
Abstract
Social media have widened access to political participation but fuelled phenomena such as gendered toxicity that hinder democratic deliberation. While female politicians are recurrent targets of misogynistic attacks, existing moderation practices fail to adequately address the problem. Focusing on Twitter (now ‘X’), we provide the first systematic corpus analysis of the presence and the type of gendered toxicity towards Italian politicians, combining natural language processing with statistical and linguistic analysis. The results show a gender difference both in quantity and quality of toxic messages: while male politicians do not receive fewer toxic replies than female politicians overall, women do receive comments tailored to stereotypes (physical appearance, age, sexual habits) which constitute ad hominem attacks.
Introduction
This article addresses gendered toxicity towards Italian female politicians on Twitter (now ‘X’) using a corpus-based approach. Women’s political participation remains significantly lower than men’s. The Beijing Platform for Action, adopted in 1995, identified the promotion of women in politics as a key objective. Since then, women’s representation in national parliaments has increased from 13% in 1999 to 26.2% in 2022 (Inter-Parliamentary Union, 2016). However, no G20 countries have parliaments or cabinets with a female majority. Interviews with female politicians show that misogynistic speech discourages women from pursuing politics, contributing to democratic backsliding.
A recent qualitative study by the NGO #ShePersisted (Di Meco and Apolito, 2023) shows that this issue is especially prominent in Italy. In the 2023 gender equality index by EIGE (European Institute for Gender Equality), Italy scored 68.2 out of 100, up 3.2 points from 2020 but still 2.0 below the EU average. Italy has made the fastest progress among Member States, rising eight places since 2010 to 13th place. In politics, it ranks 41st, up from 76th in 2006, due largely to improvements in time and power domains. Notably, the 2022 elections led to Giorgia Meloni, leader of Brothers of Italy, becoming the first female Prime Minister. These were snap elections, called after Mario Draghi’s resignation on 21 July 2022.
Social media has enabled women to amplify their voices in politics but also fuels digital misogyny and gender trolling. Moderation systems are largely ineffective: a 2023 Reset report monitoring content on Facebook, Twitter, and YouTube during Italian elections found that platforms struggle to detect and remove toxic content. Automatic detection remains difficult, especially with misogyny, which often uses sarcasm, figurative language, or cultural nuance to evade filters.
Pilot studies during the Italian elections (Musi et al., 2023; Di Meco and Apolito, 2023) show that misogynistic narratives are common, but no systematic analysis has yet classified toxic speech against Italian politicians. This study investigates the presence and nature of toxic speech targeting male and female politicians, using a comparative-contrastive approach. Through a pipeline combining natural language processing, statistics, and linguistic analysis, we ask: Does toxic speech target men and women differently? What types of toxic content qualify as misogynistic?
Our analysis draws from over 200,000 tweets, including originals and replies. Results suggest both male and female politicians face toxic speech. However, while the volume is comparable, the nature of attacks differs significantly by gender.
Previous studies
Previous studies have shown that technology-facilitated gender-based violence constitutes a global threat to women’s political representation and democracy. Uncivil discourse, marked by harsh tones, does not necessarily hinder political debate, but intolerant forms, such as toxic speech, threaten pluralism and democracy (Rossini, 2020, 2022). Cross-national case studies have highlighted the impact of toxic speech on female politicians. To cite a few, the 2016 Inter-Parliamentary Union report, based on responses from 55 women parliamentarians from 39 countries, revealed worrying patterns of gendered based violence against female politicians across the world. In India, incidents of violence against women candidates during the 2019 elections have further discouraged participation, already low at 15% in the lower house (Spary, 2020). In the UK, a 2017 BBC survey found that 9 in 10 female MPs received online and verbal abuse (BBC, 2017) with a third considering quitting politics.
An intersectional analysis by Collignon et al. (2022) using Representative Audit of Britain data showed increasing harassment, abuse and intimidation during elections in the UK, which discourages active participation. Southern and Harmer (2019) note that many women abandon social media as a result, disadvantaging them politically. In Canada, Wagner (2022) found that online harassment is a gendered phenomenon: even though it does not stop women from political participation, it creates a hostile political environment that may push them away over time. Similarly, Koch et al. (2024) found that during Brazil’s 2022 election spikes in misogynistic tweets were followed by reduced social media activity from female candidates. This scenario is amplified by the affordances of social media. Since the rise of the networked society, features of social networking sites as networked publics, have shaped participation in ways that foster toxic emotionality. Munn (2020) shows that Facebook’s engagement-driven Feed increases views but also prioritises incendiary content, creating a feedback loop of outrage, while YouTube’s recommendation system increases polarisation. Reddit’s karma system and subreddit aggregation have similarly fuelled toxic behaviours (Massanari, 2017).
Although there is broad agreement on the harmful effects of platform-driven aggression, how toxic speech targets women politicians requires in-depth, context-specific, culturally informed analysis. A few studies have adopted a discourse-based approach, analysing both the presence and the type of toxic messages from a qualitative and a quantitative perspective. In the UK, Ward and McLoughlin (2020) conducted a benchmark study of 270,717 tweets to MPs, using sentiment, keywords and manual analysis, showing that women politicians are disproportionately targeted by toxic speech.
Other research indicates that female MPs are more likely than their male counterparts to receive uncivil tweets, be stereotyped, and have their political legitimacy questioned, often with a focus on their identity (Phillips, 2017; Southern and Harmer, 2019). This gendered ‘othering’ includes misogynistic abuse, objectification, and the feminization of male MPs (Southern and Harmer, 2019). Digital microaggressions, particularly against women of colour, reinforce women’s marginalised status in politics (Harmer and Southern, 2021). More specifically, content analysis has identified four main themes: overt online abuse, everyday sexism and othering, dismissal of discrimination and victim blaming and claims of reverse discrimination. These patterns contribute to framing the political arena as a male-dominated space and perpetuating sexist portrayals of women in politics.
In many other countries, threats are the most prevalent form of toxic speech targeting women. For example, van der Vegt (2023) found that while male party leaders in the Netherlands were targets of higher levels of abuse, threats were equally distributed, with minority women disproportionately affected. In the Maldives surveys and interviews with 2014 election candidates revealed women faced more threats and degrading sexualization (Bjarnegård, 2023). In Japan, platforms like Twitter have become hubs for misogynistic hate speech towards prominent female politicians (Fuchs & Schäfer, 2021), reflecting a broader pattern of violence against women in politics, which is often downplayed or normalised (Dalton, 2019). The gendered patterns of political engagement in post-war Japan have perpetuated the persistent inequality in political participation between men and women (Takeda, 2006).
