
Abstract
Utah’s Controlled Substance Database prescription registry does not include master identifiers to link records for individual patients. We describe and evaluate a linkage protocol for Utah’s Controlled Substance Database. Prescriptions (N = 22,401,506) dated 2005−2009 were linked using The Link King software and patient identifiers (e.g. names, dates of birth) for 2,232,725 patients. Review of 998 randomly selected record pairs classified 46 percent as definitely correct links and 54 percent as probably correct links. A correct link could not be confirmed for <1 percent. None were classified as probably incorrect links or definitely incorrect links. Record set reviews (N = 100 patients/set for 10 set sizes, randomly selected) classified 27−49 percent as definitely correct links and 39−63 percent as probably correct links. Fewer had too little information to confirm a link (5%−22%) or were probably incorrect (0%−6%). None were definitely incorrect. Overall, results suggest that Utah’s Controlled Substance Database records were correctly linked. These data may be useful for cross-sectional and longitudinal studies of patient-controlled substance prescription histories.
Introduction
Unintentional fatalities due to prescription medications are a well-established problem in Utah 1 and the United States.2,3 Since 2003, the leading cause of injury death in Utah has been poisoning from prescription drugs with opioid-related poisonings as the primary offender. 1 During the years 1999–2007, deaths related to prescription pain medications increased sixfold in Utah.4,5 The increase was largely due to deaths from prescription opioid pain medications. The number of emergency department encounters stemming from prescription drug overdose has also continued to increase in Utah from 2001 to present.6,7
To support identification of potential cases of prescription medication misuse, inappropriate prescribing, and related adverse outcomes throughout the state, Utah’s Division of Occupational of Professional Licensing within the Utah Department of Commerce maintains a Prescription Drug Monitoring Program which tracks all outpatient prescriptions for Schedule II–IV drugs dispensed in Utah. 6 Legislative mandate (Utah Code Section 58-37f-101), established in 1995, requires all outpatient pharmacies to submit controlled substance dispensing records to Utah’s Controlled Substance Database (CSD) The CSD has been a valuable tool for prescribers to look up a patient’s access to controlled substances; however, due to the lack of a master patient index/identifier, the CSD has been a difficult resource to use for research and population analytics.
Our objectives are to describe and evaluate a linkage protocol for Utah’s CSD, an outpatient prescription medication registry, which does not include unique master patient identifiers to link patient records.
Methods
Data sources
Utah’s CSD contained over 22 million prescription records from approximately 500 pharmacies dated 2005−2009. On a monthly basis, using the standard of American Society for Automation in Pharmacy, Version 2, pharmacies report the following variables with each dispensing record: patient name, street address, zip code, date of birth and sex, pharmacy identification number, prescriber identification number (Drug Enforcement Agency (DEA) number), National Drug Code Number, prescription number, date written, date filled, new/refill number, metric quantity of drug, days supply of drug, and number of authorized refills. However, the CSD does not include a patient master identifier to link multiple dispensing records for each patient. Also, information submitted to the CSD does not follow a standardized, structured format, leading to considerable variability in submitted patient identifier information, which may include a mix of Social Security Number (SSN), phone numbers, names, driver’s license, or other unspecified identification numbers or text strings. It should be noted that the greatest potential for variation in patient identifiers occurs across multiple pharmacies and tends to be more consistent for a patient within a given pharmacy. Extensive record preprocessing and cleaning to standardize the linking variables were required before implementing the linkage protocol including removal of prescriptions by veterinarians by DEA number, removal of implausible patient names or birthdates, and standardization of sex coding. We also attempted to decode 9-digit identifiers that were a mix of SSN, phone numbers, and driver’s license numbers to determine whether including them as a matching variable influenced our results. Our evaluation (of a subset of records examined in this study) 8 revealed that including the 9-digit IDs did slightly improve the match likelihood but did not change our overall matching decisions; thus, we chose not to include it in our final linkage methods. The proportion of missing identifiers required for the link was low (<0.3%; Table 1).
