
Abstract
Aims and Objectives/Purpose/Research Questions:
Our paper outlines the development of vocabulary proficiency tests for minority languages and addresses the challenges in doing so.
Design/Methodology/Approach:
The strategies are exemplified based on recently developed tests for Sicilian and Venetan, two large languages in Italy without official status. Users of these types of languages tend to have only oral skills, some only receptive. They are bilingual and speak the national majority language as their primary and dominant language; they are exposed to a lot of variation, and their languages have been stigmatized in the past.
Data and analysis:
Our paper summarizes 11 challenges, including shifting proficiency, tolerance to variation, various aspects related to lack of codification, bilingualism with a typologically close language, and practical challenges when validating the tests (e.g., the lack of “monolingual” control groups)
Findings/Conclusion:
We conclude with a road map for creating vocabulary tests in minority languages. We discuss points of criticism.
Originality:
While assessment tools have been developed for official majority languages, we lack such measures for regional minority languages. Herein, we argue why they are needed and explain what is important when developing them. We provide a point of departure for future undertakings of this kind.
Significance/Implications:
Assessment material for minority languages is of practical value in educational contexts and research on multilingualism, and it contributes to creating equality in research.
Keywords
Introduction: why assessing proficiency in a minority language?
Although research on language endangerment is well established, there is a widening gap between, on the one hand, the study of official majority languages and endangered languages that benefit from corpus and acquisition planning (e.g., Friulian and Sardinian), and, on the other hand, languages that do not benefit from any measures (e.g., Sicilian and Venetan). Tamburelli and Tosco (2021) refer to the latter as “contested languages.” The creation of proficiency tests is particularly challenging for such contested languages, since it typically relies on the existence of a high level of codification and an established orthography. In this paper, we argue that it is nevertheless desirable to develop assessment material for such languages; we document the development of such tests and address the challenges specific to this setting.
Assessment is the bread and butter of second language research and teaching, because teachers and learners want to know what level of proficiency has been reached. When using assessment tools, we imply that there is a particular norm that language learners and users want to, or should strive to and conform to. This is natural in instructed second language acquisition, where the goal often, but not always, is to approach native speaker knowledge of the standard variety as closely as possible, and where those individuals who align with native speaker norms are rewarded with better grades. It is perhaps less obvious why proficiency needs to be assessed in a minority language, especially if this language has no codified norm to begin with. Among non-standardized languages, it is commonplace to consider the most frequent variety as the most “normal” one, but this comes with the problematic implication that those who do not speak the frequent variety are “less normal” speakers than those who align with it. Thus, there are challenges in assessing minority language proficiency, and this might be the reason why estimates of language vitality are traditionally not based on testing how well speakers know the language but rather on how much they use it or even how much they think they use it, that is, self-assessed use.
We argue that proficiency tests are nonetheless desirable also in these cases. First, such tests will contribute to research equality between languages, that is, official majority languages, co-official (minority) languages, and languages lacking official status. 1 Second, proficiency tests are valuable diagnostic tools for language delays or difficulties. Third, language proficiency is an indicator of how alive a language still is, how urgently it is in need of support, and, possibly, which generation should be targeted first in revitalization efforts. While vitality estimates for contested languages are typically based on self-reported use and frequency of use within domains, the testing community has long pointed out that self-reported, and subjective data are problematic if not backed up with objective data. For example, Besler et al. (2024) have shown that self-reported use and proficiency correlated well in Venetan users, but not in Sicilian users, and this further depended on how old they were, indicating that the tested populations and generations interpreted questions on language use differently. Moreover, there are individuals who have developed high proficiency in a language during childhood but who have ceased to use the language, which means that proficiency and use do not align. Finally, as we will outline in turn, assessment tools for regional languages are badly needed in contemporary research on multilingualism.
Our paper focuses on the Italian context, but similar scenarios exist in other parts of the world. Italians have often migrated to other countries during a time when using a regional language was more common than using Italian—a different language and today’s national language. This means that today’s heritage speakers, their children, or grandchildren who grew up in the diaspora are very likely to have been in contact with a regional language, although it is unclear to what extent. Researchers are well aware of the presence of regional languages among Italian migrants, but they mostly assess how well they have mastered Italian. For example, Schmitz and Diaubalick (2023) have speculated about potential traces of Neapolitan (a regional language in Italy) in the Italian spoken by heritage speakers in Germany. When tested in Italian, these speakers used clitic doubling to a degree that was unusual for Italian but standard for Neapolitan. It is indeed plausible that their participants had been exposed to Neapolitan, but no evidence was provided that they actually spoke or knew Neapolitan, which compromises the strength of their argument. Similarly, Perpiñán and Montrul (2023) showed that Southern Italians have an advantage over Northern Italians in the acquisition of direct object marking (DOM) in Spanish. DOM is also a property of some Southern Italian dialects, which can arguably result in positive transfer. However, the authors have not tested whether their participants actually knew any Southern Italian variety with DOM. Thus, both studies made plausible assumptions on regional languages in Italy being transfer sources, but these were not be backed up by tests demonstrating participants’ knowledge of these varieties.
