
Abstract
Efficient simulation of complex plasma dynamics is crucial for advancing fusion energy research. Particle-in-Cell (PIC) Monte Carlo (MC) simulations provide insights into plasma behavior, including turbulence and confinement, which are essential for optimizing fusion reactor performance. Transitioning to exascale simulations introduces significant challenges, with traditional file input/output (I/O) inefficiencies remaining a key bottleneck. This work advances BIT1, an electrostatic PIC MC code, by improving the particle mover with OpenMP task-based parallelism, integrating the openPMD streaming API, and enabling in-memory data streaming with the ADIOS2 Sustainable Staging Transport (SST) engine to enhance I/O performance, computational efficiency, and system storage utilization. We employ profiling tools such as gprof, perf, IPM and Darshan, which provide insights into computation, communication, and I/O operations. We implement time-dependent data checkpointing with the openPMD API enabling seamless data movement and in-situ visualization for real-time analysis without interrupting the simulation. We demonstrate improvements in simulation runtime, data accessibility and real-time insights by comparing traditional file I/O with the ADIOS2 BP4 and SST backends. The proposed hybrid BIT1 openPMD SST enhancement introduces a new paradigm for real-time scientific discovery in plasma simulations, enabling faster insights and more efficient use of exascale computing resources.
Keywords
Introduction
Simulating complex physical phenomena at large scale is crucial for advancing fusion energy research. Particle-in-Cell (PIC) Monte Carlo (MC) simulations provide valuable insights into plasma dynamics, including turbulence, instabilities, and confinement properties, which are essential for optimizing fusion reactors. However, achieving efficient exascale simulations requires overcoming challenges in high-performance I/O, data streaming and in-situ visualization for seamless data management and real-time analysis.
PIC MC simulations using hybrid MPI + OpenMP parallelism optimize data throughput by leveraging MPI for distributed-memory communication and OpenMP for shared-memory parallelism. While this hybrid approach improves resource utilization and reduces synchronization overhead, traditional file I/O remains a major bottleneck. Frequent disk writes and redundant data dumps slow down computations, overload storage systems, and delay analysis, making it difficult to extract meaningful results efficiently. Conventional post-processing workflows in large-scale PIC MC simulations introduce further inefficiencies. As shown in Figure 1, a BIT1 user typically checks the results by displaying the time evolution or the final state of the total number of particles per CPU for each species. This is usually done using a standard Python script that processes large output files and generates plots after the simulation has completed. This approach delays insight generation, limits opportunities for real-time diagnostics, and is often followed by costly reruns if specific data were not recorded. As simulations scale, the overhead of writing massive datasets to disk and subsequently reading them back for offline analysis becomes increasingly unsustainable. These constraints highlight the growing need for integrated in-situ data processing and visualization techniques that provide immediate feedback, reduce I/O pressure, and streamline scientific workflows at exascale. Displaying the time evolution (left) and the final state (right) of the total number of particles per MPI Rank (CPU Core) for each species in BIT1, using a standard Python script that reads simulation output data, for up to 10 nodes, after the simulation has completed.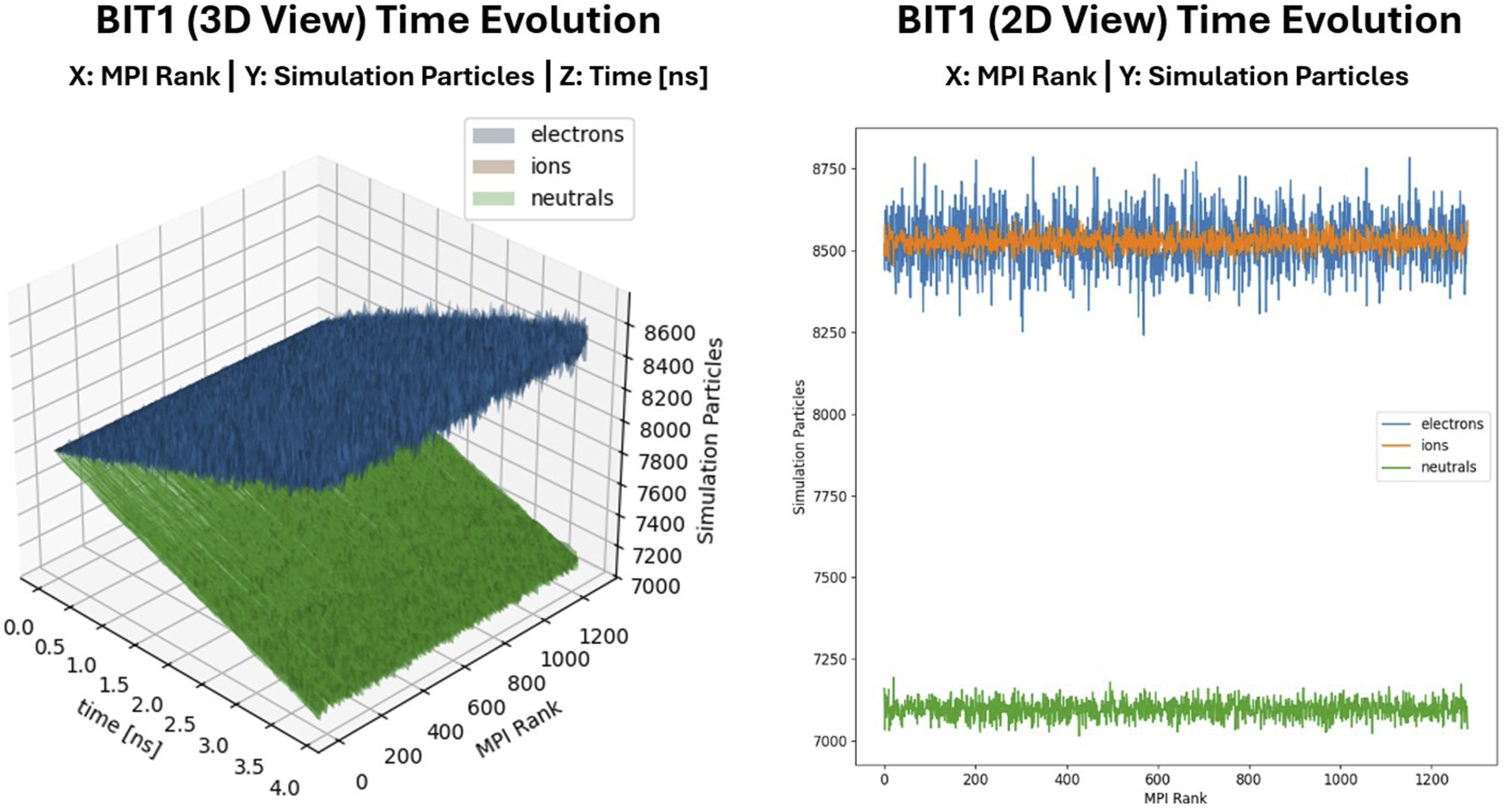
To address this, we introduce and integrate high-performance in-memory data streaming and in-situ visualization into a hybrid MPI + OpenMP version of BIT1 using openPMD and the ADIOS2 SST backend, focusing on streaming I/O performance, real-time checkpointing, and in-situ visualization. This approach builds on previous work Williams J.J. et al. (2024b, 2024c), in which BIT1’s traditional file I/O has transitioned to ADIOS2 streaming workflows coupled with OpenMP task-based parallelism, enabling fine-grained workload distribution to optimize data movement and computation for better scalability. The contributions of this work include: • We implement, for the first time, a hybrid MPI + OpenMP version of BIT1 integrated with openPMD to further enhance I/O performance, efficiency, and storage utilization. This approach addresses particle load imbalance through task-based parallelism and leverages the openPMD streaming API for both stream-based and file-based datasets. This development allows BIT1 to handle much larger simulations, reduce I/O bottlenecks, and scale efficiently across heterogeneous systems. • We identify computationally intensive parts using an I/O adaptor for the openPMD interface with ADIOS2 SST, assessing BIT1’s performance on a single node. This analysis offers a systematic understanding of where the code spends the most time • We employ profiling and monitoring techniques to understand the impact and performance of openPMD’s streaming API with ADIOS2 in scaling tests, comparing streaming-based workflows to traditional file I/O and the ADIOS2 BP4 engine when diagnostics are activated. These insights quantify the benefits of streaming I/O in practice. • We use a customized Python script with openPMD’s streaming API and ADIOS2 SST for real-time data checkpointing and visualization without interrupting the simulation, tailored for BIT1 output. This capability allows scientists and users of BIT1 to monitor and analyze simulations as they run, reducing time-to-discovery, improving fault tolerance with continuous checkpoints, and supporting interactive exploration of large-scale data.
The remainder of this paper is organised as follows. The Background section introduces the openPMD standard, the openPMD API with ADIOS2, and recent developments in BIT1, providing the necessary context for this work. The Methodology and Experimental Setup section describes the methodology and experimental configuration, including the specific changes made to BIT1. The Performance Results, Analysis, and Visualisation section presents and evaluates the performance results, supported by detailed analysis and visualisation. Next, the Related Work section discusses existing literature and highlights how the key contributions of this paper relate to and extend prior studies. Finally, the Discussion and Future Work section reflects on the results, summarises the main conclusions, and outlines directions for future research.
