
Abstract
In this article, we develop a methodological approach for organizational research regarding the construction of multidimensional and relational similarity measures by using the vector space model in natural language processing (NLP). Our vector space approach draws on the well-established premise in organizational research that texts provide a window into social reality and allow measuring theory-based constructs (e.g., organizations’ self-representations). Using a vector space approach allows capturing the multidimensionality of these theory-based constructs and computing relational similarities between organizational entities (e.g., organizations, their members, and subunits) in social spaces and with their environments, such as the organization itself, industries, or countries. Thus, our methodological approach contributes to the recent trend in organizational research to use the potential inherent in big (textual) data by using NLP. In an example, we provide guidance for organizational scholars by illustrating how they can ensure validity when applying our methodological contribution in concrete research practice.
Keywords
In this article, we build on the tradition of formal text analysis and develop a methodological approach for constructing multidimensional and relational similarity measures for organizational research. Our approach follows the notion that the investigation of texts provides a window into social reality and is useful for theory building and testing (Duriau et al., 2007; Evans & Aceves, 2016; Mohr et al., 2020; Pollach, 2012).
The backbone of our methodological approach is the vector space model (Salton, 1965; Salton et al., 1975), a well-established natural language processing (NLP) technique (Karlgren & Kanerva, 2021). The basic idea of the vector space model in NLP is that texts can be converted into high-dimensional mathematical representations (e.g., an integrated representation of all words occurring within a text). These high-dimensional mathematical representations in vector spaces enable a formal analysis of texts while still conserving their complex linguistic meaning. In this way, the vector space model in NLP differs from other approaches that process texts as sets of unrelated individual components (e.g., individual words) or classify texts into distinct categories (e.g., Bail, 2016; Fligstein et al., 2017; Goldenstein & Poschmann, 2019a; Jockers & Mimno, 2013; Kaplan & Vakili, 2015; Kobayashi et al., 2018a; Rona-Tas et al., 2019).
Our vector space approach enriches the methodological toolkit of organizational research and for various perspectives that acknowledge the meaningful connection of organizational entities (e.g., organizations, their members, and subunits) through multidimensional relationality within social spaces and with their environments, including the organization itself, industries, markets, or countries (e.g., Cattani et al., 2017; Dhalla & Oliver, 2013; Kennedy, 2008; Kostova et al., 2008; Kristof-Brown et al., 2005; Zietsma et al., 2017). Relationality acknowledges that social meaning depends on similarity patterns between organizational entities and can be revealed through comparing texts as windows into social reality (Mohr et al., 2020). For example, a degree of distinctiveness can be revealed through considering the similarity of organizations’ self-representations within the same market (Goldenstein, Hundolt, et al., 2019; Zuckerman, 2016). Moreover, relationality regularly involves multidimensionality, which implies that similarity patterns manifest in multidimensional meaning profiles (Kozlowski et al., 2019; Mohr, 1998). For example, the similarity of organizations’ self-representations encompasses multiple theory-based dimensions (e.g., all themes referring to corporate identity, products, or employees) along which organizations can communicatively position themselves within markets (Haans, 2019).
In this sense, our vector space approach allows capturing the multidimensionality of theory-based constructs (e.g., self-representations) at the level of organizational entities as units of analysis (e.g., organizations) and the relationality (e.g., distinctiveness) of these entities through computing their degrees of relational similarity. Accordingly, the construction of multidimensional and relational similarity measures in organizational research offers plenty of new opportunities for hypothesis generation and theory testing through an advanced exploitation of the potential of formal text analysis and the vast volumes of texts in and around organizations in the digital age (George et al., 2014, 2016; Kobayashi et al., 2018a).
By developing a vector space approach for organizational research for the construction of multidimensional and relational similarity measures, the main contribution of our article is twofold: (1) We lay the foundation for a systematic adaption of the vector space model in NLP to organizational research and we illustrate its general face validity. We further point to the potential of vector spaces to draw on the output of various formal text analysis approaches (e.g., word counting and word embeddings) as input for vectoral representations. (2) We provide detailed guidance for organizational scholars by using an example that illustrates how to ensure theoretical validity when applying our vector space approach in concrete research practice.
In the following sections, we expound our methodological contribution to organizational research. To this end, we first provide an overview of how organizational studies to date have used formal text analysis to study similarities. Then, we introduce the notion of the vector space model in NLP. Next, by developing a vector space approach for organizational research, we demonstrate the operationalization of theory-based constructs and the usage of their theoretical dimensions in vectors. Finally, we construct relational similarity measures and illustrate their application in the field of organizational research.
Methodological Considerations: The Relationality and Multidimensionality of Meaning
Organizational researchers have recently begun to acknowledge that analyzing large (textual) data using formal text analysis can yield valuable theoretical insights into organizational phenomena (Braun et al., 2018; George et al., 2016; Hannigan et al., 2019; Kang et al., 2020; Tonidandel et al., 2018; Wenzel & Van Quaquebeke, 2018). In this context, a common analytic focus of organizational research has been studying similarities between organizational entities and their environments across social contexts or time.
One major research stream using formal text analysis has descriptively studied the similarity of texts based on individual dimensions of various theory-based constructs (Bonilla & Grimmer, 2013; Jockers & Mimno, 2013; Kobayashi et al., 2018b, 2018a; Nelson et al., 2021; Rona-Tas et al., 2019). For example, DiMaggio and colleagues (2013) inductively discovered the differences in framings with which media corporations communicated their orientation toward government assistance for artists and arts organizations. Poschmann and Goldenstein (2022) classified semantic types of named entities (i.e., persons and organizations) with demographic characteristics and compared their occurrence in public discourses over time.
Other applications of formal text analysis have applied structural techniques such as network analysis (Mohr et al., 2013; Oberg et al., 2017), multidimensional scaling (Hannigan & Casasnovas, 2021), and cluster analysis (Goldenstein & Poschmann, 2019a), focusing on drawing descriptive two-dimensional maps of the co-occurrence of selected dimensions of theory-based constructs and using these maps for further qualitative inspection. For example, Mohr et al. (2013) constructed a visual illustration of the co-occurrences of various named entities and verb phrases to map the association of actors and actions in the U.S. National Security Strategy reports of various U.S. presidents. Hannigan and Casasnovas (2021) constructed a map with the co-occurrence of themes and actors in public discourse. Rule et al. (2015) analyzed the U.S. State of the Union addresses and mapped the co-occurrence of nominal phrases to represent how the similarity of using these terms and categories in discourse have changed with the national and international political situation. Finally, Goldenstein and Poschmann (2019a) performed a combined analysis of syntactic structures and themes by mapping the similarity of the thematic embedding of various subject–verb–object combinations in the context of corporations’ responsibility in public discourse over time.
All the approaches outlined thus far are well suited to detect the extent to which (selected) dimensions of theory-based constructs occur in texts, to map their (co-)occurrences, and to compare the similarity of these co-occurrences across contexts or time. Therefore, as illustrated, organizational scholars use valuable text analytic tools in descriptive studies or for research that aims at detecting similarity patterns in large amounts of text for further in-depth analysis.
Another goal of formal text analysis in combination with large amounts of text is the quantitative analysis of meaning to generate hypotheses and test theories (Goldenstein & Poschmann, 2019b; Kobayashi et al., 2018a; Short et al., 2010). For example, Kobayashi et al. (2018a, p. 792) stated that, “if the objective is to explain how patterns lead to categorization or how structure and form lead to meaning, then an explanatory model is required.” We argue that organizational researchers can use the potential of formal text analysis to capture similarities quantitatively based on NLP-inspired relational similarity measures. These measures follow the established methodological insight that social meaning is multidimensional and built from similarity patterns within and across social spaces (Kogut & Singh, 1988; Mohr, 1998; Scott & Davis, 2007).
Considering similarity patterns is important theoretically and methodologically. First, in line with organizational research, studying dynamics within and across social spaces builds heavily on the assumption—often only implicitly articulated—that social meaning is established based on the relationships between organizational entities and their environments (e.g., Cattani et al., 2017; Kostova et al., 2008; Kristof-Brown et al., 2005; Zietsma et al., 2017). In this context, the examination of theory-based constructs is only meaningful when considering their (co-)occurrence in relation to other organizational entities and their environments (Mohr et al., 2020). For example, the finding that organizations address themes in their self-representation at a certain percentage only becomes significant when compared with relevant public discourses or with other organizations.