In this paper, we summarize our experience in creating such tests. We start by contextualizing our research (“Background” section), then summarize the perceived challenges, before suggesting a road map for future projects developing tests for minoritized languages (“A road map” section). We also summarize the criticism we have received along the way. 2
Background
Regional languages in Italy
This paper is based on the development of tests for Sicilian (LexSIC) and Venetan (LexVEN), two regional languages in Italy. In the scientific literature, Sicilian and Venetan are often referred to as “dialects.” However, like other regional languages in Italy, and similar to Italian, they evolved independently from Latin (Berruto, 1989; Coluzzi, 2009; Tosi, 2004), which is why we refer to them as “languages.” Between the 14th and 16th century, when Florence held significant cultural, political, and economic influence, Italian developed from Florentine, a Tuscan dialect (Grassi et al., 2003; Maiden, 1995). A hierarchy has since developed between Florentine as the “high variety,” and other varieties, which were relegated to a subordinate role (Loporcaro, 2009). Around 1861, when Italy was unified, only 2.5% of the population were said to speak Italian (De Mauro, 2005, 43). The spread and dominance of Italian only happened in the 20th century, as a result of societal changes, including the introduction of compulsory military service, the growing influence of the media, industrialization, and urbanization, and especially through the education system (Cremona & Bates, 1977; De Renzo, 2008). While Italian expanded, the “dialects” became increasingly stigmatized, resulting in their repression (Baroni, 1983; Galli de’ Paratesi, 1984; Volkart-Rey, 1990). Recently, some researchers have observed their revalorization (Assenza, 2009; Berruto, 2018; Mura, 2019; Parry, 2010), but the extent to which this is happening is somewhat controversial (Ruffino, 2006), which underlines the need for proficiency measures to gauge the state in which the regional languages are, increase their visibility and investigate the extent to which (changing) attitudes, language use, and language proficiency relate to one another.
Sicilian and Venetan both have several million speakers within and outside of Italy, thus being larger than some European national languages (Eberhard et al., 2022; International Commission of European Citizens, 2022; Istituto Nazionale di Statistica [Istat], 2014). At the same time, it is not clear to what extent “speakerness” maps onto proficiency, although proficiency is crucial for minority languages to persist. Both Sicilian and Venetan have a literary tradition dating centuries back, but contemporary speakers, unless they have a special philological interest, are rarely familiar with it, and they do not normally write in these languages. Both have no official status in Italy, though within the regions of Sicily and Veneto. UNESCO classifies them as languages with “potentially vulnerable” status. None of them are used as languages of instruction in public schools. Both Sicilian and Venetan have a fair presence in social media, where spontaneous orthographies emerge (see Miola, 2021 for Piedmontese; Di Caro, 2022 for Sicilian), with the written mode reflecting oral register.
The goal: a yes/no vocabulary test
In our research on regional minority languages, we aimed for a test that is short, while nevertheless being a reliable and sufficiently valid indicator of overall language skills. From a practical perspective, one would want to test a range of skills, but this is often not realistic due to limitations in resources and time. For this reason, it is common to rely on proxy tests, such as C-tests or vocabulary tests. We opted for the latter because vocabulary tests are less dependent on writing skills.
It is common to model vocabulary knowledge along three dimensions: size (a.k.a. breadth), depth, and fluency (Gyllstad, 2013). Of these, even though our test is not strictly speaking a size test, size is the most relevant dimension for our purposes and also the most fundamental one (Meara, 1996). It refers to the number of words for which a language user has at least a basic form-meaning knowledge. Vocabulary size has persistently been shown to be a strong indicator of general language proficiency, correlating with specific language skills. Alderson (2005) observed correlations with writing (r = .70), reading (r = .64), listening (r = .61), and grammar (r = .64). Gyllstad (2007) reported on links between vocabulary and reading (r = .69); Stæhr (2008) found correlations between vocabulary size and reading (r = .83), writing (r = .73), and listening (r = .69). Uchihara and Clenton (2020) reported on correlations between vocabulary and L2 speaking abilities (r = .55). In the light of Plonsky and Oswald’s (2014) recommendations for correlations as effect sizes (.25 = small, .40 = medium, and .60 = large), receptive vocabulary knowledge is a reliable proxy for general language proficiency.
