
Abstract
Using a decision support system (DSS) that classifies various cancers provides support to the clinicians/researchers to make better decisions that can aid in early cancer diagnosis, thereby reducing chances of incorrect disease diagnosis. Thus, this work aimed at designing a classification model that can predict accurately for 5 different cancer types comprising of 20 cancer exomes, using the mutations identified from whole exome cancer analysis. Initially, a basic model was designed using supervised machine learning classification algorithms such as K-nearest neighbor (KNN), support vector machine (SVM), decision tree, naïve bayes and random forest (RF), among which decision tree and random forest performed better in terms of preliminary model accuracy. However, output predictions were incorrect due to less training scores. Thus, 16 essential features were then selected for model improvement using 2 approaches. All imbalanced datasets were balanced using SMOTE. In the first approach, all features from 20 cancer exome datasets were trained and models were designed using decision tree and random forest. Balanced datasets for decision tree model showed an accuracy of 77%, while with the RF model, the accuracy improved to 82% where all 5 cancer types were predicted correctly. Area under the curve for RF model was closer to 1, than decision tree model. In the second approach, all 15 datasets were trained, while 5 were tested. However, only 2 cancer types were predicted correctly. To cross validate RF model, Matthew’s correlation co-efficient (MCC) test was performed. For method 1, the MCC test and MCC cross validation was found to be 0.7796 and 0.9356 respectively. Likewise, for second approach, MCC was observed to be 0.9365, corroborating the accuracy of the designed model. The model was successfully deployed using Streamlit as a web application for easy use. This study presents insights for allowing easy cancer classifications.
Introduction
Decision support models
Genetic aberrations in the cancer exomes are known to be the major cause of cancers. With possible early diagnosis, understanding the cause of the disease and application of appropriate treatment strategies still being slightly blurry in cancer research, the pressing need for the development of alternative ways to comprehend the existing huge cancer data is not overstated. As the prevailing cancer scenario in the world is on a constant uprise, extensive research is also being carried out for the same. To overcome the challenge of wrong treatment decisions and prognosis, huge data interpretation as well as understanding patient specific cancer causes, modern technology is being implemented and medical decision support systems (MDSS) are being developed. This is now an emerging technology that can facilitate an early-stage detection of different cancers. Considered as an ever-evolving technology, DSS models are highly deft at augmenting the precision of decisions taken by increasing the human diagnostician’s abilities of disease diagnosis and decision-making. 1
A thorough understanding of the cancer exomes reveal a huge amount of information and data regarding the existing variations that can lead to the disease. For furthering understanding of cancer exomes, currently several DSS systems have been developed that harbors all major preliminary data and aids in the decision making.2-5 Studies have claimed that a physician’s performance may be directly influenced by the strong quality of information generated by the DSS. 6 Moreover, to implement the DSS models reliant on supervised learning algorithms, the produced information quality is dependent on the selection of an algorithm that predicts either presence or absence of a disease from a sample collection. 6 Clinical DSS systems aim to have computerized alerts, templates for documentation, condition-specific order sets, specific patient data reports and other pertinent data. This shows that a clinical DSS has enormous potential to push evidence-based standardization of care among cancer patients, thereby bettering the care delivery as well as the patient outcomes. 7 Furthermore, DSS systems upgrade and enhance the healthcare processes, betters efficiency and quality, improves access to medical data and records and saves cost. 8
Advancements in cancer classifications
Generally, a decision support system is categorized into 3 different types. Knowledge-based DSS systems offers a set of suggestions to the problem at hand through existing stored knowledge, model-driven DSS systems provides support for the decisions along with use of certain analytical tools and data driven DSS allow the retrieval of data, its management and its manipulation.9,10 There have been numerous approaches for constructing a DSS system previously such as using an empirical assessment approach 11 or by using structural equations modeling approaches. 12 However, lately, the preferred manner of incorporating a DSS system to a database is by using machine learning, neural networks or artificial intelligence.13-15 Moreover, although there are several advantages of employing a DSS system, some improvements in fields such as big data analytics, using DSS as a web application, data mining and artificial intelligence, machine learning and enhancements in Internet of Things (IoT), 9 will further aid in better application of the DSS system in healthcare and diseases. Thus, bearing in mind the prevailing cancer conditions and the existing technology for dealing with the vast cancer exome data in the best possible way and as a continuation of our previous work Padmavathi et al, 16 the present study aimed to develop a classification model and a web application in order to analyze and aid researchers in making better decisions so that better disease management can be facilitated.
Contributions of current study
The present study focuses largely on the variations uncovered from several different cancer exome datasets, which makes the DSS system very wide-spread and beneficial for prospective similar research. The primary contribution of our study is toward the development of an accurate decision support model and to provide a base for upcoming similar such models, which when used in healthcare will provide huge advantages to the early diagnosis and management of cancers. This model will serve as preliminary research to help researchers/clinicians/diagnosticians to make an early decision. With this base, other models can be developed for various kinds of genetic diseases. However, our study is novel as the model is built encompassing 5 different cancer types, which has not been previously carried out. Several different variables were considered to develop this model, overarching various SNPs as shown in Supplemental File S1, to attain better predictability. Our study showed that the final derivative dataset selected for building the model comprised of the features of importance provides insights into the workings of the model, bringing about a better accuracy than several similar such previous work, fulfilling the fundamental aim of our study, to offer backing to the control of cancers. The study also focuses on deploying the model for easy user accessibility.
Materials and Methods
Selection of variants from cancer exome datasets
To identify and select the variants prior to development of classification model, the standardized pipeline mentioned in Padmavathi et al 16 , was followed. The variants obtained from our previous study were identified from 20 cancer exome datasets that belonged to 5 cancer types. The 20 exome datasets are publicly available and can be downloaded from NCBI SRA (National Centre for Biotechnology Information-Sequence Retrieval Archive) (https://www.ncbi.nlm.nih.gov/sra) with their accession numbers (Table 1). These identified variants were carried forward in the current study for further analysis. The cancer types selected were human diffuse-type gastric cancer, high-grade serous ovarian cancer, intrahepatic cholangiocarcinoma, non BRCA1/BRCA2 familial breast cancer and pancreatic adenocarcinoma. 16 Our previous study reported 4181 identified variants (Supplemental File S1) for which the data was normalized and information on the variants were obtained in .csv format. This was selected for pattern recognition to establish a mutational pattern essential for building a decision support system.
Twenty cancer exome datasets used for the analysis of 5 cancer types in our previous work for obtaining mutation data.

Hyperlinks for the selected datasets used in our previous work are provided. Additionally, the clinical information on the datasets and the different somatic variations are provided in our previously published work, in the form of a database. 17 For further reference, clinical information on the datasets used, as obtained from NCBI-SRA are provided as Supplemental File S2.
Pattern recognition for identified variants
A basic pattern was identified for all the variants. The .csv file of the identified variants were patterned based on the type of nucleotide change in each case and in every chromosome the alteration occurred. This was performed using basic MS excel functions. The frequency of the mutations were also calculated and those having highest frequency were classified as commonly occurring, while those that occurred once or twice were categorized as unique. The function =REF_column&”-“&ALT_column was employed to merge the values in 2 separate columns into one and =COUNTIFS(B:B,"chr_no",M:M,N10) were utilized for counting the mutations with respect to the chromosome numbers.
Data clean-up and selection of features for building DSS
The initial .csv file containing comprehensive data on the variants were first cleaned-up. The clean-up was performed to eliminate all unwanted columns containing null values. Additionally, for building a baseline DSS, all the available columns in the .csv variant file could not be considered since the data present in the columns were a combination of string and numeric. Therefore, the features were selected on a trial-and-error basis and also based on the assumption that those selected were directly related to the cancer type. These required features were chosen in a way so as to reduce the noise and to build an efficient model for appropriate cancer type prediction. Once the features were finalized, appropriate machine learning algorithms were employed to arrive at a preliminary DSS model.
