
Abstract
Manual annotation of the policy content of political texts forms the basis for one of the most widely used empirical measures in comparative politics: left-right policy positions. Bridging automated “text as data” approaches and qualitative content analysis, we apply statistical scaling to this data to learn more about the association of specific policy dimensions to the left-right super-dimension, in a way that minimizes ex ante assumptions about the substantive content of left-right policy. We apply a Bayesian negative binomial variant of Slapin and Proksch’s (2008) “wordfish” model to category counts from party manifestos coded by the Manifesto Project, providing a data-driven approach that offers new insights into the policy content of left and right. We demonstrate how this method also works with content not originally designed for measuring positions. In addition, we show how the approach can be extended to measure the policy content of two latent dimensions, with some categories contributing to both.
Configurations of party positioning can be complex if the policy space includes a multitude of specific dimensions or issues (e.g., Bakker et al., 2015; Benoit and Laver, 2006). Both politicians and scholars therefore often use low-dimensional representations (e.g., Gabel and Huber, 2000; Laver and Budge, 1992) to characterize the policy preferences of political actors. The most basic of such models refers to “left” and “right,” ordering party and voter positions on a single dimension (Downs, 1957). Two-dimensional representations provide a slightly more complex but richer model of the policy space, for example by distinguishing an economic and a “socio-cultural” axis of political contestation (e.g., Bornschier, 2010; Hooghe et al., 2002; Kitschelt, 1994).
Approaches to measuring positions on the basic dimensions of the policy space vary in the extent to which they rely on prior assumptions about the meaning of left and right (e.g., Bakker, 2009; Budge and Meyer, 2013; Franzmann and Kaiser, 2006; Jahn, 2011). Some authors start from theorizing the substantive content of the policy dimension(s). As an example, consider the very widely used fixed “Rile” (right-left) index of the Manifesto Project (hereafter MP; Budge et al., 1987, 2001; Klingemann et al., 2006; Volkens et al., 2013). In promoting this measure, Budge and Meyer (2013: 89) emphasize its connections to opposing arguments about the appropriate level of market regulation and other matters, as reflected in writings by early modern political philosophers. At the other end of the spectrum, advocates of data-driven approaches recommend inferring the left-right dimension in a purely inductive manner. Gabel and Huber (2000: 96) suggest that left-right is simply “the ‘super-issue’ that most constrains parties’ positions across a broad range of policies.” This inductive route is also taken by scaling approaches that treat natural language text as the data to be analyzed (e.g., Slapin and Proksch, 2008). As discussed in detail by Lowe (2016), most existing methods toward measuring party positions, whether from content-analytic data or word frequencies, are variations of a common model of relative emphasis.
The debate about the appropriate way of measuring left and right from hand-coded party manifestos has focused on questions of reliability and validity (see e.g. Flentje et al., 2017; Franzmann, 2015; Gabel and Huber, 2000; Gemenis, 2013; Mikhaylov et al., 2012). In this research note, we point to a largely overlooked advantage provided by applying inductive approaches to content analysis data: using minimal a priori assumptions, they can help us learn about the actual content of the main dimension(s) of the policy space in an empirical manner. While Gabel and Huber (2000) and Albright (2008) also apply inductive methods to the full set of MP categories, they neither report nor discuss results for the item parameters. 1 For this purpose, we develop tailor-made Bayesian variants of the “wordfish” model (Slapin and Proksch, 2008), and apply these to data covering the full set of policy categories.
We begin by establishing that the derived left-right measure is valid, by comparing it to independent expert survey estimates. Here, it does at least as well (and in most countries better) than the MP’s Rile index. Next, contrasting each policy category’s inferred contribution to left-right to the associations that the Rile index assumes, we underscore the insight gained by applying a different tool to the same content-analytic data input. To demonstrate that scaling approaches can be applied to other annotation or coding schemes, we present results for manifesto-based data from the Comparative Policy Agendas Project (CAP) (Baumgartner et al., 2008), which provides more fine-grained data on issue coverage than the MP. Although the documents were not originally coded with the purpose of measuring policy positions at all, we can use them to measure well both where Belgian and Danish parties are located in the policy space and which issues separate them. Finally, we extend the measurement approach to two dimensions, inferring an economic and a socio-cultural axis of political competition. The model allows the researcher to select categories that can be linked to both latent variables while ensuring that the two dimensions remain easy to interpret.