In our work, we opted for the yes/no format (Meara & Buxton, 1987; following, e.g., Amenta et al., 2021; Beeckmans et al., 2001; Brysbaert, 2013; Eyckmans, 2004; Harrington & Carey, 2009; Huibregtse et al., 2002; Meara & Miralpeix, 2017; Mochida & Harrington, 2006; Pellicer-Sánchez & Schmitt, 2012; Salmela et al., 2021; Stubbe, 2012). In the yes/no format, test-takers are provided with a list of words and typically asked whether they know the meaning of each word; alternatively, whether they think the word exists or not. We opted for asking test-takers whether they know the meaning of a word, which is arguably less prone to invite extensive guessing behavior. The test-taker then indicates whether their answer is “yes” or “no” for each word. The yes/no format has prominently featured in the DIALANG project, whose goal was to provide an online language assessment tool in 14 European languages, including Italian (Alderson, 2005; Alderson & Huhta, 2005). The DIALANG test suite begins with a placement test, suggesting which difficulty level is appropriate for the continued testing. This placement test consists of 75 items, with 50 real verbs and 25 pseudoverbs in the infinitive form, sampled from dictionaries. The real words are distributed over different frequency bands to ensure discrimination between different levels of proficiency. Moreover, Alderson (2005) argued that the use of verbs was an effective means of accessing a relatively large range of vocabulary in a given language with only a small set of items. Another advantage of the yes/no test is that it does not require cognitively demanding instructions, and a large number of items can be administered in one sitting (Hashimoto, 2021). Moreover, the yes/no format is a receptive task, which can be taken by lower proficiency level users of a language, including those without productive and/or writing skills, which would be impossible with a productive task requiring a spoken or written recall answer.
In a yes/no test, test-takers do not have to supply any evidence of or justify their stated knowledge, which means that they might overstate the number of words they know. This is why yes/no tests include “pseudowords,” that is, non-existing words that follow the phonotactics of the target language, and whose function is to counter potential overestimation of test-taker scores. This is done by penalizing test-takers who extensively answer “yes” to pseudowords (referred to as “false alarms” during the scoring procedure).
The challenges
In the following, we list the challenges that we have encountered when creating vocabulary tests for the regional languages Sicilian (LexSIC, Kupisch et al., 2023) and Venetan (LexVEN, Ferin et al., 2023). 3 We divided them into four major themes: (1) shift ecologies, (2) codification, (3) typological proximity, and (4) validation.
Shift ecologies
Many minority languages are spoken in shift ecologies (Grenoble & Osipov, 2023). These are situations of unstable bi- or multilingualism, where speakers, in particular younger ones, do not use their ancestral language but rather speak the majority language; this also applies to the regional languages in Italy. Languages in shift ecologies are dynamic, as language choices, preferences, and proficiency levels change. As a result, there are multiple kinds of variation: regional (dialectal), generational (language-internal change without contact or shift), contact-based (contact with or without shift), and proficiency-based (variation which develops as a result of differing levels of input and use).
Challenge 1: Shifting proficiencies
In shift ecologies, especially speakers of the younger generation are becoming increasingly more inclined to use the majority language. As a result, they might end up having receptive skills in the minority language, while lacking or having limited production skills. Proficiency across individuals can vary substantially because there is no context which obligatorily requires using the minority language: it is not the language of instruction in schools, and there are more speakers who speak the majority language. However, we still want to map these individuals on the proficiency scale of language users, and thus, a test is needed that can be taken at all proficiency levels, including users with only receptive skills. A yes/no task is ideal because it can be taken by users at all proficiency levels and does not require production skills.
Challenge 2: Tolerance to variation
Language users in shift ecologies are exposed to regional, generational, contact-based, and proficiency-based variation. As a consequence, they might be rather tolerant when encountering words that they have never heard before, as long as they are “plausible,” which is exactly the property that pseudowords in a yes/no test have. Therefore, special care needs to be taken when designing pseudowords. In doing so, researchers typically resort to three strategies: phonological manipulation (e.g., Ven. barufare “argue” > *birufare), morphological derivation (Sic. seggia “chair”+ infinitival ending –ari > *seggiari; Ven. tola “table”+–are > *tolare), and free inventions. Phonological manipulation must follow the phonotactic constraints of the target variety. However, subtle phonological manipulation, for example, changing one vowel, might easily result in words that actually exist, or can be imagined to exist, in some dialects of a regional language. Similarly, morphological derivation might result in existing forms that are simply not listed in any dictionary (if dictionaries are available in the first place), or it can result in a form for which a proficient language user who knows the morphological rules of the language can easily infer a meaning. While these caveats also apply when creating tests for standardized languages, users of a non-standardized language may be more inclined to accept words that they have not heard before. Therefore, pseudowords must be piloted with the potential caveats in mind; speakers of all dialect areas should be included.
