
Abstract
As the number of ethical incidents associated with Machine Learning (ML) algorithms increases worldwide, many actors are seeking to produce technical and legal tools to regulate the professional practices associated with these technologies. However these tools, generally grounded either on lofty principles or on technical approaches, often fail at addressing the complexity of the moral issues that ML-based systems are triggering. They are mostly based on a ‘principled’ conception of morality where technical practices cannot be seen as more than mere means to be put at the service of more valuable moral ends. We argue that it is necessary to localise ethical debates within the complex entanglement of technical, legal and organisational entities from which ML moral issues stem. To expand the repertoire of the approaches through which these issues might be addressed, we designed and tested an interview protocol based on the re-enactment of data scientists’ daily ML practices. We asked them to recall and describe the crafting and choosing of algorithms. Then, our protocol added two reflexivity-fostering elements to the situation: technical tools to assess algorithms’ morality, based on incorporated ‘ethicality’ indicators; and a series of staged objections to the aforementioned technical solutions to ML moral issues, made by factitious actors inspired by the data scientists’ daily environment. We used this protocol to observe how ML data scientists uncover associations with multiple entities, to address moral issues from within the course of their technical practices. We thus reframe ML morality as an inquiry into the uncertain options that practitioners face in the heat of technical activities. We propose to institute moral enquiries both as a descriptive method serving to delineate alternative depictions of ML algorithms when they are affected by moral issues and as a transformative method to propagate situated critical technical practices within ML-building professional environments.
Keywords
Organisations of all kinds are increasingly adopting Machine Learning technologies (ML) to transform and improve their key operations (Chen et al., 2012). For example, ML is being used in critical activities such as medical diagnosis (Kononenko, 2001), job candidate screening (Liem et al., 2018), judicial sentencing (Kleinberg et al., 2017), consumer credit scoring and the granting of loans (Hand and Henley, 1997). These systems aim at automating decision-making processes by providing algorithmically generated insights; they articulate predictive analysis (in the case of ML in banking, calculating a credit default risk) with the consequent recommendations (e.g., granting a loan to an applicant).
Despite the significant economic value that ML technologies offer, they also entail ethical issues and risks at different levels, both for the organisations where they are deployed and for society at large 1 (Martin, 2018; Someh et al., 2019). Research communities, public institutions and industrial sectors have offered a wide variety of responses to the multiple ethical issues raised by the use of ML, reflecting different views as to what an ethical ML algorithms’ conception, development, and use would be. The diversity of these responses lies in the fundamental differences in approach towards the relation between morality and technical practices associated with ML (from database building to implementation in large-scale infrastructures). In the current fast-changing landscape of initiatives to promote ethical ML, at least three dominant types of approaches to this relation can be identified.
First, the production of guidelines both by public and private institutions is intended to express moral principles to be enforced in the technical practices associated with the design and implementation of ML algorithms (Jobin and et al. 2019). Inspired by the long tradition of medical ethics (Whittlestone and et al. 2019), they adopt a top-down approach by first defining general principles (such as non-maleficence or transparency) underpinned by moral values (such as justice or fairness), and then encouraging data scientists to follow and respect them in their technical practices. Morality, here, is understood as a matter of setting ideal ends to be achieved – or at least, not harmed – by the means of the technical practices employed to produce ML algorithms. The relation of morality to technical practices is therefore characterised by compliance.
A second approach focuses on the intelligibility of ML technical systems to improve their accountability and, therefore, better address their moral implications. The frequently criticised opaqueness of ML-based systems – especially those based on Deep Learning techniques – is addressed by the Explainable Artificial Intelligence (XAI) academic community, which aims at providing post-hoc explanations of black-boxed ML models (Guidotti et al., 2018). By exploring the inner workings of ML systems, XAI approaches seek to master the means of ML techniques in order to focus on the ends they should serve. Through the production of explicability, the relation built between morality and technical practices is one of disclosure.
Finally, a third approach addresses the quintessential challenge of producing unbiased and impartial ML algorithms through the technical integration of morality within ML systems. Researchers from the FairML community endeavour to embed moral concerns within technical indicators for assessing the ethicality of a given algorithm according to overarching values and principles. Morality is translated here into a series of metrics standing for the alignment of an algorithm with principles such as transparency and explicability of fairness. This third approach, based on a strategy of incorporation, seeks to include morality into technical practices by means of computed indicators.
These three approaches, that we could label with Mittelstadt (2019) as ‘principled’, are based on the idea that, fundamentally, the relation between morality and technical practices depends on the match between predefined normative ends in the form of general moral values or principles (e.g., transparency, justice, equity), and technical means. Without denying their usefulness, we argue that these approaches do not adequately address the relation of ML technical practices to morality in the liveliness of the actual professional settings in which they are conducted.
Compliance-based approaches, such as guidelines and recommendations, fail to address the evolving dynamics and heterogeneous particularities of the situated professional realities that ML technologies involve. For example, the changing nature of databases – which are increasingly granular and voluminous – makes it difficult to put forward stable normative principles to regulate ML (John-Mathews et al., 2022b). Furthermore, they fail to account for the multiple values – both personal or organisational – that traverse the collectives at work in the production and implementation of ML algorithms.
Neutralisation-based approaches relying on explicability – and hence, technical accountability – do not always enable the building of ‘fairer’ (John-Mathews, 2022a) and more accountable models (John-Mathews, 2021). They tend moreover to narrow ethical concerns to a solutionist perspective, hindering open discussions and backgrounding blind spots related to the socio-political context and situations in which such algorithms are designed (Selbst et al., 2019).
Incorporation-based approaches producing ethicality metrics are often unidimensional and too simplistic (Fazelpour and Lipton, 2020), and do not suffice to envision the types of alternate technical practices and workflow they might allow. As insightful as they may be, they are ineffective when not articulated to accountability mechanisms and processes, and tested within the full complexity of actual professional environments.
We argue that principled approaches to ML morality should be articulated to other approaches that are more sensitive to the complexity of ML practices – and which spawn new inquiry processes able to cast a light on morality as it plays out within situated technical practices. In this respect, Florian Jaton recently opened an interesting new line of research providing more space to the actual and practical situations in which moral issues are raised for and by practitioners. Grounding his inquiry in the pragmatic philosophy of William James, Jaton (2021) started to explore this approach by inspecting ML morality through the moments in which ML specialists face high-stake bifurcation events leading momentarily to radically different futures. 2 By addressing these moments of operational hesitation, morality is reframed as an anxious deliberation between uncertain options that will be made durable by the further development of an algorithm. The main consequence of this hesitation is an investigation in which entities usually considered as means become the object of concern regarding the quality of the attention that has been given to them, and are thus transformed into ends. As Jaton put it, ‘as soon as a scrupulous doubt as to a means turns it into an end, a relational experience is set in motion that brings about many intertwined human and nonhuman entities’ (Jaton, 2021: 7). A different kind of morality is hence obtained. It rests on the peculiar attention to the moments of hesitation and scruple arising from practical situations in which unexpected entities call to account for the choices made in the heat of the development of a specific algorithm. Morality ceases to be an outcome restricted to the realm of ends where technicality would be the one of means. Instead, it becomes a circulating force 3 connecting the multiple entities brought to light by the hesitations and doubts concerning the proper distribution of means and ends within the course of technical practice.
In this paper, to study the circulating force of morality through the experience of scruple, we propose an experimental interview setting focussing on the use of ML in the French banking sector. The setting is designed to enquire into the interplay of means and ends in the development of ML, both as a vehicle for a vivid description of ML practices, and as a way to foster transformative critical technical practices within ML professional communities. We, therefore, intend to contribute to Philip Agre’s reformist agenda for AI practices (Agre, 1998) by way of a radically empirical approach inviting practitioners to an ongoing and dynamic reflective moral inquiry. The aim is to equip them with a constant and open-ended attitude of (self-)assessment and (self-)imagination regarding the implications and possible bifurcations of their own professional actions.
In Part 1, to go beyond principled approaches to moral issues in ML technical practices, by leveraging the pragmatic radical morality developed by Florian Jaton and found in other similar approaches such as Bruno Latour’s modes of existence, we set a conceptual framework designed to enquire into the situations where morality encounters ML technical practices.
In Part 2, we present the methodological setting we invented to conduct experimental interviews aimed at provoking and amplifying scruples within the process of building a Machine Learning algorithm for granting loans to applicants in the context of the French banking system.
In Part 3, we describe the results of the protocol we experimented with by analysing our interviewees’ responses to scruples, in which moments of refusal alternated with inquiry and recomposition. From this we draw alternate depictions of the landscape of entities mattering to Machine Learning technical practices, and identify a variety of modes of recomposition that expand and diversify the repertoire of approaches developed in dominant ‘principled’ approaches to ML morality.
To conclude, in Part 4, we describe how the methodology presented in this paper contributes to the development of critical technical practices both as a productive description tool, and as a transformational endeavour aimed at developing situated approaches to morality within ML professional communities.