Scaling the “super-dimension” of left-right policy
Data: Category counts from manually coded party policy statements
Party manifestos have long formed the main source of textual data for estimating left-right ideology, both inductively and deductively (e.g. Franzmann and Kaiser, 2006; Gabel and Huber, 2000; Gemenis, 2013; Jahn, 2011; Laver et al., 2003; Mölder, 2013; Slapin and Proksch, 2008). Another large-scale qualitative content-analytic scheme in political science is the Comparative Policy Agendas Project (CAP, see Baumgartner et al., 2008). The CAP aims to identify the topic focus of policy documents, media coverage and political events such as cabinet meetings (Baumgartner et al., 2008). While the majority of the documents coded by the CAP do not represent party policy statements, their dataset does include some manifestos.
We draw on qualitative coding from both the MP and the CAP, to show how unsupervised scaling models originally developed in the quantitative, computational tradition can be applied to two different types of manually coded content-analytic data, and thus bridge automated text analysis methods with qualitative content analysis.
A measurement model for unordered categorical outcomes
We use a measurement model that allows simultaneous estimation of the left-right positions of political parties, as well as the contributions of each more specific aspect of policy—such as expansion versus limitation of the welfare state, environmental protection versus an orientation on growth, or support versus opposition to traditional morality—to this dimension. For learning about the nature of the dimension of left-right policy, the category contributions are our key focus. The scaling model is adapted from “text as data” approaches that scale word frequencies, but replaces the usual “bag of words” approach with one that treats hand-coded sentences as the units to be scaled.
We observe a set of category codings for the manifesto text. Following Benoit et al. (2009), we start from the notion that the party intends to communicate a certain position, called
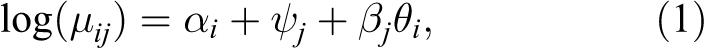
This log-linear model for the expected value
Eq. (1) posits a rather restrictive data-generating process for the statement counts. Variation is due to positioning as reflected in the product term, the overall “verbosity” of the document and the baseline frequency of the category. In practice, other factors also play a role, such as “agenda” effects making some categories more prominent in some election campaigns or coder effects arising from varying interpretations of the category scheme. We can think of these as random effects disturbing the observed counts of statements within documents, leading to additional variation. To take this into account, we relax the restrictive equidispersion assumption (that the variance of the counts equals their mean) of the Poisson distribution. Since this research note is mainly interested in the categories’ links to the latent dimension, we also model the extra variation as differing across categories. 3
We model this using the negative binomial distribution, with expected mean
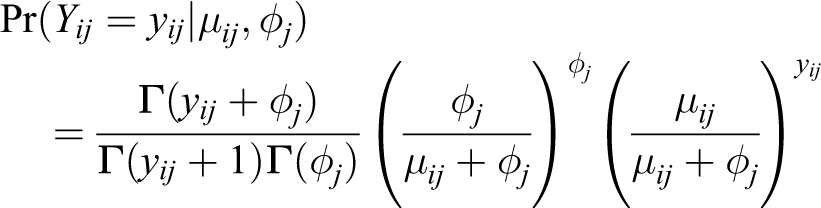
The expected value of the counts is given by
We opt for a Bayesian approach to inference, for several pragmatic reasons: the coding is easy to implement, the uncertainty in all parameters is quantified as an inherent feature of the approach, and the procedure is easily amenable to incorporating prior information. In supplementary materials, we describe in more detail how to constrain and simulate the parameters of the model and how to interpret the category parameters in the context of multiple response categories. Replication code and R functions for general use can be found on https://github.com/kbenoit/bnbwordfish.
Estimating left-right as a latent variable
In this section we fit the scaling model to manual content analysis data for party manifestos from the MP, to demonstrate how individually coded sentences can be used as units to infer the one-dimensional latent variable
Validation: Comparison to expert surveys
Before we draw any inferences about the nature of the policy space, we need to establish that the inductive scaling approach successfully recovers general left-right policy positions. We do this by validating our inferred positions of
The MP coding scheme comprises 56 core policy categories, which are used by human coders to annotate sentence units according to which policy they pertain. 4 Individual policy codes are combined into the left-right policy index known as “Rile,” by far the most widely used empirical measure of left-right party positioning in political science. Rile is based on 13 categories on each side of the spectrum, which are designated as having content intrinsically associated with either right or left ideology; the remaining 30 policy categories are treated as unrelated to left-right. Exemplifying the a priori approach, Budge and Meyer (2013: 89) argue that the construction of this fixed left-right scale reflects opposing arguments by highly influential early modern theorists, including Marx and Engels on the left and Disraeli and Spencer on the right.
