
Abstract
Soil erosion is a significant threat to both agricultural productivity and natural resources. The most commonly applied soil erosion models are the Universal Soil Loss Equation (USLE) and its revised version (RUSLE), which rely heavily on the Cover Management factor (C factor) as a critical input parameter. This study aims to improve the accuracy of C factor estimates for the Netravati catchment present in the Western Ghats and Coastal Plains of India by using the Random Forest Algorithm and Sentinel 2 satellite data. The research examined five commonly used Normalized Difference Vegetation Index (NDVI) based C factor estimating equations and found that they inadequately represented local vegetation dynamics in the study area. To address this, a high-resolution Land Use Land Cover (LULC) map was generated using the Random Forest algorithm and in situ C factor values were assigned to LULC classes. A regression analysis between Sentinel 2-derived NDVI and the actual C factor yielded a novel equation. The proposed equation estimated C factor values ranging from 0.056 to 0.99, which closely align with actual observations and outperforming existing methods. The model’s performance was evaluated using statistical metrics, including a correlation coefficient of 0.984, mean absolute error of 0.048, root mean square error of 0.058, and Kling-Gupta efficiency of 0.921, indicating superior accuracy compared to existing methods. This study presents a region-specific approach for estimating the C factor, serving as a reliable tool for improving soil erosion predictions in the Western Ghats and Coastal Plains of India. Apart from highlighting the need for local parameterisation, the results have important implications for soil conservation planning, erosion risk management, and sustainable land use practices in the region.
Introduction
Soil erosion is a critical environmental issue, which causes the quality and productivity of soil to deteriorate gradually (Huang et al., 2021; Mohammed et al., 2025). It contributes to land degradation, reduced agricultural productivity and sedimentation in water bodies, further impacting ecosystems and human livelihoods (Food and Agriculture Organization of United Nations [FAO], 2015a; Lal, 2003). The estimated annual loss through soil degradation is 12 million ha, while 24 billion tons of fertile soils are lost to erosion (FAO, 2015b). Soil erosion mitigation has gained significant importance for natural resources management and conservation (Lal, 2001; Martínez-Mena et al., 2020). Several models are available to quantify the amount of soil loss and guide direct conservation actions for preventing soil loss. An accurate soil erosion modelling is crucial for adequate soil and water conservation planning and management (Borrelli et al., 2021; Ketema & Dwarakish, 2021; Parsons, 2019; Vereecken et al., 2016).
One of the most popular models for predicting soil erosion and organising soil and water conservation measures is the Revised Universal Soil Loss Equation (RUSLE) (Renard et al., 1997), which is an updated version of the Universal Soil Loss Equation (USLE) (Wischmeier & Smith, 1978). The model has multiple factors, which include rainfall erosivity (R), soil erodibility (K), slope length and steepness (LS), land cover and management (C) and conservation practices (P), which are combined to determine the amount of Soil loss (A) using the general formula
Traditionally, in situ field experiments, consisting of soil erosion plots exposed to natural rainfall, must be conducted directly in the field to determine the C factor. However, this approach can be resource-intensive and time-consuming (Borrelli et al., 2021; Nearing et al., 2005, 1994). This approach may apply to a field or farm-size (Benavidez et al., 2018; Borrelli et al., 2016) but may not be feasible to monitor across an entire basin or large watershed (Ghosal & Das Bhattacharya, 2020; Majhi et al., 2021; Makhdumi et al., 2023). Therefore, developing alternative methods to estimate the C factor utilising readily available data is crucial. Factors including prior land management practices, vegetation canopy coverage, surface cover characteristics and roughness, and soil moisture conditions influence the C factor (Gabriels et al., 2003; Taye et al., 2018). Remote sensing (RS) data and geographical information systems (GIS) have shown the potential to estimate these parameters and map the spatial distribution of the C factor (Bagherzadeh, 2014; Kashiwar et al., 2022; Leh et al., 2013; D. Lu et al., 2004; X. Yang et al., 2020). The two prevalent approaches involve the utilisation of LULC maps and the Normalized Difference Vegetation Index (NDVI) to estimate the C factor (Xiong et al., 2023; Zhang et al., 2011).
The researchers have assigned the C factor values to respective land cover types identified by developing LULC maps of the study area. These C factor values are based on actual values reported in previous studies, experimental data and government reports of the respective study area (Benavidez et al., 2018; Borrelli et al., 2021; Ghosal & Das Bhattacharya, 2020). This approach has been applied on a regional scale (Bera, 2017; Krasa et al., 2010; Latocha et al., 2016; Markose & Jayappa, 2016; Santra & Mitra, 2020; Teng et al., 2018), country scale (Lee et al., 2017; H. Lu et al., 2003; Pásztor et al., 2016; Teng et al., 2016; Waltner et al., 2020) to global scale (Pham et al., 2001; D. Yang et al., 2003) for erosion assessment. Further, researchers have put forth multiple empirical equations that relate NDVI to C factor values (Bahrawi et al., 2016; De Jong et al., 1998; Durigon et al., 2014; Van der Knijff et al., 2000). Researchers worldwide have widely used these linear and non-linear relations between NDVI and C Factor (Colman et al., 2018; Panagos et al., 2015; Rawat & Singh, 2018; Thomas et al., 2018). The soil erosion modelling based on correlating NDVI and C factors shows enhancement in results, both spatially and temporally (Alewell et al., 2019; Benavidez et al., 2018; Xiong et al., 2023).
Although RS-based techniques have great potential, critical limitations persist in current C factor estimation approaches. These approaches could introduce ambiguities if they are not verified against accurate data from the ground, making local parameterisation essential (Almagro et al., 2019; Borrelli et al., 2021; Mukharamova et al., 2021). Two major research gaps identified are: The existing NDVI-based equations are region specific and inadequately represent the complex global vegetation dynamics. Moreover, despite India’s severe erosion rates, no study has developed a region-specific C factor model needed for precise soil erosion modelling.
