
Abstract
Soil classification is essential to agriculture, environmental management, and civil engineering. In the recent past, deep-learning algorithms have had a profound effect on solving research challenges in various fields. Soil science has also benefited substantially from the implementation of time-saving and accurate deep-learning models. Deep learning techniques have demonstrated their potential for precisely classifying soil classes and predicting soil properties. In this paper, we provide a thorough analysis of the current techniques for classifying soil using deep learning models. We also discuss emerging trends in soil classification research, such as the use of lightweight models, multi-task learning models, and transfer learning. The advancements in soil classification were the focal point of this study. The study evaluates 12 research papers out of 150 publications initially retrieved from scholarly databases pertaining to the topic. The academic publications on deep learning models for soil classification were culled based on a set of predetermined criteria for obtaining the most profound understanding. To establish an effective method for soil identification, it is necessary to extract the features from the input images with care. This review suggests additional potential deep learning models that can be anticipated for improved soil identification results. The analysis concludes with an examination of the technical and non-technical errors made by scholars and a discussion of the ramifications for the future of soil identification. In addition, we emphasize the difficulties in soil classification, such as data imbalance, limited data availability, and the interpretability of models, and suggest potential solutions to resolve these issues. This in-depth analysis could support soil science researchers to propose more effective methods for soil identification.
Keywords
Introduction
Classifying soils entails categorizing them according to their shared and distinguishing physical, chemical, and biological properties. This classification helps in understanding the properties and behavior of soils for various applications, including agriculture, engineering, environmental management, and land-use planning. Soil classification systems vary across the world, but most use similar criteria such as texture, structure, color, and organic matter content. The United States Department of Agriculture’s (USDA) Soil Taxonomy (Staff, 1999) and the United Nations Food and Agriculture Organization’s (FAO) World Reference Base for Soil Resources (FAO, 2014) are the two most widely adopted soil classification systems. The Soil Taxonomy system classifies soils based on their properties, such as color, texture, structure, and drainage. The system divides soils into 12 orders, which are further divided into suborders, great groups, subgroups, and families. The orders are named based on the dominant characteristics of the soil. For example, Alfisols are soils with high levels of aluminum and iron, while Mollisols are soils with high levels of organic matter (Staff, 1999). The WRB system is a more comprehensive soil classification system that considers the formation, distribution, and properties of soils. The system is based on soil genetic and ecological characteristics, and it classifies soils into 32 reference groups. The reference groups are based on the physical, chemical, and biological properties of soils and their location, climate, vegetation, and land use. Both the Soil Taxonomy and WRB systems are widely used for soil classification, with the Soil Taxonomy system being more common in North America and the WRB system being more common in Europe and the rest of the world. Soil classification is an essential tool for soil scientists, farmers, engineers, and environmentalists to understand the behavior of soils and make informed decisions about their use and management. It is essential in precision agriculture, environmental monitoring, and land management. Accurate classification of soil types can provide valuable information about soil properties, fertility, and potential crop yields. The need for new soil identification methods is driven by the desire to better understand and manage soils, and to meet the growing demand for accurate soil data in a changing world. Soils can vary significantly over small distances, which makes it difficult to accurately identify and classify them using traditional methods. New soil identification methods can help to better characterize these variations and improve soil management practices. With growing concerns about food security, climate change, and environmental sustainability, there is an increasing demand for accurate soil data. New soil identification methods can help to provide more detailed information about soil properties, which can be used to inform decision-making in these areas. The globalization of food production has led to increased demand for accurate soil data in different regions of the world. New soil identification methods can help to standardize soil analysis practices and improve communication between different regions and countries.
Advances in technology have made it possible to develop new soil identification methods that are more accurate, efficient, and cost-effective than traditional methods. These new methods can provide faster results and require less manual labor, which can help to improve soil analysis capabilities and reduce costs. In the recent past, machine learning and deep-learning techniques have been increasingly used for soil classification, with promising results. These techniques offer the potential for faster, more accurate, and more efficient classification of soil types, compared to traditional methods. Machine learning and deep-learning models can be trained on large quantities of datasets of soil images, soil properties, and environmental factors to learn patterns and features that are characteristic of different soil types. These models can then be used to classify new soil samples into different categories based on their features and properties. Different types of machine learning and deep learning techniques, including convolutional neural networks (CNNs), random forests, decision trees, and support vector machines (SVMs), have been used for soil classification with varying degrees of success. In addition to these traditional machine learning techniques, emerging trends in deep learning, such as transfer learning, meta-learning, and one-shot learning are also being explored for soil classification. These techniques offer the potential for even greater accuracy and efficiency, as well as the ability to work with smaller datasets.
Fundamentals of soil science
Soil science is the scientific study of soils, their formation, properties, and interactions with the environment. It is an important component of the earth’s surface, and understanding its behavior and properties is essential for successful crop production, environmental protection, and management of land resources. Soil science is the study of the physical, chemical, and biological characteristics of soil, about its use and management. Soils are formed from the weathering of rocks and minerals over long periods of time. The type of rock and climate conditions are important factors in determining the type of soil that is formed. Soils have physical, chemical, and biological properties that are important for plant growth and nutrient uptake (Delgado et al., 2016). These properties include soil texture, structure, pH, nutrient availability, and organic matter content. The physical properties of soil are the foundation of soil science studies. Soil texture refers to the size and proportion of sand, silt, and clay particles in the soil (Petersen et al., 1996). The texture determines soil water storage capacity, aeration status, and the ability to support plant roots.
Soil structure is the arrangement of soil particles, and it influences water infiltration, drainage, soil aeration, and the distribution of nutrients. Soil compaction, erosion, and crusting can all have negative impacts on soil structure, and disturb soil’s physical properties. The chemical properties of soil are critical to the growth of plants. Soil acidity and alkalinity, as measured by pH value, affect plant growth, nutrient availability, and bacterial activity. NPK (Nitrogen, Phosphorus, and Potassium) and other micronutrient elements (Ghorbani et al., 2008) such as manganese, iron, and zinc are found in soil in varying amounts, and they play different roles in plant growth and functions. Other soil chemical properties, such as cation exchange capacity (CEC) and buffering capacity, have significant impacts on the ability of soil to neutralize harmful chemicals, maintain nutrient availability, and resist acidification. Soil is home to a diverse community of microorganisms that play important roles in soil nutrient cycling, plant growth, and soil structure. These include bacteria, fungi, and other microorganisms.
The biological properties of soil (Martin et al., 1977) are closely related to its chemical and physical properties. Soil microbes, including bacteria, fungi, and viruses, can alter soil and plant health by directly attacking or supporting plant growth. Nutrient cycling, organic matter breakdown, and mineralization are all key biological processes that are fundamental to soil health. Soil biodiversity, which refers to the number and variety of living organisms in the soil, is another important aspect of soil biology. Soil biodiversity is essential to maintaining soil nutrient cycling, organic matter decomposition, and a supportive soil atmosphere for growing and maintaining plants. Soil testing is the process of analyzing soil samples to determine their nutrient content, pH, and other important properties. This information can be used to make informed decisions about fertilization and other soil management practices (M. K. Shukla et al., 2006).
Soil management practices have profound impacts on the physical, chemical, and biological properties of soil. Common soil management practices such as tillage, crop rotation, and fertilization can drastically alter soil properties, and plant growth and contribute to the loss of soil organic matter through erosion or subsequent land use changes. Soil conservation measures, such as conservation tillage, cover crops, and crop residue management, can help maintain soil fertility, increase organic matter content, and encourage soil biodiversity. Modern soil management strategies need to balance food production, soil conservation, and biodiversity preservation. Soil conservation is the practice of protecting soil from erosion and degradation. This is important for maintaining soil fertility and preventing soil loss and land degradation. Soil fertility refers to the ability of soil to support plant growth. This is influenced by the availability of essential nutrients such as nitrogen, phosphorus, and potassium, as well as other factors such as soil pH and organic matter content.
Farmers and policymakers alike must understand the principles of soil science and take proactive steps to conserve soil resources and promote biodiversity. Meanwhile, advances in soil science and technology can help farmers increase crop yields, while simultaneously reducing the excessive use of synthetic fertilizer. Soil classification is traditionally done by experts who use their knowledge and experience to identify soil types. However, with the advancement of technology, machine learning and deep learning techniques are being explored to automate this process. Machine learning and deep learning techniques offer a promising approach to soil classification, with the potential to revolutionize the field of precision agriculture and environmental monitoring.
Many scholars have researched the use of deep-learning models for soil classification. Although the ultimate goal of these studies should aim at designing and developing lightweight deep learning models that can run on edge devices such as smartphones, drones, or unmanned area vehicles (UAV) that have less computation power and are efficient enough to be used as portable, reliable AI tool to identify or predict soil types in real-time and also show their geographical locations, most of these research works fall short of these goals. By integrating soil morphology analysis with geospatial information, these AI tools can provide a comprehensive understanding of soil characteristics and their spatial distribution, which can facilitate informed decision-making in various domains. This paper’s novelty lies in its comprehensive, interdisciplinary, and up-to-date analysis of the current landscape of deep learning techniques for soil classification by delving into the nuances of soil data, its multimodality, and the challenges it presents. The paper addresses a unique and crucial aspect of deep learning applications, its exploration of multimodal data integration, emphasis on practical applications and emerging trends in this critical field of study, and the deployment of the models on resource constraint devices. The paper aims to provide a comprehensive overview of the recent developments in deep learning-based soil classification. By shedding light on the current state-of-the-art methodologies, addressing challenges, and identifying emerging trends, we hope to inspire further research and foster collaborations that will drive innovation and advancements in this critical field of study. Through the synergy of deep learning and soil science, we envision a future where accurate soil classification contributes to sustainable agriculture, environmental preservation, and informed land management decisions.
Contribution of this analysis
Our contribution to this analysis on soil classification using deep learning technique is multi-fold. First, we provide a comprehensive review of the current state-of-the-art deep learning techniques for soil classification, which can serve as a reference for researchers and practitioners in the field. Second, we discussed the emerging trends in soil classification research, such as the effective tools for data preprocessing, the use of lightweight deep learning models, multi-learning models, and transfer learning, which can help guide future research directions. Third, we highlighted the challenges in soil classification and proposed potential solutions to address these challenges. Finally, we provided insights into the potential applications of soil classification in precision agriculture, land use planning, and environmental monitoring, which can have significant implications for sustainable development. We anticipate that this analysis will contribute to the development of more accurate and efficient soil classification models, which can ultimately benefit various fields related to soil management and environmental sustainability.
Search technique and organization of this analysis
In this analysis, we consulted research publication databases such as ScienceDirect, IEEEXplore, and Google Scholar in order to identify relevant articles published in the field of soil classification. Aside from these sources, a few noteworthy articles from Springer, Geoderma, and ArXiv publications were also downloaded. The screening of these articles in the context of deep learning methods is illustrated in Figure 1. We utilized a three-step procedure to identify the most pertinent publications for this analysis. Out of 150 publications, 60 were chosen based on their title and abstract during the initial screening. Based on the specifics of the datasets and methodologies utilized, the second level of examination culled 35 publications from a group of 60 publications. The third phase of the examination involved an exhaustive investigation to comprehend the specifics and implementation aspects of the employed deep-learning method. Ultimately, 12 publications were selected through this procedure for inclusion in this review. For soil classification and identification, we have, to the best of our ability, analyzed the most significant contributions of all deep-learning research articles published up to 2023.

