
Abstract
Aims and objectives/purpose/research questions:
This paper investigates whether sustained immersion in a dominant second-language (L2) environment alters morphological processing strategies compared to those of L1-immersed speakers. Furthermore, we assess the methodological usefulness of a language-mode task in light of the validity of conducting native processing research on L2-immersed speakers.
Design/methodology/approach:
We use the design and stimuli of a previous long-lag visual lexical decision task conducted with native German speakers in Germany and use this group as a control. Thirty-two native German speakers resident in the UK (>2 years; minimal day-to-day German use) participated in two experimental sessions (one containing a 20-minute conversation task in German).
Data and analysis:
The data shows clear differences between facilitation patterns of L1 and L2-immersed participants. L2-immersed speakers display decreased sensitivity to subtle morphological differences as well as facilitation in a form condition similar to effects seen in L2 processing. Lexical decisions of pseudowords based on plausibility, however, remain similar. While the pre-experiment language-mode task resulted in overall faster responses, there was no effect on processing patterns.
Findings/conclusions:
L1 morphological processing is affected by continued exposure to a dominant second language with sensitivity to the internal structure or differences of morphologically complex items decreasing. The attrition group shows certain similarities to L2 morphological processing. Our findings also call for caution in the recruitment of L2-immersed experiment participants.
Originality:
Research on morphological processing in language attrition is scarce and no previous work has examined complex derived words. The addition of a principled manipulation of the pre-experiment task is also uncommon.
Significance/implications:
The possible similarity of L1-attrition and L2-learner processing challenges the concept of ‘native’ processing and the notion of ‘nativeness’ as a stable property. Further comparison of these populations may lead to a more thorough understanding of the adaptability of our processing system.
Introduction
The phenomenon of ‘losing your native language’ is well attested anecdotally as many speakers living in an environment where their native language is not the dominant language are aware of struggling with processes such as lexical retrieval. Nevertheless, the competence of a native adult speaker in their first language (L1) is widely perceived as a static and privileged state due to its early entrenchment which, once established, is also assumed to remain stable (e.g. Marchman, 1993; Penfield, 1965). In monolingual speakers, this may well be broadly accurate (age effects aside). When a second language (L2) is added to the language system, however, this inevitably has an effect on the L1 (Schmid & Köpke, 2019). While many of these changes may remain largely undetected and are often not detrimental to the communicative behaviour of bilinguals, 1 especially when both (or all) languages are used actively, bilinguals almost inevitably experience some degree of language attrition, especially in cases where the second language becomes dominant. 2 The more deeply entrenched the first language is through continued exposure (Van Hell & Tokowicz, 2010), the less likely modifications due to a second language are to take hold (Pallier, 2007). Thus, greater changes are likely to be observed in younger attriters who become L2-dominant at an earlier age than in those who experience this dominance shift later (Kasparian et al., 2017).
While the increasing number of studies focused on first-language attrition have not shown permanent erosion of competence provided the native competence was established before immersion in the L2 context, indications of a decrease in linguistic performance have been found on almost all linguistic levels: phonetic (e.g. de Leuw et al., 2010; Dmitrieva et al., 2020; Ulbrich & Ordin, 2014), phonological (e.g. Celata & Cancila, 2010; de Leuw et al., 2018), lexical (e.g. Opitz, 2013; Schmid & Jarvis, 2014), semantic (e.g. Grosjean & Py, 1991; Pavlenko, 2003) and syntactic/morphosyntactic (e.g. Bergmann et al., 2015; Kasparian et al., 2017; Tsimpli et al., 2004). These effects have mostly been attributed to retrieval difficulties (e.g. Hulsen et al., 2002; Olshtain & Barzilay, 1991) at the level of performance rather than underlying competence (e.g. Paradis, 1993, 2007). The precise nature of these changes is not yet well understood and a large number of variables, such as degree and type of exposure to the L1, level of education, length of residence (LoR) and age of acquisition (AoA), affect the degree to which speakers’ L1 system undergoes language attrition. In addition, different linguistic domains may not be equally susceptible to attrition effects.
This body of recent evidence calls into question the monolithic view of the L1 and thus challenges the concept of ‘nativeness’, at least on the level of language processing. Studies on L1 language attrition have thus far shown mixed evidence, some studies finding evidence of attrition (as discussed above) while others find little or no attrition in certain domains or speakers (e.g. Varga, 2012), with the lexicon frequently being cited as the domain most vulnerable to attrition (e.g. Köpke, 1999). These differences in findings suggest that language attrition is a dynamic phenomenon which is affected by a large number of linguistic and extralinguistic factors (cf. for instance Opitz, 2013), some of which are not dissimilar to the factors affecting ultimate attainment in an L2, which are also diverse, context-dependent and strongly interrelated (cf. for example Dörnyei, 2006; Ellis, 2004). A number of studies have likened certain effects, such as compensatory strategies, observed in L1 attrition to those in L2 acquisition (e.g. Celata & Cancila, 2010; Gürel & Yılmaz, 2011; Seliger, 1991) and comparing monolingual L1 speakers, L2 learners and L1 attriters may provide useful insight into the question of age effects in L2 learning (see, for instance, Schmid, 2014). The majority of psycholinguistic or neurolinguistics studies investigating the question of near-native L2 processing simply use a monolingual native control group as the benchmark for ‘nativeness’. A very small number of recent neurolinguistic studies, however, have begun to systematically explore the effects of language proficiency (in both L1 and L2) on processing and one study found proficiency, rather than AoA, was the dominant factor affecting processing patterns, with higher proficiency resulting in more native-like processing patterns (cf. Kasparian & Steinhauer, 2016; Kasparian et al., 2017; Pakulak & Neville, 2010; Prat, 2011). This calls into question the monolithic view of the L1 and thus challenges the concept of ‘nativeness’, at least on the level of language processing, and suggests that a more gradient approach than the still frequently employed binary native versus non-native distinction is needed.
In psycholinguistic experiments, for instance, native speakers are recruited for investigations into native processing but they are hardly ever tested for language proficiency (unless they are recruited for language attrition studies) since they are perceived to be a homogeneous group. This also applies to studies conducted in L2-dominant environments and while some researchers attempt to counteract the L2-dominant environment by, for instance, trying to induce a monolingual L1 language mode (cf. Grosjean, 1998) via the use of a task in the native language prior to testing; the extent to which these modifications are successful remains uninvestigated.
In order to add to the emerging literature, the present study investigates language attrition in the morphological domain by examining the decomposition of German derivationally complex words. More specifically, based on previous results (Schuster & Lahiri, 2018), we investigate whether existing complex items (e.g. Heil-ung ‘healingN’) are more successful in activating their base form (e.g. heil ‘whole, unhurt’) than non-existent but plausible words and whether a difference in the distance to the closest existing words affects the facilitation effect (e.g. *Hübschung > *hübschen > hübsch ‘pretty’ vs *Spitzung > spitzen ‘to sharpen’ > spitz ‘pointy, sharp’). The study also includes a principled manipulation of language environment. There are currently no studies known to us which examine the processing of derivationally complex items in L2-immersed speakers, and a recent summary of the field (Schmitt, 2019) has identified research on morphological processing mechanisms as one of the key directions for further study in language attrition. Using morphologically complex items allows for the probing of very subtle structural differences between items which, on the surface, display similar patterns. Thus, attrition effects may be observed using behavioural techniques rather than more sensitive neurolinguistic measures which also allow for the investigation of differences during processing.
The present study addresses the following questions:
What effect do immersion in an L2 environment and the presence of a dominant second language have on the processing of morphologically complex words?
How does a manipulation of the experimental environment (i.e. speaking only German to the participants) affect participants’ processing?
What are the potential consequences of using L2-immersed native speakers in experimental studies on native processing?
To investigate these questions, we conducted a visual lexical decision task with long-lag priming using morphologically complex German words and pseudowords as stimuli. We tested a group of German native speakers resident in the UK and compared their results with those of a previous study investigating German native speakers resident in Germany (cf. Schuster & Lahiri, 2018). Before introducing the present study in greater detail, an overview is provided of previous relevant research on language attrition in the morphological domain and the processing of morphologically complex words.
Language attrition in the morphosyntactic domain
Research on language attrition, especially from a psycholinguistic perspective, has seen a rapid increase in recent years and stretches across all domains of linguistic processing and production (cf. Schmid & Köpke, 2019). The body of research in the area of morphosyntactic attrition has shown mixed results in terms of the amount of attrition detected (Gürel, 2004; Gürel & Yılmaz, 2011; Kasparian et al., 2014; Kim et al., 2010; Schmid, 2009; Schmid & Köpke, 2011; Sorace, 2011; Tsimpli et al., 2004). Most studies use morphosyntactic properties such as gender and number agreement or pronominal usage to investigate the degree of stability of the grammatical system under attrition conditions.
However, purely morphological attrition has not received as much attention as other domains, and most of the research has focused on production of inflectional morphology (cf. Schmitt, 2019), where processes such as simplification, paradigm levelling, overgeneralisation and the reduction of the number of morphological markers have been observed. These changes have been attributed to a variety of causes including mapping difficulties (Lardiere, 2000), cross-linguistic interference (Bolonyai, 2005; Gross, 2004) and retrieval difficulties (Paradis, 2007).
Studies on derivational attrition are even less numerous and those which do exist are focused on production (e.g. Dressler, 1991; Kaufmann & Aronoff, 1991) and will therefore not be discussed in detail here. There have been no studies to date on morphological decomposition of derivationally complex items in processing and very few on morphological or morphosyntactic processing more generally. Furthermore, recent neurolinguistic studies on other morphosyntactic properties such as number agreement (Kasparian et al., 2017) and verb form combinations and gender concord (Bergmann et al., 2015) have found contradictory results with regard to attrition effects in this domain.
In an ERP study, Bergmann et al. (2015) investigated the processing of verb form violations and gender agreement violations (e.g. der/*das Tisch ‘themasc/*theneut table’) with three groups of speakers: Dutch and German native speakers in an L2-English context (attriters), early and late L2 learners of German/Dutch, and monolingual native speakers of German and Dutch. In their results, attriters show ERP patterns similar to monolingual controls while patterns for L2 learners differ. Bergmann et al. (2015) propose that these differences are due to maturational constraints on L2 acquisition, while the shift in language dominance in the attriters does not affect their morphosyntactic processing.
