
Abstract
Organizational research increasingly uses natural language processing (NLP) to measure textual similarity. Despite common usage, the meaning and consistency of similarity measures (e.g., cosine similarity and Euclidean distance) across common NLP methods (e.g., n-grams and document embeddings) is unclear. This risks misalignment between theoretical constructs and textual measures, undermining the comparability of findings across studies. To address this gap, we review studies using textual similarity in organizational and psychological research, finding a jingle-jangle fallacy: identical labels are used for similarity estimates from different NLP methods, and different labels are used for the same method. Additionally, we examine the consistency of similarity measures across and within NLP methods. Different transformer-based embeddings’ similarity results are interchangeable. However, n-grams yield distinct, inconsistent results and are less appropriate for estimating similarity with distance measures. When applied to multi-word inputs, dictionaries and word embeddings return similar results reflecting linguistic style. We provide best practice recommendations and example code for operationalizing textual similarity, including clarifying which NLP methods correspond to content similarity, linguistic style similarity, and semantic similarity at the word, sentence, and document-levels of analysis.
Textual data have become a central empirical resource in organizational research. Scholars increasingly analyze text produced inside organizations, such as internal emails and other forms of workplace communication (Barley et al., 2011; Hannigan et al., 2019), as well as text produced for external audiences, including regulatory disclosures such as SEC 10-K filings (Arts et al., 2025; Testoni, 2022), patents (Arts et al., 2018), and outward-facing communication such as CEO earnings call transcripts, letters to shareholders, websites, and press releases (Graffin et al., 2011; Haans & Mertens, 2026; Harrison et al., 2019; Nadkarni & Chen, 2014). Researchers have also leveraged text generated by external audiences and intermediaries, including employee reviews on job platforms (Corritore et al., 2020), online professional profiles and hiring data (Marchetti & Puranam, 2025), analyst communications surrounding earnings calls (Eklund & Mannor, 2026), and customer feedback in online reviews (Favaron & Di Stefano, 2025).
Across these settings, textual similarity has become a widely used analytic device for operationalizing theoretical constructs. At the macro level, researchers have used textual similarity to measure product market rivalry and competitive overlap (Arts et al., 2025; Hoberg & Phillips, 2010), strategic positioning and optimal distinctiveness in market categories (Barlow et al., 2019; van van Angeren et al., 2022), differentiation and distinctiveness (Majzoubi et al., 2024), and interfirm technological relatedness in innovation search (Arts et al., 2018). At the meso level, similarity measures have been used to study organizational vocabularies (Tasselli et al., 2020), organizational culture and cultural fit (Corritore et al., 2020; Goldberg et al., 2016), the transfer of cultural imprints (Ahn & Greve, 2025), and idea originality and distinctiveness (Piezunka & Dahlander, 2015; 2019). At the micro level, textual similarity has been applied to capture applicants’ experience-job relatedness (Parasurama et al., 2025), and interpersonal fit, accommodation, and relational dynamics in interactional contexts (Shi et al., 2019). Beyond organizational research, textual similarity is also widely used in social and experimental psychology (Günther et al., 2016; Yu et al., 2025) and in the development and validation of psychological scales (Hernandez & Nie, 2023).
Despite its widespread use, the meaning, validity, and consistency of textual similarity measures remain insufficiently understood. In practice, organizational researchers frequently compute similarity statistics, most commonly cosine similarity, on vectors generated by fundamentally different natural language processing (NLP) methods, including dictionaries, n-grams, and embedding models. These similarity estimates are often treated as interchangeable indicators of a single underlying construct, even though the underlying vector representations encode conceptually distinct aspects of language. As a result, identical similarity statistics (e.g., cosine similarity) may reflect very different properties of text, depending on how the text has been represented.
This practice raises concerns about construct validity. For instance, a cosine similarity value of .80 may indicate substantial semantic overlap when applied to transformer-based embeddings, but merely indicates shared, high-frequency vocabulary when applied to n-grams. Yet in empirical work, both are often labeled “content similarity” (e.g., Hasan et al., 2015; Patterson et al., 2024). Conversely, identical NLP methods are sometimes described using different conceptual labels, such as content, lexical, or semantic similarity (e.g., Hasan et al., 2015; Margulis et al., 2022; Rule et al., 2015). Taken together, these patterns suggest a jingle–jangle fallacy in the use of textual similarity: the same labels are applied to distinct operationalizations, while different labels are applied to the same operationalization.
A related issue concerns the consistency of similarity estimates across textual similarity measures. Textual similarity is typically operationalized by applying a similarity or distance measure—most often cosine similarity, but also Euclidean distance, Manhattan distance, and Jensen–Shannon (JS) divergence—to numerical vectors derived from text via NLP. These measures differ in how they quantify similarity. Cosine similarity captures directional alignment between vectors, whereas geometric distance measures (e.g., Euclidean distance and Manhattan distance) incorporate information about vector magnitudes. When applied to different NLP representations, these measures may yield substantially different rank orderings of similarity between text pairs. In organizational research, where textual similarity measures are frequently used as key independent variables, such inconsistencies can alter substantive conclusions.
Prior work in computer science has examined the behavior of similarity and distance measures in high-dimensional spaces (Aggarwal et al., 2001; Cantrell, 2018). However, this literature has largely focused on the abstract properties of these measures or on technical tasks such as information retrieval. Importantly, it does not address whether similarity estimates derived from different NLP methods are interchangeable for the purpose of construct operationalization in applied social science research. Nor does it provide guidance on how to align similarity measures and NLP methods with theoretically distinct dimensions of similarity. As a result, organizational scholars lack clear guidance on when different textual similarity operationalizations can be expected to yield comparable results and when they should not.
We address these issues by developing a clearer conceptual and empirical basis for the use of textual similarity in organizational research. We focus on three conceptually distinct dimensions of similarity that recur, often implicitly, in prior work. Content similarity reflects overlap in surface vocabulary. Linguistic style similarity captures how language is used, including function words, grammatical patterns, and stylistic markers. Semantic similarity reflects overlap in meaning that is not dependent on shared word choice. Each of these dimensions aligns more naturally with particular NLP methods, yet these distinctions are rarely made explicit in empirical research.
The article proceeds in four steps. First, we introduce the concept of textual similarity and demonstrate its uses across multiple NLP methods. Second, we review applications of textual similarity in organizational research, documenting how similarity measures and NLP methods are used in practice and highlighting conceptual inconsistencies in labeling and interpretation. Third, we conduct a large-scale empirical analysis examining the consistency of textual similarity estimates across commonly used similarity measures (e.g., cosine similarity and Euclidean distance) and NLP methods (e.g., n-grams, dictionaries, and embeddings). This analysis identifies when similarity estimates are robust across measures or NLP methods and when they are not. Inconsistent textual similarity scores across similarity measures and NLP methods suggest a need to critically evaluate and consider the meaning and appropriateness of each approach. Further, these analyses inform about the reliability of textual similarity measures within each NLP method.
Fourth, we build on Poschmann et al. (2024) by synthesizing these insights into broader best-practice recommendations for using textual similarity in organizational research. We specify how researchers can align NLP methods with the dimension of similarity they seek to capture and recommend comparing results across methods and measures to test robustness. We also highlight opportunities for future micro- and meso-level research using textual similarity, aiming to inspire more rigorous and conceptually grounded applications in organizational studies. Overall, this manuscript aims to improve the methodological validity, transparency, and cumulative value of NLP-based research in organizational studies.
Textual Similarity
Textual similarity involves applying a similarity measure to the numerical vectors generated from applying NLP to two texts (e.g., words, sentences, and documents), resulting in an estimate of how similar those two texts are. 1 Cosine similarity is considered the most important similarity measure for binary and real-valued vectors (Manning & Schütze, 1999) and is commonly used in organizational research to operationalize textual similarity. Cosine similarity operationalizes similarity as the cosine of the angle between two vectors (Jones & Furnas, 1987), disregarding differences in magnitude. Table 1 provides the formula for cosine similarity between two vectors A and B in an n-dimensional Euclidean space. Cosine similarity ranges from −1 to 1, where −1 indicates opposite vectors (i.e., the angle between two vectors is 180°), 0 indicates orthogonal vectors (i.e., the angle is 90°), and 1 indicates vectors pointing in the same direction (i.e., the angle is 0°). 2 Cosine similarity is closer to 1 when the angle between two vectors is smaller.
Definitions and Mathematical Formulas of Textual Similarity/Dissimilarity Measures.

Note: For cosine similarity and distance measures, each formula shows the corresponding similarity/distance between two vectors A and B in an n-dimensional Euclidean space.
Other common similarity measures include geometric distance measures (e.g., Euclidean distance and Manhattan distance), set-based measures such as Jaccard (or Tanimoto) coefficient (Jaccard, 1912; Tanimoto, 1958; de França, 2016), and probabilistic measures such as JS divergence (Lin, 1991). Tables 1 and 2 summarize the Euclidean distance and Manhattan distance, detailing their formulas (Table 1) and their properties and limitations (Table 2). 3 Euclidean distance measures the straight-line distance between two points by aggregating squared deviations across all dimensions. Manhattan distance sums the absolute differences between the coordinates across dimensions. Minkowski distance is a generalized distance measure with its parameter p (a positive integer, also known as the power). When the parameter p is set to 1, Minkowski distance is Manhattan distance; when p is set to 2, it is Euclidean distance; and as p approaches infinity, it converges to Chebyshev distance, which captures the largest difference between two vectors on any single dimension.
Properties and Drawbacks of Textual Similarity/Dissimilarity Measures.
