
Abstract
The present experimental study examined whether a different focus during a pre-task planning observation task affects learners’ subsequent oral task performance. Forty-eight ninth-grade students learning German as a foreign language were randomly assigned to two different planning conditions: video observations with a focus on language (FonL) and video observations with a focus on content (FonC). With a communicative oral task we measured the effects on oral task performance, in terms of attempted (accurate) use of the target structure and complexity, in terms of number of words, subordination and coordination. In addition we investigated whether there was a trade-off between attempted (accurate) use of the target structure and complexity. Results showed that the focus of the observations at the pre-task stage did indeed lead to different outcomes: students in the language condition used the grammatical target structure more often and more accurately, whereas students of the content condition generated more coordinate and subordinate clauses. Trade-offs were found between attempted (accurate) use of the target structure and the use of subordinate clauses. These findings imply that, depending on the purposes of the lesson, the observation of peer-model videos with different planning foci can be effectively used to promote (accurate) use of targeted grammatical structures and improve complexity during subsequent task performance.
I Introduction
1 Focus on form and meaning in the pre-task
Before we started this experimental study we interviewed five experienced task-based language teachers at a Dutch secondary school where we would conduct the experiment and asked them about the role of grammar in their lessons during the pre-task. All five of them reported that they taught grammar rules before students start to plan the task performance. Four of them asked learners to incorporate a certain number of grammatical target structures into the oral or written task they prepare, for example ‘make sure your presentation includes eight passives’. The teachers explained their choice in favor of explicit grammar teaching by stating that, since their self-designed task-based language curriculum is already very progressive (most schools in the Netherlands use standardized textbooks), they wanted to make sure that students learn the same grammar rules as students in other schools do. Although the standard textbooks in the Netherlands are based on a communicative approach to language learning, explicit grammar teaching still plays an important role in Dutch foreign language classrooms (West & Verspoor, 2016). It is therefore understandable that these task-based language teachers do not want to deviate too much from the common classroom practice. It also aligns with the view of certain researchers (e.g. Fotos, 1998; Littlewood, 2007) that, especially in contexts where the L2 is a foreign rather than a second language, as in the Netherlands, more explicit grammar teaching is necessary.
Other researchers (Ellis, 2016; Long, 2015) and teacher educators (Willis, 1996) stress the downside of explicit grammar teaching in the pre-task. Learners may approach the subsequent communicative task as an exercise to practice the grammatical target structure instead of an opportunity to improve their communicative skills. For that reason, most proponents of task-based language teaching (TBLT) are not in favor of providing grammar rules in the pre-task. Instead they prefer linguistic support in the form of vocabulary that could be useful in the upcoming main task. Of the essence here is that, while the primary focus is on meaning, learners’ attention is directed to the grammatical target structure while, at the same time, form-meaning connections are established (Ellis, 2016).
In line with the aforementioned view on focus on form in the pre-task, we designed an experimental study that incorporates a primary focus on meaning with an implicit focus on form. Put simply, conditions for learning a target grammatical structure were created, but these did not include explicit rule explanations. In the present study, students were asked to either focus on the use of a grammatical target structure (language) or on the content of the task while observing the performance of a meaning-focused communicative task by peers on video. In this study we wanted to investigate whether directing learners’ attention to language in the pre-task would lead to increased (accurate) use of the targeted grammar structure and whether directing learners’ attention to content would lead to greater complexity. The findings of this study could inform the choices teachers make while deciding whether learners’ focus on a task should be on either content and/or language. The results may also lead to a more balanced view on language development in foreign language classrooms, in which not only accuracy should be fostered but also complexity.
2 Pre-task activities
The pre-task is an essential phase of the task-based lesson cycle since it is the place in the task cycle which determines learners’ orientation to the main task and as a consequence may affect subsequent task performance (Skehan, 1996). Both Willis (1996) and Skehan consider pre-task activities to be important because they are intended to make the main task more productive. Skehan (1998) distinguishes three major types of pre-task activities: teaching, consciousness raising, and planning. Teaching activities introduce new language and usually include instructions on targeted grammatical features. Although ample research shows that explicit instructions are very effective in promoting accurate use of grammatical target features (Norris & Ortega, 2000; Spada & Tomita, 2010), some TBLT proponents (e.g. Long, 2015) object to providing learners with explicit instruction prior to performing a task. They state that a focus on form should be a reaction to a communication problem and not pre-planned. Others (Sato, 2010; Shehadeh & Coombe, 2012) see a role for pre-task grammar teaching in combination with communicative tasks, which is also known as task supported language teaching (TSLT).
Consciousness raising activities attempt to raise awareness of the language structure while providing learners with meaningful input and activities. Consciousness raising pre-task activities such as input flood and different forms of visual input enhancement (see meta-analysis by Lee & Huang, 2008) have been investigated for their effects on grammar learning. These activities appeared, to a greater or lesser extent, successful in making linguistic structures salient and noticed.
So far, the discussed pre-task activities have primarily concerned language and promoted awareness and/or production of targeted grammatical or linguistic structures. The pre-task, however, can also be used to engage learners with the content of the task. Learners may think of ideas they want to express and even think of more thorough interpretations of the content of the task. Focusing on the content could be done in pre-task discussions but also be the result of the observation of similar tasks completed on video (Willis & Willis, 1996). These content-focused pre-tasks could evoke more complex interpretations of the task, which could lead to more complex task performances, which are necessary for the more complex meanings learners want to express (Skehan, 1998; Foster & Skehan, 1999).
