
Abstract

This contribution is a reply on the article Chess and Explainable AI by Björnsson (2024). Explainable AI tools are good, and the explainability of a chess program is a nice feature. But my question is what to do as a user when your chess program gives only little or no explanations? For top-level correspondence chess-players, this is, for instance, a very important question.
Bots in Iterative Deepening Mode in Chess and 3-Hirn
Here I will tell about a story from the old computer chess days. Back in the late 1980s and 1990s, I performed many chess experiments with a combined system, which I called 3-Hirn (Figure 1).

Logo of 3-Hirn (squared symbols for the computers, round head for the human).
“Hirn” is German and means “brain” or “mind.” A 3-Hirn consists of two different (commercial) chess computers and one human decider. My intention was to show that such a human + machine team can perform better than any of its components. When 3-Hirn has to move in a chess game, both computers were started, and after observing the thinking process for an appropriate time span, the human decider selects one of the two moves just shown. If both computers propose the same move that move has to be executed (cf. Althöfer, 1985; Althöfer & Snatzke, 2003; Althöfer, 2004) (Figure 2).

Title page of the 3-Hirn book. Shown are the 3-Hirn logo and a position from a game in 1987, with candidate moves … Bf8-a3 and … f7–f5 from the two chess computers.
In those days, all chess programs were based on alpha-beta search in some iterative deepening mode. Over 13 years, from 1985 to 1997, I executed many experiments, and always the 3-Hirn performed about 200 Elo points better than the chess programs used. That was the case in 1985 (with computer ratings around 1,500) and was still the case in 1997 (with PC chess program ratings around 2,550). In all these experiments I was the human in 3-Hirn, with a rating between 1,900 and 1,950 in my normal chess life. The biggest thing I learned step by step from the experiments was how to exploit information from the program displays. That is how to make the best out of what is available.
The programs were running in anytime mode, typically showing the current candidate move, its evaluation (in centi-pawns) and the corresponding principal line. This was more than simply the candidate move, but not much more than that (cf. Althöfer et al., 2003). What I did understood better and better over the years was to identify ill principal lines. An example is: lines with repetition of moves, but showing evaluations much higher than 0.00. Or lines which harbored the danger to transfer to a drawish endgame with bishops of different colors or a pawn on the wrong rook file. As a consequence of this observation, I often steered 3-Hirn into positions where the climax would not occur before the fourth hour of play, whereas against computer opponents I preferred positions with blocked pawns.
After publication of the 3-Hirn book (in 1998) I got feedback from two strong amateur players (Elo ratings between 2,200 and 2,300). They claimed that my performances were not reproducible although they were much stronger than me in normal tournament play. For me it was clear where they had failed: they had not well understood to exploit the little hints of the chess programs, and their “Egos” were too big: often they artificially switched between the candidate moves of the two bots in their 3-Hirn teams (Figure 3).

