
Abstract
Aims and objectives:
This paper presents two artificial language learning experiments that each investigated factors affecting crosslinguistic influence (CLI) in third language acquisition by Norwegian–English sequential bilinguals.
Methodology:
We tested the effect of two factors: the structural similarity between pre-existing languages and the target language, and the input language, that is, the language used to instruct the participants during the experiment.
Data and analysis:
We fitted the data to mixed-effects logistic regression models in a step-wise step-up forward elimination procedure.
Findings and conclusions:
In Experiment 1, we found an effect of structural similarity. In Experiment 2, the results indicated that the effects of input language could override similarity.
Originality:
While the effect of structural similarity on CLI is well-attested, the effect of the input language is less explored. The latter factor is often mentioned in literature discussing CLI in third language acquisition, but is rarely explored empirically.
Significance/implications:
The findings indicated that contextual factors may exert a greater influence than previously recognized in existing models of third language acquisition.
Keywords
Introduction
While it is uncontroversial to argue that the first language (L1) influences the second (L2), there is currently little consensus about how two previously acquired languages interplay during the acquisition of a third language (L3). Over the last two decades, several studies have explored questions related to crosslinguistic influence (CLI) in L3 acquisition by asking which language the influence comes from and which factors contribute to the source selection process (e.g., Bardel & Falk, 2007; Berends et al., 2017; Falk & Bardel, 2011; Fallah et al., 2016; Flynn et al., 2004; González Alonso et al., 2021; Hermas, 2010, 2015; Jensen et al., 2021; Jensen & Westergaard, 2023; Kolb et al., 2022; Rothman, 2011; Slabakova, 2017; Westergaard, 2021; Westergaard et al., 2017).
In this paper, our goal is to contribute to the discussion about where CLI comes from and what contributes to the learners’ source selection process during early L3 acquisition. We present two experiments that both investigate CLI in artificial language (AL) learning by Norwegian–English bilinguals. We use an AL to ensure that the participants have no prior knowledge of the target language, to get insight into the very beginning of the acquisition process, and to have precise control over the stimuli (cf., Ettlinger et al., 2016; Grey, 2020). In the first experiment, the results indicated an effect of linguistic similarity. However, the findings in the second experiment indicated that the input language, i.e., the language used to instruct the participants during the experiment, may override the effect of linguistic similarity.
Background
Over the last two decades, several theoretical models have attempted to describe and explain morphosyntactic CLI in L3 acquisition. In the current paper, we focus on the predictions put forward by the Typological Primacy Model (TPM; e.g., Rothman et al., 2019) and the Linguistic Proximity Model (LPM; e.g., Westergaard, 2021). According to the TPM, the pre-existing language that is linguistically more similar to the L3 is chosen as the primary source for CLI (Rothman et al., 2015). The parser determines which language is more similar based on the following hierarchy of linguistic cues: the lexicon, phonology, morphology and syntax (Rothman, 2011, 2015). In Rothman (2011, p. 112), the TPM is presented as a model of transfer at the initial state, i.e., accounting for what the learners bring to the learning task. This is modified in Rothman (2015), in which the initial state of the L3 is described as consisting of the L1, the L2 and Universal Grammar (see also García Mayo & Rothman, 2012), while wholesale transfer takes place later, at the initial stages (see also Cabrelli Amaro et al., 2015, p. 22; Rothman, 2015). In other words, wholesale transfer should occur early, but not necessarily immediately after exposure to the L3. However, it is hard to make an exact estimation of when the initial stages occur, as pointed out by González Alonso and Rothman (2017), who define the initial stages as merely the time in which wholesale transfer takes place and that the timing varies from speaker to speaker, depending on factors such as the input quantity and quality, the language combination and the acquisition context.
González Alonso et al. (2020) investigated the predictions put forward by the TPM in an AL learning experiment using electroencephalography. The participants were L1 Spanish–L2 English speakers, exposed to either mini-Spanish or mini-English as the L3. Like Spanish, both ALs overtly mark grammatical gender. The authors predicted that wholesale transfer of the lexically more similar language would lead to sensitivity to gender violations in the mini-Spanish group, but not in the mini-English group, reflected in a P600 event-related potential component in the former group. The predicted P600 component was not observed, but the authors reported another between-groups difference, namely that gender violations in mini-Spanish, unlike mini-English, elicited positivity between 300 and 600 milliseconds (P300). A P300 component is typically related to the processing of novelty. The authors argued that this result relates to the lexical similarity between the ALs and English/Spanish, reflecting pre-transfer processing rather than outcomes of wholesale transfer. Pre-transfer processing refers to the time in-between the initial state and the moment at which wholesale transfer takes place, indicating that wholesale transfer could occur at a later stage of the acquisition process.
In contrast to the idea of wholesale transfer, the LPM holds that CLI happens on a property-by-property basis. This entails that learners have access to and may be influenced by properties from both previously acquired languages throughout the acquisition process. Importantly, since the LPM rejects the idea of wholesale transfer, there is no notion of “initial stages” in the LPM framework. Rather, when a bilingual speaker acquires a new language, all previously acquired grammars and their linguistic representations are activated in parallel and compete for the strongest activation. The winner of the competition is used in the L3 interlanguage, resulting in CLI. Different factors contribute to the strength of the activation, such as frequency, age and recency of use, but the most important factor should be structural similarity between the L3 and previously acquired linguistic properties. Importantly, this means that learners are sensitive to fine-grained linguistic cues in the L3 input, but the contributing factors may be more or less influential at different times of the acquisition process. For example, Westergaard (2021) argues that early learners may be more sensitive to lexical and phonotactic cues in the incoming input, since information about (pseudo)cognates and similar sounds is immediately available. In contrast, information about morphosyntax requires a certain level of lexical and structural knowledge and should become more important at later stages of the acquisition process.
Although previous studies have found empirical support for similarity-driven CLI, some studies show that this factor cannot be the only one affecting the source selection process. For example, Bohnacker (2006) investigated the production of L3 German by L1 Swedish–L2 English speakers. Swedish and German exhibit the Verb Second (V2) rule, which states that the finite verb is placed in the second position of main declarative clauses (the V2 rule is explained in more detail in section “The property under investigation”). English, on the other hand, is considered a Subject-Verb-Object (SVO) language. In Bohnacker’s (2006) study, similarity-driven models would predict facilitating transfer from Swedish into German, but conversely, Bohnacker found that the participants produced SVO word order, which could be interpreted as non-facilitating transfer from L2 English.
Furthermore, Fallah et al. (2016) tested several models of L3 acquisition (the L1 Factor, the L2 Status Factor (Bardel & Falk, 2007, 2012), the Cumulative Enhancement Model (Flynn et al., 2004) and the TPM), but did not find support for any of them. The study tested L1 Mazandaran–L2 Persian early learners of L3 English. The authors argued that the main predictor for the transfer source was not similarity, but rather, the language that was used more frequently by the participants in different contexts (Fallah et al., 2016, p. 194).