Fitting the main model (Eq. 1) to the 56 MP policy counts (with data pooled across countries), we infer the policy positions
Not only does our measure correlate highly with independent positional estimates from expert surveys, but also it corresponds to these more closely than does the Rile index. Additional analyses by country, based on the post-1990 set of manifestos from countries with at least four matched parties, are shown in Figure 1. When the Rile score better matched variation in the expert scores, we plotted it as a green triangle, otherwise, we plotted it as a red square. Except for four countries of Eastern Europe (Hungary, Croatia, Bulgaria and Romania), where the fit was among the poorest of all countries for both scales, our inferred position provided better correspondence with expert survey results than the Rile measure. For several countries, including Ireland, Greece and Latvia, the improvement in the correlation is above 0.2.
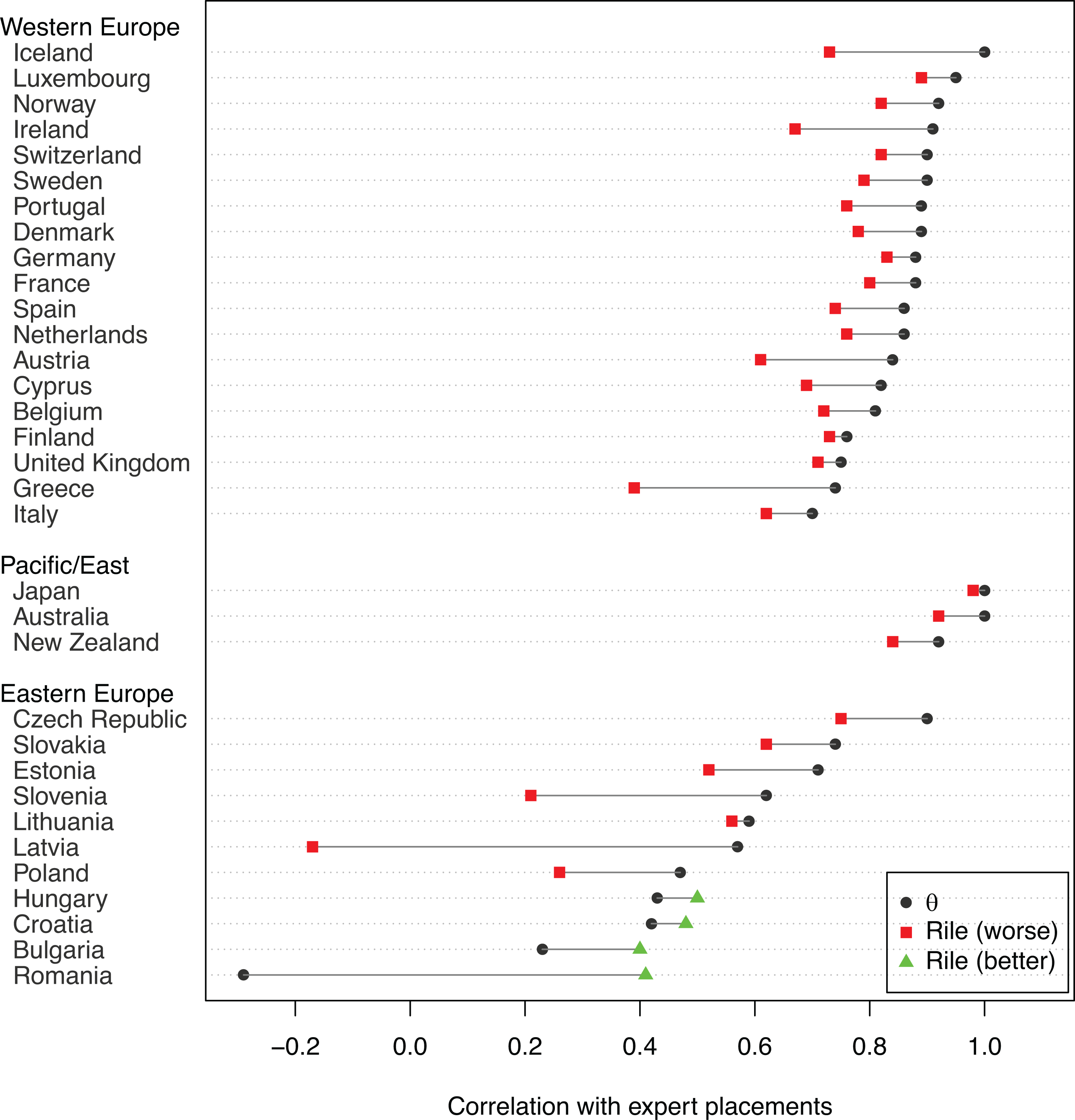
Comparison of scaled results versus Rile correlations with expert survey estimates of left-right policy, by country.
