
Abstract
Aims:
We study how emotions are represented in Polish-English and Romanian-English bilinguals, whose respective languages either mostly share emotion lexicon (Romanian-English) or not (Polish-English). We test to what extent such variance in lexical proximity between the two bilingual groups affects their decisions about emotional word content.
Methodology:
In a masked priming paradigm, participants viewed prime-target adjective pairs, and judged whether the target adjective was positive or negative in meaning. Primes and targets either named (emotion word) or evoked (emotion-laden word) emotions, and were either related – that is, belonged to one word type (emotion or emotion-laden) – or unrelated.
Data and analysis:
Behavioural data were analysed using linear mixed-effects models, with within-subject fixed effects of language, word type, valence and relatedness, and their interactions.
Findings/conclusions:
We found processing facilitation of emotion-laden rather than emotion words in both participant groups, irrespective of language of operation. Emotion target adjectives, particularly of negative valence, tended to slow down responses of Polish-English bilinguals in their first language. In the Romanian-English group, emotion target adjectives were recognized with lower accuracy in the second language. This pattern of results suggests that affective responsiveness is modulated by the lexical proximity between the first language and second language.
Originality:
Extending bilingual emotion research, this study tests how emotions are represented in languages that vary in lexical proximity with English: Polish and Romanian. We demonstrate that cross-linguistic differences between the respective languages of a bilingual impact emotional meaning processing in the first and second language.
Significance/implications:
We provide support for the emotion context-of-learning theory, language-specific episodic trace theory and the sense model in bilingualism, showing that cross-linguistic differences between the first and second language modulate emotion and emotion-laden word processing. Our findings also demonstrate that the distinction between the emotion and emotion-laden words is not as universal as previously assumed.
Keywords
Introduction
It has been accepted in studies of bilingualism that the experience of emotions in the second language (L2) is markedly different from that in one’s first language (L1). On the one hand, emotions in a bilingual’s L2 are generally perceived as being subjectively less negative (Bond & Lai, 1986; Marian & Kaushanskaya, 2008). Negative emotions in L2 appear to be emotionally blunt, as evidenced by data from electrophysiology (EEG; Jończyk et al., 2016, 2019; Wu & Thierry, 2012), eye tracking (Iacozza et al., 2017; Toivo & Scheepers, 2019) and galvanic skin responses (Jankowiak & Korpal, 2018). On the other hand, emotions experienced in L2 were shown to be perceived as insincere and artificial (Dewaele & Nakano, 2013; Pavlenko, 2006). More critically, emotions in L2 are reportedly less intense (Anooshian & Hertel, 1994; Dewaele & Pavlenko, 2002; Pavlenko, 2005). Such blunted emotional reactivity may lead to more rational and utilitarian choices in decision-making. It has been demonstrated that bilinguals make less emotional, more rational decisions when they make them in their L2 (Keysar et al., 2012). Furthermore, when faced with decisions between options that would serve the well-being of the society at large or themselves, bilinguals are more likely to opt altruistically for the former than the latter (Corey et al., 2017; Costa et al., 2014). Although these findings have been supported by a considerable body of evidence (for a recent review, see Caldwell-Harris, 2014), the core assumption that makes L1 more and L2 less emotional has started to shift in recent years.
Cross-linguistic and bilingualism studies have found that different languages conceptualize emotions differently. They have also consistently found that there are enough semantic commonalities between languages to allow effective emotional communication, even across vastly different languages (Alvarado & Jameson, 2011; Russell et al., 1989). Regarding emotion processing in bilinguals, it is becoming increasingly accepted that how a bilingual processes words denoting emotions may be affected by many factors (e.g. age of acquisition, language proficiency, language immersion, context of acquisition; Dewaele, 2010; Pavlenko, 2012). Emotion concepts are forged through experience and they can change with experience, and that includes experiencing things in a language other than L1. Emotional experiences formed in the immersive context of L2 can be as strong as those experienced in L1, and this applies to early (Dewaele, 2010; Harris et al., 2006; Schrauf & Rubin, 1998) as well as late exposures (Pavlenko, 2012) to L2 culture and language. A growing body of evidence is now leaning towards language dominance as one of the critical factors determining which of a bilingual’s two languages is the more emotional one (Jończyk et al., 2016; Pavlenko, 2012).
It has long been understood that communicating emotions is primarily the domain of non-verbal and paraverbal cues such as body language and emotional prosody, respectively (Mehrabian, 2007). In language research, the expression of emotion has been the subject of debate for decades. Because emotional and linguistic development go hand in hand, language is suffused with emotion in different aspects of semantics (Bloom & Beckwith, 1989). Emotion concepts form prototypical structures (Ekman, 1994; Russell, 1983), reflected in language as emotion words arrayed in language-specific emotion lexicons (Caldwell-Harris, 2014). Beyond the centre are the peripheries, with concepts that become less and less like the prototype the further they are from the centre (Lindquist et al., 2014). Emotions constitute a distinct conceptual category within the mental lexicon, distinct – but not discrete (Altarriba & Bauer, 2004; Altarriba et al., 1999). Prototypical emotion concepts are connected by latent aspects of their semantics with a wide range of non-emotional concepts (MacKay & Miller, 1994). For some of those distant connections the only thing a peripheral concept shares with a given prototypical emotion concept is an underlying meaning of broadly defined positive or negative emotionality or affect. Words denoting such peripheral concepts are usually called emotion-laden words. This broad category of words provides a useful contrast to the well-defined prototypical emotion concepts, allowing researchers to map the emotion concepts themselves more effectively (Altarriba, 2006; Kazanas & Altarriba, 2015a; Pavlenko, 2008).
The ‘emotion’ aspect in this area of research is typically limited to the core dimension of valence, with a simple distinction between positive and negative words. This has two major advantages. First, the valence dimension is a cultural universal (Ekman, 1999; Harkins & Wierzbicka, 2001; Russell, 1983). Second, this approach allows for deploying the growing number of affective language databases compiled in a variety of languages and containing broad selection of words evaluated for the core dimensions of valence, arousal, and dominance (e.g. Bradley & Lang, 1994; Imbir, 2016; Riegel et al., 2015; Scott et al., 2019; Warriner et al., 2013). This possibility of mapping emotion concepts is less transparent in the bilingual contexts. It has been observed that emotion lexicons in bilinguals’ L1 and L2 are typically different from those observed in monolinguals of the respective languages (Alvarado & Jameson, 2011). With that, bilinguals have been found to differentiate very clearly between words denoting emotions and those which are emotion laden (Pavlenko, 2008). Some evidence points to overall processing facilitation effects; that is, faster and more efficient processing, for emotion words for bilinguals in both L1 (Ponari et al., 2015) and L2 (Altarriba & Basnight-Brown, 2011). There is further evidence that the processing of positively valenced emotion-laden words is facilitated in whichever language the bilingual is dominant (Altarriba & Basnight-Brown, 2011). Finally, at least one study points to positive emotion words’ processing advantage in the dominant language, and disadvantage in the non-dominant language. The same study indicates that positively valenced emotion-laden words are processed more efficiently in the non-dominant language, and the negatively valenced ones are processed less efficiently in the dominant language (Kazanas & Altarriba, 2015a).
The study of emotion concepts in bilingualism utilizing the emotion versus emotion-laden word contrast has so far largely relied on Spanish-English bilinguals residing in the USA. The English-speaking western individualist culture has been at the centre of emotion research, the major point of reference and comparison virtually since the beginning of this field (Ogarkova, 2013). For our study, therefore, we selected two samples of bilinguals from countries where the spheres of influence from the individualist west and collectivist east meet: Poland and Romania. Both Polish and Romanian cultures show strongly individualistic traits characteristic of the west with certain key collectivist traits more typical of the eastern and Mediterranean cultures, respectively (Ciochină & Faria, 2009; Szarota et al., 2015). Polish is a fusional Slavic language with relatively few borrowings from English. Romanian is a fusional Balkan Romance language, heavily influenced by many languages and with a large portion of its vocabulary based on Latin and French, and currently heavily borrowing from English. As English also has a considerable portion of its vocabulary based on Latin and French, it shares many cognates with Romanian. Aside from that similarity, Polish and Romanian, both inflectional languages, have a very different structure from English. Our participant samples were intentionally selected to be dominant in their mother tongues and come from populations residing in countries where those languages are spoken. Languages lexicalize emotions into linguistic codes differently (Clore & Ortony, 1988; Clore et al., 1987; Osgood et al., 1975). We therefore theorized that both the cultural and linguistic differences between Polish, Romanian and English would manifest in different patterns of responses to emotion and emotion-laden words in their L1s (Polish/Romanian) and L2 (English).
