
Abstract
This article reviews the origins and use of the terms quasi-experiment and natural experiment. It demonstrates how the terms conflate whether variation in the independent variable of interest falls short of random with whether researchers find, rather than intervene to create, that variation. Using the lens of assignment—the process driving variation in the independent variable—we distinguish three dimensions: control of assignment by the researcher, rather than by a policy process or naturally occurring event; exogeneity of the assignment process; and directness of the link between assignment and the independent variable. These dimensions generate a typology of causal study designs that we illustrate with examples from the social and health sciences. Our framework can assist researchers and practitioners from diverse disciplines to better understand and communicate with one another and, importantly, to recognize opportunities in real-world settings to find or create variation that can be leveraged for valid impact estimates.
Keywords
Introduction
Researchers use the terms quasi-experiment and natural experiment to describe various causal study designs that have some similarities to randomized controlled trials (RCTs), considering the strongest design for estimating the impacts of policies, programs, and treatments (Cook, Scriven, Coryn, & Evergreen, 2010; Gates & Dyson, 2017). The terms quasi-experiment and natural experiment, however, are often ambiguous, used inconsistently, and fail to specify key dimensions of how to find and create causal evidence. The well-known Oregon Health Insurance Experiment (Finkelstein et al., 2012) illustrates some of this confusion. This study is often described as a “randomized controlled trial” (Baicker et al., 2013) even though researchers did not control treatment assignment; rather, administrators ran a lottery to allocate limited funding for expanded Medicaid coverage. Strikingly, a description of the study aimed at a broad audience describes it as “the first randomized controlled trial (RCT) … [which] took advantage of a fortuitous natural experiment” (Shears, 2016; italics added). The same study is described as both “controlled” and “natural.” The assignment was indeed randomized, though not controlled by researchers. It was “natural” in the sense that the researchers found this serendipitous random assignment (the lottery). Describing the study as an RCT, and thus neglecting to decouple randomness from researcher control, obscures key features of the Oregon study that shape the strength of its causal evidence. The muddled terminology also may impair researchers and practitioners from finding such natural experiments in other contexts.
In related research, Wherry and Miller (2016) studied the effects of Medicaid expansions under the Affordable Care Act (ACA) on coverage, access, utilization, and health by comparing outcome changes in states adopting the ACA Medicaid expansions to states that did not; and they clearly label their work a “quasi-experimental study.” As in the Oregon study, the assignment of the treatment (Medicaid expansion) was not controlled by researchers but, instead, by policymakers. Unlike the Oregon study, the political, economic, and social processes that drove expanded Medicaid eligibility were far from random. This suggests that non-random assignment led these studies to be described as quasi-experimental. But other studies of the ACA Medicaid expansion are labeled “natural experiments” (Bailey & Chorniy, 2016; Sammon et al., 2018), presumably because researchers found rather than created the policy variation of interest. In contrast, the What Works Clearinghouse (2020), which has established standards to judge causal research in education, uses the term “quasi-experimental design” for situations in which researchers have some control over treatment assignment. Are these studies of the effects of ACA Medicaid expansion quasi-experiments or natural experiments? If we call both the Oregon study and the ACA studies natural experiments, are we saying they have substantially the same research design?
The inconsistent and incomplete set of terms for studies often labeled quasi-experiments or natural experiments hinders communication across disciplines and fields and limits the broader application of the large strides made in causal inference (e.g., Angrist & Pischke, 2009; Imbens & Rubin, 2015; Morgan & Winship, 2015; Pearl, Glymour & Jewell, 2016; Rosenbaum, 2017; Shadish, Cook & Campbell, 2002). In addition, a growing number of practitioners and organizations in government, health, education, and business rely increasingly on various sources of causal evidence, including their own internal data analyses, to evaluate and select policies and practices. Clearer, more consistent terms can help this broader practitioner audience to better assess and obtain evidence about the impacts of policies and practices.
In the sections that follow, we first describe the history of the terms quasi-experiment and natural experiment and the problems in their use. We employ the Rubin causal model notion of assignment mechanism—the process driving the independent variable of interest, even without researcher control (e.g., Imbens & Rubin, 2015)—and use this conceptual lens to review randomized, quasi, and natural experiments from many fields. We distinguish three key dimensions—control, exogeneity, and directness—that describe whether researchers find, rather than intervene to create, identifying variation; whether such variation is generated by random assignment, or some other form of exogenous influence or events; and how directly assignment influences the causal variable of interest. Using empirical examples, we demonstrate how these dimensions capture key features of a causal study's design. Next, we show how these dimensions lead to a new typology with more precise terms that we illustrate with a variety of studies in the health and social sciences.
In the final section, we discuss how our proposed framework helps with the consumption and production of research estimating the impact of a program or other causal variable of interest. Namely, it can aid in the consumption of research by helping both researchers and practitioners better understand each other and communicate across disciplines and research traditions. The framework can also aid in the production of research by helping both researchers and practitioners recognize opportunities in real-world settings to find or create identifying variation that can be leveraged to expand the scope of valid impact estimates.
Origins of the Terms
A Google Scholar keyword search finds “natural experiment” used in over 400,000 articles and “quasi-experiment” in over 90,000 articles (as of February 2024). The terms quasi-experiment and natural experiment also appear in widely used textbooks on research methods, program evaluation, and applied econometrics (e.g., Babbie, 2020; Rossi, Lipsey, & Henry, 2018; Wooldridge, 2021). One might assume that these were well-defined labels. Curiously, this is not the case.
The term quasi-experiment was introduced in an essay by Campbell and Stanley (1963), Experimental and Quasi-Experimental Designs for Research, which has been cited over 40,000 times (according to Google Scholar). They conceptualized quasi-experiments as research designs resulting from restrictions on researcher control or practical constraints that prevent random assignment to treatment and control conditions. Quasi-experiments, in their original definition, contain “imperfections” and occur “in those settings where better experimental designs are not feasible” (p. 2). Campbell and Stanley's original formulation was expanded upon in Cook and Campbell's (1979) book, Quasi-Experimentation: Design and Analysis Issues for Field Settings, which has been cited over 30,000 times. They define quasi-experiments as “experiments that have treatments, outcome measures, and experimental units, but do not use random assignment to create the comparisons from which treatment-caused change is inferred” (p. 6). A revised, expanded version of the book was then published under the title Experimental and Quasi-Experimental Designs for Generalized Causal Inference (Shadish et al., 2002), cited over 24,000 times. In this book, the authors write: Quasi-experiments share with all other experiments a similar purpose—to test descriptive causal hypotheses about manipulable causes—as well as many structural details, such as the frequent presence of control groups and pretest measures, to support a counterfactual inference about what would have happened in the absence of treatment. But, by definition, quasi-experiments lack random assignment (p. 14).
The emphasis is again on the lack of random assignment, with quasi-experiments defined more by what they are not than what they are (e.g., Reichardt, 2019, p. 305). There is also the notion of a manipulable cause as the focus of quasi-experiments, implying that a researcher or another actor has intervened in an attempt to influence an outcome of interest.
Interestingly, writing in Econometrica, Simon (1966) independently coined the term “quasi-experimental” to refer to a difference-in-differences method of estimating the price elasticity of demand for liquor based on state-level changes in liquor taxes. However, Simon's example depends on the government making the assignment, in the sense that each state makes its own rules about liquor taxes. Indeed, as it turned out, economists mostly gravitated toward the term natural experiment to describe such studies.
The term natural experiment has less of a precise lineage but can perhaps be traced to the edited volume of Festinger and Katz (1953), Research Methods in the Behavioral Sciences. Freilich (1963) later elaborated on the idea in an article entitled “The Natural Experiment, Ecology and Culture,” seeing in it the potential to make anthropology more scientific. He defines natural experiment thus: “the socio-cultural system in which a dramatic change has occurred is, for a given time, a natural laboratory, where given variables are in a state of control so that the effects of an independent variable (the change) can be studied.” Unlike the work of Campbell and colleagues, these early definitions of natural experiment are not well known and rarely cited. Moreover, the term natural experiment was adopted in full force not in psychology, sociology, or anthropology but rather in economics.