Availability of patient identifiers for the linkage of Utah’s CSD records.
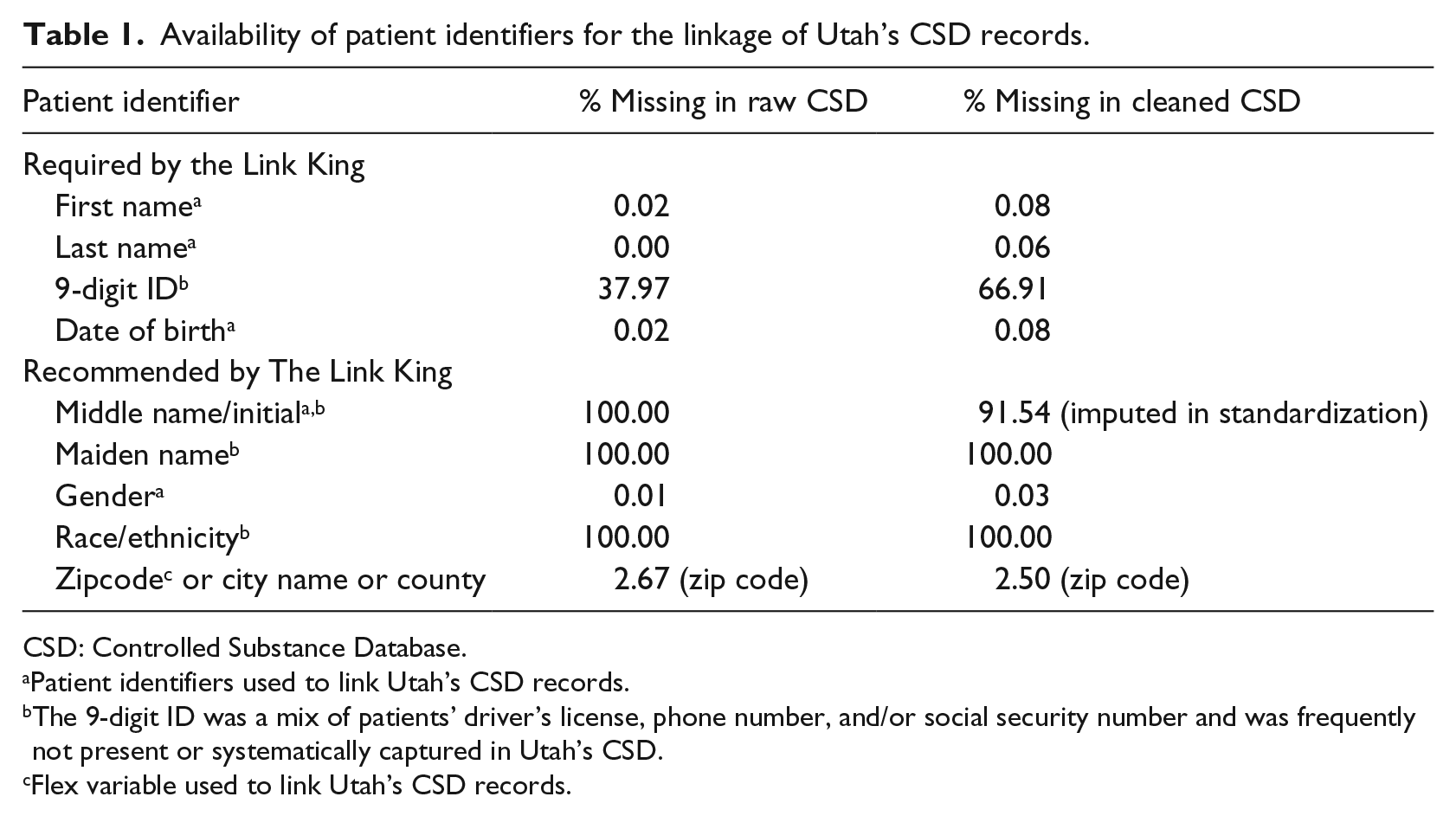
CSD: Controlled Substance Database.
