
Abstract
Background
Cognitive decline in Alzheimer's disease (AD) often includes speech impairments, where subtle changes may precede clinical dementia onset. As clinical trials focus on early identification of patients for disease-modifying treatments, digital speech-based assessments for scalable screening have become crucial.
Objective
This study aimed to validate a remote, speech-based digital cognitive assessment for mild cognitive impairment (MCI) detection through the comparison with gold-standard paper-based neurocognitive assessments.
Methods
Within the PROSPECT-AD project, speech and clinical data were obtained from the German DELCODE and DESCRIBE cohorts, including 21 healthy controls (HC), 110 participants with subjective cognitive decline (SCD), and 59 with MCI. Spearman rank and partial correlations were computed between speech-based scores and clinical measures. Kruskal-Wallis tests assessed group differences. We trained machine learning models to classify diagnostic groups comparing classification accuracies between gold-standard assessment scores and a speech-based digital cognitive assessment composite score (SB-C).
Results
Global cognition, as measured by SB-C, significantly differed between diagnostic groups (H(2) = 30.93, p < 0.001). Speech-based scores were significantly correlated with global anchor scores (MMSE, CDR, PACC5). Speech-based composites for memory, executive function and processing speed were also correlated with respective domain-specific paper-based assessments. In logistic regression classification, the model combining SB-C and neuropsychological tests at baseline achieved a high discriminatory power in differentiating HC/SCD from MCI patients (Area Under the Curve = 0.86).
Conclusions
Our findings support speech-based cognitive assessments as a promising avenue towards remote MCI screening, with implications for scalable screening in clinical trials and healthcare.
Keywords
Introduction
Early detection of Alzheimer's disease (AD) related dementia has been identified as a key health priority by the European Parliament in recognition of its growing societal burden. 1 The recent “European Dementia Monitor” report highlights continuous inequalities among European countries in national dementia policies and care, 2 underscoring the necessity for novel methods to support early diagnosis and timely interventions. Consequently, the recent focus of clinical trials for disease-modifying treatments in AD has shifted towards early screening and diagnosis specifically for individuals with subjective memory complaints and mild cognitive impairment (MCI). Similarly, observational cohort studies are focusing on effective and scalable screening methods to support early diagnosis and cognitive decline monitoring for individuals at-risk within real-life clinical settings.3,4 This transition showcases a shift from a symptom-focused, late-stage management to a biomarker-based early detection. 3 Nonetheless, patient screening and recruitment challenges within both AD clinical trials and healthcare frequently delay drug development and hinder the progress of new therapies to late-stage development and potential approval. 5
AD screening and diagnosis involve neurocognitive assessments for initial identification and disease severity staging and biomarker-based methods for confirmatory diagnosis. Cerebrospinal fluid (CSF) and positron emission tomography (PET) biomarkers of amyloid-β and tau concentrations reliably detect the pathogenic hallmarks of the disease. These methods are considered sufficient for an initial AD diagnosis based on the revised criteria for diagnosis and staging of AD, 6 although they are time-consuming, costly and stress-inducing for patients. In contrast, neurocognitive assessments like the Mini-Mental State Examination (MMSE) or the Alzheimer's Disease Assessment Scale-Cognitive Subscale (ADAS-Cog) are the ones most broadly applied in clinical practice as short screening tools to address disease severity. While quicker compared to broader neuropsychological assessments, these tools still require trained and standardized administration, they are prone to practice effects and might lack the sensitivity for MCI screening.7,8 Additionally, their scalability/accessibility in larger populations is challenging, especially in resource-limited clinical settings and rural areas. 9 Therefore, there is an emerging need for low-threshold and easily deployable initial screening measures of cognitive functions 10 that can overcome the barriers of classical paper-based neurocognitive assessments and improve prediction of the confirmatory testing 11 (CSF/PET biomarkers).
Over the past five years AD related research and trials increasingly incorporate and validate technology-driven tools to monitor disease progression and severity, with growing focus on tracking speech patterns and cognition through automated assessments. In 2021, 8.1% of digital health technologies in trials specifically tracked speech, while 14.0% tracked cognition in general. 12 Technology-based cognitive assessments can streamline patient screening, with cost-effective, automated methods that accelerate patient identification. Due to self-administration, they can widen patient outreach beyond traditional networks, 13 providing objective data, facilitating monitoring and diagnostic solutions for both clinical trials and healthcare.14,15 Among them, speech-based digital cognitive assessments offer an appealing avenue for a remote, low-burden and non-invasive pre-screening and screening process for cognitive impairment. 16 Unlike traditional pen-and-paper tests, speech analysis captures a variety of fine-grained paralinguistic (i.e., prosody, intonation, rhythm, etc.) and linguistic features (i.e., semantic clustering, lexical word frequencies, learning slopes, etc.) that provide deeper insights into one's cognitive state. Automatic speech recognition and machine learning algorithms can now objectively and automatically extract these features, 17 which are challenging to quantify by human evaluators and therefore underutilized in routine clinical practice.
Speech impairments can precede the clinical manifestations of dementia by years, with early indicators including reduced lexical complexity and increased conversational fillers and non-specific nouns.18,19 Subtle speech changes were recently linked to amyloid-β pathology in patients with subjective cognitive decline (SCD) even without associations with gold-standard language tests. 20 Moreover, language closely relates with memory, attention, and executive functioning, providing insights into general cognitive abilities. 21 Cassaleto et al. 22 showed that in AD, the total immediate recall of the California Verbal Learning Test correlated with language processing, attentional and executive control, alongside brain volumetric changes. Further, Possemis et al. 23 and ter Huurne et al. 24 demonstrated correlations between automatically extracted 15-Verbal Learning Test (VLT) and Semantic Verbal Fluency (SVF) features with global cognition, semantic memory and executive function in early-stage cognitive decline participants. However, variability in these associations highlights the need for further validation.
To meet the demands of early screening of MCI, an automated, remote and phone-based screening battery was created encompassing speech-related neurocognitive tests (SVF and VLT). 16 This allows the automatic extraction of speech-based cognitive measures alongside classical cognitive scores. This study aimed to: (a) explore how the extracted and validated speech-based digital cognitive assessment composite score (SB-C), integrating fine-grained speech-based features, associated with gold-standard neurocognitive assessment methods; (b) investigate associations between automatically extracted speech-based domain-specific composite scores (learning/memory, executive function, processing speed) with respective domain-specific neuropsychological assessments; (c) evaluate the accuracy of the SB-C in classifying diagnostic groups compared to gold-standard neurocognitive scores. The overarching goal was to assess the effectiveness and sensitivity of a fully remote speech-based digital cognitive assessment and its speech-based composite scores as reliable tools for MCI detection compared to conventional pen-and-paper neuropsychological tests.