Morality and Machine Learning practices
The machine learning algorithm as a ‘collective’
Machine Learning algorithms use data from past decisions to construct statistical rules and make decisions about present cases (Goodfellow et al., 2016). For example, ML credit scoring algorithms use information about repayments from past applicants to grant credit to new applicants. They use training databases listing past loans and their repayment to learn a statistical rule to process and (help to) decide on new cases. ML algorithms hold together a set of human and nonhuman entities separated in time and space: data about the individual who applies for a bank loan; the bank advisor – and the related organisational chain of command – in charge of making the decision according to the default risk provided by the algorithm; the past loan applicants from the training database; the data scientist who created the algorithm; the machines used to perform the learning procedure; and so on. Furthermore, the algorithm regularly invokes the past each time it is deployed to calculate the probability of a client’s present or future application being accepted.
By associating different entities, ML algorithms fold together, as a ‘collective’ (Latour 2002; 2005), heterogeneous temporalities, spaces and actors, which last owing to their regularity and extension.
Dispatching means and ends within ML collectives
When an ML algorithm folds a heterogeneous collective together, the collective becomes black-boxed into a means to be put at the service of higher ends (whether they be economic efficiency or, sometimes, compliance with guidelines and other principled approaches to ML morality). However, once inspected by an active intervention – for instance, when it comes to investigating a bug or incident (McGregor, 2020), or whenever a glitch perturbs their smooth deployment (Meunier et al., 2019) – machine learning algorithms might redisclose the collective they hold.
This has been the case for reported gender discrimination cases by credit attribution algorithms (New York DFS, 2021), controversies concerning the lack of explicability of credit denial decisions, or privacy issues related to the fact that credit attribution algorithms retain and use clients’ past personal information to make decisions (Ball, 2018).
For instance, automatic credit attribution issues stem from the fact that past credit applicants have been considered as means to optimise the performance of machine learning procedures while they were asking to be considered as ends in themselves. Similarly, a new credit applicant who wants explanations or feels discriminated against becomes an end in itself. Morality, which requires ML technical practitioners – data scientists – to invest their attention not only in the technical achievements which are required from them, but also in the large array of entities that they associate with to achieve their goals, acts as an impediment to an instrumental approach to the collective of ML algorithms. As Bruno Latour states, morality ‘is less preoccupied with values than with preventing too ready an access to ends’ (Latour, 2002).4
We argue that inventing new protocols geared towards the elicitation of the scruples at play in situated practices may address the moral question of the means and the ends in algorithmic practices, and constitute a valuable contribution to understanding the constitution and entanglements of ML algorithms within our societies.
Scruple as a vehicle of inquiry
By setting up a situation in which scruples may arise, it becomes possible to discover unnoticed entities that participate in the constitution and existence of ML algorithms. Once they become visible, it is possible to establish a new attentiveness to them. Scruple 5 becomes a vehicle for an inquiry allowing one both to explore the descriptions that can be made of ML algorithms, and to account more precisely for the technical practices that could possibly inflect and renew them. In this sense, scruple has transformative consequences that call for the delineation of alternative depictions, compositions and folding of the entities constituting a socio-technical collective.
Scruple is what ‘introduces an element of suspense into all courses of action and what we can only get beyond via a new moral experience’ (Latour, 2013). Moral beings, 6 therefore, arise during hesitations about choices that radically engage the composition of collectives into divergent futures, slowing down the course of action, while calling for a recomposition. Indeed, Latour argues that ‘moral beings [...] weigh on us and demand of us responses that make us responsible’ (Latour, 2013). Thus, the ‘collective can be composed but this is impossible without some beings becoming means and others becoming ends’. The recomposition brought into being by scruple, therefore, necessarily ends up with the production of new moral issues. By questioning the dispatching of means and ends within a given collective, morality generates a cascade of hesitation and of recomposition moments characterising the ‘trajectory’ of Latour’s mode of existence of morality. 7
As soon as we pay attention to what is assigned the role of a means (usually presupposed as the realm of technicality)8 and to what to assign the role of ends (usually presupposed as the realm of morality), we begin to slow down the taken-for-granted daily technical practices of ML practitioners. By intensifying the role of scruple, we reopen the possible descriptions of the associations on which ML algorithms rest, but also ask for a recomposition of the different roles to give to the entities constituting ML. Scruple calls for both a recalibration of accounts made by technical practitioners about their own activity and a reassessment of how and which entities to care about in the process of technical development. This produces novel ways to approach the socio-technological networks of ML algorithms in technical practices and prevents certain (possibly harmful) associations from being naturalised.
Our strategy for the mobilisation of scruple as a lever for inquiry coincides with Philip Agre’s invitation to unfold critical technical practices (CTP) in the ‘heat’ of situated actions (Agre, 1998) rather than from external critiques. Indeed, we intend to question the very ‘process of [their] technical work’ and its inclusion within ‘bureaucratic control imperatives’ through a ‘reflective conversation with the materials of computational practice’ (Agre, 1998) to foster an ‘expanded understanding of the conditions and goals of technical work’ (Agre, 1997). Since scruple calls for both redescription and recomposition, our approach towards morality in ML practices relates to CTP at two distinct levels. On the one hand, we aim at generating ‘descriptive’ Critical Technical Practices – that we repurpose here as the art of raising scruples – through a methodological setting enabling us to produce a narrative account of ML practices and their moral implications. On the other hand, our approach also allows us to call for broader collective attention to the way ML technical practices manage their way of caring about the entities they interact with. This more ambitious perspective could be defined as a transformational approach to Critical Technical Practices aimed at modifying the attitude of ML technical practitioners to morality in their professional activities.
Our two approaches to CTP – ‘descriptive’ and ‘transformational’ – are inextricably linked, as we argue that it is not possible to call for a ‘transformative’ CTP without having first mobilised ‘descriptive’ CTP methods to morally account for the networks of ML algorithms. In that sense, the next two sections develop our ‘descriptive’ mobilisation of CTP as a means to better account for the interdependencies constituting the collective of ML algorithms through the circulation of means and ends.
The experimental protocol
To describe morality as an acting force within ML technical practices we conducted a series of experimental interviews with data scientists working in the French banking sector. We used repurposed elicitation-based research methodologies to encourage our interviewees to leave aside ‘principled’ attitudes and responsibility dismissal strategies around the moral issues of ML algorithms.
Elicitation methodologies are defined as the use, within a research interview, of visual and/or material artefacts such as photographs, pictures, or objects. Their purpose is to facilitate a more precise account of ordinary lived experiences by activating body memory and focusing attention on material details as these artefacts are manipulated and discussed (Abildgaard, 2018). Elicitation techniques do not only contribute to ‘data collection’ endeavours; they can also transform the (self-)representations of the participants by inviting them to address common matters of concern outside the often more usual frame of discourse and ‘abstract’ discussion. They help to ‘break the frames’ of interviewees’ initial representations (Harper, 2002), prompting them to explore other points of view on phenomena they are familiar with. This feature of elicitation methods allowed us to follow the transformative, reflexivity-inducing goal that was part of our experiment with data scientists. 9
To deal with the situated and complex nature of the moral issues in ML practices, we defined our elicitation-based approach through a strategy of re-enactment with regard to actual algorithm practices in professional settings. As morality circulates through the interrogations raised by choices made in the heat of technical practices regarding the dispatching of means and ends, we had to produce a research setting in which it would be possible to recall, reimagine and reassess situations where data scientists’ usual methods and approaches would be visited and questioned by the enquiring force of scruples. Our strategy of re-enactment aims at: recalling past lived situations;10 provoking disorienting moments in which such past situations get revisited and called into question by scruples;11 exploring alternative ways of behaving in the face of unexpected entities revealed by the experience of scruple; and, finally, foreseeing possible future attitudes towards the technical practices that constitute the work of data scientists.
To deploy this research strategy, we set up a protocol combining qualitative interviews with software-based live experiments with the participants, conducting both commented re-enactments of their algorithm crafting practice, and scrupulous re-enactments aimed at testing more or less transformed versions of their usual practice of algorithmic production. 12 We, therefore, had to devise what Lezaun and al. Have coined a factitious situation, that is to say ‘artificial, visibly made up, but made up in such a fashion that it carries with it an irreducible element of reality – in other words, the situation [that] cannot be dismissed as simply fictitious’ (Lezaun and et al., 2013: 279). It is through these variously re-staged, reworked and revisited versions of actual professional situations that we could enquire with the participants into the implications of scruple and their consequences on the description and conduct of ML technical practices.
An experimental interview setting
Overview of the interviewees’ profiles.