Patient identifiers used to link Utah’s CSD records.
The 9-digit ID was a mix of patients’ driver’s license, phone number, and/or social security number and was frequently not present or systematically captured in Utah’s CSD.
Flex variable used to link Utah’s CSD records.
Linkage methods
The Link King
We used a freeware data linkage SAS application, The Link King (available from www.the-link-king.com/). 9 The Link King allows for integration of restrictive deterministic matching algorithms with more flexible probabilistic algorithms. The Link King was originally developed to de-duplicate the client database of Washington State’s Division of Alcohol and Substance Abuse. 9 Probabilistic algorithms used in The Link King were adapted from those developed by MEDSTAT for the Substance Abuse and Mental Health Administration’s integrated database. 10 The Link King’s probabilistic and deterministic algorithms compare record pairs that may be within a block of records that match on certain user-selected criteria. For each of the record pair comparisons, the algorithms derive a cut-point ranging from Levels 1–4 to classify the likelihood of a correct match. The highest certainty of a correctly linked record pair corresponds to Level 1 with each succeeding level corresponding to slightly lower certainty of a correct link. There are two other levels, Level 6 (probabilistic probable twins) and Level 7 (probabilistic maybe), which are considered to be possible links by the probabilistic but not the deterministic algorithms; there is no Level 5. These certainty levels allow the user to decide which record pairs to accept, reject, or manually review as correctly linked records. The probabilistic statistical algorithms adjust the weights for a given record pair based on the uniqueness of the patient identifier value. For example, a common last name (e.g. Johnson) is assigned a lower weight compared to a less common last name (e.g. Eisenhower). The program also allows the user to include a “flex variable” such as a patient’s address, date or place of birth, or zip code. Users can adjust the weight of the flex variable to positively or negatively impact the resultant probabilistic score. Authors of prior studies who have used The Link King have reported positive predictive values and sensitivity values above 90 percent depending on The Link King selected certainty score.9,11
Protocol settings
To link Utah’s CSD records, we included patient’s first and last name and date of birth since SSNs were not routinely collected (Table 1). We also included the following Link King recommended variables, when available: patient’s middle initial and gender. We used patient zip codes as the flex variable, and based on The Link King protocol recommendations, we set the program to restrict zip code from having a negative weight on the probabilistic score since we anticipated true changes in patient addresses to be frequent. Therefore, when a zip code of a given record pair was present, the probabilistic score of a correct record link was only positively impacted. Overall, we followed The Link King’s default settings which are designed to provide users with “conservative” results, consolidating only records where there is a high certainty of the linkage.12,13 Although we note that record linkage is a complex task and optimal linkage results may require the user to customize the settings. The Link King has numerous options for customizing linkage procedures and supporting documentation to help users understand how the various settings impact linkage certainty. The default settings we used included the blocking level, probabilistic weight settings, and the name rarity cut-point of 0.3. The Link King uses the “rarity/commonness” of a name as part of decision-making criteria in the deterministic protocol. Matching criteria for the data elements are relaxed when a patient’s name is considered to be “rare.” Given the number of records linked in this study and the cost and time required for manual review, we retained links classified as Levels 1–3 and excluded Levels 4, 6, and 7.
Manual review
Utah’s CSD records linked from years 2005 to 2009 which contained 22,401,506 prescription records for 2,232,725 patients; therefore, 90 percent of prescription records were aggregated for the same patient, longitudinally. Few patients (13%) had two or more name variations (Table 2). Among these 298,430 patients, where The Link King protocol classified records as true links (Levels 1–3) but where the patient names, sex, or date of birth were not an exact match for two or more linked records, a subset of record pairs and record sets were manually reviewed by two researchers and together adjudicated.