The late 1980s and early 1990s was a period of rapid growth in the use of “natural experiments” in applied microeconomics, with studies such as Angrist (1990) and Angrist and Krueger (1991) on compulsory schooling, Card and Krueger (1994) on the effect of the minimum wage on employment, Eissa (1995) on the effect of taxes on female labor supply, and many others. In 1995, the Journal of Business and Economic Statistics published a symposium on program and policy evaluation that discussed these approaches (Angrist, 1995). Several authors acknowledged the term “quasi-experiment” from psychology and addressed similarities with the idea of a natural experiment in economics (e.g., Meyer, 1995). In fact, however, the JBES forum and the use of the term natural experiment in economics more broadly show that the chief difference lies in the focus on exogeneous variation in the independent variable of interest that researchers found in the world. Economists use the term exogenous to mean that the independent variable of interest is not driven by the outcome or by other factors driving the outcome (see Cunningham, 2021, p. 13; Murnane & Willett, 2011, pp. 24–25). This approach contrasts with the initial focus of psychologists on variation that researchers create by intervening in the world.
Economists raised questions, however, about what types of found variation deserved to be considered natural experiments. Besley and Case (1994) were concerned about “unnatural experiments” where state policies were treated as natural experiments. After all, state policies could easily be driven by other causes of the outcome or by the outcome itself—and thus not exogenous but endogenous. For example, Medicaid expansion was heavily influenced by which political party controlled the state government, a factor that might also affect a state's safety net healthcare programs and thus health status. Rosenzweig and Wolpin (2000) criticized many natural experiments for being implausibly exogenous and suggested that “natural” natural experiments, based on biology, climate, or other changes in nature, provide more truly exogenous variation and thus a better foundation for causal inference. In effect, there are now competing definitions of natural experiments, as DiNardo (2008) noted disapprovingly in the Encyclopedia of Economics. He defines them as “serendipitous situations in which persons are assigned randomly to treatment (or multiple treatments) and a control group,” reserving the term natural experiment only for fully randomized situations. DiNardo uses the term “quasi-natural experiment” to refer to studies with a serendipitous assignment that falls short of random. Rosenbaum (2017) defined natural experiments as situations in which “some key elements of a randomized experiment occur on their own, even though the investigator neither creates nor assigns the treatments” (p. 100).
In his book on natural experiments, Dunning (2012) defined a natural experiment as occurring in “observational settings in which causes are randomly, or as good as randomly, assigned among some set of units” (p. 3). He goes on to distinguish natural experiments from quasi-experiments: “The key point is that with quasi-experiments, there is no presumption of random or as-if random assignment” (p. 20). For Dunning (2012), the key definitional feature of a natural experiment is the presence of random assignment or “as-if random” assignment—and that this happens naturally, without researcher control. “Natural experiments are not so much designed as discovered,” he explains (p. 41). The fuzzy part of Dunning's (2012) definition of a natural experiment, as he himself acknowledges, is that the many studies involving “as-if random” assignment, such as jurisdictional borders or staggered rollouts, require evidence and careful judgment about the context and processes influencing assignment. In other words, the “as if” random determinations may come with caveats and, if the caveats are extensive enough, one might well label such studies “quasi-experiments” in his formulation.
An important consideration in judging a natural experiment is the extent to which the context and processes influencing assignment provide good (enough) causal evidence. To address that need, economists developed the concept of identification strategy as the “manner in which a researcher uses observational data… to try to approximate a real experiment” (Angrist & Pischke, 2009, p. 7). The key idea is that some of the variation in the independent variable of interest must be driven from outside (exogenous) and, to justify causal conclusions, researchers must articulate the source of that variation and why it is exogenous. That variation is often termed identifying variation. This broad approach has become prevalent and influential, as demonstrated by the 2021 Nobel Prize in economic sciences awarded to David Card, Joshua Angrist, and Guido Imbens for their work on natural experiments.
Over the same period that interest grew in quasi-experiments and natural experiments, the potential outcomes framework for causal inference, developed by Donald Rubin (1974), became increasingly influential. In brief, the potential outcomes framework defines a causal effect as a difference between two possible outcomes for each person or unit under different values of the independent variable of interest, such as receiving either a drug or a placebo (Rubin, 2005). The framework extended the idea of the assignment mechanism, the process determining which people or units receive which treatments or conditions, beyond randomized experiments to any form of observational or other study, including natural experiments. Rubin and collaborators used the potential outcomes framework to develop many statistical tests and data analysis methods, such as the propensity-score matching method for achieving balance on pre-treatment covariates to help achieve unconfoundedness. Curiously, however, in their comprehensive book on causal inference, Imbens and Rubin (2015) made no mention of the terms quasi-experiment or natural experiment. This is surprising because they use several well-known examples of such studies in their book, including the Card and Krueger (1994) evaluation of a minimum wage increase in New Jersey—one of the “natural experiments” highlighted by the Nobel Prize committee in its announcement of the award for Card, Angrist, and Imbens. Judea Pearl and collaborators developed another influential approach to causal inference that emphasizes the use of causal diagrams, called directed acyclic graphs (or DAGs), but this work also does not mention quasi-experiments or natural experiments (Pearl et al., 2016; Pearl & MacKenzie, 2018). Neither of these influential causal inference schools, therefore, has provided explicit guidance about quasi-experiments and natural experiments—despite the predominance of such studies in many fields of applied causal research.
Dimensions of Identifying Variation in Causal Research
To better define and distinguish between and among quasi, natural, and randomized experiments, we focus on three dimensions of identifying variation that characterize the design or structure of a causal study: control, exogeneity, and directness. We begin with this basic model of a causal study:
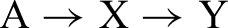
To refer to the independent variable of interest (X), we use the term causal variable (as in Morgan & Winship, 2015), rather than “treatment.” Causal variable is a more general term encompassing not only interventions but also inherently self-selected or otherwise endogenous—and therefore not directly modifiable—variables. The term causal variable further emphasizes that, as in the evaluation and causal inference literatures, we focus on counterfactual or “effect of [a single] cause” questions rather than “causes of effect” questions that seek to determine as many causes as possible of an outcome (Reichardt, 2011). We also prefer the term assignment process rather than assignment mechanism to emphasize the real-world processes, found or created, driving assignment.
We extend our basic model to include encouragement experiments, in which the assigned treatment is an indirect encouragement of change in the causal variable:

This extended model can also describe natural experiments in which Z is not controlled by the researcher but still determined by some assignment process (A) from outside (exogenous) in a way that creates identifying variation; in econometric language, Z is an instrumental variable (Angrist & Krueger, 2001). For example, cigarette prices can drive smoking, making possible estimates of the causal effect of smoking by expectant mothers on birth weight (e.g., Evans & Ringel, 1999). In econometrics, the relationship between Z and X is described as the “first stage” and the relationship between X and Y as the “second stage” in this indirect causal process (see Angrist & Pischke, 2014, chapter 3).
We summarize the three dimensions in Table 1. For added clarity, we can label A with subscripts to specify control (AC for researcher controlled, AN for natural) and superscripts to specify exogeneity (AR for fully random, AQ for quasi-random or, more precisely, non-random yet with some degree of exogenous identifying variation). Of course, A can also be largely endogenous and thus provides no identifying variation, which is the case in many observational studies in the health and social sciences (as we discuss later on). The next sections discuss each of these dimensions—and why they matter—in more detail. We begin with the dimensions of control and exogeneity in direct studies and then extend the discussion of these dimensions to indirect studies.
Dimensions of Identifying Variation for Impact Estimates.

Notes: A is the assignment process; X is the causal variable of interest; Y is the outcome; and Z is a variable (an encouragement or instrument) that affects X. Subscripts on A indicate whether or not there is researcher control; superscripts on A indicate the degree of exogeneity.
Control
The first dimension, control, refers to who or what process controls the assignment of the treatment or causal variable of interest. In a traditional RCT, researchers control assignment; but researchers may control assignment without randomizing. For example, an education researcher could select one school for an intervention and select a similar school for the control condition. Alternatively, researchers could assign a school to switch between intervention and comparison conditions at pre-determined times (such as in ABA or ABAB studies). Indeed, the What Works Clearinghouse (2020) considered the causal evidence of a single-case design, usually viewed as a somewhat weak design, only if the “independent variable indicating assignment to the intervention [is] systematically manipulated: the researcher will determine when and how the independent variable conditions change” (p. 77). Importantly, our definition of control refers only to the assignment process and not to researcher control of the scheduling of measurements or control of the context or of other causes of the outcome, although these other forms of researcher control remain important to the internal validity of a study (Shadish et al., 2002).