In research on emotion and emotion-laden word processing, an often ignored but significant aspect of word meaning is parts of speech (Palazova et al., 2011). In the present study, we chose to use exclusively adjectives because by raw counts adjectives tend to be the most numerous part of speech in the category of both emotion and emotion-laden words (Bąk, 2020). This gave us a larger pool of words from which to choose stimuli matched on word lengths and frequencies to an acceptable level. And, although it is a common practice in bilingual research to compile a list of stimuli in one language and translate that list into another (e.g. Kazanas & Altarriba, 2016), we opted not to use translation equivalents for the reasons presented below. First of all, the same emotions are both conceptualized and lexicalized differently between languages (Alvarado & Jameson, 2011; Osgood et al., 1975; Wierzbicka, 1999). Second, we aimed to preserve the structural and semantic differences afforded by Germanic (English), Slavic (Polish) and Romance (Romanian) languages. We also found that translating what is an emotion word in one language often resulted in an emotion-laden word in another. Further, in line with evidence showing unconscious nonselective access to words in L1 while performing a task exclusively in L2 (e.g. Thierry & Wu, 2007; Wu & Thierry, 2012), we chose not to include translation equivalents to preclude the unconscious lexico-semantic priming. Hence, selecting adjectives only and not relying on translation equivalents for stimuli allowed us to create a better-controlled set of stimuli that still satisfied our key requirements. Those requirements included every word clearly either denoting an emotion or being laden with emotional meaning and being unambiguously positive or negative.
As the processing of emotion versus emotion-laden words is moderated by valence (Kazanas & Altarriba, 2015a), in the present study we employed a valence decision task (VDT) in a backward masked priming paradigm. With this task, participants would focus critically on the valence of the target adjectives presented to them, deciding whether they were positive or negative. The masked primes would always match targets on valence (positive vs. negative), but not always on word type (emotion vs. emotion-laden word). We manipulated the prime-target word pairs so that the pairs were either related, meaning both prime and target belonged to one word type, or unrelated, meaning one was an emotion word, the other an emotion-laden word. Based on prior research, we predicted: (a) processing facilitation (i.e. faster reaction times) for L1 rather than L2, for related rather than unrelated, and for positive rather than negative target adjectives (e.g. Alves et al., 2017; Kazanas & Altarriba, 2015a; Larsen et al., 2008); (b) processing facilitation for emotion rather than emotion-laden target adjectives (Knickerbocker & Altarriba, 2013) – this effect was expected to be stronger in the dominant language, because emotion as opposed to emotion-laden concepts are claimed to be better grounded in that language (Kazanas & Altarriba, 2016); (c) processing slowdown (i.e. slower reaction times) for negative emotion (vs. emotion-laden) target words in L1 (Polish, Romanian) rather than L2, possibly with a stronger effect for related than unrelated target adjectives (exploratory question); (d) processing differences for emotion and emotion-laden target adjectives between the two bilingual groups as a result of variance in lexical proximity between Polish and English as well Romanian and English (exploratory question).
Methods
Participants
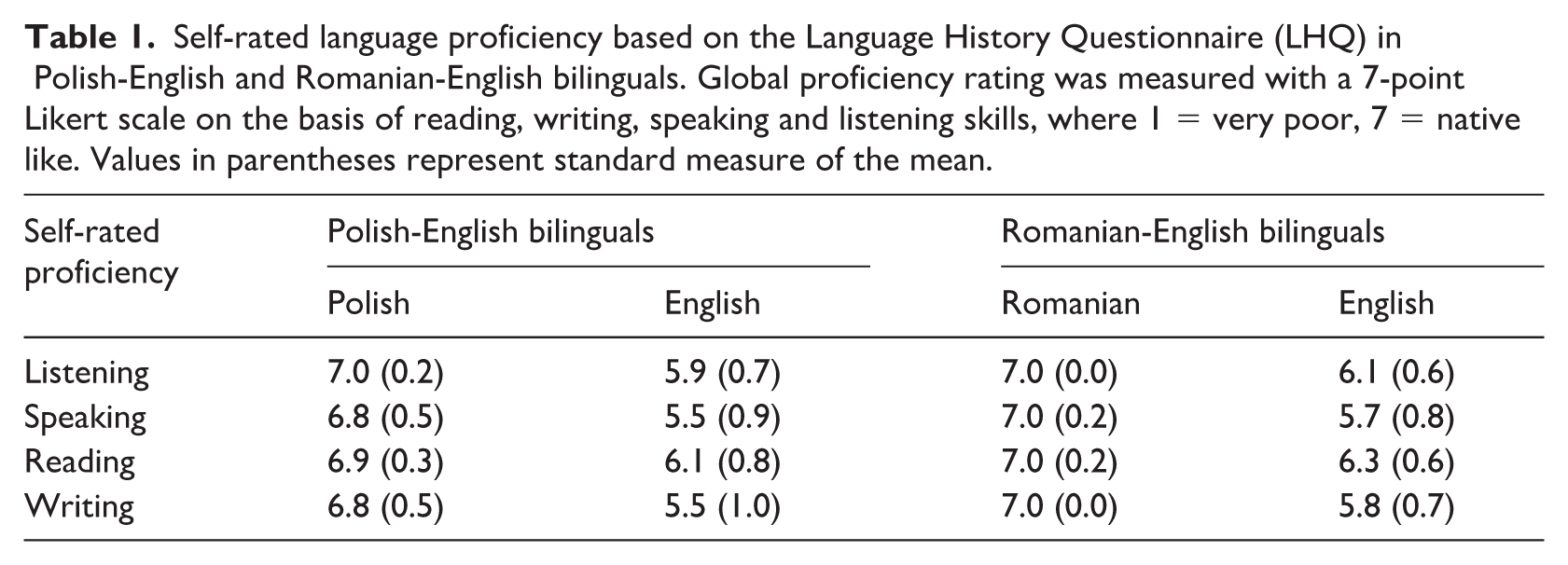
Our subjects were 49 Polish native speakers (Mage = 21, range: 19–26; 9 males, 34 females, 6 undeclared), students at the Faculty of English at the Adam Mickiewicz University, and 43 native Romanian speakers (Mage = 20.1, range: 18–24; 4 males, 34 females, 5 undeclared), students at the Faculty of Foreign Languages at the University of Bucharest. Prior to the experiment, we collected self-reported proficiency ratings in L1 and L2 from both participant groups using the Language History Questionnaire (LHQ; Li et al., 2014). The LHQ requires participants to use 7-point Likert scales (from 1 = very poor to 7 = native-like) to indicate their subjective levels of listening, speaking, reading and writing proficiency in the languages they know. Based on the results of the LHQ we determined our Polish-English sample to be dominant in their L1 Polish and the Romanian-English sample to likewise be dominant in their L1 Romanian. The results of the LHQ for the Polish and Romanian participant groups are presented in Table 1.
Self-rated language proficiency based on the Language History Questionnaire (LHQ) in Polish-English and Romanian-English bilinguals. Global proficiency rating was measured with a 7-point Likert scale on the basis of reading, writing, speaking and listening skills, where 1 = very poor, 7 = native like. Values in parentheses represent standard measure of the mean.
Stimuli
English adjectives were taken from the affective word database by Warriner et al. (2013). Polish and Romanian adjectives were selected by highly functional Polish-English and Romanian-English bilinguals. Consistent with evidence showing unconscious nonselective access to words in L1 while performing a task exclusively in L2 (e.g. Thierry & Wu, 2007; Wu & Thierry, 2012) we used independent sets of Polish and Romanian words, rather than translation equivalents, to avoid uncontrolled lexico-semantic priming. For this same reason, we controlled for cognates as much as possible, as Romanian and English vocabulary overlap mainly due to the Latin and French influences. We chose 40 adjectives as target words for each language: 10 positive emotion, 10 negative emotion, 10 positive emotion-laden and 10 negative emotion-laden words. We then created 80 prime-target word pairs: each target word was associated with a related (e.g. Eng. Joyful–happy) and an unrelated (e.g. Eng. Supportive–happy) prime. In the related pairs, both prime and target belonged to one word type (emotion or emotion laden); in the unrelated pairs, one word was an emotion word, the other an emotion-laden word. Therefore, in our study relatedness was based on word category membership, not on a pure semantic relationship (e.g. chair–table) that is commonly tested in semantic priming paradigms. The final set of prime-target pairs comprised 92 English (40 targets, 52 primes), 89 Polish (40 targets, 49 primes) and 93 Romanian adjectives (40 targets, 53 primes). The small difference in the number of primes between languages stems from inherent constraints of the stimulus selection procedure in each language. Because a limited number of matched words could have been selected for the study, some primes were used twice in the experimental procedure. To avoid within-subject stimulus repetition, the primes were rotated across two versions of each experiment, appearing once as related and once as unrelated primes. Following Kazanas and Altarriba (2015a), our prime-target pairs always agreed in affective valence. The full list of stimuli is to be found at the project’s Open Science Framework (OSF) page (https://osf.io/3k5s9/).