Planning as pre-task activity does not only allow for a focus on language but also provides the opportunity for a focus on the content of the task. From an information processing approach, pre-task planning time could help learners overcome their limited attentional resources and improve their L2 performance (Foster & Skehan, 1999). The findings of a substantial amount of research on the effects of planning (both guided and unguided planning) on oral task performance demonstrate positive effects on fluency and complexity and mixed effects with respect to accuracy (Ellis, 2009, 2016; Ortega, 2005). Since the effects of guided planning on oral task performance are the focus of the present study we will now discuss studies that investigated guided planning conditions that include measures of oral task performance. Studies that have investigated the effects of unguided planning time (e.g. Ortega, 1999) or measured the effects of focus on form only in terms of language related episodes (Kim & McDonough, 2011) are beyond the scope of our review and will not be discussed. Moreover, since the present study also examines Skehan’s trade-off theory, which claims that attention needs to be shared between linguistic complexity, accuracy and fluency, we will also discuss results that regard trade-offs between accuracy and complexity.
3 Guided planning
To the best of our knowledge, only two guided planning studies made learners focus on a particular grammatical structure during planning time and measured the effects on task performance. In Mochizuki and Ortega’s (2008) study 56 first-year high school students of English in Japan were asked to perform an oral story-retelling task with a fellow student. Students were assigned to one of three conditions: no planning, 5 minutes of unguided planning, and 5 minutes of guided planning with help of a grammar handout about English relative clauses. Results showed that, compared to unguided planning, the guided grammar planning led to more accurate use of the relative clauses and to similar levels of global complexity and fluency. In other words, no trade-off was found between the different aspects of task performance. Kim’s (2013) study examined the effects of pre-task modeling as part of learners’ planning time on attention to question structures and their subsequent question development. The effects of the guided model observations were measured by the occurrence of language related episodes and dimensions of task performance. Forty-five female Korean middle school students, learning English as a foreign language, were assigned to a modeling group with guided planning time and a no-modeling group with unguided planning time. Modeling videos of three collaborative tasks (information gap, picture difference, decision making) provided the learners with examples of how to pay attention to linguistic forms and demonstrated how they should work in pairs. Results showed that the pre-task modeling videos contributed to both learners’ attention to form, especially during planning time, and question development.
Other researchers did not focus on a particular structure but investigated the effects of combined planning instructions focused on both content, language and organization (Crookes, 1988, 1989; Foster & Skehan, 1996; Mehnert, 1998; Park, 2010; Wendel, 1997; Yuan & Ellis, 2003). Results showed that these specific planning instructions resulted in improved fluency and complexity, but not in improved accuracy. Apparently, asking learners to plan for ideas and organization leads to increased linguistic complexity, but sacrifices accuracy. This may be explained by learners prioritizing content above form. When receiving combined instructions, learners tend to focus on content and organization in the first instance and not on language or less so. This view is supported by theories on limited attentional resources (Skehan, 1996, 1998), which claim that, when learners need to produce language, they cannot pay attention to both content and form at the same time as a result of cognitive overload. Based on the positive results of the specific guiding instructions in their study, Foster and Skehan (1996) suggested a role for focus of attention during pre-task planning.
Two studies investigated this role of attention by comparing form and content conditions during pre-task planning. In Foster and Skehan’s (1999) study, sixty-six adult students with varying language backgrounds, learning English as a foreign language, were asked to carry out a decision-making task in which they discussed which person needed to be forced out of a hot air balloon which was losing altitude, to avoid a crash. Besides comparing two different planning foci, Foster and Skehan also compared teacher-fronted with group-based planning. Participants were stimulated to focus on form through either teacher-led instructions on the use of modal verbs and conditionals or instructions on paper to control for correct English. Participants were stimulated to focus on meaning by the teacher, who gave a presentation on ideas that each character might use to defend his or her right to stay in the balloon. The instructions on paper required learners to think about reasons why a certain person should not be thrown out of the balloon. Results showed no main effect for focus of planning, which led Foster and Skehan to the conclusion that ‘effects of planning are not simply attributable to whether subjects concentrate on one of these areas rather than another’ (p. 239). However, they found a main effect of the source of planning, participants in the teacher-led condition producing higher levels of accuracy than those in the group-based condition. Interestingly, the accuracy gains in the teacher-led group did not come at the expense of complexity scores. Both accuracy and complexity benefited from the teacher-led preparation. Foster and Skehan argued that even though there should have been a focus on either language or content in the teacher-led group ‘pairings of accuracy and complexity were unavoidable’ (p. 240). They reasoned that, while making form-meaning connections, the teacher functioned as a model for both accurate and complex language use.
Like Foster and Skehan, Sangarun (2005) compared the effects of form and meaning conditions in the pre-task through different kinds of guided planning conditions. Forty Thai, eleventh grade EFL learners were assigned to four strategic planning conditions: minimal planning, form planning, meaning planning, meaning/form planning. Guidance was provided in the form of written planning instructions. Effects were measured on quality of speech (i.e. accuracy, complexity, and fluency). On complexity, the two conditions that included meaning planning outperformed the other conditions. On accuracy, the meaning/form planning, meaning planning, and form planning conditions outperformed the minimal planning condition, but no significant effects between the other three conditions were found.