Methods
Study participants
All data were collected from a population participating in the multilingual Screening over Speech in Unselected Populations for Clinical Trials in AD (PROSPECT-AD) study, a multicentered longitudinal observational study. 3 For the purposes of the present study, participant data were specifically used from the German longitudinal cohorts DELCODE 25 and DESCRIBE. 26 From a subset of 190 participants that were included at the baseline of PROSPECT-AD, N = 21 were healthy controls (HC), N = 110 were reported as patients with SCD and N = 59 were reported as patients with MCI. Diagnosis was based on a review process focusing on neuropsychological and clinical observations and not necessarily on biomaterial. Specifically, in the DELCODE study, patients were classified as SCD when upon evaluation they reported cognitive decline causing concern and sought evaluation at the memory clinic within the last 6 months to 5 years. They also scored within the normal range (1.5 SD) on all of the Consortium to Establish a Registry for Alzheimer's Disease (CERAD) tests during their diagnostic evaluation. For MCI, patients had to score >−1.5 SD the normal range in the delayed recall of the CERAD word list, cognitive decline was reported by the patient, an informant, or the treating physician, and criteria for dementia were not met. In the DESCRIBE study, MCI (including amnestic and non-amnestic MCI) was classified based on the Winblad/Petersen criteria. 27 For both cohorts the NINDCS/ADRDA criteria (proposed by the National Institute of Neurological and Communicative Disorders and Stroke and the Alzheimer's Disease and Related Disorders Association) were used for AD diagnosis. 28
In general, inclusion criteria for PROSPECT-AD encompassed individuals aged 50 years or older, with cognitive status ranging from unimpaired to MCI (Clinical Dementia Rating (CDR) global score ≤0.5). Participants were required to be proficient in German with sufficient language skills to understand the consent form, have no hearing loss, possess the capacity to provide consent themselves or have consenting caregivers, and complete a signed and dated informed consent form. Further, important exclusion criteria were the absence of unstable systemic illness/organ dysfunction, substance abuse, sleep deprivation, psychotic disorder and moderate-severe depression.
All data collection processes within PROSPECT-AD adhered to ethical guidelines for medical research involving human participants, as outlined in the Declaration of Helsinki and the European General Data Protection Regulation. The study received approval from the local ethics committees as follows: University Hospital Bonn (291/22), Ethics Committee of the University of Technology Dresden (BO-EK-263062022), University Medical Center Göttingen (27/9/22), University of Cologne Faculty of Medicine (22-1284), University Hospital Magdeburg Medical Faculty (80/22), University Medical Center Rostock (A2021-0256), and University Hospital Tübingen (551/2022BO2). For Charité Berlin, no separate approval was necessary as it relied on the one from Rostock.
Clinical assessment
In both DELCODE and DESCRIBE studies, each participant underwent a structured clinical assessment in a series of annual follow-up visits. 3 PROSPECT-AD was implemented while these cohorts were already ongoing, by integrating speech data collection into the existing protocols. Therefore, for the purposes of the current study, we defined the baseline clinical assessment (T0) as the one that was conducted closest in time to the baseline speech-based digital cognitive assessment (M0) based on the PROSPECT-AD protocol (see Figure 1 for an overview of the study design).
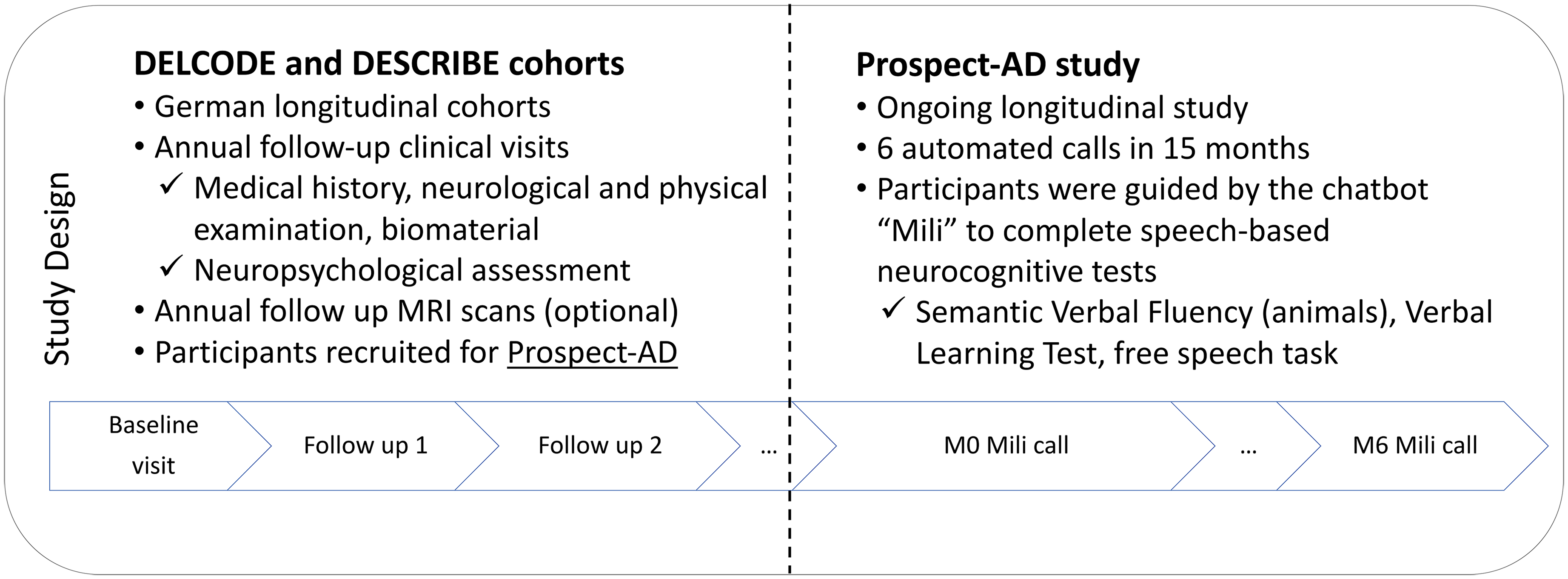
Overview of the design of the DELCODE and DESCRIBE cohorts and the PROSPECT-AD study.
In more detail, the structured clinical assessment included medical history, neurological and physical examination, biomaterial collection for research purposes (CSF biomarkers, APOE ε4 genotype) and an interview to measure disease severity (CDR 29 ). Furthermore, participants underwent a detailed neuropsychological assessment. The assessment in DESCRIBE consisted mainly of the CERAD tests while participants in DELCODE underwent a more extensive neuropsychological assessment which has already been reported before. 25 Here, we concentrated on describing the assessments pertinent to this study. Specifically, we focused on tests measuring global cognition (MMSE, 30 ADAS-Cog 31 ) and the Clock Drawing Test, 32 as well as domain-specific ones, including the Complex Figure Drawing Test, 33 SVF, Trail Making Test (TMT-A/B), 34 Digits Span (forward/backward). 35 Further, the PACC5 36 composite score was used. The calculation of PACC5 was based on the averaged z-standardized performance in the following neuropsychological tests: MMSE, free and total recall from the picture version of the Free and Cued Selective Reminding Test with immediate recall (FCSRT-IR), 37 delayed recall of Story B (Logical Memory) from the Wechsler Memory Scale IV (WMS-IV), 38 the oral form of the Symbol-Digit-Modalities Test (SDMT) 39 and the sum of two SVF tasks (animals and groceries). Z-scores were derived from the baseline means and standard deviations of cognitively unimpaired DELCODE participants and then averaged across the five measures.
Speech data collection
In PROSPECT-AD, participants received the automated phone assessment six times within 15 months. 3 Speech data were collected in a fully automated way via the ki:elements Mili platform and over the phone. Here we present the data from the call at baseline (M0) as well as at follow-up month 3 (M3) and month 6 (M6). Specifically, after giving consent, participants were contacted by the study coordinator to schedule the appointments for the automated phone assessments. During each call, Mili asked the participants to confirm consent, reminded them that the call is recorded and that participants should avoid sharing identifiable information. During the automated assessment calls, Mili gave instructions verbatim, and participants confirmed understanding before starting. The assessment included the 15-word VLT learning encoding (4 trials), the 15-word VLT delayed recall, the SVF-animal category (duration of one minute) and a narrative positive storytelling task during which participants had to describe a positive life event for one minute. In total the call lasted approximately 15 minutes. Upon completion, Mili thanked participants for their time.
