
Abstract
Objectives:
Mastery of formulaic language holds great potential for improving L2 learners’ fluency. However, the field of formulaic language is internally heterogeneous and externally fuzzy. It remains unclear what types of formulaic language deserve special attention in L2 learning and teaching and whether formulaic sequences are to be demarcated from recurrent lexicogrammatical patterns based on compositional syntax. I investigate how semantic and pragmatic idiomaticity, internal syntagmatic cohesion (degrees of chunking) and frequency of use interact. The goal is to formulate recommendations for L2 learning and teaching of formulaic language.
Approach:
The syntagmatic strengthening principle, formulated as part of the Entrenchment-and-Conventionalization Model, makes predictions concerning the ways in which these factors interact. I test these predictions in an investigation of 14 lexicogrammatical patterns, combining the corpus and the questionnaire method.
Data and Analysis:
The data are extracted from the British National Corpus and analyzed with regard to various frequency measures. Results of the frequency analysis feed into an online questionnaire study asking participants to rate the internal syntagmatic cohesion of syntagmatic sequences.
Findings:
Frequency and idiomaticity are independent predictors of syntagmatic cohesion. Frequency alone is a sufficient predictor, especially when analyzed in different ways.
Originality:
Based on the predictions of the syntagmatic strengthening principle, the study provides empirical evidence regarding the links between frequency, idiomaticity and internal syntagmatic cohesion. It offers a differentiated perspective on frequency distributions of the instantiations of partly variable syntagmatic patterns and their correlations with syntagmatic cohesion and idiomaticity.
Implications:
I discuss the implications of the study for the learning and teaching of formulaic language in L2 and identify four domains of formulaic language: formulaic syntax, must-have formulaicity, want-to-have formulaicity and nice-to-have formulaicity. How much and what kind of attention these domains require in L2 learning and teaching depends on the circumstances under which L2 learning takes place.
Introduction
Improving fluency is one of the central goals of L2 learning and teaching (Nation, 1989). Multi-word units and formulaic language in general hold enormous potential for improving fluency (Carey, 2013; Nattinger & DeCarrico, 1992; Pawley & Syder, 1983; Wood, 2010; Wray, 2008; Wray & Perkins, 2000). Working with prefabricated units and semi-prefabricated sequences enhances syntagmatic fluency and automaticity (Arnon & Snider, 2010; Christiansen & Arnon, 2017; Schmid, 2017). Partly or fully idiomatic chunks are semantically and pragmatically efficient, because they often carry holistic meanings and can encode specific pragmatic functions (Fillmore et al., 1988; Nattinger & DeCarrico, 1992). The use of formulaic language can thus contribute to efficiency and fluency in language production, and in fact also comprehension (Wray, 2002, 2012; Wray & Perkins, 2000), especially in spontaneous spoken language with its strong constraints on time and processing capacity, where conventionalized and stored routines are also particularly frequent (Erman & Warren, 2000; Stein, 1995). Therefore, investing time and effort into learning and teaching formulaic language is bound to pay off (Nattinger & DeCarrico, 1992; Pawley & Syder, 1983; Kersten, 2015; Boers, 2019).
However, the field of multi-word units and formulaic language is wide. It includes a large variety of expressions and patterns which differ with regard to characteristics such as fixedness, (ir)regularity and idiomaticity, to name just a few (see, e.g., Makkai, 1972; Moon, 1998; Schmid, 2014; Wray & Perkins, 2000). There is no clear-cut distinction between utterances that contain multi-word units, on one hand, and fully compositional utterances encoded by the application of regular syntactic rules or schemas, on the other hand (Contreras Kallens & Christiansen, 2022). Consider, for instance, the partly idiomatic expression at the end of the day, which can be used to mean ‘eventually, when all is said and done’. This expression may be a more typical multi-word unit than the almost identical compositional sequence at the end of the year, but is there really such a fundamental difference? Similarly, is the fixed expression on the other hand so different from the compositional sequence on the other side (see Carey, 2013, for the use of this sequence in learner language)?
All this indicates that the field of formulaic language is internally heterogeneous and that its boundaries to other linguistic phenomena or levels are fuzzy. This raises important questions for linguistic theory as well as language learning and teaching. What types of multi-word units, and more generally formulaic language, require special attention? Should all types of multi-word units be learnt and taught in similar ways? How should the language learner and teacher deal with the transition between chunk-like multi-word units and structurally similar instantiations of compositional patterns? And to what extent do the answers to these questions depend on the type of learners, their goals and the type of learning context?
How these practical questions are answered crucially depends on how we model the place of formulaic language in the larger architecture of language (Contreras Kallens & Christiansen, 2022). Syntax-centered structuralist and generativist models, which relegate multi-words units to an appendix to the lexicon, would argue for a clear separation based on formal and/or structural and/or semantic irregularity (Culicover et al., 2017). The idiomatic expression at the end of the day goes into the appendix; the compositional sequence at the end of the year can be generated by compositional syntax. Usage-based frameworks such as construction grammar reject this strict separation of syntax from lexis plus phraseology (Fillmore et al., 1988; Goldberg, 2003; Kay & Fillmore, 1999). They accept multi-word units as integral parts of a more flexible and unified architecture of language that allows for multiple and redundant storage at different levels of abstraction. For instance, in view of its fixedness, idiomaticity and discursive utility, the expression on the other hand can be treated as a construction in its own right, to be learnt and memorized by L2 learners as a chunk (Mollica & Stumpf, 2022). But is it not also an instantiation of the more general pattern ‘Prep Det Adj N’? And indeed, as mentioned above, what about the equally frequent compositional sequence on the other side? Should it be treated as a lexically specific construction, too, and therefore be learnt, because it is frequent, or is this not necessary because it can be derived from the more general pattern? While it seems to be clear that opaque idioms like make ends meet have the status of lexically filled constructions that must be rote-learnt, it remains an open question whether this also applies to less idiomatic but all the more frequent phrases such as at the end of the day in the sense of ‘eventually, when all is said and done’.
All these questions take for granted that there are different reasons why multi-word units should be learnt and taught in the L2 context. Idiomaticity (in the sense of non-compositionality) is clearly one of them, since it is essential to be familiar with idiomatic expressions from a decoding perspective (Fillmore et al., 1988; Makkai, 1972). From an encoding perspective, it is their formal fixedness and possible irregularity that give multi-word units a special significance. Learners have to get the exact wording right to adhere to conventions. Frequency might be another reason why multi-word units deserve special attention (Arnon & Snider, 2010). As mentioned above, processing highly recurrent sequences as prefabricated chunks is more economical and more conducive to fluency, both in production and comprehension. In light of this, the issue of ‘chunkiness’ or internal syntagmatic cohesion comes to the fore: the more a sequence hangs together internally, irrespectively of its idiomaticity, fixedness or frequency, the more predictable the later parts are and the more sense it makes for learners to memorize and process it holistically rather than compose and decompose it again and again.
Answering the questions raised above thus requires a good understanding of how idiomaticity, frequency and internal syntagmatic cohesion interact in formulaic language. Promoting this understanding and discussing implications for language learning and teaching are the two central goals of this paper. I will probe the interaction among the three factors from the perspective of the Entrenchment-and-Conventionalization Model (‘EC-Model’, for short; Schmid, 2015, 2020, 2023). Based on this discussion, I will propose a division into four types of formulaicity from the perspective of L2 language learning: must-have, want-to-have and nice-to have formulaicity plus formulaic syntax. Before I introduce the relevant components of the model and discuss what it may have to offer, I have to define central notions.
Terminology
Multi-word units and formulaic language
The notion of multi-word unit denotes recurrent sequences of two or more orthographic words which are conventionalized, stored and processed as holistic units. Against the backdrop of a modular architecture of language, these two features – polylexicality and unit status – set multi-word units apart from simple lexical items, on one hand, and combinatorial syntax, on the other hand. For all practical purposes, however, the two features delimit not more than the prototypical core of multi-word units, that is, more or less frozen and idiomatic expressions such as the proverb all is well that ends well or the idiom make ends meet (see, e.g., Stumpf, 2017). Such prototypical cases of multi-word units constitute only a small portion of the larger space of formulaic language (see, e.g., Makkai, 1972; Moon, 1998; Stumpf, 2015; Wray, 2008; Wray & Perkins, 2000), which also contains recurrent lexical sequences and lexicogrammatical patterns whose status as units is much less clear. Some such sequences and patterns are compiled in Table 1, which illustrates, labels and characterizes various types of formulaic language containing the noun or verb end. I will make reference to this list in my definitions of criteria in the next section.
Important types of formulaic language illustrated and characterized.