In our experience, most problematic items, that is, pseudowords that even the most proficient users accept, will be filtered out during pretesting, sometimes because they actually exist (Stage 2, Figure 1). If problematic pseudowords survive pretesting, they can still surface as being problematic during item analysis, specifically through the item discrimination index (or point-biserial correlation) for classical test theory (CTT) approaches, or when using a person-item map in item response theory (IRT) approaches, if sample sizes allow (see validation [Stage 5], Figure 1). The person-item map would reveal that (too) many proficient test-takers accept one and the same pseudoword, because they are among the difficult items, those that everyone accepts incorrectly (false alarms). In summary, for the creation of pseudowords, we recommend a mixed strategy, which includes phonological manipulation, morphological derivation, and free inventions. Generally, highly experienced language users should be less inclined to accept non-existing variants. However, if many highly experienced informants accept one and the same pseudoword, this item is problematic as a pseudoword, as they might have encountered this word or one that is very similar. 4
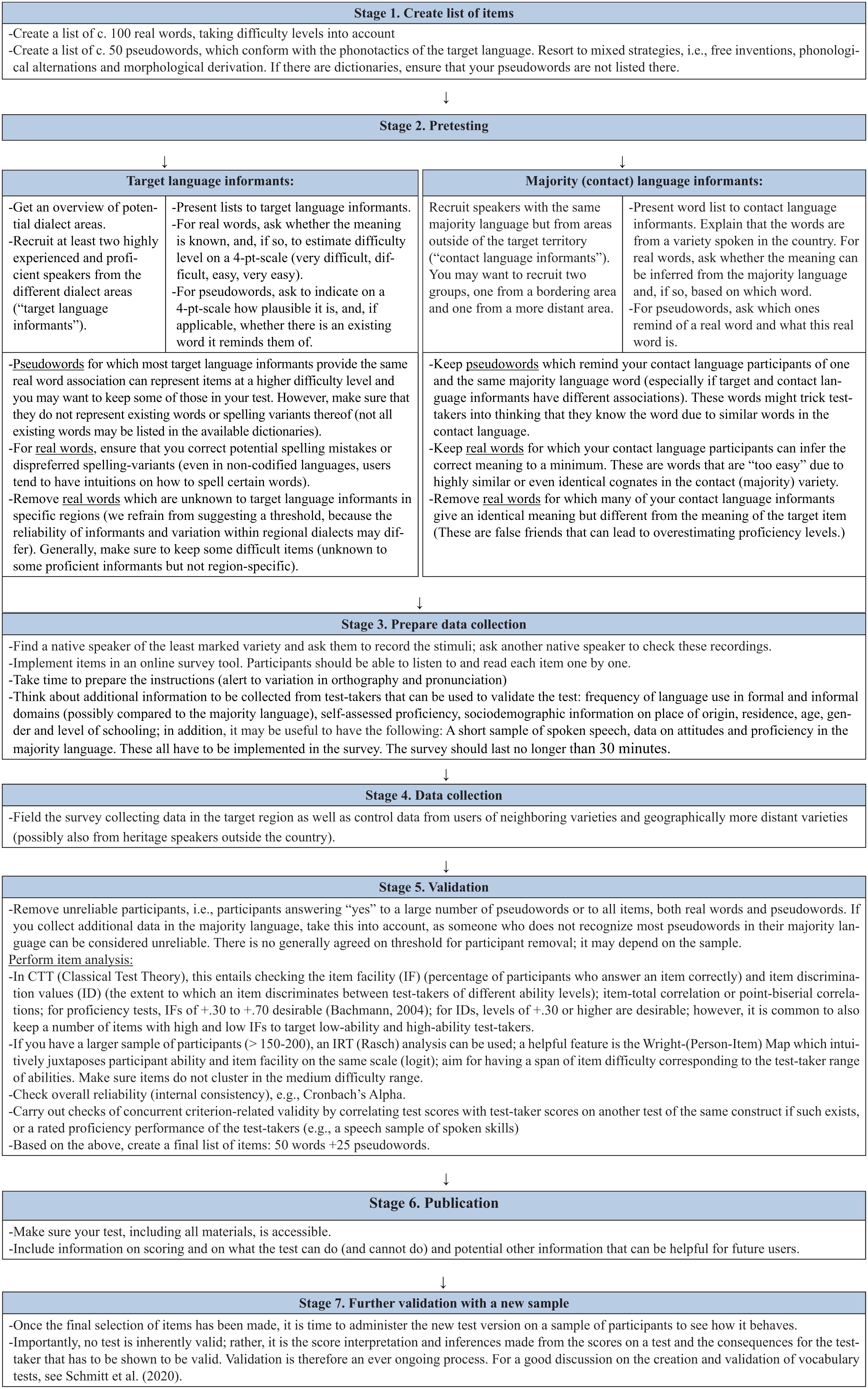
Road map with seven stages for creating a yes/no vocabulary task in a minoritized language.
