
Abstract
Learning and accountability are customarily defined as ‘the dual purpose’ of development aid evaluation, yet this notion is contested. Based on an overview of the existing literature, we identify four ideal type positions in this debate: (1) accountability and learning are complementary objectives, (2) there is a reconcilable tension, (3) there are problematic trade-offs and (4) the two are irreconcilable. Drawing on empirical evidence from Sweden and Norway relating to evaluation processes, evaluation reports and evaluation systems within the sector of development aid, we conclude that pursuing this dual purpose in practice involves trade-offs which need to be recognised. We end with implications for aid evaluation policy and practice.
Keywords
Introduction
It is common practice to assert that evaluation has a ‘dual purpose’ or a ‘double objective’: accountability and learning. But some have argued that there is a tension, if not a fundamental contradiction, between these two. Our purpose in this article is to explore this issue as it arises in the field of development assistance. In this sector, demands for accountability have been steadily growing in recent decades, accompanied by an increasing pressure for funding to be based on performance and assessed in quantitative terms (‘results-based management’ (RBM)). Unlike most other government-financed activities, such as health services, education or transport, development aid is subject to challenges to its very existence. The response by aid agencies has been, on one hand, to demonstrate that aid does indeed work, by objectively measuring what has been achieved; and on the other hand, to study what lessons can be learned so as to improve performance. Yet while accountability measures have intensified, learning remains an elusive challenge. Indeed, a consistent stream of publications during the past decades address this very concern: the lack of learning in development aid (Center for Global Development (CDG), 2006; Carlsson and Wohlgemuth, 2001; Forss et al., 1994; Independent Commission on Aid Impact (ICAI), 2014; Krohwinkel-Carlsson, 2007; Ministry of Foreign Affairs (MFA), 1993; Norad, 2016a, 2021; OECD, 2013; Pasteur, 2004; Serrat, 2010; Sida, 2005). 1
In this article, we explore how the dual purpose of aid evaluation in itself contributes to causing this problem. Our data collection and analysis have been guided by the following open-ended research question: How is the dual purpose of accountability and learning achieved in practice by aid evaluation agencies, and how has this changed over time? This historical approach is valuable because, although there have been notable shifts or ‘waves’ in evaluation theory, methods and use over time (Vedung, 2010), core dilemmas often persist (Reinertsen, 2016, 2018). By pursuing a practice-oriented research strategy for collecting and analysing our empirical material (Asdal and Reinertsen, 2022), we show how achieving the dual purpose of aid evaluation is no straightforward task: dilemmas and tensions necessarily arise between accountability and learning throughout the evaluation process, including at the textual level (in evaluation reports) and at the institutional level (in organisational systems). Our empirical focus is on the Scandinavian setting, with Norwegian and Swedish aid evaluation as our case in point. In order to capture how practices have changed (or not) over time, we include both historical and recent material in our analysis.
The article proceeds as follows: first, we present our literature review, organised into four ideal type positions commonly held in the accountability/learning debate. Second, we describe our theoretical framework and methodology for obtaining and analysing the empirical material. Third, we present our findings within the three dimensions of our empirical study: evaluation processes, evaluation reports and evaluation systems. Fourth, we discuss our findings in light of the relevant literature. Fifth, we conclude with implications for aid evaluation policy and practice.
Literature review
The relationship between accountability and learning has been debated for several decades. While we delimit the scope of this article to the sector of development aid, similar discussions are ongoing also within related fields, notably education (cf. Lumino and Gambardella, 2020; Regeer et al., 2016; Schwartz and Struhkamp, 2007; Torres et al., 2004). As noted by Balthasar (2011), the distinction between accountability-oriented and learning-oriented evaluation builds upon the concepts of summative and formative evaluations commonly used within education (cf. Patton (1996), Scriven (1991) and Vedung (2017) for foundational discussions of these concepts and their interrelation). These concepts are commonly employed also in aid evaluation guidelines (e.g. Sida, 2007 [2004]).
A wide range of definitions exist of the concepts of accountability and learning. This is indeed part of the problem explored in this article: the elastic quality of these concepts makes them imprecise in practice. They are examples of what Vedung (2017: 3) has termed ‘semantic magnets’; concepts that are open to interpretation and thus given diverse and vague meanings. For the purpose of clarity, we in this article apply the definitions by Balthasar, who equates ‘evaluation for accountability’ with summative evaluation and ‘evaluation as a learning process’ with formative evaluation (Balthasar, 2011: 201). We employ these definitions as heuristic devices for exploring how the two concepts are understood and used in practice. As noted by Kogen (2018), within the field of aid evaluation ‘these terms have been used too close to interchangeably by the world’s major donors. While accountability is relatively well-established as a concept, learning, as a cross-cutting conceptual goal of evaluations, is relatively “watery”. This has severe implications for what we can hope to achieve in terms of using evaluations to improve future interventions’ (Kogen, 2018: 99). The present article aligns with Kogen’s approach to the accountability/learning debate by exploring how the two are in practice understood and operationalised in relation to each other, thereby offering an alternative perspective to theory-based conceptualisations and case studies of this debate (e.g. Lumino and Gambardella, 2020).
The following review covers literature that explicitly discusses the relation between accountability and learning. It includes both academic and professional/practice-based publications as a means to map the full range of actors and voices in this debate. 2 In analysing this heterogeneous literature, we distinguished four ideal type positions, as shown in Table 1. We call these ‘ideal types’ to highlight that these are indeed our categorisations, and that while the various contributions are grouped together for their key similarities, there will necessarily be disparities within and overlaps between the four categories. We find this categorisation useful for navigating historical and current debates and for contextualising our empirical material.
Positions held on the relationship between accountability and learning.