Second, methodological insights emphasize that social meaning is constructed compositionally, that is, via a relationality among organizational entities (e.g., the organization and their members and subunits) and their environments and various theory-based dimensions that constitute multidimensional profiles of meaning (Kozlowski et al., 2019; Mohr, 2005). Only a few articles relevant to organizational research have included the construction of relational similarity measures based on texts. Haans (2019) investigated the market entry of new ventures and captured their self-representation by incorporating all themes that new ventures used to describe themselves when entering the market (for a similar approach on the product level, see Barlow et al., 2019). Goldenstein, Poschmann, et al. (2019) analyzed similarities in how organizations from different countries used words grammatically associated with the term “responsibility.” Finally, Kozlowski et al. (2019) captured the latent meaning facets of social class characteristics (e.g., wealth and gender). The authors then used the totality of these meaning facets to calculate their similarity with latent meaning facets of cultural products, such as types of sports.
Despite these early attempts, there is a lack of a coherent and generic methodological approach that enables the broad consideration of relational similarity measures in organizational research. In the following sections, we demonstrate how the vector space model from NLP lays the formal foundation for a vector space approach in organizational research that allows capturing the multidimensionality and relationality of social meaning. We provide detailed guidance on how organizational scholars can validly operationalize the multidimensionality and relationality of theory-based constructs and create vector spaces, which in turn, constitute the basis for computing relational similarity measures.
Constructing Relational and Multidimensional Similarity Measures
The Vector Space Model in NLP
The vector space model in NLP was invented as a means for the quantitative representation of texts in a high-dimensional mathematical space and dates back to Gerald Salton's seminal work on information retrieval (Salton, 1965; Salton et al., 1975). The author proposed mathematically representing a given set of text documents as n-dimensional vectors, with n being the number of terms in the documents. The values of each vector component represent the frequency of the respective terms. The idea of vectors advanced long-standing traditions in NLP at that time and has become an important methodological step toward quantifying linguistic meaning (Karlgren & Kanerva, 2021; Turney & Pantel, 2010).
In detail, the central intuition behind the vector space model in NLP is to bundle the complexity of linguistic meaning as components within high-dimensional vectors. In the vector space model's basic form, linguistic meaning consists of dimensions representing all the terms in a text corpus. Formally, a vector
Further, in this manuscript, we have used example sentences to provide an intuitive sense of how mathematical representations of texts capture linguistic meaning. To make this illustration as accessible as possible, we have elaborated on the most basic form of the vector space model—the representation of a text corpus as a document–term matrix. Such a matrix has a size of m × n, where m denotes the number of documents in the text corpus (i.e., the number of vectors), and n denotes the terms occurring in the entire corpus (i.e., the number of dimensions). As a typical representation, the terms in such a matrix are represented by their (relative) frequency of occurrence.
We assume that the following sentences can be found in four text documents. In line with the preprocessing conventions in NLP (Manning et al., 2008; Manning & Schütze, 2000), we also assume that only the bold-marked words (i.e., adjectives, nouns, and verbs) are used for the document–term matrix:
Document d1: “The Document d2: “The Document d3: “The Document d4: “The
In Table 1, we depict the document–term matrix for this basic example with four documents. The values in the vectors indicate the terms’ frequency per document. This basic example illustrates that documents in a vector space are represented by multiple vector dimensions at once instead of being classified into single distinct categories, such as a document being about responsibility (i.e., d1 and d2,) or performance (i.e., d3 and d4). Although this example only includes a few dimensions, vectors can be scaled to any length, thus capturing higher dimensionality (e.g., more terms).
Vector Space Resulting From the Example Sentences in the Basic Application (Shaded Cells Mark the Use of Terms across Documents).

In Figure 1, we visualize the four documents (i.e., d1, d2, d3, and d4) as vectors. Following the intuitive spatial interpretation in Figure 1, vectors capture relational similarity because they can be conceived as leading to specific points in a geometric space, with the values of the vector components determining their positions (Salton et al., 1975). Two vectors with similar values will be positioned closely to each other in the geometric space. That is, in the most basic form, the more similar the occurrence of terms in texts, the higher the proximity between the corresponding vectors in the geometric space. From an NLP perspective, the geometric proximity between vectors indicates a similarity of the linguistic meaning of the documents they represent (Manning & Schütze, 2000; Schütze, 1998).
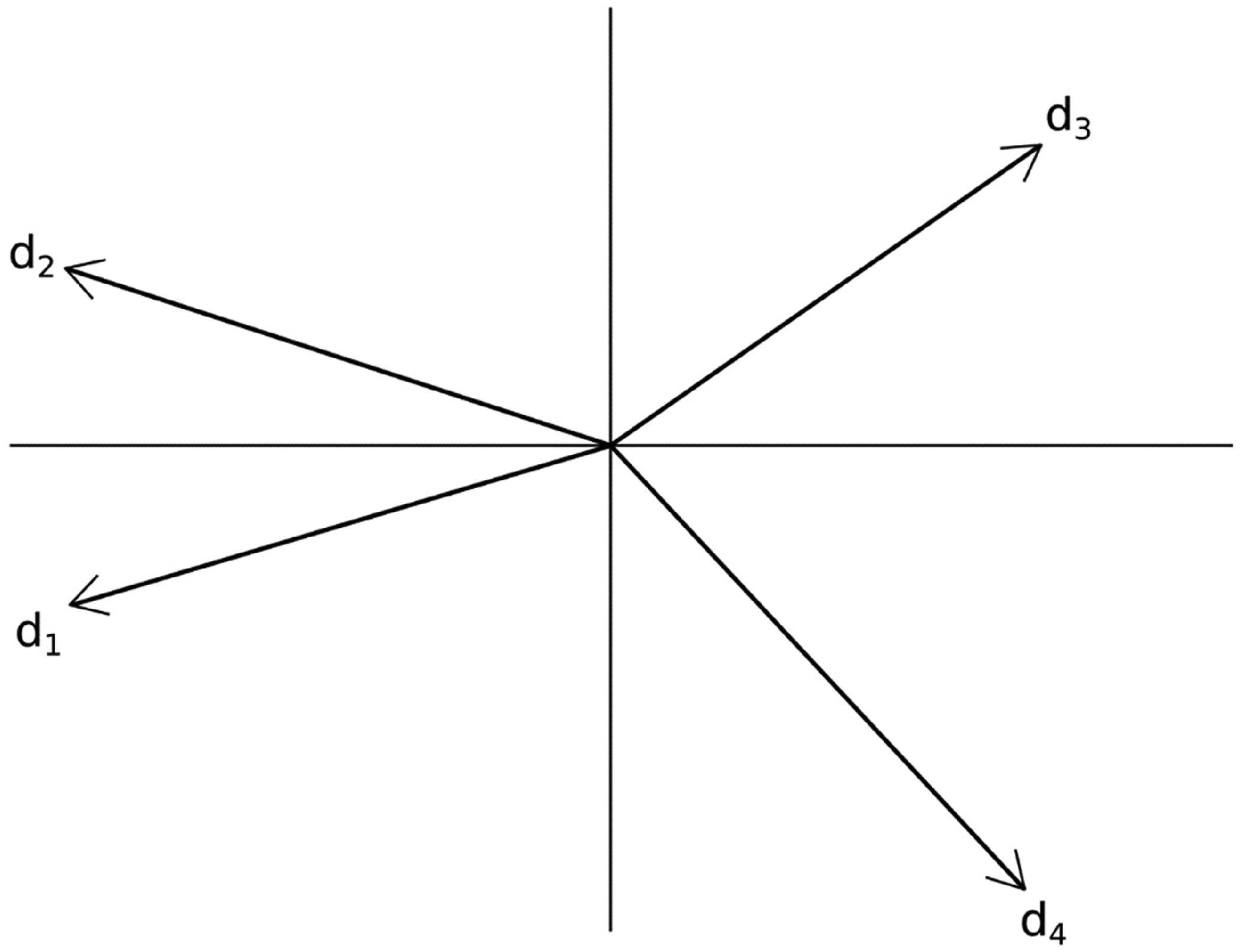
An illustration of the geometric interpretation of the vector space model in natural language processing (NLP) based on a simple model consisting of four documents. For visualization purposes, the 14 dimensions derived from the sentences were reduced to two dimensions using principal component analysis.
Figure 1 illustrates this geometric interpretation—the vector of document d1 is (much) closer to the vector of document d2 than to the vectors of documents d3 and d4. Similarly, the vector of document d3 is (much) closer to the vector of document d4 than to the vectors of documents d1 and d2. In general, documents are higher in similarity if the vector dimensions are characterized by the same values. Accordingly, vectors’ geometric proximity points to the degree of documents’ linguistic similarity, and thus, captures their relational similarity in this example.
The geometric proximity capturing the linguistic relational similarity of documents can also be quantified by using similarity metrics (see Table 2). Note that we show similarity values for illustrative purposes, and we will discuss the application of similarity metrics for organizational research in detail in the next sections. The similarity values in this basic application are produced by the cosine similarity and the inverted Euclidean distance (i.e., Euclidean similarity) because these similarity metrics have become the standard in NLP (Cassisi et al., 2012; Ljubesic et al., 2008; Manning & Schütze, 2000).