Speech data processing
The SB-C speech-based digital cognitive assessment composite score16,40 was derived from speech recordings from two common neuropsychological assessments, namely the VLT and the SVF. Speech from both assessments underwent automated processing using the ki:elements’ SIGMA proprietary speech analysis pipeline. This involved automatic speech recognition to transcribe speech and to extract features that capture various aspects of verbal output, including semantic, temporal and task-related features. For the construction of the SB-C score, 27 features were used, which were also used to generate three distinct neurocognitive subdomain scores: learning and memory, executive function, and processing speed. These subdomain composite scores relate to the most commonly affected cognitive areas in MCI, including memory deficits as the primary concern along with impairments in domains like language, executive function or visuospatial memory. 41 Finally, these subdomain scores were combined to derive the single aggregated global cognition score (see Figure 2 for an overview of the SB-C construction and components).
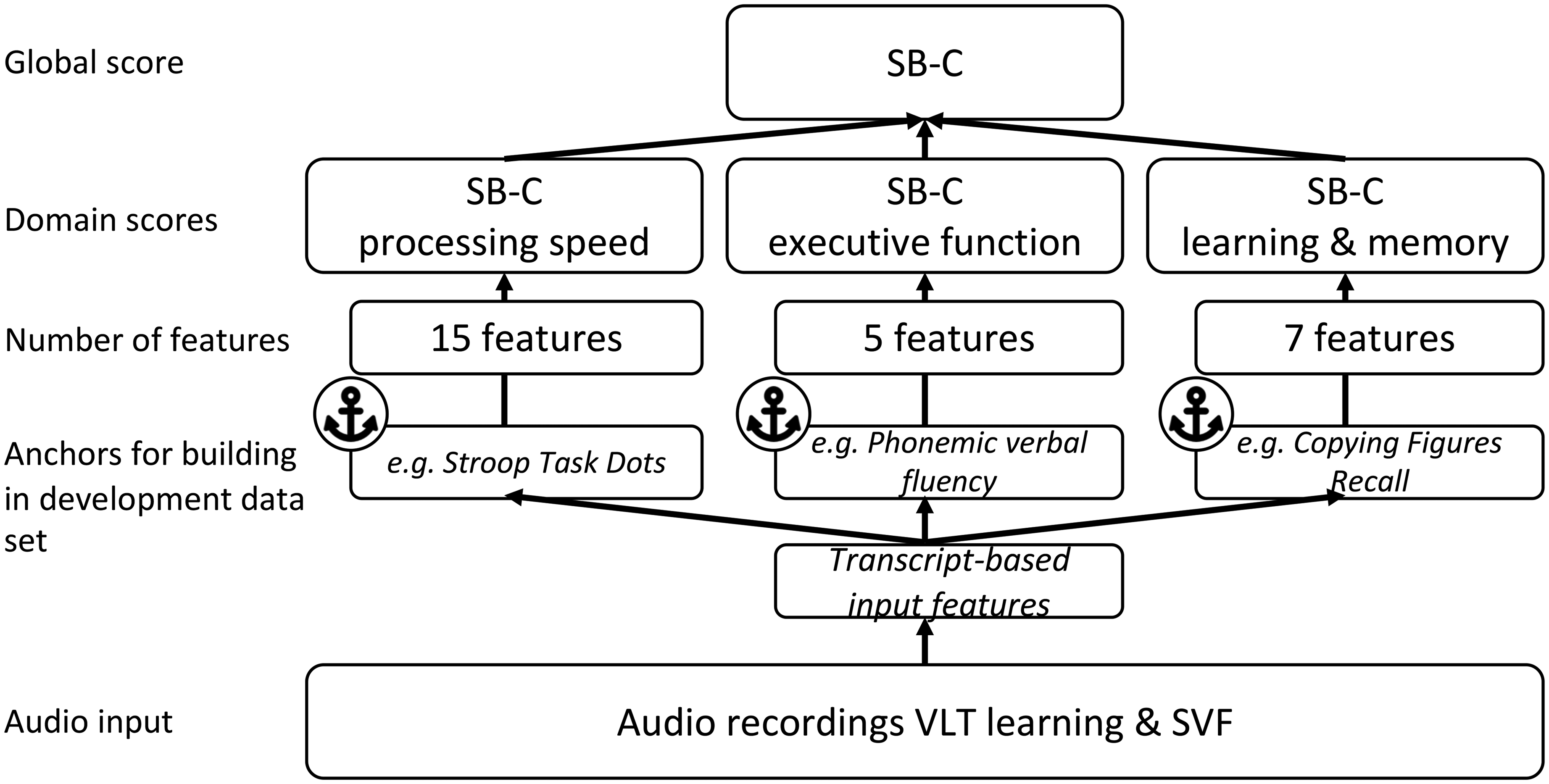
Overview of the structure of the speech-based digital cognitive assessment composite score SB-C and its domain-specific composite scores. Adapted from Tröger et al. 16 .
Statistical analysis
We analyzed all data using R version 4.2.3 (2023.03.15). 42 For group comparisons, we used the non-parametric Kruskal-Wallis H test for continuous variables and Pearson's chi squared for categorical variables due to data not being normally distributed (stats R package 42 ). For specific analyses that assumptions of normality were met we used parametric t-tests. We performed pairwise comparisons with the post-hoc Dunn's test. To adjust for multiple comparisons, we used the Benjamini-Hochberg procedure to control for the false discovery rate. We computed Spearman rank correlations and partial correlations (controlling for age, sex, education years, and the time difference between the clinical and speech assessment) between the speech-based digital cognitive assessment scores and gold-standard paper-based clinical and neurocognitive assessments (Hmisc 43 and ppcor 44 R packages). We calculated effect sizes using Cohen's d. We examined the agreement between the neuropsychological paper-based assessment and the phone-based automatic total word count for the SVF by calculating the intraclass correlation coefficient (ICC) of the total scores, using a mean-rating of two fixed raters (k = 2) with a 2-way mixed-effects model (ICC3k model) (psych R package 45 ).
In Python version 3.10.12, using the scikit-learn library, 46 we trained commonly used machine learning models (Support Vector Machine, Extra Trees, Random Forest, Logistic Regression, Decision Tree) to differentiate between HC/SCD and MCI patients. We selected these models based on literature and to capture a range of potential patterns in the data without assuming a priori which model would be most suitable. We grouped together HC and SCD since although individuals with SCD present subjective cognitive complaints, there is no objective cognitive impairment, compared to the MCI stage, where objective cognitive decline is present. We created models based on three sets of features: only global gold-standard neurocognitive assessment scores, only the SB-C, and a combination of neurocognitive assessment scores and SB-C. For the validation of models and to ensure the generalizability of the results we used the 10-fold cross-validation approach given the limited sample. The dataset was randomly divided into 10 equal folds of which 9 were used for training and 1 for testing. The process was repeated 10 times so that each fold could serve as a testing set one time and the average of all test scores across iterations was the final performance score.
We compared 5 models: (1) MMSE total score at T0, (2) ADAS-Cog 13 Sum score at T0, (3) SB-C at M0, (4) aggregated SB-C at M0, M3, and M6, and (5) a combination of MMSE and ADAS-Cog 13 Sum score at T0 and SB-C at M0). For each model we calculated a series of performance metrics. We computed specificity and sensitivity and used the area under the receiver operating characteristics curve (AUC-ROC) to visualize the trade-offs between sensitivity and specificity. Additionally, we used the “Balanced Accuracy” score, which is an improvement on the standard accuracy metric, designed to work better with imbalanced datasets. This metric achieves better results by calculating the average accuracy for each class individually, rather than combining them as standard accuracy does. 40 Finally, we statistically compared the AUCs of the models using the non-parametric DeLong test (pROC R package 47 ).