In contrast, Kasparian et al. (2017) investigated the processing of number agreement violations in Italian in a group of L1 Italian attriters (L2 English) and non-attriting native controls. Their results show both qualitative and quantitative differences in both ERP components investigated (LAN/N400 and P600). Crucially, they also conducted an investigation of the effect of proficiency in both monolingual and bilingual native speakers on processing patterns using a measure which has shown differences between highly proficient L2 speakers and native speakers (long-distance dependencies; Clahsen & Felser, 2006) and may thus be sensitive enough to uncover any differences in attriters. Their results indicated that attriters engage in shallower analysis processes during online comprehension (cf. Kasparian et al., 2017, p. 1789) but the detection rate of violations matched that of the control group (albeit with slower response times). Proficiency, for speakers processing their L1, was also found to correlate with the size and distribution of the ERP effects, with those with lower proficiency scores showing a reduced P600 effect (reminiscent of reduced P600 effects in lower-proficiency L2 learners; Rossi et al., 2006). Kasparian et al. (2017, p. 1792f.) raise the possibility that effects of attrition may be detectable using neurocognitive measures before they are evident in behaviour as well as being modulated by task (cf. also Schmid, 2011) and the type of structure examined. They did not find any differences between attriters and non-attriters in their behavioural measures of, for example, working memory and proficiency. Thus, some of the contradictory results may be a result of the types of linguistic structures used (e.g. gender agreement or long-distance dependencies) as well as the experimental method. It seems that structures where differences are less salient than in those employed in previous experiments, such as the morphologically complex items used in the present study, may provide useful ground for investigation as they may be more prone to early attrition effects which may be detectable with either psycholinguistic or neurolinguistic methods.
L1 and L2 processing of morphologically complex words
Investigations of how morphologically complex items are stored in the lexicon and accessed during processing has yielded a rich body of research. Many of these investigations have probed the question of differences between native and non-native processing and determined that there are a number of factors (e.g. proficiency, AoA, frequency of use; cf. Abutalebi & Clahsen, 2018) which influence whether language learners employ similar mechanisms and sources of information in language processing. This section will briefly introduce relevant aspects of previous research on native and non-native morphological processing.
The question of whether morphologically complex words (e.g. help-ful, un-happy, walk-ed, mice) are stored as one unit in the lexicon, or whether their component parts are stored and words are decomposed in recognition and assembled in production, has received a large amount of research interest. The notion that morphological structure plays a role in speech recognition is now well supported (cf. Rastle et al., 2000; cf. Amenta & Crepaldi, 2012; Bertram et al., 2011 for reviews) and several recent studies have shown that native speakers are extremely sensitive to fine morphological differences including, for instance, derivational depth (e.g. Pliatsikas et al., 2014; Schuster & Lahiri, 2018; Schuster et al., 2018; Wheeldon et al., 2019). Derivational depth denotes the number of derivational steps that separate a complex item from its base. In an experimental setting, sensitivity to derivational depth can be probed by manipulating the number of steps between a prime and target. For instance, prime-target pairs such as eyeing–EYE require two steps from prime to target (eyeing > eyeV > eyeN) as the suffix -ing can only attach to a verbal base, thus requiring the conversion of eyeN to eyeV, while pairs such as running–RUN require one step (running > runV). Experimental evidence has shown that the intermediate step in the former pair results in increased processing effort (see Pliatsikas et al., 2014). There is, however, no consensus so far regarding the precise mechanisms involved in this decomposition process and the circumstances under which morphological information is used in processing. Theoretical proposals regarding native morphological processing range from full-listing models (e.g. Butterworth, 1983; Seidenberg & Gonnerman, 2000), where every item is stored as one entity, to those models which propose obligatory decomposition (e.g. Fruchter & Marantz, 2015; Stockall & Marantz, 2006; Taft & Forster, 1975), where every affix is necessarily stripped from the stem and then recombined after the stem has been accessed. Others put forward a hybrid approach where both routes (decomposition and listing) are available and, depending on the item in question, the more efficient route is chosen (e.g. Baayen et al., 1997; Clahsen et al., 2010; Pinker & Ullman, 2002). Factors which affect the use of a particular processing strategy are, for instance, frequency and productivity of the process or an affix (e.g. -ness (frequent; tiredness) vs -th (infrequent; growth) in English) or regularity (irregular vs regular items; e.g. English wrote vs walked). Models proposing such a dual-route system suggest that, when encountering a morphologically complex item, native speakers have two options available to them and the faster and easier route is chosen (e.g. Baayen et al., 1997; Caramazza et al., 1988; Frauenfelder & Schreuder, 1992). There is significant evidence from studies investigating both L1 and L2 speakers that both groups of speakers engage in morphological decomposition at least to some extent (cf. for example Clahsen et al., 2010; Feldman et al., 2010; Gor & Jackson, 2013; Gor et al., 2017).
Where L2 processing is concerned, several proposals regarding the availability and use of these two routes have been put forward. Approaches such as Ullman’s (2001, 2004) procedural-declarative model originally suggested that L2 learners used their declarative knowledge to a greater extent in processing and that the procedural route, where items are decomposed, was largely unavailable to them. This claim was based on a number of studies which show either reduced facilitation effects or no facilitation for morphologically related items in masked priming studies (cf. for example Clahsen et al., 2010, 2013; Feldman et al., 2009; Neubauer & Clahsen, 2009; Silva & Clahsen, 2008). However, recent proposals have been more gradient in their approach as there is mounting evidence that language learners do use morphological structure in their processing and do not rely entirely on whole-form recognition (cf. Bosch et al., 2016; Coughlin & Tremblay, 2015; Hahne et al., 2006; Jacob et al., 2013; Pliatsikas & Marinis, 2013).
One theoretical model explaining the effects observed in previous studies is Clahsen and Felser’s (2006, 2018) Shallow Structure Hypothesis (SSH), which proposes shallower processing with a greater focus on morpho-orthographic surface features (i.e. form overlap between items which are not morphologically related; e.g. increase-crease) for language learners. This is supported by findings from studies which, in addition to morphological effects, have also found effects of pure form overlap (e.g. Duñabeitia et al., 2011; Feldman et al., 2010; Heyer & Clahsen, 2015). While research in this area has produced somewhat contradictory results, there is increasing evidence that learners are also able to use morphological structure in processing, and Clahsen and Felser (2018) stress that this is a gradient phenomenon and that highly proficient L2 learners can show native patterns of processing. The use of these native-like patterns has been shown to be influenced by a number of factors such as proficiency (Coughlin & Tremblay, 2015; Feldman et al., 2010; Gor et al., 2017), structure of the L1 (cf. for example Lehtonen & Laine, 2003; Lehtonen et al., 2006) and task type (cf. Gor et al., 2017).
Thus, it seems likely that two distinct processing routes are available to both native and non-native speakers and the most efficient route is selected based on a number of different factors. If there are several processing options, and if how these are employed is a matter of degree rather than an absolute, is it really possible to distinguish between native and non-native processing, given that high-proficiency L2 speakers show ‘native’ patterns (cf. Clahsen & Felser, 2018)? And, crucially for the present research, how do the patterns of morphological processing shown by speakers in an L2-immersed environment compare with those of L1-immersed speakers?
Processing of morphologically complex pseudowords: Legality and derivational depth
As the present study investigates the processing of both real words and pseudowords, a brief summary of morphological issues of legality and semantic transparency is provided here. The applicability of the above models has also been investigated for the processing of pseudowords and the legality of the items in question, i.e. whether a stem and affix are a permissible combination in a certain language (e.g. English happiness vs English *friendness) as well as effects of semantic transparency and derivational depth (i.e. the number of derivational stages) have been shown to influence processing (e.g. Meinzer et al., 2009; Pliatsikas et al., 2014; Wheeldon et al., 2019).
We first turn to the issue of legality of pseudowords. The identification of morphological structure is not limited to genuine cases of morphological complexity or even existing lexical items in a language. Studies have shown that legitimate affixes are stripped and facilitate access to the simpler item even when they are not acting as a suffix in a particular word (e.g. -er in corner), while prime-target pairs which only overlap in form (e.g. broth – brothel, where *-el is not a legitimate English suffix) do not lead to facilitation (cf. Rastle et al., 2004). Thus, affixes are recognised in their own right and identified as component parts which can be detached from the stem. This also extends to the processing of pseudowords, as a number of studies have demonstrated. Speakers do not only decompose items which exist in the language, but also items which follow a plausible derivational pattern but are not attested. Longtin and Meunier (2005) demonstrated this for French in a masked priming study using two sets of pseudowords with the two suffixes -ifier (creating de-adjectival verbs) and -ation (creating de-verbal nouns). In one set of pseudowords, some items (e.g. *rapidifier) were legal but non-existent stem+suffix combinations in French, while examples such as *sportation were not since -ation does not attach to nouns. In both cases, however, regardless of semantic interpretability (which was judged significantly worse for the illegal pseudowords), access to the target (e.g. rapide ‘fast’) was facilitated while a pure form-overlap prime (e.g. *rapiduit; -uit is not a legitimate French suffix) did not result in any facilitation of the target. Semantic interpretability did, however, modulate facilitation in a cross-modal follow-up study (Meunier & Longtin, 2007). Thus, it is clear that a legitimate affix is recognised and the removal of this affix allows for access to the stem and, depending on the task in question and the modality of presentation, the interpretability of pseudowords plays a role in the ease of access to the stem.
The role of derivational depth, how many levels of derivation stand between two items (i.e. prime and target), has been investigated by a number of recent neurolinguistic studies in order to determine whether added derivational depth results in greater processing effort (e.g. Meinzer et al., 2009; Pliatsikas et al., 2014). Pliatsikas et al. (2014) probed the difference between two sets of English words which differ in the number of necessary derivational steps: bridgeN > bridgeV > bridging (two-step) versus soakV > soaking (one-step). While both primes, soaking and bridging, look identical on the surface, the latter includes an additional step to convert bridgeN to bridgeV in order to be able to attach the strictly verbal suffix -ing and is thus more complex. The results showed significantly greater activation for two-step derivations compared with one-step derivations (which in turn showed greater activation than the monomorphemic control items) in the left inferior frontal gyrus (LIFG), which has been shown to respond to complexity. These results demonstrate that the processing system is sensitive to the internal complexity of words even when this does not form part of a speaker’s conscious knowledge and in cases of zero derivation where no overt marking indicates word class changes.