Background
The PIC method simulates plasma behavior by capturing the dynamics of charged/neutral particles in 1D/2D/3D spatial dimensions and resolving their 3D velocity distribution. It is particularly effective for studying plasma edge physics, where interactions with walls and particle collisions are crucial. PIC simulations often integrate MC techniques for accurate treatment of elastic and inelastic particle collisions, as well as plasma-wall interactions. BIT1 uses an explicit formulation of the PIC method and follows a well-defined workflow, as shown in Figure 2. BIT1’s PIC MC cycle involves five phases (Tskhakaya and et al. (2010); Williams J.J. et al. (2023)): interpolating particle properties, solving the electric field, handling collisions, weighting forces to particles, and advancing particle trajectories. Alongside these five phases and outlined in Figure 2, the I/O and plasma diagnostics phase (in orange) occurs only for a specific number of time steps (for instance, only every 1000 cycles), enabling key diagnostics and providing checkpointing and restart capabilities. A simplified diagram representing BIT1 PIC MC workflow used to simulate the plasma edge (Tskhakaya and et al. (2004, 2010)). After initialization, the PIC MC algorithm cycle repeats at each time step for diagnostic output and I/O performance investigations Williams J.J. et al. (2023). In orange, we highlight the I/O and plasma diagnostics step activated to integrate high-performance in-memory data streaming and in-situ visualization in BIT1 using openPMD.
Berkeley Innsbruck Tbilisi 1D3V (BIT1) is a specialized 1D3V electrostatic PIC MC code Tskhakaya D and Kuhn (2002) and based on the
Although the original version of BIT1 features reliable serial I/O (i.e. small and compressed binary files for fast dump/checkpointing), the growing scale and complexity of simulations have highlighted the limitations of this approach. As data volumes increased, serial I/O became a performance bottleneck, with an increased risk of file corruption and significant delays in data writing. These challenges prompted the development and integration of parallel I/O methods Williams J.J. et al. (2024c) to ensure reliable and scalable performance for large-scale simulations.
BIT1 is driven by a small input file (1–3 kB), ensuring efficient initialization across all processes. Its output framework consists of key parameters that control data diagnostics, state preservation, and time-dependent averaging of plasma profiles and velocity distributions. Two critical input parameters guide the output analysis Williams J.J. et al. (2024b, 2024c): • •
Unlike PIC codes such as Smilei Derouillat et al. (2018) and Warp-X Vay J.L. et al. (2018), which are optimized for high-performance plasma simulations but not for high-density plasma, BIT1 is specifically tailored for plasma edge modelling, especially the Scrape-Off Layer (SOL) in fusion devices. BIT1 addresses SOL challenges such as kinetic effects, plasma-wall interactions, and sheath physics by incorporating Direct Simulation Monte Carlo (DSMC) collision operators Tskhakaya D. (2023) and is capable of modeling next-generation fusion devices with an extremely high-density plasma edge. As the first massively parallel full-orbit Debye-scale PIC code applied to SOL simulations Tskhakaya D. (2012), BIT1 uses the “natural sorting” method Tskhakaya et al. (2007) to improve computational efficiency, accelerating collision operators by up to five times. However, “natural sorting” requires more memory per grid cell, creating a bottleneck when offloading to GPUs Williams J.J. et al. (2025), and regions with high particle concentrations may cause workload imbalances Williams J.J. et al. (2023), requiring adaptive parallel strategies. Given this, BIT1 is evolving toward a hybrid computational model with MPI and OpenMP to ensure portability across supercomputing platforms. BIT1 uses MPI-based domain decomposition for parallel execution and OpenMP for shared-memory parallelism, reducing MPI communication overhead and improving scalability on multi-core processors Williams J.J. et al. (2024d).
openPMD Standard & openPMD-api
The openPMD (Open Standard for Particle-Mesh Data) standard Huebl et al. (2015) enables the portable exchange of particle and mesh data, supporting formats such as HDF5, ADIOS1, ADIOS2, and JSON in serial and MPI workflows. The openPMD-api Huebl et al. (2018) facilitates scientific I/O, as shown in Figure 3 across these formats, with records representing physical quantities and iterations over time. In openPMD, a record is a physical quantity of arbitrary dimensionality (rank), potentially consisting of multiple components (e.g., scalars, vectors, tensors), and these records share common properties, such as describing electric fields, density fields, or particle attributes. Records may be structured as meshes (n-dimensional arrays) or unstructured, as in the case of particle species stored in 1D arrays, where each row corresponds to a particle. Updates to the values of meshes or particle species are called iterations, which represent the temporal evolution of records. A collection of such iterations forms a series, and the openPMD-api supports this concept through a variety of backends and encoding strategies. An Open Software Stack for Scientific I/O (Huebl et al. (2015, 2018); Poeschel and et al. (2021)) integrates high-performance in-memory data streaming and in-situ visualization in BIT1 using openPMD. In orange, we highlight the BP4 engine, which is aggressively optimized for I/O efficiency at large scale by reducing metadata and aggregating data, and the SST engine, which optimizes communication and manages data transfers with minimal overhead, making it ideal for exascale systems.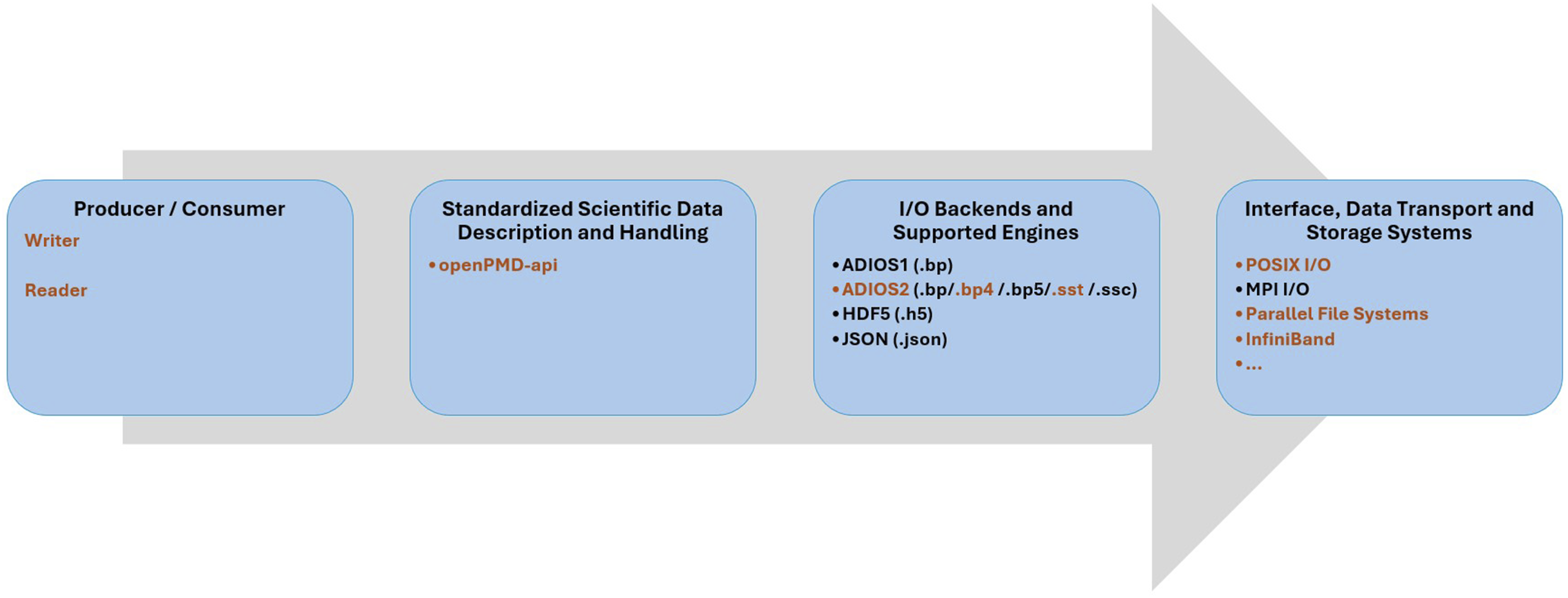
ADIOS Version 2
The ADIOS2 (Adaptable Input Output System version 2) is an open-source, scalable parallel I/O framework designed for efficient data transfer on supercomputers, with support for C, C++, Fortran, and Python. A key feature of ADIOS2 is its use of virtual I/O engines, which define how data is read and written and provide configurable settings to optimize performance for various workloads. The available engines include the Binary Packed formats versions 5 (BP5), 4 (BP4) and 3 (BP3), the Hierarchical Data Format version 5 (HDF5), Sustainable Staging Transport (SST), Strong Staging Coupler (SSC), DataMan and Inline. Previous work (Williams J.J. et al. (2024b, 2024c); openPMD-api and ADIOS2 Backends (2025)) focused on the BP4 engine, which aggressively optimizes simulations for I/O efficiency at large scale through large per process buffers and minimal write operations, enabling high throughput on parallel file systems, whereas the BP5 engine introduces certain compromises to achieve tighter control of host memory by using a linked list of equally sized buffer chunks (up to 2 GB each, configurable via the ADIOS2 “BufferChunkSize” parameter) and requires careful configuration of aggregators, subfiles and buffer flushing. While this improves memory predictability and mitigates out of memory risks, it generally delivers lower I/O throughput than BP4. In this work, we focus on the SST engine to enable streaming support in BIT1. SST is optimized for communication and large-scale data transfers with minimal overhead, making it particularly well suited for exascale systems, and it integrates seamlessly with openPMD to support efficient data exchange in MPI parallel workflows.