We ran two valence × word type × language by-item ANOVAs to evaluate potential lexical frequency differences across the two tested language pairs separately; that is, Polish–English and Romanian–English. Lexical frequency measures for English words were collected from SUBTLEXus (Brysbaert et al., 2012); lexical frequency measures for Polish words were collected from SUBTLEXpl (Mandera et al., 2015); lexical frequency measures for Romanian were collected from the CoRoLa corpus (Mititelu et al., 2018). All measures were based on the number of occurrences of a word in a corpus (i.e. frequency count measure). The lexical frequency ANOVA on the Polish–English language pair revealed a main effect of language, F(1,172) = 10.57, p = .001, η2g = .06, with English words (M = 3134, 95% confidence interval (CI) [2062, 4206]) being overall more frequent than Polish words (M = 608, 95% CI [−488.7, 1704]). All other effects did not differ from chance (ps > .05). The analysis of the Romanian–English language pair revealed a main effect of language, F(1,176) = 7.84, p = .006, η2g = .04, with Romanian words (M = 8033, 95% CI [5591, 10476]) being more frequent than English words. Also, there was a main effect of word type, F(1,176) = 5.79, p = 02, η2g = .03, with emotion-laden words (M = 7698, 95% CI [5247, 10132]) being more frequent than emotion words (M = 3478, 95% CI [1036, 5920]). Finally, the analysis revealed a language × word type interaction, F(1,176) = 5.02, p = .03, η2g = .03, with emotion-laden words in Romanian (M = 12100, 95% CI [8646, 15554]) being more frequent than emotion-laden words in English (M = 3279, 95% [−174, 6733]), with no language difference for emotion words.
In previous studies, frequency differences have been reported between Polish and English based on SUBTLEX databases, which did not seem to affect the reported results (Jończyk, 2016a; Jończyk et al., 2016, 2019). The statistical comparison of frequencies here can be explained by the relative differences in the sizes of the English and Polish lexicons overall and by the fact that in English, emotions tend to be expressed adjectivally, but in Polish nominally (Dziwirek & Lewandowska-Tomaszczyk, 2010). In a fusional language like Polish, adjectives, nouns and verbs are easily derived from common morphological roots, meaning any disparity in frequency may be compensated by basic native competence in word derivation. Additionally, for our Polish sample, any disadvantage in overall frequency in Polish is compensated by the fact they are, in fact, native speakers of Polish and therefore naturally immersed in the language. The differences reported for the Romanian–English language pair should be interpreted with caution, because a well-balanced comprehensive lexical frequency corpus for Romanian is yet to be created. The CoRoLa corpus is a 758 million token corpus composed of various text types, with legal and scientific texts accounting for around 90% of the corpus data. This explains the predominance of emotion-laden words. Some do reach very high frequency measures – for example, frumos (‘beautiful’), periculos (‘dangerous’) and bolnav (‘sick’) – because they are polysemous words and appear in different collocations and contexts. However, this is the biggest and most reliable corpus available for the Romanian language to this day.
The same analysis was performed to establish potential word length differences in Polish–English and Romanian–English language pairs. In the Polish-English analysis, the ANOVA revealed a main effect of language, F(1,172) = 45.54, p < .001, η2g = .2, with Polish words being overall longer (M = 9.4, 95% CI [8.9, 9.8]) than English words (M = 7.3, 95% CI [6.8, 7.6]). Also, there was a main effect of word type, F(1,172) = 9.67, p = .002, η2g = .05, with emotion words (M = 8.8, 95% CI [8.3, 9.2]) being overall longer than emotion-laden words (M = 7.8, 95% CI [7.3, 8.2]). Other effects did not differ from chance, ps > .05. In the Romanian-English analysis, the ANOVA revealed a main effect of word type, F(1,176) = 13.00, p < .001, η2g = .07, with emotion words (M = 7.8, 95% CI [7.4, 8.1]) being overall longer than emotion-laden words (M = 6.8, 95% CI [6.4, 7.1]). All other effects did not differ from chance (ps > .05).
Valence norming study: Polish-English bilinguals
To establish valence ratings for Polish and English stimuli we ran a norming study among 27 Polish-English bilinguals who did not take part in the experiment but were selected from the same population. A valence × word type × language ANOVA revealed a main effect of valence, F1(1,26) = 658.2, p < .001, η2g = .95, F2(1,76) = 617.4, p < .001, η2g = .89, with negative words being rated as highly negative (M = −1.8, 95% CI [−2.0, −1.7]) and positive words as highly positive (M = 1.6, 95% CI [1.5 1.8]). Also, there was a main effect of word type, F1(1,26) = 46.01, p <.001, η2g = .08, F2(1,76) = 6.56, p = .01, η2g = .08, with more negative ratings of emotion-laden (M = .03, 95% CI [−.04, .1]) rather than emotion (M = −.2, 95% CI [−.3, −.1]) words.
Valence norming study: Romanian-English bilinguals
To establish valence ratings for Romanian and English stimuli we ran a norming study among 101 Romanian-English participants, 43 of whom took part in the present experiment and the remaining ones were participants in another related study on emotion word processing. In both cases, the ratings were collected during a post-experimental session. A by-item valence × word type × language ANOVA with valence, word type and language as between-item factors demonstrated a significant main effect of valence, F(1,177) = 1063, p < .001, η2g = .86, with negative words being rated as highly negative (M = −1.6, 95% CI [−1.75, −1.46]), and positive words as highly positive (M = 1.7, 95% CI [1.6, 1.9]). Also, the analysis revealed a valence × language interaction, with negative Romanian words (M = −1.8, 95% CI [−2.0, −1.7]) being rated as more negative than English ones (M = −1.3, 95% CI [−1.6, −1.2], at p = .002); moreover, positive Romanian words (M = 2.1, 95% CI [1.8, 2.2]) were rated as more positive than English ones (M = 1.4, 95% [1.2, 1.6], at p < .001). Finally, the analysis revealed a valence × word type × language interaction, F(1,177) = 3.88, p = .05, η2g = .02. Bonferroni-corrected pairwise comparisons revealed that negative emotion words in Romanian (M = −1.7, 95% CI [−2, −1.4]) were rated as more negative than in English (M = −1.3, 95% CI [−1.6, −1]) at p = .05. In the same vein, negative emotion-laden words in Romanian (M = −2, 95% CI [−2.3, −1.7]) were rated as more negative than in English (M = −1.5, 95% CI [−1.8, −1.1]) at p = .01. Finally, positive emotion-laden words in Romanian (M = 2.1, 95% CI [1.8, 2.4]) were rated as more positive than in English (M = 1.2, 95% CI [1, 1.4]) at p < .001. Other comparisons did not differ from chance (ps > .05).
Procedure
Data collection was carried out in two research facilities: data from Polish-English bilinguals were collected in the Language and Communication Laboratory (LCL) at Adam Mickiewicz University; data from the Romanian-English participants were collected in the IT laboratory at the University of Bucharest. Prior to the experiment, participants were asked to complete an adapted version of the LHQ 2.0 (Li et al., 2014) which aimed to collect participants’ self-reported proficiency ratings in their respective languages. Subsequently, participants received written and oral instructions on the task and participated in a practice session. In the experiment, participants were asked to decide whether the words displayed on the screen were positive or negative in meaning (VDT). First, a fixation mark was displayed for 500 ms, followed by a prime for 50 ms and a mask for 200 ms. Subsequently, the target was displayed for a maximum of 2000 ms. Upon seeing the target word, participants were asked to make a decision regarding the word’s valence as soon as possible by pressing a designated key.
Participants completed language blocks in their L1 (Polish or Romanian) and L2 (English). The response keys and block order were counterbalanced across participants. Within each language block, presentation of experimental trials was fully randomized.
Data analysis
Responses faster than 200 ms and falling outside the value of 2 interquartile range (IQR) were discarded from further analyses. This resulted in discarding 65 out of 1720 observations (4%) in the Romanian data set, and 79 out of 2040 observations (4% of data) in the Polish set. Reaction time analysis was based on correct responses only. Six Polish-English bilinguals and 11 Romanian-English bilinguals were discarded from reaction time (RT) analyses due to insufficient number of trials per condition. Accuracy data and reaction time data for Romanian and Polish datasets were analysed respectively with a logit linear-effects model (GLMM) and a linear-mixed model (LMM), using the lme4 package (Version 1.1-23; Bates, Mächler, et al., 2015) in the R environment (Version 4.0; R Core Team, 2020). We included the following fixed effects in each model: (a) valence (positive, negative); (b) word type (emotion, emotion-laden); (c) relatedness (related, unrelated); (d) language (L1: Polish or Romanian; L2: English); and (e) their interactions. All fixed effects were coded using contrast coding.