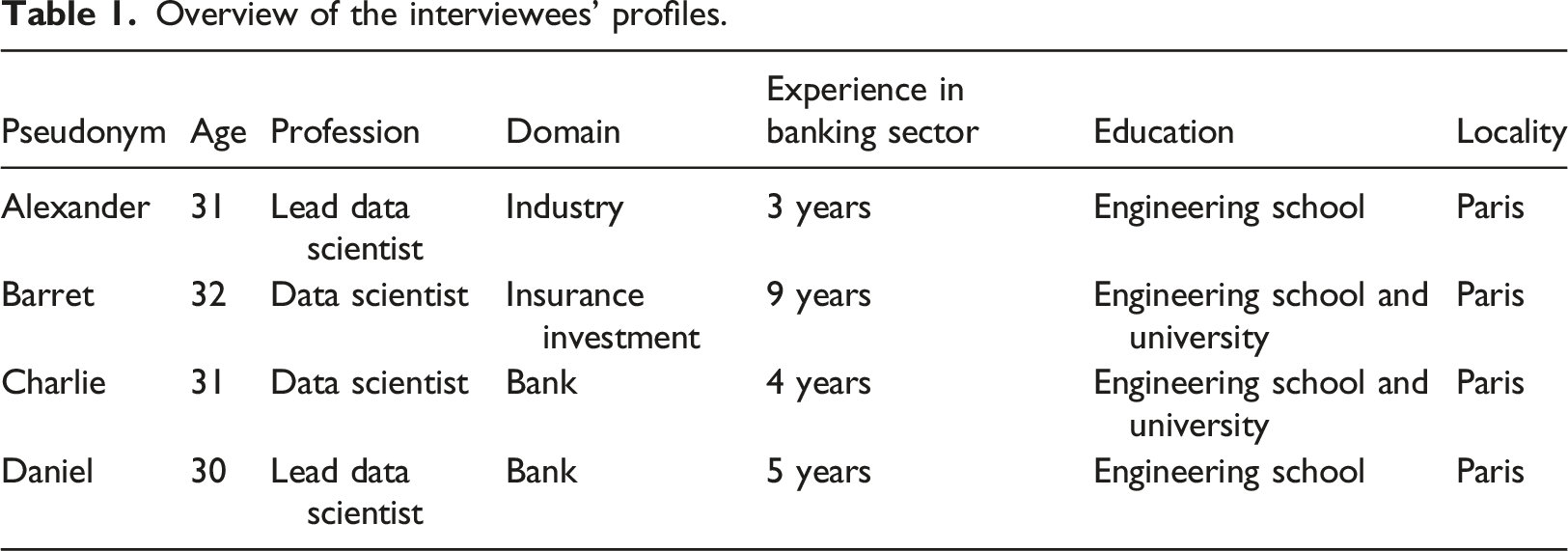
Each experimental interview was individual and lasted between 1 h 30 and 2 h. The interviews were carried out remotely using a videoconference application and a specifically developed web application presented extensively in the following paragraphs.
13
It was divided into three phases of different duration: A. Recalling: we first asked participants to perform the process leading to the production of a factitious credit attribution ML algorithm, for an imaginary client from the banking sector, urging them to comment and justify their choices in the process. B. Responding: we then asked participants to perform yet another re-enactment of the making of an algorithm for the same purpose, but this time confronted them with objections about issues raised by the algorithm they had built in phase one. We also provided them with a specific interface for a (technical) resolution of the issues proposed to them thanks to ‘ethicality metrics’ popular in the FairML community, alternating moments of objection and of recomposition through the technical tools we equipped them with. This phase was repeated three times, with different objections and a growing number of ‘ethicality metrics’ put at their disposal. C. Resituating: we gradually increased the intensity of objections so that at some point technical solutions were no longer possible. This forced our interviewees to extend the description of their practices and to broaden their account of their own practice and role in making ML algorithms.
The first phase (recalling – step 1) lasted about 30 min, while the second one (responding – steps 2–5) lasted around 1 hour, and the last one (resituating – step 6) lasted about 10 min. We recorded each participant’s reactions through screen sharing and a video camera. Figure 1 gives an overview of the whole protocol of the experimental interview, which we will break down and describe in detail in the following subsections. Overview of the experimental interview process.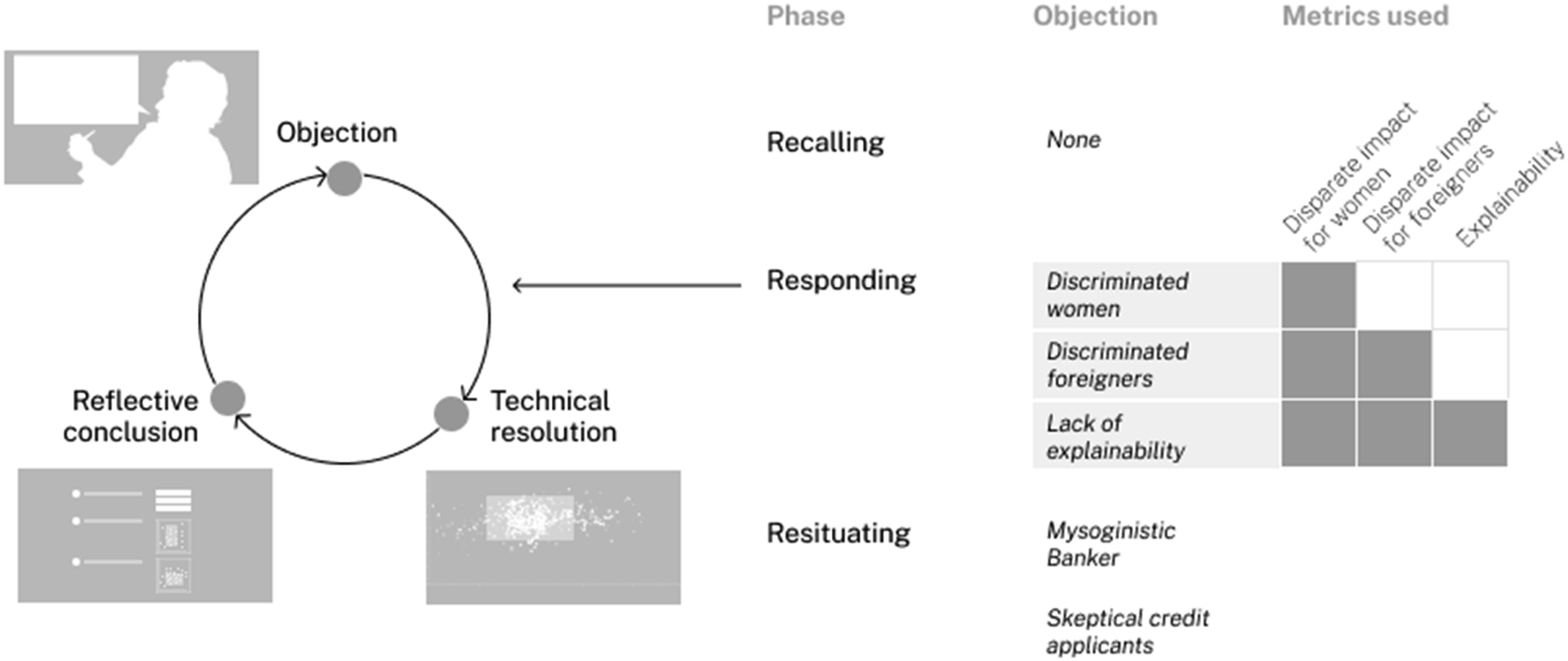
Recalling
In phase A, we asked our interviewees to create a credit attribution algorithm, providing them with a training dataset (Hofmann, 1994) and a Machine Learning platform that allowed them to quickly create a model in situ. They were not directly manipulating the tool but were asked to provide instructions to the interviewer while watching him operate on his own machine through screen sharing. This indirect setup helped the interviewer to prevent the interviewee from rushing into their usual way of crafting algorithms. Instead, each step was preceded by asking questions about the reasons behind data scientists’ choices, and the similarities between this factitious situation and the strategies they faced in their usual professional situations. In this first phase, the subject of morality was not explicitly addressed (Figure 2). Screenshot of the step 1 setting for re-enacting the production of a machine learning under the interviewee’s instructions (here, Daniel).
This introductory re-enactment process – that we would call a commented re-enactment – afforded us an initial understanding of the diverse daily situations in which data scientists engage with ML practices. It allowed participants to consider the heterogeneity and richness of entities mobilised in the making of an algorithm (e.g. context and environment of work, subjects touched upon by the interviewee) while staying very close to the technical issues that constitute the main perceived drive towards their choices. The re-enactment of a common practice also helped them to naturally recall familiar procedures and stakes in the making of algorithms (e.g. evaluating the share of false positives and false negatives, spotting common statistical bias risks, etc.). The interviewers’ insistence on explaining the stakes underlying each choice also allowed them to foster a similar attitude later on when faced with non-familiar and unexpected moral objections.
Responding
The second phase of our experimental protocol consisted of new re-enactments of the production of credit attribution algorithms, which we would call scrupulous re-enactments. These new iterations were aimed at giving a growing weight to so-called ‘moral concerns’ in the process, through the presentation of objections aimed at stimulating scruple. To do so, we set up an interface made specifically for this research, that would stage a cyclic alternance between, on the one hand, moments when the making of algorithms was assisted by morality-related technical metrics, and on the other hand, objections from factitious figures such as Data Privacy Officers, bank advisers, or refused credit applicants.
In each of the steps of this second phase, a new criticism about algorithms chosen in the previous iteration would be raised by the factitious figures by way of a cartoon (Figure 3). After a time for discussion and first reactions to this criticism, the data scientists were asked to readjust their previous choices and propose a new algorithm (see Figure 4). Overview of the objections made as a starter point of each iteration of the responding phase. Source: “NEC-Monitor-292” by NEC Corporation of America, licensed under CC BY 2.0. Overview of the unfolding of an iteration of the responding phase through the experimental re-enactment interface. Source: “NEC-Monitor-292” by NEC Corporation of America, licensed under CC BY 2.0.