At the opposite end of our control continuum, assignment can be uncontrolled, the result of a natural or historical process. We apply the term natural to any study with an assignment process that is not controlled by the researcher, which is consistent with how the term has been used in economics and other fields (Angrist, 1995; Dunning, 2012). That process can still create exogenous identifying variation in the causal variable, variation that the researcher discovers and leverages to estimate a causal effect. For example, Park, Goodman, Hurwitz, and Smith (2020) examined the effect of heat on learning, with assignment driven by whatever natural forces shape weather patterns.
Between researcher control and uncontrolled natural or historical processes lie cases with control of assignment by a human agent or institution—but not by the researcher. For example, in the Oregon healthcare study (Finkelstein et al., 2012), state government officials created a lottery to allocate expanded Medicaid. We describe such situations as policymaker control, using the term policymaker broadly to include administrators, clinicians, judges, politicians, government agencies, and others—but only when the assignment process is largely governed by some explicit process, such as rules or laws. Still, we refer to studies involving policymaker control of assignment as “natural,” which has been the tradition in economics and related literature on natural experiments, because researchers still find rather than create such identifying variation. 1
The control dimension is a continuum. The extent of control may be a mix of policymaker and researcher control if they collaborate. Alternatively, the extent of control may be a mix of policymaker control and uncontrolled history, as when new laws enacted by policymakers differ across historically defined geographic borders. For example, Card and Krueger (1994) used a change in the minimum wage—policymaker control—between two states, with boundaries determined by history. All levels of control can, in principle, have random assignment or not. Although the Oregon study involved random assignment, policymakers often assign treatments or programs based on non-random criteria, such as geography, need, or political priorities.
The source and degree of control matter for several reasons. First, controlling assignment gives researchers a greater opportunity, all else equal, to create better causal evidence. Indeed, that is the reason the What Works Clearinghouse (2020) insisted on researcher control for single-case designs, but not for all non-randomized designs. Second, controlling assignment ensures researchers understand the assignment process, thus enhancing their ability to analyze the data correctly to estimate causal effects. Indeed, Imbens and Rubin (2015, p. 31) defined experiments as having assignment processes “both known and controlled by the researcher” (italics added). Third, and relatedly, greater control enables better knowledge of what is and is not included in the causal variable, because the researcher specifies the precise intervention and comparison conditions assigned. In contrast, with uncontrolled natural experiments, the exogenous change is often a complex bundle of features or events. For example, Card (1990) used the Mariel boatlift to estimate the effect of immigrant labor supply on wages and employment, comparing outcome changes in Miami to other cities, but the Mariel boatlift was a complex event that also profoundly changed Miami's society and politics. Finally, and most importantly, identifying the control dimension emphasizes that both finding and creating identifying variation are available strategies for estimating impacts.
Exogeneity
Our second proposed dimension, exogeneity, refers to the extent to which the assignment is either fully randomized, as in a classic RCT, or it is not random but still contains exogenous identifying variation (sometimes called quasi-random). Importantly, our randomness dimension extends beyond classic random assignment to include exogeneity that can be found or created in other ways. Of course, assignment can also be largely endogenous, or even unknown, and thus not considered to be even quasi-random.
By exogeneity, as defined earlier, we mean that the causal variable of interest (X) is driven from outside the system of causal processes related to the outcome. More specifically that variation in the causal variable is caused neither by variables that also cause Y—common causes—nor caused by Y itself—reverse causation (see Remler & Van Ryzin, 2022, chapter 11). Random assignment creates perfect exogeneity because the causal variable is driven only by a flip of the coin (or random number generator), making it truly independent of any other causes of Y. Other exogenous assignment processes can provide much the same benefit—unconfoundedness, ignorability, or balance (Imbens & Rubin, 2015). 2 Although these terms do not have identical meanings, they all imply that treatment and comparison groups (or more generally, observations or cases with different values of the causal variable) are, given a sufficiently large sample, statistically equivalent in both observed and unobserved characteristics that might affect the outcome. Consequently, any differences in outcomes (larger than chance differences, as measured by a statistical significance test) can be attributed to the causal variable.
For the purpose of labeling studies, we retain the term quasi (or quasi-random) for assignment mechanisms that are not fully random yet provide some meaningful degree of exogeneity. This terminology is consistent with Campbell and colleagues’ original use of the term (Campbell & Stanley, 1963; Shadish et al., 2002), DiNardo's (2008) proposed use, Dunning's (2012) formulation, and the growing tendency to label anything not truly randomized, but with some degree of exogeneity, as quasi-experimental. Such non-random yet exogenous assignment mechanisms can achieve balance or unconfoundedness (e.g., Angrist & Pischke, 2009; Dunning, 2012; Rosenbaum, 2017). An example is the regression-discontinuity (RD) design, in which a cutoff often creates excellent balance just around the cutoff. In a study by Card, Dobkin and Maestas (2008), for example, an RD design was used to estimate the effects of universal health insurance on the use of medical care, using the fact that most Americans become eligible for universal health insurance (Medicare) at age 65 and the good balance in health characteristics of people just above and below this age cutoff. Good RD designs have been shown to produce causal estimates matching those of randomized experiments (Cook, Shadish & Wong, 2008).
Even simple non-randomized group comparisons, however, can provide strong causal evidence with sufficient exogeneity. For example, Cattaneo, Galiani, Gertler, Martinez, and Titiunik (2009) estimated the impact of a state program in Mexico that replaced dirt floors with cement floors, using essentially a cross-sectional difference in outcomes. Exogeneity stemmed from two facts: one state government implemented the program while an adjacent state government did not, and the river border between these two states bisected a metropolitan area. The latter fact resulted in very similar social, economic, and demographic characteristics on either side of the state border. While the authors used propensity matching and other strategies, exogeneity was key to the excellent balance achieved and the insensitivity of impact estimates to control variables (Cattaneo et al., 2009, Tables 2, 3 and 5). Most importantly, the exogeneity justified the conclusion that the impact estimate did not suffer from bias due to omitted, unobserved variables. Such credibility is important because the study found substantial impacts on child health outcomes (parasites, diarrhea, and anemia) and maternal mental health.
As we move along the exogeneity dimension further away from the fully random assignment, there is less exogenous variation and more endogenous variation in the assignment process. More formally, we define the exogeneity dimension as referring to the degree to which the assignment process (A) produces exogenous variation (in X) relative to endogenous variation. Rosenbaum (2017) emphasized that to provide strong causal evidence, the changes or events must be “major, sharp, out of the ordinary” (p. 110). In other words, the identifying variation must be a sufficiently large component of the variation in X. Therefore, as we move along the exogeneity dimension, away from fully random assignment toward less exogenous variation in the assignment process, we expect internal validity to decline.
At the far, non-random end of the spectrum lie situations in which the causal variable of interest (X) is largely endogenous, either caused by variables that also cause Y—common causes— or caused by Y itself—reverse causation. Examples include studies that examine the association of lifestyle factors (like diet and exercise) with mortality (Loef & Walach, 2012). In the absence of an intervention or exogenous shock of some kind, most lifestyle factors are largely self-selected behaviors that remain deeply confounded with other causes of mortality. Because there is little if any random or exogenous variation in lifestyle factors that can plausibly result in unconfoundedness, no justification exists for labeling such studies as quasi-experimental.
Assessing the degree of exogeneity, however, can be difficult in situations without true random assignment. For a given impact estimate, much depends on a thorough knowledge and understanding of the assignment mechanism—the process driving the causal variable. A useful tool for this purpose is the causal diagram or, more formally, the directed acyclic graph or DAG (Hernán & Robins, 2020; Pearl et al., 2016; Pearl & MacKenzie, 2018). Remler and Van Ryzin (2022, chapter 11) provided an accessible introduction to how to use causal diagrams to understand the assignment process. Critically, however, no technical or graphical tool can, by itself, determine exogeneity; rather, to do so requires a thorough understanding of the on-the-ground realities of the study setting.
Directness
The third dimension, directness, refers to the extent to which assignment (A) influences the causal variable (X) directly or through some other variable or process (Z). As articulated earlier, this can be represented by the extended model: A→(Z→)X→Y. The paradigmatic example is an encouragement experiment, in which the causal variable of interest, such as breastfeeding, cannot be manipulated directly, so instead researchers intervene with a treatment to encourage it. In natural experiments, indirectness often takes the form of instrumental variables used to probe the causal effects of endogenous causal variables. 3 Although the term indirect is often used to refer to an intervening variable (mediator) that lies between X and Y, we use it here to refer to an intervening variable—Z (the encouragement or instrumental variable)—that lies between A and X.