Ideal type 1: Complementary objectives
This position, common among aid donor agencies, holds that accountability and learning are different, but compatible – they are ‘two faces’ or ‘two sides’ of the same coin (Asian Development Bank (ADB), 2014; Guijt, 2010; Heider, 2016; OECD, 2001, 2016; Picciotto, 2018; U.S. Agency for International Development (USAID), 2016). The two donor agencies analysed in this article, Norad (in Norway) and Sida (in Sweden), also take this position. The instruction of Norad’s Evaluation Department states that The evaluation function of the aid administration shall contribute in part to a more knowledge-based Norwegian development cooperation and in part to hold the actors within Norwegian development policy administratively accountable. [. . .] Evaluations shall contribute to increased learning and use of knowledge. (Norad 2022a: 1; authors’ translation)
The related document ‘Evaluation strategy with procedures’ further explicates this position without any further discussion: ‘Evaluations should contribute to knowledge-based learning and accountability.’ (Norad 2022b: 1; authors’ translation). Sida’s evaluation manual adopts the same position: ‘Transparency in Swedish development cooperation contributes to accountability’, and at the same time, ‘[k]nowledge about what works for whom, under what circumstances, and how contributes to learning’ (Sida, 2020: 9). The manual notes that the difference between the two is a matter of evaluation purpose and procedure: an accountability-oriented evaluation which serves as an input to the decision on whether a project shall receive continued funding or not is likely to place emphasis on objectivity and independence. [. . .] a learning-oriented evaluation should usually be conducted in a more facilitative style, encouraging the intended users to participate and reflect. (Sida, 2020: 20)
While Norad and Sida thus describe accountability and learning as different objectives existing in parallel, other donors, like USAID, go one step further and describe the two as ‘mutually reinforcing’ (USAID, 2016: 8). The OECD Development Committee (DAC)’s Evaluation Network, which has had this discussion on the agenda for more than 20 years (OECD, 2001, 2016), concludes that: ‘Accountability and learning are not mutually exclusive, rather they feed into each other’ (OECD, 2016: 23). DfID, in the United Kingdom, has sought to actively integrate them, as evidenced by the term ‘accountability for learning’ (Gray et al., 2014). Similarly, the acronyms MEL (‘monitoring, evaluation and learning’, cf. Sida, 2020) and MELA (‘monitoring, evaluation, learning and accountability’) denote the integration of learning into the regular performance measurement and evaluation efforts (cf. McLellan, 2021; Stone-Jovicich et al., 2019).
These initiatives attest to efforts among donors to actively link accountability and learning, and thus serve to illustrate what Kogen (2018) has described as a ‘conflation’ of the two. Guijt (2010) articulates this position most strongly by asserting the need to ‘explode the myth of incompatibility’ between accountability and learning. While she explicitly states that ‘there is no inherent contradiction between accountability and learning’, she also leans towards ideal type 2, in that she puts forth a set of principles for ‘resolving the tension’ and ‘offering guidance for proceeding “arm-in-arm”’ rather than engaging in a ‘tug-of-war’ (Guijt, 2010: 289).
Ideal type 2: A reconcilable tension
This position acknowledges that tensions may arise between accountability and learning yet argues that it is possible to reconcile the two (Bossuyt et al., 2014; Lehtonen, 2005; Lumino and Gambardella, 2020; Maloney, 2017; Manning and White, 2014; Regeer et al., 2016; van der Meer and Edelenbos, 2006). As formulated by the former UK Independent Advisory Committee on Development Impact (IACDI, 2010), ‘there is always a tension between the use of evaluation for accountability and its use for lesson-learning’ (p. 3). A study of European Union’s (EU) development agency Europe Aid highlighted the task of combining of accountability and learning as one of five ‘thorny dilemmas or challenges’ that must be addressed in order to enhance uptake of evaluations: ‘In theory, there should be no contradiction between the two main objectives [. . .]. They are, in principle, two faces of the same coin [. . .] The evidence collected shows, however, that this virtuous circle often does not occur’ (Bossuyt et al., 2014: 39). Manning and White, in discussing impact evaluations, state that tensions between accountability and learning may lead to unwanted negative effects, but assert that ‘performance measurement systems that use impact evaluation can make a serious contribution to both accountability and, in particular, decision-making’ (Manning and White, 2014: 348).
Maloney (2017), in an interview study about the use of evaluations, describes ‘the tension interviewees identified between evaluation as an accountability or compliance mechanism and evaluation as a learning exercise’, and suggests different ways of prioritising and combining these (p. 35). Regeer et al. (2016), in seeking to reconcile the two objectives in practice, state that: ‘Although evaluators are increasingly asked to facilitate and support learning, [the] call for accountability remains and, despite best efforts, often gains priority – hence the need to find ways to reconcile the two’ (Regeer et al. 2016: 7). Regeer et al. seek to achieve this reconciliation by distinguishing three different forms of accountability, building on Ebrahim (2005): upwards (towards donors), downwards (towards recipients) and horizontally (towards other actors involved in the project). The potential for combining accountability and learning, they argue, lies in the downwards and horizontal forms of accountability. Furthermore, the authors separate between ‘goal-oriented evaluation, which is usually connected with accountability purposes’, and ‘learning-oriented evaluation’. In order for evaluation methodologies to support learning, ‘they should be participatory [. . .] and responsive [. . .] to the learning needs of evaluation stakeholders’ (Regeer et al. 2016: 10–11). This effort at delineating different versions and directions of accountability and learning is indeed instructive and useful, and we will return to this in our discussion below.
Ideal type 3: A problematic trade-off
This position holds that accountability and learning cannot be combined without some negative effects; in practice, accountability is achieved at the expense of learning (Cracknell, 1996, 2001; European Evaluation Society (EES), 2016; Gasper, 2000; Independent Evaluation Group (IEG), 2016; Kogen, 2018; Lennie and Tacchi, 2014; Taut, 2007). While most donor agencies position themselves within ideal type 1, one report by the World Bank’s IEG (2016), studying the Bank’s systems for self-evaluation, concludes that there are indeed problematic trade-offs between accountability and learning: ‘The systems’ focus on accountability and corporate reporting – generating ratings that can be aggregated in scorecards and so on – drives the shape, scope, timing, and content of reporting, and limits the usefulness of the exercise for learning’ (Heider and Heltberg, 2016: 1).
Cracknell identified this as a dilemma in aid evaluation 25 years ago, arguing that the two purposes of accountability and learning entail diverging methodologies, especially with regard to how stakeholders are involved: [A]id ministries are under greater pressure than other ministries to give priority in their evaluation work to the accountability objective rather than the lesson-learning objective. But this creates problems, because the evaluation approach needed for accountability (for example, random sampling; fair cross-sectional representation; the use of totally independent evaluators from outside the agency) is completely different from the approach needed for lesson-learning (for example, deliberate selection of projects with problems, or deemed of particular interest; use of own staff to ensure that the learning process stays in-house). [. . .] But as lesson-learning is the main objective, there is an increasing realization among donors that the only way to monitor and evaluate the impact of people-centred [that is, socially oriented as distinct from technological] projects is to involve stakeholders themselves in the process. (Cracknell, 1996: 23–4)
He later suggested that this divergence between accountability-oriented and learning-oriented evaluation was in fact widening (Cracknell, 2001).
Taut (2007) discusses how learning-oriented evaluations may ‘provide a necessary counter-weight’ to accountability-oriented evaluations. She describes a project for enhancing learning in an organisational context in which evaluations ‘mainly served an accountability function’, and where top-down management and distrust produced strong barriers to learning (Taut, 2007: 50, 46–47). Similarly, Gasper argues that ‘automatic choice of an audit form of accountability as the priority in evaluations can be at the expense of evaluation as learning’ (Gasper, 2000: 17).