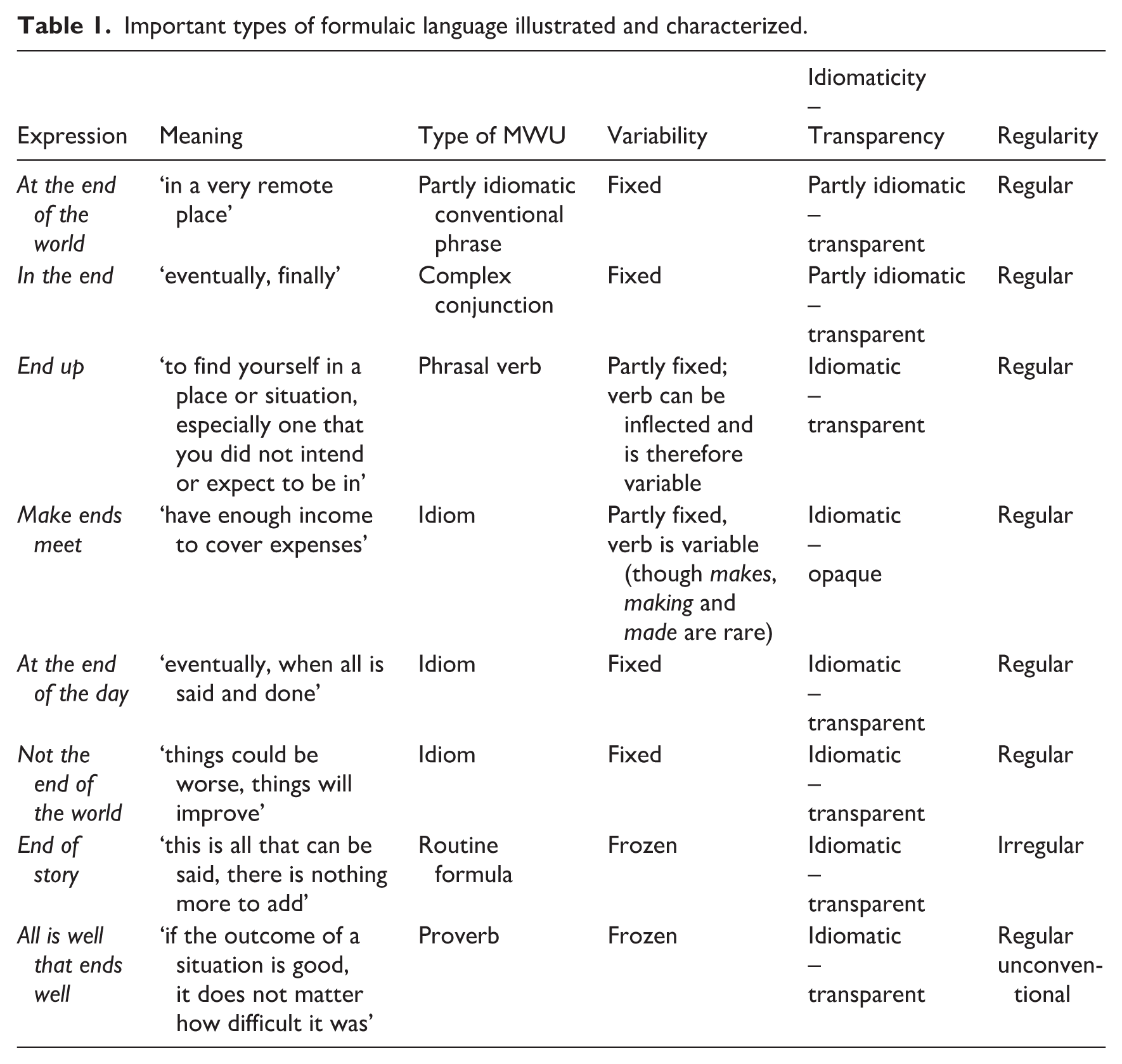
Types of formulaic language and criteria used for their definition
Multi-word units and other types of formulaic language can be categorized with the help of numerous criteria. The notions that have traditionally been used to carve up the field tend to be based on different subsets of these criteria and highlight different aspects. In Table 1, I use such notions – for example, idiom, proverb, phrasal verb, complex preposition or conjunction, routine formula, lexical bundle – in a fairly loose way, mainly as points of reference. There are many more terms, including irreversible binomials, commonplaces, winged words and proverbial sayings, which are not important in the present context.
The first criterion listed in Table 1 is variability (Fellbaum, 2019; Steyer, 2004). This is a form-based criterion, in principle ranging from fully variable syntax to totally frozen expressions. Formulaic language differs from fully variable syntax in the respect that one or more components of a formulaic expression cannot be changed or modified without compromising the expression and its meaning and function. The utterance at the end of the week, which is very similar to at the end of the day, is variable in this sense because similar utterances such as at the beginning of the month or over the course of the year are licensed by the same arrangement of variable prepositional phrases. In contrast, the routine formula end of story cannot be changed in any way without forfeiting its special discursive function and is therefore marked as ‘frozen’ in Table 1. Idioms like make ends meet are highly fixed, but allow for variation in word-forms.
The next column in Table 1 combines two criteria revolving around the mapping of form onto meanings. Idiomaticity, ranging from fully compositional to fully idiomatic, concerns the degree to which the meaning of the whole expression is a function of the combined meanings of the parts and the grammatical relations between them. Multi-word units can be semantically idiomatic, that is, with regard to their propositional meaning, or pragmatically idiomatic, that is, with regard to their communicative or discursive function (Fillmore et al., 1988, p. 506). Idioms tend to be semantically idiomatic, routine formulae and discourse markers pragmatically idiomatic. Importantly, idioms and other semantically idiomatic expressions tend to be rare, while pragmatically idiomatic expressions such as routine formulae tend to be frequent (Moon, 1998, 2007; Stumpf, 2015). Idiomaticity is partly, but not fully linear with transparency, which is dealt with in the same column in Table 1, separated by a dash. Compositional (non-idiomatic) expressions are generally transparent, in the sense that their meaning is directly recoverable from the component parts. Idiomatic expressions, however, can either be opaque (i.e., not fully transparent), that is, semantically not or only partly derivable from their parts (as in make ends meets) or transparent (as in end of story).
The criterion of regularity relates to the question whether a given expression is in line with more general syntactic rules or schemas or whether it deviates from them (Stumpf, 2015, 2018). For example, the phrase end of story is somewhat irregular, because the double omission of determiners is unusual. The somewhat archaic tone of the proverb all’s well that ends well makes it slightly unconventional, though not exactly irregular.
Two further criteria are not included in Table 1. The first is what I have called internal syntagmatic cohesion. This is a measure of the degree to which the components of an expression are glued together, so to speak, and therefore mutually or unidirectionally predictable. For example, it is due to strong internal syntagmatic cohesion that when we hear the sequence that’s not the end of the, the word world is highly predictable. This factor will come into focus in Section 4.
The second missing criterion concerns the question of whether it is mainly the demands of production (‘encoding idioms’) or those of comprehension (‘decoding idioms’) that require specific knowledge of multi-word units. The best way to explain this is to quote from the seminal paper on the let alone construction by Fillmore et al. (1988), who refer to Makkai (1972) as a source of inspiration: A decoding idiom is an expression which the language users couldn’t interpret with complete confidence if they hadn’t learned it separately. With an encoding idiom, by contrast, we have an expression which language users might or might not understand without prior experience, but concerning which they would not know that it is a conventional way of saying what it says. (Anything which is a decoding idiom is also an encoding idiom, by these definitions, but there are encoding idioms which are not decoding idioms.) The expressions kick the bucket and pull a fast one are examples of both decoding and encoding idioms; expressions like answer the door, wide awake, and bright red are examples of encoding idioms only. That is, while it is likely that each expression of the latter group could be understood perfectly on first hearing, someone who did not know that they were conventional ways of saying what they say would not be able to predict their usability in these ways. (Fillmore et al., 1988, pp. 504–505)
Learner types and learning contexts
Whether and how a given multi-word unit is learnt and should be taught crucially depends on characteristics of L2 learners and the situations or teaching environment in which they learn. For the purposes of this paper, I make the following distinctions:
learning stage: early, middle and advanced stage.
learning context: immersion/high-exposure learning vs. low-exposure classroom type of learning.
As far as the learning contexts are concerned, what I have in mind is a broad distinction between two idealized scenarios: on one hand, full immersion learning in a target-L2 environment or classroom learning supported by high exposure in the form of intensive reading and watching of movies or TV in the target language; on the other hand, learning in the classroom which is subject to high time constraints and not supported by extra exposure.
