
Abstract
I examine the cultural acoustics of voice and listening in relation to the experience of migration and displacement through an analysis of a selection of digitized audio recordings of intimate one-on-one conversations between asylum seekers originally recorded by local British Broadcasting Corporation’s radio stations in booths set up throughout the United Kingdom, with the unedited recordings digitally archived by the British Library for the public. My approach to this archive is constituted by a concept and practice I call listening to difference. My case studies are two Somali siblings, a Syrian father and son, and two friends from Algeria and the Congo, and their relationality to the norms of Standard British Listening. My aim is to show how listening to these conversations can make us aware of our own limiting preconceptions in our listening and when and why they occur. Listening to ourselves listening will work against aurally mediated racial ideologies as it necessitates reflecting upon our own automatized, enculturated biases, as well as that of technologies of recording and transcription such as automated speech recognition. It challenges preconceptions about those voices marked as deviating from unmarked norms long established by the legacies of European Enlightenment humanism. Critically listening to those who are othered and belong to communities radically different from our own involves the exposure of aural power differentials and is particularly urgent during a time of an unprecedented increase of refugees accompanied by an increased controlling of national borders antagonistic to refugees and immigrants.
Introduction
Although listening is a basic process of sensory perception, vision has been culturally prioritized in Western media when representing migrants and asylum seekers. Their silencing necessitates a long-overdue reflection on our biased ways of listening. Within the empire of the visual which conditions perception of refugees, listening to the experiences of migration as narrated by them has the potential to stimulate a dialogical approach to recognizing the othered by a potentially infinite community of earwitnesses, those with citizenships and those stateless. Providing refugees a publicly accessible platform to tell their stories carries the potential to ‘counter vicious exclusions that combine race, gender, class and means of rendering people socially abject’ and unheard (Bassel, 2017: 6) because it challenges the alienating primacy of vision in mainstream coverage of refugees.While listening is taken to be passive, listeners must be made aware of how the practice actively shapes biased judgements of who belongs in positions of authority in a particular community, and who deserves to be excluded from it (Couldry, 2009: 580). That is, merely including voices of asylum seekers in media representations for listeners who are not listening to difference is counterproductive. To listen to difference, we must listen to how our positionalities vis-à-vis institutional and inherited power and privilege train our listening to the degree to which we are ‘responsive to the inequalities and conflicts that shape speaking and listening relationships’ (Dreher, 2009: 452; Dreher and De Souza 2018: 22; Solanki 2022a) to those marked as the most politically marginalized (Bassel, 2017: 11; Bickford, 1996: 187).
It is particularly crucial to critically listen to our own biased listening practices during continual upheavals in the United Kingdom, United States and European Union accompanying the simultaneous welcoming and resisting of linguistically diverse refugees and increased nativist controlling of national borders. Since racism is taken to be a ‘discourse of power that thinks with the eyes’ in a culture driven by an ‘overdetermined politics of looking’, unreflective listening has served as a repository of ‘apprehension, oppression, and confrontation, rendered secondary – invisible – by visually driven epistemologies’ (Stoever, 2016: 33–35). A supposedly enlightened and ocularcentric listening paradigm results in mishearing which persists in producing irreconcilable difference and dehumanization. Instead of undoing them, it further entrenches pre-existing ‘raciolinguistic ideologies’, that is, implicit automatized aural understandings of culturally ‘appropriate and inappropriate ways of speaking and listening’ of those speakers who are accented and ‘language-minoritized’ in relation to a language of power such as British and American English (Flores and Rosa, 2015: 150, 153). A failure to engage in listening to difference can be a matter of life and death as in the case of Black Americans and the auditory imaginings imposed upon them by white supremacy. Listening to ourselves listening can work against aurally mediated racial ideologies as it necessitates reflecting upon our own automatized, enculturated biases and preconceptions of those marked as deviating from unmarked norms long established by the legacies of European Enlightenment humanism. What is required is ‘deep listening’, also a kind of listening to difference, in that ‘sound makes us re-think our relation to community’, including ‘how we relate to others, ourselves and the spaces and places we inhabit’. And it has the potency to make us ‘re-think our relationship to power’, (Bull and Back 2003: 4).
This article is an inquiry into practices and technologies that will allow us to listen to what I call the cultural acoustics of difference so that we do not project limiting preconceived categories, frames and expectations determined by the ‘language of appropriateness’ (Flores and Rosa, 2015) of ‘imagined communities’, ‘unified and homogeneous social world[s] in which language exists as a shared patrimony as a device, precisely, for imagining community’ (Anderson, 2006). Geographical segregation plays a part in the lack of interaction between refugees and their new communities, but what is most significant is dehumanizing stereotyping of the cultural acoustics of their speech. By cultural acoustics, I refer to aurally perceptible physiological textures of voices that include accents, tempo, pitch, timbre, tones, mumbling, sighs and silences, as well as vocal expressions which might deviate from norms of appropriateness, such as affirmative or aggressive interruptions. These acoustic expressions and vocal qualities index how the speaker and the listener’s perception of them are related to larger cultural categories. The study of acoustics under the aegis of physics and sound studies is undergirded by the assumption that listening occurs in the same way for all peoples. It is limited to the measurement and transcription of sound waves as a purely physical phenomenon. However, my approach to sound is cultural acoustics, which insists upon both historical and cultural differences in the production and reception of acoustic data. Rather than peoples belonging to these categories permanently and naturally, it is the listener who continually places qualities of voices in various categories in each act of listening, be they racial, geographic, religious, sexual, generational or socioeconomic. What we as listeners mark as ‘difference’ is continually shifting based on our previous listening experiences, regardless of the otherwise static nature of the written script from which spoken language and cultural acoustics are derived. Cultural acoustics challenges both the limited notion of acoustics as a universal and mathematically measurable and physical phenomenon and the idea that there is a correct and unaccented way in which a language’s written format must be voiced.
