
Abstract
Background:
As of September 2022, there was no globally recommended set of core data elements for use in multiple sclerosis (MS) healthcare and research. As a result, data harmonisation across observational data sources and scientific collaboration is limited.
Objectives:
To define and agree upon a core dataset for real-world data (RWD) in MS from observational registries and cohorts.
Methods:
A three-phase process approach was conducted combining a landscaping exercise with dedicated discussions within a global multi-stakeholder task force consisting of 20 experts in the field of MS and its RWD to define the Core Dataset.
Results:
A core dataset for MS consisting of 44 variables in eight categories was translated into a data dictionary that has been published and disseminated for emerging and existing registries and cohorts to use. Categories include variables on demographics and comorbidities (patient-specific data), disease history, disease status, relapses, magnetic resonance imaging (MRI) and treatment data (disease-specific data).
Conclusion:
The MS Data Alliance Core Dataset guides emerging registries in their dataset definitions and speeds up and supports harmonisation across registries and initiatives. The straight-forward, time-efficient process using a dedicated global multi-stakeholder task force has proven to be effective to define a concise core dataset.
Introduction
There is an increased awareness of the importance of utilising real-world data (RWD) in multiple sclerosis (MS) with the number of RWD collection efforts growing around the world.1–3 However, RWD collection efforts lack standardisation across sources especially due to heterogeneous content and the semantic and syntactic representation (the ‘what’ and ‘how’ of data collection). 4 Different stakeholders, such as clinicians, researchers, or regulators, have a particular interest in and need for alignment (‘harmonisation’) in RWD collection in MS. This would help facilitate collaboration between MS registries, especially when striving towards large-scale global collaborative efforts.1,3
Several initiatives in the field of MS have already faced the challenge of harmonising datasets for their research purposes, which successfully enabled collaborative RWD-driven insights.5–9 For example, the Big MS Data (BMSD) network agreed upon a minimal dataset for their network and research questions dealing with post-authorisation safety studies in MS. 10 In July 2017, the European Medicines Agency (EMA) held an MS workshop in the framework of their patient registries initiative for promoting the use of RWD for regulatory purposes. Different stakeholders discussed three aspects of real-world MS data, one being the establishment of core data elements in the data collection of MS registries. Although these initiatives working towards harmonisation in RWD in MS were a big step in the right direction, they failed to communicate the developed and used minimal or core datasets (see Figure 1 for differentiation) effectively. Also it remained unclear whether there was any alignment with more generic initiatives (not MS-specific) or inter-stakeholder validation for the development of used datasets. The published core data elements from EMA 11 could serve as a ‘core dataset’ for MS. However, as it was not inside the scope of the workshop, the proposal lacked detailed information (e.g. the operational definition of the format of the specific data elements).

For a better understanding, we defined ‘core dataset’, ‘minimal dataset’, and ‘common data model’ for the use in our paper and process of defining the MSDA core dataset.
The MS Data Alliance (MSDA) is a global multi-stakeholder collaboration aiming to develop tools to reduce the level of heterogeneity among real-world MS data sources and promote timely alignment for data harmonisation across data sources. 12 The MSDA has successfully led global data harmonisation activities throughout the COVID-19 pandemic with the MS Global Data Sharing Initiative (GDSI) and its corresponding global recommendations for data collection on COVID-19 in people with MS. 13 Within the GDSI, the MSDA, MS International Federation and a global data task force established recommendations for a ‘COVID-19 in MS core dataset’ to enable a harmonised approach to the challenge of building a global data network. These recommendations were published 13 and provided on the MSDA website 14 for prospective and retrospective alignment of participating registries and databases to promote joint analyses. This inspired the MSDA to stimulate the definition and agreement on a standardised core dataset in MS (called ‘MSDA Core Dataset’, ‘Core Dataset’) to further strengthen and speed up collaboration to generate evidence from RWD.
The aim of this paper is to present the process and outcome of defining a core dataset for RWD in MS using a global multi-stakeholder task force.