The aim of the present study is to refine and enhance the regional C factor estimation for the Western Ghats and Coastal Plain, which is one of India’s 20 agroecological regions (Pal, 2019). Due to high-intensity monsoons, steep terrains and LULC changes, soil erosion is a major concern in the region (Aulakh & Sidhu, 2015; Makhdumi et al., 2023; National Remote Sensing Centre, 2019; Space Application Centre, 2016). Focusing on the Netravati catchment present in the region, the study employs an advanced machine learning technique – the Random Forest (RF) algorithm, on high-resolution Sentinel 2 satellite data to parameterise the C factor. The study seeks to produce a highly accurate and detailed LULC map for the Netravati Catchment using RF algorithm, which is further used to assign C factor values based on established empirical data specific to the region. Further, the study investigates the potential of using NDVI to improve C factor estimation. NDVI, derived from multi-year Sentinel 2 data, offers a dynamic approach to assess vegetation cover, which directly influences the region’s vulnerability to soil erosion. The C factor was estimated using multiple equations relating NDVI to the C factor. A new region-specific C factor equation is proposed to improve the computation of the C factor specific to the region, taking into account the local variability of LULC, and the performance of the results obtained from these equations was assessed using statistical metrics.
Study Area
The Western Ghats and Coastal Plain area is covered in tropical wet deciduous forests and is one of the 20 distinct agroecological regions of India, having an area of around 11.8 Mha. (Makhdumi et al., 2023; Pal, 2019). Paddy, arecanut, coconut and spices are majorly cultivated in the region. The Netravati Catchment having an area of about 3,415 km2 and elevations ranging between 0 and 1719 m lies in the central part of the Western Ghats Mountain range (Figure 1). Due to the presence of steep slopes and heavy rainfall, soil erosion is a significant issue that needs to be addressed (Ganasri & Ramesh, 2016; Makhdumi & Dwarakish, 2019). The Netravati originates in the Western Ghats and flows west through Bantwal town and Mangalore city for which it is a major water source before its confluence with the Arabian Sea. The various industries and agricultural sectors are also dependent on the Netravati River. The annual rainfall in the catchment exceeds 3,900 mm, falling within three monsoonal periods March to May, Pre-monsoon, June through September, Southwest Monsoon and from October through December, Northeast Monsoon of which the former, Southwest Monsoon accounts for the largest share (Jose et al., 2022). The major crops grown in the catchment are paddy, arecanut, cashewnut, coconut, rubber and banana (Felix & Ramappa, 2023; Singha et al., 2014).

Location, stream network and topography of the Netravati catchment within the Western Ghats and Coastal Plain of Karnataka, India.
Materials and Methodology
Datasets
In the study, both conventional (cartographic and ground based) and remote sensing data (SRTM DEM and Sentinel 2) were used. The digitised Survey of India (SOI) toposheets of scale 1:50,000, and 30 m resolution SRTM DEM were used to create a base map of the study area. The satellite data of Sentinel 2 of 10 m resolution accessed via Google Earth Engine (GEE), sourced from the European Space Agency (ESA) from January 2019 to December 2022, were used to create the LULC and NDVI maps. These layers along with the data from Indian Council of Agricultural Research (ICAR) formed the foundation for developing the C factor maps and regional C factor equation. The summary of the data sources used is provided in Table 1. The Geospatial software like ArcGIS, ERDAS Imagine and GEE, a geospatial platform, were used to process and analyse the data. The integration of these datasets into the methodological workflow is shown in Figure 2 and is elaborated in the following sub sections in details.
Description of the Datasets Used in this Study for C Factor Estimation.


Overall methodology flowchart to estimate C factor for the Netravati catchment.
Estimation of C factor from LULC classification
Researchers assign C factor values to the LULC classes existing in the region. These C factor values are taken from relevant earlier studies, technical reports and field observations conducted in the same region (Alewell et al., 2019; Benavidez et al., 2018; Sampath & Radhakrishnan, 2023). In this study, the Random Forest (RF) classification technique developed by Breiman in 2001 was employed to produce a detailed LULC map within the GEE platform. The RF algorithm was chosen due to its superior performance in LULC classification (Belgiu & Drăguţ, 2016; Rodriguez-Galiano et al., 2012; Sampath & Radhakrishnan, 2023; Talukdar et al., 2020). RF operates on the principle of ensemble learning, where multiple decision trees are combined to enhance overall performance. RF uses bootstrap aggregation to randomly select subsets of both training data and features to create each tree. This method ensures variability and reduces the chance of any one tree becoming overly fitted to the training data (Iranzad & Liu, 2024; McClarren, 2021). The final prediction is determined by averaging the outputs from all decision trees. This approach improves generalisation, making RF particularly effective for LULC classification (McClarren, 2021).
As shown in Figure 2, Sentinel 2 data from January 21, 2022, with a spatial resolution of 10 m, and cloud cover of less than 5%, provided the basis for analysis. The bands selected—Band 8 (near infrared), Band 4 (red), Band 3 (green) and Band 2 (blue)—are well-suited for land cover classification due to their sensitivity to vegetation, water and built-up areas (Iranzad & Liu, 2024; Sankalpa et al., 2024). The imagery was pre-processed, followed by clipping it to the study area using a shapefile that defined the ROI. This ROI was defined based on the delineation done using toposheets and SRTM DEM. A total of 3,000 random sampling points were selected from across the study area, representing 10 land cover classes: Built-up, Plantation, Crop, Fallow, Forest, Scrub Forest, Grass/Shrub Land, Barren/Wastelands, River Sand and Water bodies. These points were chosen using high-resolution Google Earth imagery and supplemented by ground truth points from field surveys. The classifier was configured with 100 trees and the dataset was divided into training and testing subsets. Eighty percent of the points were used to train the model, while the remaining 20% were used for testing. After classification, it is essential to measure the accuracy of the classified map for a quantitative evaluation (Indraja et al., 2024; Paul et al., 2024). The model’s performance was assessed through a confusion matrix and accuracy assessment, providing quantitative measures of its reliability. Confusion matrices with accuracies and Kappa coefficient were computed using 600 validation points. After evaluating the accuracy of the LULC map, reflecting the spatial distribution of respective LULC classes, it was exported as a GeoTIFF file. The C factor values from the ICAR data were assigned to the corresponding LULC classes to develop the actual C factor map for the Netravati catchment.
