
Abstract
Aims and Objectives/Purpose/Research Questions:
There is scant literature on second dialect acquisition for both L1 and L2 speakers (Drummond, 2013; Gnevsheva et al., 2022), with no literature on L3 speakers. In this article, we focus on dialect acquisition in multilinguals, in participants’ third or additional language acquired in adulthood. We explore this in the context of Norway, a country with significant dialectal variation and where dialects have relative prestige.
Design/Methodology/Approach:
A translation task and an acceptability judgement task (AJT) were used to assess Polish–English–Norwegian speakers’ production (in the lexicon) and perception (in morphosyntax) of the Tromsø dialect.
Data and Analysis:
We assessed use of dialect forms in the translation task between groups (L1 Norwegian-L2 English and L1 Polish-L2 English-L3 Norwegian) with a linear mixed effects model. We also used Random Forests and a linear mixed effects model to assess dialect use within the L1 Polish group against seventeen sociolinguistic and linguistic variables. Finally, we used a linear mixed effects model to examine AJT responses between groups.
Findings/conclusions:
We find that some participants use the Tromsø dialect in production (albeit variably), and key predictors of this are how much they like the Tromsø dialect and passive language use in Norwegian. Participants do not appear to be sensitive to dialectal differences in morphosyntax.
Significance/Implications:
L3 learners who immigrated as adults can and do use the local dialect, and this use is modulated by social factors. In addition, such learners seem more able to use and exploit their knowledge of dialectal differences at the lexical level.
Keywords
Introduction
Dialect acquisition in non-native speakers of a language is a significantly underexplored area. Understanding this acquisition is vital to understanding the social realities of such speakers. This is interlinked with speaker motivations in their language use, as Ln speakers are more positively evaluated by L1 speakers when they use local dialect forms (Røyneland & Jensen, 2020). Indeed, it is contested as to whether non-native speakers of a language even acquire local dialect features of the region where they are living in the first generation (Fought, 1999; Labov, 2014; Nguyen & Anderson, 2006). Adult learners are generally expected to speak using standard forms available in language learning materials (Husby, 2009). However, recent research suggests that Ln speakers of a language can and do use dialect forms, albeit variably (Drummond, 2013). For example, Gnevsheva et al. (2022) demonstrate that, upon moving to a new place where a different dialect is spoken, L2 speakers are more likely to shift their dialect than L1 speakers.
Where the sociolinguistics of Ln dialect acquisition has been explored, it is primarily in the domain of phonology (Baker, 2008; Drummond, 2013; Sharma, 2005), though there is one study on second dialect acquisition in the lexicon (Gnevsheva et al., 2022). To our knowledge, there is no literature available to date on dialect acquisition in the third/additional language.
In this paper, we examine the acquisition and use of the Tromsø dialect in the domains of lexicon and morphosyntax by L1 Polish L2 English L3 Norwegian speakers living in the Troms area in Northern Norway. We first provide information on the unique dialectal situation in Norway and the Polish Norwegian community. We then discuss the literature surrounding Ln dialect acquisition in light of our research questions. This is followed by a description of our methodology, including participant information, the procedure for the experiment tasks, and statistical analysis techniques. We then share the results for both tasks, and in the discussion, we interpret these both in terms of group comparisons and sociolinguistic variables. This is followed by a brief discussion of study limitations and conclusions regarding dialect use and perception in Ln speakers, how such speakers are different from L1 speakers, and how sociolinguistic variables can play a role.
Dialects in Norway
The Norwegian language is characterised by high dialectal variation. There are four broad dialectal regions of Norway, those being Western Norwegian, Eastern Norwegian, the Trøndelag dialect, and Northern Norwegian, though there is a great deal of within-region variation (Helleland & Papazian, 2005; Kristoffersen, 2000). The sociolinguistic situation with regard to dialect is unique in that non-‘standard’ dialects are rather respected and are generally accepted in the public domain (Hanssen, 2010; Kulbrandstad, 2011; Sætermo & Sollid, 2021; Skjekkeland, 2010). Norwegian dialects are seen as important markers for identity and background, illustrated by the idea that one should not change or accommodate their dialect, for example, upon moving to a different region, because the dialects in Norway are supposed to stay pure (Røyneland, 2017; Sætermo & Sollid, 2021).
The two varieties of Norwegian assessed in this article are the Tromsø dialect, spoken in the Tromsø region of Troms og Finnmark, and the ‘standard’ dialect, Bokmål. It is important to note here that there are differing perspectives regarding whether Norwegian has a ‘standard’ variety. Officially, Norway has two standard Norwegian written varieties (Bokmål and Nynorsk), but no spoken standard variety. However, the eastern variety used in and around the capital, Oslo, has been argued to function as a standard variety (Mæhlum, 2009). Others argue that while this is a variety associated with higher status/prestige, it is not a standard (Sandøy, 2009). Mæhlum (2009) also uses empirical data to suggest that Norwegian dialects are changing in the direction of the eastern Norwegian variety, as part of the dialect levelling process. Sandøy (2009), however, argues that this is only one way of interpreting the findings, and that the term standard language is not suitable for the Norwegian context (Akselberg, 2009). Irrespective of whether the eastern Norwegian variety should be defined as a standard or not, it is the dominating variety in Norway when it comes to the media, and it is close to the dominant standard written variety, Bokmål. This means that Norwegian speakers will widely meet and acquire this variety, and according to Lundquist and Vangsnes (2018), this makes most Norwegians bidialectal.
In addition, the variety of Norwegian learned by adult language learners in the classroom is most often Bokmål (Røyneland & Jensen, 2020). Ln learners therefore typically find it difficult to understand the local speech in the region where they live (IMDi, 2011a), and (at least as beginners with less exposure to language in the surrounding environment) tend to use some version of Bokmål even in spoken language. Adult immigrant learners of Norwegian tend to report that they would like to learn to understand different dialects (IMDi, 2011b). Learners are often informed about dialect differences in Norway but do not receive further training in this regard (van Ommeren, 2010). At the same time, the acquisition and use of the local variety by immigrants is positively evaluated by L1 Norwegian speakers, and indexes integration, and authentic Norwegianness (Røyneland & Jensen, 2020). Indeed, there is a general preference for one’s own accent compared to other varieties of one’s native language, which may be due to increased social relevance of, or greater emotional sensitivity to in-group accents (Bestelmeyer et al., 2015). Polish migrant groups, whose dialects we investigate, may face prejudice based on their Norwegian speaking abilities in legal and institutional contexts. Evidence shows they have experienced worse access to health care services, and apart from some cultural differences in how the patients are treated in Poland and Norway, the language barrier, including understanding of the dialect, is one of the main obstacles for them (Czapka & Sagbakken, 2016).
The current study
In light of the above, we aim to address the following research questions:
1.
2.
3.
Prior to presenting our hypotheses regarding the above questions, it is important to define Ln dialect acquisition. Following Gnevsheva et al. (2022), it can involve learning one second-language dialect in one country (e.g., the United States) and then moving to where another dialect is spoken (e.g., Australia). However, it can also refer to learning or having learned a ‘standard’ dialect prior to or while residing in a place where the standard is not spoken, and thus having exposure to the ‘non-standard’. This was the case in Drummond’s (2013) study, wherein L1 Polish participants had some level of spoken English (learned in Poland) before moving to Manchester. The change investigated is thus dialectal: Drummond assesses the acquisition of a second dialect in a second language, or L2D2. This is the change we investigate in the current study, but in the L3 (L3D2). We assess whether non-native Norwegian speakers living in Tromsø produce and perceive differences between Bokmål, the ‘standard’, and the local Tromsø dialect.
To the best of our knowledge, there have not been any previous L3 dialect acquisition studies. We thus draw on L1 and L2 dialect acquisition studies to hypothesise about our expected results. Following Fought (1999) and Nguyen and Anderson (2006), we may expect that the L1 Polish ethnic group would not use Tromsø dialect forms in production. Their studies indicate that ethnic groups do not typically acquire features of the local dialect (in their L2). Indeed, Labov (2014) finds that first-generation migrants do not tend to adapt to phonological categories in regions where they live, but that the next generation acquires these patterns. As we are assessing first-generation migrants, we may thus expect participants not to use dialect forms in production. However, work by Gnevsheva et al. (2022) and Drummond (2013) suggests that L2 dialect learners can and do produce phonological and lexical items from the second dialect. As these two studies explicitly assess second dialect in a second language, we posit that it may be more likely that our results will be in line with these findings.
Fox and McGory (2007) assess L2 dialect perception in two groups of Japanese speakers living in Alabama and Ohio. They found that participants’ perception of Southern American English (as opposed to Standard American English) did not improve the perception of Southern American English vowels, and both Japanese groups generally performed worse when identifying such vowels. As we are assessing a different domain in our study (syntax as opposed to phonology), we may expect that we might expect sensitivity to dialect forms to be different in syntax in perception in the L3. Kubota et al. (2024) have investigated agreement in the two syntactic features investigated in this paper in native speakers of Norwegian with different exposure to the northern variety (including the Tromsø dialect). They tested speakers that were native to the northern variety and speakers that began being exposed to it later in life. Sensitivity to the two types of agreement violations (not used in standard Norwegian) was tested by offline judgements: a grammaticality judgement similar to the current task, and with an implicit language processing measure (Event-Related Potentials). The grammaticality judgement task revealed strong differences in the judgements in the gender condition, and an overall acceptance of both the grammatical and ungrammatical version of number agreement. The results did not reveal any statistical difference related to the nativeness of the dialect. The findings from the ERPs revealed different patterns between gender and number agreement. The central finding is that native speakers of the northern variety show greater amplitude (i.e., reacting to a violation of structure) for the presence of number agreement, the non-northern group shows the opposite. The authors also checked for effects of prolonged exposure to the northern dialect and found how it influences language processing (i.e., they become more similar to the northern natives with prolonged exposure to the dialect). We predict that the results from our study to be similar to the results of the grammaticality judgement task in Kubota et al. (2024) for the Norwegian group but cannot predict with certainty as to whether L3 dialect learners will perform in the same way that L1 dialect learners do.
In Baker (2008), social factors such as attitude towards Utah (the place of residence) and number of Hispanic friends were found to influence the production of Utah-like vowels in speech in the L2. Sharma (2005) found that phonetic variation in the speech of her Indian American participants was used in identity construction, and that positive attitudes towards the Americanisation of their speech was positively related to use of local phonological features. Gnevsheva et al. (2022) found that the Length of Residency in the first country of residence (the United States) was a negative predictor for the amount of Australian lexical items produced. This study is most similar to the situation studied by Drummond (2013), wherein the local variety is different to the standard, but both are acquired in the same place. Drummond (2013) finds that Length of Residence, having a native speaker partner, and attitude towards Manchester are predictors of production of dialect-like phonological items. We may expect, therefore, that Length of Residency in Tromsø, partner language level and attitudes towards Tromsø dialect may predict dialect use.