Materials and methods
Workflow of the Core Dataset definition and agreement
The definition and approval of this core dataset in MS was guided by a multi-stakeholder global task force. The task force consisted of 20 experts and key opinion leaders in the field of RWD in MS, including clinicians, data custodians, and leads of MS registries and cohorts, a patient organisation, pharmaceutical industry representatives, and regulatory agencies. The range of different stakeholders enabled a rich diversity of opinions and experiences contributing to in-depth discussions on the core variables in MS. The experts, with representatives from North and South America, North-Eastern Africa, Europe, and Oceania, were involved in MSDA activities and were chosen to participate in the task force. The process of landscaping, discussing, reviewing, and agreeing upon a core dataset was orchestrated and coordinated by the MSDA. A workflow was defined prior to initiating the task force to ensure the process was as efficient as possible, while keeping the time and resources requested from the task force members feasible (see Figure 2). With regards to communication, we informed the members of the task force about steps or results. The key messages from the meetings were circulated after each meeting via mail. The Core Dataset was transparently shared with the task force together with the manuscript. The final agreement was based on the absence of contrary views of the circulated versions of the Core Dataset.
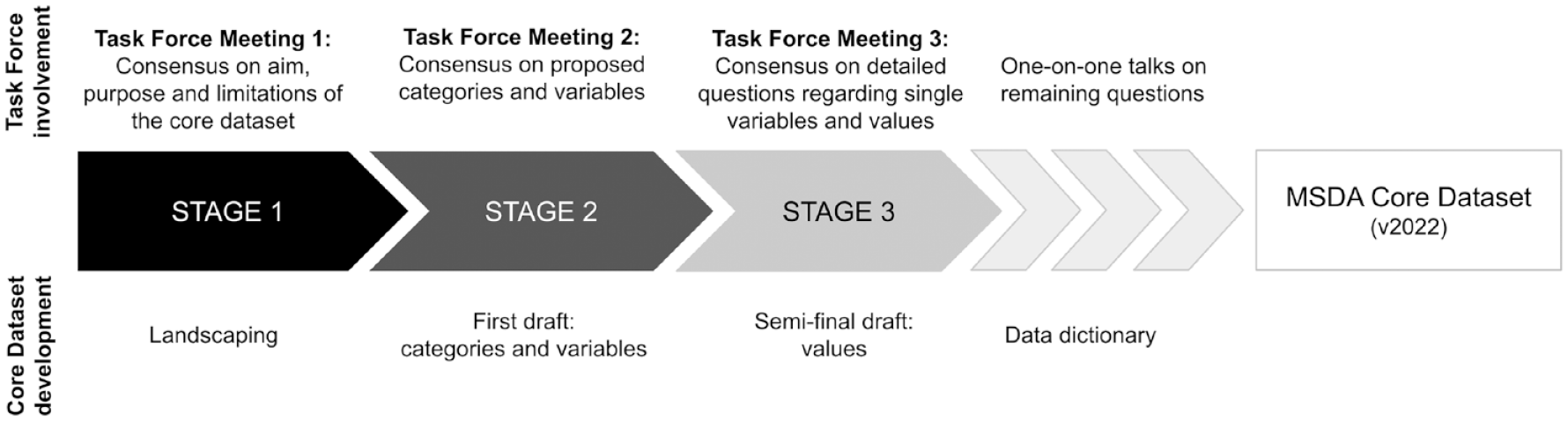
The task force meetings represented three stages of the definition and agreement workflow: The process, estimated workload, and expected engagement were shared with the task force in advance, to ensure transparency and effectiveness. The workflow of the definition and consensus process of the task force was divided into three consecutive meetings held within 3 months (June to September 2022). (1) Pre-stage of the landscaping (consensus on aim, purpose and limitations of the core dataset), (2) Consensus building on the landscaping-based proposed categories and variables, and (3) Addressing and decision-making focussed on open questions regarding single variables and values. After each stage, the experiences and input shared from the task force members were incorporated into the design of the Core Dataset. In the end, the Core Dataset data dictionary was finished and shared with the task force for final approval.