Ideal type 4: Incompatible objectives
According to this position, the trade-offs between accountability and learning are so substantial that the two objectives must be considered irreconcilable in practice (Armitage, 2011; Ebrahim, 2005; Eyben, 2005; Serrat, 2010; Vedung, 2017). According to Armitage, ‘there is an unresolved tension between accountability and learning dimensions of development evaluation which may be irreconcilable. This may explain the current trend towards performance-based models which markedly emphasize monitoring at the expense of learning’ (Armitage, 2011: 274). Similarly, Serrat asserts that ‘the two basic objectives of evaluations – accountability and learning – are generally incompatible’ (Serrat, 2010: 3). He bases his conclusion on a study of the purposes of aid evaluation, and notes that the calls for accountability in donor countries often make learning a secondary concern. This is also the concern of Ebrahim (2005), who suggests the notion of ‘accountability myopia’ to describe how accountability may have the effect of ‘nearsightedness’ in aid policy and practice: ‘Paradoxically, certain accountability requirements can hinder organizational learning, and it is thus of importance to differentiate among factors that enable and impede learning’ (Ebrahim, 2005: 57).
Eyben (2005) takes this discussion one step further. In critiquing how the concept of accountability is being operationalised, she connects this to the wider system of performance management and results-based management (RBM) which, she argues, ‘may have paradoxical effects: First, it may distort or weaken recipients’ accountability to their own citizens or intended end-users [. . .]. Second, it may constrain transformative learning’ (Eyben, 2005: 102–103; cf. also Kogen, 2018 for a similar point).
In summary, our review of the existing literature on the relationship between accountability and learning in aid evaluation has demonstrated that there exists a broad range of positions in this debate, from there being no contradiction to complete contradiction between the two. The debate has been ongoing for several decades, and positions continue to diverge markedly. The contributions are far from aligning around a common understanding of the concepts themselves and the nature of their mutual relationship. The persistence of both the unresolved debate and the diverging positions therein will serve as our point of departure as we discuss empirical findings from Norwegian and Swedish aid evaluation.
Research method
The empirical material analysed in this article consists of evaluation documents collected from archives, websites, and databases and semi-structured interviews with seven senior evaluation professionals formerly or currently working in Sida or Norad. The document collection followed two trajectories: first, a full mapping of available documents describing and discussing the institutionalisation and practice of aid evaluation in Sweden and Norway, for example, evaluation handbooks, evaluation manuals, annual reports, literature reviews, organisational charts and external reviews. 3 Second, a full mapping of all evaluation reports published by the two donors, from which we selected 20 reports for in-depth rhetorical analysis. The selection was made in order to analyse continuity and change across time, and we thus chose reports within thematic areas that have been consistently prominent within Swedish and Norwegian development aid and therefore well represented in the evaluation reports (respectively, health and natural resource management). 4 To complement this material we included two evaluations undertaken jointly by Sida and Norad. The interviews served to highlight key historical developments, elucidate practical experiences and point us towards particularly useful documents. In addition to the formal interviews, the study benefitted from consecutive rounds of feedback from a working group consisting of senior evaluation professionals from Norway, Sweden and the United Kingdom.
Our research design has been qualitative, explorative and practice-oriented (Asdal and Reinertsen, 2022), combining methods from history (e.g. Simensen et al., 2003; Reinertsen, 2016) and science and technology studies (STS) (Knorr-Cetina, 1981; Felt, 2016) with theoretical concepts from rhetoric (Aristotle, 2006; Miller and Devitt, 2019; Bjørkdahl, 2018) and political economy (Bøås and McNeill, 2004; McNeill, 2019). This combination enables an analytical framework well-suited for studying how institutional and textual practices of aid evaluation evolve over time, and how aid evaluation functions as a specific form of knowledge production and governing tool within shifting political contexts and power relations. We organised the analysis into three parts: evaluation processes, evaluation reports and evaluation systems. This approach enables us to study the accountability/learning issue in a manner that is confined to neither one particular case study nor one theoretical or professional perspective, but rather unpacks the dynamic diversity of how this challenge has been addressed in practice.
Our analysis of evaluation reports applies an analytical framework from classical rhetoric, which distinguishes three basic rhetorical genres (Aristotle, 2006; Miller and Devitt, 2019): The forensic genre was oriented towards the past and used for judicial purposes to answer ‘what happened’, establish causes and effects, and ultimately identify a ‘perpetrator’. The epideictic genre was used for ceremonial purposes to express praise or blame; it commonly included elaborate descriptions of its object and was oriented towards the present moment, rather than the past. The deliberative genre was directed towards the future and used for political purposes, trying to answer the question ‘what ought we to do?’. presenting alternative causes of action and arguing for choosing one over the others.
By exploring evaluation processes, texts and systems in an integrative manner, we gain a three-dimensional picture of how this problem unfolds over time, which in turn may get us closer to seeing how it can best be handled today. While our document collection was deliberately broad in scope as a means to map the full range of historical and present developments, the limited number of interviewees and evaluation reports selected for in-depth analysis clearly entails that our findings might have been different had this material been broader. We nevertheless find that our literature review, document collection, interviews and in-depth analysis in combination serve to triangulate our analysis in a manner that firmly substantiates our conclusion.
Empirical findings
The following sections present our analysis on how the relationship between accountability and learning plays out in practice in our material. We present our analysis in three interrelated parts: evaluation processes, evaluation reports and evaluation systems.
Evaluation processes
Most evaluation processes follow the same set of steps from initial idea through publication and follow-up. Both Sida and Norad have established formal procedures for how these steps are to be taken. As described in the literature review, both donors assert in their formal documents that evaluation can and should contribute to both accountability and learning, yet they do not formally discuss whether this dual objective may pose challenges in practice. Our empirical study therefore explores this question. In the following, we trace the typical steps of an evaluation process and highlight key moments that in practice involve negotiating the concerns for accountability and learning. Whereas the evaluation guidelines and mandates describe a theoretical situation in which the dual objective may be achieved, our interviewees concurred only to varying degrees with these ideals and reflected upon why they are often difficult to attain in practice. Their individual professional experiences highlighted in interesting ways the many choices, dilemmas and problems evaluation managers face when trying to fulfil these diverging expectations.
First, at the very outset of an evaluation process, the evaluation manager sets the key premises for whether an evaluation will contribute primarily to accountability or learning. These include defining the evaluation assignment and procuring an evaluation team. Both Norad and Sida have well-established, formalised routines for these activities, yet in practice, tensions and dilemmas often arise regardless of how aware and proactive evaluation managers are in resolving them. The main tool for defining the evaluation assignment is the evaluation mandate, normally entitled ‘Terms of Reference’ (ToR). Here, the evaluation manager describes the evaluation assignment and purpose, determines which evaluation criteria (OECD, 2019) to prioritise, delineates the scope (in size, time frame and budget), and outlines the preferred report format, team composition and methodology. The ToR document thus greatly influences how the subsequent report is composed and the objectives it may ultimately fulfil. In all but one of the reports analysed below, the ToR defines the object to be evaluated quite narrowly, leaving little room for analysis of larger-scale contextual factors which might help to explain the project outcome. According to one interviewee, this tends to limit the potential for organisational learning, or what he aptly dubbed ‘big learning’.