In sum, except for Foster and Skehan’s (1999) study, we may conclude that guided planning studies show positive effects on learners’ task performance in terms of accuracy or complexity. Studies that made learners focus on particular language structures have been successful in promoting accurate use of the structures, whereas studies that used combined or meaning-focused instructions generated increased complexity. The reason why no effect for focus on planning was found in Foster and Skehan’s (1999) study may be the fact that in the teacher-led conditions it was difficult to adhere to either a language or content preparation. The teacher integrated both complexity and accuracy, which led to a better task performance on both dimensions. It could be argued that, in this study, the teacher successfully functioned as a model for both accuracy and complexity.
In the present study, we incorporated the idea of modeling. Learners observed peer-model videos as part of their planning time and were directed to either language or content by means of written instructions. The idea for these video models was based on notions of both Zimmerman and Kitsantas (2002) and Hattie (2012), who argue that for learners to be successful in task performance they should have a clear image in mind of what successful task performance looks and sounds like. Peer-model videos could provide a clear image of successful performance in terms of accuracy and/or complexity.
II The present study
Building on the research discussed above the present study compares the effects of learners focusing on content and language during pre-task peer modeling observations on subsequent task performance. To this end two research questions were formulated.
Research question 1 Does a focus on either content or language during pre-task peer modeling observations affect subsequent task performance in terms of attempted (accurate) use of the target structure and complexity?
Research question 2 Is there a trade-off between attempted (accurate) use of the target structure and complexity?
Looking at language learning from an information processing perspective, in which accuracy and complexity compete for attention (Skehan, 1996; Foster & Skehan, 1999), we hypothesize that:
Language-focused planning through written instructions that guide the observation of peer-model videos will lead to greater (accurate) use of the targeted grammatical structure than content-focused planning. Hearing and writing down the grammatical target structures which are embedded in a communicative task may induce learners to (accurately) use these structures during subsequent task performance (Boston, 2009).
Content-focused planning through written instructions that guide the observation of peer-model videos will lead to greater complexity than language-focused planning. Focusing on the content while observing another peer perform a similar task may generate different kinds of mental activities that make the learner think about the conceptual content of the task. Learners may be willing to take more risks and experiment with more complex language. It may also be so that the engagement during the observation enables better ‘packaging’ of ideas in the upcoming performance and thus raises complexity (Bygate, 2001).
More complex language use will come at the cost of (accurate) use of the targeted grammatical structure and vice versa. This hypothesis connects with the limited capacity view, which claims that, when attention is devoted to more complex language use, less attention is left for the (accurate) use of grammatical structures, which will diminish the performance therein.
III Method
1 Participants
Participants (62 % females; 38% males) in the present study were forty-eight ninth-grade students learning German as a foreign language (A2 level of the Common European Framework of Reference for Languages; CEFR, Council of Europe, 2001) from one and the same Dutch school for secondary education, where foreign languages are taught in accordance with a version of task-based learning. Their mean age was 14.2. All had a Dutch language background. Participants had had two hours of German per week for about 17 months. They were randomly assigned to either a focus on language condition (n = 25) or a focus on content condition (n = 23 1 ). In accordance with the protocol of the University of Amsterdam’s Faculty of Humanities’ Ethics Committee, all parents were informed about the study and the possibility of their children opting out of the study.
2 Modeling task
As a pre-task, all participants got a guided planning task that consisted of watching two videos of two different girls describing the school cafeteria to prospective students to inform them about their school and persuade them to enroll. We chose the cafeteria description task because it allows for both a language and a content focus. The language-focused group observed the use of two-way prepositions plus a dative case, instructed to do so via instructions on a written hand-out (see Appendix 1). The content-focused group observed the appeal and persuasiveness of the presentations via instructions on a written hand-out (see Appendix 2). Participants observed two videos (Video 1 lasted 1.26 minutes, and Video 2 lasted 1 minute) because in this way the language group was provided with sufficient input regarding the target structures and it allowed the content group to make comparisons between the degree of appeal and persuasiveness of the two performances. Before watching the two videos participants were informed that they were going to perform a similar task as in the videos afterwards. To increase the chance of identification, confidence and motivation, the girls in the videos were about the same age as the participants. In this way, participants could experience that, if peers were able to perform this task successfully, they would also be able to do it (Schunk & Zimmerman, 1997). Based on theories on perceived competence that suggest that learners of new skills tend to follow the example of competent models (Schunk & Zimmerman, 1997), the girls in the modeling videos performed the task accurately and with confidence. The video models followed scripts written by the first author.
3 Target structure
When describing the school cafeteria to inform and recruit prospective students for their school, as the task was set for participants, the use of locative prepositions was indispensable (see task-essentialness; Loschkey & Bley-Vroman, 1993). For that reason, the dative case of an article after a two-way preposition (in, an, auf, hinter, neben, unter, über, vor, zwischen 2 ) was chosen as the target structure of the current study (see also Van de Guchte, Braaksma, Rijlaarsdam, & Bimmel, 2015). In this example, an der Wand hängt ein Poster (‘on the wall hangs a poster’) the preposition an demands the dative case and consequently the (nominative) feminine definite article die changes into der. This structure is considered a complex, rule-based structure and it has no equivalents in the Dutch L1. Students’ pre-test results did indeed show that their knowledge of the target structure was limited.
The language focused instructions during the observations aimed to prompt the students to use this complex structure instead of more simple alternatives. It appears that, like learners of English (Newton & Kennedy, 1996), learners of German find it difficult to use prepositions in a sentence. For example, learners prefer saying links steht ein Tisch (‘on the left there is a table’) rather than the more complex auf der linken Seite steht ein Tisch (‘on the left side there is a table’).
