
Abstract
This conversation analysis (CA) study extends our understanding of the complexity of three turn instructional sequences by investigating the multimodal turn design of a teacher’s third turn repetitions (TTRs) and the actions accomplished in the third turn position as well as subsequent post-expansions. The videorecorded data are from an undergraduate Korean as a foreign language classroom at a large US university. The analysis reveals how a teacher coordinates resources such as language, prosody, gaze, gesture, body movements, and objects during and immediately following TTRs to mitigate negative evaluation, direct student attention to trouble sources, and intimate answers. The findings show that actions accomplished by talk, i.e. negative evaluation, and actions accomplished by multimodal resources like gaze, i.e. directing attention, may be undertaken simultaneously. The article contributes to understandings of teaching as complex and contingent interactional work by unpacking in fine-grained detail the moment-by-moment multimodal unfolding of pedagogical practice. We conclude by discussing implications for teacher preparation, namely the central role microanalysis of videorecorded classroom interaction should play.
Keywords
I Introduction
Teacher turns are complex in design and action. They involve linguistic and prosodic resources and serve to elicit student participation, provide evaluation, direct student attention, and guide the interactional project. This study explores the complexity of three turn instructional sequences (Lee, 2007; Waring, 2016) by documenting the multimodal turn design of a teacher’s third turn repetitions (TTRs) and the actions accomplished in TTRs and subsequent post-expansions. Repetition in mundane and institutional interaction serves a variety of functions including but not limited to initiating repair (Schegloff et al., 1977), pursuing responses (Antaki, 2002; Pomerantz, 1984b; Zemel & Koschmann, 2011), and doing affiliation (Margutti & Drew, 2014; Pomerantz, 1984a; Schegloff, 1996). Work on second language learning has shown the central role repetitions play in learning and developmental processes (Anward, 2005; Brown, 1998; Chaudron, 1988; Duff, 2000; O’Connor & Michaels, 1993; Wong, 2000). An overlooked component of repetitions in classroom interaction has been analysis of the accompanying multimodal resources and the interactional work they accomplish. This multimodal classroom conversation analysis (CA) study begins to address this gap by analysing how a teacher mobilizes multimodal resources such as facial expression, gaze, pointing, objects, laughter, and language to manage a sensitive action, i.e. negatively evaluating student responses, and direct the pedagogical activity. Multimodal CA’s conceptualization of interaction as fundamentally multimodal, its unmotivated and emic analytic lens, and its precision transcription conventions make it well-suited for such analysis.
The videorecorded data come from an undergraduate Korean as a foreign language classroom at a large US university. The analysis unpacks how a teacher coordinates resources such as language, prosody, gaze, gesture, body movements, and objects during TTRs and subsequent post-expansions. The findings expand our understanding of the grammar-body interface (Pekarek Doehler et al., 2022) in the foreign language classroom by showing how multimodal resources are coordinated with linguistic resources to target trouble sources, mitigate negative evaluation, and intimate responses. Additionally, one excerpt reveals how multiple actions, i.e. negative evaluation and intimating responses, can be simultaneously accomplished by talk and gaze, respectively. The study contributes to multimodal classroom interaction research by furthering our understanding of how a teacher manages overlapping concerns of epistemics and progressivity when students struggle to produce desired responses. The findings have implications for classroom researchers and professionals involved in teacher preparation. For researchers, the analysis demonstrates the fundamental multimodality of teaching as sequential and contingent social practice. Analysts must attend to multimodal resources and how they are mobilized in pedagogical activity to appreciate the nuanced and professional work of teaching more fully. Multimodal CA is also invaluable to teacher preparation as a lens through which teachers in training can see, discuss, and reflect upon how their more experienced colleagues manage the in the moment unfolding of classroom action.
1 Third turns and repetitions
Three turn instructional sequences, often called initiation–response–follow-up (IRF), are a ubiquitous feature of classroom interaction (Mehan, 1979; Sinclair & Coulthard, 1975). These sequences begin with a teacher initiation, often an elicitation or command, in the first turn. Students respond in the second turn of the sequence, and the teacher follows up oftentimes with some form of positive or negative evaluation of the student response in the third turn. The design of third turns, their complex action, and how they facilitate or hinder student participation are longstanding concerns among classroom teaching researchers (Hall, 1997; Lee, 2007; Margutti & Drew, 2014; Nassaji & Wells, 2000; Park, 2014; Roh & Lee, 2018; Waring, 2008). Third turns are spaces in which teachers undertake complex professional work, addressing problematic turns, managing affiliation, and providing students with genuine opportunities to comprehend and subsequently produce speech (Lee, 2007; Margutti & Drew, 2014; Waring, 2008). Repetitions are a common linguistic design third turns take. These deceptively simple turns can provide either positive or negative evaluation and are intricate in their prosodic design (Hellermann, 2003; Margutti & Drew, 2014; Park, 2014; Roh & Lee, 2018; Seedhouse, 2004; Waring, 2008).
How one distinguishes a TTR that does positive evaluation from one which does negative evaluation depends on design and sequence. Repetitions with rising-falling or continuation rise intonation do positive evaluation while those with rising or level intonation do negative evaluation (Hellermann, 2003; Margutti & Drew, 2014; Seedhouse, 2004). Repetitions may occur in multi-unit turns between explicit positive assessments, and such tokens may be prosodically marked (Waring, 2008). Repetitions that do either positive or negative evaluation may project contrasting interactional trajectories. Positive assessment has been characterized as limiting participation because it marks a sequence as case closed (Hall, 1997; Waring, 2008) while negative assessment may mobilize student participation in the form of self-selection as next speaker (Jacknick, 2009). Thus, student and teacher actions in the fourth turn, i.e. the turn following a TTR, display an orientation to the polarity of the TTR as either positive or negative evaluation (Park, 2014).
Repetitions highlight ‘what is acceptable and what needs to be learned’ (Waring, 2008), but the pedagogical work accomplished in third turns extends beyond just providing positive or negative evaluation. The work ‘is not predictable, in principle, because its character is contingent upon the prior turns’ (Lee, 2007, p. 181). While not looking exclusively at TTRs, Lee (2007) illuminates three types of work teachers accomplish in third turns: parsing, steering the sequence, and intimating answers. When intimating answers, the teacher points to ‘problematic’ aspects of prior turns ‘and offers clues as to how to find the answer she is seeking’ (Lee, 2007, p. 195). Park (2014, p. 165) writes, ‘repeats . . . may not only [lead] to correction . . . but may also be used . . . to target a following action’ (Schegloff, 1997). Third turns might or might not mobilize desired responses and in such cases a teacher might resort to giving an answer or explanation she was trying to prompt (Lee, 2007; Macbeth, 2004; Margutti & Drew, 2014; McHoul, 1990).