Listening to the difference of cultural acoustics occurs in ‘contact zones’, ‘social spaces, where cultures meet, clash, and grapple with each other, often in contexts of highly asymmetrical relations of power, such as colonialism, slavery, or their aftermaths’ (Pratt, 1991: 34). Contact zones produce a dynamic in which one party is exercising its authority to constitute both the written and spoken linguistic norms of an imagined community and the other either disrupting such an imaginary or submitting to it (Pratt, 1991: 48). Listening to difference requires ‘dwelling in discomfort’ (De Souza and Dreher, 2021) in contact zones in which listeners cannot escape how ‘historical structures of privilege and inequality’ (Dreher, 2009: 451) inevitably determine their practices of listening. In these acoustic zones, listeners face their complicity with colonial histories to which each listener is ‘differently and very unevenly located’ (De Souza and Dreher, 2021) rather than remaining in the status quo of ‘polite conversation or consensus which is a depoliticization of systemic issues’ (De Souza, 2020: 85). It involves challenging the supposed inclusivity of the idea that anyone can be naturalized into the institutionl of an imagined community such as a nation-state. The belief that ‘English, like any other language, is always open to new speakers, listeners, and readers’ (Anderson, 2006: 146) further marginalizes those who do not have mastery over the English language and thus do not belong in the promise of a unified and fraternal imagined community where all are aware of and actively practice the same set of cultural acoustics of proper English. It puts pressure on the acoustic production of those who are perceived as not skilled enough to imitate the codes of power and its norms of appropriateness.
To answer my inquiry about the cultural acoustics of difference, I analysed three recorded conversations between asylum seekers included in ‘The Listening Project’, a partnership begun in March 2012 between the British Library (BL), British Broadcasting Corporation (BBC) Radio 4, BBC local and national radio stations. The recordings are of intimate one-on-one conversations between family members, friends and colleagues, all refugees, originally recorded by a number of local BBC radio stations in booths set up throughout the United Kingdom, with the unedited versions of the recordings archived on the British Library’s (2022) ‘Sounds’ website. Seventy of the archived conversations that were labelled as on the topic of migration are between immigrants and asylum seekers of different genders, cultural backgrounds, age and socioeconomic status, hailing from around the world, with varying degrees of fluency in the hegemonic language of empire and global capitalism, British English. I chose this radio programme because (1) it provides a valuable contact zone to allow the voices of migrants to be heard rather than seen from afar and (2) it has potential as a tool to train for listening to difference in how it allows for aural and oral crossing of borders that could otherwise not be crossed between peoples who would not encounter each other even within the same city. Examples include a conversation between a father and daughter about her experience growing up in Cambodia, between a mother and daughter about the mother’s experience of fleeing Zimbabwe and between a husband and wife about their experiences in Kenya. There are a few conversations between citizens with British English as first language, such as that between two brothers who discuss leaving Liverpool for Northern Ireland. My case studies are two Somali siblings with 1 year of English, a Syrian father and son, and two friends from Algeria and the Congo. Through my analysis, I shed light on how failed and effective practices of listening to difference between peoples who each relate differently to the English language can initiate alienation between each other, but also provide alternative modes of belonging and intimacy. I found that the mere existence of the archive does not necessarily lead to effective practices of listening to difference.
The descriptions on the BBC and BL websites of these conversations, automated speech recognition programmes (ASR), as well as interruptions by a standard British English speaking BBC recordist for the conversation between the Somali siblings, controlled and erased the cultural acoustics of the voices of refugees by setting the parameters and frameworks in the media and format in which they appear to the public, imposing upon them Western epistemologies and Eurocentric imaginaries of community, and obstructing listening to difference. Both by my own listening, and using the listening technology of spectrograms, I have found that those aspects of cultural acoustics indicating affects such as joy and fear are indicated not only by signifying words of English, a language that is foreign to them to varying degrees, but by the acoustic difference which does not belong to any signifying language and exceeds the limits of a ‘hegemonic positions of reception’ (Flores and Rosa, 2015: 162) such as the machine-learned algorithms ASR programmes, the ‘British’ ear, as well as the written script of standard British English. I conclude by discussing other instances of non-commercial radio, that in their format do actively allow for practices of both listening to and across difference. By providing agency to the linguistically and politically marginalized, they allow for the creation of new aural communities and a sense of belonging of those who have faced various kinds of ‘vocal injustice’ (Cahill and Hamel, 2021; De Souza, 2020; De Souza and Russell, 2022).
My methodological and analytical framework shares the approach of sound studies scholars who highlight the power-sensitive politics of listening (Bickford, 1996; De Souza and Russell, 2022; Dreher, 2009; Gautier, 2014; Stoever, 2016). Their work, like mine, seeks to ‘denaturalize hearing and reconceive listening practices as historically contingent, material, and social techniques’ (Flores and Rosa, 2015: 16; McEnaney, 2019: 84) with each act of listening ‘accompanying sets of sensory priorities, possibilities, and predispositions’ (Rice, 2015: 102). Most proximate to my study is Tanja Dreher’s proposed practice of ‘listening across difference’, through which she highlights how listeners are differentially situated in a long (colonial) history of paying attention to certain voices and not others (Dreher, 2009: 454). However, she and other scholars of the politics of listening limit the object of listening to denotative, discursive linguistic oral signifiers rather than all the other acoustic information voices communicate.