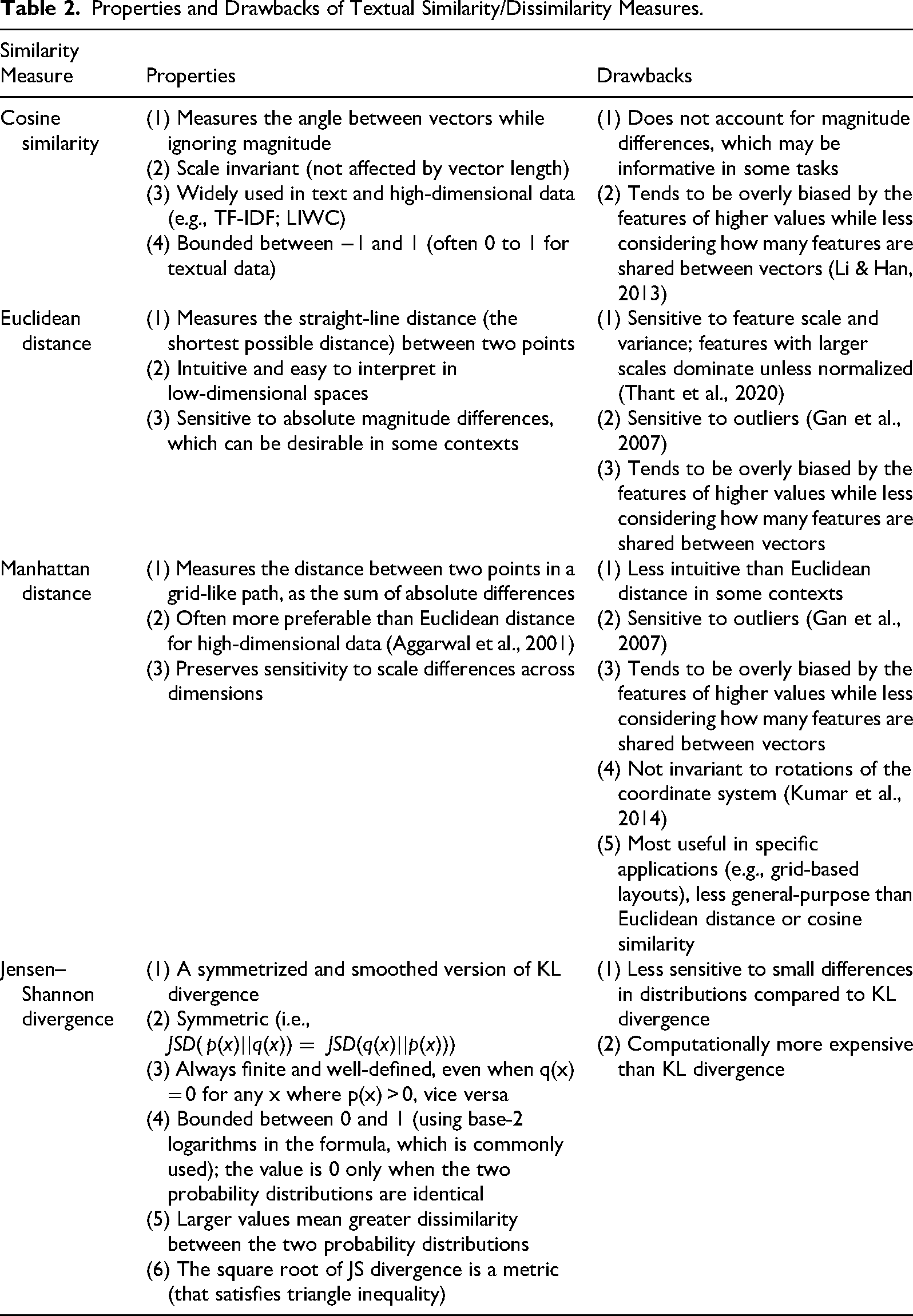
Cosine similarity and geometric distance measures differ in how they quantify similarity. Cosine similarity focuses solely on the similarity of the direction of two vectors, without considering their magnitude. In practice, this means that two vectors are considered similar if they show a comparable pattern of relatively higher/lower values across dimensions, even if one vector exhibits generally higher or lower absolute values (analogous to measures of correlation). Geometric distance measures, however, account for both direction and magnitude of vectors by quantifying the geometric distance between their endpoints. Thus, geometric distance measures such as Euclidean distance emphasize differences in the magnitude or frequency of these dimensions (analogous to measures of agreement).
When vectors are normalized by their Euclidean length, cosine similarity and Euclidean distance become mathematically linked, as shown in Equation (1).
4
Vector normalization involves dividing each element by the vector's length—for example, the vector (3, 4) normalizes to (0.6, 0.8) because its Euclidean length is 5.
5
After vector normalization, cosine similarity and Euclidean distance capture overlapping information in an inverted form: they yield the same similarity rankings across multiple text pairs (Manning & Schütze, 1999; Poschmann et al., 2024).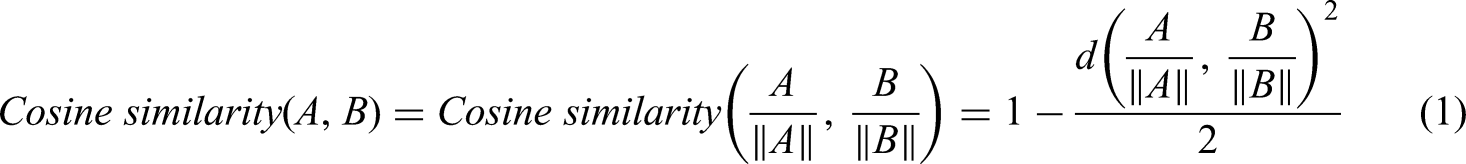
(Note:
In addition, set-based and probabilistic approaches are commonly used to assess similarity between certain types of vectors. Set-based measures such as Jaccard coefficient and Dice coefficient (Dice, 1945; Sorensen, 1948) are applicable only to binary vectors, 6 used to represent texts by the presence or absence (i.e., 1 or 0) of words. Both range from 0 (no overlap) to 1 (identical sets). Probabilistic measures are typically applied to discrete probability distributions (Prochaska & Theodore, 2018), where probabilities sum to one in each row of data. 7
Probabilistic measures include Kullbeck-Liebler divergence (KL divergence; Kullback & Leibler, 1951), JS divergence, Hellinger distance, and Bhattacharyya distance. Intuitively, KL divergence measures the difference between two distributions, which is represented by the information loss incurred when one distribution is used to approximate another distribution. In contrast, JS divergence averages the information loss incurred when each distribution is approximated by their combined data distribution (Manning & Schütze, 1999). Both KL and JS divergence are non-negative, with higher values indicating greater dissimilarity and a value of zero indicating identical distributions. Hellinger distance measures the geometric distance between the square roots of probability distributions, while Bhattacharyya distance measures the amount of overlap between two distributions.
NLP Methods and Illustrative Examples of Textual Similarity
NLP Methods
Multiple NLP approaches have been used to convert documents into numeric vectors to operationalize textual similarity. We provide an overview in Table 3. Our Open Science Framework (OSF) repository 8 includes Comparison between NLP methods in similarity calculation.ipynb that illustrates how to apply each NLP method to texts of varying lengths and estimate their similarity.
Natural Language Processing Vectorization Techniques Used in Present Study.
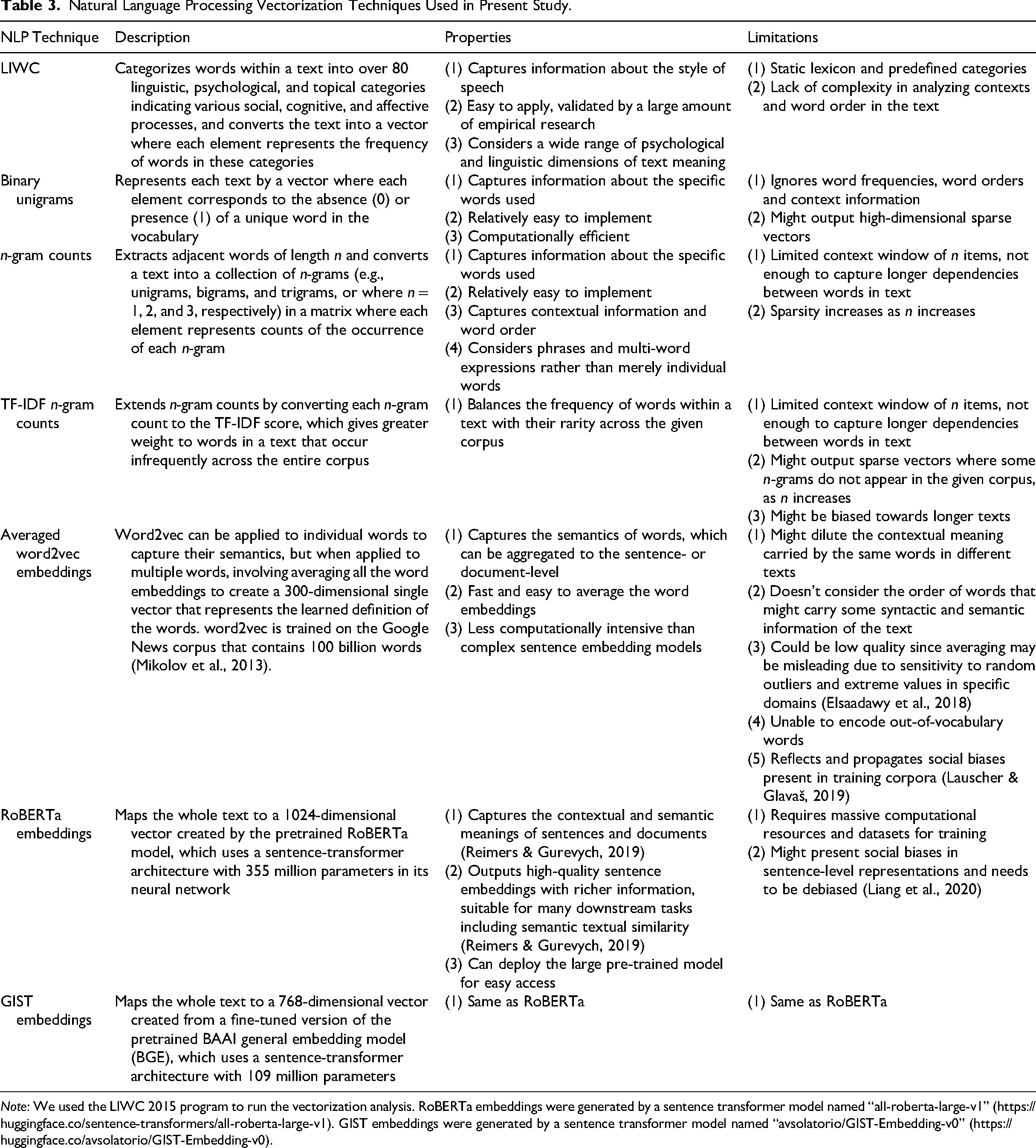
Note: We used the LIWC 2015 program to run the vectorization analysis. RoBERTa embeddings were generated by a sentence transformer model named “all-roberta-large-v1” (https://huggingface.co/sentence-transformers/all-roberta-large-v1). GIST embeddings were generated by a sentence transformer model named “avsolatorio/GIST-Embedding-v0” (https://huggingface.co/avsolatorio/GIST-Embedding-v0).
