
Abstract
Based on the notion of critical technical practice and its resonances with recent debates in digital film and media scholarship, in this article I outline a type of computational practice that aims to couple the relational-analytic powers of machine learning with the explanatory-creative powers of visual narrative. I provisionally call this approach creanalytics. To enact this coupling, I designed a system to annotate and classify a large corpus of film clips, automatically extract fragments from this corpus, and edit them into new compositions, rendered into a computational supercut, which I go on to argue can be understood as the minimal expression of a broader emergent form of media: the computational video essay. Below I describe the most salient technical aspects of this system, analyse the principles of its design, and discuss the methodological and conceptual possibilities of its use as a format that mediates between critics and their networked environments, and between individual media artefacts, their parts, and the larger collections to which they belong.
Keywords
Introduction
Philip Agre proposed the notion of critical technical practice as a way to steer research in the field of Artificial Intelligence (AI) towards self-reflexivity. He saw the possibility of exploring the discursive and ideological dimensions of AI through the field’s own technical means. A critical technical practice, Agre wrote, is ‘a technical practice for which critical reflection upon the practice is part of the practice itself’ (Agre, 1997b).
This idea of critical reflection as a type of technical practice resonates deeply with various strands of practice-based research and critical making in the arts, as well as recent generative computational approaches in the humanities. The notion of testing the limits and possibilities of a medium within the formal and technical constraints of the medium itself is a well-trodden intellectual path in film and media scholarship as well as in experimental film-making. And similarly, the rich gamut of interpretive steps and subjective dimensions involved in data analysis and computational work are known and increasingly foregrounded by researchers and practitioners in the fields of creative computing and computational humanities. However, many of the claims and aspirations of radical reciprocity between moving image studies and computational methods are yet to be fully realised in practice. There is growing interest in this intersection, from targeted approaches, for example, using deep learning to detect and classify intertitles in early cinema (Bhargav, 2019), to larger projects, such as the Film Colors project (Flueckiger, 2017), a curated database of historical film colour processes analysed using various computational methods (Halter et al., 2019). But it is fair to say scholarship in this space is young and still being defined in terms of its methodological feet and epistemological raison d'être. This is, in a sense, equivalent to becoming a whole that is more than the sum of its parts, which is to say, to move from film scholarship + computer science, toward computational moving image studies, which implies the development of reciprocal epistemic frameworks and shared cross-disciplinary methods.
With this aim in mind, I explore in depth one articulation of this deeper technico-epistemic coupling between moving image studies and computing technologies. And in the spirit of Agre, I conduct such exploration through a working system, one that enacts, however minimally, a computational instantiation of film theory. Specifically, I designed this intervention in a deliberate attempt to combine the self-reflexive modes of inquiry of the video essay, understood here as a format for moving image analysis and criticism, with the relational and analytical modalities of scientific and social computing, specifically recent types of computer vision technologies.
The central argument put forward through the prototype I present, is that the computational editing of moving images can be understood as a form of creanalytics: a creative-analytic epistemic modality, data analysis through creative generation. Analytic and generative approaches in computing tend to be split between scientific and creative domains, with their respective tools and communities of practice. In what follows I argue that scientific analysis and creative generation are two complementary operations that can both be accommodated under a common computational framework. Deployed as analytical engines, computers can be used to find patterns across vast collections of imagery, and these patterns are often expressed as relations of proximity in space. But to amount to knowledge, these spatial correlations require interpretation and explanation, which unfold sequentially, as critics seek to organise these patterns to infer causal relations and temporal representations between data objects and events. By coupling an analytical engine with a generative one, computing can be used to configure narratives about these proximity patterns and enable explanatory propositions through compositional techniques familiar to media scholarship.
This is an interdisciplinary endeavour. Below I provide a minimal review of literature to orient the reader, with the caveat that this is not intended as a comprehensive theoretical framework. Instead, the emphasis is placed on epistemic integration through technical integration, which means the works cited are those that most overtly inform the design of the system, which I hope shows through its functioning how these fields and debates are connected. This approach to theory is also a deliberate attempt to step outside the logic of linear ‘state of the art’ progression that dominates the development of contemporary AI technologies. My contribution in this piece is to approximate a definition of what this ‘art’ might be in a broader humanities context, through technical practice, and from a critical perspective.
Machine vision, cultural analytics, and videographic criticism
The history of computing predates digital technologies in the same way that the history of cinema is algorithmic. In their modern form, moving images were brought into existence through calculation and mechanical machinery, with instruments like the thaumatrope, zoopraxiscope, phenakistoscope, and zoetrope, initially used by scientists to visualise motion (see, for example, the work of Étienne-Jules Marey in Frizot, 2001; or the thaumatrope in Gunning, 2011).
Today, most of the internet’s traffic is digital video, and the large-scale datafication of visual culture, enabled by global network computation, has brought audiovisual culture and scientific computing into much closer contact. One of the resulting techno-epistemic folds in this process occurs between contemporary forms of machine vision, understood as an umbrella term for computational approaches to the processing and interpretation of images and visual phenomena, and recent developments in videographic criticism, defined here as moving image scholarship in video form.
To clarify these terms, I use machine vision here as the parent category to computer vision, and specifically to deep learning approaches, or more accurately what Cardon et al (2018) call inductive computing: the family of methods and their associated techniques and devices, in which at least some aspects of visual processing and interpretation are abstracted inductively from large datasets of annotated imagery. This form of computer vision typically involves the use of neural machine methods, which have been around since the late 1950s but became a dominant paradigm in AI research after 2012, hand in hand with wider access to imagery online. Common tasks that were improved under this paradigm include object detection, recognition, classification, summarisation, and more recently these also deeply connected to prediction and image synthesis. Work in this field has accelerated dramatically in the last decade and has since expanded its applications to nearly every discipline and domain of knowledge, visual culture included (see Deng and Yu, 2014).
Recent scholarship in computational humanities has engaged with inductive computing technologies, adapting, and applying them to large collections of images. Cultural analytics, for example, is an approach that involves the collection, analysis, and interpretation of large cultural datasets to identify patterns, trends, and relationships, using methods drawn from data and computer science to provide a quantitative and computational understanding of cultural phenomena (Manovich, 2009, 2020). Among these methods is computer vision, which has been used to annotate films and television at scale to enable their ‘distant viewing’ (Arnold and Tilton 2019). I call these approaches relational-analytic, as they rely on encoding complex cultural-cognitive cultural production into large collections of standardised digital objects, to then be able to plot proximity relations among them, for example, clustering.