Fallah et al. (2016) and Bohnacker (2006) are examples of studies that illustrate the complex nature of CLI in L3/Ln acquisition and suggest that factors beyond linguistic similarity must be explored. In the current paper, we present two experiments that investigated the effect of linguistic similarity in addition to a lesser-studied factor that we refer to as the input language – defined as the language used to inform the participants during the experiment. The latter factor has also been referred to as recency of use in a previous study by Castle et al. (2025, p. 4), who defined recency as “. . . an activator for certain language structures in the brain.” From this perspective, the present study examined whether recency of use, operationalized as the input language, may function as a trigger for CLI. Specifically, we explored whether instructing the participants in a particular language would contribute to a stronger activation and, consequently, CLI from said language. As Cal and Sypiańska (2020) pointed out, recency of use is often mentioned as a potential factor in the L3 literature (Bohnacker, 2006; Hammarberg, 2001; Westergaard, 2021; Westergaard et al., 2023), but its effect on CLI has rarely been investigated (however, see, for example, Hirosh and Degani (2021) for literature on the effect of the language of instruction at the lexical level). To the best of our knowledge, only the study by Castle et al. (2025) has directly tested the effect of instruction language on morphosyntactic CLI.
The property under investigation
The main experimental condition in both experiments was word order. Norwegian and English both exhibit SV word order (example (1)), but Norwegian is also a V2 language, which means that the finite verb moves to the second position of main declarative clauses (Vikner, 1995; Westergaard & Vangsnes, 2005). The difference between Norwegian and English word order becomes apparent in non-subject-initial declarative clauses and subject-initial declarative clauses with sentence adverbials (examples (2) and (3), respectively). In the Norwegian sentence in (2), the verb has moved across the subject, resulting in X-Verb-Subject (XVS) word order, while in English, the verb has remained in the verb phrase (XSV; Lehmann, 1978). In example (3), the verb has moved across the adverb in Norwegian, resulting in the word order SVX, while again, the verb has remained in the verb phrase in English (SXV): (1) Peter read an article ‘Peter read an article yesterday.’ (2) I går Yesterday read Peter an article ‘Yesterday Peter read an article.’ (3) Peter Peter read often articles ‘Peter often read articles.’
Experiment 1
We asked the following research question (RQ):
To answer RQ1, we made between-groups comparisons between Norwegian–English bilinguals and English monolinguals (see section “Participants”). The AL was lexico-phonotactically similar to English, but morphosyntactically similar to Norwegian (see section “Method and materials”). The alternative hypothesis (H1) was that the bilinguals would select V2 word order more often than monolinguals because of influence from Norwegian, driven by morphosyntactic similarity to the AL. This hypothesis is in line with the LPM, but also compatible with the idea of pre-transfer stages (cf., González Alonso et al., 2020). Conversely, the early version of the TPM (Rothman, 2011) would not be in line with H1, as wholesale transfer would be predicted from the lexico-phonotactically more similar language, English, in both groups. In other words, we should not be able to reject the null hypothesis (H0; no between-groups differences) if wholesale transfer has taken place.
Participants
We used a subtractive language group design (Westergaard et al., 2023) in which the experimental group consisted of L1 Norwegian–L2 English sequential bilinguals (n = 31; age range = 18–45 years, M = 29.8, SD = 7.72) and a control group consisting of L1 English monolinguals (n = 33; age range = 21–72, M = 38.13, SD = 13.47). All participants were recruited and compensated through the online recruitment service Prolific (2021). The control group reported the following nationalities: the United Kingdom, the United States, Australia and Canada.
Method and materials
The AL input
The participants were exposed to written and auditory (Voicemaker, 2021) stimuli. The lexico-phonotactic input was based on English. It consisted of (pseudo-)cognates (verbs, adverbs and function words) and nonce nouns (N = 6) that were created from a subset of the Standard British English sound inventory (Carr, 2012). Examples of AL sentences are shown in (4) and (5). The full list of nonce words and pseudo-cognates can be found in Tables S1 and S2 in the supplemental material. Morphosyntactically, the AL was based on Norwegian. That is, it was an SVO language with V2. To demonstrate the AL word order, we showed the participants SVO sentences (n = 6; see example (4)), and crucially, XVS word order (i.e., V2; n = 6; see example (5)): (4) I drink coffee ‘I drink coffee.’ (5) At 07:00 At 07:00 drink I coffee ‘At 07:00 I drink coffee’.
It follows that the participants were exposed to conflicting cues in the AL input in terms of linguistic similarity: the lexico-phonotactic cues suggested that English was the more similar language, while the morphosyntactic cues illustrated an overlap with Norwegian.
The main task and test items
We tested the participants in an acceptability judgement task (AJT) with two response levels: good and bad. The participants judged sentence pairs (n = 6 per condition) that only differed in word order across three different sentence types: SVO/SOV, XVS/XSV and SVX/SXV. As mentioned, the participants had been exposed to SVO and XVS in the input (see examples (4) and (5)), but importantly, not to SVX/SXV, as exemplified in (6). We included the unseen property to separate transfer from learning. We instructed the participants by means of animated videos instead of written instructions to avoid a potential effect of input language – a factor that will be explored in Experiment 2: (6) I ( I read often (read)books ‘I often read books.’
Design and procedure
We created and deployed the study online on the experiment builder Gorilla (Anwyl-Irvine et al., 2019; Gorilla, 2021). On average, the participants spent around 60 minutes on the experiment. The experiment consisted of three main components – an exposure phase, a training phase and a testing phase.
In the beginning of the exposure phase, the participants were shown six nonce nouns aurally and visually (see Table S1 in the Supplemental Material). Each word was displayed twice. As visual stimuli, the participants saw the spelling of the noun and a corresponding image. In the second step of the exposure phase, the participants saw a 1-minute animated video with a (fictitious) native speaker of the AL. During the video, the participants were exposed to XVS and SVO sentences that included the nonce nouns (N = 6 per sentence type). To make sure that the participants remembered the meaning of the nonce nouns, we added a final step that was identical to the first step.
In the training phase, the participants practised remembering the meaning of the nonce nouns by means of a picture–label matching task (18 trials). The phase ended with a lexicon test in which the participants had to get all the trials correct.
The third and final part of the experiment was the testing phase, which included the AJT. Here, the participants saw AL sentences successively and were asked to judge each of them as good or bad. Each trial consisted of a nonce noun, a sentence in which the nonce noun was used, and a picture that matched the noun. The participants were instructed to judge the sentences based on how natural they sounded.
