
Abstract
If service providers can identify reasons users are in favor of or against a service, they have insightful information that can help them understand user behavior and what they need to do to change such behavior. This article argues that the novel text-mining technique referred to as information-seeking argument mining (IS-AM) can identify these reasons. The empirical study applies IS-AM to news articles and reviews about electric scooter-sharing systems (i.e., a service enabling the short-term rentals of electric motorized scooters). Its results point to IS-AM as a promising technique to improve service; the data enable the authors to identify 40 reasons to use or not use electric scooter-sharing systems, as well as their importance to users. Furthermore, the results show that news articles are better data sources than reviews because they are longer and contain more arguments and, thus, reasons.
Introduction
Service providers constantly aim to improve their offerings (Dotzel et al., 2013; Edvardsson and Olsson, 1996). Knowledge about users’ reasons for using or not using a service helps in this pursuit because these reasons often point to service attributes relevant to its users that require improvement. Several quantitative techniques are available to accomplish this aim, such as conjoint analysis and customer satisfaction studies (Bacon, 2012; Baltas et al., 2013; Danaher, 1997; Schlereth, Skiera, and Wolk, 2011). Various qualitative approaches are available as well. These approaches rely on techniques such as design scenarios, storytelling, or customer journey maps, which usually require surveying or interviewing users (for an overview, see Vink and Koskela-Huotari, 2021).
However, both types of techniques have shortcomings. Some quantitative techniques, particularly conjoint analysis, require identifying the relevant attributes before conducting the survey, which is often challenging (Rao, 2014) and can vastly constrain the available service attributes space. As for qualitative techniques, the cost can be prohibitive; even if service providers were able to conduct surveys or interviews at moderate costs, their data could still suffer from users’ dishonest answers or nonresponse bias (Wertenbroch and Skiera, 2002). Moreover, it is difficult to accurately describe specific levels of intangible attributes of a hypothetical service (Bacon, 2012; Baltas et al., 2013).
Today’s world is becoming increasingly digitized, yielding an explosion of available data, most of which are unstructured, among them textual data. These data are typically available quickly, at a large scale and low cost. Harnessing these data to improve service seems promising, and service providers have already done so with textual analysis techniques, capturing users’ emotional and cognitive reactions (Huang and Rust, 2021; McColl-Kennedy et al., 2019; Rust et al., 2021), topics (Antons and Breidbach, 2018), or service attributes (Chakraborty, Kim, and Sudhir, 2022; Dhillon and Aral, 2021; Toubia et al., 2019). However, these techniques fall short of automatically identifying linguistic relationships (Berger et al., 2020) (i.e., the reasons behind changes in emotions, e.g., as measured by sentiment, topics, or attributes), such as the problem behind a service attribute that receives customer complaints.
This paper addresses these gaps in the service literature by proposing information-seeking argument mining (IS-AM) as a technique to identify reasons users are in favor or against a service. Understanding these reasons can enable service providers to better understand why users behave in a certain way and use this knowledge to improve their offerings. Suppose, for example, that a user notes that she “stopped going to a particular hairdresser because the hairdresser closes too early.” In that case, the hairdresser learns that hours of operation constitute an important attribute and that expanding these hours could help win back this customer. The hairdresser can learn because the user provided an argument. The argument contained a reason (“closes too early”) and a claim (“stopped going to the hairdresser”).
Information-seeking argument mining is a subfield of argument mining. Argument mining, which is, in turn, a subfield of computational linguistics, refers to the automatic and machine-aided identification of arguments and the argumentative structure in texts or, more broadly, in natural language (Lawrence and Reed, 2020; Stede, 2020). IS-AM automatically (1) searches for documents about a specific topic, (2) extracts arguments from documents, (3) classifies the claims in those arguments into supportive (“pro”) and attacking (“con”) claims, and (4) classifies the reasons in those arguments. In sum, it represents a technique to quickly and automatically extract and classify reasons for and against using a particular service from many documents, which could help providers improve their service. This article aims to examine whether IS-AM is actually a useful technique to identify ways to improve service. If it is, it will complement existing methods of service design (Kurtmollaiev et al., 2018; Vink and Koskela-Huotari, 2021), new service development, and service innovation (Biemans, Griffin, and Moenaert, 2016; Ordanini and Parasuraman, 2011; Sudbury-Riley et al., 2020). This research also addresses a call to use big, unstructured data in service research (Ostrom et al., 2015) and focuses on service innovation (Antons and Breidbach, 2018; Gustafsson, Snyder, and Witell, 2020).
Description of Argument Mining
Description of an Argument
Research on argumentation dates back to 2000 years ago, when Aristotle recognized arguments as a means to persuade (Aristotle, 1984). An argument has two core components: claims and reasons (Stab et al., 2018b). A claim, also referred to as a conclusion, is a defeasible statement that one should not accept without additional support. A reason, also referred to as a premise, justification, or evidence, supports the claim.
Example of Arguments and Nonarguments.

Arguments can be supportive or attacking. A supportive argument contains a reason that supports a claim; loosely speaking, it shows why a claim is true. In our setting, the claim is that people should go to a hairdresser. In contrast, an attacking argument contains a reason that rebuts a claim; it outlines why a claim is not true. So, the first sentence in Table 1 is a supportive argument, and the second is an attacking argument. Both arguments contain reasons that hairdressers could use to improve their service. For example, hairdressers could emphasize that their training allows them to identify the best colors that match a particular person or that the ability to use hair clippers only constitutes a part of a hairdresser’s job.
Overview of Argument Mining
Argument mining primarily examines the argumentative structure of a text, such as a debate. Relevant tasks are decomposing complex language into its argumentative units, identifying and classifying the function of these (discourse) units (i.e., claims and reasons), and understanding the argumentative structure in a text by recognizing the relations between argumentative units (Stab et al., 2018b; Stede, 2020). Examples of argument mining can be found in AI debaters such as IBM’s project debater (Slonim et al., 2021), applications for writing support (Stab, 2017), and the analysis of posts in web forums (Habernal and Gurevych, 2017).
In addition to argument mining, IS-AM goes a step further and focuses on extracting argumentative statements (evidence or reasoning) relevant to an externally defined topic. The central task is to find arguments related to a specific topic within a large set of texts. These texts can come from different sources and represent different points of view (Daxenberger et al., 2020). Most research in IS-AM aims to identify supporting and attacking arguments (Ajjour et al., 2019; Stab et al., 2018b), and relatively few studies address the argument search engines that detect and visualize argument components, such as claims and premises (Chernodub et al., 2019).
How Information-Seeking Argument Mining Works
Figure 1 provides an overview of how IS-AM derives its results. It proceeds in three steps, which we describe in the following subsections. Workflow of information-seeking argument mining.
Selection of the documents
Information-seeking argument mining aims to identify arguments on a particular topic in a large set of documents. Thus, it requires defining the topic and the set of documents—that is, a database. Two primary requirements are that the documents contain arguments and cover a wide range of topics and perspectives on those topics. The field of corpus linguistics (Stefanowitsch, 2020) deals with the specifics of creating representative document collections (i.e., corpora). Recent advances in language technology require enormously large collections, often too large for manual compilation. For example, the famous RoBERTa language model was trained on 160 GB of text, including several web crawls (Liu et al., 2019).
The range of feasible documents is large, including news articles, reviews (e.g., Reddit), the entire web (e.g., as collected by the Common Crawl project), and specified publications (e.g., academic journals). These documents contain the original text in full, and the algorithm must identify those parts that contain arguments. In rare cases, preprocessing has already occurred, such that the documents only contain parts (e.g., sentences) with arguments (Ajjour et al. 2019).