Methodology
Participants
We collected data from 18 L1 Polish speakers living in Norway with proficiency in Norwegian and English, and 19 L1 Norwegian Tromsø dialect speakers with proficiency in English. L1 Norwegian participants were required to have grown up in Tromsø and the surrounding area, and the L1 Polish participants were required to have lived in Tromsø for the majority of their time in Norway; the L1 Polish speakers were required to have some proficiency in Norwegian and English, and the Norwegian speakers were required to have some proficiency in English. In alignment with these requirements, we excluded four Norwegian participants and five Polish participants. Thus, we have a total of 13 Polish participants (age range 23–59, mean age = 35.4, nine females) and 15 Norwegian participants (age range 21–71, mean age = 36.7, 11 females). There is a small discrepancy in the age range between Polish and Norwegian participants, but results of a Mann–Whitney U test 1 indicate no significant difference in ages between the groups (W = 95, p = .93). The L1 Polish speakers had lived in Norway for between 1.75 and 16 years (M = 6.5 years). A majority of the Polish group started acquiring Norwegian between 22 and 35 years of age (70%), with a few participants acquiring it above the age of 36 (23%), and one participant between the ages of 15–21 (7%). Both groups represented various socioeconomic backgrounds; notably, the L3 Norwegian speakers were students (5), academics (1), physical workers (2), managers (2), artists (1), worked in trade (1) and retail (1). Participants were recruited with flyers and snowball sampling.
Procedure
The experiment consisted of a total of four tasks. These included a translation task, an acceptability judgement task, a background questionnaire, and language proficiency tests. Participants were required to do these tasks in-person, and the study was carried out in the language lab and in various quiet offices on campus. After arriving, participants were encouraged to sit at the computer and complete the tasks, following slides on Microsoft PowerPoint for instructions. The tasks were displayed to participants on a 12 or 15-inch monitor. For the translation task, the researcher sat with the participant to ensure that the sound recording was working correctly. For the other tasks, the researcher 2 allowed the participant to complete these on their own, while remaining nearby for possible questions.
Translation task
In the translation task, participants had to orally translate sentences into Norwegian, with the explicit instruction that they must translate it into their own dialect (the one that they would use in everyday situations). The sentences were recorded using a Zoom H2n Handy Recorder and an Audio-Technica Omni ATR3350 attachment microphone. Participants had to translate a total of 16 sentences, with four sentences for each feature of interest. The features of interest are lexical items which differ between Tromsø dialect and Bokmål. These are the three Wh-words ka ‘what’, kem ‘who’ and kor ‘where/how’, and the negation ikkje ‘not’ (Table 1). The lexical items diachronically represent phonological changes, but synchronically represent lexical variants available to each participant in their repertoire. Each sentence to be translated was presented on a separate PowerPoint slide, and participants could choose when to continue to the next sentence.
Features of interest.

The example below shows what might be expected in a sentence with a Tromsø dialect speaker (1) and a speaker of a variety close to Bokmål (2).
Hvor gammel er du? How old are you ‘How old are you?’
The Polish group translated the sentences from Polish, whereas the Norwegian group translated the sentences from English. Polish participants translated from their L1 due to an expectation of varying levels of L2 English proficiency (which was borne out – participant proficiency in English varied from A2 to C2 level on the Common European Framework of Reference for Languages). While this choice may affect possible cross-linguistic influence from the different translation language in terms of possible syntactic and phonological choices (e.g., use of Hva er navnet ditt ‘what is your name’, lit. what is your name from English, as opposed to Hva heter du ‘what is your name’, lit. what are you called), it should not influence the features of interest (i.e.,
Acceptability judgement task
The Acceptability Judgement Task (AJT) followed the translation task. In this task, we tested whether L1 Polish participants were sensitive to syntactic differences between Bokmål and the Tromsø dialect. Two types of grammatical agreement were thus tested: noun-adjective gender agreement in the neuter gender, and noun-adjective number agreement. Both the standard and Tromsø dialect have gender agreement, whereas only the standard has number agreement (Table 2). Our prediction is that if the Polish target group has a heightened sensibility to the dialectal variant, they should accept number agreement violations more than they accept gender agreement violations. Thus, we refer to the number agreement condition as critical, and the gender-agreement condition as the control condition (as we expect to find a more pronounced difference between grammatical and ungrammatical trials).
Overview of properties in the standard and the dialect.

Each trial consisted of a short contextualising and an aural sentence. The contextualising sentence was written in Bokmål (Figure 1) because this is the standard written language, and Norwegian speakers in Northern Norway are used to seeing written Bokmål in non-private scenarios (e.g., on advertisements, on the television; NRK, 2007). The test sentence was spoken in the Tromsø dialect, recorded by a native Tromsø dialect speaker in a recording facility. along with a short animation matching the content of the sentence (Figure 2). The participants were asked to judge the sentences which they heard according to whether a Tromsø dialect speaker would say them (i.e., ‘an acceptable sentence is one that you would say (if you speak the Tromsø dialect) or that you would hear others say in Tromsø dialect’). Participants judged the sentences on a typical Likert-type scale (1–7). The instructions in the AJT were given in Norwegian, and the experiment was built in Gorilla (Anwyl-Irvine et al., 2020) The participants were required to judge a sentence that they
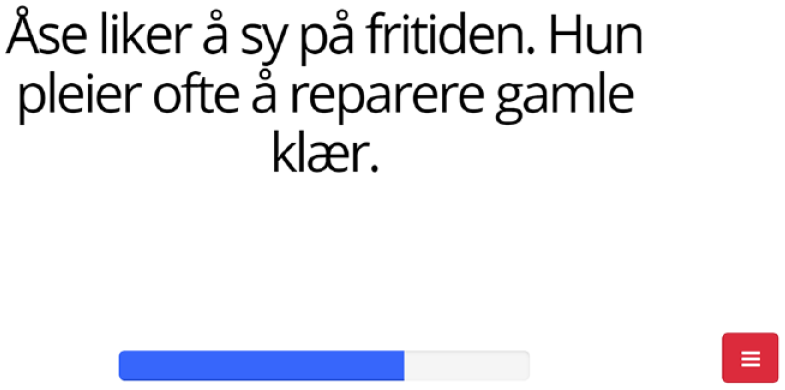
Contextualising sentence.

Screen shown when spoken sentence is heard.
Each participant heard a total of 36 test sentences each, including 12 critical sentences, 12 controls, and 12 fillers total (six in article condition, six in reflexive possessive condition). Six of the sentences in each group were grammatical, and six were ungrammatical (except for the critical condition in which both variants are grammatical depending on the dialect. However, since we are checking for sensitivity to the dialect, we refer to the variant without number agreement as the grammatical condition [in line with Tromsø dialect], and the variant with number agreement as ungrammatical [in line with Bokmål]). The sentences were randomised. Participants were randomly assigned to one of the two lists. The critical conditions for this experiment were adverb-noun number agreement and adverb-noun gender agreement. In Bokmål, there must be adverb-noun agreement in terms of number marking, as in (3). However, in the Tromsø dialect, adverbs and nouns do not agree in terms of number marking (4). In this critical condition, the ‘ungrammatical’ option is that which is grammatical in Bokmål:
(3) Åse misliker at gjest- Åse dislikes that guest-DEF.PL are rude-PL (4) Åse mislike at gjest- Åse dislikes that guest-DEF.PL are rude-Ø ‘Åse dislikes that the guests are rude’.
The control condition was adverb-noun gender agreement. In both Tromsø and Bokmål, the adjective and the noun must have gender agreement (5). Thus, if participants did not correctly give a low score to sentences where the adjective and noun do not have gender agreement (6), we may expect that their proficiency is too low to detect the difference in the critical condition:
(5) Ole fortalte at utested-
Ole said that nightclub-DEF.N was cool-N (6) *Ole fortalte at utested- Ole said that nightclub-DEF.N was cool-M/F ‘Ole said that the nightclub was cool’.
The two filler conditions were definite articles and reflexive possessives. For articles, in the grammatical condition, articles were included in the sentences, and in the ungrammatical condition, articles were not present. For reflexive possessives, in the grammatical condition, reflexive possessives were used, whereas in the ungrammatical condition, possessives were used. These conditions are laid out in Table 3.
Features tested in AJT.

Background questionnaire
The background questionnaire consisted of 26 questions regarding both typical background variables such as age, gender, and native language, in addition to a range of sociodemographic questions. These questions were created based on the variables which Drummond (2013) and Gnevsheva et al. (2022) tested in their studies on L2D2. It included questions regarding frequency of use of each language, length of residency in Norway, how one learned Norwegian (formally in the classroom or naturalistically), and the language one’s partner speaks. A full list of the questions is available in Supplementary Materials 3.
Language proficiency
The final tasks in the experiment were two language proficiency tests. To assess English proficiency, we administered the Cambridge English Proficiency Test. For Norwegian, we adapted a proficiency test from Language Trainers (2015). This adaptation allowed us to test proficiency up to a C1 level for Norwegian. Polish participants were required to do both tests, and Norwegian participants were required to do the English test only.
Statistical analysis
Task 1: translation task
Prior to creating a model, we used the MICE package (van Buuren & Groothuis-Oudshoorn, 2011) to impute the few missing values where participant responses were not discernible from the recordings. To test the use of dialect on the lexical level across participant groups, we fitted a logistic mixed model (estimated using ML and BOBYQA optimizer) to predict Dialect with Word and SG (formula: Dialect ~ Word * SG) using the lmer package (Bates et al., 2023). The model included Participant (PID) as random effect (formula: ~1| PID). Standardised parameters were obtained by fitting the model on a standardised version of the dataset. 95% confidence intervals (CIs) and p-values were computed using a Wald z-distribution approximation. The variables were sum-coded, as there is no clear reference level. Post hoc pairwise analyses were conducted to assess the differences between groups for each word using the emmeans package (Lenth et al., 2023).
We then aimed to investigate which social factors could predict dialect use in the L1 Polish group. There are 20 independent variables in our dataset. Datasets like ours with many background variables are typical for sociolinguistic studies and present a challenge for statistical analysis. The presence of many predictors and more variables than observations (‘small n large p’) can lead typical generalised linear mixed models to suffer from overfitting, that is, becoming overly complex with too many predictors relative to observations. Indeed, as there are 15 sociolinguistic variables, and the number of datapoints per participant is small, the dataset is inadequate to fit a regression model. In addition to this, background variables in such studies are often overlapping (Mitrofanova et al., 2018). For example, the proportion of use of Polish in speaking and writing is negatively correlated with the proportion of use of Norwegian in speaking and writing.