Relational-analytic methods build on previous work in quantitative film studies (Salt, 1974; Tsivian, 2009; Butler, 2014; Baxter, 2014), complementing classical statistical approaches with recent data science techniques. This also echoes existing work in the broader field of digital humanities, traditionally more focused on text and canonical artefacts than on popular audiovisual culture, but that is increasingly contributing scholarship about films and television analysed through computer vision technologies (Estrada et al., 2017; Heftberger, 2018; Mittell, 2019, 2021; Olesen, 2017; Smits and Wevers, 2022; Wevers and Smits, 2020).
Videographic criticism and the video essay, on the other hand, are emerging scholarly practices in film and media studies that use the medium of video to analyse and critique media artefacts. Their central idea is to take moving images as object and instruments of research; to use their expressive, formal, structural, and technical dimensions, as both the material and syntax of critical practice. The notion of using the medium to examine itself has occupied the imagination of film and media scholars for a long time, from Astruc’s caméra-stylo (Astruc, 1968) to Bellour’s Unattainable Text (Bellour, 1975) to Drucker’s Graphesis (Drucker, 2014). However, in a path parallel to the rise of inductive computing, it was the mass adoption of digital technologies and the datafication of visual culture over the last two decades that gave renewed currency to the idea of videographic criticism, of which the video essay is one of its most salient forms and has since matured into an ecosystem of initiatives, specialised outlets, events, and publications.
This modality of media scholarship combines traditional critical methods, such as a close reading of films and its interpretive frameworks, with practice-based research that utilises video as a medium for/of audiovisual criticism. Grant (2015, 2016), who pioneered this approach in her own practice and contributed to establishing the video essay as a legitimate scholarly practice in media studies, argues together with Keathley and Mittell (2019), that videographic criticism is particularly well-suited to digital environments, emphasising the creative and critical aspects of video essays, as well as their potential for public scholarship. I call these approaches explanatory-creative, since their overall purpose is to synthesise visual enunciates, through creative practice, and into media production that can later be inferentially followed, scrutinised, contested, and eventually incorporated back into theoretical debates.
These two epistemic modalities and their respective methods differ significantly in how they define their objects of inquiry. Yet they are also increasingly connected in a shared ambition to reconfigure the social and cultural uses of imagery and computing; moving images becoming on the one hand computational artefacts, susceptible to sophisticated forms of manipulation. through calculation, while computing on the other becomes programmable through culture, feeding from the vast archives of global visual production. Research conducted under these traditionally distinct but interrelated approaches can be said to operate at two distinct sides of the same larger phenomenon: the computational governance of the visual.
The kind of practice I outline in this piece aims to take this wider view, drawing from the above approaches, with the goal of bringing them into closer and more explicit contact under the aegis of inductive computing. From a technical perspective, the method I propose updates previous work in sequence generation by combining heuristics and rule-based systems with deep learning techniques (see, for example, Butler and Parkes, 1997). From a conceptual standpoint, the idea is to discuss the affordances of machine vision as a cultural technique (Winthrop-Young, 2013); a type of generative computational practice that is simultaneously analytic and creative, and from which new formats, standards, and more radical forms of technical and methodological reciprocity can emerge.
A computational supercut
To guide my intervention, I focus on two specific instances of computer vision and videographic criticism: face detection and emotion classification, and the supercut. These are well-documented in their respective fields, and suitable for an individual researcher to produce a minimal viable working prototype.
The supercut lends itself as a relevant format because it is, arguably, the most overtly algorithmic type of video essay. At the same time, it is already a popular format in online video platforms and digital culture more generally, and I expect readers and viewers will easily recognise it even if they are not familiar with the broader video essay format or the scholarship around it. A working definition of a supercut is as follows: it consists of an editing technique in which short video clips with common motifs or salient stylistic characteristics are extracted from their original context and are sequenced together in a montage. The commonalities are highlighted through repetition and interpreted by viewers as a form of aboutness, that is, the thematic content of the supercut.
Popular supercuts abound online in numerous non-professional compilation videos in different video platforms.
1
And scholarship on the supercut overlaps with the study of prosumer cultures, remix studies, and commons-based production. The most comprehensive genealogy and theorisation of the form, however, is appropriately best seen in video, in Tohline (2021), who researches the supercut from a moving image studies perspective. Tohline traces the history and aesthetics of the supercut, highlighting the ways in which it intensifies attention, and theorising it as a visual expression of what he calls ‘database episteme’: Over the past century, we have come to think of nearly every aspect of our lives as composed of data. The supercut is part of this; indeed, every time we use a search engine, we commission a computer to make us something quite like a supercut. Thus, the supercut entails not simply a mode of editing, but a mode of thinking expressed by a mode of editing. […] Just as capitalism treated workers as machines as a prelude to workers being replaced by machines, so also supercutters simulate database thinking in apparent anticipation of a moment, perhaps in the near future, when neural networks will be able to search the entirety of digitized film history and create supercuts themselves, automatically. (Tohline, 2021: 3)
Tohline’s genealogical project is set against a background of cinematic continuity theories, in particular, the debates about the role of narrative as the dominant structuring logic in popular audiovisual media. He draws from Smith’s attentional theory of cinematic continuity (2012) to argue that ‘there is no semiotic or structuralist reason why viewers should prefer narrative patterning to database patterning of images’ (2021: 3). This claim is largely in response to Kiss (2013), who presents a contrasting reading of Smith’s attentional approach in his analysis of György Pálfi’s Final Cut, a narrative supercut. In this piece, Kiss also suggests the possibility of an automated system: In the near future there will be a simple software or app, feeding its algorithm with keywords and other elements of interest, which will automatically generate a perfect supercut of media content of any kind within a blink of an eye. (Kiss, 2013)
Here, we have a case of two film scholars at different ends of a contested theory, each of whom considers a hypothetical computational system as a way to support their respective arguments about cinematic continuity. In their stances, Kiss and Tohline also exemplify some of the hopes and anxieties about emerging AI technologies; optimism about the new affordances and avenues of inquiry enabled by these systems, and scepticism about automation and loss of agency that they also bring with them. My intervention is wedged in these debates and aims to test these hopes and anxieties placed on inductive computing by giving technical substance to their respective claims about cinematic continuity.