Estimation of C factor from Normalised Difference Vegetation Index (NDVI)
The NDVI, derived from satellite imagery, has proven to be a valuable tool for estimating the C factor in soil erosion modelling (De Jong, 1994; De Jong et al., 1998). As a widely recognised indicator of vegetation health and density, NDVI reflects the amount of photosynthetically active radiation absorbed by plants (Equation 1) (Zhao et al., 2024). NDVI ranges from −1 to 1 and higher NDVI values correspond to denser vegetation. The denser vegetation can intercept rainfall, reduce runoff velocity and improve soil structure, thus enabling a higher ability to protect soil against erosive forces. Incorporating NDVI-derived C factor estimations have an inverse relationship with each other, into soil erosion models can significantly enhance spatial representation, particularly at regional scales.

The NDVI-based C factor estimation process, outlined in Figure 2, involved considering Sentinel 2 data of 4 years (168 tiles from January 2019 to December 2022; Cloud cover less than 5%) to calculate the NDVI for the study area. The NDVI was computed and downloaded using GEE platform. For the study, the C factor was calculated from NDVI using the five widely used equations, namely Equation 2 by De Jong et al. (1998), Equation 3 by Van der Knijff et al. (2000), Equation 4 by Durigon et al. (2014), Equation 5 by Wickama et al. (2015) and Equation 6 by Bahrawi et al. (2016). The application of these equations has also been reported by Xiong et al. (2023).





Further, an equation was proposed to estimate the C factor from the NDVI pixel value of the NDVI data that were carefully selected to correspond to specific LULC classes within the Netravati Catchment. The selection process ensured that only those NDVI values that accurately represented the respective LULC classes were included in the analysis, allowing each class to exhibit a range of NDVI values that are close but not identical. This approach preserved the natural variability within each LULC class, providing a realistic foundation for further analysis. Waterbodies and Built-up areas were excluded from this selection process due to their distinct spectral characteristics, which were considered outliers and thus not representative of the NDVI – C factor relationship. The regression analysis between NDVI and the C factor was performed and the model was chosen that provided the best fit for the data, capturing the relationship effectively. The Coefficient of Correlation (r), Mean Absolute Error (MAE), Standard Deviation (SD), Root Mean Square Error (RMSE), RMSE observation SD Ratio (RSR) and Kling-Gupta efficiency (KGE) were employed to assess the performance of the results obtained from the NDVI-based equations.
The linear relationship between observed and simulated values is represented by r (Pearson, 1895). A positive perfect correlation equals 1, while no correlation will have a value of 0. MAE is the average absolute difference between actual and predicted values (Chai & Draxler, 2014). RMSE is a critical metric for comparing methods, as it quantifies the discrepancy between model predictions and observed values (Chai & Draxler, 2014). Superior performance is indicated by lower MAE and RMSE, with 0 indicating precise alignment (Moriasi et al., 2007). The RSR standardises RMSE using the observation’s SD, which ranges from 0 to larger positive values. Superior model performance is indicated by a lower RSR (Moriasi et al., 2007). The KGE metric offers a thorough evaluation of model performance, taking into account both precision (bias and variability ratios) and accuracy (correlation coefficient r) (Gupta et al., 2009). A KGE value closer to 1 indicates superior model performance, while lower values indicate inferior performance.
Results and Discussion
This study aims to accurately estimate the C factor for the Netravati catchment using LULC classification and NDVI-based methods, which plays a key role in soil erosion modelling.
Estimation C Factor From LULC map
Level II classification was adopted, and the catchment was classified into 10 classes namely: Built-up, Plantation, Crop, Fallow, Forest, Scrub Forest, Grass/Shrub Land, Barren/Wastelands, River Sand and Water bodies, respectively using RF algorithm. The accuracy assessment was done using 600 (20%) sampling points and a confusion matrix was developed, as shown in Figure 3. An overall accuracy of 93.17% was achieved with a 0.924 Kappa coefficient. The strength of the assessment having a Kappa coefficient within the range of 0.81 to 1 is considered perfect (Abd El-Hamid et al., 2021; Anand et al., 2023). The user’s and producer’s accuracy of each class is also given in Figure 3. The chance that a pixel classified as a specific class genuinely belongs to that class is indicated by the user’s accuracy, while the chance that a specific class is correctly identified is indicated by the producer’s accuracy (Nicolau et al., 2024; Rwanga & Ndambuki, 2017; Sun et al., 2023). Apart from Barren/Wasteland with a producer’s accuracy of 87.27%, all the classes have user’s accuracy and producer’s accuracy >90%, highlighting the effectiveness of the RF algorithm in accurately classifying LULC classes as claimed by Talukdar et al. (2020).