Methodology & Experimental Setup
This work integrates a hybrid MPI + OpenMP version of BIT1 with the openPMD standard and the ADIOS2 SST backend to enhance I/O efficiency, support parallel streaming workflows, minimize data storage, and enable real-time data checkpointing and in-situ visualization, while detailing the specific modifications implemented in BIT1.
Hybrid BIT1 openPMD & ADIOS2 SST Implementation
OpenMP Tasks Particle Mover Parallelization
OpenMP is a widely used programming model for shared-memory parallelism in HPC, supported by major compilers such as GCC and LLVM, ensuring broad accessibility.
Williams et al. Williams J.J. et al. (2024d), IPP-CAS (2025a) presented an OpenMP implementation of the particle mover’s core function. In this function, the arrays
openPMD & openPMD-api Integration
BIT1 is a 1D3V PIC MC code in C, simulating particles in one dimension with three velocity components. The openPMD-api parallel I/O library is integrated to enhance I/O functionality. The integration of openPMD and ADIOS2 in BIT1 for streaming and file output involves several key steps. First, the MPI environment is initialized, determining the number of processors and their ranks to ensure proper communication. The input file is then read, and necessary initializations are performed, including memory allocations and calculations for profiles and field values. If streaming is enabled, a series is created using the ADIOS2 SST engine with configurations specifying parameters such as transport type (e.g. WAN), buffer growth factor (e.g. 2.0), and queue policies (e.g. QueueLimit = 2, QueueFullPolicy = Discard). During the main iteration loop, particle movements are simulated, boundary conditions are updated, and various calculations are performed based on specific flags. At defined intervals, data is written to ADIOS2 files in either BP4 or SST format. Time-dependent diagnostics, including system states and particle history, are saved, and when streaming with the SST engine is activated, data is written to memory instead of disk. Once the loop completes, the results are stored, resources are cleaned up, and the MPI environment is finalized.
openPMD & ADIOS2 SST Backend Activation
In Hybrid BIT1 I/O and Insight Workflow using openPMD and ADIOS2 Backends.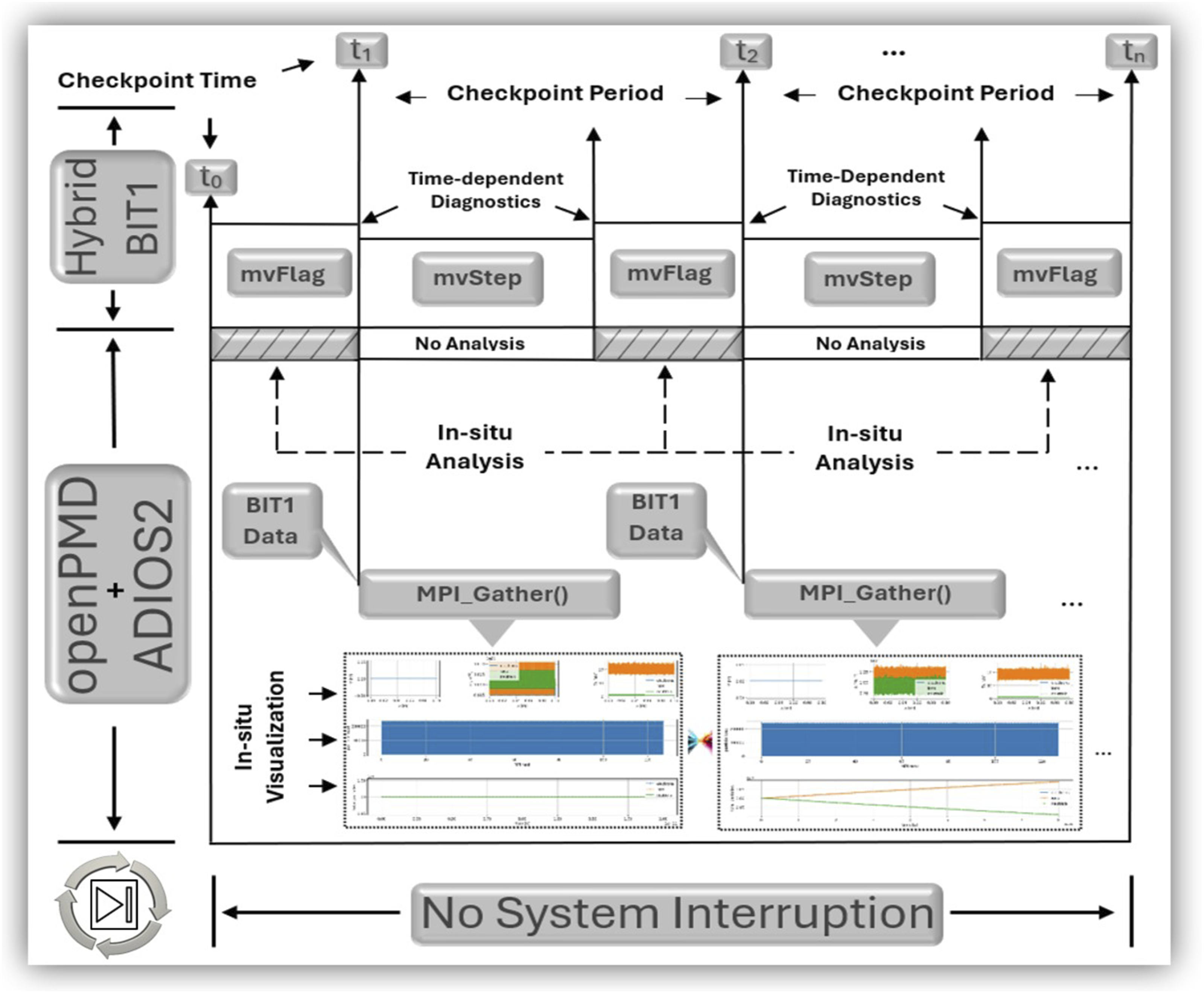
HPC Profiling & Monitoring Tools
In this work, we aim to understand the impact of the hybrid version of BIT1 with the openPMD and ADIOS2 SST backend, determining its associated performance characteristics. To achieve this, we employ a suite of sophisticated profiling and monitoring tools. Specifically, we utilize: • • • •
Use Case & Experimental Environment
We aim to improve both scalability and I/O efficiency in hybrid BIT1 by utilizing the openPMD and ADIOS2 backends. The test case involves an initial uniformly distributed hot plasma interacting with a uniformly distributed monoatomic gas, which ultimately leads to the ionization of the gas and the cooling of the plasma. The initial conditions consist of three particle species: electrons, single-ionized deuterium ions (D+), and deuterium neutrals (D), all uniformly distributed inside the system, with electron and ion initial densities of 1021 m−3 and initial temperatures of 20 eV for both charged species, while the neutral species has a density of 1021 m−3 and an initial temperature of 1 eV. The simulation assumes no electric or magnetic fields. Periodic boundary conditions are applied, meaning particles crossing a boundary are reinjected from the opposite boundary with the same velocities, resulting in no plasma-wall interaction. The computational mesh consists of 100K cells, each with 100 particles per species, yielding a system size of 1 m and a cell size of 10 μm (micrometres), resulting in a total of 30M particles. The simulation runs for 200K time steps, each with a time step of 4 × 10−14 s, simulating a total of 8 ns of plasma evolution. Particle collisions considered in the simulation include electron-neutral elastic, excitation, and ionization processes. Unless otherwise noted, the simulation runs for up to 200K time steps. The number of time steps/cycles was chosen for convenience for profiling purposes only, and it does not relate to a reached steady state or a certain maturity of the simulation. It is important to note that this test excludes the field solver and smoother phases, as in Williams J.J. et al. (2024b, 2024c, 2024d, 2025), since this use case assumes no electric field, and the field solver and smoother functions are never called in this particular use case.