Prior to selecting the features, data clean-up was performed as pre-processing, on the 20 cancer exome datasets. The NaN values were first calculated and the columns having >20% NaN percentage were dropped. Additionally, other columns having information such as Gene Id, Sample ID, etc were dropped as well. With the remaining data, the numerical and categorical values were divided and ANOVA was performed with the numerical data and the target data (cancer type). Columns with ⩽0.05 P values were considered for model training. The same was followed for categorical values, but ANOVA was not carried out on the data. The categoricals that remained after dropping columns having >20% null values were selected. These categorical values were converted to numerical values, then a correlation was performed on the data, along with the final selected numerical columns based on the heatmap results obtained. The features which showed strongly positive and negative correlation were considered for the initial model.
After deleting the columns having more than 20% NaN values, the shape of the normalized data was (4181, 59), as 29 columns (features) were dropped based on the NaN percentage criterion. The numerical columns were separated for the ANOVA test with the target columns (cancer types), for which 19 out of 59 features were selected. Features having >0.05 p values were dropped along with features less correlated features and the features containing noise values. Thus, 5 features out of 19 numerical were considered for initial model building. Moreover, from the 59 features, 40 were categorical columns. Eight features out of 40 were considered for further processing, post eliminating the remaining noisy features, which reduced the prediction accuracy of the model. Data engineering techniques to convert the categorical values to the numerical values were employed and for features such as F1R2 and F2R1, the string values for joined to float values to complete the label encoding. These 8 features of importance were added to the initial 5 features to make 13 features, along with 3 other significant features such as “GERMQ,” “MPOS” and “POPAF” to improve the model accuracy (detailed in section 4.4, method 1). The results later showed that this method of feature selection improved the overall accuracy by 1%. Supplemental File S3 shows the initial pre-processing and feature selection based on NaN value criterion and the ANOVA test score and P values for the initial selected 19 features.
Cancer classification model using machine learning (ML) algorithms
Prior to training the data, pre-processing was performed to assess the NaN (not a number) values in the 20 cancer exome datasets, to know more about the balance of class, to convert the categorical values into numerical values using sci-kit learn, 18 an open-source ML library in Python. Since data training was carried out using labeled data, supervised machine learning algorithms were preferred over unsupervised ones. 19 Generally, the supervised learning algorithms incorporate convolutional neural networks (CNNs) such as deep learning and several non-neural network algorithms. 20 Some non-neural network algorithms most commonly used include logistic regression, linear regression, decision tree, Naïve Bayes, Support Vector Machine (SVM), Random Forest (RF) and k-nearest neighbor (KNN). 21 For obtaining outcomes with accuracy and precision as the major goal, supervised learning algorithms such as SVM, RF, KNN, CNNs, and boosted trees are preferred. 20 Additionally, the Naïve Bayes classifiers employ a probabilistic method that rely on Bayes theorem 22 and is a subset of the Bayesian logic, that works on the assumption that the features that are being considered for evaluation are not dependent on each other.23,24 It has been suggested that Naïve Bayes algorithm yields reasonable results. 25 Furthermore, the KNN algorithm is non-parametric and is a clustering algorithm, primarily employed for regression and classification. 26 The utilization of KNN is considered intuitive, are generally applied for tasks related to both classification and regression, and works best when the number of input variables are small. 27 Support Vector Machine categorizes the data by outlining a hyperplane that distinguishes 2 sets of groups and has a capability to detect non-linear relationships. 28 Likewise, the decision tree algorithm works like a tree and has 2 sets of rules to arrive at a decision: building the tree and pruning it, making this model easy to interpret and very reliable. 29 Moreover, Random Forest utilizes a network of decision trees and bootstraps to generate random data that can be eventually trained. This process minimizes the challenges of overfitting and improves the generalizability of this ML technique.30,31 Thus, due to these advantages, the current study employed 5 essential supervised learning ML algorithms such as Naïve Bayes, KNN, SVM, decision tree and RF to initially train the data. The performance metrics obtained in each case was noted.
Initially, only 5 features out of 88 were selected for training the model to consider only those that were absolutely relevant to the respective variants and to eliminate all the missing features having missing values. These features included chromosome number (“CHROM”), reference nucleotide from human genome (“REF”), altered nucleotide in cancer dataset (“ALT”), the type of mutation (“CONSEQUENCE”), and the gene name (“SYMBOL”). For obtaining better comprehension of the outcomes, correlation was studied using correlation heat chart and a pairplot 32 was plotted to further analyze the relationship between the variables. However, since the accuracy for the initially selected features were not high, 2 other approaches were utilized for training to assess the model accuracy. The outcomes obtained were thoroughly scrutinized.
Method 1: Training all variants from 20 cancer exome data
In this method, a greater number of features were taken into consideration for training the datasets. The features having more numeric data were selected for obtaining a better precision, those that had missing values were removed and the features that were directly associated with the cancer variant were taken into account. Sixteen out of 88 features were considered for training, which included the class of variants (“VARIANT_CLASS”), log odds that the variant is present in the tumor sample relative to the expected noise (“TLOD”), score for sorting the variants from tolerant to intolerant (“SIFTscore”), allelic frequency of the sample (“Sample.AF”), the type of variant after SIFT sorting (“SIFT”), median base quality of each allele (“MBQ”), median fragment length of each allele (“MFRL”), median mapping quality of each allele (“MMQ”), allelic depth of the sample (“Sample.AD”), forward and reverse read counts for each allele (“Sample.F1R2” and “Sample.F2R1”), read depth (“DP”), phred-scaled posterior probability that the alternate alleles are not germline variants (“GERMQ”), median distance from the end of the read for each alternate allele (“MPOS”), population allele frequency of the alternate alleles (“POPAF”) and approximate read depth of the sample (“Sample.DP”) (https://support.sentieon.com/appnotes/out_fields/). 33 All the variants falling under these features from 20 cancer exome datasets were considered for training using the better supervised learning ML algorithms among all 5. In this case, decision tree and random forest were used. The correlation between the features were examined using correlation heat maps and pairplots for the same were plotted. The performance metrics obtained after executing the ML algorithm were analyzed. Python codes in Jupyter Notebook, an open-source application that allows sharing and developing equations, codes, visualizations and text, were employed to implement the algorithms in machine learning. This work is a continuation of our previous work (DOI: IASTEM.08122021.14897), where a general foundation for building the model was laid.
Balancing the imbalanced data using SMOTE
From correlation heat maps, when some of the target classes were found to be imbalanced, these data were balanced using SMOTE (Synthetic Minority Oversampling Technique). 29 Considered as the de facto standard framework for balancing imbalanced data, this technique is a simple and robust pre-processing algorithm that has been used in solving several class imbalances issues 34 to reduce performance issues produced by ML techniques. When there are too few instances of the minority class for a model, oversampling can be carried out using SMOTE by duplicating the samples from the minority classes in the dataset that has to be trained before fitting the model.35,36 This technique balances the distribution but does not add any additional data to the model, thereby solving the problem of imbalance. In the present study, when data imbalance was observed among the variants in the 20 cancer exome datasets belonging to 5 cancer types, oversampling was performed to balance the variations in the datasets. RF and decision tree model were then applied on the balanced classes to obtain a better model. A comparison between the 2 models revealed the better algorithm of the 2 in terms of model accuracy, which was then employed for training and testing in method 2.
A receiver operating characteristic (ROC) curve was plotted for the models developed using both decision tree and random forest for 5 classes of cancer types, to further confirm which of the 2 models was better. The true positive rates and the false positive rates were estimated for the model developed, for which an ROC plot was mapped. This plot was analyzed to estimate how the current model is capable of distinguishing the classes, by a graphical representation of area under the curves for the 5 cancer types.