Directness, like the other dimensions, is a continuum. Even a classic RCT, such as a vaccine trial, often has at least a small degree of indirectness, perhaps because some people assigned to the treatment group do not comply due to unpleasant side effects. But it is not uncommon in an RCT for noncompliance or contamination to result in more substantial indirectness, especially in social and policy research. For example, in an RCT in which low-income tenants were randomly assigned pro-bono attorneys in the New York City housing court, the inconsistencies of pro-bono legal services resulted in only 56% of tenants in the treatment group actually being represented by an attorney in court (Seron et al., 2001), while 4% of tenants in the control group managed to obtain an attorney on their own. As a result, variation in the causal variable—having an attorney, or not—was only partially and indirectly modified by random assignment.
Many studies involve intrinsic and often much more substantial indirectness. Indeed, whenever the causal variable of interest cannot be directly modified, the impact estimate must be indirect of necessity. Examples include breastfeeding, smoking, diet, exercise, marriage, fertility, school attendance, purchasing products, and many other largely self-selected human behaviors. In the Kramer et al. (2001) study of breastfeeding in Belarus, as mentioned earlier, the encouragement intervention included consultation and information for new mothers. This treatment in this setting turned out to be quite indirect: only 19.7% of mothers in the treatment group (in hospitals encouraging breastfeeding) breastfed their babies while 11.4% in the control group (in hospitals with usual practice) also breastfed their babies. Of course, some encouragement experiments can produce more change in the self-selected behavior and thus more directness; much depends on the context and causal variable of interest.
If the causal variable is considered the breastfeeding encouragement itself, rather than the individual breastfeeding behavior of mothers, the study would be more direct. Of course, a given research report may estimate both direct and indirect impacts, sometimes referring to these as to the intent to treat (ITT) and treatment on the treated (TOT) estimates. Clarifying the causal variable (impact) of interest and recognizing the indirectness of an impact estimate is critical, partly because indirect impacts are often smaller and harder to detect (Walters, 2019).
Natural experiments may be quite indirect, with some employing instrumental variables that operate through a complex mechanism of influence. For example, McClellan, McNeil, and Newhouse (1994) estimated the effect of heart bypass surgery on survival among (acute) heart attack patients, during a period when bypass surgery had become widespread. The researchers found that patients who lived relatively close to hospitals with a particular imaging technology (cardiac catheterization), received more intensive treatment, providing a source of identifying variation in bypass surgery. The logic underlying the identification strategy is that residential location drives relative distance to hospitals, which in turn drives exposure to imaging technology, which in turn drives bypass surgery, the causal variable. Consequently, the (uncontrolled) identifying variation is quite indirect and occurs through a complex, not fully understood process. Such estimates are nonetheless often valuable, especially when more direct approaches for learning the effect of medical or other treatments already in widespread use are not possible (Gould, 1995).
We can define directness as the extent to which assignment (A) affects the causal variable (X) directly, or only indirectly through an encouragement or instrumental variable (Z)—and how much assignment affects variation in the causal variable relative to other variation in the causal variable. In this way, directness also incorporates the strength of the first stage in instrumental variables: how much the instrument (Z) predicts the causal variable (X). Most causal studies, as noted, involve at least some indirectness due to noncompliance, contamination, and other practical limitations. However, we apply the label “indirect” mainly to studies in which indirectness happens by design or out of necessity because the causal variable of interest cannot be directly manipulated.
Control and Exogeneity in Indirect Studies
In our framework, the dimensions of control and exogeneity refer to the first stage of the assignment process; for indirect studies, therefore, control and exogeneity describe Z, rather than X, the causal variable of interest. Consequently, indirectness complicates—and potentially undermines—some of the advantages of control and exogeneity described earlier. In direct studies, an advantage of control is clarifying what is included in the causal variable—exactly what causal effect is being estimated—and the form of the identifying variation. However, in many indirect studies, the process through which Z (the encouragement or instrumental variable) drives X (the causal variable) cannot be known to the same degree, undermining knowledge of the sources and form of variation in X. Suppose, for example, encouraging breastfeeding also raises some mothers’ awareness of the harm of smoking on their child's health and in turn leads them to quit smoking. In this case, the estimated effect of breastfeeding would be confounded with smoking behavior and thus biased. To disentangle the effect of breastfeeding requires the exclusion restriction: that assignment affects outcomes only through its effect on the causal variable (Angrist & Pischke, 2014, p. 106; Dunning, 2012, p. 120). The greater the indirectness, therefore, the more ambiguity about what causal effect is being estimated.
Moving from direct to indirect studies also complicates and potentially undermines the advantages of exogeneity. Again, in our framework, exogeneity in an indirect study is a characteristic of the first stage of the assignment process driving Z, such as an encouragement or instrumental variable. Exogeneity in Z, however, does not by itself result in an unbiased estimate of the effect of the causal variable, X. As discussed, even randomizing Z will not produce unbiased estimates of X without the exclusion restriction. In addition, to the extent the first stage Z→X is weak, the advantages of random assignment (or other forms of exogenous identifying variation) will diminish in proportion. For example, if A→Z is fully randomized and Z→X results in perfect correlation, then X is fully randomized as well. But if Z→X results in only a weak correlation, then only a small amount of the variation is X will be driven by the random assignment. Consequently, much of the variation in X may remain potentially endogenous, and thus potentially correlated with confounding factors. In general, to the extent Z→X is a weak first stage, the strength of identifying variation from an exogenous assignment of Z is diluted and potentially outweighed by endogeneity in X (the causal variable of interest). Consequently, weak first stages tend to produce biased causal estimates (Bound, Jaeger, & Baker 1995). Therefore, in an indirect study in which the encouragement or instrumental variable (Z) only weakly influences the causal variable of interest (X), the strengths typically associated with random or exogenous assignment are diminished.
Indirect studies complicate causal estimation in other ways. As noted earlier, ITT refers to the effect of Z, such as encouragement of breastfeeding, and differs from TOT—the effect of X, such as breastfeeding itself. However indirect studies provide estimates only of the effect of the causal variable among those cases where Z affected X, such as among mothers for whom the encouragement would cause them to switch from not breastfeeding to breastfeeding. The estimate among this group is referred to as a local average treatment effect (LATE) or, alternatively, as a complier average causal effect (CACE) (Angrist & Pischke, 2009; Imbens & Rubin, 2015). Estimating the effect of the causal variable also requires monotonicity, meaning that Z cannot systematically increase X for some people but decrease X for others (Cunningham, 2021, p. 350). Monotonicity would be violated, for example, if the breastfeeding information provided by hospitals encouraged some new mothers to breastfeed but discouraged others who would have breastfed without the intervention (a backfire effect). Thus, indirectness reduces the validity of estimated impacts and requires more advanced estimation methods, even with researcher control and exogenous assignment.
Indirectness causes particular problems when the studies are not controlled by researchers (natural) and the assignment is non-random (although still with an exogenous component), like many instrumental variable studies. Indeed, epidemiologists are often skeptical of instrumental variable estimates (e.g., Hernán & Robins, 2020, chapter 16). Yet indirect studies may be the best available means to probe a particular causal effect, such as the effect of pregnant mothers’ smoking on the birthweight of their babies (Evans & Ringel, 1999).
Our directness dimension highlights the similarities between instrumental variables, encouragement experiments, and RCTs with noncompliance. Recognizing indirectness as a dimension alerts people to the option of estimating impacts of interest when they cannot find or create identifying variation in the causal variable itself. Denoting indirectness as a distinct dimension highlights that both direct and indirect approaches are possible with both randomized and not randomized (but exogenous) assignment, and with both researcher-controlled assignment and natural (policymaker or uncontrolled) assignment. Knowing that a particular estimate has substantial indirectness points to the need for more advanced estimation methods as well as potential problems with internal validity and generalizability, even in studies with researcher control and substantial exogeneity in the first stage. Clarifying and emphasizing the directness dimension highlights both the dangers and potential value of indirect studies.