Search strategy and manuscript filtering process.
The search procedure utilized keywords such as “Soil classification,” “Soil Identification,” “Soil Type classification,” “Deep learning,” “Convolutional Neural Network,” “Fully Convolutional Network,” “Soil properties classification,” “Soil Texture classification,” “Soil Color classification,” and “Soil pH classification” to retrieve the pertinent publications. Table 1 highlights the inclusion/exclusion criteria used to narrow the selection of 150 publications down to the final 12 publications. The form used to evaluate each publication’s quality is presented in Appendix A, Table A1. The remaining sections of this paper are structured as follows. First, we describe the prevailing datasets, followed by constructive recommendations for creating true representative and standardized soil datasets in Section “Data sets.” The Section “Standardized deep network architectures” describes the various deep learning models for soil classification and their analysis. The existing compression strategies of a variety of lightweight networks are also summarized. We compare the performance of conventional and intelligent algorithms on the same datasets in Section “Discussion.” The last section, “Conclusion,” concludes the various limitations and corresponding development trends of the existing deep-learning soil identification methods. Figure 1 depicts a summary of the search strategy and manuscript screening procedure.
Exclusion and Inclusion Criteria.

Datasets
Deep learning models require large datasets for training so that they can learn patterns and relationships within the data. The more data a model has access to, the better it can perform. Large datasets help in introducing diversity in the data, ensuring that the model is exposed to a variety of examples. With a diversified dataset, deep learning algorithms can identify more complicated patterns and associations in the data. Additionally, a large dataset can help in overcoming overfitting. Overfitting arises as a model becomes too familiar with the training data and performs poorly on new data. With a smaller dataset, a model can become too engrossed in the nuances of the data, and this can lead to overfitting. Large datasets, on the other hand, offer higher variance, and hence the model can train more thoroughly without becoming overfitted. An abundance of ground truth datasets manually labeled by humans, particularly for multispectral images, is a crucial requirement for developing accurate Soil Identification (SI) methods based on deep learning. Different researchers created soil image databases under variable environmental and illumination conditions based on their research objectives. The soil datasets were created using different devices, including smartphone cameras and digital single-lens reflex (DSLR) cameras. There is common knowledge that the configuration of the image acquisition system and the distance at which soil images were captured vary. To date, soil classification research employing soil images has been performed for a variety of lands in various nations.
In the majority of data repositories, soil datasets are not available in sufficient quantities. Currently, it is challenging to locate significant quantities of publicly accessible soil datasets in reputable data repositories that can be used to train deep learning models apart from the Land Use/Cover Area Frame Statistical Survey (LUCAS) Soil dataset (Stevens et al., 2013; Zhong et al., 2021), belonging to the European Union (EU), which can be acquired through a formal request to the owners. How the few known datasets utilized by the various researchers were acquired is an additional cause for concern. The vast majority of datasets were created in either a laboratory setting or a controlled environment. Due to their inability to generalize field soil samples, these laboratory-prepared datasets such as those sieved and desiccated are likely not to yield the needed accuracy when used to train deep-learning models, to identify soils in the field in real time. One of the principles of Artificial Intelligence is to assign as many human tasks as possible to a machine in order to eradicate or minimize human involvement. Therefore, the ultimate goal of researchers conducting deep learning research on soil datasets should be to automate their findings. The traditional method of transporting soil to the laboratory prior to conducting laboratory experiments on the soil should be replaced by real-time field soil detection and identification, which requires the use of field-prepared soil datasets for training deep learning models.
We highlight some of the experiments conducted with soil datasets created under different conditions. Figure 2 shows ground truth VITSoil dataset sample images.