To summarise, recent studies outside Italy confirm that women politicians are frequent targets of toxic speech, with country-specific differences in both the volume and type compared to men. This underscores the need for both quantitative and qualitative research within national contexts to fully capture the scope and unique characteristics of this phenomenon in order to develop an effective resilience strategy. The nature of toxicity reflects local norms of gender performativity. In the Italian context, Sartori et al. (2017) argue that situational barriers may exacerbate participatory gaps, but they do not explain their root causes. Cultural factors—such as differing political socialisation, attitudes towards power, perceptions of politics as distant, and public perceptions of women as more suited to the private sphere—further discourage Italian women’s political engagement and shape their policy priorities.
To our knowledge, no systematic quantitative and qualitative study has examined online toxic speech against Italian women politicians. Existing research highlights the widespread use of image manipulation to sexualize and discredit Italian women in politics (Esposito, 2022). Outside academia, the #ShePersisted report (Di Meco and Apolito, 2023) documented gendered digital abuse across parties through interviews and digital ethnography, 1 identifying eight recurrent types of offensive language (including abusive, privileged, enemies of women and children; authoritarian, incoherent; liar; unreliable, incompetent, ugly). Our study aims to expand on such insights by examining their prevalence on a larger scale on Twitter.
Materials and methods
Data
For data collection, we focused on Twitter (now ‘X’) from 2 December 2022 to 31 January 2023. We chose Twitter for two reasons: first, many prominent Italian politicians from all parties were active Twitter users following the fall of the Draghi government in July 2022, making them experienced users (Author et al., 2022). Second, at the time of data collection, the official Academic Twitter API allowed for large-scale longitudinal data collection, including posts and users’ reactions. We used real-time streaming to minimise data loss due to the removal of tweets between the time they were posted and the time of data collection. The aim was to capture the full range of toxic messages directed at politicians. The selected time frame—starting roughly 2 months after the Giorgia Meloni’s mandate began—was intended to allow the collection of a large enough corpus of replies to surface statistically significant patterns within the limits of tokens allowed by the Twitter API. We wanted to avoid online conversations being highjacked by the results of the election. Furthermore, we assumed that the Christmas period would have been especially convenient for data collection purposes since citizens tend to have more time to engage in social media discussions (Santoro, 2023).
The Italian political system marked by a multiplicity of parties and shifting alliances. Currently, it is a mixed electoral system, combining proportional and majority representation. Of the 400 MPs, two-thirds are elected proportionally, and one-third by first-past-the-post. Such a system favours the creation of coalitions: to win a seat in the lower house of Parliament, a party needs to win at least 3% of the vote, or 10% in the case of a coalition.
The four coalitions/parties which secured the most seats in the lower house of parliament after snap elections are the following:
the centre-right coalition (Brothers of Italy, League, Forza Italia, Us Moderates) led by the Brothers of Italy: 237 seats.
the centre-left coalition (Democratic Party, More Europe, Civic Commitment, Green and Left Alliance), led by the Democratic Party: 85 seats.
The anti-establishment Five Star Movement (M5S): 52 seats
The centrist electoral list Third Pole, formed by the parties Action-Italia Viva: 21 seats.
To ensure political balance, we selected seven parties: Action and Italia Viva, IV, M5S, and the main parties from each coalition with a significant number of seats, namely Brothers of Italy (FDI, 69), League (23), Forza Italia (FI, 22) and the Democratic Party (PD, 57).
To create a gender-balanced sample, we selected for each of the seven parties five female and five male politicians with highest numbers of followers and with comparable roles and visibility within the parties. The selected politicians and their party affiliations are listed in Table 6 (Appendix). Overall, our dataset amounted to 9581 original posts from the politicians and 224,656 user replies. Out of the 35 female politicians we selected, 5 received no Twitter replies at all during the time frame considered, while all 35 male politicians received some replies. We decided not to replace the 5 politicians with 0 replies in the sample. The anonymized dataset will be made accessible on the authors’ Github.
Framework and method
A key challenge in studying toxicity is the absence of a unified theoretical framework for categorising toxic content. As Vidgen et al. (2019) note, legal definitions are often too narrow, while platform guidelines are vague and serve goals beyond the mitigation of toxicity. Scholarly classifications also vary in criteria and levels of abstractions, with ‘hate’ sometimes used as an umbrella term, and sometimes used alongside other categories of abuse such as dismissal or insult. Poletto et al. (2021: 482) show that abusiveness and toxicity span concepts like offensive language, racism, misogyny and homophobia.
To navigate such a complexity, we adopt the framework used by Perspective API 2 for three main reasons. First, their definition of toxicity—‘a rude, disrespectful, or unreasonable comment that is likely to make you leave a discussion’ 3 – aligns with Twitter’s own rules and policies page against harassing and degrading behaviour. 4 Therefore, in principle, API-based classifications are both platform- and moderation-relevant. Second, the API provides five clearly defined subcategories 5 :
Severe_toxicity: highly aggressive or hateful comments likely to drive users away
Identity_attack: comments targeting individuals based on their identity
Insult: inflammatory or derogatory remarks towards a person or a group of people
Profanity: Use of obscene or profane language
Threat: Statements expressing intent to harm.
Such categories have turned out to be relevant and distinguishable in human annotation which is at the basis of the parser. This is not surprising: despite potentially overlapping, the categories are lexically anchored, thus reducing the margin of errors in classification due to implicit knowledge and contextual interpretation.
Third, this framework has been successfully used to annotate millions of comments from a variety of sources (e.g. online forums such as Wikipedia) in Italian used to train the model, thus promising to be accurate for our language of interest. An example for each of the attributes from our dataset of tweets is visualised in Table 1.
Examples of tweets classified with toxicity attributes.