Studies of the voices of the ‘subaltern’ using discursive analysis have long treated the voices of those who are not politically represented as sovereign subjects in a world of global capitalism in a metaphorical and conceptually problematic way, equivalent to people having the right to vote and power of representation whose mediation could just as well be textual (Galea, 2008; Georgiou, 2018; Spivak, 1988) thereby unintentionally silencing the embodied cultural acoustics of their voices and the situated process of listening to their difference. My study intervenes and challenges these long-standing theories by using concepts from those works in sound studies which examine how voices in their anatomical aspect, bodily processes within the throat, tongue and lungs, and their resulting timbre are embedded within sociocultural semiotic features, both personal and social, indexing a range of communities with which the speaker identifies themselves (Cahill and Hamel, 2021; Eidsheim, 2019; Harkness, 2013). However, scholars of voice do not sufficiently acknowledge the active role that listening plays in registering voices that are ‘replete with social and political meanings that exceed linguistic signification’ (Cahill and Hamel, 2021: 1). I place emphasis on examining how the aurally privileged, in policing the cultural acoustics produced by non-normative voices in the name of empowering them and giving them a voice, unwittingly perpetuate oppressions and privilege dominant norms of cultural acoustics, and how they must become aware in doing so (Cahill and Hamel, 2021: 155). My analysis of The Listening Project’s conversations makes apparent the raciolinguistic consequences of the modern forms of rational listening which Jonathan Sterne (2003) claims began after 1750, when scientific inventions rendered the world audible in new ways. I intervene in Sterne’s thesis to show how technologies such as Alexa, Siri and ASR are programmed in ways that betray what those central within the ‘networks of privilege and power’ (Dreher, 2009: 454) hear and mishear. I examine these technologies as they function as the ear of those who are occupying listening positions of the unmarked and unaccented English. If we can listen in a way as to keep difference preserved rather than expecting the cultural acoustics of migrant voices to abide by an imaginary unified conception of community with homogenized accents, we can bring to the fore new aural communities to which listeners may not otherwise belong.
The BBC’s utopian cultural acoustics and its limitations
The stated goals of the Listening Project, as written on its BBC website are to ‘bring Britain together, one conversation at a time’, ‘inviting people who don’t know each other but who would like to get to know each better to use the project to do just that’. It is meant to be an oral history project for future generations, ‘made entirely out of what we think is important about our own lives, told by us, and listened to by people we know and love’ (BBC, 2022c). Indeed, unedited conversations from the Listening Project archived in the BL allow for a global audience to listen to non-dominant narratives about asylum seekers’ displacement, trauma, stigmatization and discrimination. But there are limits to these utopian goals of a united Britain, and these limits can be heard in the 3-minute excerpts from the unedited recordings selected to be broadcast by the BBC to reflect such a united Britain, none of which included asylum seekers who recently arrived in the United Kingdom from non-European countries and their experiences (BBC, 2022a). Instead, the topics of the conversations, including those of the few conversations by immigrants, reflected a universalism which is a kind of silencing or erasure of difference (BBC, 2022a). ‘Often they have made us laugh and cry as people touch on the universal themes of life – love and loss, pain and pleasure, hope and disappointment’, is stated on the BBC’s (2022c) summary of reactions to these recordings by listeners, either reported or as imagined by the producers. However, migrants generally are removed from the privilege of individual and personal experience that is universally relatable, confirmed by the complete lack of inclusion by the BBC. In the examples I analyse, the format of the interview which constitutes them is already conditioned according to the rules of agency and subjecthood set up by the BBC, often leading to a sense of nervousness and awkwardness illegible and inaudible to ASR technology and citizens accustomed to the norms of British English.
The BBC is an example of a powerful institution that, by making a ‘plurality of voices, faces, and languages heard and seen and spoken’ (Bickford, 1996: 129; Dreher, 2010: 100) including those of refugees, can ‘shape who and what can be heard’, ‘shift institutionalized hierarchies of attention’ and ‘is central to processes of cultural domination, non-recognition and disrespect’ (Dreher, 2009: 447, 453, 454; Dreher and De Souza 2018: 21). However, historically, the BBC is profoundly grounded in globally broadcasting sonic utterances that are to represent the imagined community of United Kingdom in accord with the agendas of its stakeholders and the reigning political party at the time (Born, 2004). In turn, it is responsible for helping to create cultural acoustics of an English indexing prestige and privilege because of hiring practices of senior directors who hire news journalists who represent the entrenched aural biases of their elite strata and Oxbridge degrees (Mills, 2020). The persons involved in programming absorb the taken-for-granted ethos of catering to cultural acoustic norms driven by their own sensibilities on what is admissive and appropriate. In doing so they perpetuate a raciolinguistic ideology, intentionally or out of ignorance, by catering to listening audiences they imagine have the same sensibilities and cultural acoustic norms as themselves. The BBC, subject to ‘isomorphic pressures’ (Garbes, 2021) of conforming to the linguistic sensibilities of the broader British upper middle class, ends up creating and disseminating the linguistic norms of a homogeneous imagined community. The dissemination represses the fact that one pure and appropriate English does not exist. In fact, the UK is rather a linguistically diverse site where all speakers of English are accented; the language is fissured and shot through with difference, borrowings and adaptation, not only of word choice but of the proper manners in which English should be spoken. The sensibilities of white and/or standard British-speaking bureaucrats therefore have a long-term impact on dominant listening practices, making it difficult for the BBC to structure a piece that requires its audience to listen to the cultural acoustic difference of linguistically and racially minoritized speakers.
The BBC is free and thus accessible to all, but the ‘homogenization of accent’ of the radio announcers voices have cast into cultural disrepute the colourful variety not only of languages, but of accents and regional dialects whose possessors have now found themselves to be ‘different’ – and not only different, but not as good, because it suggested they were disruptors of the unity of a supposed community to which all must and could belong. The domination of accents marked as prestigious in the United Kingdom and the United States’ National Public Radio led to greater expectations among immigrants to imitate the cultural acoustics of the announcers for access into ‘universities, boardrooms, and country clubs of the nation’s cultural elite’ (Hilmes, 2012: 357) and even of becoming a member of a nation-state. This dynamic is reflected in their ‘Learning English’ site, which promises to ‘show you how English is really spoken’, geared towards adult immigrants, with subheadings like ‘natural spoken English’. One of the first-featured videos features a scene in a post office, where a woman in a burqa, presumably Somali, would like to send a package to Somalia, but is struggling with communicating to the white male British standard English-speaking postal worker (BBC, 2022b). When he asks her ‘what kind of package? Economy, etc.?’ her response is an overwhelmed ‘uhh’. Using her as an example solidifies the popular British assumption of Somalis as poor in English communication skills and presents what is a representative dynamic in an interaction between a Somali migrant and a British citizen. A video series called ‘Tim’s Pronunciation workshop’ consists of video interviews (BBC, 2022d). Only two out of 20 interviewees in Tim’s video on pronouncing ‘natural speech’ were visibly non-white. Interviewees were consistently smiling, emanating an attitude which would be legible as positive and optimistic for the Western world. Tim’s conversational attitude coupled with the upbeat background music promises that once the listener/viewer learns the ‘natural pronunciation’, they will be able to join in on such a cordial and carefree atmosphere. This is in stark contrast to the anxiety-evoking situation in the post office, where the scene ends with the presumably Somali woman disturbed, clearly not knowing how to respond, suggesting the situation migrants would be in if they did not master ‘natural spoken English’ as per normative British standards. The utopian promise that such contact zones between asylum seekers and British citizens should not be conflicted is exposed as a repression of tensions between them, deriving from a persistence of an imagined community which is constituted on exclusions based on raciolinguistic ideologies.