Ground truth VITSoil dataset samples: From top left to right; red soil, laterite soil, arid/desert soil, alluvial soil, saline soil, yellow soil, black soil, and forest soil. (224 × 224 PNG, RGB).
Europe has developed a substantial soil spectral database as part of the European Land Use/Cover Area Frame Statistical Survey (LUCAS), through which 20,000 geo-referenced topsoil images were gathered to evaluate the condition of the soils across Europe. 13 physical and chemical properties were analyzed, including Vis-NIR reflectance. The sampling density of the database is greater than that of other large-scale libraries. Following the same sampling protocol, all samples were collected and analyzed in a single ISO-accredited laboratory (Stevens et al., 2013). Barman et al., (2019) used a 13-megapixel Xiaomi Redmi 3S smartphone with a default camera parameter setting of focal length = 4 mm, exposure time = 1/60 S, ISO speed = ISO 125, and F-stop = f/2 to capture soil images. A total of 50 soil samples were photographed as five soil samples were taken in each field. To classify soil, Inazumi et al. (2020) used 1,000 images of clay, sand, and gravel. For simplification, he classified the soils as clay (D50 14 0.008 mm), sand (D50 14 0.7 mm), and gravel (D50 14 4 mm), with the water content set to 0. Clay, sand, and gravel, the particulate sizes of which were modified by sieving, were placed in a clear plastic cup as a deviation from previous research. The images were captured using the camera on an iPhone 7 smartphone. The iPhone 7 has 12 million pixels, whereas the digital camera (FUJIFILM X-T4) available at the time of the experiment has 26 million.
Moreover, the scale of the iPhone 7’s image sensor in relation to image noise (the larger the image, the more accurate the image) is 4.8 _ 3.6 mm, whereas the digital camera’s image sensor measures 23.5 _ 15.6 mm. The photographs were clearly taken indoors. Regarding the clay, 200 photographs were captured with and without illumination (for a total of 400). Regarding the sand, 200 photographs were captured with and without illumination (for a total of 400). Regarding the gravel, 100 photographs were captured with and without illumination for a total of 200. de Oliveira Morais et al., (2019) created images from sieved and desiccated (2.0 g) soil samples in a petri dish. Images were captured using a digital camera integrated into a Leica EZ4 D stereo microscope. Colored images with a pixel size of 2048 × 1536 were captured in sets of 3 for each sample, totaling 189 RGB digital images. Under visible light, Barman et al. (2018) acquired 40 soil images by using a Redmi 3 s Prime with 4160 × 2340 resolutions. To circumvent the uncontrolled illumination source, the images were captured from a 10 inches distance between the camera and the soil. Using a smartphone’s 13-megapixel camera, Maniyath et al. (2018) compiled a database from images of Munsell soil charts. The Munsell color chart includes all hue, chroma, and value variants of a given color. Each color variant from these images is cropped to a dimension of 256 × 256 pixels and named accordingly. G. Shukla et al. (2018) evaluated the Landsat-8 image using diverse data sources that were georeferenced. To denote environmental variables in the study location, 35 digital layers were utilized. The variables are essentially acquired from various satellite data such as the MODIS NDVI product, Sentinel-1A, Landsat-8, RISAT-1, and ALOS-DEM, as well as climatic data, including temperature and precipitation. A compact microscope with a maximum magnification of 200× and a 5 MP camera was used to construct an image acquisition system by (Ji et al., 2016). Two agricultural pastures with extremely variable soils (Field26 and Field86) are sampled. Each air-dried, ground soil sample was used to acquire three images under laboratory conditions. Among the 123 soil samples collected, 56 were from Field26 and 67 were from Field86. After scraping off surface residues at 67 locations in Field86, triplicate in-situ images were captured.
Honawad et al. (2017) used Japan Sony Corporation’s DXC-300A camera connected to a PC to obtain images. The camera was installed atop the light vestibule on a duplicate pole that allowed for straightforward vertical adjustment to precisely position the camera in relation to soil components. Using the Matrox Intellicam for Windows program, images were captured. The source of illumination was a fluorescent light tube that offered a uniform brightness throughout the entire field of view. Han et al. (2016) created the soil image database using Nikon Corporation’s D7000 SLR equipment for the experiment. The effective pixels and focal length of the CMOS sensor range from 18 to 105 mm, and the distance between the camera and the soil surface was 0.5 meters. The circular LED light used for the illumination device can be dimmed to approximately 10 different levels. Each soil sample was photographed 10 times under 10 distinct LED lighting conditions. Then, the 10 images’ RGB signals were averaged. Padmapriya et al. (2023) used a smartphone to capture a total of 5,938 Clay, Clayey Peat, Sandy Clay, and Humus Clay field soil images located at various environmental conditions in Manalur, Vriddhachalam Taluk, Tamilnadu, India. They classified the four categories of soils by using a technique called the multi-stacking ensemble model, where the authors combined both traditional machine learning models with deep learning models. Gyasi and Purushotham (2023) also used a total of 4864 RGB field soil images belonging to 9 categories, which were captured under various weather and illumination conditions from all the states in India using smartphones and digital cameras. The authors successfully predicted the various nine major Indian soils that they named the VITSoil dataset with the use of a smartphone to find the types of soils, their morphology, and their geographical locations through a deep learning model called Soil-MobiNet.
Padarian et al. (2019) applied a 2-D CNN to the LUCAS database, transforming the original spectra into 2-D spectrograms. Transfer learning was also employed to localize the global model in both references, utilizing distinct techniques. Riese and Keller (2019) classified the texture of each soil sample using the German soil textural classes by employing a second 1-D CNN on the same dataset. In a study by Azizi et al. (2020), the InceptionV4, VGG16, and Resnet50 models were used to categorize six types of soil aggregates. Using a U-Net network model, Jiang et al. (2021) classified 2,400 soil samples into four classes. Jiang drew 2400 soil samples from 160 soil profile images of four soil orders (Alfisols, Entisols, Inceptisols, and Mollisols) that were collected in the Inner Mongolia and Liaoning regions of north China. Zhong et al. (2021) proposed Resnet and VGG16 CNN models for soil classification using the LUCAS soil dataset, categorized into four classes. Their model achieved a relatively good accuracy by leveraging the rich spatial information encoded in the images. Barkataki et al. (2021) also classified soil types from GPR B scans using deep learning techniques. According to the needs of the study, Table 2 provides an outline of the numerous databases created by researchers. The “Data composition” column provides a summary of the databases developed by the researchers. The “Location” column denotes the origin (city and/or country) where soil samples for the soil images were obtained. The “Capturing Device” column identifies the device the researchers used to prepare the soil images when creating the database.
A Summary of the Numerous Databases Developed by Authors to Meet the Study’s Requirements.