To model a supercut computationally, several existing methods are enlisted, including face detection and emotion classification. Face detection is one of the most common tasks in computer vision, with many applications and associated tools and techniques. It consists of using computer systems to automatically identify and extract the region in a digital image where a face is depicted. Once a face region is detected, other processes can be performed, for example, emotion classification, which aims to identify the dominant emotion conveyed by the facial expression of the detected face. I use these techniques and integrate them with a rule-based classifier I devised and implemented based on the film-making concept of shot scale.
The goal of the system is to ‘machine-see’ a large archive of clips to identify and classify different shot types, and then concatenate this selection to output new sequences. I call this output a computational supercut. Beyond this output, however, the broader purpose is to present a way to make film theory through computational practice, expanding on previous work (Chávez Heras, 2012; Chávez Heras et al., 2019; 2020); and on performative research and material thinking in film studies more generally (Grant, 2014).
Materials, tools, and techniques
Some of the most consequential design choices in automated systems are made prior to any computational processing. This is particularly true of deep learning, where the selection, acquisition, and preparation of data plays a key role by effectively defining the learning space and therefore constraining what can be learned and how. In terms of vision, this implies abstracting and formalising some of the perceptual and cognitive processes performed by viewers, which often entails assembling large datasets of annotated imagery. This is a labour-intensive pre-processing stage during which many assumptions about images and vision play out, often unnoticed.
In the case of watching films, this layer of pre-processing includes abstracting the categories commonly used to structure cinematic viewing and that are negotiated between internal mental schemata and external cultural constructs at various levels of abstraction: from the concept of a film as a self-contained audiovisual product, to sequences, scenes, shots, frames, and pixels, as the constituent elements of such products. Decisions made at this point about what to encode and how will become very consequential in later stages. A pixel, for instance, is the most immediately computable unit, described a triad of pixel values ranging from 0 to 255 that are in themselves meaningless to regular human-viewing; a film on the other hand is one of the most recognisable audiovisual products to general audiences, but it can be too large and complex (too noisy), to be an effective unit of analysis using computational methods. A scene or a sequence is somewhere in the middle of the semantic ladder: they are meaningful in themselves to human viewers and at the same time retain some of the mechanistic traces of the film-making process, which makes them more amenable to computational analysis.
The second relevant consideration is the source of these moving images. One obvious choice is to use film archives, which tend to be internally consistent and well-structured, as well as keeping high-quality material in various stages of digitisation. However, given the emphasis on digital visual culture and the theoretical backdrop referred above, I opted for sourcing images from ‘the wilderness’ of online video platforms. This approach to data acquisition affords agile programmatic access to cinematic material at the required scale through digital platform’s Application Programming Interfaces (APIs). The trade-off is that this access is often at the expense of the structure and reliability of professionally curated film collections and archives.
To mitigate the ‘messiness’ of online video platforms, I selected an archive-like collection that is publicly available online: the Movieclips YouTube channel (2006), which serves as a corpus that is both large and consistent enough to be analysed and intervened using computational methods. This channel is operated by the American media company Fandango, which owns the popular review aggregator website Rotten Tomatoes, and the recommender platform Flixter, and which is itself jointly owned by the Warner and Universal media conglomerates. In their YouTube channel Movieclips is described as ‘the largest collection of licensed movie clips on the web’. At the time of writing, it had over 58 million subscribers and almost 60 billion aggregated views. In terms of sheer size and exposure, these numbers dwarf most film archives, but it is important to note that in terms of breadth and diversity, these movie clips are only one deep but thin slice of global film production, namely, recent Hollywood popular cinema licenced by these large media companies. 2
These caveats notwithstanding, this is a significant sample of cinematic production assembled for computational analysis. The corpus encompasses 2691 clips extracted from 350 films, made between 1931 and 2019, from 287 unique directors. In addition, an advantage of working with these Movieclips is that they are ‘hand-picked’. Unlike other corporately owned online outlets that mostly publish marketing and promotional materials such as trailers, interviews, and featurettes, these clips are ordered whole scenes from the films, which means they are in themselves already a high-quality sample of annotated moving images: our team has gone through hundreds of movies to pick out the best moments, scenes, and famous lines from all of your favorite films. Whether it's an action, comedy, drama, western, horror film, or any other genre, Fandango MOVIECLIPS has the unforgettable moments that stay with you long after you leave the theater. (Movieclips, 2006)
This emphasis on memorable moments has been theorised by Walters and Brown (2010) as a key dimension of cinephilia, and it is also germane to emerging disjunctive watching practices in online visual culture more generally ― the type of spectatorship Tohline attributes to the supercut. And in terms of structure, the sampling of these films moments is remarkably consistent: there are usually between 5 and 10 clips per film, and scenes are presented chronologically as a playlist, so that the first clip will be from early in the film while the last will be closer to the end. Clips often include dramatic sequences, set pieces, key plot points, character development exchanges, and other narrative or otherwise memorable sections of the films. For example, one can follow the basic plot of Dracula (1979), from the shipwreck sequence, where the title character escapes confinement, to its climactic defeat in the 10th clip. Watching these 10 clips will reduce watching time to approximately a fifth of the original film’s running time. 3 Browsing the channel, it quickly becomes apparent that a significant amount of human hand-picking took place to allow for this type of abbreviated movie viewing experience on YouTube.
Audiovisual semantic levels of analysis.

Following this modelling strategy, I enlisted computational methods to break down clips into their constituent parts, starting with shots. A shot can be formally defined as a consecutive sequence of frames that capture a given duration without cuts or interruptions. More than any other syntactical unit, popular narrative films are made of shots; directors, storyboard artists, and editors all work in and with shots, which they plan, produce, and organise by breaking scripts into production units, camera placements, and eventually quantified and costed as daily labour. There is a traceable relation between shots, their type and number, and the chain of production in popular cinema, which is also why they are a privileged syntactical category in film analysis.
For most casual viewers, however, shots are rarely consciously thought of. This is very often by design because in popular cinema, form tends to be subordinated to narrative, so shots are organised to flow one after the other to convey a story. A popular dictum in the film industry is that good editing is invisible, which is to say, the task of a film editor is to make the transitions between one shot to the next disappear from viewer’s consciousness to encourage the suspension of disbelief.