The present research is based on a study which combines semantic interpretability and morphological complexity to investigate both derivational depth and pseudoword processing. Schuster and Lahiri (2018) investigate derivational chains in German which follow a regular and productive pattern (adjective > conversion verb > noun in -ung; e.g. heil ‘whole, healthy’ > heilen ‘to cure, heal’ > Heilung ‘healingN’) to determine whether differences in the lexicality of the items in the chain affect processing. The suffix -ung only attaches to verbs to create deverbal nouns and thus an intermediate step converting the initial adjective (heil in the example above) into a verb is necessary before it can take the suffix -ung. In their stimuli, Schuster and Lahiri vary the number of links in the chain which are existing German words: in chains such as spitz ‘pointy, sharp’ > spitzen ‘to sharpen’ > *Spitzung the final link in the chain, the noun in -ung, is not attested in German but is perfectly interpretable (and in this case, for example, the prefixed noun Zuspitzung ‘sudden worsening of a situation’ is a real German word). In a comparable chain based on the adjective hübsch ‘pretty’, neither the verb *hübschen nor the noun *Hübschung exist. The question they asked is how speakers process pseudowords built on the basis of a real stem using a productive derivational paradigm, and whether speakers are sensitive to the number of gaps in these paradigms (i.e. whether *Spitzung provides easier access to spitz than *Hübschung to hübsch, given that in the former example, the intermediate step spitzen is a real word). L1-immersed speakers in this study showed a significant difference in facilitation depending on the lexical status of the intermediate verb. This shows a sensitivity to internal levels of morphological complexity (cf. Schuster & Lahiri, 2018). As this is a very subtle distinction, it provides a testing ground for early effects of language attrition in the morphological domain which may be observable using behavioural methods.
Present study and hypotheses
The present study thus uses the design by Schuster and Lahiri (2018; Experiment 3) in their study conducted with German native speakers in Frankfurt, Germany. As discussed above, Schuster and Lahiri (2018) used two types of non-existent nouns ending in the suffix -ung or the suffixes -bar and -keit as primes for existing base adjectives. Both types follow viable derivational sequences in German: base adjective > verb in -en > noun in -ung or base verb > adjective in -bar > noun in -keit (see Table 1 for sample stimuli). However, while in the first condition (NonEx1) the intermediate verb is an attested lexical item (e.g. spitz ‘sharp, pointy’ > spitzen ‘to sharpen’ > *Spitzung), in the second condition (NonEx2) the intermediate verb does not exist (e.g. schlimm ‘terrible’ > *schlimmen > *Schlimmung).
Sample stimuli in all conditions (Schuster & Lahiri, 2018; Experiment 3).

Using the stimulus set employed by Schuster and Lahiri (2018) in their Experiment 3 with L2-immersed native German speakers living in the UK, we aim to determine whether the sensitivity to degrees of derivational depth found in the L1-immersed speakers in Frankfurt remains stable in the context of a dominant second language. As outlined above, attrition effects have been found in morphosyntactic processing and, as morphological processing research shows differences between L1 and L2 processing, it seems plausible that a dominant second language may have an effect on the processing of complex items in the L1. English and German share broadly similar mechanisms of affixation in derivation and speakers will thus be using similar processes in both languages. However, some L2 research shows a difference in the route used for processing depending on the frequency of a complex item (Baayen et al., 1997; Clahsen et al., 2010; Pinker & Ullman, 2002) as well as proficiency in L2 speakers (Coughlin & Tremblay, 2015; Feldman et al., 2010; Gor et al., 2017) and therefore lack of use may lead to differences in processing patterns in L2-immersed speakers, especially in items which are plausible legal pseudowords such as those above which can be interpreted as low-frequency ‘words’ (e.g. Baayen et al., 1997).
If language attrition affects morphological processing, we may observe a difference in the degree of facilitation obtained for the different conditions of test items as well as possible differences in error rates, as L2-immersed speakers may be less certain regarding the lexical status of plausible pseudowords. In addition, if there are indeed similarities between L2 and L1-attrition processing, shallower processing, which is less sensitive to derivational chains, may be observed. If such differences are found, this may provide further evidence for language processing being, at least to some extent, dependent on entrenchment and proficiency and possibly less strongly governed by maturational constraints than previously thought (although we did not test late L2 learners of German and cannot make any claims regarding their processing of these structures).
As the motivation for this study sprang partly from methodological considerations, we also introduced a manipulation of the linguistic environment which is used in some experimental settings when native speakers serve as participants in L2-immersed environments. This process attempts to address concerns over whether all of a multilingual speaker’s languages are (equally) active at all times or whether certain contextual conditions affect the activation patterns of the different languages (e.g. monolingual vs bilingual language mode; Grosjean, 1998, 2001). Recent research has found that response patterns in experimental settings seem to be largely stimulus-driven (cf. for example Dijkstra & van Hell, 2004). Our participants attended two testing sessions (a minimum of one week apart) with one being led by an English-speaking experimenter and the other by a German-speaking experimenter who spent 15 to 20 minutes speaking to the participant in German in an attempt to maximally activate the participants’ L1. If this manipulation has any effect, we may see differences in either reaction times and/or error rates or processing patterns between the German-led and English-led sessions.
Methods and design
We used a visual lexical decision task with delayed (long-lag) priming, which has been shown to isolate the contribution of morphological structure without the confounding effect of semantic similarity (cf. Drews & Zwitserlood, 1995; Schuster & Lahiri, 2018). In delayed priming, several items (5–7) are inserted between prime and target and participants respond to all items presented to them as they would in a simple lexical decision task without priming. The only facilitation which is observed in L1-immersed native speakers in these tasks is that based on morphological relatedness (Drews & Zwitserlood, 1995), while control conditions with semantically and form-related prime-target pairs do not show any priming effects. This allows for the investigation of purely morphological effects and thus enables us to examine subtle structural differences between morphologically related items which seem identical on the surface (e.g. *Hübschung – HÜBSCH vs *Spitzung – SPITZ) but differ in terms of the lexicality of the intermediate verb.
Stimuli
The experimental stimuli are divided into six conditions with 24 stimuli each, resulting in a total number of 144 experimental trials. In addition, 144 non-word targets were created (e.g. *kett, *gutschen), half of which were paired with complex real word primes (e.g. Knöpfchen (‘little button’), while the others were preceded by non-word primes (e.g. *Versiebtheit) mirroring the complexity of items in the experimental conditions. In the three morphological test conditions, there are two types of common German derivational chains: 3

The complex noun (e.g. Heilung ‘healingN’) always served as the prime for the monomorphemic target (e.g. heil ‘whole, unhurt’; cf. Table 1). In the first three conditions, primes and targets are morphologically related. The Existing condition contains items where all members of the derivational chain are attested German words, while in the remaining two conditions the prime nouns are pseudowords. In condition NonEx1 the intermediate-step verb (e.g. spitzen ‘to sharpen’) is attested while in NonEx2 the verb does not exist in German (e.g. *hübschen). In addition to the morphological conditions, semantic and form overlap conditions were also included (cf. Appendix 1 for a full list of stimuli).
Form control conditions were included for both existing and non-existent items. The form conditions are built on both adjectival and verbal bases. Those for non-existent items were created by, for example, taking a real adjectival base (e.g. lang ‘long’) and adding a legitimate suffix (e.g. -lein, a diminutive marker) which does not combine with an adjectival stem to create an illegal combination of legal morphemes (e.g. *Länglein). 4 Form control items for the existing conditions were items which showed form overlap of at least three initial letters, such as Betttücher ‘sheets’ – beten ‘to pray’. These pairs are items matched for word frequency, lemma frequency, morphological, orthographic and phonological family size, word length, prime-target overlap, syllable structure and stress pattern with the test items they correspond to (cf. Appendix 2 for details).
The semantic condition comprised existing noun primes such as Blödheit ‘stupidity’ paired with adjectival or verbal targets (e.g. dumm ‘stupid’) which are related in meaning but do not have a morphological relationship. The unrelated prime was a morphologically complex but unrelated word (e.g. Räumchen ‘little room’). Semantic relatedness was corroborated by 40 German native speakers who completed a rating questionnaire (1 = entirely unrelated; 7 = same meaning, synonymous) regarding the degree of synonymity of the meanings expressed by the prime-target pairs. Related pairs received an average rating of 4.43, while unrelated pairs scored, on average, 1.57.
All experimental items were matched for target word frequency, target lemma frequency, morphological, orthographic and phonological family size, and target word length across conditions. In addition, morphological and non-existent control conditions were matched for prime-target overlap. Related versus unrelated primes were matched for prime length as well as word and lemma frequency. All frequency measures were gathered using the CELEX database (Baayen et al., 1995). Phonological and orthographic neighbourhood sizes were obtained from Clearpond (Marian et al., 2012) and morphological family size was determined using the number of semantically transparent morphologically related words from CELEX. Statistical analyses of the comparisons of these measures are given in Appendix 3 (no significant differences were found).
Participants
L1-immersed participants (Schuster & Lahiri, 2018)
Thirty-four native German speakers (aged 18–28) took part in the study conducted at Goethe University Frankfurt (Germany). All participants gave informed consent and reported no hearing impairment or dyslexia. Participants were compensated for their time.