Results
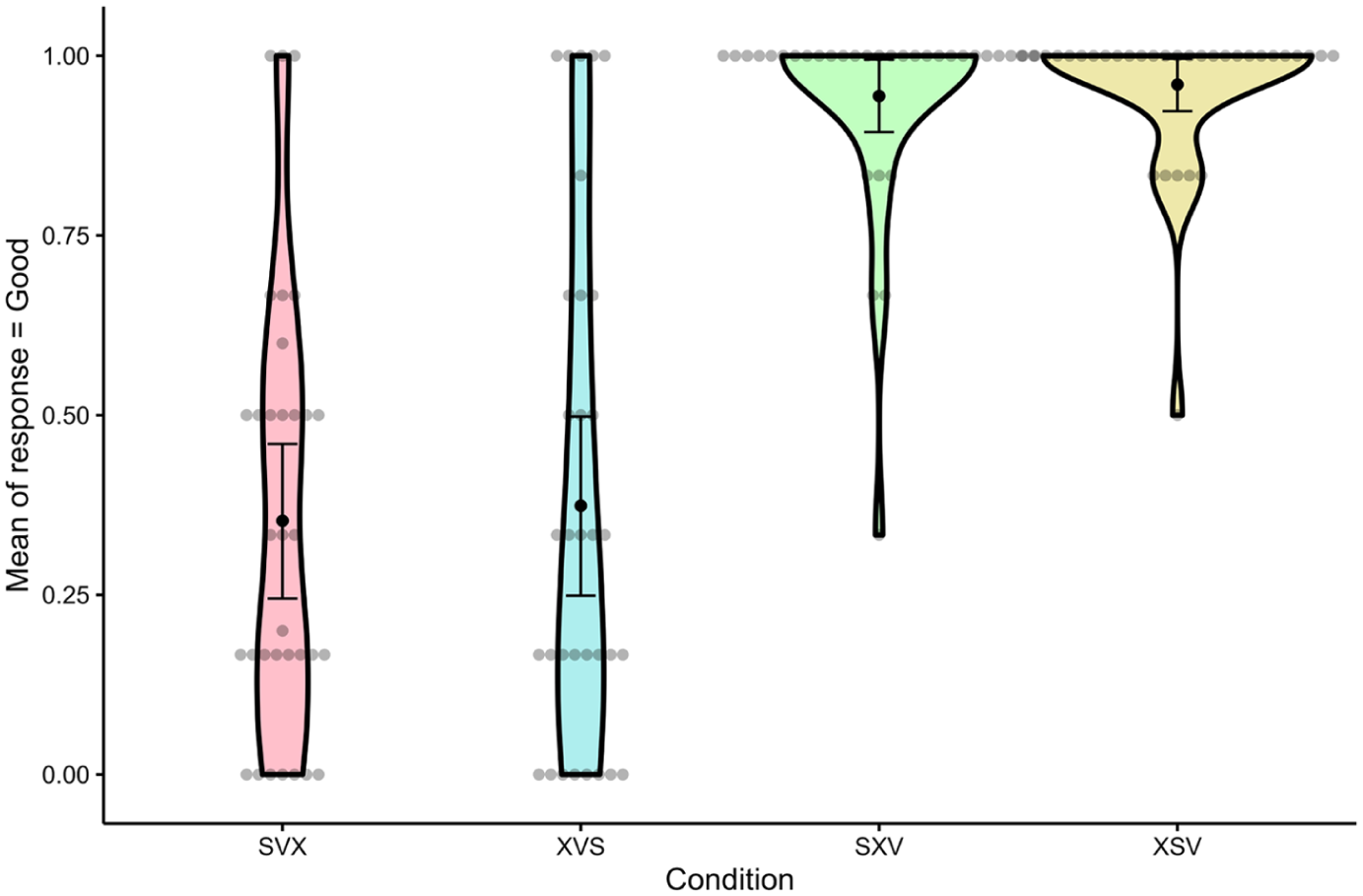
We analysed the data in RStudio, R version 4.1.2 (2021-11-01; Team, 2021). The acceptance rates (Good = 1; Bad = 0) for the experimental conditions are shown in Table 1 (mean scores per group and condition) and visualized in Figures 1 (English monolinguals) and 2 (Norwegian–English bilinguals). Figures 1 and 2 were created by means of the rempsyc R package (Thériault, 2022).
Mean acceptance rates per group and condition.
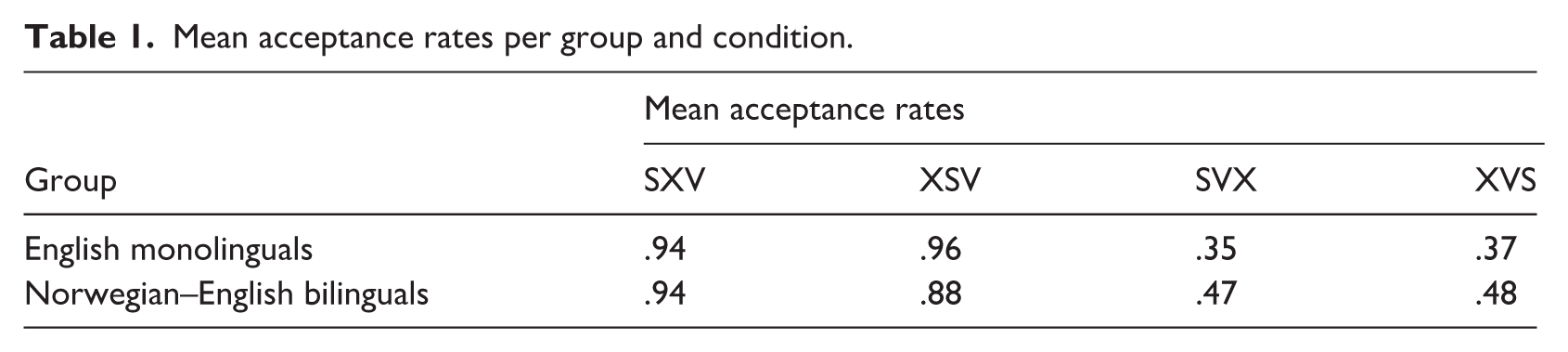
Mean proportions of Good by condition in the English group.
Mean proportions of Good by condition in the Norwegian–English group.
In the English group (Figure 1), the mean acceptance rate for V3 word order was high (mean SXV = .94; mean XSV = .96), while the acceptance rate for V2 was relatively low (mean SVX = .35; mean XVS = .37). In the Norwegian–English group (Figure 2), we found close to at-chance judgements of V2 word order (mean SVX = .47; mean XVS = .48) and high acceptance of V3 (mean SXV = .94; mean XSV = .88).
To answer the research question, we looked for linear dependencies between the response variable Acceptability judgement (Good vs. Bad) and the predictor variables Group (English vs. Norwegian–English) and Word order (V2 vs. V3) by fitting a logistic mixed model (estimated using ML and BOBYQA optimizer) to the data in a manual step-wise step-up forward elimination procedure using the lme4 R package (Bates et al., 2015). The model included Participants as a random effect. We did not include Items in the random effect structure because its inclusion led to an unstable model. Instead, we included Items as a potential fixed effect.
We added the predictors successively. For each addition, we checked whether its inclusion led to problems with multicollinearity. If there were no substantial problems, we examined the Akaike (AIC) and Bayesian (BIC) information criteria and whether the added predictor correlated significantly with the response variable (p < .05). We refer to the output of the model fitting procedure as the final minimal adequate model, that is, a model in which a maximum of variance is explained by a minimum of predictor variables. We set sum contrasts using the rms R package (Harrell, 2021) for the categorical predictor variables. Table 2 illustrates the output of the full minimal adequate model.
Model summary predicting acceptance of sentences (Good = 1, Bad = –1).
