
Abstract
Moving beyond gold standard thinking in evaluation methodology requires robust, alternative frameworks for methodological choice and justification. We develop such a framework, which we term ‘Principled Adequacy for Purpose’. We develop this account by considering recent work centring both the role of questions and values for methodological choice. While we argue that both approaches make important improvements over traditional evidence hierarchies, these frameworks by themselves also face significant limitations. We consider that combining these frameworks, while giving greater consideration to the notion of evaluative purpose, affords better guidance for methodological decision-making in evaluation. For this, we draw on recent work on Adequacy for Purpose in model evaluation, to combine these approaches under the ‘Principled Adequacy for Purpose’ umbrella.
There is no gold standard; no universally best method. Gold standard methods are whatever methods will provide (a) the information you need, (b) reliably, (c) from what you can do and from what you can know on the occasion.
Introduction
Despite sustained scholarly critique, a preference for evidence hierarchies continues to influence the commissioning, assessment and choice of evaluation methodologies. Such hierarchies, ranking methods by their supposed strength of evidence, often tout Randomised Control Trials (RCTs) as the ‘gold standard’ of impact evaluation design, placed atop the evidence pyramid (Crawford et al., 2017; EEF, 2016; Farrington et al., 2002). Yet, as Bédécarrats et al. (2019) put it, not all that glitters is gold. RCTs face important limitations, including their difficulties in helping us understand the role of context (Pawson, 2006), their inability to detect heterogenous treatment effects (Blunt, 2015), their limited external validity (Cartwright, 2012) and their limited ability to support project improvement efforts (Stern et al., 2012). Scholars have also pointed out that many real-world contexts fail to support appropriate randomisation (Befani et al., 2014), and more generally, the often-considerable distance between the idealised assumptions under which proponents of RCTs assess their benefits and the limitations real-world RCTs encounter in evaluation practice – including lack of blinding, statistical uncertainty and plausible presence of bias (Deaton and Cartwright, 2018; Krauss, 2021). Uncritically relying on evidence hierarchies hence risks overvaluing the evidence we obtain from so-called gold standard approaches, while precluding classes of methods and types of interventions from the realm of what can be evaluated.
In this article, we contribute to this counter-current by developing a theoretically grounded framework for ‘fit-for-purpose’ methodological choice. Rather than assessing methods by their place in a supposed evidence hierarchy, we develop the notion of methodological adequacy, according to which evaluation methods should be assessed relative to the evaluative purpose (teleology), the nature of interventions, their contextual conditions and what can be known about these (onto-epistemology) and stakeholder-deliberated values (axiology). We term this approach ‘Principled Adequacy for Purpose’ (PAP), aiming to provide practitioners with the conceptual resources to justify more diverse, context and purpose sensitive methodological decisions, while integrating important insights from previous frameworks seeking to move beyond evidence hierarchies.
Our argument is structured into four sections. In section one, we review previous work on alternative methodological frameworks: question-first and values-first approaches. Despite important improvements over evidence hierarchy approaches, we argue that these frameworks are unsatisfactory by themselves. In section two, we expand one important reason for this: the neglect of evaluative purpose. Drawing on recent work on adequacy for purpose, we then begin to develop an account of methodological adequacy, which we evaluate in section three. Section four concludes and presents the overall PAP framework.
Before this, it is helpful to briefly define methodology. Following Stirling (2015: 7), we understand methodology to be the broader process through which we determine the merits, capabilities and applicability of specific methods and related techniques and tools. Methodologies in this sense are similar to, but slightly broader than, what Stern et al. (2012: 15) call ‘designs’. A method is ‘a codified way deliberately to produce knowledge about a focus of interest, including RCTs, Process Tracing, or Outcome Harvesting’ (s. Stirling, 2015: 7), and a tool is an instrument to collect evidence to produce that knowledge (e.g. interview, focus group, survey). As Stern et al. (2012: 15) discuss, these distinctions are not always perfectly neat; methodology and methods often overlap (e.g. Contribution Analysis or Realist Evaluation). However, we consider this broad understanding sufficient for our purposes.
Methods choice as question-answer matching
We begin our discussion by reviewing previous work on alternative frameworks for methodological choice. A first, influential approach for this emphasised the importance of choosing methods based on the evaluation questions we want to answer, as found, for example, in Stern et al. (2012), Quadrant Conseil’s (2017) ‘Impact Tree’, Befani (2020a) and the International Initiative for Impact Evaluation’s ‘Policy and Institutional Reform Methods Menu (PIR Methods, n.d.). As all four approaches consider questions central to methods choice, we will jointly refer to them as ‘questions-first’ approaches.
The most detailed account of this view is offered by Befani (2020a), tackling what she terms the methods ‘choice problem’. Offering the ‘Refined Design Triangle’ (Figure 1), she argues that practitioners seeking to move beyond rigid gold standard hierarchies should consider methods’ appropriateness along three dimensions: their ability to answer the question they want answered; their feasibility in the context of our evaluation project; and methods’ ‘additional abilities’: that is, for example, methods’ ability to achieve external validity, capture emergent properties or surface unintended outcomes. Befani’s (2020a) approach is ultimately practically oriented; as such, she operationalises the framework into an Excel tool (Befani, 2020b). Inputting the questions to be answered, additional abilities sought and conditions of the project, the tool assigns the 15 covered methods appropriateness scores between 0 and 100, based a range of expert judgements.