The policy content of the left-right dimension
We now use the model to discover which policy emphases contribute to an inductively scaled left-right policy dimension and how. We can also test the respective assumptions made by existing indices of left-right policy, such as the MP’s Rile index. In fitting the manifesto data to the single dimension that appeared meaningfully to differentiate parties, Laver and Budge (1992: 25) emphasize that this process was “based solely on the intrinsic plausibility and coherence of the sets of issues that define the underlying policy dimension.” Presumably, this is why categories such as “Political authority: Positive (305)” are considered “right-wing”: because in the sample examined, this was the pattern of their association. Using our method that automatically includes and infers the weighted contribution of each policy input to the left-right dimension, we can compare our scaling results to those of the original MP’s categorization.
Applying the one-dimensional scaling model to the coded policy category counts, pooled across countries, we observe category positional parameters that largely confirm the Rile’s left and right policy category choices. Figure 2 plots the category discrimination parameters

Item discrimination parameters (
Among the 30 policy categories the MP excludes from the Rile index, furthermore, Figure 2 shows several to be very strongly associated with left-right policy positions: Marxist Analysis: Positive (415) and National Way of Life: Negative (602) on the left, for instance, and Labor Groups: Negative (702) and Multiculturalism: Negative (608) on the right. So there are numerous categories not used to infer left-right context that could have contributed productively to the measurement of party positions along this single dimension. With our unsupervised approach, by contrast, we can include all available policy information, measuring each category’s relative contribution to determining the latent position
Extending policy discovery to other hand-coding schemes
Using our unsupervised approach, which imposes no ex ante assumptions about policy content, we can also discover the nature of the left-right policy dimension using manual annotations from content analysis schemes never explicitly designed for the purpose of measuring policy positions. To demonstrate, we rely on a set of Belgian and Danish manifestos whose sentences were hand-coded by the CAP into 1 of 213 categories (Bevan, 2019). 8 Unlike the MP coding scheme, the CAP categories span very detailed topics including issues of political organization (e.g. “Branch relations,” code 2011), economic matters (e.g. “Unemployment rate,” code 103), social questions (e.g. “Immigration,” code 900). Additional various categories (to name a few) encompass “Sports Regulation” (code 1803), “Illegal Drugs” (code 1203) and “Diplomats” (code 1929). These were never designed to measure positions, but rather to capture relative issue attention (Walgrave et al., 2006: 1025).