The interpretive textual descriptions of the content of the unedited recordings on the BL archive are also problematic in that they consistently erase moments of difference, such as voices indexing trauma, semantically and acoustically. Their display serves to discourage listeners from listening to difference, to from discerning alternative narratives and from recognizing that they cannot directly experience what is authentic and ‘really’ happening. The descriptions expose how once sounds of any kind are transcribed and digitized, they have ‘the potential of creating and mobilizing an acoustic regime of truths’, in which ‘some modes of perception, description, and inscription of sound are more valid than others in the context of unequal power relations’ (Gautier, 2014: 33). Each of these practices, both via the listeners of the BBC, as well as that of ASR recordings, leads to mishearing their singularity and deeming them deficient, thereby erasing their particularities which exceed the grasps of transcription and inscription. Both the BBC programming as well as ASR programmes reflect what is heard by the standard British ear. Listening is based not only on individual practices of listening to discomfort but infrastructure and institutional formats which allow them to be heard, such as the BBC and digitized recordings.
When I used the dictation function in Microsoft Word to transcribe these conversations, certain conversations were accurately transcribed, one of the most accurate being the voice of Fanzi, a then 32-year-old woman who emigrated to the United Kingdom at 16 from China without her family, conversing in 2016 in London with her white British mother-in-law, who at one point remarked that, ‘well, your [Fanzi’s] English is brilliant. I mean it’s really good’. This is also a recording which, for the most part, lacked mumbling, crying or sighs (British Library, 2016). Those sounds, that exceeded the limits of the ASR software and a British listener as audible, are apparent in a conversation between two 10- and 11-year-old Somali siblings, Mohamed and Najah, and were produced in the moments of narration and performance of intense affect and trauma. This shows how listening to difference makes audible affects, in addition to accents and intonations, which exceed the format of writing or universalized inscription, that is, an excess which ‘remains when the voice is not intentioned toward a meaning, defined as the exclusive purview of speech’ (Cavarero 2012: 529).
To begin examining not only the semantics and signification, but also the cultural acoustics, of voices marked as different, I experimented with spectrogram analysis using the software Praat (Boersma P and Weenink D, 2022). The software visualizes acoustic patterns related to frequency, pitch, volume and amplitude and recognizes different vowel sounds measured by unobstructed air flow. In transcribing the words of the conversations using ASR, those who do not speak a variation of standard British English exceed the software’s aural limits. Sighs, laughter, interruptions, whispers, changes in register and in the language used, and the muffled weeping of speakers relating their trauma and happiest moments were lost in transcription by these technologies. Recent research on ASR argues that biases based on factors such as skin tone, gender, age, speech impairment, accents, language proficiency and other sociocultural differences can be reduced with more diverse data inputted into the machine-learning algorithms (e.g. Bajorek, 2019; Koenecke et al., 2020). While these studies consider it a bias that can be reduced with more diverse data fed to the ASR programmes, I focus on the inherent cultural acoustics that remain irreducible within such technologies of transcription which read numerical values rather than letters, and discard anything that cannot be transcribed with this method in natural conversations. Together, these technologies of listening expose how our own listening and that of our recording systems are never unbiased, unprejudiced and unmarked. Each listener will listen to the recordings differently from me and other listeners, whether that be the BBC recordists, ASR or the spectrogram. For example, some listeners may choose to replay the recordings repeatedly to grasp specific words, and in the process perceive differences otherwise unnoticed by the ears of artificial intelligence and media technologies along with human listeners, with their own diverse modes, habits and capabilities of listening. What is heard by each listener is therefore contingent and unpredictable and may vary upon repeated listening. Each listener will bring their own cultural and personal memories, familiarity with certain accents and not others, exhibiting aural cultural diversity.
‘How did you feel when you came to England?’: The BL’s unedited recordings of migrant voices
On November 2015 in Hull, two Somali siblings, Mohamed (10) and Najah (11), both asylum seekers from the Dabaab refugee camps, conversed for 15 minutes with their conversation digitally archived by the British Library. Mohamed and Najah are presented on the BL’s site as those who speak the least English, with the site stating they have been learning it only for 1 year, as they arrived in 2014. And at 15 minutes, it is the shortest recording (British Library, 2015a). They are not only erased from the chosen recordings on the BBC’s Listening Project site, but we can hear attempts by the male standard British English-speaking recordist to manipulate their conversations such that it would sound the way the imagined community of listeners would expect or want to hear. The BL’s description of the recording takes many interpretive freedoms, exaggerating and effacing parts of the conversation in which Mohamed in particular struggles with English. It focused instead on how proud they are of their lives in Hull and how they are making new friends. Mohamed is described as ‘very shy’ but is ‘encouraged’ by Najah during the conversation (British Library, 2015a). The description unsurprisingly fails to mention the moments when the recordist interrupted and asked Mohamed to change the content and as well as the cultural acoustics of his questions, most prominently tone, such that answers do not appear rote and preprepared, exacerbating the nervousness both in his tone and in his responses to his sister. The following is my transcription of an excerpt from the beginning of the conversation which includes the first interruption. I qualify the transcript with the understanding that this arises from my situatedness as a listener, and there could be elements that my listening did not attend to, that others could. The reader can listen to the linked recording for their own observations, along with the spectrogram of an excerpt which displays the cultural acoustics of the conversation: the intensity of their voices, intonations, accents, timbre and pitch: [Sound of pages turning] M: How do you feel when you come in England? N: I feel nervous. M: Why do you feel nervous when you come in England? N: Because I couldn’t speak English. [. . .] M: Why do you like school? N: Because I want to learn English. [. . ..] (muffled whispering, murmuring, rustling, resistance) Recordist: See what we’ll do . . . I’m gonna [rustling, muffled voices] I don’t think you . . . you don’t need them! [the written pre-prepared questions] M: [rapidly, partially incomprehensible] but the – answer – questions. R: What’s happening is that you’re going, [in exaggerated high pitch for the questions; low pitch for answers] ‘what do you like about this?’ “It’s OK” ‘What do you like about this?’ “It’s OK”. So just have a . . . Imagine [murmuring from one of the siblings] I’m going to stop the rest of the tape [pause] Start from where you were before OK? We’ll just carry on from before. M to N: [in the same tone and pitch as previous questions] Do you like your brother? (British Library, 2015a)
Instead of asking him not to read prepared questions out loud, the recordist interrupts and imitates the tone and pitch of Mohamed’s questions as well as Najah’s answers in a way that aims to make apparent how they are problematic, thereby asserting his sonic dominance over them. He authoritatively states ‘what is happening is’, as if what he heard and judged as problematic were an objective, normative judgement that any listener to the conversation would share. Collectively, we can hear not only the recordist’s prejudices towards those who do not belong in an acceptable way to a hegemonic linguistic culture, but our own, as he performs and represents what BBC listeners would like to hear if the conversation were chosen to be broadcasted.