We simulate and evaluate the impact of integrating openPMD with hybrid BIT1 using the ADIOS2 SST backend on the following three distinct systems: • • •
Hybrid BIT1 openPMD Streaming I/O & Insight Workflow
As presented by Williams et al. Williams J.J. et al. (2023, 2024d), hybrid BIT1 performs serial I/O operations throughout each simulation. Similar to the process described in Poeschel et al. (2021), this work enables the ADIOS2 SST backend in hybrid BIT1 for streaming support. Unlike BP4, which writes data to files, SST enables direct data streaming between producers and consumers, reducing I/O overhead and improving scalability in large-scale systems. SST supports full
As shown in Figures 4–6 and presented in Williams J.J. et al. (2024b, 2024c), integrated into hybrid BIT1’s openPMD workflow, the simulation uses Hybrid BIT1 openPMD SST Workflow and In-Situ Visualization Without Interruption the Simulation.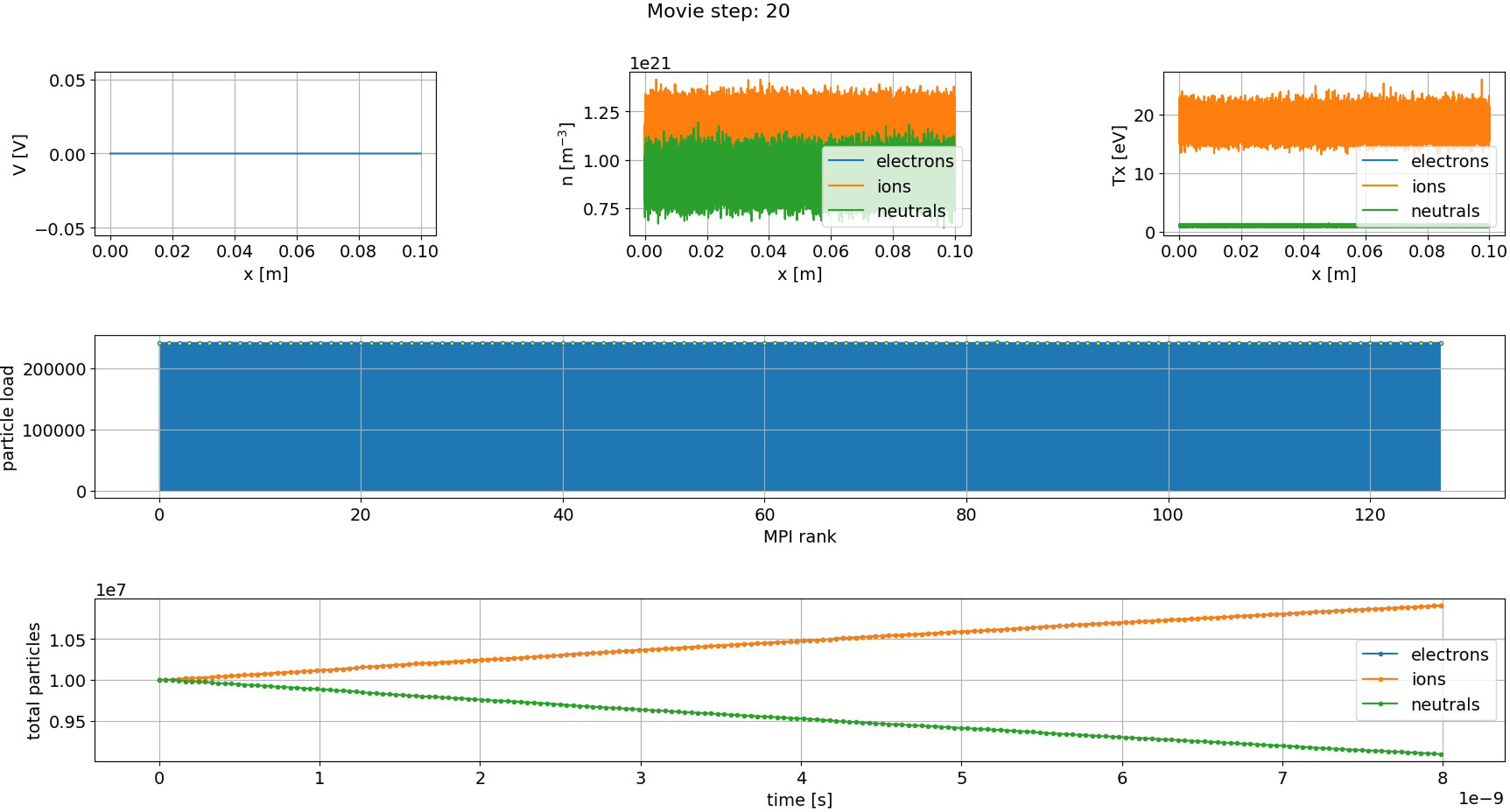
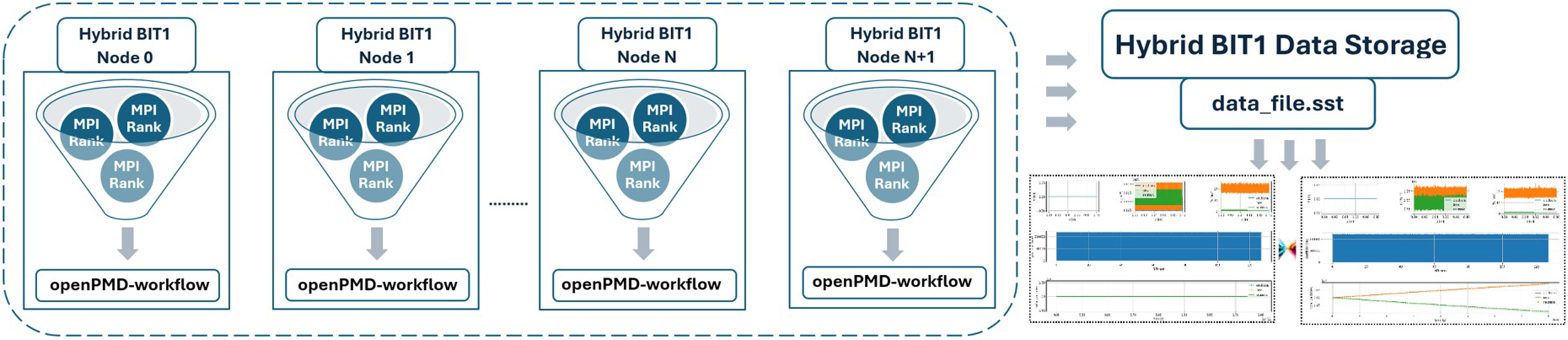
Performance Results, Analysis & Visualization
In this work, we evaluate the impact and performance of integrating openPMD with hybrid BIT1 using the ADIOS2 SST backend.
BIT1 Original Instrumentation & I/O Monitoring
As previously investigated by Williams et al. Williams J.J. et al. (2023, 2024e) and shown in Figure 7, BIT1 Original File I/O Write Throughput with Variability (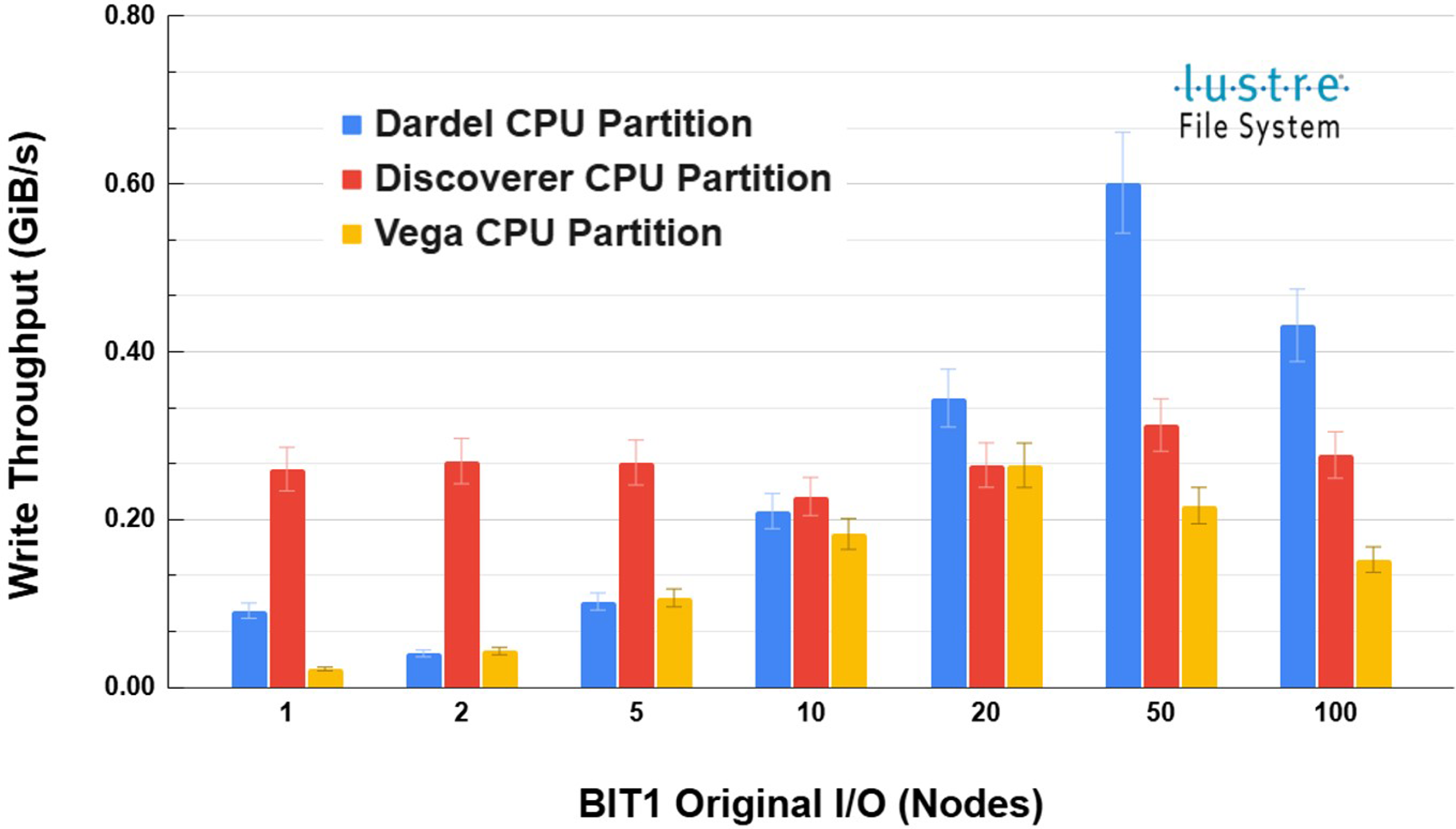
BIT1 openPMD SST Performance & I/O Costs Per Process
We begin by utilizing