Results
Demographic and clinical characteristics
The groups showed similar demographic characteristics. They significantly differed in various baseline clinical measures and severity of cognitive complaints. Table 1 provides a summary of the descriptive characteristics of the baseline dataset that we used in this study.
Sample description of the baseline dataset.
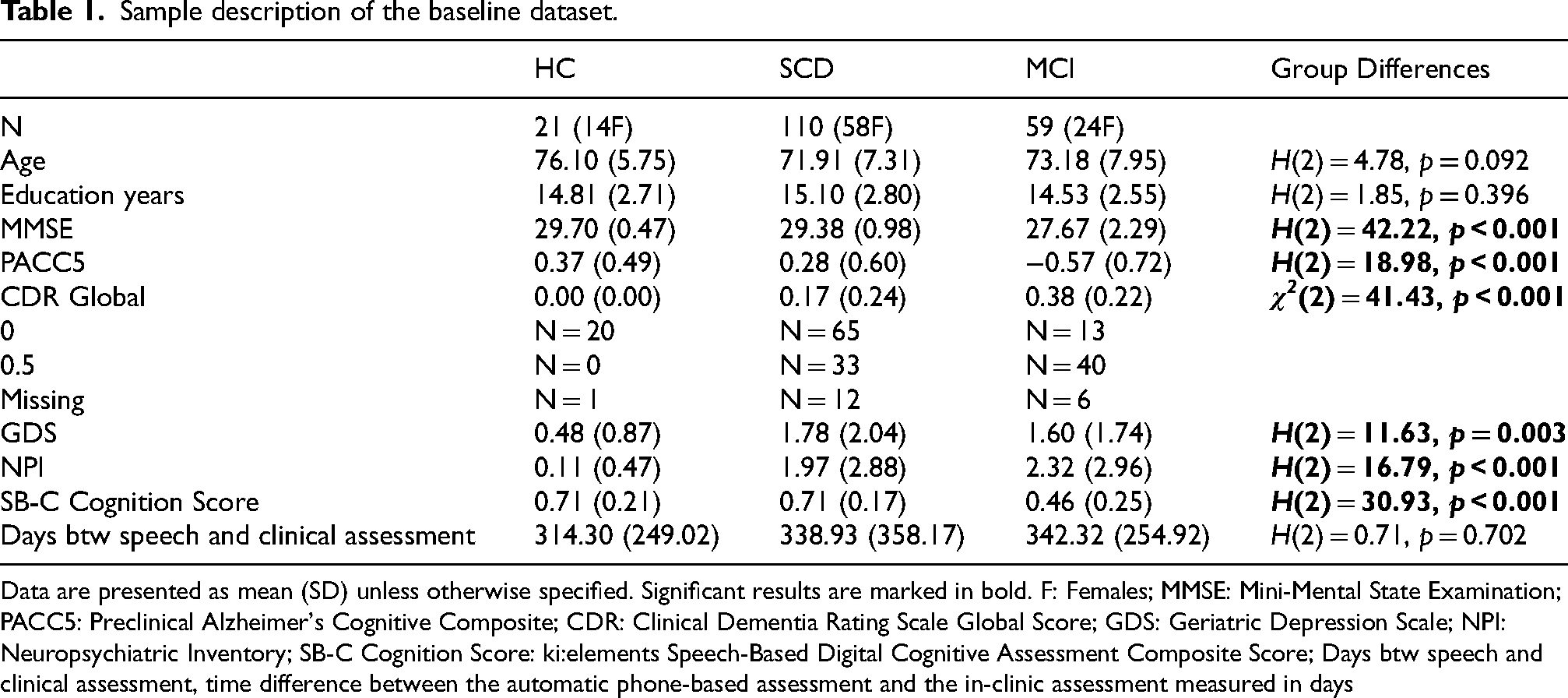
Data are presented as mean (SD) unless otherwise specified. Significant results are marked in bold. F: Females; MMSE: Mini-Mental State Examination; PACC5: Preclinical Alzheimer's Cognitive Composite; CDR: Clinical Dementia Rating Scale Global Score; GDS: Geriatric Depression Scale; NPI: Neuropsychiatric Inventory; SB-C Cognition Score: ki:elements Speech-Based Digital Cognitive Assessment Composite Score; Days btw speech and clinical assessment, time difference between the automatic phone-based assessment and the in-clinic assessment measured in days
Group differences in the SB-C
There was a significant difference in the SB-C score between the three diagnostic groups (H(2) = 30.93, p < 0.001), with higher SB-C values indicating higher cognitive performance. Pairwise comparisons using the post-hoc Dunn's test, adjusting for multiple comparisons, indicated that there was a significant difference between HC versus MCI patients (z = 3.80, p < 0.001) and MCI versus SCD patients (z = −5.30, p < 0.001). A significant difference in the SB-C was also found when splitting the total dataset based on CDR global score (0 versus 0.5) (H(1) = 23.98, p < 0.001) (see Figure 3). Further, there was a significant group difference in all domain-specific SB-C composite scores (see Supplemental Table 1).
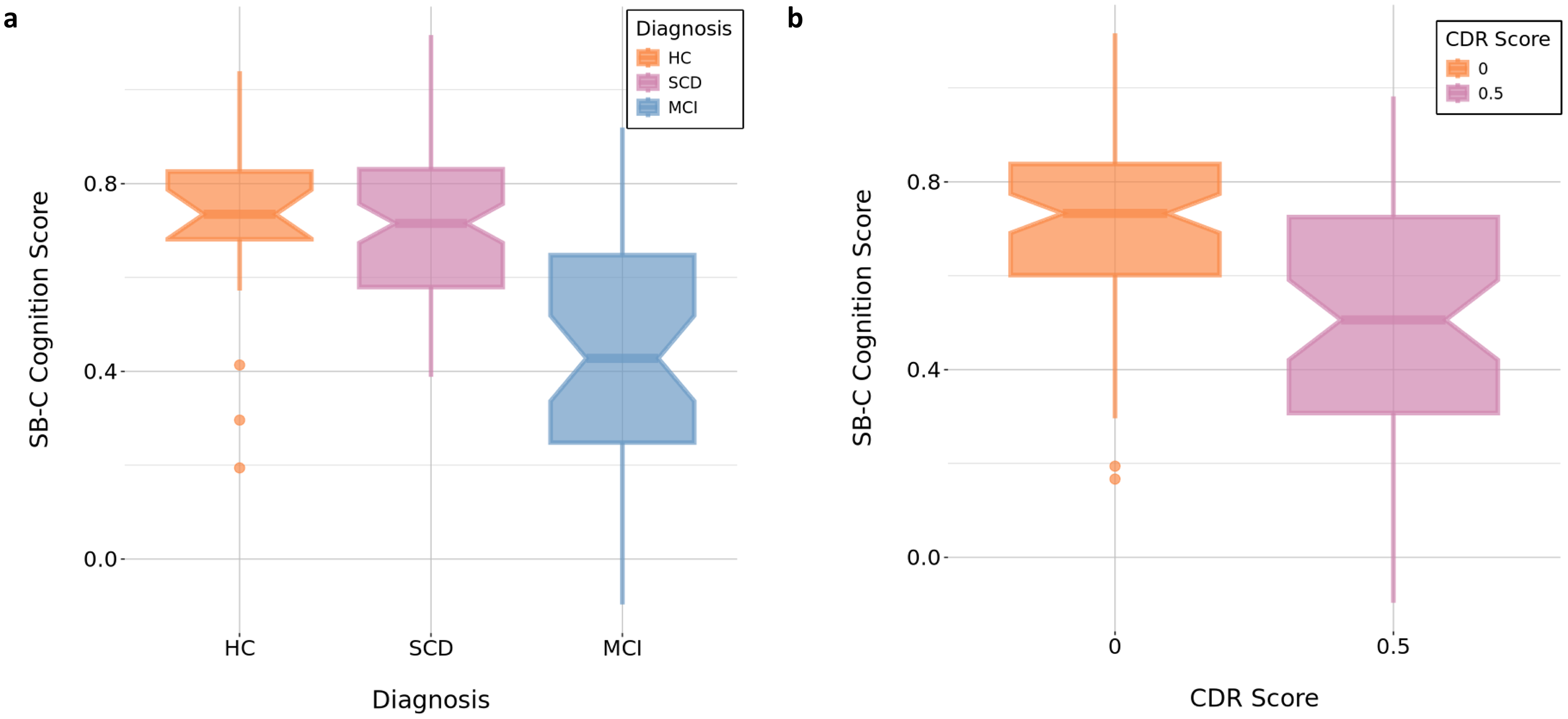
(a) Group differences in the SB-C global cognition score between diagnostic groups.