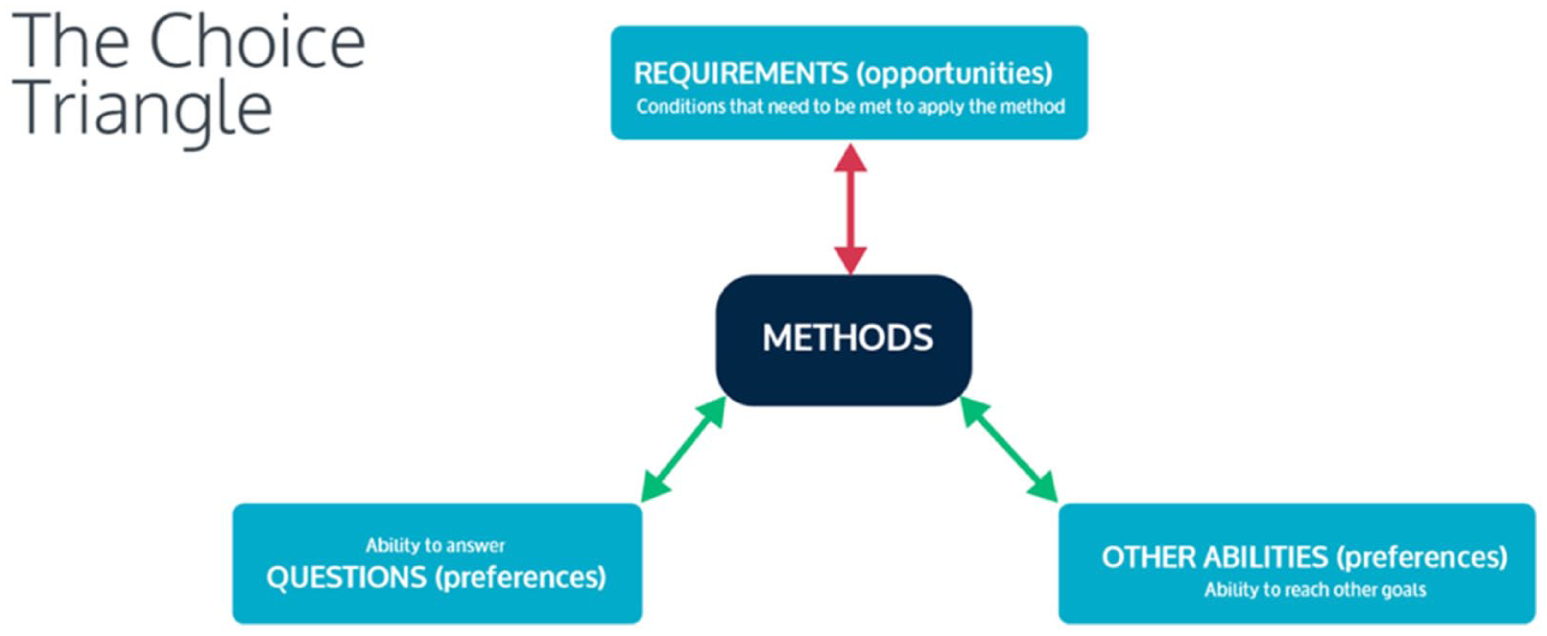
The ‘Choice Triangle’ by Barbara Befani, 2020a, sourced from “Choosing Appropriate Evaluation Methods: A tool for Assessment & Selection (version 2)”, licensed under CC BY-NC-SA 4.0 (https://creativecommons.org/licenses/by-nc-sa/4.0/.).
Evaluating questions-first approaches
Befani’s work contains two important insights for our present discussion. First, it underscores ‘that an optimal methodological choice need[s] to align with evaluation questions: what methods are best suited to answer each question?’ (Befani, 2020a: 8, see Stern et al., 2012). Second, both Stern et al. (2012) and Befani (2020a) highlight the importance of contextual constraints for applying methods. Across their work, we can identify three dimensions for these constraints: pragmatic constraints – say, the inability to randomise treatments or lack of opportunities to collect certain data; capability constraints, as relevant knowledges and skills may not be available in an evaluation team; and onto-epistemic constraints, concerning the complexity and nature of the programme, acknowledging the limits of what can be known through a particular design for a given project. Hence, the programme and its context must also shape considerations of appropriate methods.
Acknowledging the diversity of possible evaluation questions and uneven abilities of different methods to answer them highlights an important limitation of evidence hierarchies: RCTs only truly answer one among many possible evaluation questions. By contrast, questions-first frameworks promise better reasoned methodological choice by ensuring the alignment of questions and the methods. Similarly, Stern et al’s and Befani’s work highlights the importance of evaluative context. Not all methods can be effectively realised in all contexts or for all evaluands.
However, considered as a philosophical stance on method justification, questions-first approaches face important limitations. While methods answering the wrong question will always fail, there are also plausible circumstances within which methods can fail to produce relevant insights, even if they answer our questions (as well as having the right ‘abilities’ and being feasible in our context). It is in this sense that the questions-first framework is insufficient for guaranteeing successful methodological choices, and additional factors need to be included.
To see why, consider one of the evaluation questions Befani (2020a) discusses: ‘What was the additional/net change caused by the intervention?’ On a standard, counterfactual reading, we are interested in the difference between the actual world and the counterfactual world of ‘what-would-have-happened-if-the-program-had-not-been-implemented-but-everything-else-had-been-the-same’ (Reichardt, 2022: 160). Befani suggests that RCTs, instrumental variable and regression-discontinuity designs (RDDs) are best and equally well suited to answering this question. Yet, qualitative methods are not mentioned – even though they can, in principle, also produce answers to such questions. For example, what-if assessments, asking participants ‘to speculate about how they would have acted if they had not participated in the programme’ (Reichardt, 2022: 163) can be understood as producing the same counterfactual information: that is, providing an estimate of what the world would have been like without the intervention.
Of course, there might be good reasons for preferring RCTs, instrumental variable and RDDs to answer net-change-caused questions. We might question the ability of interviewees to know what they would have done in the absence of the intervention, raise concerns about the credibility or verifiability of self-assessments, and more generally, doubt the accuracy and unbiasedness of their estimates. On such grounds, what-if assessments might well be rejected as a source of credible evidence in situations where an RCT or quasi-experiment would succeed. However, this constitutes a different kind of methodological failure. We answered the right question but did so in a bad way, failing to meet the (implicit) quality criteria which underpin a preferred method.
Following this line of reasoning, an essential task for methodological choice is acknowledging the criteria we base the assessment of our methods on. However, this dimension remains unclear in the scores Befani’s tool assigns to different methods, or in how to weigh up the strengths and limitations listed in the PIR menu. For example, while RCTs and RDDs are considered equally robust by these tools, RDDs’ stronger reliance on statistical assumptions leads some authors to consider them ‘weaker’ than RCTs in many situations (Wing and Cook, 2013). This suggests that while questions-first approaches may provide an important first step in supporting better practical decision-making, they leave at least one determinant of methodological success unacknowledged: an account of what constitutes ‘good answers’, beyond their propositional content.
Methodological choice as value satisfaction
Aston et al. (2022) and Apgar et al. (2024a, 2024b) offer an account for just what this missing dimension is: values. Drawing on work on the role of values in evaluation, the authors aim to explicate stakeholders’ values as the basis for methodological choice and evidence assessment in evaluation – an approach we will term ‘values-first framework’ here. This axiological orientation is not a fundamental departure from some questions-first work, which considers that the questions to be answered are ultimately grounded in our preferences (Befani, 2020a, 2024). However, on the questions-first view, these preferences are taken as given, rather than being considered an expression of what different stakeholders value. In contrast, for ‘values-first’ scholars, deliberating values should take centre stage: At the heart of both valuing and evaluation is criteria – principles or standards that different stakeholders value. Before assessing or rating [evidence], we must first establish what we value – most. (Apgar et al., 2024a: 101f)
Thus, Apgar et al. (2024a) advise evaluators to facilitate explicit discussions about evidence criteria with stakeholders, identifying what ‘good evidence’ means to them. Such criteria are not universal; judgements will depend on local contexts and preferences and are liable to change throughout the evaluation process. Practically, values-first approaches consider a range of possible values and derived quality criteria. This includes values such as transparency about origins of data, triangulation across methods and data sources, and uniqueness, the ability of evidence to discriminate between alternative explanations for observed outcomes. The authors suggest that evaluation stakeholders work together to formalise their deliberations into evidence rubrics, before rating the produced evidence against these agreed upon standards. This, Apgar et al. (2024a: 110) conclude, ‘provide[s] a practical architecture for a deliberative process to discuss, debate, an define what success looks like with the main evaluation stakeholders’.