4 Research design and procedures
In this experiment we carried out a pre-post-delayed posttest research design, which was spread out over a period of six weeks (see Figure 1). The guided peer-model video observations were part of learners’ planning time and were carried out under two conditions: written instructions directed to language (FonL) versus written instructions directed to content (FonC).
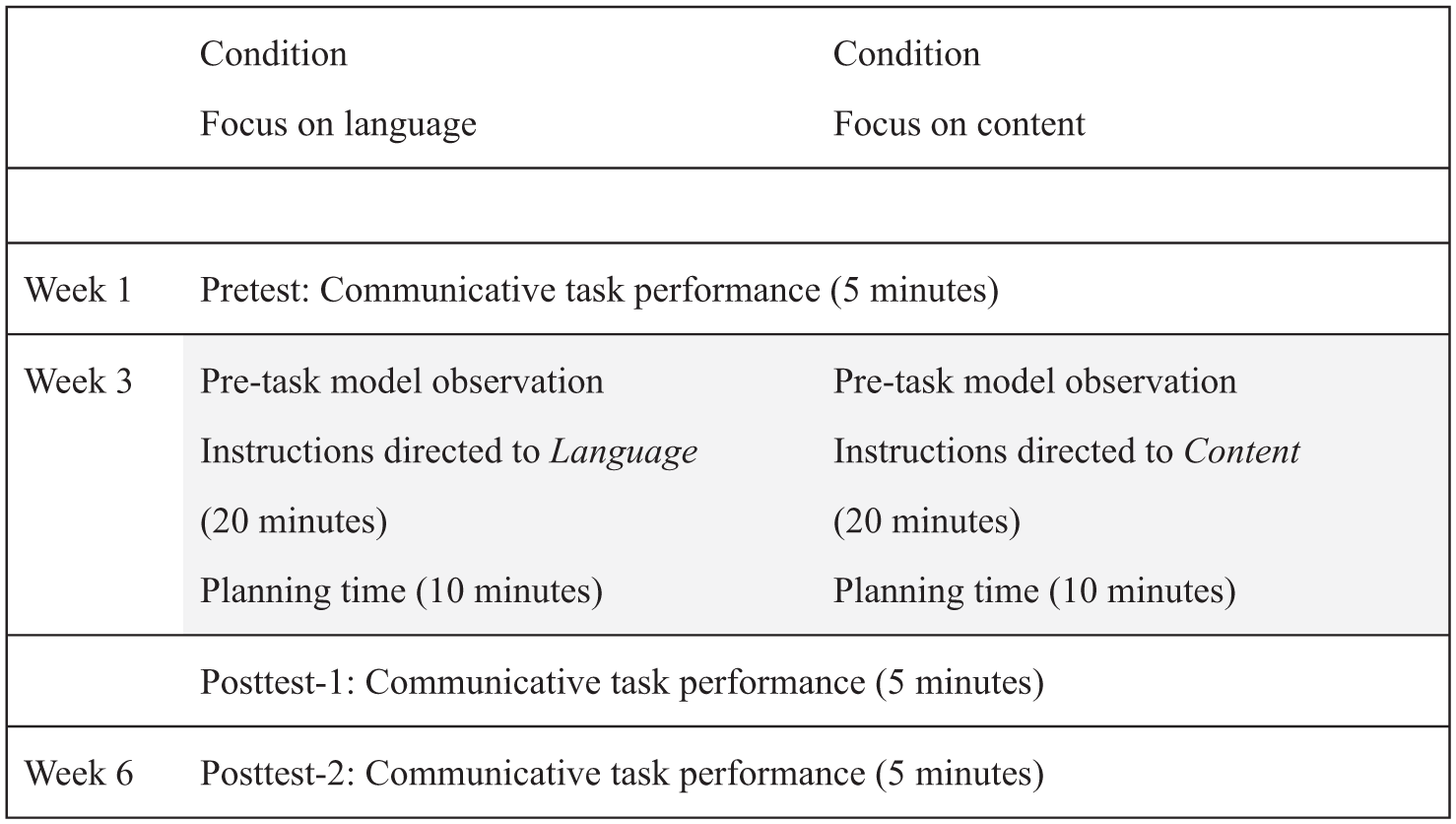
Research design.
The operationalization of the two conditions was as follows. All participants watched both videos. Observation sheets with written reflective questions directed participants’ attention to either language (FonL) or content (FonC). The language used in the model videos was not very complex. It included coordinate and subordinate sentences that referred to the atmosphere, the music and the food in the school cafeteria ‘we hang out on the sofas, play music by Rihanna and eat nice brownies and muffins’ and sentences that described (the place of) the furniture and accessories ‘in the middle, there is a stage that you can dance on’. While observing, the FonL group was asked to write down a total number of 12 linguistic structures which students in the videos used to describe the place of the furniture and the accessories in the school cafeteria (see Appendix 1). Analysis of the FonL students’ notes showed that they did indeed provide the target structures on the observation sheets (M = 11.2; SD = 1.70). The FonC group was asked to compare both presentations and what the students had done to make the presentation attractive and persuasive (see Appendix 2). Participants in both conditions were allowed to pause or scroll through the video and to take notes.
