
Abstract

Evaluation today – The need for scepticism1,2
Evaluation is no longer a fringe activity. It has never been more widespread and embedded in organizations and in our lives. It is powerful; however, all things considered, has evaluation delivered on its promise? Have the costs exceeded the benefits? Or is evaluation a victim of its own success?
We ask these questions after years of experience with institutionalized, routinized, prescribed, formal, and legally mandated evaluation. It has become obvious that evaluation systems are philosophically and sociologically different from evaluation as such.
Evaluation systems incur a new level of costs, surprise us with an unprecedented set of consequences, and make the problem of ‘use’ immensely complicated. This is also true for auditing, monitoring, accreditation, testing, and more, insofar as these practices are also justified by evaluation ideology, to borrow a term from Michael Scriven. Evaluation ideology is a belief that there is no end to learning, accountability, enlightenment, and improvement if only we evaluate more.
In this talk, we question this frozen ideology, the hopes and dreams on which evaluation systems thrive; and we give this questioning a name: The sceptical turn in evaluation.
By a sceptical turn, we mean turning evaluation around, so we can also see its more pernicious side. This is a ‘turn’ in how we think about evaluation, which should allow a more symmetrical relationship between evaluation and the world. A relationship where the world is not just an ‘evaluation object’ but is also entitled to ask as many questions of evaluation as evaluation asks of the rest of the world. The sceptical turn for us means being agnostic about the promised virtues and benefits of evaluation. It certainly does not mean thinking negatively about evaluation, but rather as sceptically as we evaluators usually think about the rest of the world – not more, not less.
We are not alone in suggesting that a turn is needed. Many observers outside our field articulate their critiques, and prominent names in our field have already expressed concerns, which we share:
We feel that even our preferred evaluation models do not capture well the complexities of the world.
We find that the collection of ever-more data does not lead to better decision-making.
We feel straight-jacketed by the codes, norms and routines of evaluation systems.
‘Our own tools have come back to bite us’ as a prominent evaluator said.
Questioning the mechanisms that we have internalized, can be nerve-wracking, but also instructive. It is a historical chance to revisit some tenets of the inherited evaluation ideology, make space for more meaningful practices, and search for new answers. In this sense, our presentation speaks to the conference theme, Evaluation at a watershed, Actions and Shifting Paradigms for Challenging Times.
However, the watershed does not just mean expanding evaluation to new domains; or preparing next year’s evaluation model. For us, it means taking a sceptical look at evaluation itself. What we are sharing are the fruits of our research, observations, and lived experiences with evaluation systems, combining international perspectives and examples from Denmark.
We wish to talk generally about the sceptical turn in evaluation in the following way:
First, we will look at the roots of the problem as we see it.
Then, we will look at the symptoms that surface because of deeper contradictions in evaluation ideology itself.
Finally, we will look at some promising ways forward. We even foreshadow a Copenhagen Framework for Sound Evaluation Systems that we release to stimulate a debate.
The roots of the problem
Let’s start with the legitimacy conundrum.
The very idea of evaluation systems can be traced back to a challenge that public administration thinkers faced during much of the 20th century: How to render public administrations more efficient, how to remedy information asymmetry and loose coupling, how to bridge the gap between rhetoric and action.
Evaluation was conceived as a key tool for rational and learning organizations. The functional role of evaluation also justified the raison d’etre of evaluation systems, their growth, and their diffusion across organizations, industries, and countries. This seminal role also explains the collective obsession in the evaluation field with ensuring ‘evaluation use and influence’.
Yet, this evaluation ideology does not pay enough attention to norms, routines, and beliefs. It cannot explain the widely recognized phenomena of non-use, political use, misuse, or symbolic use of evaluation. It does not account for the ‘use paradox’: Evaluation systems grow faster than the evidence of their functional use.
So perhaps organizations draw legitimacy from having evaluation systems, not from using them. The theoretical interpretation of the situation is: There is a kind of legitimacy in evaluation systems at the same time as the core practices of the organization remain decoupled from these selfsame evaluation systems.
So, we might ask ourselves: ‘How is it that evaluation systems – can succumb to the dysfunctions that they were supposed to remedy in the first place?’
The idea of ‘bureaucratic capture’ that Frans Leeuw and Estelle Raimondo developed, refers to situations when evaluation systems are more beholden to the organizations they are meant to hold to account (the agent) than to the public they work for (the principal).
‘Capture’ does not preclude many positive evaluation experiences. It is also compatible with the notion that collaboration and a certain form of integration make the evaluation richer and ultimately more useful. Capture can manifest itself in various ways. For instance, evaluation systems can create the wrong set of incentives for evaluators, programme managers, or policymakers. The incentive is not to develop and deliver the best policies, but rather to have evaluation systems run to reduce reputational risks. This type of capture can also mean less room to ‘speak truth to power’ and more pressure to shed a positive light on results.