Typology of Causal Study Designs
Our three dimensions can be combined to produce a typology of study designs by differentiating: researcher-controlled from not researcher-controlled (uncontrolled or policymaker controlled); random from non-random but still exogenous (quasi-random); and direct from indirect. Table 2 presents the resulting typology of eight study designs, with corresponding assignment processes and labels. A table in the Appendix shows how all the example studies given in the article fit into the typology. While we use the expression “study design,” “study type,” or simply “study” as shorthand, the categories in our typology refer more specifically to a combination of an impact estimate of interest and an assignment mechanism. It is possible, therefore, that a given published study might include two or more categories in our typology if it includes more than one estimated impact or leverages more than one assignment process.
Typology of Causal Study Designs a Based on the Assignment Process.
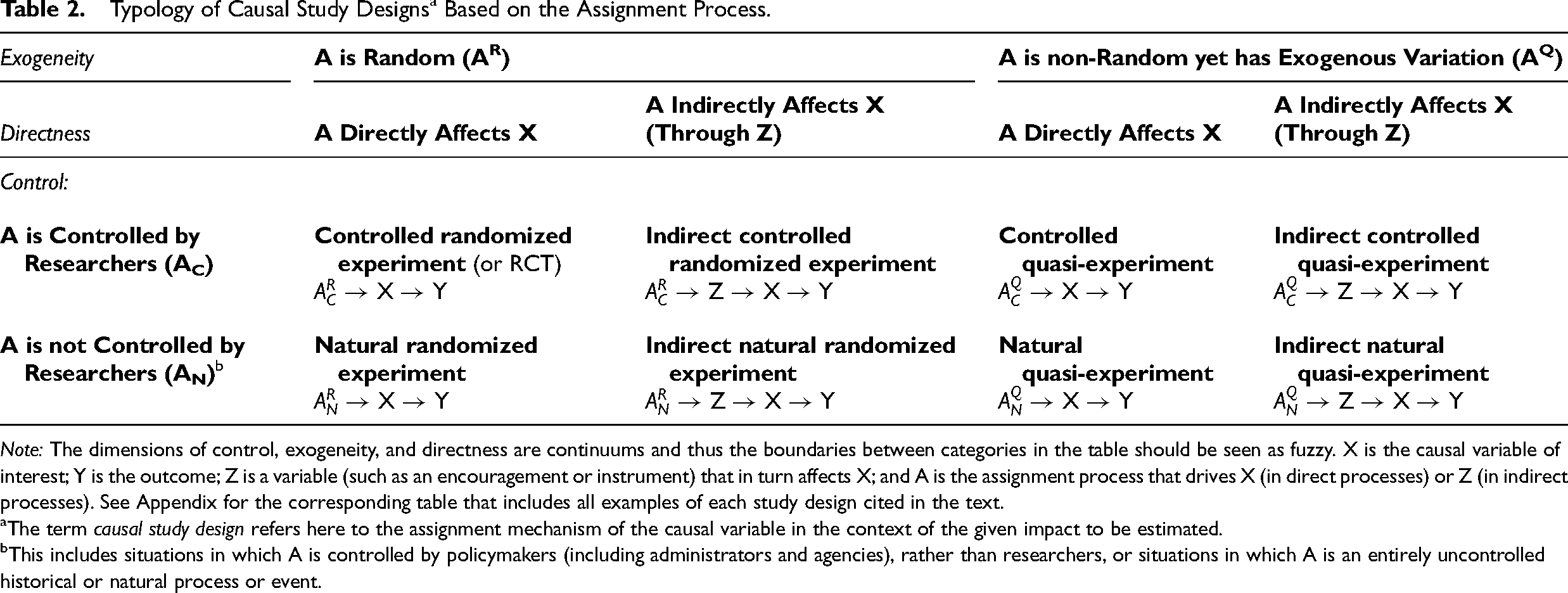
Note: The dimensions of control, exogeneity, and directness are continuums and thus the boundaries between categories in the table should be seen as fuzzy. X is the causal variable of interest; Y is the outcome; Z is a variable (such as an encouragement or instrument) that in turn affects X; and A is the assignment process that drives X (in direct processes) or Z (in indirect processes). See Appendix for the corresponding table that includes all examples of each study design cited in the text.
The term causal study design refers here to the assignment mechanism of the causal variable in the context of the given impact to be estimated.
This includes situations in which A is controlled by policymakers (including administrators and agencies), rather than researchers, or situations in which A is an entirely uncontrolled historical or natural process or event.
Since each dimension is a continuum, the demarcation line to dichotomize each dimension, such as the line between direct and indirect, is somewhat fuzzy—and substantial variation along each dimension remains within each category or study type. Still, the widespread use of categorical labels, such as quasi-experiment, illustrates the demand for categorical terms among both producers and consumers of research. The resulting 2 × 2 × 2 typology shown in Table 2 provides a clearer, more consistent, and more comprehensive set of study labels than the prevailing often muddled terminology.
We chose labels for each study design shown in Table 2 to remain as close as possible to familiar language in the literature. The term controlled refers to studies with researcher control of assignment, as in a randomized controlled trial. The term natural refers to studies with assignment that a researcher does not control but instead finds in a policy process (controlled by policymakers) or in uncontrolled historical or natural events. The term randomized refers to studies with true random assignment, while quasi refers to studies that are not randomized but that still leverage an exogenous assignment process that provides identifying variation. The label indirect describes studies that involve an encouragement, instrumental variable, or similar indirect strategy by design. We would not apply the label indirect, however, to a study that suffers from the usual problems of noncompliance, contamination, and other practical limitations that attenuate directness. Because directness is a continuum like the other dimensions, some direct studies (by design) have such high levels of noncompliance that they could be considered indirect studies. To simplify the labels, we do not explicitly name studies as direct in Table 2 because directness is often presumed as the default. Of course, the label direct could be added for emphasis when useful, especially when compared to indirect studies.
Although all three dimensions—control, exogeneity, and directness—relate to the strengths of a study, the resulting typology on its own does not represent a strict internal validity hierarchy among the study types. Assessing internal validity requires additional considerations and careful attention to the specifics of the situation, especially in any study falling short of a direct, researcher-controlled randomized experiment. The next sections discuss each category in the typology and provide examples.
Randomized Designs
We begin with fully randomized designs, the left half of Table 2.
Controlled Randomized Experiments: Classic RCTs
In a controlled randomized experiment, the researcher controls assignment, which is fully random, and the assigned treatment is the causal variable of interest. This design, of course, is also widely known as a randomized controlled trial (RCT), but our alternate phrasing helps articulate the consistency with the other study labels in the typology. The Moderna covid vaccine clinical trial is a well-known example and demonstrates the design's credibility and enormous practical value (Baden et al., 2021). The Moderna trial involved 30,420 volunteers who were randomly assigned to either the Moderna vaccine or saline placebo, and 96% of participants received their shots as assigned. A classic policy example is Bloom and colleagues’ (1997) evaluation of the effect of the Job Training Partnership Act (JTPA) on earnings over several years. Specifically, eligible applicants from 16 different program sites were randomly assigned to either JTPA job training and support services (the treatment group) or waiting 18 months for services (the control group). In the JTPA experiment, the treatment was direct: job training, although as with any real-world RCT there was some noncompliance.
Controlled randomized experiments, long used in medicine and psychology, have become widely used in policy and applied social research, including education research (e.g., What Works Clearinghouse, n.d.) and in previously non-experimental disciplines like economics (Banerjee, 2020; Davis & Holt, 2021) and political science (Morton & Williams, 2010). Controlled randomized experiments have also moved increasingly into business, where they are referred to as A/B studies (Gallo, 2017; Manzi, 2012).
Natural Randomized Experiments: Random Assignment That Researchers Find Rather Than Create
Natural randomized experiments are fully randomized studies in which assignment is not controlled by the researcher but rather by a policymaker or by a natural or historical process. For example, genes (human, animal, viral, and plant) undergo random mutations that can be leveraged for a natural randomized experiment (sometimes referred to as Mendelian randomization). A study by Rose et al. (2002) examined the effects on the femininity and fertility of girls born with a fraternal twin brother or a fraternal twin sister, which is a random event. Other than genes, however, the natural world rarely fully randomizes.