The objections staged in this phase targeted specific issues raised by the implementation of each algorithm: the first objection dealt with the fairness of the algorithm towards female credit applicants, the second with the algorithm’s fairness to foreign credit applicants, and the last one with the justifiability of the automated decisions provided by the system.
Contrary to the first phase of the experiment, this second phase did not consist in rebuilding algorithms from scratch, but rather in choosing between a selection of 1000 ready-made Machine Learning models stemming from different combinations of variables within the training dataset. This decision of offering to choose between algorithms instead of (re)making them was motivated not only by practical concerns related to the interview duration but also and above all by the fact that this strategy would allow us to provide our interviewees with a piece of new equipment in the form of ‘ethicality’ metrics attached to the proposed algorithms. Four different indicators were provided to data scientists to compare the algorithms they could choose using our interface: ❖ Algorithmic performance: this indicator is measured by the AUC (Area Under the Curve). The AUC measures the area under the ROC (Receiver Operating Characteristics) curve and is a well-known measure of algorithmic performance (Fawcett, 2006). This first indicator is not attached to any ‘ethicality’ measure; it represents the usual criteria against which data scientists assess an algorithmic model to be satisfactory. ❖ Fairness towards women: this indicator is measured using the Disparate impact indicator. Disparate Impact is one of the most used fairness metrics to assess differential treatment with respect to a sensitive category such as gender or race (Kordzadeh and Ghasemaghaei, 2021). It is defined as the following ratio: the percentage of credit acceptance of women over that of men. When this ratio is equal to 1, it is considered that there is no Disparate Impact between men and women. The ‘80% rule’ is used by US law to detect discriminatory effects: if the Disparate Impact ratio is below 80% then it is considered that there is a disparate effect between men and women. ❖ Fairness towards foreigners: this indicator is also measured by the Disparate Impact indicator (the percentage of credit acceptance of foreigners over that of non-foreigners). ❖ Interpretability: The ability to provide explanations to credit applicants who are refused by the algorithm is measured by the opposite of the total number of variables used in the algorithm to build the metric for interpretability. An algorithm that uses fewer variables will indeed allow for simpler and more interpretable explanations.
The specific interface we designed for the experiment allowed data scientists to visualise our 1000 algorithms according to two of these four metrics in the form of scatter plot visualisations (Figure 5). They then filtered subsets of acceptable algorithms by defining trade-offs between the two considered variables (e.g. Performance versus Fairness for women). Along several of these filterable scatter plot screens (one for each couple of the indicators considered), the activities of this phase consisted in progressively filtering the chosen algorithms so as to obtain a smaller and smaller number of ‘acceptable’ algorithms corresponding to the participants’ trade-offs between performance and ethicality indicators, and between these ethicality indicators themselves (e.g. Fairness to women versus Fairness to foreigners). Screenshot of a scatter plot of classifiers with respect to performance and disparate impact on women. Note: Here, the user selects the subset of classifiers corresponding to the grey area.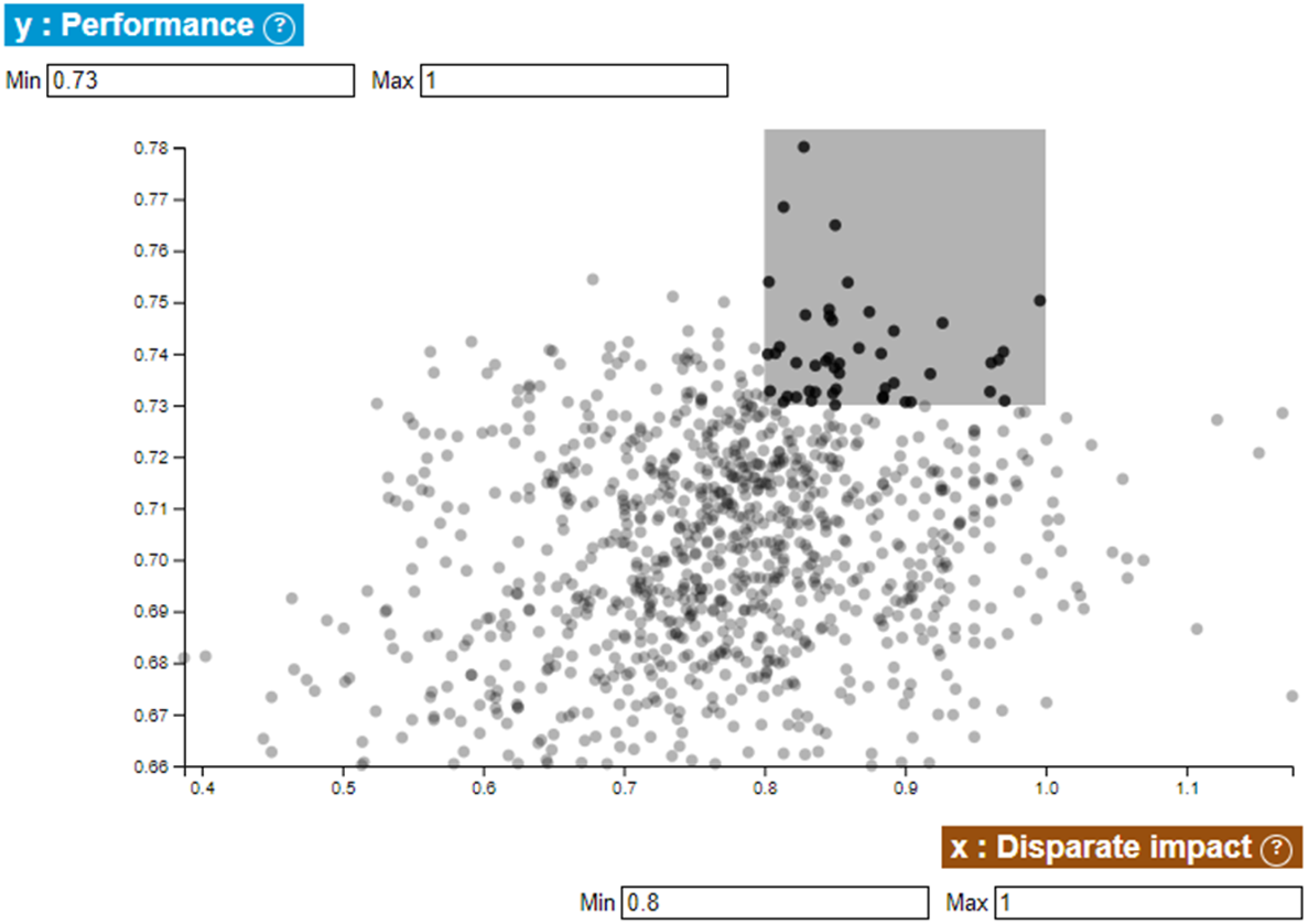