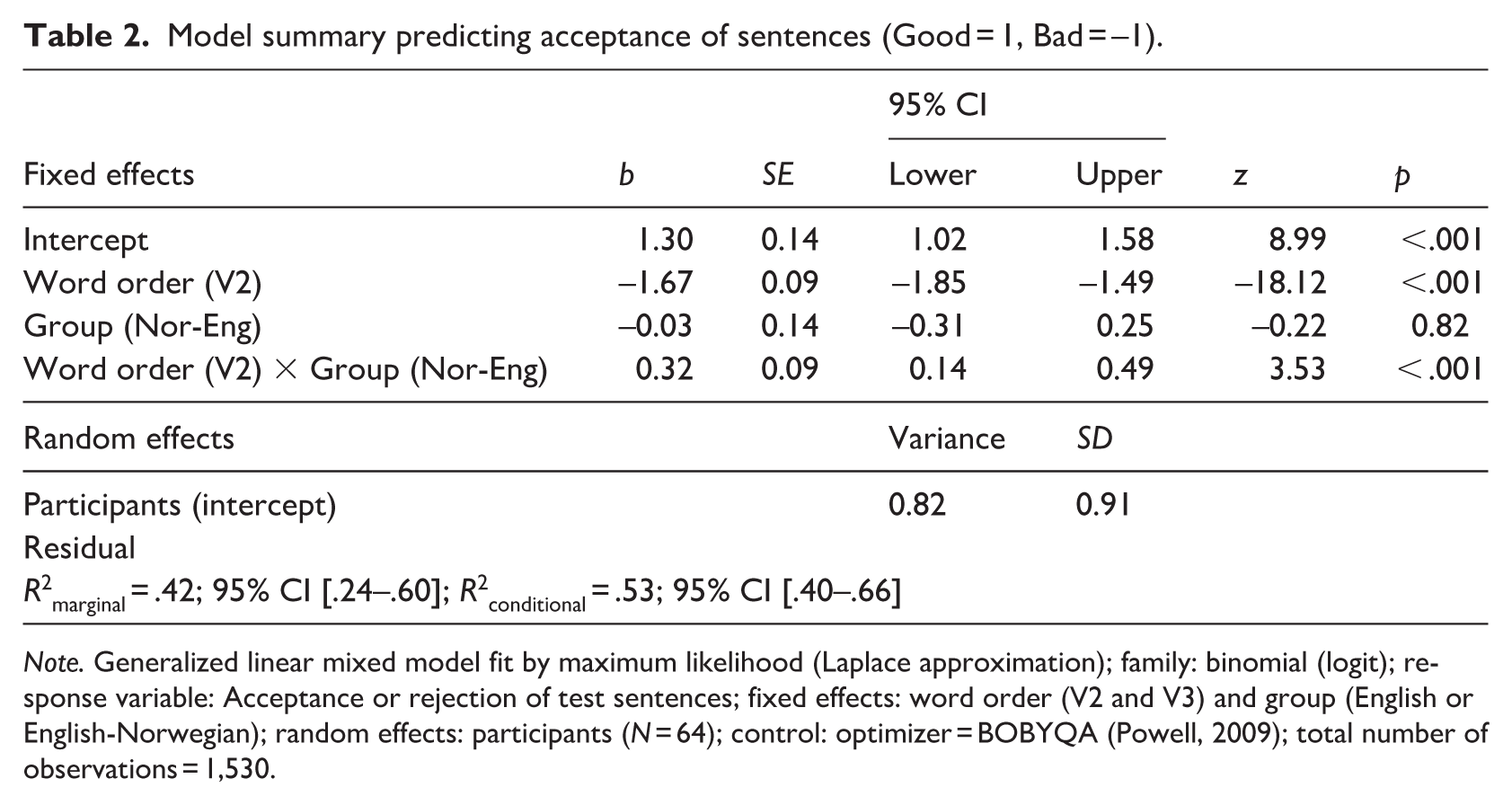
Note. Generalized linear mixed model fit by maximum likelihood (Laplace approximation); family: binomial (logit); response variable: Acceptance or rejection of test sentences; fixed effects: word order (V2 and V3) and group (English or English-Norwegian); random effects: participants (N = 64); control: optimizer = BOBYQA (Powell, 2009); total number of observations = 1,530.
The model’s total explanatory power is substantial (R2conditional = .53) and indicates a good fit. According to Ballard (2019), R 2 values lower than .5 are common in fields that investigate human behaviour. The interaction effect of Word order and Group is statistically significant and positive (b = 0.32, 95% CI [0.09, 0.14], p < .001). Standardized parameters were obtained by fitting the model on a standardized version of the dataset. Furthermore, 95% confidence intervals and p-values were computed using a Wald z-distribution approximation. The main interaction effect of Word order and Group indicates increased acceptance of V2 verb placement by Norwegian participants, as compared to the overall slope.
Figure 3 visualizes the interaction effect of Group and Word order. The figure was created using the R package sjPlot (Lüdecke, 2021). The Y-axis shows the predicted probability for the response Good to surface in the AJT. The X-axis indicates the change in predicted probability across the predictor variables and their levels. The error bars represent a 95% confidence interval on the effect.
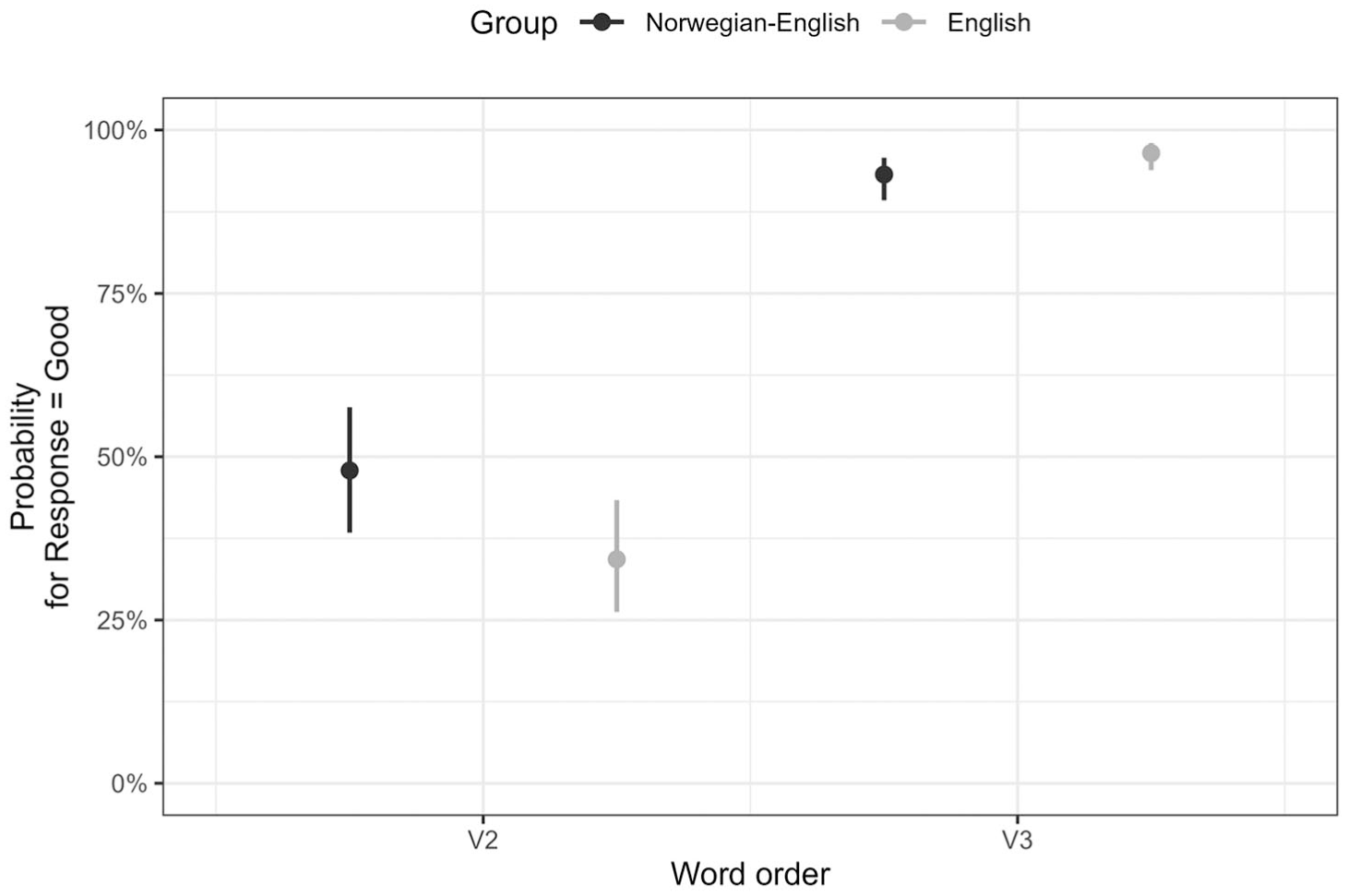
Interaction effect of Group and Word order.