Data pre-processing
The accuracy and efficiency of deep learning models can be greatly impacted by data preparation; hence it is a crucial phase in the modeling process. Some commonly used data preprocessing techniques for deep learning models are Data cleaning, Data normalization, Data augmentation, One-hot encoding, Tokenization, Padding, Feature scaling, etc. Data cleaning involves removing irrelevant data, filling in missing values, and dealing with outliers. The data normalization technique comprises scaling the data to have zero mean and unit variance. Normalization can assist in enhancing the convergence of the training algorithm. Data imbalance occurs when the distribution of classes in a dataset is not uniform. For instance, in classifying soil types, if one category of the soil has significantly more samples than the others, data imbalance could occur. This can lead to issues in deep learning models, as they may become biased towards the majority class and struggle to accurately predict the minority of soil types. One way to deal with data imbalance in soil classification using deep learning models is to use techniques such as data augmentation, which involves artificially creating additional data points for the minority class to balance out the soil dataset. Data augmentation can be performed using transformations such as flipping, zooming, rotating, cropping, or brightening the images (Bjerrum et al., 2017; Perez et al., 2017). Through data augmentation, the size of the database can be increased to the desired volume. This can help the model generalize better to new data and prevent overfitting. Another approach is to use sampling techniques, such as oversampling or undersampling, which involve increasing or decreasing the number of soil samples for the minority class, respectively. An alternative method is using class weighting, where the loss function is modified to give more weight to the minority soil class. This ensures that the model is penalized more for misclassifying soil samples from the minority class, thus encouraging it to pay more attention to these samples during training. Although the best approach for dealing with data imbalance in soil classification using deep learning models will depend on the specific model and the quality of the soil dataset, experimentation with different techniques and evaluation of their effectiveness is crucial for achieving optimal performance.
One-hot encoding technique is used to represent categorical data as binary vectors. Each class is assigned a unique binary vector, with a 1 in the position corresponding to the category and 0s elsewhere. Tokenization involves breaking up text into individual words or tokens. This is commonly used in natural language processing (NLP) tasks. Padding is usually employed in NLP tasks, where sequences of variable lengths are often used as input. Padding involves adding zeros to the end of lesser sequences so that the length of each sequence is the same. Feature scaling involves scaling the features to a specific range or scaling them to have zero mean and unit variance. This can help the model converge faster during training and avoid the vanishing gradient problem. The selection of data preprocessing method depends on the specific task and the type of data being used.
Data pre-processing tools and software
There are many tools and software available for data preprocessing techniques for deep learning models. Software such as Python libraries, MATLAB, KNIME, RapidMiner, Dataiku, Weka, Sony Neural Network Console, etc., are well known for data pre-processing. Python is a popular language for deep learning and has many libraries that provide data preprocessing functionalities, such as NumPy, Pandas, Scikit-learn, TensorFlow, Keras, and Theano (Bergstra et al., 2010; McKinney, 2012; Pedregosa et al., 2011). MATLAB is a popular tool for scientific computing and has many built-in functions for data preprocessing, such as data cleaning, normalization, and feature scaling (Etter, 1996). KNIME is an open-source data analytics platform that offers a graphical user interface (GUI) for data preprocessing (Berthold et al., 2009). It provides a range of nodes for data cleaning, transformation, and manipulation. RapidMiner is another open-source data science platform that offers a GUI for data preprocessing. It provides a range of data transformation and manipulation operators. Dataiku is a collaborative data science platform that offers a GUI for data preprocessing. It provides a range of data cleaning, transformation, and feature engineering tools. Weka is an open-source data mining tool that offers a GUI for data preprocessing (Holmes et al., 1994). It provides a range of data cleaning and transformation techniques. Neural Network Console is a deep learning platform developed by Sony Corporation. It offers a range of tools for data preprocessing, including image augmentation, normalization, resizing, and dataset partition. It also provides a graphical user interface (GUI) that enables users to build, train, and deploy deep learning models without requiring any programming knowledge. The platform offers a range of pre-built models and datasets, making it easy for beginners to get started with deep learning. The choice of tool or software depends on the specific needs and requirements of the task.
Standardized deep network architectures
Deep learning is an emerging trend in soil classification that involves training neural networks with multiple hidden layers. Deep learning can automatically extract complex soil features from raw soil data, eliminating the need for manual feature engineering. Deep learning strategies such as Convolutional Neural Networks (CNNs) have demonstrated promising outcomes for soil classification from remote sensing data. Selected deep networks have contributed so immensely to the discipline that they have become widely recognized standards. Examples of such deep networks are AlexNet, GoogLeNet, ResNet, and VGG-16. Due to their importance, they are utilized as building blocks in numerous soil classification architectures. In this section, we will examine a few of the standard deep learning methods employed in soil classification/identification. The deep learning techniques utilized for soil classification/identification are summarized in Table 3.
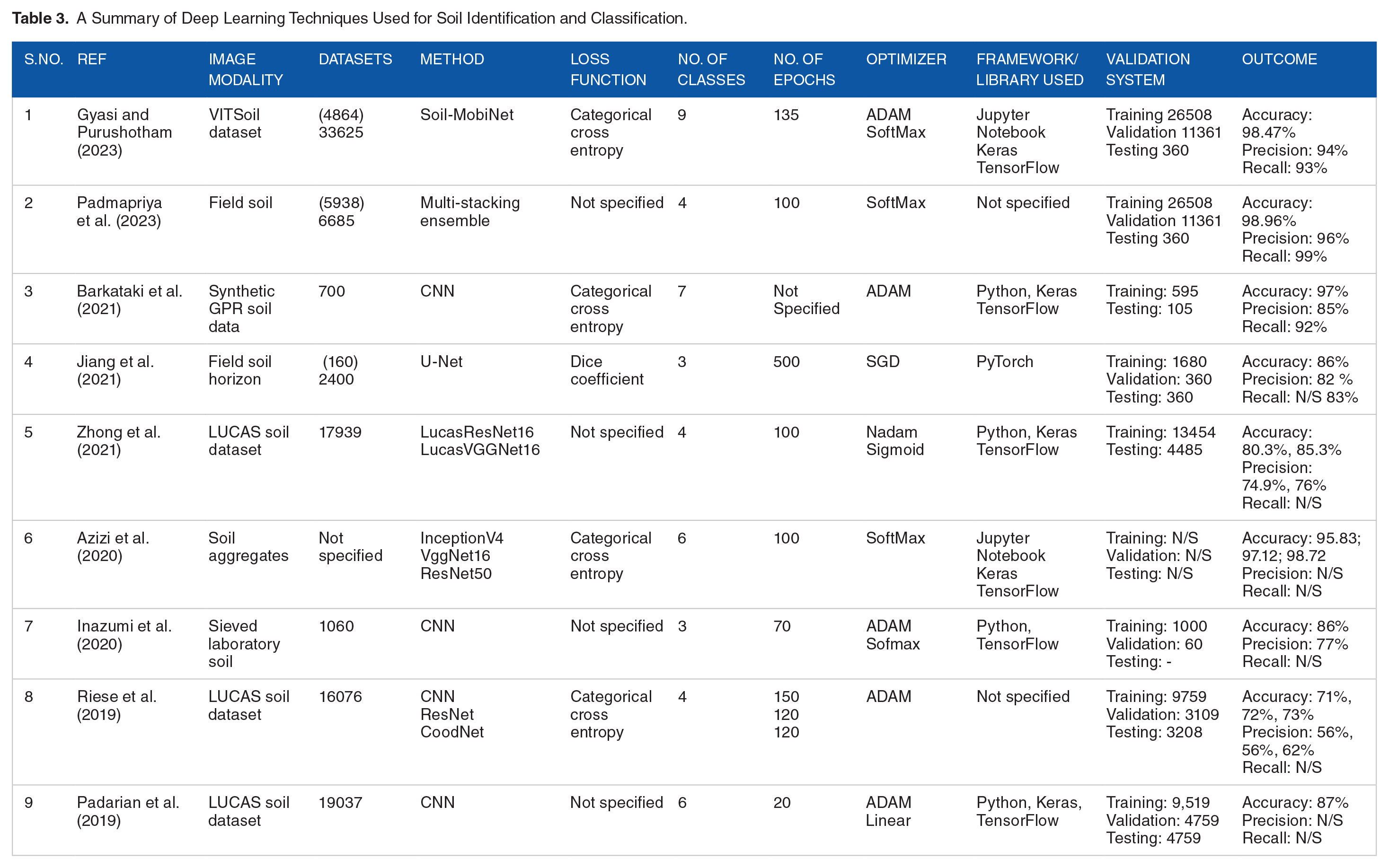
A Summary of Deep Learning Techniques Used for Soil Identification and Classification.
Visual Geometry Group (VGG)
VGG is a CNN model devised by the Visual Geometry Group (VGG) at the University of Oxford. It is one of the proposed models and configurations of deep CNNs submitted to the ImageNet Large Scale Visual Recognition Challenge (ILSVRC)-2013 (Simonyan et al., 2014). The model is now popularly known as VGG16 as it is made up of 16 weight layers and 3 entirely connected layers. The model’s 92.7% test accuracy, which ranked in the top five, has contributed to its rising popularity. Figure 3 illustrates VGG-16’s configuration. Instead of a limited number of layers with large receptive fields, VGG-16 uses a sequence of convolution layers with small receptive fields in the initial layers; thus, the primary difference between VGG-16 and its predecessors. This results in fewer parameters and an increase in nonlinearities in between, which makes the model simpler to train and the decision function more discriminatory. The VGG16 model is a deep neural network architecture that has been extensively implemented in computer vision applications, such as image classification. The VGG16 model has attained state-of-the-art performance on multiple image datasets, including ImageNet, which contains over one million images.