The intervention was conducted in both classes by the first author, who worked as a teacher in these groups. Two weeks prior to the experiment, students performed a pre-test in which they were asked to describe the school cafeteria orally to prospective students to inform and persuade them to enroll in their school. On the day of the experiment, all students were seated in the school’s computer lab and watched two videos. Students of the FonL group received form planning note-sheets, whereas learners of the FonC group were given meaning planning note-sheets. The students were aware that the task was part of a research project, but were not informed about the different conditions. The students observed peer models performing the task and answered the questions on the note sheets. A logging program on the computer tracked the students’ actions (total time, pausing, scrolling) while they were watching the two videos. The mean time spent on the video was 22.33 minutes (SD = 7.07) for the FonL group and 22.30 minutes (SD = 8.11) for the FonC group. No statistically significant differences in observation time were found between the conditions (F(1, 46) < .001, p = .984). Nor were there significant differences between groups in video use (pausing (F(1,46) = 1.46, p = .234) or scrolling (F(1, 46) = 3.89, p = .056). When students finished the observation task, they were asked to hand in the note-sheets to the research assistant. Afterwards each student went to a separate room and received written posttest-1 instructions (see Appendix 3) from a research assistant. Ten research assistants administered the tests with help of a protocol to guarantee that all tests were performed in the same way. Students were shown a picture of a school cafeteria and then asked to describe this school cafeteria to inform and recruit prospective students for their school. Before carrying out this task, students were given 10 minutes of planning time.
Students were allowed to write down a maximum of 10 keywords, but not to write down everything in detail because this might have led to verbatim reciting of pre-planned discourse and might have hampered natural speech (Sangarun, 2005). Students were free to plan the task in Dutch (L1) and/or German because we wanted to create a natural situation which resembled what they were used to in a ‘normal’ classroom situation (Kim, 2013). They did not have any resources, such as dictionaries, at their disposal.
Not all students used the full 10 minutes provided. The mean amount of planning time for the FonL group was 7.56 minutes (SD = 2.95) and 7.35 (SD = 2.60) minutes for the FonC group. No statistically significant differences between conditions were found (F(1,46) = .070, p = .793). After planning students handed over their keyword notes to the research assistant and performed the main task (post-test 1), which was a different version of the modeling task. Students performed another version of the main task (post-test 2) three weeks later.
5 Testing tasks
In all testing tasks (pre-, post-1, post-2) students were asked to describe the school cafeteria to inform and recruit prospective students. To this end, they were provided with a picture of a school cafeteria. Three parallel test versions were designed in which the nationality of the audience (German, Swiss, Austrian) and the style of the school cafeteria differed. To avoid a repetition effect, furniture and accessories were located in different places. For example, in version A participants could describe a poster on the wall, in version B a television on the wall. Since we could not expect learners to know the dative case of a word of which they did not know the gender, the three tests involved the same familiar content words, The order of the versions was fixed, (pre-test, version A, post-test 1 version B (see Appendix 3), and for post-test-2 version C). Learners’ oral task performances were audio-taped and transcribed. Transcripts were coded for the Analysis of Speech Unit (ASU) defined as ‘a single speaker’s utterance consisting of an independent clause, or sub-clausal unit, together with any subordinate clause(s) associated with either’ (Foster, Tonkyn, & Wigglesworth, 2000, p. 365).
6 Measures
The oral communicative testing task was analysed for two measures regarding attempted (accurate) use of the target structure and three complexity measures.
a Attempted use of the target structure
Because the intervention was aimed at promoting the (accurate) use of the target structure, two-way preposition plus dative case, during subsequent task performance we measured learners’ attempted use of the target structure per ASU.
Example of attempted but inaccurate use of the target structure.
In die Mitte steht ein Tisch (‘In the middle is a table’)
The nominative form of the article die should be the dative form der.
b Accurate use of the target structure
Regarding accurate use of the target structure we measured the proportion of correct use of the dative case of the article after a two-way preposition per ASU. Because the intervention was aimed at the (correct) use of this structure, we opted for this measure of accuracy instead of a more general measure such as error-free clauses per ASU.
c Complexity
Complexity was operationalized by means of three different measures, frequently used in SLA research (Norris & Ortega, 2009).
general complexity, by means of the total number of words per ASU;
complexity by subordination (amount of subordination per ASU)
Example of 1 subordinate clause within 1 ASU.
Es gibt einen Kiosk, wo man Kaffee kaufen kann.
(‘There is a kiosk, where you can buy a coffee.’)
3) complexity by coordination (amount of coordination per ASU). Following Bardovi-Harlig (1992), we included coordination as an additional measure of complexity, because for learners at lower production levels, such as those included in the present study, increased complexity is not only shown through subordination but also through an increase in number of coordinate clauses.
Example of 2 coordinate clauses within 1 ASU:
In dieser Schulkantine essen wir Brötchen und hören wir Musik.
(‘In this school cafeteria we eat sandwiches and listen to music.’)
7 Data analysis
A series of univariate GLMs was performed, to analyze learners’ performance in terms of attempted (accurate) use of the target structure and complexity. Condition was put in the model as a fixed factor. The pre-test variables were used as a covariate for the corresponding post-test variables. To establish whether there were trade-offs between attempted (accurate) use of the target structure and the three complexity measures, a series of Pearson correlation tests were run separately on the pre-test, post-test1, and post-test 2 scores. The alpha for achieving statistical significance was set at .05.
IV Results
Table 1 reports the descriptive statistics for the measures of task performance: attempted (accurate) use of the target structure and three complexity measures. Results of a series of one-way ANOVAs showed no initial differences on the pre-tests (Use of TS: (F(1,46) = .492, p = .49); Accurate use of TS: (F(1,46) = .449, p = .51); Words per ASU: (F(1,46) = .464, p = .50); Coordination per ASU: (F(1,46) = .007, p = .93); Subordination per ASU (F(1,46) = .739, p = .40)).