Correlations between the SB-C global score/domain-specific composite scores and global gold-standard neurocognitive assessments
We found significant correlations between the SB-C and all global clinical anchor scores, including MMSE (r = 0.48, d = 0.96, p < 0.001), CDR-Sum of Boxes (CDR-SoB) (r = −0.46, d = −0.92, p < 0.001), and PACC5 (r = 0.58, d = 1.16, p < 0.001) (see Figure 4). Partial correlations between the SB-C and all global clinical anchors controlling for age, sex, education years and the time difference between the speech and clinical assessment also remained significant (see Supplemental Table 2). Moreover, all domain-specific SB-C composite scores (learning and memory, executive function, processing speed) significantly correlated with all the global anchor scores. All partial correlations remained significant when controlling for age, sex, education years and the time difference between the speech and clinical assessment (see Table 2 for detailed results). SB-C and its domain-specific composites did not significantly correlate with the Clock Drawing Test score.
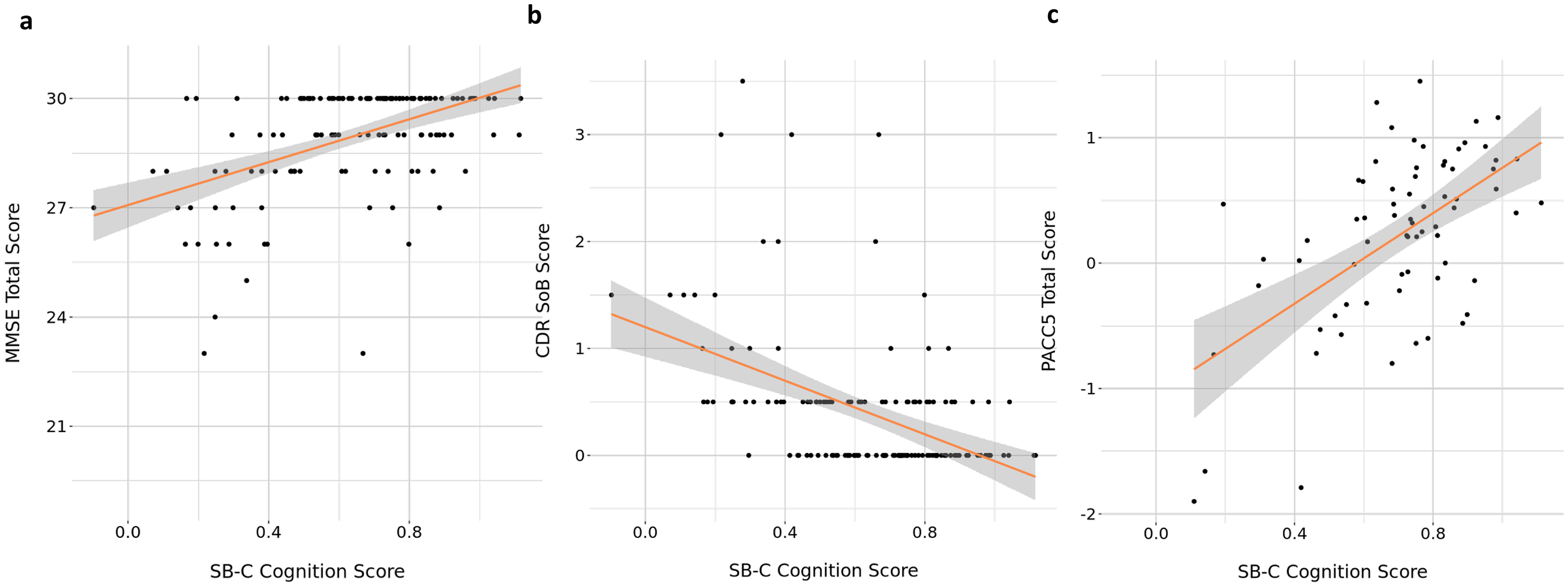
Correlations between the SB-C global cognition score and (a) MMSE total score, (b). CDR SoB score, and (c) PACC5 total score. The red line indicates the fitted smoothed regression line and the shaded area represents its confidence intervals.
Correlation and partial correlation results between the SB-C composite scores and global anchor scores adjusted for age, sex, education years, and the time difference between the speech and clinical assessments.

SB-C Score: ki:elements Speech-Based Digital Cognitive Assessment Composite Score; MMSE: Mini-Mental State Examination; CDR SoB: Clinical Dementia Rating Scale - Sum of Boxes; PACC5: Preclinical Alzheimer's Cognitive Composite.
Correlations between the SB-C domain specific composite scores and domain-specific neurocognitive assessments
We found significant correlations between all the SB-C domain-specific composite scores of learning and memory, executive function and processing speed and their respective domain-specific paper-based neurocognitive tests. Indicatively, the SB-C executive function composite score was significantly correlated with the SVF total word count (r = 0.67, d = 1.34, p < 0.001) and TMT-B scores (r = −0.34, d = −0.68, p < 0.001). The SB-C learning and memory score was significantly correlated with the Digits Span Sum (r = 0.26, d = 0.52, p = 0.002), TMT-A (r = −0.28, d = −0.56, p = 0.001), and the ADAS Word List Correct Sum (r = 0.58, d = 1.16, p < 0.001). Finally, the SB-C processing speed score was significantly correlated with the TMT-A (r = −0.38, d = −0.76, p < 0.001) and TMT-B (r = −0.35, d = −0.70, p < 0.001) scores. Most partial correlations adjusted for age, sex, education years and the time difference between the clinical and speech assessment remained significant. Detailed results of significant and non-significant correlations and partial correlations can be found in Supplemental Table 3.
Agreement between automatic and manual scoring
We calculated the ICC to assess the agreement between manual and automatic total word counts for the SVF in N = 155 participants due to data availability. The ICC results for the average rating across the two fixed raters (ICC3k) indicate a high level of agreement (ICC = 0.83, 95% CI = 0.77–0.88), suggesting the reliability of the automated method. The F-statistic for the ICC was significant (F(154,154) = 6.0, p < 0.001). However, there was a statistically significant difference between the mean manual and automatic total word scoring, t(307.39) = 5.26, p < 0.001, with approximately 24 words reported manually and approximately 20 automatically (95% CI: 2.42–5.32).