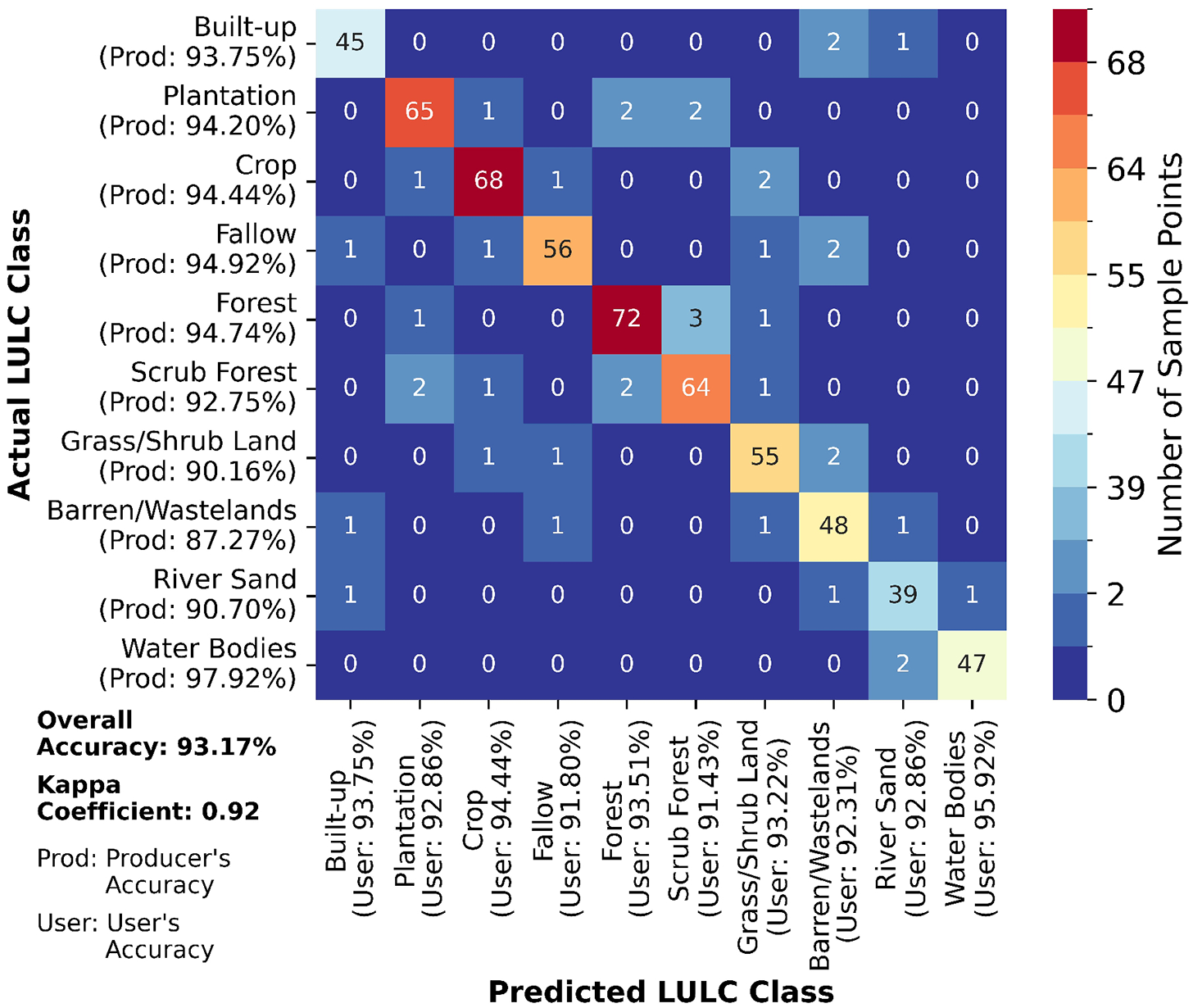
Confusion matrix of RF classified LULC in the Netravati catchment, showing sample counts and class‑wise producer’s and user’s accuracies.
An overview of land distribution within the catchment area was found, highlighting diverse land use patterns (Figure 4(a)). The area distribution in km2, and the percentage area, present the spatial extent of various LULC classes as shown in the doughnut plot in Figure 4(b). In the doughnut plot, the LULC classes have been assigned colours corresponding to those in the LULC map. Among all the classes, Forest covers a considerable 1548.10 km2 (45.33%), with plantation and Grass/Shrub land also covering sizable areas of 516.29 km2 (15.12%) and 378.47 km2 (11.08%), respectively. As the terrain towards the western side of the study area is flatter than the eastern side where the ghats are present, agricultural areas (Crops and Plantations) and Built-up areas are predominant, while Forest primarily covers the east side of the study area. This aligns with the findings by Rege et al., (2022) for parts of the Sindhudurg district, also present in Western Ghats.