Closed vocabulary approaches, such as Linguistic Inquiry and Word Count (LIWC; Pennebaker et al., 2015), count the occurrence of words and phrases in dictionaries, including both psychological and linguistic constructs (Hickman et al., 2022). LIWC focuses on “the ways people use words” (Pennebaker et al., 2015, p. 1) or the style of speech, as opposed to the content of text or its semantics (Pennebaker, 2016; Piezunka & Dahlander, 2019). LIWC counts the proportion of words in a text that occur in dictionaries such as pronouns (e.g., I and them) and causation (e.g., because and effect). For example, Srivastava et al. (2018) applied LIWC to measure cultural fit through employees’ email exchanges, focusing on similarity in the use of linguistic categories such as nouns and negations. Joseph et al. (2023) used LIWC to detect language pattern changes in corporate executive communication. Some LIWC categories were specifically targeted to code particular organizational constructs; for example, past, present, and future tenses were used to capture temporal focus of CEO language (Crilly et al., 2016; Nadkarni & Chen, 2014), positive or negative emotions to capture public attitudes towards films in news articles (Odziemkowska, 2022), and certainty to capture precise language in firm reports or start-up pitches (El-Zayaty et al., 2025; Guo et al., 2017).
A variety of open vocabulary approaches exist. The most basic rely on n-grams where n = 1, or single words (Kobayashi et al., 2018). When n = 1, this provides a document-term matrix, where each document is represented as a row and each term (i.e., unigram) as a column. The entries can be binary (i.e., one if the term is present in the document, zero if not), counts (i.e., the number of times the term appeared in that document), or the counts can be transformed to give greater weight to infrequent terms (e.g., through the term frequency – inverse document frequency, or TF-IDF transformation). Therefore, each n-gram method captures distinct aspects of the words used, since binary unigrams focus on which words were (not) used, n-gram counts focus on how often words were used, and TF-IDF transformation emphasizes words that are less frequent in the corpus. n-grams focus on the specific words used in a text, but like LIWC, n-grams ignore the context of word use (when n = 1) and their semantics. n-grams and LIWC are primarily applicable to input texts with more than one word.
More recently, researchers have begun applying embedding approaches that convert texts into high-dimensional vectors that capture semantics. Early approaches focused on word embeddings, including word2vec (Mikolov et al., 2013) and others (e.g., FastText and GloVe) that are applied to individual words. These models learn word representations based on the contexts in which words appear in the training data, resulting in a single vector for each word. An interesting application of word embeddings involves training multiple word embedding models on different subsets of data to estimate how the meaning of words changes over time or in response to discrete events. For example, Lawson et al. (2022) found that after hiring female CEOs, corporate documents represented women as more agentic than they previously did.
However, when these word embeddings are used to represent multi-word inputs, they often fail to capture full sentence semantics. For instance, given that each word has only one static vector, sentence representations are typically formed by averaging the word vectors (e.g., Abdurahman et al., 2024). This averaging procedure disregards word order and syntactic structure, so two sentences with different meanings but identical words (e.g., the dog chased the cat vs. the cat chased the dog) are assigned the same vector. Similarly, LIWC and unigram approaches also yield equivalent representations for such sentences. n-gram methods with n > 1 can reflect local word order, but they still struggle with meaning: two documents that express nearly identical ideas may receive a low similarity score if they use different but related terms, such as synonyms or hypernym–hyponym pairs (Rahutomo et al., 2012).
After 2017, transformer-based models including bidirectional encoder representations from transformers (BERT; Devlin et al., 2019) and generative pre-trained transformers (GPT; Radford et al., 2018) revolutionized NLP by providing contextualized representations that capture the semantics of multi-word inputs. While these models operate over token-level embeddings, the transformer architecture (Vaswani et al., 2017) dynamically transforms these representations based on surrounding context, enabling accurate modeling of sentence- and document-level meaning. Transformer architectures also underpin modern generative large language models, including those that power systems such as ChatGPT. In organizational applications of supervised machine learning, 9 sentence and document embeddings outperform other NLP methods (Hickman et al., 2024; Thompson et al., 2023). Unlike word embeddings, organizational researchers are unlikely to train these models from scratch. These methods can handle single words, but they are especially effective for phrases and multi-word inputs.
Illustrative Textual Similarity Example
For single words, sentences, and paragraphs, Table 4 reports cosine similarities, Euclidean distances, Manhattan distances, and JS divergences as well as the rank order of similarities in each measure (in parentheses, from most [1] to least similar [6]) using NLP operationalizations from Table 3: LIWC, n-grams (binary unigrams, n-gram counts where n = 1 and 2, and TF-IDF transformed n-gram counts), word2vec (applied to each word then averaged across the document), and RoBERTa embeddings. Supplemental Table S3 reports the same for Minkowski distance, adjusted cosine similarity, Jaccard coefficient, and KL divergence. Our aim is illustrating the potential variation in textual similarity estimates caused by different NLP methods and measures.
Examples of Natural Language Processing Vectorization Techniques Applied in Similarity Calculation.
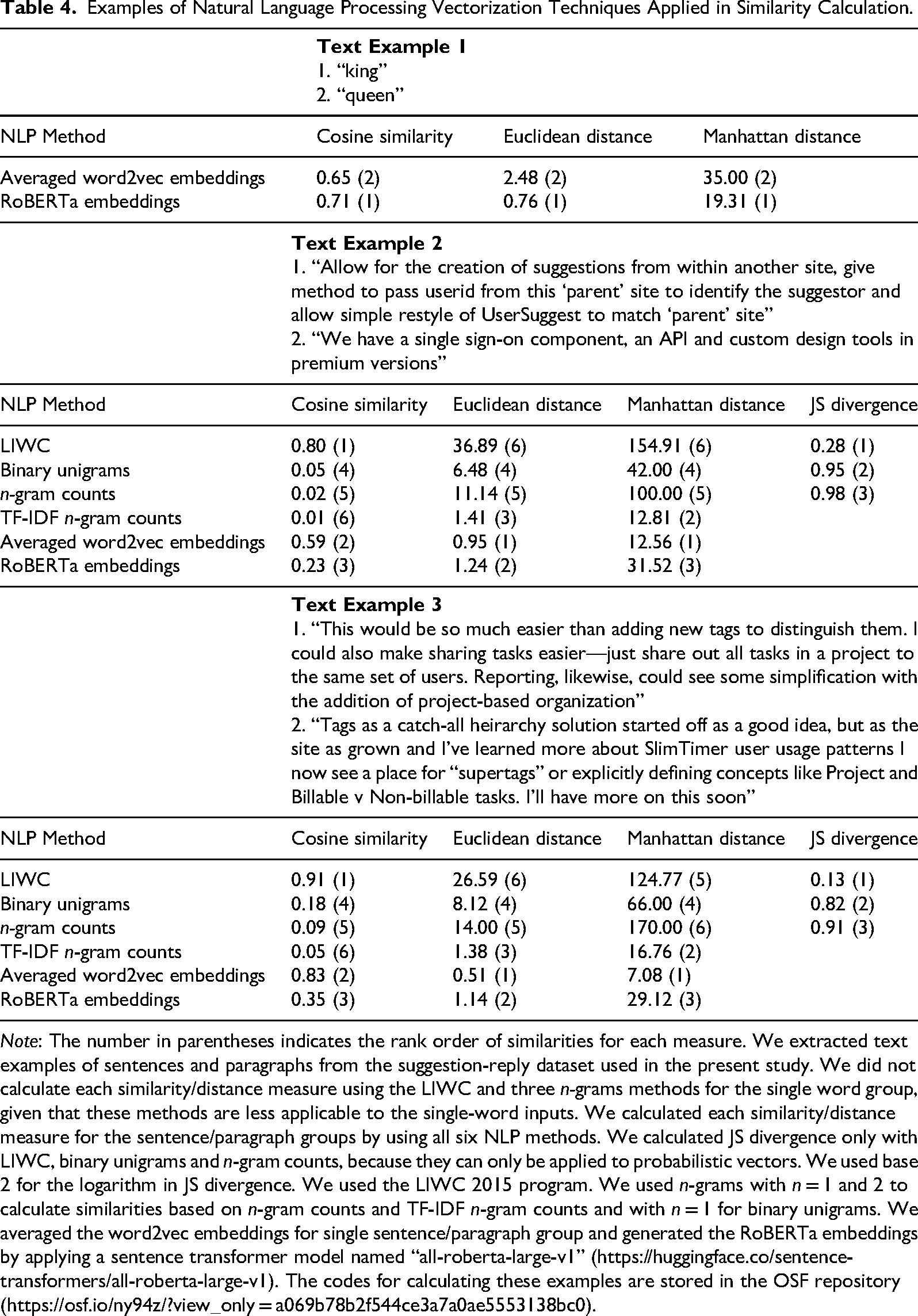
Note: The number in parentheses indicates the rank order of similarities for each measure. We extracted text examples of sentences and paragraphs from the suggestion-reply dataset used in the present study. We did not calculate each similarity/distance measure using the LIWC and three n-grams methods for the single word group, given that these methods are less applicable to the single-word inputs. We calculated each similarity/distance measure for the sentence/paragraph groups by using all six NLP methods. We calculated JS divergence only with LIWC, binary unigrams and n-gram counts, because they can only be applied to probabilistic vectors. We used base 2 for the logarithm in JS divergence. We used the LIWC 2015 program. We used n-grams with n = 1 and 2 to calculate similarities based on n-gram counts and TF-IDF n-gram counts and with n = 1 for binary unigrams. We averaged the word2vec embeddings for single sentence/paragraph group and generated the RoBERTa embeddings by applying a sentence transformer model named “all-roberta-large-v1” (https://huggingface.co/sentence-transformers/all-roberta-large-v1). The codes for calculating these examples are stored in the OSF repository (https://osf.io/ny94z/?view_only = a069b78b2f544ce3a7a0ae5553138bc0).