Most natural randomized experiments turn out to be policymaker controlled, such as the lottery Oregon used to allocate expanded Medicaid (Finkelstein et al., 2012). To give another example, Colombia used a lottery to distribute vouchers for private schools, which enabled estimates of their effects on academic achievement (Angrist et al., 2002). This study was fairly direct, although not perfectly direct, with 90% of lottery winners using the voucher and 24% of losers receiving scholarships through other means (p. 1536). The Vietnam draft lottery (the implementation of the Selective Service System) has provided another source of natural randomized experiments. While many of these studies are indirect (as discussed shortly), one direct natural randomized experiment examined the effect of the of the Vietnam draft lottery on political attitudes later in life (Erikson & Stoker, 2011). This study was direct because it estimated the effect of the risk of being drafted from having a low number, rather than using the Vietnam draft lottery as an instrument for other causal variables, such as serving in the military or receiving military educational benefits.
Indirect Controlled Randomized Experiments: Encouragement Designs
Researchers in the health and social sciences have used encouragement experiments to try to estimate the effects of behaviors that cannot be directly manipulated (Bradlow, 1998; Zelen, 1979). The breastfeeding experiment in Belarus (Kramer et al., 2001), already discussed, is an example. We label this kind of study an indirect controlled randomized experiment. Another example is the evaluation of the educational TV program Sesame Street, summarized in Cook et al. (1975). In this study, low-income families in several cities were randomized to receive encouragement to watch Sesame Street, consisting of promotional materials, telephone calls, and home visits. Importantly, those in the control group could (and did) watch Sesame Street, which turned out to be a widely popular show, while some in the treatment group watched the program only a little or not at all despite the encouragement. Still, the causal question of interest was the effect of Sesame Street on learning and cognitive development.
Despite the advantages of researcher control and random assignment, indirect randomized experiments still have the disadvantages and complications of all indirect studies. For example, researchers can estimate the effect of the encouragement (the ITT effect), with traditional methods. But to get the effect of the causal variable of interest (the TOT effect), such as the effect of breastfeeding or watching Sesame Street, requires further assumptions, such as the exclusion restriction and monotonicity (Cunningham, 2021, p. 350). The estimates, moreover, apply only to those whose choices or behaviors would be influenced by the encouragement, a local average treatment effect (LATE).
Indirect Natural Randomized Experiments: Finding Random Instruments
Many natural randomized experiments involve random assignment that, like encouragement experiments, only indirectly influences the causal variable of interest. The original Angrist (1990) Vietnam draft lottery study of the effect of military service on later earnings is a good example of this kind of indirect natural randomized experiment. The draft lottery is not the same variable as military service in Vietnam, because some men volunteered for military service. There was also substantial noncompliance since many who were drafted found ways to avoid military service. In a related, even more indirect study, Angrist and Chen (2011) used the Vietnam draft lottery to estimate the effect of education on earnings, since young men who served in the military received educational benefits through the GI Bill. The estimated effects of education on earnings apply only to those whose education was driven by their lottery number, a LATE.
In most indirect natural randomized experiments, random assignment is created and thus controlled by policymakers, like the government officials who ran the Vietnam draft lottery. True randomization from a natural process is rare, with genetic variation an exception. Unless genes are causal variables of interest, as in the Rose et al. (2002) study, “natural” randomized experiments are almost always indirect. A study by Angrist and Evans (1998) of sibling sex composition, fertility, and female labor supply provides a good example. The basic idea is that parents prefer having a mix of son(s) and daughter(s), and thus having the first two offspring of the same sex (either both boys, or both girls)—essentially a random outcome of genetics—encourages parents to have a third child. This creates some degree of random, exogenous variation in the number of children in some families. The researchers employ this sibling-sex variation as an instrumental variable influencing the decision to have another child, allowing them to estimate the effect of the number of children on the labor supply of women.
Quasi-Experimental Designs
We turn now to the right half of Table 2, which contains quasi-experimental designs in which the assignment is not randomized but still exogenous to some meaningful degree. The vagueness of this last statement points to the fuzzy boundary between a weak quasi-experiment with only limited exogeneity and a more fully endogenous study (sometimes called an observational study) as will be discussed later.
Controlled Quasi-Experiments: Researcher Control Without Randomizing
Even when researchers control assignment, full randomization of treatments may not be possible for logistical or ethical reasons. In many policy studies, just a few or even only one site (a school, housing development, or neighborhood) gets the intervention while another, similar (usually matched) site serves as the comparison. The investigator, however, still controls the assignment of treatment and comparison groups. This situation, which we label a controlled quasi-experiment, corresponds closely to the original vision of Campbell and colleagues when they invented the term quasi-experiment.
For example, a study by Formoso and colleagues (2013) evaluated a community-level campaign (involving posters, brochures, and local media ads) aimed at reducing antibiotic prescribing in Italy. The campaign was run in the provinces of Modena and Parma in the northern Italian region of Emilia-Romagna, with a comparison group composed of the other provinces in the same region. The main outcome of interest was the rate of antibiotic prescribing measured by administrative data gathered from health districts. A population survey was also conducted to measure knowledge and attitudes. The study found a decline in antibiotic prescribing rates in the treatment provinces, compared with the control provinces, but no difference in general knowledge and attitudes regarding antibiotics. The authors label their study a “non-randomized trial,” which is often how controlled quasi-experiments are referred to in the health sciences. Indeed, a search of the term “non-randomized trial” or “non-randomized clinical trial” turns up around 10,000 results in Google Scholar (as of February 2024). An example is a study published in JAMA Network Open (Tinetti et al., 2024) that examined the impact of patient priorities-aligned care (PPC) on clinical outcomes for older adults in a selected clinic (Lakewood, Ohio) compared with those receiving usual care (UC) in a matched clinic (Brunswick, Ohio) in the same primary care network. Results found the PPC program had few beneficial effects.
Importantly, also included in controlled quasi-experiments are single-case designs with switching, such as AB, ABA, or ABAB studies (Kratochwill et al., 2013; Smith, 2012). In contrast to group designs, which leverage comparisons with a control group, single-case designs employ before-after comparisons (or repeated measures) of the same group. For example, a study of the effects of an interactive robot, a seal named Paro, on nursing home patients with dementia used an ABAB design in several nursing homes in the Netherlands (Bemelmans, Gelderblom, Jonker, & de Witte, 2015). In the first and third (A) phases, patients received usual care; in the second and fourth (B) phases, the patients also interacted with Paro during their daily routine; each phase was a month in length. Results showed that intervention (interacting with Paro) was associated with better functioning and mood. The What Works Clearinghouse (2020) recognized the usefulness of single school designs with researcher control of switching back and forth between programs (p.77), but pointed out concerns about potential time confounders, such as “new distinct policies, new personnel, or new state tests” that could plausibly affect outcomes and therefore bias the estimated causal effect (p. 87). These are some of the inherent limitations of single-case designs. Still, researcher control makes it possible to time the intervention and comparison periods to try to avoid such confounders. Interrupted time series designs (McDowall, McCleary, & Bartos, 2019) are also a type of single-case design that, if the intervention is controlled by the researcher, can be considered a controlled quasi-experiment in our typology. Researcher control helps fortify a variety of designs for quasi-experiments (Reichardt, 2019; Shadish et al., 2002).
Natural Quasi-Experiments: Leveraging Policy Changes and Natural Events
Researcher control is often not possible for estimating the impacts of many important programs and policies, such as minimum wages, immigration, and government-provided health insurance. Therefore, many policy and program evaluations are natural quasi-experiments of the policymaker control variety. These studies are typically direct because the researcher wants to know the effect of the given policy or program. Policymakers may control assignment, such as by determining an intervention's site, scope, or timing, but researchers must then learn about the assignment process and come up with valid comparisons.
Many natural quasi-experiments leverage policy variation over time across states (or other political jurisdictions), often using a difference-in-differences strategy, to estimate causal effects. Examples include studies of the impacts of ACA Medicaid expansion on health insurance coverage (Courtemanche, Marton, Ukert, Yelowitz, & Zapata, 2017), financial security (Hu, Kaestner, Mazumder, Miller, & Wong, 2018; Kaestner, Garrett, Chen, Gangopadhyaya, & Fleming, 2017), health care (Wherry & Miller, 2016), and other outcomes (summarized in Antonisse, Garfield, Rudowitz, & Artiga, 2018). These studies are direct, estimating the effects of Medicaid expansion, and they are natural because researchers do not control assignment but rather take the policy variation they find in the world. This found variation, however, is far from random and of debated exogeneity, since the political forces that drove ACA Medicaid expansion might well influence some outcomes. Still, expanded Medicaid eligibility remains fairly exogenous to the individual choices of state residents. Most importantly for difference-in-differences studies, the change in the causal variable (e.g., expanded Medicaid eligibility) should have a component exogenous to changes in outcomes (Wing, Simon, & Bello-Gomez, 2018).