Throughout the evaluation process, the role of external consultants poses a key challenge of direct relevance to the accountability/learning question. The standard international practice is to engage external teams, through an open bidding round, that will undertake the evaluation process and write the evaluation report. 5 This arrangement in principle ensures independence and critical distance, which are crucial for ensuring accountability. Yet the role they are assigned can directly affect the learning potential. If they operate primarily as critics, they may conduct their work in a manner that makes people defensive, which in turn means that learning opportunities may be lost; yet if they function more as what Patton (2008) terms ‘process facilitators’, the critical distance is reduced. In addressing this dilemma, an interviewee stated that ‘you need distance to ensure credibility, yet you need local grounding to make it useful’. Another dilemma with using external consultants is that they, through the practical research and report writing, may in effect be the ones who learn the most, yet they have no responsibility for applying the lessons. The fact that the practical work of analysis and writing is mainly done by actors outside the aid agencies themselves clearly serves the accountability purpose of evaluation, yet it also means that opportunities for learning remain unavailable to the aid agencies.
Directly related to this dilemma is the question of how much evaluation managers themselves should be involved in the practical evaluation process. Commonly experienced problems were that evaluation teams might have insufficient knowledge of the specific case and context; they might submit reports of low quality; or they might offer recommendations of little practical value. A hands-off approach could thus significantly jeopardise learning. As one informant stated: ‘It is hard to strike the right balance – you want to ensure they write a good report, but without encroaching upon their independence’. Successfully managing an evaluation thus entails striking the right balance between being hands-on and hands-off the external consultants. The simple fact that any aid evaluation necessitates the coordination of a large number of actors with diverging interests in different locations across the globe over an extended period of time is by definition a challenge to learning. The importance of ownership and involvement throughout the evaluation process is explicitly stated in Sida’s (2020) manual and was also stressed by all our interviewees. They explained that in addition to upholding formal routines, evaluation managers would engage in a number of informal practices aimed at building and sustaining internal engagement in the evaluation. This they saw as critical to enabling cooperation, interest, trust, and – ultimately and ideally – learning. But this involvement had to be constantly balanced with critical distance and independence, which is crucial for accountability, since too much internal involvement can reduce external trust in the evaluation process. Evaluation managers were thus constantly balancing and negotiating between these two concerns.
Finally, ensuring that evaluations are used remains a core concern for evaluation managers. Patton’s ‘utilisation-focused evaluation’ (Patton, 1984, 2008, 2015), which most of our informants referred to as the desirable approach, suggests that initiating and sustaining interest in any specific evaluation was key to ensuring its use. In the aid sector, achieving this is complicated by the rapid circulation of staff within and between the institutions of development aid and foreign policy. Indeed, the feeding of findings, lessons learned and recommendations back into the organisation remains a considerable challenge for evaluation managers. As one interviewee stated, a key task of the evaluation managers is to be translators between the evaluation team and the policy level, by moving conclusions and recommendations from the reports into the hands and heads of both policymakers, relevant practitioners, and the public. The degree to which this succeeded was a topic of diverging views among our interviewees: Some argued that fostering ‘big learning’ was indeed extremely difficult, others argued it should be possible and pointed to examples of evaluations having had impact on policy. This attests to how the formal and institutional systems of evaluation, which we will discuss in the third empirical section, impact upon the potential for achieving accountability and learning. Yet also the specific evaluation product – the report – poses some challenges to this end.
Evaluation reports
The evaluation report is the standard outcome of any evaluation process. It is expected to convey an objective truth to the public about the results of aid and is thus a key tool for ensuring accountability. Yet it is also expected to foster learning by explicating ‘lessons learned’ and contributing to the larger accumulation of knowledge about the effects of aid. The present section analyses whether evaluation reports accomplish this dual objective in practice.
Sida and Norad published their first evaluation reports in, respectively, 1971 and 1974. These early examples clearly have a similar structure to present-day evaluation reports and should therefore be considered the same genre, yet they also differ greatly in many respects. Especially during the past 15 years, the yearly amount of published reports has increased drastically; the report length and number of appendices have expanded substantially; the layout is far more elaborate and now commonly includes illustrations, figures and colourful photographs; and the methodology is far more elaborated and sophisticated. The evaluation report genre has evolved into a number of sub-genres, including project evaluation, project review, programme evaluation, thematic evaluation, country evaluation, real-time evaluation, strategic evaluation and impact evaluation. These in turn entail diverging purposes, methodologies and potential uses. Furthermore, the evaluation departments or units have during the decades developed a number of formats for synthesising and communicating evaluation results, including annual reports, newsletters, evaluation briefs, country briefs, evaluation syntheses and meta-evaluations.
Notwithstanding this historical development and proliferation of sub-genres and formats, our rhetorical analysis shows that the structure and core features of evaluation reports are consistent through time. Early on, both countries issued evaluation manuals that defined the purpose and process of evaluation and specified report templates that clearly resemble those in use today (in Sweden: Sida, 1976 [revised 1985, 1988], 2004 [revised 2007], 2020; in Norway: MFA, 1992; Norad, 1981, 2016b). From the start, reports have been expected to include the following sections: executive summary, introduction, methods, main findings and analysis, conclusions and recommendations. As one interviewee noted, reports now indeed look more professional, yet the content may not necessarily be that different. A consistent feature of the evaluation report genre is the dual expectation of methodological rigour and practical applicability: ‘An evaluation report, no matter how good it might be – has little value unless it is being used’ (Norad, 1981: 30). This creates a dilemma, as one informant noted: ‘The reports must be short to be read, and long to be trusted’. This explains the recent trend back towards short and concise main reports supported by increasingly substantial appendices. This in turn accentuates the importance of the executive summary, as it deliberately enables readers not to read the full report. Several informants stressed that a good report must include high-quality analysis, convincing conclusions, and recommendations that are precise, relevant and workable.
Our rhetorical analysis clearly shows that this ambition is difficult to achieve. In our sample, all reports attend well to the forensic rhetorical function, answering the questions of ‘what happened?’ and ‘who is to blame?’. This is typically achieved by telling a formalised story of a practical aid effort and its consequences, discerning causes and effects, and thus pointing to factors of success or failure. This clearly contributes to fulfil the accountability objective of aid evaluation. In contrast, the accountability objective does not fit well with the deliberative rhetorical function, that is, answering the question ‘what ought we to do?’. In the analysed reports, the links between description, analysis, discussion, conclusions and recommendations were often weak. Our analysis revealed varying degrees of mismatch between these in the great majority of reports, regardless of whether they were critical or favourable. In terms of the sheer amount of text, description and analysis sections were heavily prioritised over discussion, conclusions and recommendations. This situation seems to arise from the need to factor in contextual circumstances that challenge the rationale of the specific project, programme and aid institution in question; whether economic crisis, civil war, aid dependency or existing donor policy. This has the paradoxical effect of producing recommendations that do not match the preceding analysis. Thus, some reports argue that: ‘Our findings show A, which implies that X is the most sensible action, yet given context B, we nevertheless recommend action Y’. This situation suggests that evaluation reports to some extent also have a ceremonial rhetorical function: By elaborately describing an aid intervention, the reports respond to the accountability objective and, by extension, confirm the legitimacy of the aid institution at large.