I conducted spectrogram analysis and ASR transcription of the cultural acoustics of one of the British recordist’s imitations of Mohamed’s questions, ‘What do you like about this?’ and one of Mohamed’s own questions, ‘Why do you like school?’, which the recordist sought to didactically imitate (Figure 1). The first two rows with the pink background depict changes in volume in the left ear and right ear, while the blue line in the third row tracks pitch. The red dots which appear in this row are formants, which visualize the frequencies of different vowels. We can roughly infer the tongue and throat position, and thereby how the vowel was pronounced, by looking at the highest and lowest frequencies of a sound presented by the position of the formants. The vocality of Mohamed’s question and the recordist’s mimicry appear similar in the third row, with stable pitches and similar frequencies, though Mohamed’s voice is quieter and less intense. But Mohamed’s question is transcribed entirely inaccurately, whereas the British recordist’s is transcribed perfectly, showing us how dictation programmes are prejudiced towards certain accents. We cannot easily determine which sound is clearer and more comprehensible in English just by looking at the spectrogram. What determines the transcription accuracy of the ASR is the arbitrary pattern and accents that the speech recognition programme’s ear is trained to identify, which aligns with the recordists’ standard British English. This includes proper names of the majority living in Anglophone countries, rather than a ‘foreign’ name such as Najah’s, which was also erased by the ASR. For Mohamed’s question, ‘Are you ready Najah?’ her name was transcribed as ‘Jack’. Human ears would not be affected by the non-English words, since we would not need to transcribe to hear them, but it does affect the machinic ear of the ASR, which we can think of as a new form of inscription which fails to interpret, record and transcribe in the digital age. With unreflective, habitual ways of listening, approaching spoken language as transparent mediators of sense, listeners whose first language is not that of the speaker, particularly when it comes to a language as powerful as English, tend to listen in ways not unlike these ASR programmes. The focus of the siblings’ conversation continues to be about English and their affects towards it, reflecting what is occurring in their dynamic with the recordist, and even the technical media I used while listening to them. Their conversation about English elicits the second interruption by the recordist: R: Do you want . . .. [muffled mumbling from the siblings] Is learning English hard? Mohamed ask your sister, you know, why it’s difficult, funny things that might have happened about learning English. [N and M speak in Somali] N: What happened to your life when you came in England? [N and M whisper in Somali] M: I can’t speak . . . but I can speak now [. . .] N: Mohamed are you OK? M: Yes. N: Are you nervous? M: No N: Why are you shy? (silence for about 5–6 seconds) M: because . . . because [N helps him finish his sentence] N: because I can’t speak English well [. . .] N: Do you like me? M: Yes. N: Why do you like me? M: Because you, you always help me [pause] when my homework is hard. [. . .] R: what do you find hard about homework? [. . .] M: English. N: Why do you find English hard? M: Because [hesitant pause] N: Because it’s not my language – and I’m trying to learn it. (British Library, 2015a)
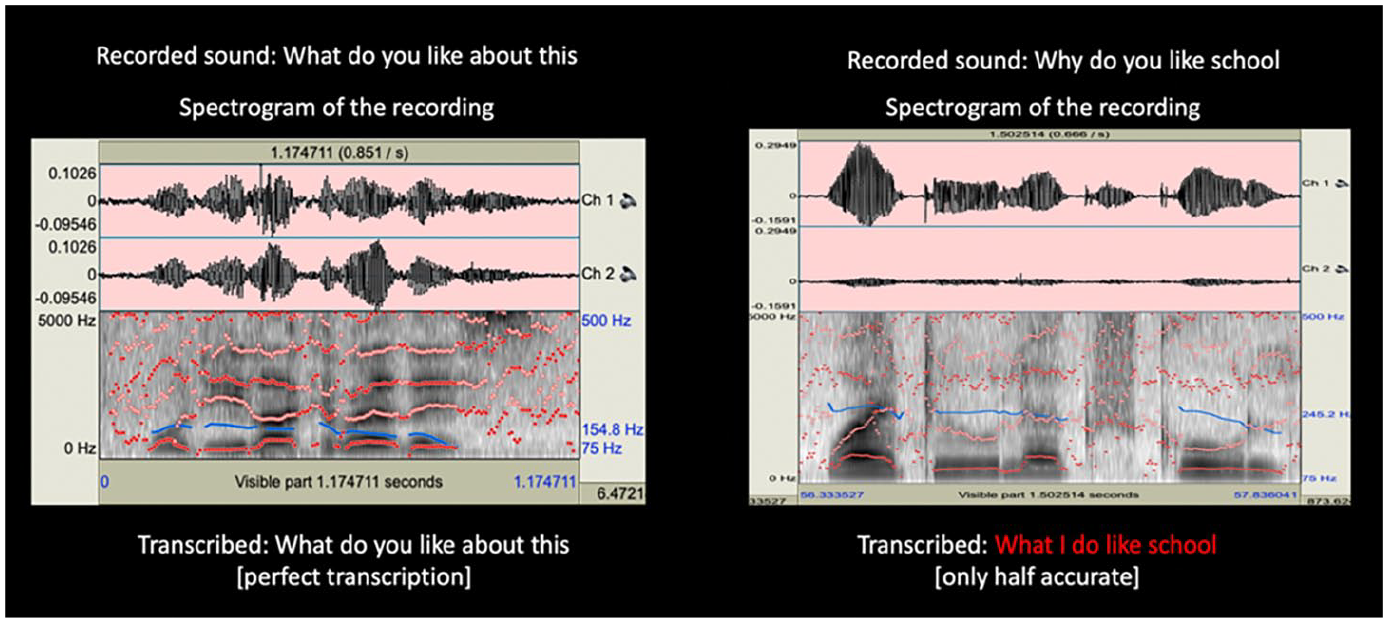
Spectrograms and ASR transcription for the recordist (Left) and Mohamed (right). The copyright of this recording is held by the BBC.