For all models, we first computed maximal models with a full random-effect structure, including subject- and item-related variance components for intercepts and by-subject and by-item random-slopes for fixed-effects (Barr et al., 2013). All models turned out to be overparameterized and too complex to support the data. Following recommendations by Bates, D., Kliegl, et al. (2015; see also Matuschek et al., 2017), we then selected parsimonious LMM and GLMM. We computed the models without correlation parameters (zero correlation parameter), removed random intercepts and small variance parameters using the lme4::rePCA function until the models were supported by the data. The final structure, summary and variance components for each of the models are available at the project’s OSF website (https://osf.io/3k5s9/).
β estimates and significance of fixed effects and interactions (p-values) are based on the Laplace and Satterthwaite approximation for GLMMs and LMMs, respectively (lmerTest package, v. 3.1.2; Kuznetsova et al., 2017).
Results
RT data
Polish-English bilinguals
We found a fixed effect of word type (β = 30.11, SE = 12.33, df = 68.14, t = 2.44, p = .017), with slower response times to emotion (M = 753 ms, 95% CI [741, 765]) than emotion-laden (M = 729 ms, 95% CI [718,740]) words. The word type × relatedness interaction was significant (β = 30.11, SE = 12.33, df = 68.14, t = 2.44, p = .017), with slower response times to emotion (M = 763 ms, 95% CI [745,781]) than emotion-laden (M = 727 ms, 95% CI [711,743]) words that were preceded by a related prime, with no observable difference in the unrelated condition (see Figure 1). Finally, the language × valence × word type interaction (β = 85.56, SE = 49.29, df = 68.12, t = 1.74, p = .087) revealed a trend towards slower responses to negative emotion (M = 765 ms, 95% CI [751, 797]) than positive emotion (M = 714 ms, 95% CI [689, 738] words in Polish (β = 48.31, SE = 26.8, df = 92.5, t = 1.8) as well as slower responses to negative emotion than negative emotion-laden words in Polish (β = 51.93, SE = 26.3, df = 88.6, t = 1.97). Emotion-laden word category showed a mirror trend, with shorter reaction times to negative emotion-laden (M = 713 ms, 95% CI [691,734] than positive emotion-laden words (M = 745 ms, 95% CI [721,769]) in Polish (β = 32.91, SE = 26.7, df = 91.1, t = 1.2). This dissociation between emotion and emotion-laden words was not observed in participants’ L2 English (see Figure 2).
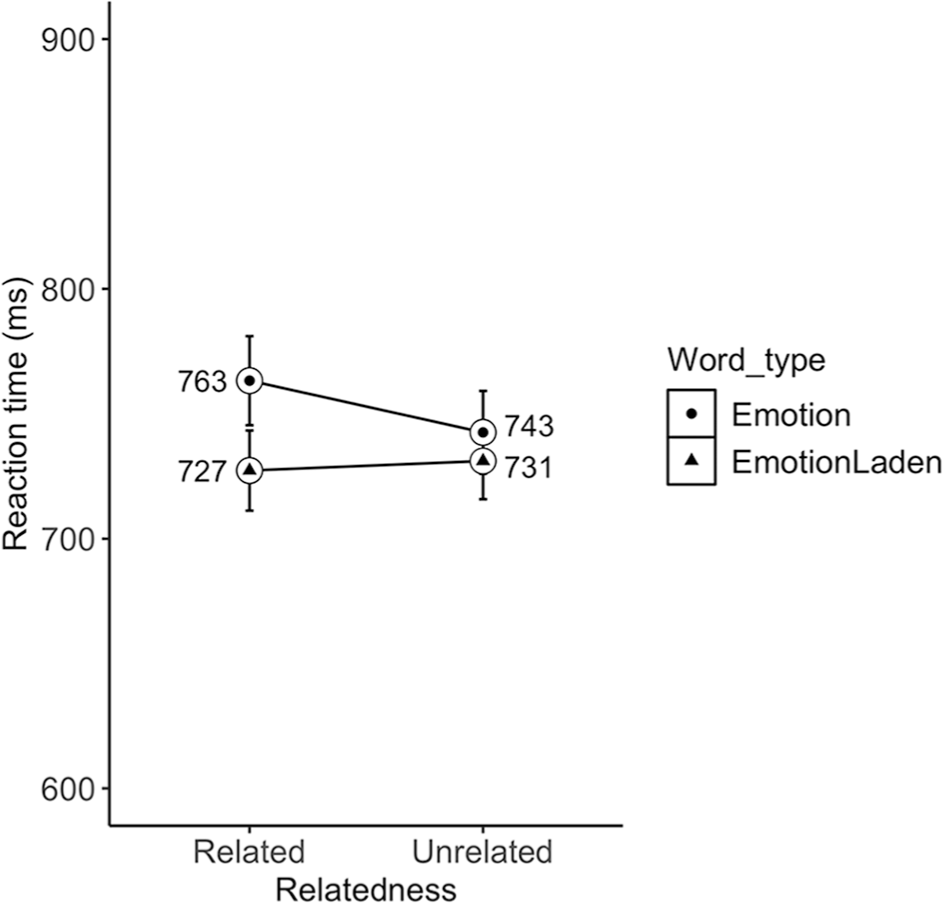
Mean reaction times (in milliseconds) to related and unrelated emotion and emotion-laden words in Polish-English bilinguals. Error bars represent 95% confidence interval (CI).
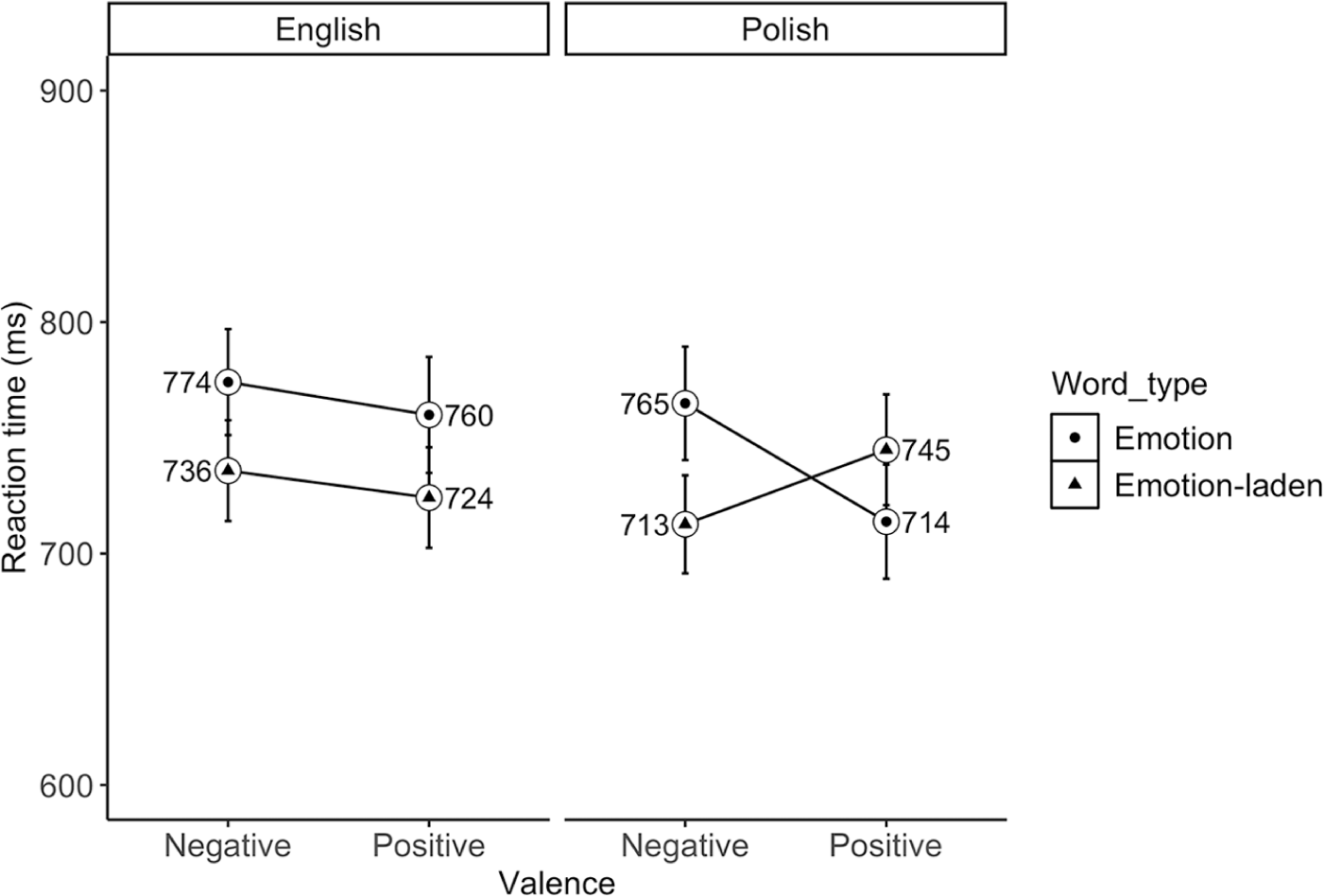
Mean reaction times (in milliseconds) to negative and positive emotion and emotion-laden words in L1 Polish and L2 English in Polish-English bilinguals. Error bars represent 95% confidence interval (CI).