Evaluating the values-first approach
Values-first approaches fill an important gap left by questions-first approaches, namely, the need to determine what constitutes ‘good answers’. Defining such an axiological orientation forces us to deliberate what we value in a way that can go unacknowledged in questions-first approaches. 1
Before proceeding, it is helpful to briefly pre-empt two possible challenges to values-first approaches. The first concerns the admissibility of value judgements in evaluation. This challenge comes in a strong and a weak version.
The strong version upholds the ‘Value Free Ideal’: that is, ‘that social, ethical and political values should have no influence over the reasoning of scientists’ (Douglas, 2009: 1). However, this strong version seems untenable, at the very least in policy evaluation. At least two relevant lines of argument exist in the literature (Bright, 2018). First, arguments from inductive risk point out that accepting or rejecting a hypothesis – or, in our case, passing evaluative judgement – involves accepting the risk of having arrived at the wrong conclusion. However, such errors bring with them morally significant consequences. Thus, the threshold of ‘confident enough’ ought to be varied in response to the moral consequences of getting it wrong, meaning that moral value judgements are central to the job of evaluation. We will return to this argument in greater detail below. Second, arguments from underdetermination point to the gap that inexorably exists between the world and our theorising of it. Because no amount of empirical data can uniquely determine which explanation or framing is the ‘best’, value judgements are involved in determining which approach to pursue and guide myriad decisions along the way. On either argument, values suffuse evaluative inquiry.
While the strong version of the Value Free Ideal in the context of evalution thus appears untenable, the weak version of this concern simply holds that not all values are (equally) admissible. For example, Kushner and Stake agree that values inevitably play a role in evaluation. However, they also maintain that social or political values must not supersede the foundational value of validity in evaluation: that is, must not lead evaluators to make claims outside the ‘validity frame’ of available data and its reasonable interpretation (Kushner and Stake, 2025: 8). However, values-first approaches are not inconsistent with this view. Rather, they are agnostic: the values-first approach only advocates for us to deliberate and define what we value in our context, with values-first authors offering a practical architecture for this deliberation. As part of this deliberation, it might well turn out that we value validity (or some version of it), that we value ethical values more strongly than validity or that we value both equally.
The second potential challenge to values-first approach is that some values are potentially too abstract to guide practical decision-making. For instance, social justice or multi-cultural validity are conceptually dense and may be difficult to translate into concrete evaluative criteria. While this practical challenge can ultimately be addressed through skilful facilitation – ensuring that stakeholders involved in the deliberation process are guided towards sufficiently concrete and operationally useful criteria – we consider that the values-first framework’s practicality can be enhanced.
Indeed, we suggest that both values-first and questions-first approaches, as currently defined, can be improved by paying greater attention to notions of evaluative purpose. In the following section, we will therefore outline the case to re-centre the notion of purpose (i.e. teleology) into our methodological decision-making, defined broadly here as the goal we seek to achieve with our evaluation.
Integrating questions, values and purposes
Integrating questions and purposes
To see how considering purposes enhances questions-first approaches, consider Cartwright’s (2012) discussion of the Bangladesh Integrated Nutrition Project (BINP). Despite a rigorous evaluation finding a near identical programme to have worked in India, the intervention failed in Bangladesh. In Cartwright’s reconstruction, this was mainly due to a failure to recognise different social structures across India and Bangladesh, leading to different behavioural responses to the programme and thus impacts (or lack thereof).
Prima facie, we can make sense of this failure from a questions-first perspective, saying that we asked the wrong question. As Cartwright emphasises, causal regularities are highly contingent on the system which produces them. As such, we must sharply distinguish evidence for the claim ‘it works somewhere’ from evidence for the claim ‘it will work for here’ (Cartwright, 2012: 976). In other words, ‘did this work in India?’ is a meaningfully different question from ‘will this work in Bangladesh?’ Hence, the purported methodological failure could be considered as having answered the wrong, overly narrow, evaluation question. Following questions-first authors’ guidance, we should have picked a method that can answer the right question and provide sufficient external validity.
However, this reconstruction fails to consider the foundational role of evaluative purposes. Judging something to be the right – or wrong – question requires us to identify an aim or goal we want to achieve by answering it. Without a purpose, no question appears intrinsically right or wrong. Indeed, the question ‘did this intervention work in India?’ was answered entirely satisfactorily, according to Cartwright’s discussion. However, it was the wrong question to ask for the purpose of replicate the scheme in Bangladesh. From our perspective, then, the task of evaluation is not only to answer questions. It is to answer the right question to enable intended uses by producing relevant knowledge for specific evaluative purposes. This means that choices regarding relevant questions should be preceded by a discussion of the purpose of an evaluation. As use-focuses authors consider, we should begin by ask why we are evaluating, and what we want to do with the knowledge we produce (cf. Saunders, 2000). After that is done we can define more appropriate questions.
This proposed phasing for evaluative inquiry is neatly illustrated by Chelimsky’s (2006) discussion of how her work for the US government has been shaped by the intertwined purposes of accountability, learning and enhancement. Purposes, combined with high-level policy questions (What are the effectiveness and cost of proposed upgrade options to America’s nuclear triad?), were refined into evaluation questions (What is the relative effectiveness of inter-continental ballistic missiles compared to submarine-launched ballistic missiles? What is the cost and value of the proposed upgrades?). It is only at this point that impact evaluation questions on the level considered by questions-first approaches (what is the net security benefit? How is the deterrence working?) become relevant. Indeed, it is only when considering the expressed purposes of the wider evaluation that it makes sense to prioritise one question over another, to guide methodological choice. An analysis aimed as cost efficiency, say, might appear better sustained by a method supporting a counterfactual assessment, whereas questions about the resilience of defensive systems might be better suited to an assessment of the ‘mechanism’ of the deterrent – understanding vulnerabilities of the approach through theory-based assessments.
Adequacy for purpose
To see how a notion of purpose similarly augments deliberations recommended by values-first authors, consider recent work on Adequacy for Purpose, and specifically, its application to the role of values in adequacy (Lusk and Elliott, 2022). Originating in Parker’s work on scientific models (2009, 2020), we adapt Parker’s definition from her modelling to our methodology context (while keeping its beautiful analytic prose). Thus, we define methodological adequacy in relation to the use of a methodology and regularity with which it achieves our purpose: ADEQUACYC: M is ADEQUATEC-FOR-P if, in C-type instances of use of M, purpose P is very likely to be achieved.
where M is a given methodology or method, P the evaluation’s purpose, and C the specific context of application. In other words, we define a methodology as adequate, given a context and for a purpose, if and only if using it in that context is very likely to lead to the achievement of our purpose. Methodological choice, in this view, begins by defining our purpose and context.