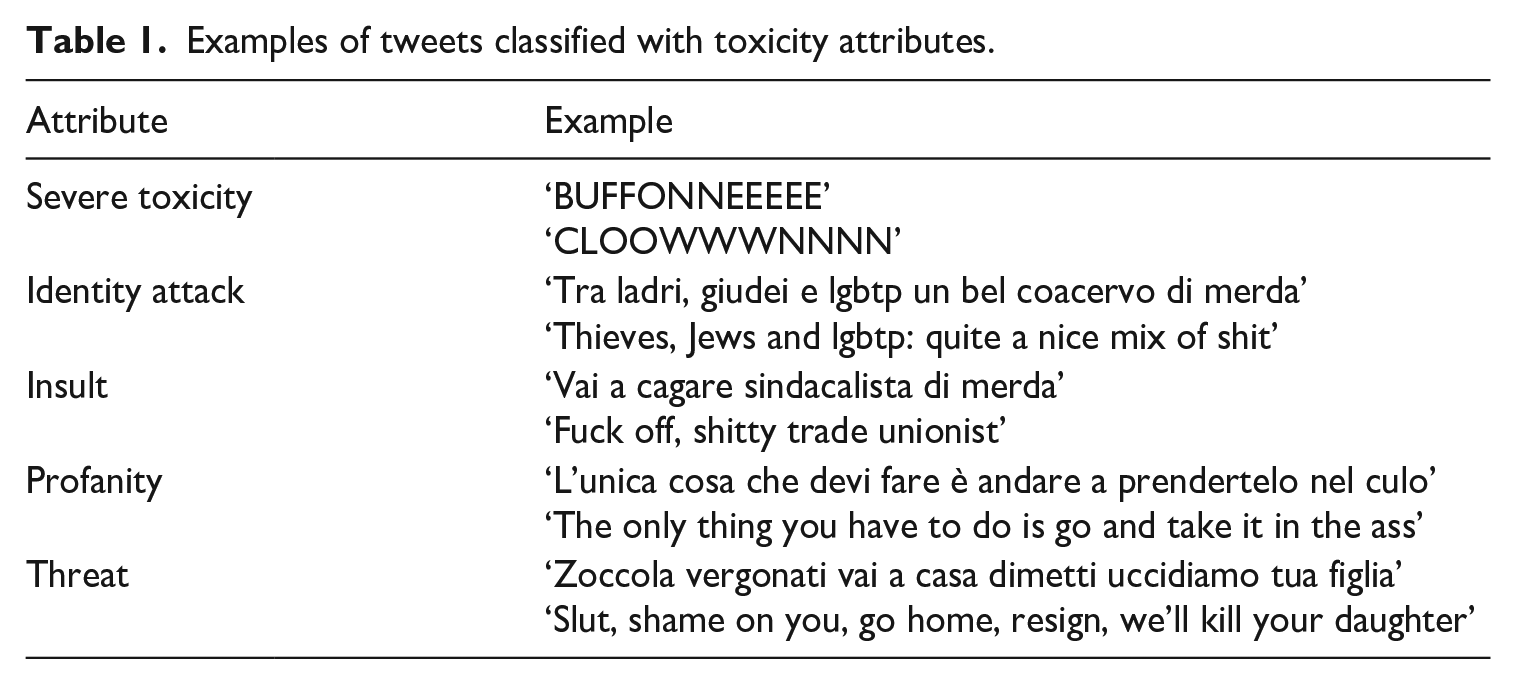
The attributes do not point to misogynistic traits which we decided to analyse qualitatively for two main reasons: first, as shown by the Automatic Misogyny Identification Challenge (AMI) for Italian (Fersini et al., 2018a, 2018b), even the best models struggle: Tweets are often misclassified as misogynistic when the target was left implicit, but the tweet contained aggressive terms; when the target was expressed by the Twitter name with no indication of gender and when uncommon targets (e.g. grandmothers) or rare verbs were used (Fersini et al., 2020). Second, the types of misogynistic attacks evolve over time requiring constant updates to detection models.
Overall, our methodological pipeline is threefold. The first step consists of toxicity classification: we assign toxicity scores to each of the replies in our dataset, using Perspective API. This multi-language machine learning model is designed to detect toxic language in text-based content. We have chosen this model since it outperforms baseline ones for multi-language detection (Lees et al., 2022). Furthermore, its primary application is to support online platforms to moderate user-generated content, thus having proved successful in empirical tasks. Unlike binary classifiers, Perspective evaluates a tweet according to a set of parameters, providing an overview of different types of toxic content. More specifically, the model takes a piece of text as input and returns a collection of key-value pairs as output, meant to quantify the toxicity content of the examined text. The keys consist of 5 different toxicity attributes identified by the authors of the model, each of which is rated by the model with a numerical value in the range [0, 1]. The score associated with each toxicity attribute is to be interpreted as the probability that a reader of the evaluated text will perceive the presence of that toxicity attribute in the given text. An example of the output is Example 1 in json format:
‘1616783740637966336’: {‘author_id’: ‘1502189576009433091’, ‘created_at’: ‘2023-01-21T13:04:16.000Z’, ‘edit_history_tweet_ids’: [‘1616783740637966336’], ‘entities’: {‘mentions’: [{‘start’: 0, ‘end’: 4, ‘username’: ‘meb’, ‘id’: ‘588200416’}]}, ‘geo’: {}, ‘in_reply_to_user_id’: ‘588200416’, ‘lang’: ‘it’, ‘public_metrics’: {‘retweet_count’: 0, ‘reply_count’: 0, ‘like_count’: 0, ‘quote_count’: 0, ‘impression_count’: 0}, ‘referenced_tweets’: [{‘type’: ‘replied_to’, ‘id’: ‘1613819865034379264’}], ‘text’: ‘@meb Tra ladri, giudei e lgbtp un bel coacervo di merda’, ‘in_reply_to_sex’: ‘F’, ‘in_reply_to_party’: ‘IV’}
After having classified all the tweets, we have statistically analysed the distribution of toxicity values across genders and parties. We first investigated the distribution of the values of each toxicity attribute obtained as output of the Perspective API classifier and computed how strong their correlation was. We then classified, for each toxicity attribute, the tweets into 3 categories, following the guidelines given by the developers of Perspective API 6 and treated it as a qualitative variable. The developers’ advice is to consider messages with a score between 0.7 and 1 to be reliably toxic for moderation purposes, while to subject to manual scrutiny, the messages with a score between 0.3 and 0.7. Messages with a score below 0.3 are unlikely to be toxic.
Since toxic attributes which are anchored to complex phrases rather than single words receive lower scores, we have kept track of the three ranges <0.3; 0.3–0.7; 0.7–1, to be able to then qualitatively classify types of identity attacks and threats next to insults and profanity. We analyse the frequencies of these classes across gender and party for the different toxicity measures and use a
To investigate whether, regardless of the quantity, toxic replies across attributes (profanity, insults, identity attacks and threats) contain misogynistic features, we have conducted a linguistic analysis at the lexical and discourse level. Misogyny has been defined by Fersini et al. (2018b: 58) as a ‘specific case of hate speech whose targets are women’. Since the manifestations of misogyny, as acknowledged by the authors, can take a plethora of forms, and they do not necessarily convey explicit hate speech, we have considered as misogynistic those expressions which disparage women based on attributes associated with their gender.
For quantitative tasks, we have used the NLTK python package and the software Sketch Engine (Kilgarriff et al., 2014). We have pre-processed the text to make it machine-readable, removing from each reply all the non-verbal terms, such as URL links, emojis and elements of the Twitter interface (e.g. the @ at the beginning of reply tweets indicating the author of the original tweet). We further turned the # and @ present inside the text into plain words. We are aware that not considering emojis, images and videos constitutes a limitation of this study. The choice of narrowing the scope of our analysis to text is empirically motivated: to our knowledge, there are no tools available for the automatic identification of toxic content at a multimodal level for the Italian language. This is partly because most tools have been developed for English. While there are automated tools for detecting toxic content in images, the textual context is essential for interpreting their meaning.