VGG16 CNN architecture.
To use the VGG16 model for soil classification, the VGG16 model needs to be fine-tuned on the soil dataset. This involves taking the pre-trained VGG16 model and updating its weights based on the soil images. This can be accomplished by freezing the initial layers of the model, and only training the last few layers to specialize the model for the classification task. Once the VGG16 model has been trained on the soil dataset, it can be used to classify new soil images into their respective categories. This can be accomplished by running the new images through the model to acquire the predicted class labels. Scholars such as Azizi et al. (2020) have classified soils using the VGG16. Notably, the efficacy of the VGG16 model for soil classification may depend on the quality and diversity of the soil dataset, in addition to the specific soil categories being classified.
GoogLeNet
Szegedy et al. (2015) introduced GoogLeNet, which won the ILSVRC-2014 challenge with 93.3% accuracy on the TOP-5 test set. Figure 4 illustrates the complexity of this CNN architecture, which consists of 22 layers and a newly introduced building block called the inception module. This novel method demonstrated that CNN layers could be layered in a manner other than the conventional sequential order. Included in these modules are a Network in Network (NiN) layer, a large-sized convolution layer, a pooling operation, and a small-sized convolution layer. They are all computed in parallel, followed by 1 × 1 convolution operations performed to decrease the dimension. By drastically reducing the number of parameters and operations with the help of these modules, this network prioritizes memory and computational costs. GoogleNet, also known as Inception-v1, is a deep convolutional neural network architecture devised for image classification tasks by Google researchers. Although it was not designed specifically for soil classification, it can be used for this purpose by adapting the network’s input and output layers to the application’s specific requirements. To use GoogleNet for soil classification, the network must be trained on a set of images of soil. To accept input images in the desired format, it would be necessary to modify the input layer of the network. It would also be necessary to modify the output layer to output the predicted soil type for each input image. An option for adapting GoogleNet for soil classification would be to fine-tune the pre-trained network using an image dataset of soil samples. Fine-tuning involves retraining the final few layers of the network on the new dataset while leaving the earlier layers unchanged, allowing the network to acquire new soil-specific features. Alternately, the soil image dataset could be used to train the network from start, but this would require a much larger dataset and lengthier training time. GoogleNet can be a powerful tool for soil classification, but accurate results require careful adaptation and training.

The GoogleNet architecture inception module with dimensionality reduction.
Residual Network (ResNet)
Microsoft’s Residual Network (ResNet) (He et al., 2016) is particularly extraordinary because it won the ILSVRC-2016 competition with an accuracy of 96.4%. Figure 5 depicts the network’s depth (152 layers) and the inclusion of residual blocks. Residual blocks deals with the problem of training an extremely deep architecture by introducing identity skip connections that allow layers to transfer their inputs to the following layer. The intuitive concept underlying this approach is that it ensures the subsequent layer learns new things different from what the input has already encoded (since it receives both the output of the preceding layer and its unchanged input). Moreover, these connections help overcome the problem of gradients that vanish into nothing (vanishing gradient). Scholars including Azizi et al. (2020) have utilized ResNet models to classify soil.
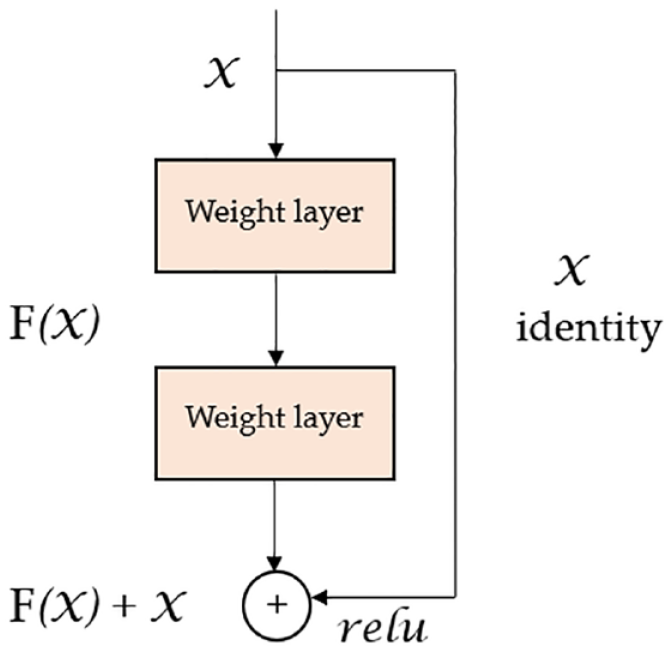
Residual block from the ResNet architecture.
ReNet
A Multi-dimensional Recurrent Neural Network (MDRNN) architecture was introduced by Graves et al. (2007), to generalize Recurrent Neural Network (RNN) designs to challenges involving multi-dimensions. In lieu of the single recurrent connection seen in traditional RNNs, this design makes use of a network of “d” connections, where d is the number of spatial and temporal data dimensions. From this basic approach, Visin et al. (2015) proposed the ReNet architecture, which uses sequence RNNs instead of multidimensional RNNs. Therefore, the number of RNNs in each layer scales linearly relative to the number of dimensions (“d”) of the input image (which is always 2d). As can be seen in Figure 6, four RNNs are used in place of each convolutional layer (convolution + pooling) to perform a full, two-dimensional scan of the image.