Notably, the possible range of textual similarity values differs across methods. The values of geometric distance measures (e.g., Euclidean distance) and JS divergence are always positive. For cosine similarity, the range varies as a function of the NLP method: for LIWC and n-gram counts, where variable values are always zero or positive, cosine similarity ranges from 0 to 1. However, with embedding approaches, variable values can be negative so the possible range extends from −1 to 1.
Substantial variation occurs both within and between similarity measures for word-, sentence-, and paragraph-level comparisons. We observe substantial rank order inconsistency in results: No two columns exhibit the same rank order across all three comparison groups. The variation in rank orders of those values arises because NLP methods encode language differently, and similarity measures highlight distinct aspects of those representations. For example, LIWC receives the highest similarity rankings for cosine similarity and JS divergence for the sentence- and paragraph-length texts, while returning the lowest (or second lowest) similarity rankings for the two distance measures. This pattern can be attributed to the fact that cosine similarity is scale invariant and JS divergence is insensitive to vector magnitude once vectors are normalized into probability distributions. In contrast, distance measures are highly sensitive to absolute magnitude differences.
Limitations of Textual Similarity Measures
Despite textual similarity's increasing use, several additional challenges and limitations can impact the validity of textual similarity measures. First, the variation across similarity measures is challenging because it could cause variations in the results of statistical significance testing. On the one hand, these differences could indicate unreliability of the analytical approach. On the other hand, textual similarity estimated from different NLP methods may indicate different constructs (e.g., Piezunka & Dahlander, 2019).
Second, the “curse of dimensionality” (Bellman, 1966) 10 undermines the effectiveness and interpretability of similarity measures in high-dimensional spaces. As dimensionality increases, data tends to become sparse (i.e., many zeroes, such as occurs with n-grams) or the number of variables exceeds the number of observations, as is common for document-term matrices (Aggarwal et al., 2001). In such contexts, distance metrics lose discriminative power because distances between points tend to converge, making it difficult to separate observations meaningfully (Aggarwal et al., 2001; Kabán, 2011). Echoing the no free lunch theorem (Wolpert & Macready, 2002), no single similarity measure performs optimally across all tasks, and the appropriate distance measure in high-dimensional contexts is often unclear (Aggarwal et al., 2001).
Third, researchers have claimed that cosine similarity tends to be overly biased towards features with higher values while being less affected by the number of features shared between two vectors (Li & Han, 2013). Adjusted cosine similarity addresses this issue by modifying the standard cosine similarity measure to reduce its bias toward high-magnitude features (Sarwar et al., 2001). We probed this in Supplemental Table S4 by examining a simple document-term matrix with three texts and three n-grams. The tendency to prioritize high-value features was observed not only in cosine similarity but also in other distance measures, suggesting that the bias stems from using the n-gram representations rather than from any specific similarity measure.
To address these issues, we next review applications of textual similarity in organizational research, including the reporting of robustness checks for similarity measurement. Notably, some papers use multiple NLP methods and similarity measures for similarity operationalizations (e.g., testing for consistent results across multiple NLP methods or similarity measures as robustness checks; Guo et al., 2021; Rule et al., 2015). These validation approaches for textual similarity measurement are crucial as they demonstrate that the research results generalize across alternative NLP methods or similarity measures, rather than being mere statistical artifacts of a specific approach. Then, we provide an empirical demonstration comparing results across NLP methods and similarity measures.
Review of Applications of Textual Similarity
Method
To build a comprehensive understanding of how textual similarity is applied in existing organizational and psychological research, we sought published studies that employed textual similarity in their NLP analyses. Specifically, as is common in organizational research reviews (e.g., Aguinis et al., 2009), we searched nine prominent journals: Academy of Management Journal, Academy of Management Discoveries, Proceedings of the National Academy of Sciences, Personnel Psychology, Journal of Applied Psychology, Journal of Management, Strategic Management Journal, Organization Science and Administrative Science Quarterly for multiple similarity measures. These search terms were “cosine similarity,” “Euclidean distance,” “Manhattan distance,” “Hellinger distance,” “Bhattacharyya distance,” “Jaccard coefficient” (or “Jaccard index” or “Tanimoto coefficient”), “Dice coefficient,” “Kullback–Leibler divergence” (or “KL divergence” or “relative entropy”), and “Jensen–Shannon divergence” (or “information radius” or “IRad”). For an initial search that returned an excessive number of papers, additional search terms were then added to narrow the focus of the results, including “Natural language processing,” “NLP,” “text,” “LIWC,” “ngram,” “word2vec,” and “embedding.” Although not commonly included in organizational reviews, we included Proceedings of the National Academy of Sciences because we were aware of organization-relevant papers published there that used textual similarity.
The initial search returned 1928 papers. We excluded papers that did not employ NLP analyses, used textual similarity only in supplementary analysis, or failed to report their NLP method. Ultimately, 58 papers published between 2010 and 2025, all utilizing one or more similarity measures with NLP, were included in our review. These papers were coded by summarizing their NLP methods, dimensions of vector representations (i.e., the number of variables used to operationalize text), research topics, measured constructs, relevant findings, supplementary analyses supporting measurement validity (if any), texts used for similarity measurement, sample sizes, and data sources.
Descriptive Results and Discussion of Textual Similarity Applications
Table 5 summarizes the aggregated results of our review. For each similarity measure, Table 5 lists the number of studies using each NLP method, constructs measured, text sources used, and the number of studies reporting robustness checks. Supplemental Material B (Supplemental Tables S5 to S9) in the Supplemental Material provides comprehensive details about each study included in the review.
Summary of Review of Applications of Textual Similarity in Organizational and Psychological Research.
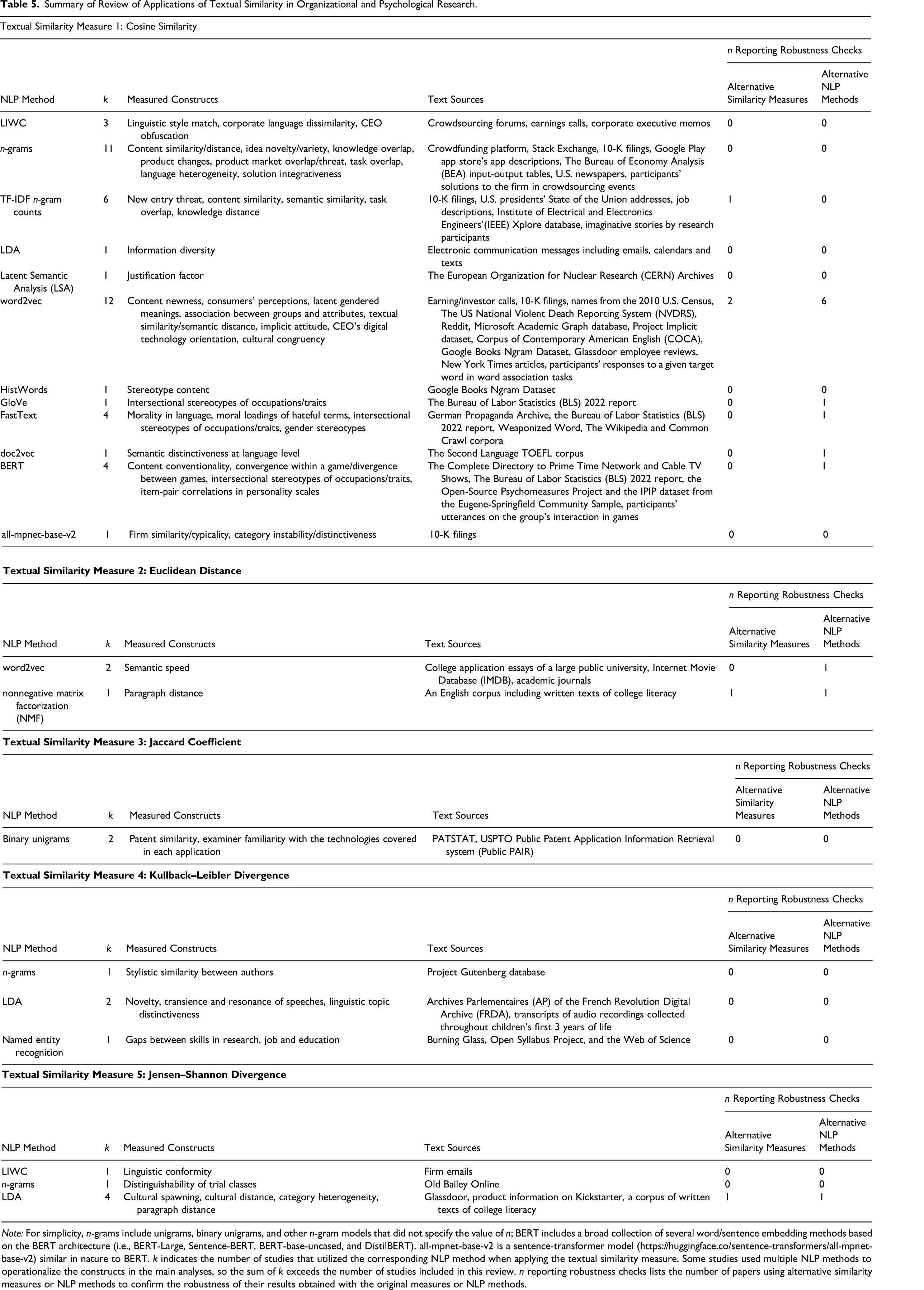
Note: For simplicity, n-grams include unigrams, binary unigrams, and other n-gram models that did not specify the value of n; BERT includes a broad collection of several word/sentence embedding methods based on the BERT architecture (i.e., BERT-Large, Sentence-BERT, BERT-base-uncased, and DistilBERT). all-mpnet-base-v2 is a sentence-transformer model (https://huggingface.co/sentence-transformers/all-mpnet-base-v2) similar in nature to BERT. k indicates the number of studies that utilized the corresponding NLP method when applying the textual similarity measure. Some studies used multiple NLP methods to operationalize the constructs in the main analyses, so the sum of k exceeds the number of studies included in this review. n reporting robustness checks lists the number of papers using alternative similarity measures or NLP methods to confirm the robustness of their results obtained with the original measures or NLP methods.