Prior work makes it readily apparent that the interactional and pedagogical work accomplished in third turns of instructional sequences is sophisticated and nuanced. TTRs specifically have been shown to provide positive or negative evaluation (Hellermann, 2003; Margutti & Drew, 2014; Seedhouse, 2004; Waring, 2008), to be affiliative when delivering positive evaluation (Margutti & Drew, 2014), and to project next actions (Lee, 2007; Park, 2014; Roh & Lee, 2018). Attention to multimodality in third turns, and more specifically TTRs, is a substantial remaining gap in L2 classroom CA. This oversight creates conditions for impoverished analysis, suffering from lack of access to that which members may be orienting (Mortensen, 2016). Ignoring resources such as laughter, gaze, and gesture obfuscates instead of illuminates the complexity of classroom contingencies and teacher action.
Several excerpts presented in studies reviewed here contain laughter and potential multimodality around third turns. The laughter is not noted in the analyses and is often transcribed as ((laughter)). Such transcription glosses over interactional details with which participants are confronted and which participants deploy (Hepburn & Varney, 2013; Jefferson, 1984, 1985). In doing so, the complexity and contingency of teaching and learning as observable forms of social action are obscured from analysis. In addition to ignoring laughter, focusing solely on linguistic and prosodic turn design blinds analysts to the potential that audibly silent moments are filled with action and that actions themselves are multimodal. Lee (2007) recognizes student silence in the second turn is itself an action, but he does not analyse what participants may be visually orienting to in interaction. The argument that teacher third turns do complex work can still stand while ignoring multimodality, but the complexity of the work teachers undertake in third turns and the contingencies proceeding and following them cannot be fully appreciated without analysis of semiotic resources such as laughter and visual resources such as gaze, gesture, and facial expression. The current study contributes to our understanding of the complexity of teaching by looking at how a teacher employs gaze, smiling, laughter, and pointing in the design of TTRs to do evaluation, mitigation, correction, and to direct the interactional project.
2 Multimodal classroom CA
Multimodality is a fundamental property of human interaction. Gaze, gesture, facial expressions, and head movements such as nodding are all semiotic resources interlocutors employ alongside or without linguistic resources. CA and related fields like Linguistic Anthropology and Interactional Linguistics have shown that social interaction is multimodal, or embodied (for a distinction between these terms, see Mondada, 2014), and language is not statically structured (C. Goodwin, 2000, 2018; M.H. Goodwin & Goodwin, 1986; Mondada, 2014, 2016; Ochs et al., 1996). In fact, language cannot be separated from other semiotic resources like prosody, gesture, gaze, nodding, and spatial arrangements, or what Goffman (1964) calls ecological huddles. Semiotic resources are combined in sequentially unfolding complex multimodal gestalts (Mondada, 2014). Local affordances and contingencies influence the shape of participants’ turns, and resources become meaningful in use. Incrementally, actions are organized and resources are reflexively shaped by the unfolding interaction. For instance, a pen’s function in interaction differs based upon the actions being done by participants, preceding and ensuing actions, and the membership categories of participants (Mondada, 2014). This also holds true for resources such as gaze, e.g. in one context a gaze shift might do mitigation work while in another it serves a deictic purpose.
The multimodality of teaching has been foregrounded in recent scholarship on classroom interaction (Hall & Looney, 2019). Resources such as gaze, gesture, facial expression, and laughter have been shown to be mobilized in the management of sensitive sequences of action and progressivity. Smiling and laughter are resources both teachers and students use in the management of sensitive actions (Looney & He, 2021; Looney & Kim, 2018, 2019; Piirainen-Marsh, 2011; Petitjean & González-Martínez, 2015; Sert & Jacknick, 2015). Issues of epistemics, i.e. knowledge, may be particularly sensitive. Students may laugh around disaligning response turns in which they respond to forward the activity but produce responses which are not to be taken seriously (Looney & Kim, 2018). These turns display uncertainty about course content and at the same time understanding that they are obligated to respond. By smiling and laughing, students preemptively mark their disaligning turns as playfully troublesome. In response to such disaligning turns, a teacher may tease students (Looney, 2021; Looney & Kim, 2019). Teases are dualistic in that they affiliate by taking up a playful stance as displayed in smiling, laughter, and exaggerated turn design, but they also provide negative evaluation and are followed by turns that redirect the interaction on a serious trajectory. These studies show that giving incorrect responses and negative evaluation are sensitive actions and participants orient to them as such. The current study contributes to research on laughter and smiling in classrooms by showing how it is used to flag trouble sources and mitigate negative evaluation in third turn repetitions.
Other studies show gaze and gesture to be essential to the management of interactional concerns such as turn taking. Research on gaze and turn allocation shows it is not so much the teacher who allocates the turn but is instead a collaborative achievement and next speaker selection is preceded by mutual of gaze between the teacher and selected student (Mortensen, 2008). Teachers may even reprimand students who make eye contact then refuse to take the next turn after being selected by name (Looney & He, 2021). Flood and Harrer (2023) show how a STEM teacher combines post hold gestures with ‘lighthouse gaze to search for a willing participant’ during IRF sequences. Simultaneous post hold gestures and gaze at the students project a clear next action, i.e. student responses, and students eventually orient to them as such. Similarly, an ESL teacher in Looney and He (2021) repeats pointing gestures while looking at the class and not receiving responses. Her repeated gestures coupled with gaze eventually elicit responses. These studies demonstrate how participants orient to gaze and gesture as resources for managing the progressivity of the classroom. Our study contributes to this vein of inquiry by investigating how gaze, objects, and facial expression are used to direct student attention in pursuit of responses around TTRs.
This article advances understandings of how multiple resources are drawn together in semiotic constellations to do pedagogical work involving the management of epistemics and progressivity. Specifically, the analysis shows 1) how smiling, laughter, and gaze mitigate negative evaluation, and 2) how gaze, gesture, facial expression, and objects are coordinated to direct student attention to trouble sources and intimate responses. The analysis also presents an example of co-occurring speech and gaze doing distinct interactional work. This lends further support to argument for the centrality of analysing multimodal resources to understand participants’ orientation to the contingencies of classroom interaction.