While our above definition of purpose P as ‘goal to be achieved’ neatly fits into the adequacy for purpose (AFP) account (including its role in defining which questions need answering), our context, C, requires refinement. In Parker’s account, C contains and is defined by the range of salient factors we consider affecting the likelihood that using a given approach will enable (or prohibit) us to achieve our purpose. However, her original modelling context yields criteria unhelpful for guiding evaluative methods choices. Hence, the key question is how we can define C to be both satisfiable and informative.
Notably, the questions-first framework already allows us to identify two principles of adequacy. M must be able to answer our question; and M must be feasible in our context, that is, it must be possible for us to use our methodology and apply it to our evaluand. A methodology failing on either count appears to be inadequate for purpose, as it cannot tell us what we want to know or cannot be used, prohibiting us from realising its benefits. However, as was argued, these principles are insufficient; we can find feasible methods answering our question and still fail to achieve our purpose, as our methods might not be ethical, accurate or transparent enough to realise our purpose.
Integrating purposes and values via adequacy
Here, the AFP account can help us refine our assessment of relevant values, offering a pragmatic maxim: that ‘good’ methodology allows us to achieve our primary purpose(s). In turn, the values-first view provides a useful account for determining key aspects of (in)adequacy, by considering values as imposing criteria which evaluators or stakeholders apply to judge whether an evaluation is good enough.
However, this function of defining criteria and deliberating what, in practice, constitutes good evaluative practice points to a subtle role of values that influence concrete decision-making and define criteria of good conduct. We call this account an evaluative praxeology. This term combines purposeful action (praxis) and thought (logos) and includes practical knowing (phrónêsis) in the service of human betterment (Coghlan and Brydon-Miller, 2014).
While praxeology relates to our broader account of ‘what we value’ (as developed the values-first approaches), it also connects to a goal or teleology, and with its focus on appropriate action, it must be sensitive to our local context. Two arguments illustrate the need for such praxeology, that is sensitive both to our context and the aims we pursue. The first, offered by Rudner (1953), presents an argument from inductive risk, as introduced in section 1.3. Rudner considers the decision scientists need to make when determining whether evidence is strong enough to accept or reject a hypothesis. He argues: Obviously, our decision regarding the evidence and respecting how strong is ‘strong enough’, is going to be a function of the importance, in the typically ethical sense, of making a mistake in accepting or rejecting the hypothesis. (Rudner, 1953: 2)
This concern straightforwardly applies to methodological choice as considered here, assuming that methodology is a key determinant for the likelihood of a mistake. A methodology adequate for assessing whether toxic ingredients are present in a drug ought to produce greater certainty than a methodology ‘only’ adequate for whether metal buckles are manufactured correctly, as the ethical cost of getting it wrong is much greater in the former than in the latter. Indeed, methods may even be (in)adequate for the same phenomenon based on goal we pursue with it: buckles made for seatbelts should require greater methodological care than buckles made for fashion belts (Lusk and Elliott, 2022).
The second argument for the importance of an evaluative praxeology is highlighted by a case-study discussed by Elliott and McKaughan (2014), drawn from Cranor (1995). They consider the California Environmental Protection Agency’s choice between two different methods to evaluate the carcinogenic risk of chemicals: one that is more reliable, but slower and more expensive; the other, faster, but less accurate. Ultimately, balancing the value of speed with the value of accuracy and the ethical cost of making a mistake must guide decisions. However, as Elliott and McKaughan point out, a central component of value deliberation in this case concerns trade-offs between our values, relative to the goal we want to achieve: how do the risks of wrong decisions compare with the value of quicker decision-making?
Considering these value-laden choices highlights that the elements currently considered by values-first accounts should be further augmented. It is not just values, purposes and questions that ought to be deliberated. Good methodological approaches also require judgements of what good (enough) conduct will look like.
Towards evaluative praxeology
In this sense, the values espoused by values-first frameworks offer a potential list of criteria influencing whether our methodology is likely to achieve our purpose (s. Figure 2). We can further strengthen these approaches by recognising that transparency, for example, is not an end in itself; it becomes a requirement that our methods and the evidence produced through them must satisfy, to a certain degree, to satisfy stakeholders and allow us to achieve our intended purpose. However, we can be more specific still by recognising that several influential discussions of evaluation methodology implicitly construct three distinct evaluative aims: credibility, ethicality and usability, for example, found in Scriven (2007), or as underpinning the branches of Alkin and Christie’s (2023) ‘Theory Tree’.
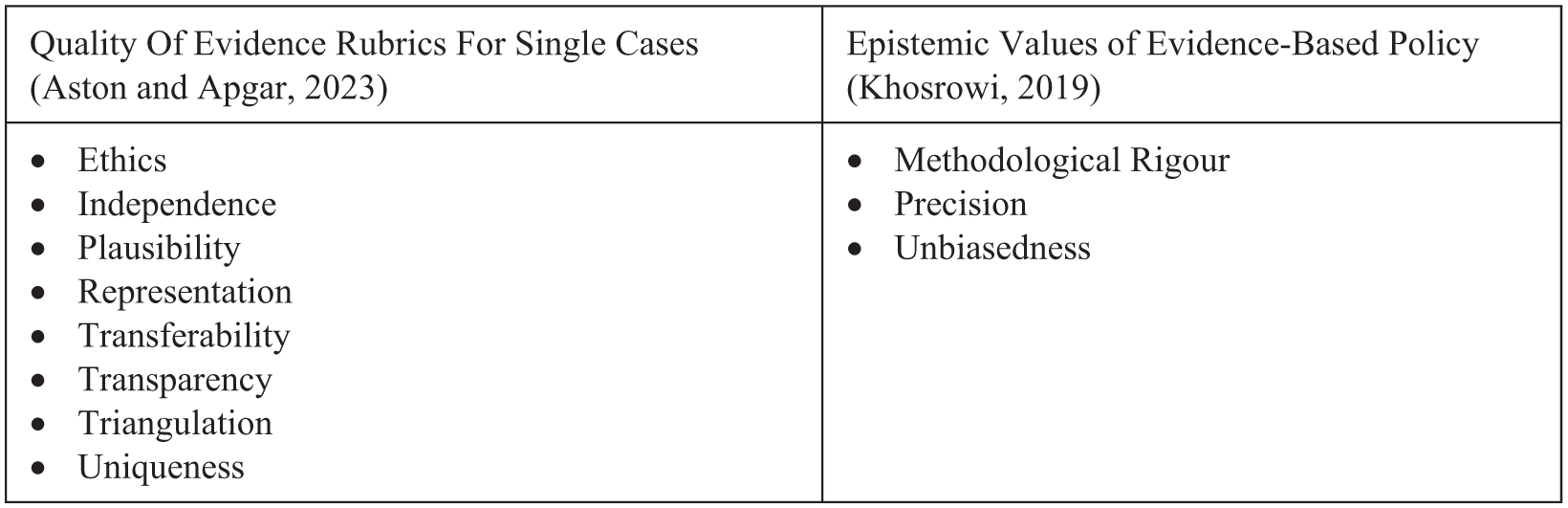
Proposed values in evaluation.