In addition to the database, the user must specify the selection criteria, including geography, language, and time. This involves defining search queries (Schütze, Manning, and Raghavan, 2008) and retrieving documents that match the search query. The search query contains the topic on either a generic level (e.g., the name of the service) or a detailed level for more specific inquiries (e.g., the name of the service provider and a geographic identifier). The retrieval then uses popular ranking functions such as BM25 (Jones, Walker, and Robertson, 2000a, 2000b). It can also use partial or semantic search (for related concepts) instead of searching for exact matches.
Identification of the arguments
After selecting documents, IS-AM uses a trained machine learning algorithm (usually a neural network) to identify the arguments from these documents. The input for the algorithm is the selected set of documents, the chosen unit of analysis (e.g., sentence, paragraph), and the search query. The output is a set of pro and con arguments. In summary, the machine learning algorithm must solve a three-class text classification problem that yields for each unit of analysis, whether it is a pro argument, con argument, or nonargument.
Unit of analysis. The documents are the input, broken down into the chosen unit of analysis, which can range from a few words over a sentence or a paragraph to a whole document. The advantage of selecting larger units of analysis (e.g., two sentences instead of one sentence) is that multiple sentences could contain the argument (e.g., two sentences: “I like apples” and “The reason is that apples are healthy”). The disadvantage is that larger units of analysis usually contain more content that is less relevant. Larger units may also contain multiple arguments, even pro and con arguments within the same unit, and separating them is challenging (Trautmann et al., 2020). For example, highlighting in one unit of analysis (e.g., a sentence) both the high quality of the service (as a supportive claim) and its high price (as an attacking claim) yields two arguments, one pro argument and one con argument. Identifying them in one unit of analysis requires a more complex argument identification process (Ma and Hovy, 2016).
Information-seeking argument mining typically uses a sentence or a paragraph as the unit of analysis (Ajjour et al., 2019; Shnarch et al., 2018; Stab et al., 2018b), such that it divides documents into the unit of analysis (e.g., a sentence) and eliminates nonsentence fragments like URLs.
Algorithm used for argument identification. A three-class sentence-level argument identification task is a supervised machine learning problem. It uses “ground-truth” (typically human-generated training data) to train a function. These training data are often difficult to get because detecting evidence or reasoning in texts is challenging. In addition, deciding what constitutes an argument always depends on the query (i.e., the topic). Therefore, IS-AM needs to classify different inputs for different queries such that the machine learning model eventually learns across topics. As a result, IS-AM researchers typically use crowdsourcing to manually generate high volumes of ground-truth training data (Ein-Dor et al., 2020; Stab et al., 2018b).
Transformer networks such as the popular BERT method have increased the quality of text classification tremendously, and argument mining has also successfully implemented them. Reimers et al. (2019) show that a BERT-based architecture outperforms previous work on three-class cross-topic IS-AM. BERT (using either base or large) word embedding maps words into numerical vector spaces that incorporate contextual information about words, which serves as the input of the model.
Argument score. The algorithm’s outputs are usually lists of pro and con arguments. The order of the arguments depends on the retrieval score itself for offline argument identification (Wachsmuth et al., 2017) or on the score from the argument classification step for online argument identification. The latter is typically some form of confidence level in the machine learning model (e.g., the likelihood that the argument belongs to a particular class (in this case, a pro argument or con argument). As a result of the ranking, the most important arguments appear at the top of each list.
A straightforward approach to summarizing the results is to calculate the number of pro or con arguments—in other words, an argument score. The argument score could equal the unstandardized difference in the number of pro arguments and con arguments or the standardized difference (i.e., the difference divided by the total number of arguments). As expressed in equation (1), we prefer the latter because the number of arguments can vary across different periods t.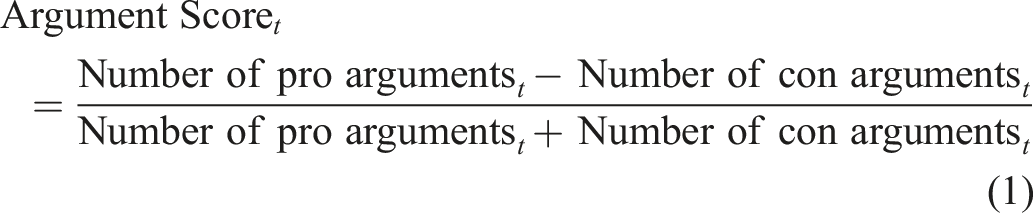
The standardized difference returns a single, interpretable score for each query between −1 and 1. A positive score shows that more positive arguments are present than negative arguments. However, we are not proposing a “best argument score” herein; we merely follow the spirit of deriving a sentiment score in the literature (for a review, see Hartmann et al., 2019) to provide a reasonable starting point for deriving an argument score.
So, we can examine the relation of the argument score with other aspects, such as time, as identified by different periods t. The index t could also refer to other dimensions such as geographical units like countries, data sources, or properties of the arguments themselves (e.g., whether it mentions a particular service provider or a particular topic).
We then compare the argument scores for different settings (e.g., we might retrieve a higher share of positive arguments for service A in Germany than in the UK). We can also plot arguments from a single query along a timeline (i.e., in a line chart where the x-axis is the time dimension and the y-axis is the argument score or the share of positive arguments). These charts would show trends or peaks and valleys for the search topic.
Clustering of the arguments
Even if the arguments are ranked, going through a potentially long list of results can still be cumbersome. Therefore, IS-AM usually summarizes all pro arguments into clusters containing similar arguments (Ajjour et al., 2018; Bar-Haim et al., 2020) using, for example, agglomerative hierarchical clustering, such as using the average linkage criterion. Such clustering builds on a pairwise similarity (Reimers et al., 2019). As a result, IS-AM derives clusters with similar pro arguments. It then follows the same procedure for all con arguments.
Description of the Empirical Study
Aims of the Empirical Study
Our empirical study aims to illustrate how IS-AM helps improve service. More precisely, we look at the service of renting electric scooters. Electric scooters are stand-up scooters with electric motors that support micro-mobility. A heated public debate has arisen about their usefulness, and we intend to exploit the information provided in news outlets. We apply IS-AM to news articles and validate them with online user reviews. Even though user reviews are the most common textual source in business research, service research emphasizes the need for an “observer view” (an entity other than the customer and the firm; see Grégoire and Mattila 2021). News articles provide such a valuable observer view and thus serve as our first data source.