L2-immersed participants (attriters)
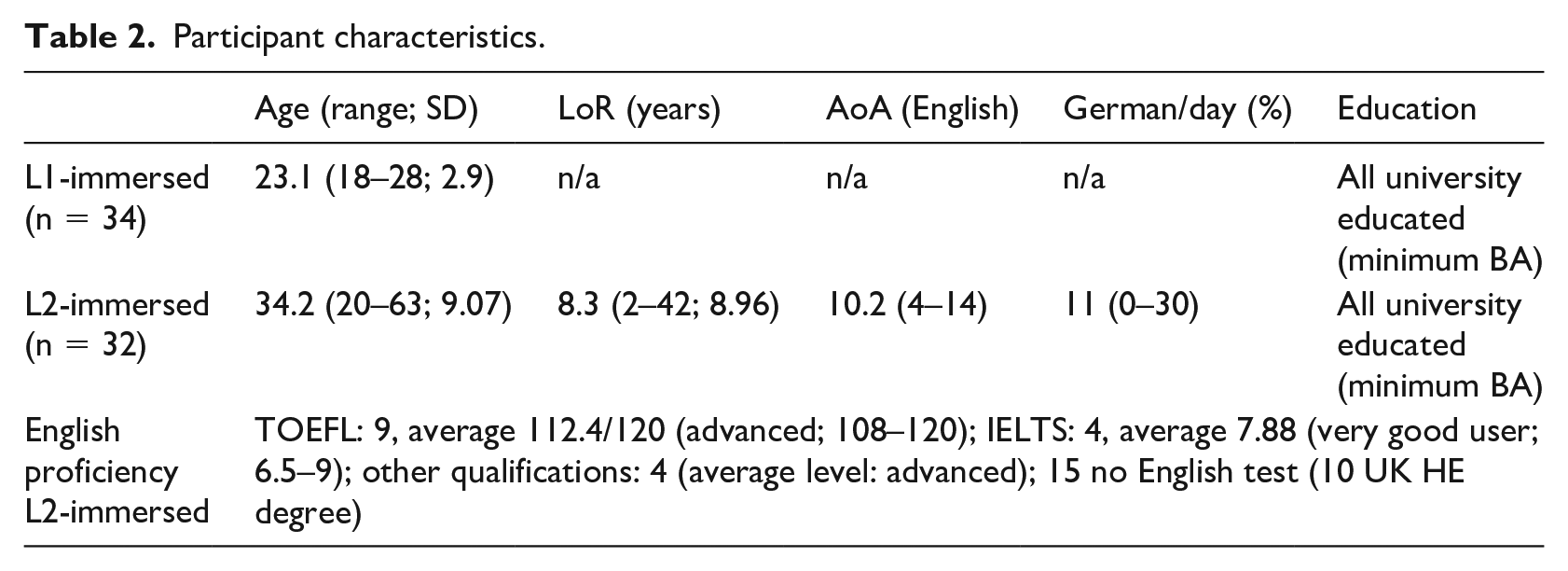
Thirty-two German native speakers living in Oxford (UK) participated in the study (16 identified as male and 16 as female). All participants had normal or corrected-to-normal vision and no known processing difficulties (such as dyslexia) or hearing deficit. To be included in the study, participants had to have been resident in the UK for more than two years and use German as little as possible in their day-to-day interactions. Any potential participants who spoke German to either their partner or children or whose work involved German in any way were not included in the study. As one aim of the study was to determine whether recruiting native speakers in L2-immersed settings was methodologically sound, we did not specify any further criteria, nor did we test English or German proficiency but asked participants to self-report English proficiency and any available proficiency test scores (see Table 2). While this means that we cannot correlate proficiency scores with our results in the present study, this set of participants consists of individuals who may well have been recruited for a native processing study. All participants were compensated appropriately for their time.
Participant characteristics.
Procedure
The procedure was identical for the L1-immersed and L2-immersed groups. Stimuli were split into two separate lists to avoid repeated exposure to the target items. Experimental conditions and control versus test trials were counterbalanced across the two lists. Within each list, items were pseudorandomised and prime-target pairs were presented with 5 to 7 intervening items. Each list comprised 576 trials and was run in three separate blocks containing 192 items each. Participants were given breaks between the three blocks. Stimuli were displayed in upper case for 500 ms and participants were given 2500 ms to respond.
Participants received experiment information in writing as well as a verbal explanation of the task after they had provided their consent. All experimental documentation for both sessions was in German. After the initial explanation, a ten-item practice task was conducted and participants were given the opportunity to ask questions if they were uncertain about the task. Data was collected using custom-made experimental software and hardware (Reetz & Kleinmann, 2003) with a Macbook Pro (OS X) and individual custom-made two-button response boxes with the buttons labelled YES and NO. Participants were instructed to use their dominant thumb for the yes-response and to respond as quickly and accurately as they were able. The experimental software and hardware were identical in the native and L2-immersed groups. Participants were tested either individually or in small groups and were instructed to wear headphones to minimise distraction during the task. Before the main experiment, all participants completed a ten-item practice task and were then given an opportunity to ask questions before beginning the testing session.
Language-environment manipulation
The L2-immersed participants attended two testing sessions which were scheduled a minimum of one week apart. In one session, the experimenter spoke only English to the participants (English-led), while in the other, only German was used (German-led). In the German-led session, a 15- to 20-minute conversation task based on cultural prompts was carried out in German before the start of the experiment to attempt to activate the participants’ first language as much as possible. Participants were randomly assigned to German-led or English-led first and language environment was counterbalanced across participants (20 English-led first; 20 German-led first).
Results
We will first present a summary of results of Schuster and Lahiri (2018) to provide a L1-immersed baseline followed by a detailed presentation of the L2-immersed results and the results of the language-environment manipulation. Analyses of reaction times (RTs) and error rates were carried out for both primes and targets and these are discussed separately for each set of data. Reactions to primes were analysed because different types of non-existent primes were expected to provide interesting insight into the interaction of complexity and lexical status. Additionally, these measures give an indication of participants’ certainty of the lexical status of the primes in the morphological test condition and will indicate whether the patterns of L2-immersed judgements of plausibility and lexical status differ from those in the L1-immersed group.
L1-immersed results (for full statistical details see Schuster & Lahiri, 2018)
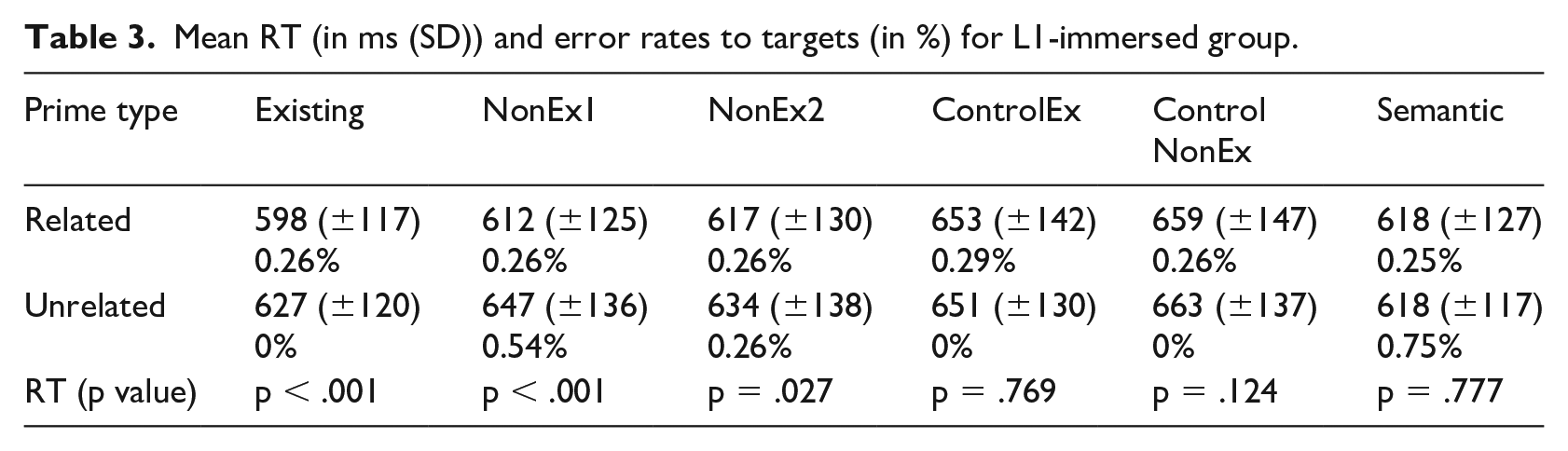
The results for the L1-immersed group are discussed in detail in Schuster and Lahiri (2018) and therefore we will only present an overview of the data in Table 3. We use the results of Schuster and Lahiri (2018) as a native-speaker baseline and compare the patterns of results with those found in our L2-immersed participant group.
Mean RT (in ms (SD)) and error rates to targets (in %) for L1-immersed group.
Reactions to targets
The L1-immersed speakers in Schuster and Lahiri’s (2018) study only showed priming in the three morphological conditions. Thus, the effect observed cannot be due to semantic similarity or form overlap but is a result of the morphological relatedness. In a further analysis comparing the two conditions with non-existent primes (NonEx1 and NonEx2), they found that those primes which were constructed on an existing form in the intermediate step (e.g. *Spitzung > spitzen ‘sharpen’) led to greater facilitation of the related target (SPITZ ‘sharp, pointy’) than those where the intermediate step was also a non-existent item (e.g. *Hübschung > *hübschen – HÜBSCH ‘pretty’; χ2(5) = 4.6029, p < .05). This indicates a sensitivity to internal structure as well as the lexical status of members in a derivational chain (see Table 3 for RT and errors).
Reactions to primes
Schuster and Lahiri (2018) did not find any differences in reaction time between the three sets of pseudoword primes (cf. Table 4). However, the error rates for primes showed lower error rates for both existing words (e.g. Heilung ‘healing’) and those primes which were illegal (ControlNonEx: e.g. *Wirrlein; wirrADJ ‘confused’ + −lein diminutive which only attaches to nouns), which elicited the lowest error rates as they were easiest to accept and discard respectively but the non-existing items still resulted in significantly greater error rates than existing items (p < .0001). Both sets of possible pseudoword primes (e.g. *Hübschung and *Spitzung) showed greater error rates compared with both existing primes and illegal combinations (both p < .0001), and those items based on an existing verb (i.e. Non-Ex1; *Spitzung) resulted in significantly higher error rates than NonEx2 items where the intermediate step is not attested (p < .0001).
Mean RT (in ms (SD)) and error rates (in %) to primes for L1-immersed group.

L2-immersed results
Due to the fact that the analysis shows task-familiarity effects in the second session, since this involved a repeat exposure to target words, two identical analyses were conducted on different datasets: one of only Session 1 (comparable with regular between-subject design) and one including both sessions. Only the results for both sessions are reported below, as there were no differences in the pattern of results. The results of the Session 1 data analysis can be found in Appendix 4. As there were no differences in the main patterns, both sessions are used for the analysis of the effect of the language environment task. In the analysis of the language environment manipulation, we report the analyses for both sessions as well as for Session 1 only, since the change in language did cause certain differences which were only evident in the Session 1 analysis.