While the forensic and ceremonial functions of evaluation reports thus enable accountability, they seem only to a limited degree to enable learning. Few of the reports in our sample included ‘lessons learned’ sections. Among these, only one specifically stated the intention to ‘bring out conclusions with a broader application than the [programme] itself’ (Sida, 2006: 36). Several of our interviewees noted that one may gain project- and programme-specific insights from an overview of past events but voiced the concern that expectations are commonly higher than this, namely ‘big learning’, that happens at the institutional level and informs changes in policy and practice. It thus appears that the learning objective is challenging to achieve within the format of the evaluation report genre.
The learning objective was explicitly emphasised in the ToR document for only one of our selected reports. This ToR explicitly denotes learning as ‘one of two cornerstones’ of evaluation and mandates its building into the very evaluation design. This particular evaluation was the only one that actively employed Michael Patton’s approach of ‘utilization-focused evaluation’, as introduced above. When describing its methodology, the team contrasts the utilisation-focused approach to conventional evaluation practice [that] takes an arm’s length posture to the evaluation object and the stakeholders involved in order to buttress independence and impartiality. [. . .] The former has tended to be divorced from the users to the extent that the findings are compiled in unread reports. The latter, on the other hand, is more likely to create ownership of the evaluation process and findings among the stakeholders because they have been actively involved. (Sida, 2011: 36)
Yet even when this ambition was explicitly posed by both the evaluation managers and the team, the actual process and subsequent report showed that it was difficult to realise in practice.
Evaluation systems
Aid evaluation is always but one part of a larger context, what one of our informants aptly called ‘a power field of diverging concerns and interests’. Political economists and political scientists have highlighted that the institutional contexts produced by foreign policy, international relations and domestic interests are important for understanding the conditions that shape aid evaluation (cf. Nordesjö and Fred, 2021; McNeill, 2019). As demonstrated in Table 2, both Sweden and Norway have as a result of shifting contextual factors during the past 40 years reorganised their aid evaluation activities several times. 6
Historical overview of aid evaluation functions in Norway and Sweden.
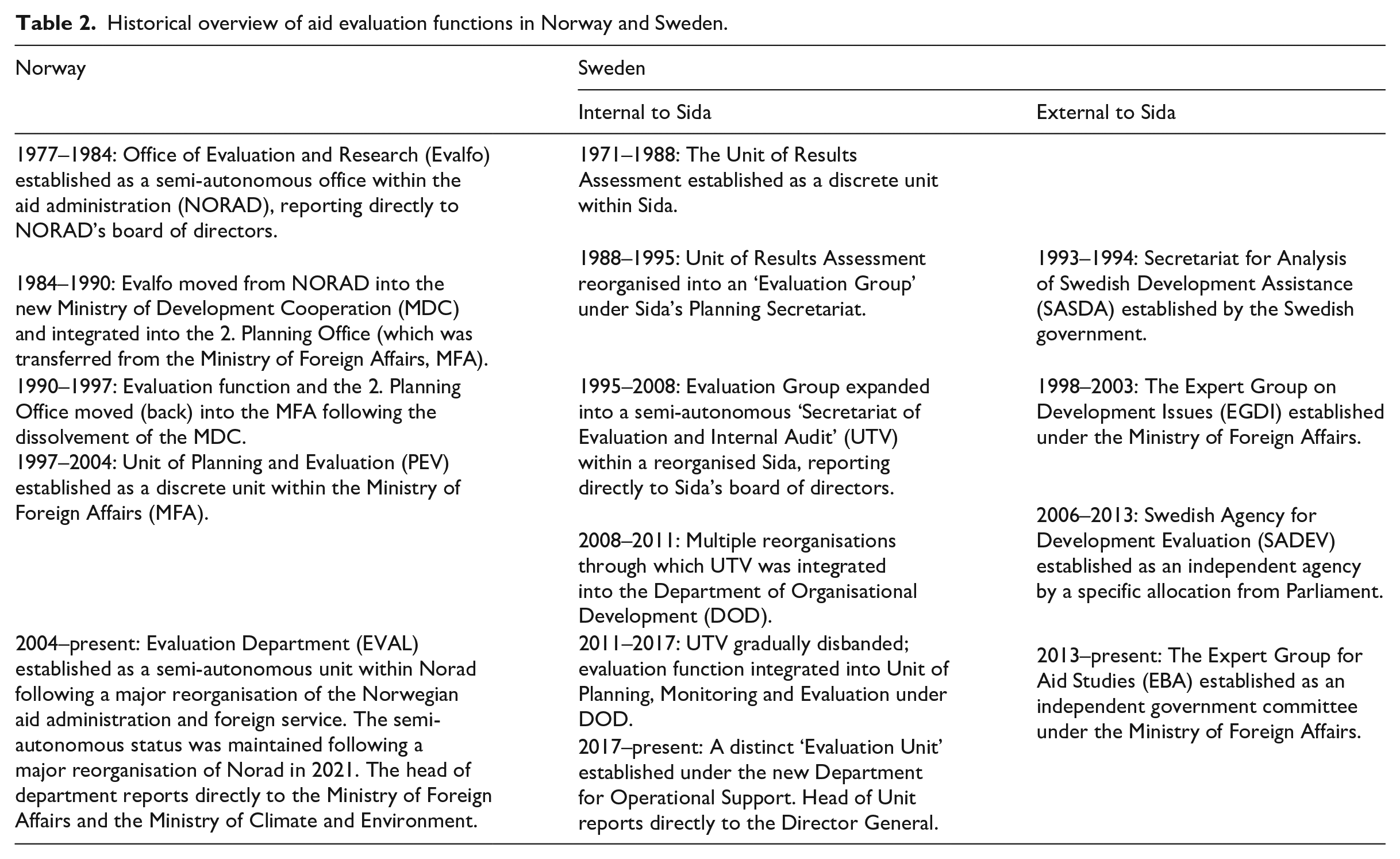
These different modes of balancing the competing concerns of integration versus autonomy for the evaluation unit and trust versus control for the public by extension affect the ability of Sida and Norad to achieve accountability and learning in different ways. As Table 2 shows, Sweden and Norway have responded rather differently to these challenges and they continue to organise their evaluation systems rather differently (see organisational charts in Figures 1 and 2). This contrast is instructive for our analysis of the potential to achieve the dual objective of accountability and learning, as it highlights how contextual factors impact directly upon the conditions for doing so.