Experiment 2
We asked the following research questions:
Note that RQ1 is identical to the research question posed in Experiment 1. However, in Experiment 2, we kept the background languages constant (all participants were Norwegian–English bilinguals) but varied the ALs to investigate how differences in the input rather than in the pre-existing grammars affected transfer source selectivity. Similarity-driven models predict between-groups differences based on how similar the AL is to either English or Norwegian. This prediction represents H1.
In RQ2, we aimed to investigate the effect of input language. If the input language exerted an effect on CLI, we expected to see a difference between the participants who were exposed to Norwegian instructions, as compared to those who were exposed to English (H1). The difference should primarily be driven by more V2 word order selections in the former group as compared to the latter, regardless of which AL the participants were exposed to.
Participants
We tested L1 Norwegian–L2 English sequential bilinguals (N = 47; age range = 22– 62, M = 31.79; SD = 8.03), recruited through personal network, flyers and snowball sampling. The participants had limited knowledge of languages other than Norwegian and English, but they had all been instructed in at least one additional foreign language in school. English had been acquired in a Norwegian classroom context from ages 5 to 12.
Method and materials
Experiment 2 involved four ALs – two that were based on Norwegian lexico-phonotactics (Kristoffersen, 2000) and another two that were based on English (Carr, 2012). We established the lexico-phonotactic similarities by means of (pseudo)cognates (verbs and function words) and nonce words (n = 8). An example is shown in (7), in which the lexicon is based on English (see the full list of nonce words and (pseudo)cognate in the supplemental material): (7) Crez wendge. Yellow flower ‘Yellow flower.’
We refer to the four ALs as Languages A–D. In Languages A and B, the input consisted of lexical items only, while C and D also included sentences (N = 6). Specifically, the participants assigned to Language C were exposed to do-support (AL = English ≠ Norwegian), and those assigned to D saw verb-initial interrogatives (AL = Norwegian ≠ English) implicitly as post-stimulus distractors during the exposure phase. The contrast between Norwegian and English is exemplified in (8): (8) Kjenner du Emma? Knows you Emma? ‘Do you know Emma?’
Note that there were conflicting cues in the input in Languages C and D. That is, in Language C, the lexico-phonotactic cues pointed towards AL = Norwegian, but the sentence structure pointed towards AL = English, and vice versa in Language D. As a result, we have an experimental set-up in which we can compare the impact of lexico-phonotactic and structural similarities.
We tested the speakers in a forced-choice AJT in which they had to choose between two non-subject-initial declarative clauses that only differed in word order (example (9)): (9) Nof ( Now (car) became (car) blue ‘Now the car became blue.’
Design and procedure
The experiment was created and deployed on Nettskjema, which is an online questionnaire service provided by the University of Oslo. On average, the experiment was completed in 45 to 60 minutes. Upon entering the experiment, the participants were randomly assigned to one of the ALs and to either Norwegian or English instructions.
In the exposure phase, the participants received written stimuli and a corresponding image. The words were each displayed three times. After the exposure phase, the participants engaged in two rounds of a picture–label matching task. The first round included feedback. In an effort to ensure that the participants had learnt the AL vocabulary, we only analysed data from participants with 100% accuracy scores on the second round. Finally, the participants were given a forced-choice AJT in which they had to choose between pairs of non-subject-initial declarative clauses that only differed in word order. We used two types of fillers that involved word order at the phrase level: adjective–noun/noun–adjective and noun–possessive/possessive–noun. There were 12 sentence pairs per condition (36 in total). We also included six post-stimulus distractors, distributed evenly throughout the task, in which we asked meaning-based multiple-choice questions. As with the instructions, half of the participants got these questions in Norwegian, and the other half in English.
Results
We analysed the data in RStudio (Team, 2021), R version 4.2.2 (2022-10-31). Table 3 shows the mean proportion of V2 selections (coded as 1) over V3 (coded as 0) in the forced-choice AJT across Languages A–D.
Mean proportion of V2 selections across artificial languages (Languages A–D).

The proportions listed in Table 3 are visualized in Figure 4 (Thériault, 2022) in which lower values on the Y-axis indicate more V3 selections and higher values indicate more V2 selections.