Landscaping
The landscaping process for Core Dataset development aimed at identifying relevant initiatives and material around the topic of minimal and core data elements in MS. Three pillars were identified: (1) an exploratory literature scan, (2) recommended material from the task force, and (3) metadata from the MSDA Catalogue, 4 a web-based platform which was launched in 2019 and allows end-users to browse metadata profiles of MS RWD cohorts.
The literature scan and recommended material focussed on two categories: (a) MS-specific recommendations and publications on common data elements and (b) examples of MS registries with available information on their datasets. Literature was identified using PubMed and Google Scholar with specific search terms ([‘core dataset’ OR ‘minimum dataset’ OR ‘minimal dataset’] + ‘multiple sclerosis’).
The recommended material from the task force members was provided electronically and included additional publications on common data elements as well as the MS registry dataset examples.
Metadata from the MSDA Catalogue was accessed internally. It was exported and further processed to serve as a look-up and validation source.
Comparison of available sources and the drafting process
The suggested core data elements and wish list items of the referred EMA workshop were used for comparison for the mapping of available datasets. Although this list has not been validated or approved by experts beyond the workshop itself to be able to act as a ‘gold standard’, it was chosen to enable a pragmatic and feasible approach for an initial Core Dataset definition. The available reference recommendations, publications, or dataset descriptions were checked for EMA variables. Variables that were collected by references but were not part of the EMA core data elements were not included for comparison. The resulting comparison table led to the selection of category and variable suggestions for the first draft of the Core Dataset. Some variables were added based on proposals during the task force meetings and thereon-based discussions. This added to the eventual final Core Dataset v2022 over the course of the three task force meetings and the subsequent finishing (see Figure 2). Determination of the variables’ values followed the definition of the categories and variables. As it is the aim of the Core Dataset to be as standardised and harmonised as possible, the values of the identified and defined variables had to fulfil certain requirements. If available and applicable, standards were used, for example, for date (ISO-8601) or educational level (International Standard Classification of Education (ISCED)). If no standard existed, values were chosen for discussion that were already established or used by one or more registries, with the data dictionary of MSBase 15 as a leading coding model due to its wide global application.
Results
Scope of the Core Dataset: consensus on aim, purpose, and limitations
The consensus of the task force was that the Core Dataset should serve as a guideline for existing and emerging registries and databases to reduce heterogeneity, provide coverage of the key data elements for care in MS and ensure feasibility of data collection. Twelve of the 20 experts of the task force were clinicians and data custodians with year- and even decade-long expertise in collection of such data and a proven scientific track record which enabled a solid feasibility assessment. The Core Dataset represents the common denominator across initiatives and experts’ input as a list of recurring variables and aims to be research question agnostic. Indeed, the Core Dataset does not aspire to enable every possible research question since a have-it-all core dataset for MS would be impossible to achieve (as for e.g. sustainability and feasibility). The decision was made to focus on a core dataset that can be augmented in future revisions and (local) adaptations regarding what (variables) and how (values, formats) to collect. Application guidelines, for example, focussing on frequency of data collection, are out of scope for the current version of the Core Dataset, but conceivable for future work.
Landscaping: identify existing (and available) sources on minimal/core datasets
Our literature scan performed in July 2022 found little published information in the field of MS-specific recommendations and publications on data elements. The literature scan on PubMed did not deliver any relevant results. Google Scholar delivered a broader picture for the chosen search terms but no publication that dealt exactly with the topic of any minimal or core dataset in MS could be found. Broadening the search term to ‘real-world data’ and ‘multiple sclerosis’ delivered a larger amount but mostly single study publications with a specific use case (mostly a certain treatment) where RWD was used. Neither dataset definition processes nor the datasets themselves were included in these publications. The scan for relevant material based on prior knowledge of MS initiatives that have published their datasets resulted only in the publication about the EMA MS patient registry workshop. 11 The additional material from task force members helped identifying initiatives and datasets that were not publicly available.