A layer of the ReNet architecture that models spatial dependencies both vertically and horizontally. Drawn from Visin et al. (2015).
Current deep learning techniques for soil classification
The current trend in training deep learning models to classify or identify soils is the use of lightweight deep learning models, transfer learning, or multi-task-learning. One-shot-learning and meta-learning are relatively new techniques that have not been thoroughly investigated in soil identification.
Lightweight deep learning model for soil classification
Lightweight deep-learning models are models designed to have a relatively small number of parameters and low computational requirements, making them suitable for deployment on low-power devices such as mobile phones, IoT devices, and other embedded systems. Some techniques that can be used to create lightweight deep learning models include: Model compression, Knowledge distillation, Architecture design, and Transfer learning. The primary difference between standard deep-learning models and lightweight deep learning models is the amount of computation and memory required for training and deploying them. Standard deep-learning models typically contain a large number of parameters and layers, which renders them both highly effective and computationally intensive. These models are typically employed for complex tasks requiring a high degree of precision, such as image recognition, natural language processing (NLP), and speech recognition. Lightweight deep-learning models, on the other hand, are designed to be more effective and require fewer computational resources.
Typically, they have fewer layers and parameters, making them simpler to train and deploy on low-power devices, such as smartphones and IoT devices. Frequently, these models are employed for tasks such as object detection, facial recognition, and text classification in which accuracy is still essential but computational efficiency is a priority. Since the objective of the soil identification task is to identify soils in real-time on the field, as opposed to the usually controlled laboratory settings, the choice of a model heavily relies on computational efficiency. Finding the optimal balance between model complexity and accuracy is a significant obstacle when developing lightweight deep-learning models. Researchers and engineers working on soil identification models must meticulously design and optimize these models to ensure that they are both accurate enough for the soil identification task and efficient enough to operate on low-power devices like smartphones. Examples of lightweight deep learning models include MobileNet, SqueezeNet, Tiny-YOLO, ESPNet, EfficientNet-Lite, and many others. The architecture of MobileNet, which is a popular lightweight deep-learning model is composed of depthwise and pointwise convolutions that constitute each depthwise separable convolution layer. Each depthwise and pointwise-convolution is followed by batch normalization and ReLu. Figure 7 shows a depthwise-separable convolution of MobileNet architecture with three optional dense layers.

One component of the MobileNet model architecture that forms a depthwise separable convolution with three optional dense layers.
Figure 8 depicts the architecture of the MobileNet model with three optional dense layers whereas Table 4 outlines some lightweight deep learning models, their sizes, and their downloading links.
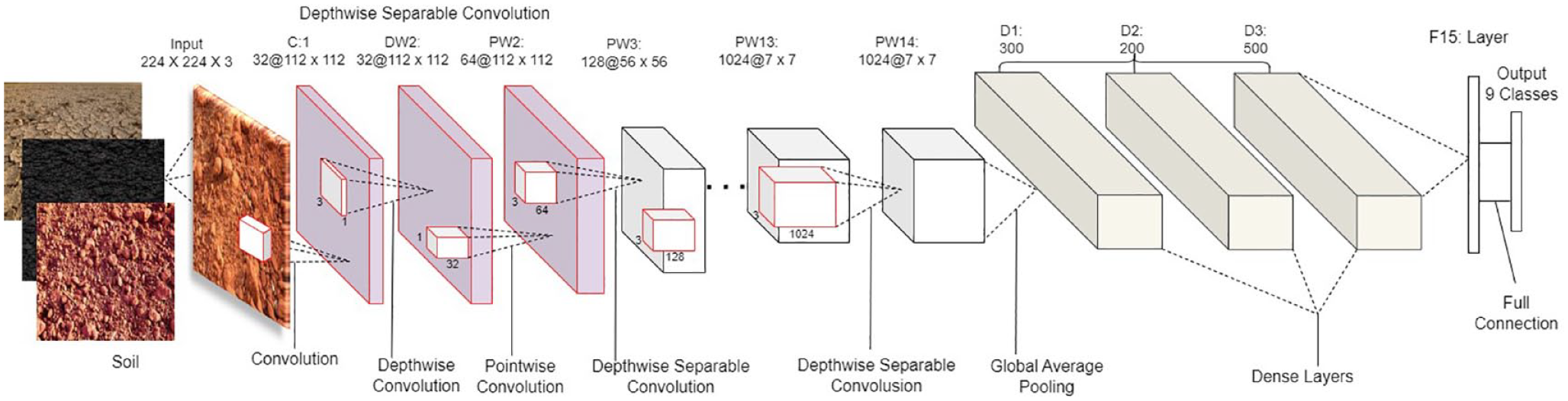
MobileNet model architecture with three optional dense layers. Extracted from Gyasi and Purushotham (2023).
List of Some Lightweight Deep Learning Models.

Transfer learning technique for soil classification
Pre-training a deep learning model on a large dataset, then fine-tuning it on a small dataset can lead to fast training and better performance on the smaller dataset. It is not always feasible to train a deep neural network from scratch since doing so requires a dataset of appropriate size, which is frequently unavailable, and because it might take a long time to achieve convergence. Starting using pre-trained weights rather than randomly initialized ones is often preferable, even if a sufficiently big dataset is available and convergence does not take that long (Oquab et al., 2014; Yosinski et al., 2014). Refining a pre-trained network’s weights by further training is a key transfer learning use case. As the distance between the pre-trained task and the target task increases, the transferability of features decreases; however, Yosinski et al. (2014) showed that transmitting features even from distant tasks can be superior to the random initialization. The application of transfer learning to the classification or identification of soils is not straightforward. To utilize a pre-trained network, there are architectural requirements that must be satisfied. In practice, however, it is more typical to make use of preexisting network designs (or components) that permit transfer learning, rather than to design a completely new architecture from scratch. When compared to initialization, the training process differs slightly during fine-tuning. Selecting the right components for fine-tuning is crucial, typically the higher-level portion of the network as the lower one tends to contain more generic features, and choosing the right learning rate procedure, which is typically smaller because the pre-trained weights are assumed to be fairly accurate, therefore, it is unnecessary to alter them significantly. The size of per-pixel labeled segmentation datasets is lower than that of classification datasets like ImageNet (Deng et al., 2009; Russakovsky et al., 2015), due to the difficulty of collecting and producing such datasets. This problem is worsened by the much smaller size of RGB-D and 3D datasets. Soil classification or identification networks are increasingly adopting transfer learning, and in particular, fine-tuning from pre-trained classification networks, which has been successfully applied in the techniques we shall cover below.
Multi-task learning model for soil classification
Multi-task learning is a technique that entails training a single neural network to perform multiple tasks that are related. Multi-task learning can be used to simultaneously classify various soil properties, such as texture, pH, and organic matter content, in soil classification. Multi-task learning can improve the accuracy of soil classification by leveraging the relationships between spectral and textural features. Multi-task learning promises to be a powerful technique for soil classification.
Soil classification model training
The infrastructure required to train the soil classification model is determined by the model selected, the model’s complexity, the type of dataset, and the size of the dataset. Once the model has been selected, the architecture needs to be designed. Model architecture design involves determining the number of layers, the input size of the image, the number of filters, the filter size, the type of activation functions, the number of neurons in each layer, and the overall structure of the model. Verify the output shape, the number of trainable parameters in each layer, and the total number of model parameters by running the soil classification model architecture summary. Since several complex computations are involved in training a deep learning model, a powerful CPU is required to handle the training process. A multi-core CPU with a clock speed of at least 2 GHz is recommended. On the other hand, a GPU can also be used to train the model. Though the use of GPU is not mandatory, it is recommended for faster training times. NVIDIA GPUs are commonly used for deep learning model training. Similarly, the amount of RAM needed to train a model is determined by the size of the dataset and the model complexity. A minimum of 16 GB of RAM is recommended for most deep-learning tasks. Deep learning datasets can be large, and therefore, a large storage device such as an SSD or HDD is required to store the data. Deep learning model training can be computationally intensive, and therefore, a reliable power supply is required to ensure that the training process is not interrupted. Apart from these hardware requirements, there are also software requirements that need to be met. For instance, if a GPU is used to speed up the training process, the GPU drivers and libraries, such as CUDA and cuDNN (Chetlur et al., 2014), need to be installed for the deep learning framework to work with GPUs. Programming languages such as Python, Jupyter Notebook hosted by Anaconda Navigator, and many others are usually used for writing deep learning codes. Python is the most widely used language for deep learning due to its simplicity, vast library support, and the popularity of frameworks like TensorFlow, Keras, Caffe, and PyTorch (Abadi et al., 2016). These frameworks provide high-level APIs for building and training deep learning models. Using Google Colab is an alternative method for procuring the required hardware and software infrastructure to train deep learning models; however, this method requires a machine with a high-speed internet connection to download datasets and frameworks rapidly.
Bearing in mind that the target device for the implementation of soil identification software is edge devices such as smartphones that lack high processors like GPU for computation, it is advisable to use a standard machine to train the soil classification or identification model. Once the hardware and software infrastructure is in place, the model can be validated using samples of the soil images to determine the exact features that the convolution layers of the model will extract from the soil images during training, followed by the visualization of the feature maps of the first convolution layer. The train set, validation set, and test set are derived from the preprocessed dataset. The objective is to have three data sets: one for training the model (training set), one for validating the training (validation set), and one for evaluating the model (test set). The validation data set is utilized for hyperparameter tuning to prevent the model from overfitting the training data (Gyasi and Swarnalatha, 2023).
Deep learning models are often considered to be black boxes because they are composed of multiple layers of neurons that transform the input data in complex ways, making it difficult to understand how the input is mapped to the output. This is especially true for models with a large number of parameters, such as deep neural networks, where the number of calculations performed during inference can be billions or even trillions. Therefore, it is always advisable to check the features of the soil dataset that the model will be extracting. The activation maps generated by the model’s convolutional layers can be used to understand the exact features identified for a particular input soil image. In deep learning, a feature map is a set of 2D arrays (also known as activation maps) that represent the outputs of the convolutional layers in a neural network. Each element in the feature map represents a feature detected by the convolutional filter at a specific location in the input image. During the training process, the weights of the convolutional filters are learned through backpropagation, which allows the network to automatically extract relevant features from the input images. As the data flows through the network, each successive layer is able to learn more complex and abstract features, leading to a more powerful representation of the input data. The number of feature maps in a convolutional layer is typically determined by the hyperparameters of the network, such as the number of filters and the size of the kernel. By increasing the number of feature maps in a layer, the network is able to learn more diverse and complex features, at the cost of increased computational complexity and memory requirements. Figure 9 shows samples of some of the soil images and their feature maps acquired by the first convolutional layer of a model.