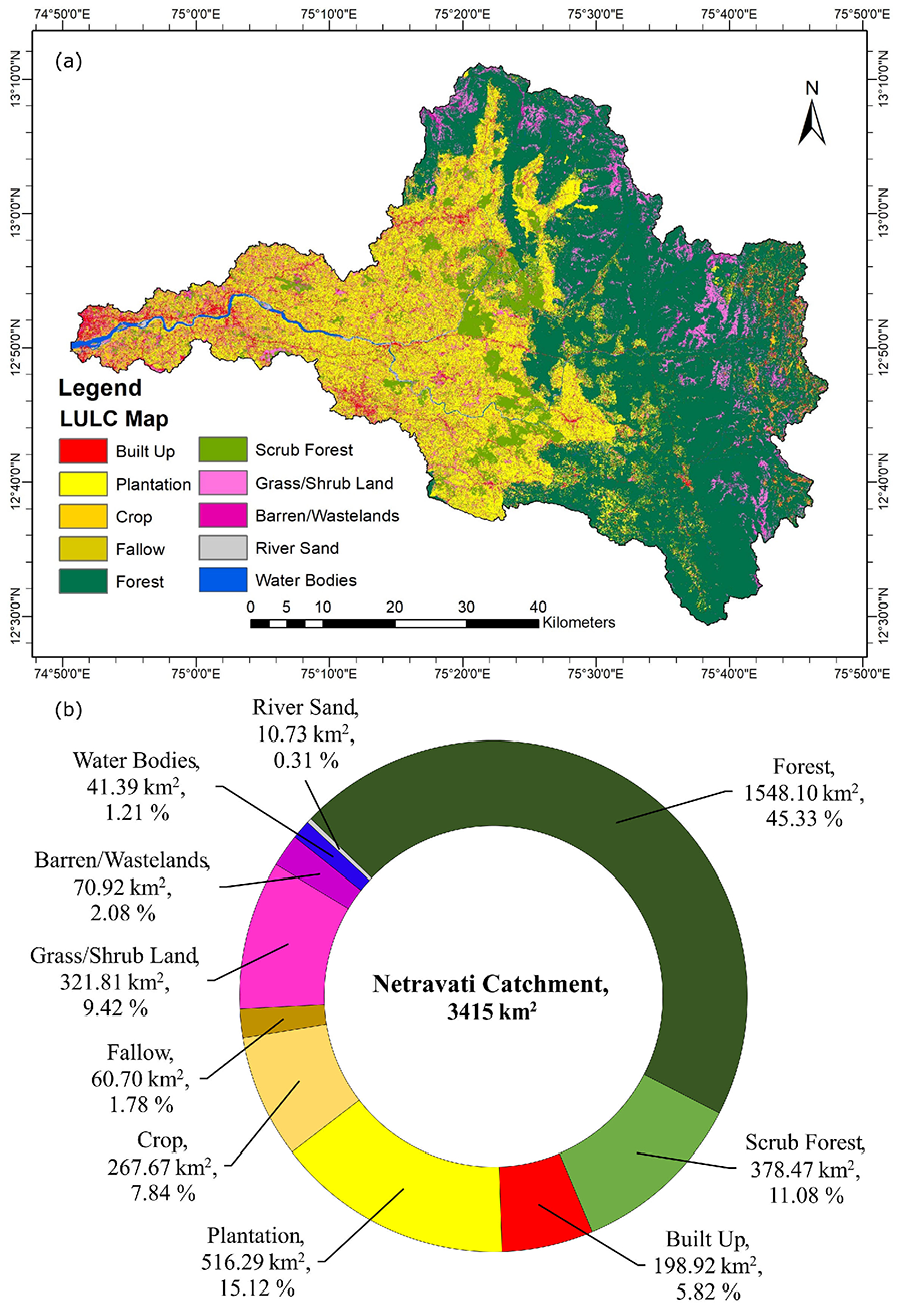
Results of LULC classification in the Netravati catchment: (a) spatial map of 10 LULC classes derived from RF algorithm (b) Doughnut chart quantifying the areal extent and percent share of each class.
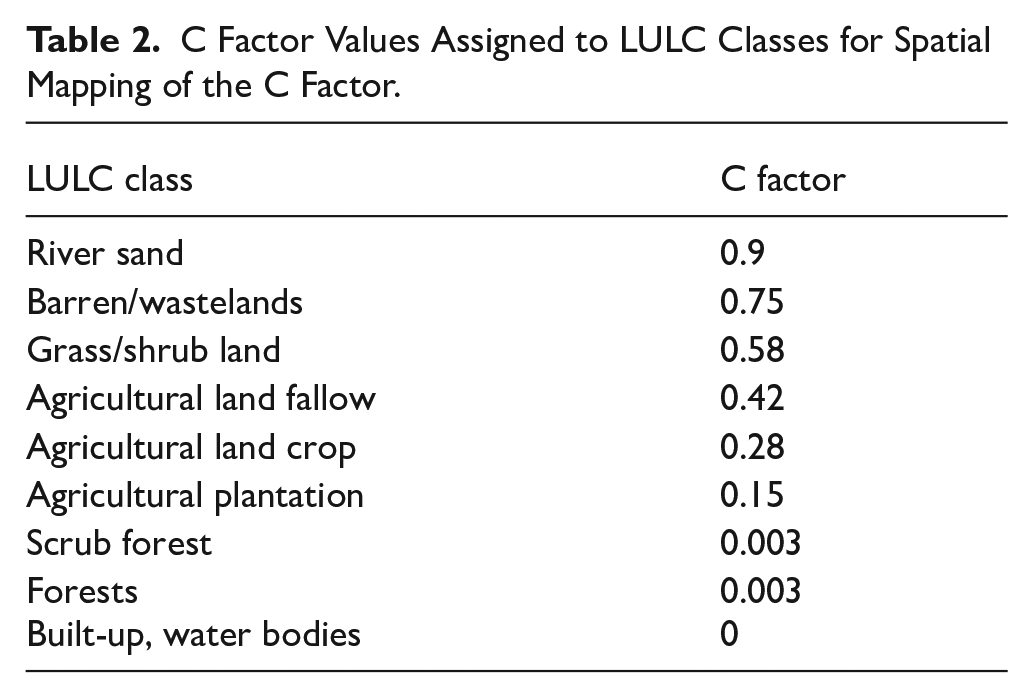
For the computation of the C factor, the LULC classes were assigned the C factor values represented in Table 2 given by ICAR. Several researchers have assigned the C factor in this agroecological region according to their own LULC maps (Ganasri & Ramesh, 2016; Markose & Jayappa, 2016). For the respective LULC classes in the study area, River Sand and Barren/Wastelands, with C factors of 0.9 and 0.75, respectively indicate higher erosion vulnerability due to limited vegetation cover. Grass/Shrubland exhibits a better comparable erosion-resistant with a C factor of 0.58, attributed to its protective plant cover. Fallow Land and Crop have C factors of 0.42 and 0.28, indicating varying degrees of erosion potential. Forests have a low C factor of 0.003, highlighting their ability to mitigate erosion through dense vegetation. Built-up and Waterbodies classes possess the lowest C factor, indicating no soil erosion potential on these surfaces. The C factor map of the catchment was developed based on these attributed values, as shown in Figure 5. The percentage of each erosive C factor value is the same as the corresponding LULC class percentage shown in Figure 4(b).
C Factor Values Assigned to LULC Classes for Spatial Mapping of the C Factor.

Spatial distribution of C factor across the Netravati catchment prepared from LULC map and corresponding C factor values.