The Entrenchment-and-Conventionalization Model and the syntagmatic strengthening principle
Introduction to the model
The Entrenchment-and-Conventionalization Model can be characterized as a functional, usage-based, sociocognitive, emergentist, complex-adaptive model. The model is designed to explain how exactly grammar emerges from usage (Schmid, 2020). One of the most important assumptions of the EC-Model is that we must keep apart the social processes that contribute to shaping communal conventions and the cognitive processes that shape the linguistic knowledge in the minds of individual speakers. This is in spite of the fact that both work together to shape the language and its system as such. Conventions are understood as multi-dimensional regularities of behavior in the model. Knowledge, which lies in the focus of the present paper, is modeled in the form of patterns of associations that become strengthened by repeated processing, depending on registered regularities in the use of conventions:
Symbolic associations are activated and become strengthened by repetition when linguistic forms activate meanings in comprehension or meanings activate forms in production.
Syntagmatic associations are activated and become strengthened by repetition when linguistic forms are sequentially combined.
Paradigmatic associations are activated and become strengthened by repetition when linguistic forms and meanings are in competition for activation in comprehension and production.
Pragmatic associations are activated and become strengthened by repetition when communicative intentions and parameters of the context of situation (including participants and their social characteristics) are connected with linguistic forms, meanings and functions.
For example, each time the phrases in the end or make ends meet are processed, symbolic associations linking the forms of the component words and the whole expression with meanings become active and are routinized and thereby refreshed in memory. Syntagmatic associations between the component words are strengthened, making the sequences more predictable. Paradigmatic associations to competing words, for example, between end and beginning or start and make and do, are strengthened by the repetition of processing events in which they competed for activation. The discursive function of in the end or at the end of the day is subserved by strengthening pragmatic associations between these forms and corresponding discourse functions.
Strengthening of patterns of associations leads to stronger entrenchment. The process of entrenchment in general is defined as the routinization of patterns of these four types of associations, driven by registered commonalities of usage events (Schmid, 2020). Linguistic knowledge is assumed to be represented in the form of an associative network. Associations serve as connections in this network, and it is these associations that are entrenched by repetition rather than the nodes (as would be assumed in construction grammar). The nodes in the associative network are very slim representations of forms and meanings, with the full formal, semantic and pragmatic complexity of constructions only emerging via the interplay of associations (Schmid, 2023).
The syntagmatic strengthening principles and their side effects
The strengthening of syntagmatic associations increases the internal syntagmatic cohesion of recurrent syntagmatic sequences and multi-word units. When word sequences are processed repeatedly, the syntagmatic associations that are activated during processing are strengthened. Typical effects of this strengthening process were mentioned in the introduction above:
internal syntagmatic cohesion and sequential predictability increase;
words within the sequence prime each other’s occurrence;
sequential fluency and automaticity in comprehension and production improve.
Syntagmatic associations can be local, connecting two or more adjacent words, or more far-reaching, for example, in longer sequences of the type at the end of the day or not the end of the world. Given the gradual and ongoing nature of repetition-driven routinization, in this framework, there is no discrete cut between syntagmatically cohesive sequences that are variable to a large extent, on one hand, and fully chunked ones, on the other hand.
The strengthening of syntagmatic associations does not take place in isolation but also affects the other types of associations. In Schmid (2020, p. 236), these combined effects are combined in the syntagmatic strengthening principle: As the syntagmatic links within a sequence are strengthened by repetition, symbolic, paradigmatic, and pragmatic connections associated with the component parts are weakened, while symbolic, paradigmatic, and pragmatic associations of the sequence become stronger.
This principle predicts corollary effects of syntagmatic strengthening relating to idiomaticity, which will be explored in Section 4. Consider the idiom make ends meet. It claims that the more a given speaker has glued these three words together by strengthening the syntagmatic associations between them, the more directly they will access the holistic idiomatic meaning, and the less active the meanings of the component words will be. The same happens to pragmatic associations when the whole expression takes on specific pragmatic functions. Arguably, for instance, speakers do not associate the discourse marker mind you with the meanings of the verb to mind. Paradigmatic associations related to the holistic meaning will also become more prominent, for example, to expressions like get by or pull through in relation to make ends meet, while paradigmatic associations to the component parts will be reduced in prominence.
The syntagmatic strengthening principle is relevant in the present context because it can contribute to our understanding of how frequency, idiomaticity and chunking or internal syntagmatic cohesion interact. If it is true that usage frequency is a fairly robust predictor of internal syntagmatic cohesion, then frequency must play a key role in deciding what types of formulaic language should receive special attention in L2 learning and teaching. Therefore, in the next section, I will report the design and results of a small-scale study that attempts to test the predictions of the syntagmatic strengthening principle.
Testing the predictions of the syntagmatic strengthening principle
The syntagmatic strengthening principle makes a number of predictions that address the properties of multi-word sequences under consideration. It states that an increase in the usage frequency of a given sequence of words leads to
stronger internal syntagmatic cohesion (‘chunkiness’),
a higher degree of semantic and/or pragmatic idiomaticity,
changes in paradigmatic relations of components parts and the whole sequence.
If the predictions of the principle were correct, this would mean that frequent word sequences increase fluency for learners, even if we find that they lie outside the more narrow field of multi-word units. To test the principle and its predictions, we need to find out if more frequent sequences are more idiomatic and more internally cohesive than less frequent sequences and also more likely to be positioned in a way in the network that reflects a change in paradigmatic associations. This requires a comparison between more and less frequent sequences that are similar otherwise (and therefore paradigmatically comparable), that is, differently frequent manifestations of the same pattern. What is also needed are ways of gauging frequency, idiomaticity, internal syntagmatic cohesion and paradigmatic relations.
Selection of patterns
As a convenient starting point for selecting the patterns for investigation, a frequency list of all 6 g was extracted from the British National Corpus (BNC) with the help of Sketch Engine. The top-ranking items in the list were sifted for the most frequent sequences that were instantiations of productive patterns. For example, the two most frequent 6-grams on the other side of the and at the end of the day were selected, while ask the Secretary of State for and mh mh mh mh mh mh, which actually ranked third and fourth in frequency, were excluded. 6-grams were not taken over slavishly but pruned or modified to yield intuitively reasonable sequences and options for comparison. For example, on the other side of the was pruned to on the other side to render it suitable for a comparison with on the other hand. In contrast, the sequence at the end of the day was kept as was, since it could be compared to by the end of the year. Further sequences such as I don’t know or do you think were identified as parts of frequent n-grams with the aim of achieving a reasonable variety of patterns in terms of length and frequency. The frequent sequences from the 6 gram frequency list were treated as potential instantiation of semi-variable patterns by turning lexical fillers into variable slots and retaining function words as fixed slots. On the other side was regarded as an instantiation of the semi-variable pattern ‘on the Adj N’, at the end of the day as an instantiation of the pattern ‘at the X of the Y’. These semi-variable patterns were turned into queries for retrieving other instantiations of the respective patterns from the BNC. Table 2 lists the target sequences investigated, including their frequencies of occurrence per million words in the BNC, as well as the patterns that were queried to retrieve frequency data on competing instantiations.
Patterns selected for investigating the interaction of frequency, idiomaticity and chunking.

As can be seen, there is a range of types in terms of frequency and complexity, from simpler ones such as I don’t + or do you + to the more complex at the + of the + . All patterns are represented by a large number of expressions.
Frequency profiles
Measuring the frequencies of the expressions listed in Table 2 seems straightforward enough. After all, normalized frequency counts are part of the information provided in Table 2. However, things are not as simple as that, because frequency as such does not mean a lot (Schmid, 2020; Tremblay & Baayen, 2009; Tremblay & Tucker, 2011). Instead, it is always relative to paradigmatic competitors. 1 Consider, for example, the sequences it is clear that and in such a way, whose usage frequencies are very similar. If we look at them in the context of the patterns they represent, it turns out that the significance of their frequency counts differs considerably. This emerges from the two charts in Figure 1, which plot the frequencies of the 20 most frequent instantiations of the patterns in such a + and it is Adj that. The figure is accompanied by Table 3, providing further quantitative information to be discussed below.