Cosine similarity was the most common textual similarity measure, appearing in 43 papers and applied to the widest range of NLP methods. In contrast, all other similarity measures were used in just 15 papers. Six used JS divergence and four used KL divergence, typically with unigram counts (Hughes et al., 2012; Klingenstein et al., 2014), LIWC (Lu et al., 2024), or LDA (Ahn & Greve, 2025; Barron et al., 2018), since these methods yield vector representations that are either inherently probabilistic or can be transformed into probability distributions (e.g., unigram counts; see p. 305; Manning & Schütze, 1999). In these cases, KL and JS divergence measured either content similarity (e.g., trial-class distinguishability and category heterogeneity) or linguistic similarity (e.g., conformity). Euclidean distance appeared in three papers, used twice with word2vec to capture the semantic speed of discourse, or how rapidly topics shift in text (Berger & Toubia, 2024; Toubia et al., 2021). Finally, the Jaccard coefficient was used only twice, both times with binary unigrams to assess overlap in patent abstracts or applications (Arts et al., 2018; Barber IV & Diestre, 2022).
Prior work included in our review used six major types of NLP methods. Four (7%) of the 58 studies used LIWC. Twenty-one (36%) used n-grams (primarily unigram counts and binary unigrams, with six using TF-IDF transformed n-gram counts). A number of these studies cited Hoberg and Phillips (2010), which is perhaps the earliest study cited by management research to apply cosine similarity to binary unigrams. Seven studies (12%) applied latent Dirichlet allocation (LDA) topic modeling to n-grams. One study (2%) used another topic modeling method latent semantic analysis (LSA). Twenty studies (34%) used techniques that capture semantic relationships between words, including word2vec, FastText, GloVe, and HistWords. One study (2%) generated document embeddings using doc2vec, an extension of word2vec. Transformer-based sentence embedding models, such as BERT and all-mpnet-base-v2, were used in five studies (9%), starting in 2023.
Twelve studies defined and examined four distinct types of similarity (content, linguistic, lexical, and semantic). For example, Piezunka and Dahlander (2015, 2019) called similarity based on binary unigrams content similarity and LIWC-based similarity linguistic similarity. Other researchers have used the term content similarity with a variety of NLP methods, including TF-IDF transformed n-grams, word2vec, and transformer-based document embeddings (Guo et al., 2021; Hasan et al., 2015; Patterson et al., 2024; Testoni, 2022). Two researchers used topic modeling methods (i.e., LSA and LDA) to measure constructs (e.g., level of justification and information diversity) related to content similarity (Tuertscher et al., 2014; Wu & Kane, 2021). One researcher also dubbed their approach as lexical similarity when using word2vec to measure similarity between digital transformation content and CEO letters to shareholders (Filatotchev et al., 2023). Finally, several researchers referred to semantic similarity, which emphasizes the meaning overlap between texts, when using TF-IDF transformed n-grams, word2vec, doc2vec, and BERT (Hernandez & Nie, 2023; Lewis et al., 2023; Margulis et al., 2022). For example, Hernandez and Nie (2023) fine-tuned a paired BERT model to generate cosine similarity scores that matched item intercorrelations.
Methodological Issues in Textual Similarity Applications
A key finding here is that the linguistic, content, semantic, and lexical similarity labels have been used inconsistently in prior research. Linguistic similarity, or similarities of style, are well captured by dictionary approaches, such as with LIWC (e.g., Piezunka & Dahlander, 2019). Content and lexical similarity are, essentially, synonyms, in that both refer to the specific words used or vocabulary of language. Thus, n-gram counts are well-suited to operationalizing such similarity. However, as mentioned above, n-grams were sometimes labelled as capturing texts’ semantics, despite being more suitable for measuring content. We recommend that semantic similarity be operationalized with embeddings (e.g., BERT). Similarly, word2vec captures the semantics of individual words, yet was labelled as measuring lexical similarity. We probe further into the meaning of different NLP methods with our empirical demonstration examining the consistency of similarity measures across NLP methods.
Further, the mismatch between NLP methods and labels of similarity dimensions often came with a lack of clarity when connecting construct conceptualization to operationalization. Some studies did not consider or discuss the dimension of textual similarity being measured in the construct, thus potentially resulting in a discrepancy between the actual dimension being measured and the nominal one being captured through the NLP method. We recommend selecting a suitable NLP method based on what the construct aims to capture when comparing the similarity between two texts and explaining the rationale.
Notably, some studies in the initial search did not specify the NLP methods used or lacked relevant details about their NLP analyses, leading to their exclusion (Angus, 2019; Catalini et al., 2015; Lawrence & Poliquin, 2023). The absence of detailed descriptions of the NLP operationalizations raises concerns about methodological transparency and reproducibility. Hence, we advocate for transparent reporting of NLP methods in future research, including data preprocessing approaches, specific NLP methods used, and (hyper)parameter settings. Further, researchers should share their NLP code so that, even if manuscript details are unclear, readers and reviewers can determine what was done and adapt the code. Standardizing such practices will enhance methodological clarity and promote collective knowledge.
Approaches to Validating Textual Similarity
For textual similarity measures, alternative similarity measures and NLP methods were occasionally utilized as robustness checks to provide evidence of reliability. Two studies found that Euclidean distance yielded findings consistent with the cosine similarity (Garg et al., 2018; Rule et al., 2015). One study replicated cosine similarity scores by using word mover's distance (WMD), which measures the dissimilarity between two text documents as the minimum distance that words from one document need to “travel” to match words in another document (Kusner et al., 2015). Four studies used multiple word embedding models (e.g., word2vec and GloVe) to compute textual similarity scores (Bhatia & Walasek, 2023; Garg et al., 2018; Rastelli et al., 2022; Toubia et al., 2021). Four studies exhibited general consistency of results by applying at least one additional NLP method (Charlesworth et al., 2022; Guo et al., 2021; Lewis et al., 2023; Sajjadiani et al., 2024) to compute cosine similarity. One study applied distinct pairs of NLP methods and similarity measures to ensure consistent results (Doxas et al., 2010).
However, when papers did not explicitly consider whether the similarity measure and NLP method were aligned with the targeted construct, this would potentially decrease the value of the robustness checks. For example, it might be less valid to use transformer embeddings as an alternative NLP method when the construct reflects content similarity. In this context, even if consistent results are obtained, this does not mean that the robustness check was a valid check on the results.
Several papers also reported evidence of textual similarity measures’ convergent, discriminant, face, and external evidence of validity. For example, Hasan et al. (2015) collected human ratings of task overlap on a subset of their data and found that cosine similarity correlated more strongly with these ratings than with another measure (i.e., task coordination), thus demonstrating convergent and discriminant evidence of validity. Schweisfurth et al. (2023) corroborated the face validity of their cosine similarity measure for idea novelty by consulting real-world experts (i.e., company managers). Toubia et al. (2021) and Berger and Toubia (2024) collected human perceptions of semantic speed to demonstrate face validity of their word2vec-based measure. Frésard et al. (2020) assessed the external validity 11 of the cosine similarity measure (i.e., vertical relatedness between upstream and downstream companies) by performing two analyses: they examined whether the measure predicted actual vertical relationships between firm pairs, and whether firm pairs identified as vertically related exhibited expected accounting properties. Similarly, Arts et al. (2018) evaluated the external validity of their patent similarity measure by comparing it with expert ratings.
Tests of Consistency of Similarity Measures Across NLP Methods
Method
To investigate the consistency of different similarity measures across a variety of NLP methods, we applied these methods to the dataset described by Dahlander and Piezunka (2014), Piezunka and Dahlander (2015, 2019), and Park et al. (2024). This dataset consists of crowdsourced suggestions made to a variety of companies on an online platform. Previous work using the dataset focused on operationalizing constructs such as idea variety and content distance between pairs of suggestions (Park et al., 2024; Piezunka & Dahlander, 2015), as well as linguistic and content match between a suggestion and its corresponding rejection explanation (Piezunka & Dahlander, 2019). In the article, we focused on a subset (N = 232,676) of the suggestions that received replies from company representatives. Then, we applied NLP to both the suggestions and the replies and estimated the similarity between each suggestion and its corresponding reply.
NLP Methods
The NLP methods applied to the present study are summarized in Table 3 and described in further detail below.
Additionally, we used the GIST-Embedding-v0 model (Solatorio, 2024), which is a BERT variant fine-tuned for semantic similarity tasks. Given that this model's neural network has 768 neurons per hidden layer, it converts text into a 768-dimension vector capturing its semantics. These document embedding models are applied to the entire input text.
Similarity Measures
In the article, we focus on cosine similarity, Euclidean distance, Manhattan distance, and JS divergence. Note that JS divergence requires inputs to be probability distributions, and are therefore applicable only to transformed LIWC outputs, transformed binary unigrams, or transformed n-gram count vectors. Additional results for Minkowski distance (parameter p = 3), adjusted cosine similarity, Jaccard coefficient, and KL divergence are reported in Supplemental Material C. These additional measures were included for completeness but showed high redundancy with other measures or could be applied to only a subset of the NLP methods. Minkowski distance (except when applied to TF-IDF n-gram counts) correlated strongly with Euclidean and Manhattan distances (rs ≥ .84), indicating substantial overlap. Adjusted cosine similarity correlated almost perfectly with cosine similarity (rs ≥ .99), suggesting that adjustment is unnecessary in typical NLP contexts. The Jaccard coefficient is only applicable to binary n-grams, limiting its generalizability. KL divergence is only applicable to outputs by transformed LIWC and n-gram methods. It is asymmetrical and requires a designated focal distribution (i.e., either the suggestion or the reply), thus making it less suitable than JS divergence in this context.
Results
Descriptive Statistics
Table 6 presents the descriptive statistics of similarity measures generated from the seven NLP methods. Assessing distributional normality serves as a descriptive tool for understanding how similarity values are distributed across text pairs, which in turn reflects the underlying characteristics of each similarity measure or NLP method. In particular, the degree of skewness and kurtosis provides insight into whether a method produces broadly distributed similarity scores or concentrates similarity values at one end of the distribution. In terms of the different similarity measures, cosine similarity and JS divergence provided values most closely resembling normal distributions, as skewness and kurtosis were both, on average, lower than for Euclidean or Manhattan distance. Skewness and kurtosis were largest, on average, for Euclidean distance.
Descriptive Statistics of Similarity/Dissimilarity Measures.