(Lack of) codification
Codification is understood as the reduction in naturally occurring variation in language. It can include the development of a writing system, developing normative rules for grammar, orthography, and pronunciation and vocabulary as well as the publication of dictionaries and grammar books. Codification precedes standardization, that is, the development of a standard variety of a language. Regional (contested) languages often lack codification.
Challenge 3: No agreed-on norm
We mentioned that minority language users may be overly tolerant because they are used to hearing speakers from neighboring varieties, whose varieties are different while still being (mostly) mutually comprehensible. For example, Sicilian represents a continuum of dialects with no standard grammar or orthography (Cruschina, 2020; Ruffino, 1991). Since developing a separate test for each dialect of a regional language is not feasible, one has to be selected. But which one? Typically, there is one variety that users and/or experts consider to be more neutral and/or that has more users than others (e.g., the Sicilian variety spoken around Palermo). This presents the least problematic choice. Nevertheless, users of other varieties should not be disadvantaged. This challenge can be addressed in Stage 2 (pretesting) by showing the first version of the vocabulary item list to highly experienced informants who represent all dialect areas. For instance, LexVEN was based on pretesting with users from seven provinces that (roughly) map onto four dialect areas (see Ferin et al., 2023, p. 10). Those items that were unknown to speakers from several provinces were discarded. If one variety has too many idiosyncrasies, one may consider excluding this variety entirely. In the creation of LexVEN, we excluded the Belluno variety, which differs substantially from the other Venetan varieties due to geographical isolation and contact with Alpine varieties. Validation (Stage 5) might also reveal that a test is not ideally suited for users from particular geographical areas, as they consistently score lower. For example, LexSIC was created with users from Sicily in mind. Although the Southern parts of Apulia and Southern Calabria are part of the Sicilian continuum (Pellegrini, 1977), the dialects in those regions overlap less in vocabulary, and this was shown by lower test scores for participants from these areas. The decision to exclude certain varieties needs to be openly communicated for potential test users. It is still possible for interested researchers to develop another test version based on the existing one, but tailored to neighboring varieties.
In addition to avoiding region-specific items, test-takers can be alerted to variation during the instructions by emphasizing that some words they will encounter may differ minimally from the ones they know due to different pronunciations across regions. In LexSIC and LexVEN, we added examples of known vocalic differences (Stage 3, Figure 1), and we encouraged test-takers to treat such forms as known forms. Generally, we encourage being up-front about variation rather than pretending that it does not exist.
Challenge 4: Oral proficiency
Regional languages are primarily oral languages, even if some of them have had a past as literary language. For example, in the 12th century, Sicilian became the first modern Italic language to be used as a literary language. However, most speakers today have never written the language, although some spontaneous orthographies are emerging (see below). This means that a vocabulary proficiency test for a regional language should be either entirely oral or bimodal (oral and written). Stimuli should be recorded by a native speaker.
Challenge 5: No standardized orthographies
The absence of standard orthographies is related to the primarily oral proficiencies is the absence of standard orthographies. However, it is possible that minority languages have been codified and have standard orthographies, but that speakers nonetheless decide not to acquire written proficiencies in formal settings, opting instead for the majority language (only) as language of instruction. As to Venetan and Sicilian, both have literary traditions, and there have been initiatives to standardize orthographies. However, it has been common for a long time to use only Italian for any kind of written communication. The situation has changed slightly with social media fostering the use of oral language in written mode, and with spontaneous orthographies under development. As a consequence, some users may not be surprised to see regional languages in writing. However, social media is a relatively new phenomenon, and one cannot expect everyone to engage in it. Given this situation, we expect to see both tolerance and disagreement about spelling in users of regional languages. For example, in the work by Kupisch et al. (2023), we documented a discussion on the spelling of the Sicilian word for “go around” (furriari or firriari), which, according to some informants, was in complementary regional distribution. However, the data we collected did not mirror this complementarity, and we ended up excluding the item (in both variants), because form and distribution were unclear. In short, some users of a regional language may not have reading or writing experience, and users with such experience may be exposed to variation.
One way of tackling this in a proficiency assessment task is to present stimuli in an oral mode. An alternative, which we opted for, is a bimodal version in which test-takers both see and hear the items. We favored a bimodal version due to feedback during piloting, which suggested that the bimodal version makes the task easier, arguably facilitating retrieval from the mental lexicon. 5 As explained above, presentation in written mode requires communication about variation in the instructions for test-takers, ideally accompanied by familiar examples.