II Methods
Classroom CA is not alone in its interest in multimodality. Other approaches including but not limited to Multimodal Interaction Analysis (Mejía-Laguna, 2023; Norris, 2020; Satar & Wigham, 2020, 2023; Wigham & Satar, 2021; Wilmes & Siry, 2021), Systemic Functional Multimodal Discourse Analysis (Halliday, 2014; Lim, 2019, 2023; O’Halloran & Lim, 2014), New Materialism (Early et al., 2015), and Language Socialization (Burdelski & Howard, 2020) have considered the role visual resources play in classroom interaction. The current study shares at least one major conceptual similarity with these frameworks: semiotic resources such as gaze, gesture, facial expression, and objects are not a priori subordinate to language but are potentially equally or more important than linguistic resources to a given situated action (Mondada, 2018). A detailed comparison of the epistemological and methodological positions of the various frameworks is beyond this article’s scope, but we will comment on the choice of multimodal CA as the framework for this study. Two reasons will be elaborated upon:
CA’s emic, unmotivated, and radically empirical perspective,
CA’s precision transcription conventions for multimodal interaction.
The first reason for our choice of CA is its emic, unmotivated, and radically empirical perspective. Instead of taxonomies of potential action (Lim, 2019) or a hierarchy of lower- and higher-level actions (Mejía-Laguna, 2023; Norris, 2020), CA provides tools to document a situated account of participants’ orientation to the unfolding interaction by asking ‘why that now’ (Schegloff & Sacks, 1973). Relying on participants’ observable orientation to interaction provides an empirical account of situated pedagogical practice instead of a top-down analysis imposed by the researcher. Some have criticized CA as being a Linguistics-Plus approach to interaction (Lim, 2023, citing Jewitt et al., 2021). While this critique might be true of much traditional work on three turn instructional sequences, it does not hold for recent classroom CA, or CA more broadly, since the embodied turn (Nevile, 2015). In fact, CA and CA-adjacent frameworks such as Interactional Linguistics have been using video data and conducting multimodal analysis for over three decades (C. Goodwin, 2000, 2007, 2018; M.H. Goodwin, 2006, 2008; M.H. Goodwin & Goodwin, 1986; M.H. Goodwin et al., 2002; Mondada, 2014, 2016, 2018; Ochs et al., 1996; Thompson et al., 2015).
Multimodal analysis demands precision in depiction of the timing of the deployment of semiotic resources. Mondada’s (2014) multimodal CA conventions, which build on Jefferson’s (2004) conventions, have three particular strengths: precise timing of auditory and visual resources, focus of embedded still frames, and readability. First, Mondada’s conventions for multimodality use a two-tiered orthographic representation of auditory (talk) and visual (bodily conduct) resources. Talk is presented on the top line and in a darker font than visual resources. This system allows for talk and bodily conduct to be precisely aligned using symbols such as +, %, and ^. This is crucial for analyses in which talk and bodily conduct may be accomplishing different work simultaneously. Such precision is not possible using MIA transcription conventions in which talk is superimposed over images (Johnson & Erickson, 2022). For example, Figure 5 in Mejía-Laguna (2023) presents two images, 3 and 4, overlayed with one utterance: ‘what is the past participle form of make?’ Nodding is depicted with a double pointed arrow in image 3. The nodding apparently began earlier, as image 2 also has a nodding arrow which is not mentioned in the analysis. Instead, the nodding began in image 3 and continued into image 4 according to the written analysis (Mejía-Laguna, 2023, p. 38). It is unclear for readers exactly where the nodding begins and ends. A rigorous application of Mondada’s transcription conventions would provide a clearer temporal account of the co-occurrence of nodding and talk. Such precision is essential to the analysis presented below.
A second advantage of Mondada’s conventions is the use of embedded still frames. Such frames, when used with a hashtag in corresponding talk, precisely mark the pictured moment in talk. Along with sequential accuracy, well-cropped still frames allow the analyst to zoom in on the specific interactional feature under investigation in a way that is easily discernable for readers. Large still frames with talk superimposed on them, while perhaps providing a wider view of the classroom, do not allow for precise timing or focused presentation particularly of gaze and facial expression both of which are prominently featured resources in the analysis below. The third strength of Mondadian transcription is readability. Talk and visual resources are presented in a sequential manner, moving left to right and top to bottom, using consistent readable fonts that align precisely and do not vary in color. There is a particular concern when overlaying text on images in which the font color and background do not sufficiently contrast (see second image in Table 1, Mejía-Laguna, 2023, p. 30).
The setting for this study is an advanced Korean as a foreign language (KFL) class at a large public US university. The participants are an L1 Korean-speaking teacher and nine advanced/intermediate L2 Korean learners. All participants consented to the use of their recordings for research and publication purposes in accordance with our institution’s Institutional Review Board. The data are two 70-minute classes. Recordings were made using three cameras. One camera at the rear left of the room captured the teacher and students. Another camera at the front right captured the teacher exclusively. The third camera was placed at the front left of the room and captured the students. Figure 1 is a visual representation of the classroom and seating arrangement.