Selection of the Documents
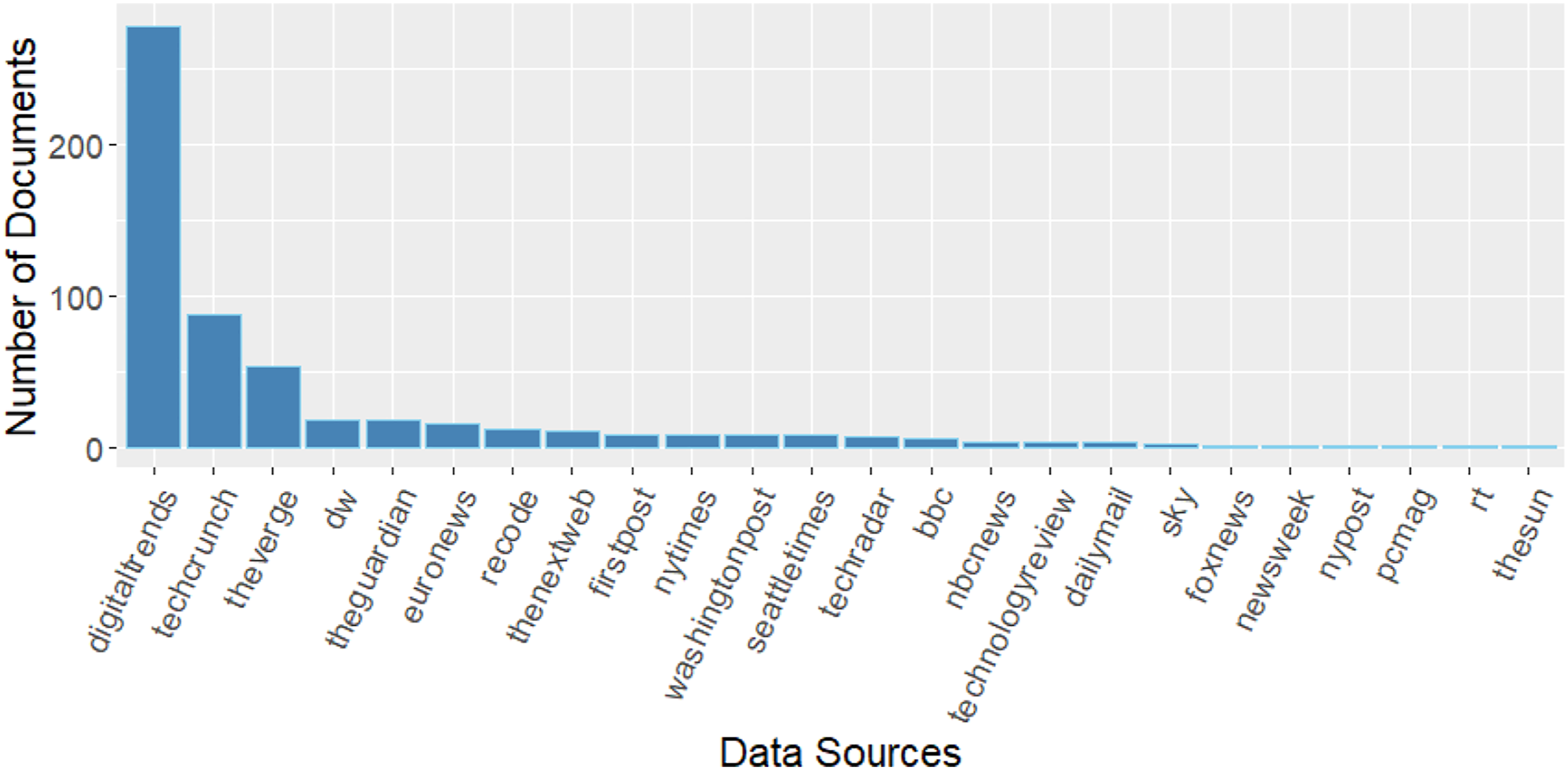
Our database contains approximately 650,000 news articles in RSS feeds of newspapers and tech magazines that the platform ArgumenText provides in several languages, such as English and German. We specified the query for relevant documents (i.e., news articles) from July 2018 to December 2019 (to avoid interference with the COVID-19 pandemic) written in English containing the search terms “e-scooter” and “electric scooter.” The two queries resulted in 560 relevant documents. Figure 2 outlines how the documents are distributed across time, and Figure 3 shows the distribution of the sources (i.e., publishers) of the documents. Distribution of documents across time. Distribution of documents across data sources (i.e., publishers).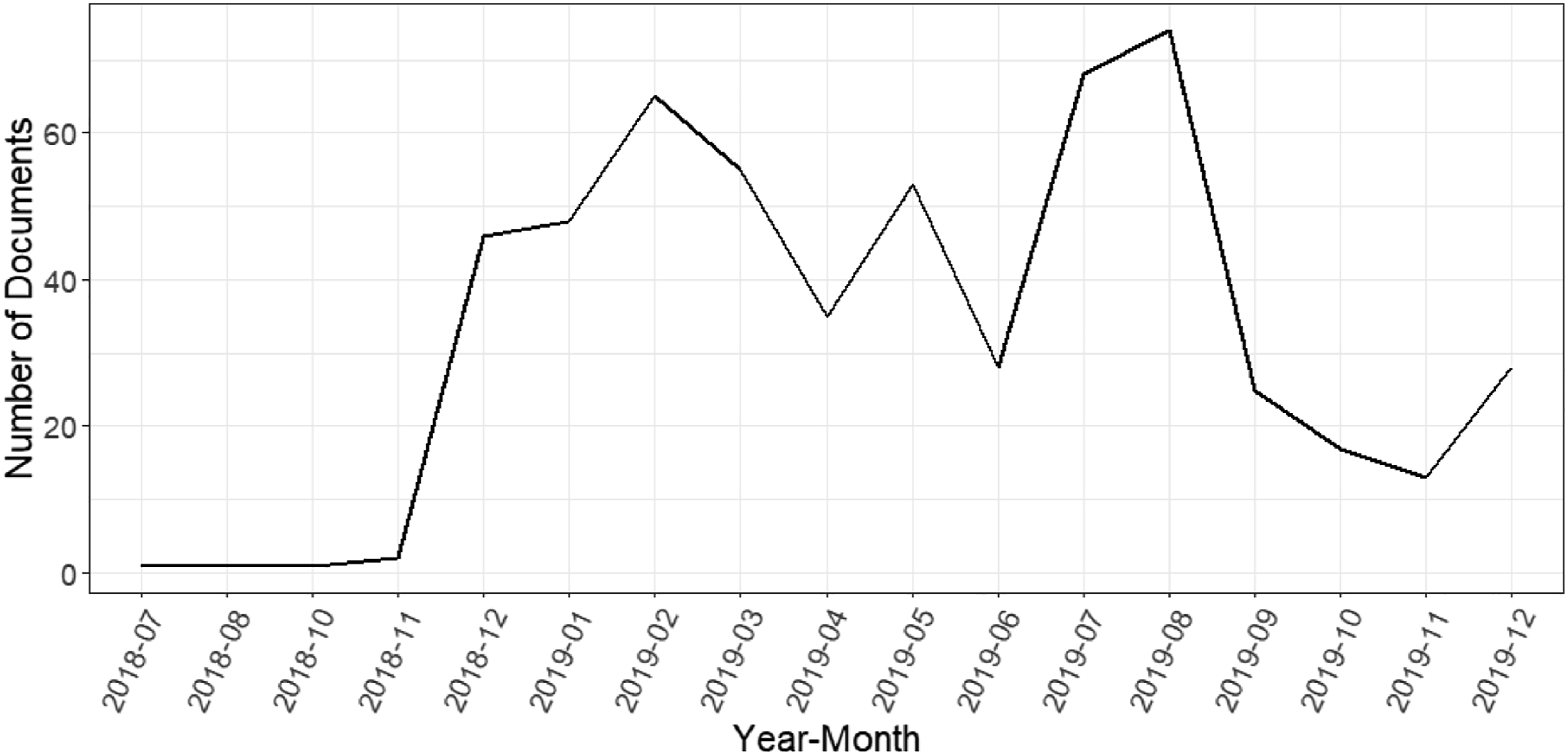
Results of Empirical Study
Identification of the Arguments
We use the platform ArgumenText (www.argumentsearch.com; Daxenberger et al., 2020) to derive our results. This publicly available software comprises publicly accessible interfaces and private backends for IS-AM. The core components of ArgumenText center around its argument detection system that builds on a transformer network to account for the dependency between the query (topic) and the argument candidate sentence (for more details, see Stab et al., 2018a). ArgumenText’s current argument detection component builds on the BERT-based architecture described in Reimers et al. (2019). Stab et al. (2018a) describe the system itself, including the training data and the searchable document collection.