Constructing a fixed index to measure left-right positions would be very difficult from this data, since we have few prior theoretical expectations as to which of the numerous policy content categories actually convey information in terms of left-right positioning. By contrast, the inductive scaling approach allows us to measure this latent dimension and infer the contribution of each item to the scale. To do so, we apply the negative binomial scaling model to manifestos from the post-1990 period (
Here, we focus on the validation of the results for the set of cases that could be matched with temporally close expert survey estimates, as above for the MP Data. Figure 3 plots the results, indicating high face validity. Green, Socialist and Social Democratic parties tend to be placed on the left, and the Far Right parties also appear on the right as expected. Overall, we obtain quite high correlations with the expert scores (
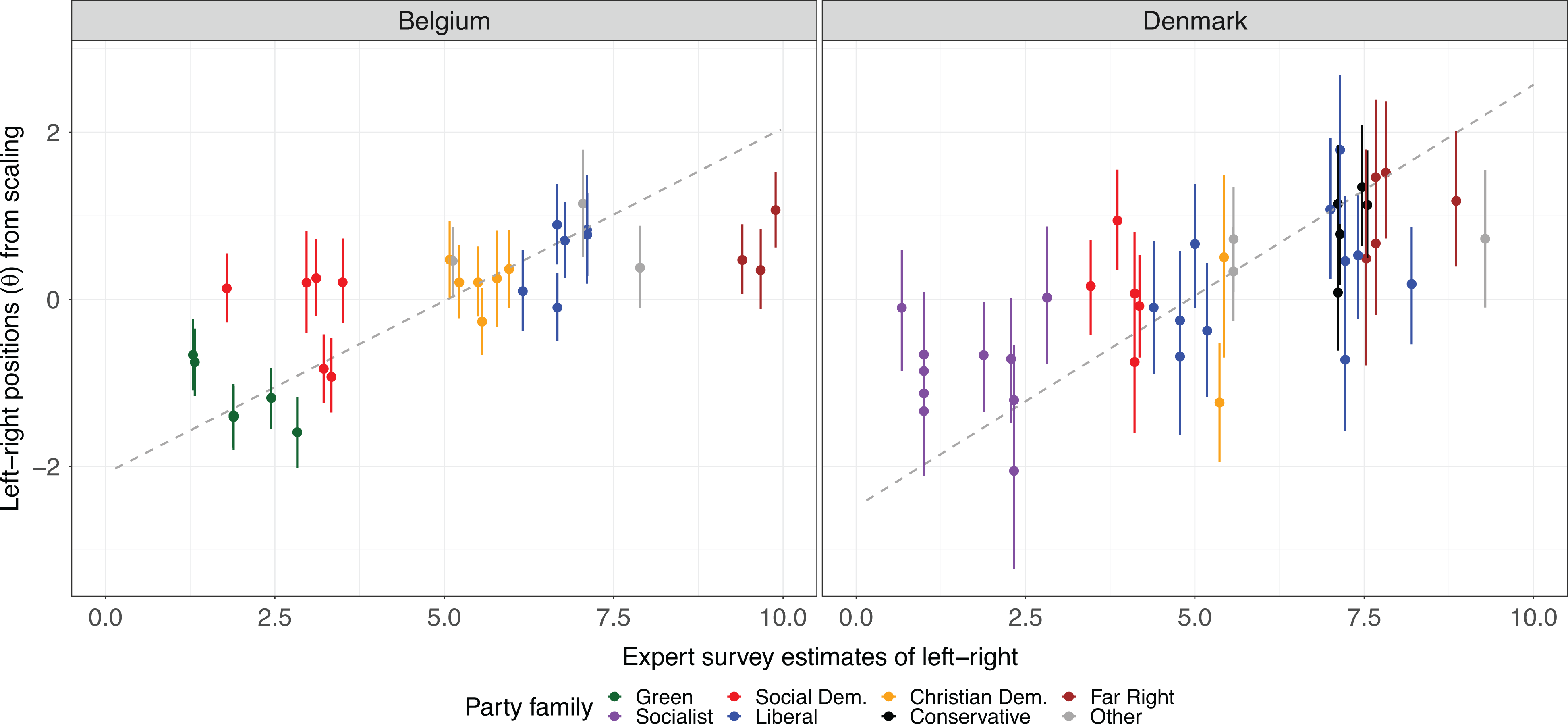
Left-right positions for Belgian (1991–2007) and Danish (1994–2011) parties scaled from the Comparative Agendas Project dataset (posterior means with 95% BCIs) compared to expert survey placements. Dashed gray line represents linear fit. Party family information is from MP Data, with minor changes.
Using a scaling approach, we can also infer the ideological association of specific policy categories, even when they were never explicitly designed for producing an ideological scale. Inspecting the distributions of the
In Belgium, the three most leftist items are “Hazardous waste,” “Energy research and development,” and “Nuclear,” while the three most rightist categories are “Political campaigns,” “Juvenile crime,” and “Handicap discrimination.” The Danish results suggest the following as the items with the strongest link to the main axis of competition: “Air pollution,” “Alternative and renewable energy,” and “Family issues” on the left; “Criminal and civil code,” “Law enforcement agencies,” and “Law and crime general” on the right. Hence, to some extent in both countries questions of environment on the one side and those of law and order on the other are the ones that clearly separate parties. Not only does the scaling approach combine these appropriately to measure ideology, but also it allows direct inference about each category’s relative contribution to left- or right-associated ideology.
Scaling multiple dimensions of left-right policy
For many applications, researchers are interested in measuring policy positions in more than one dimension. For instance, many party systems can be adequately characterized by competition along two main dimensions, an economic and a socio-cultural one (Bornschier, 2010; Hooghe et al., 2002; Kitschelt, 1994). One approach for obtaining policy positions in multiple dimensions is to assign categories ex ante to different specific policy fields/dimensions, and conduct one-dimensional scaling for each of those (Elff, 2013; Meyer and Wagner, 2019), which could also be done with the approach we introduced above. This is equivalent to determining a priori which categories are connected to which dimensions.