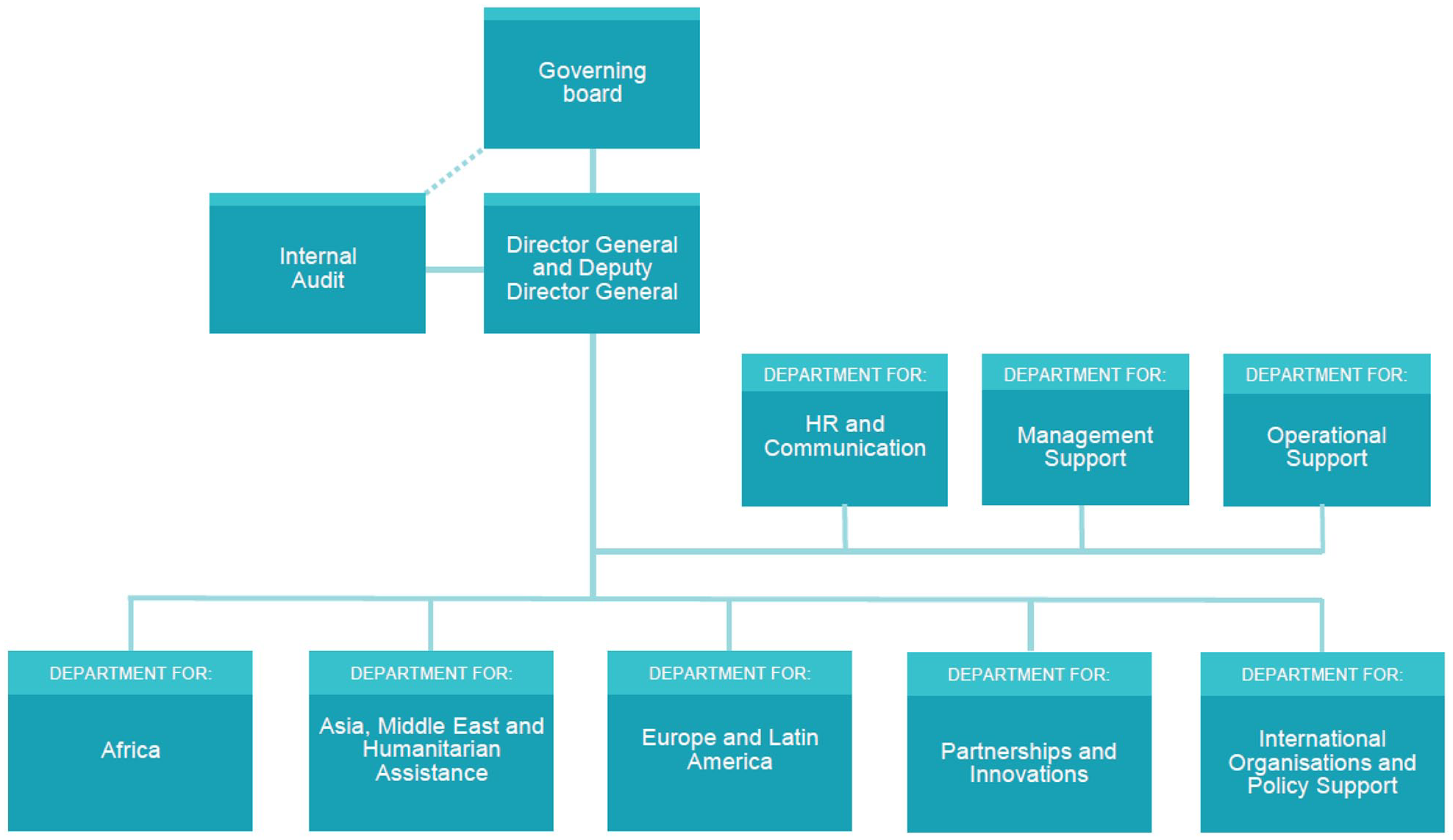
Organisational chart of Norad. The evaluation function is located outside the organisational line structure as a semi-autonomous unit reporting directly to the Ministries. Available at: https://www.norad.no/en/front/about-norad/organisation-chart/ (last retrived 9 March 2022).
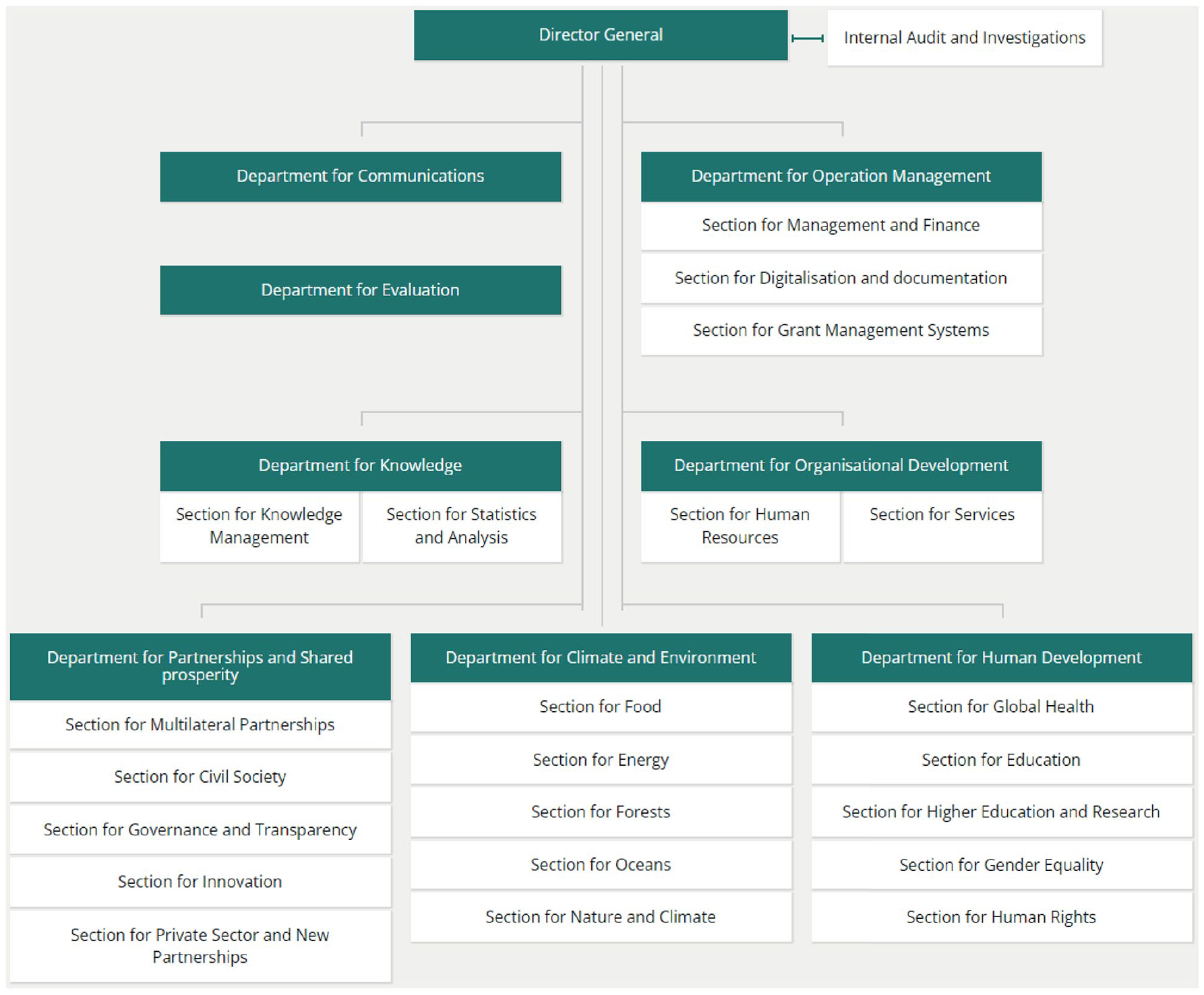
Organisational chart of Sida. The evaluation function is included in the Department for Operational Support. Source: OECD (2019): ‘Sweden 2019’. © OECD. Available at: https://www.oecd-ilibrary.org/sites/e2519d5d-en/index.html?itemId=/content/component/e2519d5d-en (last retrieved 9 March 2022).