We find 5855 arguments in 560 documents (on average, 10.45 arguments per document). Figure 4 outlines how the number of arguments per document distributes across documents. Distribution of number of arguments per document.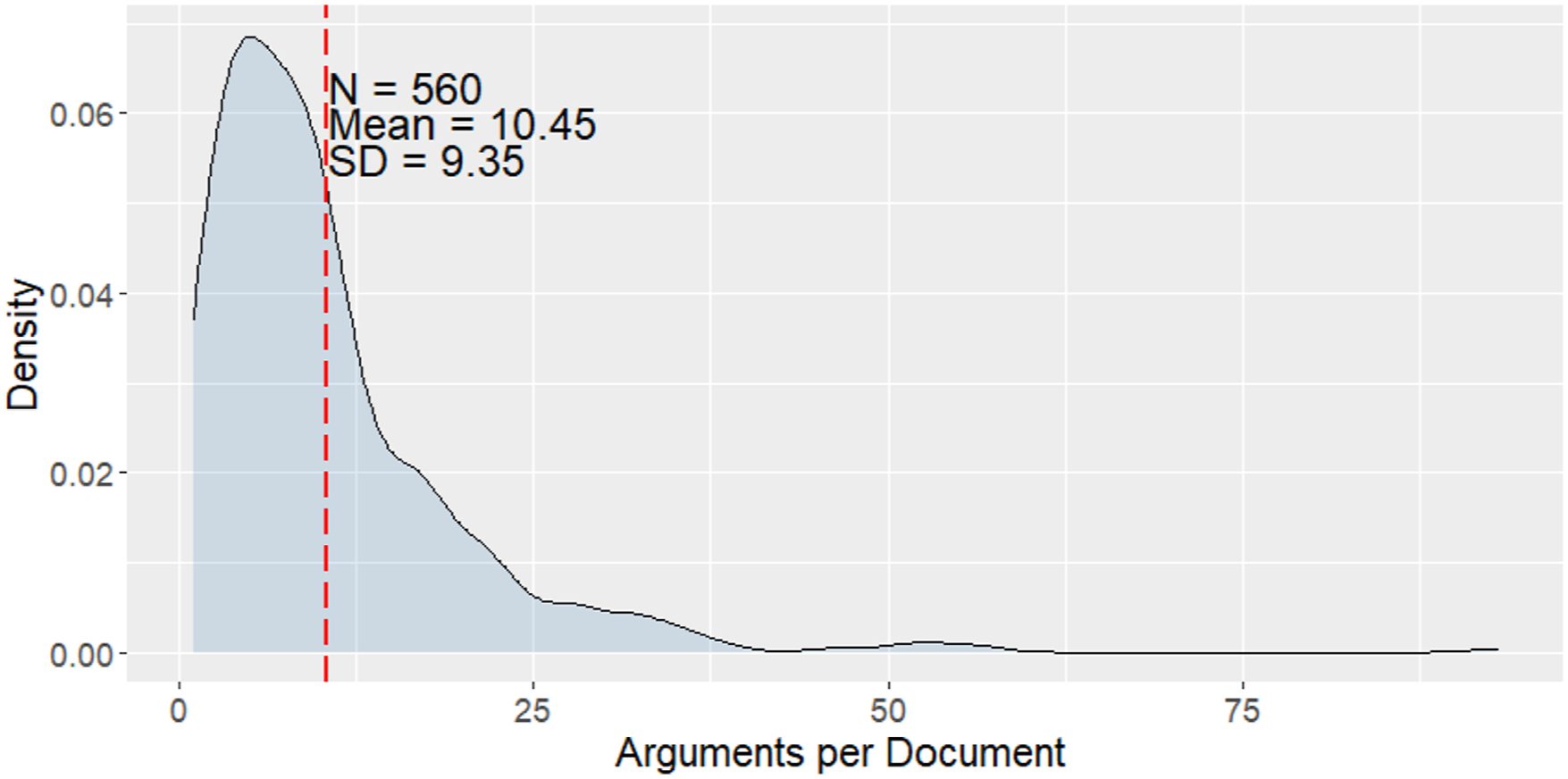
Of the 5855 arguments, 3669 are pro arguments (63%) and 2156 are con arguments (37%). They yield an argument score of 0.26 (= (3699 − 2156)/5855). The positive value indicates more supporting arguments (pro arguments) than attacking arguments (con arguments).
Equation (1) defines the argument score that varies over time, as Figure 5 outlines. Although the argument score was over 0.7 in mid-2018, showing very positive attitudes toward the electric scooter industry, it had trended down to less than 0.2 at the end of 2018. At the beginning of 2019, the argument score moved up to slightly over 0.4 but then dropped again. Development of argument score over time.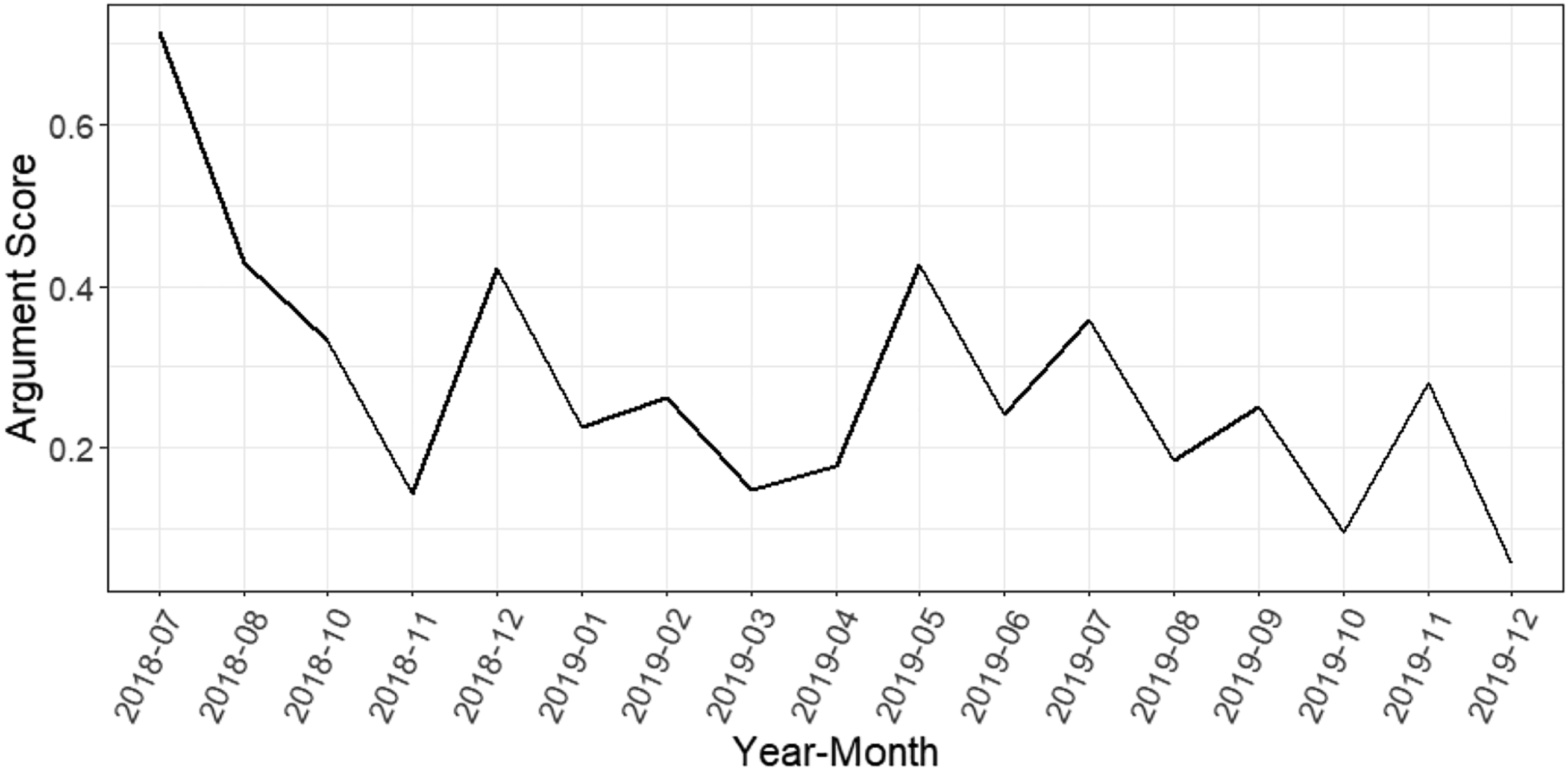
This argument score characterizes the overall attitude toward electric scooter provider services. Managers could compare this score across different markets. However, the score itself usually does not explain why people use or do not use electric scooters. Therefore, we use clustering analysis to summarize the reasons of the pro and con arguments.