The supercut operates as a reversal of this erasure, bringing the functional assemblage of these units back into conscious attention and into working memory. In some ways, the supercut can be said to operate as a form of reverse editing, or reverse engineering of popular films, often exploiting this expectation of editing invisibility by making the cuts between shots apparent; constantly reminding viewers that these shots are collected from different pro-filmic events and non-sequential past durations. And although not every supercut is a supercut of shots, the basic idea of mechanical-like sampling of self-contained units as an analytical technique is very much at the centre of the supercut as an editing technique, in much the same programmatic gesture in which data science employs different sampling strategies to account for different phenomena. And perhaps because movie shots retain traces of their intentional origins ― their beginning and endings are defined through camera controls operated by humans ― it is valuable and viable to detect traces of these transitions between shots computationally, for example, by calculating the difference in pixel or histogram values between adjacent frames. Sharp changes in these values will often correlate to an edit point, for example, the end of a shot and the beginning of the next.
In computer vision this task is commonly referred to as shot-boundary detection (SBD), and there are several tools available to perform such process (see Hanjalic, 2002). To break the collection of movie clips into shots, I performed SBD using PySceneDetect, a free and open-source tool for the Python programming language (Castellano, 2020). The output of this process is a list of time codes that can be linked as metadata to the video files and serve as a heuristic way of sampling for frames.
Shots are a key syntactic unit in film-making, but data-wise they are simply smaller pieces of video. There is usually little to be gained from sampling all frames in a video file, depending on the specific task. For most use cases in computer vision of video files, and inheriting sampling strategies from the natural sciences, frames tend to be extracted at fixed intervals for analysis: higher frequency sampling will be more accurate but slower in processing time and vice-versa.
Detected shots in The Godfather (1972) [fragment].

The next step toward a computational supercut was to model and extract features from this dataset of frames to give the montage a theme. Considering the contested theories about cinematic continuity mentioned earlier, I opted for a minimal definition of film style that could be formalised as a measure of form correlated to a measure of emotion. I selected shot scale and facial emotion as proxies for both, in the hope of picking up a signal of some of the complex cognitive-emotional response that these films elicit in their viewers.
Face detection lends itself to this purpose because unlike other categories of analysis in film, the close-up is one aspect in the study of cinema in which identifying and looking at shots in isolation has been used as a method. One of the reasons for this is what Mary Ann Doane calls ‘the theoretical fascination with the diegetic autonomy of the close-up, the repeated assertion that it escapes the spatio-temporal coordinates of the narrative’ (Doane, 2003: 107). It is precisely because faces severed from their contexts fill the cinematic screen that the ‘expression on a face is complete and comprehensible in itself and therefore we need not think of it as existing in space and time’ (Balazs, 1952: 61). Detecting, isolating, and aggregating these faces in films is an operation that corresponds well to an established scholarship tradition in films studies.
Following this logic, I used face and emotion detection techniques. These operate at the pixel level of the frames, extracting regions of the image where faces are likely to be present, and then applying a pre-trained classifier to detect facial emotions on these regions. To perform these detections, I implemented a version of Facial Expression Recognition (FER), which consists of a neural method for face detection and facial features alignment originally proposed by (Zhang et al., 2016), and combines it with a classifier trained on the FER2013 dataset of labelled faces (Open Data Commons, 2020) (see Figure 1). FER detection in Ladybird (2017).
There are several assumptions and issues that come with these methods and make them highly problematic. For instance, widely found biases in the systems for face detection and recognition, whose training data often under-represents people of colour, women, ethnic minorities, rural, and economically deprived populations (Buolamwini, 2017; Crawford and Paglen, 2021). Similarly, FER is built on a theoretical model of six discrete emotion categories, an approach that is linked to Ekman (1984, 1971), and can be traced to (Plutchik, 1980). These approaches to the study of human emotions have been widely updated and are not free of criticism (see, for example, Cohen, 2005).
Similarly, popular Hollywood cinema is equally hegemonic and universalist in its cinematic representations, and in fact, several face detection and recognition datasets are assembled from images of Hollywood celebrities, such as the popular Celeb A dataset (Liu et al., 2015). I do not endorse FER or any of the power relations embodied in popular Hollywood cinema. My purpose is, rather, to instantiate these relations so as to work through them in concrete technical ways and without giving up on the idea of an actualised working system.
With this in mind, the next step was to link these emotion detections to form. To do this I used the face region outputs from FER as inputs for a basic rule-based shot-type classifier. A measure of shot scale can be calculated as a ratio r between the frame area WH and the bounding box of the face region area wh (Figure 2). Shot scale calculation.
Shot types by their scale (frame size 1980 × 720 pixels). Images by Frank Johnen CC BY-SA 3.0.

Because every shot was described by their first, middle, and last frames, three scale measurements per face, per shot were produced. This allowed for some additional feature engineering using conditional logic: if the same number of faces were found in the three frames, and they all were classified in the same scale category, I labelled these shot as ‘stable’ assuming the little variance in these frames can be used as a proxy for motion. If the starting shot was classified in a smaller category than the ending shot, I labelled the shot ‘closing in’, and if the opposite was the case, I used the label ‘pulling out’. I also categorised data for the number of faces detected, as ‘single’ (one face), ‘two-shot’ (two faces), and ‘ensemble’ (more than two faces).
Example of shot metadata.

Furthermore, manual sampling revealed that several outliers at the extremes of shot duration are in fact misdetections, for example, explosions, muzzle fire, and other fast changes in lighting that triggered spurious detections. And conversely, actual shot changes that go undetected, particularly in black and white footage and gradual shot transitions such as wipes or iris effects. Similarly, despite setting a high FER confidence threshold to avoid false positives, I still found a considerable number of shots with under and over-detected faces, which I expected given my low-resolution, fast-prototyping approach and based on previous experience with this type of computer vision libraries. Still, errors such as these can be productive, for example, as the subject of future supercuts about the actual and spurious outliers ― a visualisation of what eludes this computational gaze. I return to this idea later in this piece.