The persistent experience in both countries that learning for aid evaluation remains elusive, as revealed by this mapping, suggests that there exists no perfect model for achieving the dual objective. This persistent feature is not a result of insular practice; both countries have been active partners in the OECD-DAC’s Evaluation Network (EvalNet, formerly the Working Group in Aid Evaluation), whose Quality Standard for Development Evaluation have been crucial for standardising aid evaluation procedures internationally (OECD, 1991, 2010, 2019). DAC member states display a variety of models for organising their aid evaluation functions (OECD, 2016).
For Sweden and Norway, two main differences in the balancing of integration and autonomy stand out. First, in Sweden, the evaluation system is largely decentralised, which means that programme staff commission the majority of the evaluations. The task of the central Evaluation Unit has been to produce strategic evaluations and assist in methodological quality assurance of decentralised evaluations. In Norway, by contrast, the central evaluation function is both larger and more autonomous. Second, there are clear differences in how the two countries have chosen to institutionalise their evaluation units. Choosing autonomy over integration may in principle increase the potential for critical distance and accountability, while integration may in principle increase the potential for trust-building and internal learning. Both countries have oscillated between the two models. The Norwegian evaluation unit has historically moved from Norad into the Ministry of Foreign Affairs and back to Norad, thus shifting from semi-autonomy to an integrated model and back to semi-autonomy. 7 Sida’s central evaluation unit has also experienced clear shifts, from being its own unit within the wider organisation, then expanded into a strong semi-autonomous unit, before again being subsumed into another department. A notable additional feature of the Swedish model has been the establishment by Parliament and the MFA of a string of external agencies that were intended to complement Sida’s evaluation work and critically interrogate the aid sector from the outside. This situation reflects that the aid administration, to a far greater extent than other sectors, must be responsive to external critics and demonstrate that expenditure on development assistance is worthwhile. Societal demands for accountability may thus in effect counteract measures promoted for fostering learning.
A contested point in the organisation of aid evaluation is the role played by the wider management system of which evaluation is an integrated part, commonly known as RBM. In Sweden, a controversial reorganisation initiated in 2006 implemented a control-oriented results agenda, and simultaneously reduced the internal evaluation function that until then had been internationally known for emphasising internal learning. Norway’s implementation of RBM was less conflictual, yet also clearly a response to political pressures on the development sector to prove its worth. Our interviewees offered diverging views on the role of RBM in the accountability/learning debate: Some held that RBM was exacerbating the problem of a lack of learning, while others held that the cause was rather that RBM had not been properly implemented. Several noted that the systems for evaluation and results reporting were oriented towards domestic needs and concerns. As one interviewee stated: ‘We evaluate for ourselves’. Several noted that recipients and beneficiaries were at best included as stakeholders, but rarely made active partners in the evaluation process itself. How donors choose to handle these questions thus directly affects the extent to which evaluation may promote learning, and for whom.
This issue cuts to the heart of the discussion of the relationship between accountability and learning: are they compatible if only the system works properly, or is the system itself inherently inhibiting learning by emphasising accountability? While our study is too modest in scope to definitively conclude in this matter, it clearly shows that there are inherent tensions within the aid system causing practical trade-offs, and that these cannot be reorganised away. (For further discussions of the implications of RBM, cf. Eyben et al., 2015; Rottenburg and Merry, 2015; Shutt, 2016; Vähämäki, 2017.)
Discussion and conclusion
Our practice-oriented analysis of evaluation processes, reports and systems demonstrates that there exist considerable contradictions between accountability and learning in aid evaluation, and that dilemmas therefore must be expected to continuously arise when trying to achieve the dual objective in practice. During evaluation processes, evaluation managers and evaluation consultants are continuously making choices that directly affect the potential for achieving the dual objective. We furthermore saw that the common format of evaluation reports might contribute to accountability but is not necessarily suited for achieving learning. Finally, evaluation systems are designed and operationalised in a way that clearly facilitates accountability towards tax payers while making internal learning more difficult. In combination, these three levels of analysis demonstrate that accountability is often achieved at the expense of learning.
Our literature review distinguished four ideal type positions in the debate on the relationship between accountability and learning: complementary objectives, a reconcilable tension, a problematic trade-off and an irreconcilable contradiction. Our own analysis clearly aligns with the third position: we have identified a number of dilemmas, tensions and contradictions between the two objectives that may and do arise during aid evaluation, yet we have not found that they are wholly irreconcilable. We rather find that they cause trade-offs that need to be recognised if more learning is to be achieved within development aid.
From analysing the accountability/learning question, we concur with Ebrahim (2005), Balthasar (2011), Lennie and Tacchi (2014), Regeer et al. (2016) and Vedung (2017) on the need to disentangle multiple forms of accountability and learning. This relates directly to the questions of ‘accountability for whom?’ and ‘learning for whom?’. Building on Ebrahim’s terminology, we may distinguish between ‘upwards’ or ‘homewards’ accountability (towards taxpayers) and ‘outwards’ accountability (towards aid intermediaries and end beneficiaries). We here found that the former is prioritised at the expense of the latter. Regarding learning, we found that ‘upwards’ or ‘homewards’ learning (towards development policy and practice) is the form of learning that continues to remain elusive, according to both the literature and our empirical analysis. Yet while organisational learning, or what our interviewee termed ‘big learning’, is difficult to achieve, we found that learning often happens at the project level and among the individuals involved in that particular aid project and evaluation process. This entails that what we might term ‘horizontal learning’ (among colleagues and collaborators in a particular evaluation process) is achievable also within the current situation. Whether aid evaluation enables ‘outwards learning’ (towards end beneficiaries), however, still remains an open question.