The National Institute of Neurological Disorders and Stroke (NINDS), 16 as part of the National Institutes of Health (NIH), has defined ‘Common Data Elements’ (CDE) for neuroscientific clinical research, with MS being one of the neurological disorders. This very extensive list of variables aims to define data collection standards for neuroscientific clinical research across NINDS-funded studies in the United States. This list was included in the comparison with the EMA core data elements to identify common data elements for MS RWD.
A few publications were identified that discuss the importance of using standardised/harmonised datasets for RWD use in MS1,3 or attempt to find a ‘common language of MS data elements’. 17 The latter study compared two registry data collections with regards to the used data elements in both data collection software and gave a list of recommendations based on these two comparators. This list of recommendations was also compared to the EMA list.
Similar to the effort to find recommendations on CDE in MS, the search for publicly accessible data dictionaries from MS registries was challenging. Some registries have published their dataset description or sent them to the MSDA for the purpose of the landscaping for the Core Dataset. For example, MSBase, 15 NARCOMS,18,19 and the German MS registry 20 have published their dataset descriptions online. The dataset descriptions of the Egyptian Registry, iConquerMS,21,22 and the Canadian Multiple Sclerosis Monitoring System (not active anymore) were provided to the MSDA.
Given that a lot of analyses in MS require derived variables, there’s also a need to have data specification documents (‘data dictionaries’) of observational MS data sources available. The publication of established datasets would be, beyond the definition of a minimal or core dataset, an important step to promote a common understanding across MS RWD sources and facilitate harmonisation.
The Core Dataset: categories, variables, values, and data dictionary
The task force discussions led to the agreement on 8 categories and 44 (plus date of visit) variables for the Core Dataset v2022 (see Figure 3). The discussions consisted of a presentation of a certain preparatory work (landscaping results, draft of Core Dataset variables, draft of data dictionary) and an inter-group debate from which the key reflections and decisions were recorded and shared with the task force afterwards. The inclusion and exclusion of variables, as well as the approach to appoint their values, were the main topics of the discussions. Excluded variables and value decisions are provided in the ‘Discussion’ section. After agreeing upon the categories, variables, and values, the data dictionary of the Core Dataset was finalised. A detailed data dictionary (see Table 1) was developed to facilitate the implementation of the dataset and to promote the harmonisation across data sources not only through content but also through the specification of the structure and syntax. To ensure alignment between the MSDA Core Dataset and important non-MS-specific initiatives, it was decided to add a disease or data source independent standard into the data dictionary of the Core Dataset: SNOMED CT (Systematised Nomenclature of Medicine Clinical Terms). SNOMED CT is, as an international validated multilingual healthcare terminology, broadly used across the globe. With its more than 358 000 standardised concepts (as of 16 May 2023), 23 it enables a harmonised and consistent representation of clinical content. SNOMED CT is mapped to other healthcare standards as well as used as a leading standard in common data models (CDM, see Figure 1). It can be an additional benefit for registries, for example, by being used for health practitioner databases or patient-reported registries, where variables can be adapted to questions to suit the needs of the circumstances.