To address these constraints, we first ran a random forests analysis (Breiman, 2001). A random forests analysis is a non-parametric non-linear statistical method wherein large ‘forests’ of conditional inference trees are created to detect whether a predictor is a significant predictor of the response (see Tagliamonte & Baayen, 2012, pp. 159–160, also Mitrofanova et al., 2018, p. 14). Random forests are able to provide information about the importance of both factorial and continuous predictors, and deal well with multicollinearity (Tagliamonte & Baayen, 2012; Tomaschek et al., 2018). They are appropriate for naturalistic, unbalanced data with complex interactions, and are applicable to problems with many variables (including those with more variables than observations). Tagliamonte and Baayen (2012, p. 135) suggest that random forests is a useful tool which can both help overcome the limitations of mixed effects models, while also complementing and guiding the selection of predictors for linear modelling. In our analysis, we used the party package to examine the importance of our predictors using a conditional permutation scheme (Hothorn et al., 2006; Strobl et al., 2008), which is important for taking collinearity into account.
However, there are limitations to random forests, including the inability to separate fixed and random effects, and the potential for confusion in interpreting main effects and interactions (Strobl et al., 2009). We thus additionally run a linear mixed effects model with the three most important variables from the random forests analysis. We selected the three most important variables because the dataset is too small (‘small n large p) to include all of the predictors and models will not converge. Using a linear mixed effects model allows us to assess the significance of the variables, check whether there is a positive or negative correlation, and to include random effects.
In our random forests model, we include seventeen linguistic and sociolinguistic variables, and three variables representing random effects which are participant (PID), Word, and Sentence. We then evaluated the variable importance. We selected the three most important variables and created a generalised linear mixed effects model. We also included the random effect of participant in this model. The full code is available on OSF.
Task 2: acceptability judgement task
To test dialect perception on the morphosyntactic level across participant groups, we fitted a cumulative link mixed model (fitted with Laplace approximation) to predict Response (on a 1–7 Likert-type scale) with Group and Condition (formula: Response ~ Group*Condition). The model included PID and Image as random effects (formula: ~(1|ID_code) + (1|Image)). We used the emmeans package to calculate pairwise comparisons between Groups for each condition.
Results
Task 1: translation task
To assess whether the L1 Polish speakers used the dialect forms differently than the L1 Tromsø dialect speakers, we fitted a linear mixed effects model. The model’s total explanatory power is substantial (conditional R2 = 0.95) and the part related to the fixed effects alone (marginal R2) is of 0.52. Post hoc pairwise analyses revealed significant differences between the groups for ka (p = .0053), kem (p = .0071) and kor (p = .0047), but not for ikkje (p = .0880; see Appendix 1). The differences between the groups in terms of dialect choices are visible in Figure 3, where 1.00 represents Bokmål and 2.00 represents Tromsø dialect use on the y axis. There were 112 observations per level in Word (ikkje, ka, kem, kor), and 240 observations in the Norwegian level and 208 observations in the Polish level for Group (n = 448).
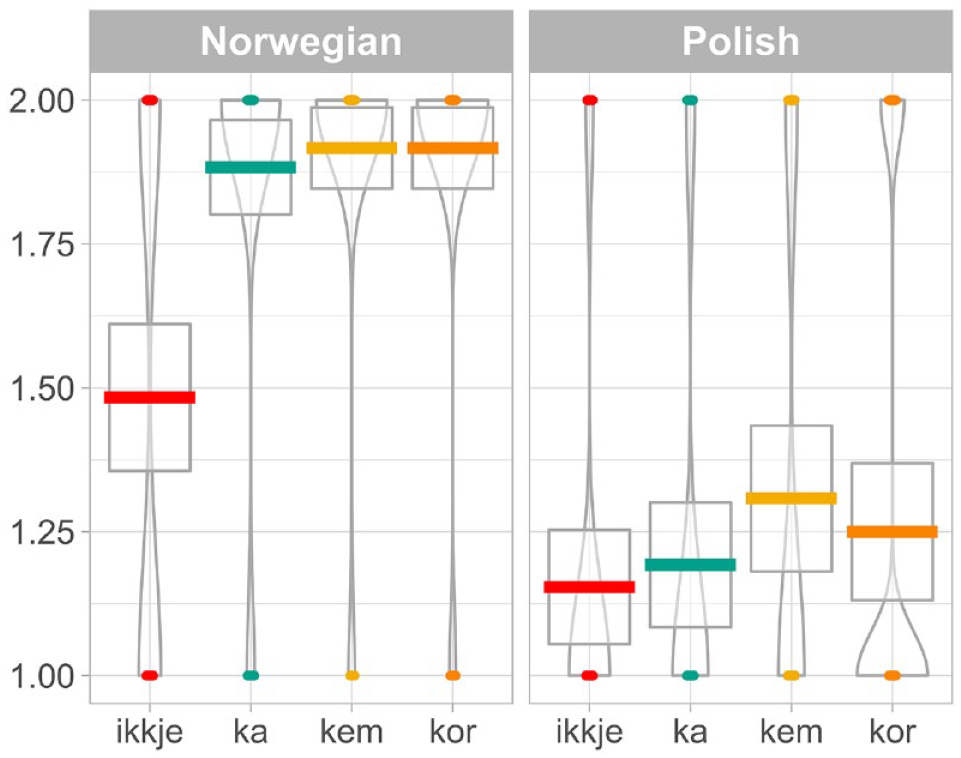
Use of dialect item between Norwegian and Polish group, n = 448.
Individual speakers
The majority of the Norwegian group used the Tromsø dialect form for ka, kem, and kor – however, several did not use ikkje (including GM7215OR, HA5809AR, JRM6413UG, KH5216OH, PS4807NG, and SL6401AR). A few participants in the Norwegian group used a combination of forms, including JRM6431UG for ka, kem, KH5216OH for ka, kem, and SL6401AR for ka (Figure 4). Most participants in the Polish group did not use dialect forms (with a score of 1.0). However, there are several participants who use a combination of Bokmål and Tromsø dialect (AK6923IC, DD6822AG, JM5321AR, KJ6814OA, KK6310OA, LF3524AL, WL3275AC; Figure 5).
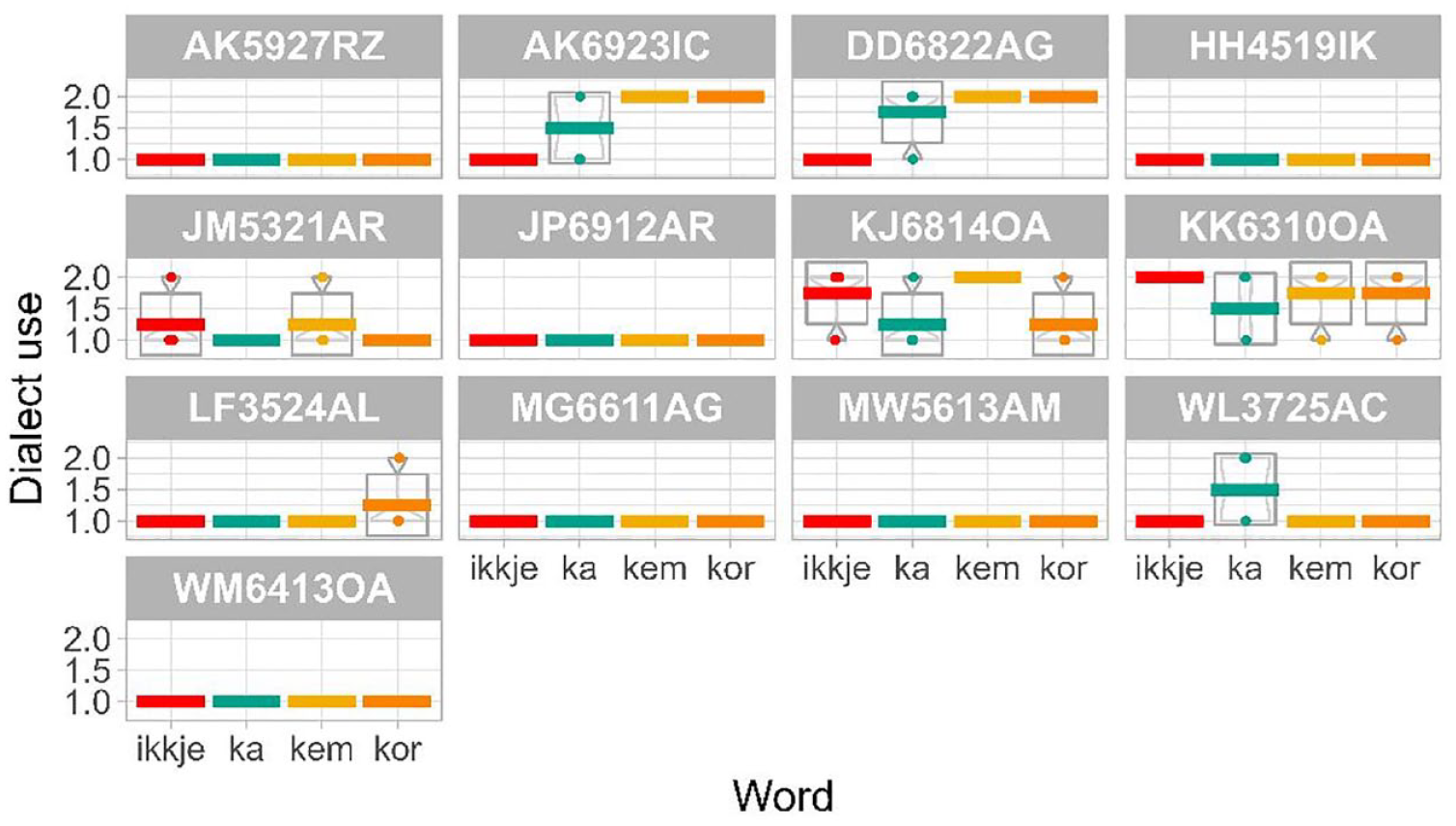
Dialect use by participant, Polish group.