The ways in which aid evaluation are commonly organised serve to sustain the inherent contradictions and practical dilemmas of the dual objective. Indeed, both development aid and aid evaluation create great expectations of improving peoples’ lives and of providing certain knowledge of the effects of aid. These expectations rest heavily on the evaluation system itself. Evaluation reports serve the critical function of ensuring accountability, and hence legitimacy, of the aid system. By making visible to outsiders what happens inside the world of aid, they serve a core democratic function needed to maintain public trust. But as our analysis suggests, they do not necessarily promote learning, despite efforts of evaluation managers to facilitate learning through participation and informal processes.
The expansive growth of evaluation reports and other available documentation about development aid leads many to assume that increased knowledge and learning will automatically follow. Yet this linear learning model does not match the practical experiences in the field, quite the contrary – it may in fact lead to a widespread experience of information overload and navigation difficulties (cf. Jensen and Winthereik, 2013; Power, 1997, 2000). This problem is only deepened by intensified calls for transparency, accountability, audit and control, which, while serving critical democratic functions, are currently operationalised in ways that clearly hamper the ability to learn.
Our analysis shows that while a set of different evaluation systems has been tried in both Norway and Sweden, the experience of a learning deficit remains stable. This clearly shows that there exists no perfect model; rather, all models entail difficult balancing acts that in effect prompt difficult trade-offs. Learning necessarily involves also openly discussing errors and accepting risks and uncertainties. To create the necessary level of internal trust, this might only be achievable in closed-off, internal spaces, which in turn also closes off the possibility of public scrutiny – thus limiting the potential for transparency, accountability and external trust. A realistic approach for enhancing learning would thus entail high tolerance for error. In reality, the expectations of aid are much stricter than this. As long as accountability remains the central concern within aid evaluation systems, ‘big learning’ might in effect be illusory.
In conclusion, this article has shown how contradictions between accountability and learning in aid evaluation emerge, both in the literature and in practice. We find that accountability is commonly prioritised at the expense of learning, even when evaluation practitioners expressly aim to foster learning. The dual objective prompts a number of practical trade-offs, yet these are rarely acknowledged as such within the donor community.
Implications for policy and practice
Our conclusion sparks some key implications for aid evaluation policy and practice. We formulate these as three core issues that we invite the donor community to discuss. We do not claim to ourselves have the answers to these questions; our goal is rather to initiate a constructive discussion. Yet we have also met some resistance from practitioners to our conclusions and suggestions. We therefore end the article with a reflection on how this lack of a common understanding of the problem illustrates our argument and attests to the need for a more open debate.
First, we invite the donor community to explore how the dual objective of accountability and learning causes trade-offs that in themselves hamper learning. Why is this a controversial issue? Why do the positions diverge so widely? What are the barriers to acknowledging a connection between the two?
Second, we invite the donor community to explore how aid evaluation may be organised differently in order to mitigate the trade-offs caused by the dual objective. This entails asking seemingly naïve and potentially provocative questions for every evaluation process, such as: Does the evaluation process need an evaluation report, and if so, what kind? How might an external and internal evaluation be combined? Are external consultants needed here, and if so, what should be their role? What forms of accountability and learning are desirable and realistic to achieve?
Third, we invite donors, policy communities and the public to adjust their expectations of what aid evaluation can realistically achieve. Should the existing systems of aid administration and results-oriented reporting be given the current high priority by donors, even when they come at the expense of learning? Indeed, those who call for increasingly comprehensive systems of control and stronger evidence of success should also be asked to recognise the costs of these demands, and to actively acknowledge that these demands in themselves hamper learning.
This article has demonstrated how there exist highly disparate interpretations of the relationship between accountability and learning in aid evaluation. Incidentally, these disparate views came into full display during a seminar in which the research report underpinning the present article was presented. 8 The four people who had been invited to comment upon the report turned out to occupy the full spectrum of positions we had identified (cf. Figure 1). First, a senior evaluation manager from Norad rejected the relevance of the topic, stating that, ‘I have big problems understanding how these terms [learning and accountability] can be in contradiction’. Second, a senior evaluation manager from Sida stated that he was ‘not as critical’ as the previous speaker, and that ‘some of the conclusions are correct’ as applied to the top of the ‘evaluation pyramid’ (i.e. at Sida headquarters), but were not so relevant at the bottom level (where evaluation is mainly carried out within Sida’s decentralised system). Next, a Swedish evaluation consultant stated: “We do often come across that there is some sort of trade-off between accountability and learning. . . But I don’t see the trade-off as fundamental [. . .] in some cases the two aspects can actually be mutually enforcing, and actually support each other.”
Finally, a leading academic within Swedish evaluation studies argued that learning and accountability ‘are incompatible, and we must keep them apart in evaluation’. He noted that the objects of accountability often experience fear of losing their jobs or reputations, and this is a severe impediment to learning. In contrast, in what he called ‘learning evaluations’, ‘there should be no accountability at all’, but rather ‘reckless learning’ and a form of evaluation that was ‘embraided’ into the project itself, as an ongoing process approximating self-evaluation.
Thus, interestingly, and consistent with our literature review, representatives from national aid agencies positioned themselves towards one end of the spectrum the external consultant more in the middle, and the independent academic at the other end. Sharply put, and consistent with our analysis, the further removed was the speaker from any current responsibility for evaluation, the more was the tension between accountability and learning acknowledged. This suggests that reluctance prevails within the donor community against acknowledging this tension, so that the lack of learning from aid evaluation is likely to persist. The topic is clearly far from settled. We therefore welcome all contributions that may advance the debate and help expand learning from aid evaluation.
Footnotes
Acknowledgements
The authors wish to thank our informants for their time and interest, the Swedish Expert Group for Aid Studies (EBA) for funding and administrative support and the EBA Working Group for insightful discussions of the research report that serves as the basis of this article. Previous versions of the article have been presented at the Centre for Development and Environment (SUM), University of Oslo; the Annual Conference of Norwegian Association for Development Research (NFU); and the Annual Evaluation Conference of the UK Evaluation Society (UKES). We thank Professor Evert Vedung for his insightful comments and suggestions to the article’s framing. Finally, we thank the anonymous reviewers and the Evaluation editorial team for their thorough and constructive comments that helped sharpen the article’s form and argument.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The Swedish Expert Group for Aid Studies (EBA) financed the study on which this article is based. The writing of this article was made possible by funding from the Research Council of Norway to the project Evaluation optics of the nation state: The past, present and future of public documentation (EVALUNATION), grant no. 301815.