On this view, the first, central requirement for evaluation to achieve its purpose is epistemic: that it is, broadly speaking, that an evaluation must produce the right kind of insight with the right kind of justification. For ease of reference, we will refer to this epistemic aim as credibility. Numerous articulations of this epistemic aim have been offered and ferociously debated, with candidates including truth, in all its definitions (Glanzberg, 2023; House, 2014); understanding (de Regt, 2017); (sufficient) justification (Rorty, 1998); validity and credibility (Scriven, 2007); and valid argument (Cartwright and Hardie, 2012).
If we assume that a foundational aim of evaluation is epistemic, we can see that the values in Figure 2 are not intrinsic values, but ‘epistemic values’: that is, specific operationalisations that are valuable to the extent that they enhance or ground the credibility of our evaluation (Kuhn, 1979; McMullin, 1982). In other words, many of the candidate values currently considered by values-first approaches are valuable only in as much as they are instrumental for achieving our ultimate, epistemic aim (whatever its definition). This includes values relating to the correctness of our evidence and assurances about the absence of different types of errors, such as representation, triangulation, precision, methodological rigour or unbiasedness; values relating to evidence being collected and ‘assembled’ in scrutable and logical ways, such as independence and transparency; and values related to the validity or credibility of our claims relative to other evidence or background assumptions such as plausibility or uniqueness.
Analogous to the distinction between the epistemic end of evaluation and the lower-level epistemic values and criteria facilitating it, we can distinguish between ethicality as an end of evaluative conduct and the concrete values and criteria it translates in practice. Thus, the ‘ethics’ dimension Aston and Apgar (2023) consider – defined as the requirement that our evidence is produced in ways consistent with our ethical principles – can be broken down further. For example, representation has not just an epistemic dimension, but might also be valued on ethical grounds, representing the value of democratic stakeholder participation in the process of determining the value and worth of activities; relatedly, transparency has an ethical dimension insofar as it relates to transparently informing stakeholders and participants about the evaluation conducted. Similarly, we may value the absence of harm to participants and their informed consent; or we might value that our findings contribute to equitable outcomes.
The third candidate aim we consider here is usability: that is, ‘the extent to which the design of an evaluation − both its output and the way it is undertaken − maximizes, facilitates or disables its potential use’ (Saunders, 2012: 422). As elaborated by Saunders, while the actual uses our evidence is to some extent unpredictable, certain practices can increase the chances that our evidence will be taken up by its intended users in support of our intended uses. Towards this aim of usability, we might value concrete practices such as the timeliness of outputs, the relevance of the evaluation questions to key stakeholders or the adaptiveness of evaluation designs: that is, their ability to respond to changing and emerging questions throughout the process. Together, these praxeological values are presented in Figure 3.
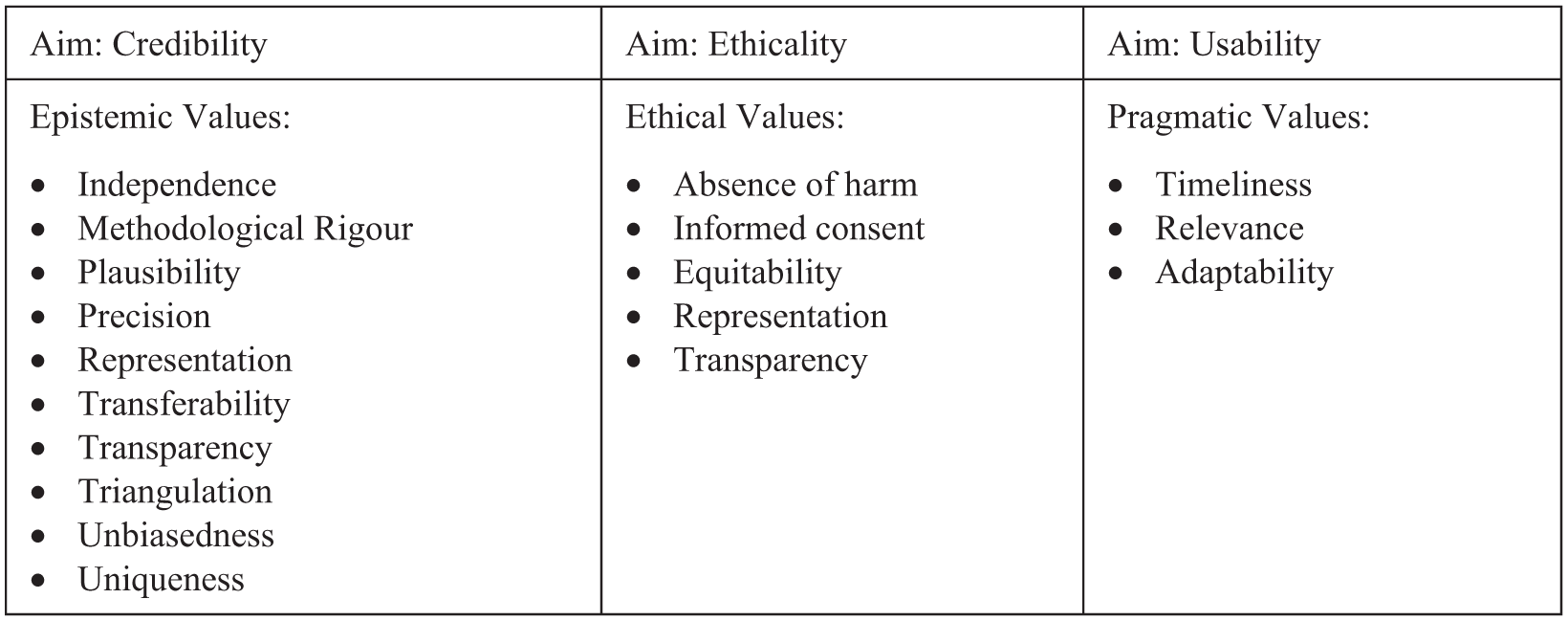
Adapted methodological values, sorted into three main dimensions (though some values might plausibly contribute to multiple aims, eg ‘transparency’).