Method 2: Splitting variation data to train and test
To further assess the prediction of the model for new sample datasets, the variants from 20 cancer exome datasets were split for training and testing. This categorization of the cancer datasets was carried out using the train-test-split command in ML, to test the model’s prediction capability for new sample data. The total number of variation data available was 4181, as assessed in our previous work. 16 For the purpose of training and testing in the current study, a train_test_split command was employed. With the original count of data being 4181, for the purpose of training, 70% of this total was selected for training while the remaining 30% for testing. This meant that 70% of the overall data count of 4181 was 2926, while 1255 variants data was selected for testing. The variation data selected for training approximately covered 15 datasets, while the rest covered the remaining 5 datasets. Therefore, our study employed the 70/30 for training and testing the overall variation data present in the 20 exome datasets. The variation data that was trained belonged to dataset sample IDs SRR894452, SRR90009, SRR941051, SRR941052, SRR941053, ERR166303, ERR166304, ERR166307, ERR166310, ERR166312, ERR166336, ERR166336, ERR232253, ERR232255 and those for testing belonged to sample IDs SRR900123, SRR941054, ERR166335, ERR035489, and ERR232254. The features used in method 1 were employed in this method as well. Using Python, codes were written in Jupyter Notebook and executed to implement Random Forest algorithm for training and testing the datasets. RF was implemented in this method since the use of this algorithm provided better model performance.
The codes for method 1 and method 2, cleaned-up data used for designing the model and the readme files are provided in Github (https://github.com/VN-Lab/DSS).
Model cross validation using Matthew’s correlation co-efficient (MCC)
To cross-validate the best working model, Matthew’s correlation co-efficient test for both imbalanced and balanced data was calculated. A cross validation using MCC provides an additional validation for the model used to develop a DSS. MCC is widely accepted as a reliable statistical metric 37 to determine the accuracy of classification models. Since studies have shown that MCC deteriorates when the class datasets are imbalanced and performs better in balanced ones, 38 the present study used this method to cross-assess the designed model. From scikit-learn, the random forest classifier was imported, the cross-validation models were trained, the model was applied to make the prediction and the performance results were printed as outputs in terms of MCC test results. The correlation co-efficient calculated from both balanced and imbalanced datasets were compared to check their accuracies. The MCC cross validation was carried out for both approaches as stated in method 1 and method 2 and the results obtained were scrutinized.
The entire protocol used for arriving at the best DSS model is illustrated in Figure 1, that was created using draw.io.
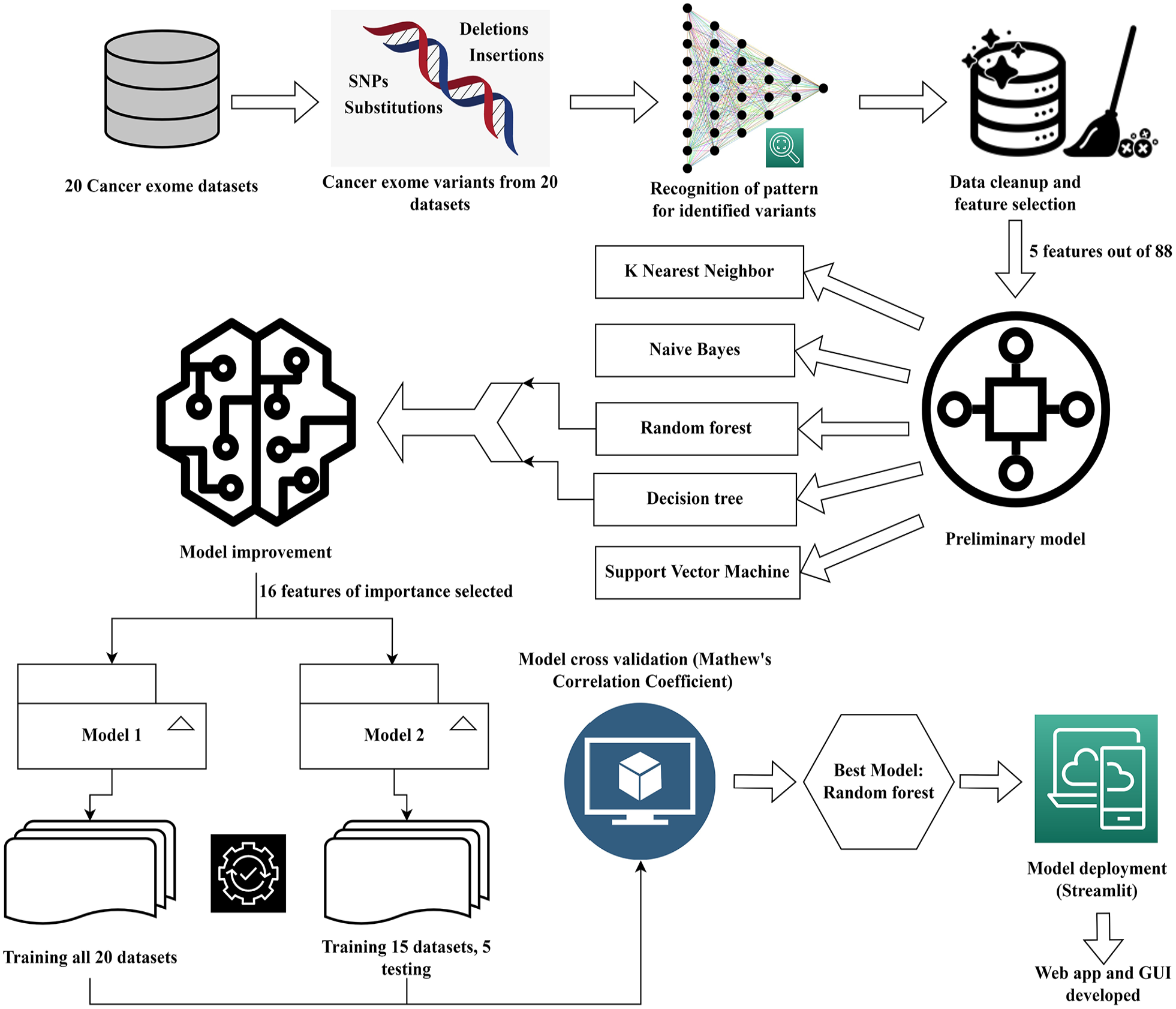
Illustration of the workflow followed for building the decision support system for various cancer types. This figure was drawn using draw.io.
Evaluation parameters
All the models were evaluated based on the following statistical parameters, as given in Gupta and Garg. 39





Model deployment
To further enhance and allow appropriate use of the designed ML model, it is essential that the model is deployed in a suitable setting. This is primarily done to take complete advantage of the decision support model and the machine learning algorithms used to deploy it in a clinical setting to obtain patient-level predictions. For this purpose, the current DSS model was deployed using Streamlit. 40 Streamlit is an open-source python library that is used for constructing customized web applications for machine learning algorithms in an uncomplicated manner, that is easy to navigate. All the necessary libraries should be installed after creating a virtual environment. The prediction code is present in a .py file that comprises of a function which takes an image that the user has uploaded and predicts the results by displaying the corresponding probability value. This working principle of Streamlit was utilized in the present study to deploy the designed model.40,41 The deployed model can be used easily by all users and is accessible via https://share.streamlit.io/sabhapathi0306/streamlit/main/dss.py. The codes employed for deploying the model can be viewed in https://github.com/VN-Lab/DSS.