Measures of task performance for two conditions on three measurement occasions.
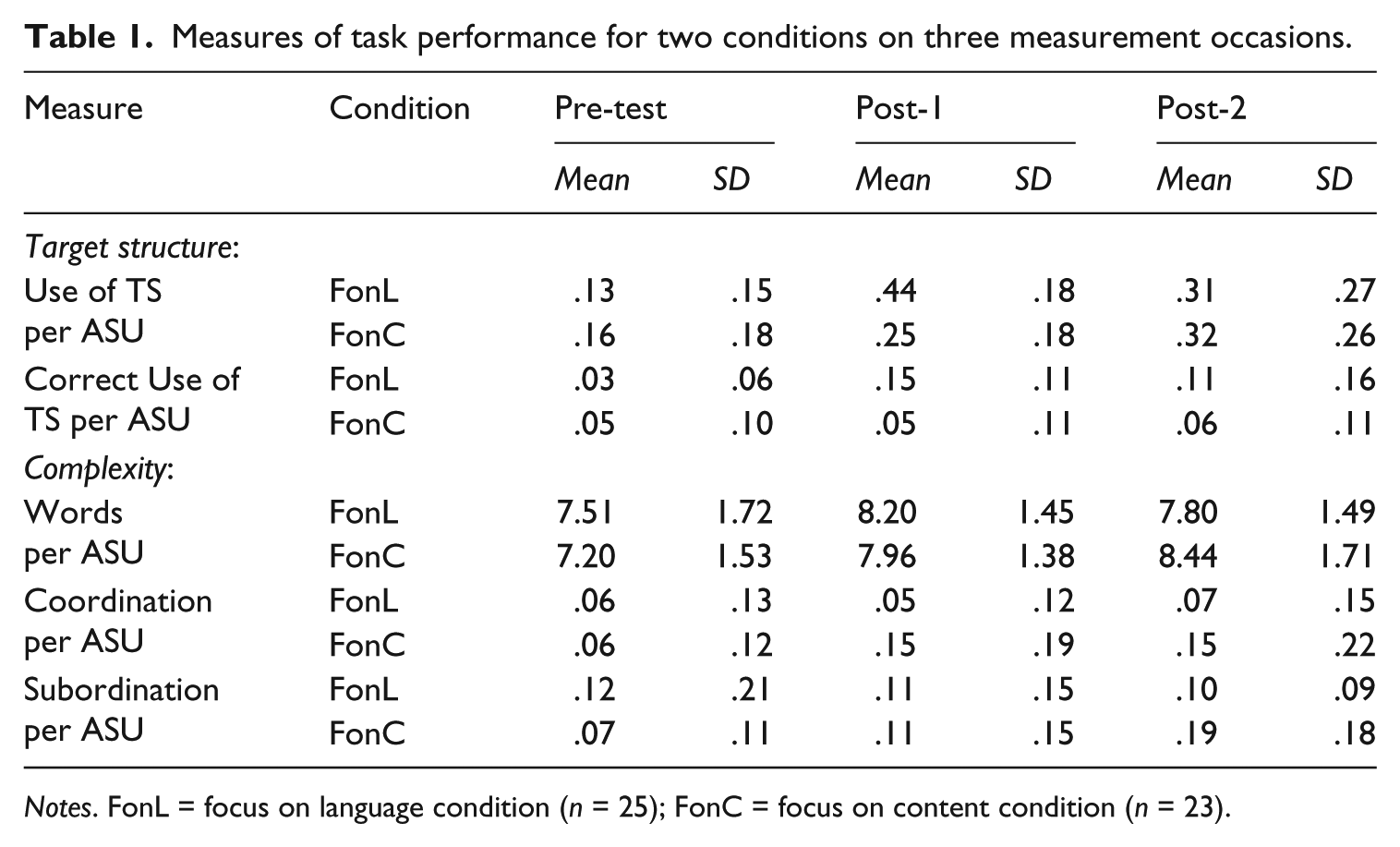
Notes. FonL = focus on language condition (n = 25); FonC = focus on content condition (n = 23).
1 Attempted (accurate) use of the target structure
a Attempted use of target structure per ASU
At Post-1 the FonL condition outperformed the FonC condition (F(1,46) = 14.06, p = .001) with a large effect size (d = 1.3). No statistically significant differences between conditions were found at Post-2 (F(1,46) = .00, p = .90).
b Accurate use of target structure per ASU
At Post-1 the FonL condition outperformed the FonC condition (F(1,46) = 11.52, p = .001) with a large effect size (d = 1.08). No significant differences between conditions were observed at Post-2 (F(1,46) = 2.35, p = .13).
2 Complexity
a Words per ASU
No significant differences between conditions were observed at either Post-1 (F(1,46) = .305, p = .58) or Post-2 (F(1,46) = 1.94, p = .17).
b Amount of coordination (per ASU)
At Post-1 the FonC condition outperformed the FonL condition (F(1,46) = 5.22, p = .027) with a medium effect size (d = .63). No significant differences between conditions were found at Post-2 (F(1,46) = 2.40, p = .128).
c Amount of subordination (per ASU)
At Post-1 no significant differences were found between conditions (F(1,46) = .226, p = .636). At Post-2 the FonC condition outperformed the FonL (F(1,46) = 4.85, p = .033) with a medium effect size (d = .57), indicating that at the delayed post-test, students of the FonC condition used more subordinate clauses than students of the FonL condition.