Reactions to targets
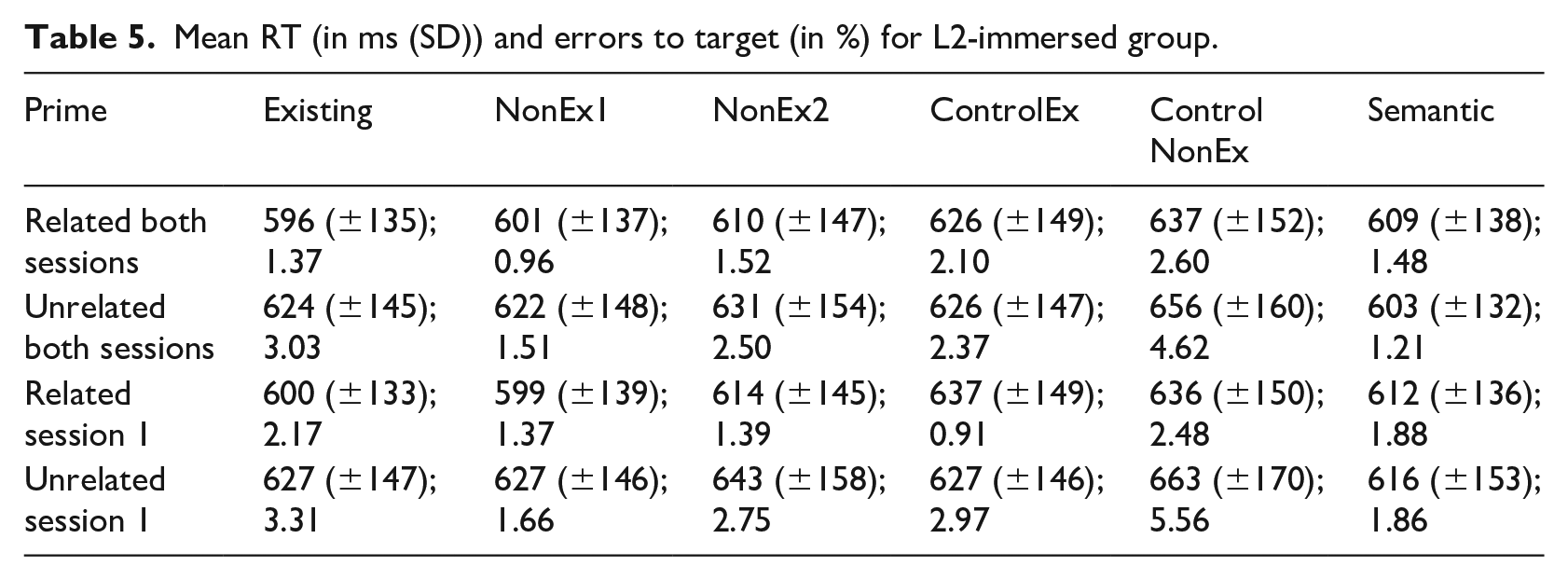
Two targets were excluded due to high error rates and one due to a coding error (1.4% of data). Three targets (weisen ‘to point’, ahnden ‘to punish, avenge’, heiß ‘hot’) were excluded due to error rates >25% (1.36% of data). Reaction times which deviated by more than two standard deviations from an individual participant’s mean RT were also excluded (2.3% of data) and only correct responses were included for analysis (4.45% of data excluded). Mean reaction times including standard deviations and mean error rates are provided in Table 5. A Box-Cox transformation (Box & Cox, 1964) was carried out (λ = −0.5858) which, combined with visual inspection of histograms and Q-Q plots, indicated that it was most appropriate to use log-transformed RT, which is used in all analyses of RT to targets (Baayen & Milin, 2010).
Mean RT (in ms (SD)) and errors to target (in %) for L2-immersed group.
Reaction time analysis
The data was analysed using a linear mixed effects model in R (R Core Team, 2013) using the lme4 (Bates et al., 2014) package with fixed effects of Prime (related vs unrelated) and Base (Exist, NonEx1, NonEx2, ControlNonEx, ControlEx and Semantic) and subject and items as random factors. Starting from the maximal model (cf. Bates et al., 2015; Matuschek et al., 2017), the model with the best fit for both data sets (both sessions combined and Session 1 only) included only random intercepts, 5 as models with random slopes for either items or subjects did not converge or produced indicators of overfitting. In addition, Q-Q plots and histograms were visually inspected for model fit and distribution of residuals.
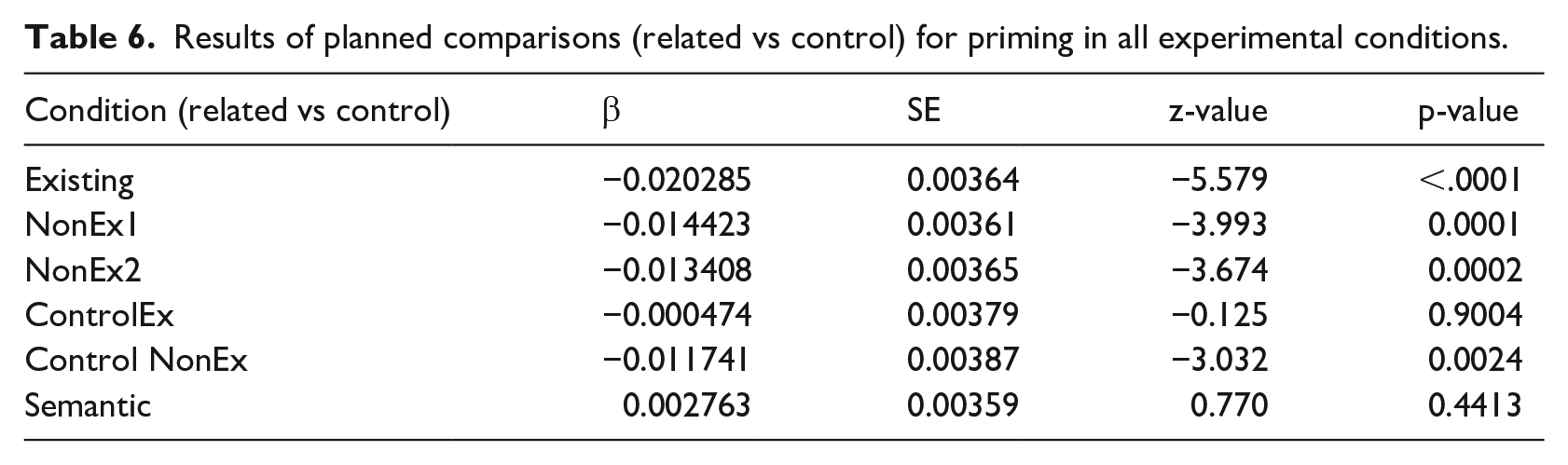
Comparisons with the maximal model indicated that the inclusion of both Prime (χ2(1) = 40.629; p < .0001) and the Prime*Base interaction (χ2(5) = 29.435; p < .0001) significantly improved model fit, while the coefficient representing the main effect of Base only did not (χ2(5) = 8.675; p = .112). As the interaction reached significance, pairwise comparisons of the priming effects were conducted in all conditions using emmeans (Lenth, 2020). The results of these comparisons showed significant facilitation in all three morphological conditions, while neither ControlEx nor the Semantic condition resulted in significant facilitation; this pattern is expected considering the results of the L1-immersed group as well as those in delayed priming experiments more generally (see Table 6 for results). This shows that the priming effect is not a result of form or semantic overlap but is driven by morphological structure. However, unlike in the L1 data, the ControlNonEx condition (pairs such as *Steillein – STEIL ‘steep’) resulted in significant facilitation in the analyses of all data combined as well as that of Session 1 only (Figure 1).
Results of planned comparisons (related vs control) for priming in all experimental conditions.
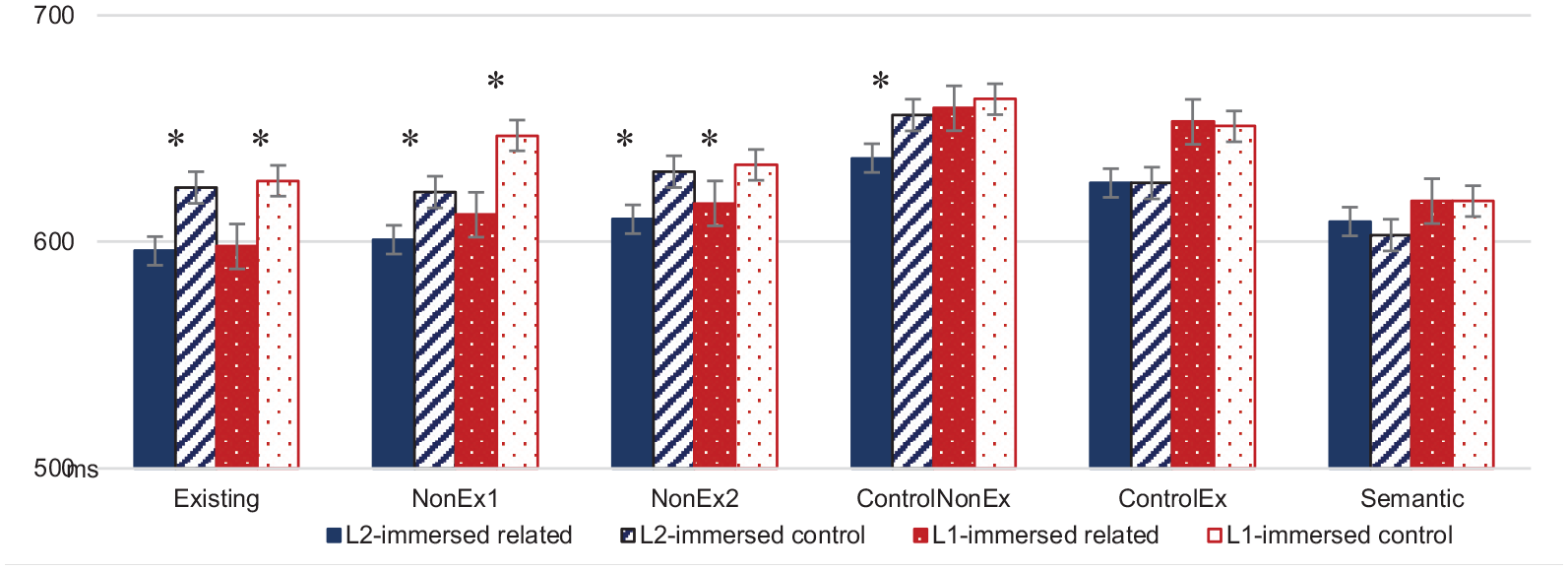
Mean RT (in ms) by condition for both L1-immersed and L2-immersed speakers.