After this preprocessing, we have parsed for part of speech (POS) the insults/profanity female and male corpora and we have compared the frequencies of the 50 most frequent adjectives and nouns. After having identified nouns and adjectives potentially gender-sensitive, we have qualitatively examined their concordances (occurrences in context) to account for polysemy. For the sub-corpora identity attack and threat, which tend to be expressed by more than one lexical item, we have analysed through content analysis the 50 replies with the highest score per subcorpus to classify them according to illocutionary force (Searle and Vanderveken, 1985).
Results
Statistical analysis
Distribution of toxicity attributes: An overall view
A total of 91,084 unique Twitter accounts interacted with the 9581 original posts from politicians. Of the collected replies, 156,236 were directed at male politicians, and 68,420 at female politicians. Due to this substantial difference, our statistical analysis focuses on comparing the relative frequencies of highly toxic replies rather than the absolute counts.
Overall, posts by male politicians were more likely to prompt user engagement, with a reply ratio of roughly 7:3 compared to posts by female politicians. The political party that received the most replies was Brothers of Italy (FDI), accounting for 29% of all replies, followed by League with 21%. The Democratic Party (PD) and Fratelli d’Italia (FI) received 12% of the replies, Action and Italia Viva (IV) 11%, while M5S had the lowest engagement, with only 4% of total replies.
Table 2 below shows the descriptive statistics for all the toxicity measures.
Descriptive statistics for the six toxicity measures computed through Perspective API.
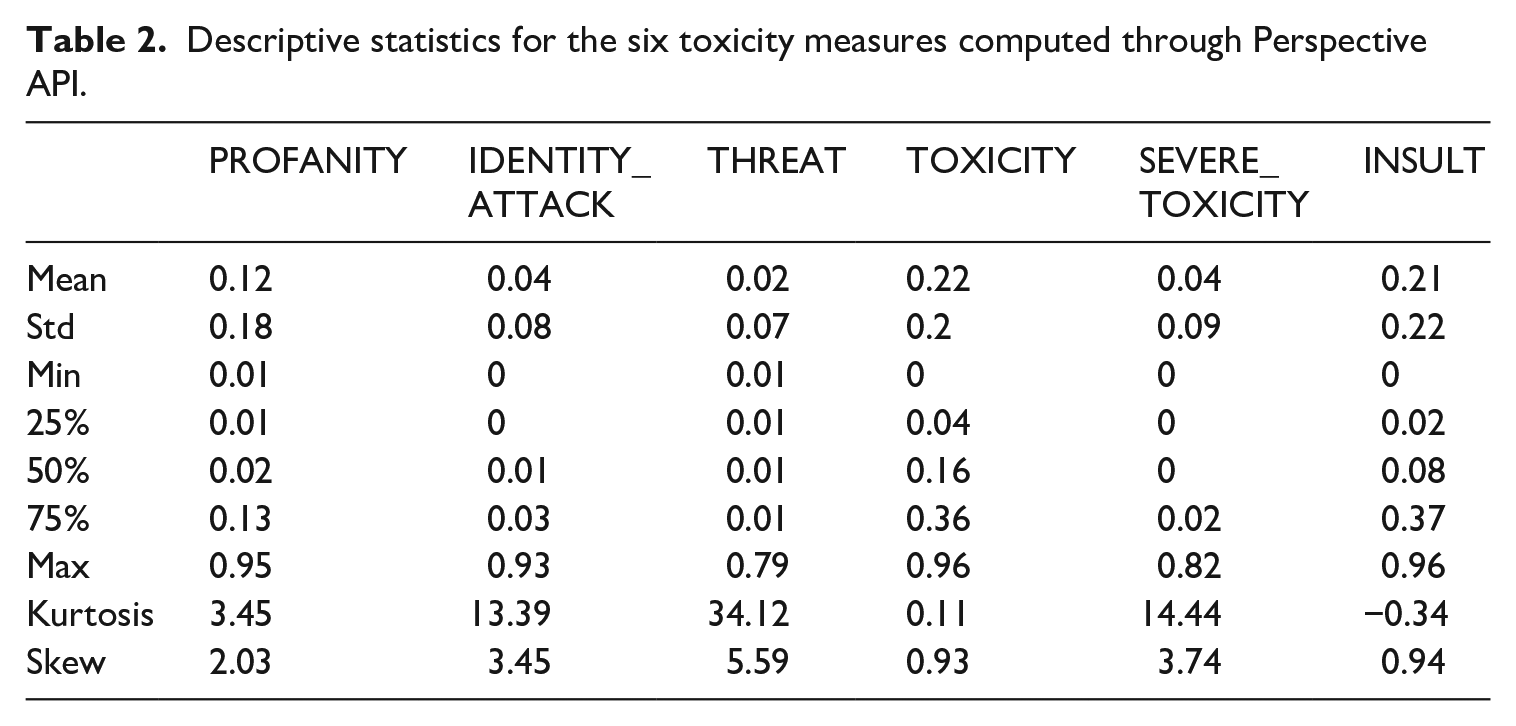
To examine the joint distribution of the toxicity attributes, we investigated the potential overlap in the classification of users’ replies, given the semantic similarities among the categories. To verify the presence of overlap, we have calculated the statistical correlation between the toxicity attributes, using the Kendall τ correlation coefficient, a non-parametric correlation parameter appropriate for our positively skewed toxicity distributions (as shown in Table 2). Thus, parametric tests such as those based on the Pearson r coefficient are not suitable, as they assume that the data is normally distributed. The values of the Kendall τ index between the different toxicities (Table 3) confirm strong positive correlations among all the toxicity attributions. In particular, the highest correlations are between toxicity and insult (0.99) and toxicity and severe toxicity (0.96). To reduce redundancy in the analysis, we defined a new parameter called tox-sev_tox-ins which corresponds to the median value of insult, severe toxicity and toxicity to be used in the rest of the statistical analysis. It is important to note that profanity shows a strong correlation with severe toxicity (0.94), but a weaker correlation with general toxicity and insults. This may be because severe toxicity is defined as an umbrella category, representing a high level of intensity that could prompt a user to leave a discussion. While profanity differs in language from general toxicity, it can still lead to the same consequences, such as being classified as severe toxicity. To maintain this distinction, we chose not to merge profanity with other attributes.
Correlation table (computed with the Kendall τ coefficient) of the toxicity measures.

Asterisks indicate that a value is higher than expected by a statistically significant margin. (*p < .05, **p < .01, ***p < .001) after Holm-Bonferroni correction for the post hoc tests.