Researchers at the Jankauskas at the Research Group for Public Administration and Organization Theory, University of Konstanz, Dr Steffen Eckhard and Dr Vytautas sought to add some data to this phenomenon by analysing more than 1000 evaluations in nine UN agencies over 8 years using a ‘natural language processing model’ (see Figure 1). They found that for most agencies, evaluations have on average a more ‘positive language’ than would be predicted when looking at project results data, and this has worsened (i.e. increased) over time.
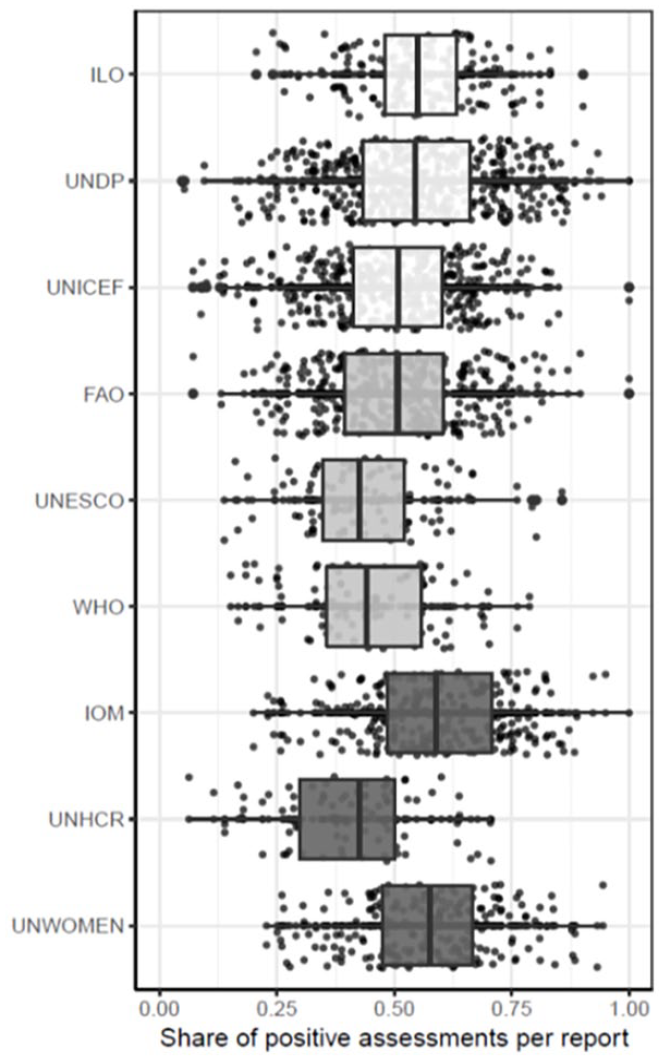
Positive descriptions of evaluations compared with evaluation results.
For illustrative purposes, let us look at the trend in the growth of evaluation reports produced by 10 development organizations who were part of the Global Delivery Initiatives, and whose project evaluations were analysed by researchers at the World Bank through text analytics.
As you can see in Figure 2, there is significant growth. (Don’t pay attention to the tail end as fewer projects approved in recent years are closed or evaluated).