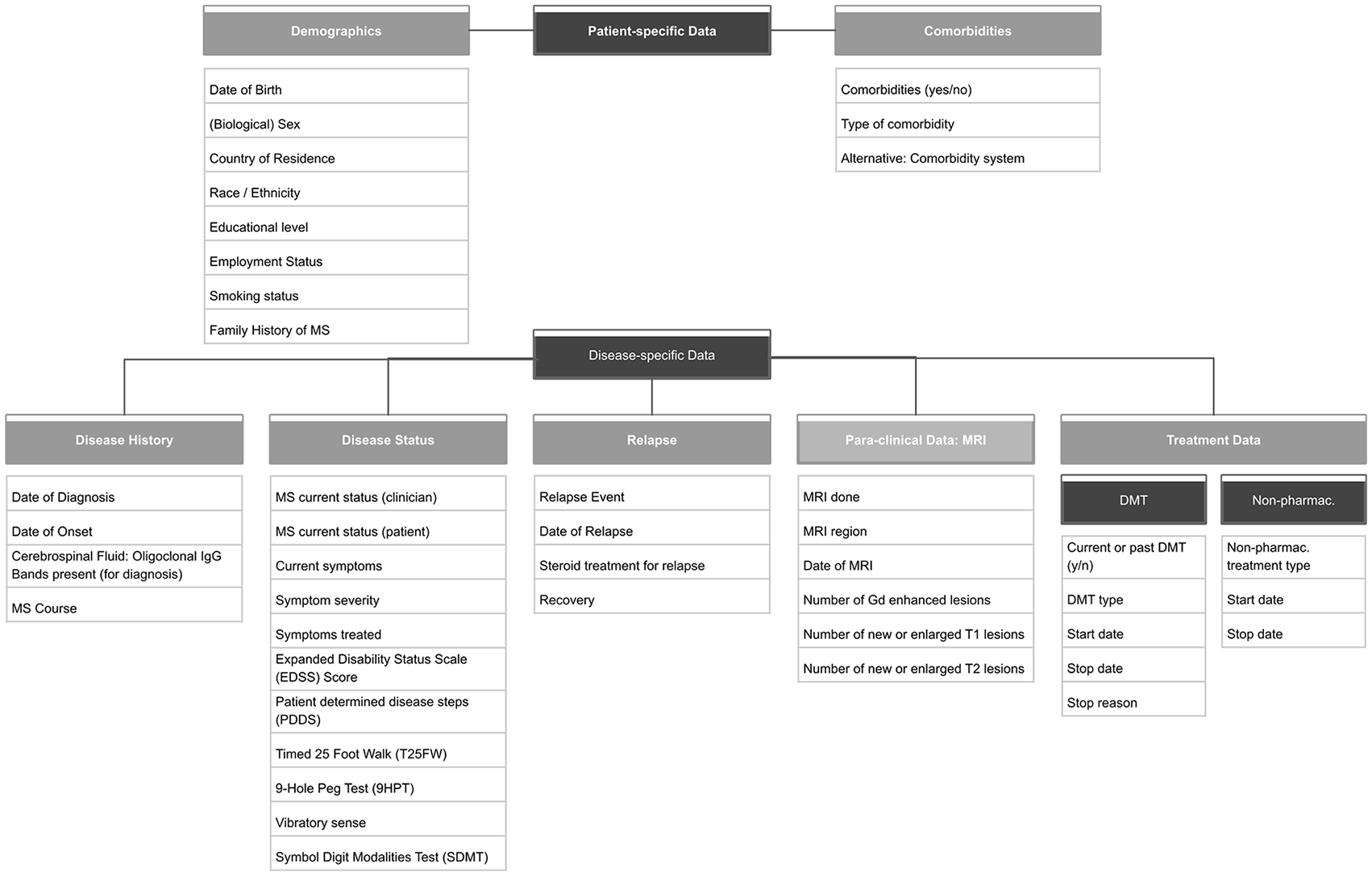
Core Dataset categories and variables: The 8 categories of the core dataset (demographic data, disease history, disease status, relapses, MRI, comorbidities, disease-modifying treatments, non-pharmaceutical treatments) with their respective 44 variables as they were agreed-upon during the task force meetings.
Core Dataset data dictionary to specify the content, structure, and syntax of the collected variables.

SNOMED: Systematised Nomenclature of Medicine Clinical Terms; Documented by: B: both; C: clinician-reported specific; P: patient-reported specific; Collection time: FV: first visit, FU: follow-up visit; RI: relapse incidence; ISO: International Organisation for Standardisation; ISCED: International Standard Classification of Education; MS: multiple sclerosis; MRI: magnetic resonance imaging; DMT: disease-modifying treatment; aHSCT: autologous haematopoietic stem cell transplantation.