Challenge 6: No formal domains of use
Regional languages are in a diglossic situation with the national majority language, and the typical domains of use are informal ones. Therefore, the choice of vocabulary items from academic and formal registers, from where test designers often draw difficult items’, is more restricted. This needs to be compensated for by drawing on other more specialized domains of use, while avoiding words that are unique to geographically isolated varieties. Regional languages may have a richer vocabulary in other domains, for example, agriculture, which can be used instead.
Challenge 7: Lack of (frequency) dictionaries and searchable corpora
A norm-referenced vocabulary proficiency test should balance easy and difficult items to discriminate between test-takers at lower and higher proficiency levels. Typically, frequency level is taken to represent difficulty: frequent items are more likely to be known, thus arguably easier (Milton, 2009), although there is currently some discussion on this (Hashimoto, 2021; Stewart et al., 2022). Therefore, it is customary to ensure that the selected words cover several frequency bands. However, for regional minority languages, there may be no frequency dictionaries or large-scale corpora with search functions by which the relevant frequencies can be established. There are two strategies to overcome this hurdle. One is the translation of existing tests into other languages, knowing that frequency in the existing test items had been controlled for. This strategy comes with the risk that some items may not be culturally relevant. Another possibility is to create items based on intuition and implement a “pretesting stage” to collect judgments by proficient informants. A combined strategy is also possible.
In the case of LexVEN and LexSIC, we created a list of words based on intuitions of what words could be easy or difficult (Stage 1). We pretested the items with users of the language, asking them whether they knew the meaning of the word and to indicate its perceived level of difficulty on a 4-point scale (1 = very easy, 2 = easy, 3 = difficult, and 4 = very difficult). Real verbs that were unknown to many informants were excluded. During validation (Stage 5), we observed significant effects of pre-judgments on real-word accuracy, as verbs pre-judged as “easy” were accepted more frequently. This indicates that pretesting and asking informants to indicate difficulty levels is a valid strategy to tackle Challenge 7. If the informants asked whether perceived difficulty means frequency, we confirmed this, while being aware that frequency is only one dimension in difficulty assessment. Generally, piloting revealed that many language users find it easier and more intuitive to judge difficulty than to judge frequency. Moreover, there are ongoing debates on the relation between frequency and difficulty (see above), and there is evidence of the lack of accurate estimates of word frequencies by users of a language (Alderson, 2007). This suggests that there are advantages in asking users about difficulty rather than frequency.
Challenge 8: Small sample size
Some regional languages are larger than some national languages. According to estimates, Venetan and Sicilian have several million speakers, respectively, which is much more than, for instance, Icelandic and Maltese do. However, while high proficiencies in national languages can be presupposed because the population is exposed to the national language at school and in all official domains, there can be considerable variation in minority language proficiency, since users are never obliged, and seldomly encouraged, to use these languages. Thus, finding participants can be challenging despite high estimates of user numbers, because some users might have low proficiency levels, which results in reluctance to participate and/or difficulties balancing the sample in terms of proficiency levels.
Ideally, a test should go through several validation processes (Stage 7). However, if the number of speakers is too low to allow for several rounds of data collection, we suggest to finalize the test and encourage other researchers to team up for further data collection in the future (see Gyllstad et al., 2025). It will be crucial to agree on the protocol and variables to ensure comparability.
Typological proximity
Challenge 9: Bilingualism with typologically close languages
The minority language for which the test is to be developed might be typologically very close to the majority language spoken in the same area, with much of the vocabulary having cognate status. Although pronunciation and spelling often diverge, some words in the regional language can be fully comprehensible to speakers of the majority language even without any knowledge of the minority language. For example, Venetan maridarse “get married” corresponds to Italian maritarsi; Sicilian curriri “run” corresponds to Italian correre. In addition, there may be words which look like known words, but which have an entirely different meaning, for example, Sicilian viviri “drink” looks like Italian vivere “live”, but Sic. viviri means “drink,” while It. vivere means “live.” These are false friends, and they may seduce test-takers to state (and believe) that they know the meaning of these words, although they do not; in a yes/no test, the test-taker would still be rewarded for giving a correct answer because the task discriminates between yes responses to real words and no responses to pseudowords. Moreover, there may be false friends among the pseudowords. For instance, in LexVEN, we excluded the Venetan pseudoword stramasare, which reminded many highly proficient informants of the Italian word stramazzare “collapse.”