Patient classification accuracy
The classifier that best discriminated between HC/SCD vs MCI patients was the logistic regression classifier. The SB-C score at M0 achieved an ROC-AUC of 0.77, whereas the MMSE had an ROC-AUC of 0.74 and ADAS-Cog 13 Sum score an ROC-AUC of 0.85. The averaged SB-C score over time (M0/M3/M6) achieved an ROC-AUC of 0.83, while the model combining MMSE and ADAS-Cog 13 Sum score at T0 and the SB-C at M0 achieved an ROC-AUC of 0.86 (see Table 3). In Supplemental Table 4 the full set of coefficients from each fold of the 10-fold cross-validation is reported per variable for the combinatorial model with MMSE and ADAS-Cog 13 Sum score at T0 and the SB-C at M0. The different ROC curves per model are shown in Figure 5. Results of the detailed performance metrics of all classifiers can be found in Supplemental Table 5. Finally, we did not find any statistically significant differences between the ROC-AUCs of the models.
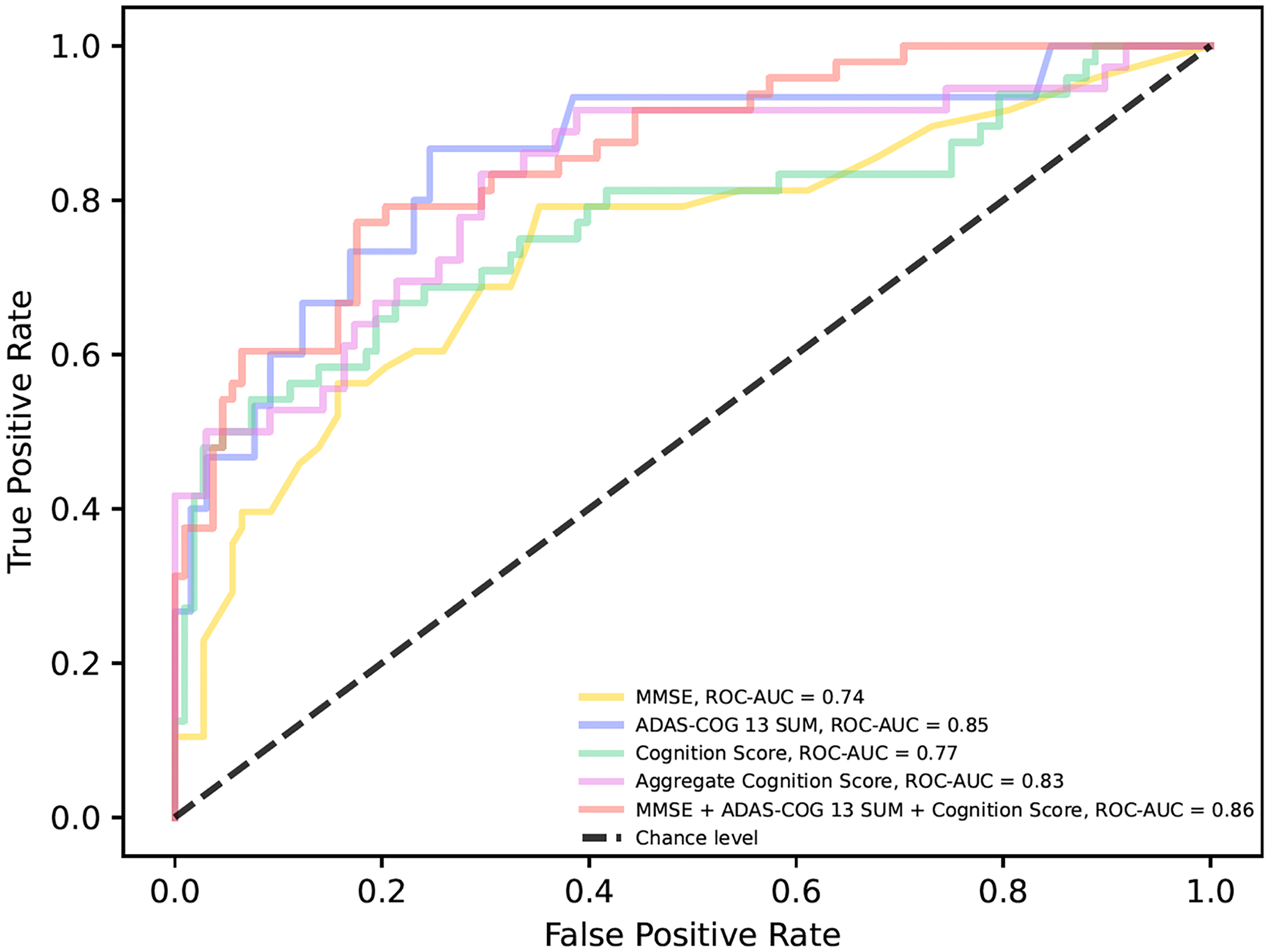
Receiver operator curves for differentiating HC/SCD and MCI patients. The MMSE total score at T0 is displayed in a yellow line. The ADAS-Cog 13 Sum score at T0 is displayed in a purple line. The SB-C global cognition score at M0 is displayed in a green line. The aggregated SB-C global cognition score of M0, M3 and M6 is displayed in a pink line. The model combining MMSE and ADAS-Cog 13 Sum score at T0 and the SB-C global cognition score at M0 is displayed in a red line. ROC-AUC: Receiver Operator Characteristic-Area Under the Curve; MMSE: Mini-Mental State Examination; ADAS-Cog 13 Sum: Alzheimer's Disease Assessment Scale 13-item Cognitive Subscale Sum score. MCI: mild cognitive impairment; SCD: subjective cognitive decline.
Performance metrics of the logistic regression classifier.
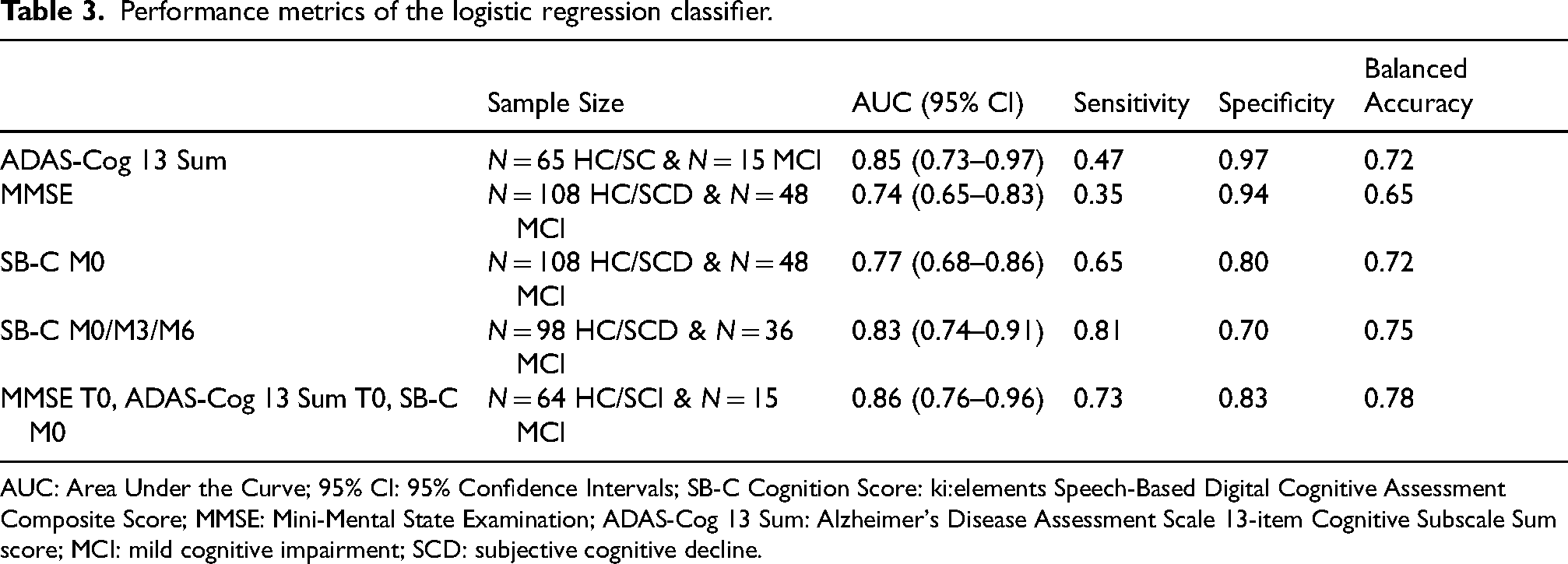
AUC: Area Under the Curve; 95% CI: 95% Confidence Intervals; SB-C Cognition Score: ki:elements Speech-Based Digital Cognitive Assessment Composite Score; MMSE: Mini-Mental State Examination; ADAS-Cog 13 Sum: Alzheimer's Disease Assessment Scale 13-item Cognitive Subscale Sum score; MCI: mild cognitive impairment; SCD: subjective cognitive decline.