Relational Similarity Measures Based on the Basic Application (Cosine/Euclidean; Shaded Cells Mark the Ranking of the Similarity Values).
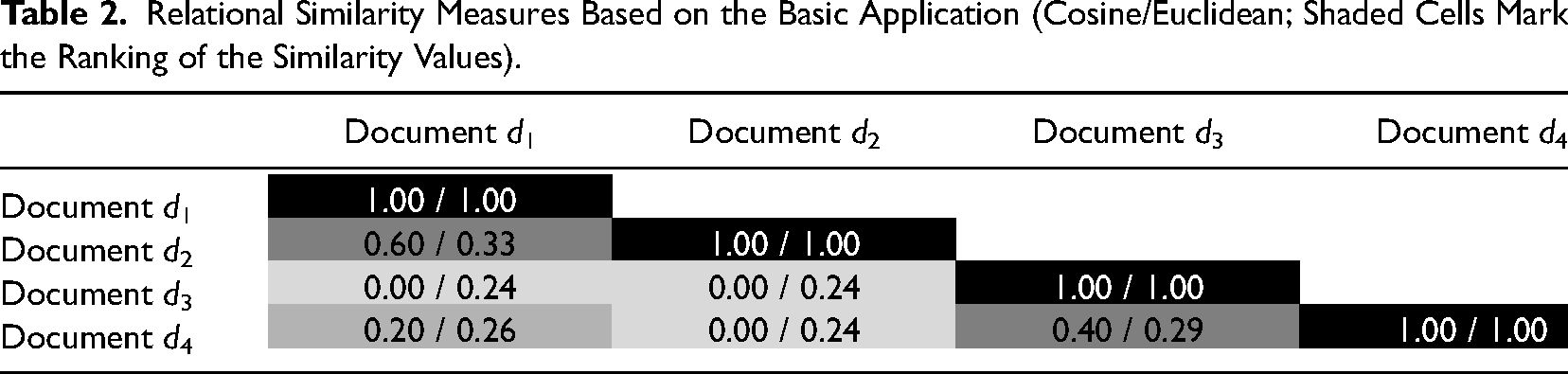
The similarity values plotted in Table 2 correspond to the visualized proximity of vectors in Figure 1. In this context, it is important to emphasize that the sizes of similarity values depend on the dimensionality of the vector space (i.e., number of vector components), the value range of the vector dimensions (e.g., the use of absolute or relative frequencies), and the similarity metric applied (i.e., cosine or Euclidean). This also implies that the sizes of similarity values are not readily interpretable and comparable across vector spaces that have been constructed differently. Instead, NLP uses the ranking of similarity values when interpreting and comparing vector spaces (Manning & Schütze, 2000). For instance, our example reveals that the documents that human readers intuitively would consider similar (e.g., d1 and d2) also receive the highest similarity values in vector spaces. In other words, even if the absolute sizes of similarity values differ, the ranking of the similarity values in our example remains the same, regardless of the similarity metric applied.
In this section, we provide an intuitive introduction to the vector space model in NLP and its most basic form (i.e., document–term matrix). However, note that (1) the vector space model can be used as the methodological backbone for various NLP applications, and thus, is by no means limited to use with terms as vector dimensions (Karlgren & Kanerva, 2021; Turney & Pantel, 2010). For example, texts can be compared based on their thematic similarity (what content do texts convey?), stylistic similarity (how is content arranged?), the similarity of the words (what terms are used?), or the similarity of word semantics (what latent semantics do terms convey?). In our basic application, we focused on comparing the occurrence of the words used in the four documents, making counting the terms a reasonable approach. However, for example, if the goal was to compare the latent semantics of the words used in the example sentences, the application of word embeddings would be more recommended (for an application of word embeddings to this basic application, see Appendix C). We will illustrate possible ways to construct vectors and vector spaces in the following sections. (2) Furthermore, up to this point, we have illustrated how the vector space model is regularly applied in the NLP context to quantify linguistic meaning. To adapt the vector space model to the requirements of organizational research, we will provide guidance on how to ensure validity when applying vector spaces to calculate relational similarity measures to investigate organizational phenomena.
Outline of a Vector Space Approach for Organizational Research
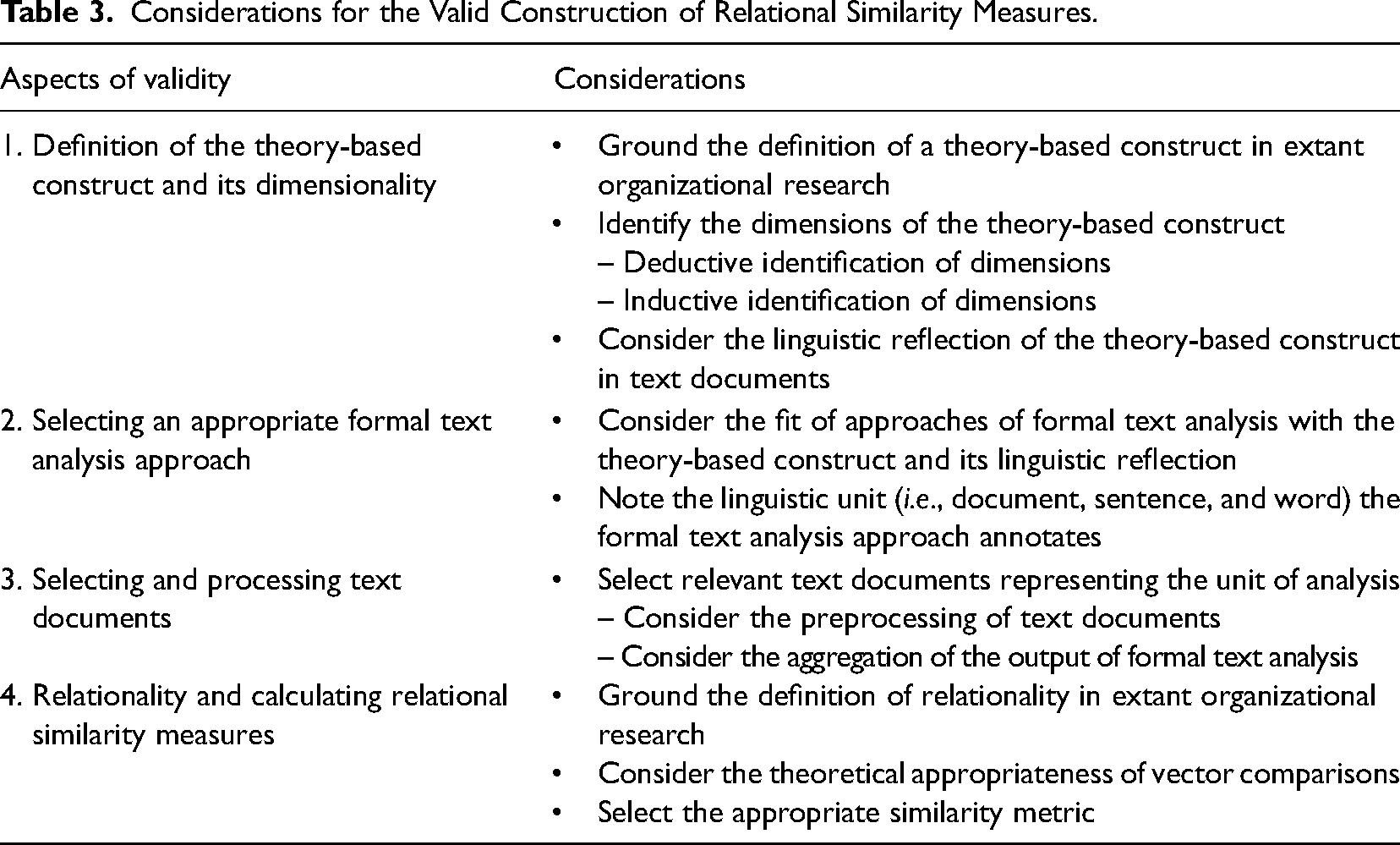
Our methodological goal is to develop a vector space approach for constructing similarity measures that account for the multidimensionality of theory-based constructs and the relationality of organizational entities (e.g., organizations, their members, and subunits). To this end, we provide guidance on how organizational scholars can ensure validity when constructing relational similarity measures based on vectoral representations. Our validity guide is organized around (1) the definition of the dimensions of theory-based constructs and their linguistic reflection, (2) the selection of approaches of formal text analysis for operationalizing the multidimensionality of theory-based constructs, (3) the selection of texts and their processing, and (4) the theoretical definition of relationality and selecting similarity metrics (see Table 3).
Considerations for the Valid Construction of Relational Similarity Measures.