Discussion
We propose a Core Dataset for MS, consisting of 44 variables (plus date of visit) in eight categories, which can greatly benefit the use of RWD and the generation of real-world evidence (RWE) in MS.
It is important to note that when designing a new collection of clinical data in the form of a disease registry, a common experience is that initial ambitions are higher than what is eventually possible to collect longitudinally with a high degree of data completeness. Even if the proposed Core Dataset has been limited to contain what was considered a reasonable minimum of variables, it indeed exceeds the current data collections and the completeness of the collected variables of most, if not all, existing registries.4,24 Thus, the value of the Core Dataset in this context is to provide a structured and formatted list of variables to be considered for a new registry, rather than as a mandatory template.
The use and implementation of the Core Dataset is recommended for prospective (i.e. improving data collection efforts moving forward) and retrospective (i.e. coping with heterogeneity of existing data sources) harmonisation efforts. The Core Dataset may benefit prospective harmonisation in:
(1) Adapting RWD collection efforts by using the Core Dataset as a blueprint for the data acquisition tool to shape or alter the source dataset of the registry/cohort. MS registries, especially those with patient-reported data, may tailor the formulation of a question for a certain variable to incorporate local differences, for example, regarding language or the level of detail needed to ask for a certain variable.
(2) Guiding new RWD initiatives. In order to reach emerging registries and initiatives, the Core Dataset will be part of the educational programme of the MSDA called ‘How to set up a registry?’ 25 as a leading example in the topic dealing with the harmonisation and alignment for data collection. The educational activities will be updated along with the revisions and (local) adoptions of the Core Dataset. In addition, the Core Dataset is made available on the website and the social media account of the MSDA and partner organisations for easy access and to promote dissemination.
When it comes to retrospective harmonisation efforts, the Core Dataset aims to serve as the target schema definition for harmonisation activities. A target schema definition is the desired output to which (an extract of) the registry’s source data is transformed. The source dataset is not altered, and the routine prospective data collection within the registry/cohort is not changed. An example of this is the transformation of a birth date in the original format (e.g. MM/DD/YYYY) to the target format (e.g. YYYY-MM-DD). Retrospective harmonisation of existing RWD has proven successful within the GDSI, where RWD from different data sources was transformed into and verified against the COVID-19 core dataset before uploading the patient-level data into the central platform.
A challenge for this version of the Core Dataset data dictionary was the value definition of some variables that had a variety of options and no straight-forward value set was identifiable. For example: (1) For the topic of ‘Comorbidities’ it was decided to use Marrie et al. 26 as the leading published list of comorbidities in MS although it may not include all the relevant comorbidities (as they are either dependent on the specific use case/research question or part of the detailed PASS data collections). As an optional variable, body systems were added for a broader collection of comorbidities. This may serve RWD collections where the granular collection of comorbidities is not possible; (2) The variable ‘race/ethnicity’ was added because of the influence of ancestry on disease prevalence, course or treatment effectiveness.27–29 Due to the large variety of local racial and ethnic categories across the globe, it was decided not to include recommendations for values but to include the variable into the Core Dataset with the note to adhere to local ethnicity/race data values;
(3) For ‘current symptoms’, SymptoMScreen, 30 a validated and published list of symptoms, was chosen for the first version of the Core Dataset to be the guide for the symptom list to address both patient-driven and clinician-driven data collection needs. It is conceivable that it will be extended in the future or adapted to further validations like Zhang et al. 31 or other (arising) symptom questionnaires. A recommendation for a severity score for those symptoms was also added to enhance granularity in symptom follow-up/management, especially in patient-driven data collections.