Proceeding this way is not recommended, however, when we have reasons to believe that there are categories which can be linked to more than one of the latent dimensions. This is especially relevant if the second dimension is understood as a broader socio-cultural axis that goes beyond moral questions (like abortion and homosexuality) and also encompasses, for example, postmaterialism or issues like nationalism and immigration (Bornschier, 2010; Hooghe et al., 2002; Kitschelt, 1994). In this case, we can say a priori what this axis should definitely exclude (categories that can uncontroversially be considered economic), but some statements, like those on the scope of environmental protection, can both reflect economic or socio-cultural positions. Hence, deriving two broader dimensions, one economic and one socio-cultural, is an excellent application for the two-dimensional scaling approach we suggest.
Extending the model to two dimensions d, we now model the expected counts as
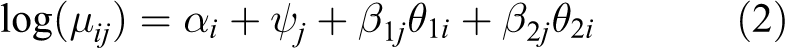
in which we infer two positions
Figure 4 plots the discrimination parameters in the two dimensions, with labels attached to items whose discrimination parameter is greater than 0.5 in absolute terms (for full results see Figure A3 in the Online Supplementary Materials). The IRT approach allows to have both categories that are linked to just one dimension and categories that can be associated with either dimension. This provides flexibility while keeping the inferred dimensions easy to interpret and in correspondence with real-world political discourse, a feature that many other scaling approaches lack. The graph shows that there are several items that are connected with both the economic and the socio-cultural dimension, and often in opposing directions. For example, negative statements about European integration may reflect economically left or socio-culturally right positions. Conversely, positive remarks about European integration can result from views that are economically rightist, or socio-culturally liberal. These results inform debates on the nature of support for the European Union (e.g. Braun et al., 2019; Hooghe et al., 2002) and could be investigated in more detail in future research. Similarly, it is interesting to see that items representing critical stances toward globalization or cosmopolitanism (Multiculturalism negative, National way of life positive, Internationalism negative) correspond to pronounced rightist positions on the second dimension, but also to leftist views about economic policy. Finally, the modeling also reveals that political parties’ calls for decentralization may originate in either rightist economic positions or strongly liberal views on the socio-cultural dimension. Overall, we find a negative correlation between the discrimination parameters in the two dimensions (
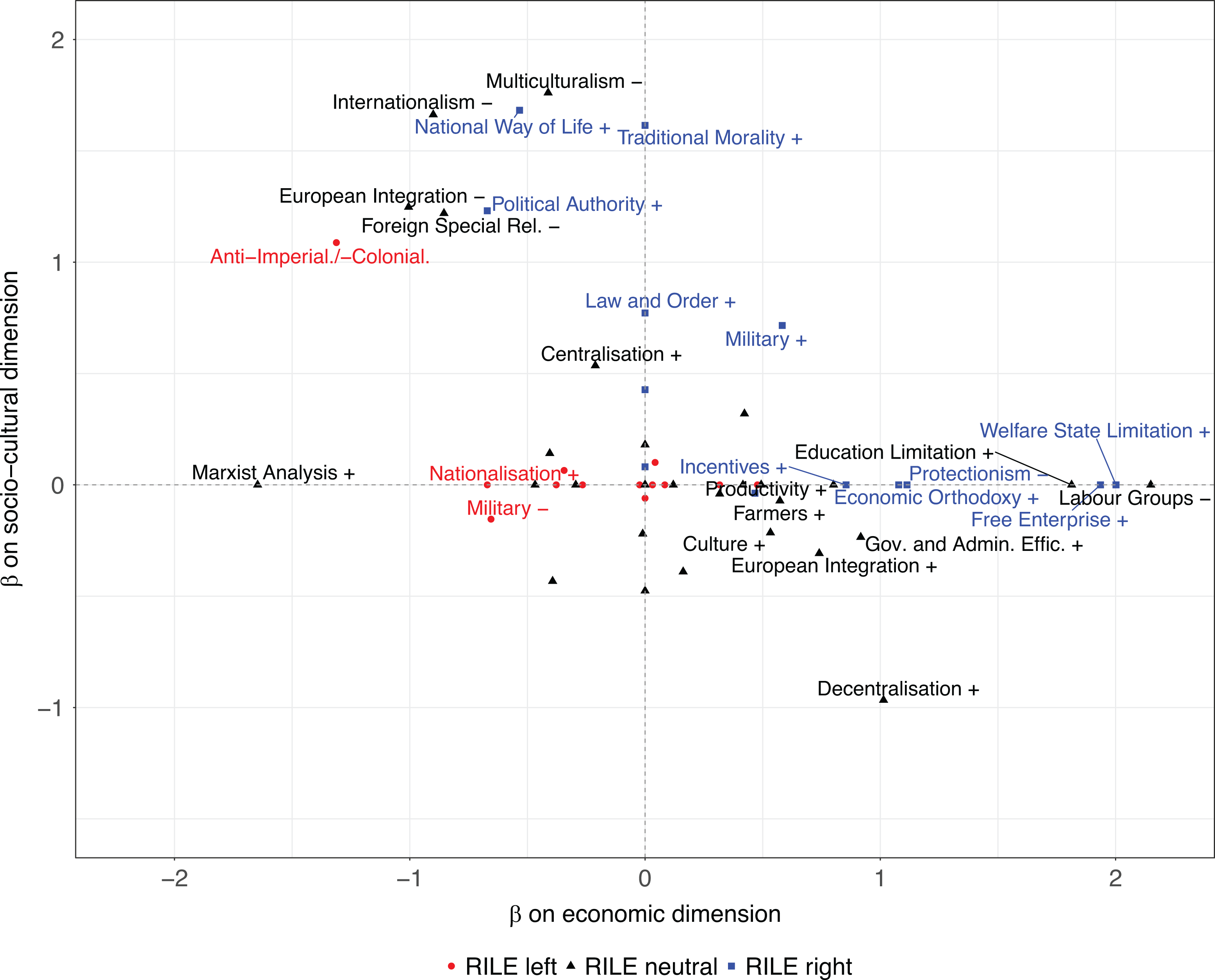
Discrimination parameters in a two-dimensional model.
Conclusion