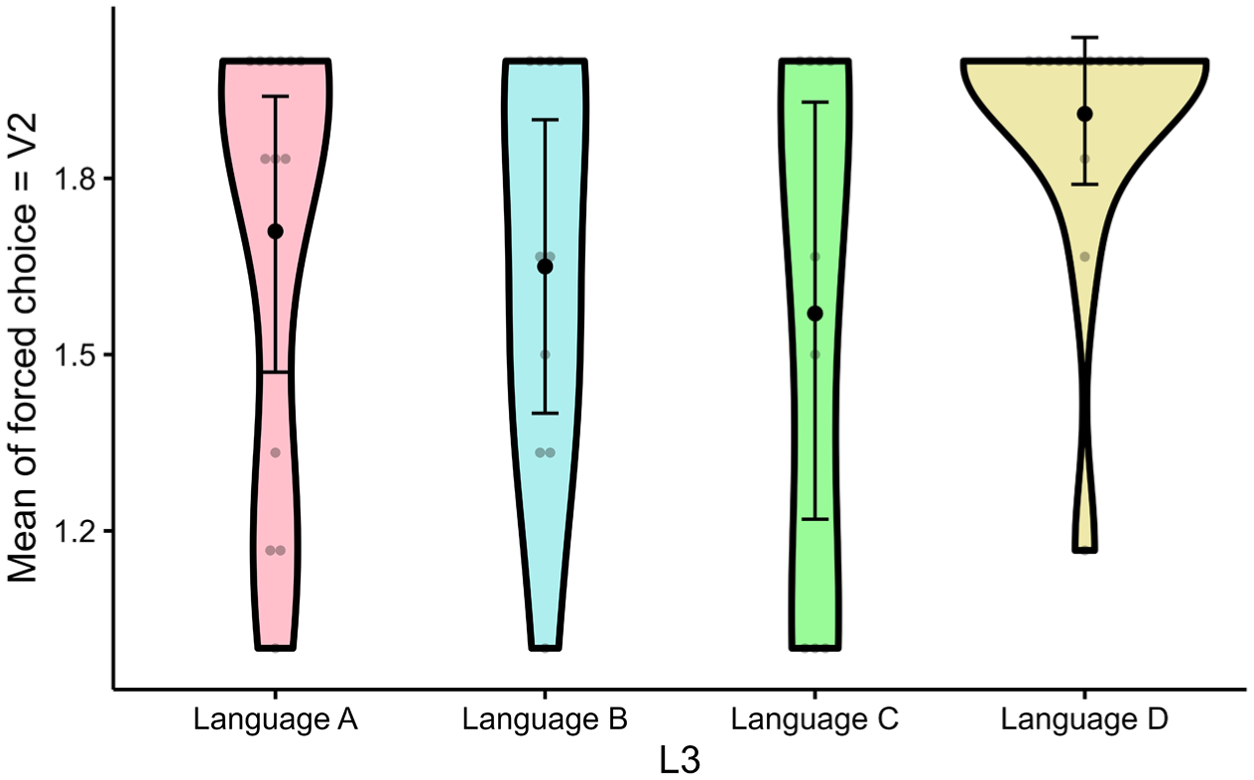
Mean proportion of forced-choice selections by group.
Table 4 shows the mean proportions of V2 over V3 selections across input languages (English and Norwegian). The proportions are visualized in Figure 5 (Thériault, 2022), in which lower values on the Y-axis indicate more V3 selections and higher values indicate more V2 selections.
Mean proportion of V2 selections across input languages (English and Norwegian).

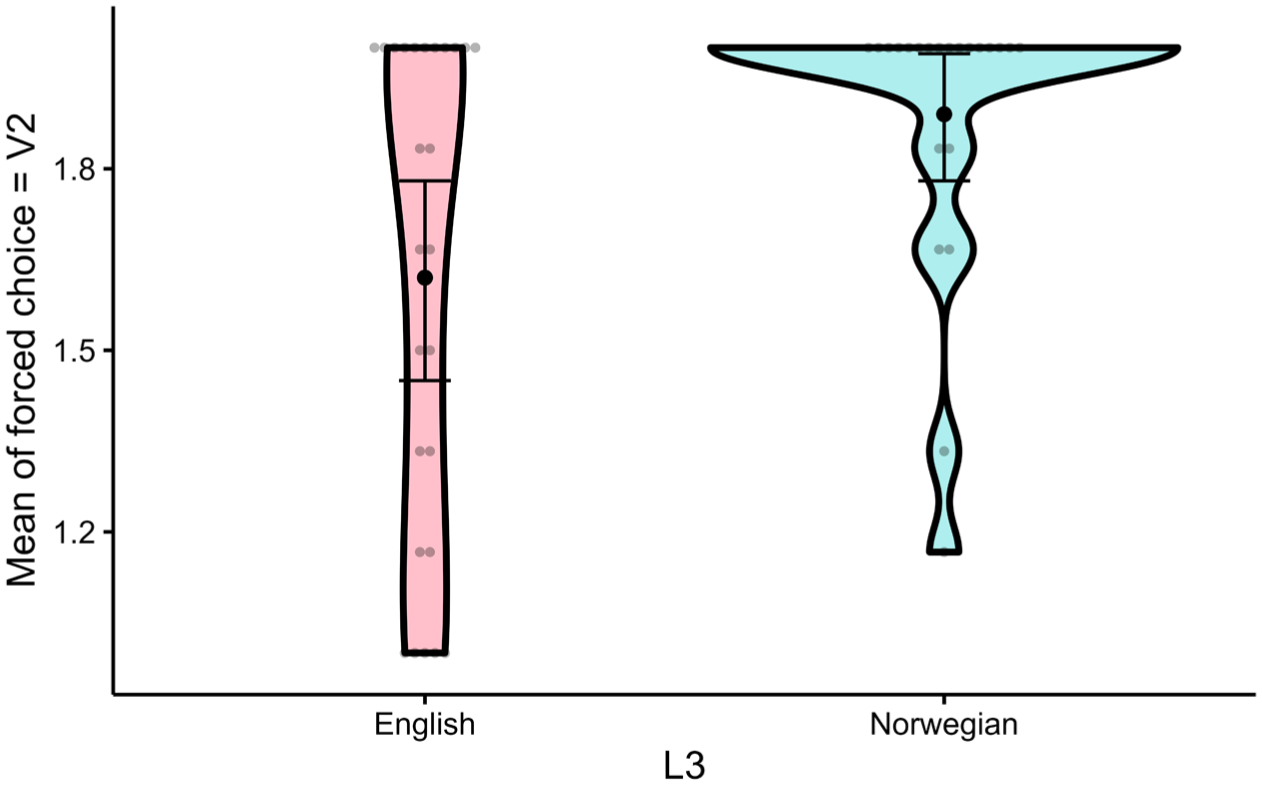
Mean proportion of word order selections by input language.
We fitted the data to a mixed-effects binomial logistic regression model with Participants as random intercepts using the same procedure as described in section “Results.” The response variable was the forced-choice acceptability judgements (V2 or V3). We added Morphosyntactic similarity (English, Norwegian and none), Lexical similarity (English and Norwegian) and Input language (English and Norwegian) as potential fixed effects. We used the rms R package (Harrell, 2021) to set sum contrasts. The final minimal adequate model performed significantly better than an intercept-only baseline model (χ2(3) = 10.53, p = .001) and had a near optimal fit (Harrel’s C = .96, Somers’ D = .92). The random and fixed effects explained a substantial amount of the variance in the response variable (R2conditional = .80), as shown in Table 5. The intercept represents the estimated mean for English and Norwegian input languages (grand mean).
Model summary predicting word order choices (V2 = 1, V3 = –1).