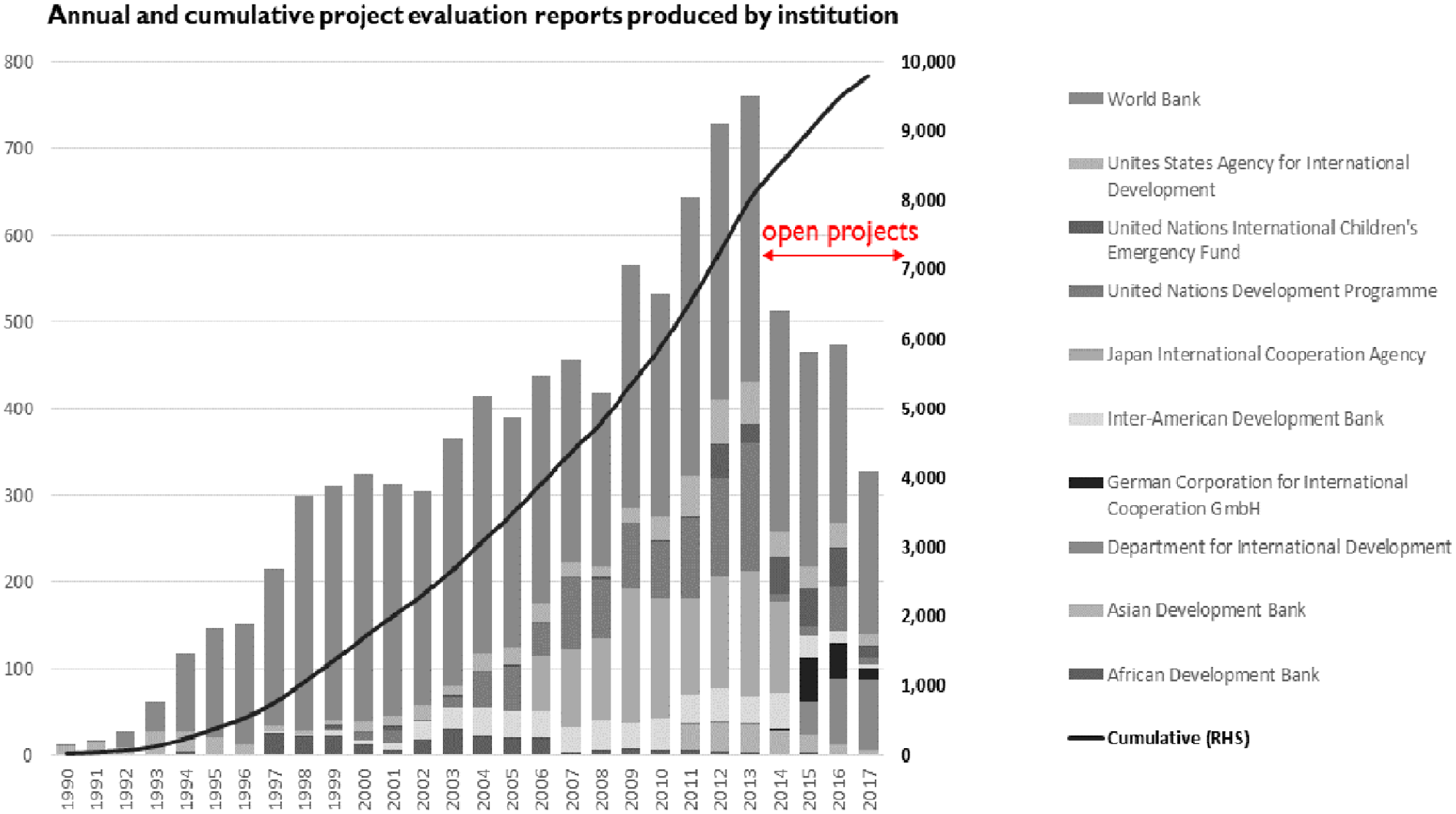
Evaluation supply across 10 institutions.
What’s even more interesting is to see the phenomenon of ‘evaluations beget evaluations’ translated in numbers (see Figure 3). When analysing the content of the ‘lessons or recommendations’ of these project evaluations, we clearly see that as project evaluations number grew, so did their recommendations to strengthen and increase monitoring and evaluation. Making evaluation more ‘systematic’ has not necessarily led to the expected outcomes of a more reflexive and transformed world. Conversely, we might be ‘trapped in a phenomenon’ whereby evaluations beget evaluations.
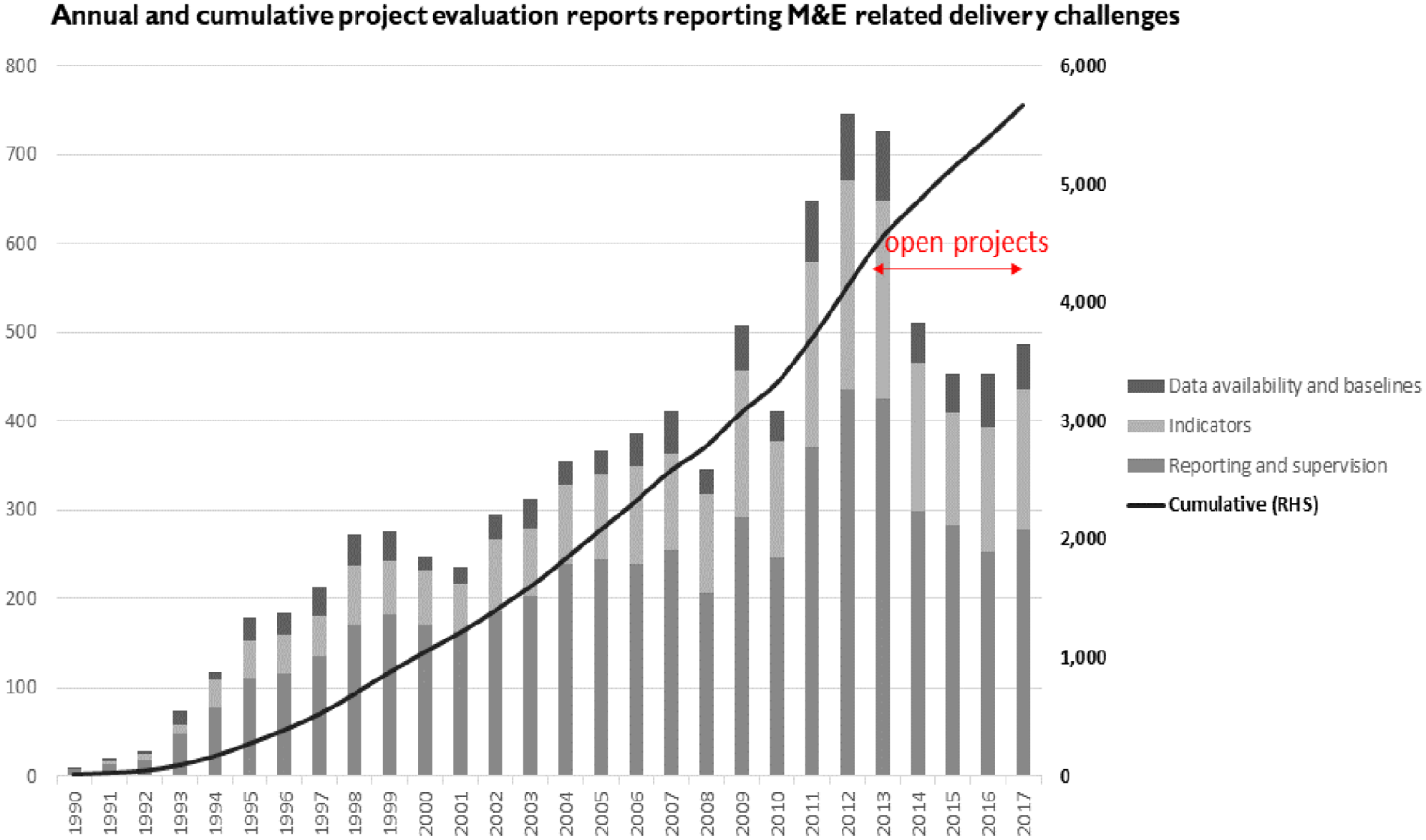
Recommendations to strengthen and increase monitoring and evaluation.
So how did we get to this point? Evaluation ideology bears some of the responsibility. When it was observed that stand-alone evaluations were insufficient to significantly change the course of