We use a statistical model for scaling category counts from hand-coded content analysis of political texts and demonstrate how it helps to infer the content of the left-right dimension in a way that avoids debates ex ante about the appropriate components of this dimension. We show that this method can produce valid left-right positions, based on inferring the contribution of each component policy dimension to the left-right super-dimension. This approach works with the MP codes that were designed for this purpose, but its flexibility also allows the use of annotations from content analysis schemes designed for other purposes, such as the CAP.
Using a parametric scaling model permits direct inference about the strength and direction of each content category’s contribution to left-right ideology, while directly quantifying the underlying uncertainty. With some minimal constraints, the model can also be extended to two dimensions of left-right policy, mapping the policy space along a primarily material/economic as well as a socio-cultural dimension.
Our application of the measurement model also underscores the great value of manually coding manifesto texts using expert human judgment. Scaling content-analytic data combines the best of two worlds: context-sensitive classification of specific policy statements originating from expert human judgment, with a valid and flexible procedure that infers low-dimensional policy measurements from the full set of coded statements.
The framework introduced is flexible enough to permit more sophisticated parameterizations. Exploiting the ability to add hierarchically dependent parameters in a Bayesian model, for instance, item parameters can be allowed to vary across space and time. Not only should this help in producing better measures of policy positions—and their uncertainty—but also it will make it possible to get a better understanding of variation in low-dimensional policy spaces across countries. The Bayesian scaling approach also has the potential to build richer models of the underlying political processes. This could not only further improve the model fit in specific contexts, but also allow for testing substantive explanations of parties’ policy shifts directly within the measurement model.
Supplemental material
Supplemental Material, sj-pdf-1-ppq-10.1177_13540688211026076 - Scaling hand-coded political texts to learn more about left-right policy content
Supplemental Material, sj-pdf-1-ppq-10.1177_13540688211026076 for Scaling hand-coded political texts to learn more about left-right policy content by Thomas Däubler and Kenneth Benoit in Party Politics
Footnotes
Acknowledgments
We thank Andrea Ceron, Michael Fop, Jouni Kuha, Ben Lauderdale, Will Lowe, and conference/seminar participants around the globe for comments and suggestions, and Korinna Veller for research assistance.
Author's Note
Kenneth Benoit is also affiliated with Australian National University, Australia.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by the European Research Council grant ERC-2011-StG 283794-QUANTESS.
Supplemental material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.