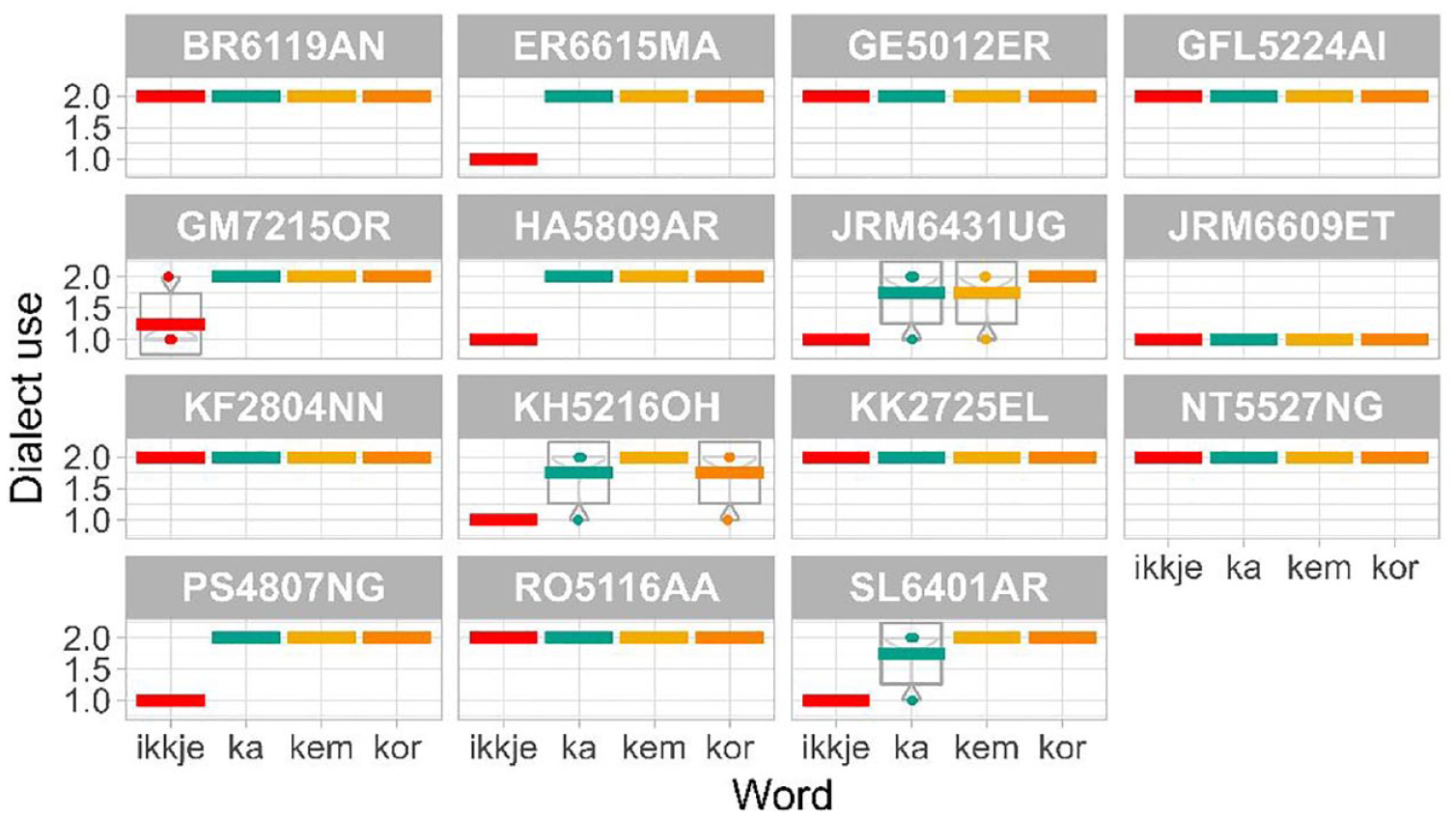
Dialect use by participant, Norwegian group.
Sociolinguistic variable importance
One of the research questions we endeavour to answer in this study is whether L3D2 dialect use can be predicted by sociolinguistic variables. To assess this, we applied a random forests analysis to the L1 Polish dataset. We included seventeen sociolinguistic and linguistic independent variables which were either already numeric or coded to become numeric. These independent variables are listed and explained in Supplementary Materials 1.
Descriptive statistics regarding each of the sociolinguistic variables are given in Table 4. They are given in the numerical form that they were coded into for the purposes of the random forests analysis (e.g., the mean age of acquisition is not 6.15, but rather 6.15 out of a 7-point scale. The scale is viewable in question 5 of Supplementary Materials 3).
Descriptive statistics for independent variables.
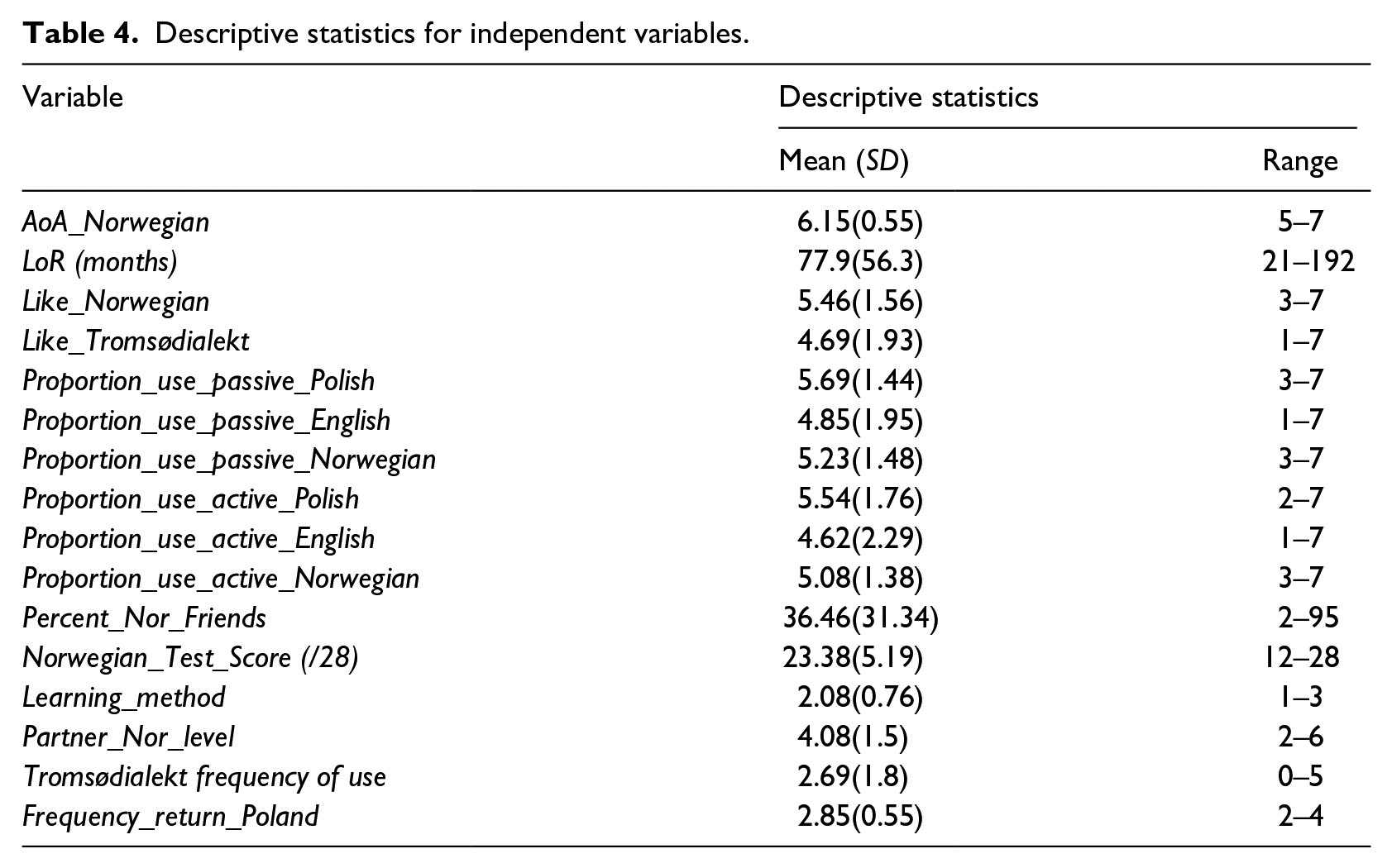
In addition to this, we included three more independent variables: participant identification number (PID), Word, and Sentence. These variables are essentially random effects. Random effects cannot be distinguished from fixed effects in the structure of a random forest model, but their relative importance can be assessed.
According to the model, the most important variable for dialect use is PID (Participant) (Figure 6). This is to be expected in linguistic research, as it is typical for significant variability to be tied to the effect of individual participants (Tagliamonte & Baayen, 2012). The next most important predictor is the proportion of passive language use in Norwegian, followed by whether participants like the Tromsø dialect. How often the Tromsø dialect is used, percentage of Norwegian friends, length of residency in Norway, Word (ka, kem, kor or ikkje – see Table 1) and frequency of returning to Poland are lower-level predictors. Proportion of passive language use in Polish and English, proportion of active language use in English, the Norwegian test score, whether participants like the Norwegian language, learning method, proportion of active Norwegian language use, age and partner Norwegian level are ranked the lowest in terms of variables with predictive power. Proportion of active language use in Polish, the age of acquisition of Norwegian and sentence are all not significant predictors of dialect use.
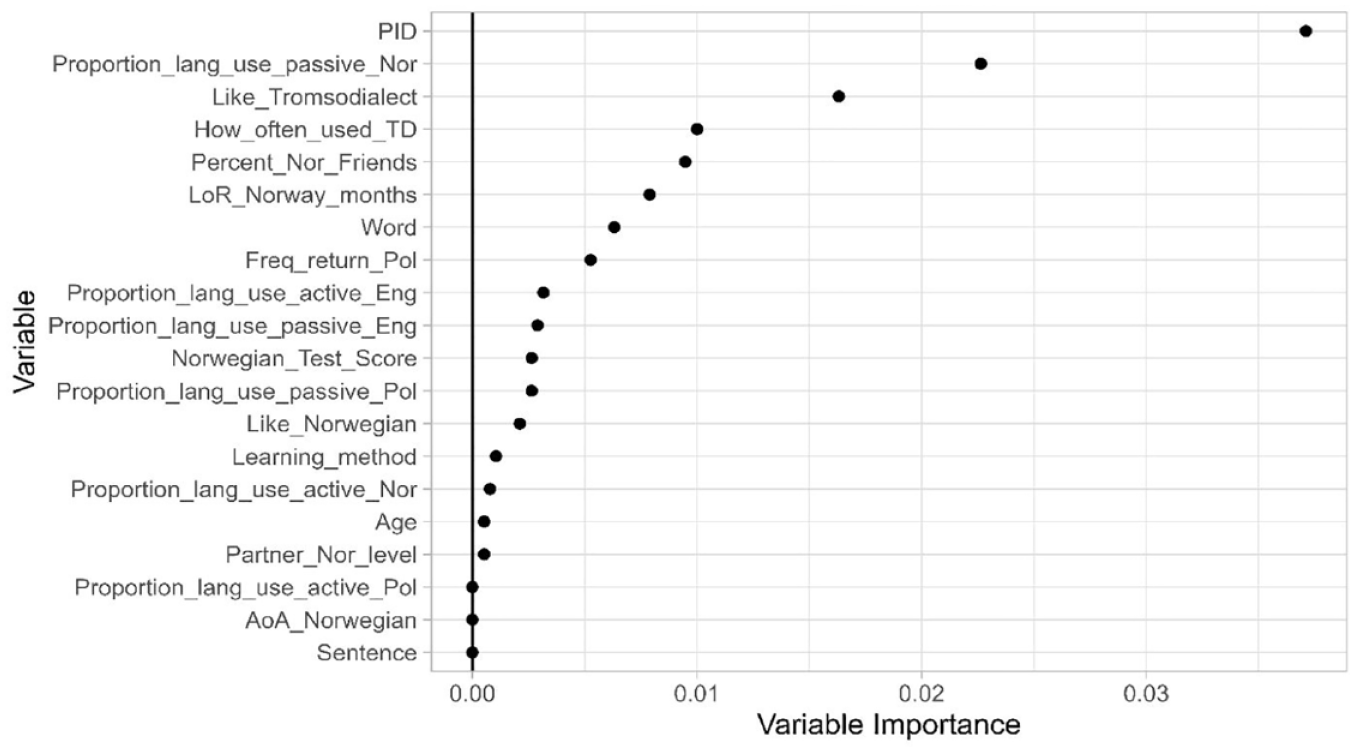
Conditional permutation variable importance for the random forest with all predictors for use of dialect forms in the translation task.