Results
Pattern recognition for identified variants
A basic pattern was identified and the common single nucleotide polymorphisms (SNPs) across every cancer exome dataset was identified. Nucleotide alteration from C-to-T and G-to-A were found to be most common among all 20 exome datasets. Nucleotide change from G-to-T occurred among 4 cancer exome datasets which all belong to non BRCA1/BRCA2 familial breast cancer. The mutational change from C-to-T occurred in 17 out of 20 exome datasets. Likewise, change from G-to-A occurred in 16 out of 20 exome datasets. Overall, base substitution C-to-T appeared 198 times out of the 4181 variants (raw mutations file-Supplemental File S1) and G-to-A appeared 191 times. In most cases, these 2 nucleotide alterations were found to be frequently occurring. The identification of this common mutational patterns is elucidated in Table 2.
Common mutational patterns recognized for 20 cancer exome datasets for 5 cancer types.

Cancer classification model using machine learning algorithms
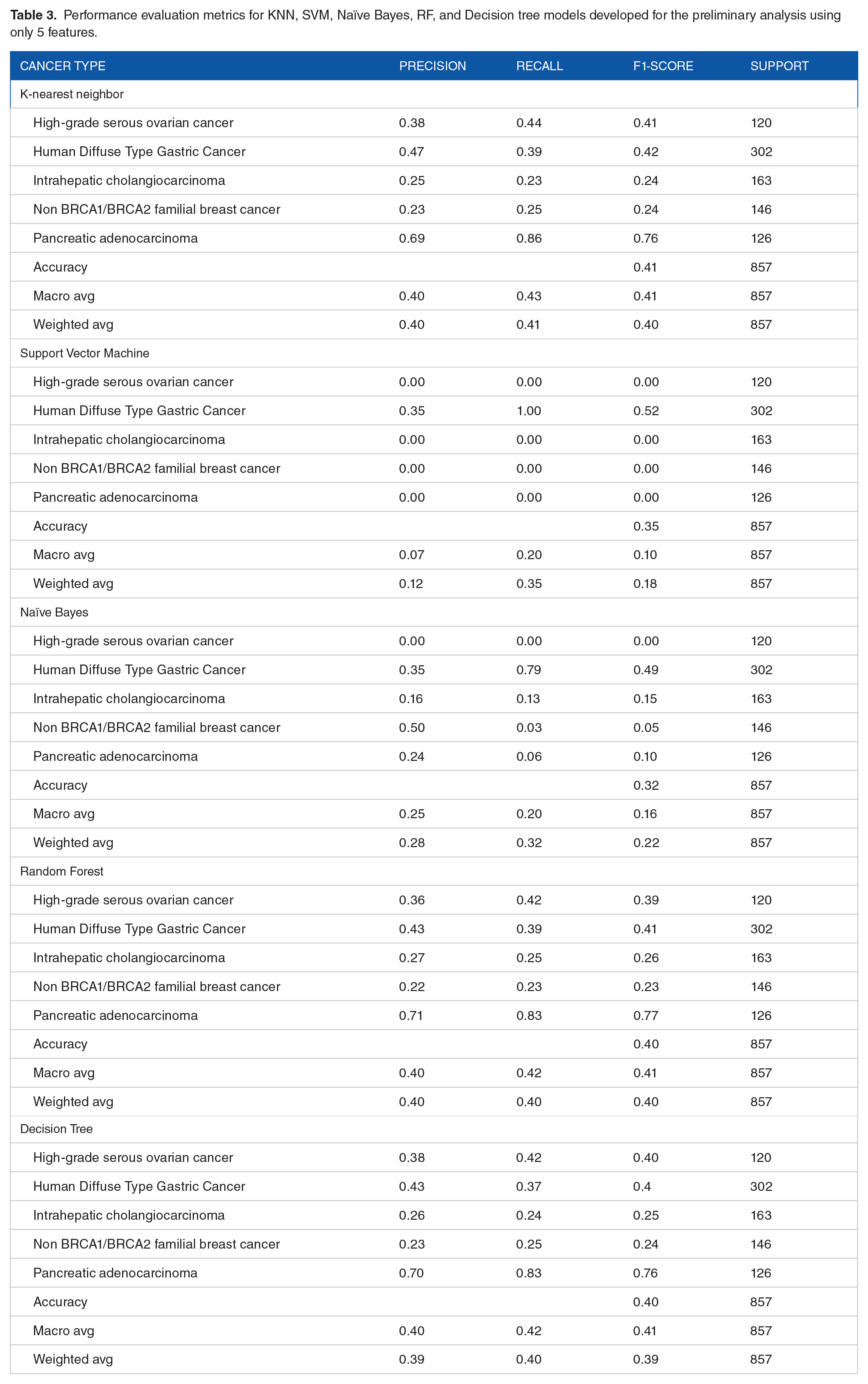
When an initial analysis was carried out with only 5 features, the model did not provide a good prediction due to less correlation between the selected features as observed in the correlation heat map (Figure 2). The heat map showed that correlation between the features was found to be less than .1. Further, from the pairplot, it was noted that the features did not show good correlation with each other (Figure 2). When KNN supervised ML algorithm was used, the weighted average for precision was found to be 0.40, 0.41 for recall and 0.40 for F1-score. The accuracy of the model was found to be 41%. Likewise, the weighted average score for precision was found to be 0.11, 0.34 for recall and 0.17 for F1-score when SVM model was employed. The accuracy of the model was observed to be 34%. With Naïve Bayes, the weighted average was for precision was found to be 0.28, 0.32 for recall and 0.22 for f1-score. The accuracy of the model was observed to be 32%. Likewise, for the decision tree algorithm, the weighted average was found to be 0.39 for precision, 0.40 for recall and 0.39 for f1-score. The model accuracy showed 40%. With RF algorithm, the weighted average was observed to be 0.39 for precision, 0.41 for recall and 0.40 for F1-score. Model accuracy when RF was used was observed to be 41% (Table 3). Thus, although decision tree and RF models showed a higher accuracy, it was still lesser than expected and the output predictions were incorrect due to less training scores. Hence, an improvement in the model was carried out using the afore-mentioned 2 approaches using decision tree and RF.
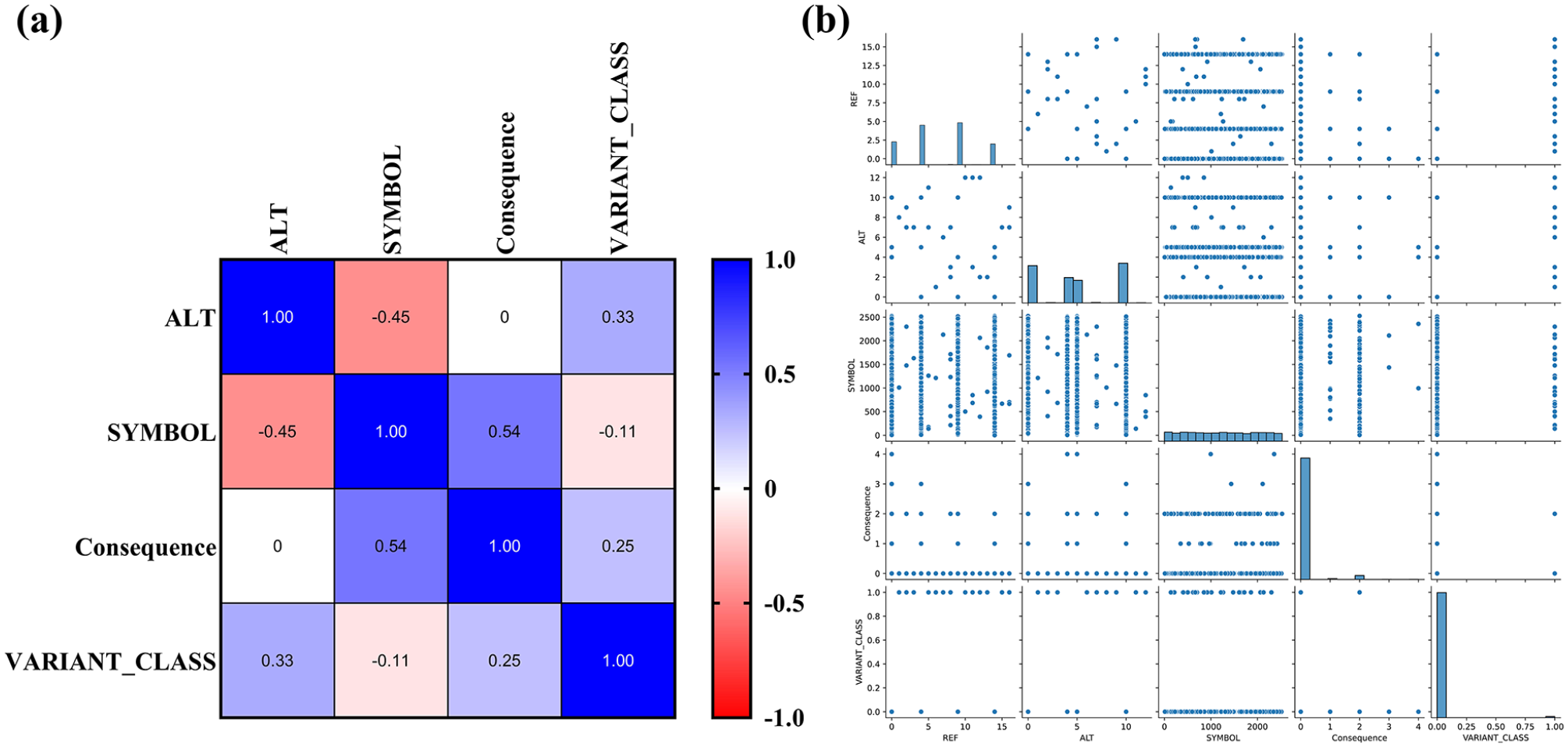
Data visualization for preliminary features selected for model building: (a) correlation heat map for initial model built using 5 ML methods and (b) pairplot of the selected features revealed weak correlation. Since very few features were selected, the correlation between the features were not conclusive.