Romanian-English bilinguals
We found a fixed effect of valence (β = 51.25, SE = 16.86, df = 62.44, t = −3.04, p = .003) with slower responses to negative (M = 793 ms; 95% CI [777, 809]) than positive (M = 742 ms; 95% CI [728, 757]) word pairs. Also, a fixed effect of relatedness (β = 17.12, SE = 8.81, df = 915.94, t = 1.94, p = .052), showed slower responses to unrelated (M = 777 ms; 95% CI [762, 793]) than related (M = 757 ms; 95% CI [742, 772]) word pairs. Finally, the word type × valence × relatedness interaction (β =60.65, SE = 35.35, df = 920.92, t = 1.71, p = .088) revealed a trend towards slower responses to negative emotion words preceded by a related prime (M = 816 ms, 95% CI [783, 849]) compared to unrelated prime (M = 771 ms, 95% CI [741, 801]; see Figure 3), β = 46.82, SE = 18.3, df = 352, t = 2.56. Also, the interaction showed a trend towards slower responses to negative emotion-laden (M = 787 ms, 95% CI [755,819] than positive emotion-laden (M = 720 ms, 95% CI [694, 748]) words in the related condition (β = 71.34, SE = 27.0, df = 140, t = 2.64), which was not observed for the emotion word category (see Figure 4).
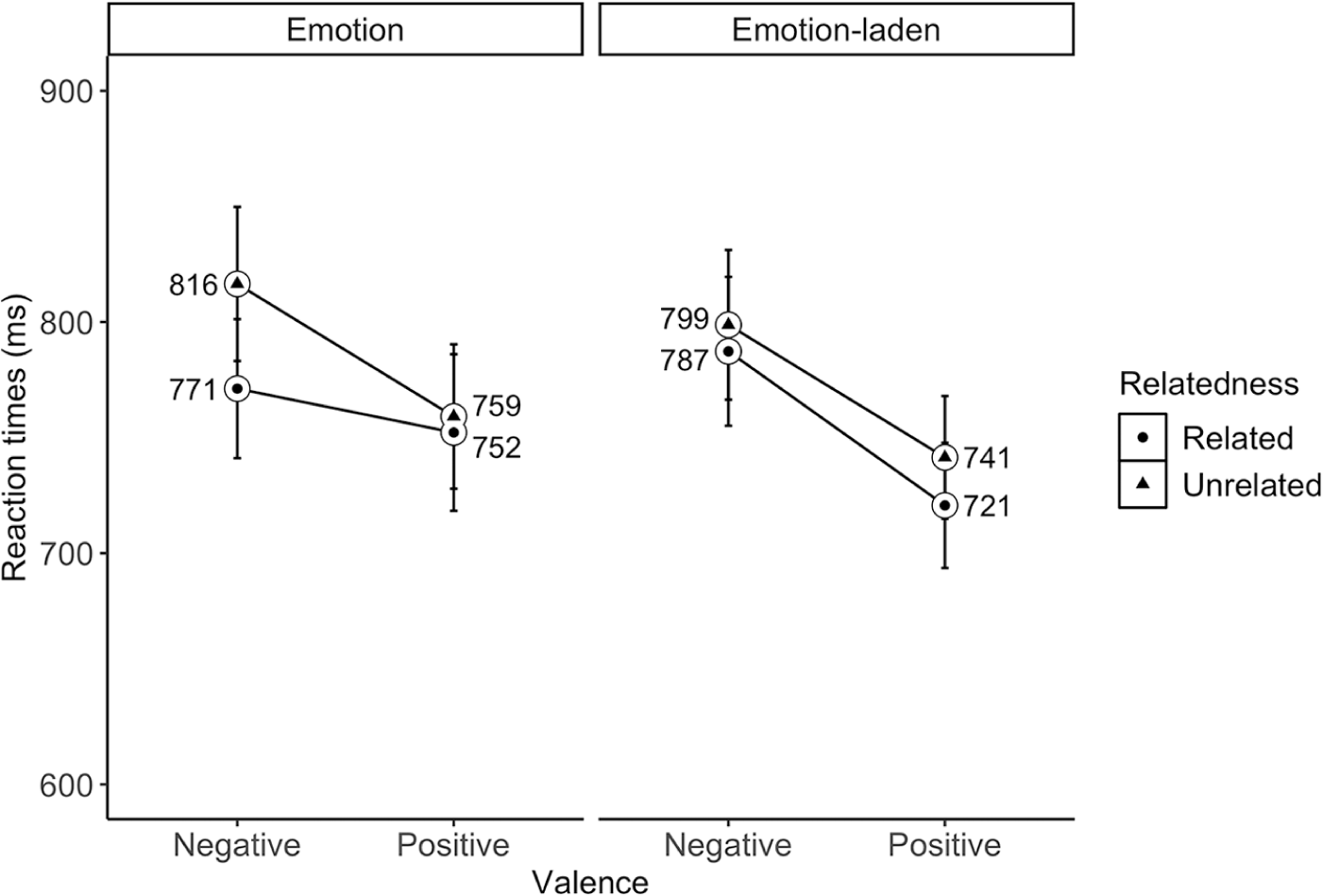
Mean reaction times (in milliseconds) to negative and positive related and unrelated words in the emotion and emotion-laden word category in Romanian-English bilinguals. Error bars represent 95% confidence interval (CI).
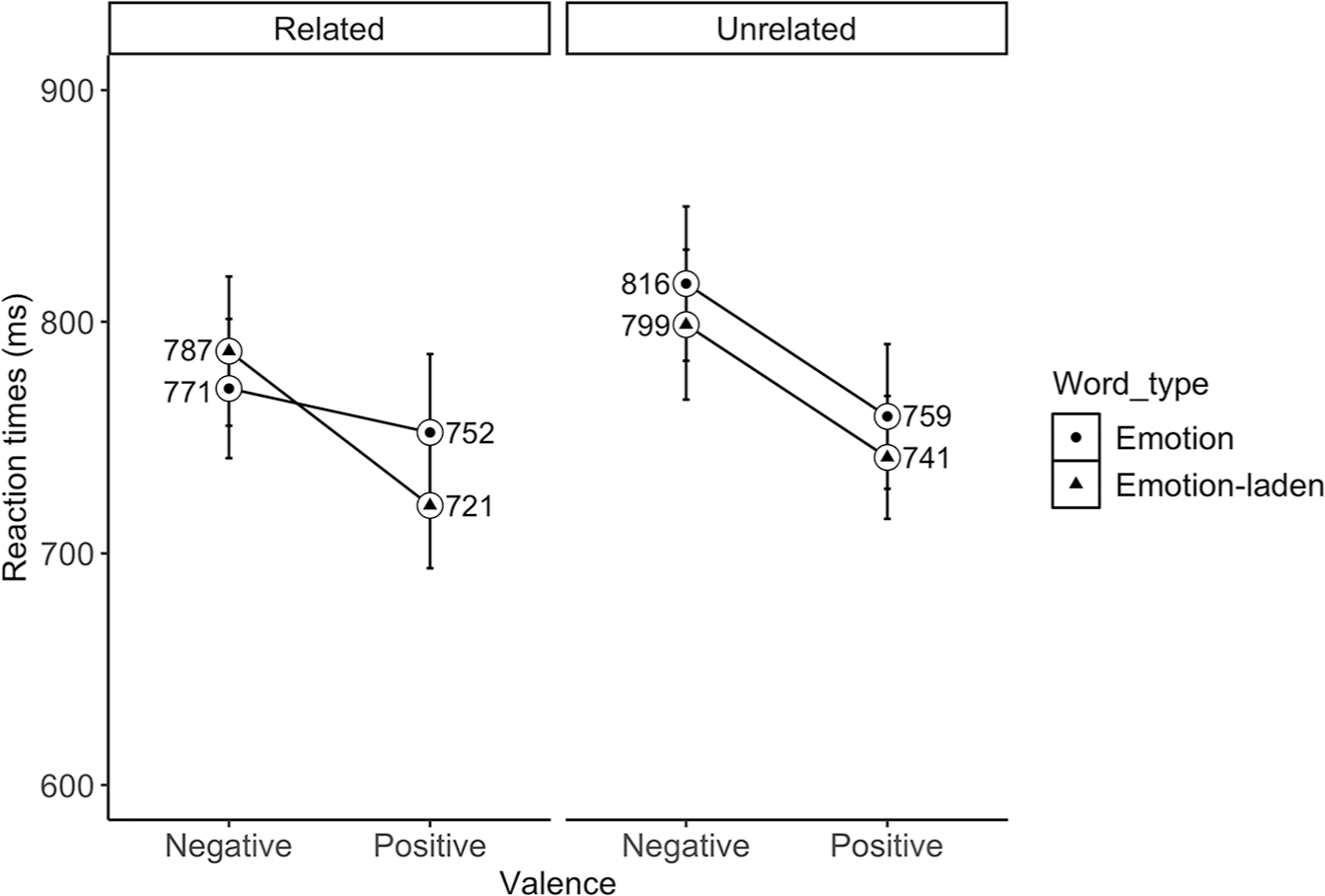
Mean reaction times (in milliseconds) to negative and positive emotion and emotion-laden words in the related and unrelated condition in Romanian-English bilinguals. Error bars represent 95% confidence interval (CI).