As previously discovered by Williams et al. Williams J.J. et al. (2023, 2024e), Figure 8 shows how the most time consuming functions perform during the “BIT1 openPMD SST”, simulation compared to the “BIT1 openPMD BP4” and “Original BIT1” simulations. In the “Original BIT1”, Percentage breakdown of the Ionization case functions on Dardel, highlighting where most of the execution time is spent for the openPMD SST, openPMD BP4, and Original BIT1 Williams J.J. et al. (2023, 2024b) versions. The 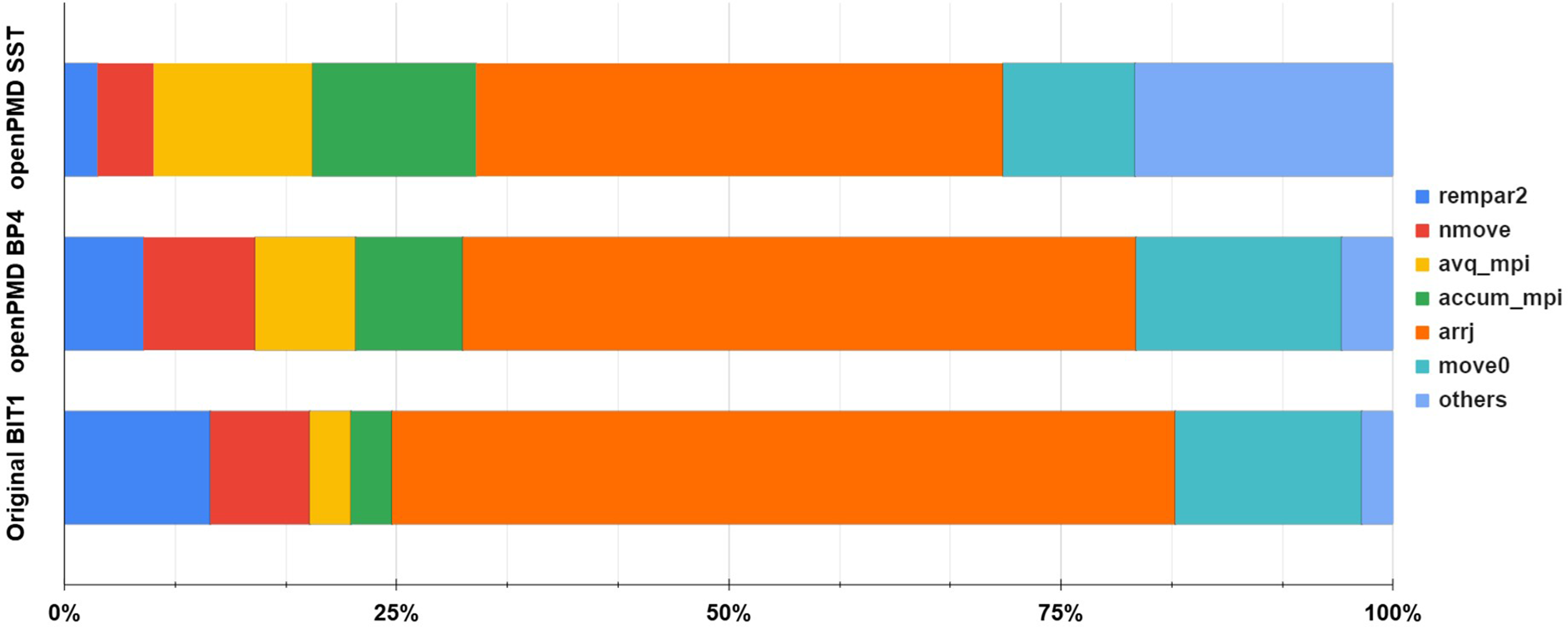
Next, we utilized BIT1 Average I/O Cost Per Process for Reads, Metadata, and Writes on Dardel using 100 nodes, normalized.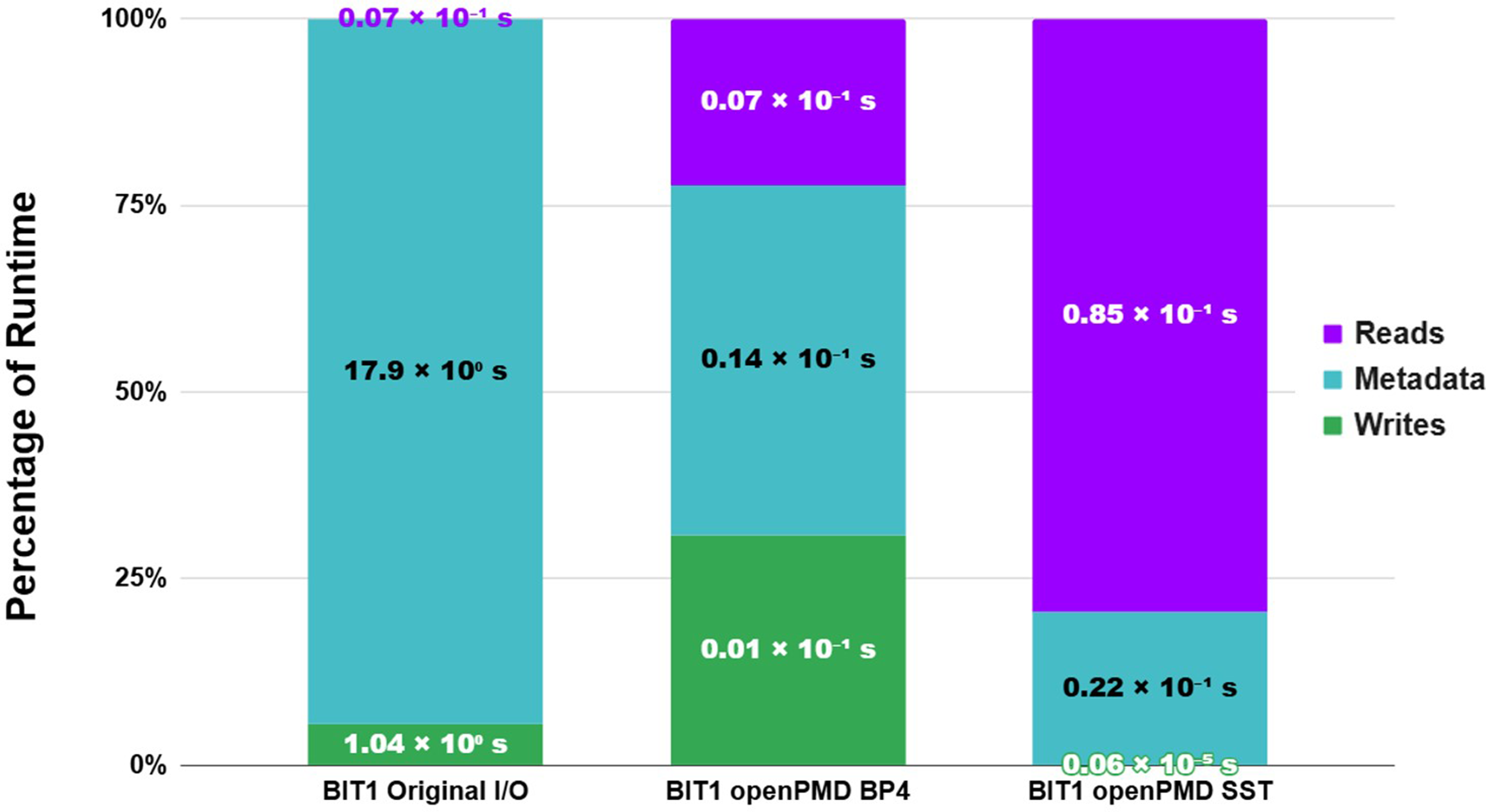
Analyzing the results reveals that the integration of openPMD with ADIOS2 backends, particularly employing BP4 and SST, has yielded remarkable enhancements in BIT1. The use of BP4 has led to a dramatic reduction in metadata overhead, from 17.87s (17.9 × 100 s) in the Original I/O to just 0.014s (0.14 × 10−1 s), a 99.92% improvement. Write times also improved significantly, dropping from 1.04s (1.04 × 100 s) in the Original I/O to 0.009s (0.01 × 10−1 s) with BP4. SST, while eliminating write times entirely at 0.0,000,006s (0.06 × 10−5 s), resulted in an increased read time of 0.085s (0.85 × 101 s), likely due to its memory-streaming approach. BP4 achieves these improvements by consolidating data into a single file per node [Williams J.J. et al. (2024b, 2024c), reducing metadata and write times, while SST streams data through memory, improving write performance but increasing memory usage and read time. Overall, BP4 provides the best I/O performance by balancing metadata reduction and efficient writes when running BIT1 openPMD BP4 simulations.