The questions that both Najah and the recordist ask are answered in the process of the conversation. His questions about ‘funny things that happened’ while they learned English and why Mohamed finds English homework hard include the recordist’s manipulative attempts in his interruptions. He imposes his own aural expectations of how a conversation in the Listening Project’s booth should proceed. The siblings form a closer bond as they both implicitly and explicitly reflect on the nervousness produced in them when it comes to their English and of England, which we can hear in real-time in the dynamic between the recordist and the siblings’ responses to him. The present communicative situation itself is the homework Najah helps Mohamed with, finishing his sentences at times when he is silent and appears to be struggling. Najah’s interruptions contrast with the recordist’s, who attempts to manipulate the conversation continually, based on how the siblings respond to him. While interruptions would, under some conditions, as in the recordist’s, reflect a failure to listen to the particularity of the other, when Najah interrupts her brother it creates intimacy between the siblings, and it allows the conversation to progress. At one point, Mohamed asks Najah ‘What happened when you came to England?’, to which her response was bleak: ‘I travelled by airplane into Hull and I couldn’t speak English, my mother and dad was with me. And I got sick in the airplane’. The recordist interrupts again, requesting they switch to a more positive topic, suggesting examples that are ‘quite nice’, and at the end, says to them, ‘do you want to say thank you for chatting with me has it been good?’. He didactically imposes British customs of finishing a conversation. Both siblings are together experiencing the failed ability of the recordist to listen to their own difference vis-à-vis British English while he marks their speech and vocality as a failure to proceed according to the norms of the kind of conversation they are expected to have, to be broadcast by the BBC.
The siblings use a variety of discursive strategies to create an impermeable boundary between the recordist’s listening and their own. Their responses to the multiple intrusive directions vary, and in their reactions, they take possession of what is already their own conversation, rather than obediently following his orders. When the recordist asks the siblings to ‘chat about living in Hull and things that you have done here’ and their life prior to moving to Hull, rather than following his orders, they begin speaking to each other in Somali, taking refuge in their own language rather than producing a conversation according to the format and expectations of British English. Mohamed then asks Najah a question which was not prompted by the recordist. By not following the orders of the recordist to converse according to normative British standards, they create a bond between themselves along with critical listeners who acknowledge this dynamic and/or speak Somali. They simultaneously distance themselves from the recordist, as well as those British English listeners who do not speak Somali. That which ASR and the BL’s description fails to transcribe, as it does not comply with normative English, is precisely what forms a closer intimate bond between the siblings but alienates them from potential listeners to the BBC. Recordists are otherwise inaudible and thus absent to listeners in almost all the other recordings. The recordist’s responses to the asylum seekers of Somalia function metonymically for the asylum seekers’ experiences in England. The interaction between the recordist and the asylum seekers makes explicit how the BBC’s goal to ‘bring Britain together’ as an imagined community is conflicted and unrealizable, as the recordist makes audible what kind of a conversation and vocality would be desirable for the BBC to broadcast to its listeners.
In contrast to the conversation between two siblings with a difference in age by 1 year, in a 2015 conversation in the Support for Wigan Arrivals drop-in centre between Syrian father, Marwan (50), and his son, Joudi (15), we can hear an increasing rift in their intergenerational relationship as the conversation proceeds (British Library, 2015b). The conversation can be framed within a larger group of intergenerational conversations between immigrant and refugee parents and children in the archive. It stands out from these recordings because the parents have usually spent at least a decade in the United Kingdom, such that they are socialized into the cultural acoustics of standard British and are able to communicate without difficulty with their child, often a second-generation immigrant born in the United Kingdom. As with Mohamed and Najah, their conversation too is significantly shorter than others, lasting roughly 25 minutes, with the two having been in the United Kingdom for 2.5 years at the time of the conversation. What is audible is a stark difference in the ability to perform standard British English language between the two, which sonically indexes the situation of Syrian refugees in the United Kingdom at the time. Marwan, who used to be a rheumatologist in Syria, now cannot afford private English lessons and struggles with English, while the son receives free English lessons at school and is comfortable in the language and able to perform a British accent. The conversation begins with the son asking the father questions limited to those that would be asked to a stranger: for example, what his father’s favourite food is, his favourite colour and so on. When the son asks the father about his life in England, the father sighs and discusses his depression and financial troubles as well the lack of money for English lessons, to which the son responds with ‘umms’ connoting a dwelling in discomfort mobilized by listening to difference. Differing fluency in British English forms an unspoken power structure between son and father, troubling the traditional generational power hierarchy, with the son socialized into the United Kingdom through the free public school system in a way inaccessible to the father, despite his education and former profession as a rheumatologist and his wife as an engineer. Due to this generational difference, a tense relationality of listening to difference emerges between the two in the cultural acoustics of their conversation, with the vocality of each indexing starkly different degrees of belonging in the United Kingdom.