Patients with one or more name variations.

Patients with one or more variations in patient identifiers also include those who were considered unmatchable (i.e. all blank values for all patient identifiers).
Record pair review
For the record pair review, we randomly selected a subset of pairs (N = 998) for manual review. Patients with more linked records in Utah’s CSD had a higher likelihood of being selected for review, and multiple record pairs for a given patient could be selected. Reviewers manually examined all linkage variables and classified each record pair as one of the following five “linkage certainty” categories: (1) definitely not the same person, (2) probably not the same person, (3) there is not enough information to determine whether or not they are the same person, (4) probably the same person, or (5) definitely the same person.
Record set review
For the record set review, we categorized patients into 10 different sampling set sizes based on the number of records linked by The Link King protocol (Table 3). Ranging from set sizes of 2 to 75+ records/patient, we randomly selected 100 sets for manual review for each of the 10 sizes or 1000 total sets. Reviewers manually examined the linkage variables across all records corresponding to each set, and each set was classified according to the same linkage certainty categories described for the record pair review.
Selection of record sets for manual review.
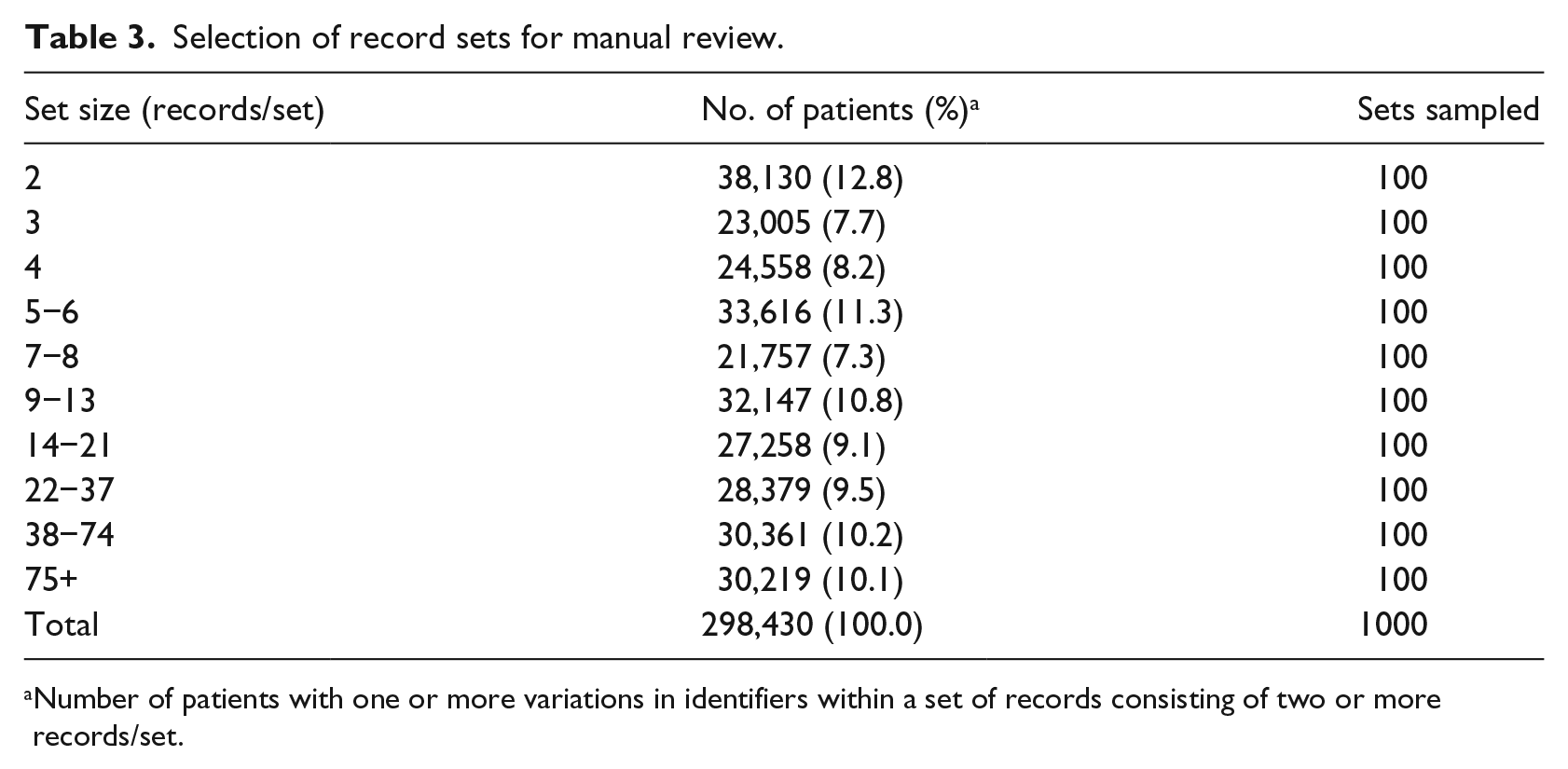
Number of patients with one or more variations in identifiers within a set of records consisting of two or more records/set.
This work was reviewed and approved by the Institutional Review Boards of the University of Utah and the Utah Department of Health.