To assess the significance and direction of the most important effects and include a random effects structure, we ran a mixed effects logistic regression model. We included Like_Tromsodialect and Proportion_lang_use_passive_Nor as fixed effects and PID as a random effect (Appendix 2). The model’s total explanatory power is substantial (conditional R2 = 0.74) and the part related to the fixed effects alone (marginal R2) is of 0.71. The model’s intercept, corresponding to Like_Tromsodialect = 0 and Proportion_lang_use_passive_Nor = 0, is at -11.29 (95% CI [-16.17, -6.40], p < .001). Within this model, the effect of Like_Tromsodialect is statistically significant and positive (beta = 0.94, 95% CI [0.37, 1.50], p = 0.001; Std. beta = 1.74, 95% CI [0.69, 2.79]), the effect of Proportion lang use passive Nor is statistically significant and positive (beta = 1.18, 95% CI [0.18, 2.18], p = .021; Std. beta = 1.68, 95% CI [0.25, 3.11]). Standardised parameters were obtained by fitting the model on a standardised version of the dataset. 95% CIs and p-values were computed using a Wald z-distribution approximation. The relationships between the relevant variables and dialect use are apparent in Figures 7 and 8.
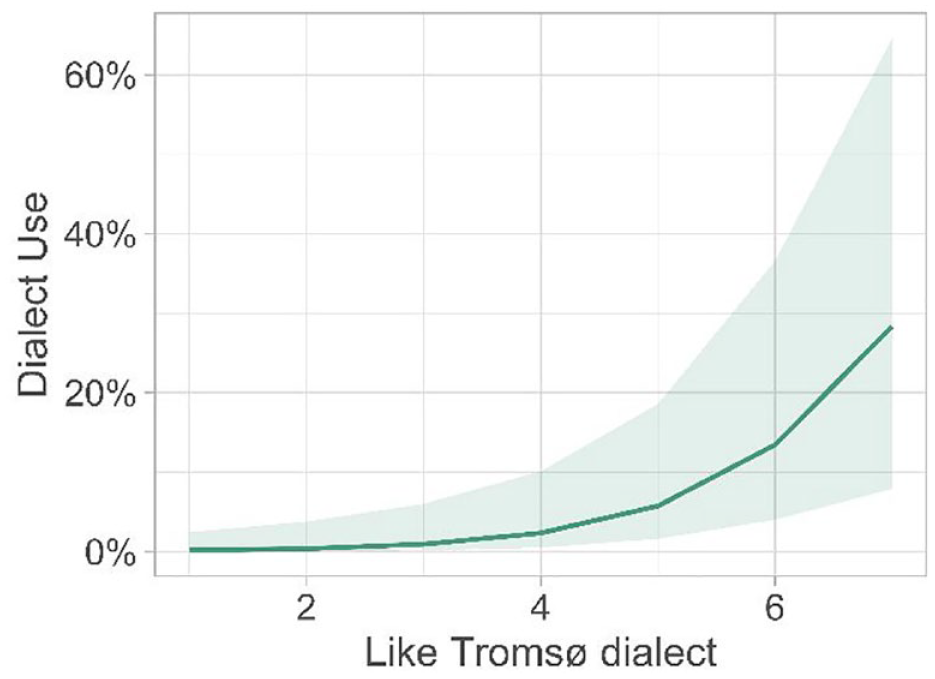
Predicted probability of dialect use by like Tromsø dialect.
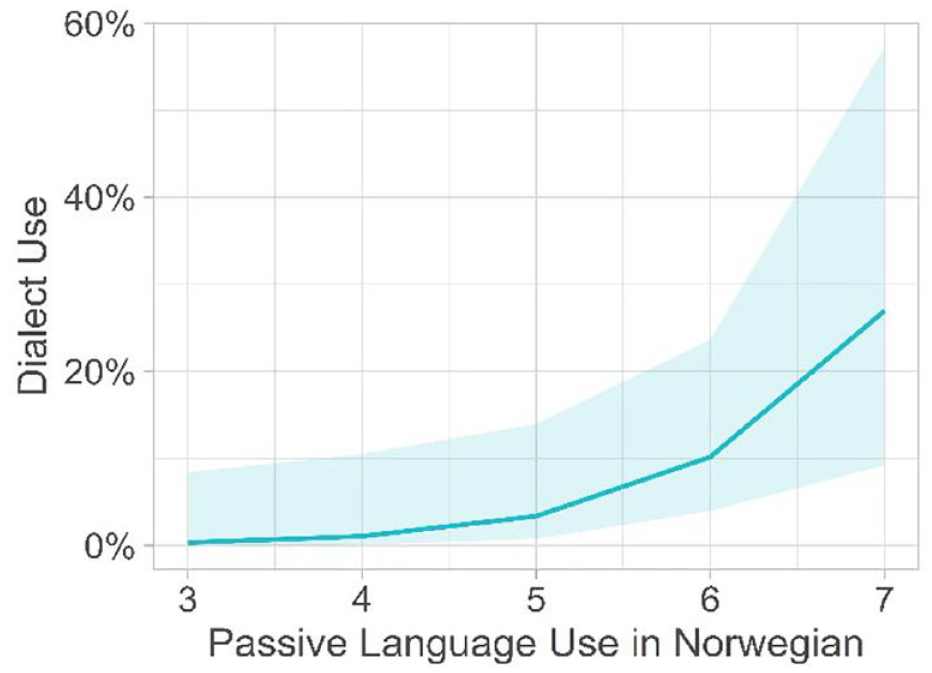
Predicted probability of dialect use by proportion of passive language use in Norwegian.
Task 2: acceptability judgement task
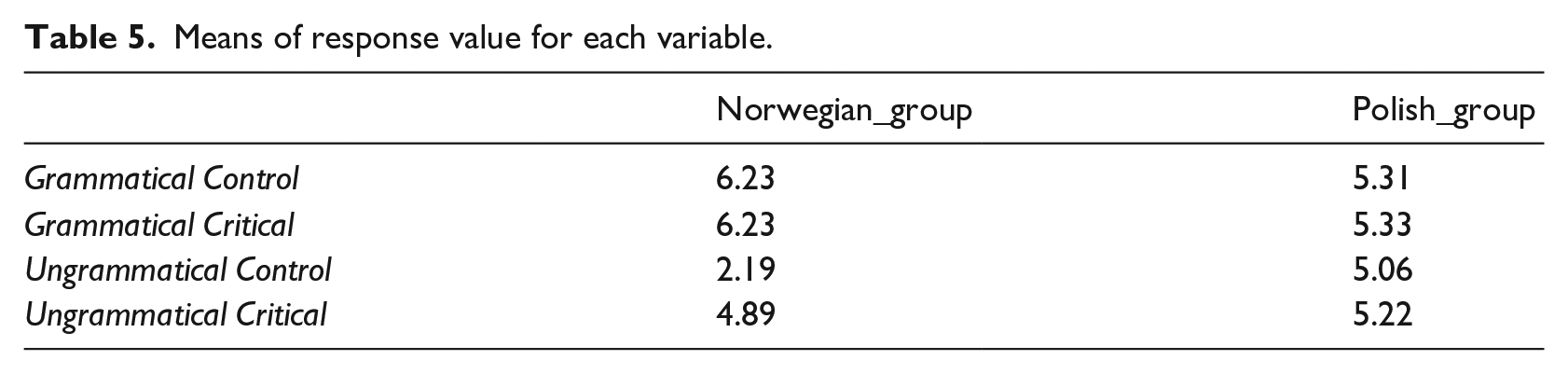
To investigate how L1 Norwegian and L1 Polish speakers respond to each condition, we fitted a linear mixed effects model (Appendix 3). The model’s total explanatory power is moderate (conditional R2 = 0.522), and the part related to fixed effects alone (marginal R2) is of 0.347. In terms of pairwise comparisons (Appendix 4), the difference between the Polish and Norwegian groups was significant for grammatical control (p = .0079), ungrammatical control (p ⩽ .0001) and grammatical critical (p = .0066). There was no significant difference for ungrammatical critical (p = .1567). These differences are visualised in Figure 9. There were 180 observations per condition (Grammatical Control, Grammatical Critical, Ungrammatical Control, Ungrammatical Critical), 432 observations in the Norwegian group and 288 observations in the Polish group (n = 720). The response value mean for each group and condition are given in Table 5.