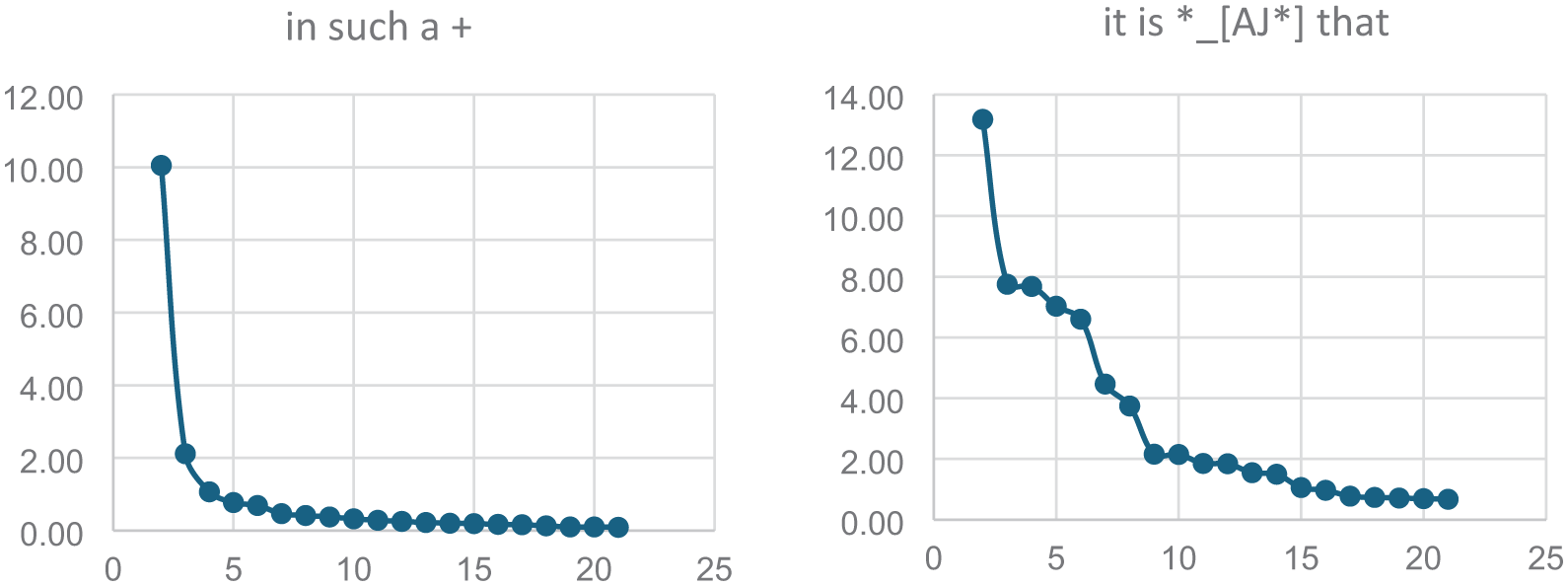
Examples of two different frequency distributions: in such a + and it is *_[AJ*] that.
Frequency data retrieved from BNC for the patterns in such a + and it is *_[AJ*] that.
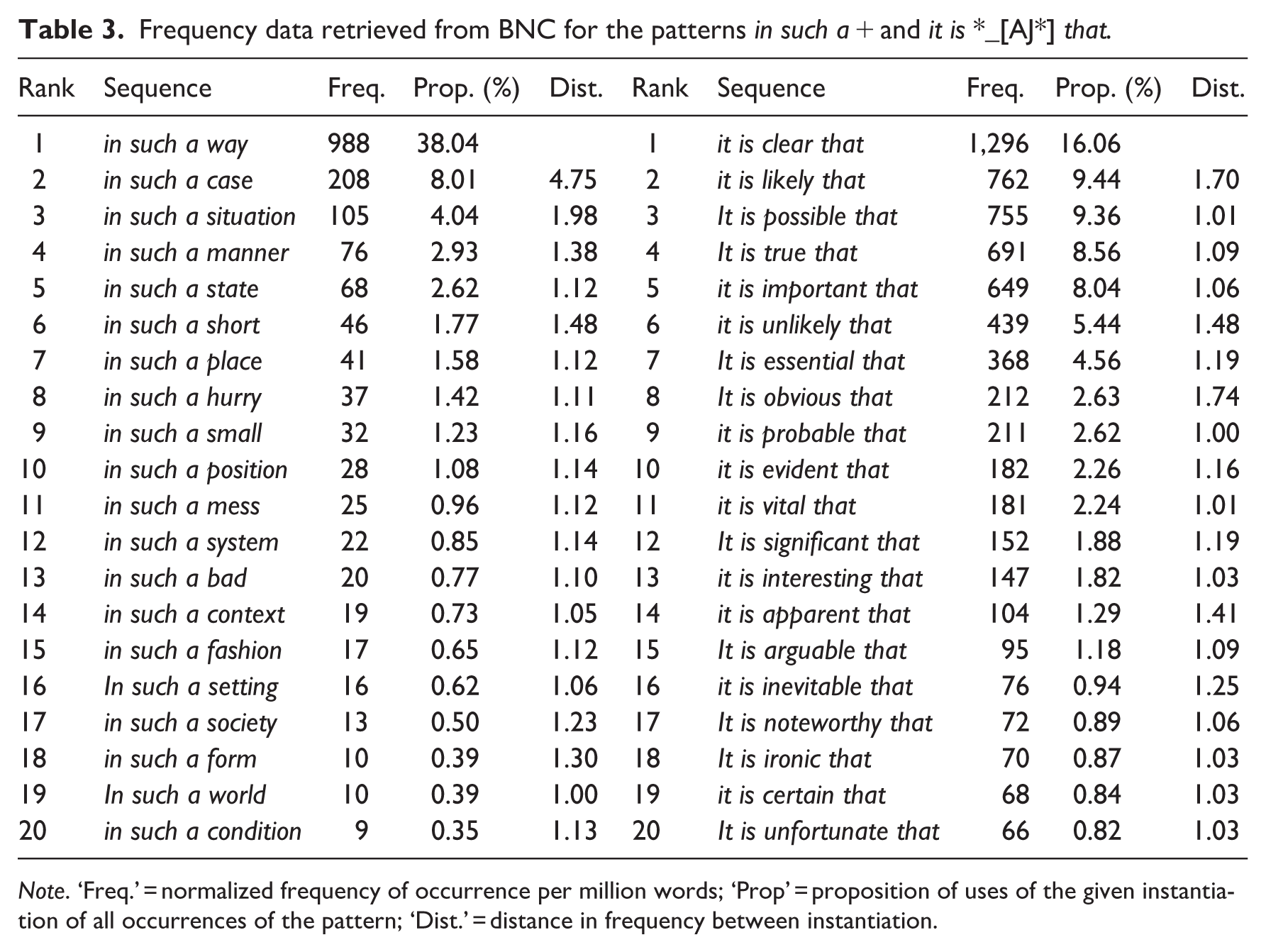
Note. ‘Freq.’ = normalized frequency of occurrence per million words; ‘Prop’ = proposition of uses of the given instantiation of all occurrences of the pattern; ‘Dist.’ = distance in frequency between instantiation.
The chart on the left in Figure 1 shows that in such a way is by far the most frequent instantiation of its pattern, almost five times as frequent as the follow-up, which is in such a case (see Table 3). In contrast, as is indicated in the chart on the right, there is not such a big distance in frequency between it is clear that and the next group of instantiations, that is, it is likely that, it is possible that, it is true that and it is important that (see again Table 3). The top-ranking item it is clear that is only 1.7 times more frequent than it is likely that in the second place. Thus, in such a way literally stands out much more from the instantiations of the variable pattern in such a + than it is clear that does from the pattern it is Adj that. Overall, the drop of the line in the chart on the left is much steeper than the drop in the chart on the right. Another distributional difference shows in Table 3: in such a way accounts for a proportion of 38% of all uses of the pattern in such a +, while the corresponding proportion of it is clear that is only 16%.
Given these differences in frequency distributions on the paradigmatic axis, it does not seem sufficient to report only frequency counts of patterns in a corpus. In spite of their similar frequencies of occurrence, in such a way seems to be more detached from its paradigmatic competitors and also more autonomous, so to speak, than it is clear that. Therefore, the quantitative information about an expression or pattern should take the form of a frequency profile consisting of the following pieces of information:
Before moving on to the discussion of idiomaticity, some general remarks on the frequency distribution are required. Not only the two graphs shown in Figure 1 but the corresponding graphs for all other patterns share certain characteristics: a steep fall from the first-ranking to the second and following items; an ‘elbow’, representing a group of items which mark the transition from the few items that are frequent to the many items which are rare; and a long tail of infrequent items. This is a very common frequency distribution of corpus and other types of frequency data, which is known as Zipf’s power law (Piantadosi, 2014). In the context of complex-adaptive system theory, it has been labeled A-curve (Kretzschmar, 2015). In the present context, it is important to keep two things in mind: first, the token frequencies of specific instantiations of any variable pattern are distributed in a non-linear fashion displayed in the graphs; and second, as the two examples in Figure 1 illustrate, the details of the curves can differ considerably from pattern to pattern.