Estimation C Factor From Normalised Difference Vegetation Index (NDVI)
The average NDVI values varied from −0.522 to 0.876 as shown in Figure 6, indicating a wide range of vegetation cover within the Netravati Catchment. This variation in NDVI reflects the heterogeneity of LULC classes present in the region, ranging from waterbodies, bare soil and fallow land to well-established forested and agricultural areas. The spatial variability in NDVI observed also aligns with the LULC map. Regions with higher NDVI values are, therefore supposed to contribute less to erosion because of good vegetation and those with lower NDVI values are more prone to erosion (Ayalew et al., 2020; Guo et al., 2023), thus calling for site-specific conservation efforts in those regions. This further validates the integration of NDVI into the C factor calculation. The C factor was computed from NDVI-based methods (Equation 2 to Equation 6). The Equations 2 and 4, given by De Jong et al. (1998) and Durigon et al. (2014) assume a linear relationship exists between NDVI and the C factor. While Equations 3, 5 and 6, given by Van der Knijff et al. (2000), Wickama et al. (2015), and Bahrawi et al. (2016), respectively assume a nonlinear relationship between NDVI and the C factor. Equation 3 has been utilised by researchers in this agroecological region (Aswathi et al., 2022; Prasannakumar et al., 2011).
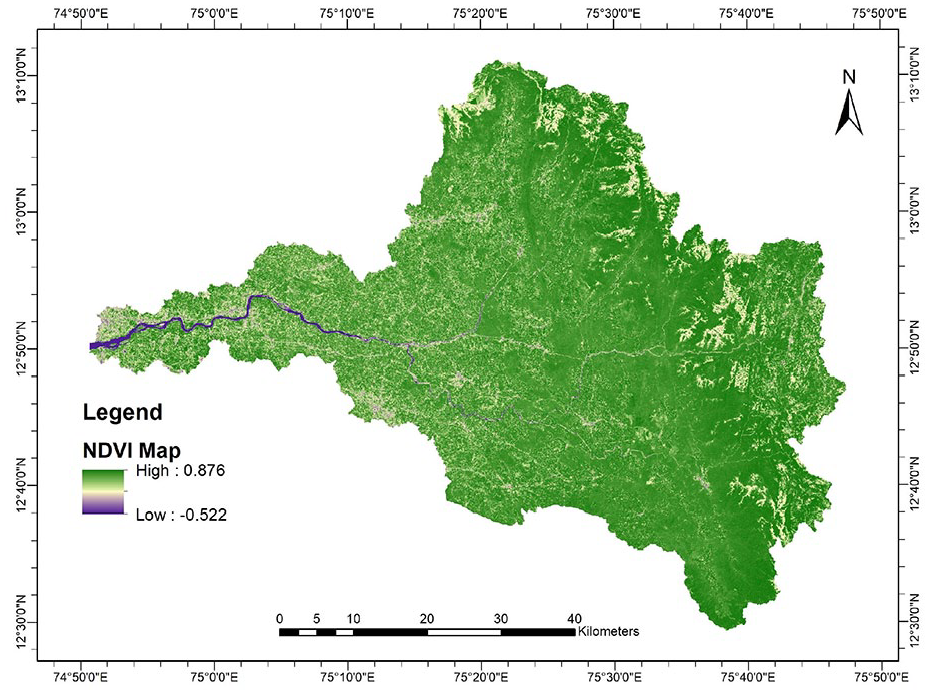
NDVI map of the Netravati catchment derived from Sentinel 2 data, showing vegetation density gradients.
The C factor values derived from these equations ranged from −0.274 to 0.851 for Equation 2 (Figure 7(a)), 0 to 1.986 for Equation 3 (Figure 7(b)), 0.062 to 0.761 for Equation 4 (Figure 7(c)), 0.095 to 0.381 for Equation 5 (Figure 7(d)), and 0.061 to 1.819 for Equation 6 (Figure 7(e)). Comparing these results with the actual C factor values reveals that these equations either overpredict or underpredict the C factor, with some values exceeding the nominal range of 0 to 1. Such C factor values can result in erroneous estimation of soil erosion as also highlighted by Pinson and AuBuchon (2023). This prompted the need to propose a new regional NDVI-based C factor equation. For the development of the equation, exclusion criteria were employed for Built-up areas and Waterbodies. The Built-up area, which gives values similar to those of the Barren area (NDVI approaching 0) and Waterbodies (negative NDVI values) (Saravanan et al., 2019), were not considered due to their limited capacity to generate reliable outcomes. The proposed exponential regression model demonstrated a strong fit to the data, as evidenced by a high R2 value of 0.96, indicating that a significant portion of the variability in the C factor was explained by the NDVI values. The regression equation derived for the C factor for the specific region is:

This equation captures the non-linear relationship between NDVI and the C factor and is specifically tailored to the conditions of the study region. The C factor values obtained using Equation 7 ranged from 0.056 to 0.99, as shown in Figure 7(f).

Comparison of C factor spatial estimates based on NDVI using Equations: (a) 2, (b) 3, (c) 4, (d) 5, (e) 6 and (f) 7.