The third case I analysed from the perspective of listening to difference is a 2012 conversation in Glasgow between two friends, Meriem (40), a refugee from Algeria, and Patricia (44), from the Congo. They differ from the prior case studies in that this was not a conversation between family members, but between two friends, and unlike the conversation between Mohamed, the recordist, and Najah, the interruptions and overlapping voices between the two are affirmative, exhibiting openness to listening to difference. Patricia echoes, repeats, uses different phrasings to affirm Meriem as she answers Patricia’s question about the ‘happiest moment in [her] life’, which, for Meriem, is when she had her first child. In her interruptions, Patricia does not intervene by offering information about her own life, or try to steer the conversation in another direction, or explain why she is affirming, echoing and repeating Meriem. The interruptions and overlapping instead affirm Patricia listening to Meriem as they are creating collectively a symphonic story. A strong affective bond forms when discussing their common values such as being a parent, their difficult in-laws, their views on divorce as an ‘easy option’ and ‘giving up’, and the war, corruption, trauma and violence they each witnessed and experienced (British Library, 2012).
What sounded to my ear as a harmonious symphony, as the two listen to each other listening, exceeded the limits of legibility and audibility of the ASR programme. In an ASR transcript of an excerpt from the recording in which their voices overlap, only Meriem’s words were transcribed (Figure 2). The spectrogram and ASR analysis of the entire conversation showed that during these moments of affirmative overlaps, either one speaker is completely effaced, or some parts of each speaker’s speech are left out in the transcription. I surmised from looking at the spectrograms that this was because one speaker’s voice had a distinctive pitch fluctuation that was dominant and effaced the other. However, in the conversation, it was precisely what was marked as the dominant pitch that elicited affirmative responses, including Patricia rewording Meriem’s responses while Meriem was speaking. Because pitch for each voice was stable, they intermingled at times and did not appear as distinct voices. While such overlap could easily be identified by our ears, certainly Meriem and Patricia’s, as well as myself, it could not be by the transcribing ear of the machine. While recording technology promises an all-encompassing archive, this case makes it clear that different types of non-normative vocal interaction arise which risk total distortion. What may, according to normative standards of British English, be marked as phonetic excess are not a failed act of listening to difference, but can work to establish intimacy. These extra-linguistic acts of cultural difference showcase that there is no correct or normative way to communicate, and that the customs expected by a set of BBC listeners, as the recordist conceived of it, foreclose listening to difference.
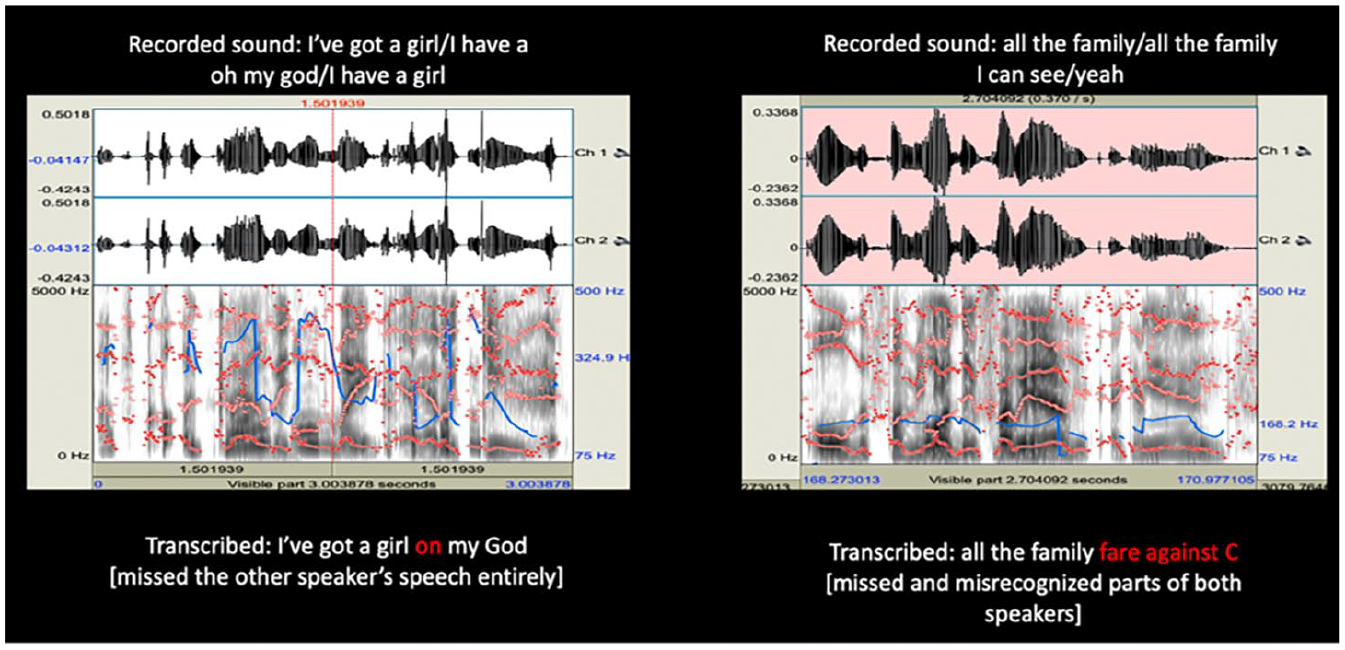
Spectrograms and ASR transcription for two moments of overlapping discourse between Patricia and Meriem. The copyright of this recording is held by the BBC.
