 2 and 3.
During the argument deletion task, participants who were using the single-layer model were prone to erroneously deleting secondary arguments. Such error was not possible in the layered model, because those arguments were included in a separate layer for which update was not required. Of the 15 participants, 3 committed such errors; 15 total arguments could have been deleted, because they were part of decisions that referenced data items that were to be deleted (only the decision on the HbA1C goal). The mean number of deletion errors in the single-layer group was 1.67 (minimum = 1, maximum = 3).
Discussion
The motivation for this research was to support healthcare organizations in customizing CIGs to the specific needs of their patient population and to the particular implementation settings of the CIG-based decision-support systems (DSSs). Such setting can be the patients’ home environment, where a CIG-based DSS monitors and communicates with patients directly or the healthcare facility, where organizational resources and regulations need to be addressed. Considering the environments’ constraints and the patients’ needs as part of the CIG’s knowledge base may help patients and clinicians to better comply with the CIG’s recommendations, because the knowledge base includes argumentation rules that are sensitive to local and patient-centric considerations. Moreover, a customized knowledge base could better standardize medical care because when clinicians want to address organizational and patient-centric considerations and preferences, which are seldom addressed by CPGs, they will not need to define their own rules but could receive CIG-based standard recommendations that are sensitive to these considerations. This could potentially help to meet one of the goals of CPGs: to reduce unjustified practice variation.
A primary contribution of the research is in opening a debate around the maintenance process of CIGs. To the best of our knowledge, no such study has been conducted before because the customization and personalization methods have only recently started to emerge and few customized CIGs have been created so far. Most customization 24 or personalization25,26 methods refer to the CIG specification process and do not address the maintenance stage. Other versioning approaches that allow customization 10 refer to adding new domain knowledge and not to the update of decisions.
As we have demonstrated, the source of most errors during update is due to the amount of knowledge in the CIG. The CIG layered model aims to separate the knowledge of the CIG into several layers in order to provide a better platform for update and maintenance. The experimental results and their statistical analysis support the conclusion that CIG model maintenance is done in a more correct and timely manner in the layered model. This is because in the layered model, update concerns one relevant layer at a time, without any change to other layers; each layer contains fewer data items and arguments that need to be updated. Moreover, as we have shown in Wilk et al., 21 constraint logic programming could be used to verify that the layered CIG specifications (the original and the updated ones) abide to two important properties: completeness of the specification, such that a recommendation would be supported for any combination of data item values, whether present in the primary or secondary layers, and secondarity, to help ascertain that the secondary arguments would not rule-in options that are not indicated in the original, evidence-based primary CIG. This helps organizations that customize CIGs guarantee that decision support would not violate the recommendation of the original CPG, thus achieving the most important goal of CIGs: to provide evidence-based recommendations in order to increase the quality of care. The rare cases where secondarity should not hold do not restrict the PROforma CIGs from being enacted.