A regular revision of the current Core Dataset (v2022) is anticipated, especially in regards to the currently excluded variables or pragmatic choices of values. Variables excluded for the 2022 version were those considered future-oriented but not yet widely collected (e.g. biomarkers, including neurofilament, optical coherence tomography, or new progression assessments). Variables on magnetic resonance imaging (MRI) measurements and outcomes focussing not only on relapsing-remitting MS (RRMS) but progressive forms of MS as well are also excluded for now due to feasibility and data coverage limitations. They are also potentially exposed to noise in the data, for example, through the use of different scanners, MRI protocols or interobserver variety for brain volume measurements. Dataset variables needing a dedicated set of data elements (e.g. in the area of patient-reported outcomes (cf. PROMS initiative)32,33 or pharmacovigilance) are also not included. The latter is anticipated to be driven by leading networks like BMSD or PROMS initiative focusing on these specific topics. For example, the BMSD has already established a ‘core BMSD post-authorisation safety studies (PASS) protocol’ for disease-modifying treatments within their network that provides a high-level concept for future PASS although further customization is required for a specific PASS depending on its research questions. The BMSD is working on an updated core PASS protocol and the registries involved in the BMSD aim to become qualified registries for PASS by the EMA. 34 For that reason, data elements on serious adverse events related to disease-modifying treatments were not included in the MSDA Core Dataset.
The Core Dataset was developed within a predefined time frame using a pragmatic approach by including clinical MS variables commonly observed in real-world datasets and feasible to collect. This pragmatic approach naturally has limitations. The task force consisted of a limited number of experts in the field of MS and RWD and only indirectly involved patients (represented by the patient registries and organisation). An extension of the task force, including patients or more experts from other countries, could be considered for future work. This is also helpful in minimising bias in the selection of the core variables. The personal and professional background and interests of the participating experts of the task force may also have influenced the selection of the core variables.
When considering future revisions of the Core Dataset, the cost/effort is another aspect to consider. Getting a task force together requires time and resources spent by involved parties. Compared to consistently new definitions of minimal or core datasets for each new collaboration, this seems to be a benevolent calculation of cost–value ratio though.
Conclusion
The Core Dataset aims to reduce heterogeneity and to promote harmonisation across MS data sources, by incorporating elements that promote faster collaboration within and outside of the MS community. This will help answer questions and solve challenges related to clinical care more quickly–benefitting people with MS. The MSDA Core Dataset v2022 can act as a consolidated step towards a more effective and efficient use of RWD in MS. It is foreseen that the future development of the current Core Dataset and the establishment of core datasets for special interest topics will further support the prospective and retrospective harmonisation in and across MS registries and cohorts. The detailed Core Dataset is presented in Table 1 and freely downloadable on the MSDA website (https://www.msdataalliance.org/).
Footnotes
Author Contributions
T.P. took the lead in writing this manuscript based on the minutes of the task force meetings and the work done in preparation and postprocessing of those. L.M.P., the chair of the MSDA, acted as the overall project leader and was responsible for the study design and the coordination. Working on behalf of the MSDA, L.G. provided minutes of the task force meetings and contributed to the manuscript by providing content, comments, and suggestions. As members of the task force, all other co-authors actively participated in the task force and contributed to the manuscript by providing content, comments, and suggestions.