Distribution of toxicity attributes by gender and political party
It must be remarked that the number of replies classified as potentially toxic (toxicity level > 0.3) is very different for the different measures. As represented in Figure 1, for profanity and tox-sev_tox-ins, there is a sizable number of potentially toxic replies (30,474 and 66,049, respectively, counting both male and female politicians), while for threat and identity attack, the numbers are way lower (4686 and 5711) with the majority of replies receiving a low toxicity score. This is not surprising, as threat and identity attack are forms of toxicity that require complex expressions and they are less likely to appear in a high percentage of replies.
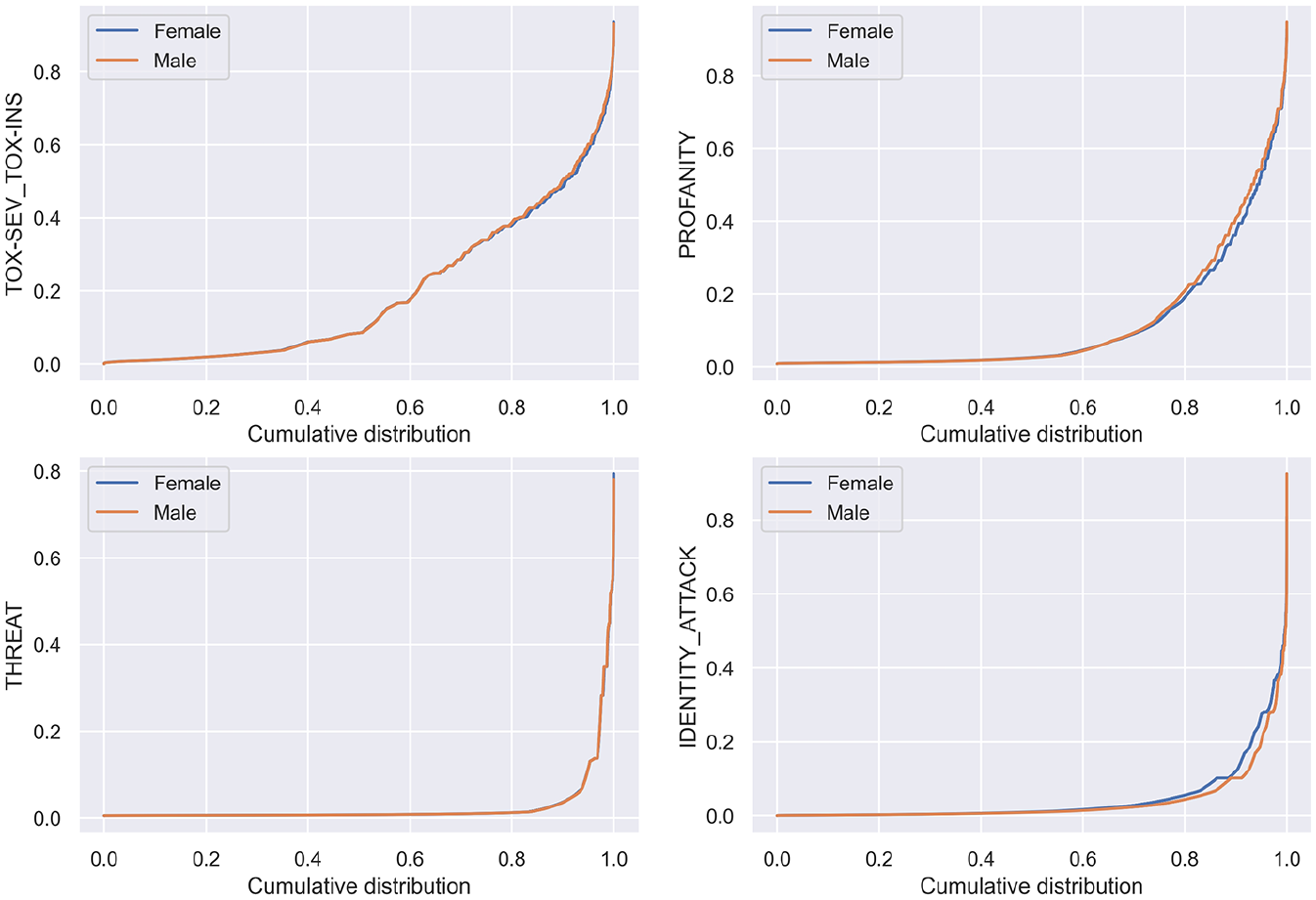
Quantile plots for the variables profanity, threat, identity_attack and tox-sev_tox-ins for replies to female and male politicians.
We, then, tested whether the distribution of replies with the different attributes of toxicity is the same for male and female politicians. We approached this problem treating the toxicity scores as qualitative variables (https://developers.perspectiveapi.com/s/about-the-api-training-data?language=en_US), in line with the guidelines provided by the developers. Given that the distributions of the various toxicity parameters are highly asymmetric (see in Table 2 that they have all positive skew), an analysis of variance (ANOVA) test is not feasible. We excluded the use of rank-base alternatives, such as the Mann–Whitney test, since it would amplify the differences between low-toxicity replies compared to the differences among the fewer high-toxicity tweets. We thus categorised the tweets into three different groups using the thresholds of 0.3 and 0.7. The latter threshold is suggested by the developers as the one to consider a comment highly likely to be toxic in social science research.
8
The former approach is retained to prevent the potential loss of comments that may contain subtle forms of toxicity. A threshold of 0.3 is recommended in the developers’ guidelines for human moderation teams with the capacity to focus on more nuanced cases of toxicity. We used a
We observed that the values of tox-sev_tox-ins and profanity are significantly higher towards male politicians, while the values of identity attacks are significantly higher towards female politicians. The distribution of threat is largely independent of the gender of the target. We repeated the same analysis dividing the politicians by party of affiliation. We first divided all the replies (to male and female politicians) by party, as visualised in Table 4.
Contingency table of the replies divided by party affiliation of the target and level of toxicity.