Clustering of the Arguments
We conducted two cluster analyses to derive groups of pro and con arguments: one for pro arguments and the other for con arguments. We used a hierarchical-agglomerative clustering approach with a similarity function based on cosine similarity to cluster the arguments derived by the query “electric scooter” (which yielded 3083 pro and 1705 con arguments).
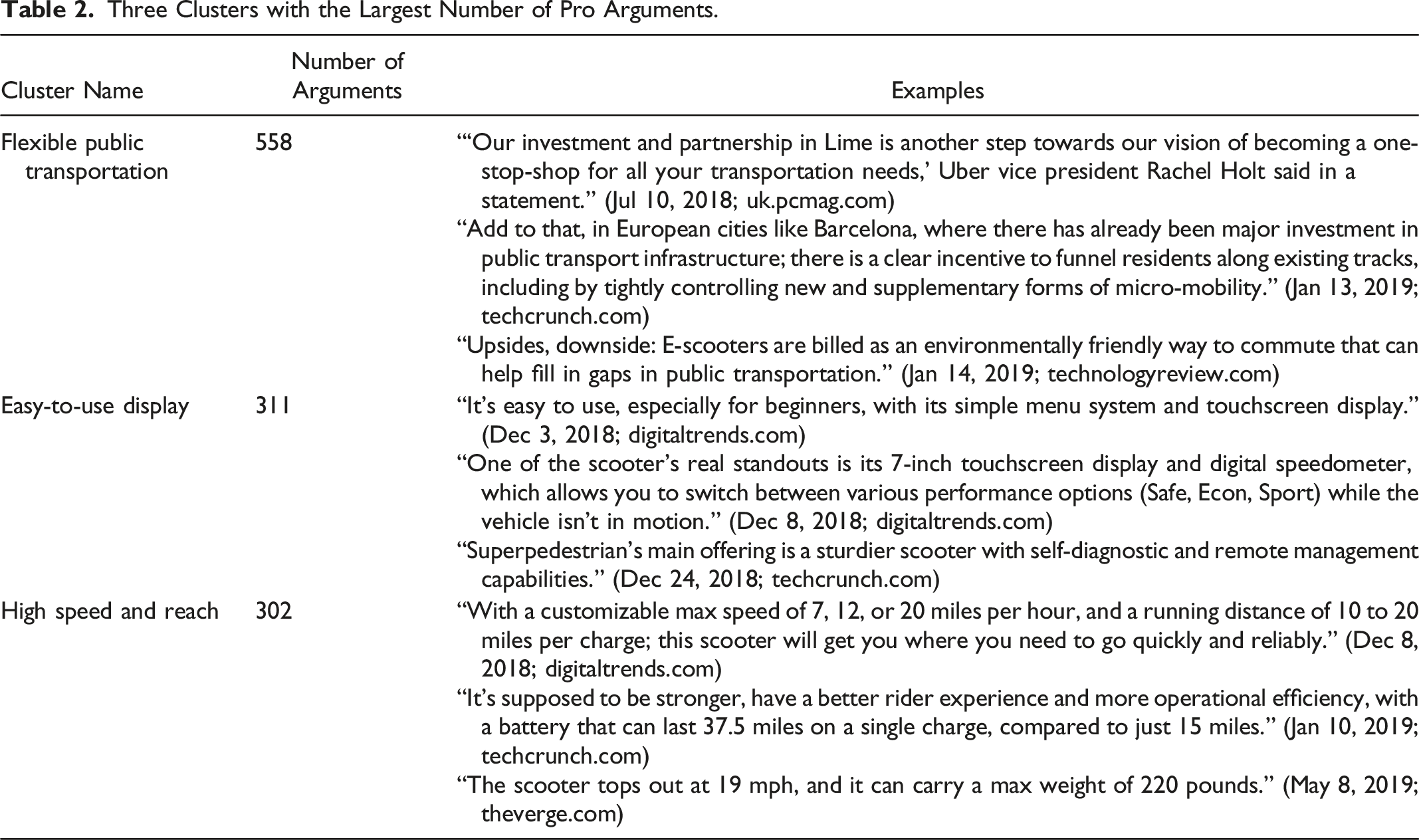
Three Clusters with the Largest Number of Pro Arguments.
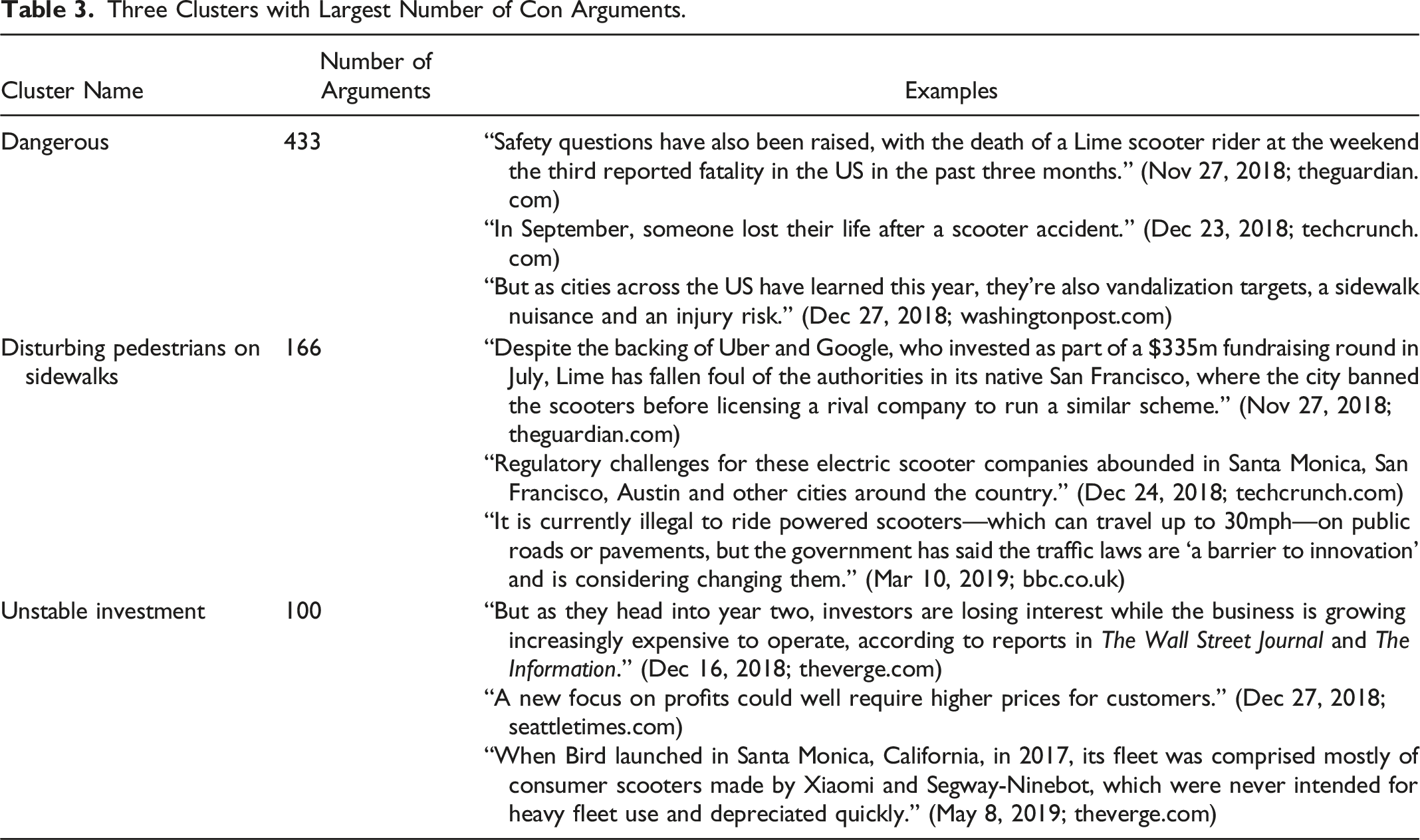
Three Clusters with Largest Number of Con Arguments.