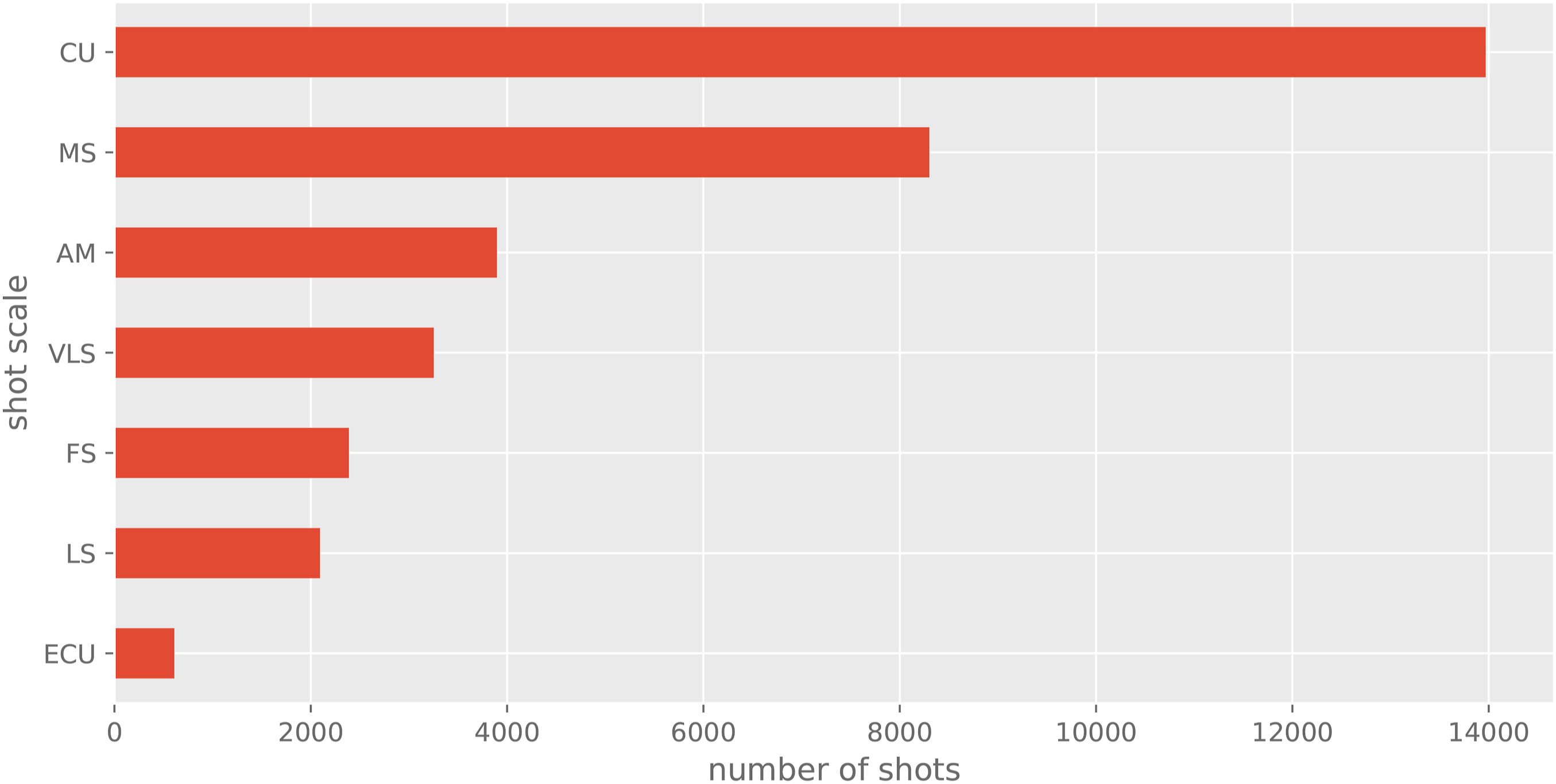
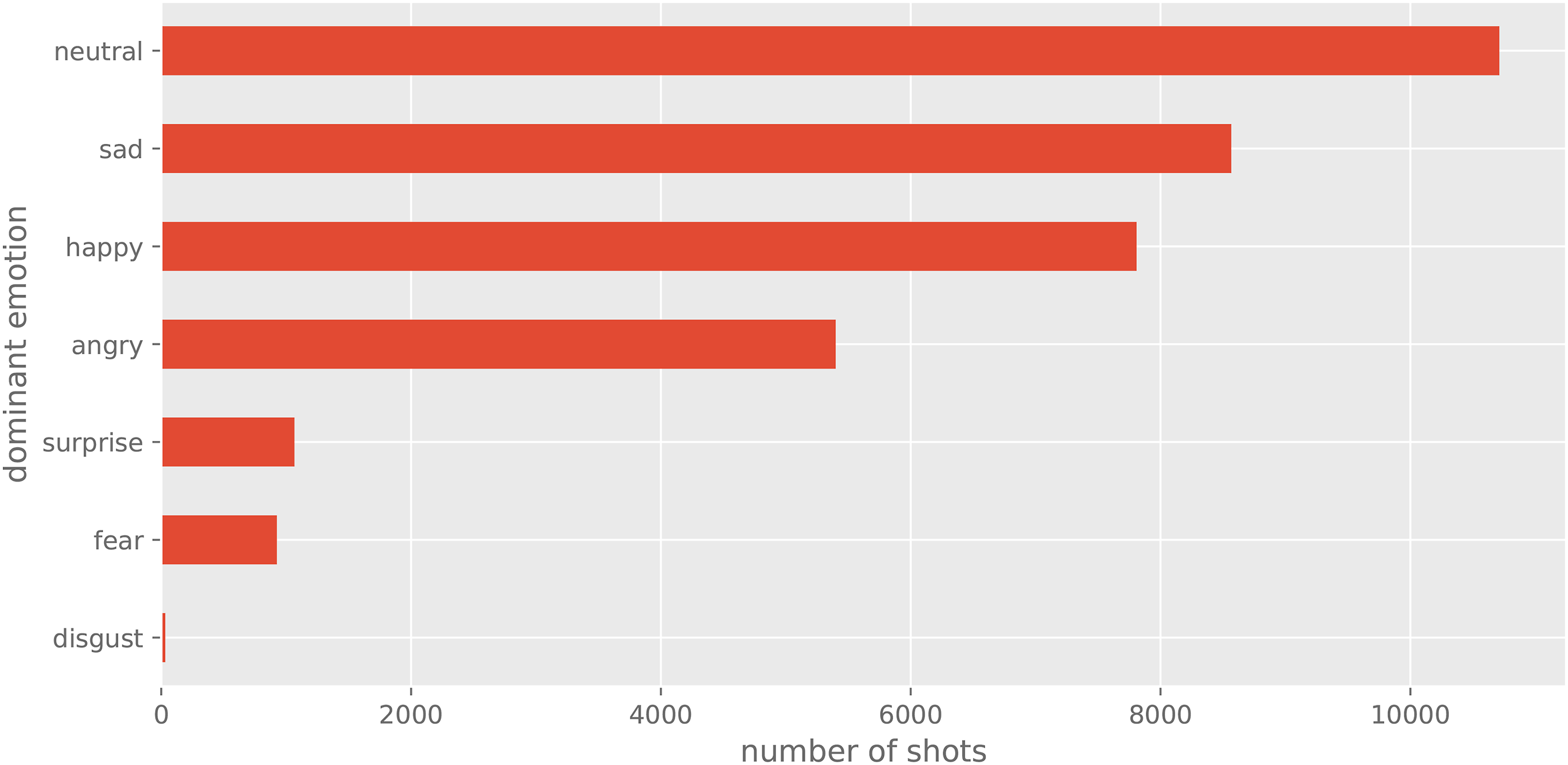
I then collated all these annotations into a single data frame and organised them hierarchically into films, clips, and shots. The result are over four hundred thousand frames corresponding to 134,727 detected shots, with an elapsed duration of 124.54 hours, and an average shot length of 3.32 s. Some descriptive features of the dataset are presented in Figure 3, Figure 4, and Figure 5. Shot duration distribution. Shot scales. Dominant emotions.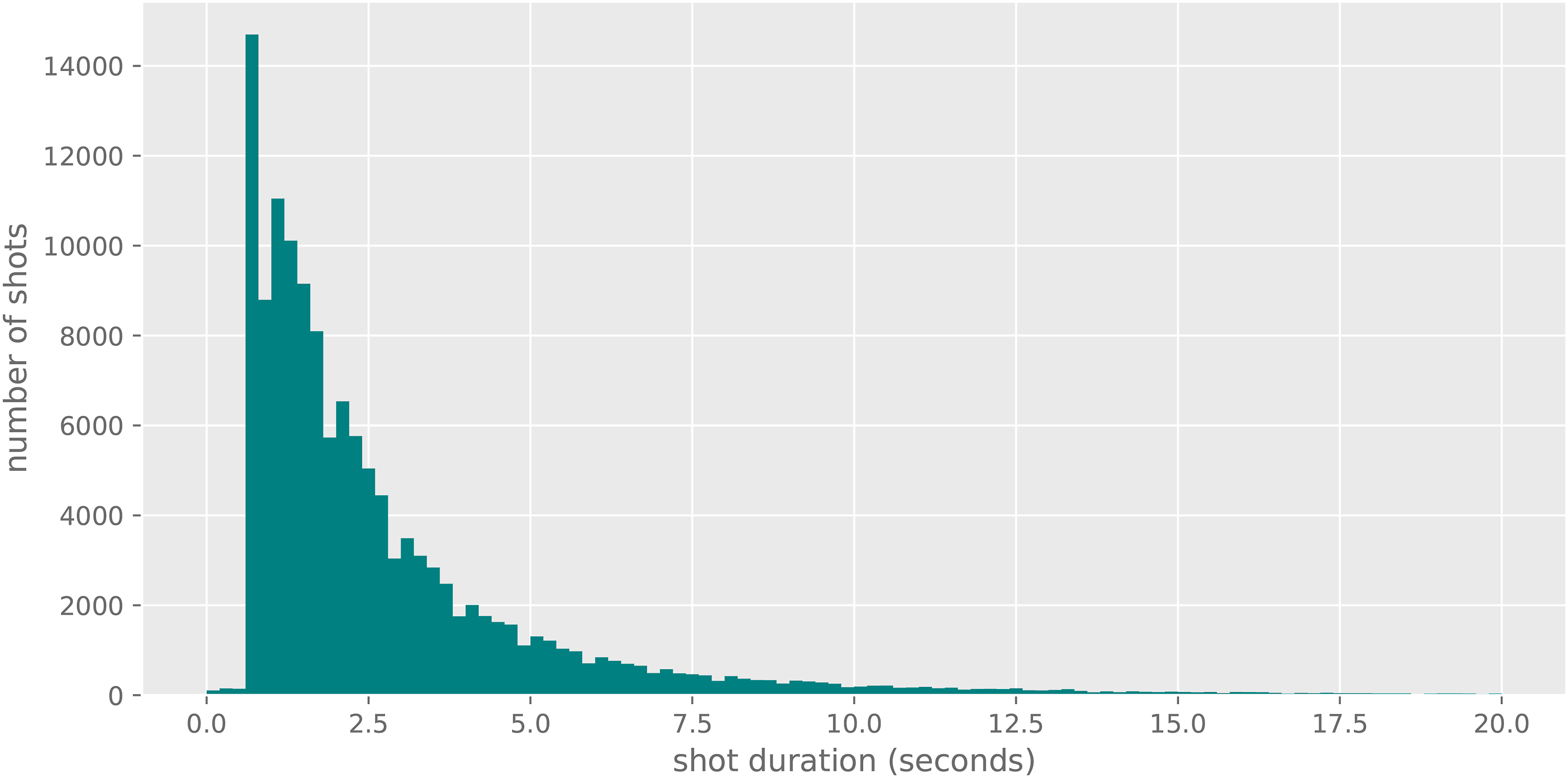
Finally, to edit the supercut together, I implemented a parametric editing engine that first compiles a list of candidate shots based on their type, as labelled by my shot type classifier, extracts these shots from their original clips using the time codes obtained through SBD, and finally concatenates them, rendering them into a new composition using ffMPEG (Fabrice Bellard and Bingham, 2000). I call this output a computational supercut.
Findings and evaluation
The first computational supercut I successfully rendered using this system is called Big Angry Faces (https://vimeo.com/showcase/8821910). It is under a minute long, and is composed of 23 shots, 1–3 seconds in length, of angry faces in extreme close-up, that were extracted from films made between 1980 and 2018. Based on this first output, it is clear that the resulting video does work as a supercut; it is recognisable as a compilation of clips with a common theme. Tohline and Kiss’ intuitions that this type of montage can be automated using inductive computing are thereby proven to be correct, even if the resulting montage is less refined than a comparable ‘handmade’ version. 5 The prototype does work as a proof of concept, and it is reasonable to assume that this and similar techniques can be optimised to improve the resulting videos in future iterations of this idea.