Response accuracy (ACC) data
Polish-English bilinguals
The fixed effect of word type (β = .66, SE = .38, z = 1.7, p = .083) showed a trend towards more accurate responses to emotion-laden (M = 97%, 95% CI [96,98]) than emotion (M = 93%, 95% CI [91,95]) words. There was a significant word type × relatedness interaction (β = 1.44, SE = .60, z = 2.4, p = .016) showing more accurate responses to unrelated emotion-laden (M = 98%, 95% CI [97,99]) than unrelated emotion words (M = 93%, 95% CI [90,95], β = 1.41, SE = .50, z = 2.83), with no such difference in the related condition (see Figure 5).
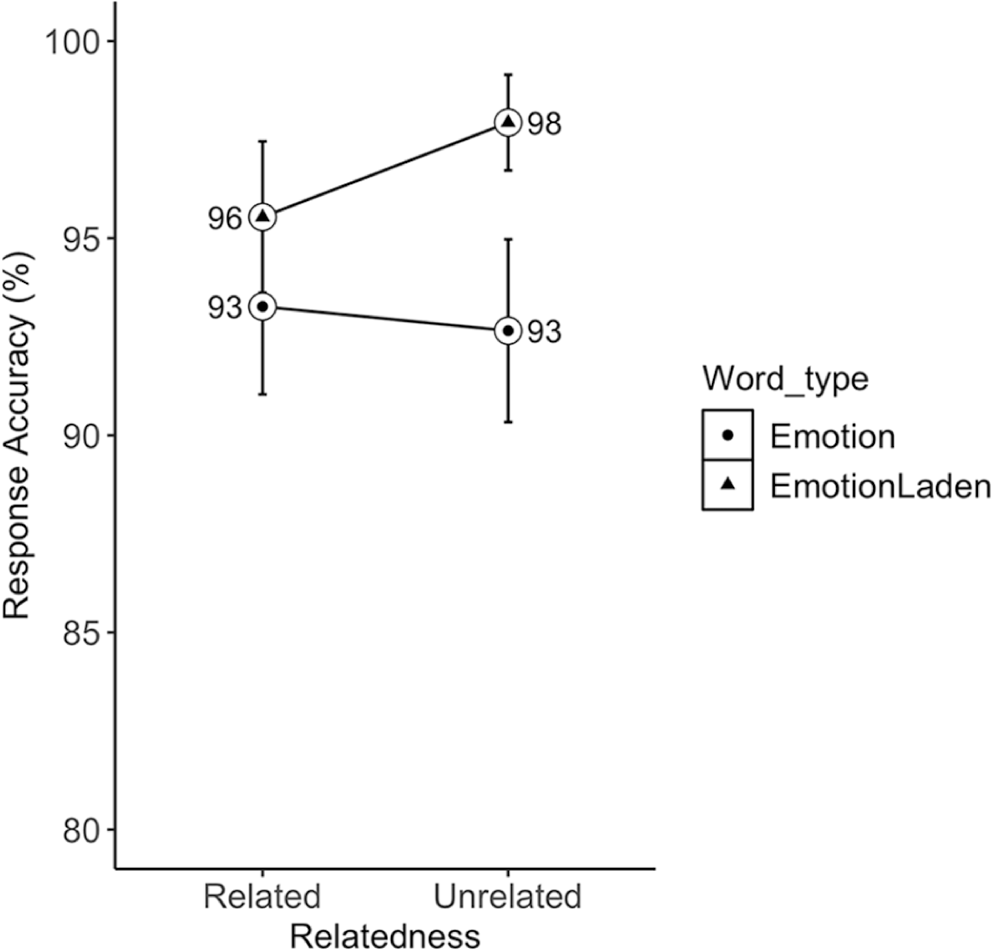
Mean accuracy rates (in percentages) to related and unrelated emotion and emotion-laden words in Polish-English bilinguals. Error bars represent 95% confidence interval (CI).
Romanian-English bilinguals
The fixed effect of word type (β = .59, SE = .34, z = 1.7, p = .088) revealed a trend showing more accurate responses to emotion-laden (M = 93%, 95% CI [91,95]) than emotion (M = 89%, 95% CI [87, 91]) words. There was a significant language × word type interaction (β = 1.36, SE = .65, z = 2.06, p = .039) showing more accurate responses to English emotion-laden (M = 94%, 95% CI [91,96]) than English emotion words (M = 87%, 95% CI [83,89]; β = 1.27, SE = .48, z = 2.63), with no word type differences in Romanian (see Figure 6). Finally, the valence × relatedness interaction (β = .77, SE = .45, z = 1.7, p = .091) revealed a small trend showing higher response accuracy to negative related (M = 93%, 95% CI [90,95]) than negative unrelated words (M = 90%, 95% CI [87, 93]; β = .54, SE = .29, z = 1.84), with positive words showing the opposite pattern (Mrelated = 91%, 95% CI [88,94], Munrelated = 93%, 95% CI [90,95]; see Figure 7).
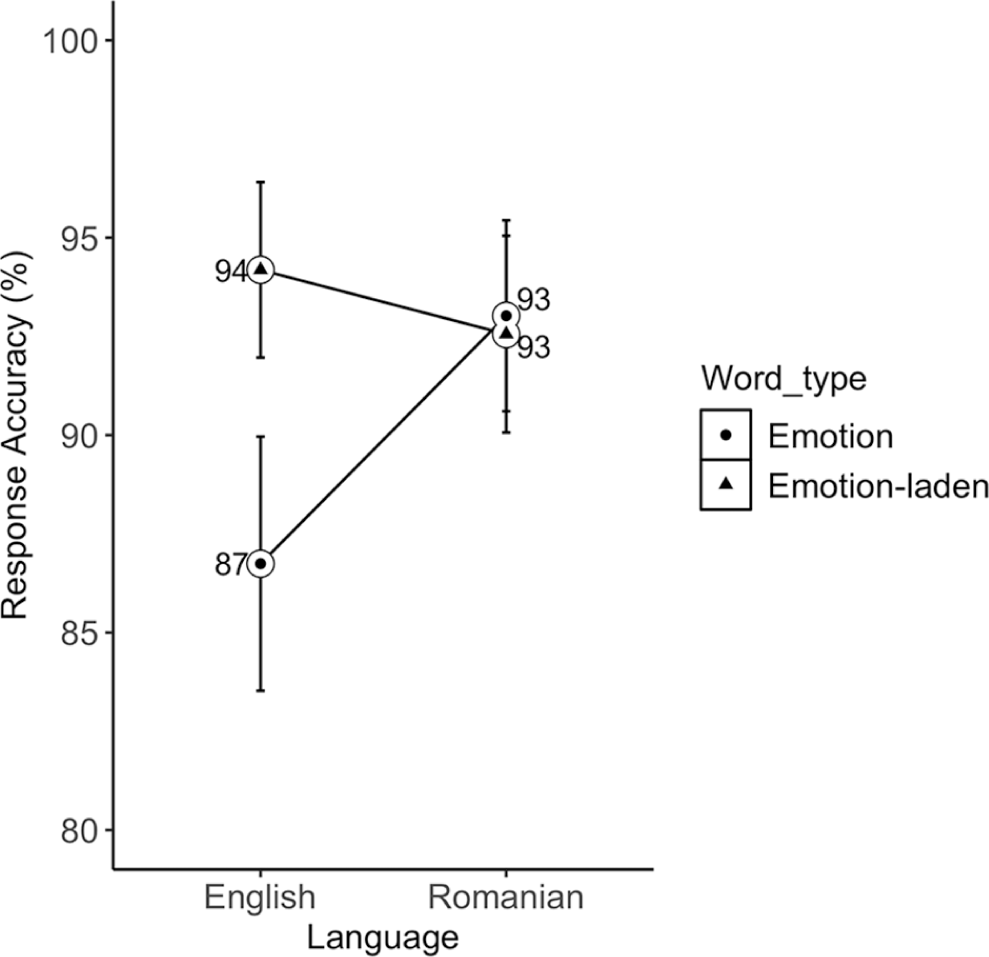
Mean accuracy rates (in percentages) to L1 Romanian and L2 English emotion and emotion-laden words in Romanian-English bilinguals. Error bars represent 95% confidence interval (CI).