A certain degree of overlap between typologically close languages is natural, simply because the languages have a common ancestor language. At the same time, we need to ensure that the test still discriminates between proficient, experienced language users and test-takers who have never been exposed to the language. Put simply, test-takers without experience in the target language should not obtain high scores. For example, it would be natural for speakers of Italian from the South to correctly guess the meaning of say 20% of a Venetan word list. However, they should not be able to score with 90% accuracy. In the development of conventional vocabulary tests, it has been stressed that frequency is an important parameter. In the development of a vocabulary test for a minority language, an additional parameter is the degree of overlap with the majority language; we can assume that more phonological and orthographic overlap make items “easier.”
Typological proximity can be tackled at several stages when developing the task. Pretesting with informants from the target community (“target language informants”) as well as from contact varieties (“contact language informants”) can help identify those items whose meaning can be correctly guessed based on knowledge of the majority language. We recommend recruiting two groups of majority language users who are not users of the target language: (a) informants from a bordering region and (b) informants from a faraway region (Stage 2). These contact language informants will be asked to indicate for each real word of the preliminary item list whether they can guess the meaning and what the meaning is. Those items for which everyone gives the same meaning are potentially problematic, because their meaning is known even by individuals who have never had any contact with the target language. If there are too many such items, these can be excluded after pretesting (Stage 2) (we recommend to keep a few for reasons of ecological validity). If too few items have been excluded in Stage 2, this will surface in a Person-Item (Wright) map during validation (Stage 5), where easy items will cluster at the bottom and can still be removed before creating the final word list. 6
Validation
Challenge 10: Native speaker and control groups
The development of vocabulary proficiency tests typically involves a group of (L1 monolingual) native speaker controls, representing those who should score at ceiling when performing the task as well as a group of second language (L2) learners, representing all other proficiency ranges. However, “native” speakers of a minority language are a more heterogeneous group than speakers of a national language. Often, they are early bilinguals with varying exposure to the language within and outside the home. They tend to have early and naturalistic exposure, but they are often dominant in the national language, being similar to heritage speakers in this respect. Finding monolingual controls and L2 learners of the language is difficult if not impossible; exposure from birth is no guarantee that users will perform at ceiling. Thus, we cannot work with categories like “L1” and “L2” because they have different meanings in this context. How can we define main test groups and control groups?
In the LexVEN and LexSIC projects, we recruited the main groups from Sicily and Veneto, respectively, the areas where we expected individuals to have most contact with the language. For LexVEN, we included a control group of participants coming from another Northern region (Lombardy), where a different but related regional language is spoken, assuming that they will recognize a fair proportion of the items. Similarly, for LexSIC, one control group included speakers from South Italy outside of Sicily, from Apuglia and Calabria, areas which, despite belonging to the “Sicilian continuum” (Extreme South varieties), do not share all vocabulary. The second control group in both cases was speakers coming from a region that belongs to an entirely different language group: For LexVEN, these were speakers from the South; for LexSIC, these were speakers from the North. 7 These latter control groups are crucial because they can reveal how much vocabulary is understood based on knowledge of Italian and/or another Romance variety, which is distant from the target one. For the sake of illustration, we present in Table 1 the final test scores from the different test groups from Ferin et al. (2023) and Kupisch et al. (2023). In LexSIC, we also included a group of heritage speakers of Sicilian who grew up in Germany.
Scores by group in LexSIC and LexVEN.
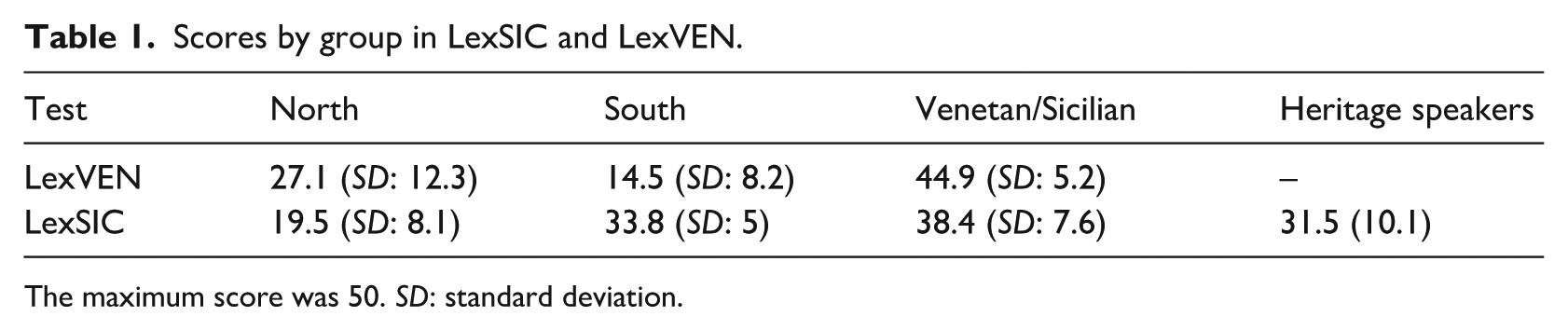
The maximum score was 50. SD: standard deviation.