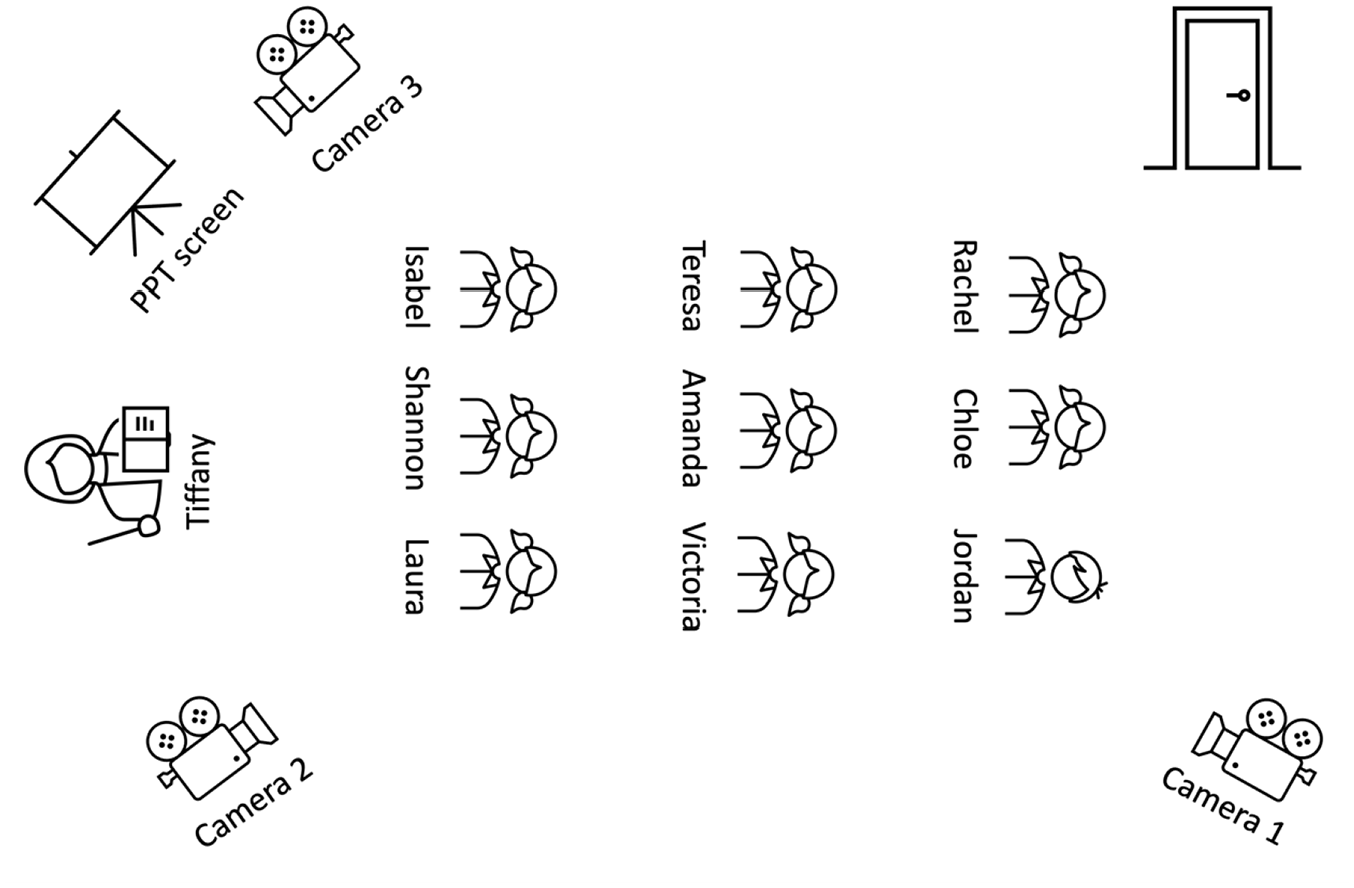
The classroom arrangement.
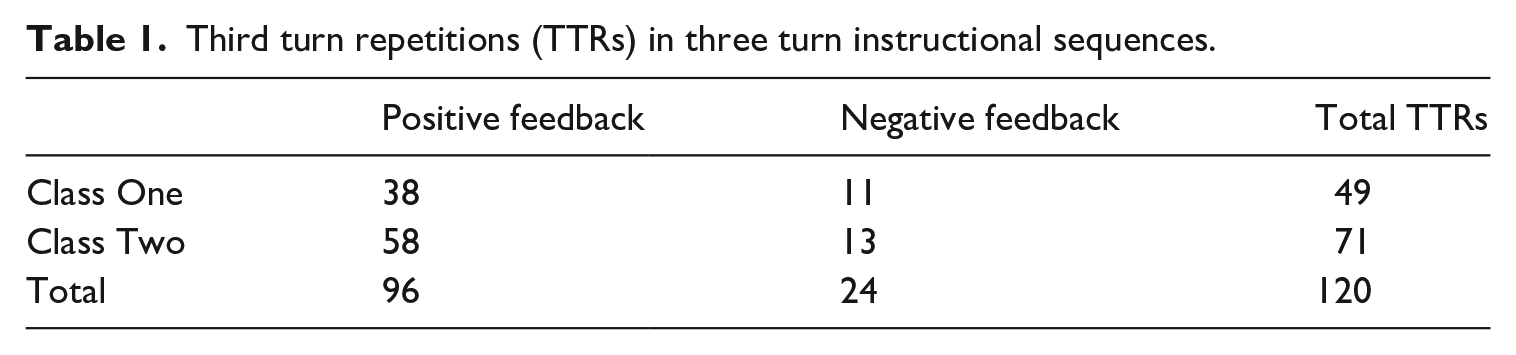
The video recordings were transcribed and translated by the first and second authors according to CA conventions (Jefferson, 2004) using CLAN (talkbank.org). The transcripts were then analysed iteratively in an unmotivated fashion (Sacks, 1984). After noticing teacher repetition, team members created a collection of teacher repetitions of student turns. Repetition was operationalized as ‘more or less strict; that is, it allows for transformations geared to deixis, tense shift, speaker change, etc., as well as changes of prosody [but] excludes paraphrase and other substantial rewording of its target’ (Schegloff, 1997). Repetitions occurring in third turns of three turn instructional sequences were then identified and analysed to determine if they provided positive or negative evaluation. Table 1 provides a summary breakdown of TTRs by class session. Positive evaluation is overwhelmingly more frequent, but 24 instances of TTRs providing negative evaluation were located.
Third turn repetitions (TTRs) in three turn instructional sequences.