The cluster analysis of the 3083 pro arguments in the query “electric scooter” (with a similarity threshold of 0.48 and a minimum cluster size of 15) results in 26 clusters that contain 2543 arguments (82.48%; 540 omitted arguments). We further use argument aspect detection (Schiller, Daxenberger, and Gurevych, 2021) to automatically assign names to each cluster. We manually adjust some of these assigned names to further improve the meaning of the clusters.
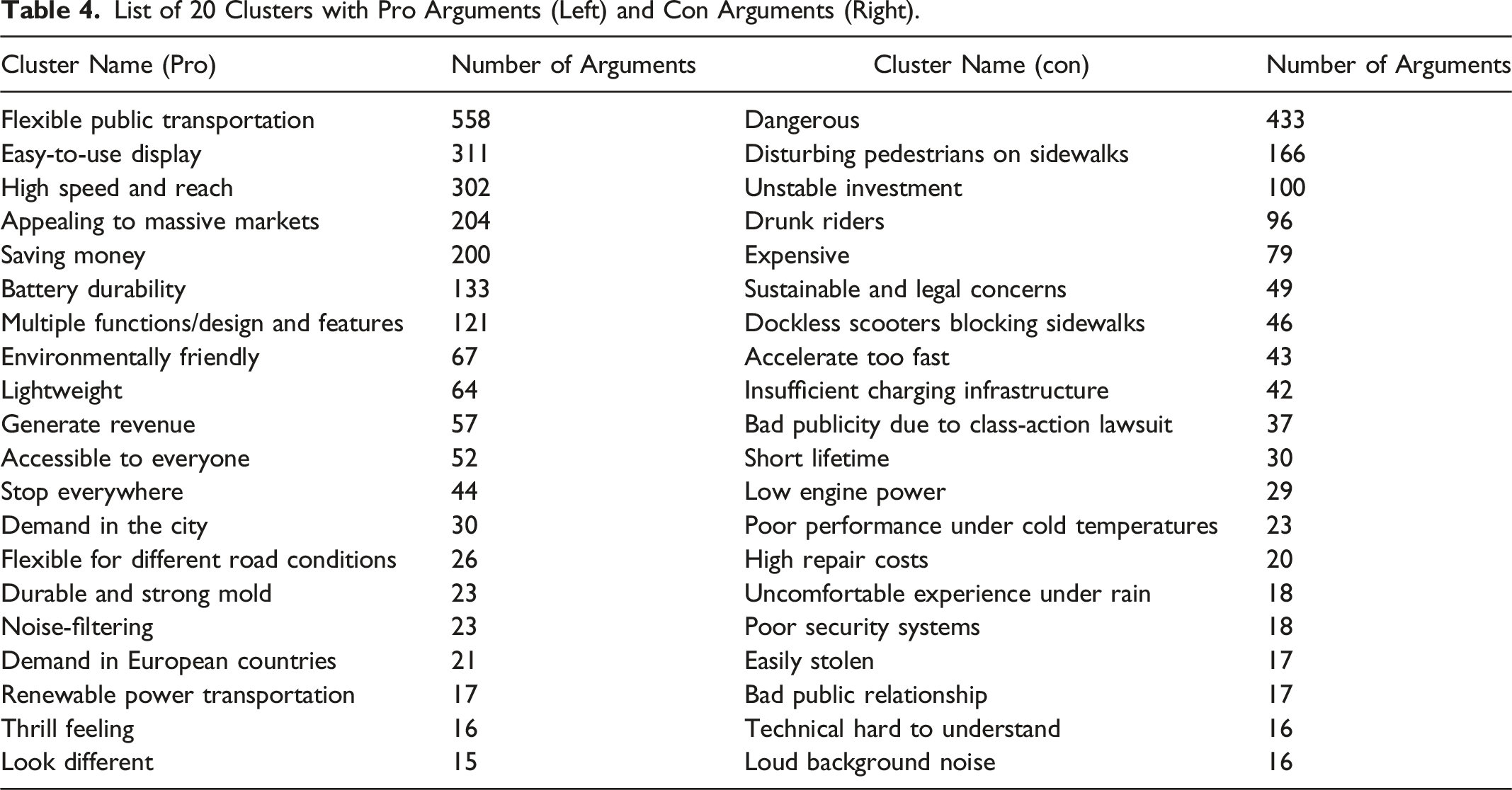
List of 20 Clusters with Pro Arguments (Left) and Con Arguments (Right).
The three most important clusters of pro arguments are Flexible public transportation, Easy-to-use display, and High speed and reach. As the examples in Table 2 show, the Flexible public transportation cluster contains arguments about electric scooters and their role in personal transportation, especially micro-mobility within a city. The cluster Easy-to-use display contains arguments that address, for example, the usability of electric scooters or the touch displays integrated into many of them. It also contains arguments on the software functionalities of the electric scooters. Finally, the High speed and reach cluster includes arguments that address the hardware specifications of different electric scooters, mainly their range and speed.
In addition, we present three example arguments and their original news source for each cluster in Table 2. For example, the Flexible public transportation cluster contains arguments highlighting the flexibility for using electronic scooters as a complement to the public transportation, such as “one-stop-shop for all your transportation needs,” “new and supplementary forms of micro-mobility,” and “environmentally friendly way to commute that can help fill in gaps in public transportation.”
The second cluster analysis (with a similarity threshold of 0.46 and a minimum cluster size of 15) uses the 1705 con arguments and yields 25 clusters that contain 1368 arguments (80.23%; 337 omitted arguments). We manually deleted unsuitable clusters, merged redundant clusters, and fine-tuned some of the clusters’ names. Table 3 presents the resulting 20 clusters (1295 arguments). The three major clusters with the largest number of con arguments are Dangerous, Disturbing pedestrians on sidewalks, and Unstable investment. The Dangerous cluster contains arguments about the safety of electric scooters, accidents, aspects of vandalism, and occasionally the recklessness of the drivers. The cluster Disturbing pedestrians on sidewalks summarizes arguments that deal with regulatory problems and bans on electric scooters. Finally, the Unstable investment cluster includes arguments that refer to electric scooter providers, especially regarding the limits of usage and finances.
Table 4 provides the complete list of derived clusters. It shows that other pro arguments include savings in terms of time and money (cluster Saving money), environmental friendliness (cluster Environmentally friendly), the low weight (cluster Lightweight), the thrill of riding electric scooters (cluster Thrill), and its attractiveness for urban customers, respectively urban mobility (cluster Demand in the city). Other con arguments include its high price (cluster Expensive), the short lifespan (cluster Short lifetime), the aggressive speed acceleration (cluster Accelerate too fast) and its high maintenance cost (cluster High repair costs).