Once the filtering process was carried out, participants were asked to choose a ‘final’ model that would represent the model to be delivered in our factitious scenario (Figure 6). In some cases, they arrived at a situation where an algorithm would be optimal for all indicators, while in other cases they would have to make an ultimate choice between algorithms with contrasting performances in their different dimensions. Screenshot of the last selection process. Note: Here, the user selects the second algorithm regarding the four metrics.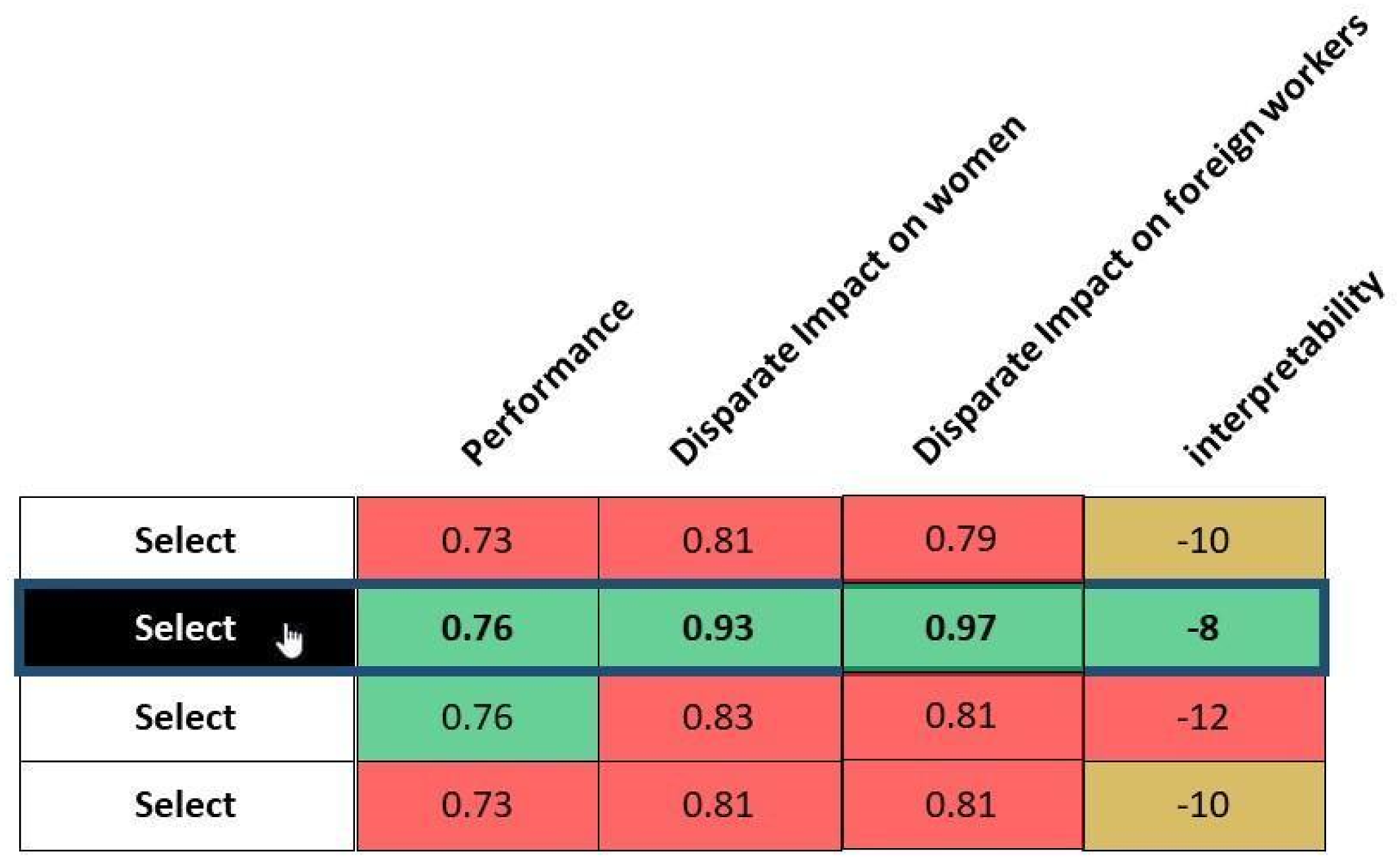
Finally, we presented the participants with a dashboard, allowing them to visualise all of their previous choices in the interface (Figure 7). They compared the score of the algorithm they had chosen to the one selected in the previous step and discussed matters such as a declining performance of the complexification of the trade-off process. Screenshot of the concluding screen of each iteration of phase B of the experiment.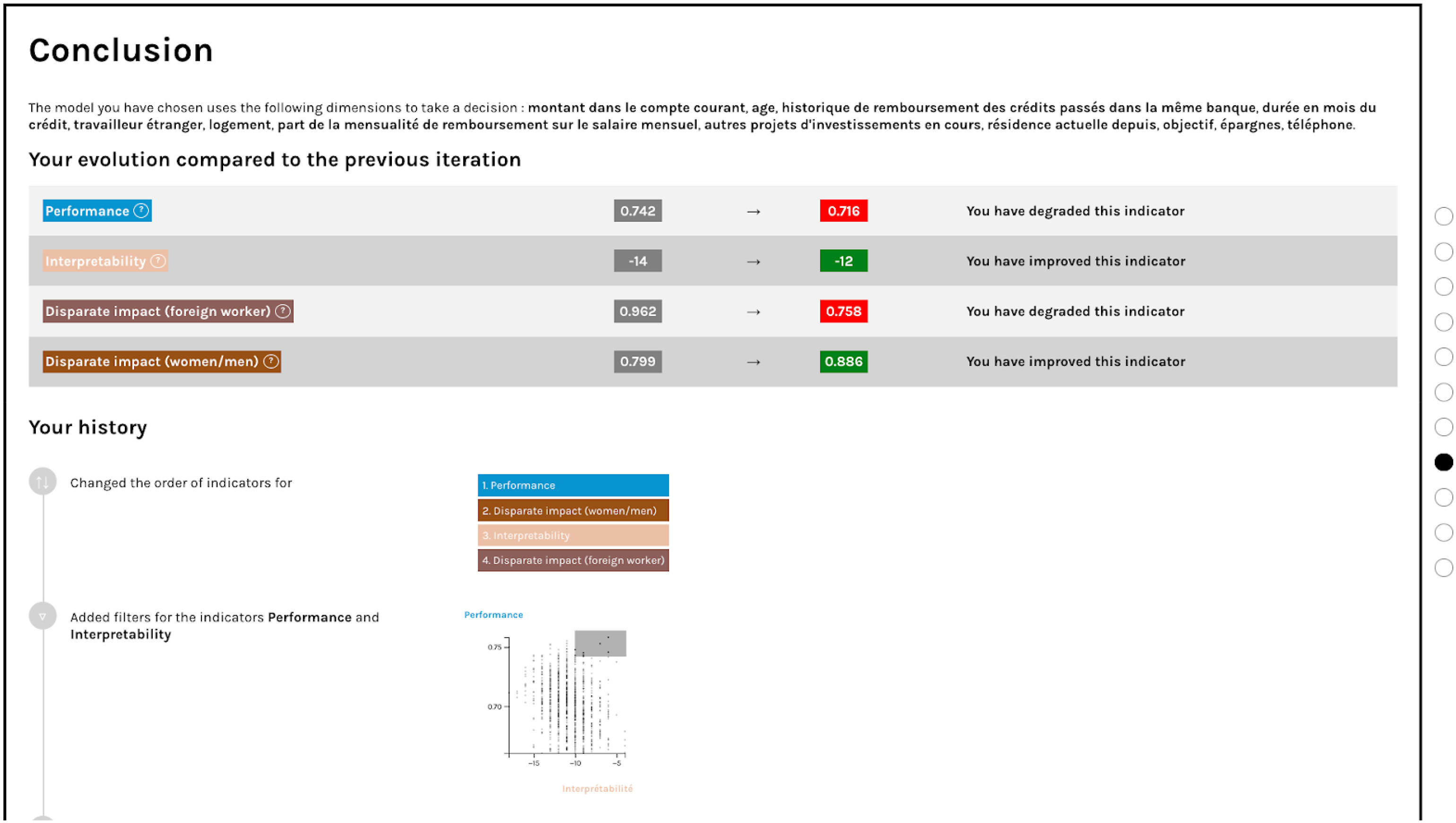
The participants were also provided with a graphic representation that summarised all the choices that would have led to the election of their final algorithm. This historical representation allowed us to stimulate the data scientists’ reflexivity by inviting them to comment on their methodological process, choices and assumptions, and to compare these with their usual practices in professional settings.
Resituating
The last phase of the interview set aside metrics and was grounded solely in objections that would not be absorbable with an approach making use of the previous ethicality metrics. In that sense, the first objection of this phase suggested that the whole database on which the experiment had been built was flawed by the practices of a misogynistic banker, the second one questioned the identity of the data scientists who built the algorithms as they were exclusively white men, while the last one radically questioned the use of algorithms for important decisions such as approval of bank loans. This third phase allowed participants to depict an even broader collective through the enquiring force of scruple. Figure 8 Screenshots of the three objections from the ‘accounting’ phase. Source: “Project (R)evolution Conference, 2012 - with Alec Ross and Emily Banks” by US Embassy New Zealand, marked with CC PDM 1.0; and “Arguing and yawning” by quinn.anya, licensed under CC BY-SA 2.0.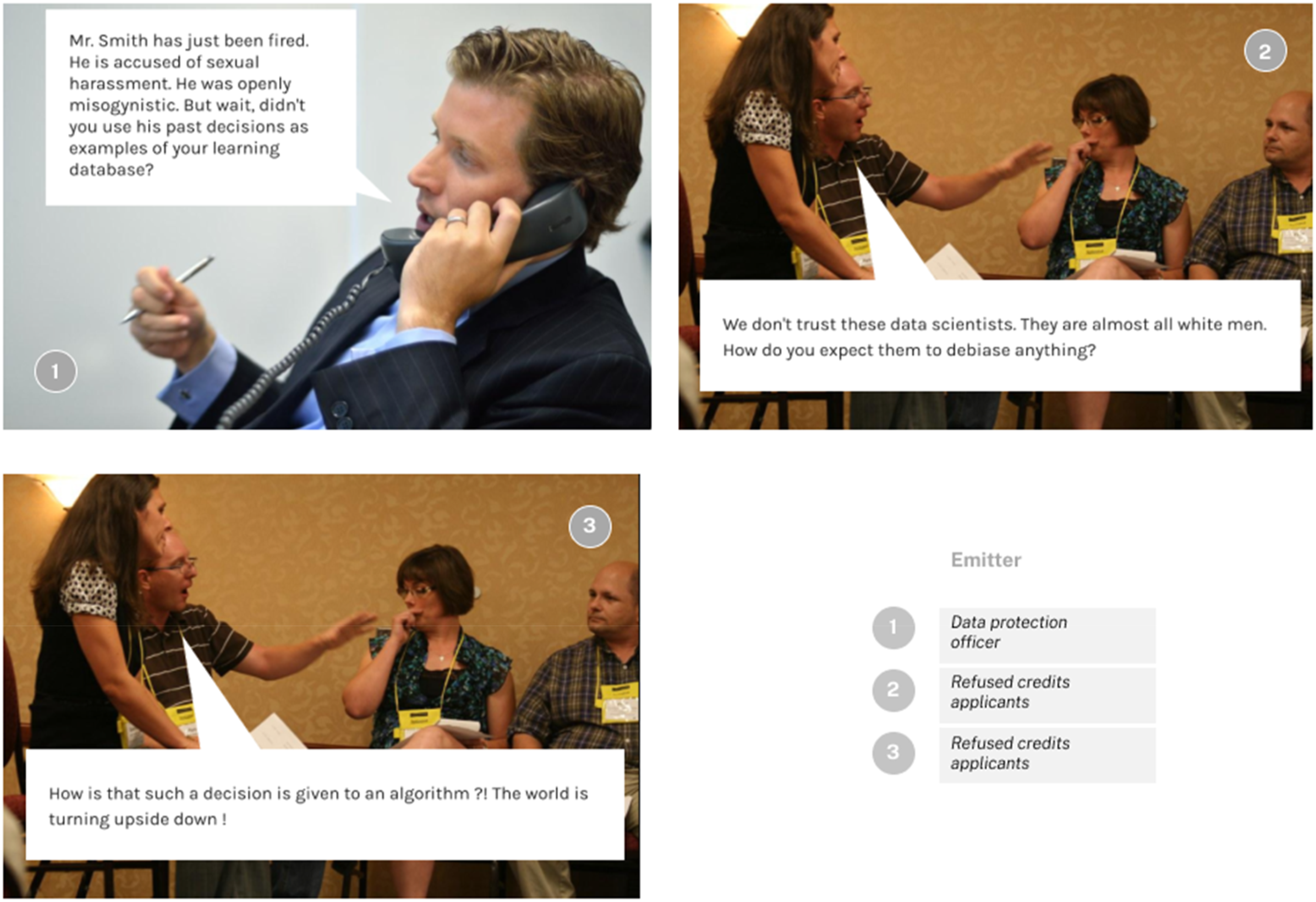
Following morality throughout the crafting of an ML algorithm
The first phase of our interview process (recalling) described the collective of ML algorithms as consisting mainly of technical entities. The data scientists implemented a set of known procedures to parameterise the model, using a very technical language. For instance, according to Alexander:14 ‘we need to check the balance of the target variable and then implement of one-hot encoding on categorical variables’.