Our experiment concerned a case where just the primary layer had to be updated; no change was required in the locally adapted secondary layer. However, we anticipate that even in cases where update to both layers is required, the layered model might reduce the updating errors, due to the fact that each layer contains fewer data items and arguments.
Limitations and future research
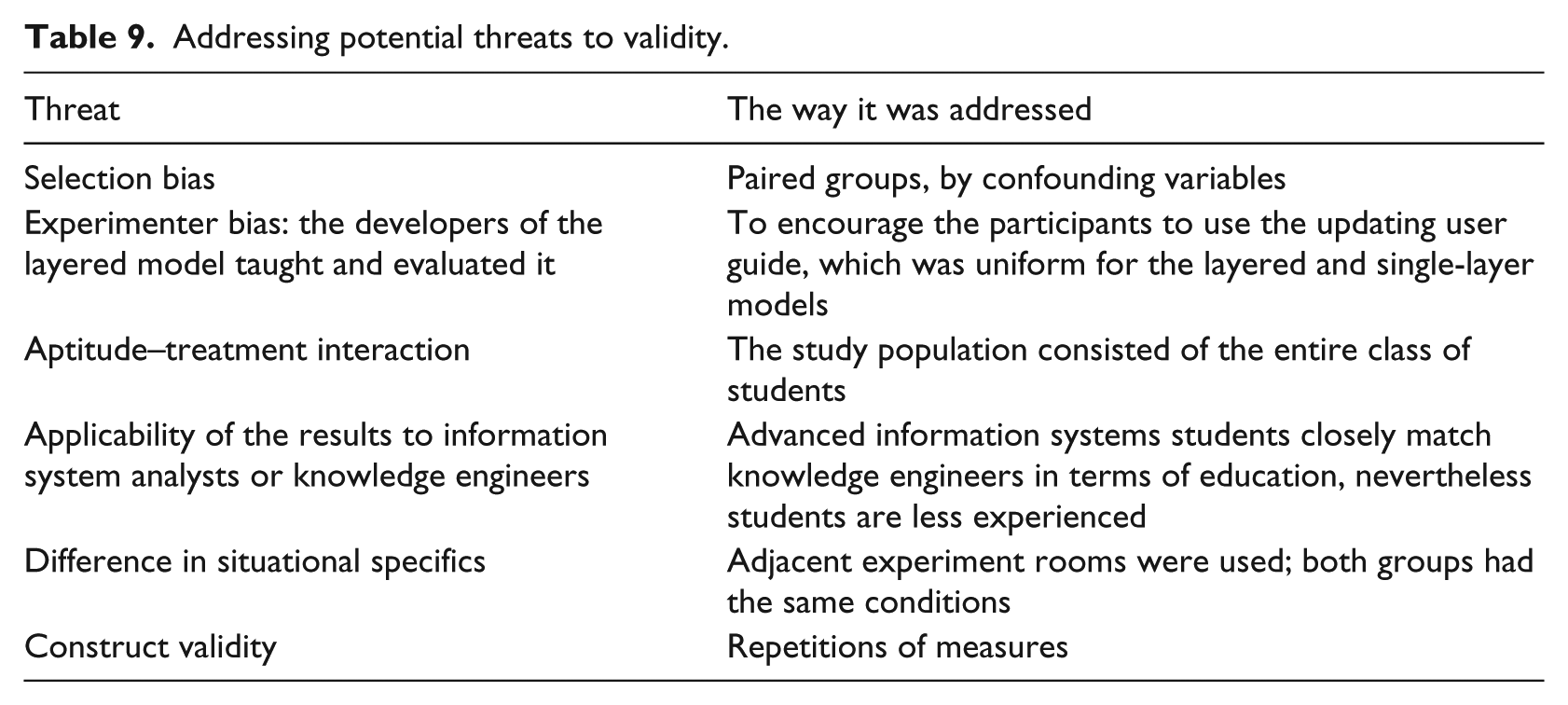
Our experimental design took care to address potential threats to validity, 27 as shown in Table 9. The study is a first attempt to evaluating the effectiveness of the layered approach but suffers from a small sample size (32), sample characteristics (information system students rather than mature knowledge engineers) and selection bias. Future research could involve repeating this experiment in another iteration of the Knowledge Representation course, or better yet, with expert knowledge engineers as participants, using a different clinical guideline, and considering additional secondary layers that address not just the psychosocial domain (but also additional knowledge such as comorbidities, organizational resources or local regulations).
Addressing potential threats to validity.
Our layered method and its evaluation focused only on one way of modulating the recommendations provided by the primary CIG layer: modulating the support for different candidates, thus changing their ranking. Future research can examine the use of CLP for verifying PROforma models where modulation also involves changes in dose or frequency of treatment or monitoring, changes in treatment or monitoring schedule and so on. A similar experiment can then be conducted to evaluate the value of the layered CIG model for such modulations.
The layered model that we presented addressed the ability to include locally adapted decision option arguments that are not addressed in the original clinical guideline; the secondary layer included these additional arguments and the new secondary data items. However, there are other meta-data aspects that could be specified and could support versioning-based queries, as suggested by Terenziani et al. 28 Such meta-data could record the time at which the locally adapted knowledge has been added, the author/organization of that knowledge, its approval status and the author/organization who approved the adapted knowledge. This would allow to query the most up-to-date knowledge as well as historical versions, versions that have not been approved, which would allow to answer legal questions about the knowledge that was available when certain decision has been made. This approach 28 could be added to the layered model in future research.
Conclusion
The CIG layered model provides a modular approach for customizing CIGs, which separates the generic decision arguments and data items from secondary ones into different layers with smaller content. In our pilot study, we have experimentally shown that maintenance of locally adapted CIG versions was improved in the layered model, in terms of time of update and correctness of specification (fewer specification errors). To the best of our knowledge, this is the first experimental study that addresses the important and real-world need of maintenance of locally adapted CIGs.
The layered CIG approach is complementary and compatible with existing CIG version-control frameworks and tools, in order to provide a holistic and better platform for CIG customization and modularity. While implemented in connection with PROforma, the layered approach is generic and can be applied to other CIG specification formalisms.
Supplemental Material
Appendix_A – Supplemental material for A layered computer-interpretable guideline model for easing the update of locally adapted clinical guidelines
Supplemental material, Appendix_A for A layered computer-interpretable guideline model for easing the update of locally adapted clinical guidelines by Jiang Bian, Francois Modave, Adi Fux, Pnina Soffer and Mor Peleg in Health Informatics Journal
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This study was part of the MobiGuide project partially funded by the European Commission 7th Framework Program (grant no. 287811).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.