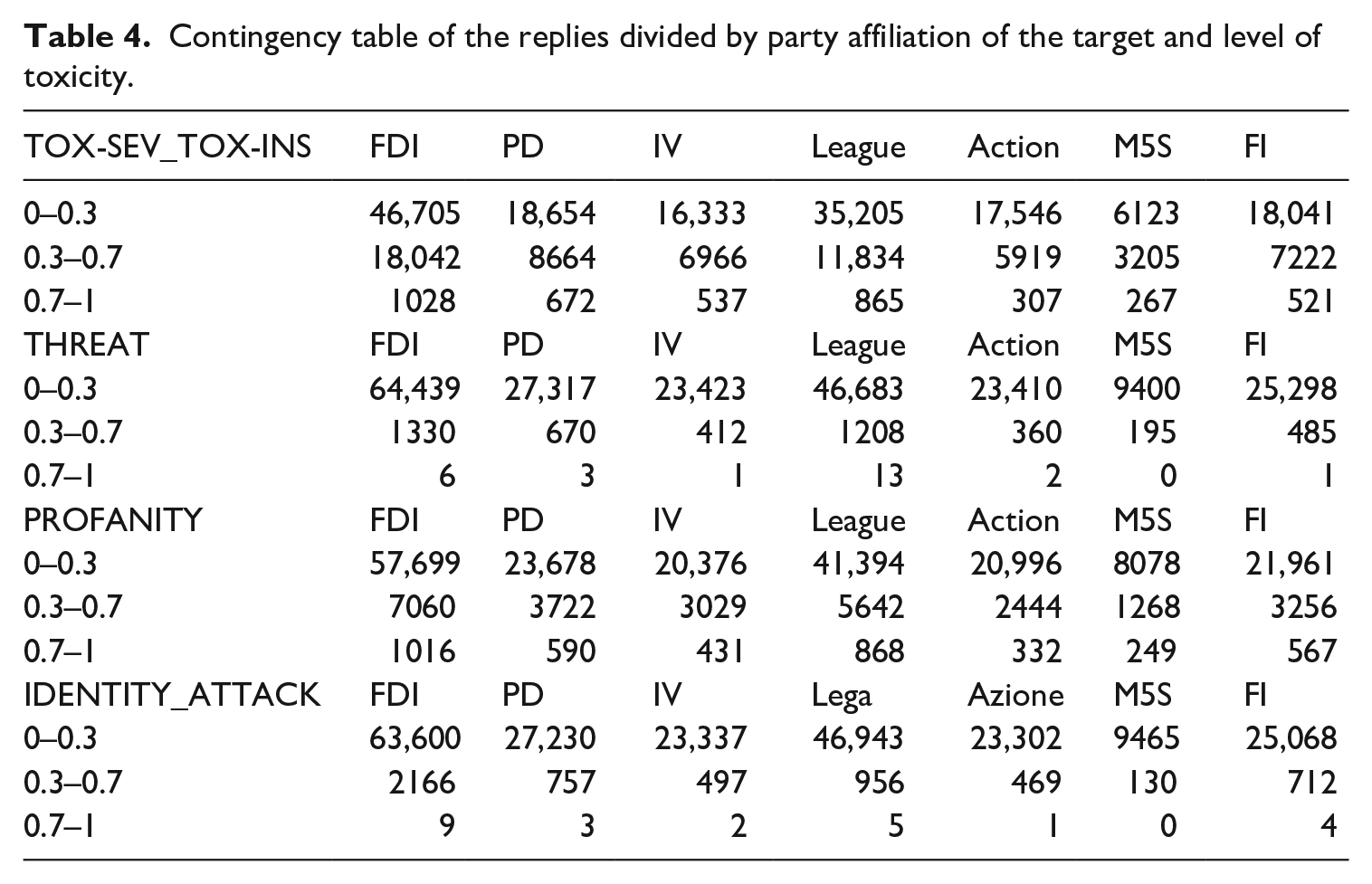
Then, for each party, we tested whether the level of each toxicity measure is independent or not of the gender of the target. Since the number of replies which are classified as being highly likely to contain threat and identity attack is very low, in some cases even 0, we use for those variables the Fisher exact test instead of the
Contingency table of toxicity levels of the replies and gender of the target, for the party which receives the highest proportion of highly toxic replies for each toxicity measure.
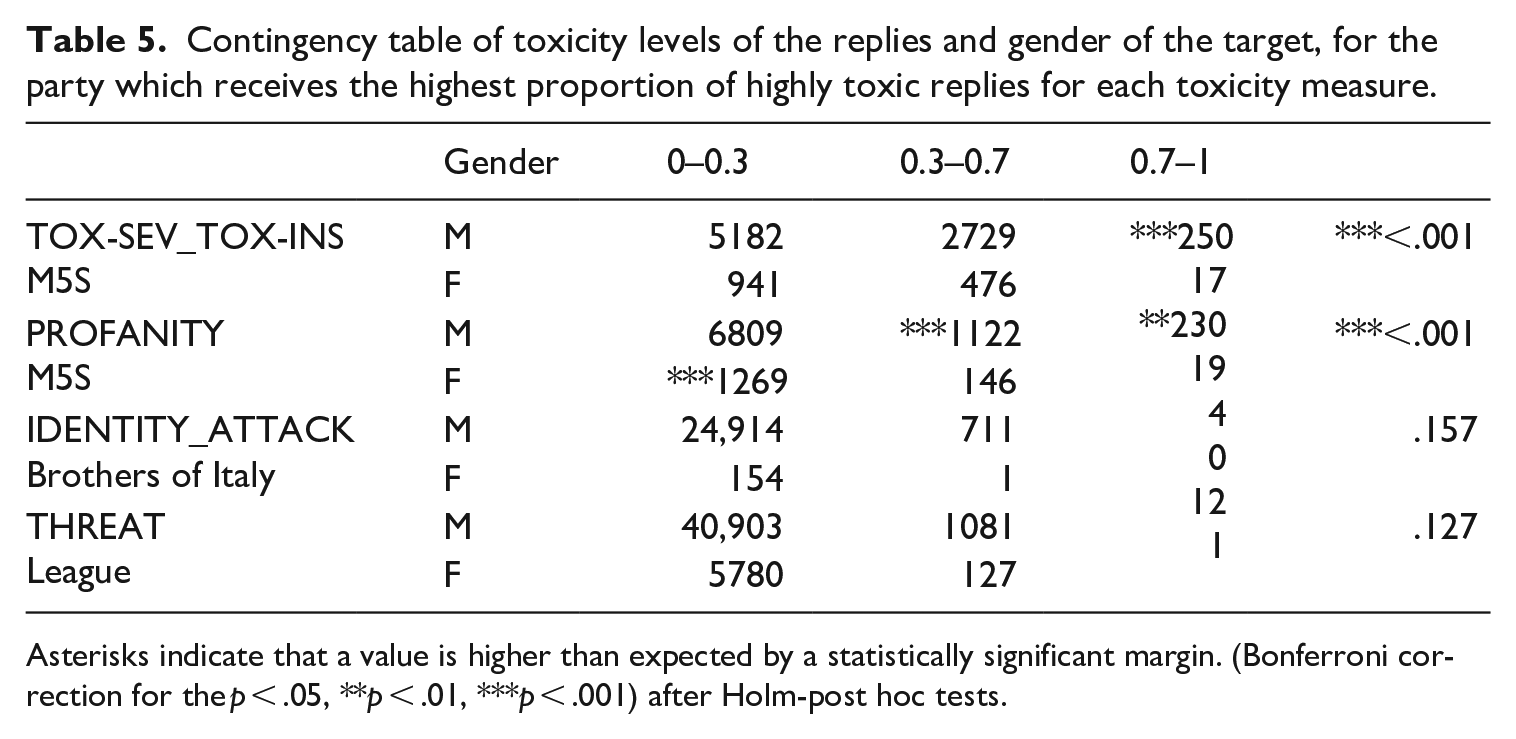
Asterisks indicate that a value is higher than expected by a statistically significant margin. (Bonferroni correction for the p < .05, **p < .01, ***p < .001) after Holm-post hoc tests.