Results
Reviewers of the record pairs (N = 998 pairs) classified 46 percent as definitely correct links and 54 percent as probably correct links (i.e. the same person). Few (<1%) had too little information to confirm a correct link. None were classified as probably incorrect links or definitely incorrect links.
Reviewers of the 10 record sets classified 27−49 percent as definitely correct links and 39−63 percent as probably correct links (Figure 1). Fewer sets were classified as having too little information to confirm a link (5%−22%) or probably incorrect links (0%−6%). None were classified as definitely incorrect links. The proportion of sets classified as either lacking enough information to confirm a link or probably an incorrect link was slightly lower for set sizes of 2–8 records compared to set sizes of 9–75+ records, 8 percent versus 15 percent, respectively. However, contrary to our expectation, there was no evidence to suggest that the proportion of incorrect links increased with higher set sizes.
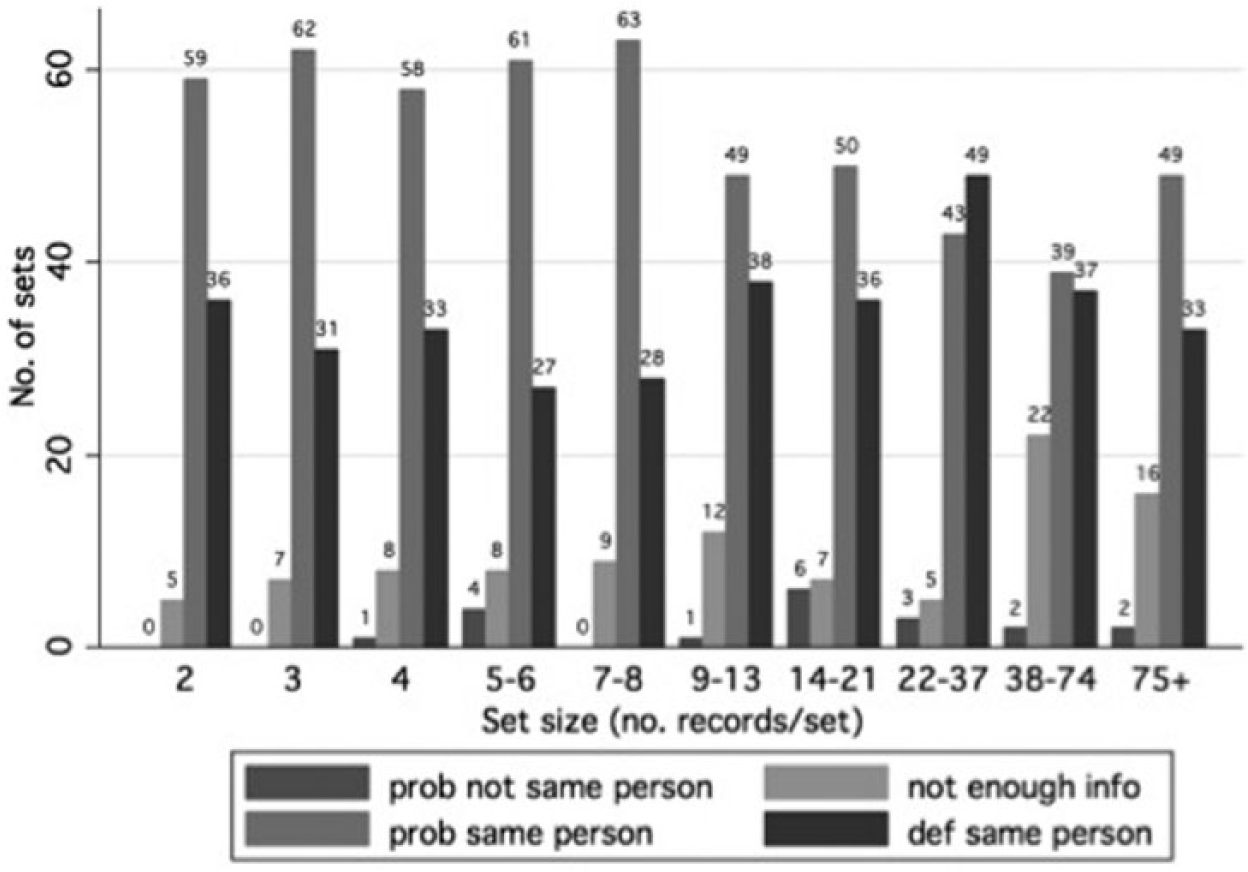
Results of manual review: for each set size, number of sets by reviewers’ confidence of a correct match.
Discussion
Using The Link King’s probabilistic and deterministic algorithms, we successfully implemented a linkage protocol among 22 million prescription records from Utah’s CSD. Overall, our manual review suggested that the pairs and sets of records corresponding to specific patients were correctly linked. Therefore, the linked records of Utah’s CSD may be valuable for cross-sectional and longitudinal studies.