Idiomaticity
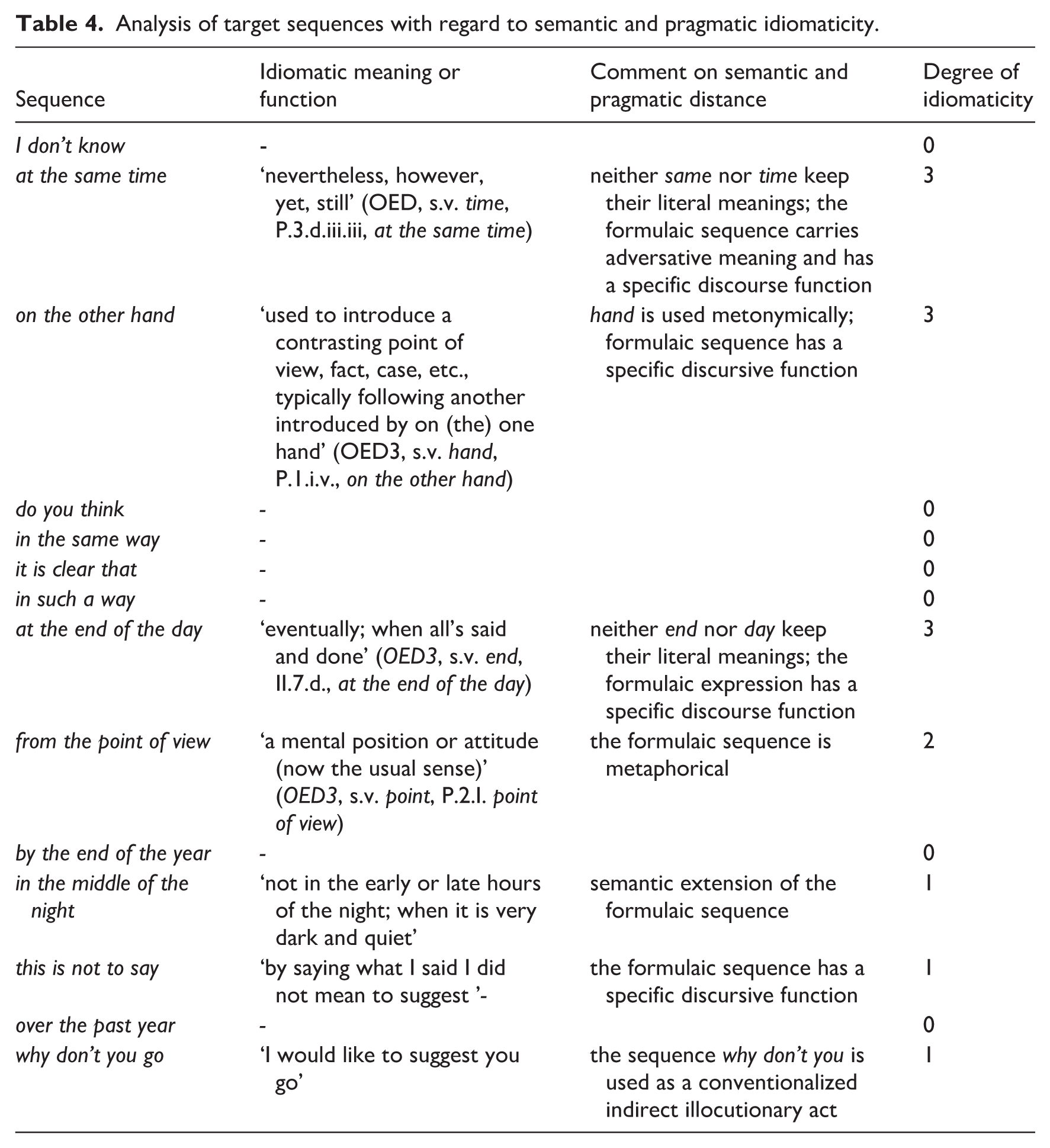
In theory, idiomaticity comes down to the difference between the compositional and the holistic meanings associated with a given word sequence. In the present context, which focuses on the implications of idiomaticity for learning and teaching formulaic language, a simple assessment of idiomaticity based on a semantic and pragmatic comparison of the compositional and holistic meanings and discourse functions should be sufficient. To operationalize idiomaticity, I first checked the OED3 to find out whether meanings indicating some degree of idiomaticity were provided. In three cases where this check failed but where I still had a strong intuition that an additional or specific meaning is conventionalized, I relied on my own judgment: in the middle of the night, this is not to say and why don’t you go. As far as the expression I don’t know is concerned, I agree with an anonymous reviewer of this paper who pointed out that it can be used idiomatically. However, since closer inspection of corpus examples revealed that there was no systematic way of distinguishing compositional from idiomatic uses of I don’t know, I decided on the more conservative option of treating it as being compositional. I distinguish between four degrees of idiomaticity:
‘0’: compositional, no idiomaticity.
‘1’: low degree of idiomaticity, due to minor semantic or pragmatic extensions.
‘2’: medium degree of idiomaticity, for example, due to unobtrusive metaphor.
‘3’: high degree of idiomaticity, due to strong invited implicatures, or salient metaphors or metonymies associated with the whole sequence.
Table 4 provides the relevant information. My overall impression is that all the items that were rated as partly or fully idiomatic are pragmatically idiomatic rather than semantically.
Analysis of target sequences with regard to semantic and pragmatic idiomaticity.
Internal syntagmatic cohesion
As far as gauging internal syntagmatic cohesion is concerned, I have decided against using corpus-based measures of attraction such as transition probabilities (McCauley & Christiansen, 2017), mutual information (Ellis et al., 2008) or others (Tremblay & Baayen, 2009). Ultimately, all these measures rely on frequency distributions in the corpus, which would create the risk of circularity: both the dependent variable of my prediction, that is, internal syntagmatic cohesion, and the independent variable, that is, frequency, would be derived from frequency counts. Rather than trusting my own intuition here, I carried out a small-scale online questionnaire study to be able to rely on the judgment of a larger group of people. Essentially, I asked participants to rate on a seven-point Likert-type scale whether they thought that a given sequence of words was produced word-by-word or as a chunk. Test instructions were as follows: We normally assume that people produce and understand sentences word by word. For example, when you say something like ‘My aunt likes to read’, you choose one word after the other in such a way that you can express what you want to say. Sometimes, however, a sequence of words may be so familiar that it can be produced or understood as one larger chunk. Consider such sequences as ‘happy birthday’, ‘the other day’, ‘once upon a time’ or ‘if you don’t mind’. It seems plausible that we do not have to go from one word to the next when producing or understanding such familiar phrases. Instead, we can deal with these phrases as larger chunks. So rather than starting with ‘happy’ and deciding what is going to come next (e.g., ‘days’ or ‘marriage’ or ‘ending’ or ‘birthday’), we produce the whole expression ‘happy birthday’ as one chunk: In the following you will see 60 word sequences, 20 per page. Please indicate on a seven-point scale whether you think you would produce them word by word or as chunks. The pole on the left indicates that you consider word-by-word production most likely, the pole on the right indicates that you consider dealing with it as one big chunk most likely. You can practice how to handle the task below for the examples you saw above. Please don’t spend much time thinking about your decisions, but trust your first intuition.
The questionnaire was designed and run on the platform SocSci. The 60 test items were randomized before they were divided into three batches of 20 each and randomized again within these groups when presented to test participants.
The screens that participants saw after having read the test instructions looked as shown in Figure 2:
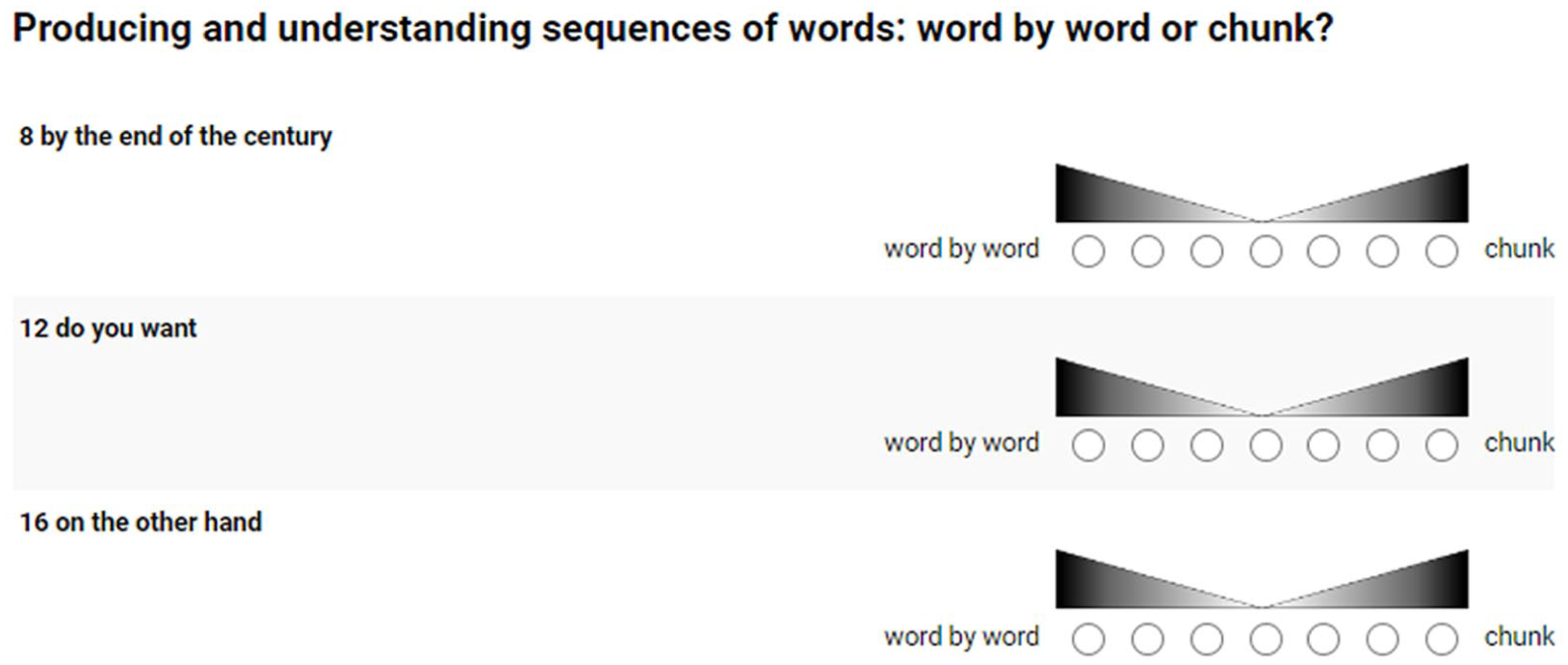
Illustration of test design in the online questionnaire.