We illustrate our vector space approach by illustrating the different validity aspects using a running example. We use the case of a cross-sectional study and we investigate the similarities (i.e., shared understanding) to which organizations from the same industries ascribe the same meaning to an organizational issue (Loewenstein et al., 2012). Organizational issues are developments that emerge exogenously to industries (Bansal et al., 2018) and can have important consequences for organizational life (Hoffman, 1999). In this regard, we focus on the latent semantics of the vocabulary (i.e., a set of words) found in organizational statements on an issue. In our running example, we focus on the issue of organizations’ responsibilities, which modern societies and organizations around the globe continuously debate (Aguinis & Glavas, 2012; Bondy et al., 2012; Chen & Bouvain, 2009; Lim & Tsutsui, 2012; Pope, 2015; Pope & Lim, 2020; Wickert et al., 2016). This running example builds on the open-system perspective in organizational research because the theoretical premises of this perspective are highly consistent with our methodological approach (for an overview, see Scott & Davis, 2007). Organization theories within the open-system perspective are based on conceptualizations of organizational entities as complex, loosely coupled systems with porous boundaries that are heavily constructed and constrained through their multidimensional relationality within social spaces and their environments (e.g., organizations, industries, markets, or countries; Cattani et al., 2017; DiMaggio & Powell, 1983; Zietsma et al., 2017; Zuckerman, 1999).
Considerations for Constructing Relational Similarity Measures
Definition of the Theory-Based Construct and Its Dimensionality
The first consideration to construct validly relational similarity measures is to define the theory-based construct of interest (e.g., the meaning of an organizational issue). A theory-based definition informs the construction of vectors directly because it specifies the nature of theoretical dimensions of the construct and guides the selection of a formal text analysis approach for its operationalization. In this sense, the definition of theory-based constructs and the selection of a formal text analysis approach resemble the procedure of common quantitative empirical research, namely that variables should validly measure the theoretical construct of interest (Klein & Kozlowski, 2000).
Organizational scholars can define the dimensions of theory-based constructs in two ways. One is to derive deductively the theoretical dimensions of a theory-based construct from extant organizational research (McKenny et al., 2012; Short et al., 2010). For example, the literature defines organizational culture as consisting of six dimensions, with each dimension having its own sub-definition (Pandey & Pandey, 2019). The second way is to derive dimensions inductively. For instance, Haans (2019) built on a multidimensional definition of organizational self-representation. However, because organizations vary in how they present themselves to audiences, there is no a priori knowledge about the concrete dimensions that represent organizational self-representations in the empirical case at hand. Accordingly, the author captured organizational self-representations through the totality of various themes that the studied organizations communicated publicly to audiences.
In this context, a critical aspect for organizational scholars is to clarify the way a theory-based construct of interest is linguistically reflected in texts. This aspect is important to justify selecting a formal text analysis approach. For example, organizational self-representations can be operationalized with the topics (i.e., themes) that organizations communicate publicly about themselves (Haans, 2019). In contrast, theory-based constructs, such as psychological capital or organizational culture, tend to be reflected linguistically in the words used in communication (McKenny et al., 2012; Pandey & Pandey, 2019).
We follow previous research and assume the facets that give rise to the meaning of a concept are reflected linguistically in the latent semantics of the words (i.e., vocabulary) that organizations use to describe the issue's various aspects (Loewenstein et al., 2012; Nelson, 2021). Accordingly, the vector space in this running example consists of vectors representing the meaning that organizations assign to an organizational issue, with vector dimensions representing the different meaning facets that the vocabulary organizations use provides.
Selecting Appropriate Formal Text Analysis Approaches
Due to the general nature of vectors, various formal text analysis approaches can be applied to construct vector spaces. In selecting approaches of formal text analysis, organizational scholars need to ensure the fit between the use case of the formal approach, the definition of the theory-based construct, and its linguistic reflection in texts. In this section, we refer to some formal text analysis approaches (word counting, topic modeling, grammatical parsing, and word embeddings) to illustrate how they have been applied to operationalize theory-based constructs in organizational contexts. We draw on some formal text analysis approaches only because a comprehensive overview of approaches is beyond our article's scope (for a broader overview, see classical textbooks, such as Baeza-Yates & Ribeiro, 2004; Eisenstein, 2019; Jurafsky & Martin, 2009; Manning et al., 2008; Manning & Schütze, 2000; Zhang & Teng, 2021). 1
Inductive word counting has been applied in organizational research, for example, to operationalize management's focus of attention when making sense of poor business performances (Pollach, 2012). In contrast, a deductive application of word counting is the measurement of constructs such as psychological capital by counting the frequency of word collections (i.e., dictionaries; McKenny et al., 2012). With word counting, organizational scholars can use (collections of) terms as the dimensions of vectors and the (relative) term frequencies as the values of these dimensions (forming a document–term matrix).
Topic modeling offers a sophisticated opportunity to describe texts through word clusters (for overviews, see Boyd-Graber et al., 2017; Dieng et al., 2020; Mohr & Bogdanov, 2013; Vayanskya & Kumarb, 2020). Topic modeling has been used in organizational research, for example, to operationalize organizations’ self-representation inductively by capturing themes organizations present to their audiences (Haans, 2019). In other examples, topic modeling has been used to measure the prevalence of predefined communicative frames deductively (Fligstein et al., 2017; Kaplan & Vakili, 2015). Using topic modeling, the dimensions of vectors relate to topics and the values indicate the relative prevalence of topics in documents (forming a document–topic matrix).
Other approaches of formal text analysis such as grammatical parsing focus on the structure of texts. Grammatical parsing classifies words according to their grammatical function in sentences (Ágel & Fischer, 2015; Kübler et al., 2009). For example, organizational researchers have applied grammatical parsing to capture actor–action–object triplets inductively in public discourse (Goldenstein & Poschmann, 2019a; Sudhahar et al., 2013) or to capture words at grammatical positions deductively that linguistically reflect organizations’ actions on others’ behalf (Goldenstein, Poschmann, et al., 2019). Using grammatical parsing, organizational scholars can select words based on their grammatical roles as the dimensions of vectors and their (relative) frequencies as values of these dimensions.
As a final example, we refer to word embeddings (for an overview, see Wang et al., 2020). Word embeddings draw the latent semantics of individual words from patterns of word co-occurrences in plain text corpora (for a more detailed description, see Kiela et al., 2015). As a result, word embeddings represent latent word semantics as high-dimensional vectors of real numbers (embedding vectors). In plain text, the dimensions of embedding vectors mathematically represent the latent dimensions of words’ semantics. Even if the representation of word semantics by real numbers may appear uncommon, embedding vectors computationally makes sense because they capture the similarity of word semantics astonishingly well (Bojanowski et al., 2017; Pennington et al., 2014). For example, words with similar semantics (e.g., “cat” and “tiger”) are represented by more similar real numbers in their embedding vectors than words with dissimilar semantics (e.g., “cat” and “oxygen”). Word embeddings have already been applied to study divergent latent meanings associated with cultural categories inductively and deductively, such as “institutions” or “socio-economic situation.” These studies have applied word embeddings due to researchers paying attention to capture social meaning via words’ latent semantics (Kozlowski et al., 2019; Nelson, 2021; Stoltz & Taylor, 2021). Organizational scholars can use the dimensions of word embeddings as dimensions of vectors and the real numbers of these word embeddings as the values of these dimensions.
At the end of this section, we would like to encourage organizational scholars to explore approaches other than those mentioned here. Especially formal text analysis approaches such as named entity recognition (Li et al., 2020), part-of-speech tagging (Schmid, 2008), or sentiment and emotion analysis (Alswaidan & Menai, 2020) may be suitable for interesting vector space applications (see Appendix A and B).
Selecting and Processing Text Documents
A key advantage of formal text analysis and vector spaces is their ability to analyze large collections of texts that reflect the unit of analysis directly (for example, see McKenny et al., 2012; Short et al., 2010). The unit of analysis—usually the organization, their members, and subunits—can be specified based on the definition of the theory-based construct under consideration. Then, organizational scholars can select an appropriate text collection reflecting this specific unit of analysis (Braun et al., 2018; Krippendorff, 2004). 5 For example, if a study is focused on communication from specific organizational subunits, the units of analysis are the subunits of organizations and will be represented by a specific text corpus, such as newsletters these subunits published. In contrast, research focus on the overarching self-representation of organizations and their positioning toward the wider public might change the text selection profoundly, such that the organization as a unit of analysis will be represented by its communication in various texts at the organizational level (e.g., annual reports and corporate websites).