Linguistic analysis
According to the statistical analysis, male politicians receive more insults and profanity attacks than female politicians. To assess whether these types of insults and of profanity are gendered-sensitive, we extracted all nouns and all adjectives—POS most often involved in insults and profanity—from the four sub-corpora (insults_male; insults_female; profanity_male; profanity_female), all with classification scores above 0.7.
A comparison of the most frequent 50 nouns and adjectives in the insult_male and insult_female corpora reveals that both rely lexically on similar semantic categories aimed at discrediting the politician’s trustworthiness: lack of credibility (e.g. ‘pagliaccio/a’ ‘buffone’, ‘clown’), insincerity (e.g. ‘falso/a’, ‘bugiardo/a’, ‘ipocrita’, ‘liar’), incompetence (e.g. ‘ignorante’, ‘ignorant’, ‘incapace’, ‘not competent’; ‘stupido/a’, ‘stupid’) or morally reprehensible behaviour (‘fascisti’/‘nazi’). These undermine the politicians’ reputations based on benevolence, competence and integrity, as defined by organisational models of trust (Schoorman et al., 2007).
Other shared lexicon refers to physical aspects (‘brutto/brutta’, ‘ugly’) and age (‘vecchio’, ‘old’) which are not politically relevant and instead function as ad hominem attacks. Concordance analysis shows that in the male_insult corpus, ‘brutto’ (‘ugly’) is used just once out of the 76 occurrences to reference physical appearance; the rest serve as intensifiers (e.g. ‘brutto coglione/bastard’, ‘big bastard’). In contrast, in the female_insult corpus, only 5 of 46 uses are non-physical traits. Most stress unpleasant appearance to discredit women (e.g. ‘brutta nana false’, ‘ugly midget lier’, ‘tanto brutta quanto idiota’, ‘both ugly and idiotic’). One tweet reads: ‘ma rifatte la faccia che sei brutta come la merda’ (‘but get your face done that you are ugly as shit’), entirely void of political reference, while the user advocates for a change in the politician’s appearance.
Similarly, the adjective ‘vecchio’ (‘old’) targets male politicians as mentally unfit (e.g. ‘rincoglioniti’—‘dim-witted’/ ‘stupid.’), while in female-directed insults, it supports degrading stereotypes of women as witches or hens (‘vecchia befana’, ‘vecchia gallina’).
In the profanity sub-corpora, equivalent swear words (e.g. ‘cazzo’, ‘dick’, ‘vaffanculo’, ‘fuck you’, ‘merda’, ‘shit’) constitute the most common terms across board (example: ‘Fottiti, grandissima zoccola fascista del cazzo’, ‘Fuck you, you big fucking fascist slut’). Focusing on etymologically gendered terms, there is a striking difference in the use of the noun ‘puttana’ (lit. ‘prostitute’): while in the male_profanity corpus the term is used in idiomatic expressions such as ‘porca puttana’ (‘holy shit’) where the sexual connotation is not available, in the female_profanity corpus it is also used to address the female politician (e.g. ‘Se fate saltare la 194 vi inculiamo senza lubrificante. Puttana non osarti manco a nominarlo borsellino’, ‘If you blow the 194 9 we’ll fuck you in the ass without lube. Bitch, don’t you dare even mention Borsellino’.
To investigate identity-based attacks and threats directed at women, we carried out a qualitative content analysis of the 50 highest-scoring replies for each category (identity attack and threat), regardless of political affiliation. Only four identity attacks directly targeted politicians; the majority focused on immigrants, Palestinians and Ukrainians. In these cases, the identity attack functions less as a speech aimed at politicians and more as an invitation to act upon a group of people whose identity is discredited. This situation demonstrates that online haters target politicians, encouraging them to engage in violent acts against certain groups, while framing identity-based hate as a political stance (e.g. ‘Cacciate via tutti gli spacciatori e delinquenti africani arrivati illegalmente con barchini o tramite ONG. Ripulire l’Italia dalla sporcizia africana illegale’, ‘Throw out all the African drug dealers and criminals who arrived illegally on boats or through NGOs. Clean Italy from illegal African filth’).
The four direct attacks on politicians leverage conspiratorial thoughts labelling, for instance, Giorgia Meloni as ‘schiava degli states’ (‘slave of the States’) and Elly Schlein as ‘bastarda sionista’ (‘zionist bastard’). As for threats, 18 of the 50 analysed cases were aimed at politicians. The type of attacks varied by political party: members of PD and M5S are repeatedly threatened with variations of the directive speech act ‘Dovete sparire’ (‘you must disappear’), while politicians from other parties received more personal and violent threats (e.g. ‘@GiorgiaMeloni. Zoccala vergognati vai a casa dimetti uccidiamo tua figlia’, ‘Bitch, shame on you, go home, resign, we’ll kill your daughter’).
Discussion and conclusion
In this article, we have examined toxic speech directed against Italian politicians on Twitter (now ‘X’) by analysing 224,656 user replies to political posts over 40 days. Combining natural language processing, statistical analysis and linguistic analysis, we offer the first systematic corpus-based study in Italian to investigate whether toxic speech is gendered and, if so, in what ways (quantity and/or type). We chose the Italian context not only because it is underexplored but also due to it the recent historic rise of a woman to the position of Prime Minister, marking a shift in Italy’s long history of excluding women from political leadership.
The automatic classification of the replies revealed four main categories of toxicity (in order of frequency): insults/severe toxicity, profanity, identity attacks and threats. Statistical analysis shows that insults/severe toxicity and profanity are more frequently directed at male politicians, while identity attacks mostly target female politicians. Threats appeared to be gender-neutral.
These findings align with patterns observed in the Netherlands, suggesting that misogyny in Italy manifests more in the type of toxic/hate messages received than in volume. The fact that male politicians receive more replies on average than female colleagues may reflect a form of ‘othering’ (Harmer, 2023), implying women are seen as less relevant political actors. These results are specific to Italy and reflect the country’s historical and cultural constraints, including gendered socialisation that has led women to be more focused on local, domestic, and private spheres, and a delayed feminist movement. Unlike in other countries, Italy’s feminist movement concentrated more on micro-social issues rather than political representation.
A closer look at political affiliations shows that M5S attracts the most insults/severe toxicity and profanity, while Forza Italia is the main target of identity attacks and la League receives the most threats. A hypothesis for future research is whether the content of the original posts (topic) correlates with the volume and type of the toxic replies.