organizations, evaluation ideology logically responded with more ‘systematic’ and general evaluation policies and rules, infrastructures to support evaluation machineries, evaluation capacity building, evaluation culture. However, when evaluation is mandatory across time and space, its distribution may become disconnected from the distribution of problems.
In a survey among health and safety representatives in Denmark, we asked them about their use of workplace assessments (which are mandatory as a result of EU Directive 89/391). We measured use in terms of action taken as a result of these assessments (see Table 1). Using regression analyses, we found that the predictors of use were fully consistent with textbook prescriptions. For instance, we found that workplace assessments were more likely to be used where management support was adequate, or where they were integrated in organizational strategies.
Distribution of evaluations and of problems.
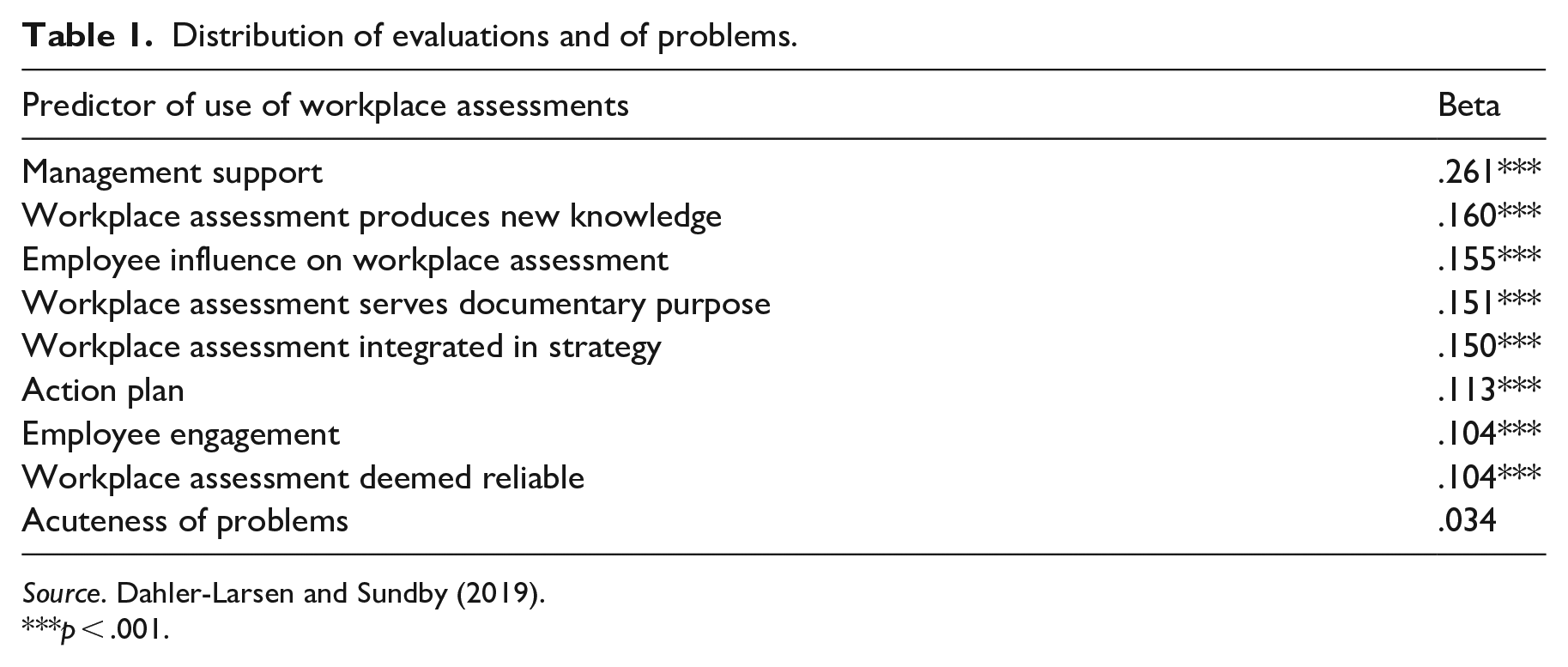
Source. Dahler-Larsen and Sundby (2019).