Declaration of Conflicting Interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: T.P. has no other conflicts of interests to disclose than that she is funded by the Flemish Government under the ‘Special Research Fund (Bijzonder Onderzoeksfonds, BOF)’: BOF22OWB01. L.G. has no other conflicts of interests to disclose than that she is funded by the Flemish Government under the ‘Onderzoeksprogramma Artificiële Intelligentie Vlaanderen’. A.H. has no personal pecuniary interests to disclose, other than being an employee of the MS International Federation, which receives income from a range of corporate sponsors, recently including: Biogen, BristolMyersSquibb, Coloplast, Janssen, Merck, Viatris (formerly Mylan), Novartis, Roche and Sanofi – all of which is publicly disclosed. J.H. has received honoraria for serving on advisory boards for Biogen, Bristol-Myers-Squibb, Sanofi-Genzyme, Merck KGaA, Novartis, and Sandoz and speaker’s fees from Biogen, Novartis, Merck KGaA, Teva and Sanofi-Genzyme. He has served as P.I. for projects, or received unrestricted research support from, Biogen, Bristol-Myers-Squibb, Merck KGaA, Novartis, Roche and Sanofi-Genzyme. His MS research was funded by the Swedish Research Council and the Swedish Brain foundation. H.S. works for the Accelerated Cure Project for MS (ACP), which has received grants, collaboration funding, payments for use of assets, or in-kind contributions from the following companies: EMD Serono, Sanofi/Genzyme, Biogen, Genentech, AbbVie, Octave, GlycoMinds, Pfizer, MedDay, AstraZeneca, Teva, Mallinckrodt, MSDx, Regeneron Genetics Centre, BC Platforms, and Celgene. A.C.P. has also received funding from the Patient-Centred Outcomes Research Institute (PCORI) and the National MS Society (NMSS). A.S. is on the editorial board for Neurology and serves as a consultant for Gryphon Bio, LLC. She has received research funding from the Department of Defence, MS Society of Canada, National MS Society and the Consortium of MS Centres. A.S. works for the NARCOMS Registry which is supported by the Consortium of MS Centres (CMSC) and the Foundation of the CMSC. R.M. has received no personal funding from any sources, the UK MS Register is funded by the MS Society, and has received funding for specific projects from Novartis, Sanofi-Genzyme, and Merck KGaA. A.S. has no personal pecuniary interests to disclose, other than being the lead of the German MS-Registry, which receives funding from a range of public and corporate sponsors, recently including: The German Innovation Fund (G-BA), The German MS Trust, The German Retirement Insurance, German MS Society, Biogen, Celgene (BMS), Merck, Novartis, Roche and Sanofi. P.D. is a full-time employee and a shareholder of Biogen. E.H.M.-L. and K.P. have no conflicts of interest to disclose. The views expressed in this article are the personal views of the author(s) and may not be understood or quoted as being made on behalf of or reflecting the position of the EMA or one of its committees or working parties. P.I. has served on scientific advisory boards for Biogen Idec, Bayer, Teva, Roche, Merck Serono, Novartis and Genzyme and has received funding for travel and/or Speaker honoraria from Sanofi Aventis, Genzyme, Biogen Idec, Teva, Merck Serono, Alexion and Novartis. J.I.R. has received honoraria from Novartis as a scientific advisor. He has received travel grants and attended courses and conferences on behalf of Merck-Serono Argentina, Novartis, Roche, Sanofi-Genzyme, Biogen, Bayer and Teva. He receives unrestricted research funding from Novartis, Biogen, Roche, Merck and Sanofi. M.M. has served in scientific advisory board for Sanofi, Novartis, Merck, and has received honoraria for lecturing from Biogen, Merck, Novartis, Roche, Genzyme, Bristol-Myers Squibb. She received research support and support for congress participation from Biogen, Genzyme, Roche, Merck, Novartis. A.v.d.W. has received honoraria and unrestricted research funding from Novartis, Biogen, Roche, Merck and Sanofi. G.C. reports that he has received consulting and speaking fees from Novartis, Teva Pharmaceutical Industries Ltd, Teva Italia Srl, Sanofi-Genzyme Corporation, Genzyme Europe, Merck KGgA, Merck Serono SpA, Celgene Group, Biogen Idec, Biogen Italia Srl, F. Hoffman-La Roche, Roche SpA, Almirall SpA, Forward Pharma, Medday, and Excemed. L.M.P. has no conflict to report related to this work other than being the chair and the coordinator of the MSDA initiative, receiving funding from a range of corporate sponsors, including Biogen, Bristol-Myers Squibb, Janssen Pharmaceuticals, Merck, Novartis, and Roche. All other co-authors have no relevant competing interests to report. The authors declare that the funding sources did not influence the content of this work.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was funded by the MS Data Alliance Initiative. The MS Data Alliance is a global multi-stakeholder non-for-profit organisation working under the umbrella of the European Charcot Foundation, financially supported by a combination of industry partners including Novartis, Merck, Biogen, Janssen, Bristol-Myers Squibb and Roche. None of the co-authors received any personal financial reimbursement for their work and time contributed to this manuscript and/or their involvement within the task force.