After selecting an appropriate text collection representing the unit of analysis, formal text analysis can be applied. The output of formal text analysis approaches usually needs to be aggregated by moving from “lower” to “higher” linguistic units (e.g., by applying basic statistical operations such as counting and subsequent averaging), which is a common task in formal text analysis (e.g., McKenny et al., 2012; Pandey & Pandey, 2019). 9 However, organizational scholars must ensure that the aggregation of the output of formal text analysis approaches validly captures a theory-based construct. Thus, selecting an approach of formal text analysis and aggregating its output resembles the common quantitative empirical research procedure, namely that variables should validly operationalize the theoretical construct of interest. For example, counting word collections can be used to measure the prevalence of theory-based constructs, such as psychological capital. The prevalence hereby is operationalized by summing the frequency with which words in the word collections appear in organizational text documents (McKenny et al., 2012). 10
We followed previous research on organizational contexts that has suggested to sum the embedding vectors of words occurring in the same text (e.g., sentence, paragraph, and document) into a representative average embedding vector (Arseniev-Koehler, 2022; Stoltz & Taylor, 2021). For example, Nanni and Fallin (2021) summed the embedding vectors of words per abstract in scientific articles (i.e., one document in this research endeavor) to capture the latent semantics of the vocabulary used within this text section. Accordingly, we aggregated the embedding vectors of words from all sentences containing the key word “responsibility” in the same annual report to an average embedding vector (forming the document–embedding matrix). That is, our application of fastText word embeddings reveals the latent semantics of the vocabulary that organizations use in one annual report to describe the issue of responsibility (for an intuitive illustration of the application of word embeddings, see Appendix C).
When more than one text document represents a unit of analysis, the same aggregation process can be applied. By aggregating information derived from individual documents of one organization (e.g., annual reports), a collection of texts (e.g., all annual reports) can also represent the organization as a unit of analysis. However, aggregating information across individual text documents is only useful when organizational scholars are not interested in comparing these documents. To illustrate aggregation across individual text documents, consider a case in which words are counted to investigate the similarity of the vocabulary that organizations use in six documents (e.g., annual reports). Accordingly, the procedure results in six vectors representing the six documents (forming the document–term matrix). However, to construct vectors at the organizational level (modelled as an organization–term matrix), positioning individual documents in vector space is not sufficient. Instead, computing the average of the values of the dimensions of the document vectors for each organization produces vectors that reflect the organizational level (see org1 and org2 in Figure 2).
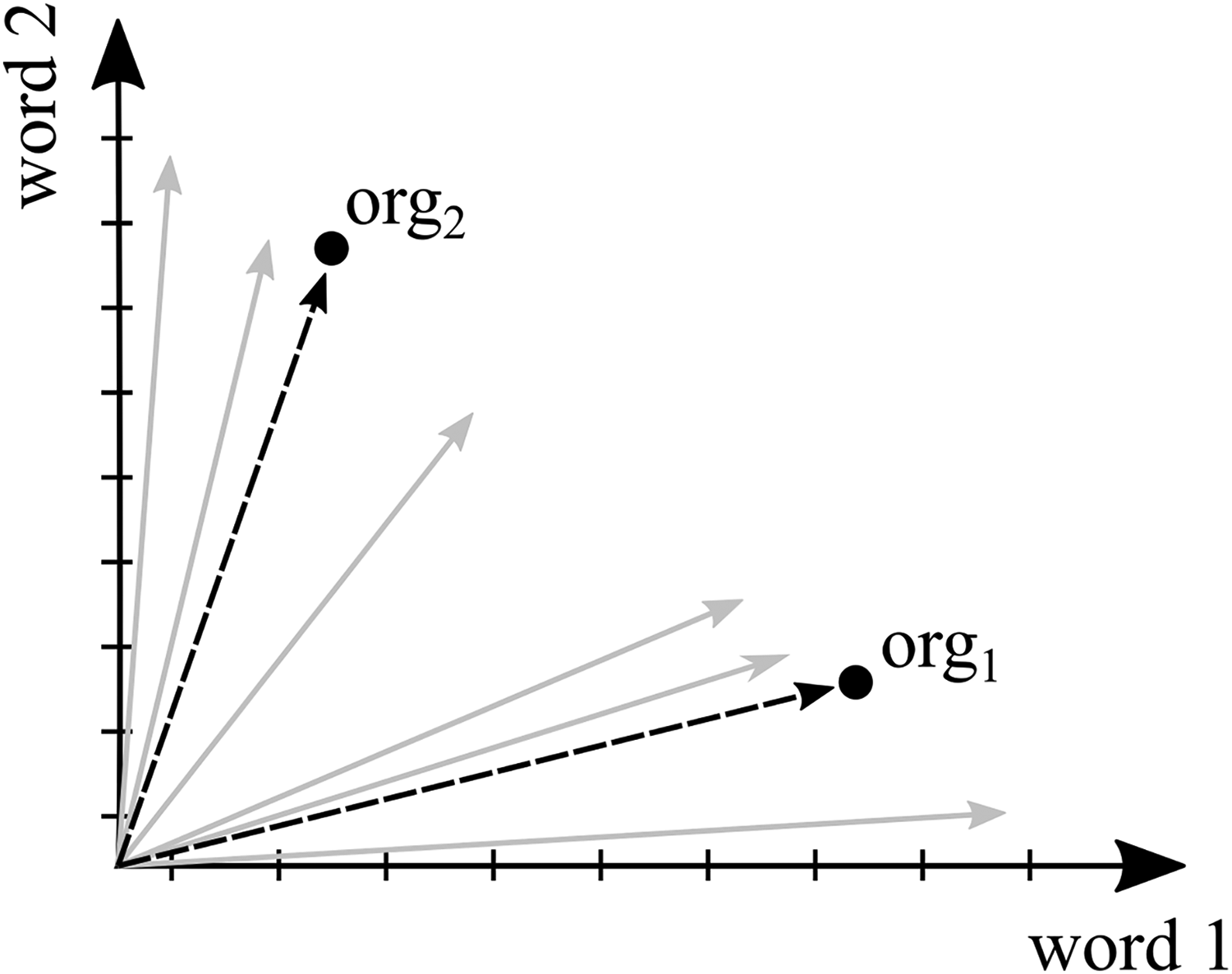
An illustration of the aggregation of single document vectors to an organization vector in a simple vector space consisting of six documents and two words as dimensions. Gray arrows represent the document vectors; the black dotted arrows represent the organization vectors.
Relationality and Calculating Relational Similarity Measures
A precondition for the geometric interpretation of vectors is a specification of what the relationality between vectors means theoretically. This specification is connected to the theory-based construct under consideration. For example, if subunits communicate their organizational culture in similar ways, relationality can capture the coherence of values within an organization (Kristof-Brown et al., 2005; Pandey & Pandey, 2019). If organizations present the features of their products dissimilarly, relationality can capture their degree of distinctiveness within a market (Goldenstein, Hunoldt, et al., 2019; Zuckerman, 2016). After specifying the theoretical meaning of relationality, organizational scholars can utilize the geometric interpretation of vectors to calculate the relational similarity between organizational entities or to their environments. However, quantifying and analyzing the similarity of units of analysis requires decisions about applying arithmetic operations.
The first decision concerns specifying the type of comparison between vectors. Organizational scholars can calculate similarities from dyadic comparisons between vectors (i.e., the respective comparison of two units of analysis) or from the average of multiple dyadic comparisons (i.e., the average calculated from the comparison of a unit of analysis with multiple others). For example, the first type of comparison captures the degree of distinctiveness of organizations regarding an outstanding exemplar within the same industry (Younger & Fisher, 2020), whereas the second one is well suited to measure the degree to which organizations from the same country align on a shared understanding of an organizational issue (Goldenstein, Poschmann, et al., 2019).
The second decision regarding applying arithmetic operations concerns selecting an appropriate metric to quantify similarities between vectors. We illustrate the selection of similarity metrics by focusing on the cosine similarity and Euclidean similarity, because these metrics have become the standard in NLP (Cassisi et al., 2012; Ljubesic et al., 2008; Manning & Schütze, 2000).