The qualitative linguistic analysis of replies containing insults/severe toxicity and profanity reveals themes common across genders, pointing to coprolalic language and references to lack of sincerity, credibility and competence. However, derogatory references to physical appearance and age appear only in attacks on women. Although words like ‘brutto/a’ (‘ugly’) and ‘puttana’ (‘prostitute’) are not significantly more frequent towards women, their usage is gendered: they function as general intensifiers towards men, but reference women’s physical appearance or sexuality when directed at them. This reflects broader tendencies in Italian media to focus more on women’s personal features than their political skills (Belluati, 2020).
These gendered differences cannot be captured through the outputs of classifiers or word frequencies alone and are, thus, often missed by moderation systems that rely on preliminary automatic filtering. Qualitative analysis turns out to be especially crucial for detecting identity attacks and threats, which are often expressed through complex speech acts and receive low classifier scores. For example, the qualitative analysis of 50 tweets per attribute with the highest score revealed that prototypical identity attacks scored far less than 0.7. Another issue is identifying the actual target of the identity attack: many tweets contain identity attacks not aimed at the politician, but at immigrants and minorities. In the few cases where politicians are targeted, attacks focus on traits like ethnic origin or motherhood. This highlights the need for political parties to address the gendered identity attacks. However, the Brothers of Italy party currently frames gender issues only around protecting mothers, without acknowledging the broader importance of gender equality in political representation.
This study is limited in scope: it focuses on a time-bound sample from a single platform, so the volume of toxic speech directed at male and female politicians cannot be generalised across social media. Due to the depreciation of the Twitter Academic API when the platform became ‘X’, we were unable to verify how many toxic replies classified flagged by Perspective API were later removed through moderation. Furthermore, the lack of knowledge about users’ gender limits insights into the profiles of haters. In the future, we will explore the network centrality of the most targeted politicians to assess whether female figures are targeted by habitual haters.
In conclusion, this study reveals that misogynistic language used before and during Italian snap elections persists even after the election of Italy’s first female Prime Minister. This unhealthy digital environment cannot be improved by relying solely on automatic classification systems which are unable to identify complex phrases or covert cases of toxicity, underscoring the need for a more solid human moderation across digital platforms.
Footnotes
Appendix
List of all politicians with party affiliation.
| Politician name | Twitter handle | Party | Gender |
|---|---|---|---|
| Debora Serracchiani | serracchiani | PD | F |
| Beatrice Lorenzin | BeaLorenzin | PD | F |
| Roberta Pinotti | robertapinotti | PD | F |
| Elly Schlein | ellyesse | PD | F |
| Alessandra Moretti | ale_moretti | PD | F |
| Enrico Letta | EnricoLetta | PD | M |
| Nicola Zingaretti | nzingaretti | PD | M |
| Dario Franceschini | dariofrance | PD | M |
| Giuliano Pisapia | giulianopisapia | PD | M |
| Graziano Delrio | graziano_delrio | PD | M |
| Giorgia Meloni | GiorgiaMeloni | FDI | F |
| Daniela Santanchè | DSantanche | FDI | F |
| Isabella Rauti | isabellarauti | FDI | F |
| Chiara Colosimo | ChiaraColosimo | FDI | F |
| Augusta Montaruli | augustamontarul | FDI | F |
| Guido Crosetto | GuidoCrosetto | FDI | M |
| Ignazio La Russa | Ignazio_LaRussa | FDI | M |
| Raffaele Fitto | RaffaeleFitto | FDI | M |
| Lucio Malan | LucioMalan | FDI | M |
| Fabio Rampelli | fabiorampelli | FDI | M |
| Maria Elena Boschi | meb | FDI | F |
| Teresa Bellanova | TeresaBellanova | FDI | F |
| Lucia Annibali | LAnnibali | IV | F |
| Raffaella Paita | raffaellapaita | IV | F |
| Daniela Sbrollini | DaniSbrollini | IV | F |
| Matteo Renzi | matteorenzi | IV | M |
| Roberto Giachetti | bobogiac | IV | M |
| Ivan Scalfarotto | ivanscalfarotto | IV | M |
| Luigi Marattin | marattin | IV | M |
| Davide Faraone | davidefaraone | IV | M |
| Francesca Donato | ladyonorato | League | F |
| Giulia Bongiorno | gbongiorno66 | League | F |
| Laura Ravetto | lauraravetto | League | F |
| Silvia Sardone | SardoneSilvia | League | F |
| Barbara Saltamartini | BSaltamartini | League | F |
| Matteo Salvini | matteosalvinimi | League | M |
| Claudio Borghi | borghi_claudio | League | M |
| Alberto Bagnai | AlbertoBagnai | League | M |
| Luca Zaia | zaiapresidente | League | M |
| Antonio M. Rinaldi | Rinaldi_euro | League | M |
| Michela V. Brambilla | mvbrambilla | FI | F |
| Renata Polverini | renatapolverini | FI | F |
| Anna Maria Bernini | BerniniAM | FI | F |
| Deborah Bergamini | DeborahBergamin | FI | F |
| Annagrazia Calabria | CalabriaTw | FI | F |
| Silvio Berlusconi | berlusconi | FI | M |
| Renato Brunetta | renatobrunetta | FI | M |
| Maurizio Gasparri | gasparripdl | FI | M |
| Antonio Tajani | Antonio_Tajani | FI | M |
| Elio Vito | elio_vito | FI | M |
| Paola Taverna | PaolaTavernaM5S | M5S | F |
| Chiara Appendino | c_appendino | M5S | F |
| Giulia Grillo | GiuliaGrilloM5S | M5S | F |
| Carla Ruocco | carlaruocco1 | M5S | F |
| Roberta Lombardi | robertalombardi | M5S | F |
| Beppe Grillo | beppe_grillo | M5S | M |
| Giuseppe Conte | GiuseppeConteIT | M5S | M |
| Roberto Fico | Roberto_Fico | M5S | M |
| Danilo Toninelli | DaniloToninelli | M5S | M |
| Alfonso Bonafede | AlfonsoBonafede | M5S | M |
| Mara Carfagna | mara_carfagna | Action | F |
| Emma Fattorini | EmmaFattorini | Action | F |
| Giulia Pastorella | PastorellaGiu | Action | F |
| Mariastella Gelmini | msgelmini | Action | F |
| Elena Bonetti | elenabonetti | Action | F |
| Carlo Calenda | CarloCalenda | Action | M |
| Andrea Mazziotti | _AMazziotti | Action | M |
| Matteo Richetti | MatteoRichetti | Action | M |
| Marco Lombardo | mlombardo81 | Action | M |
| Enrico Costa | Enrico__Costa | Action | M |
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.