The Link King has been used to link a variety of administrative data such as from Medicaid files, 11 surveillance data including Colorado, Connecticut, and Oregon’s Hepatitis C and HIV/AIDS data, 14 and Washington State’s Division of Alcohol and Substance Abuse data.9,15 Prior studies have demonstrated the utility of The Link King for linking administrative records. For example, Beil et al. 11 attempted to link 80,414 records in the North Carolina Medicaid files to public health surveillance files using The Link King. Authors reported validity estimates based on manual review of two randomly selected subsets of record pairs: those that were and were not successfully linked. For The Link King certainty Levels of 1, 2, and 3 (those considered to be correct links in our study), Beil et al. reported sensitivities (95% confidence intervals) of 83.7 percent (78.5%−89.2%), 89.2 percent (83.8%−94.9%), and 89.2 percent (83.8%−95.0%), respectively. Specificities (95% confidence intervals) for Levels 1, 2, and 3 were 89.3 percent (81.6%−97.6%), 88.2 percent (80.7%−96.5%), and 88.2 percent (80.7%−96.5%), respectively. Had we considered our manual review as the reference standard and that true links were those identified as definitely or probably correct links, we would have reported a positive predictive value (95% confidence interval) of 99.1 percent (98.5−99.7%) for the linked (Levels 1–3) record pairs. Since we did not manually review records that were not linked, we cannot compare the sensitivity or specificity of our link to Beil et al. As in our study, Beil et al. chose to exclude Levels 4 and 5, which had lower specificities, since their priority was to have a correct link rather than capturing all possible matches.