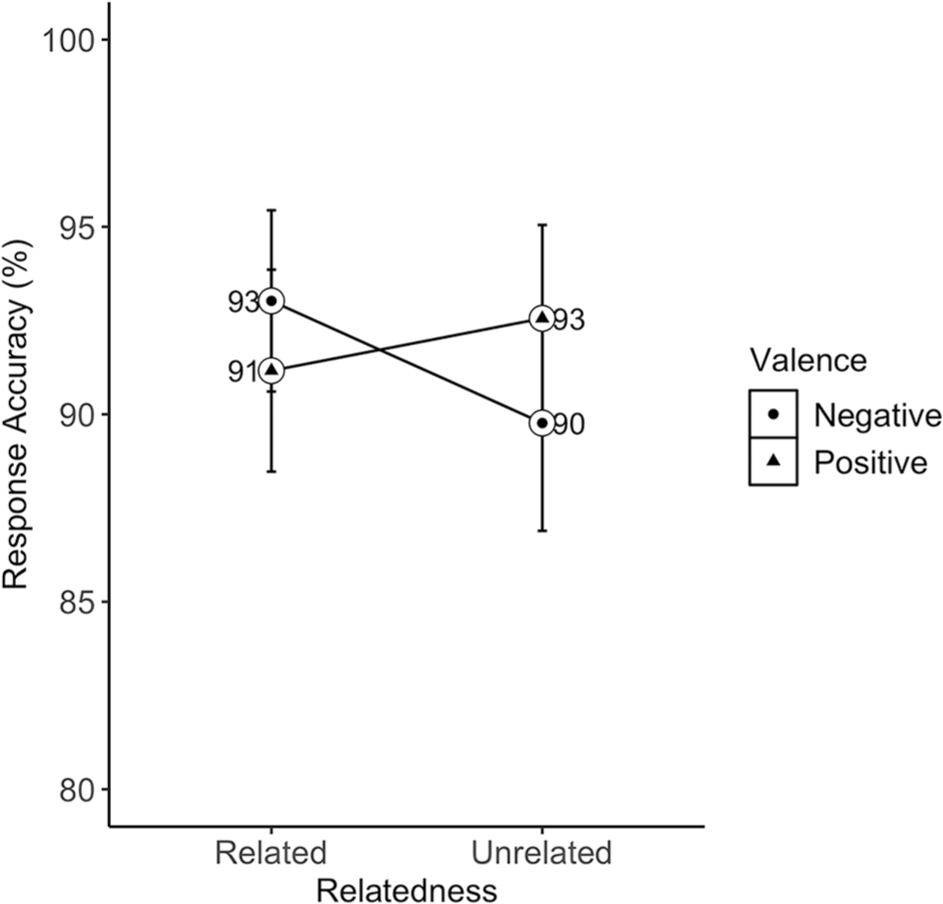
Mean accuracy rates (in percentages) to related and unrelated positive and negative words in Romanian-English bilinguals. Error bars represent 95% confidence interval (CI).
Discussion
In this study we tested how Polish-English and Romanian-English bilinguals process adjectives that name emotions (emotion words) or evoke emotions (emotion-laden words) in their first, dominant language (Polish, Romanian) and in their second, non-dominant language (English). Extending prior monolingual and bilingual research (Kazanas & Altarriba, 2015a, 2015b, 2016; Zhang et al., 2018a, 2018b, 2019), we focused on two relatively under-studied inflectional languages, Polish and Romanian, to investigate how emotions are represented in bilinguals whose emotion lexicons are either largely shared between L1 and L2 (Romanian-English), or not (Polish-English). We examined if such differences in lexical proximity between the two bilingual groups may differentially affect the speed and accuracy of their decisions about emotional word content.
Building on prior evidence in monolingual (Alves et al., 2017; Cacioppo & Berntson, 1994; Estes & Adelman, 2008; Kazanas & Altarriba, 2015a, 2015b; Larsen et al., 2008) and bilingual emotion research (Altarriba & Basnight-Brown, 2011; Iacozza et al., 2017; Jankowiak & Korpal, 2018; Jończyk et al., 2016, 2019; Kazanas & Altarriba, 2016; Sheikh & Titone, 2016; Toivo & Scheepers, 2019; Wu & Thierry, 2012), we predicted (a) processing facilitation for L1 rather than L2, for related rather than unrelated, and for positive rather than negative target adjectives; (b) processing facilitation for emotion rather than emotion-laden target adjectives, with a possibly stronger effect in the dominant language; (c) processing slowdown for negative emotion (vs. emotion-laden) target adjectives in L1 (Polish, Romanian) rather than L2, possibly with a stronger effect for related than unrelated target adjectives; and (d) processing differences for emotion and emotion-laden target adjectives between the two bilingual groups due to variance in lexical proximity between Polish and English as well Romanian and English.
Overall, we observed marked differences in how the two bilingual groups responded to emotional word content in their respective languages. We now turn to the discussion of findings in Polish-English bilinguals, followed by Romanian-English bilinguals, to finally discuss the observed differences between the two groups.
Polish-English bilinguals responded faster to emotion-laden relative to emotion adjectives in the related condition, with no observed difference for unrelated target adjectives, and irrespective of language. This effect was reflected in accuracy data, showing more accurate responses to emotion-laden rather than emotion adjectives in the unrelated condition, and – by trend – overall more accurate responses to emotion-laden rather than emotion words. These findings stand in contrast to a series of studies by Kazanas and Altarriba (2015a, 2015b, 2016) who reported facilitated processing of emotion rather than emotion-laden words. However, they are in line with more recent studies by El-Dakhs and Altarriba (2018, 2019) where the emotion and emotion-laden word distinction was found to be task-dependent, as well as with behavioural data reported recently in a series of electrophysiological experiments by Zhang et al. (2019). Note, however, that in the experiments by Kazanas and Altarriba as well as El-Dakhs and Altarriba language was treated as a between- rather than within-subject factor, which precludes direct comparisons with our study where each participant responded to stimuli in both L1 and L2. Beyond this, we think that the observed inconsistencies at least partially stem from differences in: (a) task demands; (b) stimulus characteristics; and (c) patterns of emotion lexicalization across languages.
First, while Kazanas and Altarriba (2015a, 2015b, 2016) employed a lexical decision task (LDT), we opted for a VDT known to enable deeper affective processing (Abbassi et al., 2015; Niedenthal et al., 1994). This task was also used by Zhang et al. (2019) who reported shorter response latencies to emotion-laden than to emotion words. It is therefore possible that the reported difference is driven by the activation of more widespread and deeper affective associations afforded by VDT. Second, emotion words were overall longer than emotion-laden words, possibly influencing their processing time. Note, however, that word length differences between emotion and emotion-laden adjectives were observed in all of the languages tested in this study, thus pointing to a potential intrinsic confound that could not have been eliminated. Because prior studies did not report separate word length measures for emotion and emotion-laden words (e.g. El-Dakhs & Altarriba, 2018, 2019; Kazanas & Altarriba, 2015a, 2015b, 2016; Zhang et al., 2018a, 2018b, 2019), it is difficult at this point to argue that such a difference could have driven the observed effect. Alternatively, we think that a more likely explanation comes with how emotion and emotion-laden words may be represented in mental lexicons across languages. Namely, contrary to emotion words that seem to form a more distinct category, emotion-laden words form multiple connections with the general lexicon (Altarriba & Bauer, 2004; Altarriba et al., 1999). Emotion-laden words could therefore create more dense associative networks, some emotional, some not, which might overall weaken their emotional load and speed up their processing time. This interpretation finds support in a recent study by Wu et al. (2020) who showed that emotion words rather than emotion-laden words facilitated decisions about the emotional valence of pictures following them. Future studies will further verify these findings.
Finally, Polish-English bilinguals tended to respond more slowly to negative emotion adjectives when compared to negative emotion-laden adjectives and positive emotion adjectives in Polish only. Building upon prior research on embodied cognition (Barsalou et al., 2008; Havas et al., 2007; Niedenthal, 2007; Scorolli et al., 2011), we think that positive and negative emotion adjectives (e.g. happy, sad) may be more strongly grounded in interoceptive experiences that are typically formed and relived in the dominant language. Thus, in that language, emotion words may be additionally enhanced via talking about those experiences (naming them) interpersonally. If this were true, then one would predict facilitation of positive and inhibition of negative emotion adjectives in L1 (consistently with positivity offset and negativity bias), the language of socialization and emotional interaction. By contrast, the less affectively embodied L2 (for recent reviews, see Caldwell-Harris, 2014; Jończyk, 2016b; Pavlenko, 2012) would show processing advantage for emotion-laden words. This is particularly the case for negative emotion words that generated a slowdown relative to negative emotion-laden words and positive emotion words in L1, with no such effect in L2 where both categories of words showed a similar processing pattern.