Hybrid BIT1 openPMD SST Performance & Scalability
Previously presented by Williams et al. Williams J.J. et al. (2024d), the hybrid MPI + OpenMP version of BIT1 reduces total simulation and mover function time by leveraging OpenMP threads for concurrent execution. We extend this work by integrating openPMD with the ADIOS2 SST backend, using
As shown in the • • • • • • MPI aggregated communication time for the Hybrid BIT1 openPMD SST simulation on Dardel using 100 nodes, totaling 12,800 MPI processes.
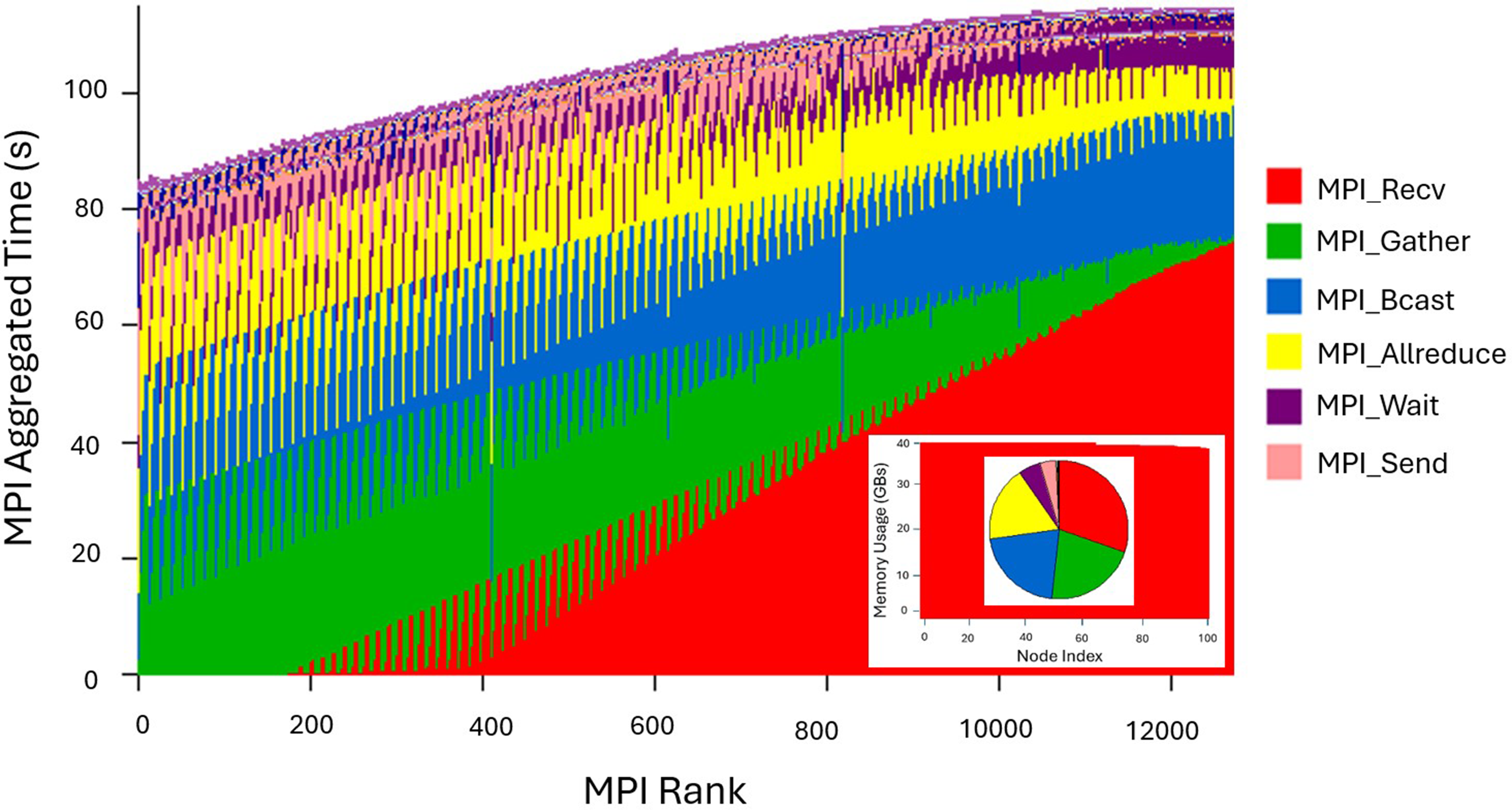
While the hybrid BIT1 openPMD SST simulation demonstrates efficient MPI communication and scalability across nodes, the notable overhead associated with data exchange, aggregation, and synchronization highlights areas that could benefit from further investigation as the system scales.
Using Hybrid BIT1 Total Simulation (Relative) Speed Up - strong scaling up to 100 Nodes (12,800 MPI ranks) on Dardel for 200K times steps.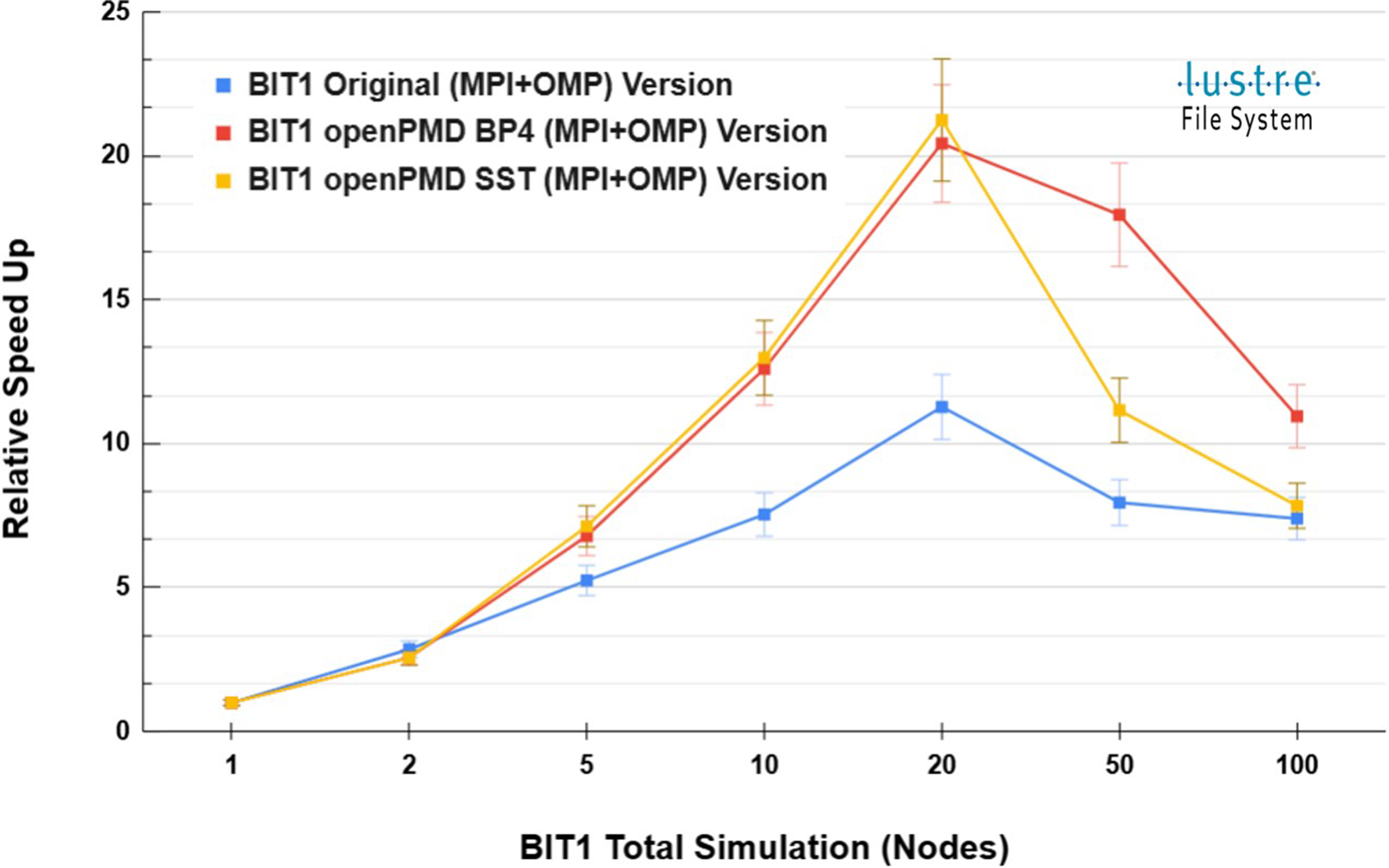
Hybrid BIT1 openPMD SST In-Situ Visualization
One of the key aspects of this work is enabling real-time data checkpoint analysis and visualization in large-scale PIC MC simulations without interrupting the simulation. This addresses I/O bottlenecks and minimizes data movement overhead. Traditional post-processing, as shown in Figure 1, requires storing vast amounts of data, which can significantly impact performance. In contrast, real-time data checkpoint analysis allows data to be processed and visualized directly within the simulation, eliminating the need for extensive storage and data transfer.