The cosine similarity is calculated as follows (xi and yi are the n components of the vectors 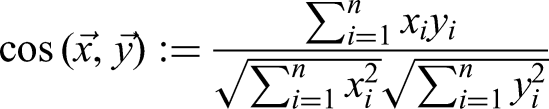
The calculation of Euclidean similarity is based on the Euclidean distance formula: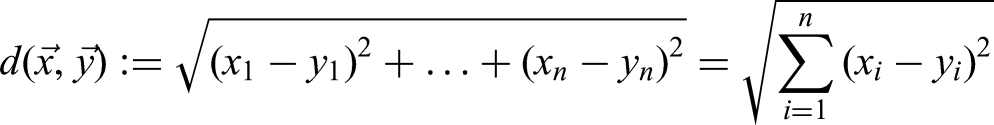
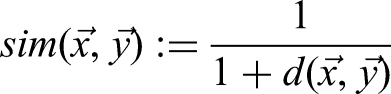
Selecting a similarity metric hinges on the methodological consideration of whether organizational scholars want to capture similarities between vectors based on (1) the distribution of values or (2) the magnitude of values in these vectors. That is, cosine similarity captures which vector dimensions organizational entities primarily use. In contrast, Euclidean similarity considers the frequency with which organizational entities use the dimensions of the vectors representing these entities. For example, for a study investigating the frequency with which organizations use specific words, rather than focusing only on the distribution of these words, selecting Euclidean similarity as a similarity metric is appropriate. Figures 3a and b illustrate the importance of this consideration because applying Euclidean similarity reveals a higher similarity between org2 and org3, whereas cosine similarity captures a higher similarity between org1 and org2. To clarify, both similarity results are meaningful, but the selection of a specific similarity metric depends on whether the distribution of values or the magnitude of values is important for the specific organizational research endeavor.
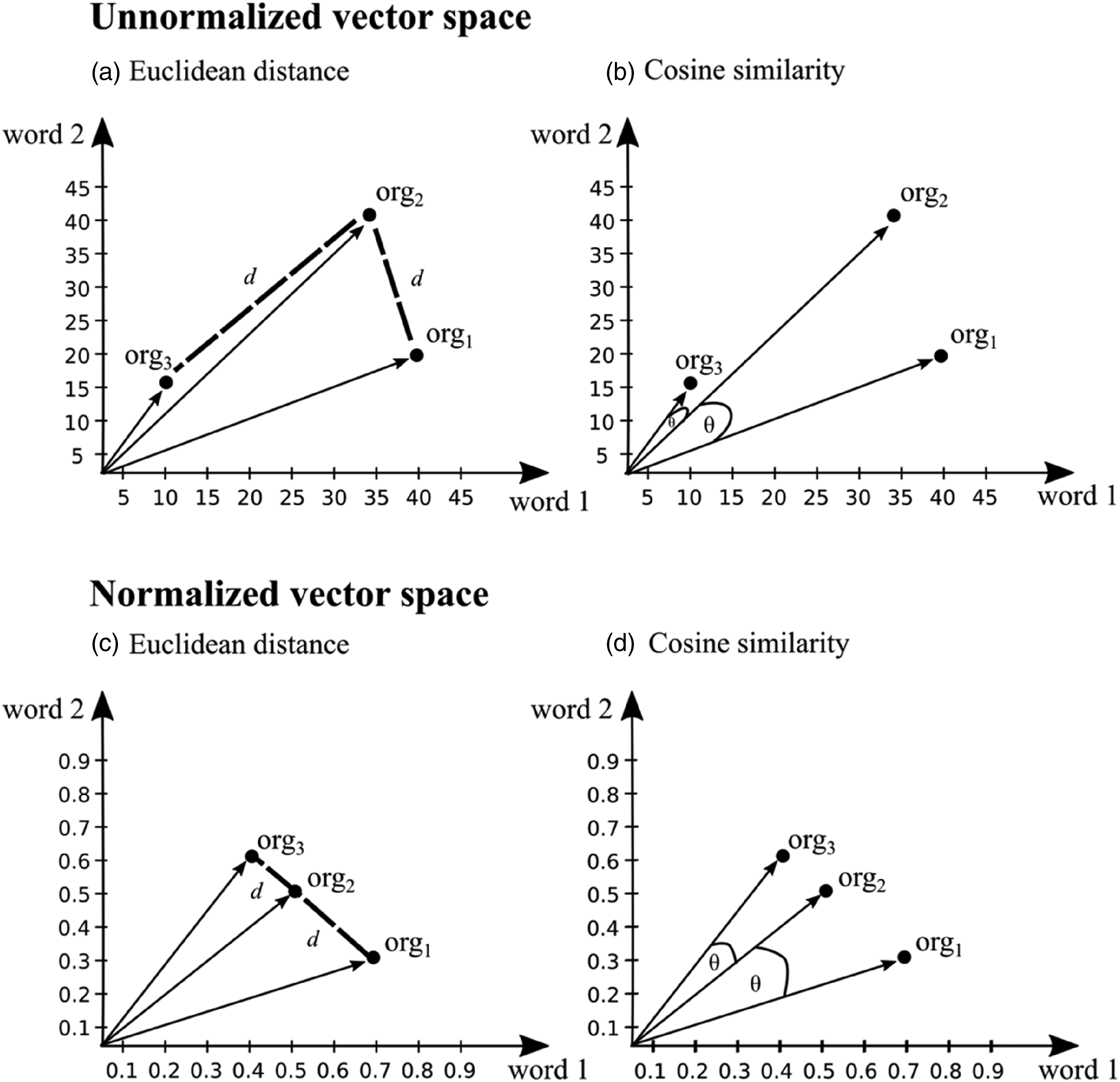
Illustration of Euclidean distance and cosine similarity in a simple normalized and unnormalized two-dimensional vector space consisting of three organizations as units of analysis and two words as dimensions.
However, the difference between cosine similarity and Euclidean similarity dissolves in applications in which the values of the vector dimensions are normalized. Normalization means that the value differences between vectors are aligned to the same value range (i.e., the sum of the values of the vector dimensions does not differ across units of analysis). Consequently, the rankings of similarity between vectors calculated with the two similarity metrics are the same (Manning & Schütze, 2000). That is, these similarity metrics come to the same estimation regarding the nearest, and thus, most similar neighbors of a particular vector. Figures 3c and d illustrate that both cosine similarity and Euclidean similarity reveal the same ranking of similarity among org1, org2, and org3.
Exemplary Regression Analysis
Once the relational similarity measures results have been calculated, they need to be converted into a format suitable for subsequent statistical analysis. Depending on the research focus and the statistical method to be applied, the relational similarity measures need to be transformed into appropriate data formats suitable for a given research focus (e.g., data frames, panel data, or network data). Although it is not possible here to provide a comprehensive overview of how to transform data and how to handle relational similarity measures statistically, we use our running example to illustrate a possible cross-sectional analysis by applying linear mixed-effects regression models.
Descriptive Statistics and Pearson Correlation Coefficients.
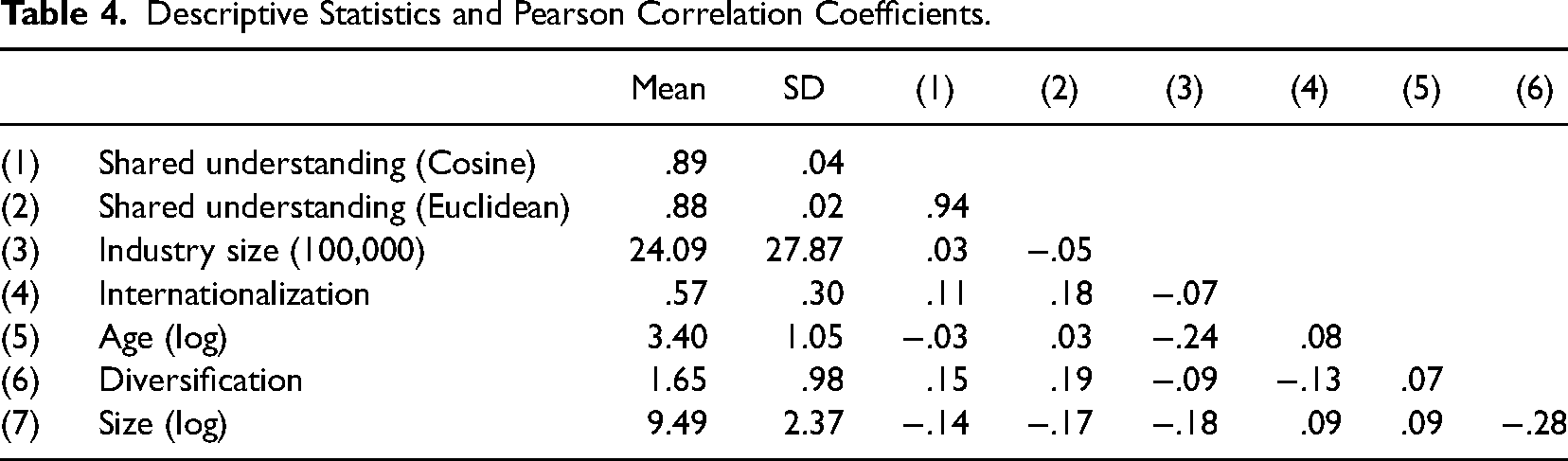
Linear Mixed-Effects Models Explaining the Degree of a Shared Understanding Within the Same Industry (Standardized Coefficients).