Distinguishing these different aims underlying our praxeological values has three advantages when applying a values-first approach. First, thus typologised, our praxeology may be better suited to facilitate deliberation of appropriate evidentiary values, emphasising their context-dependent role to act as criteria of our epistemic, ethical and usability aims. Second, recognising this distinction means recognising common ground in cases of methodological disagreement. For example, Apgar et al. (2024a) critique experimental methods precisely because they fail to produce valid evidence in complex systems interventions and contexts. That is to say, on onto-epistemic grounds, such methods fail to handle the nature of complex phenomena and thus produce invalid knowledge about it. Indeed, similar to Kushner and Stake (2025) above, we agree that a minimum threshold of validity is necessary for any evaluative effort; however, disagreement will arise regarding what practices best facilitate this epistemic aim in our context, and to what degree a given practice instantiates our validity criteria (sufficiently). Finally, a pluralistic conception of evaluative values allows us to explore interdependencies and trade-offs between methodological functions of the kind highlighted by Rudner, Elliott and McKaughan. Insufficiently justified findings might be harmful or not be used in the first place; unethical conduct may limit the degree to which an evaluation is used by policy makers or produces credible data; and methods may increase their usability by becoming available in a timelier fashion, though possibly at the expense of their credibility, with less evidence being collected or being analysed less thoroughly. The relation of specific epistemic, ethical and usability criteria in any one methodological context might be even more complex. We illustrate these interdependent dimensions – which aims to emphasise, which trade-offs to accept and how to operationalise them into criteria – in Figure 4, presenting two assessments drawing from stylised experiences of the authors.
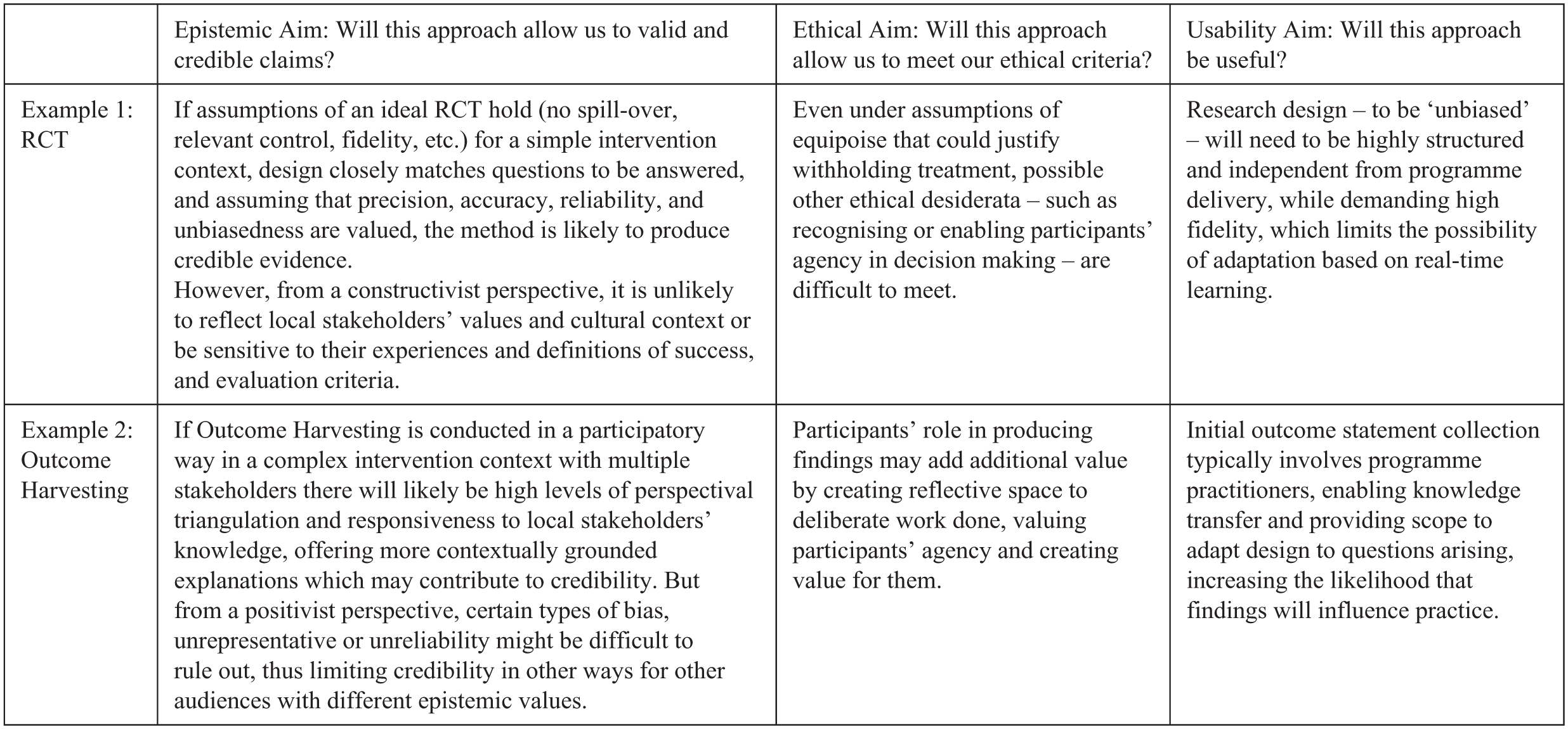
Vignettes for comparative adequacy assessment of two methods.
As these vignettes seek to highlight, any real-world assessment of methods relative to values will encounter plenty of ‘it depends’: choices depend on our purpose; on how much emphasise we place on our epistemic, ethical and usability aims; which values we consider most conducive to these ends and to what extend we consider that these values are satisfied, in our context, by a given method or approach, including inevitable trade-offs between what we value most.
Adequacy for purpose
Returning to our definition of ADEQUACYC, we can now offer a more substantive definition of our contextual constraints (C), further highlighting how questions and values-first approaches offer a complementary account of the constraints operative for adequate methodology. Drawing on praxeological account developed above – and integrating the earlier questions and feasibility dimensions from the questions-first approaches – we arrive at the following definition, along four key dimensions of adequacy in a given context and for a given purpose:
Questions & epistemic values: is the methodology likely to produce valid and credible answers for the question we want to answer? If achieving P in our context requires an assessment of cost-effectiveness, then C’s epistemic constraints might demand a large degree of precision and plausible absence of bias. Depending on the values prioritised, an experimental evaluation such as an RCT which require high levels of evaluator independence might be deemed adequate, while a deliberative qualitative approach and participatory methods might be considered inadequate.
Ethical values: Is the method likely to produce insights in a way that is consistent with relevant ethical constraints and desiderata? Methods not permitting informed consent and (plausible) absence of harm are likely inadequate for most purposes. However, if P requires considerations of equitability and participant agency, relatively more ‘extractive’ methods (Cousins and Whitmore, 1998) such as RCTs can create problematic power dynamics and negative externalities and may thus be deemed inadequate, while participatory approaches or appreciative interviews might be more adequate.
Usability values: is the method likely to produce sufficiently usable evidence? If P requires us to enhance an activity in highly dynamic and changing environments, usability constraints might include preference for methods that are adaptable and produce timely insights. A flexible and often timely approach such as Outcomes Harvesting which includes a specific step for use might be deemed adequate, while more time-intensive theory-based methods such as Process Tracing might be deemed inadequate if timeliness is valued highly (cf. Patton, 2010).