Artistic view of a black box, which is not completely black. Generated by DALL-E-3, prompt by Ingo Althöfer.
MCTS Bots in Go and Shadows
From 2008 onwards, in the game of Go commercial bots based on Monte Carlo tree search (MCTS) became available. Prominent examples were Many Faces of Go, Leela, and Crazy Stone. I tried to repeat the 3-Hirn story of success, but my understanding of Go was not strong enough (20th kyu). So I engaged other human players to take the decider role in Go-3-Hirns: in particular Guido Tautorat (amateur 4-dan), Georg Snatzke (amateur 3-dan) and Manja Marz (amateur 4-dan; several times European champion). Manja was particularly suited for 3-Hirn settings, because some of her successes were in the category pair-Go, where two human players form a team and make their moves alternatingly. I was then sitting next to them and gave hints on little pieces of explanation given by the bots.
Of course, (a) the candidate move was shown and (b) the expected probability of win (from the Monte Carlo playouts), but no true evaluations (like in chess programs) and no principal lines were given. What sometimes helped, was the distribution of playout results (in absolute points). Figure 4 shows such distributions for several positions in a 3-Hirn game against Go professional Catalin Taranu (from the European Go Congress 2012 in Bonn) (see Althöfer, 2012).
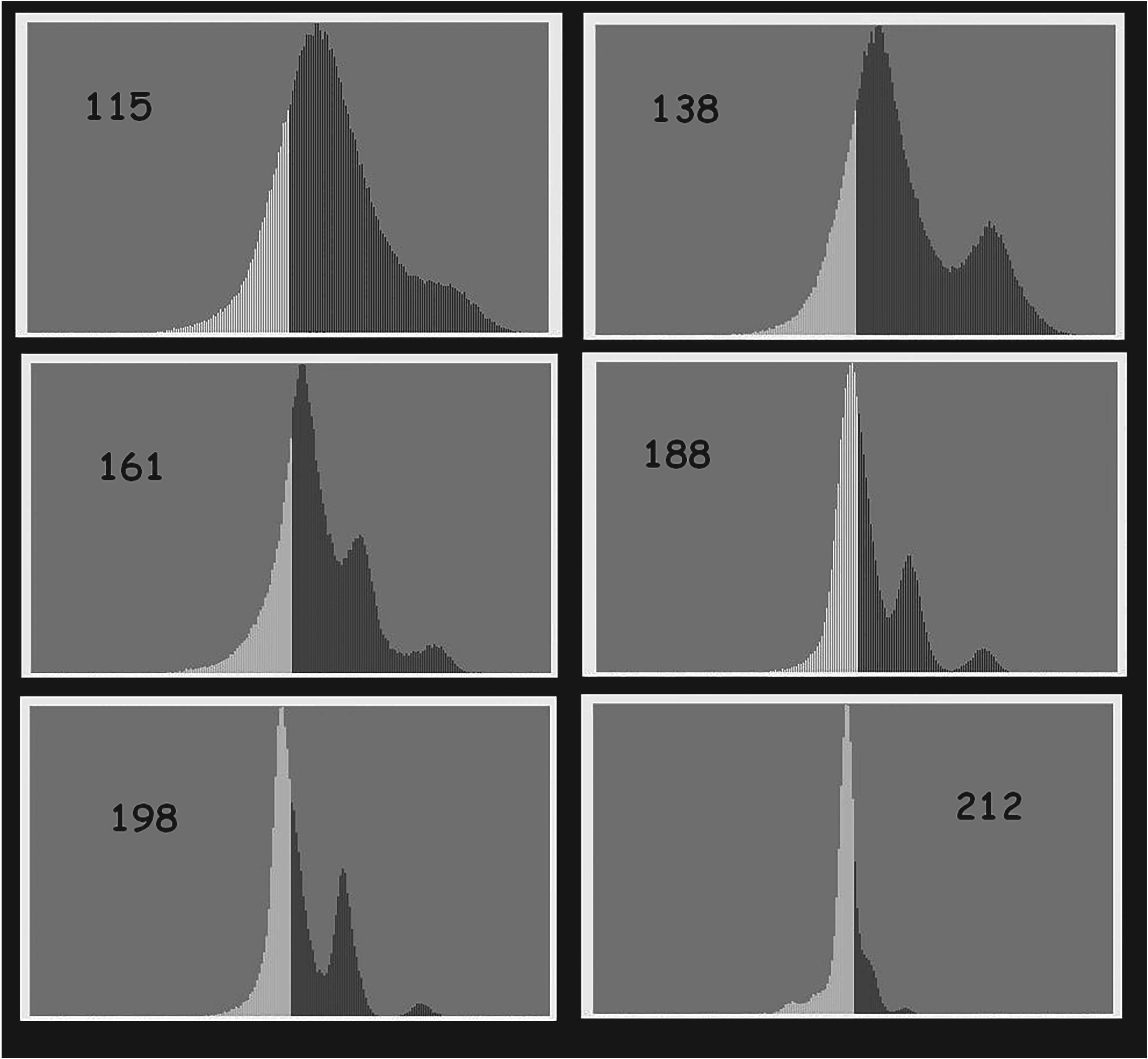
Shadows in the display of MCTS bot Crazy Stone in Go.
My philosophy was as follows. When the distribution is not unimodal (unimodal means one peak somewhere in the center), but has several peaks instead, then it is likely that the bot is going to missinterpret the position. In Figure 4 the situation is still “normal” at move 115, but later (at move 138) a second peak is growing up on the right side. I called these diagrams shadows and in particular crazy shadows, when generated by Remi Coulom's bot Crazy Stone.
Open Questions and Conclusions
The central (new) question is: how to exploit small signals in the display of bots of Artificial Neural Network type? (and for the designers: how to give good signals?)
Using chess computer programs wisely in correspondence chess is an art: for instance in 1 + 23 hour modes: the machine is running around the clock, and the human expert checks only for something like 1 hour per day.
My lesson from the past: it helps for a user to put energy in exploiting small explanations and signals given by a game playing program.
An additional aspect of exploiting “almost black boxes” concerns the human opponents with respect to reading facial and body expressions during tournament games. It plays an even more important role in other games such as Poker (“reading the opponents”) and Bridge (“reading the partner,” which is not officially allowed).
Footnotes
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.