A further analysis using only the data from the three morphological conditions (Existing, NonEx1, NonEx2) showed only an effect of the inclusion of Prime (χ2(1) = 59.125; p < .0001) but no effect of Base (χ2(2) = 0.3136; p = .8549), and including an interaction of Prime*Base did not significantly improve model fit (χ2(2) = 2.1774; p = .3367). This is in contrast to the results in the L1-immersed group and indicates no difference in the degree of facilitation between the three morphological conditions in the L2-immersed speakers. This result, combined with the facilitation in the ControlNonEx condition, suggests reduced sensitivity to the differences in the derivational chains of morphologically complex items as well as to the legality of combinations which are not attested in the lexicon.
Error analysis
The error data was analysed using a binomial logistic regression (GLM) with Base and Prime as fixed factors and Error as the dependent variable. The same exclusion criteria as for the reaction time analysis were used but both correct and incorrect responses were included in the analysis. In the analysis of errors in both sessions combined, both main effects showed a significantly improved fit of the model (Base: χ2(5) = 22.959; p < .0001; Prime: χ2(1) = 7.641; p = .0057), while the interaction of Prime*Base did not reach significance (χ2(5) = 3.990; p = .5509). Thus, no planned comparisons were carried out for the interaction Prime*Base. A closer investigation of Base showed marginally significant differences in error rates between the conditions NonEx1 and Existing and between NonEx1 and ControlEx as well as significantly greater error rates in the ControlNonEx condition than in all other conditions.
Reactions to primes
Due to the nature of the primes in the three morphological conditions, an analysis of reaction times and errors to primes was conducted to determine whether L2-immersed speakers showed similar difficulties to L1-immersed speakers in rejecting plausible non-existent items (Conditions NonEx1 and NonEx2) as well as morphologically illegal combinations (ControlNonEx; see Table 7).
L2-immersed group responses to primes: mean RT (in ms (SD)) for both correct and incorrect trials and error rates (%).

Reaction time analysis
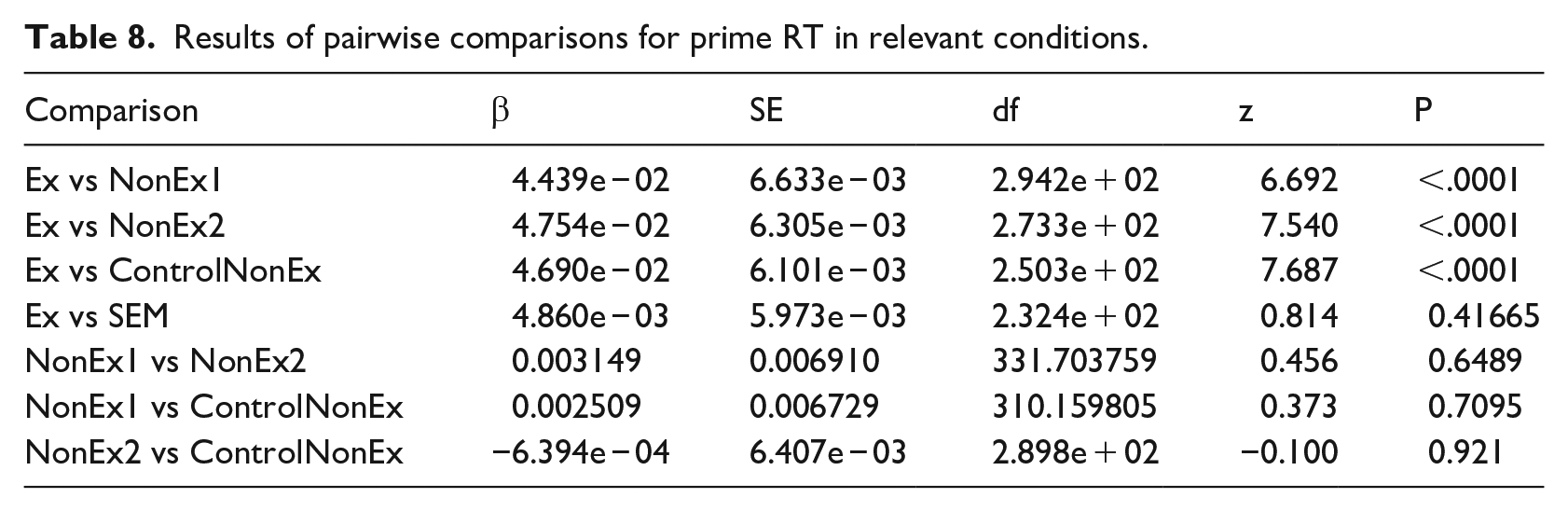
Despite the fact that the primes in some conditions were non-words and in certain conditions the error rate indicated that performance was no better than chance, only trials with correct responses were included in the reaction time analysis presented below. As above for target RT, the data was analysed using a linear mixed model with Base as a fixed factor and Subject and Item as random factors. Data was log transformed (Box-Cox transformation: λ = −0.18182) as visual inspection showed an improved fit for log transformed RT compared with raw RT. There was a significant main effect of Base (χ2(5) = 102.65; p < .0001), with RT to the real word primes (in both the Existing and Semantic conditions) being significantly faster than to the non-word primes. There were no significant differences between the reaction times to the three types of non-word primes. For a summary of comparisons, see Table 8. This matches the patterns observed in the L1-immersed dataset.
Results of pairwise comparisons for prime RT in relevant conditions.
Error analysis
Participants operate at chance level in condition NonEx1 (with error rates of 46% to 52% on target recognition), while in all other conditions their level of accuracy is >70%. As for error rates to targets above, the error data was analysed using a binomial generalised linear model (GLM) with Base as the fixed factor and Error as the dependent variable. The same exclusion criteria were used as in the reaction time analysis but both correct and incorrect responses were included in the analysis. The main effect of Base was highly significant (χ2(5) = 881.93), which was driven by large differences between the word and non-word primes.
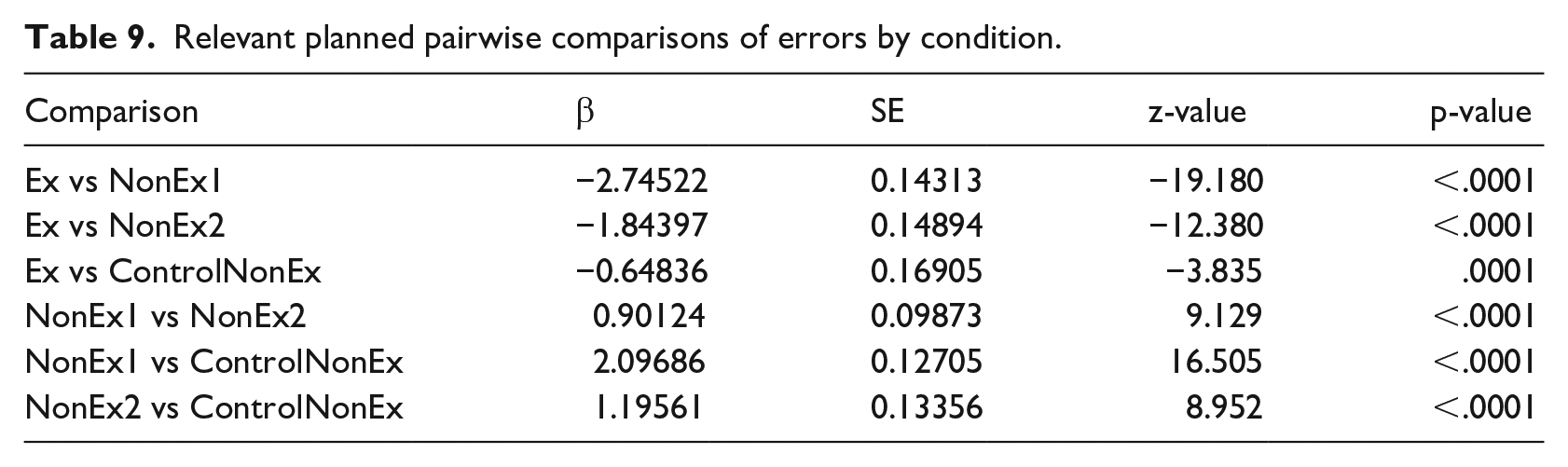
All three non-word conditions, NonEx1, NonEx2 and ControlNonEx, elicited significantly higher error rates than the Existing condition (see Table 9 for results), indicating that all types of non-words were more difficult to reject. The same gradient pattern in terms of difficulty of rejection is seen as in the L1-immersed speakers (see Figure 2 for a comparison), with the more plausible items (NonEx1) generating higher error rates. It thus seems that L2-immersed speakers are still as receptive to differences in plausibility generated by the existence of the intermediate verb or adjective in the *Spitzung cases. These differences affect participants’ ultimate decision but are not reflected in the degree of facilitation of the stem.
Relevant planned pairwise comparisons of errors by condition.