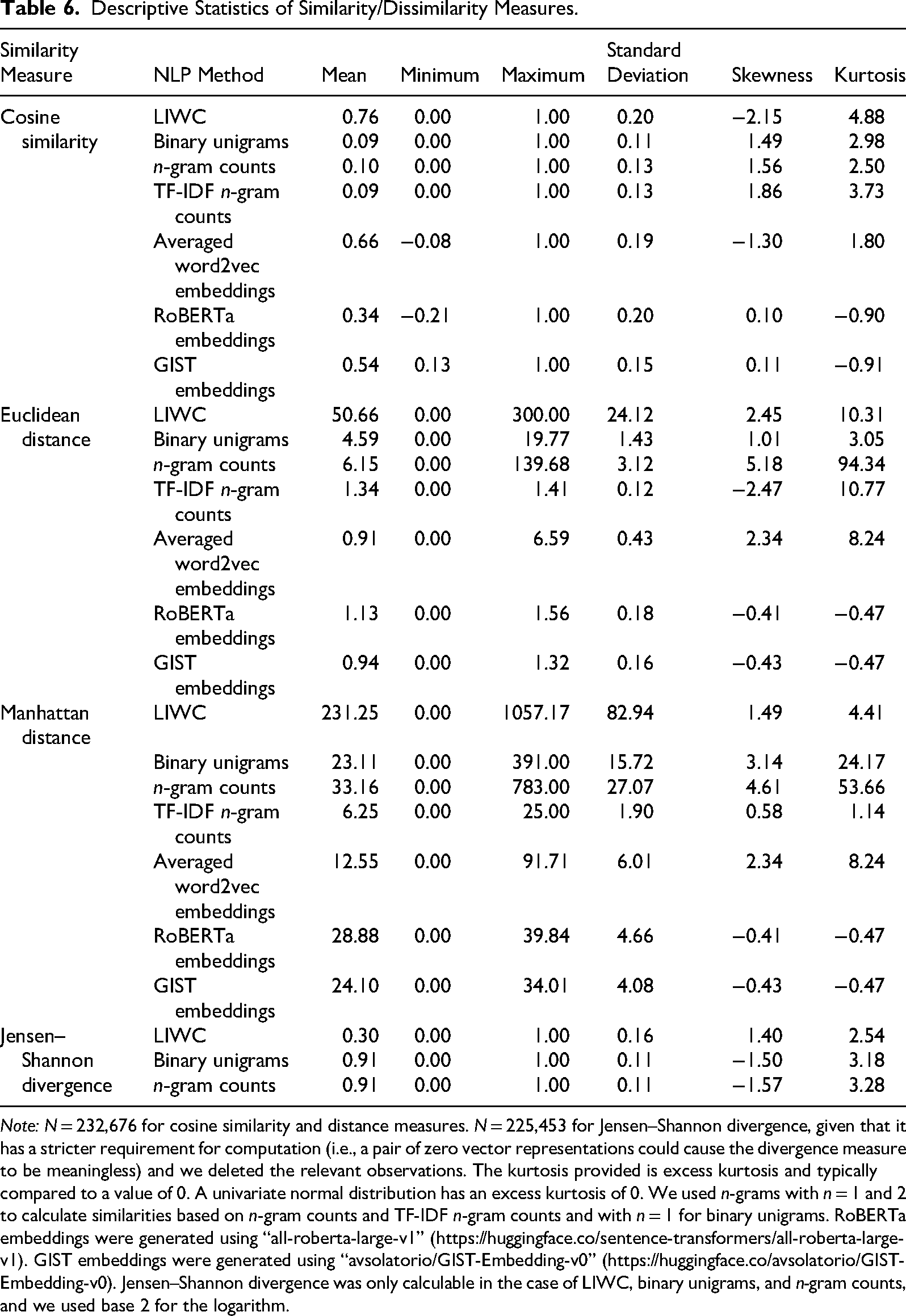
Note: N = 232,676 for cosine similarity and distance measures. N = 225,453 for Jensen–Shannon divergence, given that it has a stricter requirement for computation (i.e., a pair of zero vector representations could cause the divergence measure to be meaningless) and we deleted the relevant observations. The kurtosis provided is excess kurtosis and typically compared to a value of 0. A univariate normal distribution has an excess kurtosis of 0. We used n-grams with n = 1 and 2 to calculate similarities based on n-gram counts and TF-IDF n-gram counts and with n = 1 for binary unigrams. RoBERTa embeddings were generated using “all-roberta-large-v1” (https://huggingface.co/sentence-transformers/all-roberta-large-v1). GIST embeddings were generated using “avsolatorio/GIST-Embedding-v0” (https://huggingface.co/avsolatorio/GIST-Embedding-v0). Jensen–Shannon divergence was only calculable in the case of LIWC, binary unigrams, and n-gram counts, and we used base 2 for the logarithm.
In terms of NLP methods, n-gram counts exhibited highly right skewed and sharply peaked distance distributions (skewness around 5 and kurtosis higher than 50). This type of distribution indicates that most text pairs exhibited minimal overlap, with a small number of pairs generating disproportionately small distance values. This distributional pattern reflects the inherent sparsity of exact n-gram matching in textual similarity assessment. A similar, though less extreme, distributional pattern was observed for binary unigrams (skewness ranging from 1 to 3 and kurtosis from 3 to 24). Binary unigrams reduce sensitivity to word frequency by encoding only whether a word appears, rather than how often it appears. However, they remain fundamentally limited to surface-level overlap and therefore fail to capture synonymy or semantic similarity because words not overlapping in surface form are treated as completely different. TF-IDF n-gram counts showed similarly skewed and peaked distance distributions when used with Euclidean distance, indicating that the method remains primarily driven by surface-level word overlap despite differential weighting of words.
Similarities based on LIWC and averaged word2vec embeddings exhibited highly similar distributions, with substantial skewness and kurtosis. Similarities from document embeddings (GIST and RoBERTa) tended to have more normal distributions, as skewness and kurtosis tended to be small (absolute values < 1). This suggests that document embedding-based similarities offer more nuanced comparisons because semantically similar texts (even with no word overlap) can have moderate similarity scores and consistently scaled distances.
Correlations
We conducted correlation analyses to investigate consistency across similarity measures and NLP methods. Table 7 shows the Pearson's correlations within and between similarity measures across NLP methods. Strong correlations indicate reliability and suggest that different methods are capturing similar information. 12
Correlation Matrix of Similarity/Dissimilarity Results Calculated by Various NLP Methods.
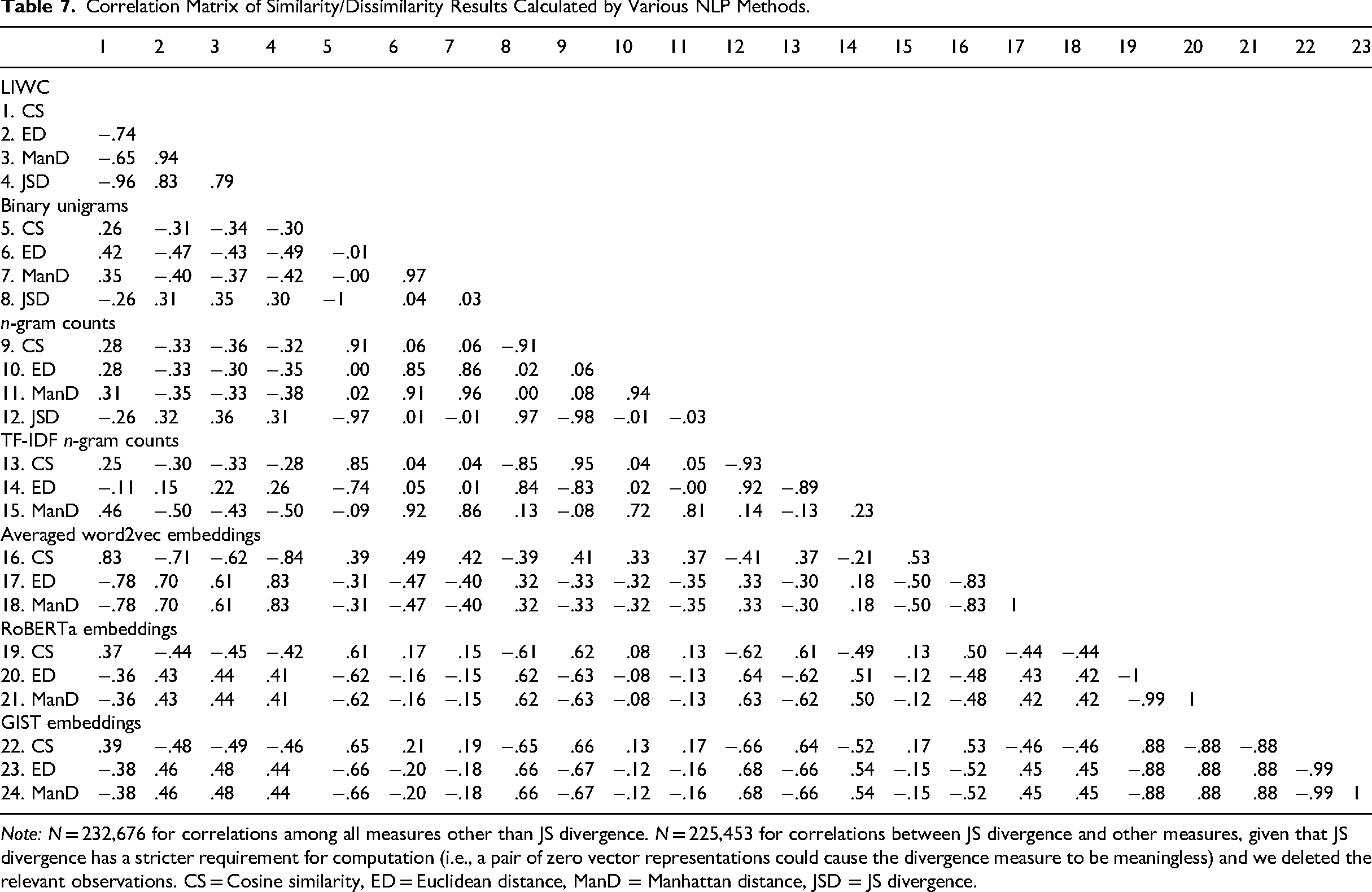
Note: N = 232,676 for correlations among all measures other than JS divergence. N = 225,453 for correlations between JS divergence and other measures, given that JS divergence has a stricter requirement for computation (i.e., a pair of zero vector representations could cause the divergence measure to be meaningless) and we deleted the relevant observations. CS = Cosine similarity, ED = Euclidean distance, ManD = Manhattan distance, JSD = JS divergence.