Charlie also checked the balance of the target variable and then implemented a ‘Random Forest’ algorithm as soon as possible. He said: ‘The sooner I have an MVP (Minimal Valuable Product), the better. You have to improve the model by iterating using a first model as a reference’.
In this first phase, the technical practice leading to the production of an ML algorithm out of a given training dataset seemed quite unproblematic. Entities such as the ‘target variable’, the ‘minimum viable product’ or ‘the model’ seemed at first to constitute the ML algorithm as a homogeneous collective, circumscribed in time and space by the experienced choices and proven methods of each of the four data scientists. It also seemed relatively manageable as an unquestioned means to be put at the service of a performance-oriented end. 15
However, when faced with the second (responding) and third (resituating) phase of the protocol, and the objections made by the factitious actors that we staged through our experimental interface, their language and actions became more hesitant. They began to broaden the description of ML algorithms while questioning the data scientists’ professional environment and attention to the entities involved in the algorithms they produced.
In the following we first qualify the forms taken by increasingly expressed scruples about technical practices, then describe the variety of entities discovered through our interviewees’ enquiries into moral issues. We finally analyse the effect of these entities on the conduct of data scientists’ technical practices, describing how they handled the moral ‘recomposition’ process they had to invent by associating different entities.
Qualifying heterogeneous responses to the calls of scruple
Initial reactions towards the objections raised in the second phase (responding) of our protocol (‘When the credit applicant is a woman, the algorithm refuses most of the time! What kind of algorithm is this?!’) provoked diverse responses ranging from perplexity to fatalism and indignation.
Faced with the first objection, Alexander reacted with self-criticism about his technological methodology in the previous recalling phase, expressing perplexity as to the existence of a solution to the moral issue presented to him: ‘[...] That's the risk. [...] That's why I like to do descriptive statistics before making the model. [...]. There is not necessarily a solution [...]’.
Barret, on the contrary, first dismissed the possibility of the moral objection being connected to the technical choices he had made previously, by expressing fatalism about algorithms’ irreducible flaws: ‘I don't know, what am I supposed to answer? [...] The algorithm is a model, so it has its weaknesses’.
Some interviewees, such as Daniel, also expressed a covert rejection of the whole facticity of our protocol by underlining their understanding of its supposed goal (‘Ah, I see what you want to get at …’).16 Daniel repeatedly adopted such a sarcastic attitude during the various iterations of objections we presented, thus highlighting his opinion about the lack of meaning of the objections about algorithms’ unfairness towards specific populations. Faced with the second objection about his algorithm’s unfairness towards foreign workers, he first reacted: ‘This sentence makes no sense. It is stupid. If you have to take into account all the variables, what about redheads? You can't think about all the variables’.
Similarly, for Alexander, ‘it could be endless… What about overweight people? If we keep going, we end up with a situation where the model is not very efficient’.
All these reactions can be cast as spontaneous attitudes in response to the call of scruple stirred up by the objections, and characterised by different strategies of refusal.
After the first phase of spontaneous reactions towards the presentation of scruples, the data scientists tried to cope with their state of helplessness and refusal by asking for an opening of the description of the situation. Charlie referred to the factitious bank specialist he was supposed to be in contact with: ‘I don't have experience with this. I don't deal with personal data in my job. I’ll ask the person for examples. Maybe the person has only seen 10 cases’.
Alexander also unfolded the temporal inscription of the algorithm by asking for previous cases: ‘I’d like to know more, to have more data to validate. Has this situation arisen in several cases? Is this a one-time thing?’
Data scientists’ accounts of the collective they were interacting with started to get situated in a network of actors (including themselves) that had to be questioned and enquired into through further investigations.
Despite the variety of reactions toward our protocol, we, therefore, observed a two-staged undertaking of the objections presented to our interviewees, qualifying the effect of scruple toward their technical practices: the first stage of rejection taking the form of different strategies toward the turning of events provoked by the raise of moral issues, then the start of an inquiry broadening of the purely technical description provided by the first stage by making associations with previously unnoticed entities.
Describing ML collectives as unfolded by the circulation of morality
The second phase of our protocol (responding) asked data scientists to deal with moral objections by choosing a ‘better’ algorithm through interactive visualisations. These visualisations portrayed performance and ‘ethical’ indicators as means for possible resolution of the inquiry. This second phase helped to broaden the description of the algorithm and to uncover new associations.
In the different iterations of the responding phase, organisational entities concerned with the professional ecosystem and processes in which the data scientists’ technical practices were embedded took a major place. They touched upon different moments of the algorithm-making process, from data preparation and ‘ground truthing’ (Jaton, 2021) – for example, Alexander saying ‘In the data preparation phase, we need to validate certain assumptions with the business’ – to the final implementation within business organisations – for example, Barret saying ‘We need business expertise to put the model into production; without business expertise, there are risks, such as not getting the right features’. They also revealed the embedding of data scientists’ technical practices within means-ends associations through their relation to their ‘management’. In that regard, Daniel, quite annoyed with the repetitive aspect of the protocol, asked at some point that the inquiry be closed, by calling for a clearer statement of the goal provided to him by his management chain: ‘Give me the whole list of variables to debias from the management and I will make sure to debug the algorithm!’
Strong associations between technical and organisational entities were clearly revealed by the concept of ‘putting to production’, a technical and organisational term standing for the deployment of an algorithm within ‘real-life’ contexts after a phase of circumscribed development and testing. This operation, as not only an irremediable transfer of the data scientist’s responsibility but also a loss of control over the consequences of their work, proved to be a source of anxiety and incertitude for the interviewees. They coped with this through various organisational strategies designed to distribute their responsibility by involving new entities. Thus, Alexander and Daniel articulated technical and organisational matters through the practice of ‘AB testing’ which enabled them to extend the algorithm training data to new individuals, involving ‘business expertise’ as a decision-maker in the shaping of the algorithm. Daniel’s plan was ‘to put it into production, [and then] do AB testing for 6 months with business people’, while Alexander insisted on the need to produce new ground truth data: ‘I would do AB testing since, in this database, we only have people to whom we’ve granted credit’. Similarly, Charlie asked for a temporal broadening of the algorithm’s description, to ensure more stability to his choices, through the creation of a ‘sandbox’: ‘We need to test it for 3 months in a sandbox if we want to put it into production’.
Legal entities were also often invoked in the process of justification accompanying the interviewees’ choices, in which they took different roles. Alexander explained: ‘what drives the method is the legislation. If there’s nothing that compels the producer, nothing will be done’. The law thus acts there as a way to stabilise the collective by using constraints to determine strictly which associations may be possible to respond to the issue. Charlie, however, saw legal entities more as a problematic parameter in the choices he had to make. He wondered whether it would be acceptable to modify training data in order to correct the ‘biases’ presumably causing the objection he faced regarding his algorithm’s lack of fairness towards female credit applicants: ‘In banking, we often buy data. You have to refer to the contract to know if you have the right to modify the data’.