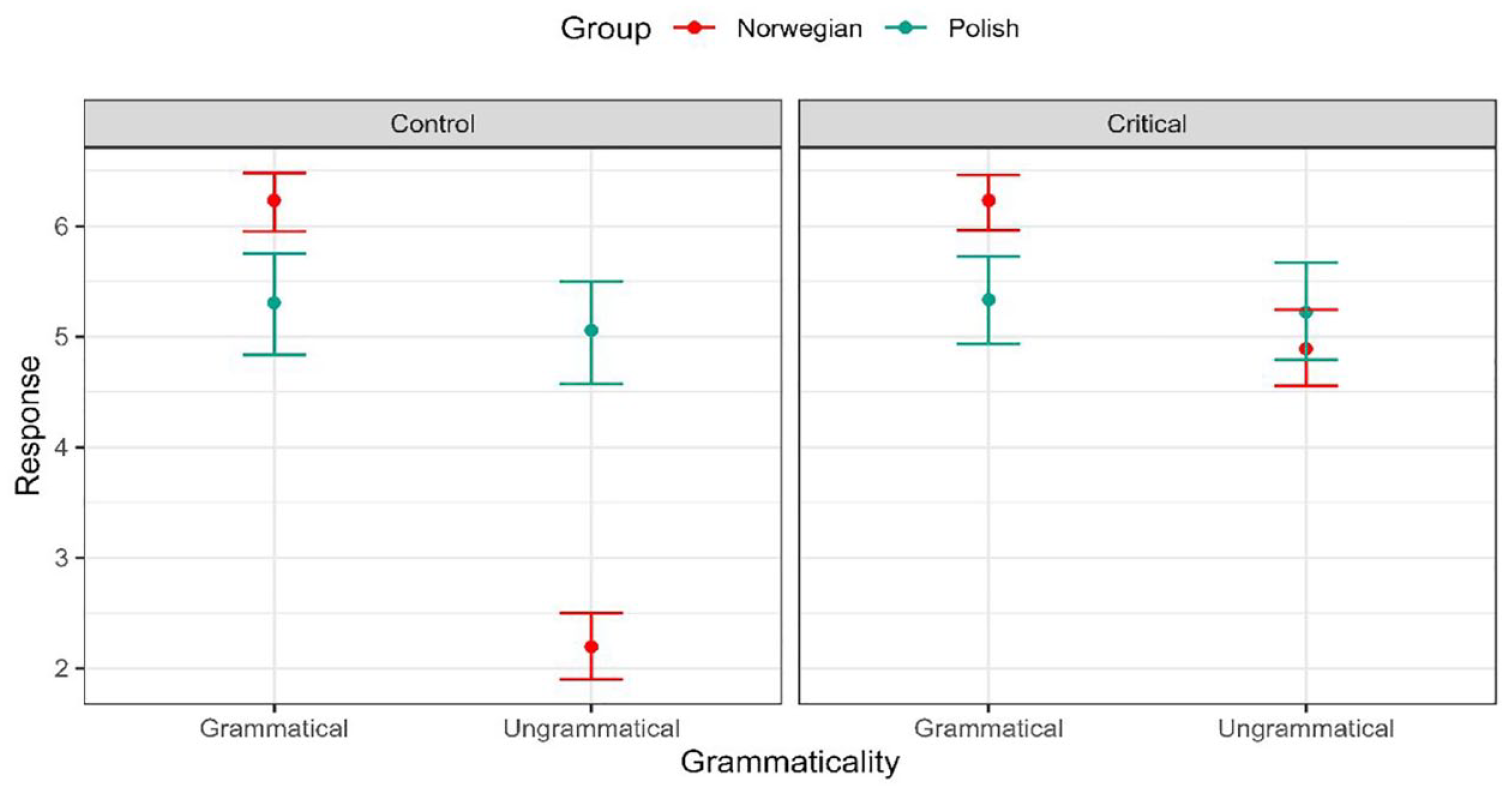
AJT task results across groups, n = 720.
Means of response value for each variable.
Here, the control condition refers to grammatical gender agreement, wherein the ‘grammatical’ condition is grammatical in both dialects, and ‘ungrammatical’ is not. The critical condition refers to number agreement, wherein the ‘grammatical’ condition is grammatical in the Tromsø dialect only, and ‘ungrammatical’ is grammatical in Bokmål only. While there are differences in performance between the two groups on three of the conditions, it is important to note that this appears to be led by the Norwegian group. There are no significant differences in performance between conditions for the Polish group (see Appendix 5). They are sensitive to neither the differences in syntax between dialects (critical) nor adjectival gender (control).
Individual speaker comparison
In the Norwegian group, an analysis of the individual participants shows that, for the most part, each individual follows the pattern in Figure 9 (see Figure 10). They are generally quite accepting of the grammatical control condition and the grammatical critical condition. They tend to reject the ungrammatical control condition (though with some variance), and vary more considerably on the ungrammatical critical condition, that is, the one in which the sentence would be acceptable in Bokmål. Overall, this pattern sets expectations for how native Tromsø dialect speakers behave in this experiment.
Unlike in the lexicon task, none of the individual Polish participants follow a pattern similar to what we would expect of L1 Tromsø dialect speakers (Figure 11). Most of the participants appear to err on the side of weak acceptance. AK5927RZ and DD6822AG are different here, but their performance does not resemble the L1 Tromsø dialect speakers. AK5927RZ rejects many of the grammatical control sentences, and DD6822AG rejects most of the grammatical critical sentences.
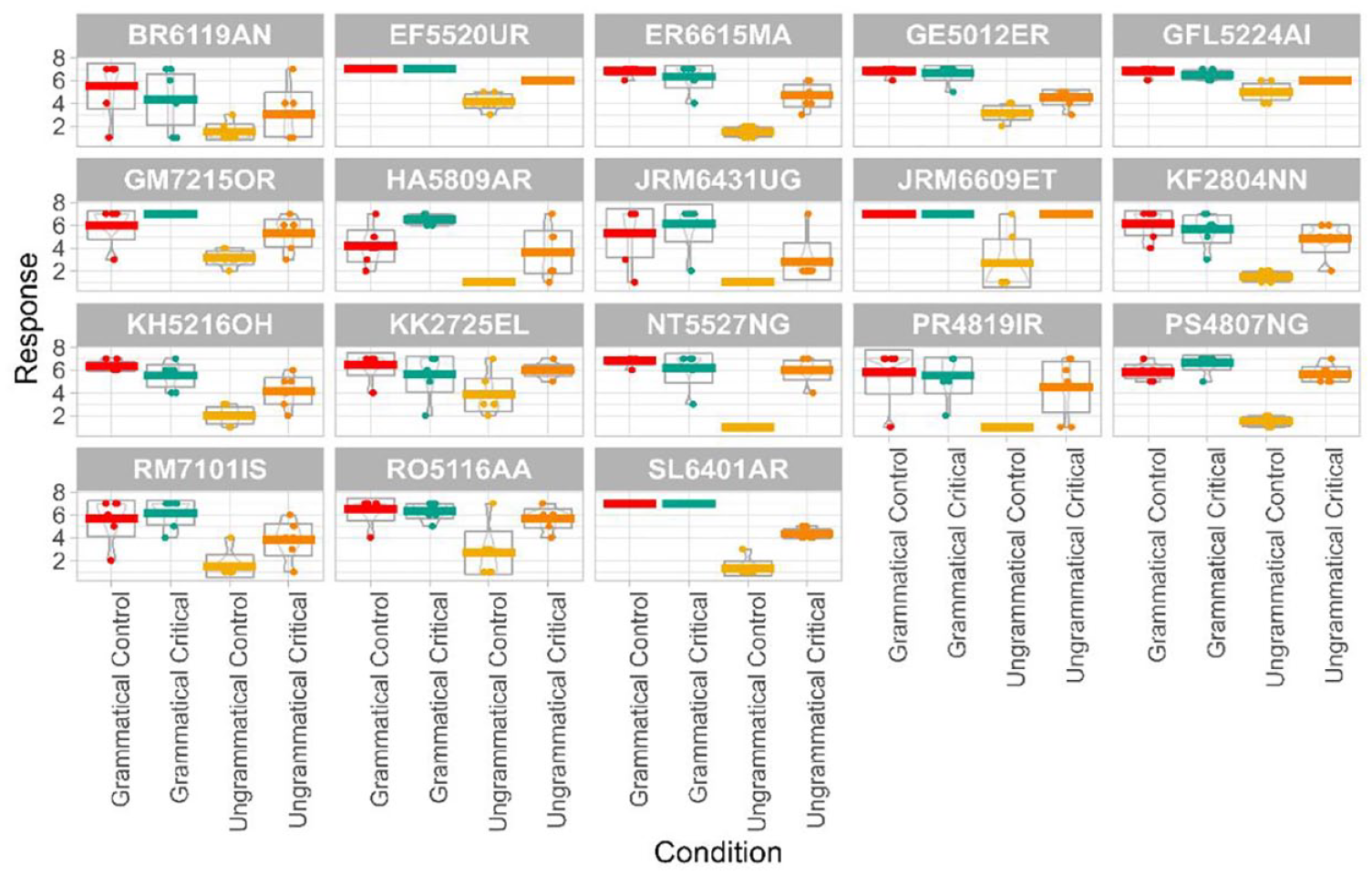
AJT task scores per participant, Norwegian group.
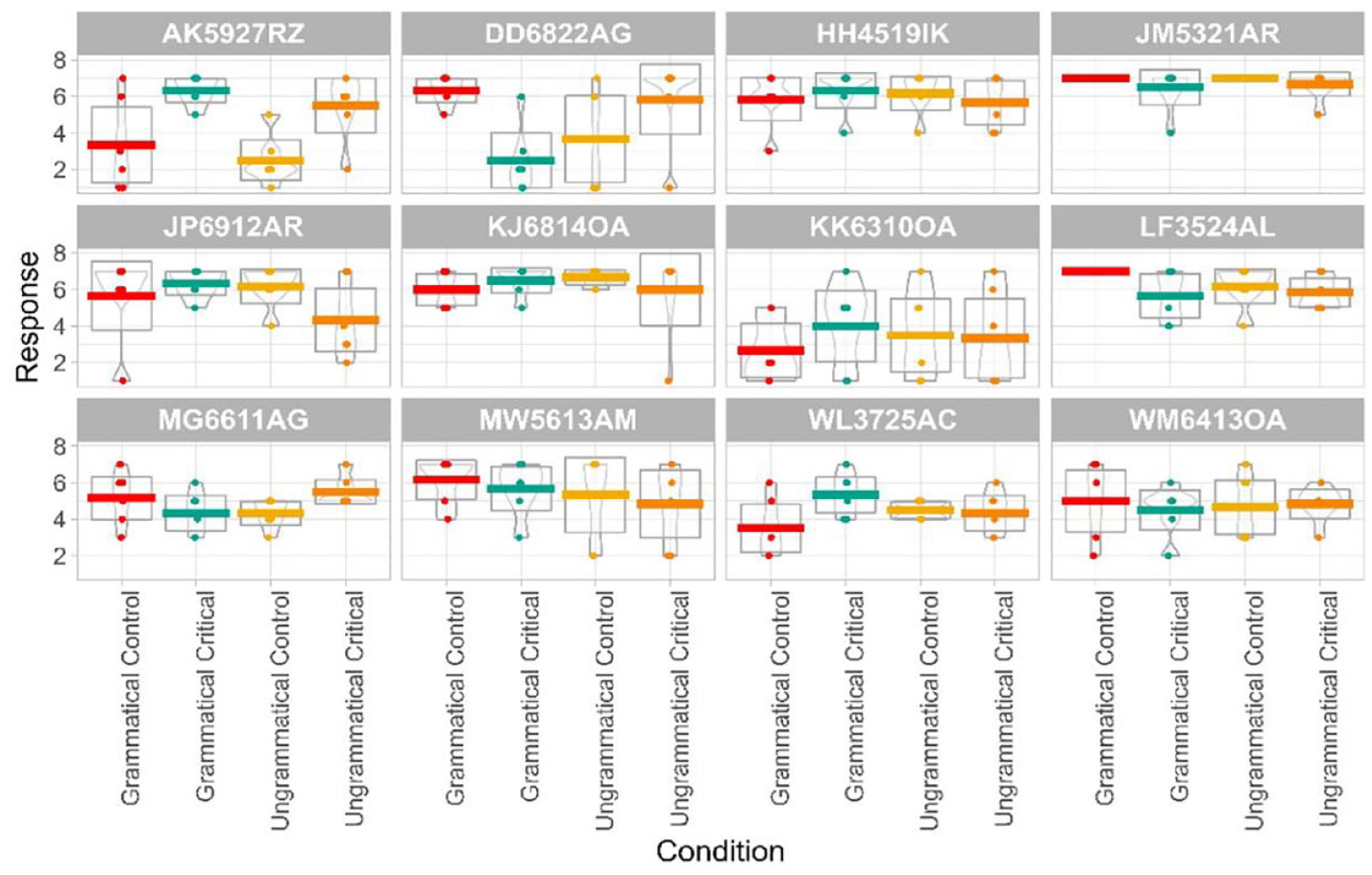
AJT task scores per participant, Polish group.