The questionnaire was disseminated via the platform X by means of the following post: Some sequences of words are produced word by word, e.g. ‘my aunt likes milk’, others as larger chunks, e.g. ‘needless to say’. If you want to contribute to research in this field, please complete this short questionnaire https://survey.ifkw.lmu.de/schmid_LMU/ and retweet this post.
Forty-one participants started the questionnaire; 25 of them completed it. The incomplete data were not taken into consideration. The data from three more participants were also excluded from the data analysis, because their ratings were totally out of tune with the remaining participants. One participant selected the rating 7 for 58 of the 60 items, another participant did so for 46 items; the third participant excluded selected the rating 1 for 51 items. The interquartile ranges of all three participants, indicating the dispersion of responses, amounted to 0.
As for demographic characteristics of the 22 remaining participants, their ages ranged from 24 to 67 (M = 40). Only two participants identified as native speakers of English. The other participants identified as L1 speakers of Spanish/Galician (5), German (4), Chinese/Mandarin (3), as well as Dutch, French, Greek, Norwegian, Polish, Russian, Swedish and Urdu (1 each). Twenty of the 22 participants stated that they had received training as linguists or language teachers. It would of course have been preferable to have a larger number of lay participants with English as a first language, but since the whole design of the study is preliminary, the results have to be interpreted with a grain of salt anyway.
Test items were selected in the following way. For each of the 14 patterns listed in Table 2, a frequency table of the type shown in Table 3 was produced. From each of these 14 frequency tables, I selected the specific patterns ranked 1st, 2nd, 5th and 20th. This selection was motivated by two considerations: first, the prediction of the syntagmatic strengthening principle that more frequent patterns are more likely to be chunked than less frequent patterns; and second, the assumption that the first and the second item would lie in the steep part of the curves of the types shown in Figure 1, the fifth item somewhere in the ‘elbow’ region marking the transition from frequent to less frequent items, and the 20th item in the early parts of the tail of many infrequent items. This selection gives rise to the expectation that degrees of internal lexical cohesion will decline in correlation with declining frequency from items ranked 1 to 2, 5 and 20. Four items were added as controls to check whether participants understood the task. Three of them were designed with the expectation that they would receive high scores for chunkiness, that is, if you know what I mean, it goes without saying and over my dead body, and one suspected to be rated as not being so chunky, that is, as one would expect.
Participants’ responses per test item were summarized in two measures: first, the median, which is the appropriate measure of central tendency for the type of interval data that Likert-type-scale judgments produce; and second, the interquartile range (IQR), which is a measure of the dispersion or variation across speakers, that is, a measure of the agreement among them. In the numerous cases of ties for the median, for example, in the four cases where the median was 6, we can use the IQR to rank these elements, if helpful.
Results
I have chosen two strategies for reporting the results of this small-scale empirical investigation. The first focuses on the basic prediction that higher usage frequency correlates with stronger internal syntagmatic cohesion of chunkiness. I test this prediction by checking whether there is a correlation between the frequency rank of items representing one pattern and the way they were rated by participants in the chunking questionnaire. The relevant scores are listed in Table 5. Taking the first section of the table to illustrate, we see that the table reports three scores for each of the four items representing the pattern I don’t +: their normalized frequencies, the median (as a measure of central tendency) and the interquartile range score (as a measure of dispersion) of the questionnaire study. The column on the right indicates whether the prediction of the syntagmatic strengthening principle holds: the tick mark (✓) indicates that the median (indicating degrees of syntagmatic cohesion) decreases or at least remains the same when normalized frequency decreases; the mark ✗ indicates that this prediction of the syntagmatic strengthening principle does not hold.
Pattern-wise correlations of normalized frequency and syntagmatic cohesion indicators.
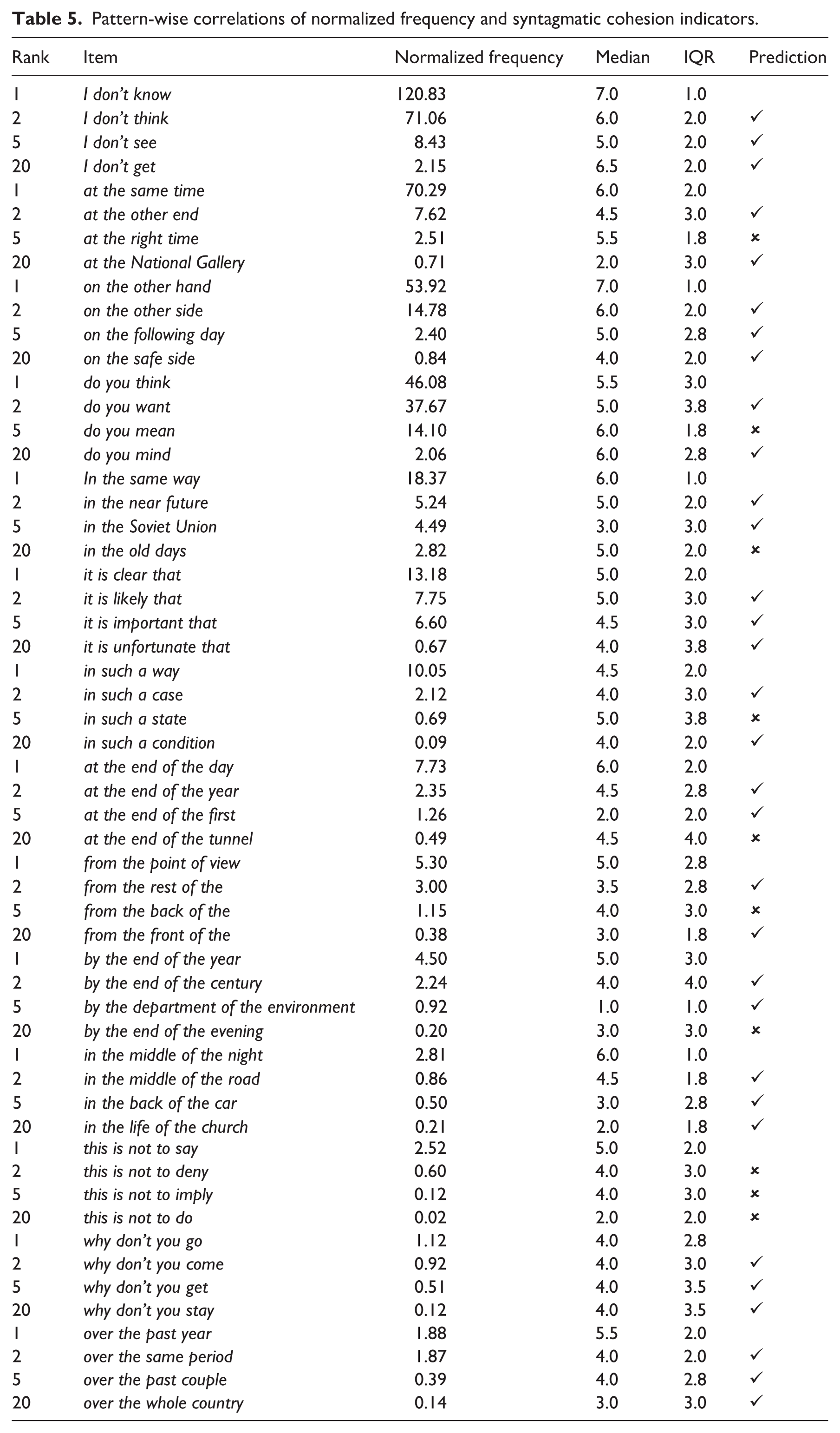
The results reported in the table clearly support the predictions of the syntagmatic strengthening principle regarding the correlation between frequency and syntagmatic cohesion. In all 15 patterns, the most frequent instantiation ranked more highly for syntagmatic cohesion than the second most frequent instantiation. Seven patterns – marked by three ticks – show a perfect correlation between frequency and syntagmatic cohesion as rated by the test participants. Seven instantiations go against the prediction. In five of these, the reason is that instantiations with lower frequencies are semantically or pragmatically idiomatic and therefore rated as more syntagmatically cohesive. This applies to at the right time, do you mean, in the old days, in such a state and at the end of the tunnel. In one case, the failed correlation between frequency and syntagmatic cohesion is due to the name-like nature of the more frequent instantiation, viz. by the Department of the Environment, which seems out of place among the test items and may therefore have received a very low rating for syntagmatic cohesion. For the remaining case, that is, from the back of the, I cannot offer a reasonable explanation.