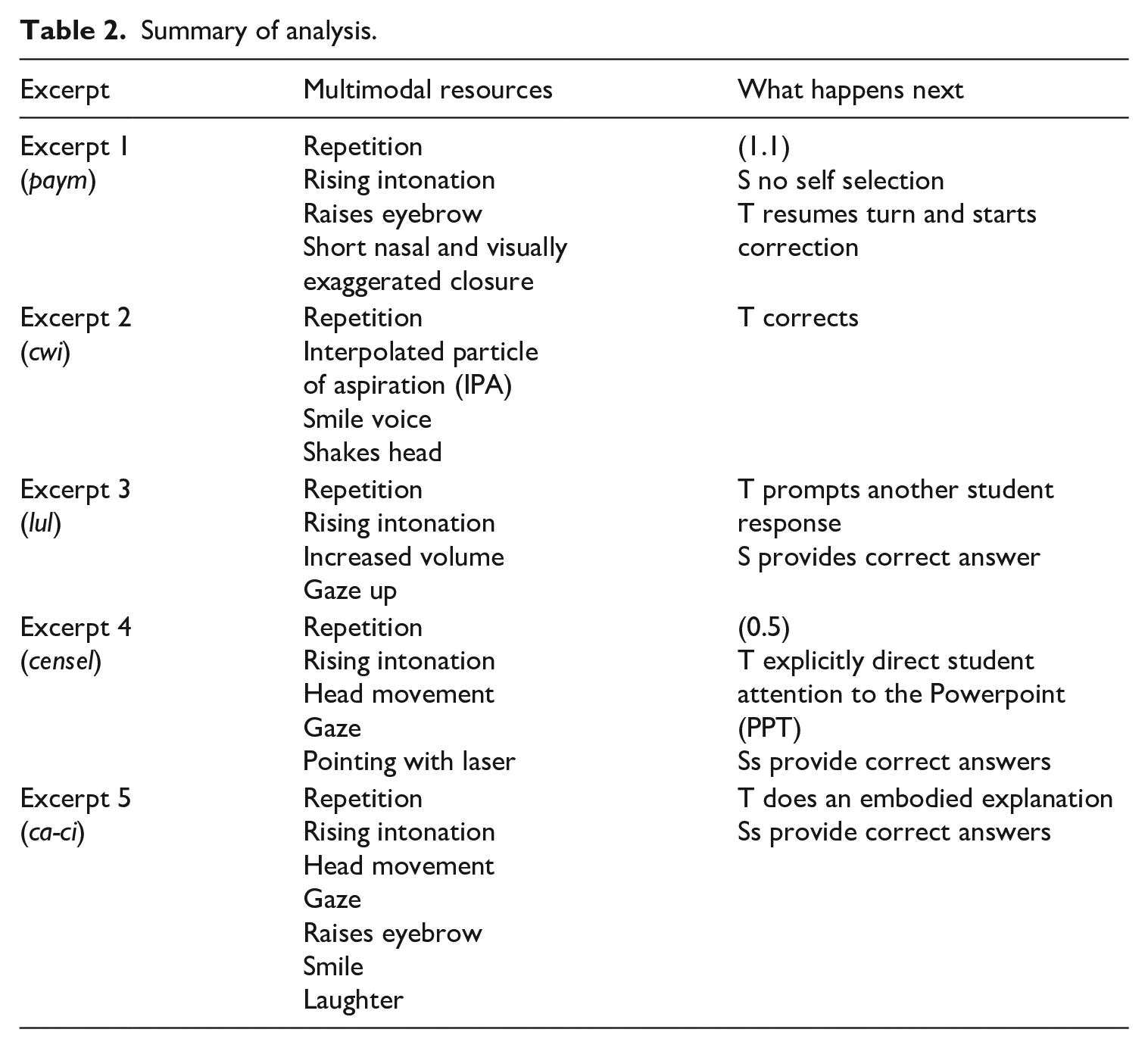
Next, we narrowed our focus specifically to sequences containing negative evaluations after which the teacher attempted to prompt further responses or provided explicit correction. This yielded five instances (for overview, see Table 2). These examples were repeatedly analysed by the authors using both the transcripts and videos, then transcribed according to Mondada’s (2018) conventions for multimodality.
Summary of analysis.
The multimodal transcripts used in this article include three tiers. The first is a romanization of Korean or English. This tier appears in black Courier New font. The second tier of talk accounts for multimodal resources such as gaze, gesture, and body movements. It is transcribed in grey Courier New font. The onset and coda of gestures, facial expressions, and directions of gaze are marked with symbols (+, %, $, ^) and aligned with the talk in the first tier. The plus sign denotes head movements. The percent sign marks gaze. The dollar sign marks smiling, and the carat identifies gesture or the use of a laser pointer. The third tier of transcription is an English gloss where needed. The gloss is presented in Times New Roman and roughly aligns with the Korean talk. Exact alignment of the gloss with the Korean talk is not always possible due to the quite distinct grammars of the two languages. Figures depicting the use of multimodal resources are presented below the English gloss and are located in the talk with aligning hashtags (#).
The questions guiding the analysis presented below are:
How does the teacher mobilize multimodal resources to mitigate TTRs and locate trouble sources when delivering negative feedback?
How does the teacher mobilize multimodal resources in the pursuit of responses following TTRs delivering negative feedback?
III Analysis
Excerpt 1 comes from a longer sequence during which students take turns reading sentences from the textbook aloud in Korean. The sentences come from the three-paragraph passage titled ‘Animals with Special Meaning in Korea’. After Isabel reads a line about a pig symbolizing wealth, Tiffany explains how dreaming about a pig is regarded as auspicious (not included in the excerpt). She then asks what animal appears in an inauspicious dream, content they previously covered. This is where the excerpt begins.
Excerpt 1: Paym

Tiffany initiates the three turn instructional sequence in line one with a declarative sentence. A one second gap ensues before Isabel responds, paym, snake in English. Isabel’s response is spoken quietly with rising intonation, both indices of uncertainty. Tiffany initiates repair in the form of a tooth suck followed by the open-class repair initiator (Drew, 1997; Schegloff, 1997) ung, spoken while smiling and gazing at S02. Tiffany does not nominate next speaker by name, but the action of initiating repair, coupled with gaze does the selection. After six tenths of a second (line 5), Isabel produces a revised response, this time adding a particle, ul, to the noun paym (line 6). This displays Isabel’s orientation to grammar as the trouble source to which Tiffany was orienting. The next turn reveals grammar is not the trouble source to which Tiffany was attending. Tiffany repeats the noun paym with no particle, rising intonation, and while raising her eyebrows (line 7). By doing a TTR with transformation, i.e. omitting the particle in her third turn, Tiffany directly locates the trouble source as a lexical issue, not a grammatical issue. Her segmental pronunciation and facial expression also assist in this work. The bilabial nasal at the end of paym is audibly short and the closure of the mouth is exaggerated, making it salient that no particle is forthcoming (Figure 2). This TTR exemplifies how lexico-grammatical, segmental, and prosodic resources can intersect with facial expressions in the accomplishment of teaching and learning as social practice. ‘Recipients can hear [and see] that such turns were designed to be repeats even if, and for repair purposes especially if, they mis-represent their target in some important respect’ (Schegloff, 2007). No student self-selects in line 8 so after over a second of silence the teacher reminds student that snakes appear in dreams about conception (line 9). Students respond in line 10 with a change of state token ah (Heritage, 1984).