Discussion
In this study, we assess whether Polish–English–Norwegian speakers living in Tromsø are sensitive to lexical and morphosyntactic features of the Tromsø dialect in production and perception. We analyse whether the L3 Norwegian speakers’ performance differs from L1 Tromsø dialect speakers. We then examine whether participant behaviour in terms of L3 dialect use and perception differs based on sociolinguistic and linguistic variables.
Dialect use in the lexicon
The Norwegian group provide a baseline for how we can expect native speakers of the Tromsø dialect to perform. We can see here that there is a significant difference between how the Norwegian and Polish groups behave for the words ka, kem, and kor. The Norwegian group use the dialect form of these words significantly more than the Polish group. Therefore, as a whole, at the level of the lexicon, the Polish group do not seem to be using the Tromsø dialect lexical items in the same way as the L1 Tromsø dialect speakers. This is not unexpected, as adult Norwegian learners are typically taught Bokmål in the classroom (Røyneland & Jensen, 2020). In addition, language learning apps such as Duolingo (2024) teach Bokmål.
The lack of difference between the groups for ikkje appears to be driven by the Norwegian group rather than the Polish group. This is not unexpected, as ikkje is a variably used form which has decreased in popularity in the Tromsø dialect and is mostly used in surrounding areas and/or in older generations (Fiva, 2016; Nesse & Sollid, 2010; Sollid, 2019). Indeed, we see that the mean age of L1 Norwegian ikkje users is higher than that of
When assessed individually, it is clear that some in the Polish group use the Tromsø dialect forms, albeit variably. We used a Random Forests model and a generalized linear mixed model (GLMM) to determine possible sociolinguistic factors behind the use of Tromsø dialect forms for some speakers. The most important variable in predicting dialect use in the lexicon is Participant ID, or individual variation. This is ranked as most important in the Random Forests model, and it is captured in the random effects component of the linear mixed effects model. Following this, proportion of passive language use in Norwegian and whether participants like the Tromsø dialect are both important factors in the random forests model and are statistically significant in the linear mixed effects model.
A larger proportion of passive language use in Norwegian for those living in Tromsø would indicate more time spent listening to the Tromsø dialect being spoken, thus leading to a greater awareness of dialect forms. From this, we might propose that naturalistic learning is important for development of the Tromsø dialect, as hearing it often in everyday use is an important predictor of being a dialect user. Proportion of daily passive Norwegian language use could also be linked to proficiency in Norwegian and the length of residency in Norway, both of which are important in the Random Forests model. However, it is important to note here that the directionality of influence with regard to length of residence cannot be known from the Random Forests model, only the importance of the variable. The role of Length of Residence is a predictor of dialect use in Drummond (2013).
It is somewhat unsurprising that attitude towards the Tromsø dialect predicts dialect use. Attitude towards the local area and to the local dialect is a predictor of dialect use in several studies (Baker, 2008; Drummond, 2013; Sharma, 2005). Drummond (2013) posits that dialect use indicates a conscious or unconscious positioning of the self within the target culture, and that an individual’s attitude to the target culture helps in identity construction in relation to that culture. It appears that Tromsø dialect users tend to like the Tromsø dialect, and indeed use it in their own identity construction in relation to the mainstream Norwegian culture. Indeed, dialect use in terms of identity in Norway is very clear (Røyneland, 2017). Thus, this attitude and positioning may indicate a social desire to signal to other Tromsø-dialect speakers an in-group belonging, and to other speakers a Tromsø-speaker identity. Purposeful dialect use to position oneself as an in-group member is particularly possible in a sentence-by-sentence translation task, where metalinguistic knowledge can be drawn on to produce the dialectal forms. Translation is a two-level task, which requires both communicative and metalinguistic skills (Malakoff & Hakuta, 1991).
Indeed, it is the case that the more one likes the Tromsø dialect, the more that they use it. However, the causation behind this relationship may run in the other direction: the more one uses the Tromsø dialect, the more that they like it. According to Social identity theory (Tajfel & Turner, 1979), group membership is linked to favouritism and enhancement of the in-group. The group to which a speaker belongs can be conveyed by a speaker’s accent (Labov, 2006), and speakers typically judge their own accent as the most favourable and trustworthy (Coupland & Bishop, 2007; Edwards, 1982; Lev-Ari & Keysar, 2010; Mulac et al., 1974; Ryan & Sebastian, 1980). It is therefore possible that those using the Tromsø dialect in their speech would reap the most benefits from interactions in the host society and thus have a positive experience with the dialect. This is in opposition to those who do not use it or understand it and are unable to reap such benefits. Lower proficiency in a language can represent a barrier to a feeling of belonging in the host country (Amit & Bar-Lev, 2015), which may be extended to lower proficiency in a dialect.
Dialect perception in morphosyntax
In the AJT, the Norwegian group responded as expected. They accepted sentences in the grammatical control condition (grammatical gender agreement, grammatical in both dialects), and rejected the ungrammatical control. They additionally accepted grammatical critical (number agreement, grammatical in Tromsø dialect only) significantly more than ungrammatical critical (p < .0001, see Appendix 5). This pattern is similar to what was found by Kubota et al. (2024) in their investigation of the same two syntactic conditions in L1 Norwegian speakers, except that, in their study, number agreement was accepted to a similar degree in both grammatical and ungrammatical conditions. This may be explained by the fact that, in their study, participants were asked to assess whether a native Norwegian speaker would produce such sentences. Therefore, lack of number agreement (grammatical critical, Tromsø dialect form) would be acceptable, but presence of number agreement (ungrammatical critical, Bokmål and other dialect form) would also be acceptable. In the current study, participants were asked to assess whether a Tromsø dialect speaker would produce such utterances. Thus, it makes sense that participants accepted the Tromsø dialect syntax (grammatical critical) more than the Bokmål syntax (ungrammatical critical). However, despite this, they did not reject ungrammatical critical as strongly as ungrammatical control (p < .0001). This could be attributed to the use of Bokmål in written language in educational and professional contexts and the pervasiveness of Bokmål/standardtålemal and other dialects on television and in daily life (Lundquist et al., 2020; Sandøy, 2009).
The Polish group perform significantly differently to the Norwegian group on all conditions except ungrammatical critical. The differences between the Polish and Norwegians across groups are led by the Norwegian group. There is no significant difference in how the Polish group responded across conditions. There are several possible explanations for this. First, this may suggest that participants’ proficiency in Norwegian is not adequate for detection of the small differences in suffixes required to properly assess the conditions. The sentences were not syntactically simple, and were presented via audio, so it is thus possible that it was too difficult to detect the differences. However, the majority of participants have a proficiency of B1 or above and the average participant was at B2 level (just two participants have an A2 level of Norwegian: WL3725AC and LF3524AL).
Alternatively, it may be possible that participants do not know of all the differences between the Tromsø dialect and Bokmål (or other dialects), especially on the level of syntax. Adult learners of Norwegian are often informed that there are dialect differences, but not further trained in what these differences are (van Ommeren, 2010), especially beyond commonly used lexical items. As the sentences that participants had to judge were in the Tromsø dialect, it may have been difficult to pinpoint what a Tromsø dialect speaker would and would not say in terms of the conditions tested. Indeed, as ‘ungrammatical’ sentences were spoken in the Tromsø dialect (but with the ‘ungrammatical forms’), learners may have recognised Tromsø dialect words (such as ho ‘she’, Bokmål form: hun) and been inclined to loosely accept the sentences. In addition, those weak acceptance may indicate participants’ assumption that sentences contained a Tromsø dialect form that they were unaware of.
Dialect use in different domains
In the lexical domain, the L1 Norwegians and the L1 Polish groups perform significantly differently: the L1 Norwegians use the Tromsø dialect forms much more frequently. However, some L1 Polish speakers do variably use the Tromsø dialect in the lexicon. This is similar to what was found in Malarski et al. (2024) at the level of phonology in the same (slightly broader) participant group. In Malarski et al. (2024), participants were recorded in reading tasks, a picture description task, and a sociolinguistic interview in Norwegian (also in English and Polish). These were then coded for instances of phonological Tromsø dialect features, for example, lowering of /e/ to /æ/ and palatisation on /n/. In this case, participants also used such dialect forms variably, and use was linked with variables including length of stay in Norway and level of Norwegian proficiency.
In the morphosyntactic domain, the L1 Norwegians and L1 Polish groups also perform differently. However, none of the Polish participants patterned with the L1 Norwegian group, and there was no difference between their ratings across the conditions. This discrepancy between the use of Tromsø dialect lexical items and perceptual ability in morphosyntax may be linked to a lack of knowledge about how syntax differs between dialects (discussed above). This is supported by the fact that participants did not have a time limit in making the acceptability judgements and thus would have been able to draw on metalinguistic knowledge. The lack of difference between participant judgements in the different conditions may also be related back to the Bottleneck Hypothesis (Slabakova, 2009, 2019). The Bottleneck Hypothesis argues that functional morphology is the ‘bottleneck’ in L2 acquisition because it represents a bundle of semantic, syntactic and morphophonological features which effect the acceptability and meaning of the entire sentence (Slabakova, 2019). Thus, it is possible that, while participants are aware of lexico-phonological differences between dialects and can utilise these forms, they will be later to fully acquire differences in functional morphology (and indeed, later to acquire it in the L3D1, Bokmål).
Limitations
Ideally, the dataset for the lexicon task would be large enough to support a generalised linear mixed effects model which includes all variables deemed important by the Random Forests analysis, as done in Mitrofanova et al. (2018). This would allow for the detection of main effects, interactions, and directionality of influence for all of the important variables. In the current article, we use behavioural methods (AJT) to assess perception in morphosyntax, similarly to Kubota et al. (2024). However, they also use Event-Related Potentials for a more precise measure of this, and, in doing so, find results different to that of the AJT. It would be pertinent to include online methods such as ERP in future research in dialect perception in the L2/L3. In addition, in the current article we assess production in lexicon and perception in morphosyntax. In future work, it would be ideal to compare production in lexicon and morphosyntax and perception in lexicon and morphosyntax (or production and perception in lexicon, and production and perception in morphosyntax). Future research should also consider stylistic choices in audience design and variability and shifting relating to conversational topic throughout the sociolinguistic interviews (Bell, 1984; Sharma & Rampton, 2015). This is particularly relevant in a study such as this, wherein data was collected by three researchers with differing L1s.