Implications for the Improvement of Service
We identify a positive but declining attitude toward providing electric scooters from the argument score. More importantly, we learn from the cluster analysis about the reasons to use or not use an electric scooter. As shown in Table 4, the five major reasons for using electric scooters are that they (1) enable an easy commute (see arguments in cluster Flexible public transportation), (2) are easy to use because of their convenient display (see cluster Easy-to-use display), (3) provide long reach and high speed (see cluster High speed and reach), (4) are attractive for a lot of countries (see cluster Appealing to massive markets), and (5) are inexpensive (see cluster Saving money).
From the clusters of pro arguments, providers can learn that the flexibility of electric scooters provides a major advantage. Thus, they can conclude that because electric scooters require using the existing infrastructure, their design must be such that they can use streets (e.g., by having proper lighting and a minimum size) or sidewalks (e.g., not being too fast or too noisy) and can be carried on public transportation (e.g., not being too large or too heavy). Filling gaps in public transportation also requires careful thinking about where to offer electric scooters (e.g., not only at railway stations, where public transportation is likely to already be sufficient). Providers can also learn that a 7-inch display offers users comfort and helps beginners better engage with the service. Moreover, the data show that users appreciate a high speed and reach, so electric scooter providers should conclude that these features are necessary and design their scooters with, for example, a higher battery capacity. Finally, the data show that electric scooters seem to fulfill a widespread user need. So, electric scooter providers should conclude that economies of scale matter and understand that the size of the served markets represents a competitive advantage.
Interestingly, the data show that low cost is the fifth most important pro and high cost is the fifth most important con argument, indicating varying price perceptions of whether prices for renting electric scooters are too high. Electric scooter providers could conclude that customers’ willingness to pay varies enormously, implying that market segmentation should enable providers of electric scooters to target less price-sensitive customers.
The most important con argument refers to the safety of electric scooters. Thus, electric scooter providers need to ensure that they are safe (e.g. high-quality brakes, extensive riders’ education). The data show that electric scooters also annoy pedestrians, so providers should invest in ideas that make electric scooters more compatible with pedestrians (e.g., lower speed on sidewalks) or think about how electric scooters could better use streets. Furthermore, initiatives aimed to increase intensive use of electric scooters should acknowledge that investors in electric scooter providers might lose interest because of unprofitable short-term returns or at least need to have “big pockets,” considering the long period of time before they might see a profit. Scooter providers should aim for incremental innovation that they can launch quickly at a low cost. Finally, drunk drivers represent a severe problem. Providers might avoid this issue by incorporating features to detect intoxicated drivers (e.g., detecting a driving behavior indicating an intoxicated driver).
Validation of the Results of Information-Seeking Argument Mining
In this section, we confirm the validity of our results by demonstrating the convergent validity of our results across methods and data sources. First, we compare the argument score with a sentiment score. Second, we use Reddit reviews as an alternative data set to identify reasons.
Comparison of Information-Seeking Argument Mining with Sentiment Analysis
We introduce a novel textual analysis method that extracts the reasons behind positive and negative sentiments toward a topic. For such new methods, Berger et al. (2020) suggest providing evidence of concurrent validity of the new method by comparing how the results derived from the new method relate to the results derived from a prior and well-validated method. The most related textual analysis method widely used in marketing and service research is sentiment mining (Berger et al., 2020). We thus provide concurrent validation of IS-AM by comparing its result with sentiment mining.
Researchers have mainly used dictionary-based sentiment mining (Berger et al., 2020; Rust et al., 2021), which assigns a polarity of sentiment (i.e., positive or negative) to a predefined list of words (i.e., dictionary). A simple approach calculates a sentiment score for the text based on the frequency of these positive or negative words. The most widely used dictionary is Linguistic Inquiry and Word Count (LIWC) (Blaseg, Schulze, and Skiera, 2020; Kübler, Colicev, and Pauwels, 2020), which has been well validated, as indicated by traditional brand tracking surveys and stock prices (Schweidel and Moe, 2014).
Contingency Table of Stances of Argument and Polarity of Sentiment.