Tiffany then switches to English saying, ‘somebody pregnant’ (line 11). She points to her stomach while saying pregnant and then shifts back to Korean, producing a coordinating conjunction. While class is conducted mostly in Korean, correction sequences like this are places Tiffany shifts to English. She does so in this case to elaborate upon what she has previously stated in Korean. Interestingly, Tiffany gestures to her abdomen when saying pregnant in English but not when saying conception dream (thaymong) in Korean. Gesture, while a meaning making resource, is not acting in direct support of the L2 here. Excerpt 2 follows immediately after Excerpt 1 as Tiffany continues pursuing a response from her students. Line numbers have been maintained across Excerpts 1 and 2.
Excerpt 2: Cwi

Tiffany initiates a three turn sequence with a partial repetition of her previous initiation (line 12). After a gap of over two seconds in line 13, Rachel puts forth a candidate response quietly and with rising intonation, cwi (‘mouse’), in line 14. As in the first excerpt, volume and prosody reveal uncertainty on the part of the student. Tiffany repeats cwi in line 15 with increased volume, rising intonation, widened eyes, upward gaze, and smiling. She affixes the word with a form of laughter known as an interpolated particle of aspiration (IPA), marking cwi as problematic in some way (Potter & Hepburn, 2010). She then explicitly rejects the prior turn, saying cwi while shaking her head and smiling as part of a clausal turn with another IPA. Smiling, smile voice, and aspiration mitigate the explicit rejection embodied in both the clausal turn design and head shaking. She then immediately proceeds to ask students what she has previously taught them, chastises them for not remembering, and provides the desired response, kay (‘dog’), herself (not shown in transcript). In the first two excerpts, Tiffany draws on grammar, rising intonation, IPAs, facial expression, and head movements to design TTRs. By withholding a particle or adding an IPA, she flags the troublesome aspect of the prior turn. At the same time, smiling and laughter, in the form of an IPA, mitigates the action of negative evaluation.
Excerpt 3 comes from a sequence in which students are learning a construction ta-ko/la-ko hay-se, which translates to ‘be called and then’. In this particular task, the students are asked to translate the sentence ‘August 15th in lunar calendar is called Chuseok, and it is like Thanksgiving in the United States’ into Korean using the newly learned construction. During the translation task, students encounter difficulty with the sentence-ending phrase that requires them to express that Chuseok ‘corresponds to’ or ‘is like’ Thanksgiving in America.
Excerpt 3: Lul

Tiffany opens this sequence with an explicit positive evaluation of the prior turn before shifting to English (line 1). The clause prompts students to produce a specific grammatical form, i.e. a locative case marker. The English clause is followed by an elicitation in Korean (line 2) which is met with almost a half second of silence (line 3). In line 4, Tiffany again prompts students by producing the noun for Thanksgiving without the locative particle. The prompt is followed by six tenths of a second of silence (line 5) before a student responds in line 6. The response is spoken with rising intonation, indicating uncertainty. Tiffany’s TTR in line 7 is produced with rising intonation, increased volume, and an extended lateral. She also averts her gaze upward, as demonstrated with the arrow in Figure 5. This TTR like the examples already presented draws on volume and multimodal resources that work with linguistic resources, i.e. lexis and phonemes, and intonation to flag the turn as negative evaluation. Without pause, Tiffany again prompts students for the particle corresponding to Thanksgiving with a partial repetition of her previous initiation turn (line 7). Her gaze is averted upwardly to the left while speaking (Figure 6). By averting her gaze, Tiffany opens the floor for students to self-select. This contrasts with Excerpt 1 in which Tiffany gazed at the student during her TTR to target a next speaker. A student immediately responds with the correct particle (line 8). Tiffany provides positive evaluation in line 9 with a TTR before launching into an explanation in which she provides an alternative particle that can work as well as ey (not included in transcript).
The analysis has shown so far that the teacher manipulates linguistic resources, intonation, volume, laughter, gaze, and facial expression to design TTRs. The resources do not operate in isolation but come together to locate prior trouble sources, mitigate negative evaluation, and manage turn taking in the pursuit of responses. The remaining two excerpts present examples of TTRs that overlap with or are followed by the intimation of desired responses. Prior to Excerpt 4, the class has been taking turns reading sentences aloud from a passage regarding animals with significant meanings in Korean culture. The final paragraph of the passage discusses highly regarded mythical creatures in Korean culture, including the dragon, phoenix, and haythay (a legendary unicorn lion). The students are instructed to identify the term that encompasses these creatures, which is stated in the topic sentence of the paragraph and displayed on the projection screen.
Excerpt 4: Censel

Lines 1–2 are a multi-unit turn in which Tiffany names three mythical animals and asks students how the creatures are introduced. Her initiation is followed by over half a second silence (line 3) before multiple students respond with the word censel, legend in English (line 4–5). The student responses are produced quietly, one with an extended nasal and the others with rising intonation. The delay and the quiet design of student responses display uncertainty. Tiffany does a TTR with rising intonation while turning her head and gaze to the left toward the projection screen (line 6). Tiffany designs her turn lexically and prosodically to deliver negative evaluation while simultaneously managing other pedagogical work, i.e. directing students attention to the desired response, by turning her head and gaze left toward the projection screen (line 6, Figure 7). The averted gaze in Excerpt 4 does distinct work from earlier examples in that it intimates a desired response (Lee, 2007) by visually orienting to it on the projection screen. Thus, in this example, two actions are accomplished in the temporal space of one turn constructional unit (TCU) (Schegloff, 2007) via different modalities. This insight into the nuance of teaching is impossible without video recordings and multimodal analysis. It also opens larger questions for CA like how does analysing multimodality impact how units of action, design, and sequence are conceptualized.