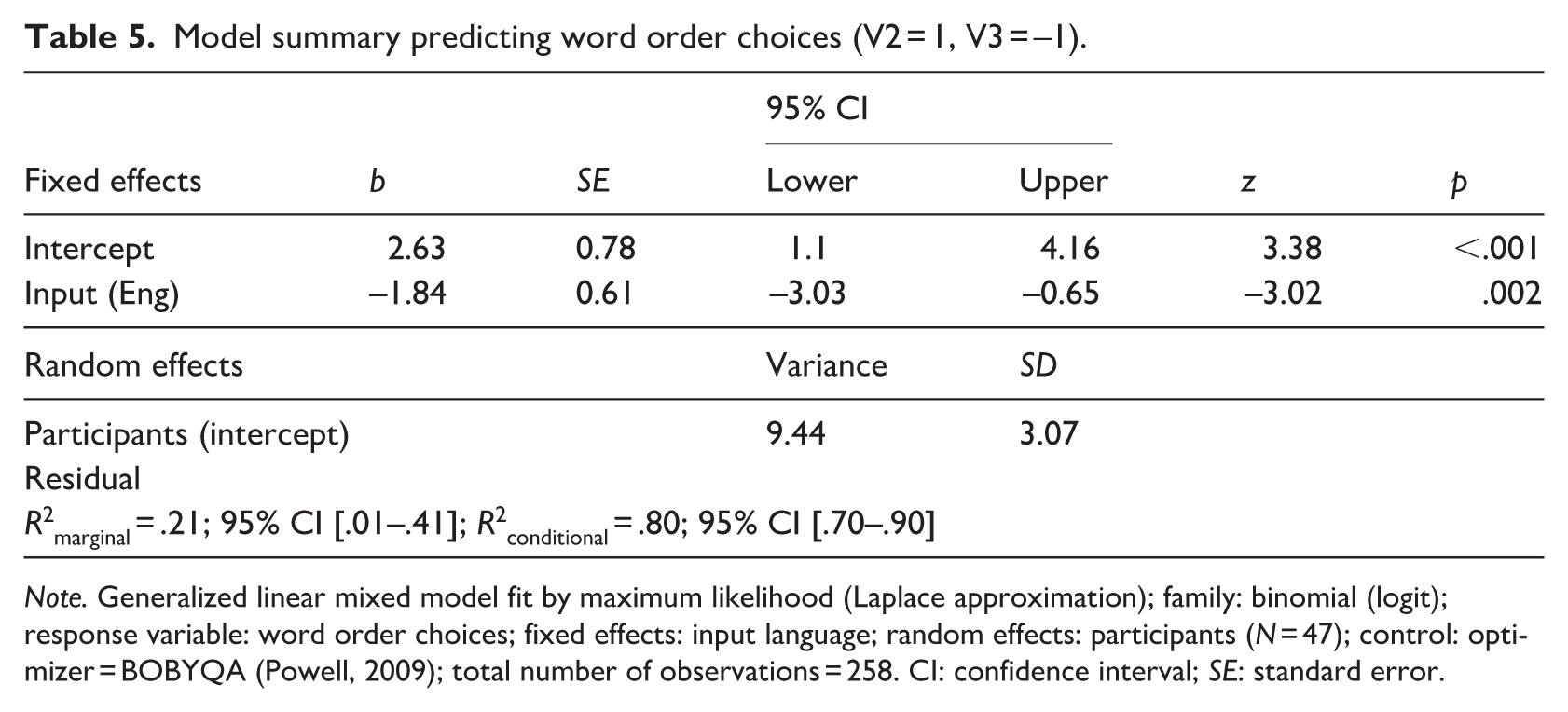
Note. Generalized linear mixed model fit by maximum likelihood (Laplace approximation); family: binomial (logit); response variable: word order choices; fixed effects: input language; random effects: participants (N = 47); control: optimizer = BOBYQA (Powell, 2009); total number of observations = 258. CI: confidence interval; SE: standard error.
We found a main effect of input language (b = –1.84), which represents the difference between the mean score for English and the grand mean, indicating that the occurrence of English instructions generated fewer V2 selections than the average. Figure 6 visualizes the main effect, showing that the probability of a V2 selection is lower when the information was given in English, as compared to when the information was given in Norwegian.
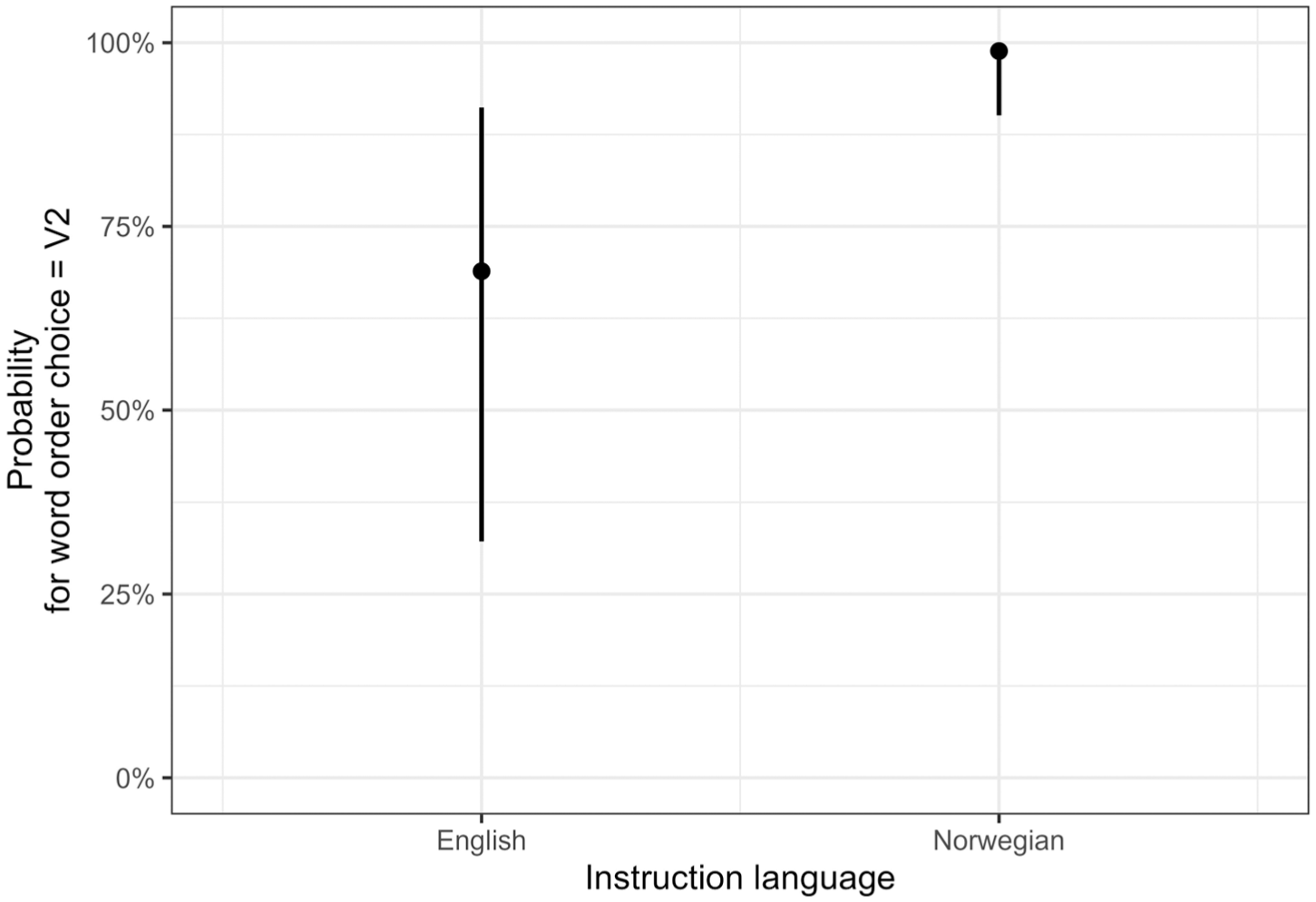
Main effect of input language.