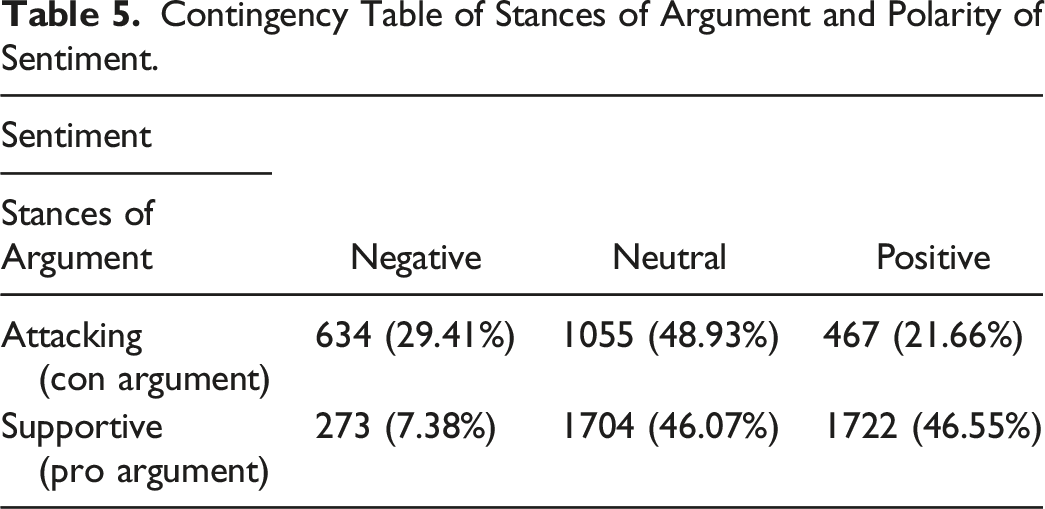
Table 5 shows that negative sentiment is more likely in a con argument. Despite many neutral sentences, positive sentiment is also more likely in a pro argument. We formally evaluate this relationship between the polarity of sentiment (i.e., positive, neutral, and negative) and the stance of argument (i.e., pro and con) with a chi-squared test and report the result in Figure 6. The p-value of the chi-squared test at the bottom right shows that we can reject the null hypothesis of the independence between these two measures. Chi-squared test of argument and sentiment.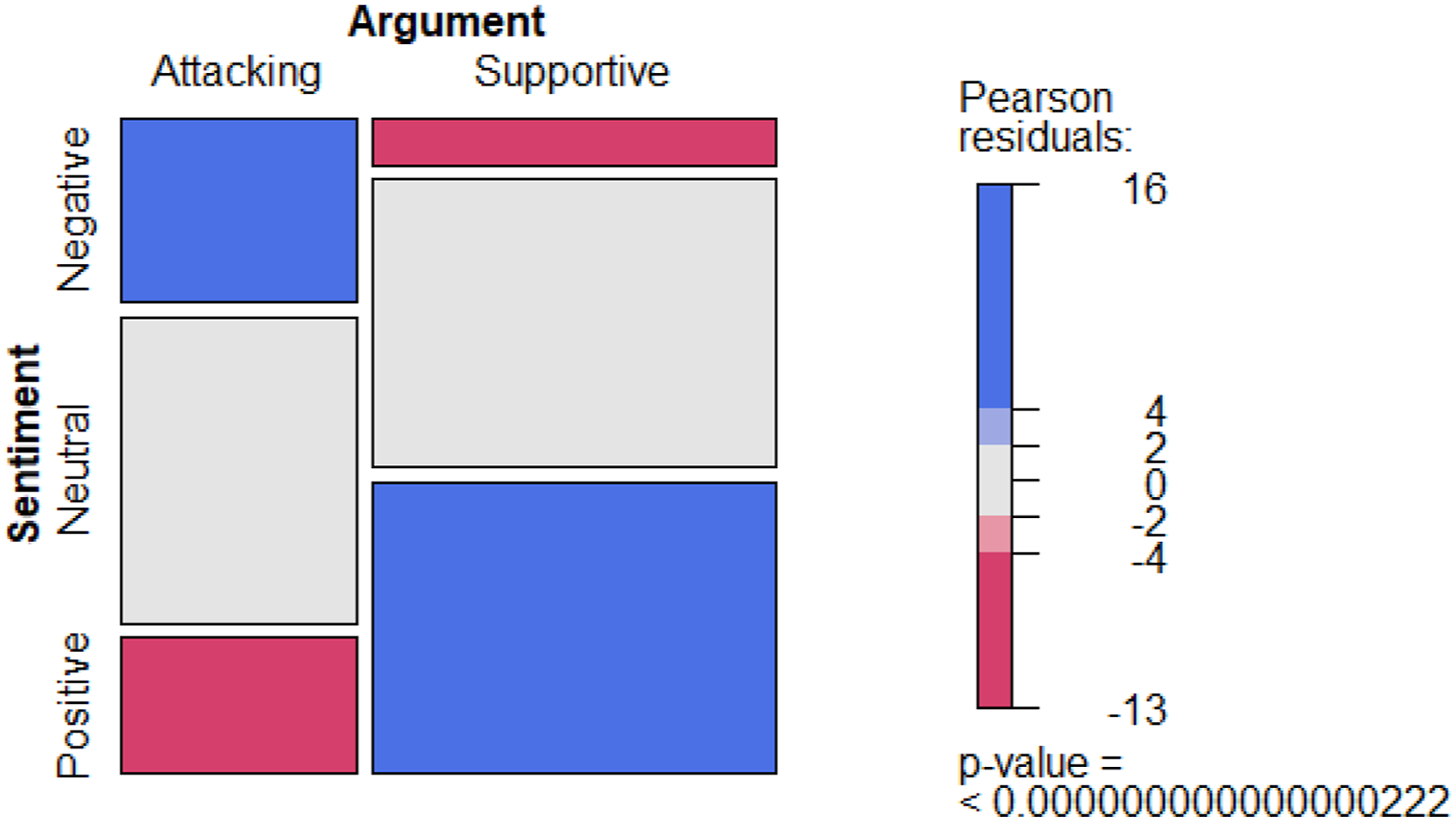
The color of the bars indicates whether the observed frequencies deviate from the expected frequencies if the measures are independent. The blue bars (i.e., negative-contra sentence and positive-pro sentence) show that the observed frequencies are larger than expected if they were independent. The red bars indicate the opposite. Overall, the results show a positive relationship between IS-AM and sentiment analysis, supporting concurrent validity.
Comparison of News Articles with Reddit Reviews
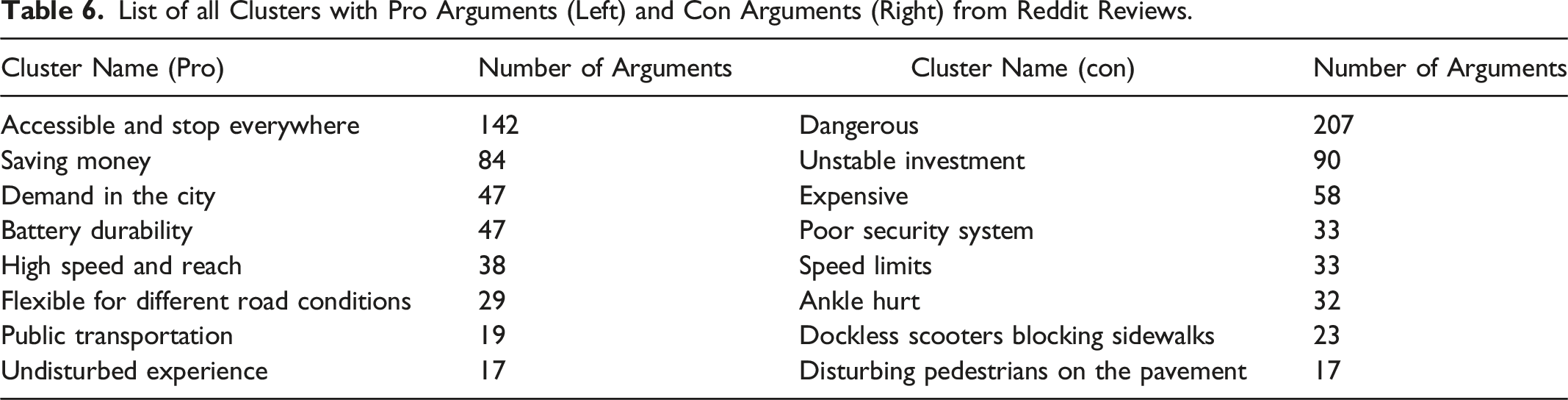
List of all Clusters with Pro Arguments (Left) and Con Arguments (Right) from Reddit Reviews.
Summary and Conclusions
A major challenge for service providers is identifying the attributes of their service that require improvement. We address this challenge by suggesting a text-mining technique in a subfield of computational linguistics, IS-AM, which identifies and classifies arguments from a large body of documents or, more broadly, natural language. The arguments contain reasons for and against using a service, which points to attributes that users find important. Therefore, IS-AM moves textual analysis toward capturing reasoning, which Berger et al. (2020) have identified as a pressing problem in business research using textual analysis.
We are the first to show and validate an application of IS-AM in service and marketing research. Our empirical study applies IS-AM to news articles and reviews about electric scooter-sharing systems. We find evidence that IS-AM is a promising technique to improve service; in our data set, it enabled us to identify 40 reasons and their importance for using or not using electric scooter-renting systems. The comparison of IS-AM with sentiment analysis also supports the validity of our results.
Furthermore, we find that using news articles as a data source for identifying service attributes is more effective than reviews because news articles are longer and contain more arguments and, thus, reasons. New articles also provide the advantage of being widely available, which means they are accessible to new service providers considering entering a market.
Our research shows that service providers can use IS-AM to extract reasons for identifying attributes from publicly available or internal textual data to develop and improve service. Researchers can use IS-AM as an additional tool for textual analysis to understand the reasoning in addition to attitudes, such as sentiment. Policy makers could use it to understand controversial topics better.
One limitation of the IS-AM method applied in this study is that it conducted argument detection on the sentence level. A single sentence is enough for many text types, including news text, to form a valid and comprehensive argument. However, more complex reasoning, as found in the scientific literature, often spans multiple sentences, making IS-AM much more difficult. Some methods detect arguments on the word level and allow for detecting arguments spanning multiple sentences. However, none of them has been adapted to detect multi-sentence arguments. Analyzing complex argumentation spanning several sentences is typically only workable with approaches from discourse analysis, which detect pro and con arguments and chains of arguments. Future work should seek to create methods combining methods from IS-AM and discourse analysis, which also apply to argument mining in scientific literature.
Service researchers can further explore how argument mining can benefit businesses. For example, most services receive customer complaints, and Van Vaerenbergh et al. (2019) recommend that service providers appropriately address those complaints. Future research could use IS-AM to identify the customer’s most crucial argument and guide the customer complaint agent toward addressing it instantly. In addition, our paper uses IS-AM to cluster the arguments to identify the most important pro and con arguments for all providers. Future research could analyze subsets of providers or periods to see how competition between providers evolves.
Footnotes
Acknowledgments
We thank Simeng Han, Maximilian Matthe, and Daniel Ringel for their very helpful comments.
Author's Note
Bernd Skiera is also a Professorial Research Fellow at Deakin University (Australia).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work of the TU Darmstadt has been funded by the “Data Analytics for the Humanities” grant by the Hessian Ministry of Higher Education, Research, Science and the Arts.