3 Trade-off
At Post-1 no negative correlations were found between measures of (accurate) use of the target structure and complexity. At Post-2, within the FonL condition, significant negative correlations were observed between attempted use of the target structure and the ratio of subordination (r = −.55, p = .004) and accurate use of the target structure and the ratio of subordination (r = −.43, p = .033). This trade-off implies that at the delayed post-tests students of the language condition that used the target structure more (accurately), used fewer subordinate clauses in their oral performances. However, in the FonC condition at the immediate post-test, students’ use of the target structure correlated positively with the amount of subordination (r = .45, p = .031).
V Discussion
In Table 2 a summary of the results is presented.
Summary of results: Best performing condition per criterion.
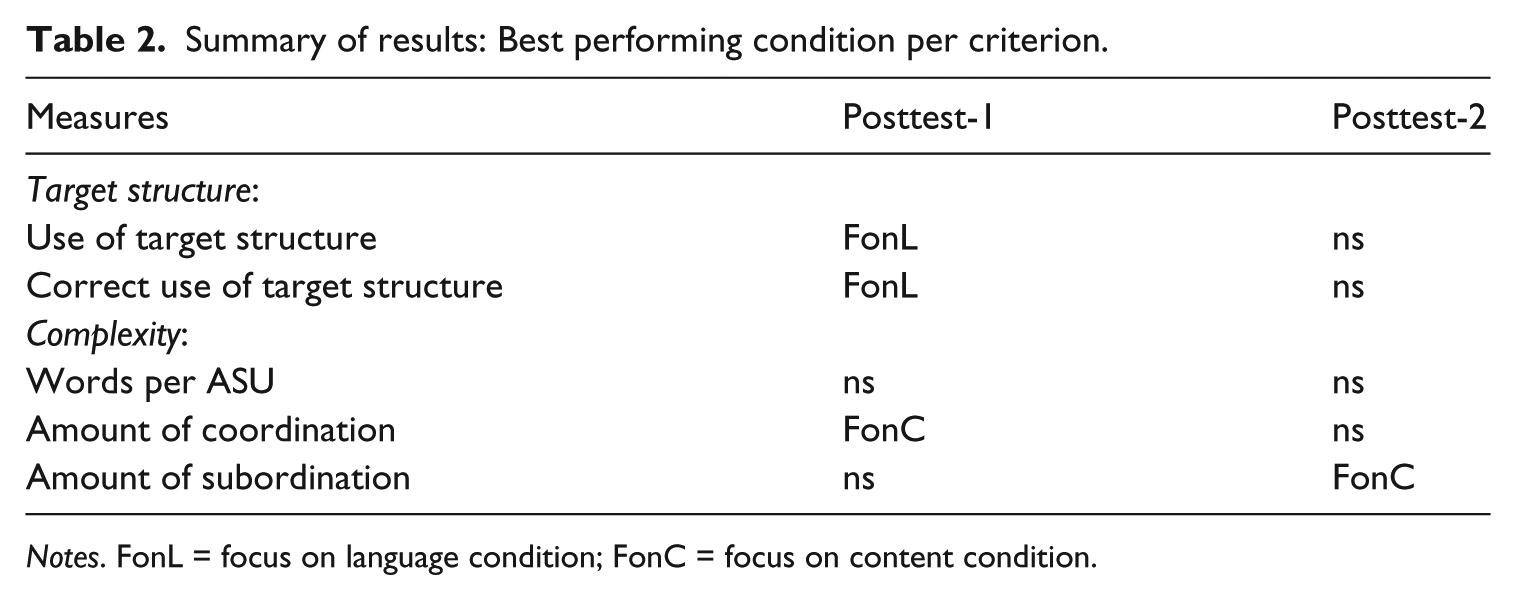
Notes. FonL = focus on language condition; FonC = focus on content condition.
The purpose of this study was to examine whether focusing on content or language through guided pre-task video model observations affected the learners’ subsequent task performance. As far as we know, this is the first study that used guided observation of peer-model videos as part of a planning strategy. With the results of the study we aimed to contribute to research on pre-task instructional strategies that may be effectively used to direct learners’ attentional resources (content or language) and affect learners’ subsequent task performance.
Regarding the first research question, whether a ‘focus on either content or language in pre-task peer modeling observations may affect subsequent task performance’ the findings were inconclusive. Our first hypothesis, in which we predicted that a focus on language would lead to increased (accurate) use of the target structure, was confirmed. Students in the FonL condition outperformed those in the FonC condition on both attempted and accurate use of the target structure at posttest-1. It appeared that students in the FonL condition used the target structure significantly more often and more accurately. We assume that observing and hearing the naturally embedded two-way prepositions plus the dative structure in the video, guided by the written instructions, succeeded in making the target structure salient and noticed. Analysis of students’ notes on the preposition plus dative structures on the observation sheets supported this assumption. Their awareness may have primed the (accurate) use of the target structure during immediate, subsequent task performance. However, at posttest-2, three weeks later, these differences disappeared. The reason for the absence of significant long-term effects may be that the use of the structures was induced by a ‘short-term activation from a memory representation’ (see Bock & Griffin, 2000, p. 177). In other words, learners may have remembered exemplars of the structure from the video. To achieve long-term effects, the focus on form in the pre-task may need to be followed by other additional learning activities at a later stage in the task-based language teaching cycle. This view is supported by Whitehurst and Vasta (1975), who argue that an implicit focus on form is only a first step to introducing syntactic structures into the productive mode, and Schunk (2007), who proposes that the observation of models could be combined with guided practice and corrective feedback.