Tiffany’s initial attempt to prompt a response is met with a half second of silence (line 7). Tiffany further pursues a response by maintaining her gaze and body position, pointing at the projection screen with a laser pointer, and using deictic language (line 8, Figure 8). Holding this position is similar to the post-hold gestures or repeated gestures in earlier studies in that it projects a clear interactional trajectory for students (Flood & Harrer, 2023; Looney & He, 2021). While speaking, Tiffany points to the desired construction in writing on the projection screen. A chorus of student responses ensue (line 9). The responses are spoken at a higher volume and without the rising intonation that marked earlier student response turns. Tiffany produces positive evaluation in the form of a TTR in line 10. Excerpt 4 uniquely displays the possible complexity of action and design in TTRs that provide evaluation and simultaneously attempt to mobilize further student contributions. When this attempt fails, Tiffany refines her unfolding complex multimodal gestalt (Mondada, 2016) to more explicitly guide student attention by using a clausal construction, the laser pointer, and the projection screen.
Excerpt 5 is taken from a sequence in which the students have just learned the Korean equivalent expression of ‘Please don’t’, which is formed using a verb stem followed by a negative command -ci -maceyo (‘to stop doing something’). Tiffany asks students to translate the clause ‘Please don’t doze off during class’ into Korean. This is where our excerpt begins.
Excerpt 5: Ca-ci maceyo

In lines 1 and 2, Tiffany initiates a three turn sequence by reading from the projection screen. The text she reads is in English. Following a half second of silence (line 3), Amanda responds with ca-ci map-si-ta, or ‘let’s not sleep’ (line 4). Tiffany smiles as Amanda produces the clause to which the student affixes an IPA (Figure 8). Two students respond in overlap with ca-ci (lines 4–5). Tiffany begins her TTRs in overlap with Laura and Shannon (line 6). The repetition begins with a ca- and an IPA. The IPA planted in single word ca-ta (‘sleep’) signals to the students that it is the specific lexical item that needs to be revisited, rather than the sentence-ending form. Tiffany repeats ca-ci ma-sey-yo with rising intonation while raising her eyebrow and slightly tilting her head to the right (line 7, Figure 10). Tiffany immediately produces a clausal English utterance with negation and the word ‘sleep’ while leaning further to her right and bringing her palms together and toward her right cheek, as if laying her head on a pillow (line 7, Figure 11). This complex multimodal gestalt is the first part of a comparison between what students translated (ca-ci, or ‘sleep’) and the word Tiffany is seeking (col-ci, or ‘doze off’). Following a pause, Tiffany continues in English, producing only the phrasal verb students should translate and then shifts to Korean, saying ilehkey (‘like this’ in English) three times while dropping her head forward and down as if dozing off (lines 8 and 11, Figures 12 and 13). Tiffany’s head movements and gestures in chorus with linguistic material from two languages (lines 7 and 8, Figures 9–11) do pedagogical work to differentiate the meaning of two target language lexical items. The action of the talk cannot be precisely understood without reference to the accompanying gesture and head movement. The inextricability of language and gesture is clearest in lines 8 and 11 (Figures 12 and 13) when Tiffany repeatedly says ilehkey while dropping her head to contrast doze off with sleep. One must see the head movement to understand ilehkey. Similarly, the talk and the gestures combined can only be understood as they unfold sequentially. The gesture and talk in line 7 and 8 (Figure 11) imbue subsequent talk with contrastive meaning and are in turn imbued with meaning by subsequent talk.
Students orient to Tiffany’s turn in lines 6 and 7 as negative evaluation as demonstrated in the self-selections in lines 9 and 10. Tiffany does not attend to these responses though, continuing her pursuit of responses (lines 11–13). Victoria responds in overlap in line 12, but it is Victoria’s repetition of her response in line 14 that finally receives recognition from Tiffany. Tiffany does positive evaluation in the form of half nod, stressing the verb stem (line 15), again combining multimodal semiotic resources to identify what is correct and what needs to be learned (Waring, 2008).
IV Discussion
This study further illuminates the complexity of third turns in instructional sequences by analysing the role of multimodal resources in TTRs in a Korean as a foreign language classroom. Multimodal resources intersect with grammar, segmental pronunciation, and prosody to provide negative evaluation, direct attention to trouble sources, and intimate answers (Hellermann, 2003; Lee, 2007; Seedhouse, 2004; Waring, 2008). Four findings add to our understanding of the complexity of third turns (Lee, 2007; Waring, 2016) and the grammar-body interface (Pekarek Doehler et al., 2022) in language teacher talk: (1) TTRs combine lexis, grammar, prosody, and other resources such as volume, gaze, facial expression, and IPAs to target trouble sources in negative evaluation, (2) Smile, laughter, and facial expression are used to mitigate negative evaluation in TTRs, (3) Gaze and head movements are resources teachers can use to intimate desired responses while simultaneously delivering a TTR, and (4) Gesture and head movements may be combined with English and Korean linguistic resources in the pursuit of responses.
TTRs combine lexis, prosody, and other resources such as volume, gaze, facial expression, and IPAs to target trouble sources in negative evaluation. As is true of repetitions in everyday conversation (Schegloff et al., 1977), the TTRs presented above act as close-ended repair initiators that specifically locate the trouble source. Our analysis supports prior findings that TTRs with rising intonation deliver negative evaluation (Hellermann, 2003; Seedhouse, 2004). It expands our understanding of TTRs by showing how multimodal resources are mobilized in the targeting of trouble sources. Our analysis finds that in addition to intonation, segmental pronunciation, grammar, gaze, facial expression, and laughter are resources the teacher uses to do repetitions with transformations (C. Goodwin, 2000, 2018) that mark TTRs as negative evaluation. Excerpts 1 and 3 illustrate the teacher using pronunciation (shorten nasal Excerpt 1, extended lateral Excerpt 3) and grammar (dropping final particle Excerpt 1) to target prior trouble sources, i.e. what needs to be learned (Waring, 2008). Laughter in the form of IPAs (Potter & Hepburn, 2010) is affixed to TTRs in Excerpts 2 and 5. These practices reveal TTRs are not just lexical repetitions with different prosodic patterns. They draw on several resources to target the trouble source and at times a specific aspect of the trouble source.