These features—policymaker control and potential endogeneity—underlie the concerns of Besley and Case (1994) and of Rosenzweig and Wolpin (2000) about referring to such studies as “natural experiments,” implying an internal validity these studies often lack. Our preferred term, natural quasi-experiment (as distinct from natural randomized experiment), better clarifies such limitations. But sometimes a simple natural quasi-experiment can produce good exogeneity. As discussed earlier, the cement floors study in Mexico (Cattaneo et al., 2009)—a natural quasi-experiment—took advantage of strong exogeneity stemming from the luck of policy differentiation across a state border bisecting a single metropolitan area. This found policy variation across two very similar communities enabled an estimate of the program's impact on child and maternal health, with little bias despite only a cross-sectional analysis of post-test outcomes.
In addition to intentional policies and programs, historical and natural events also produce natural quasi-experiments. For example, Card (1990) used the Mariel boatlift to estimate the effect of immigrant labor supply on wages, employment, and other labor market outcomes, by comparing outcome changes in Miami to other similar cities. A study by Park et al. (2020) probed the direct effect of hot weather on learning, comparing school districts with varying exposures to hot weather. But despite these examples of fairly direct natural quasi-experiments, history or nature most often exogenously varies the causal variable of interest only indirectly.
Indirect Controlled Quasi-Experiments: An Under-Used Approach
While indirect controlled randomized experiments (encouragement experiments) are common, indirect controlled quasi-experiments are less frequently seen in the literature. One example is a study by Golsteyn, Jansen, Van Kann, and Verhagen (2020) in which researchers implemented a school-level intervention aimed at encouraging physical activity among low-income students in the Netherlands, with a similar school selected for comparison. This encouragement in one school, compared to a control school, allowed the researchers to estimate the causal effect of physical activity, which is mostly a self-selected behavior, on learning outcomes. The relative lack of controlled indirect quasi-experiments suggests potential opportunities, with the weaknesses of indirectness and quasi-randomness partly mitigated by the strength of researcher control.
Indirect Natural Quasi-Experiments: Finding and Employing Instrumental Variables
Instrumental variables studies require finding some exogenous instrument that drives identifying variation in an endogenous independent variable of interest. Some indirect natural quasi-experiments are fully uncontrolled, stemming from weather, geography, or other sources of identifying variation from nature itself. For example, Marcotte (2007) examined the effect of instructional time on learning by leveraging variation in school days driven by snow storms in Maryland's public school system, finding significant effects on standardized state test scores (especially in mathematics and in earlier grades). This indirect approach contrasts with Park et al. (2020), which used the same dependent variable (test scores) and the same type of uncontrolled assignment process (weather). The Park et al. (2020) study is direct, with weather as the causal variable, while the Marcotte (2007) study is indirect, with weather driving the causal variable, instructional time. Another example of an indirect natural quasi-experiment is the study by McClellan et al. (1994), discussed earlier, which used relative residential distance to hospitals as an instrumental variable to estimate the effect of access to imaging technology and (in turn) bypass surgery on survival after a heart attack.
Other indirect natural quasi-experiments leverage policymaker-controlled variation. In contrast to the direct natural quasi-experiments described above, such as the Medicaid expansion studies, here the policymaker-controlled variation plays the role of an encouragement (Z) rather than directly influencing the causal variable of interest (X). For example, Evans and Ringel (1999) used state-time variation in cigarette taxes, which affect the prices of cigarettes, which in turn affect smoking, to identify the effect of maternal smoking on birthweight. Again, the indirectness means that the estimates apply only to expecting mothers for whom cigarette price changes their smoking behavior, and not to mothers who would smoke or not smoke, irrespective of price. Although indirectness reduces and makes more ambiguous both internal and external validity, indirectness is often the only possible route to probe effects of inherently endogenous causal variables, such as the effect of maternal smoking on infant health.
Endogeneous (Observational, non-Experimental) Studies
Our typology includes a wide variety of studies that involve either research-controlled assignment or more naturally occurring assignment (including policymaker-controlled assignment) that is random or otherwise exogenous to some meaningful degree. Such studies warrant the label experiment or at least quasi-experiment. What about the many studies with neither researcher control nor with any plausible exogenous, identifying variation? In such studies, the causal variable of interest (X) is endogenous, or nothing like random, such as our earlier example of the many health studies that examine the association of largely self-selected lifestyle factors (such as diet and exercise) with mortality (Loef & Walach, 2012). These studies can be referred to as observational studies, but that term is problematic because some use the term observational studies also to include natural experiments. The term non-experimental studies is a possible alternative, but again some consider all studies without researcher control to be non-experimental. We prefer to term these studies endogenous studies.
To see the distinction, consider again the cement floors study in Mexico (Cattaneo et al., 2009), which in our typology is a natural quasi-experiment because of the exogenous variation in the availability of free cement floors that was driven by state policies and geographic borders. In contrast, we would describe as an endogenous study an analysis that merely compared households who, on their own, did or did not install cement floors (even if the analysis included control variables or other adjustments for confounding). The treatment self-selection inherent in this situation would make endogeneity inevitable.
If we were to include such endogenous studies in our typology, they would be past the lower-right corner of Table 2. However, we do not include them because no form of the label experiment, natural experiment, or quasi-experiment is justified for such studies. Indeed, the focus of our typology—and the very invention of the terms quasi-experiment and natural experiment—represent attempts to distinguish studies that provide experiment-like causal evidence (at least to some extent) from the many endogenous studies in the health and social sciences that do not provide good evidence of causation.
Admittedly the boundary with endogenous studies is fuzzy, especially for indirect natural quasi-experiments with a weak first stage (the lower-right quadrant of Table 2). Our framework, however, helps articulate the key point that natural experiments must contain some meaningful degree of identifying variation in the causal variable that strengthens causal evidence. Articulating this difference is particularly important because natural quasi-experiments and endogenous studies share analytical methods. Those methods include propensity matching (Rosenbaum & Rubin, 1985), machine learning (Athey, 2017), and choosing control variables using causal diagrams (e.g., Hernán & Robins, 2020; Morgan & Winship, 2015; Pearl et al., 2016).
Relation to Other Frameworks and Issues of Causal Research
We next discuss how our proposed framework relates to other frameworks for and features of causal research design and analysis. Because our framework focuses on the assignment of the causal variable, it does not address measurement, sampling, and context—additional factors that influence the generalizability and accuracy of impact estimates.
The Campbell Tradition of Design Types and Threats to Validity
Campbell and colleagues (Campbell & Stanley, 1963; Cook & Campbell, 1979; Shadish et al., 2002) developed a widely used set of design types and associated threats to validity. For example, they identify the one-group pretest–posttest design, the posttest-only design with nonequivalent groups, and the untreated control group design with dependent pretest and posttest samples, to name just a few. They describe how the various designs reflect combinations of elements: assignment (random, cutoff, non-random, etc.), measurement (posttest, pretest, repeated measures, etc.), comparison groups (none, one, several, etc.), and treatments (switching, removed, repeated, etc.). They show how these designs address, or fail to address, various threats to internal validity, including selection, history, maturation, regression (to the mean), attrition, and testing.
Although inspired by the Campbell tradition's attention to quasi-experimental designs, our typology is mostly orthogonal and complimentary. Take for example the untreated control group design with dependent pretest and posttest samples. Our approach calls attention to who or what controls assignment, the degree of exogeneity, and whether the treatment is direct or indirect. Treatment selection is more of a concern when researchers lack control of assignment. Indirectness implies that the causal variable remains partially self-selected or otherwise endogenous, and indirectness also undermines generalizability. Our framework is particularly valuable for assessing the weaker quasi-experimental designs, what Campbell and Stanley (1963) originally termed pre-experimental designs. For example, even a weak one-group pretest–posttest design, a before-after study, can be fortified by a direct treatment assigned exogenously by the researcher.