First, the NLP document embeddings return highly consistent (although not identical) results. Specifically, the RoBERTa-based and GIST-based similarity measures exhibit absolute correlations r = .88, demonstrating that both capture a similar dimension (i.e., semantics) of texts. This suggests that, at least within the BERT-family of models, the alternative modern embedding methods will likely return highly reliable results as robustness checks.
Second, similarities based on LIWC and averaged word2vec embeddings also exhibit consistent results. Their absolute correlations ranged from .61 to .83. word2vec was trained to measure the semantics of individual words. However, this suggests that LIWC and averaged word2vec embeddings appear to capture similar information (i.e., linguistic style) when applied to sentences/documents.
Third, the n-gram methods usually returned consistent results if the same similarity measure was used (most rs ≥ .81). This means that overall, they measure the same dimension (i.e., content) of texts, despite differing in how and whether they count the frequency of word use. The exception is that Euclidean distance based on TF-IDF transformed n-grams correlated minimally with Euclidean distances based on binary unigrams or n-gram counts (rs < .06).
Fourth, the binary unigram results exhibit the lowest consistency across similarity measures. Binary unigrams exhibited an average absolute correlation of .34 across the four similarity measures. This is followed by n-gram counts and TF-IDF n-gram counts, which demonstrate average absolute correlations of .35 and .42, respectively (although JS divergence was not calculated for TF-IDF).
Fifth, within a given NLP method, geometric distance measures (Euclidean distance and Manhattan distance) tend to be negatively correlated with cosine similarity. This is expected, given that similarity is the inverse of distance. However, this was not always the case: for binary unigrams, cosine similarity and distance measures were independent (i.e., |rs| ≤ 0.02) and were slightly positively correlated for n-gram counts.13,14 This means that for n-gram counts, on average, the vectors representing the suggestion and the reply move slightly farther apart (e.g., the magnitude of one vector increases relative to the other) as the angle between the two vectors decreases.
Similarly, geometric distance measures (Euclidean, Manhattan, and Minkowski distances with parameter p = 3) tended to be positively correlated, as expected. However, for TF-IDF transformed n-gram counts, Manhattan distance and Minkowski distance were negatively correlated (r = −.48; Supplemental Table S11). Further, Euclidean and Manhattan distances correlated only r = .23. 15
Sixth, JS divergence correlated almost perfectly with cosine similarity (i.e., |rs| ≥ .96) across the LIWC, binary unigrams and n-gram counts. It was independent from Euclidean and Manhattan distances (i.e., |rs| ≤ 0.04) for the two n-gram methods.
Last, NLP document embeddings return essentially the same results across cosine similarity, Euclidean distance and Manhattan distance. Within each document embedding method (i.e., RoBERTa and GIST), the absolute correlations between all similarity measures ranged from .99 to 1.00. These high correlations among different similarity measures indicate high reliability for document embedding-based similarity measures.
General Discussion
Textual similarity is increasingly used in a variety of ways in organizational research. Our review of organizational research revealed a jingle-jangle fallacy: The same label is sometimes applied to different NLP methods (e.g., content similarity used to refer to similarity based on n-grams, word2vec, or document embeddings) while different labels are sometimes used for the same method (e.g., both content and semantic similarity used to describe the n-gram-based approach). In our empirical investigations, we found notable differences in the similarities obtained from different NLP methods. These differences arise not because particular similarity methods are inherently flawed, but because different NLP methods encode conceptually distinct properties of natural language text.
Importantly, n-gram methods—the most common NLP methods used in organizational research—often produced inconsistent results across similarity measures, raising concerns about conclusions based on analyses that rely on n-gram-based textual similarity. Addressing these issues requires alignment between the construct of interest, the NLP method, and the similarity measure. Accordingly, we provide best practice recommendations for using textual similarity in future research below and in Table 8, as well as suggestions for where NLP and textual similarity could be applied in future research (Table 9).
A Checklist of Construct Operationalization Based on Textual Similarity in Organizational Research Practice.

Recommendations on Future Organizational Research Using Textual Similarity Measures.
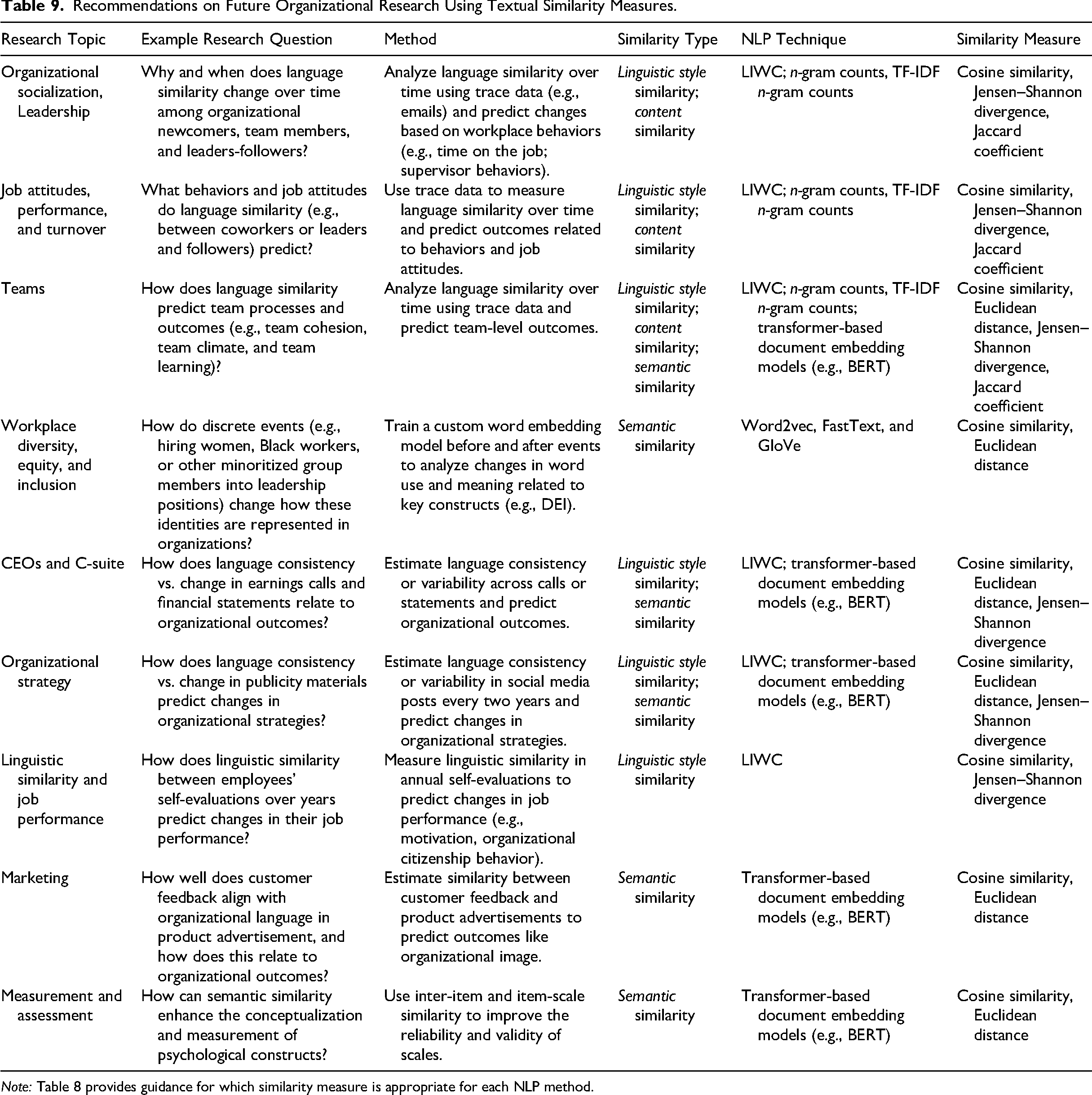
Note: Table 8 provides guidance for which similarity measure is appropriate for each NLP method.
Best Practice Recommendations for Textual Similarity
Table 8 provides step-by-step guidance for using NLP-based textual similarity in future research. We suggest that the first, key step to rigorously conducting such research is clearly specifying the similarity construct of interest and how it will be used in the study. Our review uncovered three conceptually distinct types of similarity mentioned in the literature: content (used interchangeably with lexical), linguistic style, and semantics. These distinctions are conceptual, but closely tied to NLP methods, with important implications for how similarity should be operationalized. Further, because results of different NLP methods are not interchangeable, each type of similarity is best operationalized using different NLP methods, as done in some prior research (e.g., Piezunka & Dahlander, 2019).
n-gram-based similarities reflect content similarity (e.g., Piezunka & Dahlander, 2019). Concerningly, our results suggest a lack of consistency when estimating textual similarity with different n-gram methods or with different similarity measures in each n-gram method. In particular, when using any n-gram approach, Euclidean, Manhattan, and Minkowski distances generally showed weak correlations with cosine similarity—as well as occasionally positive correlations with cosine similarity—and sometimes negative correlations with each other. Early guidance on textual similarity claimed that Euclidean distance is less appropriate for non-normally distributed data (Manning & Schütze, 1999), yet recent work has applied it to n-grams (e.g., Poschmann et al., 2024). Since n-gram features—whether binary, based on raw counts, or TF-IDF weighted—are inherently non-normal, this limitation raises concerns about the suitability of applying distance measures to n-grams.
A key issue with n-gram-based similarity arises in datasets where text pairs share limited vocabulary, which is more common with (a) shorter texts and (b) larger or more heterogeneous datasets. Without proper preprocessing, n-grams might conflate lexical overlap with content similarity, such as cases where documents share many surface-level n-grams (e.g., function words) despite being unrelated (Hickman et al., 2022). This reflects a conceptual limitation of the n-gram-based representation, rather than a problem inherent to similarity measures. When some n-gram overlap exists, however, the choice of similarity measure can exacerbate or attenuate these representational limitations. Distance-based measures such as Euclidean or Minkowski distance apply squaring (or higher-order) operations that disproportionately amplify large dimension-wise differences (Thant et al., 2020; Xia et al., 2015). This amplification emphasizes surface-level overlap and text-length differences, potentially obscuring more substantive aspects of similarity. In contrast, cosine similarity normalizes vector magnitude and depends solely on the angle between vectors, making it less sensitive to such amplified dimensional differences and therefore more suitable for high-dimensional, sparse n-gram representations. Its relative robustness also extends to binary n-gram vectors due to its strong correlation with alternative measures tailored to binary data—such as Jaccard coefficient (as shown in Supplemental Table S11).