Samples of some soil images and their feature maps acquired by the first convolutional layer of the MobileNet model.
In order not to overtrain the model, you must set an early stop. Through early stopping, you can monitor the performance of the model on a validation set during training and stop the training process when the performance on the validation set starts to degrade. This is done by selecting a stopping criterion, such as the validation loss or accuracy, and monitoring it during training. When the stopping criterion does not improve for a certain number of epochs, the training process is stopped, and the model with the best performance on the validation set is selected as the final model. By doing so, early stopping helps to prevent the model from overfitting and improves its ability to generalize to new data. The number of epochs and the patience (i.e., the number of epochs to wait for improvement) are hyperparameters that can be tuned to achieve optimal performance on the validation set. Assess the model’s training process by analyzing the training and validation accuracy and that of the training and validation loss graphs to determine how training was conducted. Since the process of deep learning model training is iterative, adjustments may need to be made to the model and the training process depending on the outcome of validation and testing. If the model is overfitting, adjustments need to be made to the architecture or the training process, or the hyperparameters such as the batch size, learning rate, optimizer, or activation function used (Chilimbi et al., 2014). The final step is to test the model with the test dataset that was not utilized in either the training or validation phases. This step provides an accurate measure of the model’s performance and helps determine if it is ready for deployment. Figure 10 shows the graph of training and validation accuracy and training and validation loss.

The graph of training & validation accuracy and training & validation loss.
Evaluation metrics for soil classification
For the soil classification/identification system to be beneficial and make a substantial impact on the field, its effectiveness ought to be rigorously assessed. Furthermore, the assessment has to be conducted using benchmark-accepted measures that allow for reasonable comparisons to current practices. Execution time, accuracy, and memory footprint are only a few of the numerous criteria that must be assessed to determine the system’s validity and utility. Some metrics may be more important than others based on the objectives or the context of the system; for instance, in a real-time application, execution speed may be enhanced at the expense of accuracy. However, it is of the uttermost importance, for the sake of scientific consistency, to specify all conceivable metrics for a proposed method. The selection of an evaluation metric depends on the nature of the problem, the project’s objectives, and the specific data. It is important to select the right metric(s) to ensure that the model’s performance is accurately assessed. Numerous evaluative metrics are available to assess the efficacy of deep learning algorithms used in the classification/identification of soil. Accuracy, Precision, Recall, F1 Score, Confusion matrix, Intersection over Union (IoU), micro average, macro average, and many others are typical metrics. Table 5 shows the mathematical operations for these metrics.
Mathematical Operations of Some Classification Report Metrics.

Note. True negative (TN) = indicates that the case was negative and the prediction was also negative; true positive (TP) = indicates that the case was positive and that it was predicted to be positive; false negative (FN) = implies that the case was positive, when it was predicted to be negative; false positive (FP) = implies that the case was negative, but the prediction was positive.
A confusion matrix is a table that summarizes a classification model’s performance. It indicates the number of accurate positives, accurate negatives, false positives, and false negatives. Figure 11 depicts an example of a confusion matrix, and Table 6 provides an overview of a classification report.

Sample confusion matrix (extracted from Gyasi and Swarnalatha. (2023)).
Sample Classification Report.

Implementation of soil classification model on edged devices (smartphones)
The implementation of a deep learning model on resource-constrained devices, such as smartphones and unmanned aerial vehicles (UAV), to predict soil varieties, is a complex endeavor involving numerous steps. The implementation procedure begins with the model selection phase of the soil classification procedure. The selection of a model is a critical factor in determining its feasibility for deployment on a resource-constrained device since it directly affects the model’s size and efficacy. After training and validating the model using the soil dataset to achieve the specified level of accuracy, it is necessary to save the learned model. The model is capable of being saved in TensorFlow file format. To efficiently execute a deep learning model on a smartphone, the saved model may need to be quantized to reduce its size and computational requirements. After undergoing training and optimization, the model becomes ready for deployment on a smartphone device. The conversion of the trained model into a format appropriate for mobile devices, such as TensorFlow Lite or Core ML, is dependent on the platform chosen for the development of mobile applications. The model is then incorporated into a mobile application development environment, such as Android Studio or Xcode. Execution of the necessary code for loading the model and performing inference on the smartphone device constitutes the subsequent stage.
In addition, the implementation of a mechanism to capture input data on the mobile device is essential. This could entail using the smartphone’s camera to capture soil images or sensors to collect pertinent environmental data such as geospatial location (Gyasi and Purushotham, 2023). The subsequent phase entails applying inferences to the input data collected by the smartphone using the deployed model. The soil classification will be determined by the algorithm based on the specified data. The deployment of deep learning models on mobile devices may impose substantial resource requirements. Deploying deep learning models on smartphones can be resource-intensive; therefore, it is crucial to account for the device’s processing capacity and memory constraints from the outset when designing the model and app. In addition, it is necessary to optimize the model to increase inference speed and memory efficiency, thereby assuring a seamless user experience. Figure 12 depicts the interface design of the mobile application SC-MobiNet created by Gyasi et al. This application seeks to provide geospatial location determination and real-time soil type prediction.