Discussion
In this study, we examined how novel speech-based digital cognitive assessment composite scores were associated with gold-standard neurocognitive assessment methods in individuals at-risk of AD. We also compared the digital speech-based scores and the paper-based scores on their ability to differentiate between clinical groups. As expected, we found significant group differences in the SB-C score across diagnostic groups. Correlation analyses revealed that the SB-C and its domain-specific composite scores of learning and memory, processing speed and executive function were significantly associated with both global and domain-specific neurocognitive assessments. The agreement between manual and automated scoring for the SVF total word count was high, indicating the reliability of the automated acquisition and processing method. This was also recently established in a subset of the DELCODE and DESCRIBE cohorts, using Bayesian statistical methods. 48 Finally, diagnostic accuracy analyses showed that the SB-C presented more balanced performance metrics compared to MMSE and ADAS-Cog 13 in distinguishing between clinical groups, with improvements when averaged over multiple time points. Combining SB-C with gold-standard assessments augmented diagnostic performance although the difference was not statistically significant.
In previous research, SB-C has been validated using the extensive V3 framework established by the Digital Medicine (DiME) Society. 16 V3 specifically examines the digital assessment methods and determines their suitability for clinical trial use. Here, we replicate and extend these results in a SCD/MCI population. Specifically, we demonstrated that the digital speech-based assessment composite score and its subdomain scores can effectively measure cognition as a concept of interest in SCD/MCI cases, yielding results similar to gold-standard neurocognitive tests. The significant correlations between the speech-based scores and the classical paper-based assessment methods (MMSE, PACC5, CDR), revealed that the SB-C and its subscores can correctly capture cognitive abilities. Despite this significance, the strength of the correlations observed was relatively moderate, especially with the MMSE scale. Indeed, previous research with early-stage cognitive decline patients has also shown moderate correlations between speech-based markers of cognition and global cognition scores including MMSE 16 or the Montreal Cognitive Assessment 49 .
Although the MMSE is the most widely used screening test for assessing cognitive impairment in routine clinical practice and research, it is not sensitive enough for the earliest stages of cognitive decline. 7 Specifically, in our dataset there were obvious ceiling effects and limited variability in the MMSE total score. More complex scales such as the ADAS-Cog can offer an increased sensitivity compared to MMSE; however, they still present limitations in detecting subtle cognitive changes especially in patients with early-stage cognitive impairment. In contrast, digital speech-based assessment scores can offer a more fine-grained evaluation of cognition and incorporate an abundance of information compared to paper-based assessment methods, which may lack the sensitivity to detect cognitive changes in individuals in the earliest stages of cognitive decline. As an indication, the SB-C incorporates information from 27 automatically extracted features, which encompass information from the traditional VLT and SVF tests (i.e., correct word count recalled per trial, count of correctly named words per category), but also additional temporal and semantic information (i.e., temporal clustering mean cluster size, temporal clustering switches, word frequency mean). Thus, while both global paper-based neurocognitive assessments and SB-C can provide a cognitive evaluation, the strength of the SB-C lies in its capacity to automate complex data extraction and processing, and capture it in such a nuanced way that even comprehensive paper-based scales could overlook. This difference could explain the moderate correlations between digital and paper-based global cognition measures.
We found significant correlations between all the SB-C subdomain scores and global clinical scales. First, the correlations of the subdomain scores with the CDR SoB scale, as well as the group differences in SB-C based on the global CDR scores, showcase how these associations are clinically relevant in the context of cognitive impairment due to dementia severity. Further and most notably, PACC5 was strongly correlated with all speech-based domain-specific scores and especially with the SB-C executive function score. PACC5 is a composite score which specifically has been optimized for MCI with the addition of category fluency 36 and derives information from multiple cognitive domains. Verbal fluency is often characterized as an executive function in a series of reviews,50,51 while the SB-C executive function score also derives information and features from the SVF task. Thus, this can potentially explain the stronger correlation between the two measures.
Domain-specific speech-based composite scores were also significantly associated with their respective domain-specific paper-based neurocognitive tests. Our results are consistent with research showing how VLT and SVF automatically derived features correlate not only with language but also with other cognitive scores, particularly those related to executive function and episodic memory.22,24 This consistency supports the validity of using speech-based assessment scores to reflect broader cognitive functions. Although further investigation is needed to determine how well VLT and SVF measures correlate with other domain-specific scores, our findings show that grouping these speech-based measures into distinct domain-specific composites effectively summarizes respective neuropsychological tests of broader cognitive functions, emphasizing their potential for screening purposes.
Regarding the comparison of SB-C and paper-based scores in their ability to discriminate between clinical groups, the SB-C at baseline yielded a comparable AUC to MMSE and lower to ADAS-Cog 13, although AUCs were not significantly different. However, the overall performance metrics of the automated assessment method compared to pen-and-paper tests were more evenly distributed taking into account sensitivity, specificity and balanced accuracy. The SB-C at M0 in our study had an AUC of 0.77. This result aligns with previous research which has reported varying accuracies in identifying patients at the earliest stages of AD, with results ranging from 68% to 80%.52–54 This variation in results is likely due to methodological differences between studies.
The AUC of SB-C increased to 0.83 when aggregating the score over three timepoints, yielding the highest sensitivity overall. Although the AUC alone was not significantly different, these findings suggest that digital speech-based assessments offer a unique opportunity of accurately identifying cognitive decline through access to continuous and longitudinal measurements. Neuropsychological assessments provide a “momentary glimpse” based on limited measurements collected over time. While these measures are crucial for disease diagnosing, they depend on trained clinical personnel in specialized memory units, are time-intensive, and thus are not convenient for broader patient-outreach. In contrast, the advantage of digital speech assessments is the automated, easy and cost-effective opportunity to widen patient-outreach and enable broader accessibility in the future. They have the potential to offer access to continuous and fine-grained data, making them more sensitive to dynamic changes in cognition, even at the earliest stages of cognitive decline. 55 However, these results should be interpreted with caution given our limited sample size and future thorough longitudinal analysis is required to fully confirm these conclusions.
The combinatorial model which included the classical neuropsychological assessments and the SB-C at baseline presented an increased AUC, reduced disparity between sensitivity and specificity and the highest balanced accuracy (0.78) compared to the models with the individual assessments. While again the AUC alone was not significantly different, these results indicate that each assessment potentially captures distinct information and therefore by integrating them in one model enhances the classification performance. Indeed, previous research has shown how integrating information from various neuropsychological assessments and repeatedly administered speech measures can significantly improve classification accuracies in early-stage AD patients.56–58 Since most tests provide complementary information, integrating multiple and diverse data sources can enhance the overall predictive power and open an avenue towards combinatorial approaches to screening and diagnostics in early-stage cognitive decline. In general, the augmentation of traditional disease-related markers with digital technologies has the potential to offer more detailed and thorough understanding of the characterization and progression of AD, 15 therefore improving screening efforts.