A second finding from this experiment in parametric editing is that it allows to make more informed inferences about the system, how it works and how it fails; what machine vision currently can and cannot see, and how its computational gaze draws from and remediates human-viewing. The shots in Big Angry Faces, for example, are smaller in scale than what is commonly expected from extreme close-ups of human faces that would likely be recognised as regular close-ups. An explanation is that in cinema, faces in extreme close-up tend to be cropped because the frame format is horizontal, and in some cases much wider, such as in anamorphic widescreen (2.39:1), or 70 mm (2.76:1). A degree of top-of-the-head cropping is fine, but cropped jawlines and especially incomplete or occluded mouths push the images below the minimum confidence threshold to be reliable detected as faces. Because faces in extreme close-up were not detected as faces, this type of shot simply did not make into the candidate list for the supercut. My shot detector and classifier, for example, would not have recognised some of the first ever recorded close-ups, such as the ones seen in George Albert Smith’s Grandma's Reading Glass or As Seen Through a Telescope (1900a, 1900b) (Figure 6). In other words, computer vision of the type I used can be said to be blind, or at least weak sighted, to a fundamental cinematic technique that is easily processed and understood by human viewers. Close-up in Grandma's Reading Glass (1900).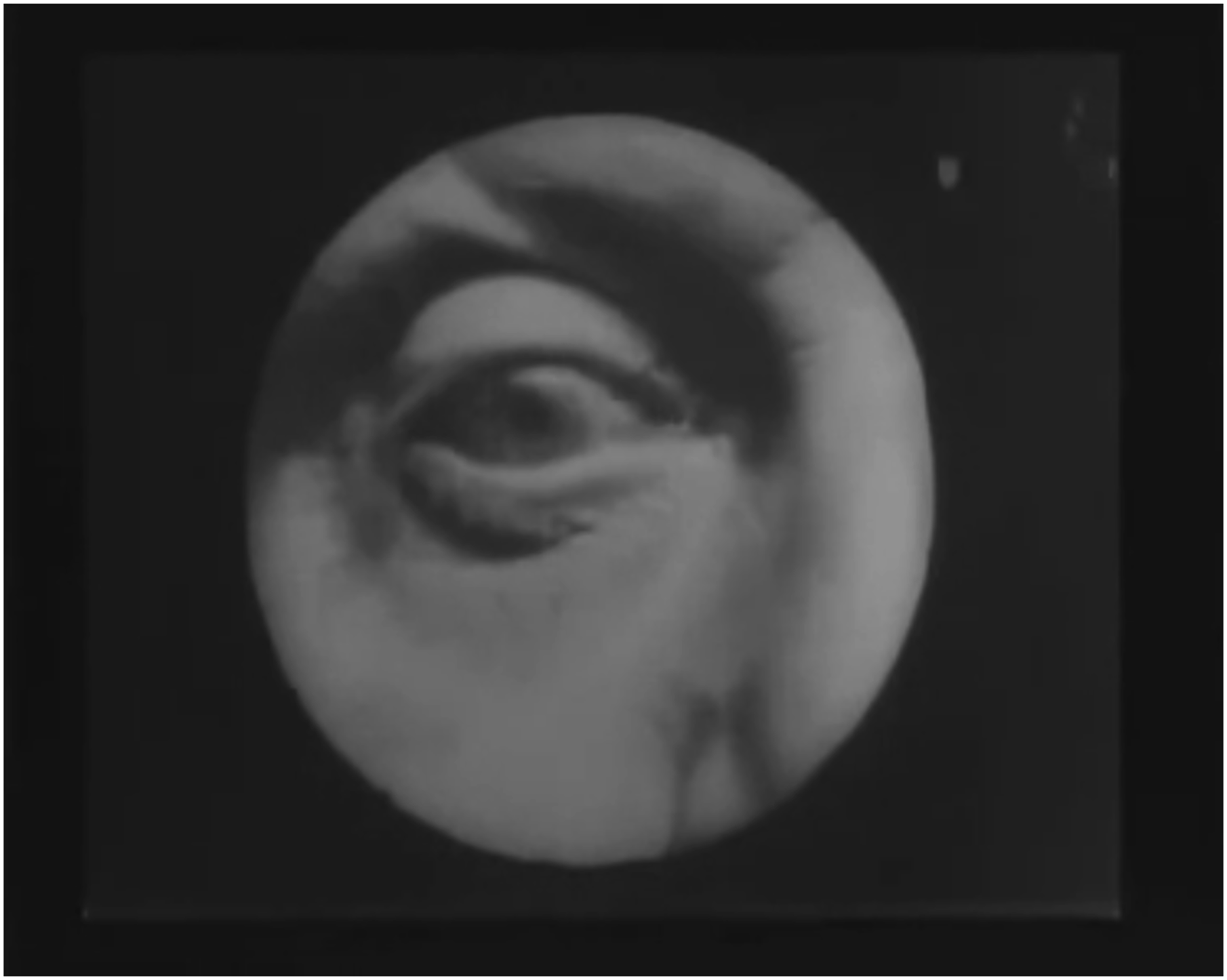
Even more apparent to human viewers is that the faces are not all consistently angry. At least three of the selected shots seem predominantly neutral, and others would be more accurately described as confused, frightened, sad, or in pain. Emotion classification is particularly sensitive to frowning and teeth as features of angry facial expressions, which intuitively makes sense, but also means the detector performs better when performers exaggerate their facial gesticulations and/or shout, in other words when actors ‘chew the scenery’. FER is less sensitive to nuanced performances that rely on micro expressions to convey more complex emotions, for example, the shots in Big Angry Faces of Tom Hanks in Inferno (2016) or Winona Ryder in Little Women (2019), neither of whom would be unequivocally recognised by human viewers as being purely or merely angry What is more, this teeth and frown sensitivity is likely to compound with makeup and prosthetics of the kind commonly used in horror films, as in the shot of The Others (2001) suggests. Figure 7. FER misdetections.