p < .001.
One factor, however, which was found not to be correlated with use, was the acuteness of problems in the work environment. Why? Because mandatory assessments are the same everywhere, independent of whether problems are acute or not.
Turning evaluation into a standard operating procedure might be beneficial for politicians and bureaucracies but does not embody the best possible version of evaluation. Which brings us to how we see these problems manifest themselves.
How do the problems in evaluation systems manifest themselves?
There are many constitutive effects of evaluations.
The most straightforward is when evaluation criteria become the new goals, which in turn shape new behaviours and have constitutive effects for the activities being evaluated.
Take an example from Denmark, this time in research evaluation. In this field, there is an increasing emphasis on citations, in particular with a focus on international journals which are recognized as ‘the best’. Figure 4 shows total citations on the horizontal axis.
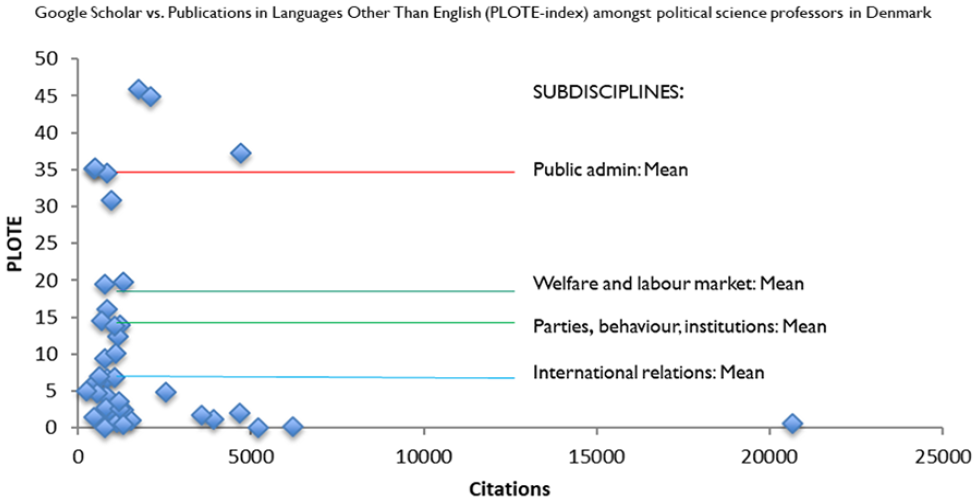
Publications in languages other than English.
However, some researchers also serve national debates and decision-makers: in Danish. The PLOTE index (on the vertical axis) is the proportion of citations stemming from publications in languages other than English (e.g. Danish). If you look at the total number of citations for professors in political science in Denmark against the PLOTE index, you will find that it is difficult to score highly on both.
But not all professors in all subdisciplines have the same starting point.
For example, public administration scholars have traditionally written a significant share of their publications in Danish to serve Danish decision-makers. Over time, to maximize the number of citations in the face of bibliometric evaluation, researchers have increased their citations and reduced their PLOTE index. This trend is illustrated with the black arrow pointing downwards and to the right in Figure 5.
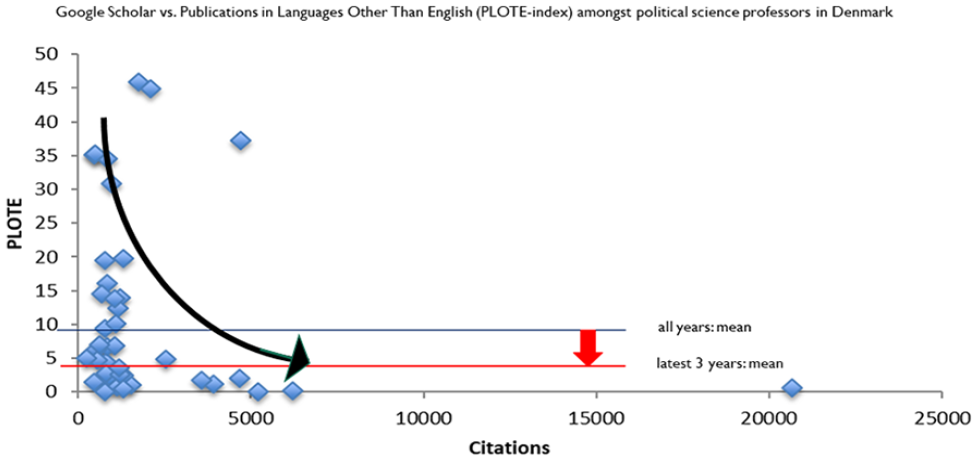
Constitutive effects of citations.