A comparative analysis of different NDVI-based C factor equations and the actual C factor was carried out considering r, MAE, SD, RMSE, RSR and KGE. This comparison was conducted for all LULC classes except Built-up areas and Water bodies, which were considered outliers due to their unique spectral characteristics in the proposed equation. The results are presented in Table 3. In terms of r, most equations show high values around 0.987, except for Wickama et al. (2015) (0.319), which indicates a significant discrepancy in capturing the spatial variability of the C factor. When examining MAE, the proposed equation has the lowest error at 0.048, suggesting it offers the most accurate estimation, whereas other equations like De Jong et al. (1998) (0.370) and Wickama et al. (2015) (0.275) exhibit much higher errors, reflecting less precise estimates. For SD, while the proposed equation shows a value of 0.275, which is higher than most others, this reflects its greater sensitivity to capture local variability. RMSE, another critical measure of error, is notably lowest for the proposed model (0.058), followed by Bahrawi et al. (2016) (0.145), emphasising its robustness in prediction accuracy. Conversely, the Wickama et al. (2015) method (0.350) demonstrates poorer performance. In terms of RSR, a lower value indicates better performance, with the proposed model leading at 0.197, far surpassing other models like (De Jong et al., 1998) (1.329) and Wickama et al. (2015) (1.189), which show substantial errors. The KGE metric, which combines multiple aspects of model performance, highlights the superiority of the proposed equation with a score of 0.921, indicating a near-optimal balance between correlation, bias and variability. Other methods, such as (Bahrawi et al., 2016) (0.552) and Van der Knijff et al. (2000) (0.428), show moderate efficiency, while De Jong et al. (1998) (−0.095) and Wickama et al. (2015) (−0.099) have negative values, signifying poor performance. Based on the statistical measures, the results of proposed Equation 7 are well-aligned with actual observations (Figure 8).
Performance Assessment of the Methods Used for Estimation of C Factor.

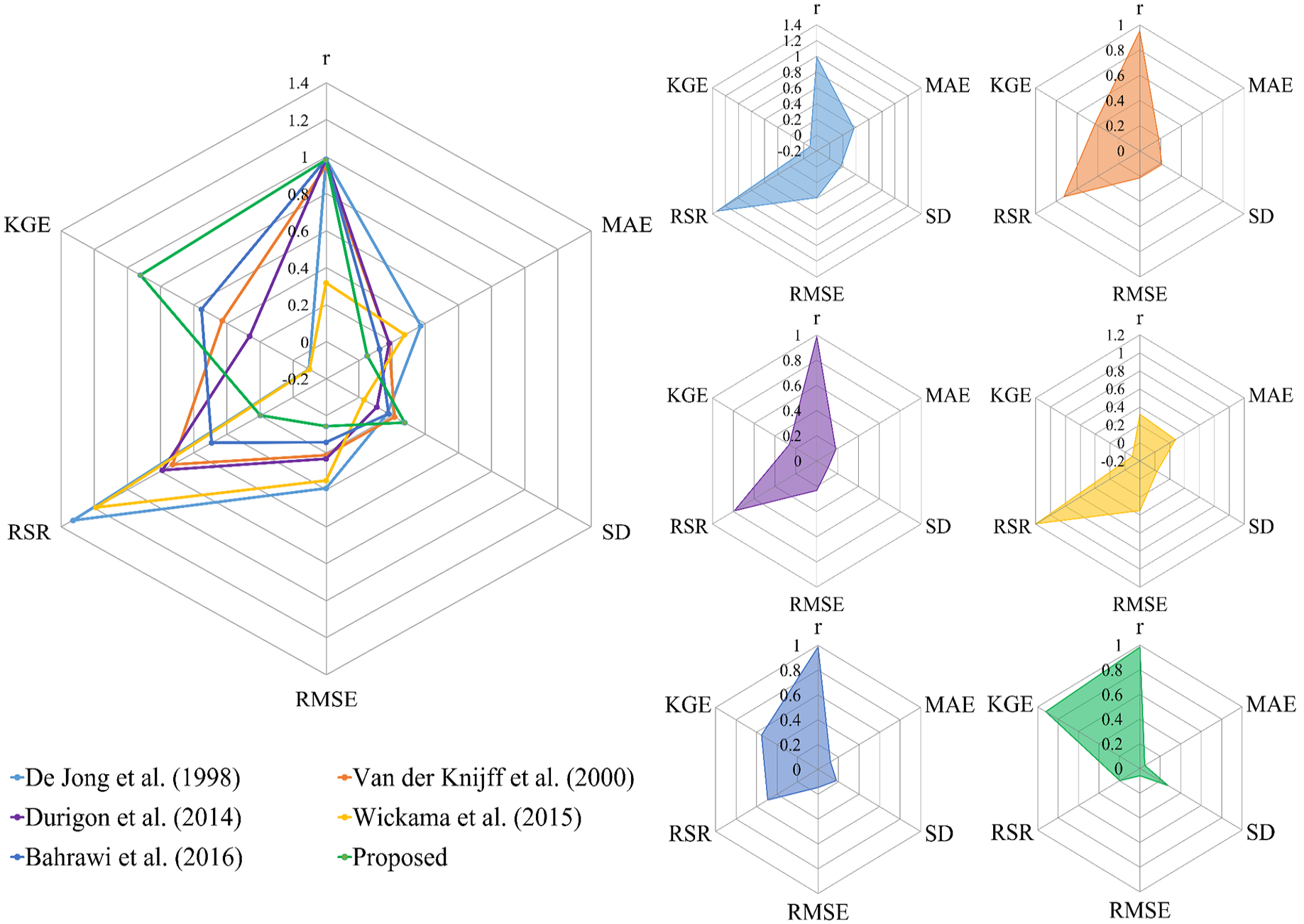
Comparison of different methods to estimate C factor using a radar plot, highlighting relative accuracy and reliability.