It may also be argued that a more explicit focus on the German dative structures, for example by providing grammar rules, would have led to gains in explicit knowledge, resulting in long-term acquisition. Nevertheless, the choice for an implicit focus on form was a carefully considered decision. To minimize the interruption to learners’ communication of meaning, we argue for a focus on form in the pre-task that attracts learners’ attention to form and avoids metalinguistic talk about grammar (Doughty & Williams, 1998).
Our second hypothesis, in which we predicted that a content focus would lead to increased complexity, was partly confirmed. Results indicated that students in the FonC condition outperformed those in the FonL condition on two complexity measures: 1) amount of coordination per ASU at post-1; and 2) amount of subordination per ASU at post-2. No effects were found on number of words per ASU. In sum, students did not use more words to describe the school cafeteria, but at the immediate post-test they used more coordinated clauses and three weeks later significantly more subordinated clauses. These findings suggest that observing and hearing others perform a similar task, in conjunction with written instructions directed towards content of the task, may lead to a syntactically more complex subsequent task performance. It can be argued that the video models provided students with a clear image of a successful task performance and that the evaluation of and reflection on the model performances (Braaksma, Rijlaarsdam, Van den Bergh & Van Hout-Wolters, 2004) made students think actively about how to give an attractive and persuasive presentation. This may have resulted in more risk-taking and experimentation with the language they wanted to use. The reason why no immediate effect on subordination was found may be due to learners’ lower production levels. At this level of performance (A2 level of CEFR), increased complexity may not directly be shown through subordination but start with coordination and be followed by subordination (Bardovi-Harlig, 1992).
The second research question refers to the assumed trade-off between attempted (accurate) use of the target structure and complexity. For the FonL condition at post-2, we found a moderate negative correlation between attempted use of the target structure and the amount of subordination and a weak negative correlation between correct use of the target structure and the amount of subordination. This implies that, when learners focus on language during video observations in the pre-task and subsequently try to use the grammatical structure (accurately) during task performance, this may have negative consequences for the complexity of the task performance. However, in the content group we observed a significant positive correlation between students’ use of the target structure and the amount of subordination. These findings may give support to Robinson’s (2005) Cognition Hypothesis, in which a competitive relationship does not exist between an L2 learner’s language complexity and accuracy. Learners in the content condition showed gains in complexity. Apparently, the input of the video, combined with the content-focused written instructions, created conditions in which the learners improved these capabilities simultaneously during task performance.
Some limitations of the current study need to be acknowledged. First, one may argue that the use of observational learning as a pre-task activity may conflict with the principle of task-based language teaching that allows learners to choose their own linguistic and non-linguistic resources to fulfill the task (Ellis, 2003; Willis, 1996). Providing learners with a model may promote imitation instead of learners’ use of their own creativity. On the other hand, imitation is a basic learning principle in foreign language acquisition (Whitehurst & Vasta, 1975). Second, the observation of peer-model videos was part of the students’ pre-task planning time. After the observations the students were given a maximum of 10 minutes of planning time to prepare their subsequent task performance. We cannot be sure how this planning time may have influenced learners’ performance either. Thirdly, one may argue that the focus on the targeted grammatical structures was too implicit to generate long-term effects. Although we believe that the pre-task is not the right place for explicit grammar teaching, investigating more explicit ways to focus on form through video modeling could be interesting for teachers who want to implement tasks in their curriculum but also want to incorporate (inductive) grammar teaching. Another challenging task for further research would be to investigate other forms of guided instructions through video modeling in relation to other grammatical structures and task types.
VI Conclusions
The current study aimed to investigate whether the direction of learners’ attention to either form or meaning through the guided observation of models would affect subsequent task performance. The results indicate that a focus on language may generate more and accurate use of the targeted grammatical structure, whereas a focus on meaning may promote a more complex task performance. In some cases, these gains were achieved at the expense of other aspects of performance, supporting Skehan’s (1996, 1998) Trade-off Theory, which claims that learners have limited attentional resources, which compete with each other. We found trade-offs between (accurate) use of the grammatical target structure and complexity for the group that focused on language. The content group, however, showed that, at the same time, learners could use the grammatical target structure and subordinate sentences, which is more in line with Robinson’s (2005) Cognition Hypothesis.
Considering that the current study was carried out under real classroom conditions, we argue that the findings of our study may have an important implication for language pedagogy in a foreign task-based language learning context. Teachers and teacher educators always search for activities that are motivating for learners and at the same time make the task itself more effective. Guided observations of peer-model videos could be a motivating and effective pre-task activity that may guide learners to either form and or meaning and affect subsequent task performance. Furthermore, the observation of peer-model videos can easily be implemented in the classroom, given that electronic devices are often already present. A teacher can record a video of a learner carrying out a task, and then use this video in the following years. Also guided ‘live modeling’ with either the teacher or a student acting as a model is a possibility.
Depending on the purposes of the lesson, the observation of peer-model videos may be directed towards either content or language, or both content and language. Teachers who want their learners to focus on both aspects can ask them to observe twice: first for content, then for language. All three options may provide a useful pre-task activity to achieve balanced language development in the modern task-based classroom, which does not only embrace accuracy but also gains in complexity.
Footnotes
Appendix 1
Appendix 2
Appendix 3
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.