Multimodal resources such as smile, laughter, and facial expression, in the form of widened eyes and averted gaze, are also used to mitigate negative evaluation in TTRs. Negative evaluations are dispreferred responses (Pomerantz, 1984a). They delay the progression of the activity, and they are mitigated by speakers who might bury the explicitly negative elements of a dispreferred action or implement actions such that an explicitly negative action such as rejection never surfaces in the talk (Schegloff, 2007; Seedhouse, 1997). Each of the TTRs presented delay the progression of interaction as do the subsequent actions. The delay involves pedagogical work that attempts to mobilize student participation. Our repetitions do not usually involve explicit negative assessments (ENA). Excerpt 2 is an exception, but the ENA comes after the repetition and is at the end of multiple three turn sequences that do not elicit the desired response and just before she tells the students the desired response. Excerpts 2 and 5 are both examples of TTRs being mitigated with smiling and IPAs (Potter & Hepburn, 2010). These findings contribute to past classroom research showing how a teacher deploys smiling and laughter as part of sensitive actions involving epistemics (Looney, 2021; Looney & Kim, 2018, 2019; Sert & Jacknick, 2015). Attention to multimodal resources including but not limited to smiling and laughter in its various forms provides a clearer picture of how participants treat pedagogical interaction as sensitive work.
Multimodal resources can accomplish complementary or contrasting work alongside language. Excerpts 1, 2, and 3 are examples of facial expression and head movements doing the same or complimentary work as corresponding talk. Gaze shifts, facial expression, laughter, and headshaking combine with intonation and linguistic resources to isolate and highlight trouble sources, manage mitigation, and intimate responses (Lee, 2007). At other times, gaze manages the intimation of answers while the verbal and prosodic components of the turn provide negative evaluation (Excerpt 4). Here, gaze and language simultaneously manage distinct interactional work. Resources such as gaze and pointing are the aspects of the turn that guide student attention while language and prosody do the evaluation. This example starkly illuminates the multivocalic complexity of pedagogical practice (Waring, 2016) as Tiffany simultaneously evaluates the response and attempts to direct student attention. This finding is significant for studies of human interaction and the grammar-body interface (Pekarek Doehler et al., 2022) because it demonstrates that many people manage at least two modalities, visual and auditory, during interaction, and those modalities can do either complementary or contrasting work of various sorts simultaneously.
In a related vein, this analysis begins to unpack the multilingual nature of teachers’ and learners’ semiotic registers (Agha, 2005; Hall, 2019) in empirical detail by showing how a foreign language teacher of an advanced-level Korean course at a university in an English-speaking country uses her students’ L1 as a pedagogical resource in three turn instructional sequences (Excerpts 1, 3, and 5). Her language choice is sequentially bound in activity, pedagogically motivated, and fundamentally multimodal. Excerpt 5 is a particularly salient example of how the teacher does negative evaluation in Korean with smiling and laughter then combines languages, head movements, and gesture to intimate a response. Tiffany’s use of English emerges during a sequence in which she has asked students to translate, an activity in which both languages must be used. It is also contingent on students’ responses being incorrect. English grammar (negation) works with lexis (sleep, doze off) and body movements to form part of a comparison that is finished in an adjacent pair of Korean phrase (ilehkey) and head movements. Tiffany’s body and head movements tie the English and Korean TCUs together and imbue them with meaning. Such effervescent moments, when unpacked in microanalytic detail, make observable the complexity of second and foreign language teaching in a manner that can be informative for teachers and teachers in training. Multimodal CA is particularly helpful for understanding her use of languages and visual resources because of its focus on members’ methods and transcription practices.
V Conclusions
Fine-grained attention to the multimodal details of classroom interaction is essential for understanding the work teachers and students are undertaking from moment to moment (Hall & Looney, 2019; Mortensen, 2016). This study’s findings are significant to applied linguists and other classroom researchers because they illuminate the intricacy of face-to-face classroom interaction and demonstrate that language teaching is a complex multimodal interactional accomplishment. Future research must continue to unpack teaching and learning as multimodal social practice in face-to-face and virtual contexts. Multimodal analysis offers researchers and pedagogues a more fine-grained and holistic ‘procedural description [which] allows us to get closer to an understanding of classroom teaching and learning as practical enactments’ (Lee, 2007). Understanding the practical enactment of the classroom must inform teacher preparation as well.
Using naturally occurring video-recorded classroom data in teacher preparation courses can help teachers-in-training see how their future colleagues manage in the moment contingencies such as delivering negative evaluation and pursuing further responses. Analysing the contingencies teachers encounter and how they negotiate them can be instructive for others who may not yet have classroom teaching experience. Recordings and transcripts are advantageous because they can be shared and iteratively analysed. This allows group discussions and analysis in a way that observations do not. It also provides authentic examples of teaching to observe and reflect upon that recorded micro-teaching and role-playing lack. Praxis-oriented scholars have advocated for the use of CA and CA-inspired frameworks for reflection in teacher preparation (Balaman, 2022; Waring & Creider, 2021). Using micro-analysis of video recordings can help teachers in training discuss and reflect upon classroom teaching. Waring and Creider (2021) propose three principles of skillful classroom practice: (1) Fostering student participation, (2) Attending to learner voices, and (3) Balancing competing demands. The data presented above could be used to analyse how the teacher multimodally fosters student participation by mitigating potentially face threatening actions such as negative evaluation and by providing space for students to self-select following TTRs. Excerpt 4 in which the teacher delivers her TTR while attempting to direct student attention with gaze and head movements is an excellent example of the complexity of teacher turns and how they balance competing demands. By providing mediation that highlights the specifics of classroom interaction, teacher preparation professionals can develop mentees’ awareness of the complexity (Lee, 2007; Waring, 2016) of teacher action and classroom contingencies. While certainly not a panacea for language teacher preparation, multimodal analysis of classroom interaction is an invaluable tool for orienting novice teachers to teaching as complex and contingent social practice.
Footnotes
Acknowledgements
An earlier draft of this article was presented at the 2023 meeting of the American Association for Applied Linguistics in Portland, OR, USA. The authors thank Dr. Ok-sim Kim from the Department of Asian Studies at Pennsylvania State University for allowing us the opportunity to record and analyse her classroom. We also thank all students in her classroom who granted us permission to record their class participation. We thank Christianna Otto for her contributions to the initial stages of this study. Finally, we thank three anonymous journal reviewers for their comments on earlier drafts. The responsibility for the content and any remaining errors lies exclusively with the authors.
Disclaimer
This article has been approved for public release by the Defense Language Institute Foreign Language Center’s Public Affairs Office. For verification please e-mail:
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.