Finally, the inquiry also raised the issue of more distant associations by questioning the credit applicants’ identities embedded in the training dataset. This type of association was mainly considered in the second iteration of the objections, addressing a critique about interviewees’ algorithms’ unfairness towards foreign credit applicants, after a step focused on unfairness towards women. At that point, they often had to choose to advantage one of the two populations (either women or foreigners) and to produce justifications for their choices. For instance, Charlie explained: ‘Non-foreigners have stronger ties to the country, since they may have more things to lose. It can be justifiable to score them with a lower risk of default’.
The ‘stronger ties to the country’ mentioned then indirectly opened a whole series of associations to each credit applicant’s life story, that suddenly had to take a part within the choice that Charlie had to make. A similar broadening of the perspective was observed when Daniel pointed out the ‘merit’ of foreign workers associated with the training data, compared to female credit applicants, in his reasoning for prioritising the former over the latter. Alexander questioned the ‘representativeness’ of the training dataset that he considered leaned in favour of foreign workers in most cases. He even challenged the various practices that had led to the design of the spreadsheet on which the whole algorithm development process was based.
Inventing modes of recomposition
The call for better alternatives embedded in the protocol that we proposed to interviewees allowed us to identify different modes of recomposition that associate together certain entities of the collective to resolve moral issues.
Our protocol was partially grounded on ‘ethicality’ metrics stemming from the FairML community, which we previously characterised as a ‘principled’ incorporation-based approach to morality. Consequently, most of the recomposition responses were based on associations with these ‘techno-moral’ entities in order to perform and justify recomposition procedures. This was clearly the case in the first iteration of the responding phase when data scientists were presented solely with a performance indicator (‘AUC’) and a gender fairness metric (‘disparate impact’) and had to choose an algorithm responding to the objection concerning their previous algorithm’s fairness to women. Faced with this first situation, most data scientists adopted an arbitration strategy, trying to find a good trade-off between the different numerical indicators. For instance, Alexander explained his strategy as follows: “I want to take the models that have the best AUC while having a good disparate impact. I’m optimising performance”.
Then, when evaluating the result of the iteration through the dashboard of the interface comparing his chosen algorithm’s metrics with the previous one, he commented: “Oh it's not so bad. I think it's a good balance we've achieved with this new algorithm. We’ve lost little in performance. [...] Here we remain on acceptable measures, justifiable because the trade-off is fine”.
However, the diversity of metrics that were progressively added in the subsequent steps – fairness to foreigners, then explicability – complicated the situation as the recomposition could then not always be achieved through the search for a “good balance” between all variables. When faced with the second objection, Barret acknowledged the difficulty of the first strategy by noting that “it’s a vicious circle. If you pull the string on one side, you’ll lose it on the other side”.
Data scientists were therefore forced to adopt other strategies which in some respects were still grounded on ethicality metrics, but which stopped trying to arbitrate evenly between the different parameters presented to them. They started instead to turn towards a mode of reasoning that we could define as thresholding, trying to define ranges of ‘acceptability’ for the performance and ‘ethicality’ indicators they had to work with. For instance, after long hesitation, Daniel defined a range of acceptability around the ‘fairest’ value of one of the women’s disparate impact indicators: “I’m choosing points whose disparate impact is close to 1. I'll take that little group of points. It looks like it hasn't overfitted too much”.
Faced with the necessary trade-off between fairness to women and fairness to foreigners, he then engaged another strategy that one could qualify as prioritisation:
“Between foreigners and women, I would rather prioritise foreigners, but I’m not sure why. Maybe because leaving their own country and finding a job in another country has more merit”.
Barret adopted yet another strategy towards the metrics, trying to achieve an acceptable recomposition through the search of identical numbers between the different disparate impact indicators: “I want it to be symmetrical so that if someone asks me something, I’ll be able to justify my choice”.
Trade-off, thresholding, prioritisation and symmetrisation were different modes of recomposition that data scientists experimented with while working with the ethicality metrics provided to them. For that matter, our protocol helped to show how incorporation-based approaches to morality embedded in ethicality metrics, while very helpful, do not solve the question of ML morality on their own; nor do they allay the anxiety provoked by scruples or extinguish the variety of possible responses to moral issues. Incorporating moral concerns into technical entities does not stabilise ML algorithms; rather, it calls for the production of new enquiries and modes of recomposition.
The recomposition strategies of our interviewees were also based on entities other than the ethicality metrics provided to them. Looping back to their initial reaction of refusal, some of them finally tried to recompose their situation by delegating responsibility to other actors. Barret eventually called for the constitution of a ‘steering committee’ to evaluate the acceptability of his algorithm, while Daniel, when faced with criticism about the lack of explicability of his chosen algorithm, decided to delegate the responsibility of understanding the system to the factitious banker challenging him: “There are only 8 variables, this model is interpretable. She should understand”.
Similarly, we also witnessed dismissal strategies that called for a delegation of responsibility, questioning data scientists’ position in the collective while not pointing out specific actors to delegate to. At the end of the last iteration of the responding phase, Charlie extended the collective involved in the choices he had to make to ‘society’ as a whole: “I don't think that, as a data scientist, I have to do affirmative action. It's not up to the data scientist to integrate these issues [...] It seems complicated to me to correct the biases of society”.
Barret, pursuing that dismissal strategy to the point of talking about himself in the third person, asked to be removed from the collective as it was delineated by the situation: “There’s a human part in the features selection procedure made by the data scientist. The importance of this part must be reduced to avoid the biases created by the data scientist”.
The last type of recomposition strategy was based on the alignment of technical practices with other entities’ recommendations. For instance, conformation strategies allowed them to neutralise their agentivity by referring to the norms produced by ‘the law’ or ‘standards’. 17 Other moments of the interview process featured strategies of objectification based mainly on references to ‘scientificity’, 18 where the interviewee sought associations with ‘objectivable’ entities that would presumably help to mitigate hesitation.
Through the protocol we designed, we, therefore, observed a recurrent process that we could stage as a cycle of morality linking the enquiring effect of scruple to different strategies of recomposition. Scruples generated strategies of refusal before provoking a hesitant inquiry that invoked associations with unforeseen entities within technical practices, delineating alternative ways to describe the collectives of ML algorithms. These descriptions were then temporally stabilised through strategies of recomposition that demonstrated various ways to respond from within technical practices. We will now conclude this brief outline of the experiment’s result by qualifying the role of the entities invoked in the cycle of morality we observed.
Following the (shifting) roles of ML collectives’ entities when facing moral issues
The diverse entities invoked by our interviewees’ attempts at dealing with moral issues during the experiment did not play an identical role in the modes of recomposition that they experimented with. We found that some associations – such as Barret trying to ‘fit into the standards’ – accelerated the recomposition and stabilisation of a practical response to the objections presented to the interviewees’ productions. Other associations, on the other hand, decelerated the process of dealing with scruples – such as Charlie worrying about the agency offered by the contract with the banking client – thus amplifying hesitations and calling for further enquiries on the attention paid to previously neglected entities within the ML algorithms (see Figure 9). The cycle of morality observed during the experiment.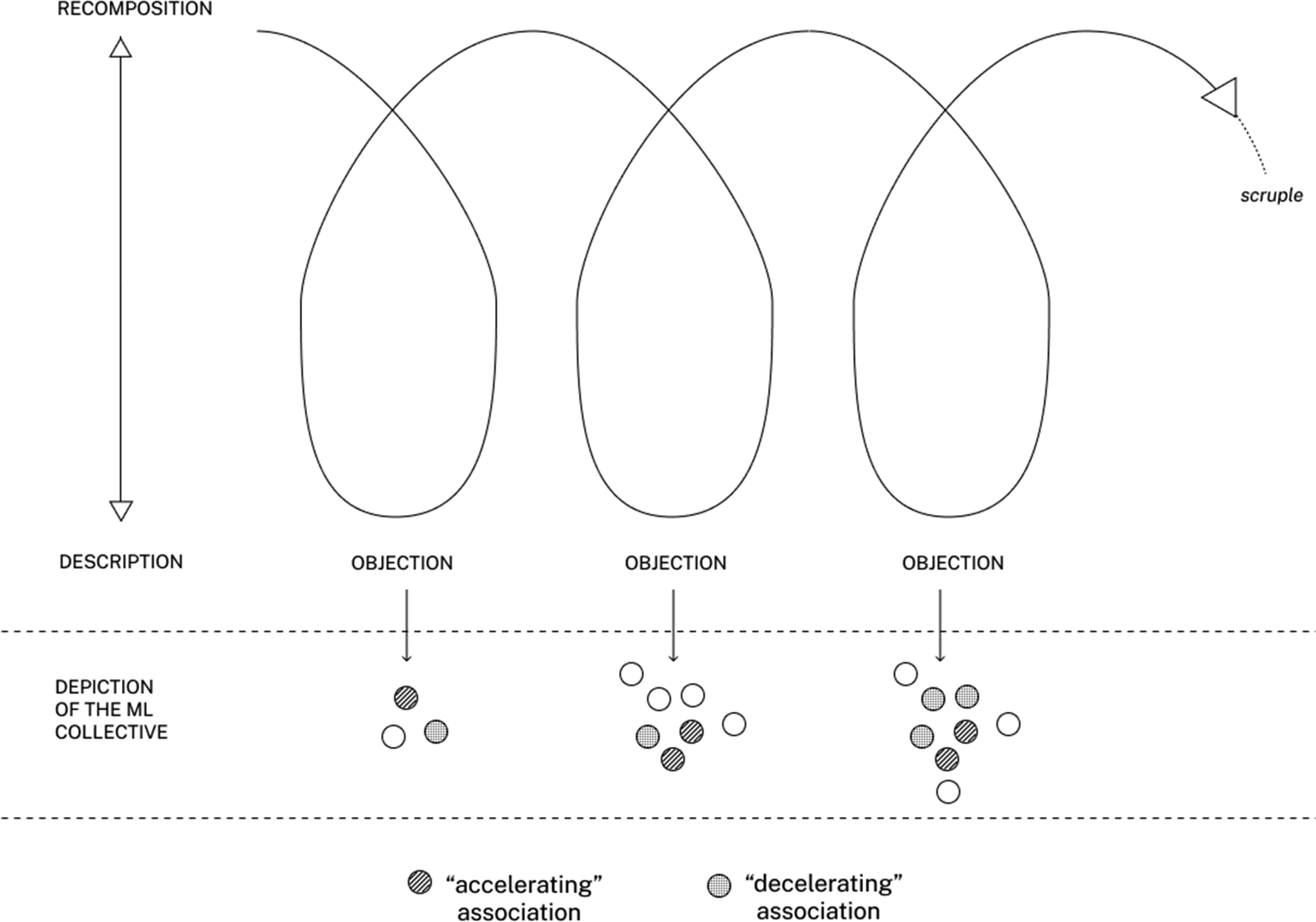
The experiment however precluded us from indexing certain types of entities with stable and inherent roles within the cycle of morality alternating between inquiry and recomposition – for instance, by qualifying technical entities as inherently associated with recomposition and organisational or ‘societal’ entities as inherently associated with hesitation and inquiry.