Data Structures and Analytical Strategies
Typologies of causal research are often based on the structure and dimensions of the data—over time, cross-sectional, cohort, across geographical areas, and so on—and on how the data are analyzed to estimate causal effects—difference-in-differences, interrupted time series, regression discontinuity, and so on (e.g., Pirog, 2008). In essence these typologies focus on the comparisons being made and on corresponding analytical strategies. Reichardt (2011, 2019 chapter 10) proposed a comparison-based typology using dimensions for the unit of assignment, context, and some elements of assignment (random, based on a quantitative variable, or based on a non-quantitative variable).
Our typology provides insights that are different from and complementary to the understanding of data structures and analytical techniques. For example, we illustrated direct natural quasi-experiments using several data structures and forms of analysis, including longitudinal and cross-state difference-in-differences (Medicaid expansion studies, Antonisse et al., 2018), regression discontinuity (universal health insurance at age 65; Card et al., 2008), and cross-sectional comparison (the cement floors study by Cattaneo et al., 2009). Knowing that all three studies are direct, natural, and non-random, but with exogenous identifying variation, provides important insights about various issues and limitations, as we discussed earlier, that are different from issues of data structure and analysis. Of course, knowing the data structure and type of analysis alerts the researcher to a number of important, more technical concerns, described in the existing causal methods literature (e.g., Cunningham, 2021). For example, specifying that a study is an RD design reveals concerns about what else changes, other than the causal variable, right at or close to the cutoff.
Conclusion: Usefulness of the Framework
We have shown how the historical and current uses of the terms quasi-experiment and natural experiment are often ambiguous, inconsistent, and fail to comprehensively specify key dimensions of how to find and create identifying variation. Current usage sometimes muddles whether variation in the causal variable falls short of random—“quasi-randomness” or exogeneity—with whether researchers find, rather than intervene to create, such identifying variation—"naturalness". The terms obscure whether the natural or quasi variation is in the causal variable of interest itself or in another variable (such as an encouragement or instrumental variable) that drives the causal variable of interest. As research methods have expanded to include many studies labeled quasi-experiment or natural experiment, clarifying these issues while still honoring prior, and often widespread, terminology is critical.
To address these terminology shortcomings, we focus on the assignment process because it is key to the internal validity of the estimate and because it is what the terms “natural” and “quasi” mainly refer to in the literature. Our proposed framework specifies three key dimensions of identifying variation: (1) control of treatment assignment by the researcher, as opposed to a policymaker or other natural or historical process (uncontrolled); (2) exogeneity of the assignment process; and (3) directness of the link between assignment and the causal variable whose effect is to be estimated. We then combined these dimensions to form a new typology of eight study designs with corresponding, more precise labels. This framework of dimensions and study labels helps organize a diverse and complex variety of studies spanning many fields, mapping out similarities and differences in some of the key determinants of internal validity.
Our framework, of course, does not address all aspects of causal research design. Because it focuses on assignment, the framework does not address measurement, sampling, and context, which also shape the generalizability and accuracy of impact estimates. Our framework also does not create a strict internal validity hierarchy among the eight study types, which can contain a variety of stronger and weaker studies within each category. Assessing internal validity requires careful attention to the specifics of the situation, especially in any study falling short of a direct, researcher-controlled randomized experiment. Our framework does not provide new analytical methods or statistical tests. Nonetheless, we argue that our proposed framework remains very useful in two important ways: in the consumption of research, by helping both researchers and practitioners better understand each other and communicate across disciplines and research traditions; and in the production of research, by helping both researchers and practitioners recognize opportunities in real-world settings to find or create identifying variation that can be leveraged to generate causal evidence.
With respect to the consumption of research, as the many examples discussed in this article demonstrate, causal research comes in many forms and from a wide range of substantive fields and disciplines. This can make it difficult for researchers to communicate with and understand each other across disciplinary boundaries. It creates confusion for policymakers, funders, practitioners, and other consumers of causal research who need to make sense of evidence from diverse sources. Our framework can help these audiences recognize similarities in previously unfamiliar causal study designs from other fields or disciplines. For example, those familiar with instrumental variables studies in economics can use our framework, particularly the directness dimension, to better recognize similarities and differences with encouragement experiments in psychology. Such conceptual mapping facilitates the understanding and acceptance of unfamiliar approaches that nevertheless have the potential for shedding light on important causal questions. Importantly, this kind of conceptual mapping is especially helpful for policymakers, funders, and other practitioners who often have a specific policy or practice focus—such as early childhood education, drug abuse prevention, or nutrition assistance—yet rely on evidence coming from disparate disciplines, such as economics, education, epidemiology, and psychology.
Our framework could also potentially aid with systematic literature reviews and meta-analyses that synthesize causal evidence by providing a clearer and more consistent organizing structure, especially for studies that are not RCTs. Systematic reviews and meta-analyses are extremely important for summarizing evidence on many topics, and they have been well developed by prominent organizations such as the Cochrane Collaboration in medicine, the Campbell Collective in social research, and the What Works Clearinghouse in education. These organizations generally agree about the definition and priority of RCTs, but they differ in their organization of and attention to other types of causal studies and impact estimations. Indeed, they often lump such studies into just a few broad categories, such as what the What Works Clearinghouse labels quasi-experimental designs (QEDs) or what the Cochrane Collaboration labels non-randomized studies of interventions (NRSIs). Within these broad categories lies a wide variety of causal estimation strategies that differ in control, exogeneity, and directness. Our framework can be of potential use by providing a more precise, comprehensive approach to classifying studies that are not RCTs but that still have the potential to provide good causal evidence.
With respect to the production of research, our framework could help expand the supply and scope of good causal evidence by providing a comprehensive list of options for finding or creating identifying variation to estimate a specific policy or program impact of interest. One channel highlights the availability of previously unconsidered options used by other fields or disciplines. For example, economists tend to either look for natural experiments or conduct RCTs while often ignoring the important option of researcher-controlled quasi-experiments. To take another example, medical researchers predominantly rely on RCTs and often view other causal estimation strategies as merely observational (endogenous) studies, thus not meriting causal conclusions at all (Hernán, 2018). Our framework highlights how non-RCT studies with exogenous identifying variation (such as controlled quasi-experiments or randomized natural experiments) differ from endogenous studies and suggests a wider range of approaches for estimating impacts of interest when RCTs are not possible. More generally, our framework provides a road map of options for creating or finding identifying variation by highlighting the key dimensions of the assignment process and how they can be combined to produce various options or study types.
The value of a framework that cuts across disciplines can be seen in the causal inference literature, especially the Rubin causal model, which has done much to advance the range and quality of causal evidence. That work provides rigorous underpinnings, empirical tests for internal validity, and methods for analyzing data that now cross many disciplines. However, presentations of the Rubin causal model do not mention the terms quasi-experiment or natural experiment (e.g., Imbens & Rubin, 2015). Consequently, the causal inference literature does not provide a wide audience with practical guidance for how to find or create situations that will satisfy causal inference standards, other than through random assignment. The popularity of the terms natural experiment and quasi-experiment demonstrates the demand for such guidance.
Finally, our framework can guide researchers and evaluators in interactions with practitioners as well as empower practitioners themselves. Public, nonprofit, for-profit, and clinical organizations have more and more data available to them. They are increasingly likely to both analyze these data themselves and engage others to do so. They often know which impacts are the most useful to estimate, and, importantly, practitioners have the on-the-ground knowledge or influence needed to find or create identifying variation. The dimensions in our framework can help them map out their options. Practitioners can either find existing variation or create it themselves. The identifying variation can be truly random—the best option—or it may fall short of random but still include some exogenous component. The variation can be either in the causal variable of interest or in some other variable that drives the causal variable of interest. A consistent and comprehensive map of strategies to find and create identifying variation, one that bridges disciplines and appeals to both researchers and practitioners, could help facilitate more productive collaborations and expand the supply of well-estimated impacts of programs and other causal variables of interest.
Footnotes
Acknowledgements
The authors thank the anonymous reviewers as well as colleagues who commented on previous versions of this paper: Diana Epstein, Diane Gibson, Sebastian Jilke, Sanders Korenman, Oliver James, Ted Joyce, Inkyu Kang, Dave Marcotte, George Mitchell, Matt Potowski, and participants at conferences and seminars at Baruch College/CUNY, Rutgers University, Aarhus University, the Annual Research Conference of the Association for Policy Analysis and Management, and the Annual Conference of the Public Management Research Association. Finally, they thank their students for asking thoughtful questions that highlighted the need for this framework.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Notes
Appendix