What can be perceived as harmony in the conversation shifts when they discuss Patricia’s experience in Glasgow, which is very different from Meriem’s, who is now in the position of asking questions. She asks Patricia about studying English and the financial difficulties she is having. Patricia frequently responds with ‘it was hard’, repeatedly answering Meriem’s questions with an assertive ‘no’, and disagreeing with Meriem’s assumptions and interruptions. This, to some degree, unravels the previous intimacy, as it explicitly places Meriem in a position of not fully comprehending Patricia’s difficulties in Glasgow. There are no affirmative overlaps between the two. When Patricia explains her attempts to enrol in a full-time English course, Meriem surmises, ‘Because you were in temporary accommodation you weren’t able to do full time course’, to which Patricia reacts, ‘No I was able to do it but it was very difficult for me’, with a tone of frustration, indicating her perception of Meriem’s failure to listen to the differences between the two. Around this point, a female recordist who speaks standard British English interrupts, but the dynamic is a friendly one between the three. She suggests the two discuss life in Congo and Algeria, which is what the imagined audience may be interested in hearing about, along with what brings the two together as asylum seekers from war-torn countries. Meriem discusses the coup d’état in Algeria, her witnessing of murdered women next to her home, and Patricia the war in Congo. Unlike the conversation between Mohamed and Najah, where intimacy increases during the conversation, or between Marwan and Joudi, where the difference between the two increases as they listen to the other, and intimacy decreases, here we have a rhythmic heightening and loosening of intimacy in the process of listening to difference. The experiences as asylum seekers in Glasgow are where the differences between Meriem and Patricia lie, although that is also what has brought them together in the listening booth, parallel to the situation of Marwan and Joudi, vis-à-vis Joudi’s socialization into British life and language, and Marwan’s alienation from it. In two of these recordings, we can listen to the way in which the recordist listens to them and how they listen to the recordist, and for all the recordings, how each interlocutor listens to the other, and finally the way the media technological ear listens through spectrogram and ASR analysis. The colonial imposition of a language with strict norms of voicing produces, on the one hand, an inescapable sense of anxiety and alienation but at the same time always leaves open gaps for performative subversion which we see in the case of Somali siblings. A subversive intimacy is created because, and not despite, their English being spoken not according to normative standards. It is when their voices are least mediated by the conventions of the BBC, a listener is led to feel intimate with them.
Conclusion
While the BBC’s Listening Project is limited in the agency its speakers have in the format, it is instructive to study radio programmes which are ‘accented productions’, allowing complete agency to those who are marked as misplaced, migrant, and diasporic and challenge authoritative ways of speaking that are marked as nonaccented, (Naficy, 2001). Two projects by Manus Recording Project Collective (2018, 2020), how are you today? and where are you today? broadcast and archived recordings answering either one or both questions by men incarcerated for indefinite time periods in detention centres on Manus Island and Australian immigration transit accommodation. If it were not for these recordings, the men would be invisible, silenced and have no interaction with those in Australia (De Souza, 2020; De Souza and Russell, 2022). In where are you today? a group of detainees recorded their answer for up to 10 minutes with no pre-set format. When the recordings were uploaded, subscribers who agreed to share their location received a text message alerting them about the new recording and informing them about how many kilometres away the recording was made. The description of each archived recording informs the website’s visitor of how far away they are from where the recording was made, the date on which it was made, who made it, and where and what they were doing. They listen not only to spoken language, but to sounds from the detainees’ daily life such as the forests around the prison camp, cooking fish or listening to the radio while working out at the gym. These are forms that elude the traditional narrative forms, exposing the limits of what ‘settler-colonial carceral logic’ is not ‘structured not to hear’ (De Souza, 2020: 81). As a result, the listener gains a sense of intimacy with what they hear and when they hear it, allowing them to listen across and to the difference of someone whom they will never meet, but whose exact location they can measure. This project is an exemplary case study of how listeners who are geographically and temporal distanced can share aural intimacy through transborder solidarities build by listening to difference, thereby ‘connecting groups dispersed in space but united by a shared experience of dispossession, insecurity, and struggle’ (Whittington, 2022: 2). Intimate exchanges can be made accessible to the public sphere through the radio, and my case studies show that ‘sonic intimacy’ (James, 2020) does not belong to two people but crosses borders, both geographical and temporal, and leads to shifting relationships and creation of new communities based on who gets heard and by whom.
Mohamed, manipulated to speak in the confines of the norms of appropriateness within the BBC interview format, as set up by the British English-speaking recordist, describes his relation to English with words like ‘nervous’ and ‘difficult’. In contrast where are you? features a recording of a man named Farhad who has complete agency in teaching another detainee English. Farhad chose to record the moment in which he teaches the word ‘gentle’, pronouncing it slowly for his friend, mimetically pronouncing ‘gentle’ with a gentle tone with which he introduces a possible relationality to English: ‘Gen-tle. You are so gentle. Can you say it again?’ When his interlocutor repeats the phrase, Farhad encourages him: ‘You will learn, no worries’, and follows up with teaching the phrase ‘I am so happy’ (De Souza and Russell, 2022: 15). This dialogue shows another way of intimately relating to the linguistic and cultural acoustics of English within the framework of an accented production which is not shot through with a raciolinguistic pedagogy, as in the dynamic between the recordist and Mohamed on The Listening Project, or in English as Second Language classrooms (Flores and Rosa, 2015). The example of Farhad illustrates that it is possible for a sense of belonging and intimacy within an English-speaking community for the linguistically minoritized by listening to and honouring the difference of an accented English. Ethically, we are bound to listen to ourselves listening to our differing relationalities to the cultural acoustics of so-called unaccented English, rather than outsourcing listening to technical media or our own internalization of the normative expectations and pressures to speak in certain formats and in certain accents, deeming what deviates from these norms as deviating from the bounds of proper pronunciation (Solanki 2022b). Through the practice of listening to our own listening, we observe too that the process of accessing the past or cultural difference is recognizing the impossibility of fully accessing it but honouring it nonetheless.
Footnotes
Acknowledgements
My thanks to the anonymous peer reviewers and editors of ECS for their generous critical engagement and recommendations, the audiences at the “Sounds of Migration” conference hosted by Pennsylvania State University, the Aural Diversity Network’s workshop on “Hearing Sciences and the Arts and Humanities” hosted by the University of Leeds and University of Nottingham, and at my workshop at the “Coming to Know” book launch hosted by the Alserkal Arts Foundation in Dubai for their questions and comments, and to my student Hosung Choo for the insightful feedback and assistance with using Praat and experiments with spectrographs of the recordings.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Yonsei University Research Grant of 2023.