We observed ‘shifting’ roles for given entities that acted in some situations as vectors of deceleration to recomposition; in some situations, associating with these entities asked for opening the inquiry and delaying the stabilisation of moral issues through technical practices, while in other situations the same entities became vectors of acceleration that supported recomposition through the data scientists’ choices. Some entities were problematic to some interviewees regarding the conduct of their actions (they worried about them as ends), while for others they were a means to achieve stable decisions. We will now examine two cases of these ‘shifting’ entities to describe the implications of the situated nature of our inquiry protocol with regard to the moral qualification of associations within the ML algorithms.
A first instance of ‘shifting entity’ has been the ‘80% rule’, a figure found in some American official legal guidelines that recommend producing selection decisions featuring a disparate impact metric lower than 0.8 towards women and minorities. While operating in the European ecosystem which does not have such a rule, the four French data scientists drew on this legal-technical entity to discuss and adjust their recomposition strategies in a variety of ways. In Barret’s case, the ‘80%’ rule helped him to lessen his hesitation while choosing a fairer algorithm, using it as an accelerating association for the recomposition: The 0.8 seems to be an official figure. [...] It’s fine for me, we found a model that doesn’t degrade the performance but is close to 1. According to the law, it's 0.8. So, we are really clean, we’re close to 1.
By contrast, the 0.8 rule provoked a great deal of anxiety and deceleration for Alexander, who questioned the proximity of the algorithm he chose with the 0.8 figure: 0.82 in a law that imposes 0.8 on us … it’s quite borderline ….
In the frame of the thresholding mode of recomposition envisaged by Alexander, the 0.8 rule challenged the technical practitioner’s agency with regard to a normative entity that did not totally allow him to find a better and stable recomposition.
Daniel clearly considered the 0.8 rule as an obstacle to his action. He called into question the prioritisation strategy that was imposed on him within recomposition, at the expense of other associations that he perceived as more valuable, such as the one with ‘performance’: For me, performance is the most important thing. For the company, it looks like the opposite. [...] If there is a law that tells me I have to have a disparate impact between 0.8 and 1.2, I will do it and optimise the performance. But I won't be particularly happy doing that.
A second instance of the ambiguous role of associations within these situations was the recourse to data science as a disciplinary and professional category. Barrett used the reference to data science in the context of a conformation strategy that helped him to justify his choice and move forward. During the last resituating phase, when he was faced with a critique about his sensitivity to biases as a ‘white male’ data scientist, he responded: As far as I’m concerned, data science … [...] If you’re doing your job well, normally the model allows you to be quite fair.
However, at an earlier point in the responding phase, the same interviewee had also invoked data science while giving it a more uncertain and anxious texture, stressing the uncertainty inherent to the practices associated with data science: In my view, this lacks business expertise about the features, we have to give it another go … data science is a bit of a trial and error process.
As for Daniel, during the third iteration of the responding phase, and after having set up many delegation strategies, he ended up questioning the very accountability of data science in the face of explicability issues: On a very complex subject, which affects people, if the model is too complicated, we won't produce it, because you'll get these kinds of questions. And if you do, you won't be able to answer them yourself. The truth is that nobody, not even Yann LeCun, can give you an explanation of this model. Poor Yann doesn't understand anything, and neither do we. We don't understand what’s going on behind it. We are able to make vague projections [...] the reality is that people put in things that look like elephants and then when we parse them they become missiles. [...] Adversarial is exactly that, [...] the fact that we can make an algorithm do that is the proof that we don't understand anything.
Through these two examples, we can see that several entities played an ambiguous role in the associations necessary for recomposition. This ambivalence, we argue, demonstrates the situated nature of the recomposition strategies implemented in response to moral issues, that cannot be disconnected from the trajectories of the enquiries they respond to, and for which an optimal response cannot be generalised in a deterministic way. Recomposition rests on fragile associations that enable the participant to draw alternative configurations for their practices.
Conclusion: moral enquiries as transformative critical technical practices
By re-enacting technical practices in the light of moral issues, we have encouraged the deployment of critical technical practices as a way to produce alternative depictions of Machine Learning algorithms when they are faced with moral issues. To do so, we produced a re-enactment environment that we augmented with a series of objections and subsequent equipment in order to elicit unexpected accounts of ML algorithm collectives. Through their hesitations, doubts and recomposition strategies, our interviewees invoked an extended range of entities which are usually absent from principled accounts of the morality of algorithms, while demonstrating the situatedness and fragility of the associations that allow them to respond to moral issues through the modes of recomposition stemming from their technical practices.
The kind of morality which we followed through the experience of scruple is characterised by a constant tension between inquiry and recomposition. Any arrangement ends up being reconfigured by the changing events of the world brought out by moral issues. Entities that were stabilised as means may become ends, and vice-versa. Permanently stable composition may not be possible. However, it may be possible to create situations that lead to the constant renewal of the question of means and ends. We call such situations moral enquiries. 19
Moral enquiries generate hesitations and interrogations that require the course of action of Machine Learning collectives to slow down. This is a necessary condition to make actors — such as the data scientists we interviewed — more reflexive and engaged with the variety of unexpected events stemming from the collective in which they are embedded.
We also argue that the perspective of recomposition is indispensable to allow moral enquiries to circulate in the collectives that are traversed by technical practices of crafting ML algorithms. Moral enquiries, therefore, include the necessity of equipment for the possibility of recomposition, which we proposed here in the form of an experimental interface resting on incorporation-based ‘ethicality’ metrics. Our experiment thus highlighted a variety of modes of recomposition, which expand and enrich the repertoire of attitudes that can be adopted towards ML morality as they are developed in dominant principled approaches.
Moreover, moral enquiries never completely settle the issues that they deal with. They require a constant re-evaluation of technical practitioners’ attention to the entities they interact with, rather than the search for definitive solutions. They must be renewed and repeated to allow for constant denaturalisation of the business as usual of technical practices related to ML.
The description of the effect of morality within the core of technical practices calls for a more complex consideration of the difficult moral issues raised by the implementation of ML algorithms, and simultaneously for close scrutiny of the methodological processes and divisions of work in ML-related professional settings. The practice of moral inquiry through the experiment described in this paper could therefore be reframed as a prototype for novel professional practices outside of research contexts. They would not solve the moral issues raised by the diffusion of ML in a variety of sectors, but they would nevertheless act as a regular self-inspection technique for organisations and individuals to assess – and perhaps, improve – their agency regarding the many entities that their technical practice contributes to composing together within ML algorithms. The descriptive critical technical practice we have used to describe the circulation of morality within ML algorithms could therefore be repeated and adjusted in order to propagate genuine transformative critical technical practices, calling for renewed work organisations and processes within ML-related professional settings.
Many thanks to Elizabeth Libbrecht for English proof-reading.
This research received support from Good In Tech Chair, under the aegis of the Fondation du Risque in partnership with Institut Mines-Télécom and Sciences Po.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The author did receive support from the academical Chair Good In Tech (IMT-BS, Sciences Po, AAP 2020)