Given the general trend over time, public administration as a field will likely perform ‘poorly’ in research evaluations or transform itself to become more oriented towards international journals (which is exactly what has happened). There is a general, constitutive effect of using total citations as a success criterion. But the effect is different in different subdisciplines – it is especially dramatic for public administration.
Experiences from international development practice echo the previous example. Dan Honig, in his book ‘Navigation by Judgement’, puts it simply: ‘accomplishing results and accounting for results are sometimes in tension; focusing agents on meeting metrics sometimes undermines performance’. Daniel Rogger of the World Bank Bureaucracy Lab also shows that civil servants working in developing countries often carry out ambiguous tasks in uncertain environments and must multi-task across many types of work. Under these circumstances, results-based and monitoring practices, were found to be counterproductive.
In short, evaluation systems create new behaviours – a focus on metrics, risk-aversion, conformism and a compliance mind-set – when what is needed to achieve the goal in the first place is a different set of behaviours such as assumed autonomy, flexibility, and confidence in self-judgements. Theoretically, we are beyond the idea of ‘loose coupling’ when evaluation in depth, reconfigures core professional practices. It is a ripple effect set in motion by evaluation systems in interaction with complex social systems. We do not dare to say this effect is intended. Nor do we call it ‘unintended’ because that would neutralize its political, practical and moral status. All those designing evaluation systems should be curious about how constitutive effects occur. Let’s also talk about costs.
Evaluation studies can be costly, but their price is usually known, at least to their commissioners. Evaluation systems, however, may be mega-costly, but their total costs, including indirect and non-monetary costs, are usually unknown. This is especially because evaluation’s toll on attention is rarely counted, yet as Herbert Simon argues, attention may be the scarcest resource in organizations.
Other indirect or hidden costs such as the time needed for reporting by professionals and street-level bureaucrats, are also not accounted for. Yet, we know that some universities set aside many salaried posts devoted merely to feeding information to accreditation agencies. Likewise, nongovernmental organizations (NGOs) in developing countries receiving grant money from donors consider that the cost of reporting is sometimes so onerous that they would rather refuse a grant than deal with reporting burdens.
Despite this, there are few attempts to identify the true cost of evaluation systems even though merely introducing the idea of costs as compared to benefits can be instructive. Imagine we rank all students in a classroom in Denmark according to how much they are likely to benefit from an individualized evaluation report – a ‘pupil plan’. Some students may not benefit much. For instance, if the feedback they receive is something like: ‘you did a good job in German this year; continue your good work with both oral and written German’, it is not particularly helpful information. The decreasing benefits of individual evaluation reports across 24 students are depicted in the bar chart (Figure 6).
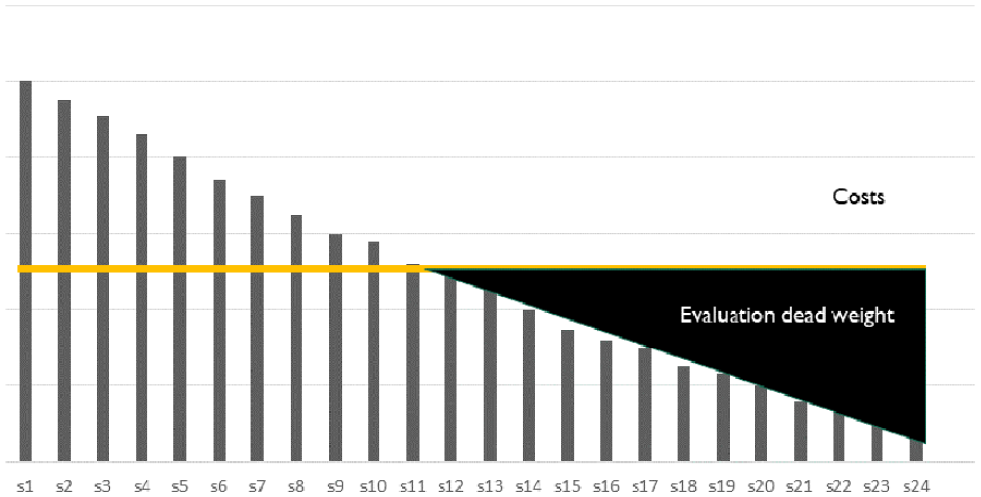
The benefits and costs of producing evaluation reports.
However, if we measure the costs of producing the report, we get the following graph. For half of the students (to the left of the break-even point), the benefits from the plan exceed their costs.