One of the main limitations of this study is the relatively small sample size, which precludes more robust predictive modeling experiments and the homogeneous population of white European Germans, which hinders the generalizability of the findings to other cultural and ethnic backgrounds. Limited access to fluid biomarkers prevented validation of the results and hindered drawing conclusions on the etiology of cognitive impairment. Additionally, the time gap between the automated speech assessment and the in-person neuropsychological assessment (although controlled for) may affect the comparability of the correlations. The higher manual scoring of SVF compared to the automated one could reflect progressive cognitive challenges but also technical limitations in the automated method. Moreover, ceiling effects and reduced variability in neuropsychological tests like the MMSE could potentially limit the sensitivity of the correlation analysis. In general, the cross-sectional nature of the study restricted inferences regarding longitudinal progress. Therefore, a future longitudinal examination of the cognitive trajectories of participants and how it is represented in the digital speech compared to paper-based assessment scores will be performed. Future research should also explore how SB-C performs across different cognitive reserve measures (i.e., IQ, education) since this was not directly examined in our analysis.
In summary, we contributed to a unique approach that showcases the effectiveness and sensitivity of a fully remote speech-based digital cognitive assessment as a reliable tool for early detection of MCI compared to conventional pen-and-paper neuropsychological tests. We conclude that automated and semi-automated assessments and specifically speech-based digital cognitive assessments can be used within the context of longitudinal cohort studies with access to real-life settings such as memory clinics, and more importantly, streamline screening processes of individuals at risk. Prospectively, in relation to clinical trials, the abundance of fine-grained information that can be extracted from speech can provide a reliable approximation of a participant's cognitive abilities and potentially accelerate recruitment times and ultimately access to care. Eventually, utilizing digital assessments in drug development in combination with fluid markers can enhance the faster and improved patient screening and therefore the use of digital health technologies has been increasingly recognized as a component of clinical trials for disease modifying treatments. 12 To summarize, the integration of speech-based digital cognitive assessments has the potential to enhance the early screening of MCI patients within clinical settings, as well as potentially expedite screening procedures in clinical trials.
Supplemental Material
sj-docx-1-alz-10.1177_13872877251343296 - Supplemental material for Speech-based digital cognitive assessments for detection of mild cognitive impairment: Validation against paper-based neurocognitive assessment scores
Supplemental material, sj-docx-1-alz-10.1177_13872877251343296 for Speech-based digital cognitive assessments for detection of mild cognitive impairment: Validation against paper-based neurocognitive assessment scores by Zampeta-Sofia Alexopoulou, Stefanie Köhler, Elisa Mallick, Johannes Tröger, Nicklas Linz, Eike Spruth, Klaus Fliessbach, Claudia Bartels, Ayda Rostamzadeh, Wenzel Glanz, Enise I Incesoy, Michaela Butryn, Ingo Kilimann, Sebastian Sodenkamp, Matthias HJ Munk, Antje Osterrath, Anna Esser, Sandra Roeske, Ingo Frommann, Melina Stark, Luca Kleineidam, Annika Spottke, Josef Priller, Anja Schneider, Jens Wiltfang, Frank Jessen, Emrah Düzel, Bjoern Falkenburger, Michael Wagner, Christoph Laske, Valeria Manera, Stefan Teipel and Alexandra König in Journal of Alzheimer's Disease
Footnotes
Acknowledgements
The authors extend their gratitude to all investigators involved in the DESCRIBE and DELCODE cohorts and their teams involved in the PROSPECT-AD study.
ORCID iDs
Ethical considerations
All data collection processes within PROSPECT-AD adhered to ethical guidelines for medical research involving human participants, as outlined in the Declaration of Helsinki and the European General Data Protection Regulation. The study received approval from the local ethics committees as follows: University Hospital Bonn (291/22), Ethics Committee of the University of Technology Dresden (BO-EK-263062022), University Medical Center Göttingen (27/9/22), University of Cologne Faculty of Medicine (22-1284), University Hospital Magdeburg Medical Faculty (80/22), University Medical Center Rostock (A2021-0256), and University Hospital Tübingen (551/2022BO2). For Charité Berlin, no separate approval was necessary as it relied on the one from Rostock.
Consent to participate
All participants provided written informed consent, after which they were contacted by the study coordinator to schedule the appointments for the automated phone assessments. Moreover, during each call, the chatbot Mili asked the participants to confirm consent verbally.
Author contribution(s)
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work of author Zampeta-Sofia Alexopoulou was supported by funding received from the European Union’s HORIZON-MSCA Doctoral Networks 2021 program under grant agreement No 101071485. The PROSPECT-AD study is supported by the Alzheimer’s Drug Discovery Foundation Diagnostic Accelerator program.
Declaration of conflicting interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Zampeta-Sofia Alexopoulou has nothing to disclose. Alexandra König, Johannes Tröger, Nicklas Linz and Elisa Mallick are employed by the company ki:elements, which developed the application for the automatic phone assessment and calculated the speech-based digital cognitive assessment scores. Johannes Tröger and Nicklas Linz own shares in the ki:elements company. Alexandra König is an Editorial Member of the special issue of this journal but was not involved in the peer-review process of this article nor had access to any information regarding its peer-review. Stefanie Köler has received funding from the Alzheimer Drug Discovery Foundation and the Lilly Deutschland GmbH as well as lecture fees from Eisai. Eike Spruth has nothing to disclose. Klaus Fliessbach has nothing to disclose. Claudia Bartels received funding from the German Alzheimer Association and lecture fees from Lilly, Roche Pharma and Eisai. Ayda Rostamzadeh has nothing to disclose. Wenzel Glanz has nothing to disclose. Enise I. Incesoy has nothing to disclose. Michaela Butryn has nothing to disclose. Ingo Kilimann has nothing to disclose. Mathias Munk has nothing to disclose. Sebastian Sodenkam has nothing to disclose. Antje Osterrath has nothing to disclose. Anna Esser has nothing to disclose. Sandra Roeske has nothing to disclose. Ingo Frommann has nothing to disclose. Melina Stark has nothing to disclose. Luca Kleineidam has nothing to disclose. Annika Spottke has nothing to disclose. Josef Priller has nothing to disclose. Anja Schneider has nothing to disclose. Jens Wiltfang has received funding from the BMBF (German Federal Ministry of Education and Research), consulting fees from Immunogenetics, Noselab, Roboscreen and lecture fees from Beijing Yibai Science and Technology Ltd, Gloryren, Janssen Cilag, Pfizer, Med Update GmbH, Roche Pharma, Lilly. Jens Wiltfang participated on a Data Safety Monitoring Board or Advisory Board of Biogen, Abbott, Boehringer Ingelheim, Lilly, MSD (Merck Sharp and Dohme) Sharp & Dohme, Roche. Frank Jessen has nothing to disclose. Emrah Düzel has nothing to disclose. Bjoern Falkenburger has received funding from the Deutsche Forschungsgemeinschaft. Michael Wagner has nothing to disclose. Christoph Laske has nothing to disclose. Valeria Manera has nothing to disclose. Stefan Teipel participated in scientific advisory boards of Roche Pharma AG, Biogen, Lilly, and Eisai, and received lecture fees from Lilly and Eisai. Stefan Teipel is an Editorial Member of the supplemental issue of this journal but was not involved in the peer-review process of this article nor had access to any information regarding its peer-review.
Data availability statement
The data supporting the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy or ethical restrictions.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.