Feasibility: is the method likely to be feasible for what we can do and know? This includes the nature of the programme itself – both defining ontology and epistemology, that is, what there is to know and how it can be known (Stern et al., 2012) – and the wider ‘ecological’ constraints of the evaluation, for example, constraints of data availability or limits to the approaches we can competently apply. An approach may be appropriate in theory but not in practice if data cannot be collected or analysed in ways that align with a method’s standards and protocols. Realist evaluation, assuming relevant skills on behalf of the research, will be adaptable and thus adequate for many contexts in which data from primary stakeholders can be collected; in turn, RDDs might be inadequate if no suitable discontinuities exist among beneficiaries of an intervention.
In this way, the AFP approach asks us not just to consider our purpose, but also, how our methods will allow us to achieve that purpose in our context, including by considering the values of our stakeholders and the key questions they hope to be answered. Practically, methodological choice on this account begins by conducting an AFP evaluation: what do we want, and how do we want to get there? Assessing individual methods and their tools and judging whether, across all relevant values, they are jointly adequate or inadequate, we are left with a (possibly empty) set of adequate methods which are justifiable to meet an evaluation’s primary purposes.
Advantages of the AFP framework
Beyond offering a practical architecture in which to integrate purposes into values-first and questions-first approaches, we consider that an AFP framework has four key advantages.
First, the framework acknowledges that methodological choices are inherently uncertain, defining adequacy via likely achievement of a stated purpose in our context. This means that well-intentioned but poorly executed methods might still end up being inadequate, leaving room for ongoing AFP evaluations and adjustment and refinement. This also means that, along Rudner lines, values will play an important role in determining what likelihood of methodological success is likely enough.
Second, moving away from optimal choice, AFP defines a threshold concept of adequacy; several methodologies may well be considered adequate in our context, if they satisfy all constraints. This could support greater methodological flexibility and exploration, while maintaining a clear lower bound – much but not everything goes. In several respects, this is reconcilable with other approaches. Befani’s (2020b) tool has potentially comparable bounds through scores and scale categories, though the question what value defines ‘good enough’ means would still require additional justification. While not always desirable, following Parker (2020), the AFP framework can also accommodate a fully hierarchical account of methods in contexts. We would simply need to define a rank order, such that each methodology is said to fulfil our criteria for appropriateness to a lesser or greater degree or impose an additional measure such as ‘cost’ by which to rank all adequate methodologies.
Third, the assessment of practices in context allows us to move beyond narrow conceptions of methodology, towards broader ‘evidence generating practices’. This can include proposals for multi-method evaluation or ‘bricolage’ by using relevant parts of methods as a mosaic to suit purposes, such as Aston’s and Apgar’s (2022) discussion of methodological functions. Similarly, purpose satisfaction is also reconcilable with Pawson’s (2006) proposal to mine ‘nuggets of wisdom’ from otherwise less credible research by combining or picking elements that jointly satisfy our contextual criteria.
Fourth, the AFP framework allows us to explicate which value influences are legitimate in our context – addressing the concern raised in 1.3, essentially in the same way discussed by values-first approaches, though in a more structured manner. Exploring what adequacy means in context allows us to explore which constraints operate in that context. For example, deliberation with our stakeholders might reveal that usability is valued little, or that certain ethical values are considered as illegitimate influences on methodological choice (Lusk and Elliott, 2022). This contributes to wider discussions on the legitimate role of (non-epistemic) value judgements in scientific practice generally.
Limitations of the AFP approach
While the adequacy for purpose approach, with its focus on the contextual criteria of goal-achievement presents an integrative alternative to existing frameworks, the approach nonetheless faces three key limitations.
The first limitation is practical: deeply entrenched value preferences will make application challenging. While the AFP approach provides a space for discussion with stakeholders on why certain methods should be considered adequate or inadequate, stakeholders perspectives on adequacy may be anchored by evidence hierarchies, with certain methods being seen as superior. RCTs may, for example, simply be the only tool adequate for persuading Australia’s Treasury Minister Andrew Leigh (author of a book titled Randomistas: How Radical Researchers Are Changing Our World) to replicate a programme. This speaks to the political economy of evidence architectures and the need for evaluators to be sensitive to the values, interests and political calculations of decision-makers (see Dercon, 2025) in their deliberation of how to best produce evidence. In turn, questions of power and influence will inevitably shape local adequacy criteria, raising foundational questions about who gets to determine what matters (cf. Apgar et al., 2024b; Aston et al., 2022).
The second limitation concerns the AFP framework’s prescriptive power: the framework is highly flexible. This means that, considering the range of possible purposes and contextual constraints, any methodology might be judged adequate for certain rarified purposes, leaving room for abuse through post hoc rationalisations. Applying an AFP approach in practice thus requires principled action. We need to carefully define what our purposes are in line with espoused values and deliberate what achieving that purpose in our context requires. This, at the very least, imposes a procedural constraint, asking evaluators to provided well-reasoned and informed choices which are clearly rooted in evaluation stakeholders’ values and ethical conduct.
The last limitation concerns the framework’s completeness: mirroring our discussion of questions-first approaches, the question of the ‘right’ purpose is exogenous to the framework. Thus, unless we are faced with a well-articulated purpose in the outset of the evaluation – for example in a tendering process – an AFP approach cannot fully guide methodological choice. Cartwright’s (2012) discussion illustrates this. In our context C, M1 (e.g. an RCT) is ADEQUATEC-FOR-P1 (understanding whether the project worked in India), but inadequate for P2 (predicting whether the project will work in Bangladesh). Some M2 (e.g. a cross-country econometric design) is ADEQUATEC-FOR-P2 but inadequate for P1. 2 The AFP approach allows us to clearly articulate this inconsistency; however, it cannot answer the prescriptive question whether to pursue M1 or M2. For this, we must settle on either P1 or P2 as our purpose. Here, the best way forward appears a return to more fundamental, axiological, values: what is it that we and our stakeholders value? And which purpose is more conducive to these values?
Principled adequacy for purpose
To summarise the argument so far. Considering evidence hierarchies, question-first approaches and values-first approaches, we argued that while all three offer important insights for guiding methodological choices, they all also face important limitations. In section 3, we further argued that questions, values and purposes can be integrated under an AFP umbrella – though the question of ‘right purpose’ remained unanswered. This leads us to propose a synthetic framework intended to draw on the strengths of questions, values and purpose-focused approaches, which we term ‘principled adequacy for purpose’ (PAP). Towards such a framework, we expand previous work by Brown and Dueñas (2020) and Apgar et al. (2024a), incorporating the roles of teleology (practical purpose) and praxeology (values in action). The resulting iterative map outlining an idealised deliberative process, with key guiding questions, is presented in Figure 5.