In the Romanian-English bilingual group, we observed longer responses to negative relative to positive adjectives, consistent with a well-established effect of negativity-bias showing more effortful processing of negative stimuli (Kawasaki et al., 2001; Pratto & John, 1991; Taylor, 1991). This effect may also be interpreted as driven by positivity offset, and demonstrating faster and smoother processing of positive stimuli (Cacioppo & Berntson, 1994). Romanian-English bilinguals also showed processing facilitation for target adjectives that were related rather than unrelated to the preceding prime, demonstrating the previously reported priming effect (Kazanas & Altarriba, 2015a, 2015b, 2016). This participant group also responded more accurately to emotion-laden rather than emotion adjectives in English only, and – by trend – to emotion-laden rather than emotion adjectives, reflecting the pattern in the Polish-English group. This finding may be seen as supplementary to the observation of affective disembodiment in L2 reported in reaction time data in the Polish group, such that poorer accuracy to emotion adjectives in English may arguably reflect less distinct and weaker (i.e. not so strongly experience-grounded) representation of emotion words in the mental lexicon in L2. Finally, Romanian-English bilinguals responded more slowly to negative emotion adjectives preceded by a related rather than unrelated prime and more slowly to negative rather than positive emotion-laden words in the related condition only. Previous research demonstrated that negative words tend to delay the processing of words that directly follow them in an experiment (Fox et al., 2001; Most et al., 2005). This effect may have been boosted in the present experiment, particularly in prime-target pairs where both the prime and the target belonged to the same word type category (emotion or emotion-laden), thus leading to a build-up of negative emotional content and – consequently – greater processing slowdown.
Note that although the positivity facilitation and negativity slowdown between L1 and L2 were observed in the offline valence ratings in the Romanian group, they were not replicated in the online task. We think that this possibly stems from task differences: whereas the valence norming study was based on a 7-point Likert scale and was not limited by time, the online VDT required making decisions that were binary, time-constrained and more implicit in nature. Additionally, the Romanian lexicon builds heavily on Latin, sharing a large number of cognates not only with other Romance languages (e.g. French, Italian), but also with English. This may have led to a greater cross-language co-activation of words tested in Romanian-English bilinguals, modulating online word processing. We therefore think that the absence of valence effects across L1 and L2 in the Romanian bilinguals may stem from the cognate facilitation effect (Van Assche et al., 2016; Van Hell & Dijkstra, 2002) that may have eased the processing of lexical items in the VDT in both languages.
A direct comparison between the Polish-English and Romanian-English bilinguals offers the following key observations. Although the language of operation modulated word type, valence and relatedness differently in both groups, the observed effects together show that emotion target adjectives tend to slow down, or lead to more accurate responses in the dominant L1, particularly for negative valence. In line with prior work indicating affective disembodiment in the second language (Jończyk et al., 2019; Sheikh & Titone, 2016; Toivo & Scheepers, 2019), we interpret this finding as pointing to experience-grounded and thus stronger emotional value of emotion relative to emotion-laden target adjectives in the L1s of both participant groups. Note, however, that the described effects are of relatively low power and therefore call for future validation. Also, in this study we compared two bilingual groups whose L1s differ in lexical proximity with English and, on top of that, belong to different language families. We think that this impacted the processing of emotion and emotion-laden target adjectives differently, indicating that they may not form as homogenous categories across languages as previously assumed.
The observed trend towards greater responsiveness to negative emotion words in L1 corroborates previous behavioural and psychophysiological evidence demonstrating less affective embodiment for negativity in the non-dominant language (Iacozza et al., 2017; Jankowiak & Korpal, 2018; Jończyk, 2016b; Jończyk et al., 2019; Toivo & Scheepers, 2019). Higher emotional responsiveness in L1 and, at the same time, greater affective distance in L2 have also been observed in decision-making research, a phenomenon referred to as the ‘foreign language effect’ (Costa et al., 2014; Keysar et al., 2012). Notably, when bilinguals make decisions in their L2, they seem to be more affectively detached, which translates into more utilitarian behaviour (Corey et al., 2017; Costa et al., 2014, 2017; Geipel et al., 2016). This foreign language effect corroborates observations of affective detachment previously reported by introspective studies in the field of bilingualism and emotion (for recent reviews, see Caldwell-Harris, 2014; Dewaele, 2010; Jończyk, 2016b; Pavlenko, 2012).
Finally, our findings also have implications for theoretical models in bilingualism. First, our data provides support for the emotion context-of-learning theory (Harris et al., 2006) and the language-specific episodic trace theory (Puntoni et al., 2008). Both models favour the idea that language is encoded together with its contexts of acquisition and occurrence. The first language is acquired along with the accompanying experiences and used in a natural and highly emotional context, thus carrying strong emotional resonance; the second language, by contrast, is typically learned in formal settings, is poorer in emotional resonance and can benefit only partially from the emotionality of the experiences triggered by L1 words. Both bilingual groups in our study learned English as a foreign language in formal settings. One would therefore assume that their emotional sensitivity in L2 would be blunted and less resonant. However, this is not entirely the case in our study, because the Romanian-English participants responded similarly to L1 and L2 emotion and emotion-laden words. This observed difference between the two bilingual groups could be accounted for by the Sense Model (Finkbeiner et al., 2004) which proposes that priming between semantically related words depends on the proportion of shared senses within a given language. According to the model, L1 words have more links to semantic senses than their L2 counterparts, which may have important implications for how emotional words are processed in L1 and L2. Not only do emotion words have fewer links to semantic senses in L2, they also have fewer links to experiences in which these words were encoded, as stipulated by the emotion context-of-learning and language-specific episodic trace theories. From this it follows that in the Romanian-English group, due to closer between-language proximity in emotional lexicons, one might expect a greater priming and cross-activation of emotional senses that could weaken language-specific valence and word type differences between L1 and L2. By contrast, in the Polish-English group the observed differences may have come to surface because of weaker emotional lexicons proximity.
In conclusion, in this study we investigated how Polish-English and Romanian-English bilinguals responded to emotion and emotion-laden adjectives in a VDT. We found processing facilitation of emotion-laden rather than emotion words in both participant groups, irrespective of the language of operation. Critically, emotion target adjectives, particularly of negative valence, tended to slow down responses of Polish-English bilinguals in their dominant L1. Although such a modulation was not observed in the Romanian-English group, possibly a result of a considerable similarity between the Romanian and English lexicon, emotion target adjectives were recognized with lower accuracy in the L2 of Romanian-English bilinguals. In our view, both effects could be explained by the affective disembodiment account (Pavlenko, 2012), proposing greater affective distance in the second language. The fairly complicated pattern of results reported here for the two bilingual groups further suggests that affective responsiveness is modulated by cross-linguistic differences between L1 and L2.
Altogether, although our findings reveal a different pattern of results relative to the early work by Kazanas and Altarriba (2015a, 2015b, 2016), they corroborate recent evidence by Zhang et al. (2019) as well as El-Dakhs and Altarriba (2018, 2019). In light of this prior work, our findings offer one key conclusion: word representation of emotion and emotion-laden words may be more language-specific than previously assumed while their processing seems task-dependent. As results from this study show, bilinguals whose languages belong to different language families may process emotion and emotion-laden words differently. Therefore, these results do not lend support to emotion/emotion-laden word type category as a universally respected linguistic distinction, and postulate further research testing the relations between emotion and languages.
Limitations
Previous research showed that processing patterns for parts of speech differ (Kemmerer, 2014). In this study, we used adjectives only to control for previously reported differences in the processing of words belonging to different lexical categories (Bąk & Altarriba, 2019; El-Dakhs & Altarriba, 2018, 2019; Palazova et al., 2011). We hope that future studies will take into account the fact that different languages may lexicalize emotional content via different parts of speech (Wierzbicka, 1999). Thus, testing other parts of speech – for example, nouns (e.g. El-Dakhs & Altarriba, 2019) or verbs in different combinations of languages in bilinguals – may provide different results.
This study could have benefitted from testing a bigger set of emotion and emotion-laden words; however, due to a limited number of emotion words meeting our selection criteria (e.g. word length, frequency, relatedness, cognates) and a large number of emotion cognates in Romanian and English, we had to rely on a smaller set of words than we aimed at originally, prior to stimuli selection. Additionally, we found that what was an emotion word in one language turned out to be an emotion-laden word in another, which further depleted our stimuli set. Note, however, that our stimuli sample is of comparable size to that of previous research (e.g. Kazanas & Altarriba, 2015a, 2015b, 2016), while our results may have overall more statistical power due to the use of a within-subject factorial design.
Footnotes
Acknowledgements
The authors would like to thank Lidia Karpińska for data collection for the Polish part of the project. We would also like to extend our gratitude to Prof. Ad Backus and two anonymous reviewers for constructive feedback on the manuscript.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The project has been funded by the Romanian Academy (to A-G N-G) in collaboration with the Polish Academy of Sciences (to K B-D).