***p < .001; **p < .01; *p < .05.
The results correspond with theoretical assumptions in the open-system perspective. This perspective assumes that an organization's size reflects its public visibility, and thus, may evoke pressure to align with other organizations in the same industry (DiMaggio & Powell, 1983; Fiss & Zajac, 2004). Internationalization is a source of dissimilarity, because organizations operating in many different countries are exposed to a multiplicity of (potentially) diverging requirements and expectations regarding their responsibilities, which they need to consider to maintain legitimacy (Kostova & Zaheer, 1999).
Discussion
Methodological Contribution
In our article, we have followed contemporary calls in organizational research to take advantage of the increasing availability of big collections of (textual) data (Braun et al., 2018; George et al., 2016; Tonidandel et al., 2018; Wenzel & Van Quaquebeke, 2018). The ubiquity of texts, including newspaper articles, press releases, and annual reports, inspired organizational researchers using NLP to quantify meaning and study organizational phenomena on a larger, thus far unprecedented scale (Gentzkow et al., 2019; Hannigan et al., 2019; Kobayashi et al., 2018a, 2018b).
Although NLP can accelerate knowledge discovery, organization researchers have just begun to exploit the methodological reservoir of NLP. That is, they have applied NLP to cluster and classify textual information (DiMaggio et al., 2013; Poschmann & Goldenstein, 2022), or scale in-depth text analysis (Nelson, 2017). However, even if suggested by various theoretical approaches (e.g., Cattani et al., 2017; Dhalla & Oliver, 2013; Kennedy, 2008; Kostova et al., 2008; Kristof-Brown et al., 2005; Zietsma et al., 2017), organizational research up until now lacked an methodological approach that allows the quantitative analysis of the multidimensional relationality of organizational entities in social spaces and with their environment, such as the organization itself, industries, markets, or countries. With the methodological approach outlined in this article, we expand the application of NLP to “areas where research goals are not only to classify or to cluster but also to explain, using existing knowledge or theory and incorporating this into the analysis from the start” (Kobayashi et al., 2018b, p. 756).
As a step toward this visionary goal, we featured the vector space model in NLP. Vectors make possible representing the full multidimensionality of theory-based constructs at once and transforming it into relational similarity measures. For example, this differs from earlier approaches of computer-aided text analysis that generally calculated the sum of the dimensions of theory-based constructs when using regression analyses (McKenny et al., 2012). Our running example provides an intuitive sense of how organizational scholars can apply vectoral representations in concrete research practice.
Outlining the Broad Applicability of the Vector Space Model
Our running example draws on the open-system perspective in organizational research (for an overview, see Scott & Davis, 2007). The perspective includes theoretical streams such as the resource dependence theory, institutional theory, category research, and organizational ecology (DiMaggio & Powell, 1983; Hannan & Freeman, 1977; Meyer & Rowan, 1977; Pfeffer & Salancik, 1978; Zuckerman, 1999). However, to provide an intuitive sense of the broad applicability of the vector space model, we have emphasized some streams in organizational research that could similarly benefit from our methodological approach when applying text analysis. Note that the research streams we mention can only serve as illustrations.
One theoretical stream concerns organizational cognition and emphasizes the importance of sensemaking for the retrospective interpretation of significant actions or events within organizations and their environments (Brown et al., 2015; Gephart, 1993; Weick, 1995). Our methodological approach can contribute to this research stream by studying the antecedents of shared sensemaking outcomes among employees within and across organizational subunits (Brown et al., 2009). For example, future research could use email communication to study whether and how managerial communication and communication styles influence the degree of similarity of employees’ sensemaking outcomes.
We also see potential to enrich empirical research in the literature on stakeholder management (Cornelissen, 2014). One stream in this literature focuses on the congruence between the identity an organization wishes to convey and the image stakeholders have of this organization (Christensen et al., 2013; Hooghiemstra, 2000). In this context, our methodological approach can assist in conducting large-scale studies to test conditions in which this perceived congruence is particularly significant. For example, researchers could measure the similarity between how organizations portray themselves on websites and how they are characterized on social media or in newspaper articles.
Our methodological approach could also contribute to research on social evaluation (Pollock et al., 2019). One stream within this literature emphasizes the importance for organizations to describe corporate crises in concordance with stakeholders’ perceptions (Bundy & Pfarrer, 2015). Future research could use our methodological approach to investigate the tension between organizational communication and stakeholders’ evaluations in texts such as press releases, social media posts, or newspaper articles. Such analyses could provide new insights into the conditions that lead to greater or lesser congruence between organizational communication and stakeholders’ perceptions. Additionally, studies could investigate the factors that exacerbate or mitigate the consequences of a weak congruence between organizational communication and stakeholders’ perceptions.
Future Developments
In this article, we have provided organizational scholars high-level guidance on how to ensure validity when constructing relational similarity measures. Nevertheless, we see potential for future research. First, organizational scholars could further elaborate the details of our four considerations (see Table 1) and provide a step-by-step manual for use cases connected to specific streams in organizational research (for similar approaches, see McKenny et al., 2012; Short et al., 2010). Second, as illustrated in our article, the application of the vectors is not only connected to theoretical validity, but also to issues of the technical validity of formal text analysis approaches. This technical validity concerns the quest for best practices of how to apply techniques developed in another scientific field to organization studies. Recently, organizational scholars have begun to develop and discuss ways to harness the potential of sophisticated formal text analysis for the needs of organizational research (Kobayashi et al., 2018b). Progress in this direction would be helpful for organizational research, as a technically valid use of NLP approaches would help to ensure a suitable operationalization of theory-based constructs.
As a caveat, our methodological approach does require some technical expertise. However, we believe that the formal foundation of our methodological approach—the vector space model—is comprehensible and adoptable for organizational scholars with less technical expertise. Furthermore, basic approaches of formal text analysis such as word counting and topic modeling are relatively easy to implement. Admittedly, depending on the research focus and NLP approach, some advanced methodologies still require a deeper NLP and machine learning background. However, a benefit of this constraint is that our approach makes it possible for organizational researchers to gather entirely new insights, because it helps address the intricate complexity of social meaning.
Furthermore, formal text analysis has its limitations. It is, for example, not readily equipped to capture various types of non-literal or figurative speech, including irony or metaphors (Hossain et al., 2020; Zayed et al., 2020) as well as uncertain or fuzzy wordings (Engelmann & Hahn, 2014; Štajner et al., 2017)—and these aspects of language might be of particular interest for organizational researchers. Finally, some formal approaches are heavily biased toward covering the English language and might be sufficient for analyses of few other languages (e.g., Chinese, French, or German), but they mostly lack sufficient support for what has been called low-resourced languages.
Footnotes
Appendix A: Selected Formal Text Analysis Approaches
Overview of Selected Formal Text Analysis Approaches.