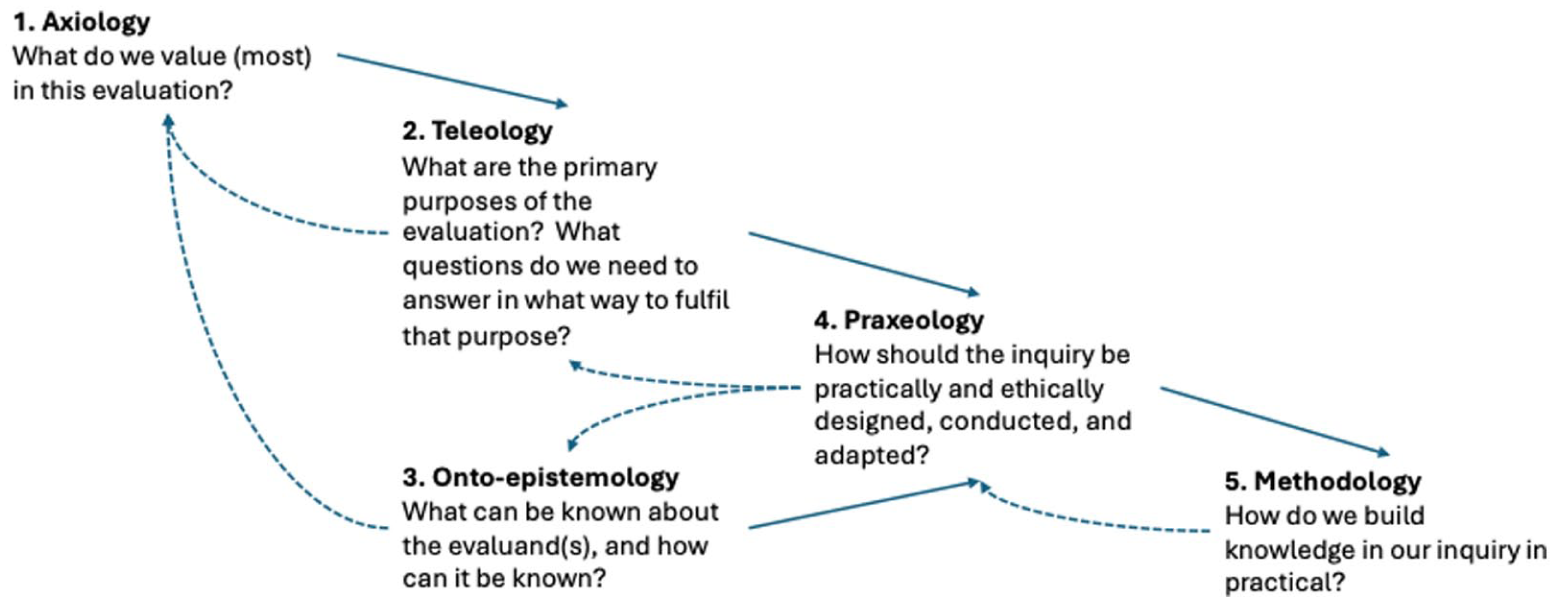
Stylised process map for the iterative deliberation on a Principled Adequacy for Purpose view.
Axiology
Our methodological choice process starts with consideration of our axiology (Biedenbach and Jacobsson, 2016; Brown and Dueñas, 2020). This contains a set of the foundational values we hold for the evaluation: the practical, scientific and moral motivations that make us – and our stakeholders – pursue evaluation. Candidate values include validity, credibility, ethicality, usability or even more broadly, integrity, social justice, well-being, democracy. These deliberations define and ground the foundational motivations of the inquiry. As argued in 2.4, we consider that three candidate goals – the epistemic, ethical and usability function of evaluation – will likely play a central role in our axiological foundations.
Teleology
Next, we consider teleology: the account of the goal we want to pursue with our evaluation. Deliberation at this level includes several elements, including how our purpose fits with our axiological values; what questions we consider this purpose to raise; the possible operationalisations of axiological values in more concrete categories (from ‘ethics’ to ‘representation’); deliberation of what potential trade-offs between values, aims and purposes we are willing to accept, and what minimum standards are required. How quick is quick enough to achieve our purpose? What level of risk are we willing to take? Candidate values at this level might include, following Chelimsky, accountability, learning or enhancement and, derivatively, the value of speed relative to accuracy. Subsequently, our notion of teleology includes Befani’s ‘questions’ and ‘other abilities’ dimensions but remains ultimately wider and explicitly grounded in values.
Onto-epistemology
In our approach, our onto-epistemology contains the set of beliefs about what exists and how it can be known. We use the term onto-epistemic, as popularised in feminist and decolonial scholarship, to highlight the close link between being and knowing (Gatt, 2023). We also note that the onto-epistemic framing of our project is separate from the stream of values-led considerations, reflecting the importance of facts external to the evaluation to constrain our otherwise values-led reasoning. 3 Deliberations at this stage concern the (best) understanding of the entities under evaluation, for example as persons, programmes, ideas, policies, products, systems, performances, that is, an ontology; and foundational epistemic criteria like logical consistency or empirical adequacy that set out the basic constraints of how we can know about these entities. This dimension closely resembles the ‘programme attributes’ in Stern et al’s (2012) work, as noted above.
Praxeology
Last, we consider our praxeology, the account of good purposeful action and conduct in a particular evaluative context (Coghlan and Brydon-Miller, 2014). Deliberation at this stage brings together both the teleological question (what must our evaluation be like to achieve our purpose?) and the constraints imposed by the onto-epistemic account. Thus, it involves developing the operational criteria and standards; identifying and navigating epistemic, usability and ethical trade-offs and navigating tensions between our values and the ‘worlds’ onto-epistemic impositions. At the praxeological level, these impositions additionally take on a pragmatic character: based on the nature of the evaluand and our requirements of knowing it, we must consider what we can know on the occasion. Limits on the data we collect and methodological proficiencies will act as important constraints on our conduct and its ability to be ‘good enough’ to achieve our purpose.
Methodological choice
Choosing preferred methods, then, should be the culmination of the aforementioned systematic process through which we determine the merits, capabilities and applicability of underlying methods (codified ways to produce knowledge) and related techniques and tools (i.e. instruments) to build knowledge through our inquiry in a particular evaluative context regarding a focus of interest (see Stirling, 2015: 7).
Conclusion
To choose and justify methodology appropriately, we need effective frameworks to guide choice and enable us to justify our choices to other. We show that current approaches – centring the questions and values as primary guides to decision-making – contain important ingredients for such an account, but ultimately, remain insufficient to justify choices. These approaches also neglect the role of evaluative purpose. To overcome these limitations, we develop an integrative account, termed ‘Principled Adequacy for Purpose’ that we argue can better guide methodological choice by recognising the context-dependent role of praxeological values, questions and feasibility constraints to act as criteria our methodological choices must meet to enable us to achieve our purposes.
Footnotes
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Ethical considerations
Not applicable.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.