We are unaware of prior studies of The Link King that included manual reviews of record sets (greater than 2) corresponding to a single patient; previously, the focus has been on record pairs. While our manual review revealed that record set sizes of 9 or greater had a slightly higher proportion of incorrect links or links that lacked enough information to confirm a link compared to set sizes of 2–8, there was no evidence to suggest that the proportion of incorrect links increased as the number of corresponding patient records increased. It may be important to examine the certainty of links across larger set sizes for future studies that rely on linked, aggregated data for longitudinal analyses. In the particular case of controlled substance data where individuals might be actively attempting to evade detection in order to obtain more medications, this limitation may be even more critical when interpreting results.
Limitations
The results of our study should be interpreted in view of several limitations. First, since we relied on manual reviews in our evaluation of the linkage, and manual reviews are vulnerable to human error, we did not report the validity of the linkage. In cases where there was limited information to determine the correctness of a link, one could argue that human judgment is less precise and possibly less valid than The Link King’s decision-making, such as for record links categorized by our manual review as “not enough information to determine whether or not they are the same person.” Our manual review of record pairs revealed that The Link King’s decision-making appears valid, and for the record sets unlike the manual reviewers, The Link King is able to make a decision regarding sets in the context of all record pairs. Second, we did not review unlinked records and were thus unable to comment on the proportion of these that could have been deemed by our manual review as missed links. A third limitation is that we used strict criteria in our manual review of record sets. For example, a set size of 5 records or a set size of 75 records would both be classified as “probably not the same person” if only 1 record had a different last name than the other 4 or 74 records, respectively. In other words, we did not down-weight the impact of incorrect/questionable records as the set size increased in our manual review. Nonetheless, we show that the error rate is consistently low, regardless of the set size. Our conservative criteria may have led to lower sensitivity. Finally, since we did not retain The Link King assigned levels of certainty, we were unable to examine the concordance of certainty assignments given by The Link King and the manual review for the record pairs.
Strengths
Strengths of our study included use of Utah’s CSD, a large database that had a low proportion of records missing the required linking variables. Also, we included a large number of record pairs and record sets in our manual review, and to date, no study has reviewed match certainties for record sets of three or more.
Conclusion
The Link King software is accessible and efficient, and it allowed us to develop a protocol for successful and cost-effective linkage of prescription records in Utah’s CSD. Contrary to our expectation, the proportion of incorrect links remained stable, even as the number of records in a set increased. Overall, our manual review suggested a high proportion of correct links, including for patients with 75 or more records. With the growth of many record linkage methods, future studies are needed to compare results and efficiency across methods that include reports of sensitivity, specificity, precision, and recall. Extensions of our work include the application of The Link King to merge Utah’s CSD to external data sources, such as from Medicaid, Medical Examiner, or Emergency Department databases, thus broadening the scope of public health and epidemiologic research that can be accomplished with this resource.
Footnotes
Acknowledgements
This manuscript is the result of work supported with resources and the use of facilities at the VA SLC IDEAS Center, Salt Lake City, UT. J.C., C.A.P., E.M.J., R.T.R., and B.C.S. designed the study and wrote the protocol. J.C. carried out the data linkage protocol. A.F.M., J.C., and B.C.S. undertook the statistical analysis. A.F.M., J.C., C.A.P., and B.C.S. assisted with interpretation. A.F.M. wrote the first draft of the manuscript. All authors contributed to and have approved the final manuscript.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Utah Department of Health; the Centers of Disease Control and Prevention Grant (5 R21 CE001612); the Department of Veterans Affairs; and the VA Advanced Fellowship Program in Medical Informatics of the Office of Academic Affiliations, Department of Veterans Affairs. Utah Department of Health personnel were involved in the study and in the authorship of this article.