Challenge 11: Absence of other proficiency tests
Test development often entails the use of other already existing tests of the same constructs to investigate the presence of criterion-related concurrent validity, by establishing how much the test scores correlate (see Section 2 above). However, in the case of regional (contested) languages, comparison with other tests is often impossible because no other tests are available. We therefore validated LexSIC by comparing the total scores to data on self-reported language use and self-reported proficiency. When creating LexVEN, we had, in addition, collected spoken data from users with active speaking skills. These spoken data were rated by another group of highly proficient Venetans. The speech samples from our test-takers were presented along with samples from Italians who had no relation to Venetan whatsoever as well as to samples from speakers from the Venetan region but when speaking Italian. For a sample of 56 test-takers, rated proficiency correlated significantly with the LexVEN scores, confirming that LexVEN scores can be argued to be a valid indicator of Venetan proficiency (Ferin et al., 2023, p. 18), to be used in low-stakes contexts. While proficiency ratings are a reliable way of testing proficiency in the absence of standardized tests, they come with three caveats. First, on a practical level, they require additional steps, that is, the collection of speech samples from test-takers, setting up a rating task, recruitment of another group of highly proficient raters who can judge proficiencies (ideally, balanced by regional origin). This is a luxury that will be impossible to realize with smaller communities than the Venetan-speaking one. Second, not all users of the minority language have production skills, which means only the higher end of the proficiency scale can be included in these ratings.
A road map
In what follows, we summarize the procedures we have explored when creating LexSIC and LexVEN with some adjustments that we think will be useful for the development of future tests with minoritized languages. Preferably, an argument-based validation framework should be used (Kane, 2012; see Ferin et al., 2023, for an example). An assumption is that the steps below are couched in such framework.
FAQs and future directions
Three points of criticism came up repeatedly when we presented LexVEN and LexSIC, namely the focus on verbs, the degree to which test-takers can rely on knowledge of the typologically related majority language, and the question whether it is possible for receptive users of the language to achieve high scores and whether this is a problem for the test.
As to the choice of verb items, for the LexVEN and LexSIC, we followed the DIALANG design and deviated from LexITA (Amenta et al., 2021), which also includes nouns and adjectives. Our main motive for having a test that is maximally comparable to the DIALANG placement test was that it existed in all languages, as we were aiming to use it in a situation with multilingual speakers who have to be tested in several languages. 8 The advantage of verbs is that they are acquired later (at least than nouns) and more difficult to learn (Horst & Meara, 1999); arguably, they are also more central to the clause, as they determine the number and semantic role of their arguments. Moreover, verbs may be less likely than nouns to display diatopic variation, which would hinder comparability across participants in different regions (Challenge 3). 9 This said, we do not think that using adjectives and nouns is generally disadvantageous. On the contrary, it could outbalance the existing constraints concerning register and the strong presence of cognates (Challenges 6 and 9).
As to typological proximity (Challenge 9), in a yes/no test there is no way of preventing that speakers draw on all languages they know when asked about the meaning of a word presented to them. This is in line with language non-selective activation of lexical representations in the mental lexicon (Schwartz & Kroll, 2006). Therefore, it is correct that test-takers might draw on their majority language knowledge when judging items in their minority language. Also, since code-switching is very acceptable for speakers of regional languages, it may be very natural to accept items of the standard language in the minority language. It is known that bilingual speakers draw on all linguistic knowledge at their disposal; this may be facilitated if the languages in contact are typologically close. For example, a native speaker of German will correctly infer the meaning of many Swedish words even if they have never learnt the language. This constitutes a problem for all vocabulary tests and is not specific to regional languages. Nevertheless, we have described procedures during pretesting and initial validation by which the number of such words can be kept to a minimum. Not only real words might be identified due to cognates in a known typologically close language, but also pseudowords might be (falsely) identified because they look like existing words in another language. As to the latter, the formula that takes false alarms into account will distinguish between users who accept false friends and those who correctly reject false friends, and thus ensures that a distinction is made between more proficient test-takers (less tempted to accept pseudowords due to similar words in a typologically close language) and less proficient test-takers (not entirely sure about the existence of all words in the test). In this particular case, we recommend keeping the number of identical cognates to an absolute minimum, or to exclude them entirely.
As to the situations where LexSIC and LexVEN should be used, we recommend to use them in low-stakes situations only, that is, to gauge independent proficiency levels or get insights into vitality rather than any situations where the test score interpretations have far-reaching consequences for educational possibilities, migration, and legal matters.
We hope our ideas will be useful for other such settings, where similar tests will be needed in the future.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.