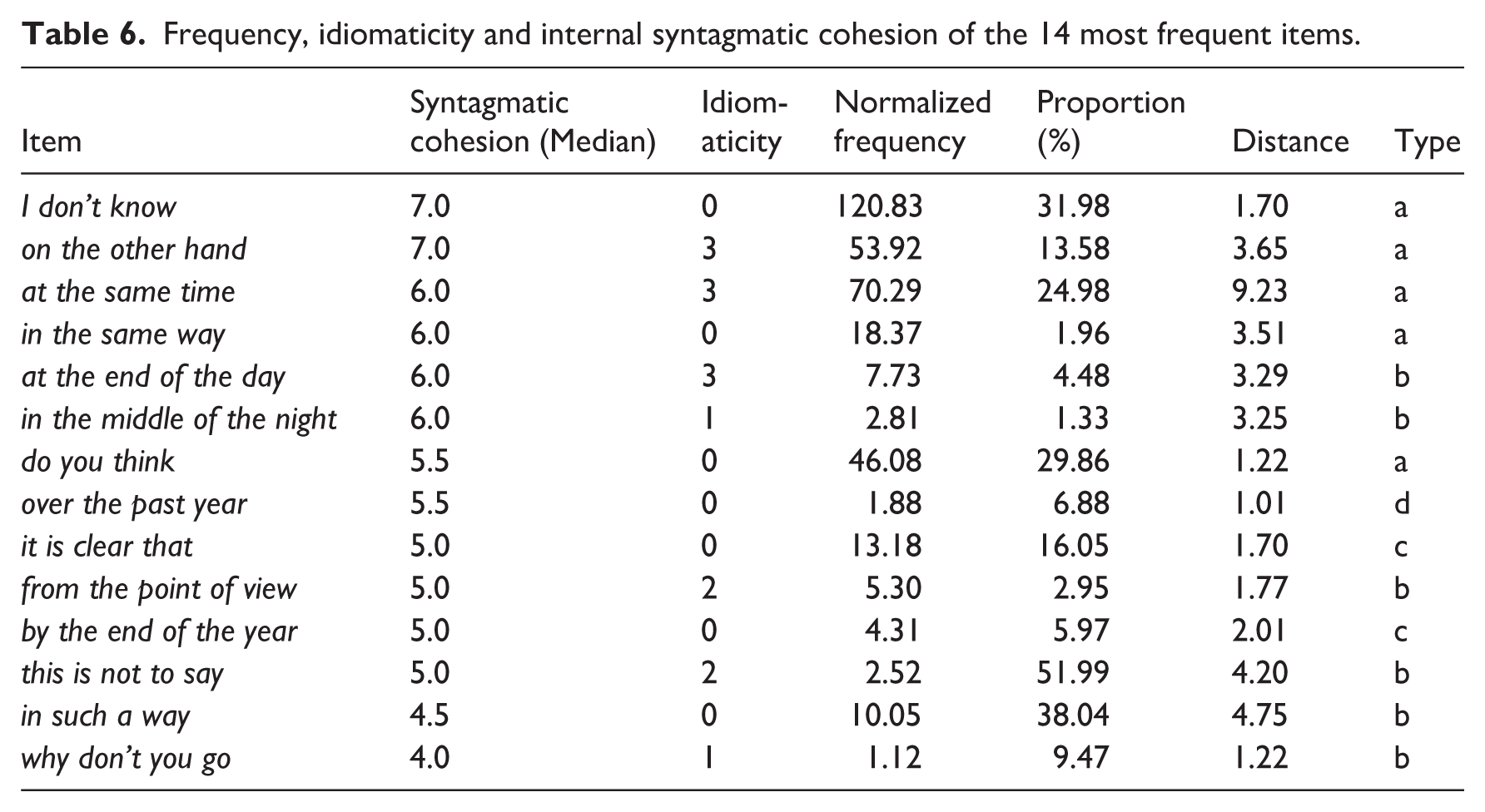
As a second way of analyzing the data, I compare the 14 items ranking first in frequency with regard to their frequency profiles, idiomaticity and internal syntagmatic cohesion. To also take into account the paradigmatic aspects of frequency, all three components of the frequency profiles are included here. The data are summarized in Table 6, ordered according to the median reflecting participants’ rating of syntagmatic cohesion. (The final column allocates the items to four types reflecting recurrent constellations of values, which will be taken up below in Section 5.)
Frequency, idiomaticity and internal syntagmatic cohesion of the 14 most frequent items.
Beginning with
As far as
The frequency parameters of
The four types indicated in the final column of the table, which will be taken up below, can be distinguished by the following constellations of values:
(a) Extremely cohesive items which are highly frequent and/or idiomatic and boast high values for
(b) Highly cohesive items which have high scores for
(c) Items rated very cohesive, showing medium
(d) One item where the source of the high rating for
Summary
The main result of the study is that frequency and syntagmatic cohesions seem to correlate. This finding emerges from both types of analysis. Based on the prediction of the syntagmatic strengthening principle, I would venture the causal interpretation of this correlation that higher frequency is conducive to cohesion rather than the other way round.
Regarding idiomaticity, both types of analysis indicate that this factor is also conducive to syntagmatic cohesion, as was to be expected on the basis of the existing literature. However, the prediction of the syntagmatic strengthening principle that idiomaticity increases with frequency was only partly confirmed. This is also not surprising, since it is known that semantically idiomatic expression such idioms or proverbs tend to be used infrequently. The expectation that pragmatically idiomatic expressions such as routine formulae, discourse markers or partly idiomatic conventional phrases tend to be frequent is partly confirmed, but it is not the case that frequent expressions become idiomatic more or less automatically.
In short, idiomaticity and frequency may work together to increase syntagmatic cohesion, and if they do, cohesion can be very strong. Each of the two factors alone seems to be sufficient to increase syntagmatic cohesion: items which are either highly idiomatic or highly frequent are also likely to be very cohesive syntagmatically.
Implications for L2 learning and teaching
Charting the field of formulaic language
The purpose of the preceding was to find out if the predictions of the syntagmatic strengthening principle have the potential to inform strategies of L2 learning and teaching of formulaic language. To home in on potential implications, I will return to the typology of expressions introduced in Table 6 and identify subdomains of the field of formulaic language derived from the findings above. To do so, I will continue the tradition, summarized very helpfully by Wray (2012), of cross-tabulating variables that define formulaic language. To do justice to the complexity of the findings, the cross-tabulation proposed in Figure 3 tries to integrate all the variables investigated here.

Charting the space of syntagmatic sequences in terms of frequency, idiomaticity and syntagmatic cohesion.
The basic coordinates of Figure 3 are idiomaticity on the x-axis and frequency on the y-axis. Semantic idiomaticity is indicated at the bottom of the figure, since semantically idiomatic expressions tend to be infrequent. In contrast, pragmatic idiomaticity is indicated at the top, because discursively idiomatic expressions tend to be frequent. Strength of syntagmatic cohesion is indicated by shading. The white area at the origin of the coordinate system, where frequency and idiomaticity are low, indicates a very low degree of syntagmatic cohesion. Increasingly dark gray tones indicate stronger syntagmatic cohesion. The area in the top right corner, marked by maximal frequency and idiomaticity represents the best candidates for fully chunked sequences. Items that have been discussed in the preceding are added for illustrative purposes (the only three ‘new’ ones are the discourse marker you know, used to illustrate maximal frequency combined with high idiomaticity, the idiom not the end of the world, which is highly idiomatic but infrequent, and the infrequent and non-idiomatic sequence over the whole country). To include information not only about frequency as such, numbers indicate normalized frequencies (before the slashes) and distance (after them).