Performance evaluation metrics for KNN, SVM, Naïve Bayes, RF, and Decision tree models developed for the preliminary analysis using only 5 features.
Improving model accuracy
Since the features selected in the initial attempt did not produce expected outcomes, an attempt to improve the model via the 2 stated methods yielded tremendous outcomes with doubled accuracy.
Method 1: Training all variants from 20 cancer exome datasets
When 16 features were selected and all 20 exome data were trained, the correlation between the features were found to be good, as observed in the correlation heat map (Figure 3). The pairplot for the same also showed good relationship between the features (Figure 4). Despite this, the target classes were imbalanced, hence these were balanced using SMOTE. Initially, human diffuse type gastric cancer had 35.58% of the overall mutation data, 12.41% in high-grade serous ovarian cancer, 14.87% for pancreatic adenocarcinoma, 16.61% for non BRCA1/BRCA2 familial breast cancer and 20.54% in intrahepatic cholangiocarcinoma. After oversampling, the all datasets were balanced equally with 20% variation data in each cancer type (Figure 5). Total training data of the selected features prior to balancing was 2926 and after oversampling via SMOTE, the count of training data increased to 5330 (Table 4).

Correlation heat map of model improvement approach using 16 important features for building DSS model. The features showed very good correlation among one another. Blue boxes indicate a very high correlation, closer to 1.0, while red boxes point toward a lesser correlation. The results are more conclusive here due to increase in the number of selected features and hence a better DSS model was built.

Pair plot of the selected features for model improvement. Sixteen substantial features were selected to improve upon the model. The pair plot shows good relationship between each variable in the x-axis to each variable in the y-axis.
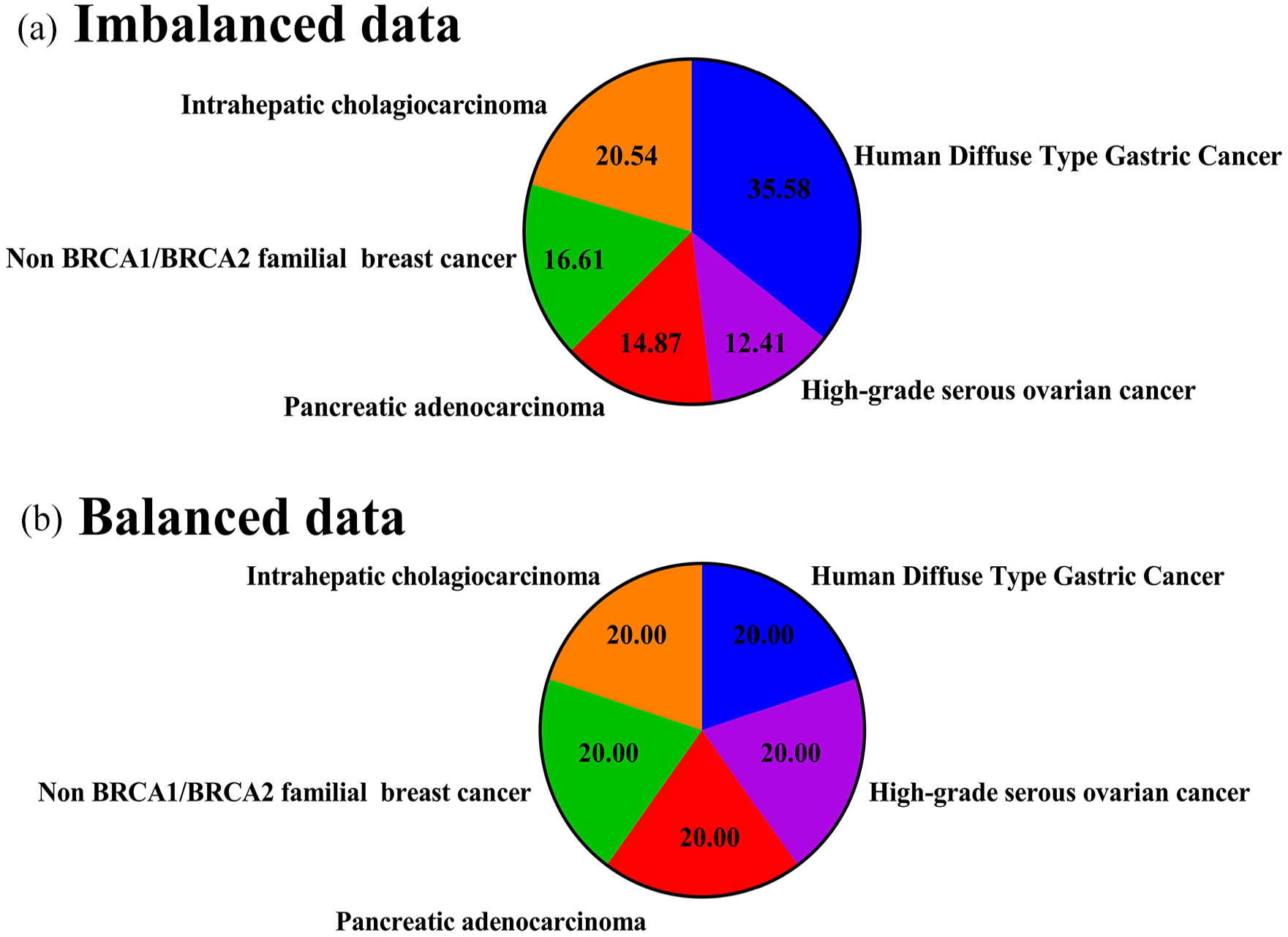
Balancing imbalanced data using SMOTE. (a) Imbalanced classes among the 5 different cancer types before oversampling. Oversampling via SMOTE was employed to balance the classes to obtain more conclusive results. (b) Balanced classes among the 5 cancer types after oversampling.
Total count of training data before and after oversampling using SMOTE.