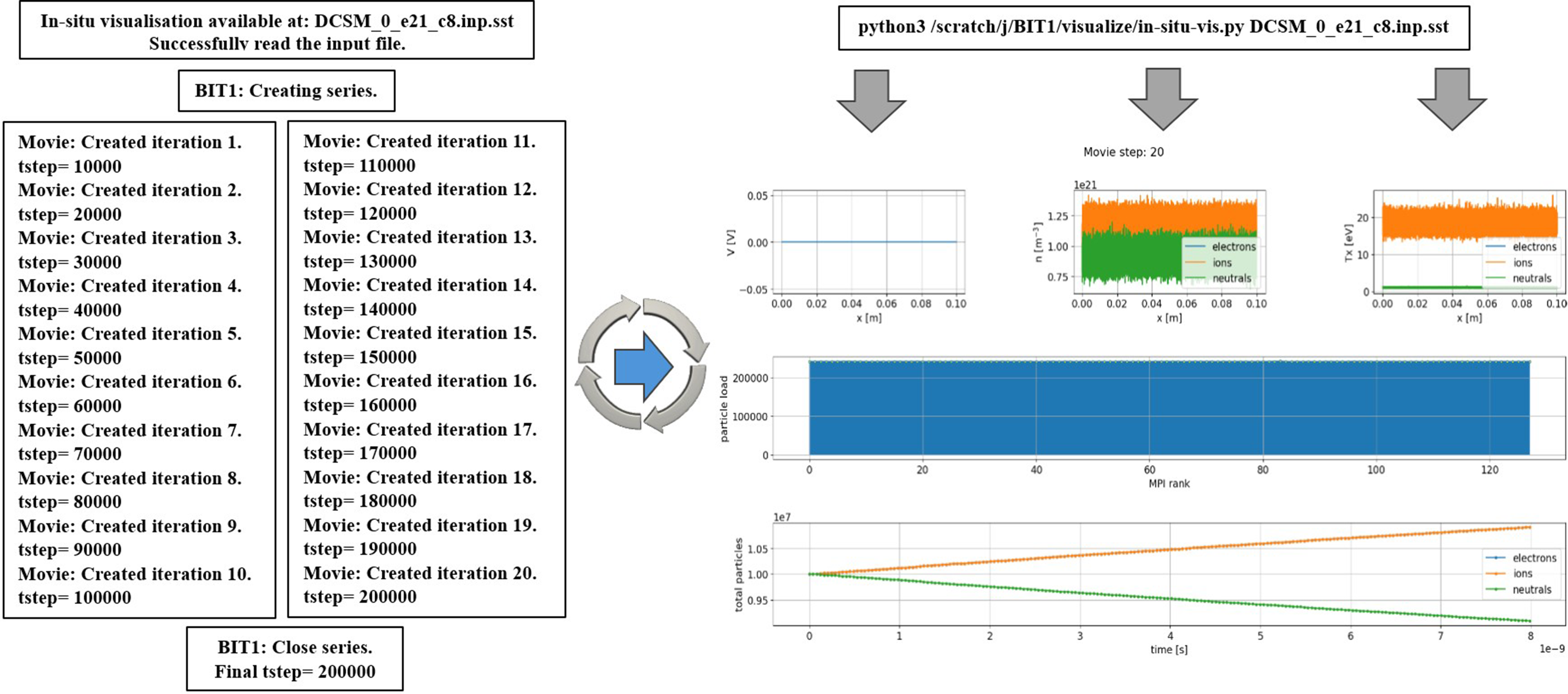
In this work, hybrid BIT1 leverages openPMD with ADIOS2 SST for low-latency memory-to-memory data streaming, enabling seamless real-time data checkpoint analysis and visualization. Unlike BP4, which writes data to disk for later processing, SST allows for immediate interaction with live simulation data, enabling continuous analysis. Figure 12 illustrates the information displayed to a BIT1 HPC system user on Dardel compute nodes after logging in, showing the hybrid BIT1 openPMD SST simulation performing real-time data checkpoint analysis and visualization. A customized Python script, utilizing openPMD’s streaming API and the ADIOS2 SST engine, facilitates the process. Visualizations include: • – – – • • Performing real-time data checkpoint analysis and visualization using the hybrid BIT1 openPMD SST simulation on Dardel, up to 200K time steps (tsteps), highlighting a reduced set of plasma profiles, the particle load per MPI rank, and the time evolution of the total number of particles for each species.
In the “Neutral Particle Ionization (Hybrid BIT1) Simulation”, where uniform plasma interacts with deuterium gas, causing ionization, and as shown in Figure 12, electron and ion numbers increase due to neutral ionization, while neutral particles decrease over time. In-situ analysis and visualization provide immediate insights into system states, enabling prompt adjustments to simulation parameters without interrupting execution.
Related Work
BIT1, an advanced PIC MC code for simulating plasma-material interactions, is extensively used in fusion research, including tokamak simulations Tskhakaya et al. (2010). It builds on the XPDP1 code Verboncoeur J.P. et al. (1993), developed by Verboncoeur’s team at Berkeley, and incorporates an optimized data layout for efficient handling of collisions Tskhakaya et al. (2007). Chaudhury et al. Chaudhury et al. (2019) applied hybrid parallelization to low-temperature plasma simulations, using OpenMP and MPI for scalable performance on HPC clusters. Recently, Williams et al. Williams et al. (2023, 2024e) identified the possibility to optimize particle mover using OpenMP task-based parallelism Williams et al. (2024d). In a separate study, Williams et al. Williams et al. (2024c) tackled parallel I/O challenges by incorporating openPMD with BIT1 and using Darshan for I/O monitoring. Poeschel et al. Poeschel et al. (2021) shifted from traditional file-based workflows to streaming data pipelines with openPMD and ADIOS2, highlighting the benefits of streaming I/O for better flexibility and performance in HPC environments. Huebl et al. Huebl et al. (2015, 2018) developed the openPMD-api, a C++ and Python API to standardize I/O and facilitate integration with in-situ analysis tools, promoting interoperability across simulation codes. Williams et al. Williams J.J. et al. (2024b) investigated the impact of openPMD on BIT1’s performance through instrumentation, monitoring, and in-situ analysis. Williams et al. Williams J.J. et al. (2024a) also characterized the performance of the implicit massively parallel PIC code iPIC3D, analyzing communication efficiency, optimal node placement, overlapping communication with computation, and load balancing to improve large-scale 3D plasma simulations relevant to magnetic reconnection and space physics, with profiling and tracing guiding recommended communication strategies for advancing Geospace Environmental Modeling challenges. As in-situ analysis becomes crucial for large-scale simulations, Ayachit et al. Ayachit et al. (2015) introduced ParaView Catalyst to integrate data processing into the simulation workflow, reducing storage needs and improving real-time insights. Similarly, Karimabadi et al. Karimabadi et al. (2013) explored in-situ visualization for global hybrid simulations, demonstrating its advantages in reducing data movement and enhancing temporal resolution for scientific analysis. Building on these developments, libraries such as Fides Pugmire, David, et al. (2021) provide flexible, high-performance data models for both post hoc and in-situ visualization, enabling efficient streaming and zero-copy access to complex simulation data.
Discussion & Future Work
This work presents the integration of openPMD with ADIOS2’s SST backend into the hybrid BIT1 code. This novel method has effectively addressed the data management and storage (I/O) challenges, enhancing I/O performance and computational efficiency for the fusion energy community. The adoption of OpenMP task-based parallelism has optimized the particle mover function, improving load balancing and reducing execution times. Profiling tools such as gprof, perf, IPM, and Darshan have provided valuable insights into computation, communication, and I/O operations, confirming the effectiveness of this approach. The transition from traditional file-based I/O to ADIOS2’s streaming capabilities has reduced metadata overhead and write times, further improving overall simulation performance.