We recommend using LIWC or word2vec to capture linguistic style similarity for sentences, paragraphs, and documents. Our results show LIWC and averaged word2vec embeddings correlate highly, suggesting that they capture similar information about text. LIWC has been described as capturing linguistic style similarity in previous research (e.g., Piezunka & Dahlander, 2019). It seems that word2vec is also well suited to capturing linguistic style similarity and is an open-source alternative to LIWC for multi-word inputs.
We recommend using transformer-based embeddings to capture semantic similarity. These models are particularly effective because they capture the semantics of sentences and documents. Transformer models such as BERT, GPT, and RoBERTa are pre-trained on vast amounts of text and designed to capture meaning (Li et al., 2020). Our empirical results further support this, showing that embeddings generated by sentence transformers are consistent between models and across different similarity measures.
word2vec is also useful for capturing the semantic similarity of individual words. Transformer-based embeddings are designed to capture the semantics of longer input sequences, and although they can be applied to individual words, transformer-based embedding models are larger and more expensive to train from scratch. Thus, word2vec provides researchers the opportunity to not only understand relationships between individual words but also how those relationships change in response to continuous or discrete events (e.g., Kozlowski et al., 2019; Lawson et al., 2022). This makes word-level embeddings particularly useful for studying semantic shifts in topics or groups (e.g., gender and social class) over time or across contexts.
Notably, similarities in content, linguistic style, and semantics can be used to operationalize other, downstream constructs. Researchers have used similarity measures to capture the similarity of products (e.g., Jung et al., 2024; Testoni, 2022) and cultural fit (e.g., Goldberg et al., 2016). In specifying the construct to be measured, the key is to consider which type of similarity (i.e., content, linguistic style, or semantic) indicates that construct. For example, Goldberg et al. (2016) used similarities based on LIWC—which captures linguistic style similarity—to capture changes over time in individuals’ cultural embeddedness. Product similarity has often been measured with binary unigrams (Testoni, 2022). Such downstream constructs should be defined in ways that make explicit which type of textual similarity they rely on, thereby clarifying the link between theory and operationalization.
After specifying the construct of interest and selecting an NLP method, we suggest that these study designs be preregistered. Such pre-analysis plans ensure that results are not achieved through fishing by attempting multiple NLP methods or similarity measures. This will minimize the odds of spurious results and strengthen confidence in research findings.
We recommend selecting similarity measures that align with the NLP method used. While some similarity measures such as Jaccard coefficient are restricted to specific data types (i.e., binary n-grams), cosine similarity is broadly applicable to n-grams, embeddings, and probabilistic vectors. When applied to data that is appropriate for other measures, cosine similarity generally yields consistent results (Supplemental Tables S11 and S12). Additionally, JS divergence can be used for probabilistic vectors generated by LIWC, topic modeling or n-gram methods. Euclidean distance can be considered for averaged word2vec and transformer-based embeddings, as it aligns with the conceptualization of certain constructs (e.g., semantic speed of words; Toubia et al., 2021) and supports a geometric interpretation of semantic change in embedding space.
After primary analyses are complete, it is important to conduct robustness checks. These can take three forms: using alternative NLP methods, testing different similarity measures, and validating with subject matter experts. Consider applying multiple NLP operationalizations and assessing the consistency of findings across methods, as different approaches can yield varying outcomes. Nonetheless, over 75% of the reviewed studies reported only a single operationalization of textual similarity. Each similarity type can be implemented with multiple NLP techniques—for instance, semantic similarity can be assessed using different document embeddings (e.g., RoBERTa vs. GIST). Replicating results across NLP methods helps ensure findings are not artifacts of a specific methodological choice. Moreover, researchers should seek to confirm the consistency of their results using alternative similarity measures when appropriate. For example, Jaccard coefficient can be a suitable alternative to cosine similarity for binary n-grams.
Last, like Kobayashi et al. (2018) emphasized, providing validity evidence, rather than assuming validity, will increase confidence in the results. This validity evidence can come in multiple forms. Convergent evidence can be provided by asking subject matter experts to judge the similarity of texts on the same focal type of similarity, then correlating those judgments with the textual similarity results (e.g., Hasan et al., 2015). It can also be provided through data triangulation, by comparing the similarity measure with a measure operationalized using external data but theoretically correlated with the measure (Kobayashi et al., 2018; e.g., Lu et al., 2024). Although face validity is not generally considered a type of validity evidence, it can be useful to check whether subject matter experts agree that texts identified as (dis)similar on the focal dimension are indeed (dis)similar (Kobayashi et al., 2018; e.g., Schweisfurth et al., 2023).
Limitations and Future Work
Our empirical demonstration focused on a single dataset. While that dataset is large, its properties shape how specific similarity measures perform, which matters for interpreting our results. For example, the n-gram results may differ on longer texts, and future work could more thoroughly investigate the reliability and validity of n-gram-based similarity in a variety of texts. More broadly, our evidence suggests that the stability of n-gram similarity is most at risk in corpora with sparse overlap (short texts, heterogeneous corpora, and large vocabularies), where many text pairs share few n-grams and similarity distributions become highly skewed. Future work could test this directly by systematically varying text length, corpus heterogeneity, and vocabulary overlap to map the boundary conditions under which n-gram similarity measures are interchangeable versus when they diverge.
A deeper understanding of whether, when, and how NLP embedding dimensions matter is needed to improve the operationalization of textual similarity. The dimensionality of embeddings can influence cosine similarity results (Elekes et al., 2018), although prior work that altered the dimensionality of custom-trained word2vec embeddings has found consistent results (e.g., Lawson et al., 2022). On the one hand, a higher dimension tends to capture richer word representations (Chiu et al., 2016); on the other hand, effective dimensionality reduction algorithms achieve similar performance to the original word embeddings, suggesting potential redundancy (Raunak et al., 2019). Theoretically, meaningful representations require sufficient, but not necessarily maximal, dimensionality to accommodate the complexity of the underlying semantic relationships (Aceves & Evans, 2024). We found highly consistent results across two document embedding methods that have different dimensions, but this may not be the case in all settings. We do not adjudicate whether dimensionality interacts with domain shift, corpus size, or construct complexity—questions that matter when researchers move from general benchmarks to specialized organizational corpora.
There is a lack of consensus on standardized validity assessments for constructs operationalized using textual similarity. While some studies have addressed construct validity concerns in NLP-based research, these efforts have largely focused on validating models or representations rather than extending construct validity frameworks to similarity-based measurement approaches. For example, Short et al. (2009) outlined a general framework for validity testing in computerized text analysis. Aceves and Evans (2024) proposed a set of validation procedures designed to assess the embedding space as a representation of conceptual structure. At the same time, a well-established gold standard, such as expert manual coding (i.e., ground truth; Kobayashi et al., 2018), can be difficult to obtain, as many organizational studies introduce novel constructs that capture nuanced concepts in texts. Our recommendations provide some guidance on how to validate constructs derived from NLP-based similarity measures, but future work could provide further guidance, such as construct-specific validation guidelines.
To spur future organizational research utilizing these methods, Table 9 presents some possible research questions. Some of these research questions have received prior investigation (e.g., Lawson et al., 2022), but many are novel. These suggestions span micro- and meso-level organizational research topics. Some of them require textual datasets that are difficult to acquire, but they could deepen our understanding of important organizational phenomena including organizational socialization, teamwork, leadership, job attitudes, and performance. The main implication of our findings is practical: when the substantive claim hinges on “similarity,” researchers need to show that the claim is not an artifact of one particular NLP-method × similarity-measure combination.
Although not the primary focus of this present, the choice of similarity measures is also relevant to text clustering. Text clustering has gained increasing attention as a valuable methodological tool in organizational research, particularly for conducting systematic literature reviews (Simonetti et al., 2025) and for construct operationalization—such as identifying patterns of corporate communication through email analysis (Wu & Kane, 2021). Because similarity measures serve as a critical input to clustering algorithms (Jain et al., 1999), their selection can influence the resulting cluster structures. For instance, topic modeling techniques like LDA and LSA are widely used probabilistic approaches to text clustering (Schmiedel et al., 2019). However, Niraula et al. (2013) showed that the alignment between LDA-generated topics and expert-labeled categories varied substantially depending on the similarity measure employed. This reinforces our broader point: similarity measures are not interchangeable, and in clustering, they can change the substantive story by changing the structure of the solution.
Conclusion
As organizational scholars increasingly use NLP methods to operationalize constructs through textual similarity, it becomes crucial to improve our understanding of the nuances and best practices of these methods. We offer best practice recommendations for employing textual similarity measures in organizational studies based on the findings of our organizational literature review and empirical analyses. Our hope is that these recommendations will support more robust and reliable research that harnesses the significant potential of textual data. Two implications follow directly from our review and results. First, the field needs cleaner construct language: we document a jingle-jangle problem in which the same labels are used for different NLP pipelines, and different labels are used for the same pipeline. Second, researchers should treat similarity as a design choice rather than a plug-in statistic: the NLP representation and the similarity measure jointly define what “similarity” means. Table 8 is meant to make that choice explicit: define the similarity construct, choose the method that matches it, default to measures that behave consistently with that representation, and then present robustness and validity evidence. Doing this reduces avoidable researcher degrees of freedom, limits method-driven conclusions, and makes empirical claims that rely on “similarity” easier to evaluate, replicate, and build on.
Supplemental Material
sj-docx-1-orm-10.1177_10944281261432629 - Supplemental material for Textual Similarity in Organizational Research: Review of Applications, Consistency of Methods, and Best Practice Recommendations
Supplemental material, sj-docx-1-orm-10.1177_10944281261432629 for Textual Similarity in Organizational Research: Review of Applications, Consistency of Methods, and Best Practice Recommendations by Siyi Liu, Louis Hickman, Linus Dahlander and Henning Piezunka in Organizational Research Methods
Footnotes
Acknowledgments
Not applicable.
Ethical Considerations
No ethical approval was required.
Consent to Participate
Not applicable.
Consent to Publication
Not applicable.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data is not available due to a confidentiality contract with the third-party data provider.
Supplemental Material
Supplemental material for this article is available online.
Notes
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.