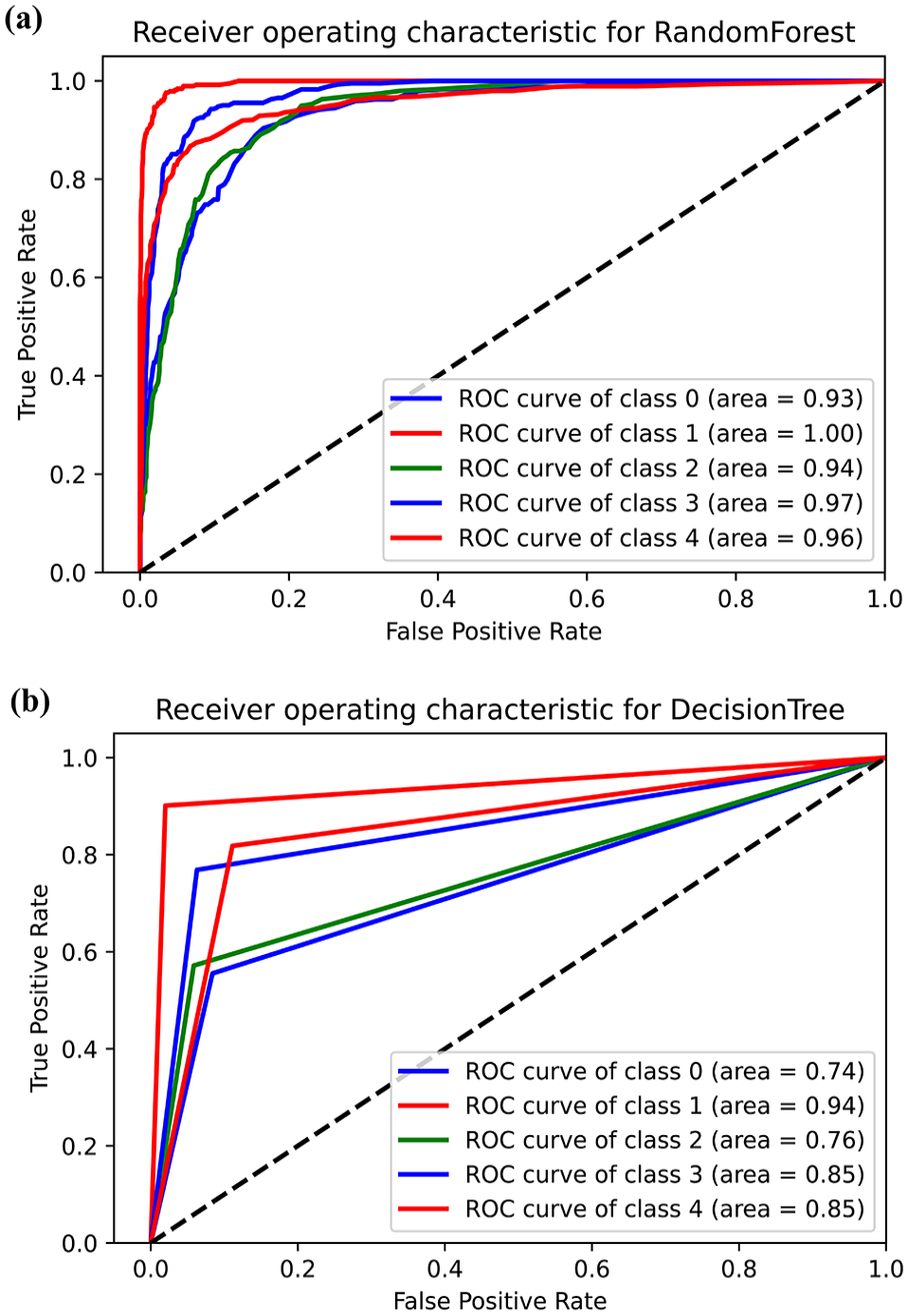
Thus, decision tree model for imbalanced data showed a weighted average value of precision, recall and f1-score of 0.75, bringing the model accuracy up to 75%. When the dataset of each exome sample was balanced, the weighted average for precision, recall and f1-score were found to be 0.77, further improving the model accuracy to 77%. To compare this model with RF, RF for imbalanced data revealed the weighted average values for precision, recall and f1-score to be 0.81, with a model accuracy of 81%. The RF model for balanced data revealed the weighted average for precision was found to be 0.82, 0.82 for recall and 0.82 for f1-score, further upping the accuracy of balanced model to 82% (Table 5).
Performance evaluation metrics for decision tree and random forest for the model developed using 16 features (method 1).
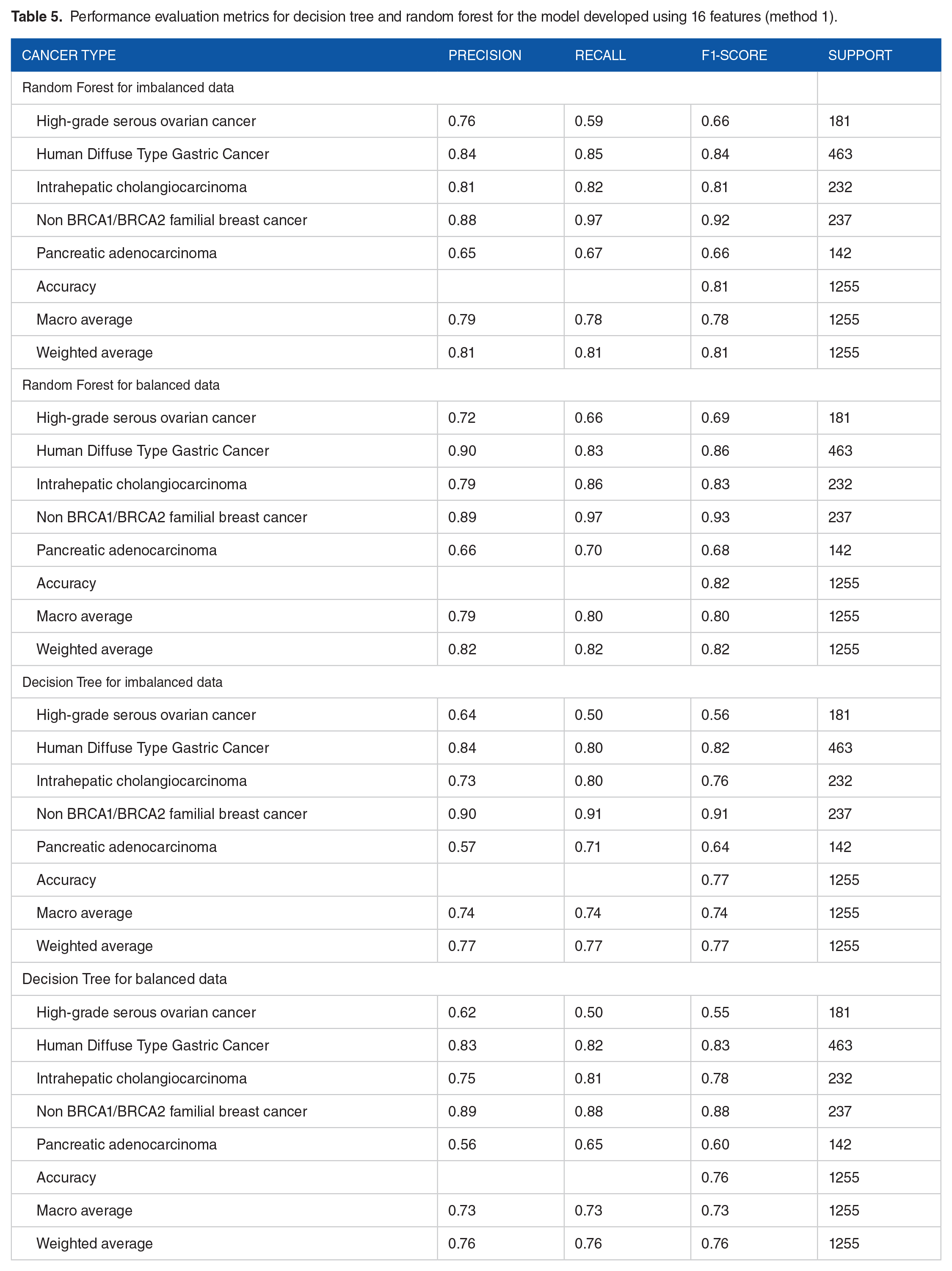
Since the best model was found to be Random Forest, an ROC curve plotted for both decision tree and random forest models to obtain additional confirmation on random forest’s effectiveness, which revealed area under the curves for the 5 classes of cancers selected for building the model. The area under the curve (AUC) for random forest model was found to be 0.93 for high grade serous ovarian cancer, 1.00 for non BRCA1/BRCA2 familial breast cancer, 0.94 for pancreatic adenocarcinoma, 0.97 for intrahepatic cholangiocarcinoma and 0.96 for human diffuse type gastric cancer. The AUC for decision tree model was found to be 0.74 for high grade serous ovarian cancer, 0.94 for non BRCA1/BRCA2 familial breast cancer, 0.76 for pancreatic adenocarcinoma, 0.85 for intrahepatic cholangiocarcinoma and 0.85 for human diffuse type gastric cancer (Figure 6, Table 6). From this, it is evident that the areas under the curves were better for random forest model than for decision tree, corroborating the previous outcomes and demonstrating that random forest worked better for accurately predicting the 5 cancer types.