The interface design of SC-MobiNet mobile application.
Discussion
In this work, a comprehensive examination of various deep-learning approaches for classifying or identifying soils has been investigated in depth. We can infer a variety of conclusions based on the results. Reproducibility is the most essential of these factors. Our observation shows that, numerous methodologies either report results on nonstandard datasets or their methods are never tested. A significant proportion of the papers neglected to describe how the dataset was separated into training, validation, and test sets, as well as their respective sizes. Thus, comparisons are unattainable. Since the majority of the works lacked a model summary, crucial details such as the model employed, the image size, the total number of convolutions, the total number of parameters, the activation function, and the optimizer were absent. In addition, some of them do not specify the experimental setup or provide the implementation’s source code, which significantly hinders reproducibility. The paucity of information regarding other metrics, such as the learning rate, number of iterations (epoch), classifier, batch size, execution time, and memory consumed, was uncovered by this study. Methods must disclose their performance on benchmark datasets, meticulously define their training process, and avail their models and weights accessible to the public to facilitate advancement. The majority of papers do not report this type of detail, and even when they do, the previously mentioned reproducibility problems plague such reports. The vacuum is caused as a result of most studies prioritizing accuracy at the expense of time or space. The majority of papers also neglected to specify the programming language, the type of system used to execute the model, and the system’s specifications, such as CPU or GPU type, speed, memory, and operating system. However, it is essential to consider where these models are applied.
In practice, these models will operate on embedded devices, such as mobile phones, drones, and robots, which have limited computational capacity and memory. The deployment of soil classification models on portable devices such as smartphones, and drones will enable accessible and on-the-go analysis, empowering users with valuable information about their environment (Gyasi and Purushotham, 2023; Padmapriya et al., 2023). It can aid in monitoring changes in soil quality and health over time. This capability is invaluable for assessing environmental impacts, detecting soil degradation, and implementing appropriate conservation measures to protect ecosystems and natural resources. By providing detailed soil classification information, deep learning models can assist farmers in selecting suitable crops and tailoring farming practices to match specific soil characteristics. This targeted approach promotes sustainable agriculture and reduces the use of fertilizers and pesticides, minimizing environmental impacts. The model can process soil images captured by remote sensing technologies, such as satellites and drones, enabling soil classification on a large scale. This scalability is vital for covering extensive areas, including remote or inaccessible regions, where traditional soil sampling may be impractical. In contaminated or degraded areas, the model can assist in identifying areas that require remediation efforts. Accurate classification can guide restoration initiatives and help restore soil health and fertility.
Deep learning-based soil classification data can serve as a valuable resource for policymakers, environmental agencies, and researchers. It facilitates data-driven decision-making in various domains, including agriculture, land management, urban planning, and natural resource conservation. The application of the deep learning model to soil classification encourages interdisciplinary collaboration between soil scientists, geographers, remote sensing experts, and machine learning researchers. This collaboration can lead to innovative solutions and a deeper understanding of soil dynamics and interactions. Moreover, the geospatial data generated by deep learning model-embedded portable devices such as smartphones, drones, etc., can be integrated with existing geographic information systems (GIS) and remote sensing technologies to create detailed soil maps and enhance the accuracy of land resource assessments (Zeraatpisheh et al., 2019). Deep learning models can continuously learn from new data, enabling iterative improvements in soil classification accuracy and adaptability to changing environmental conditions and land use patterns.
Future research directions
Based on the assessed research, which represents the current state of the discipline, we offer a selection of intriguing directions for future research as follows:
It is recommended to use field soil datasets instead of datasets derived from the Munsell color chart, laboratory-prepared sieved soil datasets, and artificially generated 3D soil datasets. It is essential to always specify the size, format, and channel of soil images, while also partitioning the dataset into distinct subsets for training, validation, and testing purposes. The data augmentation procedure performed on the dataset must be explained while ensuring that it does not include the test set. Researchers need to verify that the test set included in their study has not been exposed to the model during the training phase. This will ensure that the field soil identification model’s test accuracy is reliable. More importantly, consideration should always be given to lightweight deep learning models, taking into account the devices on which the model will be implemented. Additionally, the model must be illustrated with all of its features identified and must be stated if the model was used as transfer learning, a modified model, or a model created from scratch. Furthermore, the programming language and system used to train the model, as well as all of its specifications, must be specified. All parameters, including model size, total model parameters, filter size, stride, learning rate, batch size, number of iterations (epochs), optimizer, activation function, number of classes or categories, total training time, memory consumed, and metrics used, must be described. Attention should be paid to metrics such as training & validation accuracy, and training & validation loss graphs, accuracy, classification reports, and confusion metrics. These metrics should be presented comprehensively, providing detailed information. It is important to provide a comprehensive explanation of the implementation procedure after achieving the necessary level of accuracy and saving the model. We propose that strict adherence to the assessment criteria outlined in Appendix A, Table A1 is essential for conducting rigorous research on deep learning-based soil identification. Furthermore, editors might use this evaluation framework as a standard for assessing and revising articles submitted for peer review and publication.
Conclusion
In contrast to other reviews, this article focuses on a topic that is on the rise, namely deep learning models for soil classification, and examines the most cutting-edge research in this field. We developed the soil identification problem and supplied the essential prior information on deep-learning for this endeavor. We examined the current literature on datasets and methods to provide an exhaustive overview of available datasets and methods. The datasets were meticulously defined, including their purposes and features, for researchers to readily choose a dataset that fits their requirements or replicate their acquisition procedures. The methods were analyzed based on two vantage points: their utility and their accuracy. In addition, we provided a tabular comparison of the datasets and methodologies, categorizing them based on various criteria. In conclusion, we provided valuable insight regarding prospects in research and outstanding issues in the discipline. In all, soil identification has been approached with a great deal of success, but it is still an unresolved problem whose resolution would be incredibly beneficial for a far-reaching variety of practical uses in the real world. Soil classification has significant implications for sustainable development. Providing information about the properties and characteristics of soils can help optimize agricultural practices, guide land use planning, and monitor the environment, all of which are crucial for sustainable development. In addition, deep learning has proven to be highly effective at addressing this issue.
Deep learning-based soil classification can achieve higher levels of accuracy and efficiency compared to traditional manual methods. Deep learning models can process large volumes of soil images rapidly and extract intricate patterns that may be challenging for human experts to discern accurately. Accurate soil classification through deep learning models enables a better understanding of soil properties and spatial variability. This information can be utilized for optimized soil management practices, precision agriculture, and informed land use planning, leading to higher crop yields and resource conservation. Deep learning-based soil classification can be incorporated into educational programs to raise awareness about soil importance and conservation. It can also empower farmers and landowners with essential knowledge about their soil resources; therefore, new research avenues and innovations will likely emerge rapidly soon.
Footnotes
Appendix A
Third Step Evaluation: Detailed Questionnaire Based on Architecture, Design Elements, and Validation for DL Method.

| S/No. | Questions | Yes | No | Remarks (UR/CD) |
|---|---|---|---|---|
| 1 | Deep architecture type utilized √ Does the suggested model utilize CNN? √ Does the suggested model utilize FCN? √ Does the suggested model utilize a hybrid design? |
√ | ☒ | |
| 2 | Architectural specifications and design components |
√ | ☒ | |
| 3 | Training and validation |
√ | ☒ |
Note. UR = unreported; CD = cannot determine
Acknowledgements
We extend our sincere appreciation to Vellore Institute of Technology (VIT) University for its support.
Author Contributions
Authors made equal contributions.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.