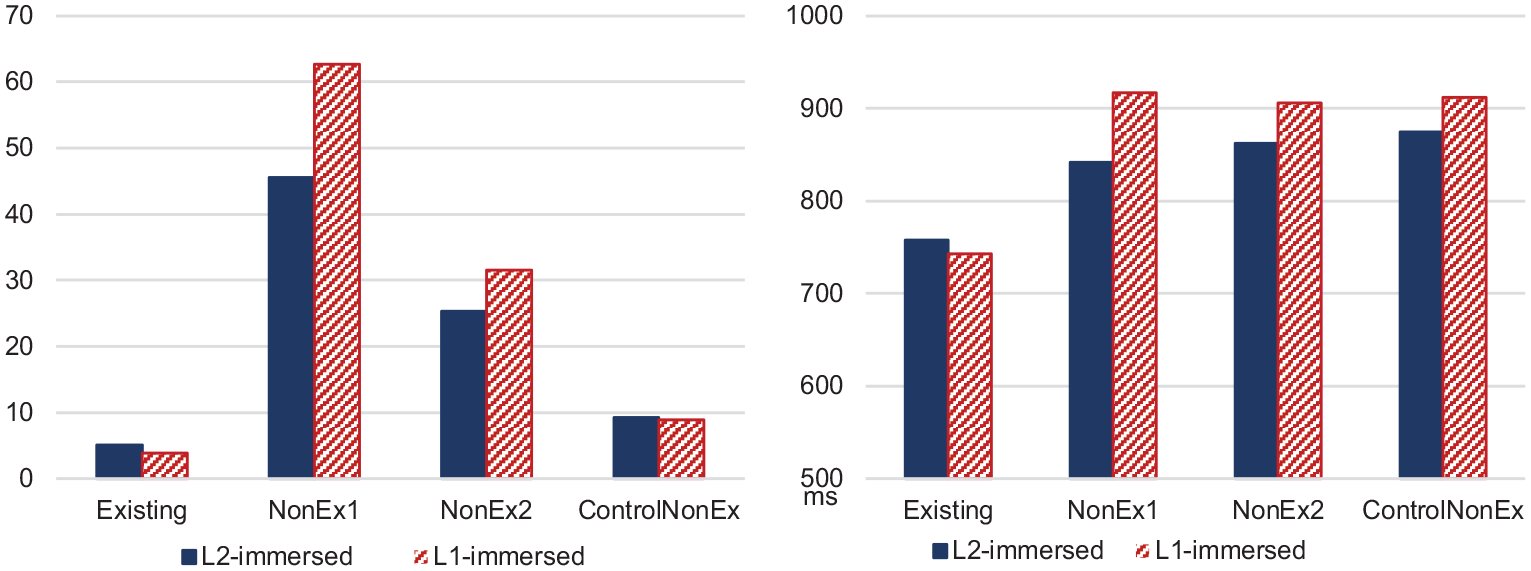
Error rates (in %) and RT (in ms) to primes for L1-immersed and L2-immersed speakers.
Results of the language-environment manipulation
To establish the effect of the language-environment manipulation conducted before the experiment in one of the two sessions for each participant, we conducted a linear mixed effects model with the fixed effects Prime (related vs unrelated), Base (Existing, NonEx1, NonEx2, ControlNonEx, ControlEx and Semantic) and Environment (English and German) with subject and items as random factors (with random intercepts only as the inclusion of slopes resulted in indicators of overfitting). In the analysis of the complete dataset (both sessions), neither the individual factor Environment (χ2(1) = 0.1184; p = .7308) nor any of the interactions including Environment reached significance (Prime*Environment: χ2(1) = 2.7291; p = .0986; Base* Environment: χ2(5) = 1.0952; p = .3607; Prime*Base* Environment: χ2(5) = 1.7965; p = .1009).
Analysis of session 1 only
In an analysis of Session 1 only, however, Environment (χ2(1) = 11.4247; p = .0020) and Prime* Environment (χ2(1) = 4.7642; p = .0291) are both significant, while the interactions of Base* Environment (χ2(5) = 0.9711; p = .43395) and Prime*Base* Environment (χ2(5) = 1.2912; p = 0.2646) do not reach significance. The effect in the interaction Prime* Environment is driven by a significant effect of Prime in the German-led condition only (β = −0.061, SE = 0.0137, z = −4.446, p < .0001).
In the data for Session 1 only, participants’ reaction times are overall significantly faster in the German-led set (mean RT: 576 ms) than in the English-led set (mean RT: 676 ms), and relatedness of prime and target is affected by language environment with a facilitative effect of relatedness in the German-led set.
However, even if we perform an analysis of the morphological conditions in the German-led set only, there is no significant difference in the degree of facilitation between the morphological conditions (i.e. no effect of Base (χ2(2) = 1.2972; p = .2689) and no difference in the degree of priming between the three morphological conditions (Ex-NonEx1: β = −0.001, SE = 0.0036, z = −4.446, p < .0001; Ex-NonEx2: β = 0.0048, SE = 0.0036, z = −1.3389, p = .1807; NonEx1-NonEx2: β = 0.006, SE = 0.0036, z = 1.6929, p = .0906), which would be comparable with the differences between the morphological conditions found in the L1-immersed group. In addition, the ControlNonEx condition, which showed facilitation in the complete dataset, still shows significant priming effects in the German-led set only (β = 0.0138, SE = 0.005, z = 2.5599, p = .0.0105). Thus, performing a ‘settling-in task’ in the non-dominant L1 has some facilitative effect, especially on overall reaction times, but does not, in this instance, result in the same processing patterns observed in L1-immersed processing. The results and their implications will be discussed below.
General discussion
The purpose of the present study was twofold: (i) to investigate the effects of first-language attrition on morphological processing and (ii) to determine the suitability of L2-immersed native speakers for participation in investigations into native language processing with and without a ‘language-environment task’. We thus asked the following questions:
What effect do immersion in an L2 environment and the presence of a dominant second language have on the processing of morphologically complex words?
How does a manipulation of the experimental environment (i.e. speaking only German to the participants) affect participants’ processing?
What are the potential consequences of using L2-immersed native speakers in experimental studies on native processing?
To address these questions, we compare morphological processing in German native speakers immersed in their native-language environment with that of speakers who are L2-immersed (L2 English). Using the same experimental design and stimulus set as Schuster and Lahiri’s (2018) Experiment 3, we examine speakers’ sensitivity to differences in derivational depth and violations in the derivational chain in German words where either one or two intermediate stages are non-existent. Stimuli consisted of existing nouns with two-step derivations as well as plausible pseudowords such as *Spitzung and *Hübschung which follow a common derivational process: adjective > verb (-en) > noun (-ung), in order to investigate whether the effects found by Schuster and Lahiri, which indicate a sensitivity to the internal structure of lexical items and pseudowords, are also found in speakers who are undergoing language attrition. In addition, with a methodological aim in mind, we introduced an experimental manipulation of language environment to determine whether exposing the subjects to a native-language environment prior to the experiment would result in any differences in the experimental results. We will first revisit Schuster and Lahiri’s (2018) original results and summarise our results with reference to their findings before exploring possible reasons for the observed differences. Then we will discuss the effects of the language environment task and the notion of native processing in light of the present study and previous recent research.
L1 attrition effects in morphological decomposition
Schuster and Lahiri (2018) found that native speakers of German showed sensitivity to both the differences in the distance from the prime to the nearest attested word as well as the plausibility of pseudowords depending on the number of ‘missing’ links in the derivational chain. Their results show priming in all three morphological conditions, but significantly stronger facilitation for non-word items such as *Spitzung, where the intermediate verb spitzen ‘sharpen’ is an existing word, than for those items where the verb does not exist (e.g. *Hübschung). This shows that stems are accessed even when a word is not represented in the lexicon and that this priming effect is weakened by a higher processing cost when the closest real word in the derivational chain is further away (i.e. *Spitzung > spitzen is more direct than *Hübschung > *hübschen > hübsch). This sensitivity must therefore be contingent on the availability of subconscious knowledge of morphological paradigms and the use of this knowledge during processing. Reactions to primes also showed a discrimination of the degree of plausibility of the non-words, with primes such as *Spitzung being considered more plausible than the *Hübschung kind, as can be seen from the significantly larger number of errors made in the *Spitzung cases. Schuster and Lahiri (2018) state that the increased interpretability and plausibility of these items results from the presence of the intermediate form (e.g. spitzen ‘to sharpen’) in the derivational chain. They conclude that speakers are sensitive to both the number of steps in a derivational chain (cf. also Meinzer et al., 2009; Pliatsikas et al., 2014) and the lexical status of individual items of the chain.
In the language attrition data, priming is also observed in all morphological conditions, which indicates that the decomposition process has remained unaffected by the exposure to an L2-dominant environment and that stems are primed by plausible complex forms regardless of their lexical status. There is, however, no significant difference in the degree of priming between any of the three conditions. It seems that the L2-immersed group treat existing words (e.g. Heilung ‘healing’) and both types of non-existent items in the same way. Thus, for the attriters, access to the stem is facilitated equally regardless of the lexicality, plausibility and number of gaps in the derivational chain of the complex item. A further difference is the facilitation effect observed for morphologically illegal items (ControlNonEx, e.g. *Steillein – STEIL) where suffixes are combined with stems they do not attach to (e.g. the diminutive suffix -lein only attaches to nouns), which was not found in the L1-immersed data. Previous research has shown that semantic interpretability, for instance, is affected by legality and only morphologically legal combinations are judged as interpretable (cf. Meunier & Longtin, 2007). However, as discussed above, greater reliance on form overlap (rather than morphological or semantic relatedness) has been observed in studies of L2 processing (e.g. Heyer & Clahsen, 2015) and has been cited as evidence of shallower processing (Clahsen & Felser, 2006, 2018). It is possible that L2-immersed native speakers are showing a similar processing tendency to proficient L2 learners. This will be discussed further below.
Where the reactions to the primes are concerned, however, the L2-immersed group behaves much like the L1-immersed group in terms of the overall pattern. Here, we also find much higher error rates to primes of the *Spitzung type which are considered more plausible and subjects were at chance level (52% errors), while primes of the *Hübschung kind were much easier to discard (27% errors) as non-words. Reaction times to primes only showed a difference between the existing items and both non-existent conditions, with real word primes being responded to significantly faster. This is the same pattern of results observed for L1-immersed speakers and indicates that L2-immersed speakers’ lexical judgements have remained stable, as has their assessment of plausibility based on the violations of the morphological chain. Like the L1-immersed group, the attriters rejected illegal non-words (e.g. *Steillein) much more accurately than the legal pseudowords and reacted to all three types of pseudowords at similar speed.