Discussion
In Experiment 1, we tested word order preferences in two groups: English monolinguals and Norwegian–English bilinguals. The AL was lexico-phonotactically closer to English but morphosyntactically more similar to Norwegian. In the English group, the results showed a higher preference for V3 as compared to V2 word order, as expected. However, the mean acceptance rate for V2 word order was relatively high, at 35% and 37% (see Table 1 in section “Results”). This was surprising, considering that acceptance of V2 by English monolinguals cannot be attributed to CLI from the L1 – as English is not a V2 language – nor learning from the AL input, as movement past the subject was not shown to the participants prior to the AJT. However, there are several possible explanations for the observed behaviour among the English monolinguals. First, the high acceptance rate could be a result of the response bias known as agreement tendency, which refers to the general tendency to accept, rather than reject, sentences in AJTs (T Schütze, 2016). Alternatively, the high acceptance rate for V2 word order could be a result of the residual V2 in English (Rizzi, 1996; Westergaard, 2007), making English speakers more prone to accepting V2 word order because they know that it is possible in certain cases. The latter explanation would account for why we do not observe the same agreement tendency in the filler/control condition (SVO/SOV), and why we do not observe a robust V3 representation.
Regarding the Norwegian–English bilinguals, the results in Experiment 1 showed a high acceptance of V3 word order, which could be interpreted as CLI from English. This behaviour is not surprising considering the lexico-phonotactic similarity between the AL and English. That is, lexical and phonotactic cues are expected to be more influential than syntactic cues early in the acquisition process because of the immediate access to information about overlapping words and sounds. Such behaviour is predicted by both wholesale-and property-by-property-based accounts of L3 acquisition – that is, by both the TPM and the LPM (see section “Background”).
Alternatively, the high acceptance of V3 word order could represent a general tendency towards accepting SV word order. Previous studies have reported similar results (Bohnacker, 2006; Busterud et al., 2023; Dentler, 2000) and attributed such behaviour to a preference for the unmarked SV word order (Clahsen & Muysken, 1986) or non-movement due to matters of cognitive economy (Busterud et al., 2023), while others have argued that it could be a result of CLI (Bohnacker, 2006).
Crucially, the interaction effect reported in section “Results” shows that we can reject the null hypothesis for RQ1 in Experiment 1. That is, the Norwegian–English bilinguals accepted more V2 word order compared to the English monolinguals. In other words, despite the unexpectedly high acceptance of V2 word order among the L1 English speakers, the monolinguals still clearly differed from the Norwegian–English bilinguals. This between-groups difference suggests that the strong lexico-phonotactic similarity between the AL and English had not triggered wholesale transfer at the point of testing. This result is in line with a property-by-property view on CLI, which rejects the idea of wholesale transfer, but could also be explained by pre-transfer stages cf., González Alonso et al. (2020). Specifically, in light of the LPM (e.g., Westergaard, 2021), the between-groups difference could be explained by Norwegian–English learners being able to make use of the syntactic information in the input, which revealed a structural overlap between Norwegian and the AL. A similar result was reported in Jensen and Westergaard (2023). However, as mentioned in section “Background,” it is inherently difficult to determine when the initial stages occur, and therefore we cannot rule out that the result may reflect pre-transfer stages (cf., González Alonso et al., 2020), meaning that participants in Experiment 1 had not yet made a decision about which language – Norwegian or English – to copy at the point of testing.
In Experiment 2, we kept the pre-existing languages stable by only testing Norwegian–English bilinguals, but we varied the target language (Languages A-D) in terms of linguistic similarity to the previously acquired languages (Norwegian and English). Similarity-driven models of L3 acquisition would predict that such manipulation of the input should lead to between-groups differences. However, the results presented in section “Results” show that we failed to reject the null hypothesis for RQ1 in Experiment 2. That is, we did not find a statistically significant difference between the participants on the basis of linguistic similarity between the ALs and pre-existing languages.
However, we found a significant main effect of the language input. That is, we were successful in rejecting the null hypothesis for RQ2. Specifically, the participants who were given English instructions accepted a higher proportion of V3 word order as compared to those who were exposed to Norwegian instructions. Considering the fact that this between-groups difference holds across different degrees of lexical, phonotactic and structural overlaps between the target language and pre-existing languages, we could argue that the effect of input language weighs heavier than linguistic similarity for the very early L3 learners tested in the current experiment. This result could be seen in light of the idea of parallel activation, as described in the “Background” section, in which associated linguistic representations compete against each other. The winner of the competition, and ultimately what is transferred to the L3, is the representation that – overall – fits the incoming L3 input better.
In other words, what Experiment 2 might indicate is that it is not only the linguistic cues in the L3 input that affect the outcome of the competition, but also the linguistic cues that occur in the context of the acquisition process. Moreover, in the case of the current experiment, we could argue that the English (pseudo)cognates that occurred in the AL were associated with the English conceptual system (meaning), while at the same time, the syntactic structure (V2) was associated with Norwegian. Arguably, factors such as the input language may gradually become less influential when learners advance in the L3, as their proficiency – and thus their access to the L3 system – increases.
Conclusion
In this paper, we presented two AL learning experiments that both investigated factors affecting CLI at very early stages of L3 acquisition. In Experiment 1, we compared English monolinguals to Norwegian–English bilinguals who were exposed to the same AL. In Experiment 2, we compared groups of Norwegian–English bilinguals who were exposed to different ALs. In both experiments, our goal was to investigate how linguistic similarity between the AL and previously acquired languages affected CLI. In Experiment 2, we also aimed at exploring a lesser-studied factor, namely the effect of the input language.
In Experiment 1, we successfully rejected H0 for RQ1, indicating that the Norwegian–English bilinguals had not selected English as the primary source for CLI at the point of testing, despite clear lexico-phonotactic similarities between the AL and English. This is in line with a property-by-property view on CLI, which argues that learners have access to all previously acquired languages throughout the acquisition process and that the learners are sensitive to fine-grained structural cues in the input. However, our results do not rule out the possibility that wholesale transfer might occur later. Looking forward into the future of L3 studies, longitudinal designs might be appropriate to investigate whether wholesale transfer takes place at later stages of the acquisition process.
In Experiment 2, we were not able to reject H0 for RQ1,that is, we did not find a statistically significant effect of linguistic similarity. However, we successfully rejected H0 for RQ2, indicating that the input language exerted a significant effect on word order choices. The results reported in Experiment 2 suggest that the language used to inform the participants during the experiment is a non-trivial matter that should be considered during the experimental design of L3/Ln acquisition studies.
Supplemental Material
sj-docx-1-ijb-10.1177_13670069261440351 – Supplemental material for Input language and structural similarity: Competing factors in early third language acquisition
Supplemental material, sj-docx-1-ijb-10.1177_13670069261440351 for Input language and structural similarity: Competing factors in early third language acquisition by Isabel Nadine Jensen in International Journal of Bilingualism
Footnotes
Ethical considerations
This study was approved by Sikt – the Norwegian Agency for Shared Services in Education and Research.
Consent to participate
Written informed consent was obtained before participation.
Consent for publication
Not applicable.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
Author biography
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.