ROC curves for decision tree and random forest models. The x-axis indicated the false positive rate while the y-axis showed the true positive rates. (a) The ROC plot showing area under the curves for random forest model. The AUCs were found to be very close to 1 for all classes, indicating a good model. (b) ROC plot showing area under the curves for decision tree model. The AUCs were found to be lesser than random forest model, proving that random forest worked better for accurately predicting the 5 cancer types.
Area under the curve for the 5 cancer classes used to build the model.

Method 2: Training variants from 15 datasets and testing 5 datasets
When 15 exome variation datasets were used for training and 5 for testing, it was observed that the model predicted accurately for only 2 types of cancers- pancreatic adenocarcinoma and non-BRCA1/BRCA2 familial breast cancer, while the prediction was found to be inaccurate for the remaining 3 cancer types. Out of all the cancer types, pancreatic adenocarcinoma showed 97.80% prediction and non BRCA1/BRCA2 familial breast cancer displayed 97.83% prediction.
Model cross-validation using Matthew’s correlation co-efficient
When the model was cross-validated using Matthew’s correlation coefficient for method 1, for imbalanced data, the performance metric values for MCC cross validation was found to be 0.7797 and 0.7881 for MCC test. Likewise, for balanced data, the MCC cross validation value was observed to be 0.9356 and 0.7796 for MCC test. For method 2, the Matthew’s correlation coefficient was found to be 0.9365 (Table 7). Therefore, from this, it is evident that the MCC scores were better for balanced data than imbalanced and the cross validation of the model proved that the designed DSS model is highly accurate.
The Matthew’s correlation co-efficient and MCC test values for method 1 and method 2 to cross-validate the model.

Model deployment
The deployed model, now available as a web application, predicts the model based on already trained model. The model GUI provides the basic steps that the users can follow to upload their files and obtain results. The uploaded files (200 MB limit) must contain the required columns that will be used to predict the cancer type. The NAN processing should then be selected according to the user’s requirement. The user can either drop the values or calculate the mean for the same by choosing the suitable options in the drop-down menu for NAN processing. For reference, a sample data file is provided which the users can go through and make their data in the appropriate format. The files can be dragged and dropped or browsed and uploaded in the side bar provided in the application. One of the 3 calculations can be carried out by selecting the options- data visualization or testing or both. In data visualization, a correlation heat map and a pairplot for the dataset file uploaded is obtained. In the testing option, the data file uploaded will be tested with the trained model and graphical output for the same is revealed. The third selection reveals outcomes of both data visualization and testing. Additionally, the user can select the type of graph that will be displayed as prediction result- a heat map of correlation of the features or a pairplot. The about us page reveals information on the web application and a source code link for the same that connects to the Github repository, is also provided. Screenshots of the GUI of the deployed model, with the options it displays is provided in Figure 7 and a sample dataset run is provided in Figure 8.

Home page of the decision support system deployed on Streamlit. The web application provides several options such as choosing the file of interest, selecting the NAN process method, data visualization, data testing or performing both. The predictions are provided based on an already trained model.

Sample results viewed on the web application when the original file was run: (a) shows the original file and the features required for the system to run the operation and (b) sample correlation heat map obtained when the file was run on the system.
Discussion
The current study presents results that have not been previously reported where 5 different cancer types have been used to build a single all-in-one decision support model. Another contribution of our study is toward the use of this model as a base for similar upcoming models, not only for cancer but for other diseases as well. This preliminary research serves to aid in early decision making. Moreover, several variables were considered in the development of the model and web application. These variables, through our methods were proved to be important attributes to the different types of cancers and therefore contributed to better classifications. Decision support systems for personalized radiation oncology have been developed previously for the prediction of normal tissue toxicity and tumor responses. 42 Additionally, prognostic DSS model has also been built previously using ML and random optimization by the extrication of prognostic data for breast cancers. 43 Classification using computed tomography scan images have also been carried out using deep fully convoluted neural networks to improve detection of pulmonary cancers. 44 Studies have also highlighted the importance of machine learning and DSS in healthcare for the identification of complicated disease patterns, detection and diagnosis of diseases, and suggestion of appropriate treatment strategies. 45 The present study worked on similar concepts with the added value additions as stated above. Thus, the following sections discuss the results obtained in the present study with similar such work to highlight the importance of the present research.
Previous studies have stated distinctly the significance of employing pattern recognition for the detection of various types of cancers and discusses that to predict the occurrence of cancer in a better way, different integrative patterns that arise from analysis of omics data such as genomics, proteomics, transcriptomics, and metabolomics vastly contribute to cancer precision medicine. 46 The current study has also recognized patterns from SNP data that were previously collected using omics approaches in our previous study. 16 Moreover, another study has identified intelligent phenotypic patterns using computer-aided detection of genetic syndromes. 47 To add to this list, lung cancer has been previously diagnosed using patterns that were identified using deep learning. 48 In the present research, the basic recognized patterns assist in rapid cancer type detection that can be integrated in analogous decision support models. Generally, repetitive base substitutions from G-to-A have been previously identified in the cancer of the gall bladder 49 and high rates of C-to-T alterations have been reported in several metastatic melanomas. 50 Hence, the current work has reported beneficial patterns, which when further analyzed will aid in early cancer diagnosis.
When an initial analysis was carried out with only 5 features, the model did not provide a good prediction due to less correlation between the selected features as observed in the correlation heat map (Figure 3). Although DT and RF models showed a higher accuracy, it was still lesser than expected and the output predictions were incorrect due to less training scores. Hence, an improvement in the model was carried out using the afore-mentioned 2 approaches using decision tree and RF. A recent study has reported using machine learning models such as KNN, naïve bayes, SVM, decision tree and logistic regression for early breast cancer detection, wherein, the study concluded that aside from KNN algorithm, logistic regression, decision tree and naïve bayes showed good performance, with SVM having the best accuracy and performance. 51 Likewise, another study tested out several ML algorithms such as KNN, SVM, RF, Naïve Bayes, decision tree and logistic regression for breast cancer prediction and reported SVM to be the best performer. 52 In the present work however, random forest model and decision tree performed better in terms of preliminary model accuracy, which were then taken forward for model improvement studies.