Figure 4 essentially repeats Figure 3 but adds information about the types introduced in Table 6. It carves up the space represented in the Figure according to these types and adds labels indicating their role in language learning and teaching.
Compositional syntax, illustrated by over the whole country, is the domain of syntactic combinations which are generated by recourse to general rules or constructions, on the fly, and with cognitive effort. The specific combinations of lexical items, e.g., over the past year, are infrequent and therefore part of the long tail of rare instances of patterns. They are neither idiomatic nor syntagmatically cohesive. This domain is not part of formulaic language.
The notion of formulaic syntax covers the domain of recurrent, but not very frequent and largely compositional instantiations of productive lexciogrammatical patterns. This domain includes top-ranking instantiations of infrequent patterns (e.g., in such as way, it is clear that) and medium-frequent instantiations of frequent patterns found in and slightly below the elbow region of A-curves. They are not idiomatic, but show lexicogrammatical co-occurrence tendencies, depending on frequency and distance to other items. This region marks the transition zone between online computation and holistic access and retrieval. Though represented in Figure 4 in a way that suggests it is small and unspectacular, the domain of formulaic syntax is very important for fluency and competence, as it supplies numerous semi-routinized solutions for recurrent communicative tasks. As I will argue, this region serves as an important hub for increasing fluency of compositional syntax.
The term must-have formulaicity labels the domain of highly frequent and also highly cohesive instantiations of frequent patterns, typically found above the elbow region in A-curves. These are highly routinized and chunked solutions for highly recurrent communicative tasks, ranging from fully compositional to highly idiomatic expressions. Idiomaticity is driven by the frequency of discursive goals and corresponding linguistic means. Processing works in a highly automatic way by holistic access and retrieval. I label this domain must-have formulaicity, as it makes a key contribution to fluency and conventionality by supplying the linguistic toolbox for dealing with everyday communication. Note that this contribution does not depend on idiomaticity but solely on frequency; idiomaticity may or may not be involved.
The domain of want-to-have formulaicity is less essential than must-have formulaicity, mainly because it subsumes less frequent items which range from medium to high idiomaticity. The larger the number of items in this domain that are processed holistically by a given speaker, the more fluent and effortless their language production and comprehension will turn out to be.
I apologize for the term nice-to-have formulaicity and only use it for lack of something more appropriate. The apology is required because this is actually the fun part of formulaic language. It is the domain of all the wonderful idiomatic expressions that add so much flavor and expressive potential to language: the playground of idioms, proverbs, weird tautologies, irreversible binomials and all the other types of multi-words units that first come to mind when thinking about this term. These sequences are generally rare; they can exhibit medium to high idiomaticity, mainly of the semantic type. If idiomatic, they are clearly chunked and can be used with considerable automaticity when triggered by context and a specific communicative task.

Charting the space of syntagmatic sequences in terms of domains for L2 learning.
Goals of L2 learning
The overall goal of second-language learning (and teaching) is to increase fluency and automaticity. Solving communicative tasks by means of compositional syntax is non-automatic by definition and hence a potential threat to fluency. The more formulaic the solution of a given communicative task is for the learner, the more effortlessly and efficiently it will be solved. Therefore, the goal of second-language learning and teaching must be to increase the stock of available formulaic routines.
As pointed out above, the domain of formulaic syntax plays a key role in reaching this goal. Recurrent lexicogrammatical co-occurrence tendencies can be exploited for experience-based implicit learning. The domain of formulaic syntax thus ‘hosts’ the large number of medium-frequent instantiations of productive patterns, for example, it is clear that, in a such a way (that) or by the end of the year. This is the place where the increasing variety of communicative tasks the learner faces and the available repertoire of ready-made solutions are balanced out, giving rise to the frequency profiles observed in Figure 1. The more frequently such recurrent solutions to recurrent communicative tasks have been processed, the more internally cohesive they become and can thus be ‘passed on’ to the domains of must-have or want-to-have formulaicity (depending on how frequent they are).
Due to the very low frequency of the items subsumed under the label of nice-to-have formulaicity, implicit learning by repeated processing is not a viable option. There is simply not enough input around for that. Learning can only work in one of two ways: first, in the form of one-shot learning, that is, by high awareness that an expression one has encountered is very special indeed and might be useful in the future even though it is very rare; and second, by explicit learning in a classroom context.
Pathways of L2 learning of formulaic language
To appreciate what these findings mean for the L2 learning of formulaic language, we have to keep in mind the different types of learners and learning circumstances mentioned in Section 2.
The immersion learner
Immersion learners essentially get must-have formulaicity for free. The routines that fall under this label are so frequent and communicatively useful that learners who get massive input can hardly fail to learn them. The more exposure they manage to accumulate, and the more variable their input becomes, the larger the repertoire of want-to-have formulaicity and formulaic syntax will grow and the larger the proportion of communicative tasks that can be solved without recourse to compositional syntax will become.
With most of the increase in fluency handled by implicit learning, the advanced immersion learners’ main task for explicit learning is to extend their repertoire of nice-to-have formulaicity. This will not so much improve their close-to-ceiling fluency but contribute to stylistic variability and richness. A large volume of stylistically varied input and/or dedicated measures such as working with specialized material is presumably required to make progress in this domain.
The classroom learner
For classroom learners who suffer from severe shortage of input, the situation is very different. Their most important tasks by far are to move from compositional syntax to formulaic syntax and to build an increasingly large repertoire of must-have formulaicity. The first task, that is, to develop formulaic syntax, can be accomplished by strengthening syntagmatic associations reciprocally connecting lexical elements and grammatical patterns. Essentially, it is the emergence of what is referred to as lexicogrammar: learners routinize the syntagmatic associations that subserve recurrent complementation patterns of verbs, nouns and adjectives, on one hand, and recurrent fillers of variable slots in grammatical patterns, on the other.
Teaching strategies that separate instruction for vocabulary learning from units on grammar fail to provide the right environment to promote the emergence of formulaic syntax. Teaching aimed at facilitating both explicit and implicit learning should focus on creating and establishing syntagmatic associations in the minds of learners. The pragmatic associations which are often linked to frequent lexicogrammatical patterns can be put into the service of this mission. After all, learners are rewarded for the use of pragmatically efficient routines by immediate communicative success. As far nice-to-have formulaicity, the classroom learner can benefit from the institutionalized learning environment, because most text books and teachers enjoy spicing up daily routines by including exotic or funny idioms.
Conclusion
Idioms and proverbs are fixed, non-compositional and rare. Therefore, they require special attention in L2 learning and teaching, even though knowing them does not contribute much to fluency. While this is not exactly a revolutionary insight, the more original finding of the present paper concerns the role of usage frequency and the ways in which we can look at usage frequency. The study reported here has indicated that the frequency of syntagmatic sequences correlates with their internal syntagmatic cohesion, which in turn can be expected to have a positive effect on fluency. In addition, we have seen that the most frequent instantiations of partly variable syntagmatic sequences – especially the top-ranking ones – tend to stand out from the patterns in terms of syntagmatic cohesion and to become detached from them paradigmatically. Instantiations of patterns above and within the ‘elbow’ region of the graphs showing the frequency distributions certainly deserve special attention, regardless of their absolute frequency and idiomaticity.
Based on these insights, I have argued that the domains of must-have formulaicity, want-to-have formulaicity and formulaic syntax promise the greatest benefits for improving L2 fluency. In contrast, the domain of rare idioms and other infrequent idiomatic expressions such as proverbs (labeled as nice-to-have idiomaticity) is not so relevant for improving fluency. It is important for comprehension, since idiomaticity must be recognized, and for stylistic variety and richness in production.
How and when the various domains should come into the focus of L2 learning and teaching depends on the learning circumstances. However, no matter what these are, it seems to be of utmost importance to get as much input and exposure as possible, because this will contribute to strengthening the syntagmatic associations which connect the components of syntagmatic sequences, thus promoting implicit learning of must-have and want-to-have formulaicity as well as formulaic syntax. The strengthening of pragmatic associations facilitates this process, especially in the domain of must-have formulaicity, where frequency also tends to correlate with pragmatic idiomaticity.
Finally, I hope to have encouraged L2 learners and language teachers to connect lexis and grammar as much and as early as possible. Lexicogrammatical learning should have precedence over separate attention to lexis and grammar. This will help learners to move from compositional syntax to formulaic syntax and must-have formulaicity, and increase their awareness of the context-dependence of lexical meanings.
Footnotes
Acknowledgements
I would like to thank Nicole Benker, Saskia Kersten and Sören Stumpf for their highly inspiring comments on an earlier version of this paper.
Funding
The author received no financial support for the research, authorship and/or publication of this article.
Declaration of conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.