For the other half, costs override benefits, creating evaluation dead-weight. Still, everybody has a legal right to a pupil plan. This rule has been determined far away from teachers, students and parents. The institutionalization of evaluation systems has increased the ‘social distance’ between evaluators and evaluands either to avoid conflict of interest or confer to evaluators their status as ‘distant, neutral observers’.
Yet, let’s talk about the elephant in the room: these arrangements do not guarantee the independence of judgement of evaluators, in their behaviour and mind-set. Who holds the evaluators accountable for delivering on their learning and enlightenment promises? For the most part, it is other evaluators, through processes of ‘meta-evaluation’, ‘external evaluation of the independent evaluators’.
At the same time, the picture of projects and results depicted by evaluation systems can be quite removed from the lived experience of implementers and citizens. This disconnect came out loud and clear in several reviews of the World Bank’s results systems that the Independent Evaluation Group conducted over the past decade. The World Bank systems are stellar in implementing results-based management principles and work for corporate reporting, but they do not resonate with the experience of staff, implementing agencies or citizens – who see little value in the information they produce and engage with them with a compliance mind-set.
The World Bank is not alone here; this experience is echoed again and again across organizations. An Organization for Economic Cooperation and Development (OECD) 2019 comparative review of RBM shows that issues of ‘counterproductive implementation’ are widespread, in part because of the social distance that most evaluation systems have embraced as a rule (Vahamaki and Verger, 2019).
What to do?
Let us move to what can be done. Fellow evaluators, do not fear a sceptical turn! It might well help improve evaluation. Evaluation is, by definition, a self-reflective activity. Let us give you a taste of what can be done.
Deinstitutionalize! Pulling back is hard as few organizations have the luxury to start from an evaluative blank slate, and those who do, have a hard time resisting isomorphic mimicry, or blindly adopting the rulebook set out by others. Yet some are starting over, others are starting anew. For example, the radical model adopted by Ms Mackenzie Scott for her philanthropic debut is to identify organizations whose work, mandate and operating model fit her, and write a ‘blank check’: few strings attached, no itemized budgeting, no results frameworks, mandatory M&E and reporting. If you don’t operate in this radical world, you may still find interstices in the rulebook to create more space for meaningful learning.
More flexible evaluation policies! Let us say goodbye to one-size-fits all evaluation policies. A refreshing example can be found in the Bill & Melinda Gates Foundation Evaluation Policy, which differentiate between various scenarios:
Evaluation is a high priority when programme outcomes are difficult to observe and knowledge is lacking about how best to achieve results . . . (Bill & Melinda Gates Foundation, 2022). Evaluation is a low priority when the results of our efforts are easily observable . . . (Bill & Melinda Gates Foundation, 2022).
You may define different contingencies for when evaluation has high or low priority in your organization, but the very idea that evaluation is not the solution in all instances is . . . refreshing.
We think that Evaluability Assessments deserve a renaissance. The original definition of ‘evaluability’ has been distorted to mean that all projects should be ‘checked at design’ and ensure that they are all ‘evaluable’. Instead, we mobilize the original version of evaluability assessment – a procedure that determines whether evaluation is the right and the best thing to do under given circumstances – which also means that sometimes evaluation is not the best fit, and should take a step back, just as suggested by the Gates Foundation evaluation policy.
Keep an eye on costs of evaluation, including indirect costs! Coming back to our earlier example: An evaluation has shown that teachers in Denmark spend 17 hours on the average on the production of pupil plans (EVA, 2020). If the approximate 50,000 teachers in Denmark work approximately 1700 hours per year, then the production of pupil plans cost the equivalent of 500 teachers. If eliminating the legally mandated pupil plans is impossible, maybe their costs can be reduced. Let’s say teachers are allowed to give oral instead of written feedback to students and their parents, thereby cutting time spent by teachers on producing these reports in half. This measure alone could save the equivalent of 250 full time teachers directly into our school system. Politicians should know that if they will accept a more light-footed version of these reports, they can have additional 250 full time teachers at no extra cost in comparison to the present situation.
We suggest the following:
Acknowledge that evaluation dead weight exists. Use evaluability assessments and pilot studies to identify and minimize it. Do not let the term ‘systematic’ evaluation become a buzz-word. Consider whether money, time, and precious attention can be spent better.
Attend to constitutive effects! Let’s not call them ‘unintended’, because that would make the effects less serious – almost as if they did not exist because they were not meant to exist.
Let’s not measure the success of the evaluation systems only by the criteria by which they wanted to be judged. Instead, let’s be interested in knowing more about constitutive effects. Let’s observe the many ways that evaluations influence practices.
Let’s listen to others, not only evaluators, and read other literatures. Maybe the best books on evaluation are not written by evaluators.
Let’s attend to issues of language. The language of evaluation gives us a particular view of the world. It carries with it all the assumptions inherent in the existing evaluation ideology. It is difficult to translate evaluation language into local languages. Let’s not treat translation problems simply as technical problems which can be resolved with ‘google translate’. Let’s use translation problems to realize that evaluation is only one worldview among many.