Additionally, when the initial models were designed using 5 ML algorithms, it was observed that selecting different and a greater number of features increased the model accuracy, suggesting that features play a very important role in model building. By designing ML based DSS with appropriate features, accuracy of the best model shot up to 82%, thereby, acting as a powerful tool to doctors and patients. Increasing the size of the data further may aid in providing more variability to the data, however, at the cost of increasing the classification errors. From AUC, it was evident that curves were better for RF than for DT model, corroborating the previous outcomes and demonstrating that random forest worked better for accurately predicting the 5 cancer types. Furthermore, among all cancer types, pancreatic adenocarcinoma showed 97.80% prediction and non BRCA1/BRCA2 familial breast cancer displayed 97.83% prediction. This indicated that although the model has high accuracy of 82%, when datasets were split for training and testing, some issues persisted. This could be associated with lesser number of datasets and reduced variability and thus, the problem will be resolved by adding more mutations from different cancer exome datasets to enhance the variability and bring about accurate predictions, as part of the prospective work. Another important way of improving the number of data available would be to use Generative Adversarial Networks (GAN) that could add to better predictability, as part of future work.
A recent study has used ML models to predict the survival prognosis of breast cancer patients, wherein, the training datasets were split into 5 subsets for testing. 53 Similarly, in the present study, the approach used in method 2 was to test 5 datasets and train 15, so as to assess the model ability when new samples were given as input. Additionally, previous studies have also effectively predicted the metastasis of breast cancers using serum biomarkers such as CEA, CA15-3, and sHER2 via machine learning models. The study determined random forest to be the optimum model for predicting metastasis 3 months in advance. 54 Likewise, another study utilized ensemble machine learning techniques, specifically, an ensemble of random forests to predict abnormalities related to cervical cancer. 55 The present study also reports random forest as an optimal machine learning algorithm for designing a DSS model with a high accuracy. Typically, DSS models are built for specific cancer types, as evidenced from previous studies. However, our study has explored all possible variations from 20 cancer exomes, belonging to 5 different cancer types, thereby offering a wide range of accurate predictions for early diagnosis of various cancers and better treatment management, making it a novel finding.
The MCC correlation proved that our model showed very good accuracy and corroborated the results obtained in previous steps. A study carried out previously to predict the immune responsiveness against specific cancer types reported an 88% accuracy using SVM model and MCC value of 0.27. 56 The current study demonstrated a high MCC value of 0.93, that cross validated the accuracy obtained in our model from both the approaches. Moreover, research has stated that an MCC value close to +1 indicates very good performance, while closer to −1 suggests bad model performance. 57 Since the current study showed very good MCC values for both method 1 and method 2, it indicates that the model developed is robust.
Additionally, other similar studies to our work have been carried out previously and web applications have been developed. Comparisons for the same is provided here to showcase the novelty of our work. A recent study created a decision support system for predicting the probability of 30-day mortality of post-operative specific spinal metastasis. 58 This model used 4 machine learning techniques and deployed the designed model as an open access web page via Shiny, a publicly available software interface. Another study has designed an online calculator for the survival prediction of patients suffering from glioblastoma, using machine learning algorithms such as regression. 59 The study utilized Shiny to deploy the model, which can now be accessible by all. In the current study, Streamlit was employed for deploying the designed model to make it accessible for all users. With the right information, user can upload the files and obtain required results and plots. Since Python was employed as the main language for implementing the model, Streamlit was used, contrary to the above-mentioned studies where R was used for analytics, hence deployed using Shiny. The present study is an extension and part of our previous work, wherein, the preliminary DSS model building was carried out.60,61
Conclusion and Future Scope
Since currently, there is a paucity in precise cancer diagnosis, a need for appropriate prediction models that aid diagnosticians/researchers/clinicians to make that decision is required. The present study designed a model-driven decision support system using supervised machine learning algorithms. An initial attempt using classifiers such as K-nearest neighbor, support vector machine, decision tree, naïve bayes and random forest revealed that random forest and decision are potentially accurate models. When all 20 datasets were trained after efficiently balancing the datasets, random forest model provided a high accuracy of 82% with correct predictions for all 5 cancer types. However, when 5 datasets were tested and 15 trained, predictions were accurate for only pancreatic adenocarcinoma and non BRCA1/BRCA2 familial breast cancers. A cross-validation of the model via Matthew’s correlation coefficient proved that our model is highly precise and is designed accurately. This model was successfully deployed as a web-application that is easy to navigate so that it can have a better reach. In the future, the authors have planned to extend the study by adding more variation data and datasets to improve the model accuracy and to include other cancer types. By implementing advanced ML techniques such as ensemble algorithms and XgBoost, the current model can further be enhanced. Thus, the present study provides massive insights into the use of the designed model for easy diagnosis of various cancer types.
Supplemental Material
sj-csv-1-cix-10.1177_11769351221147244 – Supplemental material for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications
Supplemental material, sj-csv-1-cix-10.1177_11769351221147244 for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications by K Chandrashekar, Anagha S Setlur, Adithya Sabhapathi C, Satyam Suresh Raiker, Satyam Singh and Vidya Niranjan in Cancer Informatics
Supplemental Material
sj-xlsx-2-cix-10.1177_11769351221147244 – Supplemental material for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications
Supplemental material, sj-xlsx-2-cix-10.1177_11769351221147244 for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications by K Chandrashekar, Anagha S Setlur, Adithya Sabhapathi C, Satyam Suresh Raiker, Satyam Singh and Vidya Niranjan in Cancer Informatics
Supplemental Material
sj-xlsx-3-cix-10.1177_11769351221147244 – Supplemental material for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications
Supplemental material, sj-xlsx-3-cix-10.1177_11769351221147244 for Decision Support System and Web-Application Using Supervised Machine Learning Algorithms for Easy Cancer Classifications by K Chandrashekar, Anagha S Setlur, Adithya Sabhapathi C, Satyam Suresh Raiker, Satyam Singh and Vidya Niranjan in Cancer Informatics
Footnotes
Acknowledgements
We would like to thank Dr. Shobha G, Professor, Department of Computer Science and Engineering, RV College of Engineering, Bangalore, for providing us with QuADro GV100 GPU for performing computational analysis. The authors would like to acknowledge Mr. Akshay Uttarkar for reviewing the manuscript and providing valuable suggestions. We would also like to acknowledge Ms. Padmavathi P for providing insights on the methodology. Special thanks to Mr. Aravind Ganessin, Managing Director, Intergene Biosciences Pvt. Ltd, Bangalore, for the inputs.
Funding:
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration Of Conflicting Interests:
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Author Contributions
Chandrashekar K (C.K) and Anagha S Setlur (A.S.S): collected the preliminary data required for the study, analyzed the data and wrote the main manuscript.
Adithya Sabhapathi C (A.S.C), Satyam Suresh Raiker (S.S.R) and Satyam Singh (S.S): Implemented the algorithms required for the study and analyzed the data.
Vidya Niranjan (V.N): Conceptualized the idea, analyzed the results and project implementation. All authors reviewed the manuscript.
Data Availability
The derivative datasets used in the current study are generated from analysis of datasets downloaded from publicly available NCBI SRA database. The below NCBI SRA datasets were used in our previous work to arrive at the data that was used in the current study.
SRR894452, SRR900123, SRR900099, SRR941051, SRR941052, SRR941053, SRR941054, ERR166303, ERR166304, ERR166307, ERR166310, ERR166312, ERR166335, ERR166336, ERR035487, ERR035488, ERR035489, ERR232253, ERR232254, ERR232255
The raw data of identified variations used for building the DSS system in the current study are available in Supplemental File S1. For further reference, clinical information on the datasets used, as obtained from NCBI-SRA are provided as Supplemental File S2. Supplemental File S3 shows the initial pre-processing and feature selection based on NaN value criterion and the ANOVA test score and P values for the initial selected 19 features.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.