Conclusion
In summary, L3 speakers of Norwegian can and do use Tromsø dialect lexical items in speech production. Those who use Tromsø dialect lexical items do so variably both across and within word (ka, kem, kor, ikkje). The use of such forms is dependent on variables including how much they like the Tromsø dialect, and the proportion of passive exposure to Norwegian that they have. While dialect levelling towards the ‘standard’ Bokmål by L1 Norwegian speakers is occurring in a move away from an ‘older’ way of speaking, L3 speakers of Norwegian are acquiring and using Tromsø dialect forms to express their identities as Tromsøværinger (people who live in Tromsø). However, L3 speakers of Norwegian do not appear to detect morphosyntactic differences between the two dialects, likely due to a lack of metalinguistic awareness regarding such differences. In teaching Norwegian to adults, it would be useful to include lessons on the specific ways in which dialects differ from the ‘standard’ Bokmål.
Footnotes
Appendix 1
Appendix 2
Lexicon task, sociolinguistic variables within participant groups, lmer.
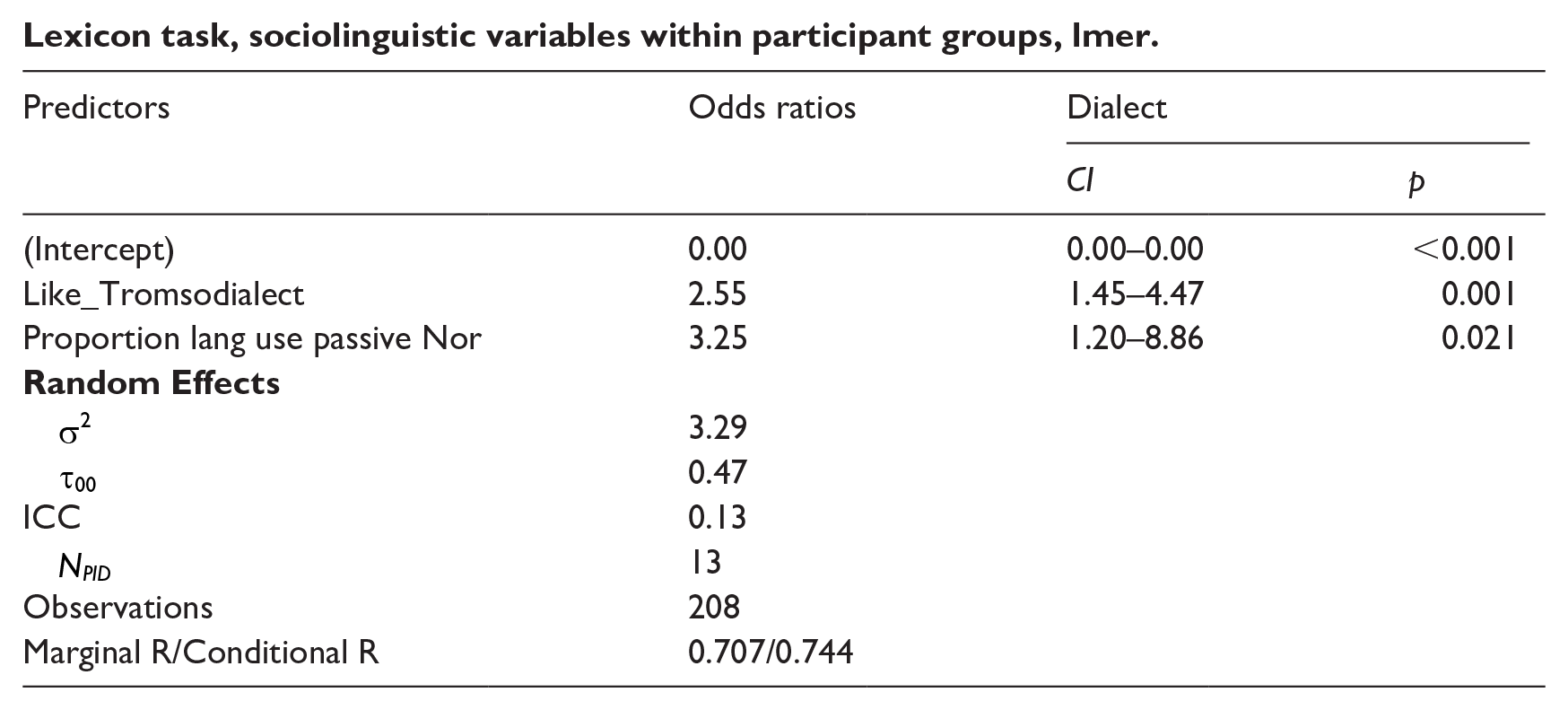
| Predictors | Odds ratios | Dialect | |
|---|---|---|---|
| CI | p | ||
| (Intercept) | 0.00 | 0.00–0.00 | <0.001 |
| Like_Tromsodialect | 2.55 | 1.45–4.47 | 0.001 |
| Proportion lang use passive Nor | 3.25 | 1.20–8.86 | 0.021 |
|
|
|||
| 3.29 | |||
| |
0.47 | ||
| ICC | 0.13 | ||
| |
13 | ||
| Observations | 208 | ||
| Marginal R/Conditional R | 0.707/0.744 | ||
Appendix 3
AJT task, across participant groups.
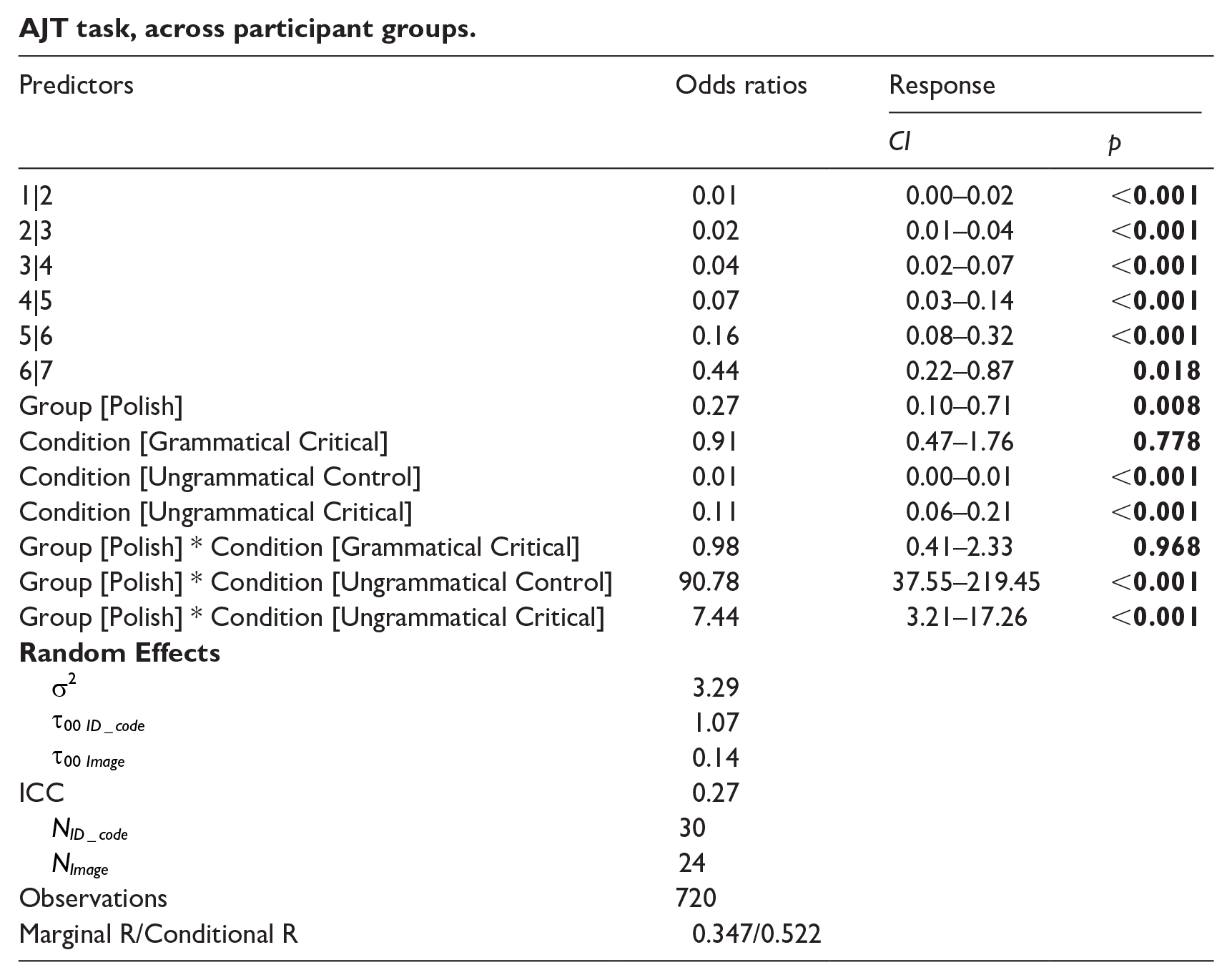
| Predictors | Odds ratios | Response | |
|---|---|---|---|
| CI | p | ||
| 1|2 | 0.01 | 0.00–0.02 |
|
| 2|3 | 0.02 | 0.01–0.04 |
|
| 3|4 | 0.04 | 0.02–0.07 |
|
| 4|5 | 0.07 | 0.03–0.14 |
|
| 5|6 | 0.16 | 0.08–0.32 |
|
| 6|7 | 0.44 | 0.22–0.87 |
|
| Group [Polish] | 0.27 | 0.10–0.71 |
|
| Condition [Grammatical Critical] | 0.91 | 0.47–1.76 |
|
| Condition [Ungrammatical Control] | 0.01 | 0.00–0.01 |
|
| Condition [Ungrammatical Critical] | 0.11 | 0.06–0.21 |
|
| Group [Polish] * Condition [Grammatical Critical] | 0.98 | 0.41–2.33 |
|
| Group [Polish] * Condition [Ungrammatical Control] | 90.78 | 37.55–219.45 |
|
| Group [Polish] * Condition [Ungrammatical Critical] | 7.44 | 3.21–17.26 |
|
|
|
|||
| 3.29 | |||
| |
1.07 | ||
| |
0.14 | ||
| ICC | 0.27 | ||
| |
30 | ||
| |
24 | ||
| Observations | 720 | ||
| Marginal R/Conditional R | 0.347/0.522 | ||
Appendix 4
Appendix 5
Acknowledgements
This study was approved by Sikt (the Norwegian Agency for Shared Services in Education and Research). We would like to thank Dr Kamil Kaźmierski for his comments on data analysis.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by Norway funds/NCN project grant GRIEG-1 (UMO-2019/34/H/HS2/00495) ADIM ‘Across-domain investigations in multilingualism: Modeling L3 acquisition in diverse settings’.
Ethics approval statement
This study was approved by both the Norwegian Agency for Shared Services in Education and Research (Sikt) (approval no. 702426) on April 24, 2023, and the AMU Ethics Committee at Adam Mickiewicz University (approval no. 1/2022/2023) in April 2023.