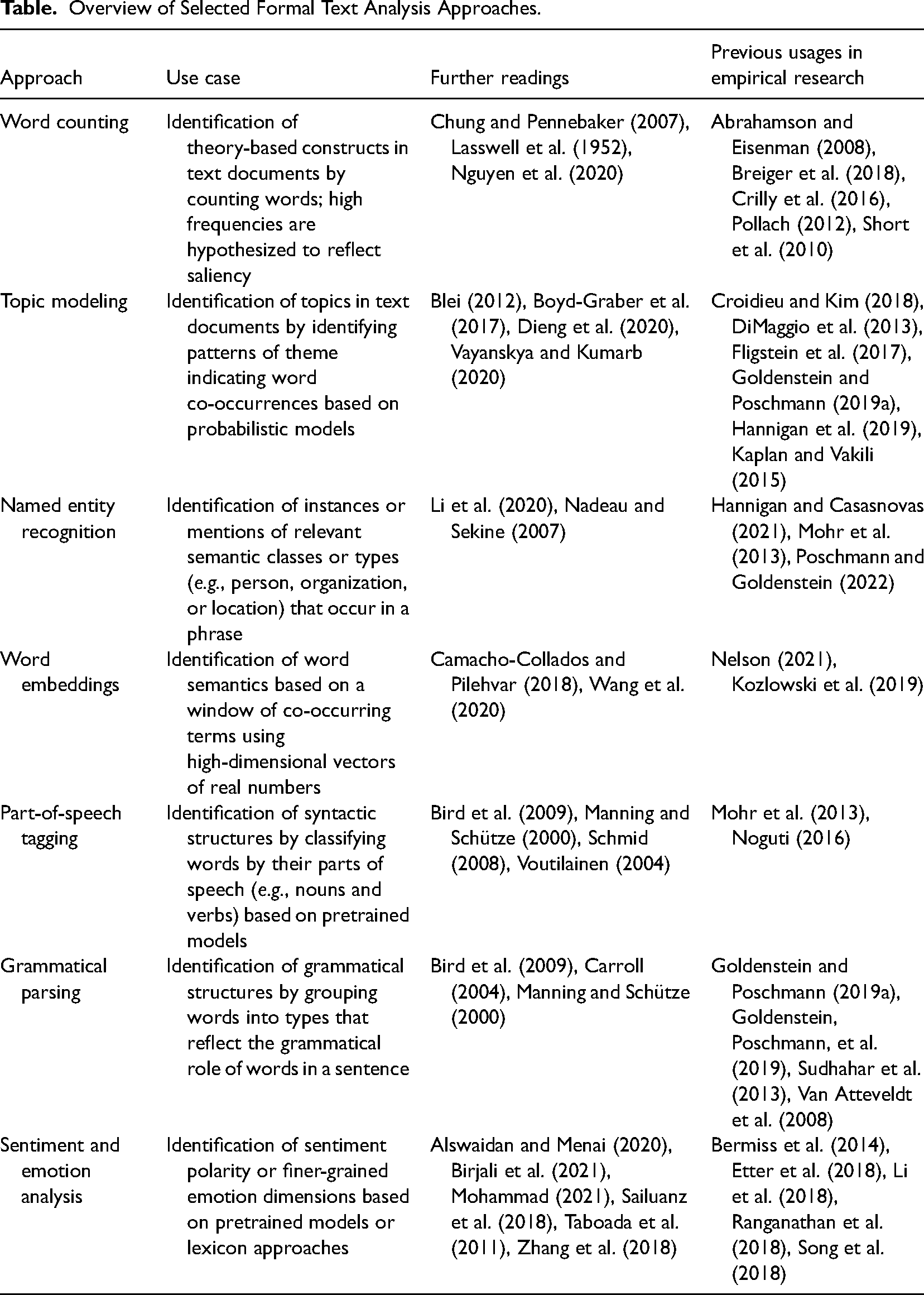
| Approach | Use case | Further readings | Previous usages in empirical research |
|---|---|---|---|
| Word counting | Identification of theory-based constructs in text documents by counting words; high frequencies are hypothesized to reflect saliency | Chung and Pennebaker (2007), Lasswell et al. (1952), Nguyen et al. (2020) | Abrahamson and Eisenman (2008), Breiger et al. (2018), Crilly et al. (2016), Pollach (2012), Short et al. (2010) |
| Topic modeling | Identification of topics in text documents by identifying patterns of theme indicating word co-occurrences based on probabilistic models | Blei (2012), Boyd-Graber et al. (2017), Dieng et al. (2020), Vayanskya and Kumarb (2020) | Croidieu and Kim (2018), DiMaggio et al. (2013), Fligstein et al. (2017), Goldenstein and Poschmann (2019a), Hannigan et al. (2019), Kaplan and Vakili (2015) |
| Named entity recognition | Identification of instances or mentions of relevant semantic classes or types (e.g., person, organization, or location) that occur in a phrase | Li et al. (2020), Nadeau and Sekine (2007) | Hannigan and Casasnovas (2021), Mohr et al. (2013), Poschmann and Goldenstein (2022) |
| Word embeddings | Identification of word semantics based on a window of co-occurring terms using high-dimensional vectors of real numbers | Camacho-Collados and Pilehvar (2018), Wang et al. (2020) | Nelson (2021), Kozlowski et al. (2019) |
| Part-of-speech tagging | Identification of syntactic structures by classifying words by their parts of speech (e.g., nouns and verbs) based on pretrained models | Bird et al. (2009), Manning and Schütze (2000), Schmid (2008), Voutilainen (2004) | Mohr et al. (2013), Noguti (2016) |
| Grammatical parsing | Identification of grammatical structures by grouping words into types that reflect the grammatical role of words in a sentence | Bird et al. (2009), Carroll (2004), Manning and Schütze (2000) | Goldenstein and Poschmann (2019a), Goldenstein, Poschmann, et al. (2019), Sudhahar et al. (2013), Van Atteveldt et al. (2008) |
| Sentiment and emotion analysis | Identification of sentiment polarity or finer-grained emotion dimensions based on pretrained models or lexicon approaches | Alswaidan and Menai (2020), Birjali et al. (2021), Mohammad (2021), Sailuanz et al. (2018), Taboada et al. (2011), Zhang et al. (2018) | Bermiss et al. (2014), Etter et al. (2018), Li et al. (2018), Ranganathan et al. (2018), Song et al. (2018) |
Appendix B: Overview of Natural Language Processing Software
Overview of NLP Software: Libraries (to be Used by Other Programs) vs. Tools (Stand-Alone).

| Type | Word counting | Topic modeling | Word embeddings | Named entity recognition | Part-of-speech tagging | Parsing | Sentiment and emotion analysis | |
|---|---|---|---|---|---|---|---|---|
| Meaning Extraction Helper | Tool (graphical user interface) | ✓ | ||||||
| LIWC | Tool (graphical and command line interface) | ✓ | ✓ | |||||
| WordStat | Tool (graphical user interface) | ✓ | ✓ | |||||
| Scikit-Learn | Python library | ✓ | ✓ | |||||
| Mallet | Java library | ✓ | ||||||
| Tomotopy | Python library | ✓ | ||||||
| Gensim | Python library | ✓ | ✓ | |||||
| FastText | Tool (command line interface) | ✓ | ||||||
| GloVe | Tool (command line interface) | ✓ | ||||||
| NLTK | Python library | ✓ | ✓ | ✓ | ✓ | |||
| spaCy | Python library | ✓ | ✓ | ✓ | ||||
| Stanford CoreNLP | Java library | ✓ | ✓ | ✓ | ✓ | |||
| TextBlob | Python library | ✓ | ✓ | |||||
| JEmAS | Tool (command line interface) | ✓ |
Appendix C: Using the Vector Space Model in NLP With Word Embeddings
Our basic example illustrating the vector space model in NLP focuses on comparing the vocabulary (i.e., terms) of four documents, each containing one sentence. Due to this focus, we counted the terms in the example sentences.
However, organizational researchers experienced in formal text analysis might consider that instead of comparing the vocabulary; another option would be to compare the latent semantics of the vocabulary using a word embedding algorithm. Even if word embeddings have been scarcely used in organizational research (Arseniev-Koehler, 2022; Kozlowski et al., 2019; Nelson, 2021; Stoltz & Taylor, 2021), we see the contemporary interest in this formal approach for text analysis (for an overview, see Wang et al., 2020).
Word embeddings capture the latent semantics of individual words (for a more detailed description, see Kiela et al., 2015). Word embeddings represent word semantics as high-dimensional vectors of real numbers (embedding vectors). Even if the representation of word semantics by real numbers may appear uncommon, embedding vectors computationally makes sense because they capture the similarity of word semantics astonishingly well (Bojanowski et al., 2017; Pennington et al., 2014).
To provide readers an intuitive sense of word embeddings, we repeat our analysis of the sentences of our basic example with this formal text analysis approach. We again removed function words (i.e., articles, conjunctions, prepositions, and pronouns).
Document d1: “The Document d2: “The Document d3: “The Document d4: “The
For this appendix, we used the fastText word embedding algorithm (Bojanowski et al., 2017). FastText comes with a pre-trained model based on the widely used Common Crawl data set, which has been repeatedly applied successfully in textual contexts similar to our example sentences (Bojanowski et al., 2017; Büchel et al., 2018; Sedoc et al., 2020). In other words, the pre-trained model for fastText is suitable because the latent semantics of individual words is likely to be stable across similar textual contexts (Stoltz & Taylor, 2021). We follow past research and averaged the embedding vectors of words in the same example sentence (Arseniev-Koehler, 2022; Nanni & Fallin, 2021; Stoltz & Taylor, 2021) to capture the latent semantics of the vocabulary used within each document.
In Table 6, we depict the document–embedding matrix for the four documents. The dimensionality of the document–embedding matrix is defined by the 300 embedding dimensions (i.e., dimensions of the embedding vectors) fastText provides.
The semantic similarity of documents can be quantified using similarity metrics (see Table 7). The similarity values in this example are produced by the cosine similarity and the inverted Euclidean distance (i.e., Euclidean similarity; Cassisi et al., 2012; Ljubesic et al., 2008; Manning & Schütze, 2000). Note that applying word embeddings reveal subtle nuances in word semantics. The similarity values indicate a ranking of document pairs that the human reader intuitively would expect when considering the semantics of the vocabulary used in the example sentences.
Acknowledgements
We are grateful to Peter Walgenbach for his very supportive comments on a previous draft of this manuscript. Moreover, we appreciate the help of Antonia Lipka and Toni Wengerodt during the data preparation process. Finally, we thank our editor Michael Withers and anonymous reviewers for their great support and recommendations during the review process.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Deutsche Forschungsgemeinschaft (grant number GO 3213/3-1).