The mean and SD for each class (excluding Water and Built-up) from each method are shown in Table 4, enabling a detailed comparison of each method’s performance against the actual C factor values from Table 2. Further, to visualise the variability of the C factor among the LULC classes, boxplots were plotted for De Jong et al. 1998) (Figure 9(a)), Van der Knijff et al. (2000) (Figure 9(b)), Durigon et al. (2014) (Figure 9(c)), Wickama et al. (2015) (Figure 9(d)), Bahrawi et al. (2016) (Figure 9(e)), and proposed Equation 7 (Figure 9(f)). When comparing the C factor values with the actual values, clear deviations are observed, with some methods generating inaccurate negative values, which suggests the failure of those equations in capturing the C factor effectively for this region. Barren/Wastelands, which have an actual C factor value of 0.75, significantly contribute to erosion. The C factor values computed by proposed Equation 7 are well approximated with a value of 0.758 ±. 0.045, followed by (Bahrawi et al., 2016) with a value of 0.522 ± .0.033. Wickama et al. (2015) significantly underestimates the C factor values at 0.173 ± .0.005, as do the other equations. For LULC class Crop having actual C factor 0.28, proposed Equation 7 with value 0.265 ± .0.042 provides a close estimate. Bahrawi et al. 2016) is the next best (0.217 ± .0.026), but values from De Jong et al. (1998) show a negative value (–0.050 ± .0.029) which is inaccurate. For the LULC class Forest Van der Knijff et al. (2000) estimated the C factor values (0.001 ± 0.001), closest to the actual but underestimated C factor value for other LULC classes. The proposed method overestimates slightly at 0.077 ± 0.016, but this is a minor deviation compared to other methods. Similarly, for other LULC classes namely Fallow, Grass/Shrub land, Plantation and River Sand, proposed Equation 7 gives mean values closer to the actual C factor values, whereas other equations show varying degrees of underestimation.
LULC Class-wise Mean and SD of C Factor Values Computed by Different Methods.


Boxplot representing the LULC class-wise comparison of the actual C factor with estimated C factor from Equation: (a) 2, (b) 3, (c) 4, (d) 5, (e) 6 and (f) 7, showing the precision and bias across the LULC classes.
The results show that Wickama et al. (2015) gave the values of the C factor in the range of 0.10 to 0.2 for individual LULC classes. This close range suggests an inability of the method to deal with diverse LULC classes in this region. De Jong et al. (1998) gave negative values for LULC classes Plantation (–0.136 ± .0.034), and Forest (–0.202 ± .0.023) as well, highlighting the failure of this method to compute the C factor for this region. The study by Xiong et al. (2023) stated that global models underestimate C factors at regional scale, aligning with our findings. Similarly, Colman et al. (2018) evaluated Durigon et al. (2014) method and found the equation gave 10 times the C factor values compared to the actual values for the Upper Paraguay Basin located in Brazil and recommended using a multiplying factor of 0.1, which highlights the need for local parameterisation. The proposed Equation 7 consistently provided more precise C factor estimates across the LULC classes present in the study area. This also indicates that regionally parameterised equations are essential for addressing spatial heterogeneity. Additionally, integrating tailored equations can improve erosion estimation, enabling more precise planning of targeted soil conservation efforts like crop rotation and afforestation.
While the proposed NDVI-based equation outperformed other equation in estimating the C factor for the catchment, it is essential to recognise its limitations. The equation is parameterised to the local agroecological conditions, thus restricting its applicability to other agroecological regions. To address this, it is necessary for researchers to calibrate available equations or propose appropriate equations at regional scale. In the study, Built-up and Waterbody classes were considered as spectral outliers due to their reflectance characteristics. The integration of additional RS-derived indices, such as Normalized Difference Built-up Index (NDBI), Normalized Difference Water Index (NDWI), Bare Soil Index (BSI) could enhance the interpretation of spectral characteristics associated with urban surfaces, water bodies and barren land. This could help to capture the LULC dynamics more accurately. Future research can enhance C factor estimation by considering seasonal or monthly scale analysis as done by Allataifeh et al. (2024) and Macedo et al. (2021) and by employing advanced machine learning techniques.
Summary and Conclusions
The study presented a comprehensive approach for parameterising the C factor for the Netravati catchment in the Western Ghats and Coastal Plains region of India. For the study, the LULC and NDVI-based approaches, integrated with the RF algorithm and 10 m high-resolution Sentinel 2 data, were explored for C factor estimation, which proved effective. For the study area, 10 distinct LULC classes were identified, and an overall accuracy of 93.17% was achieved for a detailed LULC map created with a Kappa coefficient of 0.924. The River Sand (10.73 km2), Barren/Wastelands (70.92 km2) and Grass/Shrubland (321.81 km2) are highly vulnerable to erosion due to limited vegetation cover, have C factor of 0.9, 0.75 and 0.52 respectively. Fallow Land (60.70 km2), Crop (267.67 km2) and Plantations (516.29 km2) with lower C factors of 0.42, 0.28 and 0.15 respectively, signifies varying erosion potentials due to their protective vegetation cover. Through the dense vegetation cover, the forest (1926.57 km2) can significantly mitigate erosion and have a C factor of 0.003.
The comparison of previous NDVI-based C factor equations with the actual C factor values revealed significant variation in the results, stressing the importance of regional parameterisation. The proposed region-specific NDVI-based nonlinear equation demonstrated superior performance (R2 value of 0.96, r of 0.984, MAE of 0.048, RMSE of 0.058 and KGE of 0.921) compared to other equations representing a near-optimal balance between correlation, bias and variability. The proposed equation gave a mean C factor value close to the actual for distinct LULC types, effectively capturing the variability in the C factor, making it a valuable tool for soil erosion modelling and supporting sustainable land management practices in the region. Although the equation is specific thus limiting its applicability to other regions, the methodology followed in the study can be replicated by researchers elsewhere. Future work could focus on exploring alternative RS-derived indices and machine learning techniques to improve C factor estimation for better soil erosion modelling and mitigation.
Footnotes
Acknowledgements
The authors wish to acknowledge the National Institute of Technology Karnataka, Surathkal for providing the support to carry out the study. We also thank the European Space Agency (ESA) for providing the Sentinel-2 data through the Copernicus program.
Author Contributions
MW, DGS and SHR formulated the methodology. MW did the acquisition of the data and carried out the analysis under the supervision of DGS and SHR. MW drafted the manuscript DGS, SHR and PBJ revised the manuscript and approved this version to be published.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Data Availability
The primary datasets used and analysed during the current study are freely available online and are available from the corresponding author upon reasonable request.