In-situ visualization, enabled through openPMD’s streaming API and the ADIOS2 SST engine, facilitates real-time data analysis without interrupting the simulation workflow. This advancement provides immediate insights into plasma behavior, enabling prompt adjustments to simulation parameters and more efficient use of computational resources. However, as simulations scale to larger node counts, increased communication overhead and synchronization costs have been observed, highlighting areas for further optimization to maintain scalability and performance. It is important to note that this analysis was conducted for a moderate-size problem (neutral particle ionization case), which is not representative of large-scale production workloads. As such, better scalability is expected for the largest production cases, where I/O can be effectively hidden behind the now computation-intensive workload, up to the hardware bandwidth limit of the machine. Visualizations can be of the form shown in Figure 13, performing real-time checkpointing, data analysis, and visualization of a magnetized plasma tube bounded by grounded walls. Performing real-time checkpointing, data analysis, and visualization of a magnetized plasma tube bounded by grounded walls.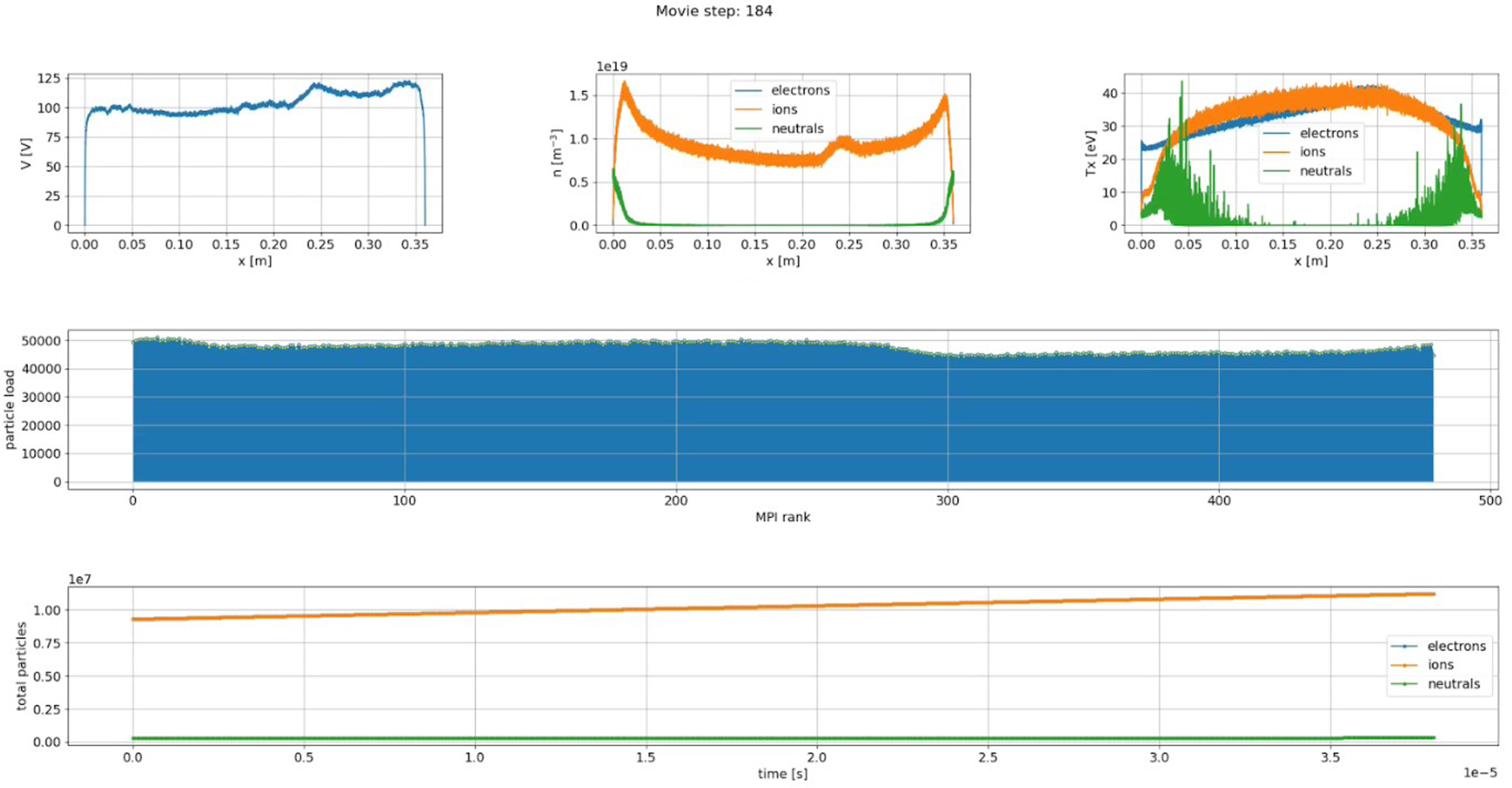
Future research will focus on enhancing hybrid BIT1 simulations by leveraging the strengths of the BP4 and SST backends. BP4 is optimized for high-throughput storage through efficient indexing and compression, while SST enables low-latency, memory-to-memory data streaming for real-time analysis and visualization. The integration of openPMD and ADIOS2 with ParaView further improves the efficiency of data visualization and analysis. ADIOS2 supports high-performance I/O by using BP4 for checkpoint storage and SST for real-time data streaming. Hybrid BIT1 outputs are stored in multidimensional arrays, typically indexed first by particle species. Within ParaView, filters process these arrays to extract and visualize key physical quantities such as density, temperature, velocity, and energy flux for selected species. As shown in Figure 14, the Hybrid BIT1 openPMD BP4, on Dardel, using the 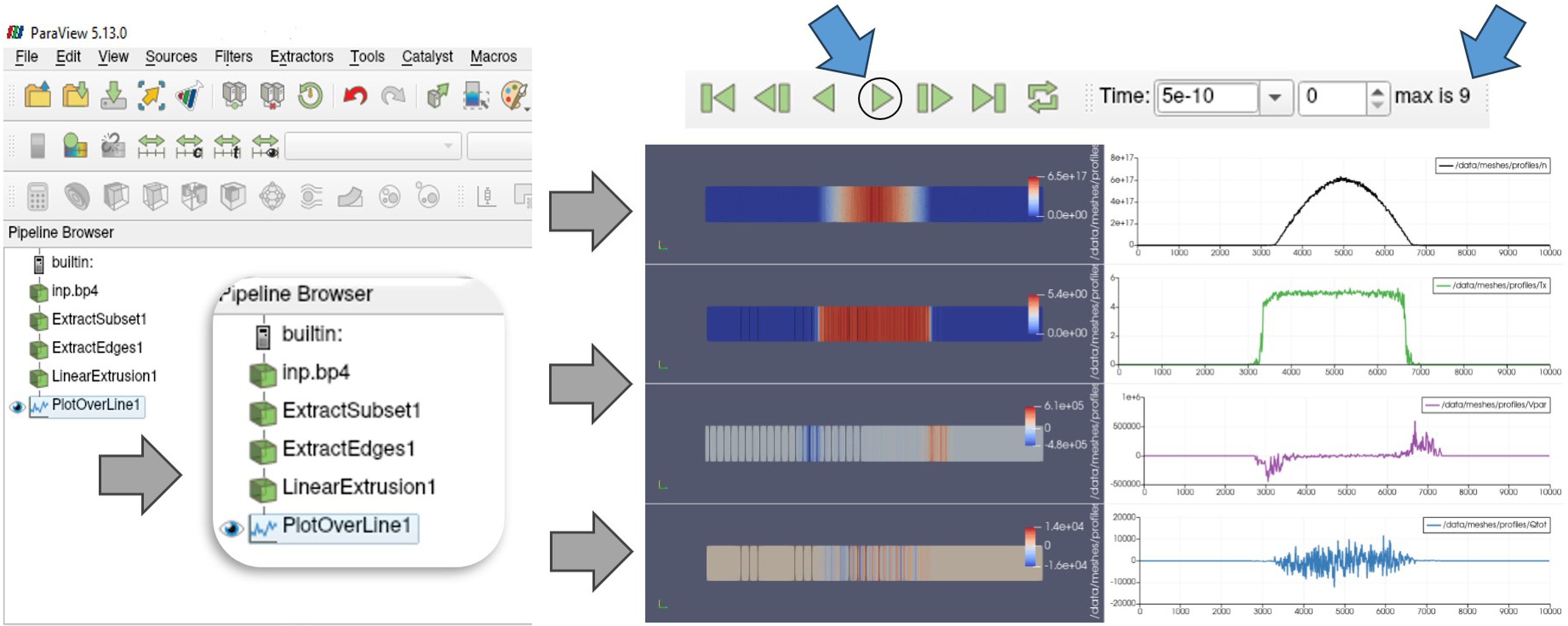
The integration of openPMD and Catalyst-ADIOS2 with ParaView Mazen and et al. (2023) will also be explored. This approach enables data reduction on simulation nodes using Catalyst, followed by the transfer of reduced data to dedicated visualization nodes for in-transit processing. These hybrid analysis frameworks aim to accelerate scientific discovery by supporting detailed real-time visualization and optimizing both post-processing and in-situ analysis for large-scale PIC MC simulations.
Footnotes
Acknowledgements
Funded by the European Union. This work has received funding from the European High Performance Computing Joint Undertaking (JU) and Sweden, Finland, Germany, Greece, France, Slovenia, Spain, and Czech Republic under grant agreement No 101093261 (Plasma-PEPSC). The computations/data handling were/was enabled by resources provided by the National Academic Infrastructure for Supercomputing in Sweden (NAISS), partially funded by the Swedish Research Council through grant agreement no. 2022-06725.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Vetenskapsrådet; 2022-06725, Plasma-PEPSC; 101093261.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.