The reaction time results indicate reduced sensitivity to the internal structure of derivational chains, while the result of the illegal pseudoword condition, while surprising in a native-speaker context, may be an indication of a shallower processing approach where form-based similarity plays a more central role regardless of legality. Thus, it seems a morphologically complex item is decomposed into its constituent morphemes regardless of the legality of the combination. However, if this were the sole factor, we would have expected to see facilitation in the ControlEx condition (e.g. Täublein – TAUB). However, if anything, there is a numerical tendency towards inhibition in this condition. Täublein ‘little dove’ would have facilitated access to Taube ‘dove’ rather than taub ‘deaf’, which would not even be a competitor or might even be suppressed. While, when stripping -lein from steil ‘steep’ in *Steillein, it is the only possible stem with no competitors to inhibit access. The reduction in sensitivity and apparent decomposition of illegal combinations is reminiscent of proposals for L2 processing such as the Shallow Structure Hypothesis (Clahsen & Felser, 2006, 2018) or a greater reliance on declarative knowledge (Ullman, 2004). Shallower processing could account for the fact that the difference evident in L1-immersed native speakers’ processing of the three morphological conditions does not seem to apply in the attrition group’s processing. There may, of course, be a number of other contributing factors which the present study cannot definitively account for and which will need further investigation. These factors include, for instance, the effect of the morphological structure of the dominant L2: for instance, the fact that the intermediate stage in the examined derivational chain for some of the stimuli (verb in -en) is frequently zero-derived in English may have lessened the effect of this particular step. This would have to be tested with speakers of a dominant L2 where comparable paradigms are available (e.g. German speakers with Dutch as an L2). However, previous studies (e.g. Meinzer et al., 2009; Pliatsikas et al., 2014) have shown native speakers’ sensitivity to derivational depth in zero-derived items, which, if we assume ‘native’ processing in the L2, makes the above hypothesis unlikely. Other factors such as the precise degree of attrition, exposure and use of L1 and proficiency in L2 may well also modulate the morphological attrition effects, and their effect on L1 attriters’ morphological processing will need to be investigated in further studies.
Manipulating language environment
A second aim of the present study was the methodological issue of using L2-immersed native speakers in experimental research, given the (often subconscious) assumption that L1 proficiency or ‘nativeness’ is a stable property which remains intact and unaffected even when faced with a dominant L2 and concomitant decrease in everyday L1 use. In an effort to replicate the conditions of research carried out on native speakers, we did not test our speakers for proficiency in either language and collected only minimal language history data. To increase the likelihood of attrition effects, we stipulated that our participants did not use their native German as part of their jobs or with anyone living in their household and reported a very low day-to-day use of German. LoR in the UK had to be a minimum of two years but varied widely. As detailed in the methodology section, the participants attended two experimental sessions: one where they were spoken to entirely in English and one where they spoke German with the experimenter for 15 to 20 minutes prior to the start of the experiment to investigate whether this would more strongly activate their L1 and affect the experimental results. The data from German-led sessions showed significantly faster reaction times overall but the type of session did not affect the patterns of facilitation. Thus, while participants were faster overall and the German-led session also showed a slightly greater facilitation effect overall, the data did not show the same sensitivity observed in the L1-immersed group. Thus, ‘settling’ tasks seem to have an effect of overall ease of access to the lexicon but not on the processing patterns. How long re-exposure to the L1 would have to be for attrition effects to subside is, of course, a question of great interest and there have been a very small number of ‘re-entry’ studies (e.g. Chamorro et al., 2016), which are, for methodological reasons, generally case studies of individuals returning to their L1 environment. Much more research is necessary to establish whether, and how soon, language performance returns to L1-immersed patterns, and research indicates that (similarly to the timeline of attrition effects setting in) this will differ for individuals depending on a large number of interconnected factors. Nevertheless, our results seem to indicate that recruiting L2-immersed native speakers for experimental studies investigating ‘native’ processing without any assessment bears a certain risk, as they may not employ the same mechanisms as their L1-immersed counterparts. A language activation task cannot with any certainty induce a more native-like processing pattern. Precisely what is understood by ‘native’ processing, or ‘nativeness’, and whether this is a stable property, is addressed in the following section.
Nativeness, L2 acquisition and L1 attrition
The term ‘native competence’ or ‘nativeness’ is most frequently used in the context of language teaching and then generally with reference to attainment in a second language. Late second-language learners (i.e. those learning their L2 after the age of 15; cf. White & Genesee, 1996) had long been thought to be unable to achieve native-like competence in their second language and cases where learners achieve such high proficiency were thought to be comparatively rare. This has been called into question more recently by a number of studies (e.g. Birdsong, 1992; Ioup et al., 1994; cf. Abutalebi & Clahsen, 2018 for an overview of recent studies on critical periods for language acquisition), with a number of psycholinguistic and neurolinguistic studies finding native-like processing patterns in highly proficient L2 learners. In addition, recent research has found differences in processing which correlate strongly with proficiency scores in the native language (cf. Kasparian et al., 2017; Pakulak & Neville, 2010; Prat, 2011), suggesting not all native processing is identical.
Since there is no precise definition of what native linguistic competence entails and which elements should be measured to ascertain whether a speaker has such competence, it can also not be entirely clear what learners are aiming for. This has, of course, been a much-debated topic in language testing, since it is not always easy to determine what precisely is being (or should be) measured. Proficiency measurement usually entails the assessment of learners in terms of their language use, i.e. in the four skills (speaking, listening, reading and writing). However, this shows their knowledge and application of, for instance, grammatical knowledge as well as their receptive skills but is not strictly speaking a measure of competence (cf. White & Genesee, 1996). In L2 learners, there may be a difference in two areas: their underlying implicit knowledge of, for instance, the grammatical system of the language and/or the access to and use of this information during language production and processing (cf. Chamorro et al., 2016; White & Genesee, 1996). Proficiency tests do not usually measure language processing (e.g. lexical access speed) and while proficiency testing and fluent and effortless communication can indicate native-like knowledge of the language, it cannot tell us which mechanisms learners are using to achieve the execution of these skills and whether these mechanisms are similar to those used by native speakers. However, in language attrition studies, a number of measures are used in addition to traditional proficiency measures (e.g. the language attrition test battery; Schmid, 2002, 2011), but most of these are still offline measures.
In morphological processing, recent studies have shown that the processing of complex morphological words, for instance, recruits similar brain areas in learners and native speakers (e.g. Pliatsikas, Johnstone, & Marinis, 2014) and also shows behaviourally similar processing patterns (e.g. Coughlin & Tremblay, 2015; Gor et al., 2017; Jacob et al., 2013). In addition, studies conducted with native monolingual speakers have shown effects of proficiency on L1 processing even in the absence of a dominant second language (Kasparian et al., 2017; Pakulak & Neville, 2010; Prat, 2011). Thus, if there are differences in processing patterns in native speakers depending on their degree of proficiency and immersion in their L1, is the concept of ‘native processing’ a useful one or does a more gradient approach need to be taken which includes the whole continuum of degrees of language dominance?
Discourse about the two languages of a bilingual in terms of language dominance does exist but is often still restricted to discussion of simultaneous bilinguals or bilinguals with exposure to both languages from an early age (e.g. Luk & Bialystok, 2013; Prior & Gollan, 2011) where a clear sequence of acquisition cannot be established, rather than those individuals who have acquired one language natively (and often monolingually) before being exposed to a second language, such as the participants in the L2-immersed group in the present study. Further investigation is needed in this area, which may necessitate a shift in the well-entrenched perception of ‘nativeness’ as a stable monolithic property.
Conclusions
The present research was partly motivated by methodological questions relating to the participation of L2-immersed native speakers in L1 processing studies. Our results indicate that the effect of a dominant L2 on the L1 system should not be underestimated and should be taken into account in participant recruitment.
However, the key findings of the present paper are those that indicate changes in the processing patterns of morphologically complex words in speakers whose L1 is undergoing language attrition. While the results show stability in word-pseudoword recognition and acceptance as well as similar plausibility judgements compared with an L1-immersed test group, the patterns of facilitation seen in the L2-immersed group show a lack of sensitivity to the legality of combinations as well as differences in the existence of links in a derivational chain. L2-immersed speakers’ lexical decisions on pseudowords are guided by the plausibility and legality of these items in a similar way to those of L1-immersed participants, which indicates that their judgement of the legality of morphological complex items is unaffected. However, in terms of processing, the L2-immersed group seem to employ a shallower approach to morphological decomposition, which resembles that of L2 learners found in other research. Thus, while the mechanism of morphological decomposition as such remains stable in L1 attrition, it seems that the degree or ease of access to the stem is not affected by finer morphological distinctions such as the existence of intermediate links in a derivational chain. If, as some proposals advocate (Baayen et al., 1997; Caramazza et al., 1988; Frauenfelder & Schreuder, 1992), there are two routes available to speakers in dealing with morphologically complex items, the distribution of use may change in the presence of a dominant L2 in a way which may be similar to that observed in L2 learners of increasing proficiency. More research encompassing L2 learners, L1 attriters and stable monolinguals is needed to establish the precise factors which contribute to changes in processing and whether L2 learners and L1 attriters do indeed use available resources and mechanisms in similar ways. If this is the case, this leads inevitably to the need to re-evaluate and reframe the concept of ‘nativeness’.
Supplemental Material
sj-pdf-1-ijb-10.1177_13670069211019480 – Supplemental material for Still ‘native’? Morphological processing in second-language-immersed speakers
Supplemental material, sj-pdf-1-ijb-10.1177_13670069211019480 for Still ‘native’? Morphological processing in second-language-immersed speakers by Sandra Kotzor, Swetlana Schuster and Aditi Lahiri in International Journal of Bilingualism
Footnotes
Acknowledgements
We would like to thank, first and foremost, our participants without whom this study could not have taken place. In addition, thanks are due to Yoolim Kim and Kim Fuellenbach for helping with data acquisition and to Emily Darley, Hilary Wynne and Steven Kaye for assisting with data analysis and proofreading. We also thank the two anonymous reviewers as well as Allison Wetterlin and Linda Wheeldon for their constructive comments on previous versions of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by a Horizon 2020 ERC Advanced Grant awarded to Aditi Lahiri (695481).
Supplemental material
Supplemental material for this article is available online.
Notes
Author biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.