Let’s reinvent the democratic dialogue (as more than just ‘participation’).
The idea of listening to others can be used systematically. Democratic dialogue can help change an evaluation system. Let’s take an example: National tests in schools in Denmark. In a recent evaluation of this evaluation system, an advisory group played a key role that went well beyond mere participation. The group consisted of researchers, test specialists, school principals, bureaucrats, teachers, parents; and even a student! The advisory group helped define evaluation questions and discussed the evaluation findings (summarized in Figure 7). These findings showed various kinds of use of the tests among stakeholders, depending on how far from the classroom they were. While municipal administrators (first three columns) made great use of the tests, school principals (next two) only used them to check on their targets. As for teachers (last column), they did not find them useful. The closer we get to the classroom, the less constructive use there is of the tests.
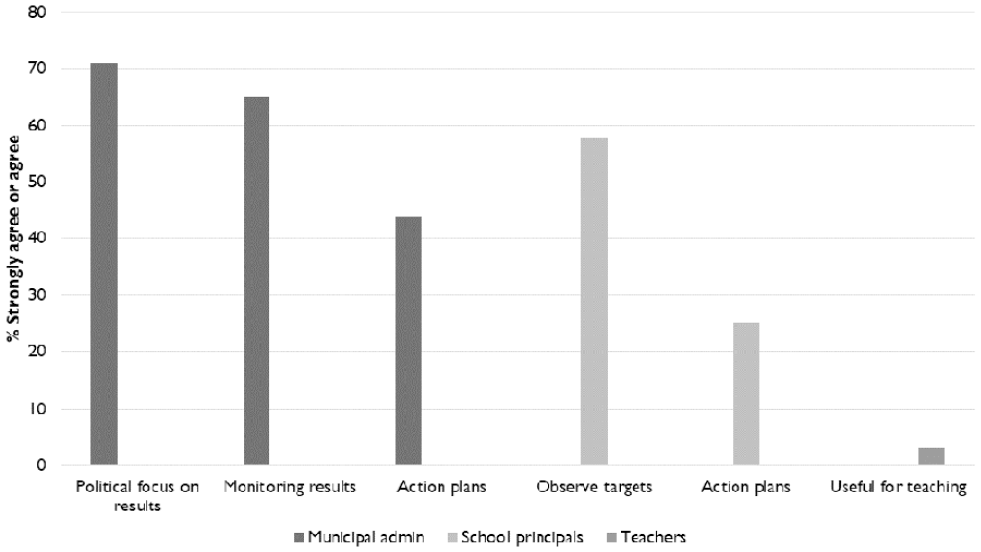
Uses of tests and how they work.
In the advisory group, all recommendations were discussed, and voted on, and everybody listed pros and cons of the recommendations. This process curtailed the potential dominance of the experts in the group. Intense democratic deliberation among a variety of stakeholders made it possible to communicate feedback about the actual functioning of the testing system back to decision-makers. Last year, they adopted a new policy which includes more user-friendly testing principles and tests administered early in the school year to emphasize formative use. The advisory group did much more than just ‘participate’ in an evaluation. It influenced policy. It helped transform the design of the evaluation system. This case shows that deliberation about an evaluation system can be useful. But it may take as much time and energy to change the components of the evaluation system as it took to build it.
It may also mean having to embrace ambiguity – something that is uncomfortable for us evaluators operating in codified environments. The most productive practices can sometimes take place below the radar of the formal evaluation systems – these practices can be elevated. For instance, IEG, has launched ‘learning engagements’ between evaluators and evaluands operating in the ambiguous space between what is and what is not systematic evaluation. The feedback received on these ‘learning engagements’ show that this space can be extremely productive even if they blur conventional principal–agent relationships. As evaluators enter into informal dialogues with the people they are trying to inform and influence, co-learning and co-creation take place: candour is eased by informality.
Conclusion: Less is more
We’d like our parting thoughts to be ‘Less is more’. This aphorism is attributed to the architect Mies van der Rohe, a pioneer of minimalist architecture, who in the 1930s sought to create an architecture that could represent modern time, where clarity and simplicity in the structure could leave space to a lot of freedom. Maybe these principles could help guide the next phase of evaluation systems.
There are encouraging signs that a healthy dose of scepticism is infiltrating evaluation practice. Evaluation systems have started to look more intensely in the mirror to question some of their deep-rooted beliefs and work towards evaluation activities that are fit for purpose.
To that end, you might want to take a look at the Copenhagen Framework for Sound Evaluation Systems, that we produced as a spin-off of this presentation and which you can be found at DOI: 10.13140/RG.2.2.17166.74563.
It contains 10 principles we suggest will keep evaluation systems slim, well-adjusted and effective. Tell us what you think! Participate in the debate!
Thank you.
Footnotes
Authors’ note
With the permission of the editor, we submit the manuscript used for our keynote presentation. The text therefore follows the conventions of an oral keynote, not those of an academic article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.