More testing and additional research are needed to refine these claims. However, these initial findings provide enough evidence to give pause and temper Kiss's forecasts of ‘perfect’ ready-made supercuts that are rendered at the stroke of a button. He dismisses supercuts as creatively inert on the grounds of their mechanical-like processes, which, he argues, lack a ‘human factor’, and can therefore be easily replicated by a computer. But as I have shown, when these claims are tested against actual computational practice designed to automate supercuts, seeing through machines reveals its own kind of creative ‘manual’ interventions and reliance on pro-computational events. It should be apparent from the practice outlined above that there are several layers of cognitive and affective labour encoded in various parts of the system, which are mobilised at various points during its design, implementation, and deployment.
When automation is seen in through a wider lens, which is to say, not only as a problem to be solved, but rather as a modality of critical inquiry in its own right, the subjectivities that creep into the system become productive epistemic features, as opposed to ‘dirty’ human interventions that tend to be tactically hidden in popular discourse about machine learning and AI. Automated computer systems mobilise ideologies, labour, and agencies, which makes them inevitably subjective and cognitively biased, much like non-computational film criticism, but with the added complication that these subject positions are aggregated and abstracted through the network effects of large-scale inductive computing. These are the subject positions and effects that I argue need to be made explicit and mobilised for critical inquiry. The question is therefore not if there is human intervention in the outputs, but whether and how these computational models of meaning-making can be creatively and intellectually useful while still bound by ethics.
More than instantaneous and ‘perfect’ computational artefacts that fulfil or dispel fantasies about what machines can see and do by themselves, the automation of the supercut affords a technical exploration of the changing relation between critics and their machinery, and between computation and aesthetics. From this point of view, one of the most productive aspects of the computational supercut is how it reorganises the gap between analytical and creative practices. On the one hand, the computational supercut involves applying computer vision methods to annotate large collections of moving images to find patterns, much in the guise of cultural analytics. But on the other, as well as plotting these images in space to view them at a distance, like Taylor and Arnold suggest, the approach I propose reinscribes these patterns in time, giving data objects a duration again, and enabling interpretation through the familiar operations of montage and the syntactic and synoptic apparatus of (dis)continuity as a modality for meaning making and explanation. The reverse editing of the kind proposed in the computational supercut links in this way analytical and creative epistemic strategies: knowledge created through a feedback loop between the making and unmaking of moving imagery; visual culture that feeds machine vision that feeds back into visual culture.
Automating the supercut aims to produce knowledge about moving images through computational methods, but simultaneously to productively ‘contaminate’ machine learning engineering with film theory by (de/re)forming the models it produces. In this, it links to performative and deformative criticism in the humanities (Sample, 2012; Samuels and McGann, 1999), contributing to recent work in deformative film scholarship (Mittell, 2021; O’Leary, 2021), and to a growing interest in generative humanities (Offert and Bell, 2020). This deformative-generative logic echoes Agre’s notion of critical technical practice, whose point, he argues: … is to work from the inside, driving the customary premises and procedures of technical work toward their logical conclusions. Some of those conclusions will be problematic, and the whole complex process of reaching them will then provide the horizon against which critical reflection can identify fallacies and motivate alternatives. (Agre, 1997a: 107)
Actualised systems, as Agre points out, do not simply work, or fail to work, every method has ‘its subtle patterns of success and failures’ (1997b: 107). My contention is that the patterns of failure of the computational supercut are useful because they open a conjectural horizon between computational methods used to detect style patterns, and the empty spaces these patterns reveal, including the outliers, the missing, and the undetected, all of which, through computation, can also be supercut, creatively made visible, explored, and critically assessed. This is the broader scope of creanalytics.
Future research
As stated earlier, the supercut is the most overtly algorithmic editing technique, and only one among many in the broader palette available to video essayists. With the development of self-supervised and contrastive machine learning techniques, and the emergence of Large Language Models (LLMs) in AI research more generally, there come novel ways of connecting linguistic and visual representations. Building on recent work on multi-modal systems, for example, the logic of language-guided image generation in DALL·E 2 or Stable Diffusion are now being extended to train text-to-video models such as Make-A-Video (Singer et al., 2022), Imagen Video (Ho, 2022), and Phenaki (Villegas, 2022). It is reasonable to expect that these and similar generative models will enable a wider variety of more ambitious and thematically richer computational video essays in the next few years.
In this piece I present a first version of a generative system designed to analytically break moving images apart and creatively edit them back together. In the short term I expect to render more supercuts using this system and to make them available in the same online repository as Big Angry Faces. But while this initial version focused on faces and shot types, the generative logic introduced above can be expanded to objects, actions, and other more complex modelling tasks. In a follow up project, I plan to model these shots without explicit classifiers. In the logic of text-to-image models, shot representations will instead consist of multi-modal vectors that combine visual and sound style features with publicly available (con)textual data from the clips and the films themselves. If this works, it would allow for more complex manipulations, such as a measure of continuity/discontinuity, and a nuanced analysis of editing patterns, allowing for next-shot type prediction and text-guided sequence generation with additional control parameters such as film genre, period, director, and performer. Future video essays based on the computational coupling of visual and linguistic representations are likely to afford new aesthetic and expressive media formats.
Earlier I alluded to the hegemonic logic of both computer vision and popular Hollywood cinema. Taking the computational video essay to one of its logical conclusions, as Agre suggests, I finalise by inviting the reader to imagine a hypothetical system trained on peripheral moving images whose aesthetic forms resist detection, classification, and analysis. The resulting model would be sensitive to the under-seen, and thus able to bring critical attention the non-canonical, and perhaps even to access the unseen and the unthought norms that structure collective viewing; a step closer to what Walter Benjamin (1936) called ‘the optical unconscious’.
If instead of thinking of the failure of computers to accurately simulate human vision, we think of these limitations as potential epistemic openings, machine vision becomes much more palatable to a critical programme in the computational humanities; a tool or a method to analyse visual culture, no less than a constituent of new visualities, that for example afford the the possibility of unseeing Hollywood through machine vision. This second and broader approach signals a shift from computer science methods applied to film studies, and towards the configuration of computational moving image studies as a distinct field that links creative and analytical practices. My hope is that the computational video essay contributes to this programme, and feeds into a new wave of generative approaches in computational humanities, one that feeds back into computer science and machine learning engineering to inform the development of the next generation of aesthetically sensitive machine vision systems.
Footnotes
Acknowledgements
The author wishes to acknowledge the valuable contribution of Catherine Grant in the initial stages of this project.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.